a parametric framework for video compression using region-based texture models
TRANSCRIPT

IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011 1
A Parametric Framework for Video CompressionUsing Region-Based Texture Models
David R. Bull, Senior Member, IEEE, and Fan Zhang, Member, IEEE
Abstract—This paper presents a novel means of video compres-sion based on texture warping and synthesis. Instead of encodingwhole images or prediction residuals after translational motionestimation, our algorithm employs a perspective motion modelto warp static textures and utilizes texture synthesis to createdynamic textures. Texture regions are segmented using featuresderived from the complex wavelet transform and further classifiedaccording to their spatial and temporal characteristics. Moreover,a compatible artifact-based video metric (AVM) is proposed withwhich to evaluate the quality of the reconstructed video. This isalso employed in-loop to prevent warping and synthesis artifacts.The proposed algorithm has been integrated into an H.264 videocoding framework. The results show significant bitrate savings,of up to 60% compared with H.264 at the same objective quality(based on AVM) and subjective scores.
Index Terms—Compression, synthesis, texture, video, videoquality assessment, warping.
I. INTRODUCTION
R ECENT advances in communication and compres-sion technologies have facilitated the transmission of
high-quality video content across a broad range of networksto numerous terminal types. However, many networks do notsupport transmitting high-quality video in real time becauseof the limited bandwidth and the large bitrates required forcontemporary formats. In this context, there is renewed activityto devise algorithms which offer enhanced compression effi-ciency. For example, a framework for High Efficiency VideoCoding (HEVC/H.265) [1] has been proposed and is currentlybeing developed by the Moving Picture Experts Group (MPEG)and the Joint Collaborative Team on Video Coding (JCT-VC).The techniques currently under evaluation for HEVC are allextensions to the conventional hybrid (motion compensated,block transform) compression model.In most cases, the target of video compression is to provide
good subjective quality rather than to simply produce the mostsimilar pictures to the originals. Based on this assumption, it is
Manuscript received February 22, 2011; revised June 03, 2011; accepted July29, 2011. Date of publication August 18, 2011; date of current version nulldate.This work was supported by the Overseas Research Students Awards Scheme(ORSAS). The associate editor coordinating the review of this manuscript andapproving it for publication was Dr. Edward J. Delp.The authors are with the Department of Electrical and Electronic
Engineering, University of Bristol, Bristol BS8 1UB, U.K. (e-mail:[email protected]; [email protected]).Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org.Digital Object Identifier 10.1109/JSTSP.2011.2165201
possible to conceive of a compression scheme where an anal-ysis/synthesis framework is employed rather than the conven-tional energy minimization approach. If such a scheme werepractical, it could offer lower bitrates through reduced residualand motion vector coding, using a parametric approach to de-scribe texture warping and/or synthesis. This approach has beenreported previously by authors such as Ndjiki-Nya et al. [2]–[6],Bosch et al. [7], [8], Bryne et al. [9], [10], and Zhang and Bull[11], [12]. Although this approach has shown significant poten-tial, a number of problems introduced by texture analysis andsynthesis still need to be resolved.This paper introduces a new framework for video com-
pression which robustly combines dynamic and static texturesynthesis using robust region segmentation, classification andquality assessment. The new compression system is hostedby a conventional block-based codec which is used wherevertexture synthesis fails or is inappropriate.Textured regions in images or video frames have arbitrary
shapes and these must first be segmented into homogeneous re-gions, each sharing similar texture properties. We employ a spa-tial texture-based image segmentation algorithm using an en-hanced watershed transform [13] to obtain reliable textured re-gions. This provides an important basis for further processing.Texture in image sequences differs from that in static images,since both time-static textures (e.g., wood, floor and wall) anddynamic textures (e.g., moving water, fire, leaves in the wind)exist. Therefore, classification rules must be employed to dif-ferentiate them from each other and also from non-textured re-gions. In this paper, a classification method is presented basedon an analysis of wavelet subband coefficients and motion in-formation within each texture region.Texture synthesis is commonly employed in computer
graphics, where synthetic content is generated using spatialand temporal methods [14]. In our work, we apply differenttexture synthesis methods to static and dynamic textured re-gions according to their statistical and spectral characteristics.The primary benefits of this approach is that residual codingis generally not required and only side information (motionparameters and warping/synthesis maps) need to be encoded.For synthesis-based video compression, the most difficult
problem is to create a reliable in-loop quality assessmentmeasure with which to estimate subjective quality and detectany possible coding artifacts. Existing distortion-based met-rics, such as peak signal-to-noise ratio (PSNR) and structuralsimilarity (SSIM) [15], are shown here to be inappropriatefor this type of compression. A meaningful objective videometric is thus needed to evaluate the quality of the decodedcontent and to provide comparison with competing methods.
1932-4553/$26.00 © 2011 IEEE

2 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
Fig. 1. Synthesis-based image or video compression.
As a consequence, we propose an artifact-based video metric(AVM). This is utilized in-loop to detect synthesis and codingartifacts in order to make decisions on whether to synthesiseor conventionally encode textures. It is also used to provide anobjective evaluation of perceptual video quality. The proposedmetric has been tested on the VQEG database and offers a per-formance (on non synthesized content) comparable to PSNRand SSIM. Unlike other metrics, however, it also works well onparametrically coded content. Subjective testing is also appliedto characterize the results of our method using a triple-stimuluscontinuous quality-scale (TSCQS) method [16].The remainder of the paper is organized as follows. Section II
presents a brief background covering texture segmentation,texture synthesis, video metrics, and synthesis-based imageand video coding. Section III describes the proposed videocoding framework, explaining the texture models used togetherwith details of the novel artifact-based video metric. Theperformance results are presented and discussed in Section IV.Finally, Section V concludes the paper and offers some sugges-tions for future work.
II. BACKGROUND
A synthesis-based image or video compression system, asillustrated in Fig. 1, normally consists of three sub modules:texture segmentation, texture analysis, and quality assessment.Texture segmentation segments images or frames into regions,which are analyzed and synthesized by the texture analyzermodule using appropriate synthesis models. The synthetictextures are evaluated by the quality assessment module, whichidentifies unacceptable coding artifacts. Regions which cannotbe synthesized are usually encoded by a Host Codec, forexample JPEG2000 [17] or H.264/AVC [18].
A. Texture Segmentation
Reliable automatic image segmentation is normally con-sidered difficult, since a meaningful image partition is highlycontent and task dependent. Segmentation based on rudimentalvisual characteristics, for example edges and textures, ishowever possible and can be used to produce robust homoge-neous parameterized regions. Such approaches can be dividedinto three major groups: discontinuity-based methods, simi-larity-based methods, and watershed transformation methods.A detailed review of image segmentation can be found in [19]and [20].
Discontinuity-based methods observe that discontinuities inan image often represent the boundaries of meaningful regions.The locations of these discontinuous edges often have local gra-dient maxima, and the gradient can be obtained bymethods suchas the Sobel operator [21] or the Canny edge detector [22]. Sim-ilarity-based segmentation focuses on the relationship betweenpixels within a homogeneous region. Although these methodsare simple and easy to use, their performance in segmenting tex-tured images is often poor in the case of highly textured regions.Furthermore, these methods can lead to disjoint regions whensegmenting complex images.Watershed transformation is a method merging the concepts
of region growing and discontinuity detection. A number of wa-tershed methods (e.g., [23] and [24]) exist based on the originalwork of Lantuéjoul et al. [25]. This approach solves some of theproblems described above, but also tends to result in over-seg-mentation, especially when the objects in the image have com-plex structures and wide ranging intensity values. This problemhas been addressed by authors such as O’Callaghan et al. [13],who presented a method based on DT-CWT feature [26], com-bining watershed methods with spectral clustering.
