discovering correlations in annotated databases
TRANSCRIPT

Discovering Correlations in Annotated Databases
Xuebin He Stephen Donohue Mohamed Y. EltabakhWorcester Polytechnic Institute, Computer Science Department, MA, USA
{xhe2, donohues, meltabakh}@cs.wpi.edu
ABSTRACTMost emerging applications, especially in science domains, main-tain databases that are rich in metadata and annotation information,e.g., auxiliary exchanged comments, related articles and images,provenance information, corrections and versioning information,and even scientists’ thoughts and observations. To manage theseannotated databases, numerous techniques have been proposed toextend the DBMSs and efficiently integrate the annotations into thedata processing cycle, e.g., storage, indexing, extended query lan-guages and semantics, and query optimization. In this paper, weaddress a new facet of annotation management, which is the dis-covery and exploitation of the hidden corrections that may exist inannotated databases. Such correlations can be either between thedata and the annotations (data-to-annotation), or between the anno-tations themselves (annotation-to-annotation). We make the casethat the discovery of these annotation-related correlations can beexploited in various ways to enhance the quality of the annotateddatabase, e.g., discovering missing attachments, and recommend-ing annotations to newly inserted data. We leverage the state-of-art in association rule mining in innovative ways to discover theannotation-related correlations. We propose several extensions tothe state-of-art in association rule mining to address new challengesand cases specific to annotated databases, i.e., incremental additionof annotations, and hierarchy-based annotations. The proposed al-gorithms are evaluated using real-world applications from the bio-logical domain, and an end-to-end system including an Excel-basedGUI is developed for seamless manipulation of the annotations andtheir correlations.
1. INTRODUCTIONMost modern applications annotate and curate their data with
various types of metadata information—usually called annotations,e.g., provenance information, versioning timestamps, executionstatistics, related comments or articles, corrections and conflict-related information, and auxiliary exchanged knowledge from dif-ferent users. Interestingly, the number and size of these annotationsis growing very fast, e.g., the number of annotations is around 30x,120x, and 250x larger than the number of data records in Data-
c©2016, Copyright is with the authors. Published in Proc. 19th Inter-national Conference on Extending Database Technology (EDBT), March15-18, 2016 - Bordeaux, France: ISBN 978-3-89318-070-7, on OpenPro-ceedings.org. Distribution of this paper is permitted under the terms of theCreative Commons license CC-by-nc-nd 4.0
Bank biological database [3], Hydrologic Earth database [4, 47],and AKN ornithological database [5], respectively. Existing tech-niques in annotation management, e.g., [9, 15, 17, 21, 24], havemade it feasible to systematically capture such metadata annota-tions and efficiently integrate them into the data processing cy-cle. This includes propagating the related annotations along withqueries’ answers [9, 15, 17, 24, 46], querying the data based ontheir attached annotations [21, 24], and supporting semantic an-notations such as provenance tracking [11, 14, 20, 43], and beliefannotations [23]. Such integration is vey beneficial to higher-levelapplications as it complements the base data with the auxiliary andsemantic-rich source of annotations.
In this paper, we address a new facet of annotation managementthat did not receive much attention before and has not been ad-dressed by existing techniques. This facet concerns the discoveryand exploitation of the hidden correlations that may exist in anno-tated databases. Given the growing scale of annotated databases—both the base data and the annotation sets—important correlationsmay exist either between the data values and the annotations, i.e.,data-to-annotations correlations, or among the annotations them-selves, i.e., annotations-to-annotations correlations. By systemati-cally discovering such correlations, applications can leverage themin various ways as motivated by the following scenarios.
Motivation Scenario 1−Discovery of Missing Attachments: As-sume the example biological database illustrated in Figure 1. Typi-cally, many biologists may annotate subsets of the data over time—each scientist focuses only on few genes of interest at a time. Forexample, some of the data records in Figure 1 are annotated with a“Black Flag” annotation. This annotation may represent a scien-tific article or a comment that is attached to these tuples. By ana-lyzing the data, we observe that most genes having value F1 in theFamily column have an attached “Black Flag” annotation. Suchcorrelation suggests that gene JW0012 is probably missing thisannotation, e.g., none of the biologists was working on that geneand thus the article did not get attached to it. However, by discov-ering the aforementioned correlation, the system can proactivelylearn and recommend this missing attachment to domain expertsfor verification. Correlations may also exist among the annotationsthemselves, e.g., between the “Black Flag” and the “Red Flag” an-notations. Without discovering such correlations the database maybecome “under annotated” due to these missing attachments.
Motivation Scenario 2−Annotation Maintenance under Evolv-ing Data: Data is always evolving and new records are alwaysadded to the database. Hence, a key question is: “For the newlyadded data records, do any of the existing annotations apply tothem?”. Learning the correlations between the data and the an-notations can certainly help in answering such question. For ex-

GID Name Seq Family Exp-Id
JW0013 grpC TGCT… F1 101
JW0014 groP GGTT… F6 105
JW0015 insL GGCT… F1 105
… … … … …
JW0018 nhaA CGTT… F1 101
JW0019 yaaB TGTG… F3 101
JW0012 Yaal TTCG… F1 103
Sequence needs to be shifted by 2 bases
JW0027 namE GTTT... F4 101
This value is wrong
Incorrect value
Does not seem correct
Newly inserted record
Figure 1: Examples of Annotation-Related Correlations.
ample, the cloud-shaped comment in Figure 1 is attached to alldata records having value 101 in the Exp-Id column. Basedon this correlation, the system can automatically predict—at inser-tion time—that this annotation also applies to the newly insertedJW0027 tuple. Otherwise, such attachment can be easily missedand important information is lost. Clearly, delegating such taskto end-users without providing system-level support—which is thestate of existing annotation management engines—is not a practi-cal assumption.
Motivation Scenario 3−Annotation-Driven Exploration: Thediscovered correlations may reveal information about the under-ling data that trigger further investigation or exploration by do-main experts. For example, as highlighted in Figure 1, the “RedFlag” annotation semantically means invalid or incorrect data.Since these annotations can be added by different biologists andat different times, none of them may observe a pattern in the data.In contrast, by discovering (and reporting) that the “Red Flag” an-notation has strong correlation with experiment id 105, the domainexperts may re-visit the experimental setup of this wet-lab experi-ment and may revise and re-validate all data generated from it.
These scenarios demonstrate the potential gain from capturingthe annotation-related correlations. Unfortunately, relying on do-main experts or DB admins to manually define or capture thesecorrelation patterns is evidently an infeasible approach. This is be-cause the correlations may not be known in advance, hard to cap-ture or express, dynamically changing over time, or even not 100%conformed. Moreover, the manual exploration process is error-prone, will not scale to the size of modern annotated databases, andit is a very time- and resource-consuming process. For example, theUniProt biological database has over 150 people working as full-time to maintain and annotate the database [6, 12]. Certainly, suchscale of investments may not be viable to many other domains andscientific groups, e.g., it is reported in a recent science survey [49]that 80.3% of the participant research groups do not have sufficientfund for proper data curation. For these reasons, we argue in thispaper that the analysis and discovery of the annotation-related as-sociations and correlations should be an integral functionality ofthe annotation management engine. As a result, the correlationscan be timely discovered and maintained up-to-date, and also sys-tematic actions can be taken based on them as highlighted by themotivation scenarios.
In this paper, we investigate applying the well-known techniquesof association rule mining, e.g., [8, 31, 52], to the domain of anno-tated databases. This is a new and promising domain for association
rule mining due to the following reasons:
• Many emerging applications—especially scientificapplications—maintain and rely on large-scale annotateddatabases [3, 5, 6]. It is reported in [1] that the ebird or-nithological database receives more than 1.6 million annotationsper month from scientists and bird watchers worldwide. Theseapplications will benefit from the proposed techniques.
• Many annotated databases go under the very expensive andtime-consuming process of manual curation, e.g., [2, 6]. The goalfrom this process is to ensure that correct annotations and curationinformation are attached to the data, and to enrich the annotationswhenever possible. Nevertheless as illustrated in the motivationscenarios, the discovery of the annotation-related correlations canhelp in enhancing the quality of the annotated database in an auto-mated way. And hence, reducing the effort needed in the manualcuration process and freeing the domain scientists for their maintask, which is scientific experimentation.
