discerningintelligencefromtext)€¦ · documents triple store ... nick saban$ lou saban$...
TRANSCRIPT

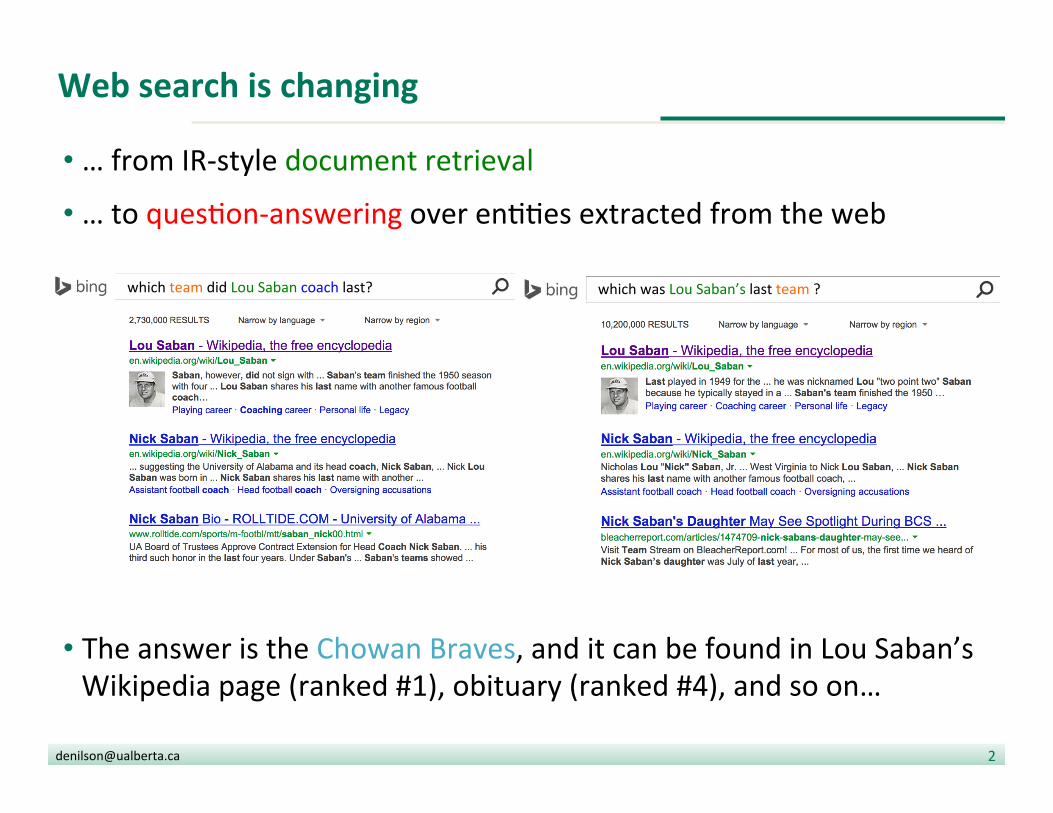
Web search is changing
• … from IR-‐style document retrieval
• … to ques?on-‐answering over en??es extracted from the web
• The answer is the Chowan Braves, and it can be found in Lou Saban’s Wikipedia page (ranked #1), obituary (ranked #4), and so on…
which team did Lou Saban coach last? which was Lou Saban’s last team ?
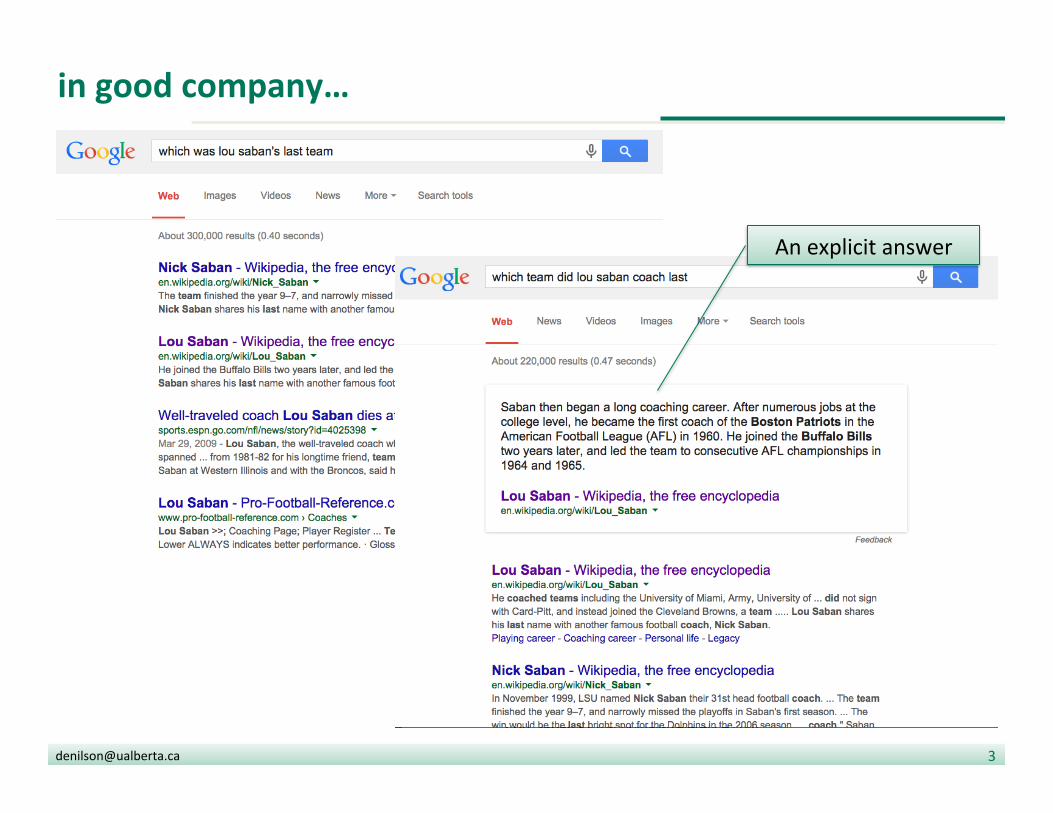
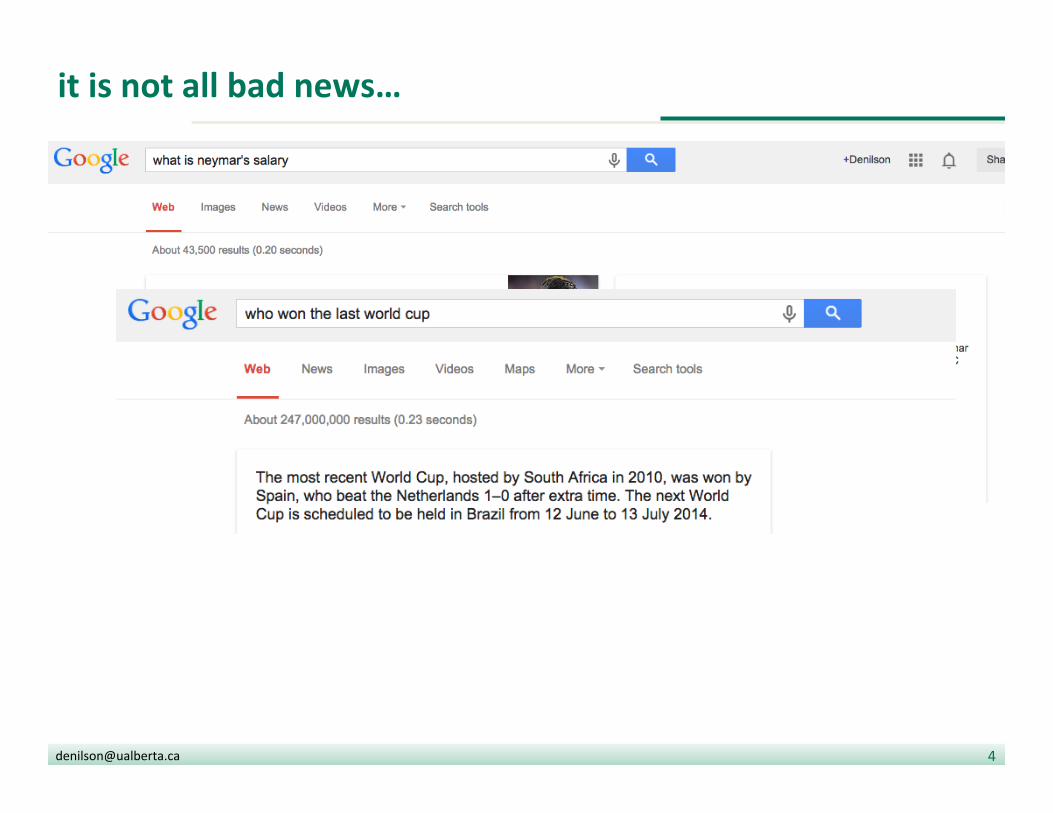

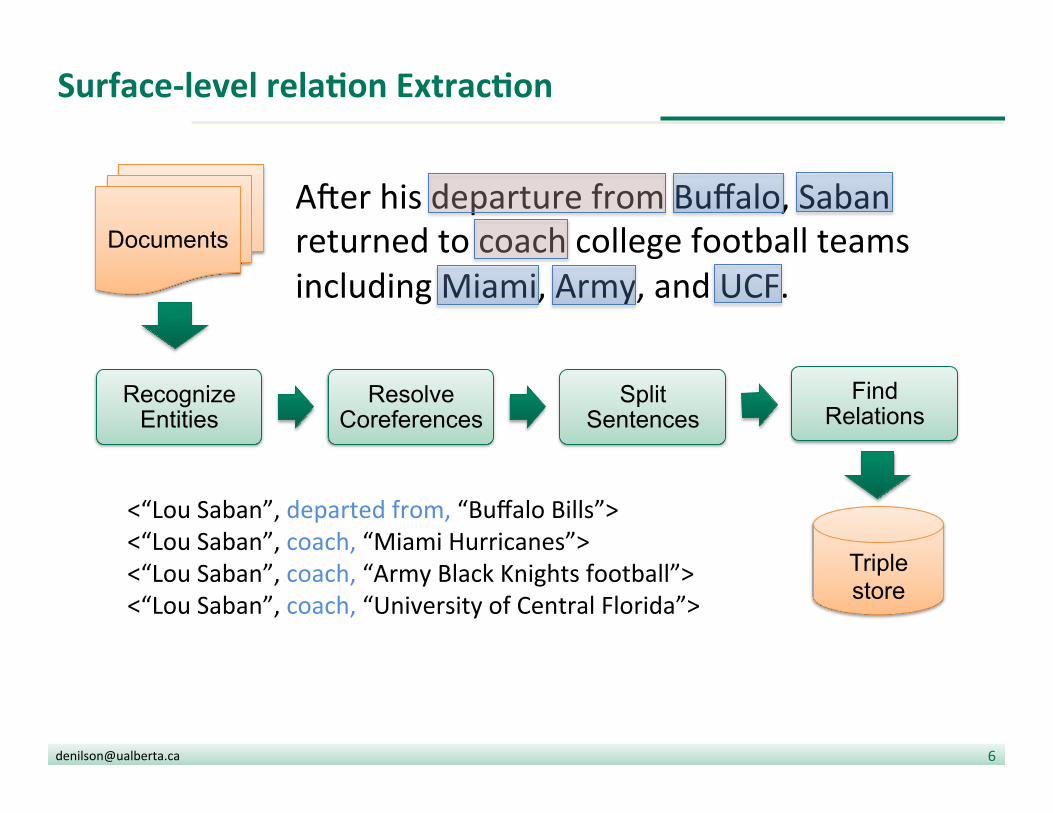
AUer his departure from Buffalo, Saban returned to coach college football teams including Miami, Army, and UCF.
Surface-‐level relaDon ExtracDon
Recognize Entities
Resolve Coreferences
Split Sentences
Find Relations
Documents
Triple store
<“Lou Saban”, departed from, “Buffalo Bills”> <“Lou Saban”, coach, “Miami Hurricanes”> <“Lou Saban”, coach, “Army Black Knights football”> <“Lou Saban”, coach, “University of Central Florida”>
6
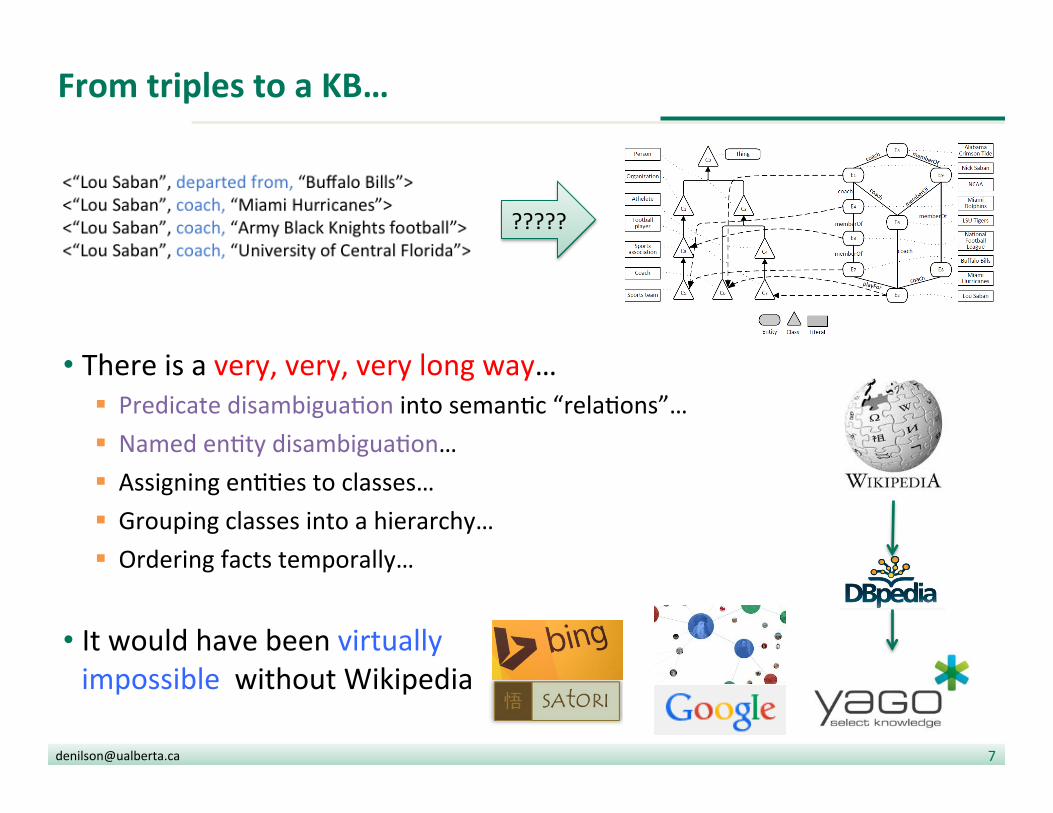
From triples to a KB…
• There is a very, very, very long way… § Predicate disambigua?on into seman?c “rela?ons”… § Named en?ty disambigua?on… § Assigning en??es to classes… § Grouping classes into a hierarchy… § Ordering facts temporally…
• It would have been virtually impossible without Wikipedia
?????

In this talk…
• Work on en?ty linking with random walks … [CIKM’2014]
• A bit of the work on open rela?on extrac?on – less on disambigua?on § SONEX (clustering-‐based) [TWEB ‘2012] § EXEMPLAR (dependences based) [EMNLP’2013] § With Tree Kernels [NAACL’2013] § EFFICIENS (cost-‐constrained)
• A bit of our work on understanding disputes in Wikipedia [Hypertext2012] [ACM TIST’2015]
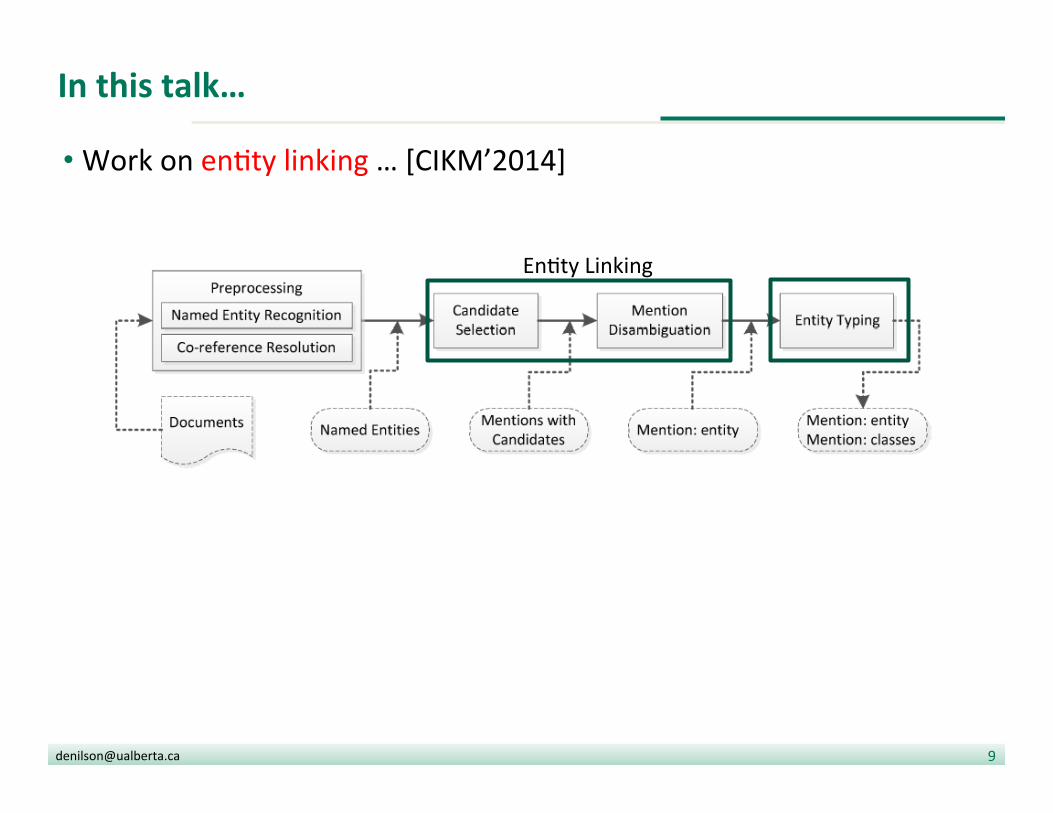
The enDty graph
• We perform disambigua?on of a graph where nodes have ids of en??es in the KB with their respec?ve context (i.e., text!)
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
UCF Knights football
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army
≠ The En?ty Graph has text about the en??es
The KB has facts and asser?ons

