desab-ginftlilertibevninoitomevitpaadmrofsnrat)tami(l ... · soal etartmnsode thesseenvicteefo...
TRANSCRIPT

Lifting-based Invertible Motion Adaptive Transform (LIMAT)
Framework for Highly Scalable Video Compression
Andrew Secker and David Taubman∗
Abstract
We propose a new framework for highly scalable video compression, using a Lifting-based
Invertible Motion Adaptive Transform (LIMAT). We use motion-compensated lifting steps to
implement the temporal wavelet transform, which preserves invertibility, regardless of the motion
model. By contrast, the invertibility requirement has restricted previous approaches to either
block-based or global motion compensation. We show that the proposed framework effectively
applies the temporal wavelet transform along a set of motion trajectories. An implementation
demonstrates high coding gain from a finely embedded, scalable compressed bit-stream. Results
also demonstrate the effectiveness of temporal wavelet kernels other than the simple Haar, and
the benefits of complex motion modeling, using a deformable triangular mesh. These advances
are either incompatible or difficult to achieve with previously proposed strategies for scalable
video compression. Video sequences reconstructed at reduced frame-rates, from subsets of the
compressed bit-stream, demonstrate the visually pleasing properties expected from low-pass
filtering along the motion trajectories. The paper also describes a compact representation for
the motion parameters, having motion overhead comparable to that of motion-compensated
predictive coders.
Our experimental results compare favourably with others reported in the literature, however,
the principle objective of this paper is to motivate a new framework for highly scalable video
compression.
∗The authors are with the School Of Electrical Engineering & Telecommunications, The University Of New South
Wales, Sydney 2052, Australia. Contact: A. Secker*; email: [email protected], ph: +61 (2) 9385 4803, fax:
+61 (2) 9385 5993. D.Taubman; email: [email protected]. ph: +61 (2) 9385 5223. EDICS code: 1-VIDC
1

1 Introduction
The objective of highly scalable video coding is to produce a dense family of embedded bit-streams,
each an efficient compressed representation of the video, at successively higher bit-rates. Scalable
representations are important for efficient utilization of limited channel capacity, and have applica-
tions in many areas including simulcast, videoconferencing and remote video browsing. In addition
to bit-rate scalability, other important forms of scalability for video compression include spatial
resolution and temporal (frame-rate) scalability.
Highly scalable compression imposes an important restriction on the encoder. Specifically, it
must operate without prior knowledge of the rate at which the compressed video will be decoded.
For this reason, the predictive feedback paradigm inherent in traditional motion-compensated video
compression algorithms is fundamentally incompatible with highly scalable compression. Instead
the preferred method is that of feed-forward compression, in which a spatio-temporal transform
precedes embedded quantization and coding.
Karlsson and Vetterli first proposed the use of a separable three-dimensional (3D) discrete
wavelet transform (DWT) for video compression [1]. Separable 3D transforms are also employed
in [2], which extends the well-known SPIHT [3] coding algorithm into the temporal dimension.
However, without motion compensation, temporal filtering produces visually disturbing ghosting
artefacts in the low-pass temporal subband. This is clearly undesirable where temporal scalability
is of interest. The challenge therefore lies in finding a way to effectively exploit motion within the
spatio-temporal transform.
Taubman and Zakhor proposed an approach in which frames are invertibly warped so as to align
spatial features prior to the application of a separable 3D-DWT [4]. We refer to this and related
approaches as “frame-warping” schemes. While a variety of warping operators may be considered,
invertible warpings are unable to represent the localized expansion and contraction effects exhibited
within most video sequences. This is because any warping involving local expansion and contraction
2

essentially corresponds to a non-uniform resampling of the video frame, thus violating the Nyquist
sampling criterion in regions of expansion. In some proposed schemes, such as that of Tham et
al. [5], the invertibility requirement is deliberately violated so that high quality reconstruction is
impossible.
Another class of approaches can be described as block displacement methods, originally pro-
posed by Ohm [6]. In these approaches, video frames are divided into blocks, where each block
undergoes rigid motion, usually translation. The 3D-DWT is essentially applied in a separable
fashion along the displaced blocks, but the effects of expansion and contraction in the motion field
are observed by the appearance of “disconnected” pixels between the blocks. For the transform
to remain invertible, these disconnected pixels must be treated differently, which seriously affects
coding efficiency. In addition, perfect reconstruction is only possible with integer block displace-
ments, although extensions to half-pixel accuracy have been demonstrated [6], [7]. These methods
invariably involve block-based motion models, which cannot capture expansive or contractive mo-
tion. In [6] the concept of applying the separable DWT along displaced blocks is also generalized
to encompass arbitrary motion trajectories. However, this results in loss of perfect reconstruction,
unless the motion trajectories are confined to integer displacements, in which case the occurrence
of disconnected pixels increases significantly.
Temporal transforms based on either frame-warping or block displacement methods generally
employ only the Haar wavelet kernel. Extensions to longer temporal filters have been reported
[6],[4], with no significant improvement in performance.
In this paper, we propose a Lifting-based Invertible Motion Adaptive Transform (LIMAT),
which overcomes the limitations of the existing methods mentioned above. We elaborate on pre-
liminary work previously published in [8] and [9]. Our proposed framework employs a lifting
realization of the temporal DWT, in which each lifting step is compensated for the estimated scene
motion. The LIMAT framework enables the construction of motion adaptive temporal transforms
3

based on any wavelet kernel and motion model, while retaining the perfect reconstruction prop-
erty. Video coding based on 3D lifting structures has also been proposed in [10], as a means for
addressing some of the weaknesses of block displacement methods.
Section 2 describes the proposed framework, beginning with examples based on the Haar and
5/3 wavelet kernels. By contrast to previous methods, our results indicate that the 5/3 transform
offers superior coding efficiency compared to the Haar transform. In this section we also show that
if the video frames and motion mappings are both spatially continuous, the LIMAT framework
is equivalent to applying the DWT along the motion trajectories. In the discrete spatial domain,
this behaviour is retained for the most important spatial frequencies, and the remaining higher
frequencies are dealt with in a way that preserves the invertibility of the transform.
In practice, the performance of a motion adaptive transform is inevitably dependent on the
properties of the selected motion model. In Section 3 we provide the example of a deformable mesh
motion model, comparing its performance with that of a simple block motion model. Only in the
context of continuous motion fields, such as those yielded by the deformable mesh, can the proposed
transform be truly understood as filtering along the motion trajectories. Our experimental results
also indicate coding efficiency improvements when using the deformable mesh instead of block-based
motion.
In Section 4, we propose an efficient representation for the motion information associated with
the LIMAT framework. This representation allows us to reduce the number of explicitly coded
motion mappings to approximately one per original video frame. As a result, the motion overhead
is comparable to that of motion-compensated predictive coders.
Our experiments are described in detail in Section 5 where we provide compression results for
several standard test sequences. In the experiments, the proposed temporal transform is followed
by spatial wavelet decomposition and embedded block coding, using an implementation of the
JPEG2000 image compression standard. Our compression results compare favourably with others
4

