a novel data-path for accelerating dsp kernels
TRANSCRIPT

A Novel Data-Path for Accelerating DSP Kernels †
M.D. Galanis1, G. Theodoridis2, S. Tragoudas3, D. Soudris4, and C.E. Goutis1
1University of Patras, Patras, Greece, {mgalanis, goutis}@vlsi.ee.upatras.gr 2 Aristotle University, Thessalonica, Greece, [email protected] 3 Southern Illinois University, Carbondale, USA, [email protected]
4 Democriteus University, Xanthi, Greece, [email protected]
Abstract. A high-performance data-path to implement DSP kernels is proposed in this paper. The data-path is based on a flexible, universal, and regular component that allows to optimally exploiting both inter- and intra-component chaining of operations. The introduced component is a combinational circuit with steering logic that allows in easily realizing any desirable complex hardware unit, called template; so that the data-path’s performance benefits by the intra-component chaining of operations. Due to the component’s flexible and universal structure, the Data Flow Graph is realized by a small number of such components. The small numbers of the used components coupled with a configurable interconnection network allow adopting direct inter-component connections and optimally exploiting any inter-component chaining possibility over to the existing template-based methods. Also, due to universal and flexible structure of the component, scheduling and binding are accomplished by simple, yet efficient, algorithms achieving minimum latency at the expense of an area penalty and a small overhead at the control circuit and clock period. Results on DSP benchmarks show an average latency reduction of 20%, when the proposed data-path is compared with a high-performance data-path.
1 Introduction
Digital Signal Processing (DSP) and multimedia applications usually spend most of their time executing a small number of code segments with well-defined characteristics, called kernels. To accelerate the execution of such kernels, various high-performance data-paths have been proposed [1-4]. Research activities in High-Level Synthesis (HLS) [1, 3, 5, 6, 8] and Application Specific Instruction Processors (ASIPs) [2], [7, 9] have proven that the use of complex resources instead of primitive ones improves the performance of the data-path. In these works, at the behavioral level, complex operations (or complex instructions) are used instead of groups of primitive ones, while at the architectural level the complex operations are implemented by optimal custom-designed hardware units, called templates or clusters. A template may be a specialized hardware unit or a group of chained units. Special hardware is used for common-appeared operations (e.g. multiply-add). Chaining is the removal of the intermediate registers between the primitive units improving the total delay of the units combined. The templates either can be obtained by an existing library [1, 3], or can be extracted by the kernel’s Data Flow Graph (DFG) [2, 4], [8-9].

Corazao et al. [1] shown that templates of two levels with at most two operations per level can be used together with primitive resources to derive a high-performance data-path. Given a library of templates, a method for implementing a portion of the DFG, which corresponds to the critical path, was proposed. Primitive resources implement the rest of the DFG. The reported results show high performance gains with an affordable area increase. Although intra-template chaining of (usually) two operations is exploited, chaining among operations assigned in distinct templates is not utilized. Thus, the templates and primitive resources exchange data through the register bank, which results in a latency increase. Also, as the library consists of many different templates, complex algorithms are needed to cover the DFG.
Kastner et al. [2] addressed the definition of complex instructions for an application domain. The templates implemented in ASIC technology are embedded in a hybrid reconfigurable system consisting of the templates and FPGA units. They observe that the number of operations per template is small and conclude that simple pairs of operations are the most appropriate templates for DSP applications. However, as FPGA units implement the uncovered DFG operations, the system’s performance is reduced and the power consumption is increased. Cathedral [3] HLS system generates a high-performance data-path that consists of special components called Application Specific Units (ASUs). ASUs are clusters of operations comprised of chained units that match selected parts of the application’s Signal Flow Graph. The chained units of an ASU, which are called Abstract Building Blocks (ABBs), are available from a given library. SFG matching is achieved via manual clustering of operations into more complex ones. However, direct connections among ABBs are not permitted resulting in non-optimal exploitation of chaining.
Rao and Kurdahi [4] examined the regularity extraction in a digital system and presented a methodology for clustering operations based on the structural regularity. They showed that identifying clusters in a circuit can simplify an important CAD problem -system-level clustering - resulting in simplifications in several design tasks. Cadambi and Goldstein [8] proposed a constructive bottom up approach to generate single-output templates. In both methods the generated templates are restricted to the area and number of their inputs and outputs, while a complete graph covering is not achieved.
