dictionary techniques (lempel-ziv codes)herbir/www/?download=notes 8.pdf · dictionary techniques...
TRANSCRIPT

Dictionary Techniques (Lempel-Ziv Codes) Aknowlegement: In this lecture I use notes of Dr Antonios Symvonis from University of Sydney
Incorporate the structure in the data in order to
increase the amount of compression
Built a list of commonly occurring patterns, the dictionary, and encode these patterns by transmitting their index in the list
In block coding, the datavector is partitioned into blocks of equal length. In Lempel-Ziv coding the datavector is partitioned into variable-length blocks (Lempel-Ziv parsing)
Can be static or dynamic
Based on the seminal work of Jacob Ziv and Abraham Lempel
LZ77 LZ78 LZW

Applications include: Unix “compress” V. 42 bis Graphics Interchange Format (GIF) Tape/ disc drives ARC, PKARC, PKZIP, LHArc, ARJ
Lawyers have been involved… Unisys holds a patent for LZW algorithm Microsoft was forced to remove Stacer-like compression from MS-DOS (Version 6) after lawsuit by Stac Electronics

The static dictionary technique - Frequently occurring patterns are
kept in the dictionary and encoded by their index in the list. Other patterns are encoded by some other less efficient method.
Appropriate when considerable prior knowledge about the source is available
Suitable for particular applications
Digram coding The dictionary consists of all letters of the source alphabet followed by as many pairs of letters, called digrams, as can be accommodated by the dictionary Example
Assume the alphabet { , , , , }A a b c d r . Code the
sequence abracadabra based on the dictionary: Code Entry Code Entry 0 a 4 r
1 b 5 ab 2 c 6 ac
3 d 7 ad
Sequence:
Code 5 4 6 7 5 4 0
a b r a c a d a b r a

Adaptive dictionary techniques - techniques that a d a p t to the
characteristics of the source file
Based on the work of Ziv and Lempel
LZ77 - Assumes patterns recur close together
LZ78 - Based on the entire previously coded sequence
The LZ77 (LZ1) approach
J. Ziv, A. Lempel, A universal algorithm for data compression, IEEE Transactions on Information Theory, Vol. 23(3), pp. 337-343,May 1977.
Asymptotically, the performance of the algorithm approaches the best that could be obtained by using a scheme that had full knowledge about the statistics of the source
The encoder examines the input sequence through a sliding window which is partitioned into:
- Search buffer : contains portion of most recently encoded sequence
- Look-ahead buffer : contains next portion of sequence to be encoded

Example search
pointer 7o
c a r r a d
Search buffer Look-ahead buffer The coding process
To encode the sequence in the look - ahead buffer, the encoder moves a search pointer back through the search buffer until it encounters a match to the first symbol in the look-ahead buffer.
The distance of the pointer from the look–ahead buffer is called the offset.
The encoder then examines the symbols following the symbol at the pointer location to see if they match consecutive symbols in the look-ahead buffer. The number of consecutive symbols in the search buffer that match consecutive symbols in the look-ahead buffer is called the length of the match. The encoder searches the search buffer for the longest
match and encodes it with a triple , ,o l c , where
o is the offset, l is the length of the match, c is the codeword corresponding to the symbol in the look-ahead buffer that follows the match.
4l
a b r a c a d
a b r a c a d
a b r a r r