reported in the literature.
2 Motion Adaptive Temporal DWT Based on Lifting
The key to efficient scalable video coding is to effectively exploit motion within the spatio-temporal
transform. Specifically, we identify three primary objectives for a motion adaptive temporal trans-
form, suitable for highly scalable video compression. Firstly, the low-pass temporal subband frames
should represent a high quality reduced frame-rate video. In particular, the transform should not
introduce ghosting artefacts into the low-pass frames, so that the visual quality is comparable to
that obtained by temporally subsampling the original video sequence prior to compression. In fact,
if the low-pass temporal subband frames are obtained by filtering along the true scene motion tra-
jectories, the reduced frame-rate video sequence obtained by discarding high temporal frequency
subbands from the compressed representation, may have an even higher quality than that obtained
by subsampling the original video sequence. This is because low-pass filtering along the motion
trajectories tends to reduce the effects of camera noise, spatial aliasing and scene illuminant varia-
tions.
Secondly, the transform should exhibit high coding gain. This means the high-pass temporal
subband frames should contain as little energy as possible, after adjusting for the energy gains
associated with the subband synthesis system. It is also important to minimize the introduction of
spurious spatial details in both the high-pass and low-pass frames, since these reduce the effective-
ness of subsequent spatial transformation and coding techniques. If the subbands are obtained by
applying suitable wavelet filters along the true scene motion trajectories, there should be minimal
introduction of spurious spatial details, and the high-pass subbands should have particularly low
energy. Moreover, so long as the quality of the low-pass temporal subband frames is preserved,
iterative application of the temporal decomposition along the low-pass channel should yield a multi-
resolution hierarchy with similar properties. For the experimental results reported in this paper,
5

we invariably consider three “stages” of such iterative decomposition.
As suggested, the above objectives are both closely related to the use of temporal filtering
and subsampling along the motion trajectories associated with a realistic motion model. However,
realistic motion models inevitably accommodate expansion and contraction, which makes it difficult
to achieve our third objective, that the transform should be invertible. Of course, lossy compression
generally prevents the original video sequence from being recovered exactly, but lack of invertibility
in the transform limits the range of compressed bit-rates over which the complete compression
system can be used efficiently.
In the LIMAT framework, the key to accomplishing invertibility is the use of lifting [11]. Any
two-channel FIR subband transform can be described as a finite sequence of lifting steps [12, 13].
In the proposed scheme, the original lifting steps are modified to exploit motion, which in no way
compromises the invertibility of the transform. In fact, by introducing integer rounding into our
modified lifting steps, in the manner suggested by Calderbank et al. [14], it is possible to achieve
efficient lossless compression of the original video sequence. Most significantly, however, the lifting-
based transform may be understood as applying the temporal wavelet transform along the motion
trajectories established by the selected motion model.
2.1 Example with the Haar Transform
It is instructive to begin with an example based upon the Haar wavelet transform. Up to a scale
factor, this transform may be realized in the temporal domain, through a sequence of two lifting
steps, as
hk [n] = x2k+1[n]− x2k[n]
lk[n] = x2k[n] +1
2hk[n]
where xk[n] ≡ xk [n1, n2] denotes the samples of frame k from the original video sequence and
hk [n] ≡ hk [n1, n2] and lk [n] ≡ lk [n1, n2] denote the high-pass and low-pass subband frames. This
6

decomposition of the Haar transform into two steps is also known as the S-transform [15].
The reader can verify that lk [n] and hk [n] correspond to the scaled sum and the difference of
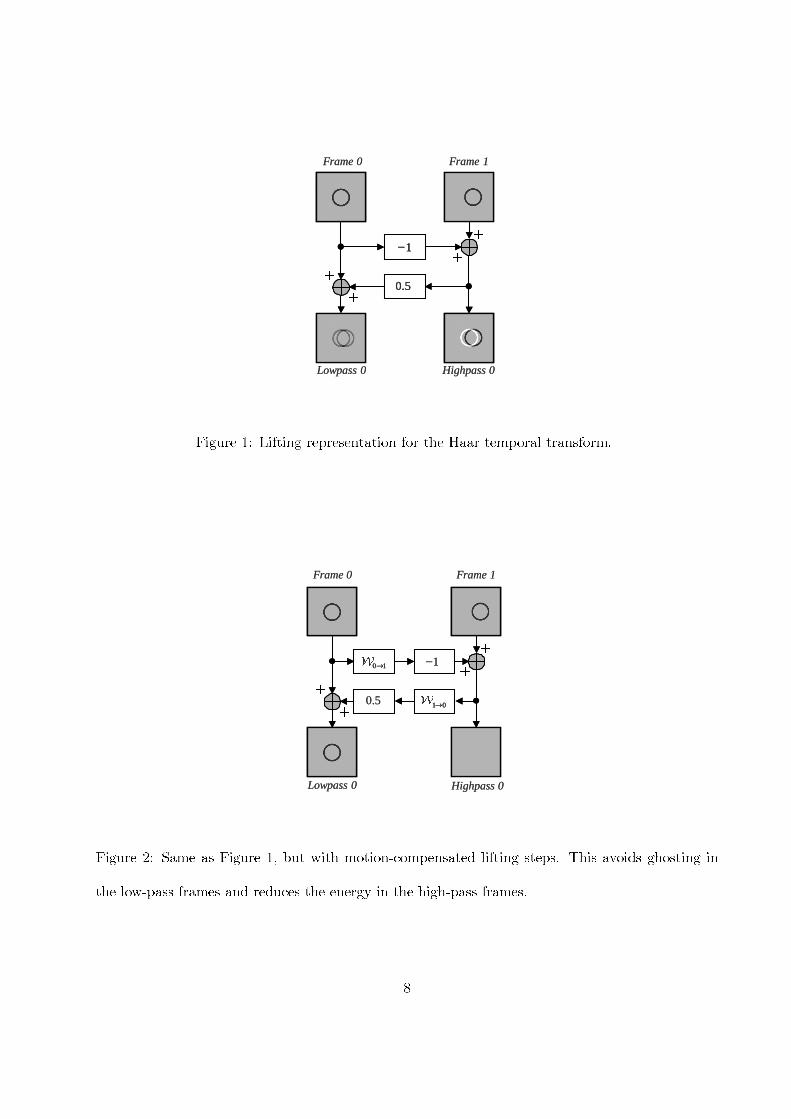
each original pair of frames. An example is shown in Figure 1. Since motion is ignored, ghosting
artefacts are clearly visible in the low-pass temporal subband, and the high-pass subband frame
has substantial energy.
Now letWk1→k2denote a motion-compensated mapping of frame k1 onto the coordinate system
of frame k2, so that Wk1→k2(xk1)[n] ≈ xk2
[n], for all n. No particular motion model is assumed
here. The lifting steps are modified as follows.
hk[n] = x2k+1[n]−W2k→2k+1(x2k)[n]
lk[n] = x2k[n] +1
2W2k+1→2k(hk)[n]
Observe that W2k→2k+1 and W2k+1→2k represent forward and backward motion mappings, respec-
tively. The high-pass subband frames correspond to motion-compensated residuals. These will be
close to zero in regions where the motion is accurately modelled. As we shall see in Section 2.3,
so long as the motion is well modelled by W2k→2k+1 and W2k+1→2k, the low-pass frames lk [n], are
effectively the result of applying a low-pass temporal filter along the motion trajectories. For the
Haar wavelet, this low-pass analysis filter has transfer function
H0 (z) =1
2(1 + z)
The visual effects of motion compensation can be seen by comparison of Figures 1 and 2. In the
example of Figure 2, we assume that the motion is captured perfectly. As a result, the high-pass
frame has no energy, and the low-pass frame is an excellent representation of frame 0, free from the
ghosting artefacts observed in Figure 1. If the signal amplitude on the surface of the moving object
fluctuates over time, possibly due to noise, the low-pass frame represents a temporal average of the
object’s surface intensity, while the high-pass frame represents the temporal difference.
The modified Haar lifting steps evidently achieve the first two objectives identified above, in
7
1 Frame
0Lowpass 0Highpass
1−
5.0
0Frame 1 Frame
0Lowpass 0Highpass
1−1−
5.0 5.0
0Frame
Figure 1: Lifting representation for the Haar temporal transform.
5.0
1−
0Frame 1Frame
0Lowpass 0Highpass
10→W
01→W5.0
1−
0Frame 1Frame
0Lowpass 0Highpass
10→W 10→W
01→W 01→W
Figure 2: Same as Figure 1, but with motion-compensated lifting steps. This avoids ghosting in
the low-pass frames and reduces the energy in the high-pass frames.
8

