a robust and secure video steganography method in dwt
TRANSCRIPT

Sacred Heart UniversityDigitalCommons@SHU
Computer Science & Information TechnologyFaculty Publications School of Computing
4-2017
A Robust and Secure Video SteganographyMethod in DWT-DCT Domains Based onMultiple Object Tracking and ECCRamadhan J. MstafaUniversity of Bridgeport
Khaled M. ElleithyUniversity of Bridgeport
Eman AbdelfattahSacred Heart University
Follow this and additional works at: http://digitalcommons.sacredheart.edu/computersci_fac
Part of the Numerical Analysis and Scientific Computing Commons, and the Theory andAlgorithms Commons
This Article is brought to you for free and open access by the School of Computing at DigitalCommons@SHU. It has been accepted for inclusion inComputer Science & Information Technology Faculty Publications by an authorized administrator of DigitalCommons@SHU. For more information,please contact [email protected].
Recommended CitationMstafa, R.J., Elleithy, K.M., Abdelfattah, E. (2017). A robust and secure video steganography method in DWT-DCT domains basedon multiple object tracking and ECC. IEEE Access, May 2017. doi:10.1109/ACCESS.2017.2691581

Received March 5, 2017, accepted March 30, 2017, date of publication April 6, 2017, date of current version May 17, 2017.
Digital Object Identifier 10.1109/ACCESS.2017.2691581
A Robust and Secure Video SteganographyMethod in DWT-DCT Domains Based on MultipleObject Tracking and ECCRAMADHAN J. MSTAFA1, (Member, IEEE), KHALED M. ELLEITHY1, (Senior Member, IEEE),AND EMAN ABDELFATTAH2, (Member, IEEE)1Department of Computer Science and Engineering, University of Bridgeport, Bridgeport, CT 06604, USA2School of Computing, Sacred Heart University, Fairfield, CT 06825, USA
Corresponding author: Ramadhan J. Mstafa ([email protected])
ABSTRACT Over the past few decades, the art of secretly embedding and communicating digital data hasgained enormous attention because of the technological development in both digital contents and commu-nication. The imperceptibility, hiding capacity, and robustness against attacks are three main requirementsthat any video steganography method should take into consideration. In this paper, a robust and secure videosteganographic algorithm in discrete wavelet transform (DWT) and discrete cosine transform (DCT) domainsbased on the multiple object tracking (MOT) algorithm and error correcting codes is proposed. The secretmessage is preprocessed by applying both Hamming and Bose, Chaudhuri, and Hocquenghem codes forencoding the secret data. First, motion-based MOT algorithm is implemented on host videos to distinguishthe regions of interest in the moving objects. Then, the data hiding process is performed by concealingthe secret message into the DWT and DCT coefficients of all motion regions in the video depending onforeground masks. Our experimental results illustrate that the suggested algorithm not only improves theembedding capacity and imperceptibility but also enhances its security and robustness by encoding the secretmessage and withstanding against various attacks.
INDEX TERMS Video steganography, multimedia security, data hiding techniques, multiple object tracking,DWT, DCT, ECC, imperceptibility, embedding capacity, robustness.
I. INTRODUCTIONIn spite of the fact that the Internet is utilized as a mediumto access desired information, it has also opened a new doorfor attackers to obtain precious information of other userswith little effort [1]. Steganography has functioned in a com-plementary capacity to offer a protection mechanism thathide communication between an authorized transmitter andits recipient. Steganography is defined as the art of concealingsecret information in specific carrier data, establishing covertcommunication channels between official parties [2], [3].Subsequently, a stego object (steganogram) should appear thesame as an original data that has a slight change of the sta-tistical features. The primary objective of the steganographyis to eliminate any suspicion to the transmission of hiddenmessages and provide security and anonymity for legiti-mate parties. The simplest way to observe the steganogram’svisual quality is to determine its accuracy, which is achievedthrough the Human Visual System (HVS). The HVS cannot
identify slight distortions in the steganogram, thus avoid-ing suspiciousness [4]. However, if the size of the hiddenmessage in proportion with the size of the carrier objectis large, then the steganogram’s degradation will be visi-ble to the human eye resulting in a failed steganographicmethod [5].
Embedding efficiency, hiding capacity, and robustness arethe three major requirements incorporated in any successfulsteganographic method [6]. First, embedding efficiency canbe determined by answering the following questions [7], [8]:1) how safe is the steganographic method to conceal thehidden information inside the carrier object? 2) how preciseare the steganograms’ qualities after the hiding procedureoccurs? and 3) is the secret message undetectable from thesteganogram? In other words, the steganography method ishighly efficient if it includes encryption, imperceptibility,and undetectability characteristics. The high efficient algo-rithm conceals the covert information into the carrier data
53542169-3536 2017 IEEE. Translations and content mining are permitted for academic research only.
Personal use is also permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
VOLUME 5, 2017

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
FIGURE 1. General diagram of the steganography method.
by utilizing some of the encoding and encryption techniquesprior to embedding stage for improving the security of theunderlying algorithm [9]. Fig. 1 represents the general modelof steganographic method.
Steganograms with low alteration rate and high qualitydo not draw the hacker’s attention, and thus will avoid anysuspicion for the covert information [10]. If the steganogra-phy method is more effective, then the steganalytical detec-tors will find it more challenging to detect the hiddenmessage [11].
The hiding capacity is the second fundamental requirementwhich permits any steganography method to increase the sizeof hidden message taking into account the visual qualityof the steganograms. The hiding capacity is the quantity ofthe covert messages inserted inside the carrier object [12].In ordinary steganographic methods, both hiding capacityand embedding efficiency are contradictory [13]. Conversely,if the hiding capacity is increased, then the quality of thesteganograms will be diminished, decreasing the efficiencyof underlying method. The embedding efficiency is affectedby embedding capacity [14]. To increase the hiding capacitywith the minimum alteration rate of the carrier object, manysteganographic methods have been presented using differ-ent strategies. These methods utilize linear block codes andmatrix encoding fundamentals which include BCH codes,Hamming codes, Cyclic codes, Reed-Solomon codes, andReed-Muller codes [15], [16].
Robustness is the third requirement which measures thesteganographic method’s strength against attacks and signalprocessing operations [17]. These operations contain geomet-rical transformation, compression, cropping, and filtering.A steganographic method is robust whenever the recipientobtains the secret message accurately, without bit errors.An efficient steganography method withstands against bothadaptive noises and signal processing operations [18], [19].
A. RELATED WORKChang et al. [20] presented a data concealing algorithmusing a High Efficiency Video Coding (HEVC) utilizing bothDCT and Discrete Sine Transform (DST) methods. In thisscheme, HEVC intra frames are used to conceal the hiddenmessage without propagating the error of the distortion driftto the adjacent blocks. Blocks of quantized DCT (QDCT)and DST coefficients are selected for embedding the secretdata by using a specific intra prediction mode. The combina-tion modes of adjacent blocks will produce three directionalpatterns of error propagation for data hiding, consisting ofvertical, horizontal, and diagonal. Each of the error propa-gation patterns has a range of intra prediction modes thatprotect a group of pixels in any particular direction. Therange of the modes begins at 0 and ends at 34. Chang et al.’salgorithm has a low embedding payload because the selec-tion of blocks for the embedding process must meet certainconditions.