Cong et al. [9] addressed the problem of generating application-specific instructions for configurable processors aiming at improving delay. The instruction generation considers only Multiple-Input Single Output (MISO) format, which cannot take into advantage of register files with more than one write port. The pattern library is selected to maximize the potential speedup, subject to a total area constraint. Nevertheless, this does not exclude the generation of a large number of different patterns, which complicates the step of application mapping. The mapping stage is formulated as a minimum-area technology mapping problem and it is solved by a binate covering problem, which is an NP-hard problem. So, the complexity of the application mapping is an important disadvantage of their approach. This paper proposes a high-performance data-path to realize DSP kernels. The aim is to overcome the limitations of the existing template-based methods regarding the exploitation of chaining and to fully utilize both intra- and inter-template chaining. This is achieved by introducing a uniform and flexible component (template) called Flexible Computational Component (FCC). The FCC is a combinational circuit

consisting of a 2x2 array of nodes, where each node contains one ALU and one multiplier. Each FCC is able to realize complex operations. Direct inter-FCC connections exist to fully exploit chaining between nodes of different FCCs in contrast to existing template-based methods [1, 2, 9]. Furthermore, the stages of synthesis are accommodated by unsophisticated, yet effective, algorithms for scheduling and binding with the FCCs. A set of experimental results shows that the proposed data-path achieves higher performance than primitive resource- and existing template-based data-paths. The performance gain stems from the features of the FCC data-path and the respective synthesis methodology. A motivational example regarding the optimal chaining exploitation is shown in Fig. 1. If direct inter-template connections are permitted (as in the case of the FCC data-path) the chaining of operations is optimally exploited and the DFG is executed in one cycle (Fig. 1a). On the other hand, if direct inter-template connections are not allowed as in [1, 2], the result of operation b is produced and stored in the register bank at the first clock cycle and it is consumed at the second cycle. Thus, the DFG is now realized in two cycles (Fig. 1b).
x x x
x x
a b c
d e
Direct inter-template connection isallowed
x x
x
b
x
x
a
d
c
e
Cycle1
Cycle2
template1
template2
Cycle1
(a) (b)
Direct inter-template connection isnot allowed
Fig. 1. Latency gain with direct inter-template connections
The rest of the paper is organized as follows. Section 2 presents the detailed architecture and the main features of the FCC. The synthesis methodology for executing applications in the proposed data-path is given in section 3, while section 4 presents the experimental results. Finally, section 5 concludes the paper and describes future research activities.
2 FCC-based data-path
2.1 Architecture description
The proposed data-path architecture consists of: (a) the FCCs, (b) a centralized register bank, and (c) a reconfigurable interconnection network, which enables the inter-FCC connections.
The FCC’s internal architecture is shown in Fig. 2. It consists of four nodes whose interconnection is shown in Fig. 2a, four inputs (in1, in2, in3 in4) connected to the centralized register bank, four additional inputs (A, B, C, D) connected to the register bank or to another FCC, two outputs (out1, out2) also connected to the register bank and/or to another FCC, and two outputs (out3, out4) whose values are stored in the register bank. Multiplexers are used to select the inputs for the second-level nodes.

Concerning the FCC’s structure chaining of two operations is achieved. This is in compliance with the conclusions of [1, 2, 9] regarding the number of nodes in their proposed templates. An FCC with chaining larger than two levels could have been considered, but it has been shown in [1] that templates with depth larger than two comes with high area and time penalties and more control overhead, as well. Also, it has been proved in [2, 9] that templates with two operations in sequence contribute the most in the performance gains.
Each FCC node consists of two computational units that are a multiplier and an ALU as shown in Fig. 2b. Both of these units are implemented in combinational logic to exploit the benefits of the chaining of operations inside the FCC. In applications where consecutive ALU-type operations is a common place, the clock period of the primitive resource data-path is set to the multiplier’s delay, and the ALU’s delay is less than the half of clock period, then a modified FCC can be used to allow the chaining of two ALUs in series and thus improve performance. The flexible interconnection among the nodes is chosen to allow the control-unit to easily realize any desired hardware template by properly configuring the existing steering logic (i.e. the multiplexers and the tri-state buffers). The ALU performs shifting, arithmetic (add/subtract), and logical operations. Each time either the multiplier or the ALU is activated according to the control signals, Sel1 and Sel2, as shown in Fig. 2b. Each operation is 16-bit, because such a word-length is adequate for the majority of the DSP applications.