Note: the string starting in the search buffer can extend into the look-ahead buffer
The encoder repeats: - Find the longest match
- Transmit triple , ,o l c
- Advance the windows by 1l positions The decoding process
Similar to the coding: builds the search buffer
Faster/simpler since no searching is required
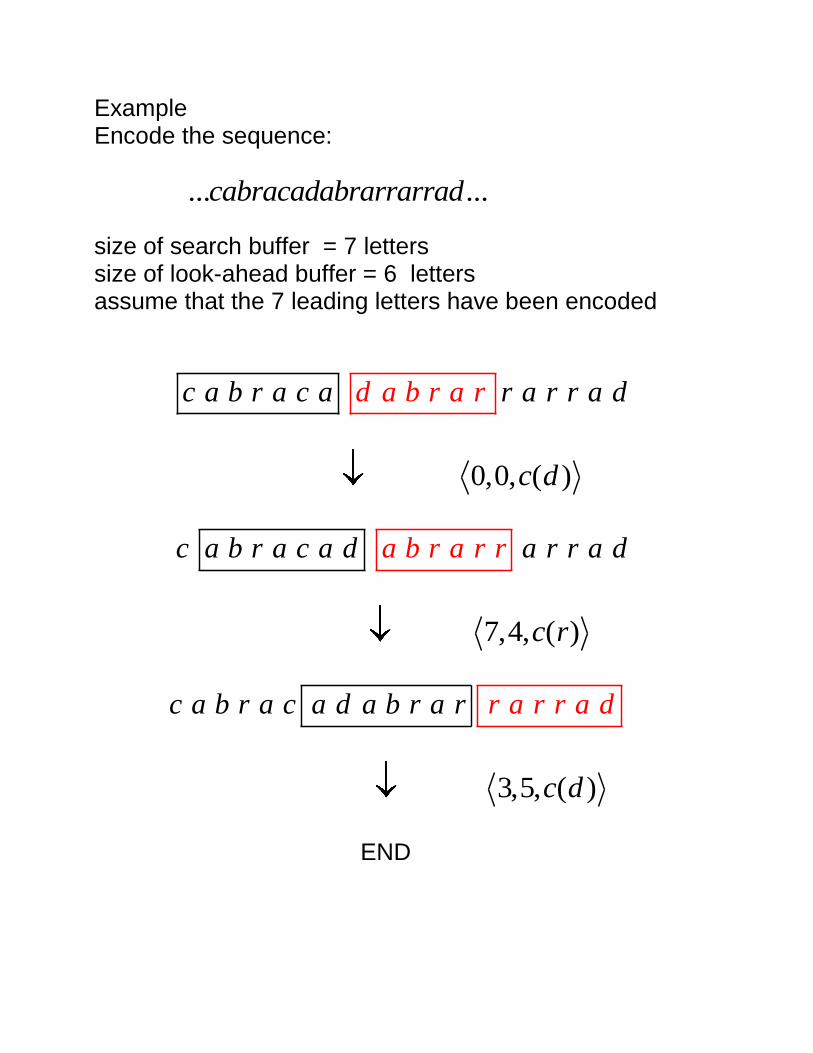
Example Encode the sequence:
... ...cabracadabrarrarrad size of search buffer = 7 letters size of look-ahead buffer = 6 letters assume that the 7 leading letters have been encoded
d a b r a rc a b r a c a r a r r a d
0,0, ( )c d
a b r ac a b r r ra c a d a r r a d
7,4, ( )c r
c a b r a c a d a b r ar a r r r a d
3,5, ( )c d
END

Example (continued) Decode the sequence:
0,0, ( )c d , 7,4, ( )c r , 3,5, ( )c d
size of search buffer = 7 letters
assume that the sequence cabraca have been decoded
c a b r a c a 0,0, ( )c d
a b r a c a d
a b r a c a d 7,4, ( )c r
a d abr a r
a d abr a r 3,5, ( )c d

Variations of the LZ77scheme
Encode triples with variable length code PKZip, Zip, LHArc, ARJ
Variable size of search and look-ahead buffers
Eliminate third member of triple by using a flag bit to indicate whether what follows is the codeword for a single letter. It also eliminate the situation we use a triple to encode a single character (LZSS algorithm)

The Achilles’ hill of LZ77
search buffer look-ahead buffer
abc d e fabc d e f g hi a bc d e f g hi hig
A periodic sequence with a period longer than a search buffer None of the new symbols will have match in the search buffer and will have to be represented by separate codewords
The LZ77 approach assumes that like patterns will occur close together. Any pattern that recurs over a period longer than that covered by the coder window will not be captured. The LZ78 algorithm solves this problem.