• Interestingly, annotated databases stretch the traditional tech-niques of association rule mining, and present new challenges asdiscussed in Section 3. For example, the state-of-art techniquesin association rule mining fall short in efficiently handling severalnew cases specific to annotated databases, i.e., they cannot performincremental maintenance of the discovered rules and they have tore-process the entire database. These cases include:
(1) Generalization of Annotations: Annotations can be free-textcomments, which may differ in their values but have the same se-mantics. And hence, discovering the correlations based on the val-ues of the raw annotations may miss important patterns. For ex-ample, referring to Figure 1, the correlation pattern involving theBlack Flag annotation, i.e., “Family:F1 =⇒ Black Flag”can be detected based on the raw annotation value. This is becauseall instances of the Black Flag annotation refer to the same scien-tific article. In contrast, for the Red Flag annotation, the actualannotations inserted by scientists have different values, and thusno correlation pattern can detected based on the raw values. How-ever, by generalizing the annotations to a common concept—theRed Flag annotation in our case—we can detect the correlation pat-ten between them and the experiment Id 105. Therefore, buildinga generalization hierarchy on top of the annotations is an importantstep.
(2) Integration with the Annotation Manager: We propose tobuild a coherent integration between the association rule miningmodule and the Annotation Manager component in contrast to theoffline mining techniques. As a result, the Annotation Manager cantake informed actions based on the discovered rules, e.g., discoverpotential missing attachments and report them for verification (Mo-tivation Scenario I), and annotate newly inserted data tuples withexisting annotations (Motivation Scenario 2). Moreover, since theAnnotation Manager cannot guarantee with 100% confidence thatthe predicted attachments are correct, we propose developing a ver-ification module that enables domain experts to verify the predictedattachments.
(3) Incremental Maintenance under Annotation Addition: In an-notated databases, the discovered correlations and association rulesneed to be incrementally updated under two scenarios, i.e., the ad-dition of new data tuples, and the addition of new annotations.The former case can be handled by existing techniques that ad-dress the incremental update of association rules, e.g., [16]. Thesetechniques assume that the new delta batch changes the size of thedatabase, i.e., the number of data tuples increases. In contrast, in

the latter case, the new annotation batches will not change the num-ber of data tuples, instead they change the content of the tuples—assuming the annotations are part of the tuples. Therefore, the ex-isting incremental techniques need to be extended to handle thelatter case.
In this work, we develop an end-to-end solution that addressesthe above challenges in the context of a real-world applicationand annotation repository, which is a data warehouse for theCaenorhabditis elegans (C. elegans) Worm from biological sci-ences. To facilitate scientists’ usage of the developed system, wedesigned an Excel-based GUI—A tool that most scientists are fa-miliar with—through which all of the proposed functionalities canbe performed.
The rest of the paper is organized as follows. In Section 2, wepresent the needed background, preliminaries, and our case study.In Sections 3, and 4, we present the techniques for the discoveryand maintenance of the annotation-related correlations, and theirexploitation, respectively. Section 5 overviews the related workwhile Section 6 contains the experimental evaluation. Finally, theconclusion remarks are included in Section 7.
2. PRELIMINARIESIn this section, we give a brief overview on annotation manage-
ment and association rule mining techniques, and then present ourcase study.
2.1 BackgroundAnnotation Management in Relational DBs: Annotation man-
agement techniques in relational databases enable end-users to at-tach auxiliary information to the data stored in the relational ta-bles [9, 15, 17, 21, 24, 46]. Annotations can be attached to individ-ual table cells, rows, columns, or arbitrary sets and combinationsof them. Some systems provide a GUI through which the annota-tions can be added [17, 25], while other systems extend the SQLlanguage with new commands and clauses to enable annotation ad-dition [17, 21, 25]. For example, the work in [21] introduces a newAdd Annotation command to SQL as follows:
1- Selecting 2,000 real annotations at random and manually labeling them. Moreover, we created synthetic annotations for each category that include the common keywords in that category.
2- Selecting 1% of the real annotations (around
3,700) at random and classifying them using the trained classifier.
3- Manually verifying the results, and re-labeling
the wrong classification to refine the model. 4- Repeating Steps 2 & 3 until achieving an
acceptable accuracy.
Case III (δ Addition): Updating Existing Association Rules Input: - New annotations delta δ = {a1, a2, …, an} - Set of existing association rules U = {u1, u2, …, um} - Original DB
Output: - Updated set of association rules U’
- New DB’ = DB + δ
Step1: Existing Data-to-Annotations rules - For (each rule ui having annotation “a” && δ in R.H.S) Loop
- // Update the support and confidence of ui - T ! The data tuples newly annotated with “a” - Based on T update the ui.supp & ui.conf - Copy ui to U’ // ui is guaranteed to be valid
- End For
Step2: Existing Annotation-to-Annotations rules - For (each rules ui where none of δ appears in L.H.S & “a” && δ in R.H.S) Loop - // Update the support and confidence of ui
- T ! The data tuples newly annotated with “a” - Based on T update the ui.supp & ui.conf - Copy ui to U’ // ui is guaranteed to be valid
- End Loop
- δ’ ! annotations in δ that appear in L.H.S of some rules - For (each rule ui where any of δ’ appears in L.H.S) Loop
- // Update the support and confidence of ui - T ! The newly annotated data tuples having an annotation from δ’ - Based on T update the ui.supp & ui.conf - If ( ui is still a valid rule) Then - Copy ui to U’ - End If
- End Loop
Add Annotation
[Value <text-value> | Link <path-to-file>]
On <sql-statement>;
This command will first trigger the execution of the specified
<sql-statement> to identify the data tuples and the attributes towhich the annotation will be attached. The annotation can be pro-vided as a text value (using the Value clause), or as a link to a file(using the Link clause). In all of these systems, the organization ofannotations, i.e., storage scheme and indexing, is fully transparentto end-users.
At query time, when a standard SQL query is submitted, the un-derlying database engine will not only compute the data tuples in-volved in the answerset, but will also compute the related annota-tions that should be reported along with the answerset. This is notstraightforward since the data may go though complex transforma-tions, e.g., projection, join, grouping and aggregations. Therefore,the semantics of the query operators have been extended to manip-ulate the data as well as their attached annotations in a systematicway. For example, one possible semantic is to union the annota-tions when performing grouping, joining, or duplicate eliminationover a group of tuples. According to this semantic, the SQL queryin Figure 2 produces the illustrated output—assuming duplicate an-notations on the same tuple are eliminated.
Select Family, Count(*) As CNT
From Gene
Group By Family;
Family CNT
F1 4
F6 1
F3 1
F4 1
Sequence needs to be shifted by 2 bases
This value is wrong Incorrect value
Does not seem correct
Sequence needs to be shifted by 2 bases
Figure 2: Automatic Propagation of Annotations at QueryTime.
Since in large-scale annotated databases, the number of reportedannotations on a single output tuple can be large, the work in [32,50] proposed summarizing the annotations using data mining tech-niques, e.g., clustering, classification, and text summarization, andreporting the summarize instead of the raw annotations. The pro-posed work of discovering the correlations in annotated databasesis complementary to the existing techniques and can be integratedwith any of the existing systems.
Association Rule Mining: Association rule mining is a well-known problem in data mining that concerns the discovery ofcorrelation patterns within large datasets [8, 44, 45, 52]. Anassociation rule in the form of “X =⇒ Y, support = α,confidence = β” means that the presence of the L.H.S itemsetX implies the presence of the R.H.S itemset Y (in the same trans-action or tuple) with support equals to α and confidence equalsto β. Typically, X ∩ Y = φ, and the support is computedas the fraction of transactions (or tuples) containing X ∪ Y rel-ative to the database size, while the confidence is computed assupport(X ∪Y )/support(X). Therefore, given a minim supportmin_supp and minimum confidence min_conf, the association rulemining technique discovers all rules having support and confidenceabove the specified min_supp and min_conf, respectively.
It has been observed in many real-world applications, that thenumber of generated rules can be very large and many of them maynot be interesting. Therefore, additional measures have been pro-posed in [31, 44], which include the lift and conviction measures.The former is computed as support(X∪Y )
support(X) ∗ support(Y ), and the latter
is computed as 1−support(Y )1−confidence(X=⇒Y )
. The higher these measures,the more interesting the rule. Another related extension to the stan-dard association rule mining problem is the mining of multi-levelrules [44, 45]. In this extension, the technique is given a domaingeneralization hierarchy over one or more attributes, and we needto discover the association rules that may span different levels ofthe hierarchy. For example, in market analysis, the items “pants”,“shirts”, and “t-shirts” can be generalized to “clothes”. Becauseof this generalization, some rules may hold at the higher level(s)of the hierarchy which may not be true for the lower more-detailedlevels. Association rule mining has numerous applications in var-ious domains including market analysis, biology, healthcare, envi-ronmental sciences, and beyond [31]. The proposed work extendsthese applications to the emerging domain of annotated databases.