Buffer Buffer
In A In B
Out
Sel 1 Sel 2
* ALU
(a) (b)
Fig. 2. Detailed architecture of a FCC (a) and the FCC node architecture (b)
The direct connections among the FCCs in the data-path are implemented through a configurable full crossbar interconnection network. This interconnection network introduces a routing overhead, which is small - not degrading the performance - when the number of the FCCs is a small constant, e.g. equal to 4. When a large number of FCCs is required to support a high concurrency of operations, the simple crossbar network cannot be used, as it is not scalable network. In this case we can use an interconnection structure similar to those used in supercomputing domain. Such an interconnection network is the fat-tree [10]. For the FCC data-path, a modification of this network structure like the one presented in [11] can be used. Particularly, connecting FCCs into clusters, we can create an efficient interconnection network. Firstly, k FCCs are clustered and connected via a switch device, which provides the
Node1
Node2
Node3
Node4
In 1 In 2 In 3 In 4
Out 3 Out 4
To register bankor to another FCC
To register bankor to another FCC
B C C D
2 2 2 2
BA
A,B,C,D comefrom register bankor from other FCC
Out 1 Out 2

full connectivity among the k FCCs. Then, k clusters are recursively connected together to form as a supercluster and so on. It was showed that a value of k=4 results in large performance gains [11]. Any two FCCs can be connected with fewer than 2logkN-1 switch devices, where N is the total number of FCCs in the data-path. Thus, the interconnect delay increases logarithmically with the number of FCCs in the data-path and not in a quadratic manner as in a crossbar network, where O(N2) switches are required. Although, a fat-tree like scheme can be also employed by the existing methods, the interconnect delay of the introduced data-path is smaller as it consists of a smaller number of regular and uniform hardware resources (FCCs) compared to the data-path derived by the existing template-based methods. In other words fewer switches are required for implementing the interconnection for the FCC data-path, since their number is smaller than the template instances.
2.2 Data-path characteristics
It is adopted that there is trade-off between area and performance when templates are used to implement a data-path. In general, the template-based data-path has larger area but better performance compared with a data-path implemented by primitive resources. The area of the introduced data-path is the sum of the area of the FCCs and the area of the external to the FCCs steering, wiring and control logic. However, since we target to accelerate DSP kernels, the data-path is a resource-dominated circuit [5], which means that the data-path’s area is dominated by the computational resources (i.e. the FCCs). To minimize the area overhead due to FCCs, we perform post synthesis optimization by a procedure called FCC instantiation. In particular, when a unit (ALU or multiplier) in an FCC node and/or a whole FCC node is not used at any control steps (c-steps) of the scheduled DFG, then it is not included in the final data-path. When the FCC data-path is compared with a data-path implemented by primitive resources or templates, extra control signals are required to configure the proposed data-path. However, the control-unit can be designed in such a way that does not introduce extra levels of combinational logic. Thus, in this case the control circuit will not affect the critical path of the FCC-based data-path. This can be achieved by grouping control signals to define a subset of the control state in a c-step. This feature is supported by the majority of the advanced CAD synthesis tools [12], where the control-unit can be automatically synthesized under a given delay constraint. For example, the extra control signals that are required to set-up the connections and enable the proper operations inside the FCC, can be grouped, thus forming a subset. In this way, the delay of this control-unit is not increased compared to a data-path consisting of templates and/or primitive resources. Regarding the power consumption, each time an operation is assigned to a FCC node, only one unit either the multiplier or the ALU is activated by properly controlling the corresponding buffers. When a FCC node is not utilized at a c-step, neither the multiplier nor the ALU are activated, thus reducing the power consumption. Compared with a data-path realized by templates [1, 2, 9], the FCC’s critical path increases due to the delays of (a) two tri-state buffers, and (b) a 4-to-1 multiplexer. To have an indication of this delay increase, an experiment has been performed. Two

multipliers in a sequence are considered as template. We described the FCC and the two multipliers in sequence in structural VHDL. The multiplication unit is a 16-bit Booth-Wallace. We synthesized both designs in an ASIC CMOS process at 0.13µm and an increase in delay of 4.2% has been measured. Thus, the performance improvements of our data-path over the template-based one are not negated (see Table 1), since the measured % delay increase (and thus the % increase in clock cycle period) is significantly smaller than the expected reduction of the latency cycles.