spatial regions where the motion is well modelled. Moreover, invertibility is an inherent property
of the lifting structure, regardless of how we choose to compensate for motion. To invert the
transform, one must simply apply the same lifting steps in reverse order, reversing the sign of the
updates. The reverse transform in this example is given by
x2k[n] = lk[n]−1
2W2k+1→2k(hk)[n] (1)
x2k+1[n] = hk[n] +W2k→2k+1(x2k)[n])
2.2 A More Interesting Wavelet Transform
The framework described above is readily extended to any two-channel FIR subband transform, by
motion-compensating the relevant lifting steps. We demonstrate this in the important case of the
biorthogonal 5/3 wavelet transform [16], whose lifting incarnation plays an important role in the
highly scalable JPEG2000 image compression standard [13]. As before, x2k[n] and x2k+1[n] denote
the even and odd indexed frames from the original sequence. Without motion, the 5/3 transform
may be implemented by alternately updating each of these two frame sub-sequences, based on
filtered versions of the other sub-sequence. The lifting steps are
hk[n] = x2k+1[n]−1
2(x2k [n] + x2k+2[n])
lk[n] = x2k [n] +1
4(hk−1[n] + hk [n])
As before, we introduce arbitrary motion warping operators within each lifting step, which yields
hk[n] = x2k+1[n]−1
2(W2k→2k+1(x2k)[n] +W2k+2→2k+1(x2k+2)[n]) (2)
lk[n] = x2k[n] +1
4(W2k−1→2k(hk−1)[n] +W2k+1→2k(hk)[n])
In Figure 3 we see the effect of these modified lifting steps. The high-pass frames are now
essentially the residual from a bidirectional motion-compensated prediction of the odd-indexed
original frames. When the motion is adequately captured, these high-pass frames have little energy
9

and the low-pass frames correspond to low-pass filtering of the original video sequence along its
motion trajectories. In this example, the surface intensity of the moving object varies randomly
over time. These variations are effectively low-pass filtered, improving the visual quality of the
low-pass temporal subband. The low-pass analysis filter in this case has transfer function
H0 (z) = −1
8z2 +
1
4z +
3
4+
1
4z−1 −
1
8z−2
whose frequency response is much closer to that of an ideal low-pass filter than was the Haar filter.
As before, failure to capture the motion reduces the coding gain, and introduces multiple ghosting
artefacts into the low-pass subband frames, as suggested by the figure.
In our experiments, the 5/3 wavelet consistently outperforms the Haar, which contrasts with
observations reported in the context of the frame-warping and block displacement methods [17, 4].
Table 1 presents indicative compression results, comparing the behaviour of the Haar and 5/3
wavelet kernels. These results are obtained using block-based motion warping operators, over three
stages of temporal transform. The reconstruction bit-rate is 1 Mbps, but similar results are obtained
at other bit-rates. A full description of the experimental conditions associated with these and other
results presented in this paper may be found in Section 5.
According to Table 1, the 5/3 transform provides an improvement in PSNR of between 1.25
dB and 2.35 dB, relative to the Haar transform. This can be attributed to the use of both forward
and backward motion compensation, which reduces the energy of the high-pass frames, as well
as improved low-pass filtering along motion trajectories. Note that these results exclude the cost
of coding motion information. The amount of information and preferred methods for coding the
motion are different in each case. For the moment, however, we defer consideration of these effects
so as to focus on the merits of the transforms themselves. We later show that the observations
presented here apply even when the cost of motion is taken into account, subject to the use of
appropriate coding techniques.
10

Table 1: Reconstructed PSNR using 5/3 and Haar wavelets at 1 MbpsSequence Haar 5/3 GainMobile 26.55 27.80 +1.25Flower 26.84 28.83 +1.99Table 31.40 33.75 +2.35
Football 26.05 28.26 +2.21
4 Frame
5.0−
0 Frame 1 Frame 2 Frame 3 Frame
12→W
23→W25.0
34→W
21→W 25.0
32→W10→W 5.0− 5.0− 5.0−
1 Lowpass 1 Highpass0 Highpass
oncompensatimotion Ideal
oncompensatimotion No
4 Frame
5.0−
0 Frame 1 Frame 2 Frame 3 Frame
12→W
23→W25.0
34→W
21→W 25.0
32→W10→W 5.0− 5.0− 5.0−
1 Lowpass 1 Highpass0 Highpass
oncompensatimotion Ideal
oncompensatimotion No
Figure 3: Motion adaptive 5/3 temporal transform. The low-pass frame is the result of low-pass
filtering along the motion trajectories.
11

2.3 Generalization and Interpretation of the Lifting Transform
We have already mentioned that motion-compensating the lifting steps of a temporal subband
transform effectively results in the relevant subband filters being applied along the motion trajecto-
ries described by the motion model. In this section, we provide justification for this statement. To
do so, we first consider the application of the motion-compensated lifting transform to a sequence
of spatially continuous video frames, denoted xk (s) ≡ xk (s1, s2), where s ∈ R2 represents the
continuous spatial location and k ∈ Z is the frame index.
It is known that any two-channel FIR subband transform may be factored into a finite sequence
of Λ lifting steps [12, 13]. Each successive lifting step converts its input sequence, denoted x(λ−1)k
,
into an output sequence, x(λ)k
, where λ = 1, 2, . . . ,Λ, and x(0)k� xk is the input sequence supplied
to the subband transform. For odd λ, the odd indexed sub-sequence x(λ−1)2k+1 is updated using a
filtered version of the even indexed sub-sequence x(λ−1)2k , according to
x(λ)2k+1 = x
(λ−1)2k+1 +
∑
i
u(λ)i
· x(λ−1)2(k−i)
; x(λ)2k = x
(λ−1)2k
Here u(λ)i
denotes the impulse response of the λth lifting step filter. For even λ, the even sub-
sequence is updated using a filtered version of the odd sub-sequence, according to
x(λ)2k = x
(λ−1)2k +
∑
i
u(λ)i
· x(λ−1)2(k−i)+1
, x(λ)2k+1 = x
(λ−1)2k+1
The even and odd sub-sequences output from the final lifting step are the low-pass and high-pass
subband sequences, respectively. That is
lk = x(Λ)2k and hk = x
(Λ)2k+1
The succession of lifting steps is illustrated in Figure 4 and its inverse is illustrated in Figure 5.
Using this notation, our motion-compensated temporal transform may be expressed through
12