B. Texture Analysis and Synthesis
Many parameters can be used to characterize the textureproperties of an image region. These include smoothness,coarseness, and regularity. Texture analysis has attractedsignificant attention over recent years with authors focusingon: statistical models, spectral models, structural models andstochastic models. A detailed review of texture analysis andsynthesis methods is presented in [14]. A brief discussion ofthe methods appropriate for video coding application is givenbelow.Kwatra et al.’s graph cut texture synthesis [27] is a
patch-based model and provides good performance especiallyfor image compression. It uses graph cut techniques to deter-mine the location of boundaries between overlapped patchesin order to produce smooth synthesis results. This method canbe easily extended to video synthesis, where video frames areconsidered as a 3-D volume and image patches are replaced by3-D volumes. Several difficulties are however associated withthis 3-D approach if it is applied to video compression. Firstof all, there is an obvious need for a larger picture memory tostore the reference pictures. Second, the method only worksfor temporally static textures—synthesized results for dynamictextures are visually artificial. The approach has however beenapplied in image coding applications, e.g., [9] and [10], withsome success and in video coding by Ndjiki-Nya et al. [2]–[6].Doretto et al. [28] presented the definition of dynamic video
texture, in the form of the output of an auto-regressive movingaverage process (ARMA). Based on this model, unlimitedframes can be synthesized after training the model using a finitenumber of frames. This provides excellent results in dynamictexture synthesis, producing natural and consistent images. Inaddition to the above synthesis approaches, Portilla et al.’sparametric statistical texture model [29] produces excellentresults. However, methods of this type are generally targeted

BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 3
at generating new natural textures rather than synthesizingexisting textures.
C. Video Quality Metrics
Video quality metrics are an essential component for as-sessing the performance of a video compression system. Thetwo approaches to quality assessment are: subjective andobjective. Subjective video assessment captures the visualperception of human subjects and provides a benchmark forobjective analysis. Generally, a mean opinion score (MOS) iscomputed based on the scores which the subjects give to testvideo content. This is direct and meaningful but resource in-tensive. Objective methods such as mean squared error (MSE)and PSNR are commonly used by the compression communityas a convenient alternative to subjective evaluation. Althoughthese distortion-based metrics are simple to implement, they aremathematical models rather than perceptually based metrics.A number of video metrics have been proposed recently withthe aim of pounding better correlation with subjective scores.These are described below.Structural information is an important factor for human vi-
sual perception. Wang et al. developed an image quality assess-ment approach [15] based on the structural similarity betweena reference and a distorted image. This metric was tested onJPEG and JPEG2000 Image Databases and shows significantimprovement in correlation with subjectivemean opinion scorescompared with PSNR.Motion information is also an essential component for
human perception. Seshadrinathan et al. proposed a motiontuned spatio-temporal quality assessment (MOVIE) method[30] for natural videos. Test and reference material is decom-posed by a Gabor filter family, and the quality index consistsof spatial quality, based on SSIM, and temporal quality, mainlycomputed using motion information. Using the VQEG FRTVPhase 1 Database [31], MOVIE provides a competitive per-formance including higher correlation and fewer outliers,compared with PSNR and SSIM. The drawback of MOVIE isits complexity, as a large number of filters are used to generatesubband coefficients. As a result, it is difficult to integrate thisapproach for in-loop assessment. Its performance on synthe-sized content is also poorer than with conventionally codedmaterial.Other metrics devised with the aim of improving on PSNR
and MSE include VSNR [32]. It is clear that further workis needed to fully characterize perceptual quality in texturedregions especially with synthesized content. For example thehuman visual system is less sensitive to textures (static ordynamic) than to structured objects.
D. Image and Video Coding With Texture Models
Several image and video coding methods based on texturesynthesis have been proposed to reduce bitrate for a given visualquality compared to conventional compression methods. Manyof these employ JPEG, JPEG2000, or H.264/AVC as the hostcodec, and because of this, the partitioning of video frames inthese methods is almost always block-based. However, for tex-ture synthesis, region-based methods are more attractive, since
segmented regions possessing homogeneous textures cannot bedivided exactly into blocks.Byrne et al. presented image compression algorithms [9],
[10] with a region-based rather than block-based synthesisstructure. Segmented using a combined morphological andspectral image segmentation technique [13], images are parti-tioned into regions with homogeneous texture and then eachregion is iteratively analyzed by a clustering algorithm untila texture sample is extracted. Inhomogeneous sub-blocks areremoved from the area of a single texture class. In the texturesynthesis stage, a 2-D graph cut synthesis method [27] isapplied using each texture sample as side information (samplecoordinates and region map). This model is integrated into aJPEG-2000 framework [10] and performs well especially whenencoding images with complex textures.Ndjiki-Nya et al. have proposed a series of video coding
methods [2]–[6] employing texture analysis and synthesis. In[2], they introduce a generic video coding method with texturewarping and 3-D graph cut synthesis which is integrated into anH.264/AVC video codec. This method has a competitive perfor-mance compared H.264/AVC in terms of bit rate savings, andprovides good subjective visual quality. However, as discussedabove, the 3-D graph cut technique can introduce temporal arti-facts and decrease the subjective quality of video especially forcomplex time-varying textures.An alternative video coding approach [7] proposed by Bosch
et al. increases compression efficiency using a spatial texturemodel which consists of texture feature extraction, texturesegmentation, and texture warping. They report bitrate savingsup to 26% compared with H.264/AVC. Bosch et al. present asecond algorithm including motion classification in [8] whichachieves further bitrate savings. In this case, the backgroundof each B frame is warped via a global motion model withoutencoding the residual, while the foreground is encoded witha traditional codec. However, they report a “stepping zoomeffect” perceived as a temporal artifact, which causes the videoto appear unnatural. In addition, dynamic textures cannot beproperly warped because of the associated complex motions.It is clear that an alternative method is required to compressdynamic textures.Other image and video coding algorithms based on texture
models include Wang et al.’s image compression method [33]which factors repeated content, Liu et al.’s method [34] based onimage inpainting, Stojanovic et al.’s method [35] which appliesdynamic texture extrapolation using Dorreto’s model [28], andZhu et al.’s methods [36] using motion threading [37] and spritegeneration techniques [38].
III. PROPOSED ALGORITHM
The basic motivation underpinning our work is to develop anefficient and perceptually related method for reconstructing tex-tures in moving images. Texture regions comprise regular or ir-regular patterns with associated motion, and can be classified aseither static or dynamic. Static textures, whose movements aresimple (typically due to the motion of the camera), are recon-structed via high-order motion models, while dynamic textures,which have complex movements, are analyzed and synthesizedacross a temporal window.

4 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
Fig. 2. Proposed video coding framework.
Fig. 3. Example GOP structure with three B frames in every five frames.
Fig. 2 shows a diagram of the proposed video coding scheme.An IBBBPBBBP GOP (group of pictures) structure is used,as illustrated in Fig. 3. I or P frames are defined as key frames,and these are encoded by a host video codec (H.264 in thiscase). The three intervening B frames are processed using thefollowing steps. First, each B frame is segmented into regionsbased on texture content and then classified as static, dynamic,or non-textured. Non-textured regions are encoded by H.264without processing, and static textures are warped by an iter-ated perspective motion model. Dynamic textures are analyzedand synthesized using the texture synthesis approach describedbelow. All synthetic results are evaluated by a video qualityassessment (VQA) module based on a novel video metric de-scribed in Section III-E and compared with the frame encodedby H.264. If the quality of a warped or synthesized texture fallsbelow a given threshold, then it is encoded using the host codec,otherwise, the host encoder will skip the associated blocks asthey will be reconstructed by texture warping and synthesis atthe decoder. Side information, including warping and synthesismaps and motion parameters, is entropy-encoded and combinedwith the H.264 bitstream.