3 Synthesis methodology
The introduced data-path offers a lot of advantages to develop unsophisticated, yet efficient, synthesis algorithms. As the data-path consists of one type of resources, (i.e the FCC) resource allocation can be accomplished by a simple algorithm. The universal and flexible structure of the FCC further simplifies binding allowing in achieving a full DFG covering using only FCCs. Also, the flexibility of the whole data-path provided by the FCC and the interconnection network gives extra freedom to realize the DFG by a small number of FCCs, while inter- and intra-FCC chaining is fully exploited. To implement an application onto the FCC data-path, a synthesis methodology has been developed. The methodology consists of (a) scheduling of DFG operations, and (b) binding with the FCCs. The input is an unscheduled DFG. For scheduling and binding Control Data Flow Graphs (CDFGs) the methodology is iterated through the DFGs comprising the CDFG of an application [5]. We consider that the data-path is realized by a fixed number of FCCs. Hence, scheduling is a resource-constrained problem with the goal of latency minimization. We accomplish scheduling by developing a scheduler based on list scheduling, which is widely used in HLS and compilers. The priority function of the scheduler is derived by properly labeling the DFG’s nodes. The nodes are labeled with weights of their longest path to the sink node of the DFG [5], and they are ranked in decreasing order. The most urgent operations are scheduled first. In the proposed data-path the list scheduler handles one resource type, thus it is simpler than a list scheduler, which handles various types of resources. This happens since the input DFG consists of ALU and/or multiplication type of operations and each FCC node contains ALU(s) and a multiplier; thus each DFG node is considered of one resource type (i.e. the FCC). The pseudo-code of the binding algorithm is illustrated in Fig. 3. The input is the scheduled DFG, where each c-step has Tprim clock period, and this type of c-step is called from here after c-stepprim. For example, Tprim can be set to the multiplier’s delay, so each DFG node can occupy one c-stepprim, since all DFG nodes have, in this case, unit execution delay. The binding algorithm maps the DFG nodes to the FCC nodes in a row-wise manner. We define a term called FCC_index that it is related to the new period TFCC of the c-steps (i.e. the clock period), after the binding is performed. It represents the current level of FCC operations that bind the DFG nodes. The FCC_index takes the values of 0 and 1, as the FCC consists of two levels of operations. Also, the clock period TFCC is set so as each operation is executed in one cycle. The algorithm covers the operations in c-stepprim (s) for FCC_index equal to 0

or until there are no DFG nodes left uncovered in a c-stepprim. Then it proceeds with FCC_index equal to 1, if there are DFG nodes left to be covered. This procedure is repeated for every FCC in the data-path. The binding starts from the FCC assigned to the number 1, and it is continued, if it is necessary, for the next FCCs in the data-path. A FCC is not utilized, when they are no DFG nodes to be covered. Also, an FCC is partially utilized when there is no sufficient number of DFG nodes left and the mapping to FCC procedure (map_to_FCC) has already been started for this FCC. If there are p FCCs in the data-path the maximum number of operations per c-stepprim is equal to 2p, as each FCC level consists of two nodes.
do { for the number of FCCs for (FCC_index=0; FCC_index<2; FCC_index++) while (col_idx < 2 && col_idx < number of DFG nodes not covered) map_to_FCC (dfg_node, FCC_index, col_idx) end while; end for; end for; } while (the DFG is covered) FCC_instantiation(); /* Instantiating the FCCs */ Determine_register_bank_size(); /* Defining the register bank size */
Fig. 3. The proposed binding algorithm
4 Experimental results
A prototype tool has been developed in C++ to demonstrate the efficiency of the proposed data-path in well-known DSP benchmarks. The first set of benchmarks contains data flow structures described in VHDL, which have been used extensively in the HLS domain. The second set is described in C and consists of: (a) a set of DSP kernels from the Mediabench suite [13], and (b) an in-house JPEG encoder and an IEEE 802.11a OFDM transmitter. The DFGs were obtained from the behavioral VHDL descriptions using the CDFG tool of [14], while for extracting the DFGs from the C codes, the SUIF2 compiler [15] was used. Regarding the DFGs shown in the first column of Tables, the ellip to wdf7 are extracted from the HLS benchmarks, the jpeg to ofdm from the in-house benchmarks, and the gsm_enc till the end from the Mediabench suite.