Ma et al. [21] presented a video data hiding for H.264coding without having an error accumulation in the intravideo frames. In the intra frame coding, the current blockpredicts its data from the encoded adjacent blocks, specif-ically from the boundary pixels of upper and left blocks.Thus, any embedding process that occurs in these blockswill propagate the distortion, negatively, to the current block.In addition, the distortion drift will be increased toward thelower right intra frame blocks. To prevent this distortiondrift, authors have developed three conditions to determinethe directions of intra frame prediction modes. To select4 × 4 QDCT coefficients of the luminance component fordata embedding, the three raised conditions must be sat-isfied together. However, this method has a low embed-ding capacity because only the luminance of the intra frameblocks that meet the three conditions are selected for hidingdata.
VOLUME 5, 2017 5355

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
Shahid et al. [22] proposed a reconstruction loop forembedding information of intra and inter frames forH.264/AVC video codec. This method embeds the secretmessage into the LSB of QDCT coefficients. Only non-zero QDCT coefficients are chosen for data hiding process,utilizing the predefined threshold, which directly depends onthe size of secret information. Edges, texture, and motionregions of intra and inter frames are utilized in the conceal-ing process. Shahid et al.’s algorithm extracts the hiddenmessage easily and maintains the efficiency of compressiondomain.
Wang et al. [23] presented a real-time watermarkingmethod in the H.264/AVC codec based on the contextadaptive binary arithmetic coding (CABAC) features. TheCABAC encoder uses a unary binarization, which is a pro-cess of concatenating all binary values of syntax elements.A certain number of motion vectors for both predicted and bi-directionally predicted frames are utilized for the data hidingprocess using the CABAC properties. The secret watermarkis concealed by displacing the binary sequence of the selectedsyntax elements orderly. This method achieves a low degra-dation of the video quality because of the difference betweenthe original code and the replacement code is very small (atmost 1 bit is altered out of the 8-bits of the selected motionvector). This small difference is also the reason of achievinga little bit-rate increase. The percentage of the increased bit-rate, µ, is calculated as follows:
µ =m− uu× 100% (1)
Where u and m indicate the bit-rate of the original andthe watermarked videos respectively. Liu et al. [24] pre-sented a robust data hiding using H.264/AVC codec with-out a deformation accumulation in the intra frame basedon BCH codes. By using the directions of the intra frameprediction, the deformation accumulation of the intra framecan be prevented. Some blocks will be chosen as carrierobject for concealing the covert message. This procedure willrely on the prediction of the intra frame modes of adjacentblocks to prevent the deformation that proliferates from theneighboring blocks. The authors applied BCH encoding tothe hidden message before the embedding phase to enhancethe method performance. Then, the encoded information isconcealed into the 4 × 4 QDCT coefficients using only aluminance plane of the intra frame. Liu et al. defined Nas a positive integer and Yij as selected DCT coefficients(i, j = 0, 1, 2, 3). The embedding process of this method iscarried out by the following steps:
1) If∣∣∣Yij∣∣∣ = N + 1 or
∣∣∣Yij∣∣∣ 6= N, then the Yij will bemodified as follows:
Yij =
Yij + 1 if Yij ≥ 0 and
∣∣∣Yij∣∣∣ = N + 1
Yij − 1 if Yij < 0 and∣∣∣Yij∣∣∣ = N + 1
Yij if∣∣∣Yij∣∣∣ 6= N + 1 or
∣∣∣Yij∣∣∣ 6= N
(2)
2) If the secret bit is 1 and∣∣∣Yij∣∣∣ = N , then the Yij will be
changed as follows:
Yij =
{Yij + 1 if Yij ≥ 0 and Yij = NYij − 1 if Yij < 0 and Yij = N
(3)
3) If the secret bit is 0 and∣∣∣Yij∣∣∣ = N, then the Yij will not
be modified.
Ke et al. [25] presented a video steganography methodrelies on replacing the bits in H.264 stream. In this algorithm,context adaptive variable length coding (CAVLC) entropycoding has been applied in the data concealing process. Dur-ing the video coding and after the quantization stage, authorsused non-zero coefficients of high frequency regions for theluminance component of the embedding process. Here, non-zero coefficients in high frequency bands are almost ‘‘+1’’or ‘‘-1’’. The embedding phase can be completed based onthe trailing ones sign flag and the level of the codewordparity flag. The sign flag of the trailing ones changes if theembedding bit equals ‘‘0’’ and the parity of the codewordis even. Also, the sign flag changes if the embedding bitequals ‘‘1’’ and the parity of the codeword is odd. Otherwise,the sign flag of the trailing ones does not change. The trailingones are modified as follows:
Trailing Ones =
{even codeword; if secret bit = 0odd codeword; if secret bit = 1
(4)
The modification of high frequency coefficients does nothave an impact on the video quality. However, the embeddingcapacity is low because Ke et al.’s method is established onthe non-zero coefficients of the high frequencies that consistof a large majority of zeros.Alavianmehr et al. [26] presented a robust uncompressed
video steganography by utilizing the histogram distributionconstrained (HDC). In this method, the Y component of everyframe is segmented into non-overlapping blocks (C) of sizem × n. Then, the secret message is concealed into theseblocks based on the shifting process. The selected blocksare changed only when the secret message bits are ‘‘1’’.Alavianmehr et al.’s method withstands against compressionattack. However, it utilizes only Y plane for data embeddingprocess.
B. MOTIVATIONS AND RESEARCH PROBLEMVideo steganography is getting the attention of researchersin the area of video processing due to substantial growth invideo data. The recent literature reports a significant amountof video steganography algorithms. Unfortunately, many ofthese algorithms lack the preprocessing stages. Particularly,there is no video steganography algorithm that includes pre-processing stages for both secret messages and cover videos.Moreover, existing steganography techniques suffer majorweakness in several aspects including security, embeddingcapacity, imperceptibility, and robustness against attacks.
5356 VOLUME 5, 2017

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
This paper is motivated by the limitations of the existingvideo steganography algorithms, and is based on the follow-ing reasons to improve the performance of these algorithms:
• By utilizing the preprocessing stages to include themanipulation on both secret messages and cover videosearlier to the embedding stage in order to enhance thesecurity and robustness of the steganographic method.
• Using a portion of each video frame as regions of interestfor the concealing process, the imperceptibility of stegovideos will improve. Accordingly, we track multiplemoving objects in video. Since it is very challenging forhackers to recognize the position of the hidden messagein video frames because the hidden message is onlyconcealed into moving objects, which changes over timefrom one frame to another, it is necessary to preserve thesecurity and robustness of embedded data.
• Applying encryption methods and ECC such as Ham-ming codes and BCH codes to encode the hidden mes-sage earlier to the concealing stage will produce a secureand robust steganographic algorithm.
• Transforming video frames into frequency domain suchas DWT and DCT transformations will improve therobustness of the steganographic method against attacks,hence preserving imperceptibility of stego videos.