2u� Lu�
)1(2kx)0(
22 kk xx =
1−Lu�� 1u
)2(2kx )2(
2−L
kx )1(2
−Lkx k
Lk lx =)(
2
)1(12 +kx)0(
1212 ++ = kk xx )2(12 +kx )2(
12−+
Lkx )1(
12−+
Lkx k
Lk hx =+
)(12
subbands out
Figure 4: Network of L lifting steps, used to realize a two-channel subband transform, with subband
sequences lk and hk.
2u� Lu�1−Lu�� 1u
)1(2kx)0(
22 kk xx = )2(2kx )2(
2−L
kx )1(2
−Lkx k
Lk lx =)(
2
)1(12 +kx)0(
1212 ++ = kk xx )2(12 +kx )2(
12−+
Lkx )1(
12−+
Lkx k
Lk hx =+
)(12
subbands in
Figure 5: Synthesis network corresponding to the analysis system in Figure 4.
13

the lifting steps
x(λ)2k+1 (s) = x
(λ−1)2k+1 (s) +
∑
i
u(λ)i
·W2(k−i)→2k+1
(x(λ−1)2(k−i)
)(s) , λ odd
x(λ)2k (s) = x
(λ−1)2k (s) +
∑
i
u(λ)i
·W2(k−i)+1→2k
(x(λ−1)2(k−i)+1
)(s) , λ even
Suppose now that our motion model is invertible, meaning that there is a one to one correspondence
between locations s in frame 0, and locations sk = Vk (s) in frame k. Equivalently, we are assuming
that our motion model assigns unique trajectories, represented by the sequence, {sk}, to each
location s in frame 0, such that the trajectories do not intersect. In this assumption, we are clearly
ignoring the finite spatial support of the frames, as well as the possibility of occlusion.
Since the motion model is invertible, we must have
Wk1→k2(xk1) (sk2) = xk1
(Vk1
(V−1
k2(sk2)
))
That is, to find the location sk1in frame k1 which corresponds to a location sk2
in frame k2, we can
map sk2back to the origin of its motion trajectory through V
−1
k2, and then map it forward along
the same trajectory into frame k1, using Vk1 . We can now rewrite the motion-compensated lifting
steps in terms of the sequence of locations sk = Vk (s), corresponding to a single motion trajectory
anchored at location s in frame 0. We get
x(λ)2k+1 (s2k+1) = x
(λ−1)2k+1 (s2k+1) +
∑
i
u(λ)i
·W2(k−i)→2k+1
(x(λ−1)2(k−i)
)(s2k+1)
= x(λ−1)2k+1 (s2k+1) +
∑
i
u(λ)i
· x(λ−1)2(k−i)
(s2(k−i)
), λ odd
x(λ)2k (s2k) = x
(λ−1)2k (s2k) +
∑
i
u(λ)i
·W2(k−i)+1→2k
(x(λ−1)2(k−i)+1
)(s2k)
= x(λ−1)2k (s2k) +
∑
i
u(λ)i
· x(λ−1)2(k−i)+1
(s2(k−i)+1
), λ even
Finally, let x̃k (s) denote the warped frame obtained by mapping xk (s) from the coordinate
system associated with frame k onto the coordinate system associated with frame 0. That is,
x̃k (s) =Wk→0 (xk) (s) = xk (sk)
14

The lifting steps may be expressed in terms of the sequence of warped frames as
x̃(λ)2k+1 (s) = x̃
(λ−1)2k+1 (s) +
∑
i
u(λ)i
· x̃2(k−i) (s) , λ odd
x̃(λ)2k (s) = x̃
(λ−1)2k (s) +
∑
i
u(λ)i
· x̃2(k−i)+1 (s) , λ even
This means that we are effectively applying the original temporal subband transform directly to the
sequence of warped frames, x̃k (s). Equivalently, the original subband transform is being applied
along the motion trajectories, sk = Vk (s). The low-pass temporal subband sequence, lk (s) =
x(Λ)2k (s) is equivalent to the low-pass subband, x̃
(Λ)2k , of the warped sequence, warped back onto
the coordinate system of frame 2k. Similarly, the high-pass temporal subband sequence, hk (s) =
x(Λ)2k+1 (s) is obtained by warping x̃
(Λ)2k+1 back onto the coordinate system of frame 2k + 1.
We turn our attention now to the case of discrete frames, xk [n], each of which we model
as a unit sampled version, xk [n] = xk (s)|s=n, of a continuous frame, xk (s), obtained through
Nyquist bandlimited (sinc) interpolation of xk [n]. In the special case of purely translational motion,
application of the warping operator Wk1→k2to xk (s) yields another Nyquist bandlimited frame,
whose unit sample sequence may be obtained directly from xk [n] by ideal sinc-interpolative filtering.
Under these idealized conditions, the discrete and continuous realizations of our proposed lifting
framework are truly equivalent and the discrete subband frames are warped versions of those which
would be obtained if we had directly applied the temporal subband transform, after first warping
the original video frames onto a consistent reference coordinate system. This suggests a strong
connection between the LIMAT framework and the frame-warping methods proposed in [4] and [5],
in which the original frames are explicitly warped prior to the application of the temporal subband
transform.
In the above, we considered only translational motion and ideal sinc interpolation for the mo-
tion warping operators. The key innovation of the proposed LIMAT framework lies in its ability
to handle non-translational motion and non-ideal interpolation. In the LIMAT framework, the
temporal subband transform is not applied directly to the warped frames, x̃k [n]. Instead, the
15

terms in each lifting step are compensated for motion. This ensures that the transform remains
invertible, even if the individual frame warping operations are not invertible. Suppose the motion
field describing the relationship between frames k1 and k2 is contractive, meaning that features
are smaller and closer together in xk2 (s) than they are in xk1(s). Then warping xk1
(s) onto the
coordinate system of frame k2 will not generally leave a Nyquist bandlimited image, even if xk1 (s)
was Nyquist bandlimited. As a result, high spatial frequencies must generally be lost whenWk1→k2
is applied in the discrete image domain.
Since motion fields typically contain both expansive and contractive regions, the relationship
between continuous and discrete warped frames cannot generally be preserved. Nevertheless, with
carefully designed motion compensating interpolation filters, it is possible to accurately preserve
the discrete/continuous relationship at lower spatial frequencies. The range of spatial frequencies
over which the relationship can be considered preserved, depends on the nature of the motion
field, as well as the complexity of the interpolation filters. In the neighbourhood of any subband
frame of interest, we may model the video sequence as the sum of two component sequences: a
“base” sequence, containing the lower spatial frequencies which are correctly preserved by the
motion warping operators; and a “residual” sequence, containing the higher spatial frequencies.
Since the transform and warping operators are all linear, the subband frame in question may also
be regarded as the sum of two components, one of which is effectively obtained by applying the
temporal subband filters along the motion trajectories of the “base” video sequence. While we
cannot provide a similar interpretation for the second component, produced by processing the
“residual” sequence, this component is usually much less significant than the base component,
especially in regions where the motion field is nearly translational or the video frames are relatively
smooth.
16

3 Motion Modelling and Preliminary Observations
To realize a subband decomposition along the underlying motion trajectories, the motion in the
sequence must be accurately modelled. The LIMAT framework provides a flexible solution to this
challenging problem because advanced motion models may be employed without sacrificing the
invertibility of the transform. In this section we demonstrate this by comparing a deformable mesh
motion model with a typical block-based motion model. Our main objective here is to observe the
effect of the motion model on the energy compaction properties of the temporal transform. For this
reason we ignore the cost of coding the motion until Section 5, where it is shown to have relatively
little effect on the experimental results.
3.1 Block Motion Model
Block-based motion models are predominant in traditional motion-compensated video coders. A
typical block motion model involves partitioning the current frame into a regular grid of blocks,
where each block undergoes translation to a new location in the reference frame. The block motion
mapping is represented by the field of block displacement vectors.
The block motion field corresponds to a piecewise constant approximation to the underlying
motion field. In general, this is only an accurate representation of very smooth motion fields, or
those consisting of only simple translational motion. In particular, block motion models poorly
represent expansions and contractions in the true motion field, which commonly arise due to de-
formations of scene objects, camera translation and zooming. Furthermore, the introduction of
artificial discontinuities into the motion field can produce disturbing visual artefacts.
Our experiments use a hierarchical block-matching algorithm. In comparison to full-search
approaches, hierarchical motion estimation is more robust to image noise and illumination fluctu-
ations. Hierarchical motion estimation also tends to produce more uniform motion fields, which
facilitate efficient coding of the motion overhead.
17