(b) Time course of intestinal distention in C. elegans worms exposed to S. cerevisiae. Worms were exposed to RFP-marked, wildtype yeast from hatching and photographed on day 3 (A and D), day 4 (B and E), and day 5 (C and F). The experiment was done three times, and 60 to 75 worms were observed over a 3-day period. (A to C) Anterior region of the worm; (D to F) posterior region of the worm. Accumulation of yeast began in the pharynx region (compare panels A and D) and proceeded to the posterior. (G to I) S. cerevisiae also induces vulval swelling in the worms. Worms exposed to S. cerevisiae (H to I) show abnormal vulval swelling (white circles) compared to the control sample grown on E. coli (G). Bars: A to G, 50 µm; H and I, 20 µm. (a) Caenorhabditis elegans. Lives in garden soil
and feeds on bacteria, e.g., E. coli.
Figure 3: Case Study: Building Data-Annotation Repository for Caenorhabditis elegans (C. elegans) Worm.
2.2 Case Study: Annotated Repository for C.elegans Worm
Although the proposed work is applicable to annotated databasesin general, we consider one case study as an example. This casestudy focuses on building a database repository for the Caenorhab-ditis elegans (C. elegans) worm, which integrates data from multi-ple databases and labs studying the genetics and fungal pathogen-esis of the organism (Refer to Figure 3). Some of these sourcesmaintain relational databases, while other use excel sheets to storetheir data. Each of the sources maintains various types of cura-tion information and annotations related to the data records, e.g.,images, publications, observations, corrections, and experimentalsetups. In these data sources the curation information is not mod-eled as annotations. Instead, they are modeled as regular data withrelationships to the data tuples, e.g., in the relational databases, theimages and observations are stored in separate tables linked to theprimary data tables through PK-FK constraints.
The disadvantage of this modeling scheme, i.e., modeling the an-notations as data, is that applications lose the benefits of annotationmanagement. That is, annotation management tasks are entirelydelegated to end-users and higher-level applications starting fromthe storage and indexing of annotations and ending by explicitly en-coding the propagation semantics within each of the users’ queries.Both tasks have been shown to be very complex and sophisticated.For example, the storage and indexing mechanisms need to dealwith the combinatorial relationship between annotations and data,e.g., annotations can be attached to single table cells (attributes),rows, columns, arbitrary sets and combinations of them, or even at-tached to sub-attributes [21, 24]. Moreover, manually encoding theannotations’ propagation within each query is not only error-prune,and lacks optimizations, but also renders even simple queries verycomplex [9, 13, 26, 46]. That is why annotation management en-gines have been proposed to efficiently and transparently managesuch complexities across applications.
To address the above limitations, we opt for leveraging our previ-ous systems and work in annotation management [21, 50] to modelthe metadata information as annotations. These systems are builton top of PostgreSQL DBMS, and thus the repository will acquirethe benefits of both a DBMS and an annotation management en-gine. We developed an Excel-based user interface to enable seam-less visualization of the data as well as the annotations (See Fig-ure 4). For the purpose of this project, the annotations are cate-gorized into three basic types, which are: (1) Regular commentsor observations, which covers any free-text values, (2) Articles and
View annotations on selected data
Query-By-Example (QBE) section
New Annotation Management tab
Figure 4: Excel-Based GUI for Annotation Management.
documents, and (3) Images. In the Excel-based GUI, scientists canquery their data either by writing direct SQL queries, or thoughta QBE interface as illustrated in Figure 4. Then, they can selectspecific rows or table cells of interest, and click the View Annota-tion button, which reports the annotations related to the selecteddatasets in a new window. This window has three sections for thethree annotation types mentioned above as shown in the figure. Forthe articles and images, they are uploaded to a web-server and canbe opened by clicking the corresponding link.
3. DISCOVERY OF CORRELATIONSGiven an annotated database, the primary challenge is to dis-
cover and incrementally maintain the hidden annotation-relatedcorrelations within the database, which is the focus of this section.The basic unit in an annotated database is an “annotated relation”.In the following, we formally define an annotated relation and thetarget correlations.
Definition 3.1 (Annotated Relation). An annotated relation R isdefined as R = {r =< x1, x2, ..., xn,a1,a2,a3, ... >}, where

each data tuple r ∈ R consists of n data values x1, x2, ..., xn, anda variable number of attached annotations a1,a2, ...,ak.
Definition 3.2 (Data-to-Annotation Correlations). Given an an-notated relation R, a minimum support α, and a minimum con-fidence β, the data-to-annotation correlations over R is theproblem of discovering all association rules in the form of:x1:v1, x2:v2, ..., xk:vk =⇒ a, where the L.H.S is a set of col-umn names (xi) and corresponding data value (vi), the R.H.S is asingle annotation, the rule’s support≥ α, and the rule’s confidence≥ β.
Definition 3.3 (Annotation-to-Annotation Correlations). Given anannotated relation R, a minimum support α, and a minimum con-fidence β, the annotation-to-annotation correlations over R isthe problem of discovering all association rules in the form of:a1 a2 ... ak =⇒ a, where the L.H.S is a set of annotations, theR.H.S is a single annotation, the rule’s support≥ α, and the rule’sconfidence ≥ β.
According to Definitions 3.2 and 3.3, the rules to be discoveredmust involve an annotation in the R.H.S of the rule. In addition,these rules focus on the raw annotations without generalization.This is applicable especially for annotations of type image or publi-cation, where a single image or publication can be attached to manydata tuples. Discovering these rules is straightforward using any ofthe state-of-art techniques, e.g., the A-priori [8], or FP-Tree [30]algorithms. The only modification that we introduced to these al-gorithms is the early elimination of candidate patterns that do notinclude at least one annotation value.
3.1 Incremental Maintenance of CorrelationsAn annotated database may evolve and change in three different
ways, which are: (1) Adding new un-annotated data tuples (refer toit as ∆unannotated), (2) Adding new annotated data tuples (refer toit as ∆annotated), and (3) Adding new annotations to existing datatuples (refer to it as δ). Each of these changes may affect the dis-covered association rules as summarized in Figure 5. The mainte-nance of association rules under incremental data updates has beenstudied in existing work [16, 41]. However, these existing tech-niques can handle only the first two cases mentioned above, i.e.,the ∆unannotated and ∆annotated cases, but not the third case, i.e,the δ case. The reason is that the assumption in these techniques isthat the number of data tuples change (get increased), which is truefor the first two cases. In contrast, in the third case, the number ofthe data tuples is fixed, but their content changes due to the additionof new annotations.
Figure 5 summarizes the three cases mentioned above and theireffect on the association rules. The ∆unannotated case does not addany new rules since no new annotations are added. For the exist-ing rules, both the support and confidence of the data-to-annotationrules may get decreased and need to be re-computed (Column 2in Figure 5). Nevertheless, for the annotation-to-annotation rules,only the support may decrease and need to be re-computed, butthe confidence remains unchanged (Column 3 in Figure 5). The∆annotated case may introduce new association rules since the newdata tuples are annotated. Moreover, all of the existing rules mayget affected positively or negatively. For these two cases, the exist-ing techniques in [29, 44] can be directly applied to efficiently andincrementally update the association rules.
The third case—which is not handled by existing techniques—concerns the addition of new annotations to existing data tuples.For this case, all existing data-to-annotation rules are guaranteedto remain valid because the support and confidence of these rules
New Rules
Existing Rules
x1, x2, …xk => a a1, a2, …, ak => a
Δunannotated S# & C# S# & C =
Δannotated S#$ & C#$ S#$ & C#$
δ S$ & C$ In L.H.S: S$ & C#$ In R.H.S: S$ & C$
Change
Effect
#!May only decrease May only increase
May increase or decrease Fixed
$!
#$! =
#!May only decrease
May only increase
May increase or decrease
Remain Fixed
$!
#$!
= Δunannotated
Δannotated
δ
New un-annotated data tuples
New annotated data tuples
New annotations on existing data tuples
Figure 5: Effect of Evolving Data on Support (S) and Confi-dence (C).
cannot be decreased. The same intuition applies to the annotation-to-annotation rules if the new annotation appears in the R.H.S of therule, i.e., the support and confidence may only increase. However,if the new annotation appears in the L.H.S of a rule, then the confi-dence of this rule needs to be re-computed because it may decreaseand becomes below the min_conf threshold. Finally, this third casemay introduce new association rules that need to be discovered asindicated in Figure 5. In the following, we present a pseudocodeon how these changes take place incrementally.