The remaining parts of the paper are organized as follows:Section 2 explainsDWTandDCT transformations. Hammingand BCH ECC are given in Section 3. Section 4 presentsthe motion-based MOT. The proposed video steganographymethodology is illustrated in Section 5. Section 6 providesexperimental results and discussion. Finally, Section 7 con-cludes the paper and suggests future directions.
II. DWT AND DCT TRANSFORMATIONSDWT and DCT are well-known methods which convert digi-tal data from the spatial domain to the transform domain [27].First, the two-dimensional DWT is a multi-resolution processthat decomposes the video frame into approximation, hori-zontal, vertical, and diagonal sub-bands using low and highpass decomposition filters. Fig. 2 illustrates the first level ofa two-dimensional DWT decomposition showing each of LL,LH, HL, and HH sub-bands. In order to perform an absolutereconstruction process, the following wavelet equations arerequired:
Lo_D(z)Hi_D(z)+ Lo_R (z)Hi_R(z) = 2 (5)
Lo_R(z) = z−kHi_D (−z) (6)
Hi_R (z) = zkLo_D(−z) (7)
Where Lo_D (z) and Hi_D (z)indicate the decompositionwavelet filters, and Lo_R (z) and Hi_R (z) represent thereconstruction wavelet filters. Haar wavelet filters are givenin the following questions:
Lo_D(z) =12(1+ z−1) (8)
Hi_D(z) = (z+ 1) (9)
FIGURE 2. First level of a two-dimensional DWT decomposition [28].
Hi_R (z) =12(z− 1) (10)
Lo_R(z) =(z−1 − 1
)(11)
Second, the DCT is mainly applied in video and imagecompression. A two-dimensional DCT represents to aone-dimensional DCT which applies on the first dimen-sion followed by a one-dimensional DCT on the seconddimension [29], [30]. A video frame, A, of size M × N , thetwo-dimensional DCT and the inverse of the two-dimensionalDCT are calculated as follows, respectively [31]:
Bpq = ∝p∝q∑M−1
m=0
∑N−1
n=0Amn
cosπ (2m+ 1) p
2Mcos
π (2n+ 1) q2N
(12)
Amn =∑M−1
p=0
∑N−1
q=0∝p∝q Bpq
cosπ (2m+ 1) p
2Mcos
π (2n+ 1) q2N
(13)
Where ∝p =
1√M, p = 0√
2M, 1 ≤ p ≤ M − 1
And ∝q =
1√N, q = 0√
2N , 1 ≤ q ≤ N − 1
p and q are the transformations of m and n, and they havethe resolution of M × N .
III. HAMMING AND BCH ECCIn our proposed work, the Hamming (7, 4) codes is uti-lized (n = 7, k = 4, and p = 3), where a unique biterror can be fixed. A message of size M (m1,m2, . . . ,mk )is encoded by adding p(p1, p2, p3) additional bits as par-ity to be converted into a codeword of 7-bit length [32].
VOLUME 5, 2017 5357

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
FIGURE 3. Venn diagram of the Hamming codes (7, 4).
The ordinary combination of each message and parity are tosort parity bits at the order of 2i (i = 0, 1, . . . , n− k) such asp1, p2,m1, p3,m2,m3,m4 arrangement. A Venn diagram ofthe hamming codes (7, 4) is illustrated in the Fig. 3.
In addition to Hamming codes, BCH (7, 4) codes are alsoused over the Galois field GF (2m), where m = 3, k = 4, andn = 23 − 1 = 7. BCH codes are strong random cyclic codeswhich are utilized to detect and correct errors. The generatorpolynomial g(x) is the polynomial of the lowest degree in theGalois field GF (2), with ∝,∝2,∝3, . . . ,∝2t as roots on thecondition that ∝ is a primitive of GF (2m). When Mi (x) is aminimal polynomial of ∝i where (1 ≤ i ≤ 2t), then the leastcommon multiple (LCM) of 2t minimal polynomials will bethe generator polynomial g(x). The parity-checkmatrix H andg(x) function of the BCH codes [19], [33] are illustrated asfollows:
H =
1 ∝ ∝2
∝3 . . . ∝n−1
1(∝
3) (
∝3)2 (
∝3)3
. . .(∝
3)n−1
1(∝
5) (
∝5)2 (
∝5)3
. . .(∝
5)n−1
· · · · ·
· · · · ·
· · · · ·
1(∝
2t−1) (∝
2t−1)2 (∝
2t−1)3. . .
(∝
2t−1)n−1
(14)
g (x) = lcmM1 (x) ,M2 (x) ,M3 (x) , . . . ,M2t (x) (15)
g(x) = M1 (x)M3 (x)M5 (x) . . .M2t−1 (x) (16)
A binary BCH (n, k, t) codes can fix t-bit errors in acodeword W = {w0,w1,w2, . . . ,wn−1 of size n and asecret message A = {a0, a1, a2, . . . , ak−1 of length k [34].An embedded codeword C = {c0, c1, c2, . . . , cn−1 is calcu-lated as follows:
C = W ∗ HT (17)
At the recipient end, the code R = {r0, r1, r2, . . . , rn−1is acquired. Each of the original and obtained codewordsare described as polynomials, where C (X) = c0 + c1x1 +. . .+ cn−1xn−1, and R (X) = r0 + r1x1 + . . .+ rn−1xn−1. E
represents the error between C and R. E and syndrome Y arecalculated as follows:
E = R− C (18)
Y = (R− C)HT= EHT (19)
IV. MOTION-BASED MOTDue to its various applications, computer vision is one ofthe fastest emerging fields in computer science. The detec-tion and tracking of moving objects within the computervision field has recently gained significant attention [35].Lin et al. [36] proposed a tube-and-droplet-based approachfor representing and analyzingmotion trajectories. This paperaddressedmain issues of motion trajectories in an informativemanner. Firstly, a 3D tube is constructed to represent thetrajectories. Then a droplet vector is derived from the con-structed 3D tube, which has the following properties: 1) themotion information of a trajectory is maintained, 2) the entirecontextual pattern throughout a trajectory is embedded, and3) information about a trajectory in an obvious and unifiedmanner is visualized.Another related work is presented by Ma et al. [37] about
long-term correlation tracking by addressing visual track-ing issues caused by abrupt motion, heavy occlusion, defor-mation, and out-of-view. The method decomposed the taskof tracking into translation and scale estimation of objects.The accuracy and reliability of the translation estimation isimproved by considering the correlation between temporalcontexts, resulting in better efficiency, accuracy, and robust-ness compared to existing methods of literature.Ma et al. [38] proposed hierarchical convolutional features