Fig. 4. Segmentation results of O’Callaghan et al.’s method.
The decoder reconstructs frames from the host decoder andthe side information for warping and synthesis is used to recon-struct the remaining data using models identical to those at theencoder.
A. Texture Segmentation
Each frame is segmented into homogeneous regions usinga spatial texture segmentation method [13]. This approachemploys the dual-tree complex wavelet transformation [26] toobtain texture features. A primitive segmentation is achievedusing a perceptual gradient function with watershed transfor-mation. Segmentation is then refined by spectral clusteringwhich merges over-segmented regions. An example segmenta-tion is shown in Fig. 4, where the picture on the left representsthe first frame of the “coastguard” sequence, while that on theright is the corresponding segmented region.
B. Texture Classification
Textured regions contain more high-frequency componentsthan smooth regions. Hence, after segmentation, textured andnon-textured regions can be classified based on the statisticalproperties of their complex wavelet subbands. In our algorithm,if the subband coefficient magnitudes of most pixels in a regionfall below a threshold , this region is defined as non-tex-tured and sent directly to the host codec. Otherwise, the region

BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 5
Fig. 5. Results of region classification. The left picture is the second frameof the coastguard sequence. On the right, the red area represents static texture,while blue regions are dynamic textures. Non-textured regions are shown inblack.
is considered as textured. The condition of texture determina-tion is given by
(1)
where is the amplitude of the subband for pixel, and is the set of pixels in the current region. is
number of the pixels in , and is a threshold defining the min-imum percentage of pixels in a textured region which is derivedempirically.Textured regions are classified as either static or dynamic
based on motion analysis. Static textures will exhibit regularmotion, which is always the result of camera motion or the mo-tion of rigid objects in the scene. The motion of a dynamic tex-ture on the other hand is complex and irregular. The proposedclassification method divides every region into 8 8 blocks andperforms motion estimation with respect to neighboring frames.Motion vectors and motion-compensated differences are thenanalyzed to determine the class of each region. If the motion ofone textured region is regular and the absolute differences be-tween the compensated region and original region are small, thisregion is defined as a static texture, otherwise it is considered asa dynamic texture.The classification process is represented by equation (2).
When a textured region meets these two conditions, it is con-sidered to be a static texture. Fig. 5 demonstrates the result ofthis classification for the “coastguard” sequence, as follows:
(2)
Here, is the motion vector between the referenceframe and the current frame for block in region . isthe absolute difference of region after motion compensation.
and are the two thresholds used for classification.
C. Texture Warping With a Perspective Motion Model
In modern video compression algorithms, motion estimation(based on a given motion model) is often used to temporallydecorrelate and hence reduce the redundancy between videoframes. Motion estimation between two images is considered asa 2-D projective transformation with the assumption that images
are all captured by perspective cameras. With advanced motionmodels, warping or mesh based algorithms may be used. How-ever, for the majority of conventional codecs, a block-basedlinear translational model is employed.In our approach, we apply bi-directional texture warping to
each B frame to process static textures. This is based on aneight parameter perspective motion model. The motion infor-mation generated at the classification stage is reused, and allthe motion vectors in a static-texture region are utilized to com-pute the motion parameters of a perspective motion model usinga least-squares method [39]. The perspective motion model isgiven by
(3)
in which, and are a pair of points between the cur-rent and reference frames. With more than four pairs of pointsknown, the eight parameters of the perspective motion model
can be computed. The texturewarping method thus consists of three sub stages: 1) extract mo-tion vectors; 2) compute motion parameters; and 3) warp statictextures. These are described in more detail below.1) Extract Motion Vectors: In this stage, the current frame
is motion estimated using its two nearest key frames. Motionvectors of all 8 8 blocks within a static texture region are ob-tained using conventional motion estimation with a translationalmodel and an MSE metric. Unlike normal motion estimation,a weighting matrix is applied to emphasize the centre of eachblock.2) Compute Motion Parameters: Each motion vector is as-
sumed to be represented by the actual motion of the central pointof its block. Motion parameters are then computed using the fol-lowing steps.First, equation (3) is extended to give
(4)
Assuming there are more than four sub blocks in static textureregions, (4) can be rewritten in matrix format as (6) and (7)
(5)
where
(6)
and
(7)

6 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
Based on the mean of least-squares method, motion parame-ters can be computed by
(8)
In the case of isolated points which do not share the samemotion as the majority of their neighbors (defect points), an it-erative method is used to remove them and to ensure that themotion parameters are computed accurately. Specifically, afteris obtained, vector can be generated by equation (3). Com-
paring the points in and , the longest pair of points canbe found by
(9)
where is a point in vector .This iterative method terminates if the maximum is smaller
than a threshold or if there are less than four pairs ofpoints remaining. Bosch et al.’s motion-based model [8] usesa similar iterative scheme to compute motion parameters butthey treat isolated blocks with distinctivemotion vectors as fore-ground information. Furthermore, their approach is not region-based, but block-based.3) Warp Static Textures: Static textures are reconstructed by
warping reference frames. All warped textures are assessed bythe video quality assessment (VQA) module. Recall that, in ourcurrent system, two out of every five frames are key frames andthese are used as references. The key frame with the greaternumber of warped blocks is selected. Based on VQA results, themotion vectors of warp-failure static textures are used to com-pute a second set of motion parameters to account for multiplemotions and this continues until nomore textures can bewarped.It should be noted that texture warping tends to introduce blur-ring. In order to solve this problem and to provide better subjec-tive quality, a Gaussian deblurring filter is applied to the warpedtextures before quality assessment.
D. Dynamic Texture Synthesis
For conventional video coding algorithms, the compressionof dynamic textures is most challenging—they typically con-sume a significant proportion of the bit rate and are prone toboth spatial and temporal artifacts. In the proposed algorithm,Doretto et al.’s synthesis method [28] is utilised, in which dy-namic textures are defined as the output of an auto-regressivemoving average process (ARMA), described by
(10)
where is considered as the input to the model and is a videosequence with images. , , and are parametric matricesof the model, and and are assumed to be independent andidentically distributed random variables. In Doretto’s theory, themodel is trained with a limited number of frames in order to
Fig. 6. Synthesis approach using a dynamic texture model. (a) Original texture.(b) Synthesized texture.
synthesize an unlimited number of new frames. For practicalpurposes, the second equation in (10) can be replaced by
(11)
in which is the mean of all the training images.We present a synthesis method based on the assumption that
the variation of a texture is temporally uniform within a smallgroup of frames (five frames in this case). Within every fiveframes, only dynamic textures of the second and fourth framesare synthesized. The first, third, and fifth frames are first motioncompensated (warped) relative to the second (or fourth) frameusing the method described in Section III-C. The three warpedframes are then analyzed by Doretto’s approach. This process isdescribed by
and (12)
Here are warped frames for analysis. The initial stateof the input, , and parametric matrices , , and arecomputed using singular value decomposition (SVD).Applying the model again to all five frames with these pa-
rameters, the dynamic textures in the second (or fourth) frame(or ) are synthesized by (13).
(13)
in which , , , , and are assigned by
(14)
Example synthesis results are shown in Fig. 6(a)–(b), inwhich the original texture is taken from the second frame ofthe “coastguard” sequence. While subtle differences betweenthese frames can be observed, noticeable “artifacts” in theconventional sense are difficult to detect.In synthetic textures, spatial and temporal artifacts may be in-
troduced because of the limited number of training frames used

BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 7
and the approximate nature of the synthesis. In order to min-imize their impact on rate-quality performance, a compatibleVQA module is therefore essential. This is described in the fol-lowing section.