The algorithm depicted in Figure 6 presents the main steps ofupdating the existing rules. In Step 1, the data-to-annotation rulesare updated. Basically, the denominator in the support and confi-dence of these rules does not change, and thus only the numeratorvalues need to be re-computed. This update can be performed bychecking only the newly annotated data tuples and counting thenumber of new occurrences of the rule’s pattern (L.H.S ∪ R.H.S).This count will be added to the old numerator to compute the newvalues. Since all of these rules are guaranteed to be in the outputset U ′, they are directly copied to U ′ after updating their supportand confidence values.
In Step 2, the annotation-to-annotation rules are updated. Thefirst For...End For loop handles the case where the new an-notations do not appear in the L.H.S of an existing rule, but appearon the R.H.S. This case is very similar to Step 1, where all therules will get their support and confidence updated (only the nu-merator values), and then copied to the output set U ′. The secondFor...End For loop handles the case where the new annota-tions appear on the L.H.S of the rules. in this case both the nu-merator and the denominator values of the confidence may changeand hence, it may increase of decrease. Fortunately, updating thesevalues can be also performed by only checking only the newly an-notated data tuples and counting the number of new occurrencesthat will be added to either of the numerator or denominator val-ues. Depending on the new confidence, if the rule is still valid, thenit will be copied to the output set U ′. It is worth highlighting thatin updating the existing association rules (Steps 1 & 2 in Figure 6),we only need to process the newly annotated data tuples withouttouching the rest of the database.
The addition of the new annotations (the δ batch) may also createnew association rules. The algorithm depicted in Figure 7 outlinesthe procedure of incrementally discovering the new rules. In Step 1,the new data-to-annotation rules in the form of x1 x2 ... xk =⇒ a
will be discovered, where a ∈ δ. First, a must be a frequent an-

1- Selecting 2,000 real annotations at random and manually labeling them. Moreover, we created synthetic annotations for each category that include the common keywords in that category.
2- Selecting 1% of the real annotations (around
3,700) at random and classifying them using the trained classifier.
3- Manually verifying the results, and re-labeling
the wrong classification to refine the model. 4- Repeating Steps 2 & 3 until achieving an
acceptable accuracy.
Case III (δ Addition): Updating Existing Association Rules Input: - New annotations delta δ = {a1, a2, …, an} - Set of existing association rules U = {u1, u2, …, um} - Original DB
Output: - Updated set of association rules U’
- New DB’ = DB + δ
Step1: Existing Data-to-Annotations rules - For (each rule ui having annotation “a” && δ in R.H.S) Loop
- // Update the support and confidence of ui - T ! The data tuples newly annotated with “a” - Based on T update the ui.supp & ui.conf - Copy ui to U’ // ui is guaranteed to be valid
- End For
Step2: Existing Annotation-to-Annotations rules - For (each rules ui where none of δ appears in L.H.S & “a” && δ in R.H.S) Loop - // Update the support and confidence of ui
- T ! The data tuples newly annotated with “a” - Based on T update the ui.supp & ui.conf - Copy ui to U’ // ui is guaranteed to be valid
- End Loop
- δ’ ! annotations in δ that appear in L.H.S of some rules - For (each rule ui where any of δ’ appears in L.H.S) Loop
- // Update the support and confidence of ui - T ! The newly annotated data tuples having an annotation from δ’ - Based on T update the ui.supp & ui.conf - If ( ui is still a valid rule) Then - Copy ui to U’ - End If
- End Loop
Figure 6: Case III (δ Addition): Updating Existing Rules.
notation by itself. To perform this check efficiently, the systemmaintains a table containing the frequency of each annotation, andit is updated whenever a new annotation is added. If a is frequent,then from the newly annotated tuples, denoted as T , we extractthe data-value patterns that are already frequent, say x1 x2 ... xk.Notice that since x1 x2 ... xk is already frequent, then the denom-inator for the support and confidence of rule x1 x2 ... xk =⇒ a isalready known. What is left is to compute the frequency of patternx1 x2 ... xk,a, which can be performed by checking only the datatuples in the database annotated with a. As illustrated in Figure 7, asimilar procedure will be taken in Step 2, i.e., discovering the newannotation-to-annotation rules where the new annotations a ∈ δcontribute only to the R.H.S of the rule.
Discovering the new annotation-to-annotation rules where thenew annotations a ∈ δ contribute to the L.H.S is slightly differ-ent (Step 3). This is because the denominator of the new rules is nolonger known and it has to be computed. The procedure works byconsidering each new annotation a ∈ δ, and verifying first that it isfrequent (if not, then the process stops). And then, for each data tu-ple t that is receiving a as a new annotation, we extract the already-frequent annotation patterns, say p = a
′1,a′2, ...,a
′k, i.e., p is al-
ready frequent and attached to t. By augmenting a to p, we gener-ate several candidate new rules in the form of a′1,a, ...,a′k =⇒ a
′i.
Notice that a can be a new annotation over tuple t, but it is analready-existing annotation over many other tuples in the database.Therefore, to compute the support and confidence of these rules,we need to check all data tuples in the database having annotationa. This is enough to compute the support and the confidence of therule and to verify whether or not it is a valid rule.
It is clear that the algorithm of maintaining the existing rules(Figure 6) is less expensive than that of discovering new rules (Fig-
Case III (δ Addition): Discovering New Association Rules Input: - New annotations delta δ = {a1, a2, …, an} - Original DB
Output: - New set of association rules U’
- New DB’ = DB + δ
Step1: New Data-to-Annotations rules x1, x2, …, xk => ai - If (ai is frequent) Then - T ! the data tuples newly annotated with ai. - Find patterns “x1, x2, …, xk” within T that are already frequent. - Check if x1, x2, …, xk => ai is valid - De-numerators of the support and confidence are known
- Compute the frequency of pattern “x1, x2, …, xk, ai” by checking only the data tuples annotated with ai - Now the support and confidence of the rule can be verified. - If the rule is valid " add it to U’ - End If Step2: New Annotation-to-Annotations rules a’1, a’2, …, a’k => ai - If (ai is frequent) Then - T ! the data tuples newly annotated with ai - Find patterns “a’1, a’2, …, a’k” within T that are already frequent. - Check if a’1, a’2, …, a’k => ai is valid - De-numerators of the support and confidence are known
- Compute the frequency of pattern “a’1, a’2, …, a’k, ai” by checking only the data tuples annotated with ai - Now the support and confidence of the rule can be verified. - If the rule is valid " add it to U’ - End If Step3: New Annotation-to-Annotations rules where ai may appear in
L.H.S of the rule - For (each frequent annotation patterns “a1, a2, …” from δ) Loop - T ! the data tuples newly annotated with “a1, a2, …” - Find patterns “a’1, a’2, …, a’k” within T that are already frequent. - Create candidate rules where subset (or all) of “a1, a2, …” appear in the L.H.S of the rule - Compute the support and confidence by checking only the data tuples annotated with “a1, a2, …” - If the rule is valid " add it to U’ - End Loop
Figure 7: Case III (δ Addition): Discovering New Rules.
ure 7). This is because the former requires access to only the newlyannotated data tuples, whereas the latter requires access to all datatuples that have annotation a ∈ δ (even if the tuples are not newlyannotated with a. To efficiently support the latter case, the systemindexes the annotations such that given a query annotation, we canefficiently find all data tuples having this annotation. In all cases,there is no need for full database processing or re-discovering therules from scratch.
3.2 Generalization-Based CorrelationsGeneralizing the raw annotation values to higher concepts may
lead to discovering important association rules that cannot be dis-covered from the raw values. The Red-Flag annotation in Figure 1is a good example of this case. The reason this case is important inannotated databases is that the annotations can be added by manycurators, and they may not follows specific ontology. And thus,multiple annotations may carry the same semantics but differ intheir raw values. There are extensions to association rule miningtechniques that can discover the rules under the presence of a gener-alization hierarchy [29, 44, 45]. However, these techniques assumethat the hierarchy, and the assignments between the raw values to

A (Set of annotations)
T (set of tuples)
E(set of attachments)
0.9
0.7
0.85
0.9
Predicted Attachments (Confidence < 1)
True Attachments (Confidence = 1)
Invalidation Provenance Missing Info Question Others
“Invalid”, “wrong”, “incorrect”, “not … correct”, …
“provenance”, “lineage”, “generated by”, “downloaded from”, …
“missing …”, “need verification”, “null”, … …
“what…?” “How…?” … …
Figure 8: Example of Annotation-Generalization Hierarchy.
the hierarchy elements are given as input, which is usually not thecase in annotated databases.