The LZ78 approach
J. Ziv, A_.Lempel, Compression of individual sequences via variable-rate coding, IEEE Transactions on Information Theory, Vol_24(5), pp. 530-536, September 1978
Problem with LZ77: assumes that like patterns occur close together
LZ78 keeps an explicit dictionary containing “all” distinct patterns seen during the encoding
Both the encoder and the decoder have to build the dictionary
The input sequence is coded as a sequence of tuples
,i c , where
- i is the index corresponding to the dictionary index that was the longest match to the input
- c is the codeword for the input character that follows the matched portion of the input



The compression performance of Lempel-ZiV code Let 1 2( , ,..., )nX X X X denote the datavector to be
compressed. Let ( )LZ X denote the length of the codeword assigned
by the Lempel-Ziv code to X . For arbitrary j ,
2 2
2
log log( )( )
logj j
nLZ XH X c
n n,
where ( )jH X is the entropy of the j-th order blocks for X .
Lempel-Ziv alghoritm yields a compression rate approximately no worse than that of the block code, provided the datavector is long enough relative to the order of the block.

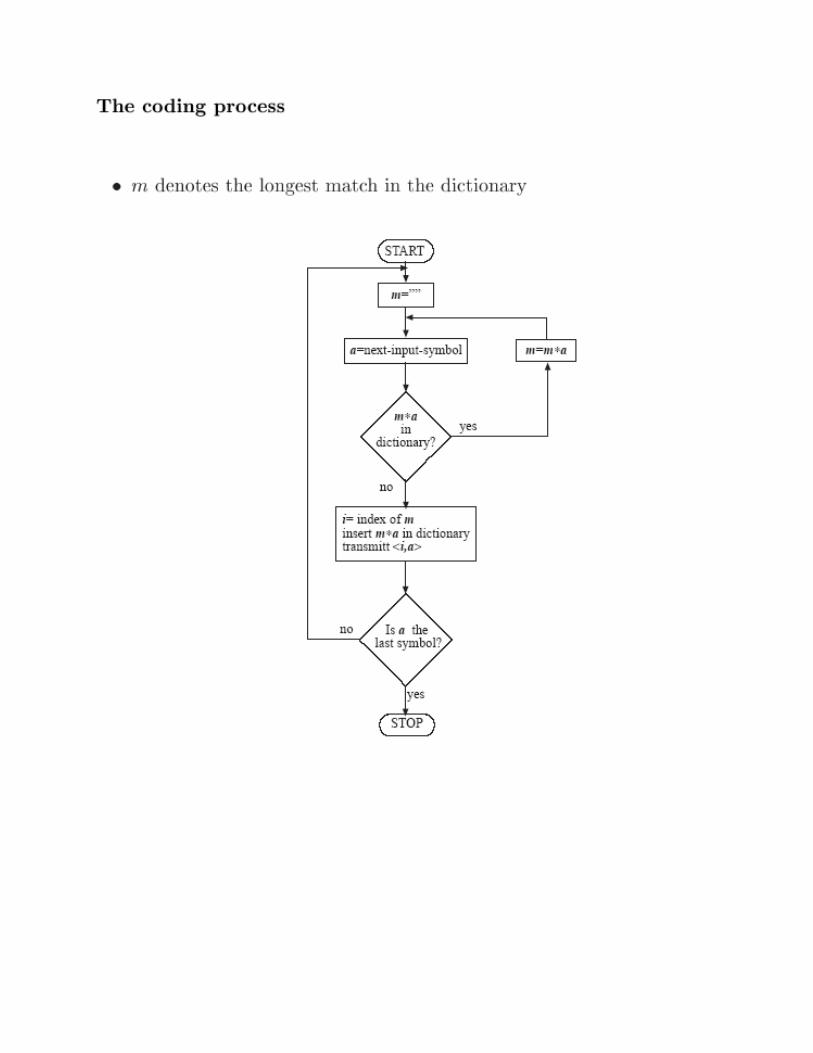
The LZW approach
A variation of LZ78 which avoids the transmission of the input character that follows the “match”
The dictionary, at both the coder and the decoder sides, initially contains all alphabet symbols
Assume that string m is the match and that a is the input character that follows it.
The encoder repeats: - Transmit the index of m in the dictionary - Insert m a into the dictionary - Built the next match starting with a