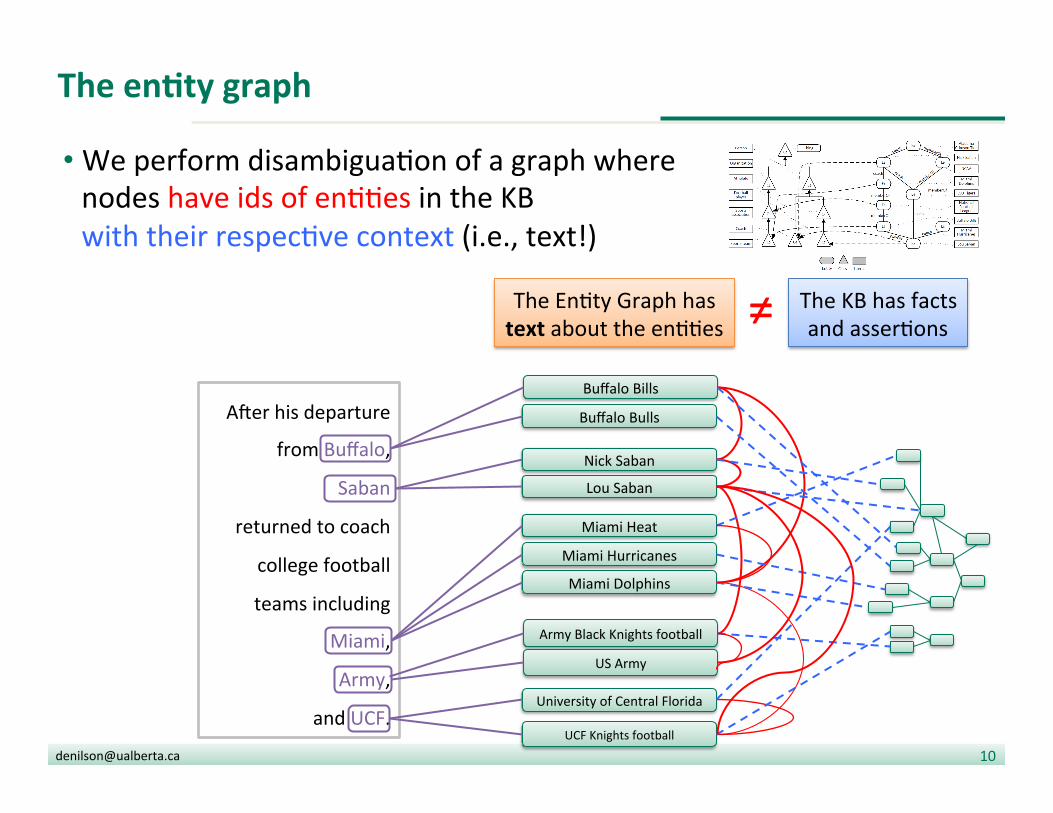
The enDty graph
• Typically, built from Wikipedia
• Nodes are Wikipedia ar?cles § All known names § Context: whole ar?cle § Metadata:
• types, keyphrases, • type compa?bility…
• Edges: E1 – E2 iff: § There is a wikilink from E1 to E2 § There is ar?cle E3 that men?ons E1 and E2 close to each other
• Alias dic?onary: § Mapping from names to ids
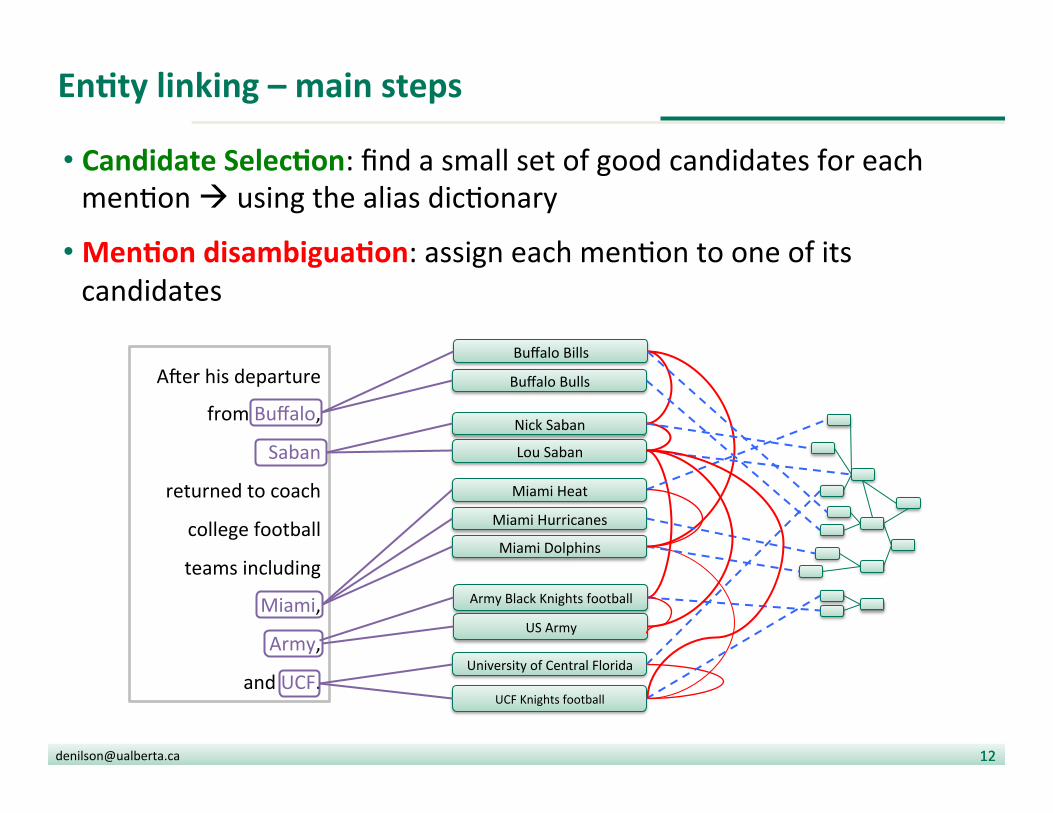
EnDty linking – main steps
• Candidate SelecDon: find a small set of good candidates for each men?on à using the alias dic?onary
• MenDon disambiguaDon: assign each men?on to one of its candidates
[email protected] 12 12
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
UCF Knights football
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army

Candidate SelecDon
• On the KB: alias-‐dic?onary expansion § Saban : {Nick Saban, Lou Saban, Saban Capital Group, …}
• On the document: § Lookups: alias-‐dic?onary/Wikipedia disambigua?on pages § Co-‐reference resolu?on[Cucerzan’07] § Acronym expansion[Zhang et.al’10, Zhang et.al’11] (ABC -‐> Australian Broadcas?ng Corpora?on)

Local menDon disambiguaDon—e.g., [Cucerzan’2007]
• Disambiguate each men?on in isola?on
ent(m) = argmax
e2candidates(m)(↵ · prior(m, e) + � · sim(m, e))
• freq(e|m) • indegree(e) • length(context(e))
• cosine/Dice/KL( context(m), context(e))
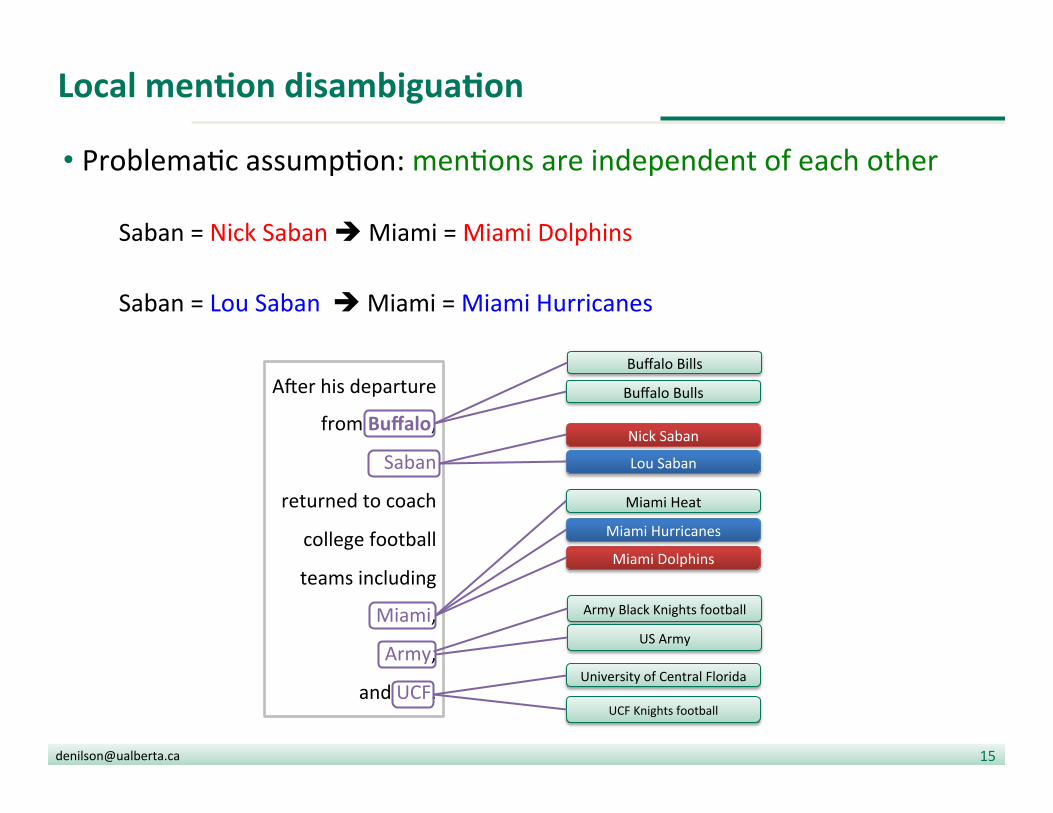
Local menDon disambiguaDon
• Problema?c assump?on: men?ons are independent of each other Saban = Nick Saban è Miami = Miami Dolphins Saban = Lou Saban è Miami = Miami Hurricanes
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
UCF Knights football
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army
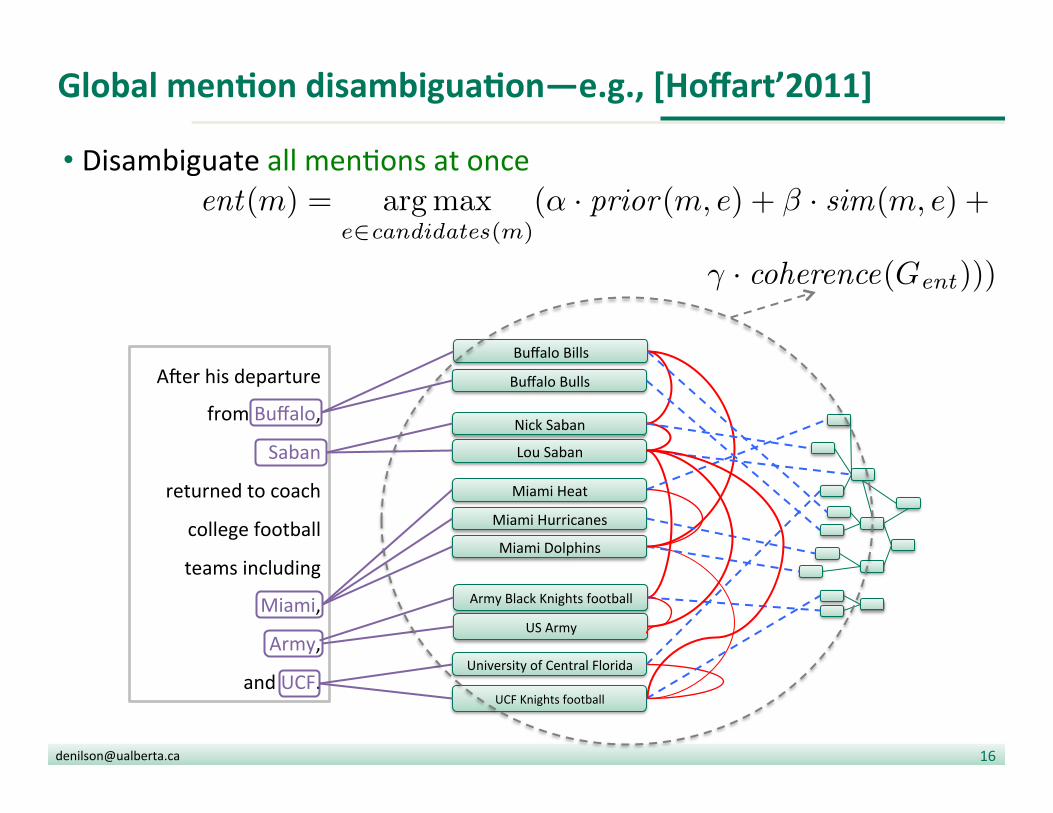
Global menDon disambiguaDon—e.g., [Hoffart’2011]
• Disambiguate all men?ons at once
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
UCF Knights football
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army
ent(m) = argmax
e2candidates(m)(↵ · prior(m, e) + � · sim(m, e) +
� · coherence(Gent)))
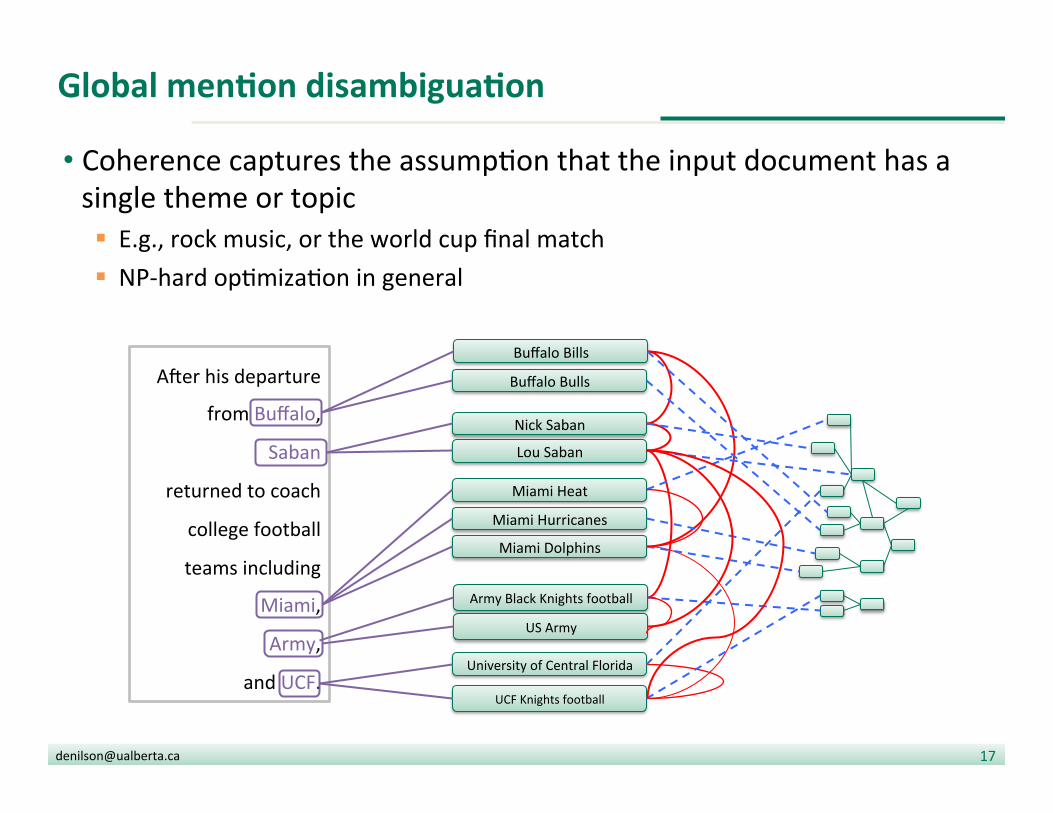
Global menDon disambiguaDon
• Coherence captures the assump?on that the input document has a single theme or topic § E.g., rock music, or the world cup final match § NP-‐hard op?miza?on in general
UCF Knights football
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army

