development of hybrid sql/nosql panda metadata storage panda/ cern it-sdc meeting dec 02, 2014...
TRANSCRIPT

Development of Hybrid SQL/NoSQL PanDA Metadata
Storage
<Big/Mega>PanDA/ CERN IT-SDC meetingDec 02, 2014
Marina Golosova and Maria GrigorievaBigData Technologies
for mega-science project Laboratory, NRC KI

2
• BigData Technologies for mega-science projects
• Metadata Hybrid storage
Overview
02/12/2014

BigData Technologies for mega-science projects
• The project is supported by the Russian Federation Government grant
• Scientific program is tightly coupled with LHC experiments priorities and address challenges we will meet in 2-3 years.
• Project objective: Development of the novel Workload and Data Management System for Big Data, based on PanDA (MegaPanDA)
MegaPanda features:
• Support for large-scale data handling • HPC support• Cloud and web-based computing
services support
3A. Klimentov , Russian «MegaProject» https://indico.cern.ch/event/276497/session/0/contribution/10/material/slides/1.pdf

PanDA: metadata storage challenges
• Archive: 900 M jobs (since 2006)
• Current rate: ~2M jobs per day
• RDBMS: Response time increases as the volume of stored metadata grows up
• Dividing metadata:– actual (read-write part): for the
most recent and changing records (ATLAS_PANDA)
– archive (read-only part): for all records since 2006 (ATLAS_PANDAARCH)
• Oracle
• 2015 (Run-2): current rate x5• 2020 (Run-3): current rate x10
• …?
Completed Jobs 2009 – 2014 years
402/12/2014

RDBMS (SQL) Storage
METADATA SQL Storage
SQL standard : ACID
AtomicityConsistencyIsolationDurability
ActualAccess type:Read / Write
ArchiveAccess type:
Read
Applications
PanDA Server
PanDA Monitor
…502/12/2014

…
SQL standard : ACID NoSQL standard : BASE
AtomicityConsistencyIsolationDurability
Basic AvailabilitySoft-stateEventual consistency
NoSQL: not only SQL storage
METADATA Hybrid Storage
ActualAccess type:Read / Write
ArchiveAccess type:
Read
Applications
PanDA Server
PanDA Monitor
Storage API
NoSQL
602/12/2014

7
Objective:Architecture and implementation of storage and access to PanDA metadata.
Stage 1: Subject area research.
Stage 2: Technology research. NoSQL
Stage 3: Storage schema.
o Stage 4: Storage software.
o Stage 5: PanDA adaptation.7
Hybrid Storage project
Design o Implementation o Testing
PanDA metadata structure
PanDA DB architecture
Design Implementation Testing
02/12/2014

TypeColumn-oriented (Java)
Document-based (C++) Column-oriented (Java)
Point of failure
single point of failure – namemode (HDFS)
Database sharding mechanism
Peer-to-peer architecture;no-single-point-of-failure architecture
Storage Engine
HDFS
B-tree based storage engine;per database write lock makes writes problematic
locally-managed storage;storage engine only appends updated data;SSD & mixed SSD and HDD support
Read/Writes
optimized for reads, single-write master Well suited for doing range based scans
only one writer may modify a given database at a time - even a small number of writes can produce stalls in read performance
constant-time writesuses advanced concurrent structures to provide row-level isolation without locking
Analytical Capabilities
uses the Hadoop Infrastructure
custom map/reduce implementation
CFS (HDFS compatible Cassandra File System)
Cassandra v 2.1 improvements
Faster reads and writes & Improved row cache
Incremental repair Off-heap memtables,
reducing memory pressure on the Java heap
More performant implementation of counters
CQL improvements: collection indexes and user-defined types
Post-compaction read performance
Improved Hadoop support Improvements to
bootstrapping a node that ensure data consistency
OUR CHOISE - Cassandra:
Scale out without explicit partitioning/sharding Time-based data (log file analysis, time series) Low-latency application backend
Stage 2: NoSQL compare
802/12/2014