We have synthesized the control-units of small DFGs (fir11, volterra and ellip) for a data-path consisting of two FCCs and we have measured their delay. The specification of the control-units has been performed manually (that’s why small DFGs were used), since by this time we do not support a method for automatically defining control-units from the scheduled and bounded DFG. The DFGs that have been considered are the: fir11, volterra and ellip. For the synthesis of the derived control-units, a 0.13µm CMOS process has been used. The average delay of the control-units is a small fraction (bellow 10%) of the delay imposed by the FCC. This indicates that the delay of the control-unit does not affect the critical-path of the proposed data-path. Analogous results in the control-unit’s delay are expected for DFGs consisting of large number (e.g gsm_enc) of nodes.

For the selected set of benchmarks, another experiment was performed which showed that a data-path with two FCCs achieves an average latency cycles decrease of 58.1%, when compared with a data-path composed of primitive resources. The clock cycle of the primitive resource data-path is set to the ALU delay. So, for this data-path, a multiplication operation takes two cycles to complete. As already mentioned, for the FCC data-path, the clock period is set for having unit execution delay. It can be easily proved that the performance of the proposed data-path is higher when TFCC<2.4 ⋅ Tprim (1), where TFCC and Tprim is the clock period for the FCC and the primitive resource based data-path, respectively. Equation (1) has been satisfied after comparing the FCC delay with a 16-bit ALU delay, where both resources implemented in structural VHDL and synthesized at 0.13µm ASIC process using the Leonardo SpectrumTM tool. The results showed that TFCC=2.14 ⋅ Tprim. If the physical layout of the FCC is manually optimized, then the TFCC should become smaller. Similar constrains, like equation (1) have been also satisfied for other template-based methods as in [1, 2, 9], where properly designed templates outperformed the combination of primitive resources. This is due to the fact that the worst-case delay of a whole operator chain (i.e. the operations inside the template) is usually smaller than the sum of the worst-case delays of the operators in the chain.
Table 1. Latency cycles and area results when FCC approach is compared with a template-based data-path when 6 operations are executed concurrently
Latency cycles Area increase (%) DFG Template-
based FCC-based Latency
decrease (%) Multiplier ALU
ellip 9 6 33.3 0.0 12.5 fir11 7 6 14.3 66.7 -40.0 nc 9 7 22.2 -14.3 0.0 volterra 8 6 25.0 9.1 0.0 wavelet 9 7 22.2 33.3 -41.7 wdf7 9 7 22.2 20.0 20.0 jpeg 66 54 18.2 33.3 -29.4 ofdm 28 23 17.9 50.0 -14.3 gsm_enc 80 69 13.8 100.0 -33.3 gsm_dec 92 73 20.7 140.0 20.0 mpeg2 8 6 25.0 125.0 50.0 rasta 15 13 13.3 140.0 -7.7 Average 20.7 58.6 -5.3
A third experiment was performed to compare the performance and the area utilization of the introduced data-path with another high-performance data-path, which is composed of complex hardware units (i.e. templates). The template library consists of the following templates: multiply-multiply, multiply-alu, alu-alu, and alu-multiply. These templates are chosen because they are proposed by the majority of the existing methods [1, 2, 9] to be used to derive high-performance data-paths for DSP kernels. The FCC data-path consists of two (case 1) and three (case 2) FCCs. So, in case 1, four operations can be executed concurrently in each c-step, while in case 2, six operations can be executed concurrently. The assumptions of this experiment are: (a) template partial matching is enabled, and (b) the clock period for all the
synthesized template-based data-path is set to the delay of the multiply-multiply template (i.e. unit execution delay for all the templates). The template partial matching enables the full DFG covering, without needing extra primitive resources to be present in the data-path. As shown in subsection 3.2, the delay of a FCC is marginally larger than a multiply-multiply template (i.e. unit execution delay for all the templates in the data-path). Since, our design decision is to set the clock period TFCC for having unit execution in a FCC data-path, it is a fair assumption to consider that the clock period is the same in both data-paths. Hence, assumption (b) is made so as the performance comparison in Table 1 is straightforward.
To derive the latency for the template data-path, covering with templates is performed in the unscheduled DFG and then scheduling is performed by a proper developed list scheduler. The binding with the templates is performed so as the available primitive computational resources (multipliers and/or ALUs) in each c-step is equal with the ones available from the FCC-based data-path.
