a convex exemplar-based approach to mad-bayes dirichlet
TRANSCRIPT

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
A Convex Exemplar-based Approach to
MAD-Bayes Dirichlet Process Mixture Models
Presenter: Jimmy Xin Lin
Joint work with Ian E.H. Yen, Kai Zhong, Pradeep Ravikumarand Inderjit S. Dhillon
The University of Texas At Austin
June 9, 2015
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Table of Contents
1 MAD-Bayes: MAP-based Asymptotic Derivation from Bayes
2 Convex Exemplar-based Approach
3 Optimality Guarantees
4 ADMM for Structural-Regularized Programs
5 Experiments and Results
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
MAD-Bayes: Dirichlet Process Mixture
MAD-Bayes derives the asymptotic log-likelihood of DP mixture whenvariance s2
X of dist. P(xi |µzi ) approaches 0.
where D(xi ,µk ) is the Bregman Divergence (corresponds to P(x |z ,µ))between sample xi and k-th mean parameter µk , and K is the number ofclusters.
Inference (by MCMC etc.) is replaced by a MAP optimization programw.r.t. zi , µk , and K .
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin
MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
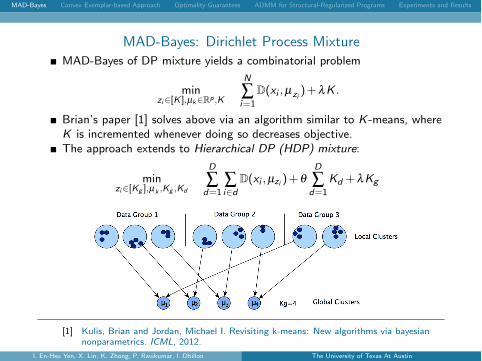
MAD-Bayes: Dirichlet Process MixtureMAD-Bayes of DP mixture yields a combinatorial problem
minzi2[K ],µk2Rp ,K
N
Âi=1
D(xi ,µzi )+lK .
Brian’s paper [1] solves above via an algorithm similar to K -means, whereK is incremented whenever doing so decreases objective.The approach extends to Hierarchical DP (HDP) mixture:
minzi2[Kg ],µk ,Kg ,Kd
D
Âd=1
Âi2d
D(xi ,µzi )+qD
Âd=1
Kd +lKg
[1] Kulis, Brian and Jordan, Michael I. Revisiting k-means: New algorithms via bayesiannonparametrics. ICML, 2012.
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Table Of Contents
1 MAD-Bayes: MAP-based Asymptotic Derivation from Bayes
2 Convex Exemplar-based Approach
3 Optimality Guarantees
4 ADMM for Structural-Regularized Programs
5 Experiments and Results
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Convex Exemplar-based Approach
Observation:
minzi2[K ],µk2Rp ,K
N
Âi=1
D(xi ,µzi )+lK .
is equivalent to
minW2{0,1}N⇥J
D�W +lkW k•,1
s.t. W1= 1,
where Dij = D(xi ,µj ),
assuming there is a Exemplar Set E = {µj}Jj of possible mean parameters. The
program becomes convex when we relax wi ,j from {0,1} to [0,1]. This conceptof exemplar was also employed in K -medoid problem [1].
[1] Nellore, Abhinav and Ward, Rachel. Recovery Gurantees for exemplar-based clustering.arXiv:1309.3256, 2013.
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Convex Exemplar-based Approach
For HDP:
D
Âd=1
Âi2d
D(xi ,µzi )+qD
Âd=1
Kd +lKg
is equivalent to
minW
D�W +qkW kG +lkW k•,1
s.t. W1= 1
where Dij = D(xi ,µj ),
assuming there is a Exemplar Set E = {µj}Jj of possible mean parameters. The
program becomes convex when relaxing wi ,j from {0,1} to [0,1].
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Table Of Contents
1 MAD-Bayes: MAP-based Asymptotic Derivation from Bayes
2 Convex Exemplar-based Approach
3 Optimality Guarantees
4 ADMM for Structural-Regularized Programs
5 Experiments and Results
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Optimality Guarantee
Suppose the convex relaxation
minW2[0,1]N⇥J
D�W +lkW k•,1
s.t. W1= 1,(1)
has integer solution, the solution is also optimal to the original combinatorialproblem. The following shows a clustering satisfying a separation conditionwhich leads to an Integer solution for the Convex Program (1) for a range of l .
Theorem
Suppose there exists a clustering {Sk}k2M for which we can find l such that
maxk2M
maxi ,j2Sk
Nkdij < l < min(k,l2M,k 6=l)
min(i2Sk ,j2Sl )
Nkdij (2)
where Nk = |Sk | and dij = D(xi ,xj )�D(xi ,xM(i)), then the integer solution W ⇤
realizing {Sk}k2M is unique optimal solution to (1).
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin
MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Optimality Guarantee
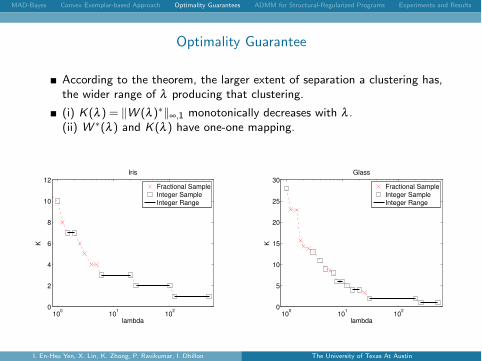
According to the theorem, the larger extent of separation a clustering has,the wider range of l producing that clustering.