for visual tracking by improving the tracking accuracy androbustness using deep features of convolutional neural net-works. In order to encode the target appearance, the corre-lation filters have learned on each convolutional layer. Theexperimental results show thatMa’s algorithm outperformedrelated works.The tracking of moving objects is commonly divided into
two major phases: 1) detection of moving objects in anindividual video frame, and 2) association of these detectedobjects throughout all video frames in order to constructcomplete tracks [39], [40].In the first phase, the background subtraction technique
is utilized to detect the regions of interest such as movingobjects. This technique is based on the Gaussian mixturemodel (GMM), which is the probability of density func-tion that equals to a weighted sum of component Gaussiandensities. The background subtraction method computes thedifferences between consecutive frames that generate theforeground mask. Then, the noises will be eliminated fromthe foreground mask by using morphological operations.As a result, the corresponding moving objects are detectedfrom groups of connected pixels.The second phase is called data association. It is based
on the motion of the detected object. A Kalman filter isemployed to speculate the motion of each trajectory. In each
5358 VOLUME 5, 2017
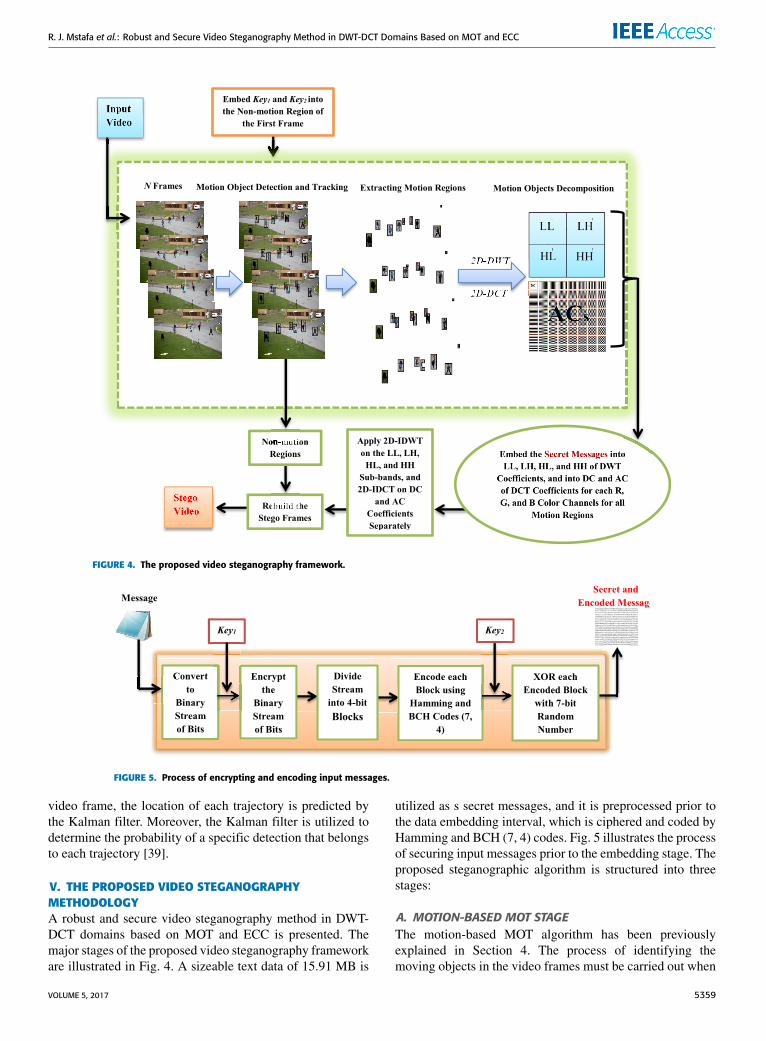
R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
FIGURE 4. The proposed video steganography framework.
FIGURE 5. Process of encrypting and encoding input messages.
video frame, the location of each trajectory is predicted bythe Kalman filter. Moreover, the Kalman filter is utilized todetermine the probability of a specific detection that belongsto each trajectory [39].
V. THE PROPOSED VIDEO STEGANOGRAPHYMETHODOLOGYA robust and secure video steganography method in DWT-DCT domains based on MOT and ECC is presented. Themajor stages of the proposed video steganography frameworkare illustrated in Fig. 4. A sizeable text data of 15.91 MB is
utilized as s secret messages, and it is preprocessed prior tothe data embedding interval, which is ciphered and coded byHamming and BCH (7, 4) codes. Fig. 5 illustrates the processof securing input messages prior to the embedding stage. Theproposed steganographic algorithm is structured into threestages:
A. MOTION-BASED MOT STAGEThe motion-based MOT algorithm has been previouslyexplained in Section 4. The process of identifying themoving objects in the video frames must be carried out when
VOLUME 5, 2017 5359

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
FIGURE 6. Left column: four video frames from S2L1 PETS2009dataset [41], middle column: detecting multiple motion objects in thecorresponding frames, and right column: foreground masks for thecorresponding frames.
motion object regions are utilized as host data. This process isachieved by detecting each moving object within an individ-ual frame, and then associating these detections throughoutall of the video frames. The background subtraction methodis applied to detect the moving objects based on the GMM.It also computes the differences between consecutive framesthat generate the foreground mask. Then, the Kalman filteris employed to predict estimation trajectory of each movingregion. Fig. 6 shows a number of video frames that containmultiple objects and their foreground masks.
B. DATA EMBEDDING STAGEIn entire video frames, the host data of our proposedmethod isthe motion objects that are considered as regions of interest.By using the motion-based MOT algorithm, the process ofdetecting and tracking the motion regions over all videoframes are achieved. The regions of interest altered in eachvideo frame is dependent on the number and the size of themoving objects. In every frame, 2D-DWT is implemented onRGB channels of each motion region resulting LL, LH, HL,and HH subbands.
In addition, 2D-DCT is also applied on the same motionregions generating DC and AC coefficients. Thereafter, thesecret messages are concealed into LL, LH, HL, and HH ofDWT coefficients, and into DC and AC of DCT coefficientsof each motion object separately based on its foregroundmask. Furthermore, both secret keys are transmitted to thereceiver side by embedding them into the non-motion area ofthe first frame. Upon accomplishment, the stego video framesare rebuild in order to construct the stego video that canbe transmitted through the unsecure medium to the receiver.Algorithm 1 clarifies the major steps of our embeddingalgorithm.
C. DATA EXTRACTION STAGEIn order to recover hidden messages accurately, the embed-ded video is separated into a number of frames throughthe receiver side, and then two secret keys are obtainedfrom the non-motion region of the first video frame. Topredict trajectories of motion objects, the motion-basedMOTalgorithm is applied again by the receiver. Then, 2D-DWT
Algorithm 1 Data Embedding Stage
and 2D-DCT are employed on the RGB channels of eachmotion object in order to create LL, LH, HL, and HHsubbands, and DC and AC coefficients, respectively. Next,the extracting process of the embedded data is achieved byobtaining the secret messages fromLL, LH, HL, HH,DC, andAC coefficients of each motion region over all video framesbased on the same foreground masks used in the embeddingstage. The extracted secret message is decoded by Hammingand BCH (7, 4), and then decrypted to obtain the originalmessage. The essential steps of data extracting algorithm areshown in the Algorithm 2.
VI. EXPERIMENTAL RESULTS AND DISCUSSIONA S2L1 video sequence was used from the well-knownPETS2009 dataset [41]. The proposed algorithm results areachieved using MATLAB implementation of the algorithm.