E. Artefact-Based Video Metric (AVM) for PerceptualVideo Coding
In order to remove spatial and temporal artifacts and to ensuregood subjective visual quality, we present a new video metricfor synthesis-based video coding. This metric detects visual ar-tifacts between reference and test content. Three primary visibleartifacts are considered: blurring distortion, similarity distor-tion, and visible edge artifacts. The proposed metric estimatesthe extent of these artifacts and determines an AVM index mapfor each frame. A pooling strategy is followed to produce a finalquality score.1) Blurring Estimation: In synthesis-based video compres-
sion, texture warping plays an important role in reconstructingtextures. However, warping will tend to cause blurring, and thelevel of blurring depends on motion parameters and interpola-tion method used. Furthermore, traditional video compressionmethods can also introduce blurring through the application ofde-blocking filters.The blurring estimate is obtained by comparing subband co-
efficients (excluding DC) between reference and test frames forthe six high-frequency subbands in a single stage DT-CWT de-composition. This is described by
(15)
(16)
where, for location , is the blurring artifact, andand are the amplitudes of one of the six
subband coefficients in reference and test frames, respectively.is used as to threshold the invisible blurring artifacts and
has been empirically derived.In order to prevent interference from encoding noise, a
Gaussian pre-processing filter is applied on both the referenceand test frames. Wavelet subbands here are also obtained byapplying complex wavelet transformation [26].2) Similarity Estimation: The human visual system is less
sensitive to spatial and temporal textures which contain energyat high frequencies. Based on this concept, a thresholding maskcomprising spatial and temporal sub-masks is presented. Thespatial mask is applied to wavelet subband coefficients whilemotion analysis provides the basis of the temporal mask. Equa-tions (17) and (18) describe both the spatial, , and tem-poral, , masks, as follows:
(17)
(18)
Here is as defined in (15), and is the mo-tion vector of the 8 8 block in which the pixel lies. Acombined thresholding mask is now defined by
(19)
Here, , and are all thresholding parameters.By applying the tolerance map on the absolute difference be-
tween original and distorted frames, visible similarity differenceare detected by
(20)
(21)
where is a thresholding parameter obtained empirically.3) Edge Artefact Detection: Edge artifacts can occur at the
boundary between blocks in conventional coding and in tex-ture regions after synthesis. Whereas block-based codecs canreduce this effect using a loop filter or overlapped motion esti-mation, this is not so easily achieved in synthesis-based codecs.We therefore employ a metric to characterize edge artifact sim-ilar to that presented by the authors in [9] and [10]. The edgeartifact index is given by
(22)
where and are vertical and horizontal edge artifactsmaps, and is a parameter for thresholding perceptible edgeartifacts. Further details on producing edge artifacts maps isdescribed in [9].Finally, the artifact index (AVM) is obtained from
(23)
in which , , and are weighting parameters empiricallyderived to yield the best correlation with psychovisual ob-servation. The score is computed by averaging the
values over the image/region and converting todecibel units:
(24)
F. Integration Into a Host Codec
The proposed algorithm has been fully integrated into anH.264/AVC video codec (JM15.1) in order to test its per-formance. It should be noted that, while the texture analysis(Section III-A) produces segmentations of arbitrary shape,these must be mapped on to the block structure of the hostcodec. We use a two-pass coding strategy for B frames. Theyare first encoded using H.264/AVC to generate preliminaryframes and to assess the number of bits consumed by each
8 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
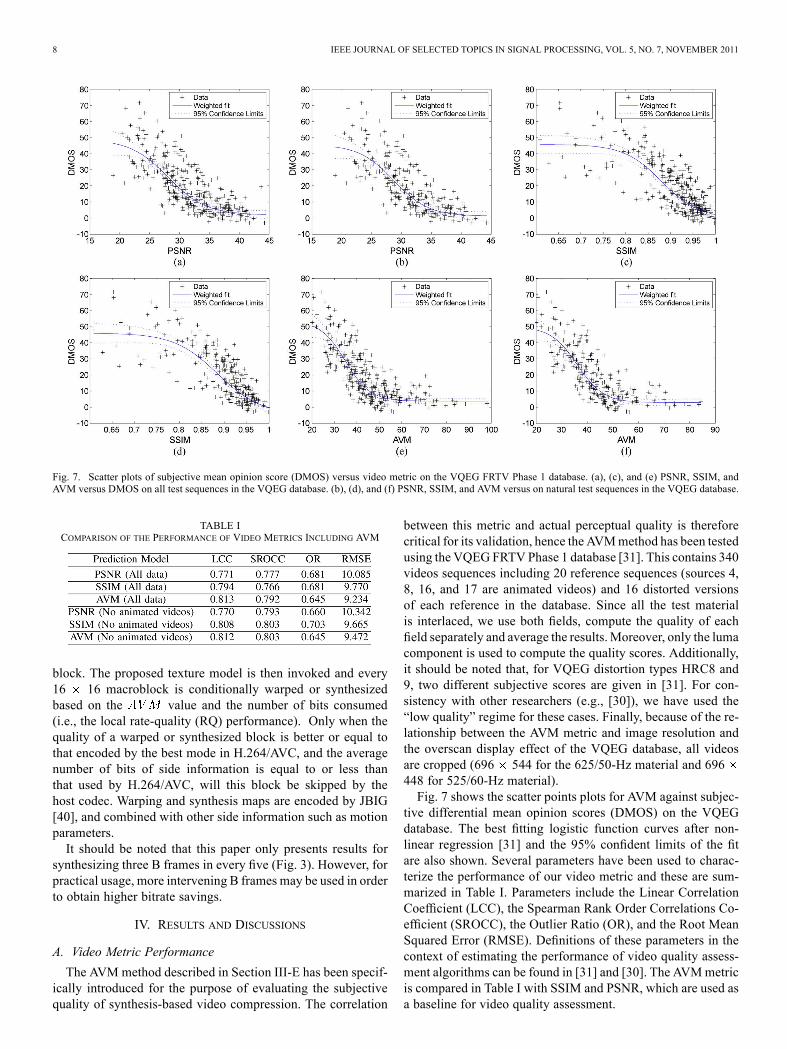
Fig. 7. Scatter plots of subjective mean opinion score (DMOS) versus video metric on the VQEG FRTV Phase 1 database. (a), (c), and (e) PSNR, SSIM, andAVM versus DMOS on all test sequences in the VQEG database. (b), (d), and (f) PSNR, SSIM, and AVM versus on natural test sequences in the VQEG database.
TABLE ICOMPARISON OF THE PERFORMANCE OF VIDEO METRICS INCLUDING AVM
block. The proposed texture model is then invoked and every16 16 macroblock is conditionally warped or synthesizedbased on the value and the number of bits consumed(i.e., the local rate-quality (RQ) performance). Only when thequality of a warped or synthesized block is better or equal tothat encoded by the best mode in H.264/AVC, and the averagenumber of bits of side information is equal to or less thanthat used by H.264/AVC, will this block be skipped by thehost codec. Warping and synthesis maps are encoded by JBIG[40], and combined with other side information such as motionparameters.It should be noted that this paper only presents results for
synthesizing three B frames in every five (Fig. 3). However, forpractical usage, more intervening B frames may be used in orderto obtain higher bitrate savings.