In this work, we assume the more practical case where the do-main experts know the generalization hierarchy, i.e., the generictypes of annotations of interest, but the raw annotations are notyet labeled. An example of this hierarchy is illustrated in Fig-ure 8, where several types can be of interest, e.g., “Invalidation”(comments that highlight errors or invalid values), “Provenance”(comments capturing the source of data or how it is generated),“Question” (comments including questions), and “Missing Info”(comments highlighting missing values or more investigation). Thehierarchy will always include a separate class, called “Others” towhich any un-generalized annotation will belong.
In general, any text classification technique can be used. As aproof of concept, we use the technique proposed in [18]. Since weassume no training set or classifier model is given, the model is firstcreated as follows:
1- Select α real annotations at random and manually label them to build the 1st classifier model.
2- Select β% of the real annotations at random and
classify them using the trained classifier. 3- Manually verify the results, and re-label the
wrong classification to refine the model. 4- Repeat Steps 2 & 3 until achieving an acceptable
accuracy.
In Step 1, in addition to manually labeling an initial set of αannotations, we also create synthetic annotations to each class cap-turing the keywords in that class. For example, as highlighted inFigure 8, keywords like “wrong”, “incorrect”, “invalid” are em-bedded in synthetic annotations under the 1st class label, whilekeywords like “source”, “generated from” are added under the 2nd
class label. The creation process iterates between labeling and ver-ifying a small subset of annotations (β%) until the classier reachesan acceptable accuracy (Step 4).
After building the classifier model, it is applied over all anno-tations in the dataset, and data tuples get annotated with the classlabels corresponding to their raw annotations—Except for “Others”label for which its annotations are not generalized. A data tuple canhave a given label at most once even if there are multiple raw an-notations mapping to the same label. This is the same model usedin association rule mining techniques that handle a generalizationhierarchy [29, 44, 45]. For example, the top data tuple in Figure 9has two attached annotations classified into the “Invalidation” la-bel, i.e., the Red Flag, and thus after attaching the classificationdecision, it generates the tuple at the bottom of the figure.
After building the extended annotated database, existing tech-
GID Name Seq Family Exp-Id
JW0013 grpC TGCT… F1 101
JW0014 groP GGTT… F6 105
JW0015 insL GGCT… F1 105
… … … … …
JW0018 nhaA CGTT… F1 101
JW0019 yaaB TGTG… F3 101
JW0012 Yaal TTCG… F1 103
Sequence need to be shifted by 2 bases
JW0027 namE GTTT... F4 101
This value is wrong
Incorrect value
Does not seem correct
GID Name Seq Family Exp-Id
JW0013 grpC TGCT… F1 101
Incorrect value Has a mistake
GID Name Seq Family Exp-Id
JW0013 grpC TGCT… F1 101
Incorrect value Has a mistake
After annotation generalization
Figure 9: Applying Annotation-Generalization over ExampleTuple.
niques can mine and extract the data-to-annotation association rulesin the form of: x1 x2 ... xk =⇒ b, where b is either a raw annota-tion or an annotation’s class label. The same applies for annotation-to-annotation rules, which are in the form of: b1 b2 ... bk =⇒ b,where none of the L.H.S or R.H.S values (either raw or class labelvalues) have an ancestor-descendant relationship in the generaliza-tion hierarchy.
4. EXPLOITATION OF CORRELATIONSAs discussed in Section 1, one of our goals is to exploit the
discovered correlations to enhance the quality of the annotateddatabase. We consider two exploitation scenarios: (1) The pre-diction of related annotations to newly inserted tuples (MotivationScenario 2), and (2) The discovery of missing attachments whennew association rules are found (Motivation Scenario 1).
Insertion of New Data Tuples: For this case, an automaticdatabase trigger (at After Insert at Row Level) is created for eachdatabase table. The trigger forwards a newly inserted tuple t to theAnnotation Manager, which checks t against the available associa-tion rules. If the L.H.S pattern of a rule is present in t without theR.H.S annotation, then the system creates a recommendation thatthe R.H.S annotation is potentially applicable to t. For example,referring to the motivation example in Figure 1, the following rulecan be derived from the data:
Exp-Id:101 =⇒ “Sequence need to be shiftedby 2 bases.”
The newly added tuple JW0027 contains the L.H.S of the rule,and hence the system predicts and creates a recommendation thatthe R.H.S annotation may be related to the new tuple. The end-user will be notified that the system has created annotation predic-tions for the new tuple, and the prediction(s) will be stored in asystem table along with its supporting rule (the rule generated therecommendation) for later verification and approval as explained insequel.
To enable efficient searching for the association rules match-ing the newly inserted tuple, the L.H.S of the rules are in-dexed. Since the L.H.S may contain several pairs in the form ofcolumnName:value, we first itemize and store the L.H.S in anormalized form, i.e., one record for each pair, and then index themusing a B-Tree index. In this case, given a new data tuple, the AfterInsert database trigger will create lookup keys from the new tuple,i.e., each column name and its value will form one lookup key, andthen search the normalized table to find a “superset” of the candi-date rules. The tuple will be checked against this candidate set tofind the actual matches.

New Annotation Management tab
Data Sheet
Predicted Attachment Sheet Verification
Decision
Figure 10: Exploitation of Correlations and Annotation-Related Recommendations.
Updating the Association Rules: As presented in Section 3.1,the annotation-related association rules may change periodicallywhen new batches of data or annotations are applied. The changemay take three forms: (1) Valid rules remain valid, (2) Valid rulesbecome invalid, and (3) New rules are discovered. In the 1st case,nothing will change in the system. In the 2nd case, the pendingrecommendations awaiting verification whose supporting rules be-come invalid will be eliminated. This is because the system willnot recommend attachments without rules supporting available asevidences. 1 In the 3rd case, the discovery of new rules will triggerthe system to search for data tuples matching the L.H.S of the newassociation rules, but missing the R.H.S annotation in the rule. Ifa matching is found, then a new pending recommendation will beadded to the system table. Given a newly discovered rule having aL.H.S in the form of: “C1:v1, C2:v2, ..., Cm:vm”, whereCi is a column name and vi is the column’s value, the searchingfor the matching data tuples is performed as follows. A query onthe same table to which the new rule is related is formed, and itconsists of a set of conjunctive predicates in the form of Ci = vi∀ 1 ≤ i ≤ m. The returned tuples will be then checked if theyare missing the R.H.S of the rule, i.e., the annotation value, and ifso, then a new recommendation is generated.
It is worth highlighting that the number of discovered rules byconsidering solely the support and confidence thresholds is in mostcases very high [31, 44]. This will result in many uninterestingpredictions and recommendation. To overcome this problem, weintegrate additional properties such as lift and conviction measuresthat measure how interesting the rule is (See Section 2). That is,
1Recommended attachments that have been approved by the end-users will remain in the system even if their supporting rules be-come invalid at a later point in time. This is because an approvedattachment is viewed as a correct and permanent one.
among all the rules that satisfy the support and confidence require-ments, we use in the exploitation process only a subset of theserules that also satisfy the lift and conviction requirements.
Manipulation Interface: To seamlessly enable the verificationprocess, we extend the Excel-based GUI presented in Section 2.2such that domain experts can visualize the recommendations fromthe tool and decide whether or not each prediction will be accepted(See Figure 10). The tool enables reporting and visualizing thepending predictions either by providing a database table name, orby specifying a select statement to limit the scope of interest. Thereported predictions can be then sorted according to various crite-ria, e.g., the confidence of the association rule suggested the pre-diction. As Figure 10 illustrates, the data tuples from a given table(or a select statement) are reported on the top-level excel sheet, andthen when a tuple is selected, its related predictions and recommen-dations are dynamically reported on the bottom-level sheet. Foreach prediction, the supporting association rule is displayed alongwith its properties, e.g., the support, confidence, lift, and convic-tion. Curators can then use the checkbox highlighted in the figureto decide on whether or not to accept the recommendation.
