dictionaries and data-aware measures ankur gupta butler university
TRANSCRIPT

Dictionaries and Data-Aware Measures
Ankur GuptaButler University

The Attack of Massive Data• Lots of massive data sets being generated
– Web publishing, bioinformation, XML, e-mail, geographical data
– IP address information, UPCs, credit cards, ISBN numbers, large inverted files, XML
• Real-life data sets have low information content• Data sets need to be compressed and are compressible• The Goal: design data structures to manage massive
data sets– Near-optimal query times for powerful queries– Near-minimum amount of space
• Measure space in data-aware way, i.e. in terms of each individual data set

Indexing Equals Compression• Suffix trees/arrays are used for pattern
matching and take O(n log n) bits with O(polylog(n)) query time
• GV00 improves the space to O(n log Σ) bits• FM00, FM01, GGV03, GGV04 further
improve the space to O(nHk) bits of space with the same time bounds
• Key point: these indexes support sufficient searching and compression of the text simultaneously

Indexing Is So Needy
• These indexes depend on many data structural building blocks that need to be space-efficient with reasonable query times
• Two particular building blocks are rank/select dictionaries and wavelet trees
• In this talk, we focus on compressed representations of dictionaries with near-optimal search times

Dictionary Problem• Canonical problem: the input is an ordered set S of
n items out of a universe U = {0, 1,…, u-1}• Support the operations:
– member(i) – true if i is in S, false otherwise– pred(i) – the item immediately before i– rank(i) – the number of items from S up to i– select(i) – the ith item from S
• rank(i) and select(i) can solve member(i) and pred(i)

The Information-Theoretic Minimum
• There is a limit on the best compression you can get for any arbitrary subset S called the information-theoretic minimum, which is
or, roughly n log (u/n) bits.• This is better than n log (u) by a 1/n factor
inside the logarithm.
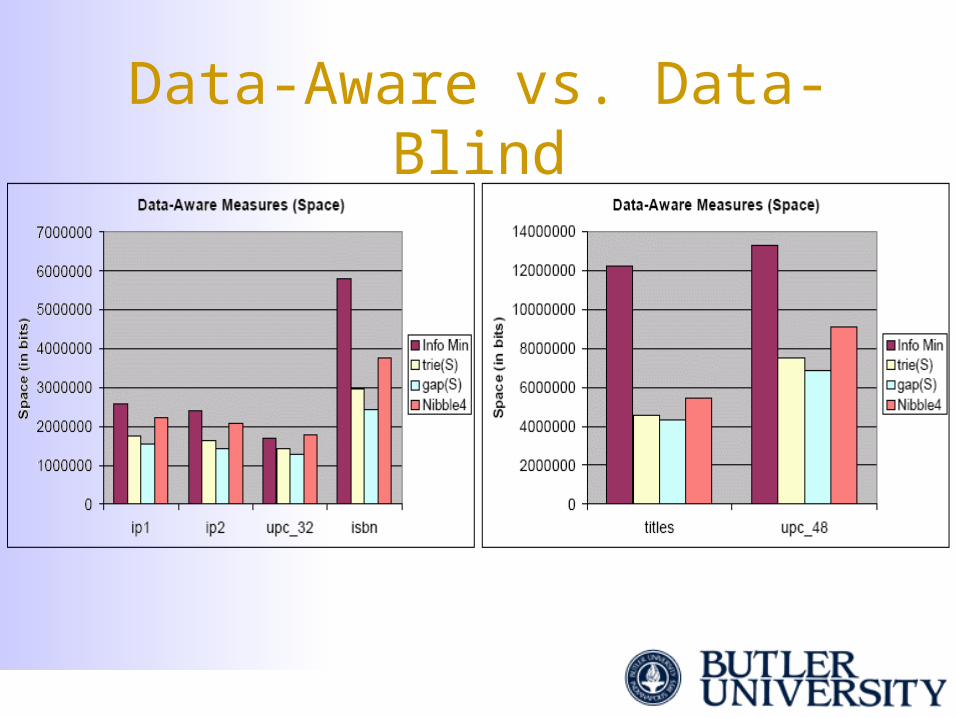
Data-Aware vs. Data-Blind

• Example: Encode n = 7 values out of a universe of size u = 16
• A natural way is to encode the differences between items in the set (gaps)
• Better than the worst-case information-theoretic measure for real-life data
• gap measure is
Gap Encoding
1 4 13128 9
3 4 1 3 11
15
2

Prefix Omission Method (POM Encoding)
• Example: Encode n = 7 bitstrings drawn from a universe u = 16
• POM encoding can also be seen as a subtrie (of n leaves) of the complete binary trie on u leaves
• trie measure is the number of edges in the subtrie
100 1000 1 100 10001
0001 0100 110111001000 1001 1111
11