Global menDon disambiguaDon
• [Hoffart et al 2011] – dense sub-‐graph problem
• Greedy algorithm: remove non-‐taboo en??es un?l a minimal subgraph with highest weight is found
en?ty-‐en?ty • overlap anchor words • overlap links • type similarity
men?on-‐en?ty • sim(m,e) • keyphraseness(m,e)
post-‐processing
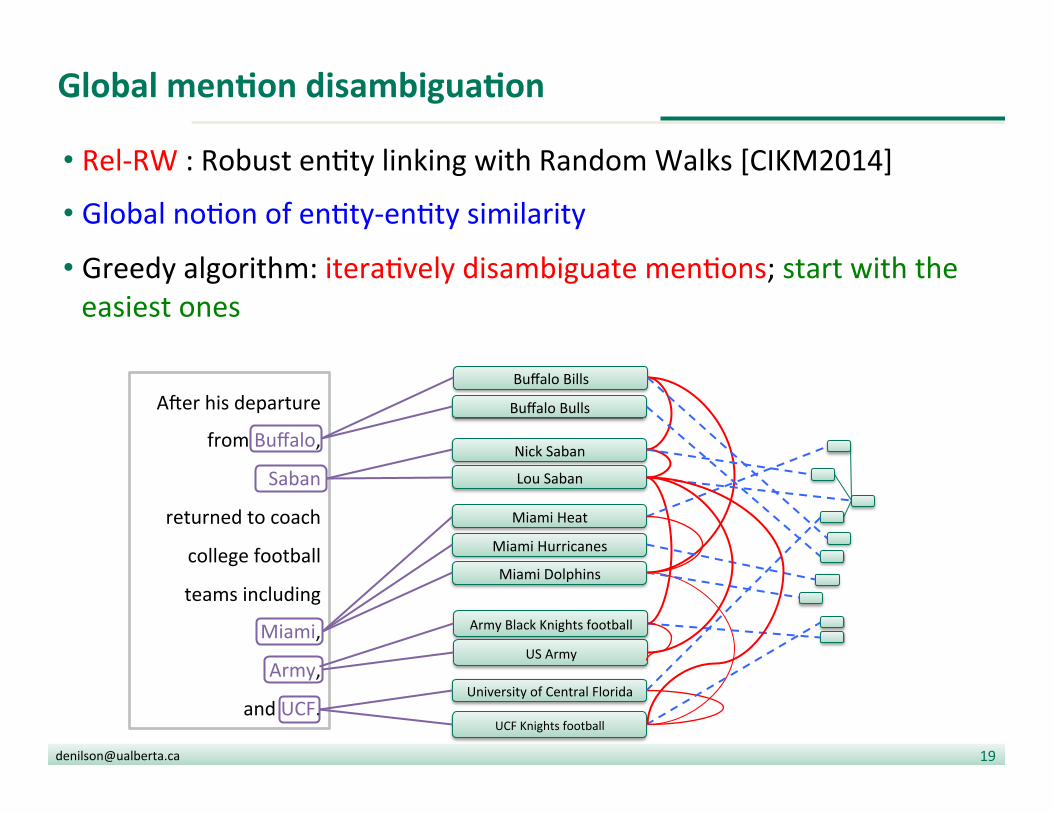
Global menDon disambiguaDon
• Rel-‐RW : Robust en?ty linking with Random Walks [CIKM2014]
• Global no?on of en?ty-‐en?ty similarity
• Greedy algorithm: itera?vely disambiguate men?ons; start with the easiest ones
UCF Knights football
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army

Random Walks as context representaDon
• Random walks capture indirect relatedness between nodes in the graph
UCF Knights football
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army
k candidates n nodes in total

Random Walks as context representaDon
• One vector for each en?ty, and another for the whole document
• Similarity is measured using Zero-‐KL Divergence
Relatedness between en??es
En?ty Seman?c Signature
Document Seman?c Signature

SemanDc Signatures of EnDDes
• Restart from the en?ty with probability α (e.g. 0.15) § Un?l convergence
• Repeat for the candidate men?ons only
UCF Knights football
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army
. . .
. . .
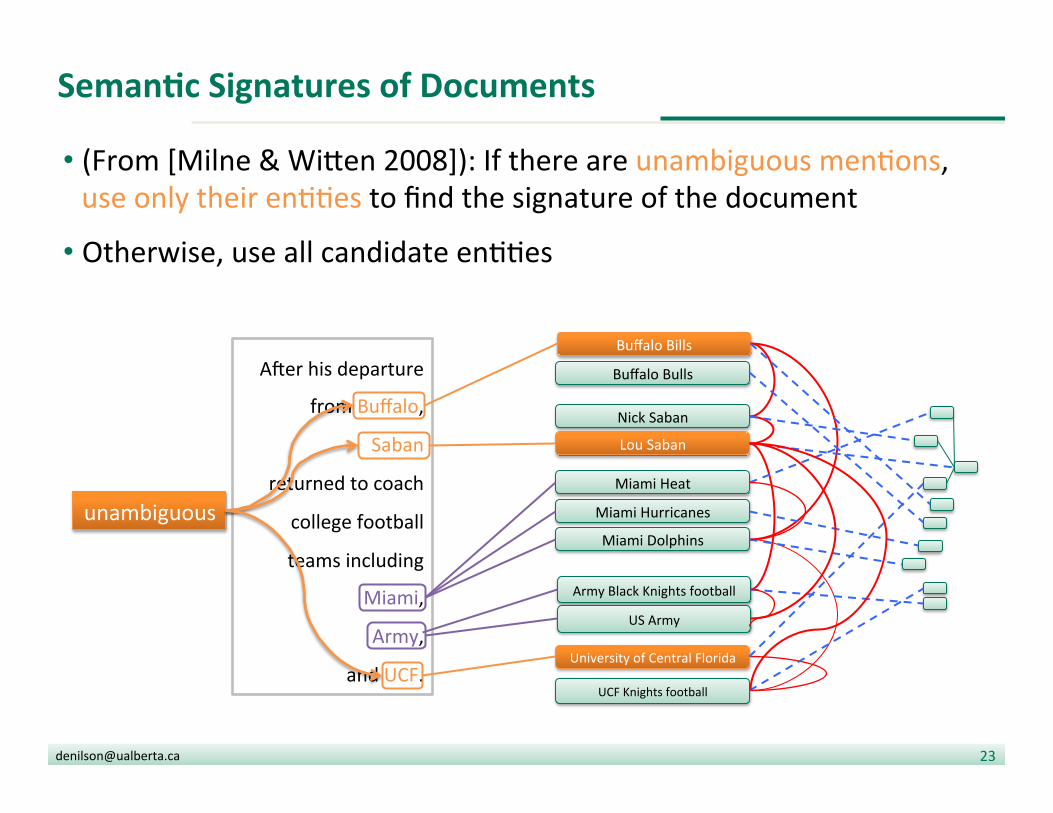
SemanDc Signatures of Documents
• (From [Milne & Wi|en 2008]): If there are unambiguous men?ons, use only their en??es to find the signature of the document
• Otherwise, use all candidate en??es
unambiguous
UCF Knights football
AUer his departure
from Buffalo,
Saban
returned to coach
college football
teams including
Miami,
Army,
and UCF.
Nick Saban
Lou Saban
Buffalo Bills
Buffalo Bulls
Army Black Knights football
Miami Heat
Miami Hurricanes
Miami Dolphins
University of Central Florida
US Army

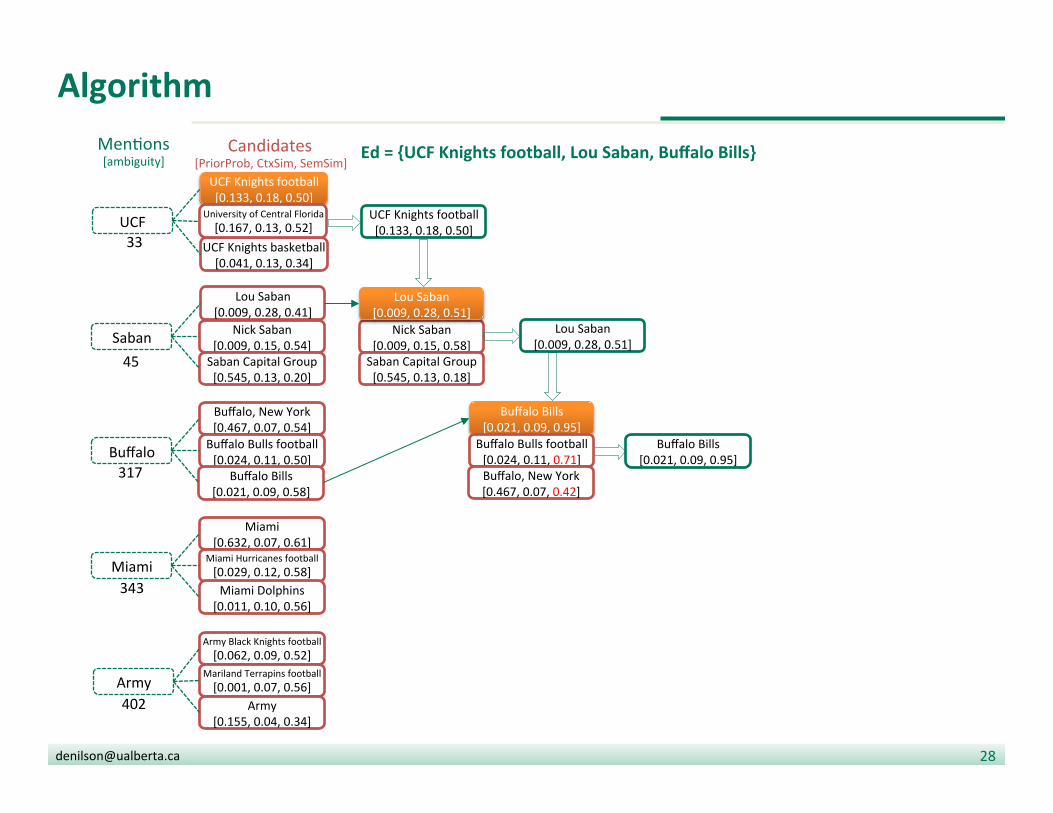
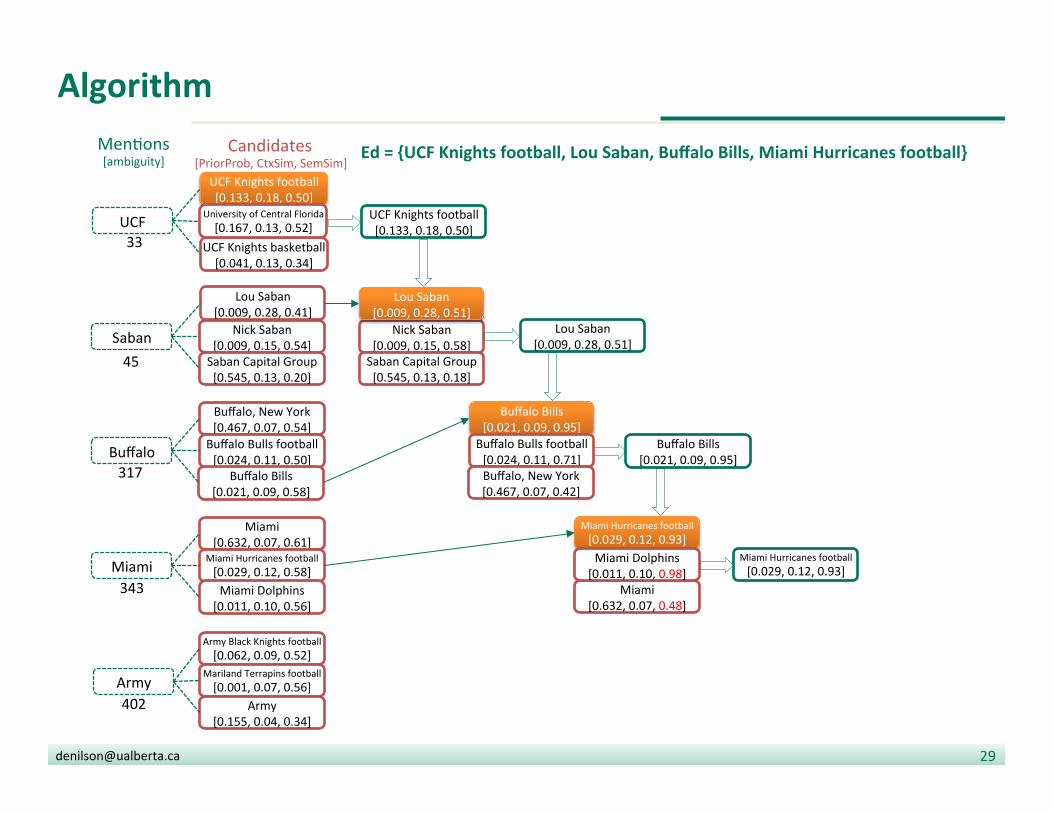
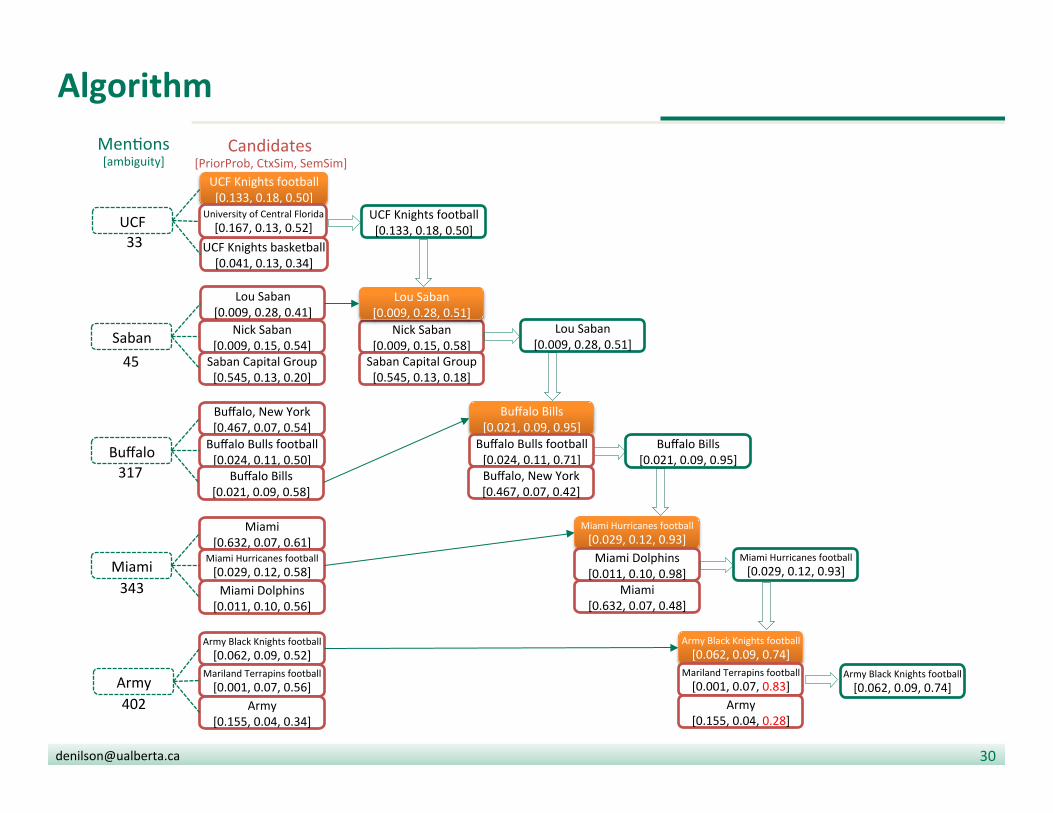
Algorithm
• Find candidate en??es for each men?on
• Compute prior(m,e) and the context(m,e)
• Sort men?ons by ambiguity (i.e., number of candidates)
• Go through each men?on m in ascending order:
• SSd = seman?c signature of document
• Assign to m the candidate e with highest combined score prior(m,e) * context(m,e) + sim(SSe , SSd)
• Update the set of en??es for the document

Algorithm
UCF Knights football [0.133, 0.18, 0.50]
University of Central Florida [0.167, 0.13, 0.52]
Miami [0.632, 0.07, 0.61]
Miami Hurricanes football [0.029, 0.12, 0.58]
Buffalo, New York [0.467, 0.07, 0.54]
Miami Dolphins [0.011, 0.10, 0.56]
Lou Saban [0.009, 0.28, 0.41]
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
UCF Knights basketball [0.041, 0.13, 0.34]
Nick Saban [0.009, 0.15, 0.54] Saban Capital Group [0.545, 0.13, 0.20]
Buffalo Bulls football [0.024, 0.11, 0.50]
Buffalo Bills [0.021, 0.09, 0.58]
Saban 45
UCF 33
Buffalo 317
Miami 343
Army 402
Army Black Knights football [0.062, 0.09, 0.52]
Mariland Terrapins football [0.001, 0.07, 0.56]
Army [0.155, 0.04, 0.34]
Use all candidates for SSd

UCF Knights football [0.133, 0.18, 0.50]
Miami [0.632, 0.07, 0.61]
Miami Hurricanes football [0.029, 0.12, 0.58]
Buffalo, New York [0.467, 0.07, 0.54]
Miami Dolphins [0.011, 0.10, 0.56]
Lou Saban [0.009, 0.28, 0.41]
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
UCF Knights basketball [0.041, 0.13, 0.34]
Nick Saban [0.009, 0.15, 0.54] Saban Capital Group [0.545, 0.13, 0.20]
Buffalo Bulls football [0.024, 0.11, 0.50]
Buffalo Bills [0.021, 0.09, 0.58]
Saban 45
UCF 33
Buffalo 317
Miami 343
UCF Knights football [0.133, 0.18, 0.50]
Army 402
Army Black Knights football [0.062, 0.09, 0.52]
Mariland Terrapins football [0.001, 0.07, 0.56]
Army [0.155, 0.04, 0.34]
Ed = {UCF Knights football}
Algorithm
University of Central Florida [0.167, 0.13, 0.52]