Table 2 shows reconstructed video PSNR at a bit-rate of 1 Mbps. Evidently, incorporating
motion compensation into the transform can significantly improve the PSNR. Consider, for example,
the Mobile and Calender sequence, in which increases of 4.63 dB and 5.43 dB are observed for the
Haar and 5/3 wavelets, respectively. Similar gains of 4.84 dB and 6.65 dB are observed with
the Flower Garden sequence, but there is little improvement for the Table Tennis and Football
sequences. In these sequences, motion-compensating the Haar lifting steps actually reduces the
PSNR.
Although motion compensation generally increases energy compaction, it can also expand the
quantization error energy during synthesis. Most video sequences contain local expansions and
contractions, and therefore do not exhibit a one-to-one correspondence between pixel locations in
consecutive frames. This is essentially the source of the “disconnected” pixel problem observed in
block displacement approaches. It manifests itself in this scheme when displaced blocks overlap in
the reference frame, causing some pixels to be mapped to multiple locations in the current frame.
During temporal synthesis, the quantization error in these pixels will also be mapped to multiple
locations in the reconstructed frames, causing an overall increase in frame distortion.
Our current quantization and coding strategies treat the 3D transform as though it were fully
separable. As a result, PSNR performance is only improved if the increase in energy compaction
outweighs quantization error energy expansion during synthesis. The motion adaptive Haar trans-
form does not achieve this with the Football and Table Tennis sequences, because the motion is
difficult to exploit. In particular, the Football sequence contains rapid translations, deformations
and complex camera motion. The Table Tennis sequence consists of segments in which the camera
is either still or zooming, neither of which benefit substantially from the use of a block motion
model.
In the case of the 5/3 transform, inadequacies in the motion model are partially alleviated by
the bidirectional motion compensation associated with the first lifting step. The corresponding
18

Table 2: Reconstructed PSNR using block motion model, at 1 MbpsNo DWT 3-stage Haar DWT 3-stage 5/3 DWT
Sequence None Block Gain None Block GainMobile 19.55 21.92 26.55 +4.63 22.37 27.80 +5.43Flower 21.10 22.00 26.84 +4.84 22.18 28.83 +6.65Table 28.50 31.77 31.40 −0.37 32.00 33.75 +1.75
Football 26.25 27.03 26.05 −0.98 27.00 28.26 +1.26
(a) (b)(a) (b)
Figure 6: Demonstrates the visual effect of block-based motion compensation on the low-pass
frames, using 3 stages of 5/3 temporal DWT. The ghosting artefacts observed in (a) are avoided in
(b) by motion compensation.
increase in energy compaction leads to improved compression performance for all test sequences.
Nevertheless, further improvements should be possible if the expansion in quantization error energy
were correctly compensated during quantization of the spatial subband samples.
In all cases, the use of motion-compensated lifting steps significantly improves the visual quality
of the low-pass temporal subband. As an example, we compare the visual effect of motion compen-
sation on the low-pass frames from the Flower Garden sequence. Figure 6a shows a low-pass frame
produced using three stages of the original 5/3 temporal transform. In Figure 6b, the substantial
ghosting artefacts are avoided through the use of motion compensation.
19

3.2 Deformable Mesh Motion Model
Unlike block-based models, deformable meshes can track complex motion, including local expansion
and contraction, while maintaining a continuous motion field. A regular deformable mesh is created
by partitioning the current frame into a regular grid of patches, usually either triangles [18] or
quadrilaterals [19],[20]. The mesh node-points move to form a warped mesh on the reference frame,
and the mapping is represented by the set of node displacement vectors. The motion vector at any
given location within a patch is approximated by linearly interpolating the motion vectors at the
patch vertices. This corresponds to an affine transformation for triangular meshes, and a bilinear
transformation for quadrilateral meshes
Deformable meshes yield motion fields that are piecewise smooth and continuous at patch
boundaries. These motion fields can provide a much better representation of the underlying mo-
tion field than discontinuous block motion fields. Determination of a globally optimum set of
node vectors is not usually possible within reasonable computational constraints. Local searches,
or gradient-based approximations are commonly used instead, which typically find only a local
minimum of an appropriate objective function, such as the energy of the displaced frame differ-
ence. Nevertheless, deformable meshes have been found to offer superior motion compensation in
comparison to block-based models.
We incorporate a triangular deformable mesh model into the LIMAT framework using a hexago-
nal refinement estimation algorithm similar to that proposed in [21]. As mentioned, local expansions
and contractions in the motion field can cause an increase in reconstruction error energy during
synthesis. With a deformable mesh, the expansion in quantization error energy is directly related
to expansion in the mesh itself. The expansion of a patch in a triangular mesh is given by the
determinant of the corresponding affine transform. To discourage excessive error expansion, we
weight the estimated distortion within each patch by the determinant of its affine transform or
the reciprocal of the determinant, whichever is larger. This provides a significant increase in com-
20

Table 3: Reconstructed PSNR using deformable mesh motion model, at 1 Mbps3-stage Haar DWT 3-stage 5/3 DWT
Sequence None Mesh Gain cf. Block None Mesh Gain cf. BlockMobile 21.92 27.07 +5.15 +0.52 22.37 28.09 +5.72 +0.29Flower 22.00 27.90 +5.90 +1.06 22.18 29.40 +7.22 +0.57Table 31.77 32.79 +1.02 +1.39 32.00 34.07 +2.07 +0.32
Football 27.03 28.24 +1.21 +2.19 27.00 29.03 +2.03 +0.77
pression performance. Further improvement could be obtained by directly adapting the spatial
quantization and coding of the temporal subbands, according to the affine determinants.
Table 3 shows the reconstructed video PSNR using the mesh motion model, with 3 stages
of temporal transform, and a bit-rate of 1 Mbps. The mesh model consistently outperforms the
block motion model, so that motion compensation of the lifting steps is now seen to improve the
compression performance for every sequence.
The deformable mesh serves as a good example of how superior motion modelling can lead
to improved video compression within the LIMAT framework. Of course, a variety of more so-
phisticated motion modelling techniques exist in the literature. For example, hierarchical meshes
can achieve superior motion compensation by allocating a denser distribution of motion vectors to
regions with more complex motion [22].
3.3 The Importance Of Motion Trajectories
In Section 2.3, we showed that motion-compensating the lifting steps is equivalent to applying
the temporal DWT along an underlying set of motion trajectories, so long as the motion model is
invertible. Referring to equations (1) and (2), we see that for each forward motion warping operator,
Wk2→k1, the reverse warping operator,Wk1→k2
, is also required. In the results presented so far, only
one set of motion parameters is explicitly estimated for each such pair of warping operators. Where
the forward motion parameters are estimated, a set of reverse motion parameters is determined
using an inversion procedure, and vice-versa. Details of the inversion procedure are discussed in
Section 4.2. However, it is worth noting here that discontinuous motion models such as block-
21