IV. RESULTS AND DISCUSSIONS
A. Video Metric Performance
The AVMmethod described in Section III-E has been specif-ically introduced for the purpose of evaluating the subjectivequality of synthesis-based video compression. The correlation
between this metric and actual perceptual quality is thereforecritical for its validation, hence the AVMmethod has been testedusing the VQEG FRTV Phase 1 database [31]. This contains 340videos sequences including 20 reference sequences (sources 4,8, 16, and 17 are animated videos) and 16 distorted versionsof each reference in the database. Since all the test materialis interlaced, we use both fields, compute the quality of eachfield separately and average the results. Moreover, only the lumacomponent is used to compute the quality scores. Additionally,it should be noted that, for VQEG distortion types HRC8 and9, two different subjective scores are given in [31]. For con-sistency with other researchers (e.g., [30]), we have used the“low quality” regime for these cases. Finally, because of the re-lationship between the AVM metric and image resolution andthe overscan display effect of the VQEG database, all videosare cropped (696 544 for the 625/50-Hz material and 696448 for 525/60-Hz material).Fig. 7 shows the scatter points plots for AVM against subjec-
tive differential mean opinion scores (DMOS) on the VQEGdatabase. The best fitting logistic function curves after non-linear regression [31] and the 95% confident limits of the fitare also shown. Several parameters have been used to charac-terize the performance of our video metric and these are sum-marized in Table I. Parameters include the Linear CorrelationCoefficient (LCC), the Spearman Rank Order Correlations Co-efficient (SROCC), the Outlier Ratio (OR), and the Root MeanSquared Error (RMSE). Definitions of these parameters in thecontext of estimating the performance of video quality assess-ment algorithms can be found in [31] and [30]. The AVMmetricis compared in Table I with SSIM and PSNR, which are used asa baseline for video quality assessment.

BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 9
Fig. 8. Examples of reconstructed frames and warping/synthesis maps for CIF resolution sequences. (a), (d), (g), and (j) correspond to the second frames recon-structed by JM15.1 for “coastguard,” “football,” “football2,” and “waterfall” sequences, respectively. (b), (e), (h), and (k) show warping/synthesis maps of thesecond frames of these sequences. Black stands for JM encoded blocks. Blocks in red are static textured which have been warped, while blue represents synthesizeddynamic texture. (c), (f), (i), and (l) show the second reconstructed frames by the proposed algorithm for each of these sequences.
The results in Table I demonstrate that AVM performs com-petitively compared with PSNR and SSIM on the VQEG data-base. It should be noted that the results shown are slightly dif-
ferent from those in [31] and [30], due to the cropping of se-quences described above. The RMSE between subjective scoresand AVM scores after nonlinear regression is 9.234 across all

10 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
Fig. 9. Examples of reconstructed frames and warping/synthesis maps for 720p resolution sequences. (a) and (d) correspond to the second frames reconstructedby JM15.1 for “cliff” and “volcano” sequences, respectively. (b) and (e) correspond to warping/synthesis maps of the second frames of these sequences. Blackstands for JM-encoded blocks. Blocks in red correspond to static textured which have been warped, while blue represents synthesized dynamic texture. (c) and(f) show the second reconstructed frames by the proposed algorithm for each of these sequences.
sequences and 9.472 when applied to only natural video se-quences. These are 8% smaller than those for PSNR. The re-sults in Table I suggest that AVM has higher correlation withsubjective scores on the VQEG database than both SSIM orPSNR. Fig. 7 shows the scatter plots for AVM against DMOS onthe VQEG database and demonstrates good correlation. It canbe ovserved that the AVM scatter plots are closer to the fittingcurve than those for PSNR and SSIM. Most importantly how-ever, AVM works on parametrically coded (synthesized) con-tent, whereas other metrics fail. This statement is validated bythe results in Section IV-B (Figs. 10 and 12).
B. Performance of the Proposed Video Coding Framework
The proposed algorithm has been compared with theH.264/AVC reference codec (JM15.1). Six test sequencesare used including four at CIF resolution (352 288) andtwo at 720 p resolution (1280 720). The CIF sequences:“coastguard,” “waterfall,” and “football” are well-knowntest sequences, and “football2” is a further CIF sequence, inwhich a player dribbling the ball from the left to the right iscaptured by a zooming camera. Two 720 p videos “cliff” and“volcano” are truncated version from the Microsoft WMVHD Content Showcase [41]. The test conditions used are:JM 15.1 (used as host codec); Main Profile; CAVLC; 25frames per second; rate distortion optimization; no interlace;fast full search for Quarter-Pixel ME; 2 reference frames;