Miami [0.632, 0.07, 0.61]
Miami Hurricanes football [0.029, 0.12, 0.58]
Buffalo, New York [0.467, 0.07, 0.54]
Miami Dolphins [0.011, 0.10, 0.56]
Lou Saban [0.009, 0.28, 0.41]
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Nick Saban [0.009, 0.15, 0.54] Saban Capital Group [0.545, 0.13, 0.20]
Buffalo Bulls football [0.024, 0.11, 0.50]
Buffalo Bills [0.021, 0.09, 0.58]
Saban 45
Buffalo 317
Miami 343
Nick Saban [0.009, 0.15, 0.58]
Lou Saban [0.009, 0.28, 0.51]
Saban Capital Group [0.545, 0.13, 0.18]
Lou Saban [0.009, 0.28, 0.51]
Army 402
Army Black Knights football [0.062, 0.09, 0.52]
Mariland Terrapins football [0.001, 0.07, 0.56]
Army [0.155, 0.04, 0.34]
Ed = {UCF Knights football, Lou Saban}
Algorithm
UCF Knights football [0.133, 0.18, 0.50]
UCF Knights basketball [0.041, 0.13, 0.34]
UCF 33
UCF Knights football [0.133, 0.18, 0.50]
University of Central Florida [0.167, 0.13, 0.52]
Miami [0.632, 0.07, 0.61]
Miami Hurricanes football [0.029, 0.12, 0.58]
Buffalo, New York [0.467, 0.07, 0.54]
Miami Dolphins [0.011, 0.10, 0.56]
Lou Saban [0.009, 0.28, 0.41]
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Nick Saban [0.009, 0.15, 0.54] Saban Capital Group [0.545, 0.13, 0.20]
Buffalo Bulls football [0.024, 0.11, 0.50]
Buffalo Bills [0.021, 0.09, 0.58]
Saban 45
Buffalo 317
Miami 343
Nick Saban [0.009, 0.15, 0.58]
Lou Saban [0.009, 0.28, 0.51]
Saban Capital Group [0.545, 0.13, 0.18]
Lou Saban [0.009, 0.28, 0.51]
Buffalo Bills [0.021, 0.09, 0.95]
Army 402
Army Black Knights football [0.062, 0.09, 0.52]
Mariland Terrapins football [0.001, 0.07, 0.56]
Army [0.155, 0.04, 0.34]
Buffalo Bills [0.021, 0.09, 0.95]
Buffalo Bulls football [0.024, 0.11, 0.71] Buffalo, New York [0.467, 0.07, 0.42]
Ed = {UCF Knights football, Lou Saban, Buffalo Bills}
Algorithm
UCF Knights football [0.133, 0.18, 0.50]
UCF Knights basketball [0.041, 0.13, 0.34]
UCF 33
UCF Knights football [0.133, 0.18, 0.50]
University of Central Florida [0.167, 0.13, 0.52]
Miami [0.632, 0.07, 0.61]
Miami Hurricanes football [0.029, 0.12, 0.58]
Buffalo, New York [0.467, 0.07, 0.54]
Miami Dolphins [0.011, 0.10, 0.56]
Lou Saban [0.009, 0.28, 0.41]
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Nick Saban [0.009, 0.15, 0.54] Saban Capital Group [0.545, 0.13, 0.20]
Buffalo Bulls football [0.024, 0.11, 0.50]
Buffalo Bills [0.021, 0.09, 0.58]
Saban 45
Buffalo 317
Miami 343
Nick Saban [0.009, 0.15, 0.58]
Lou Saban [0.009, 0.28, 0.51]
Saban Capital Group [0.545, 0.13, 0.18]
Lou Saban [0.009, 0.28, 0.51]
Buffalo Bills [0.021, 0.09, 0.95]
Army 402
Army Black Knights football [0.062, 0.09, 0.52]
Mariland Terrapins football [0.001, 0.07, 0.56]
Army [0.155, 0.04, 0.34]
Buffalo Bills [0.021, 0.09, 0.95]
Buffalo Bulls football [0.024, 0.11, 0.71] Buffalo, New York [0.467, 0.07, 0.42]
Miami [0.632, 0.07, 0.48]
Miami Hurricanes football [0.029, 0.12, 0.93] Miami Dolphins [0.011, 0.10, 0.98]
Miami Hurricanes football [0.029, 0.12, 0.93]
Ed = {UCF Knights football, Lou Saban, Buffalo Bills, Miami Hurricanes football}
Algorithm
UCF Knights football [0.133, 0.18, 0.50]
UCF Knights basketball [0.041, 0.13, 0.34]
UCF 33
UCF Knights football [0.133, 0.18, 0.50]
University of Central Florida [0.167, 0.13, 0.52]
Miami [0.632, 0.07, 0.61]
Miami Hurricanes football [0.029, 0.12, 0.58]
Buffalo, New York [0.467, 0.07, 0.54]
Miami Dolphins [0.011, 0.10, 0.56]
Lou Saban [0.009, 0.28, 0.41]
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Nick Saban [0.009, 0.15, 0.54] Saban Capital Group [0.545, 0.13, 0.20]
Buffalo Bulls football [0.024, 0.11, 0.50]
Buffalo Bills [0.021, 0.09, 0.58]
Saban 45
Buffalo 317
Miami 343
Nick Saban [0.009, 0.15, 0.58]
Lou Saban [0.009, 0.28, 0.51]
Saban Capital Group [0.545, 0.13, 0.18]
Lou Saban [0.009, 0.28, 0.51]
Buffalo Bills [0.021, 0.09, 0.95]
Army 402
Army Black Knights football [0.062, 0.09, 0.52]
Mariland Terrapins football [0.001, 0.07, 0.56]
Army [0.155, 0.04, 0.34]
Buffalo Bills [0.021, 0.09, 0.95]
Buffalo Bulls football [0.024, 0.11, 0.71] Buffalo, New York [0.467, 0.07, 0.42]
Miami [0.632, 0.07, 0.48]
Miami Hurricanes football [0.029, 0.12, 0.93] Miami Dolphins [0.011, 0.10, 0.98]
Miami Hurricanes football [0.029, 0.12, 0.93]
Army Black Knights football [0.062, 0.09, 0.74]
Army Black Knights football [0.062, 0.09, 0.74]
Mariland Terrapins football [0.001, 0.07, 0.83]
Army [0.155, 0.04, 0.28]
Algorithm
UCF Knights football [0.133, 0.18, 0.50]
UCF Knights basketball [0.041, 0.13, 0.34]
UCF 33
UCF Knights football [0.133, 0.18, 0.50]
University of Central Florida [0.167, 0.13, 0.52]
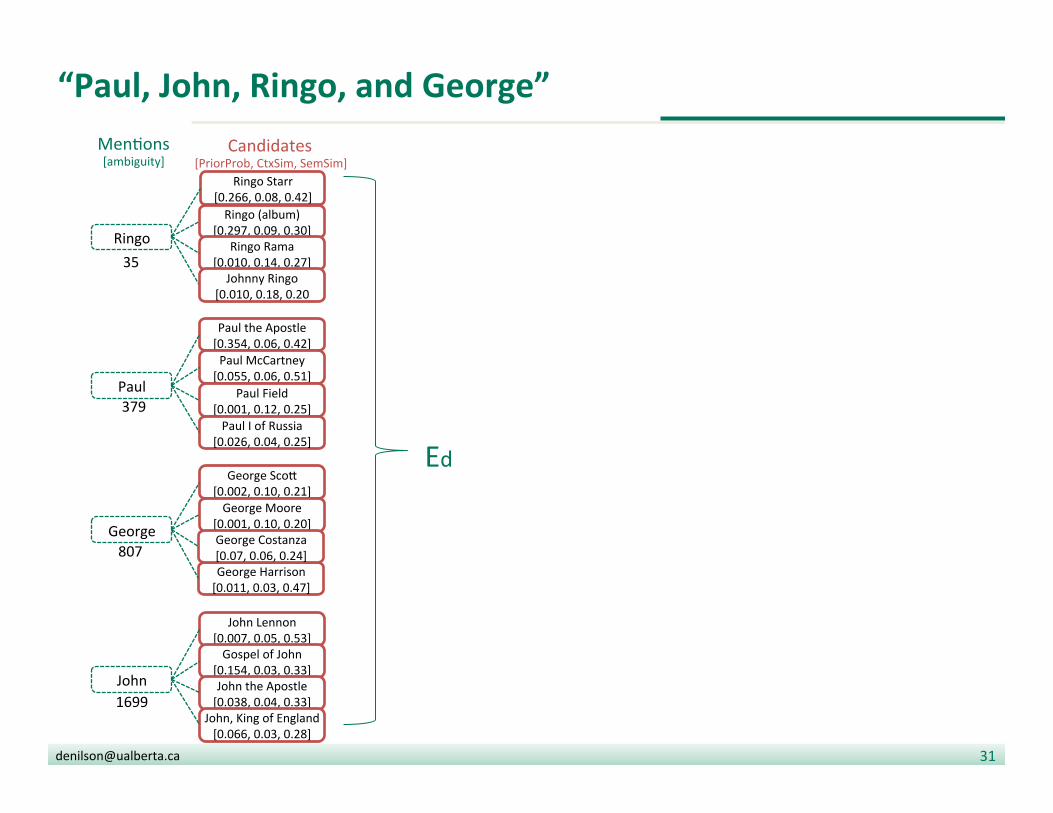
“Paul, John, Ringo, and George”
Paul the Apostle [0.354, 0.06, 0.42] Paul McCartney [0.055, 0.06, 0.51]
John Lennon [0.007, 0.05, 0.53] Gospel of John
[0.154, 0.03, 0.33]
George Sco| [0.002, 0.10, 0.21]
George Harrison [0.011, 0.03, 0.47]
John the Apostle [0.038, 0.04, 0.33]
Ringo Starr [0.266, 0.08, 0.42]
Paul
John
Ringo
George
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Paul Field [0.001, 0.12, 0.25] Paul I of Russia
[0.026, 0.04, 0.25]
John, King of England [0.066, 0.03, 0.28]
Ringo (album) [0.297, 0.09, 0.30]
Ringo Rama [0.010, 0.14, 0.27] Johnny Ringo
[0.010, 0.18, 0.20
George Moore [0.001, 0.10, 0.20] George Costanza [0.07, 0.06, 0.24]
35
379
807
1699
Ed
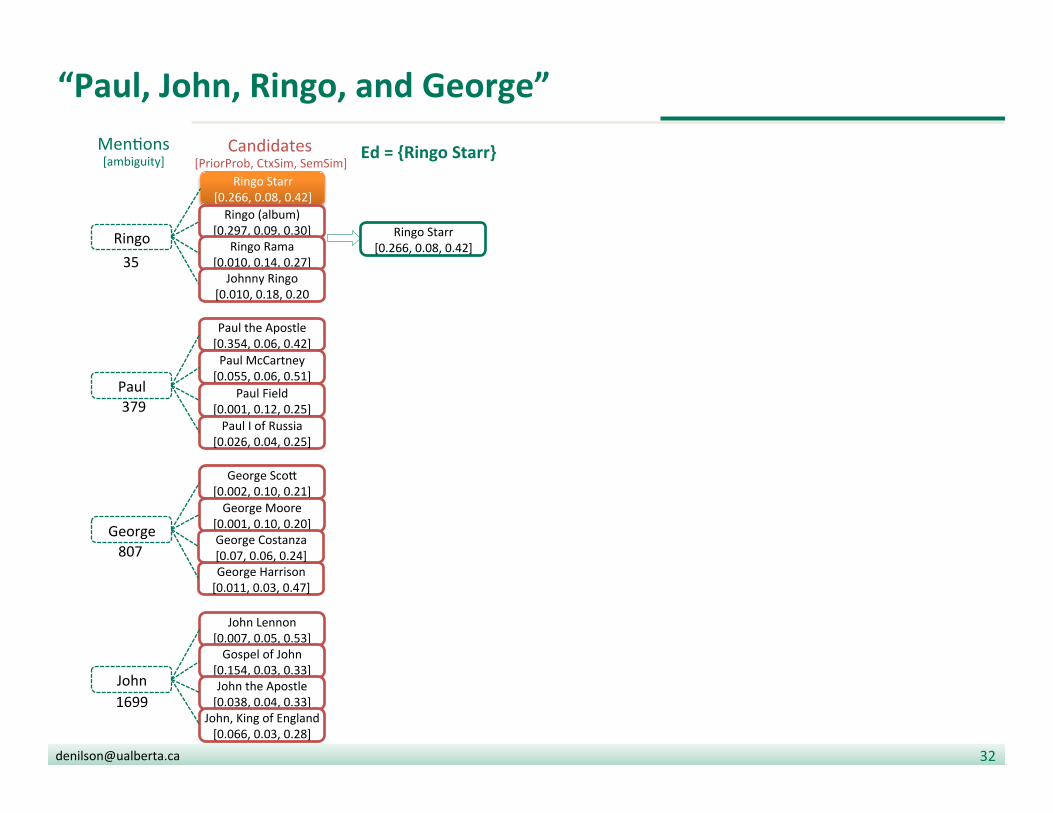
“Paul, John, Ringo, and George”
Paul the Apostle [0.354, 0.06, 0.42] Paul McCartney [0.055, 0.06, 0.51]
John Lennon [0.007, 0.05, 0.53] Gospel of John
[0.154, 0.03, 0.33]
George Sco| [0.002, 0.10, 0.21]
George Harrison [0.011, 0.03, 0.47]
John the Apostle [0.038, 0.04, 0.33]
Ringo Starr [0.266, 0.08, 0.42]
Paul
John
Ringo
George
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Paul Field [0.001, 0.12, 0.25] Paul I of Russia
[0.026, 0.04, 0.25]
John, King of England [0.066, 0.03, 0.28]
Ringo (album) [0.297, 0.09, 0.30]
Ringo Rama [0.010, 0.14, 0.27] Johnny Ringo
[0.010, 0.18, 0.20
George Moore [0.001, 0.10, 0.20] George Costanza [0.07, 0.06, 0.24]
35
379
807
1699
Ringo Starr [0.266, 0.08, 0.42]
Ed = {Ringo Starr}

“Paul, John, Ringo, and George”
Paul the Apostle [0.354, 0.06, 0.42] Paul McCartney [0.055, 0.06, 0.51]
John Lennon [0.007, 0.05, 0.53] Gospel of John
[0.154, 0.03, 0.33]
George Sco| [0.002, 0.10, 0.21]
George Harrison [0.011, 0.03, 0.47]
John the Apostle [0.038, 0.04, 0.33]
Ringo Starr [0.266, 0.08, 0.42]
Paul
John
Ringo
George
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Paul Field [0.001, 0.12, 0.25] Paul I of Russia
[0.026, 0.04, 0.25]
John, King of England [0.066, 0.03, 0.28]
Ringo (album) [0.297, 0.09, 0.30]
Ringo Rama [0.010, 0.14, 0.27] Johnny Ringo
[0.010, 0.18, 0.20
George Moore [0.001, 0.10, 0.20] George Costanza [0.07, 0.06, 0.24]
35
379
807
1699
Paul the Apostle [0.354, 0.06, 0.24]
Paul McCartney [0.055, 0.06, 1.25]
Ringo Starr [0.266, 0.08, 0.42]
Paul Field [0.001, 0.12, 0.22] Paul I of Russia
[0.026, 0.04, 0.19]
Paul McCartney [0.055, 0.06, 1.25]
Ed = {Ringo Starr, Paul McCartney}