based models cannot be strictly inverted, so approximations must be employed. No significant
approximations are required to invert the mesh motion models.
It is tempting instead to independently optimize the parameters of each individual motion
mapping, with respect to a displaced frame difference measure. In this case, Wk1→k2and Wk2→k1
are obtained through independent forward and backward motion estimation. The resulting motion
mappings will not generally be inverses of one another. Even in the absence of modelling or
estimation errors, discrepancies between Wk1→k2and W−1
k2→k1(if it exists) can be expected in
regions of occlusion and uncovered background. In such regions the relationship between successive
frames cannot truly be described in terms of a set of motion trajectories. Nevertheless, if we
choose to use independently optimized motion mappings, abandoning motion trajectories, we find
in practice that compression performance suffers significantly.
To quantify this effect, we compare the reconstructed PSNR obtained using directly inverted
motion mappings, with that obtained by estimating every motion mapping independently. The
results are taken using 3 stages of temporal transform, at a bit-rate of 1 Mbps. According to
Table 4, the reconstructed PSNR is uniformly higher with inverted motion fields, by as much as
2.51 dB in one case. The presented results do not include the cost of motion information1. Note
that the improvement is also generally larger for the deformable mesh model, as compared to
the block model, which lacks a true inverse. These results reinforce our earlier analysis, which
provides a meaningful interpretation to the LIMAT framework only in the context of an invertible
motion model. Even if the motion trajectories assigned by the model do not perfectly describe the
underlying scene, at least we know that the wavelet filters are being applied along those trajectories.
WhenWk1→k2andWk2→k1
are not inverses of one another, there is no clear way to understand the
behaviour of the transform, but our experimental observations suggest that enforcing the existence
1Including this cost would further penalize the performance achieved with independently estimated motion fields.
This is because there is no need to transmit motion parameters which are determined by inversion of another motion
field, but independently estimated motion fields must each be separately encoded and transmitted.
22

Table 4: Gain in reconstruction PSNR from using inverted motion fields instead of estimated motion
fields, at 1 Mbps
Sequence Haar, Block Haar, Mesh 5/3, Block 5/3, Mesh
Mobile +0.29 +0.21 +0.13 +0.09Flower +0.21 +0.46 +0.07 +0.22Table +0.51 +1.75 +0.15 +0.54
Football +0.74 +2.51 +0.31 +0.96
of motion trajectories is important for compression performance.
4 Motion Representation
In this section, we propose a representation for the motion information that allows us to avoid
coding one motion field for every motion warping operation. Instead, both encoder and decoder
derive all of the necessary motion fields by applying appropriate transformations to a much smaller
set of distinct motion mappings.
Recall that our complete temporal transform is constructed by iterative application of a single
stage. Each stage produces a low-pass and a high-pass temporal subband, using motion compen-
sated lifting steps, as described previously. Each filter tap of each lifting step in each stage involves
its own motion warping operator. The Haar transform involves two warping operators per pair of
input frames, at each stage. With multiple stages this total approaches two warping operators per
original video frame. This is doubled in the case of the 5/3 wavelet kernel. If we were to explicitly
code a motion field for every warping operator, the resulting motion overhead would reduce the
performance of the coder at low bit-rates. Instead, the motion representation proposed here allows
us to code only one motion mapping per original frame, plus occasional refinement information,
regardless of the selected wavelet kernel. The resulting motion overhead is comparable to that of
motion-compensated predictive coders.
We reduce the number of distinct motion mappings in two ways. The first arises directly from
observations in the previous section. Specifically, if we find each forward-backward pair of motion
23

mappings by estimating one and applying an inversion procedure to get the other, we actually
obtain higher coding efficiency than if each were estimated independently. Clearly then, one set of
motion parameters can represent both motion mappings.
Secondly, we exploit the relationship between the motion mappings at each decomposition stage.
Note that mappings at each stage of the transform essentially represent the same scene motion
trajectories, at different temporal resolutions. This allows us to represent a motion mapping at
any particular stage as being a composition of mappings from other stages. Section 4.2 discusses
inversion and composition of motion mappings for the block-based and deformable mesh motion
models.
4.1 Examples with the Haar and 5/3 Transforms
Figure 7 shows the motion representation associated with two stages of the proposed temporal
transform, using the 5/3 wavelet kernel. The mappings required to perform the lifting steps are
shown as arrows. At the jth transform stage, the ith forward and backward mappings are denoted
Fji and B
ji , respectively. In this paper we define a forward mapping as one which serves to warp
an earlier frame onto a later frame.
In the proposed scheme, motion mappings for each stage of the decomposition are estimated
using the corresponding original video frames, rather than the frames which are actually input
to that stage. This is more conducive to accurate estimation since the input frames may contain
ghosting artefacts caused by inadequate motion modelling in previous stages. This strategy also
allows us to determine motion mappings for any stage of the transform before knowing the input
frames to that stage, which turns out to be crucial to the representation developed here.
The entire set of motion fields in Figure 7 is represented by only F2
1and B1
2, which are shown in
black. Only these mappings need to be coded and delivered to the decoder. Inverting F2
1produces
the backward mapping B2
1. The forward mapping F1
1is recovered by compositing the second-stage
24

0 Frame 1 Frame 2 Frame
1 Lowpass0 Lowpass
11
B
12
B
21
B
11
F
12
F
21
F
0 Frame 1 Frame 2 Frame
1 Lowpass0 Lowpass
11
B
12
B
21
B
11
F
12
F
21
F
Figure 7: Motion representation for two stages of 5/3 temporal transform. Grey mappings are
inferred from the coded mappings, shown here in black.
forward mapping F2
1with the first-stage backward mapping B1
2. The remaining mappings B1
1and
F1
2are recovered by inverting F1
1and B1
2, respectively.
The representation for the Haar wavelet is a simplification of the above. In this case, mappings
F1
2and B1
2are not required, so we simply code F1
1and F2
1, and recover the corresponding backward
motion fields by inversion.
This motion representation can be iterated to any number of transform stages, and the total
number of coded mappings is never more than one per original frame. Furthermore, because the
mapping between any two frames may be recovered through a series of compositions and inversions
of the coded mapping sequences, F2
iand B1
2i, it follows that this motion representation is sufficient
for use with any wavelet kernel.
Finally, note that the motion representation scales with the temporal resolution at which the
video sequence is to be reconstructed. This is because the motion information required at any stage
in the transform involves no mappings from higher resolution stages.
25

4.2 Motion Field Inversion and Composition Strategies
We begin by presenting methods for inverting block-based and triangular mesh motion fields. A
true inverse mapping only exists for motion mappings that are continuous and one-to-one, so block-
based motion mappings are not strictly invertible. For block motion fields, we adopt an ad-hoc
approach that involves simply reversing each motion vector. This is a good approximation when
the motion is smooth and relatively small.
To invert the triangular mesh motion field, the affine transformation associated with each trian-
gular patch must be inverted. Performing the motion warping operation with an inverted mesh is
somewhat more complicated than with the original mesh, since the triangular patches do not form a
regular mesh in the warped coordinate system. This makes it more difficult to locate the triangular
patch associated with each pixel to be mapped, although this is not the dominant computational
cost for the process.
We allow the mesh to detach from the frame boundaries, employing a zero-order hold boundary
extension policy. This is important for accurate motion modelling near frame boundaries, partic-
ularly in the presence of global motion. However, the inverse only exists over the extent of the
deformed mesh, which may exclude some regions near the frame boundary. To approximate the in-
verse in these regions, we extrapolate the mesh using a point-symmetric extension technique which
preserves affine motion flows.
The inverse would be undefined in certain regions if the mesh were allowed to fold over itself,
since the one-to-one nature of the mapping would then be lost. However, this cannot happen in
practice, because our motion estimation algorithm already prevents excessive expansion or con-
traction in the motion field. As noted in Section 3.2, a weighted minimization objective function
is employed so as to avoid excessive expansion of quantization errors in the reconstructed video
sequence. Of course, this may prevent the mesh model from accurately tracking true scene mo-
tion in some regions of the video sequence. However, as already noted, the weighted minimization
26