Table 1 shows the results in latency and area when three FCCs are used to realize the DFGs of the benchmarks applications. As illustrated in Table 1, the FCC data-path achieves better performance than the data-path consisting of templates, since fewer cycles are required to implement the considered benchmarks. The area overhead of the FCC-based data-path is measured in terms of the number of multipliers and ALUs. A negative number in area increase indicates a decrease. For the case of two FCCs, an average reduction in latency of 20.4% has been reported. The average increase, in this case, for the multipliers’ area is 53.8% and a decrease in the ALUs’ area of 10.4%. The increase in the multiplier’s area is due to the fact that in the considered DFGs the majority of operations were of ALU type, and in this case the relative usage of the FCC node as an ALU was greater than the usage as a multiplier.
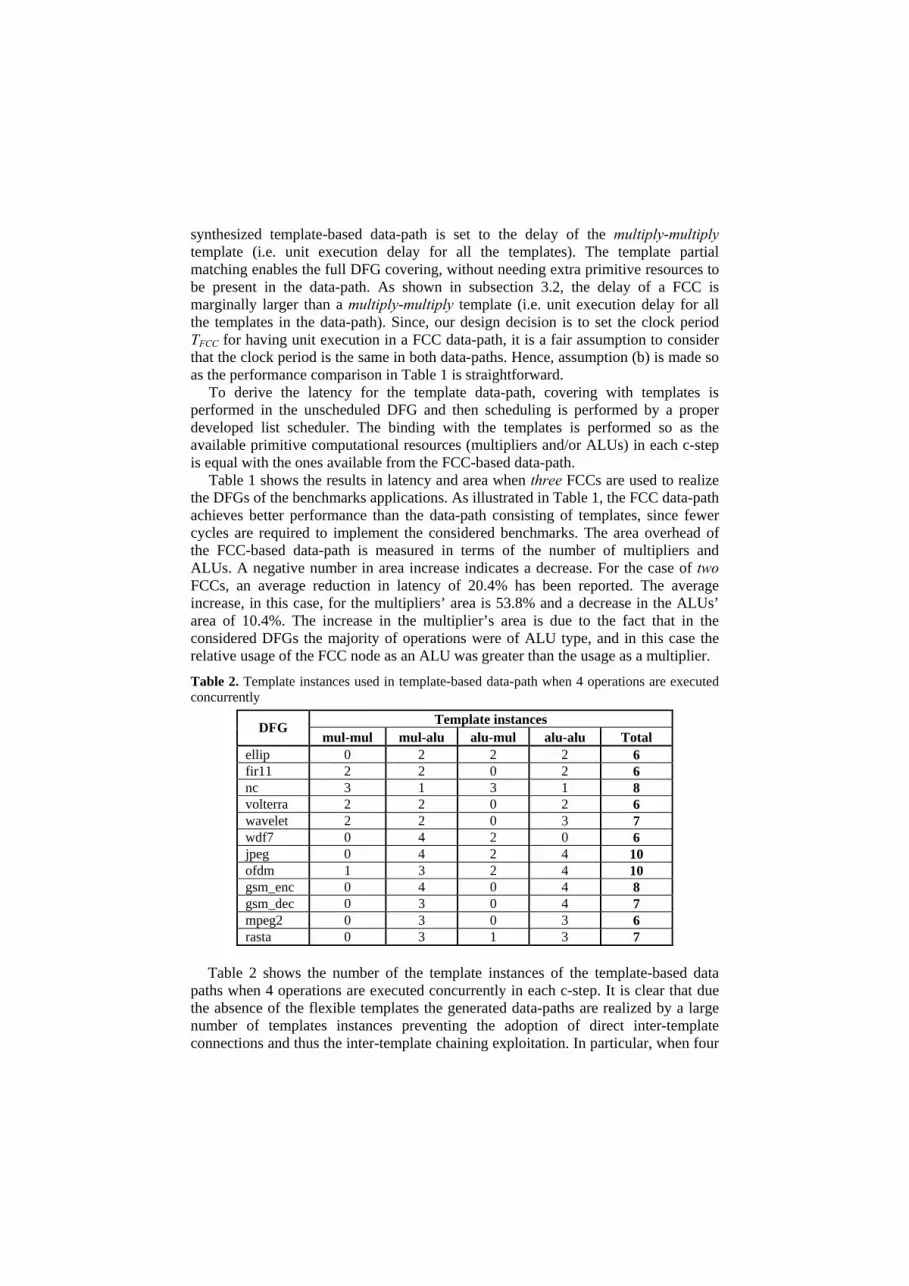
Table 2. Template instances used in template-based data-path when 4 operations are executed concurrently
Template instances DFG mul-mul mul-alu alu-mul alu-alu Total
ellip 0 2 2 2 6 fir11 2 2 0 2 6 nc 3 1 3 1 8 volterra 2 2 0 2 6 wavelet 2 2 0 3 7 wdf7 0 4 2 0 6 jpeg 0 4 2 4 10 ofdm 1 3 2 4 10 gsm_enc 0 4 0 4 8 gsm_dec 0 3 0 4 7 mpeg2 0 3 0 3 6 rasta 0 3 1 3 7
Table 2 shows the number of the template instances of the template-based data
paths when 4 operations are executed concurrently in each c-step. It is clear that due the absence of the flexible templates the generated data-paths are realized by a large number of templates instances preventing the adoption of direct inter-template connections and thus the inter-template chaining exploitation. In particular, when four

operations are executed concurrently at each c-step, the FCC-based data-paths are realized by only two FCCs while the template-based data-paths are implemented by a lot of template instances.