“Paul, John, Ringo, and George”
Paul the Apostle [0.354, 0.06, 0.42] Paul McCartney [0.055, 0.06, 0.51]
John Lennon [0.007, 0.05, 0.53] Gospel of John
[0.154, 0.03, 0.33]
George Sco| [0.002, 0.10, 0.21]
George Harrison [0.011, 0.03, 0.47]
John the Apostle [0.038, 0.04, 0.33]
Ringo Starr [0.266, 0.08, 0.42]
Paul
John
Ringo
George
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Paul Field [0.001, 0.12, 0.25] Paul I of Russia
[0.026, 0.04, 0.25]
John, King of England [0.066, 0.03, 0.28]
Ringo (album) [0.297, 0.09, 0.30]
Ringo Rama [0.010, 0.14, 0.27] Johnny Ringo
[0.010, 0.18, 0.20
George Moore [0.001, 0.10, 0.20] George Costanza [0.07, 0.06, 0.24]
35
379
807
1699
Paul the Apostle [0.354, 0.06, 0.24]
Paul McCartney [0.055, 0.06, 1.25]
Ringo Starr [0.266, 0.08, 0.42]
Paul Field [0.001, 0.12, 0.22] Paul I of Russia
[0.026, 0.04, 0.19]
Paul McCartney [0.055, 0.06, 1.25]
George Sco| [0.002, 0.10, 0.20]
George Harrison [0.011, 0.03, 1.30]
George Moore [0.001, 0.10, 0.19]
George Costanza [0.07, 0.06, 0.24]
George Harrison [0.011, 0.03, 1.30]
Ed = {Ringo Starr, Paul McCartney, George Harrison}
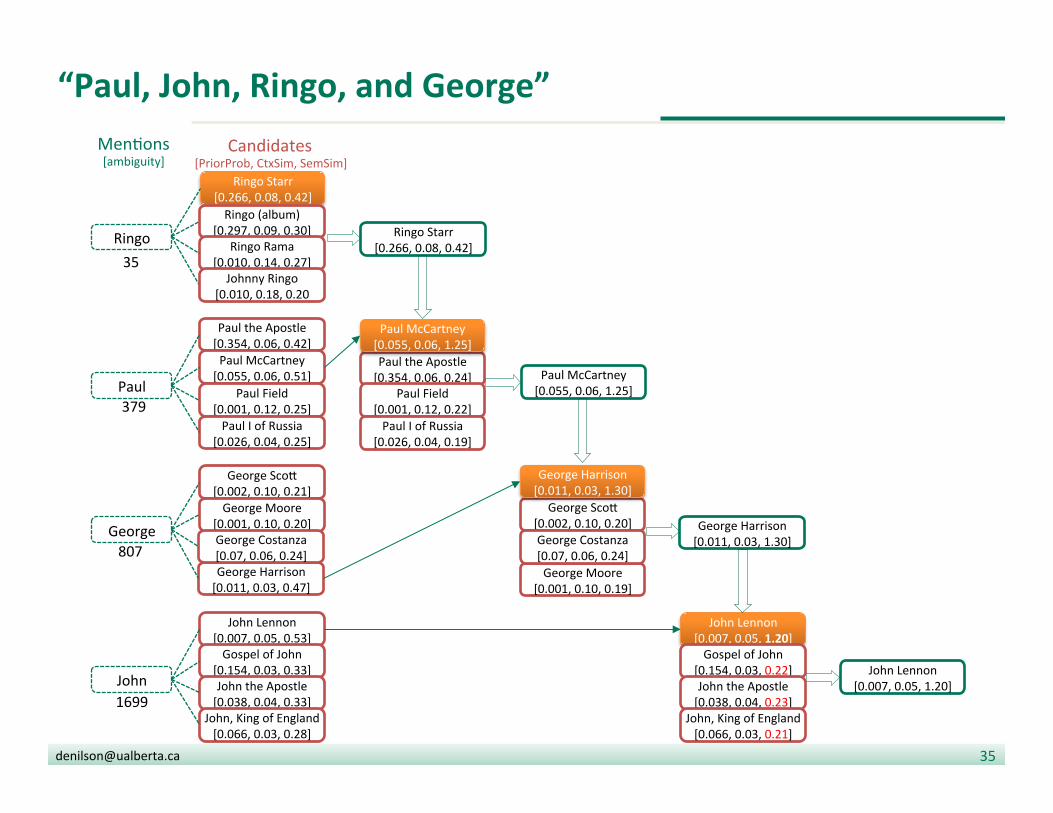
“Paul, John, Ringo, and George”
Paul the Apostle [0.354, 0.06, 0.42] Paul McCartney [0.055, 0.06, 0.51]
John Lennon [0.007, 0.05, 0.53] Gospel of John
[0.154, 0.03, 0.33]
George Sco| [0.002, 0.10, 0.21]
George Harrison [0.011, 0.03, 0.47]
John the Apostle [0.038, 0.04, 0.33]
Ringo Starr [0.266, 0.08, 0.42]
Paul
John
Ringo
George
Men?ons [ambiguity]
Candidates [PriorProb, CtxSim, SemSim]
Paul Field [0.001, 0.12, 0.25] Paul I of Russia
[0.026, 0.04, 0.25]
John, King of England [0.066, 0.03, 0.28]
Ringo (album) [0.297, 0.09, 0.30]
Ringo Rama [0.010, 0.14, 0.27] Johnny Ringo
[0.010, 0.18, 0.20
George Moore [0.001, 0.10, 0.20] George Costanza [0.07, 0.06, 0.24]
35
379
807
1699
Paul the Apostle [0.354, 0.06, 0.24]
Paul McCartney [0.055, 0.06, 1.25]
Ringo Starr [0.266, 0.08, 0.42]
Paul Field [0.001, 0.12, 0.22] Paul I of Russia
[0.026, 0.04, 0.19]
Paul McCartney [0.055, 0.06, 1.25]
George Sco| [0.002, 0.10, 0.20]
George Harrison [0.011, 0.03, 1.30]
George Moore [0.001, 0.10, 0.19]
George Costanza [0.07, 0.06, 0.24]
John Lennon [0.007, 0.05, 1.20] Gospel of John
[0.154, 0.03, 0.22]
George Harrison [0.011, 0.03, 1.30]
John the Apostle [0.038, 0.04, 0.23]
John, King of England [0.066, 0.03, 0.21]
John Lennon [0.007, 0.05, 1.20]
EnDty Linking – EvaluaDon
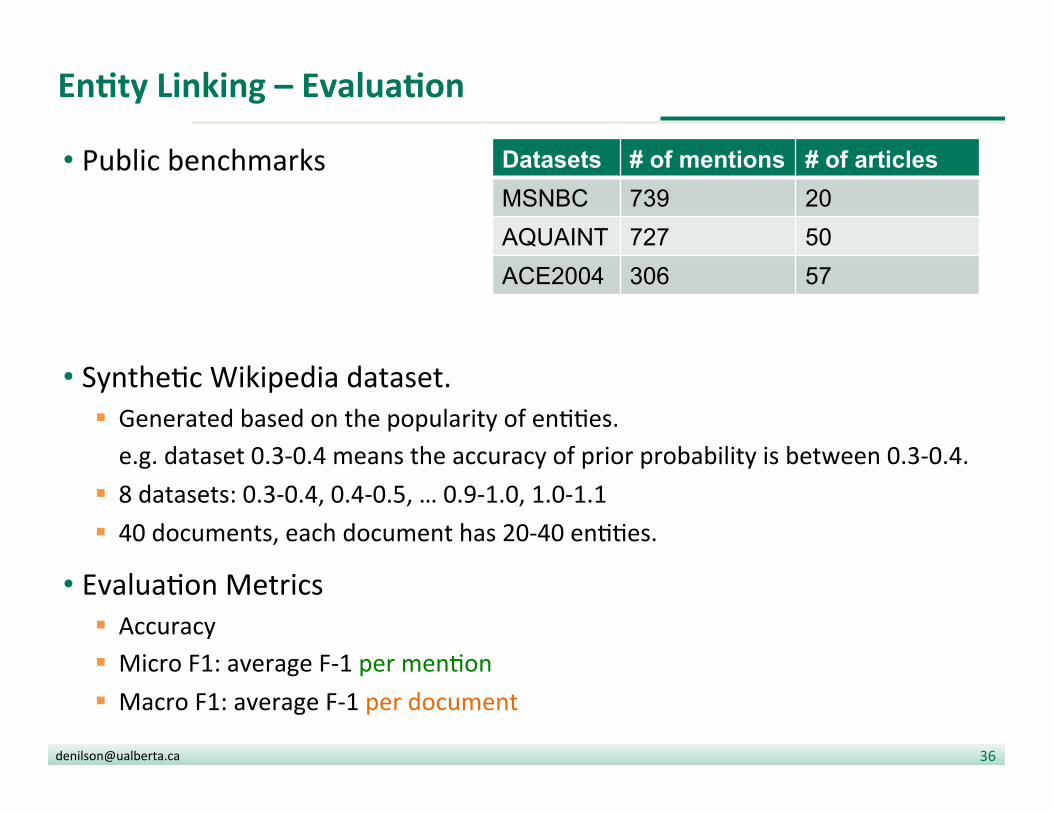
• Public benchmarks
• Synthe?c Wikipedia dataset. § Generated based on the popularity of en??es. e.g. dataset 0.3-‐0.4 means the accuracy of prior probability is between 0.3-‐0.4. § 8 datasets: 0.3-‐0.4, 0.4-‐0.5, … 0.9-‐1.0, 1.0-‐1.1 § 40 documents, each document has 20-‐40 en??es.
• Evalua?on Metrics § Accuracy § Micro F1: average F-‐1 per men?on § Macro F1: average F-‐1 per document
Datasets # of mentions # of articles MSNBC 739 20 AQUAINT 727 50 ACE2004 306 57
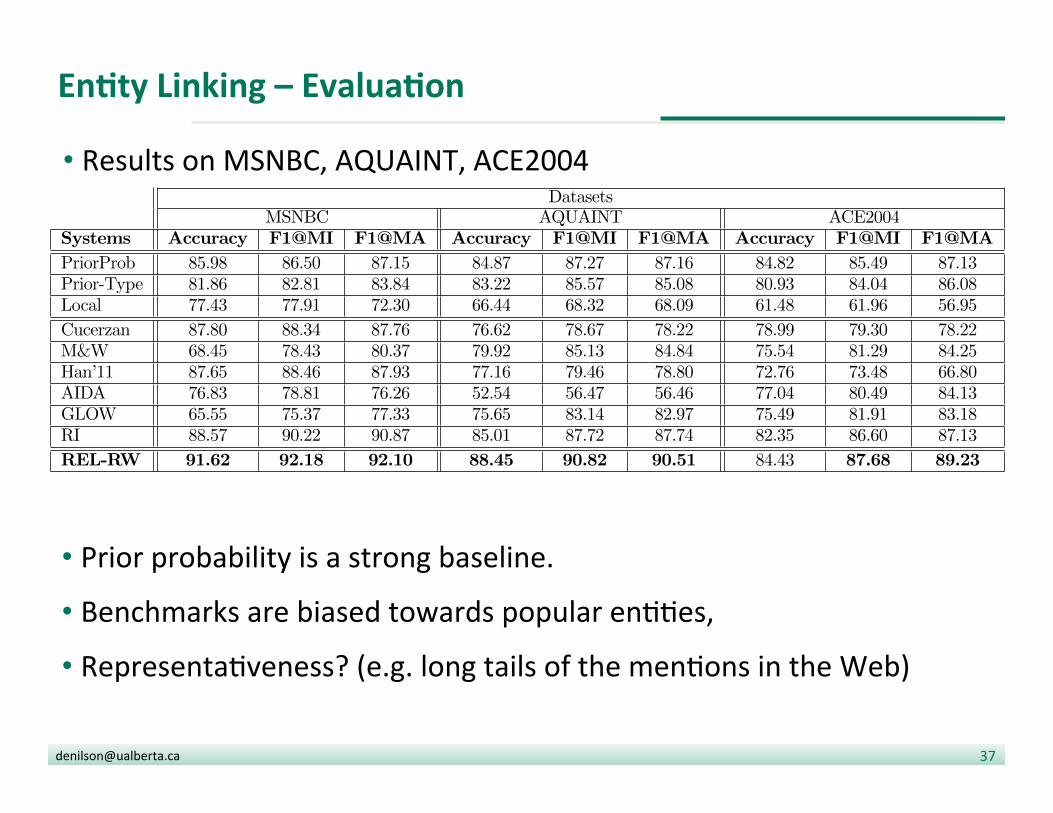
EnDty Linking – EvaluaDon
• Results on MSNBC, AQUAINT, ACE2004
• Prior probability is a strong baseline. • Benchmarks are biased towards popular en??es,
• Representa?veness? (e.g. long tails of the men?ons in the Web)
DatasetsMSNBC AQUAINT ACE2004
Systems Accuracy F1@MI F1@MA Accuracy F1@MI F1@MA Accuracy F1@MI F1@MA
PriorProb 85.98 86.50 87.15 84.87 87.27 87.16 84.82 85.49 87.13Prior-Type 81.86 82.81 83.84 83.22 85.57 85.08 80.93 84.04 86.08Local 77.43 77.91 72.30 66.44 68.32 68.09 61.48 61.96 56.95
Cucerzan 87.80 88.34 87.76 76.62 78.67 78.22 78.99 79.30 78.22M&W 68.45 78.43 80.37 79.92 85.13 84.84 75.54 81.29 84.25Han’11 87.65 88.46 87.93 77.16 79.46 78.80 72.76 73.48 66.80AIDA 76.83 78.81 76.26 52.54 56.47 56.46 77.04 80.49 84.13GLOW 65.55 75.37 77.33 75.65 83.14 82.97 75.49 81.91 83.18RI 88.57 90.22 90.87 85.01 87.72 87.74 82.35 86.60 87.13
REL-RW 91.62 92.18 92.10 88.45 90.82 90.51 84.43 87.68 89.23
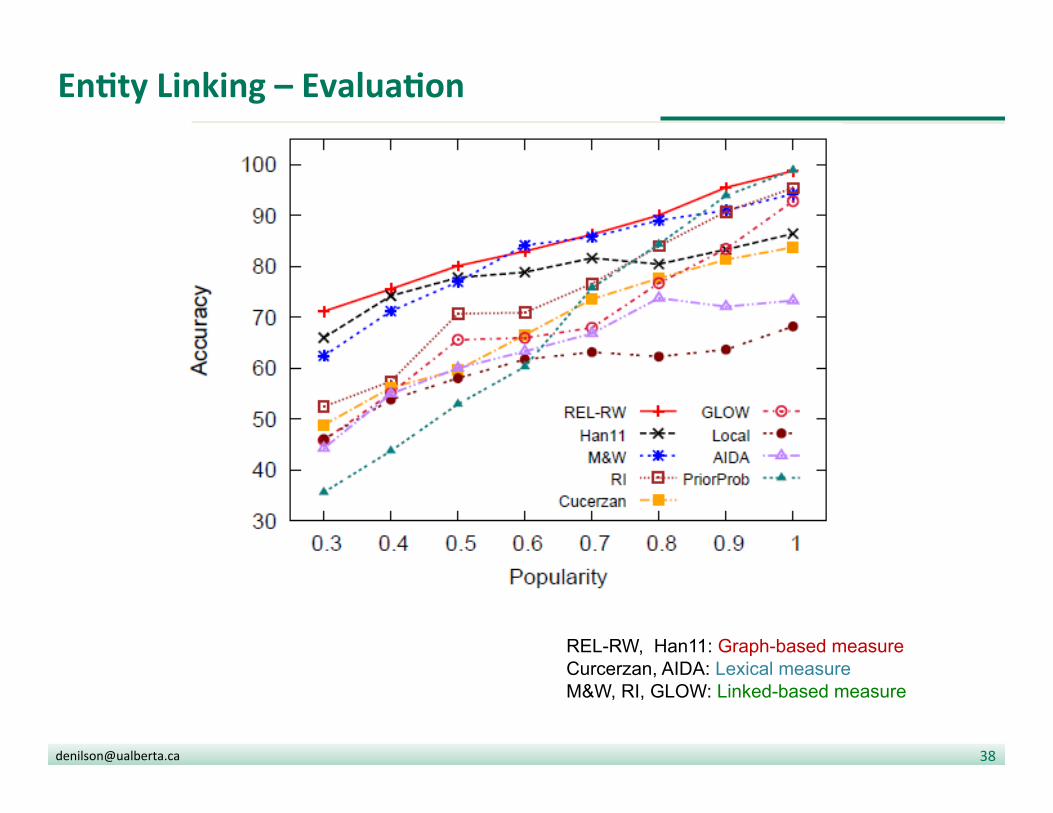
EnDty Linking – EvaluaDon
REL-RW, Han11: Graph-based measure Curcerzan, AIDA: Lexical measure M&W, RI, GLOW: Linked-based measure

EnDty Linking – EvaluaDon
• Different configura?ons § Itera?ve process performs best § Unambiguous men?ons are more informa?ve than candidates.
§ Robust performance with different weigh?ng schemes.

Robust EnDty Linking with Random Walks
• Intui?on: less popular en??es are more likely to be be|er linked than well described (i.e., have a lot of text)
• Our seman?c similarity has a natural interpreta?on and relies more on the graph than on the document content
• Men?on disambigua?on without global no?on of coherence
• Use a greedy itera?ve approach: disambiguate the ``easiest’’ men?on, re-‐compute everything, repeat
• Robust against bad parameter choice
• No learning! Previous state of the art [Hoffart’2011, Milne&Wi|en’2008] learn similarity weights
• Future work: improving the first step of the algorithm § Maybe exploring a few alterna?ves

OPEN RELATION EXTRACTION
Shallow (SONEX): Clustering-based [ACM TWEB’12]
Not-‐so-‐shallow (dependency parsing) Reified networks/Nested relations [ICWSM’11] Rule-based (EXEMPLAR) [EMNLP’13] Tree-kernels on dependency parses [NAACL’13]
Improving ORE with text normaliza?on [LREC’14] Cost-‐constrained ORE
EFFICIENS

ORE “one sentence at a Dme”
• Rela?on extrac?on as a sequence predic?on task § TextRunner: [Banko and Etzioni, 2008] a small list of part-‐of-‐speech tag sequences that account for a large number of rela?ons in a large corpus
§ ReVerb: [Fader et al., 2011] use an even shorter list of pa|erns
• The ReVerb/TextRunner tools have extracted over one billion facts from the Web
• Efficient: no need to store the whole corpus
• Bri|le: mul?ple synonyms of the the same rela?on are extracted
Frequency Pattern Example
38% E1 Verb E2 X established Y 23% E1 NP Prep E2 X settlement with Y 16% E1 Verb Prep E2 X moved to Y 9% E1 Verb to Verb E2 X plans to acquire Y
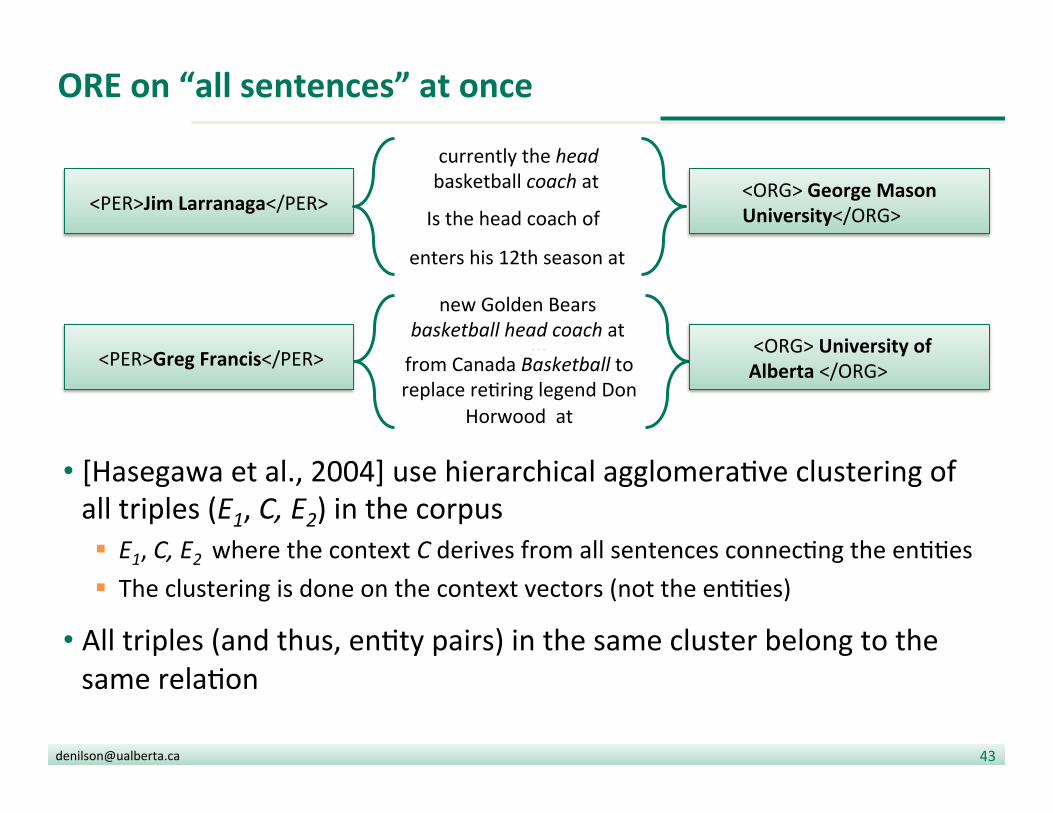
... <PER>Greg Francis</PER>
new Golden Bears basketball head coach at
from Canada Basketball to replace re?ring legend Don
Horwood at
<ORG> University of Alberta </ORG>
currently the head basketball coach at
enters his 12th season at
Is the head coach of <PER>Jim Larranaga</PER> <ORG> George Mason
University</ORG>
ORE on “all sentences” at once
• [Hasegawa et al., 2004] use hierarchical agglomera?ve clustering of all triples (E1, C, E2) in the corpus § E1, C, E2 where the context C derives from all sentences connec?ng the en??es § The clustering is done on the context vectors (not the en??es)
• All triples (and thus, en?ty pairs) in the same cluster belong to the same rela?on

SONEX
• Offline (HAC clustering) – ACM TWEB 2012
• Online (buckshot): cluster a sample and classify the remaining sentences, one at a ?me § No discernible loss in accuracy, but much higher scalability § Also allows the same en?ty pair to belong to mul?ple rela?ons