5360 VOLUME 5, 2017
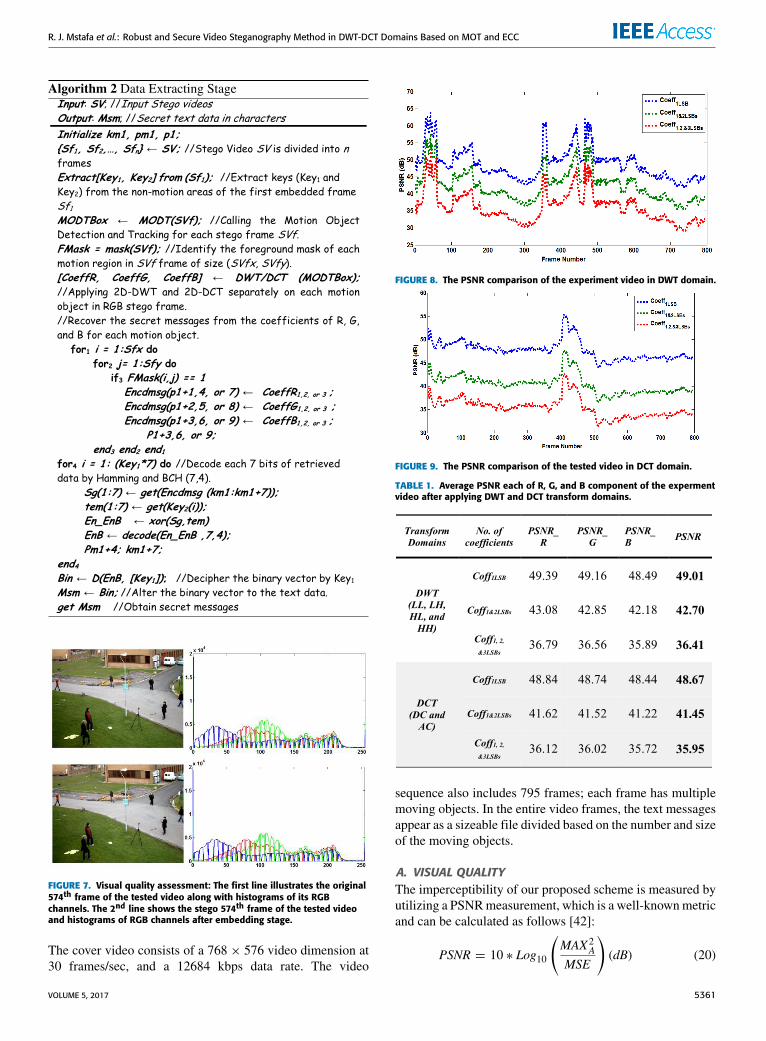
R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
Algorithm 2 Data Extracting Stage
FIGURE 7. Visual quality assessment: The first line illustrates the original574th frame of the tested video along with histograms of its RGBchannels. The 2nd line shows the stego 574th frame of the tested videoand histograms of RGB channels after embedding stage.
The cover video consists of a 768 × 576 video dimension at30 frames/sec, and a 12684 kbps data rate. The video
FIGURE 8. The PSNR comparison of the experiment video in DWT domain.
FIGURE 9. The PSNR comparison of the tested video in DCT domain.
TABLE 1. Average PSNR each of R, G, and B component of the expermentvideo after applying DWT and DCT transform domains.
sequence also includes 795 frames; each frame has multiplemoving objects. In the entire video frames, the text messagesappear as a sizeable file divided based on the number and sizeof the moving objects.
A. VISUAL QUALITYThe imperceptibility of our proposed scheme is measured byutilizing a PSNRmeasurement, which is a well-knownmetricand can be calculated as follows [42]:
PSNR = 10 ∗ Log10
(MAX2
A
MSE
)(dB) (20)
VOLUME 5, 2017 5361
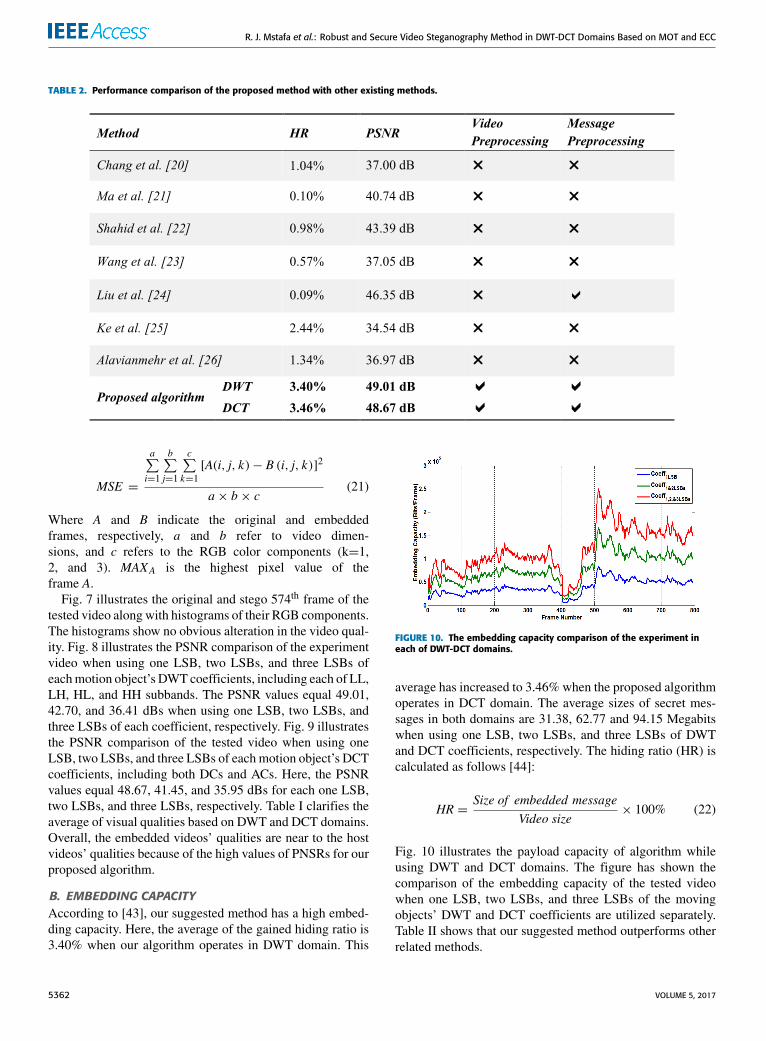
R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
TABLE 2. Performance comparison of the proposed method with other existing methods.