Relationship Between GAP and TRIE• The gap(S) is no more than trie(S)• The trie(S) can be much more than gap(S)
• Such a scenario cannot occur too often; an amortized argument shows that trie(S) ≤ 2 gap(S)
• To improve the analysis, a randomized shift shows that randomized_trie(S) ≤ gap(S) + 2n – 2
• gap(S) = 15, trie(S) = 30, trie(S+3) = 26

Searchable Encoding Methods(AKA Gap sucks?)
• Previous methods are compressed, but are not easily searchable
• In particular, these require a linear scan to answer any rank and select query – Block-and-walk method [BB04] is a good scheme
• BSGAP data structure is our key building block– BSGAP stores a (modified) POM-encoded sequence of
strings, but queries using a binary search rather than a linear scan
– Takes nearly the same space as a linearly-encoded POM sequence
– In particular, we take gap + O(n log log (u/n)) bits

Binary Searchable GAP Encoding (BSPOM shown on right)
• gap encoding is related to the number of edges in the best trie (figure on right)• Each node encoded as the relative gap encoding from its best ancestor• Pointers point to the right subtree stored on disk and use O(n log log (u/n)) extra bits• We never use more bits than the number of edges in the trie!• Support rank and select queries on n items in O(log n) time
9845
1

A Lower Bound on Query Time(AKA your best isn’t good enough)
• Predecessor lower bound [BF99] applies, since pred(i) is solved with rank(i) and select(i) – Requires non-constant time for predecessor queries
with a data structure of O(n polylog(u)) bits– Many data structures take O(1) time for rank and
select, but require o(u) additional bits• Two lines explored in previous work:
– Spend o(u) extra bits of space and get O(1) time– Spend only O(n polylog(u)) bits total and take time

Our Dictionary Structure
Andersson/Thorup’sPredecessor Data Structure
BSGAP BSGAP BSGAP BSGAP BSGAP
AT on n/log3 n itemsperforms predecessorin AT(u, n/log3 n) timewith O(n log u/log3 n) bits
BSGAPs on log3 n itemstaking O(log log n) time
and gap(S) + O(n log log (u/n)) bits
This dictionary structure takes
gap + O(n log log (u/n)) +
O((n log (u/n))/log n) bits and performs rank and select in
AT(u,n) time

Theoretical ResultsDictionary Problem
• We just described a novel dictionary structure that requires gap + O(n log log (u/n)) + O((n log (u/n))/log n) bits and performs rank and select in AT(u,n) time.– “Second-order” terms come from encoding pointers in
the BSGAP and the space required for the top-level predecessor data structure
– A further improvement reduces the time for select to just O(log log n) time
• When n « u, we have the first O(n log (u/n)) bit dictionary with AT(u,n) query time

Cheating Predecessor Time Bounds• If we relax our definition of rank so that it only
supports queries on items in S, we can avoid the predecessor lower bound– This partial rank function prank(i) = rank(i) for i in S,
and -1 otherwise• We also achieve a dictionary supporting prank and
select queries in O(log log n) ≤ AT(u,n) time with the same space as before– prank dictionary replaces AT’s top level predecessor
structure with a van Emde Boas-like distributor structure– Some complications arise with this scheme; details in the
paper

“Comparisons” With Prior Work
For the above, n = 100,000 and u = 232.

Practical Results
• Engineering on prefix codes– space/time tradeoffs of various prefix codes
• Tuning BSGAP data structure– best choice of code for pointers– parameter h to avoid some pointers
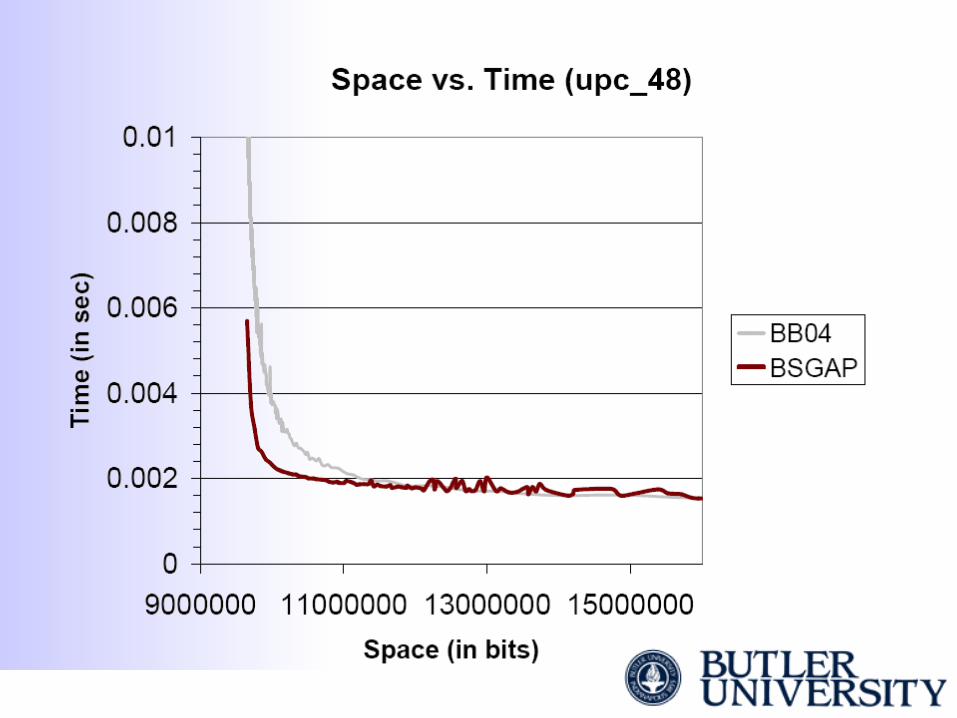
• Space/time tradeoffs between a simple block-and-walk scheme [BB04] and our practical dictionary