SONEX: Clustering features
• Clustering features derived from the context words between en??es § Unigrams: stemmed words, excluding stop words.
• [Allan, 1998] Allan, J. (1998). Book Review: Readings in Informa?on Retrieval edited by K. Sparck Jones and P. Wille|. Inf. Process. Manage., 34(4):489–490.
§ Bigrams: sequence of two (unigram) words (e.g., Vice President). § Part of Speech Paherns: small number of rela?on-‐independent linguis?cs pa|erns from TextRunner [Banko and Etzioni, 2008]
• Weights: Term frequency (<), inverse document frequency (idf) and Domain frequency (df) [SIGIR’10]
df i(t) =fi(t)P
1jn fj(t)
45
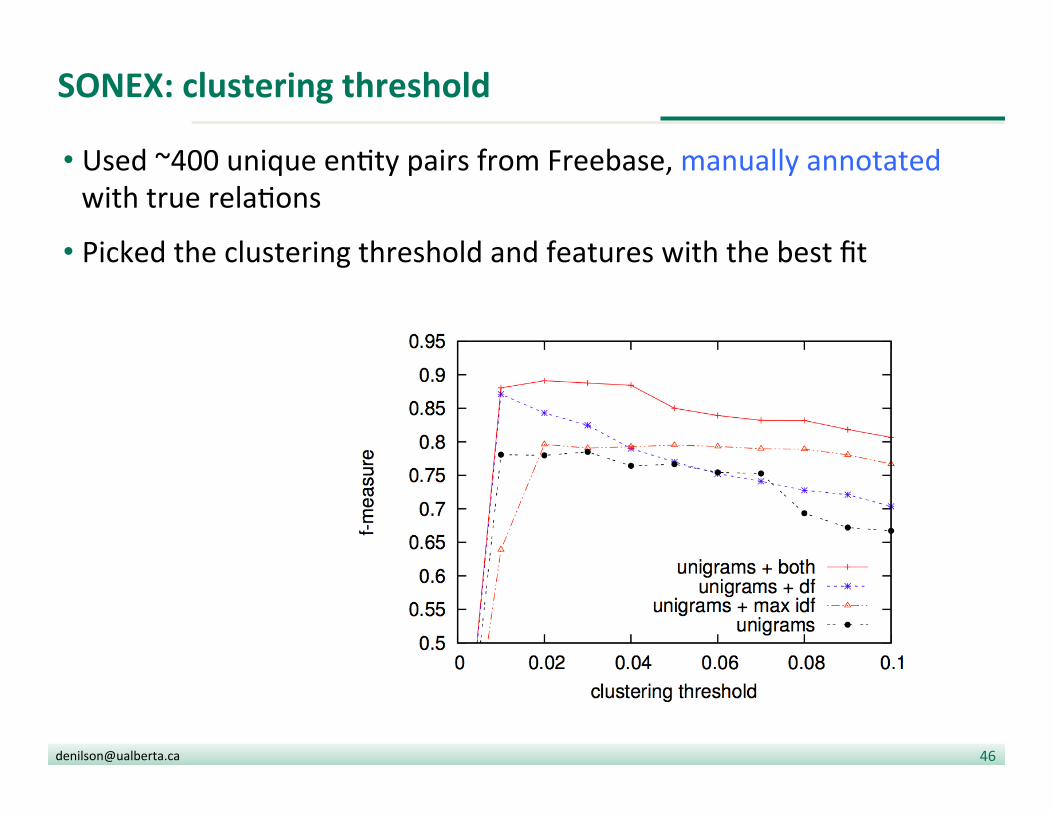
SONEX: clustering threshold
• Used ~400 unique en?ty pairs from Freebase, manually annotated with true rela?ons
• Picked the clustering threshold and features with the best fit

SONEX: importance of domain
• DF works really well except when MISC types are involved
• Example: coach § LOC–PER domain: (England, Fabio Capello); (Croa?a, Slaven Bilic)
§ MISC–PER domain: (Titans, Jeff Fisher); (Jets, Eric Mangini)
• Overall, df alone improved the f-‐measure by 12%
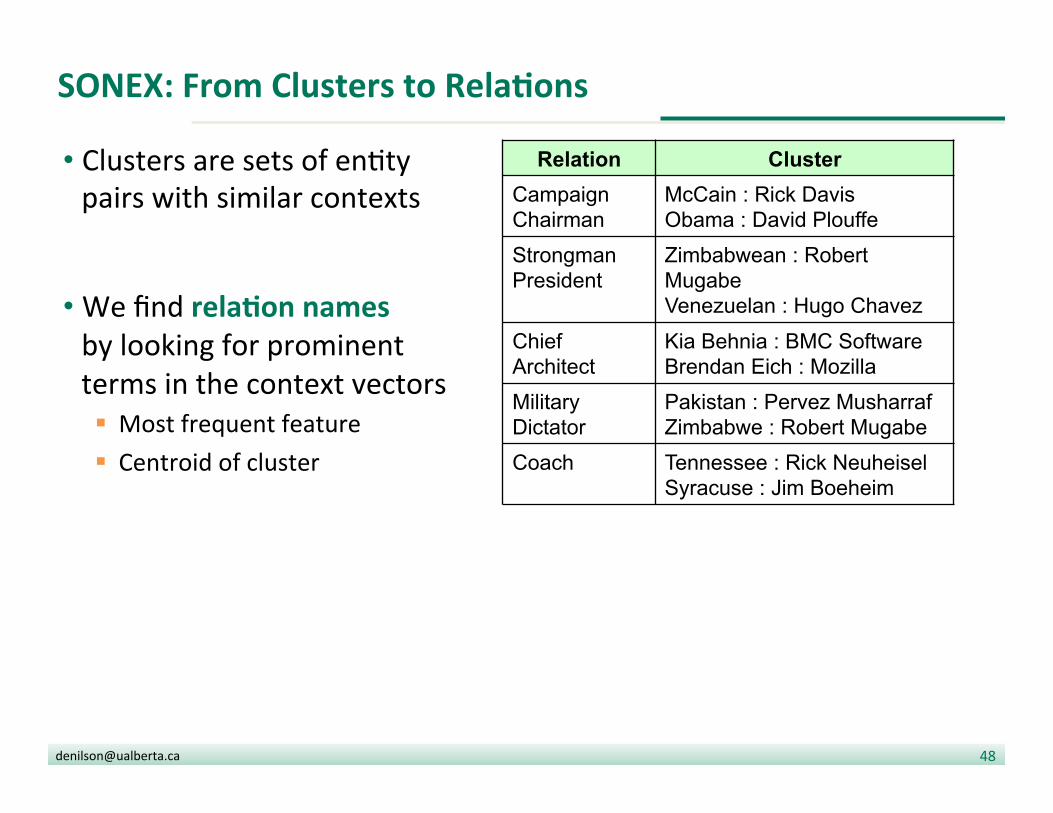
SONEX: From Clusters to RelaDons
• Clusters are sets of en?ty pairs with similar contexts
• We find relaDon names by looking for prominent terms in the context vectors § Most frequent feature § Centroid of cluster
Relation Cluster Campaign Chairman
McCain : Rick Davis Obama : David Plouffe
Strongman President
Zimbabwean : Robert Mugabe Venezuelan : Hugo Chavez
Chief Architect
Kia Behnia : BMC Software Brendan Eich : Mozilla
Military Dictator
Pakistan : Pervez Musharraf Zimbabwe : Robert Mugabe
Coach Tennessee : Rick Neuheisel Syracuse : Jim Boeheim
48

SONEX: from clusters to relaDons
• Evaluate rela?ons by compu?ng the agreement between the Freebase term and the chosen label § Scale: 1 (no agreement) to 5 (full agreement)

SONEX vs. ReVerb: qualitaDve comparison
• Local methods like ReVerb do not understand synonyms, and return all variants of the same rela?on for the same pair
• Global methods like SONEX produce a single rela?on for each en?ty pair, derived from all sentences connec?ng the pair
• Trade-‐off: local methods are best when there are mul?ple rela?ons, whereas global methods aim at the most representa?ve rela?on § The biggest problem is we can’t tell which is the case just by looking at the corpus
Barack Obama married Michelle Obama Barack Obama `s spouse is Michelle Obama
<“Barack Obama”, married, “Michelle Obama”> <“Barack Obama”, spouseOf, “Michelle Obama”>
50

SONEX vs ReVerb—clustering analysis
• Purity: homogeneity of clusters § Frac?on of instances that belong together
• Inv. purity: specificity of clusters § Maximal intersec?on with the rela?ons § Also known as overall f-‐score [Larsen and Aone, 1999]
System Purity Inv. Purity
ReVerb 0.97 0.22SONEX 0.96 0.77

Deep vs shallow NLP in ORE
• Adding NLP machinery increases cost, but brings in be|er results
• What is the right trade-‐off?
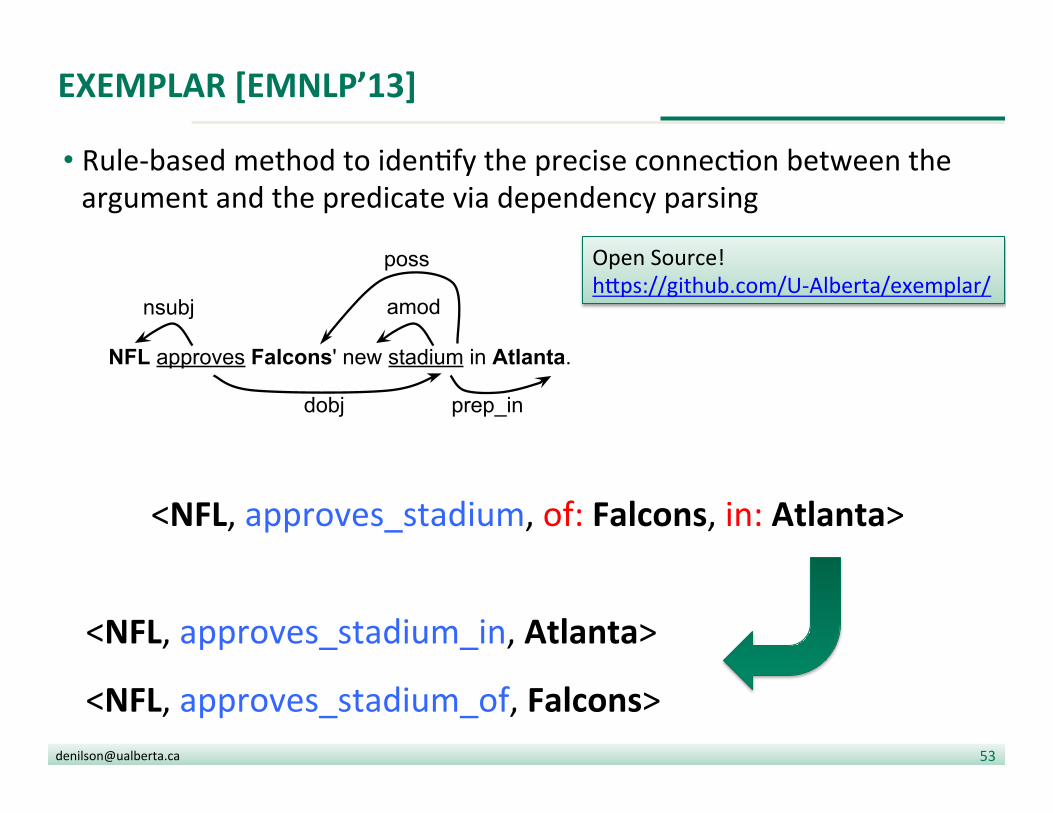
EXEMPLAR [EMNLP’13]
• Rule-‐based method to iden?fy the precise connec?on between the argument and the predicate via dependency parsing
1)/�DSSURYHV�)DOFRQV�QHZ�VWDGLXP�LQ�$WODQWD�
QVXEM DPRG
SRVV
GREM SUHSBLQ
<NFL, approves_stadium_in, Atlanta>
<NFL, approves_stadium_of, Falcons>
<NFL, approves_stadium, of: Falcons, in: Atlanta>
Open Source! h|ps://github.com/U-‐Alberta/exemplar/

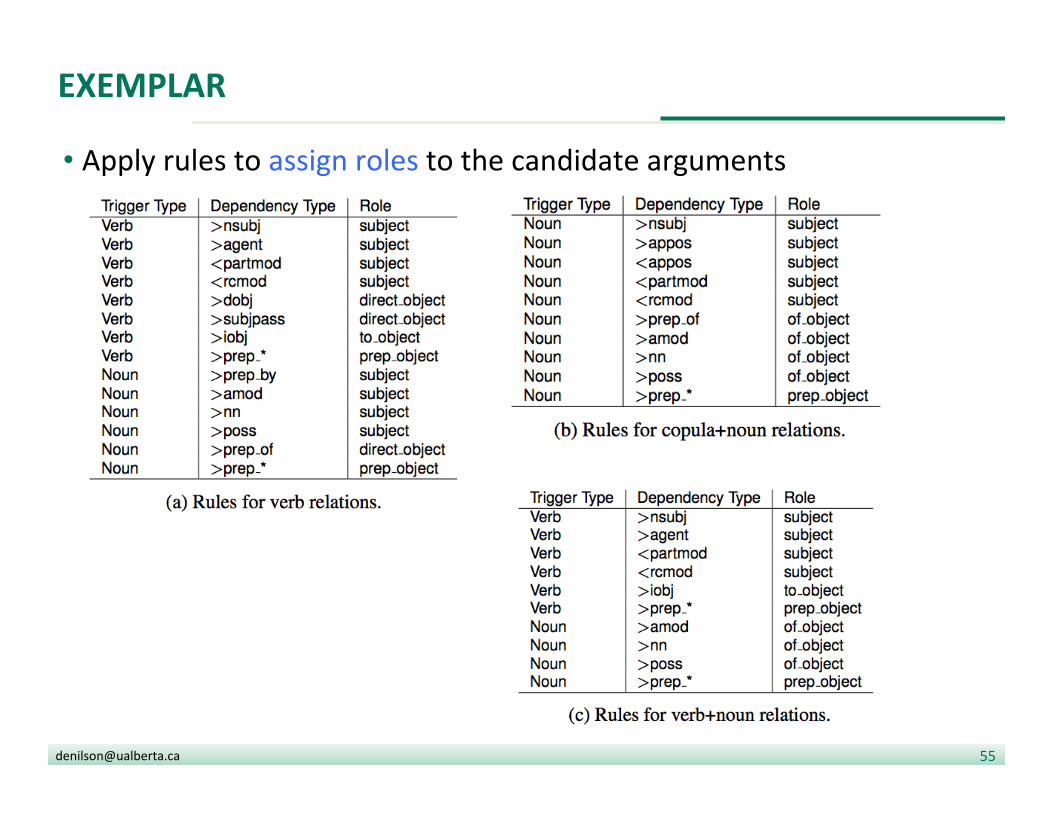
EXEMPLAR
• Standard NLP pipeline to break document into sentences and find named en??es (or just noun phrases)
• Find triggers (nouns or verbs not tagged as part of an en?ty men?on)
• Find candidate arguments (dependencies of triggers)