; quantization parameter (QP) from14 to 34; JBIG [40] is used to encode warping/synthesis maps;the number of frames tested is 300 for “coastguard,” 150 for“football,” 100 for “football2,” 260 for “waterfall” and 100 foreach of the two 720 p test sequences “cliff” and “volcano.”Sample decoded frames are presented in Fig. 8 and Fig. 9.
These compare original JM coding with reconstructed framesfrom the proposed algorithm. The warp/synthesis maps are alsopresented, created based on the assessment of AVM as describedin Section III-E. Almost all the static texture in “waterfall” can
be warped by the proposed algorithm, leading to high bitrategains over H.264. Although there is small area of dynamic tex-ture in each frame of “waterfall,” the gains from synthesis aremarginal when the number of saved bits is comparable with thatconsumed by side information. Structured objects, such as theboats in “coastguard,” the football players in “football” and theship in “container,” are generally not warped or synthesized bythe proposed algorithm. In such cases, the synthesis-based videocompression must be assisted by waveform coding.The rate-quality curves for the proposed video coding frame-
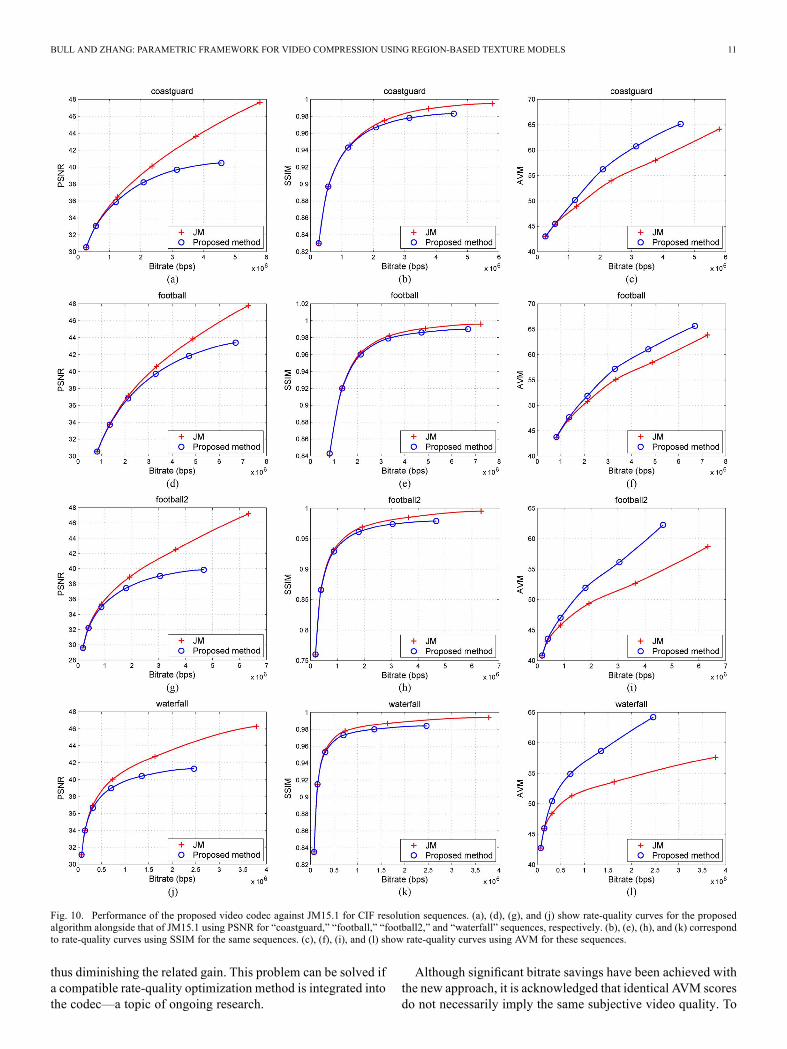
work compared to H.264/AVC based on PSNR, SSIM, andAVM are shown in Fig. 10 and Fig. 11. At identical bitrate, thereconstruction quality using our algorithm is always lower thanthat of H.264/AVC when assessed by PSNR. This is becausethe mean squared error introduced by texture warping and syn-thesis is significant. Our algorithm also performs poorly basedon the assessment using SSIM. Again this negative result is tobe expected, since SSIM is not designed for synthesis-basedvideo compression.In contrast to PSNR and SSIM, AVM shows a consistent cor-
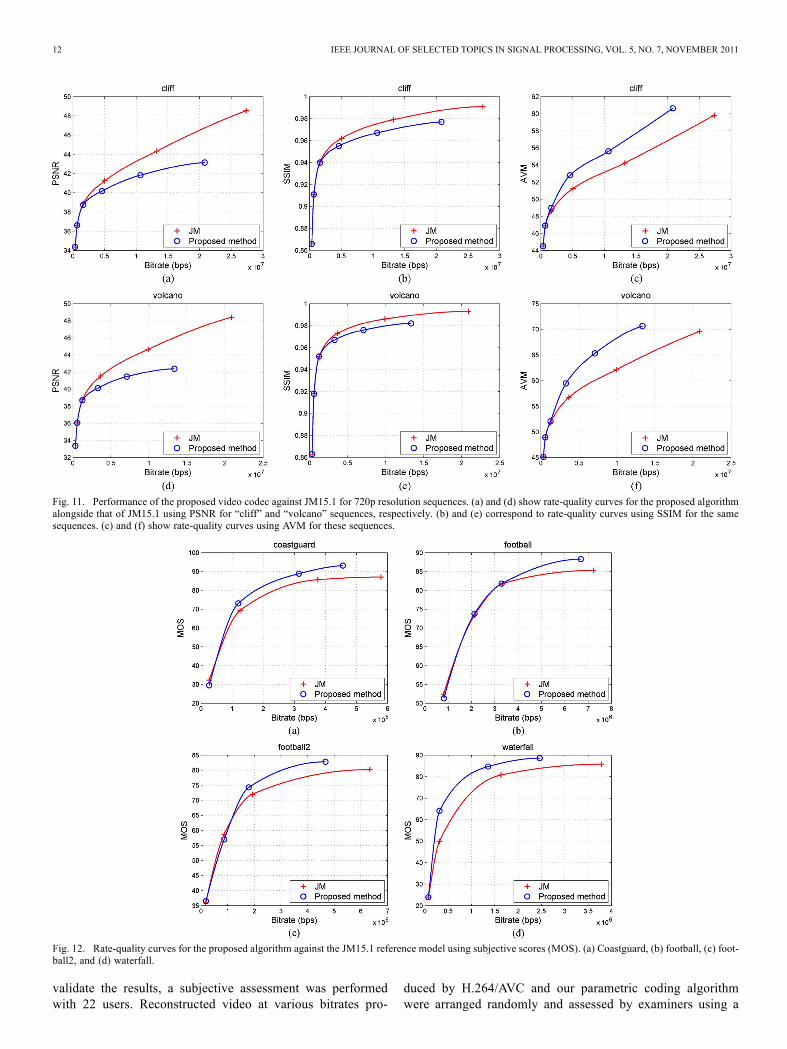
relation advantage from our approach and this has been vali-dated by subjective assessment. Savings vary according to se-quence since the amount and complexity of texture in each se-quence varies. The largest bitrate gain (in excess of 60%) re-sults from with “waterfall” where a large number of bits aresaved during warping and the reconstructed quality is also im-proved. “Coastguard” contains both static and complex dynamictextures and the savings up to 30% have been observed in thiscase. Our algorithm also performs well on “football” and “foot-ball2” where it is noticed that the grass is perfectly warped asa static texture. Furthermore, the performance of the proposedalgorithm for 720 p resolution test videos is competitive, withsavings of up to 45% for “cliff” and 50% for “volcano.” Theresults also show that benefits improve with increasing bitrate.At lower bitrates, the number of bits used for side informationbecomes comparable to the bits saved through block skipping,
BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 11
Fig. 10. Performance of the proposed video codec against JM15.1 for CIF resolution sequences. (a), (d), (g), and (j) show rate-quality curves for the proposedalgorithm alongside that of JM15.1 using PSNR for “coastguard,” “football,” “football2,” and “waterfall” sequences, respectively. (b), (e), (h), and (k) correspondto rate-quality curves using SSIM for the same sequences. (c), (f), (i), and (l) show rate-quality curves using AVM for these sequences.
thus diminishing the related gain. This problem can be solved ifa compatible rate-quality optimization method is integrated intothe codec—a topic of ongoing research.
Although significant bitrate savings have been achieved withthe new approach, it is acknowledged that identical AVM scoresdo not necessarily imply the same subjective video quality. To
12 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
Fig. 11. Performance of the proposed video codec against JM15.1 for 720p resolution sequences. (a) and (d) show rate-quality curves for the proposed algorithmalongside that of JM15.1 using PSNR for “cliff” and “volcano” sequences, respectively. (b) and (e) correspond to rate-quality curves using SSIM for the samesequences. (c) and (f) show rate-quality curves using AVM for these sequences.
Fig. 12. Rate-quality curves for the proposed algorithm against the JM15.1 reference model using subjective scores (MOS). (a) Coastguard, (b) football, (c) foot-ball2, and (d) waterfall.
validate the results, a subjective assessment was performedwith 22 users. Reconstructed video at various bitrates pro-
duced by H.264/AVC and our parametric coding algorithmwere arranged randomly and assessed by examiners using a
BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 13
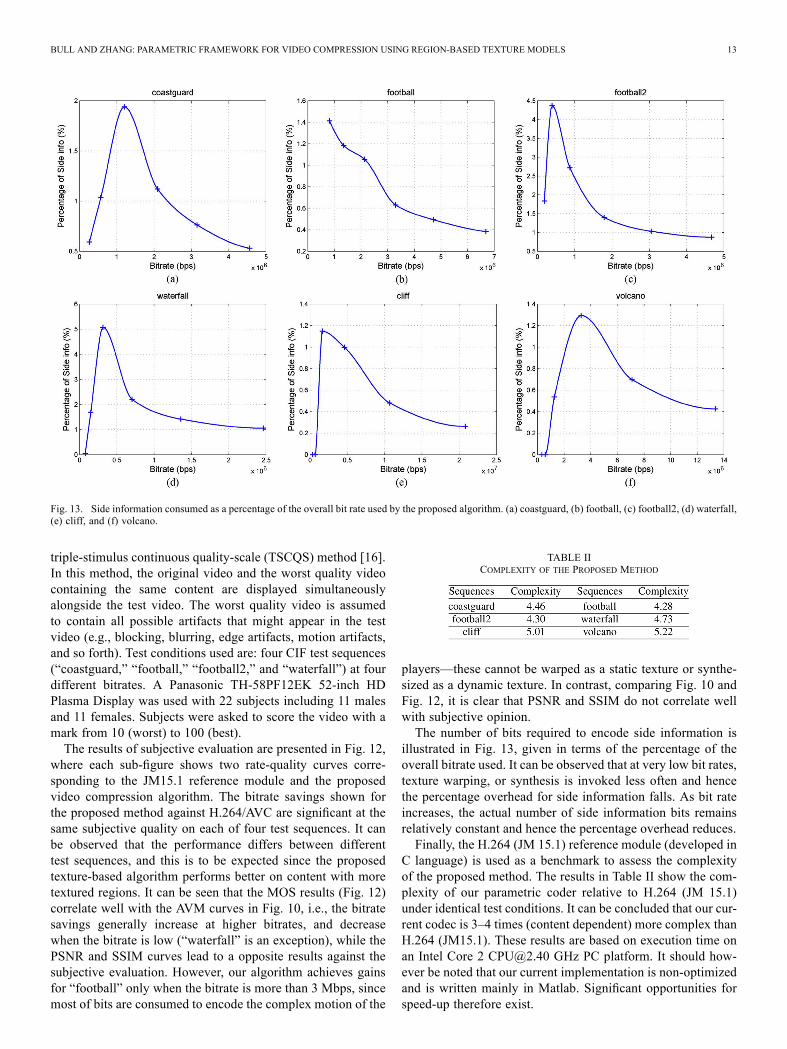
Fig. 13. Side information consumed as a percentage of the overall bit rate used by the proposed algorithm. (a) coastguard, (b) football, (c) football2, (d) waterfall,(e) cliff, and (f) volcano.