Prefix Codes Used• We encode the gap g as follows:
– γ code: log (g +1) in unary; g in binary– δ code: log (g+1) using γ code; g in binary– δ2 code: log (g+1) using δ code; g in binary– nibble4: ¼ log (g+1) in unary; g in binary, padded to
a multiple of 4 bits– nibble4gamma: ¼ log (g+1) using γ code; g in
binary, padded to a multiple of 4 bits– fixed5: log (g+1) in five bits; g in binary
• We use tables to compute prefix codes quickly
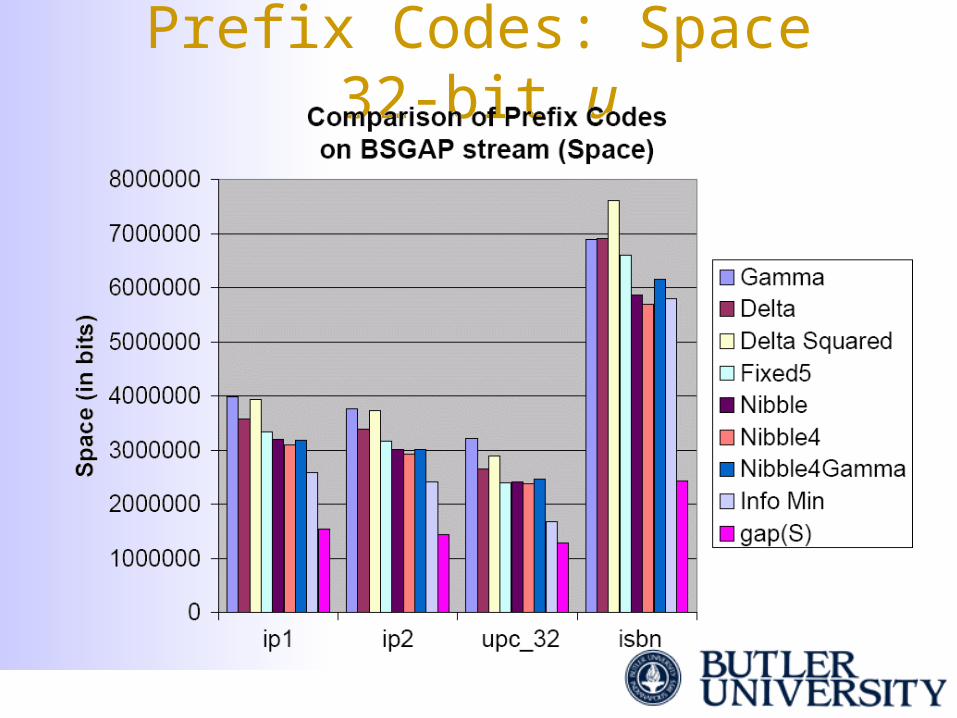
Prefix Codes: Space 32-bit u

Prefix Codes: Time 32-bit u

Prefix Codes: Space 64-bit u

Prefix Codes: Time 64-bit u

Pointer Cost: Space 32-bit u

Pointer Cost: Space 64-bit u

Tuning BSGAP• Pointer cost is non-
trivial part of BSGAP– Low-level pointers
jump over a few bits but take a lot of space
– Decoding pointers can take a lot of time
• Use a simple sequential encoding scheme when there are at most h items to search. Call this the hybrid value h
BSGAP
Each leaf node of BSGAP encodes up to h items sequentially

Practical Dictionary Structure
Binary Search Tree
BSGAP BSGAP BSGAP BSGAP BSGAP
BST on n/b itemsfinds correct BSGAP
BSGAPs on b items, eachusing a hybrid value h
This dictionary structure D(b, h) supports searching in O(log (n/b)) time and overhead space according to the value of h. The [BB04] is when h = b.

Description of Experiments• We allow blocksize b to range from [2, 256] (32-
bit files) and [2,2048] (64-bit files).• We range the hybrid value h over [2,b]. • Collect space and time required for all D(b, h)
over 10,000 (1,000) randomly generated rank queries.
• [BB04] curve is generated from the 256 (2048) points corresponding to D(b, b).
• BSGAP curve is generated from 300 samples from the above data.


Any questions?

Any questions?