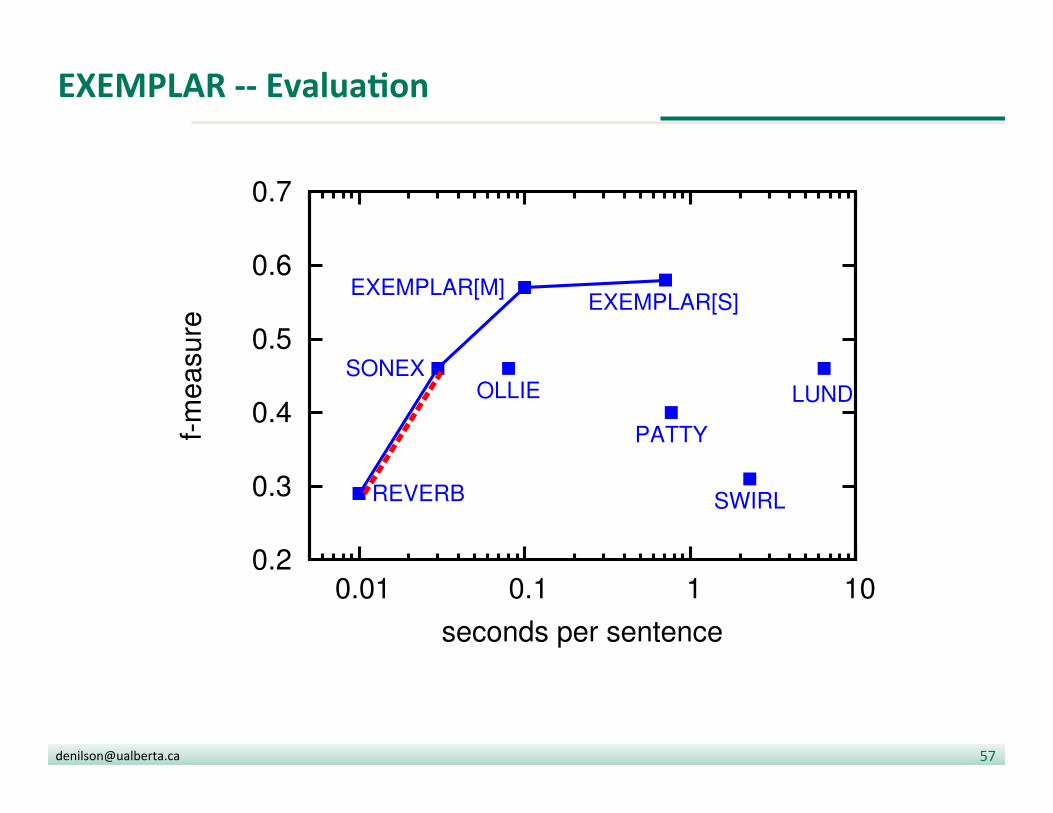
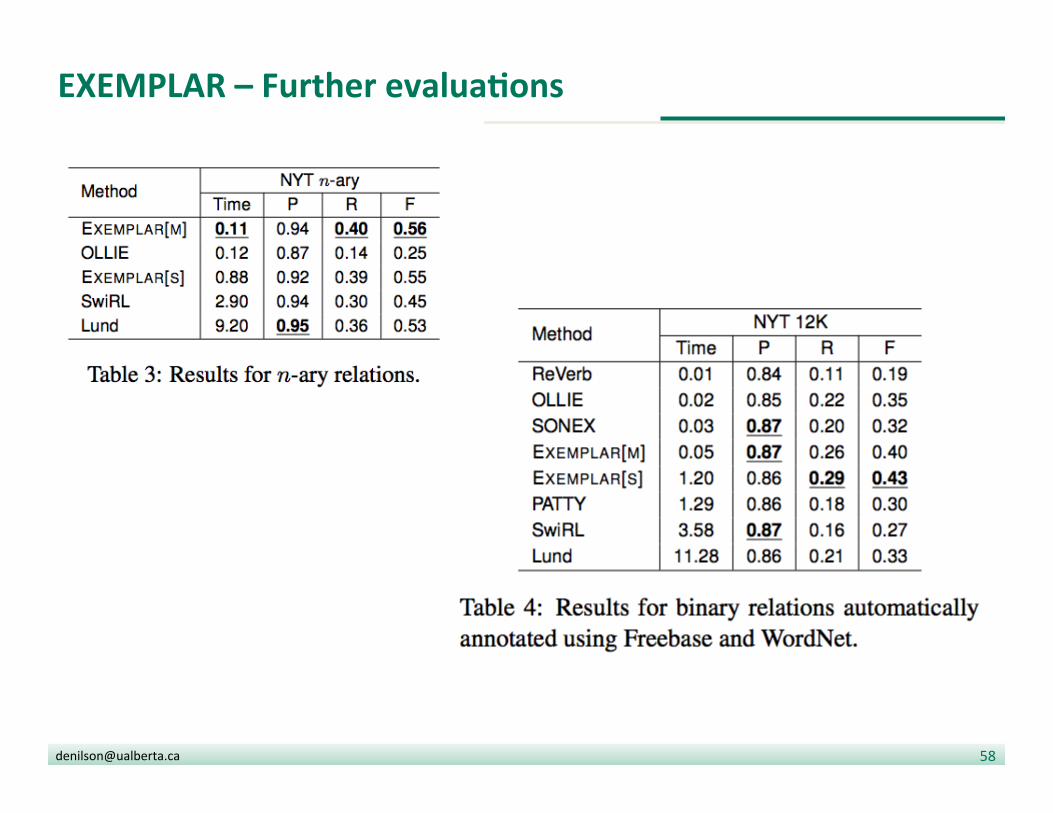
EXEMPLAR -‐-‐ EvaluaDon
• Binary mode
• Each sentence is annotated with: § Two named en??es § A trigger § A window of allowed tokens
• An extrac?on is deemed correct if it contains the trigger and allowed tokens only
I’ve got a media call about [ORG Google] ->’s {acquisition} of<- [ORG YouTube] ->today<-
EXEMPLAR -‐-‐ EvaluaDon
0.2
0.3
0.4
0.5
0.6
0.7
0.01 0.1 1 10
f-m
ea
sure
seconds per sentence
EXEMPLAR[S]EXEMPLAR[M]
REVERB
SONEXOLLIE LUND
SWIRL
PATTY

Text NormalizaDon
• ORE systems, even with dependency parsing make trivial mistakes as soon as sentences become slightly more evolved
• Problem: an en?ty (Mrs. Clinton) is too far from the trigger (received); so EXEMPLAR (or ReVerb, SONEX) will miss the extrac?on
• Solu?ons: § Modify the rela?on extrac?on system à BAD: fixing one issue oUen breaks other kinds of extrac?on
§ Modify the input text à GOOD
Mrs. Clinton, who won the Senate race in New York in 2000, received $91,000 from the Kushner family and partnerships, while Mr. Gore received $66,000 for his presidential campaign that year

Text NormalizaDon [LREC’14]
• Focused on rela?ve clauses and par?ciple phrases • Method:
§ Apply chunking [Jurafsky and Mar?n‘08] to break sentences § Classify all pairs of chunks as:
• Connected: are part of the same clause, and should be merged (usually to correct mistakes in chunking)
• Dependent: are in different clauses but one depends on the other
• Disconnected: clauses that are ``leU alone’’
§ Apply the original ORE system
Mrs. Clinton | won the Senate race in New York in 2000
Mrs. Clinton + received $ 91,000 from the Kushner family and partnerships
Mr. Gore received $ 66,000 for his presidential campaign that year

Text NormalizaDon
• Ideal case is when we have a dependence parse of the sentence § But this adds cost
• Used a Naïve Bayes classifier that looks at the parts of speech of the 2 words at each “end” of the chunks, and decides the rela?onship among them § Training Data: 37,015 parse trees of The Wall Street Journal sec?on of OntoNotes
§ Accuracy (10-‐fold cross valida?on): • 77% overall • 85% for disconnected • 75% for connected
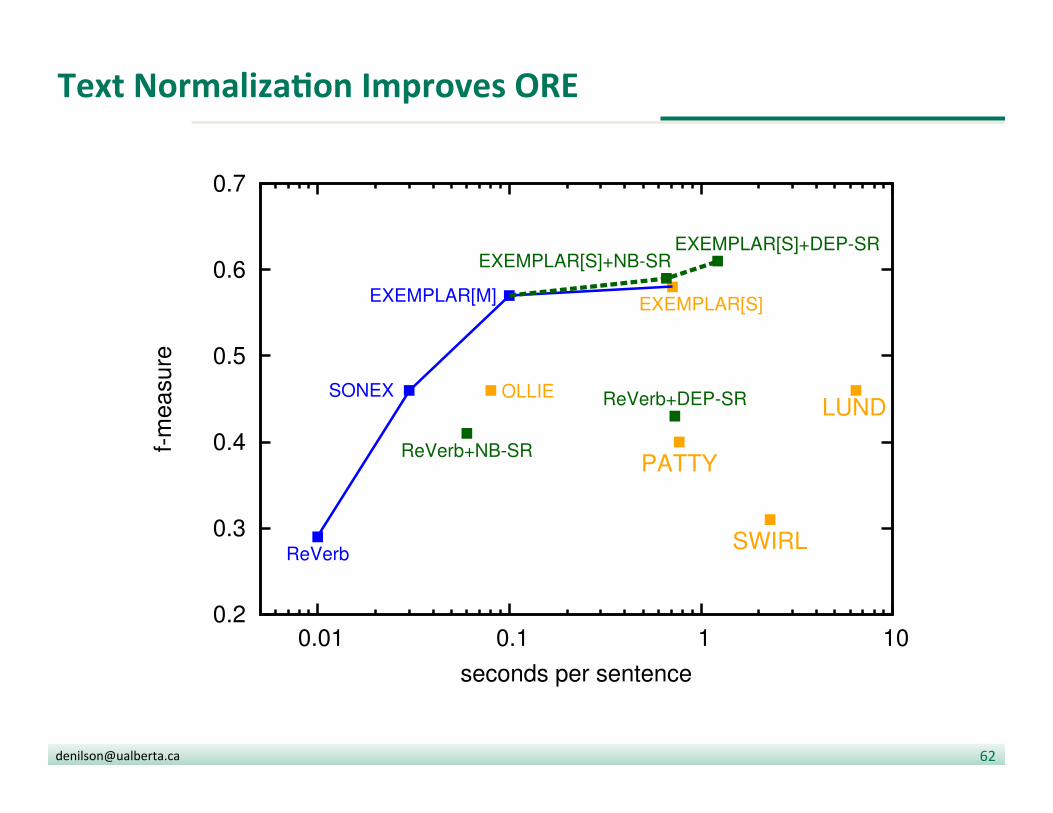
Text NormalizaDon Improves ORE
0.2
0.3
0.4
0.5
0.6
0.7
0.01 0.1 1 10
f-m
ea
sure
seconds per sentence
EXEMPLAR[M]
ReVerb
SONEX
EXEMPLAR[S]
OLLIELUND
SWIRL
PATTYReVerb+NB-SR
ReVerb+DEP-SR
EXEMPLAR[S]+DEP-SREXEMPLAR[S]+NB-SR
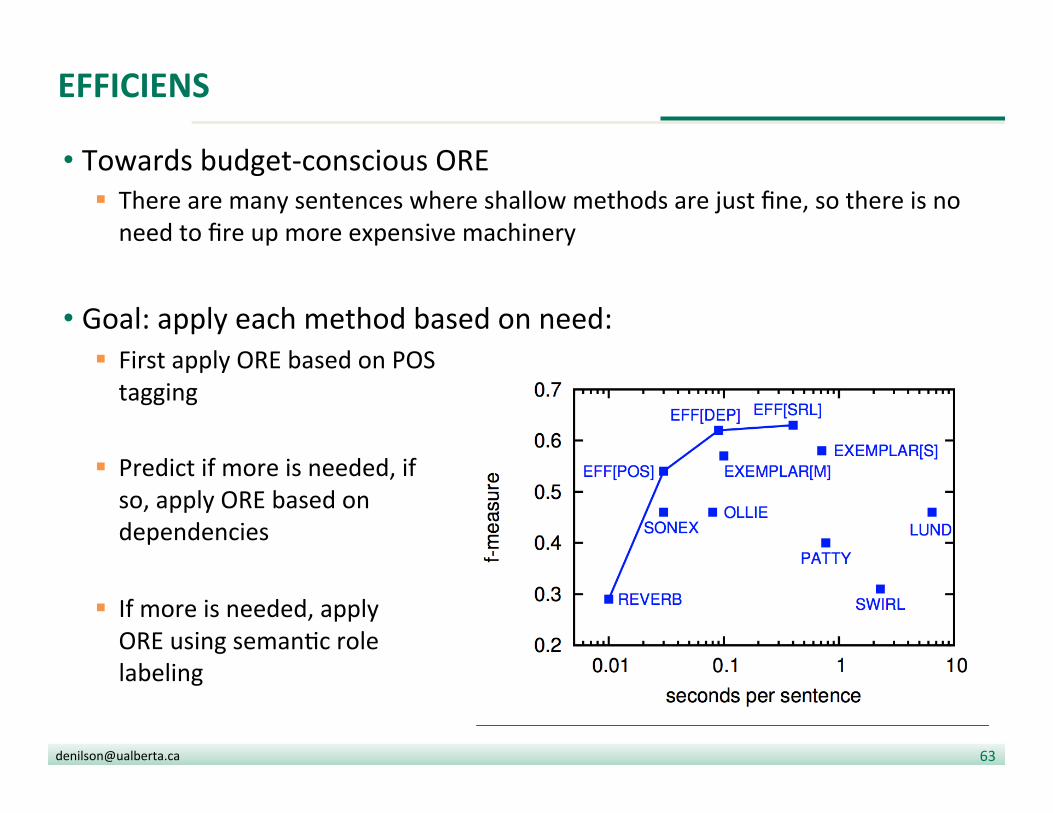
EFFICIENS
• Towards budget-‐conscious ORE § There are many sentences where shallow methods are just fine, so there is no need to fire up more expensive machinery
• Goal: apply each method based on need: § First apply ORE based on POS tagging
§ Predict if more is needed, if so, apply ORE based on dependencies
§ If more is needed, apply ORE using seman?c role labeling


Controversy
• Controversy leads to confusion for the reader and propagates misinforma?on, bias, prejudice,…
• Example: the ar?cle about abor?on was the stage for a discussion around breast cancer
controversy |ˈkäntrəәˌvəәrsē| noun (pl. controversies) disagreement, typically when prolonged, public, and heated
4K words on the ini?al revision of the
ar?cle alone!

Quality control delegated to the crowd
• If a topic is important to a large enough group of editors, the collabora?ve edi?ng process will (eventually) lead to a high-‐quality ar?cle
• Editors can tag whole ar?cles or sec?ons as controversial § Controversial tags are tags such as {controversial}, {dispute}, {disputed-‐sec?on} § Less than 1% of the ar?cles are tagged as controversial
• Readers can only determine whether an ar?cle is controversial based on the tags, inspec?on of the talk page, or the edit history
• Our Goal: automate the quality control process
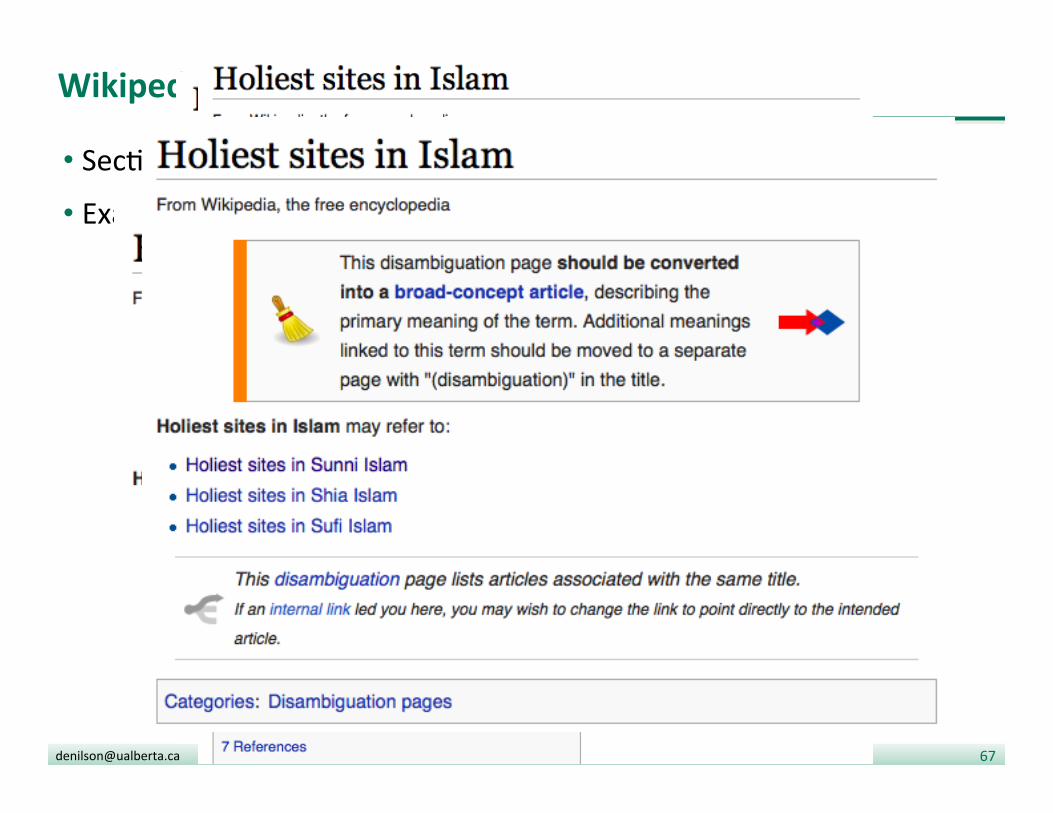
Wikipedia takes care of the issue
• Sec?ons of the the controversial ar?cles spawn new ar?cles • Example: Holiest sites in Islam
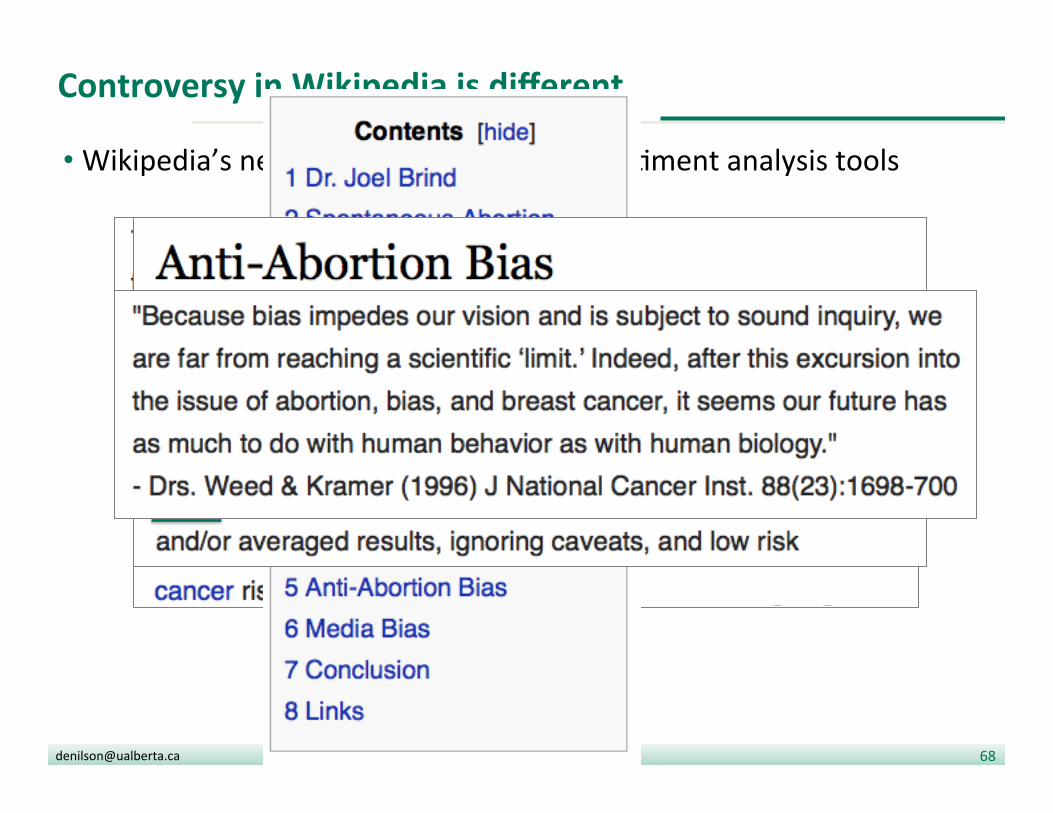
Controversy in Wikipedia is different
• Wikipedia’s neutral point of view fools sen?ment analysis tools