5 Conclusions
A high-performance data-path to accelerate computational-intensive DSP kernels has been presented. Chaining is optimally exploited resulting in a latency reduction. Compared, with a high-performance data-path produced by existing template-based method, an average latency reduction of approximately 20% has been achieved. The universality and regularity of the FCC allows for simpler, yet efficient synthesis algorithms. A methodology for accelerating loop structures (like for, while, do-while structures) when these are mapped to the FCC data-path, is a topic of future work.
6 References
1. M. R Corazao et al., “Performance Optimization Using Template Mapping for Datapath-Intensive High-Level Synthesis”, in IEEE Trans. on CAD, vol.15, no. 2, pp. 877-888, August 1996.
2. R. Kastner et al., “Instruction Generation for Hybrid Reconfigurable Systems”, in ACM Transactions on Design Automation of Embedded Systems (TODAES), vol 7., no.4, pp. 605-627, October, 2002.
3. W. Geurts, F. Catthoor, S. Vernalde, and H. DeMan, “Accelerator Data-Path Synthesis for High-Throughput Signal Processing Applications”, Boston, MA: Kluwer, 1996.
4. D. Rao and F. Kurdahi, “On Clustering for Maximal Regularity Extraction”, in IEEE Trans. on CAD, vol.12, no. 8, pp. 1198-1208, August, 1993.
5. Giovanni De Micheli, “Synthesis and Optimization of Digital Circuits”, McGraw-Hill, International Editions, 1994.
6. D. Gajski et al. “High-Level Synthesis: Introduction to Chip and System design”, Boston, MA. Kluwer, 1997.
7. M. Jain et al. “ASIP Design Methodologies: Survey and Issues”, in Proc of Int. Conf. on VLSI Design, pp. 76-81, 2001.
8. S. Cadambi and S. C. Goldstein, “CPR: a configuration profiling tool”, in Symp. on Field-Programmable Custom Computing Machines (FCCM), 1999.
9. J. Cong et al., “Application-Specific Instruction Generation for Configurable Processor Architectures”, in Proc. of the ACM International Symposium on Field-Programmable Gate Arrays (FPGA 2004), February 2004.
10. C.E. Leiserson, “Fat-Trees: Universal Networks for Hardware Efficient Supercomputing”, in IEEE Trans. on Computers, vol 43., no. 10, pp. 892-901, Oct. 1985.
11. Y. Lai, “Hierarchical Interconnection Structures for Field Programmable Gate Arrays”, in IEEE Trans. on VLSI, vol 5., no. 2, pp. 186-196, June 1997.
12. Cadence BuildGatesΤΜ, www.cadence.com. 13. C. Lee et al., “MediaBench: a tool for evaluating and synthesizing multimedia and
communications systems”, in Int. Symposium on Microarchitecture, 1997. 14. CDFG toolset, http://poppy.snu.ac.kr/CDFG/cdfg.html. 15. M. W. Hall et al., “Maximizing multiprocessor performance with the SUIF compiler”,
Computer, vol. 29, pp. 84-89, 1996. (URL: http://suif.standford.edu)