objective results in motion fields which yield superior compression performance.
We now turn our attention to compositing motion mappings. One possible way to implement
a composited mapping is by applying each individual mapping in turn. However, this approach
suffers from the accumulation of spatial aliasing and other distortions that typically accompany
each warping step. To avoid these problems, we construct a single forward mapping, by projecting
the motion vectors through the various component mappings.
In the case of the block motion model, we determine each pixel’s trajectory through the set of
component mappings. The composit motion vector for a particular block is then approximated by
the average trajectory for all pixels within the block.
We composit triangular mesh mappings by warping the mesh node points through each com-
ponent mapping. The sequence of component mappings are therefore approximated by a new
triangular mesh, which serves to interpolate the projected trajectories of its nodes.
To avoid possible loss in performance due to the approximations made by our composition
strategy, our coder has the option of refining any motion mapping that is inferred by the compositing
process. Using the directly estimated field as a reference, if the composited field contains significant
error, a refinement field is also coded. Refinement fields are irrelevant for the Haar transform, which
involves no composited mappings. The 5/3may require a maximum of one refinement field for every
pair of mappings, at each stage in the transform. In any event, the refinement fields consist mostly
of zeros, and so are less costly to encode.
The decision of when to code refinement fields raises the classic problem of rate allocation
between motion parameters and subband coefficients. For the purpose of these experiments, we
circumvent this issue by coding all refinement fields. At very low bit-rates the motion cost becomes
more significant and superior results may be achieved by selectively coding the refinement fields.
It is worth noting that the proposed motion representation strategy is well aligned with efficient
methods for motion estimation. Wherever possible, an initial guess for the motion parameters
27

is found by inverting and compositing previously estimated motion fields, as appropriate. This
significantly reduces the computational load associated with motion estimation. In total, only one
full motion estimation operation is required per original frame.
To actually code the motion information, we apply the JPEG-LS algorithm [23] directly to the
arrays of horizontal and vertical motion vector components.
5 Experimental Results
We provide results for the block-based motion model and the triangular deformable mesh model,
using three levels of temporal transform. We use the first 96 frames of the standard test sequences,
Mobile and Calender, Table Tennis, Flower Garden and Football. The original full colour sequences
have a frame-rate of 30 fps and a spatial resolution of 352 × 240. Chrominance components are
subsampled by 2 in each dimension.
The block-based model is implemented using a hierarchical search algorithm. A coarse motion
field is first estimated by full-search block matching at half the spatial resolution. The search range
is relative to the temporal displacement of ±8 pixels per frame, except for the Football sequence
where a search range of ±16 is used. The coarse motion field is successively refined up to 1/4
pixel accuracy, using cubic spline interpolation of the original frames. The block size is 16 × 16
pixels, giving 330 motion vectors per field. The estimation algorithm uses the mean-squared error
distortion metric.
Our triangular mesh is created with a node spacing of 16 pixels, by dividing 16 × 16 blocks
along their diagonals. Motion vectors are estimated for each node in the mesh, resulting in 368
vectors per motion mapping. A coarse motion field is estimated by full-search block matching at
half the spatial resolution, with overlapping blocks centred at each node-point. We use the same
search ranges and motion vector precision as with the block model. As discussed in Section 3.2,
refinement of the motion field is performed using a hexagonal refinement algorithm, where the
28

Table 5: PSNR performance of LIMAT at 1 MbpsSequence No DWT Haar Haar, Block Haar, Mesh 5/3 5/3, Block 5/3, MeshMobile 19.55 +2.37 +6.86 +7.32 +2.82 +7.98 +8.16Flower 21.10 +0.90 +5.40 +6.51 +1.08 +7.19 +7.59Table 28.50 +3.27 +2.60 +3.98 +3.50 +4.77 +4.97
Football 26.25 +0.78 −0.59 +1.54 +0.75 +1.37 +2.08
estimated distortion is weighted by the determinant of the relevant affine transformation.
The temporal subband frames are subjected to spatial wavelet decomposition and embedded
block coding of the quantized wavelet coefficients, using an implementation of the JPEG2000 image
compression standard. Although results are given only for luminance components, the chrominance
components are also coded and are assigned equal importance (energy weight) during rate alloca-
tion. A constant number of bits are allocated to each group of 8 original frames.
Tables 5 and 6 give the reconstructed luminance PSNR at bit-rates of 1 Mbps and 500 kbps,
respectively. These results include the cost of coding the motion information. To emphasize
the scalability of the compression system, the test bit-rates were obtained by simply discarding
unwanted bits from an original bit-stream compressed to a much higher bit-rate.
Evidently, including the cost of coding the motion information does not affect the conclusions
drawn so far. For example, the 5/3 wavelet still consistently outperforms the Haar, although
the improvement is slightly diminished at the lower bit-rate, where the added cost of coding the
refinement fields comes into effect. Selective coding of the refinement fields is likely to be beneficial
here. The mesh motion model is still largely superior to the block model, although the difference
is less significant at the lower bit-rate. This is because the block motion fields tend to be more
spatially coherent and hence code more efficiently. We expect that improved regularization of the
mesh, especially around frame boundaries, should close the gap between block and mesh motion
coding efficiencies. However, these matters are not central to the conclusions of the present paper.
Our compression results compare favourably with others reported in the literature. Table 7
compares LIMAT with the Motion-Compensated 3D Subband Coder (MC-3DSBC) proposed in [7],
29

Table 6: PSNR performance of LIMAT at 500 kbpsSequence No DWT Haar Haar, Block Haar, Mesh 5/3 5/3, Block 5/3, MeshMobile 17.97 +2.13 +5.22 +5.47 +2.44 +5.89 +5.85Flower 18.93 +0.98 +4.56 +5.18 +1.15 +5.71 +5.69Table 26.02 +2.98 +2.35 +3.42 +3.37 +4.18 +4.20
Football 23.87 +0.71 −0.71 +1.34 +0.67 +0.93 +1.45
Table 7: PSNR performance of LIMAT, compared with MC-3DSBC, at 1.2 MbpsSequence MC-3DSBC LIMATMobile 27.01 +1.77Flower 27.55 +2.17Table 33.78 +0.57
Football 28.02 +1.11
at 1.2 Mbps. MC-3DSBC uses the block-displacement approach, employing the Haar wavelet and
a hierarchical block motion model. Evidently, the LIMAT framework, employing the 5/3 wavelet
transform and the deformable mesh motion model, outperforms MC-3DSBC in each sequence.
The proposed coder also significantly outperforms that proposed in [4], which employs a frame-
warping approach in the temporal transform. For example, using 120 frames of the Flower Garden
sequence, a luminance PSNR of 23.3 dB, at 1Mbps, was reported in [4]. For the same test scenario,
the proposed 5/3 transform with deformable mesh motion modelling achieves 28.6 dB PSNR.
To appreciate how the LIMAT framework adapts to scene motion, consider the frame-by-frame
PSNR results shown in Figure 8, for the Table Tennis sequence. The reconstructed bit-rate is
1Mbps, and we use the 5/3 wavelet with deformable mesh motion modelling. The camera is
stationary in the first and last parts of the sequence; the only motion is that of the rapidly moving
table-tennis ball, so motion-compensating the transform provides little added benefit. In the middle
of the sequence the camera is zooming. This motion is captured by the mesh model, providing 2-3
dB gain in PSNR. Improved results would be possible by detecting the scene change at the 68th
frame, and modifying the wavelet transform accordingly. Note that in regions of significant motion,
the temporal transform by itself does nothing to improve the coding efficiency, compared to coding
the original frames directly.
30