triple-stimulus continuous quality-scale (TSCQS) method [16].In this method, the original video and the worst quality videocontaining the same content are displayed simultaneouslyalongside the test video. The worst quality video is assumedto contain all possible artifacts that might appear in the testvideo (e.g., blocking, blurring, edge artifacts, motion artifacts,and so forth). Test conditions used are: four CIF test sequences(“coastguard,” “football,” “football2,” and “waterfall”) at fourdifferent bitrates. A Panasonic TH-58PF12EK 52-inch HDPlasma Display was used with 22 subjects including 11 malesand 11 females. Subjects were asked to score the video with amark from 10 (worst) to 100 (best).The results of subjective evaluation are presented in Fig. 12,
where each sub-figure shows two rate-quality curves corre-sponding to the JM15.1 reference module and the proposedvideo compression algorithm. The bitrate savings shown forthe proposed method against H.264/AVC are significant at thesame subjective quality on each of four test sequences. It canbe observed that the performance differs between differenttest sequences, and this is to be expected since the proposedtexture-based algorithm performs better on content with moretextured regions. It can be seen that the MOS results (Fig. 12)correlate well with the AVM curves in Fig. 10, i.e., the bitratesavings generally increase at higher bitrates, and decreasewhen the bitrate is low (“waterfall” is an exception), while thePSNR and SSIM curves lead to a opposite results against thesubjective evaluation. However, our algorithm achieves gainsfor “football” only when the bitrate is more than 3 Mbps, sincemost of bits are consumed to encode the complex motion of the
TABLE IICOMPLEXITY OF THE PROPOSED METHOD
players—these cannot be warped as a static texture or synthe-sized as a dynamic texture. In contrast, comparing Fig. 10 andFig. 12, it is clear that PSNR and SSIM do not correlate wellwith subjective opinion.The number of bits required to encode side information is
illustrated in Fig. 13, given in terms of the percentage of theoverall bitrate used. It can be observed that at very low bit rates,texture warping, or synthesis is invoked less often and hencethe percentage overhead for side information falls. As bit rateincreases, the actual number of side information bits remainsrelatively constant and hence the percentage overhead reduces.Finally, the H.264 (JM 15.1) reference module (developed in
C language) is used as a benchmark to assess the complexityof the proposed method. The results in Table II show the com-plexity of our parametric coder relative to H.264 (JM 15.1)under identical test conditions. It can be concluded that our cur-rent codec is 3–4 times (content dependent) more complex thanH.264 (JM15.1). These results are based on execution time onan Intel Core 2 [email protected] GHz PC platform. It should how-ever be noted that our current implementation is non-optimizedand is written mainly in Matlab. Significant opportunities forspeed-up therefore exist.

14 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 5, NO. 7, NOVEMBER 2011
V. CONCLUSION AND FUTURE WORK
In this paper, a parametric video compression framework,using a closed-loop approach incorporating static texturewarping and dynamic texture synthesis, is described. A com-patible artifact-based video metric for synthesis-based videocompression (AVM) is also introduced to provide an assess-ment of video quality. AVM is designed specifically to workwith both conventional and synthesis-based coding regimes.In tests using the VQEG database, AVM demonstrates highercorrelation with subjective scores and competitive performancecompared with other well-known video metrics such as SSIM.Importantly, AVM is shown to correlate well with subjectiveassessment of synthesized content, whereas SSIM, PSNR,VSNR, and MOVIE do not work well. For identical AVMquality our algorithm achieves significant bit rate savings (upto 60%) compared to a reference H.264 codec.Work on parametric video compression is still in its infancy
and we believe there is scope for significant improvement overthe results presented here. For example, future work in this fieldneeds to focus on a long term rate-quality optimization frame-work which provides mode optimization performance boundsand a basis for bit allocation and rate control. This would lead toa rate control framework capable of encoding video at a pre-de-terminated bit rate while achieving optimum video quality.
REFERENCES
[1] JCT-VC, 2010, High Efficiency Video Coding, [Online]. Available:http://www.vcodex.com/h265.html
[2] P. Ndjiki-Nya, T. Hinz, and T. Wiegand, “Generic and robust videocoding with texture analysis and synthesis,” in Proc. IEEE ICME,2007, pp. 1447–1450.
[3] P. Ndjiki-Nya, C. Stuber, and T. Wiegand, “Texture synthesis methodfor generic video sequences,” in Proc. IEEE Int Conf. Image Process.,2007, vol. 3, pp. 397–400.
[4] P. Ndjiki-Nya, T. Hinz, C. Stuber, and T. Wiegand, “A content-basedvideo coding approach for rigid and non-rigid textures,” in Proc. IEEEInt Conf. Image Process., 2006, pp. 3169–3172.
[5] P. Ndjiki-Nya, T. Hinz, C. Stuber, and T. Wiegand, “A generic andautomatic content-based approach for improved H.264/MPEG4-AVCvideo coding,” in Proc. IEEE Int Conf. Image Process., 2005, vol. 2,pp. 874–877.
[6] P. Ndjiki-Nya, B. Makai, G. Blattermann, A. Smolic, H. Schwarz, andT. Wiegand, “Improved H.264/AVC coding using texture analysis andsynthesis,” in Proc. IEEE Int Conf. Image Process., 2003, vol. 3, pp.849–852.
[7] M. Bosch, F. Zhu, and E. J. Delp, “Spatial texture models for videocompression,” in Proc. IEEE Int Conf. Image Process., 2007, pp.93–96.
[8] M. Bosch, F. Zhu, and E. Delp, “Video coding using motion classifica-tion,” in Proc. IEEE Int Conf. Image Process., 2008, pp. 1588–1591.
[9] J. Byrne, S. Ierodiaconou, D. R. Bull, D. Redmill, and P. Hill, “Unsu-pervised image compression-by-synthesis within a JPEG framework,”in Proc. IEEE Int Conf. Image Process., 2008, pp. 2892–2895.
[10] S. Ierodiaconou, J. Byrne, D. R. Bull, D. Redmill, and P. Hill, “Unsu-pervised image compression using graphcut texture synthesis,” inProc.IEEE Int Conf. Image Process., 2009, pp. 2289–2292.
[11] F. Zhang, D. R. Bull, and N. Canagarajah, “Region-based texture mod-elling for next generation video codecs,” in Proc. IEEE Int Conf. ImageProcess., 2010, pp. 2593–2596.