(i) K(l ) = kW (l )⇤k•,1 monotonically decreases with l .(ii) W ⇤(l ) and K(l ) have one-one mapping.
100
101
102
0
2
4
6
8
10
12
lambda
K
Iris
Fractional SampleInteger SampleInteger Range
100
101
102
0
5
10
15
20
25
30
lambda
K
Glass
Fractional SampleInteger SampleInteger Range
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin
MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Optimality Guarantee
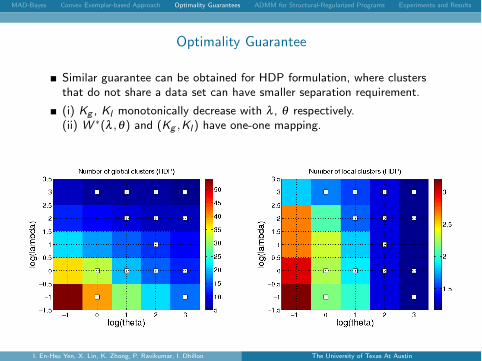
Similar guarantee can be obtained for HDP formulation, where clustersthat do not share a data set can have smaller separation requirement.
(i) Kg , Kl monotonically decrease with l , q respectively.(ii) W ⇤(l ,q) and (Kg ,Kl ) have one-one mapping.
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Table Of Contents
1 MAD-Bayes: MAP-based Asymptotic Derivation from Bayes
2 Convex Exemplar-based Approach
3 Optimality Guarantees
4 ADMM for Structural-Regularized Programs
5 Experiments and Results
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Solving Structural-Regularized Programs
We employ an ADMM procedure that has linear convergence to the optimumof the given convex program
minW
D�W +qkW kG +lkW k•,1
s.t. W1= 1
(3)
by introducing dual variables Y1,Y2 and consensus variables Z s.t. (3) can bedecomposed into a sequence of (i) sub-problem with only simplex constraint
W(t+1)1 = argmin
W2[0,1]N⇥JD�W +Y
(t)1 �W +
r2kW �Z (t)k2
s.t. W1= 1
and (ii) sub-problem with only structural regularizer
W(t+1)2 = argmin
W2[0,1]N⇥JqkW kG +lkW k•,1+Y
(t)2 �W +
r2kW �Z (t)k2.
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Solving Structural-Regularized Program
The 1st sub-problem:
W(t+1)1 = argmin
W2[0,1]N⇥JD�W +Y
(t)1 �W +
r2kW �Z (t)k2
s.t. W1= 1
can be solved via Simplex Projection.
The 2nd sub-problem:
W(t+1)2 = argmin
W2[0,1]N⇥JqkW kG +lkW k•,1+Y
(t)2 �W +
r2kW �Z (t)k2.
has closed-form solution via proximal mapping proxl (proxq (.)).
ADMM Update:
Z (t+1) (W(t+1)1 +W
(t+1)2 )/2
Y(t+1)q Y
(t)q +a(W
(t+1)q �Z (t+1)), for q = 1,2
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Table Of Contents
1 MAD-Bayes: MAP-based Asymptotic Derivation from Bayes
2 Convex Exemplar-based Approach
3 Optimality Guarantees
4 ADMM for Structural-Regularized Programs
5 Experiments and Results
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin
MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
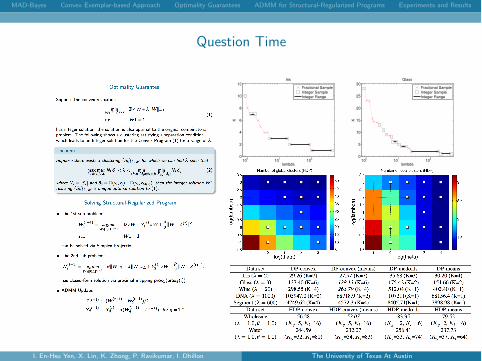
Results
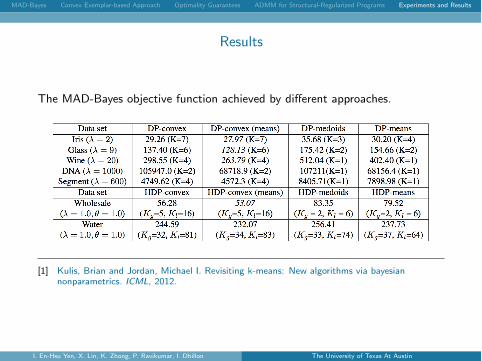
The MAD-Bayes objective function achieved by di↵erent approaches.
[1] Kulis, Brian and Jordan, Michael I. Revisiting k-means: New algorithms via bayesiannonparametrics. ICML, 2012.
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin

MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Future Works
The convex optimization approach applies to other exemplar-basedunsupervised learning problems such as Multiple Sequence Alignment andSequence Motif Finding, which can be seen as exemplar-based version ofHidden Markov Model.
For DP mixture models, the current algorithm runs in O(N2) time. Agreedy Column Generation method that reduces complexity from O(N2)to O(NK) is desired.
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin
MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Question Time
100
101
102
0
2
4
6
8
10
12
lambda
K
Iris
Fractional SampleInteger SampleInteger Range
100
101
102
0
5
10
15
20
25
30
lambda
K
Glass
Fractional SampleInteger SampleInteger Range
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin
MAD-Bayes Convex Exemplar-based Approach Optimality Guarantees ADMM for Structural-Regularized Programs Experiments and Results
Thank you!
I. En-Hsu Yen, X. Lin, K. Zhong, P. Ravikumar, I. Dhillon The University of Texas At Austin