The edit history
• The edit history contains the log of all ac?ons performed in the making of the ar?cle
• The ?me-‐stamp of each commit
• The ac?on performed in each commit
• An op?onal comment explaining the intent of each commit
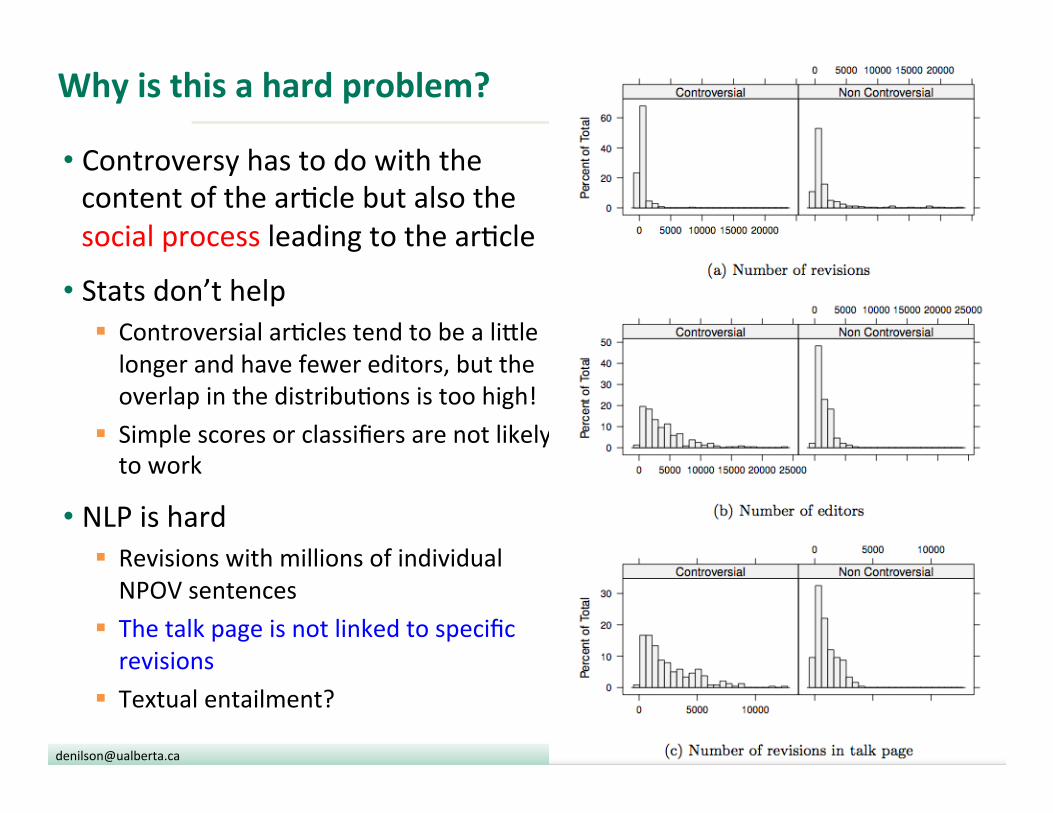
Why is this a hard problem?
• Controversy has to do with the content of the ar?cle but also the social process leading to the ar?cle
• Stats don’t help § Controversial ar?cles tend to be a li|le longer and have fewer editors, but the overlap in the distribu?ons is too high!
§ Simple scores or classifiers are not likely to work
• NLP is hard § Revisions with millions of individual NPOV sentences
§ The talk page is not linked to specific revisions
§ Textual entailment?
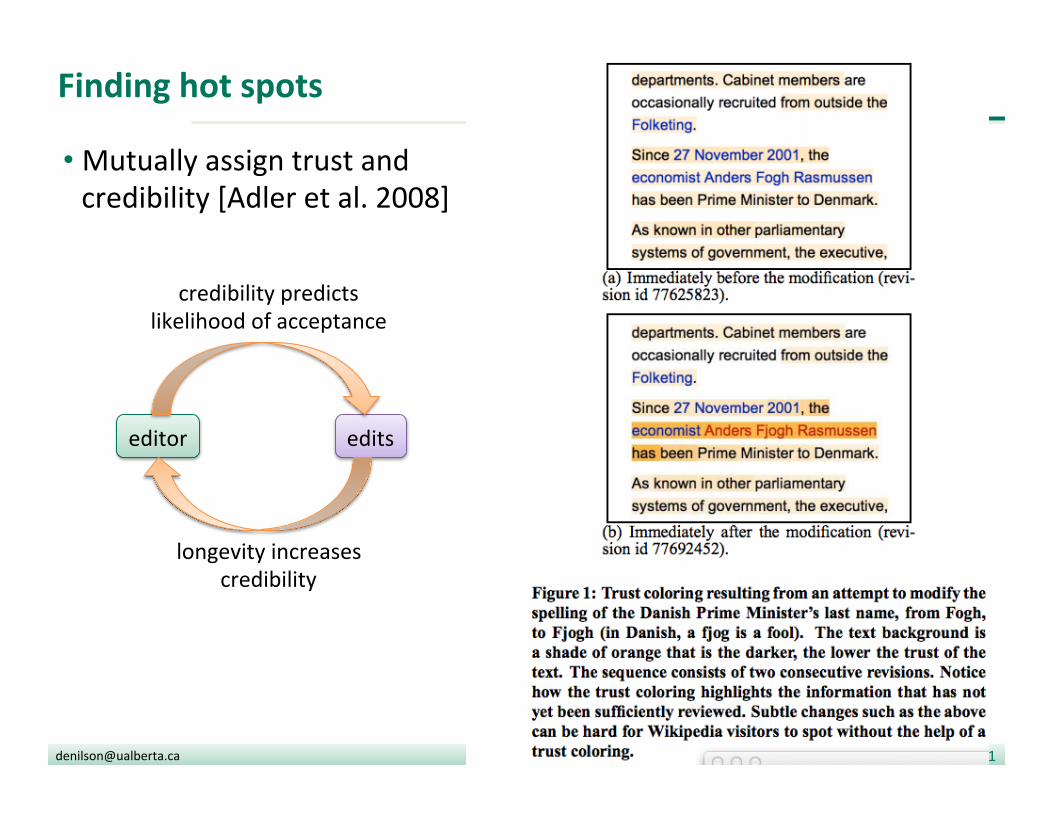
Finding hot spots
• Mutually assign trust and credibility [Adler et al. 2008]
editor edits
longevity increases credibility
credibility predicts likelihood of acceptance
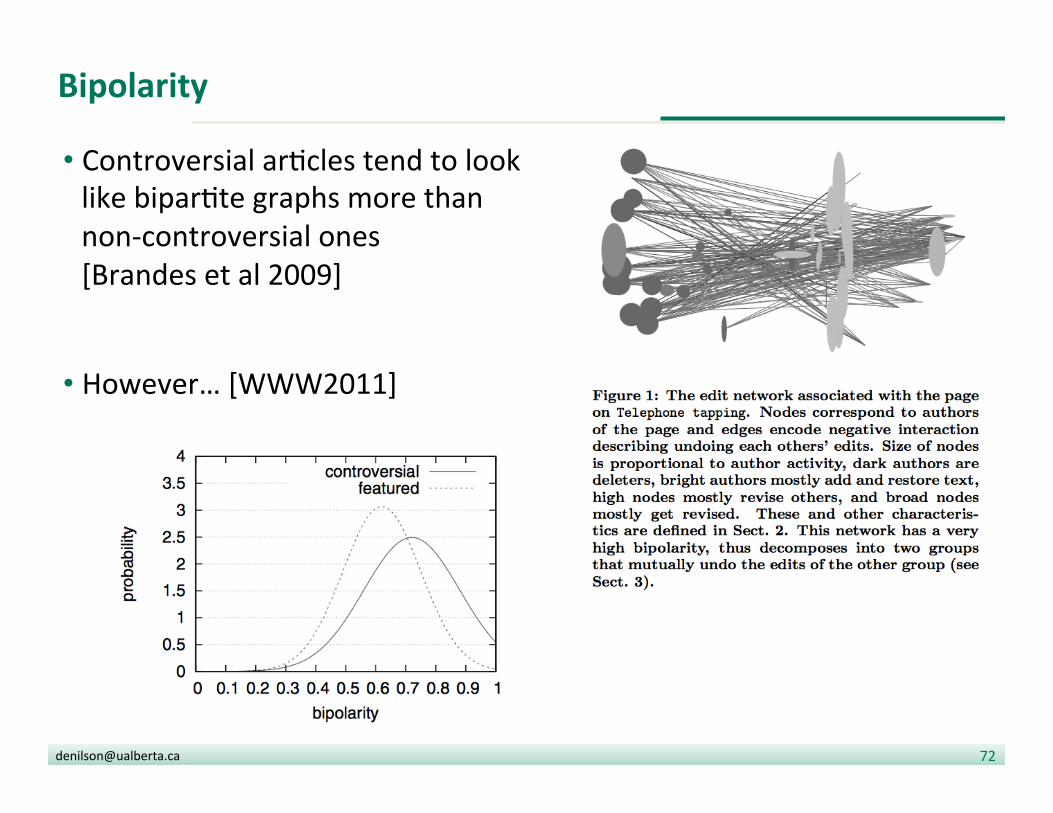
Bipolarity
• Controversial ar?cles tend to look like bipar?te graphs more than non-‐controversial ones [Brandes et al 2009]
• However… [WWW2011]

Discussions in Wikipedia: exploiDng the edit history
• [Ki|ur et al., 2007] train a classifier to predict the number of controversial tags in an ar?cle § Features are based on metrics such as the number of authors, the number of versions, the number of anonymous edits, etc.
• [Vuong et al., 2008] build a model to assign a controversy score to ar?cles assuming a mutual reinforcing rela?onship between controversy score of ar?cles and their editors
• [Druck et al., 2008] extract features from editor collabora?on to establish a no?on of editor trust
• Extrac?ng affinity/polarity networks: ver?ces are editors, edges indicate agreement/disagreement among them § [Maniu et al., 2011] [Leskovec et al., 2010]
• Bipolarity [Brandes et atl. 2009]: compu?ng how much a network approximates a bipar?te graph

Discussions in Wikipedia [Hypertext’12] [TIST’15]
• Main idea: model the social aspects of the edi?ng of the ar?cles

Finding the Aptudes of editors
• Look at all interac?ons between a pair of editors, and predict whether one would vote for the other § Use Wikipedia admin elec?on data for training and tes?ng § Consider all ar?cles they worked together with 34 revisions of each other
• 87 % Accuracy § Test on Wikipedia admin elec?on data (~100K votes) § High bias for posi?ve votes; § Nega?ve impressions persist for a long ?me

Controversy in Wikipedia
• Once we know how the editors would vote for each other, we look for signs of ``fights’’ within the ar?cle’s history
• We classify each collabora?on network
• Edi?ng Stats + light NLP features § Various stats capturing the edi?ng behavior § Use of sen?ment words (adapted to the domain)
• Social networking Features § Several stats about the shape of the graph § Number and kind of triads
• “A friend of my friend is my friend” • “An enemy of my friend is my enemy”
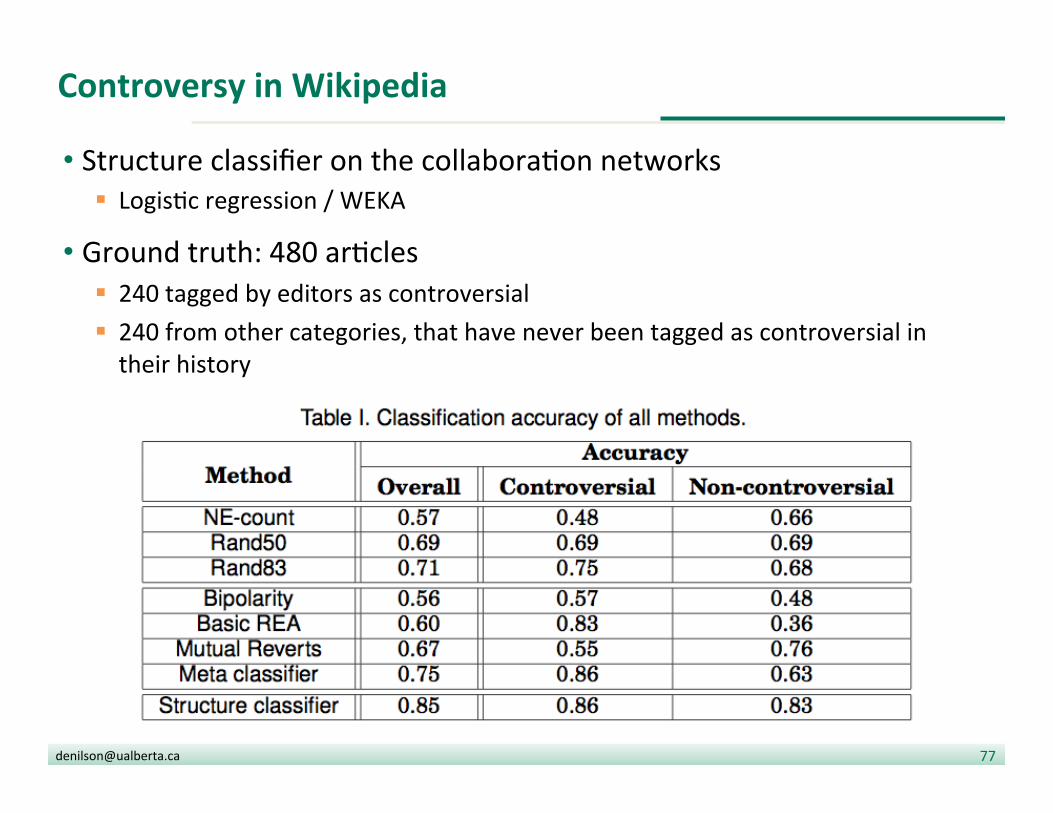
Controversy in Wikipedia
• Structure classifier on the collabora?on networks § Logis?c regression / WEKA
• Ground truth: 480 ar?cles § 240 tagged by editors as controversial § 240 from other categories, that have never been tagged as controversial in their history

Controversy in Wikipedia: feature ablaDon
An enemy of my enemy is my friend
number of triads
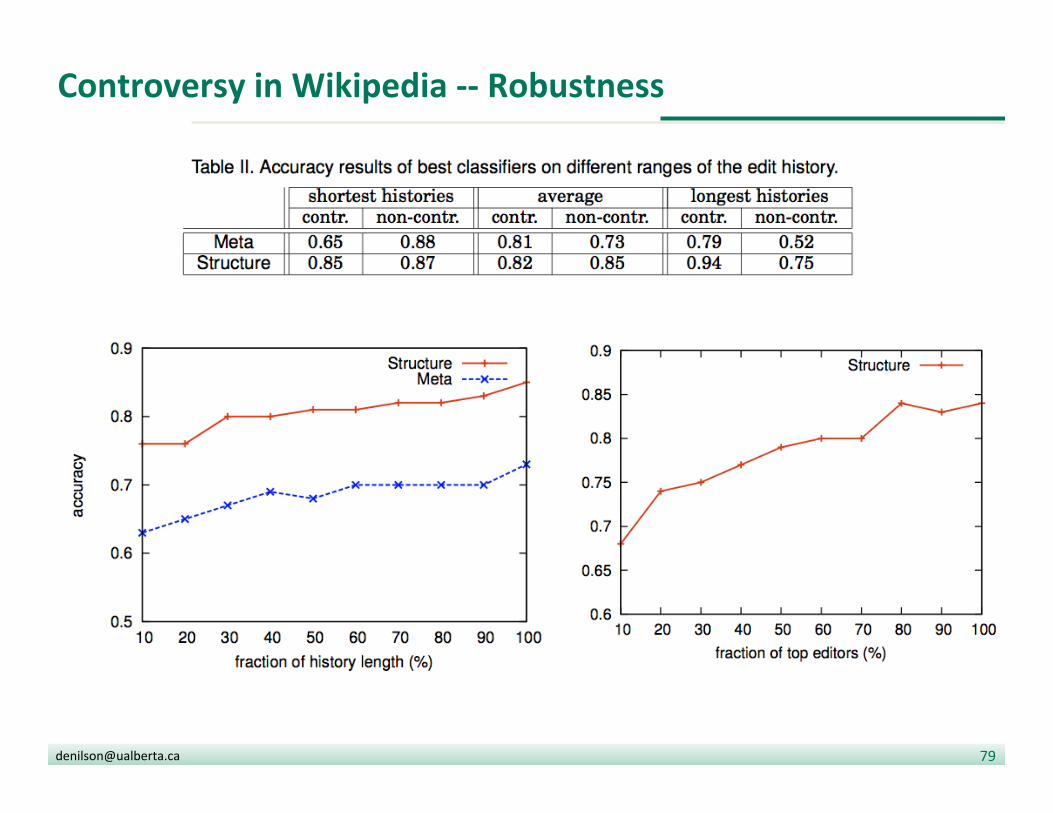

Finer-‐grained noDons of controversy
• OUen, the source of controversy in an ar?cle comes from a single sec?on or even a sentence § In the ar?cle about abor?on, the sec?on which connects it to breast cancer is the main dispute
• Finding the text units that contribute the most to the controversy § Typical NP-‐hard op?miza?on problem
§ Good news: if the controversy func?on is sub-‐modular and monotonic, there is a nice approxima?on algorithm
§ Bad news: the best classifiers can’t be made into monotonic and sub-‐modular func?ons

Controversy in Wikipedia -‐-‐ NEXT
• Summary: § Detec?ng controversy in Wikipedia is challenging § Sta?s?cal features alone are not enough § Social networking theories help a lot in finding disagreement
• Use more NLP machinery § Link the discussion in the ar?cle history to the discussion/talk page
• Be|er understanding the Wikipedia dynamics
• Impact on ORE tools § how hard is it to find contradictory informa?on on subsequent versions?

Thank you
• Robust en?ty linking with Random Walks [CIKM’2014]
• Rela?on extrac?on [TWEB’2012], EXEMPLAR (get the code!)
• Understanding Conflict in Wikipedia
Zhaochen Guo PhD (2015)
Filipe Mesquita, PhD (2014)
Yuval Merhav, PhD(2012)
Illinois Int. Technology
Jordan Schmidek, MSc (2014)
Hoda Sepehri-‐Rad PhD (2014)
Aibek Makhazanov MSc (2013)