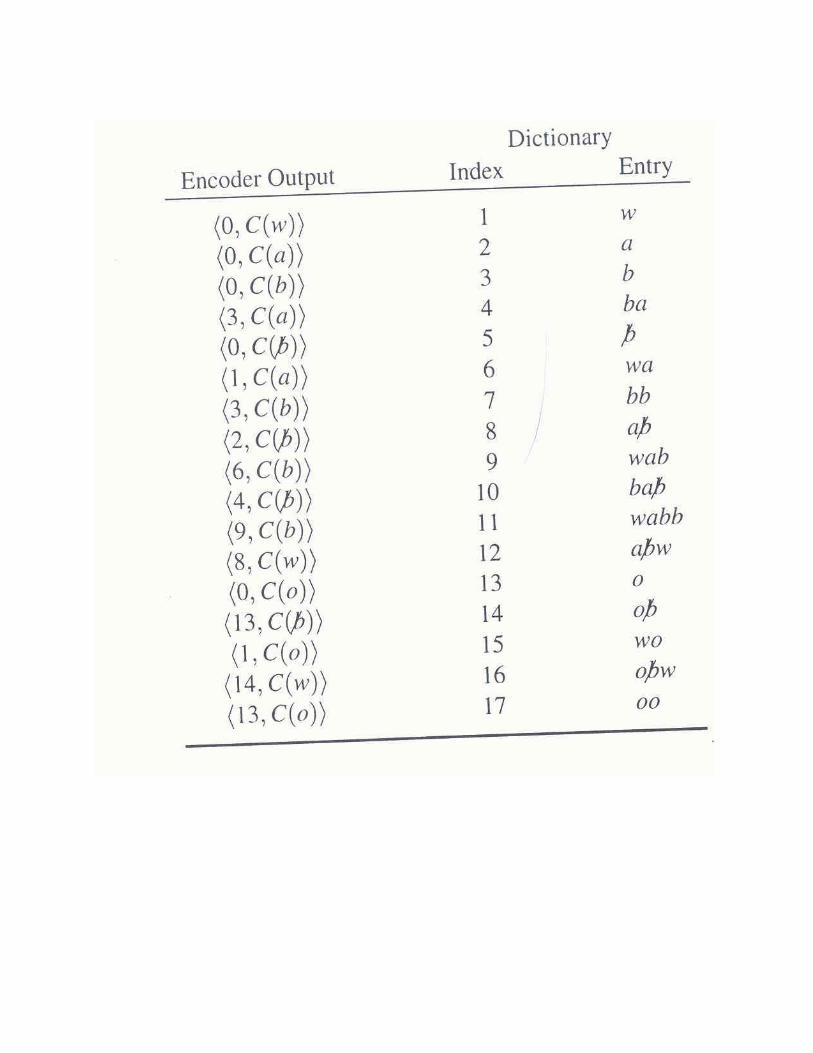
LZW decoding A complication arises when the input sequence contains
KwKwK , where Kw is already in the dictionary (K is a letter of the alphabet and w a string)
The coder:
- sends code for Kw
- inserts KwK in the dictionary
- Sends the code for KwK and …
The decoder:
- On receiving the code for KwK will not yet have added that code to the dictionary since it does not yet know the last character to add to the
previously received string



Applications of LZW coding
Unix “compress”
- Adaptive dictionary size; 9 162 2 entries
- Codewords increase in length as dictionary size increases - When dictionary reaches maximum size:
o It performs static coding o It monitors the compression ratio and
flashes dictionary if compression ratio drops below a threshold
Graphics Interchange Format _GIF_ - Developed by Compuserve Information Service - An implementation of LZW similar to “compress “ - “Unclear” future due to patent hold by Unisys for LZW - Works well with computer generated images - It is an unfortunate choice for continuous tone images
Compression over modems; V.42 bis - Consultative Committee on International Telephone and Telegraph CCITT Recommendation V.42 - Operates in two modes:
Transparent mode No compression; used when sequence does not contain repeating patterns (usually previously compressed files)
Compressed mode LZW algorithm; forbids the transmission of an entry immediately after its insertion into the dictionary

- Recommends periodic testing to detect if data expansion takes place; does not specify the test
- Variable size dictionary Negotiated during link-time Minimum dictionary size 512 entries Recommended dictionary size 2048 entries When the dictionary is full the “oldest” entry
which was not encountered since its creation is removed
- Maximum string size
Used to reduce errors during transmission over phone lines
Negotiated during link-time Recommended string length: 6-250