5. RELATED WORKAnnotation management is widely applicable to a broad range
of applications, yet it gained a significant importance within thecontext of scientific applications [27, 35, 40]. Therefore, to helpscientists in their scientific exterminations and to boost the discov-ery process, several generic annotation management frameworkshave been proposed for annotating and curating scientific data inrelational DBMSs [9, 17, 24, 25, 26, 46]. Several of these sys-tems, e.g., [9, 17, 24, 46], focus on extending the relational al-gebra and query semantics for propagating the annotations alongwith the queries’ answers at query time. The techniques presentedin [46] address the annotation propagation for containment queries,while the techniques [13] address the propagation in the presenceof logical database views. They address, for example, the mini-mum amount of data that need to annotated in the base table(s)in order for the annotation to appear (propagate) to the logicalview. The work in [21] proposed compact storage mechanisms forstoring multi-granular annotations at the raw-, cell-, column-, andtable-levels, as well as defining behaviors for annotations under thedifferent database operations. Moreover, the techniques proposedin [21, 36] enable registering annotations in the database systemand automatically applying them to newly inserted data tuples ifthey satisfy pre-defined predicates.
Other systems have addressed special types of annotations,e.g., [15, 23]. For example, the work in [15] have addressed theability to annotate the annotations, and hence they proposed a hier-archal approach that treats annotations as data. On the other hand,the BeliefDB system in [23] introduced a special type of annota-tions, i.e., the belief annotation, that captures the different users’beliefs either about the data or others’ beliefs. In both systems,the query engine is extended to efficiently propagate/query theseannotations. It have been also recognized in [28, 34] that annota-tions may have semantics and based on these semantics the prop-agation in the query pipeline may differ, e.g., instead of gettingthe union of annotations under the join operation, getting the in-tersection makes more sense under some annotation semantics. Inour previous work [50], we addressed the challenge of managingnumber of annotations that can be orders of magnitude larger thanthe number of base data tuples. In this case, reporting the raw an-notations will be overwhelming and useless. Instead, we proposedsummarizing the annotations into concise forms, and then proposedan extended query engine to efficiently propagate these summaries.

0
100
200
300
400
500
600
0.99 0.95 0.9 0.99 0.95 0.9 0.99 0.95 0.9 0
20
40
60
80
100
1 2 3 4 # Iterations Confidence
(0.1% Support)
Acc
urac
y
Confidence (0.2% Support)
Confidence (0.4% Support)
# In
tere
stin
g R
ules
(a) Accuracy of the Generalization Algorithm. (b) Effect of Generalization on the Generated Rules
0
5
10
15
20
25
0.99 0.95 0.9 Confidence
With Generalization
No Generalization
Support = 0.4%
Support = 0.2%
Support = 0.1% +"
Tim
e (s
ec)
Figure 11: Annotation Generalization and Rule Generation.
Although the above systems provide efficient query processingfor annotations, none of them have addressed the facet of min-ing the rich repositories of annotations to discover interesting pat-terns, e.g., discovering the annotation-related correlations proposedin this paper. Therefore, the proposed work is complementary toexisting systems and creates an automated mechanism for enhanc-ing the quality of annotated databases, which is currently handledthrough a manual curation process [2, 6]. In this process, domainexperts manually curate the data, ensure correct and high-qualityannotations are attached to the data, and potentially add or removefurther attachments between the annotations and the data. Cer-tainly, this curation process is very time consuming, error-pruneand does not scale well, and more importantly consumes valuablecycles from domain experts and scientists. With the proposed work,a significant effort in discovering missing attachments and relation-ships between the data and the annotations can be automated.
Annotations have been supported in contexts other than rela-tional databases, e.g., annotating web documents [10, 33, 37, 51],and pdf files [38, 39, 48]. These techniques focus mostly on an-notating different pieces within a document (or across documents)with useful information, e.g., extracting the key objects or provid-ing links to other related objects. In the domains of e-commerce,social networks, and entertainment systems [22, 42], the annota-tions are usually referred to as tags. These systems deploy ad-vanced mining and summarization techniques for extracting thebest insight possible from the annotations to enhance users’ experi-ence. They use such extracted knowledge to take actions, e.g., pro-viding recommendations and targeted advertisements [7, 19, 42].However, none of these systems focus on mining and discoveringcorrelations within the annotation repositories.
6. EXPERIMENTSSetup and Dataset: The experiments are performed using our
annotation management engines [21, 50], which are based on theopen-source PostgreSQL DBMS. The experiments are conductedusing an AMD Opteron Quadputer compute server with two 16-core AMD CPUs, 128GB memory, and 2 TBs SATA hard drive.Our objectives are: (1) To quantify the effectiveness of the annota-tion generalization technique, (2) The performance of discoveringthe annotation-based association rules over static data, and (3) Theefficiency of the proposed incremental techniques to update therules under new batches of annotations. The experimental datasetrepresent the C. elegans repository, which we are building on site.The repository consists of 27 database tables, where the main ta-ble of our focus is the Gene table that contains approximately17,500 genes integrated from multiple sources. The table has nine
columns, e.g., Gene Id, Locus, Strain, Stage, Location, and Length.The table has a total number of 43,000 publications attached to thegenes in addition to other 8,120 free-text comments. These pub-lications and comments represent the annotations attached to theGene table. In the dataset, each record has between 0 annotations(the minimum) and 16 annotations (the maximum).
In Figure 11, we study the effect of annotation generalization onthe generation of interesting annotation-related association rules.Figure 11(a) illustrates the accuracy of the generalization algorithmpresented in Section 3.2. The x-axis indicates the number of itera-tions from 1 to 4, while the y-axis represents the obtained accuracyfrom the manual verification step (Step 3 of the algorithm). As thefigure shows, there is a big jump in accuracy from Iteration 1 toIteration 2, and then as more iterations are performed the accuracyslightly increases. This is mostly because our generalization modelis simple and consists of one level only. However, as the general-ization model becomes more complex, we expect to more iterationswill be needed to reach the desired accuracy. In the subsequentexperiments, we will use the results obtained after performing 4iterations.
In Figure 11(b), we present the number of interesting associa-tion rules discovered in the entire dataset under varying confidenceand support degrees (the x-axis). Since the expected rules are notnecessarily globally frequent, we use very low support, e.g., 0.1%to 0.4%, while setting the confidence to a very high threshold asindicated in the figure. As expected, as the support or confidencethresholds increase, less number of interesting rules are discovered.The number of discovered rules is relatively manageable and notvery large because we also enforce minimum lift and convictionthresholds to narrow down the reported rules to the strongest onesonly. Both thresholds are set to value 5. In the remaining experi-ments, we will consider the dataset under the annotation general-ization case, i.e., the annotations have been generalized to enablethe discovery of more rules.
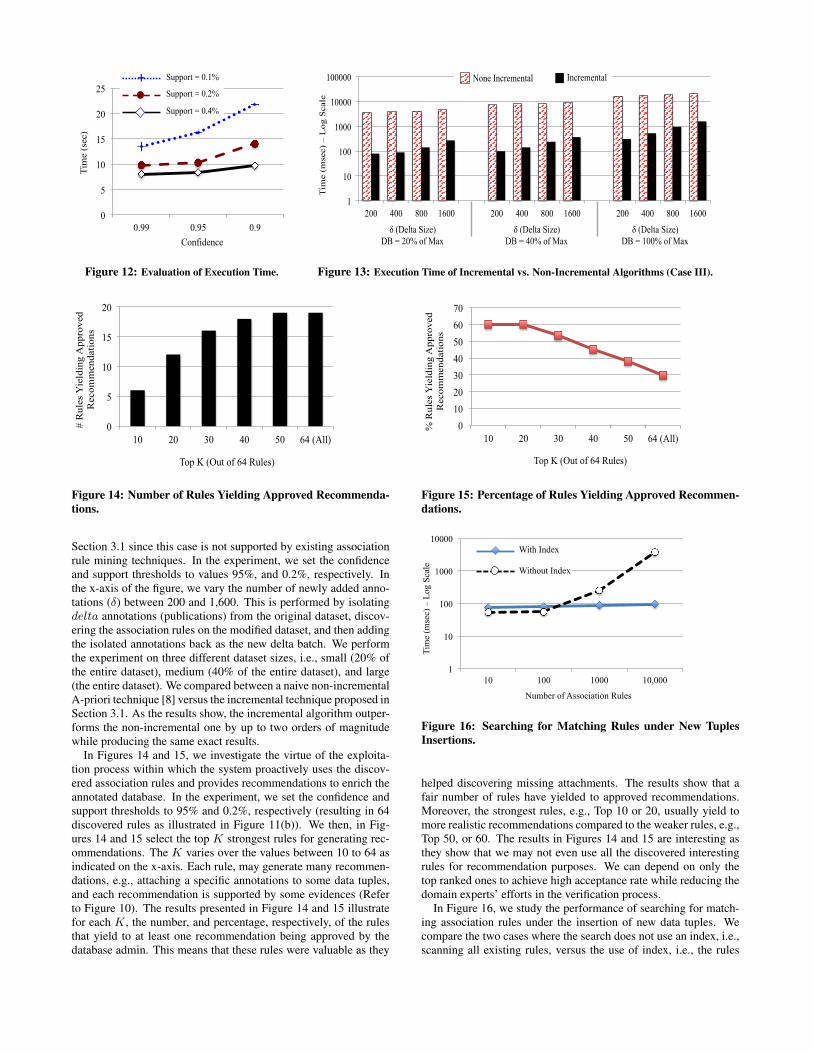
In Figure 12, we study the execution time of discovering theannotation-related rules in the entire dataset. We vary the confi-dence and support thresholds as depicted in the figure. In this ex-periment that dataset is static, i.e., there are no new batches of dataor annotations. As the figure illustrates the execution time rangesfrom 8 secs to 22 secs depending on the used thresholds. We havealso studied the execution time of the mining algorithm withoutannotation generalization and the observed differences are not sig-nificant, e.g., the technique without generalization are faster by 1%to 7% compared to the other case.