MSE =
a∑i=1
b∑j=1
c∑k=1
[A(i, j, k)− B (i, j, k)]2
a× b× c(21)
Where A and B indicate the original and embeddedframes, respectively, a and b refer to video dimen-sions, and c refers to the RGB color components (k=1,2, and 3). MAXA is the highest pixel value of theframe A.Fig. 7 illustrates the original and stego 574th frame of the
tested video along with histograms of their RGB components.The histograms show no obvious alteration in the video qual-ity. Fig. 8 illustrates the PSNR comparison of the experimentvideo when using one LSB, two LSBs, and three LSBs ofeachmotion object’s DWT coefficients, including each of LL,LH, HL, and HH subbands. The PSNR values equal 49.01,42.70, and 36.41 dBs when using one LSB, two LSBs, andthree LSBs of each coefficient, respectively. Fig. 9 illustratesthe PSNR comparison of the tested video when using oneLSB, two LSBs, and three LSBs of each motion object’s DCTcoefficients, including both DCs and ACs. Here, the PSNRvalues equal 48.67, 41.45, and 35.95 dBs for each one LSB,two LSBs, and three LSBs, respectively. Table I clarifies theaverage of visual qualities based on DWT and DCT domains.Overall, the embedded videos’ qualities are near to the hostvideos’ qualities because of the high values of PNSRs for ourproposed algorithm.
B. EMBEDDING CAPACITYAccording to [43], our suggested method has a high embed-ding capacity. Here, the average of the gained hiding ratio is3.40% when our algorithm operates in DWT domain. This
FIGURE 10. The embedding capacity comparison of the experiment ineach of DWT-DCT domains.
average has increased to 3.46% when the proposed algorithmoperates in DCT domain. The average sizes of secret mes-sages in both domains are 31.38, 62.77 and 94.15 Megabitswhen using one LSB, two LSBs, and three LSBs of DWTand DCT coefficients, respectively. The hiding ratio (HR) iscalculated as follows [44]:
HR =Size of embedded message
Video size× 100% (22)
Fig. 10 illustrates the payload capacity of algorithm whileusing DWT and DCT domains. The figure has shown thecomparison of the embedding capacity of the tested videowhen one LSB, two LSBs, and three LSBs of the movingobjects’ DWT and DCT coefficients are utilized separately.Table II shows that our suggested method outperforms otherrelated methods.
5362 VOLUME 5, 2017
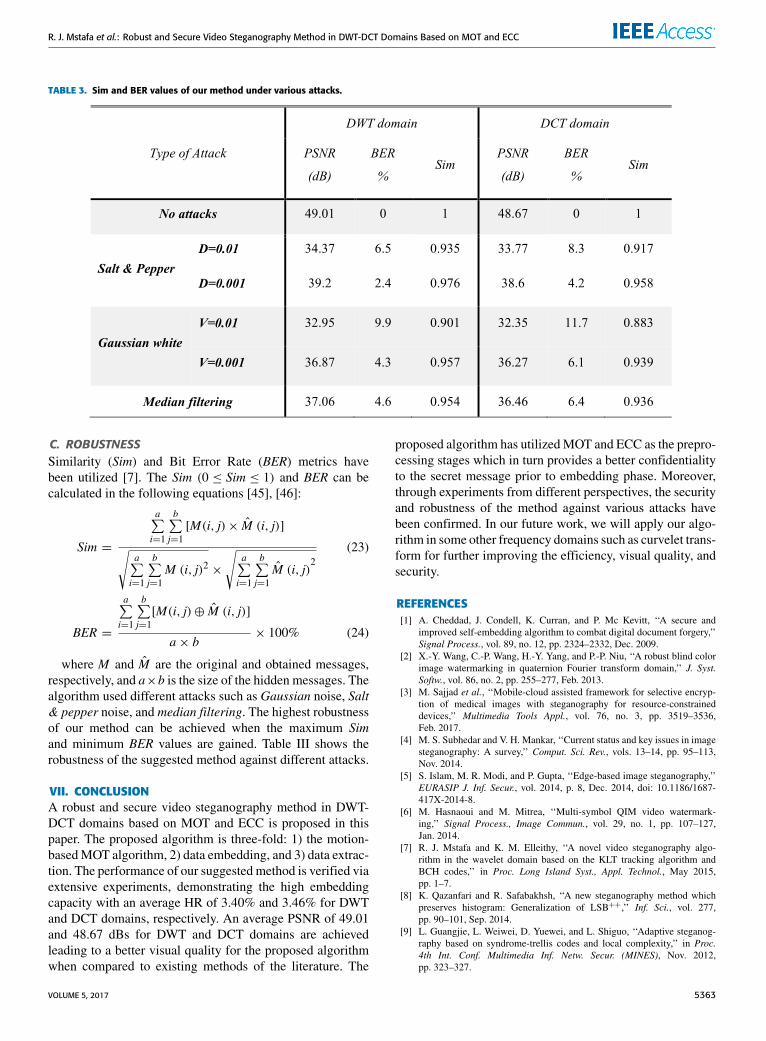
R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
TABLE 3. Sim and BER values of our method under various attacks.
C. ROBUSTNESSSimilarity (Sim) and Bit Error Rate (BER) metrics havebeen utilized [7]. The Sim (0 ≤ Sim ≤ 1) and BER can becalculated in the following equations [45], [46]:
Sim =
a∑i=1
b∑j=1
[M (i, j)× M (i, j)]√a∑i=1
b∑j=1
M (i, j)2 ×
√a∑i=1
b∑j=1
M (i, j)2
(23)
BER =
a∑i=1
b∑j=1
[M (i, j)⊕ M (i, j)]
a× b× 100% (24)
where M and M are the original and obtained messages,respectively, and a×b is the size of the hidden messages. Thealgorithm used different attacks such as Gaussian noise, Salt& pepper noise, and median filtering. The highest robustnessof our method can be achieved when the maximum Simand minimum BER values are gained. Table III shows therobustness of the suggested method against different attacks.
VII. CONCLUSIONA robust and secure video steganography method in DWT-DCT domains based on MOT and ECC is proposed in thispaper. The proposed algorithm is three-fold: 1) the motion-basedMOT algorithm, 2) data embedding, and 3) data extrac-tion. The performance of our suggested method is verified viaextensive experiments, demonstrating the high embeddingcapacity with an average HR of 3.40% and 3.46% for DWTand DCT domains, respectively. An average PSNR of 49.01and 48.67 dBs for DWT and DCT domains are achievedleading to a better visual quality for the proposed algorithmwhen compared to existing methods of the literature. The
proposed algorithm has utilizedMOT and ECC as the prepro-cessing stages which in turn provides a better confidentialityto the secret message prior to embedding phase. Moreover,through experiments from different perspectives, the securityand robustness of the method against various attacks havebeen confirmed. In our future work, we will apply our algo-rithm in some other frequency domains such as curvelet trans-form for further improving the efficiency, visual quality, andsecurity.
REFERENCES[1] A. Cheddad, J. Condell, K. Curran, and P. Mc Kevitt, ‘‘A secure and
improved self-embedding algorithm to combat digital document forgery,’’Signal Process., vol. 89, no. 12, pp. 2324–2332, Dec. 2009.
[2] X.-Y. Wang, C.-P. Wang, H.-Y. Yang, and P.-P. Niu, ‘‘A robust blind colorimage watermarking in quaternion Fourier transform domain,’’ J. Syst.Softw., vol. 86, no. 2, pp. 255–277, Feb. 2013.
[3] M. Sajjad et al., ‘‘Mobile-cloud assisted framework for selective encryp-tion of medical images with steganography for resource-constraineddevices,’’ Multimedia Tools Appl., vol. 76, no. 3, pp. 3519–3536,Feb. 2017.