[12] F. Zhang and D. R. Bull, “Enhanced video compression with re-gion-based texture models,” in Picture Coding Symp. (PCS), 2010,pp. 54–57.
[13] R. O’Callaghan and D. Bull, “Combined morphological-spectral unsu-pervised image segmentation,” IEEE Trans. Image Process., vol. 14,no. 1, pp. 49–62, Jan. 2005.
[14] M. Mirmehdi, X. Xie, and J. Suri, Handbook of Texture Analysis.London, U.K.: Imperial College Press, 2008.
[15] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality as-sessment: From error visibility to structural similarity,” IEEE Trans.Image Process., vol. 13, no. 4, pp. 600–612, Apr. 2004.
[16] H. Hoffmann, HDTV—EBU Format Comparisons at IBC 2006, EBU,Technical Rev., 2006.
[17] JPEG-2000: Core Coding System Int. Telecommuncation Union, 2006,ITU-T Rec. T.800, Tech. Rep..
[18] Advanced Video Coding for Generic Audiovisual Services Int.Telecommuncation Union, 2005, ITU-T Rec. H.264 & ISO/IEC14496-10 AVC, Tech. Rep..
[19] R. C. Gonzales and R. E. Woods, Digital Image Processing, 2nd ed.Upper Saddle River, NJ: Prentice-Hall, 2002.
[20] P. Hill, “Wavelet based texture analysis and segmentation for imageretrieval and fusion,” Ph.D. dissertation, University of Bristol, Bristol,U.K., 2002.
[21] I. E. Sobel, “Camera models and machine perception,” Ph.D. disserta-tion, Stanford Univ., Stanford, CA, 1970.
[22] J. Canny, “A computational approach to edge detection,” IEEE Trans.Pattern Anal. Mach. Intell., vol. PAMI-6, no. 6, pp. 679–698, Nov.1986.
[23] L. Vincent and P. Soille, “Watershed in digital spaces: An efficient al-gorithm based on immersion simulations,” IEEE Trans. Pattern Anal.Mach. Intell., vol. 13, no. 6, pp. 583–298, Jun. 1991.
[24] L. Shafarenko, M. Petrou, and J. Kittler, “Automatic watershed seg-mentation of randomly textured color images,” IEEE Trans. ImageProcess., vol. 6, no. 1, pp. 1530–1544, Jan. 1997.
[25] C. Lantuéjoul, “La Squelettisatoin et son application aux mesurestopologiques des mosaiques polycristalines,” Ph.D. dissertation,School of Minews, Paris, France, 1978.
[26] N. G. Kingsbury, “Complex wavelets for shift invariant analysis andfiltering of signals,” J. Appl. Comput. Harmon. Anal., vol. 10, no. 3,pp. 234–253, 2001.
[27] V. Kwatra, A. Schodl, I. Essa, G. Turk, and A. Bobic, “Graphcuttextures: Image and video synthesis using graph cuts,” in Proc.SIGGRAPH. ACM, 2003, pp. 277–286.
[28] G. Doretto, A. Chiuso, Y. N. Wu, and S. Soatto, “Dynamic textures,”Int. J. Comput. Vis., vol. 51, no. 2, pp. 91–109, 2003.
[29] J. Portilla and E. Simoncelli, “A parametric texture model based onjoint statistics of complex wavelet coefficients,” Int. J. Comput. Vis.,vol. 40, no. 1, pp. 49–70, 2000.
[30] K. Seshadrinathan and A. C. Bovik, “Motion tuned spatio-temporalquality assessment of natural videos,” IEEE Trans. Image Process., vol.19, no. 2, pp. 335–350, Feb. 2010.
[31] “Final report from the Video Quality Experts Group on the validation ofobjective quality metrics for video quality assessment,” Video QualityExperts Group, 2000 [Online]. Available: http://www.its.bldrdoc.gov/vqeg/projects/frtv_phaseI, VQEG, Tech. Rep.
[32] D. Chandler and S. Hemami, “VSNR: A wavelet-based visualsignal-to-noise ratio for natural images,” IEEE Trans. Image Process.,vol. 16, no. 9, pp. 2284–2298, Sep. 2007.
[33] H. Wang, Y. Wexler, E. Ofek, and H. Hoppe, “Factoring repeated con-tent within and among images,” ACM Trans. Graphics (Proc. SIG-GRAPH), 2008.
[34] D. Liu, X. Sun, F. Wu, S. Li, and Y. Zhang, “Image compression withedge-based inpainting,” IEEE Trans. Circuits Syst., vol. 17, no. 10, pp.1273–1287, Oct. 2007.
[35] A. Stojanovic, M. Wien, and J. Ohm, “Dynamic texture synthesis forH.264/AVC inter coding,” in Proc. IEEE Int Conf. Image Process.,2009, pp. 1608–1611, IEEE.
[36] C. Zhu, X. Sun, F. Wu, and H. Li, “Video coding with spatio-temporaltexture synthesis and edge-based inpainting,” in Proc. ICME, 2008, pp.813–816, IEEE.
[37] L. Luo, F. Wu, S. Li, Z. Xiong, and Z. Zhuang, “Advanced motionthreading for 3D wavelet video coding,” Signal Process.: ImageCommun., vol. 19, pp. 601–616, 2004.
[38] Y. Lu, W. Gao, and F. Wu, “Efficient background video codingwith static sprite generation and arbitrary-shape spatial predictiontechniques,” IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 5,pp. 394–405, May 2003.
[39] C. T. Kiang, “Novel block-based motion estimation and segmentationfor video coding,” Ph.D. dissertation, Univ. of Bristol, Bristol, U.K.,2004.
[40] ISO/IEC 11544:1993, Information technology-coded representation ofpicture and audio information-progressive bi-livel image compressionISO, Geneva, Switzerland, 1993, Tech. Rep., JBIG.
[41] Microsoft,, 2004, WMV HD Content Showcase [Online]. Available:http://www.microsoft.com/windows/windowsmedia/musicand-video/hdvideo/contentshowcase.aspx

BULL AND ZHANG: PARAMETRIC FRAMEWORK FOR VIDEO COMPRESSION USING REGION-BASED TEXTURE MODELS 15
David R. Bull (M’94–SM’07) PhD, FIET, SMIEEE,CEng received the B.Sc. degree from the Universityof Exeter, Exeter, U.K., in 1980, the M.Sc. degreefrom the University of Manchester, Manchester,U.K., in 1983, and the Ph.D. degree from theUniversity of Cardiff, Cardiff, U.K., in 1988.His previous roles include: Lecturer at the Uni-
versity of Wales (Cardiff) and Systems Engineerfor Rolls Royce. He was Head of the Electricaland Electronic Engineering Department at Bristolbetween 2001 and 2006 and is now Director of the
Bristol Vision Institute (BVI). In 2001, he cofounded ProVision Commu-nication Technologies, Ltd. He has worked widely in the fields of 1-D and2-D signal processing. He has won two IEE Premium awards for this workand has published numerous patents, several of which have been exploitedcommercially. His current activities are focused on the problems of image andvideo communications and analysis for low bit rate wireless, Internet, military,
and broadcast applications. He has published some 400 academic papers,various articles and two books and has also given numerous invited/keynotelectures and tutorials.
Fan Zhang (M’11) received the B.Sc. and M.Sc. de-grees from Shanghai Jiao Tong University, Shanghai,China. He is currently pursuing the Ph.D. degree inthe Visual Information Laboratory, Department ofElectrical and Electronic Engineering, Universityof Bristol, Bristol, U.K., with a thesis on parametricvideo coding with texture models.His research interests include perceptual video
compression, video metrics, and texture synthesis.