In Figure 13, we study the execution time under the addition ofnew annotation batches. We focus on the 3rd case presented in
0
100
200
300
400
500
600
0.99 0.95 0.9 0.99 0.95 0.9 0.99 0.95 0.9 0
20
40
60
80
100
1 2 3 4 # Iterations Confidence
(0.1% Support) A
ccur
acy
Confidence (0.2% Support)
Confidence (0.4% Support)
# In
tere
stin
g R
ules
(a) Accuracy of the Generalization Algorithm. (b) Effect of Generalization on the Generated Rules
0
5
10
15
20
25
0.99 0.95 0.9 Confidence
With Generalization
No Generalization
Support = 0.4%
Support = 0.2%
Support = 0.1% +"T
ime
(sec
)
Figure 12: Evaluation of Execution Time.
1
10
100
1000
10000
100000
200 400 800 1600 200 400 800 1600 200 400 800 1600
δ (Delta Size) DB = 20% of Max
δ (Delta Size) DB = 40% of Max
δ (Delta Size) DB = 100% of Max
Tim
e (m
sec)
– L
og S
cale
Incremental None Incremental
Figure 13: Execution Time of Incremental vs. Non-Incremental Algorithms (Case III).
0
5
10
15
20
10 20 30 40 50 64 (All) 0
10 20 30 40 50 60 70
10 20 30 40 50 64 (All)
Top K (Out of 64 Rules) Top K (Out of 64 Rules)
# R
ules
Yie
ldin
g A
ppro
ved
R
ecom
men
datio
ns
% R
ules
Yie
ldin
g A
ppro
ved
R
ecom
men
datio
ns
Figure 14: Number of Rules Yielding Approved Recommenda-tions.
Section 3.1 since this case is not supported by existing associationrule mining techniques. In the experiment, we set the confidenceand support thresholds to values 95%, and 0.2%, respectively. Inthe x-axis of the figure, we vary the number of newly added anno-tations (δ) between 200 and 1,600. This is performed by isolatingdelta annotations (publications) from the original dataset, discov-ering the association rules on the modified dataset, and then addingthe isolated annotations back as the new delta batch. We performthe experiment on three different dataset sizes, i.e., small (20% ofthe entire dataset), medium (40% of the entire dataset), and large(the entire dataset). We compared between a naive non-incrementalA-priori technique [8] versus the incremental technique proposed inSection 3.1. As the results show, the incremental algorithm outper-forms the non-incremental one by up to two orders of magnitudewhile producing the same exact results.
In Figures 14 and 15, we investigate the virtue of the exploita-tion process within which the system proactively uses the discov-ered association rules and provides recommendations to enrich theannotated database. In the experiment, we set the confidence andsupport thresholds to 95% and 0.2%, respectively (resulting in 64discovered rules as illustrated in Figure 11(b)). We then, in Fig-ures 14 and 15 select the top K strongest rules for generating rec-ommendations. The K varies over the values between 10 to 64 asindicated on the x-axis. Each rule, may generate many recommen-dations, e.g., attaching a specific annotations to some data tuples,and each recommendation is supported by some evidences (Referto Figure 10). The results presented in Figure 14 and 15 illustratefor each K, the number, and percentage, respectively, of the rulesthat yield to at least one recommendation being approved by thedatabase admin. This means that these rules were valuable as they
0
5
10
15
20
10 20 30 40 50 64 (All) 0
10 20 30 40 50 60 70
10 20 30 40 50 64 (All)
Top K (Out of 64 Rules) Top K (Out of 64 Rules)
# R
ules
Yie
ldin
g A
ppro
ved
R
ecom
men
datio
ns
% R
ules
Yie
ldin
g A
ppro
ved
R
ecom
men
datio
ns
Figure 15: Percentage of Rules Yielding Approved Recommen-dations.
Number of Association Rules
Tim
e (m
sec)
– L
og S
cale
1
10
100
1000
10000
10 100 1000 10,000
With Index
Without Index
Figure 16: Searching for Matching Rules under New TuplesInsertions.
helped discovering missing attachments. The results show that afair number of rules have yielded to approved recommendations.Moreover, the strongest rules, e.g., Top 10 or 20, usually yield tomore realistic recommendations compared to the weaker rules, e.g.,Top 50, or 60. The results in Figures 14 and 15 are interesting asthey show that we may not even use all the discovered interestingrules for recommendation purposes. We can depend on only thetop ranked ones to achieve high acceptance rate while reducing thedomain experts’ efforts in the verification process.
In Figure 16, we study the performance of searching for match-ing association rules under the insertion of new data tuples. Wecompare the two cases where the search does not use an index, i.e.,scanning all existing rules, versus the use of index, i.e., the rules

are normalized and indexed using the B-Tree index (Refer to Sec-tion 4). In the experiment, we varied the number of rules from 10to 10,000 (the x axis), and measured the search time (the y axis).The experiment is repeated 10 times, and the average values arepresented in the figure. As expected, the “With Index” case scalesmuch better and remains stable as the number of association rulesgets larger. Whereas, the “Without Index” case has slightly betterperformance when the number of rules is very small. This is be-cause the key lookups over the index—which are multiple lookupsper tuple—add unnecessary overhead when the number of rules isvery small. In this case, one scan over all rules becomes faster.
7. CONCLUSIONIn this paper, we investigated a new facet of annotation man-
agement, which is the discovery and exploitation of the hiddenannotation-related correlations. The addressed problem is drivenby the emerging real-world applications that create and maintainlarge-scale repositories of annotated databases. The proposed workopens a new application domain to which the well-known associa-tion rule mining can be applied. We show cased several scenariosspecific to annotated databases that cannot be efficiently handled bythe state-of-art in association rule mining. We then proposed algo-rithms for efficient and incremental maintenance of the discoveredassociation rules under these scenarios. We proposed two impor-tant applications for leveraging the discovered annotation-relatedcorrelations and enhancing the quality of the underlying database,which are the discovery of missing attachments, and the recommen-dation of applicable annotations to newly inserted data. To enableseamless use by scientists, we integrated the proposed algorithmswithin the annotation management engine and developed an end-to-end system including an Excel-based GUI through which all ofthe proposed functionalities can be performed.
8. REFERENCES[1] eBird Trail Tracker Puts Millions of Eyes on the Sky.
https://www.fws.gov/refuges/RefugeUpdate/MayJune_2011/ebirdtrailtracker.html.
[2] EcoliHouse: A Publicly Queryable Warehouse of E. coli K12Databases. http://www.porteco.org/.
[3] Gene Ontology Consortium.http://geneontology.org.
[4] Hydrologic Information System CUAHSI-HIS.(http://his.cuahsi.org.
[5] The Avian Knowledge Network (AKN).http://www.avianknowledge.net/.
[6] The Universal Protein Resource Databases (UniProt) .http://www.ebi.ac.uk/uniprot/.
[7] G. Adomavicius and A. Tuzhilin. Toward the next generationof recommender systems: A survey of the state-of-the-artand possible extensions. IEEE TKDE, 17(6):734–749, 2005.