[4] M. S. Subhedar and V. H. Mankar, ‘‘Current status and key issues in imagesteganography: A survey,’’ Comput. Sci. Rev., vols. 13–14, pp. 95–113,Nov. 2014.
[5] S. Islam, M. R. Modi, and P. Gupta, ‘‘Edge-based image steganography,’’EURASIP J. Inf. Secur., vol. 2014, p. 8, Dec. 2014, doi: 10.1186/1687-417X-2014-8.
[6] M. Hasnaoui and M. Mitrea, ‘‘Multi-symbol QIM video watermark-ing,’’ Signal Process., Image Commun., vol. 29, no. 1, pp. 107–127,Jan. 2014.
[7] R. J. Mstafa and K. M. Elleithy, ‘‘A novel video steganography algo-rithm in the wavelet domain based on the KLT tracking algorithm andBCH codes,’’ in Proc. Long Island Syst., Appl. Technol., May 2015,pp. 1–7.
[8] K. Qazanfari and R. Safabakhsh, ‘‘A new steganography method whichpreserves histogram: Generalization of LSB++,’’ Inf. Sci., vol. 277,pp. 90–101, Sep. 2014.
[9] L. Guangjie, L. Weiwei, D. Yuewei, and L. Shiguo, ‘‘Adaptive steganog-raphy based on syndrome-trellis codes and local complexity,’’ in Proc.4th Int. Conf. Multimedia Inf. Netw. Secur. (MINES), Nov. 2012,pp. 323–327.
VOLUME 5, 2017 5363

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
[10] A. K. Singh, B. Kumar, S. K. Singh, S. P. Ghrera, and A.Mohan, ‘‘Multiplewatermarking technique for securing online social network contents usingBack Propagation Neural Network,’’ Future Generat. Comput. Syst., to bepublished. doi: 10.1016/j.future.2016.11.023
[11] C. Rupa, ‘‘A digital image steganography using sierpinski gasket frac-tal and PLSB,’’ J. Inst. Eng. (India), B, vol. 94, no. 3, pp. 147–151,Sep. 2013.
[12] R. J. Mstafa and K. M. Elleithy, ‘‘Compressed and raw video steganogra-phy techniques: A comprehensive survey and analysis,’’Multimedia ToolsAppl., pp. 1–38, 2016, doi: 10.1007/s11042-016-4055-1.
[13] K. Muhammad et al., ‘‘A secure method for color image steganographyusing gray-level modification and multi-level encryption,’’ KSII Trans.Internet Inf. Syst., vol. 9, no. 5, pp. 1938–1962, 2015.
[14] A. K. Singh, M. Dave, and A. Mohan, ‘‘Hybrid technique for robust andimperceptible multiple watermarking using medical images,’’ MultimediaTools Appl., vol. 75, no. 14, pp. 8381–8401, Jul. 2016.
[15] R. Zhang, V. Sachnev, and H. J. Kim, ‘‘Fast BCH syndrome codingfor steganography,’’ in Information Hiding (Lecture Notes in ComputerScience), vol. 5806, S. Katzenbeisser and A.-R. Sadeghi, Eds. Berlin,Germany: Springer, 2009, pp. 48–58, doi: 10.1007/978-3-642-04431-1_4.
[16] C. Fontaine and F. Galand, ‘‘How can Reed–Solomon codes improvesteganographic schemes?’’ in Information Hiding (Lecture Notes in Com-puter Science), vol. 4567, T. Furon, F. Cayre, G. Doërr, and P. Bas, Eds.Berlin, Germany: Springer, 2007, pp. 130–144, doi: 10.1007/978-3-540-77370-2_9.
[17] A. Khan, A. Siddiqa, S. Munib, and S. A. Malik, ‘‘A recent survey ofreversible watermarking techniques,’’ Inf. Sci., vol. 279, pp. 251–272,Sep. 2014.
[18] Y. Tew and K. Wong, ‘‘An overview of information hiding in H.264/AVCcompressed video,’’ IEEE Trans. Circuits Syst. Video Technol., vol. 24,no. 2, pp. 305–319, Feb. 2014.
[19] R. J. Mstafa and K. M. Elleithy, ‘‘A high payload video steganographyalgorithm inDWTdomain based onBCHcodes (15, 11),’’ inProc.WirelessTelecommun. Symp. (WTS), Apr. 2015, pp. 1–8.
[20] P.-C. Chang, K.-L. Chung, J.-J. Chen, C.-H. Lin, and T.-J. Lin,‘‘A DCT/DST-based error propagation-free data hiding algorithm forHEVC intra-coded frames,’’ J. Vis. Commun. Image Represent., vol. 25,no. 2, pp. 239–253, Feb. 2014.
[21] X. Ma, Z. Li, H. Tu, and B. Zhang, ‘‘A data hiding algorithm forH.264/AVC video streams without intra-frame distortion drift,’’ IEEETrans. Circuits Syst. Video Technol., vol. 20, no. 10, pp. 1320–1330,Oct. 2010.
[22] Z. Shahid, M. Chaumont, and W. Puech, ‘‘Considering the reconstructionloop for data hiding of intra- and inter-frames of H.264/AVC,’’ Signal,Image Video Process., vol. 7, no. 1, pp. 75–93, Jan. 2013.
[23] R. Wang, L. Hu, and D. Xu, ‘‘A watermarking algorithm based on theCABAC entropy coding for H.264/AVC,’’ J. Comput. Inf. Syst., vol. 7,no. 6, pp. 2132–2141, 2011.
[24] Y. Liu, Z. Li, X. Ma, and J. Liu, ‘‘A robust data hiding algorithm forH.264/AVC video streams,’’ J. Syst. Softw., vol. 86, no. 8, pp. 2174–2183,Aug. 2013.
[25] N. Ke and Z. Weidong, ‘‘A video steganography scheme based on H.264bitstreams replaced,’’ in Proc. 4th IEEE Int. Conf. Softw. Eng. ServiceSci. (ICSESS), May 2013, pp. 447–450.
[26] M. A. Alavianmehr, M. Rezaei, M. S. Helfroush, and A. Tashk, ‘‘A losslessdata hiding scheme on video raw data robust against H.264/AVC compres-sion,’’ in Proc. 2nd Int. eConf. Comput. Knowl. Eng. (ICCKE), Oct. 2012,pp. 194–198.
[27] B. G. Vani and E. V. Prasad, ‘‘High secure image steganography based onhopfield chaotic neural network and wavelet transforms,’’ Int. J. Comput.Sci. Netw. Secur., vol. 13, no. 3, pp. 1–6, 2013.
[28] S. G. Mallat, ‘‘A theory for multiresolution signal decomposition:The wavelet representation,’’ IEEE Trans. Pattern Anal. Mach. Intell.,vol. 11, no. 7, pp. 674–693, Jul. 1989.
[29] A. K. Jain, Fundamentals of Digital Image Processing. Englewood Cliffs,NJ, USA: Prentice-Hall, 1989.