1) Main table – JOBS 2) Helper tables for most popular queries
Jobs (~90 columns) (model #1)
Stage 3: Data model for
PandaID assignedPriority atlasRelease …
2038679208 1000 Atlas-17.2.7 …
2033030636 … … …
Primary key (Jobs)• Partition key: PandaID• Clustering keys: ---
Task (10-15 columns)(model #1)
TaskID JobStatus ModificationTime PandaID …
769 failed 2014-01-06 2037208385 …
2037208386 …
… …
finished 2014-01-01 2032493594 …
2014-01-06 2037208384 …
… … … … …
Primary key (Task #1)• Partition key: TaskID • Clustering keys: JobStatus,
ModificationTime, PandaID
A…Z
A…Z
902/12/2014
Primary key (Task #2)• Partition key: (TaskID , JobStatus)• Clustering keys: ModificationTime, PandaID
TaskID JobStatus ModificationTime PandaID …
769 failed 2014-01-06 2037208385 …
2037208386 …
… …
769 finished 2014-01-01 2032493594 …
2014-01-06 2037208384 …
… … … … …
A…Z
Task (~90 columns) (model #2)
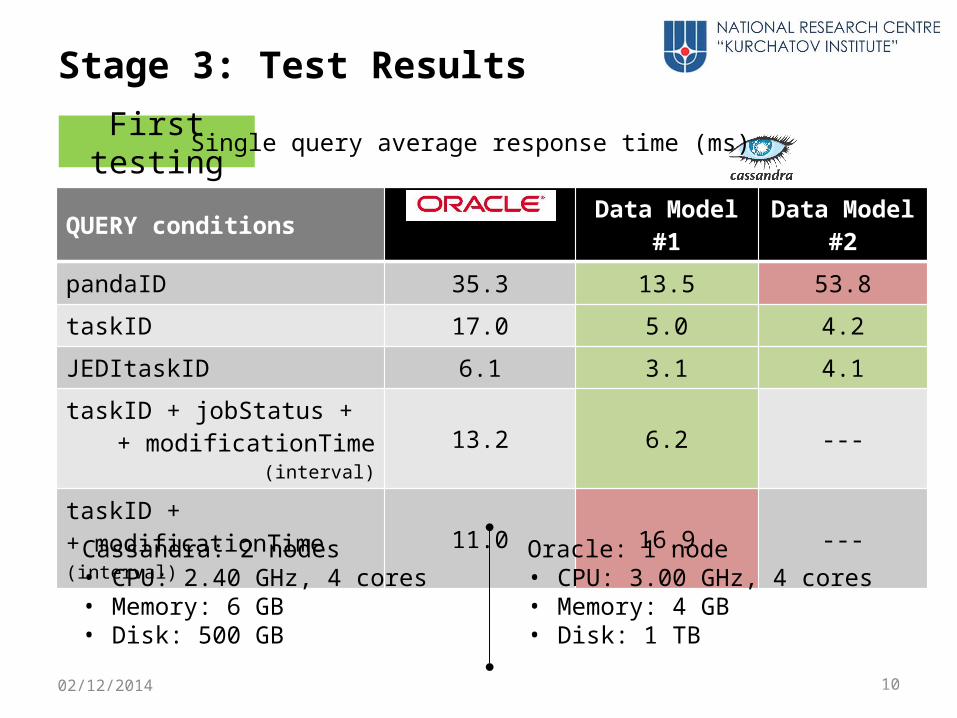
First testing
QUERY conditions Data Model #1 Data Model #2
pandaID 35.3 13.5 53.8
taskID 17.0 5.0 4.2
JEDItaskID 6.1 3.1 4.1
taskID + jobStatus ++ modificationTime
(interval)13.2 6.2 ---
taskID ++ modificationTime (interval)
11.0 16.9 ---
Stage 3: Test Results
Single query average response time (ms)
1002/12/2014
Cassandra: 2 nodes• CPU: 2.40 GHz, 4 cores• Memory: 6 GB• Disk: 500 GB
Oracle: 1 node• CPU: 3.00 GHz, 4 cores• Memory: 4 GB• Disk: 1 TB

Stage 4: Storage architecture
1102/12/2014

12
Development of NoSQL schema Creating test bed for schema testing Loading a two weeks slice of ATLAS archive
data into both Cassandra cluster and Oracle DB
NoSQL schema testing
Storage software design Basic functionality implementation:
• wrappers: Cassandra, Oracle, MySQL• data export (Oracle)• data import (Cassandra)• full copy (export-import) from SQL to
NoSQL
Storage
NoSQL
Cassandra
SQL
MySQL
Oracle
utils
interaction
SQLtoNoSQL
Hybrid Storage: current status
02/12/2014

1302/12/2014
Acknowledgements
Gancho Dimitrov,Jaroslava Schovancova,Eygene Ryabinkin,Maxim Potekhin,Michail Borodin