[8] R. Agrawal and R. Srikant. Fast algorithms for miningassociation rules in large databases. In Proceedings of the20th International Conference on Very Large Data Bases,VLDB, pages 487–499, 1994.
[9] D. Bhagwat, L. Chiticariu, and W. Tan. An annotationmanagement system for relational databases. In VLDB, pages900–911, 2004.
[10] A. J. B. Brush, D. Bargeron, A. Gupta, and J. Cadiz. RobustAnnotation Positioning in Digital Documents. InProceedings of the 2001 ACM Conference on Human Factors
in Computing Systems (CHI), pages 285–292. ACM Press,2001.
[11] P. Buneman, A. Chapman, and J. Cheney. Provenancemanagement in curated databases. In SIGMOD, pages539–550, 2006.
[12] P. Buneman, J. Cheney, W.-C. Tan, and S. Vansummeren.Curated databases. In Proceedings of the 27th ACMsymposium on Principles of database systems (PODS), pages1–12, 2008.
[13] P. Buneman and et. al. On propagation of deletions andannotations through views. In PODS, pages 150–158, 2002.
[14] P. Buneman, S. Khanna, and W. Tan. Why and where: Acharacterization of data provenance. Lec. Notes in Comp.Sci., 1973:316–333, 2001.
[15] P. Buneman, E. V. Kostylev, and S. Vansummeren.Annotations are relative. In Proceedings of the 16thInternational Conference on Database Theory, ICDT ’13,pages 177–188, 2013.
[16] D. Cheung, J. Han, V. Ng, and C. Wong. Maintenance ofdiscovered association rules in large databases: anincremental updating technique. In Data Engineering, 1996.Proceedings of the Twelfth International Conference on,pages 106–114, Feb 1996.
[17] L. Chiticariu, W.-C. Tan, and G. Vijayvargiya. DBNotes: apost-it system for relational databases based on provenance.In SIGMOD, pages 942–944, 2005.
[18] P. R. Christopher D. Manning and H. Schutze. BookChapter: Text classification and Naive Bayes, in Introductionto Information Retrieval. In Cambridge University Press,pages 253–287, 2008.
[19] A. S. Das, M. Datar, A. Garg, and S. Rajaram. Google newspersonalization: scalable online collaborative filtering. InProceedings of the 16th international conference on WorldWide Web (WWW), pages 271–280, 2007.
[20] S. B. Davidson and J. Freire. Provenance and scientificworkflows: challenges and opportunities. In SIGMOD, pages1345–1350, 2008.
[21] M. Eltabakh, W. Aref, A. Elmagarmid, and M. Ouzzani.Supporting annotations on relations. In EDBT, pages379–390, 2009.
[22] A. Gattani and et. al. Entity extraction, linking, classification,and tagging for social media: a wikipedia-based approach.Proc. VLDB Endow., 6(11):1126–1137, 2013.
[23] W. Gatterbauer, M. Balazinska, N. Khoussainova, andD. Suciu. Believe it or not: adding belief annotations todatabases. Proc. VLDB Endow., 2(1):1–12, 2009.
[24] F. Geerts and et. al. Mondrian: Annotating and queryingdatabases through colors and blocks. In ICDE, pages 82–93,2006.
[25] F. Geerts, A. Kementsietsidis, and D. Milano. iMONDRIAN:a visual tool to annotate and query scientific databases. InProceedings of the 10th international conference onAdvances in Database Technology (EDBT), pages1168–1171, 2006.
[26] F. Geerts and J. Van Den Bussche. Relational completenessof query languages for annotated databases. In Proceedingsof the 11th international conference on DatabaseProgramming Languages (DBPL), pages 127–137, 2007.
[27] J. Gray, D. T. Liu, M. Nieto-Santisteban, A. Szalay, D. J.DeWitt, and G. Heber. Scientific data management in thecoming decade. SIGMOD Record, 34(4):34–41, 2005.

[28] T. J. Green. Containment of conjunctive queries on annotatedrelations. In ICDT, pages 296–309, 2009.
[29] J. Han and Y. Fu. Discovery of multiple-level associationrules from large databases. In In Proc. 1995 Int. Conf. VeryLarge Data Bases, pages 420–431, 1995.
[30] J. Han, J. Pei, and Y. Yin. Mining frequent patterns withoutcandidate generation. In Proceedings of the 2000 ACMSIGMOD International Conference on Management of Data,SIGMOD, pages 1–12, 2000.
[31] J. Hipp, U. Güntzer, and G. Nakhaeizadeh. Algorithms forassociation rule mining — a general survey andcomparison. SIGKDD Explor. Newsl., 2(1):58–64, June2000.
[32] K. Ibrahim, D. Xiao, and M. Y. Eltabakh. ElevatingAnnotation Summaries To First-Class Citizens InInsightNotes. In EDBT Conference, 2015.
[33] J. Kahan and M.-R. Koivunen. Annotea: an open RDFinfrastructure for shared Web annotations. In Proceedings ofthe 10th international conference on World Wide Web(WWW), pages 623–632, 2001.
[34] E. V. Kostylev and P. Buneman. Combining dependentannotations for relational algebra. In Proceedings of the 15thInternational Conference on Database Theory (ICDT), pages196–207, 2012.
[35] L. S. P. Lee, Woei-Jyh; Raschid. Mining MeaningfulAssociations from Annotations in Life Science DataResources. Proceedings of the Conference on DataIntegration for the Life Sciences, 1(1), 2008.
[36] Q. Li, A. Labrinidis, and P. K. Chrysanthis. ViP: AUser-Centric View-Based Annotation Framework forScientific Data. In Proceedings of the 20th internationalconference on Scientific and Statistical DatabaseManagement (SSDBM), pages 295–312, 2008.
[37] M. Markovic, P. Edwards, D. Corsar, and J. Z. Pan. DEMO:Managing the Provenance of Crowdsourced DisruptionReports. In IPAW, pages 209–213, 2012.
[38] C. MARSHALL. Annotation: from paper books to thedigital library. ACM Digital Libraries (1997).
[39] C. MARSHALL. The future of Annotation in a Digital(paper) world. The 35th Annual GSLIS Clinic: Successesand Failures of Digital Libraries University of Illinois atUrbana-Champaign (1998).
[40] L. MartŠnez-Cruz, A. Rubio, M. MartŠnez-Chantar,A. Labarga, L. Barrio, and A. Podhorski. GARBAN:genomic analysis and rapid biological annotation of cDNAmicroarray and proteomic data. Bioinformatics,19(16):2158–2163, 2003.
[41] B. Nath, D. K. Bhattacharyya, and A. Ghosh. Incrementalassociation rule mining: a survey. Wiley Interdisciplinary,Data Mining and Knowledge Discovery, 3(3):157–169, 2013.
[42] A. Rae, B. Sigurbjörnsson, and R. van Zwol. Improving tagrecommendation using social networks. In Adaptivity,Personalization and Fusion of Heterogeneous Information,RIAO, pages 92–99, 2010.
[43] Y. L. Simmhan, B. Plale, and D. Gannon. A survey of dataprovenance in e-science. SIGMOD Record, 34(3):31–36,2005.
[44] R. Srikant and R. Agrawal. Mining generalized associationrules. In Proceedings of the 21th International Conferenceon Very Large Data Bases, VLDB, pages 407–419, 1995.
[45] R. Srikant and R. Agrawal. Mining quantitative association
rules in large relational tables. In Proceedings of the 1996ACM SIGMOD International Conference on Management ofData, pages 1–12, 1996.
[46] W.-C. Tan. Containment of relational queries with annotationpropagation. In DBPL, 2003.
[47] D. Tarboton, J. Horsburgh, and D. Maidment. CUAHSICommunity Observations Data Model (ODM),Version 1.1,Design Specifications. In Design Document, 2008.
[48] P. TUCKER and D. JONES. Document annotation - to write,type or speak. In International Journal of Man-MachineStudies, pages 885–900, 1993.
[49] M. Twombly. Science online survey: Support for datacuration. Science Journal, 331, 2011.
[50] D. Xiao and M. Y. Eltabakh. InsightNotes: Summary-BasedAnnotation Management in Relational Databases. InSIGMOD Conference, pages 661–672, 2014.
[51] H. Yang, D. T. Michaelides, C. Charlton, W. J. Browne, andL. Moreau. DEEP: A Provenance-Aware ExecutableDocument System. In IPAW’, pages 24–38, 2012.
[52] M. J. Zaki. Scalable algorithms for association mining. IEEETransactions on Knowledge and Data Engineering,12(3):372–390, 2000.