[30] R. J. Mstafa and K. M. Elleithy, ‘‘A novel video steganography algorithmin DCT domain based on Hamming and BCH codes,’’ in Proc. IEEE 37thSarnoff Symp., Sep. 2016, pp. 208–213.
[31] R. J. Mstafa and K. M. Elleithy, ‘‘A DCT-based robust videosteganographic method using BCH error correcting codes,’’ in Proc.IEEE Long Island Syst., Appl. Technol. Conf. (LISAT), Apr. 2016,pp. 1–6.
[32] K. Muhammad, M. Sajjad, and S. W. Baik, ‘‘Dual-level security basedcyclic18 steganographic method and its application for secure transmissionof keyframes during wireless capsule endoscopy,’’ J. Med. Syst., vol. 40,no. 5, pp. 1–16, 2016.
[33] H. Yoo, J. Jung, J. Jo, and I.-C. Park, ‘‘Area-efficient multimode encodingarchitecture for long BCH codes,’’ IEEE Trans. Circuits Syst. II, ExpressBriefs, vol. 60, no. 12, pp. 872–876, Dec. 2013.
[34] R. J. Mstafa and K. M. Elleithy, ‘‘An efficient video steganography algo-rithm based on BCH codes,’’ in Proc. Northeast Section Conf. Amer. Soc.Eng. Edu. (ASEE), 2015, pp. 1–10.
[35] K. Muhammad, J. Ahmad, M. Sajjad, and S. W. Baik, ‘‘Visual saliencymodels for summarization of diagnostic hysteroscopy videos in healthcaresystems,’’ SpringerPlus, vol. 5, no. 1, p. 1495, 2016.
[36] W. Lin et al., ‘‘A tube-and-droplet-based approach for representing andanalyzing motion trajectories,’’ IEEE Trans. Pattern Anal. Mach. Intell., tobe published.
[37] C. Ma, X. Yang, Z. Chongyang, and M.-H. Yang, ‘‘Long-term correlationtracking,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR),Jun. 2015, pp. 5388–5396.
[38] C.Ma, J.-B. Huang, X. Yang, andM.-H. Yang, ‘‘Hierarchical convolutionalfeatures for visual tracking,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV),Dec. 2015, pp. 3074–3082.
[39] A. Yilmaz, O. Javed, and M. Shah, ‘‘Object tracking: A survey,’’ ACMComput. Surv., vol. 38, no. 4, pp. 1–45, 2006.
[40] R. J. Mstafa and K. M. Elleithy, ‘‘A new video steganography algorithmbased on the multiple object tracking and Hamming codes,’’ in Proc. IEEE14th Int. Conf. Mach. Learn. Appl. (ICMLA), Dec. 2015, pp. 335–340.
[41] J. Ferryman and A. Shahrokni, ‘‘PETS2009: Dataset and challenge,’’ inProc. 20th IEEE Int. Workshop Perform. Eval. Tracking Surveill., Dec.2009, pp. 1–6, doi: 10.1109/PETS-WINTER.2009.5399556.
[42] R. J. Mstafa and K. M. Elleithy, ‘‘A video steganography algorithm basedon Kanade–Lucas–Tomasi tracking algorithm and error correcting codes,’’Multimedia Tools Appl., vol. 75, no. 17, pp. 10311–10333, Sep. 2016.
[43] T.-H. Lan and A. H. Tewfik, ‘‘A novel high-capacity data-embeddingsystem,’’ IEEE Trans. Image Process., vol. 15, no. 8, pp. 2431–2440,Aug. 2006.
[44] K. Muhammad, M. Sajjad, I. Mehmood, S. Rho, and S. W. Baik, ‘‘A novelmagic LSB substitutionmethod (M-LSB-SM) usingmulti-level encryptionand achromatic component of an image,’’Multimedia Tools Appl., vol. 75,no. 22, pp. 14867–14893, Nov. 2016.
[45] Y. He, G. Yang, and N. Zhu, ‘‘A real-time dual watermarking algorithm ofH.264/AVC video stream for video-on-demand service,’’ AEU-Int. J. Elec-tron. Commun., vol. 66, no. 4, pp. 305–312, Apr. 2012.
[46] A. K. Singh, B. Kumar, M. Dave, and A. Mohan, ‘‘Robust and imper-ceptible dual watermarking for telemedicine applications,’’ Wireless Pers.Commun., vol. 80, no. 4, pp. 1415–1433, Feb. 2015.
RAMADHAN J. MSTAFA (M’14) was bornin Duhok, Kurdistan Region, Iraq. He receivedthe bachelor’s degree in computer science fromSalahaddin University-Erbil, Erbil, Iraq, and themaster’s degree in computer science from the Uni-versity of Duhok, Duhok. He is currently pursuingthe Ph.D. degree in computer science and engi-neering with the University of Bridgeport, Bridge-port, CT, USA. His research areas of interestinclude image processing, mobile communication,
security, watermarking, and steganography. He is an ACM Student Member.
5364 VOLUME 5, 2017

R. J. Mstafa et al.: Robust and Secure Video Steganography Method in DWT-DCT Domains Based on MOT and ECC
KHALED M. ELLEITHY is currently the AssociateVice President of Graduate Studies and Researchwith the University of Bridgeport. He is also aProfessor of Computer Science and Engineering.He has over 25 years of teaching experience.His teaching evaluations are distinguished in allthe universities he joined. He supervised hundredsof senior projects, M.S. theses, and Ph.D. dis-sertations. He supervised several Ph.D. students.He developed and introduced many new under-
graduate/graduate courses. He also developed new teaching/research labo-ratories in his area of expertise. He has authored over 350 research papers ininternational journals and conferences in his areas of expertise. He is an Edi-tor or a Co-Editor for 12 books by Springer. He has research interests in theareas of wireless sensor networks, mobile communications, network security,quantum computing, and formal approaches for design and verification.He is a member of technical program committees of many international con-ferences as recognition of his research qualifications. He was the Chairmanof the International Conference on Industrial Electronics, Technology andAutomation, IETA 2001, 2001, Cairo, Egypt. Also, he is the General Chairof the 2005–2013 International Joint Conferences on Computer, Information,and Systems Sciences, and Engineering virtual conferences. He served as aGuest Editor for several International Journals.
EMAN ABDELFATTAH received the M.S. degreein computer science and the Ph.D. degree in com-puter science and engineering from the Universityof Bridgeport in 2002 and 2011, respectively.
She was a Professional Assistant Professor ofComputer Science with the School of Engineeringand Computing Sciences, Texas A&MUniversity-Corpus Christi. She was also an Adjunct Professorwith the Department of Computer Science andEngineering and the Department of Mathematics,
University of Bridgeport. She is currently a Lecturer with the School ofComputing, SacredHeart University, and also anAdjunct Assistant Professorwith American Intercontinental University Online. Her research results werepublished in prestigious international conferences. She has research interestsin the areas of network security, networking, and mobile communications.She actively participated as a Committee Member of the International Con-ferences on Engineering Education, Instructional Technology, Assessment,and E-learning from 2005 to 2014.
VOLUME 5, 2017 5365