0 10 20 30 40 50 60 70 80 90 10026
28
30
32
34
36
38
40
Frame Number
PSN
R (
dB)
5/3, No motion5/3, Mesh
No DWT
0 10 20 30 40 50 60 70 80 90 10026
28
30
32
34
36
38
40
Frame Number
PSN
R (
dB)
5/3, No motion5/3, Mesh
No DWT5/3, No motion5/3, Mesh
No DWT
Figure 8: Reconstructed PSNR at 1 Mbps for the Table Tennis sequence.
To investigate the scalability of the proposed transform, the first three curves plotted in Figure
9 reveal rate-distortion performance for full, half and quarter frame-rate reconstruction of the
Flower Garden sequence at 1Mbps. Observe that the rate-distortion behaviour is the same for
each temporal resolution. These curves are generated from a single highly scalable compressed
bit-stream, discarding unwanted bits and temporal resolutions, as appropriate. As expected, for
a given bit-rate, we could choose to decode the video at a reduced frame-rate, and achieve higher
PSNR for each decoded frame. In this way one could exchange smooth rendition of the scene
motion for higher individual frame quality.
An important consideration when comparing reduced frame-rate video sequences, is the selected
reference video sequence. Simply subsampling the original video does not necessarily represent the
most appropriate reduced temporal resolution reference, particularly in the presence of noise. For
the results presented in Figure 9, we use the unquantized reduced temporal resolution sequences
as our references. These are the result of motion-compensated temporal low-pass filtering, which
can be considered a valid method for downsampling video.
31

As an alternative, we could take every second or fourth original video frame as our respective
references for the half and quarter resolution video sequences. In this case, somewhat higher PSNR
can be obtained by using a different temporal transform, in which only the first (prediction) lifting
step shown in equation (2) is used. The equivalent low- and high-pass analysis filters have one and
three taps, respectively. Accordingly, we may refer to this as the 1/3 transform. Unlike the Haar
and 5/3 wavelets, the low-pass subband frames are now obtained without any filtering at all, so
they do not exhibit ghosting artefacts if the scene motion is poorly modelled. In fact, the reduced
resolution video sequences obtained by discarding temporal synthesis stages from the 1/3 transform
correspond directly to subsampled frames from the original sequence.
Using the 1/3 transform we find that compression performance at full frame-rate suffers by 1
to 2 dB, relative to that obtained using the full 5/3 transform. However, for the 1/3 transform
it is meaningful to plot the half resolution rate-distortion performance using the original frames
as our reference. The behaviour is illustrated by the dotted curve in Figure 9. Interestingly, the
figure reveals that higher individual frame PSNR values can sometimes be achieved by decoding the
5/3-coded sequence at full resolution, than by decoding the 1/3-coded sequence at half resolution.
6 Conclusions
We have proposed a new framework for the construction of invertible motion adaptive temporal
transforms. The LIMAT framework is based on the lifting representation of the temporal DWT,
with motion-compensated lifting steps. Invertibility is an inherent property of the lifting structure,
irrespective of the manner in which we model or compensate for motion.
Incorporation of sophisticated motion models allows the transform to adapt to complex motion.
We demonstrate this with a deformable mesh motion model. Deformable meshes can improve mo-
tion compensation by tracking expansions and contractions, while maintaining a continuous motion
field. More importantly, only continuous motion mappings allow us to understand the proposed
32

50 100 200 400 800 1600 320015
20
25
30
35
40
45
50
Bit-rate (kbps)
PSN
R (
dB)
1/3 Half Res.
5/3 Full Res.
5/3 Quarter Res.5/3 Half Res.
50 100 200 400 800 1600 320015
20
25
30
35
40
45
50
Bit-rate (kbps)
PSN
R (
dB)
1/3 Half Res.
5/3 Full Res.
5/3 Quarter Res.5/3 Half Res.
1/3 Half Res.
5/3 Full Res.
5/3 Quarter Res.5/3 Half Res.
Figure 9: Rate-Distortion Curves for Flower Garden Sequence
transform as truly applying the temporal DWT along a set of motion trajectories. Experimental
results reveal that this is particularly desirable for compression performance.
The LIMAT framework is amenable to any temporal wavelet kernel. We observe consistently
superior performance with the 5/3 wavelet as compared to the Haar transform. This differs from
evidence reported in the context of block-based and frame-warping approaches.
We also provide a compact representation for the motion parameters, which reduces the number
of distinct motion mappings to the point where the motion overhead is comparable to that of
motion-compensated predictive coders.
References
[1] G. Karlsson and M. Vetterli, “Three-dimensional subband coding of video,” Proc. Int. Conf.
Acoust. Speech and Sig. Proc., vol. 2, pp. 1100—1103, Apr 1988.
33

[2] B.J. Kim and W.A. Pearlman, “An embedded wavelet video coder using three-dimensional set
partitioning in hierarchical trees (SPIHT),” Proc. IEEE Data Compression Conf. (Snowbird),
pp. 251—260, Mar 1997.
[3] A. Said and W. Pearlman, “A new, fast and efficient image codec based on set partitioning in
hierarchical trees,” IEEE Trans. Circ. Syst. for Video Tech., pp. 243—250, June 1996.
[4] D.S. Taubman and A. Zakhor, “Multi-rate 3-d subband coding of video,” IEEE Trans. Image
Proc., vol. 3, no. 5, pp. 572—588, September 1994.
[5] J. Tham, S. Ranganath, and A. Kassim, “Highly scalable wavelet-based video codec for very
low bit-rate environment,” IEEE Journal on Selected Areas in Comm., vol. 16, pp. 12—27, Jan
1998.
[6] J. Ohm, “Three dimensional subband coding with motion compensation,” IEEE Trans. Image
Proc., vol. 3, pp. 559—571, Sep 1994.
[7] S. Choi and J. Woods, “Motion compensated 3-D subband coding of video,” IEEE Trans.
Image Proc., vol. 8, pp. 155—167, Feb 1999.
[8] A. Secker and D. Taubman, “Motion-compensated highly scalable video compression using
an adaptive 3D wavelet transform based on lifting,” Proc. IEEE Int. Conf. Image Proc., pp.
1029—1032, Oct 2001.
[9] A. Secker and D. Taubman, “Highly scalable video compression using a lifting-based 3d wavelet
transform with deformable mesh motion compensation,” Proc. IEEE Int. Conf. Image Proc.,
pp. 749—752, Sep 2002.
[10] B. Pesquet-Popescu and V. Bottreau, “Three-dimensional lifting schemes for motion compen-
sated video compression,” Proc. Int. Conf. Acoust. Speech and Sig. Proc., pp. 1793—1796, May
2001.
[11] W. Sweldens, “The lifting scheme: A custom-design construction of biorthogonal wavelets,”
Applied and Computational Harmonic Analysis, vol. 3, no. 2, pp. 186—200, April 1996.
[12] I. Daubechies and W. Sweldens, “Factoring wavelet and subband transforms into lifting steps,”
Tech. Rep., Technical report, Bell Laboratories, Lucent Technologies, 1996.
[13] D.S. Taubman andM.W. Marcellin, JPEG2000: Image Compression Fundamentals, Standards
and Practice, Kluwer Academic Publishers, Boston, 2002.
[14] R. Calderbank, I. Daubechies, W. Sweldens, and B. Yeo, “Wavelet transforms that map
integers to integers,” Applied and Computational Harmonic Analysis, vol. 5, no. 3, pp. 332—
369, July 1998.
[15] V.K. Heer and H.-E. Reinfelder, “A comparison of reversible methods for data compression,”
Proc. SPIE conference, ‘Medical Imaging IV’, vol. 1233, pp. 354—365, 1990.
[16] D. Le Gall and A. Tabatabai, “Sub-band coding of digital images using symmetric short kernel
filters and arithmetic coding techniques,” IEEE International Conference on Acoustics, Speech
and Signal Processing, vol. 2, pp. 761—764, April 1988.
34

[17] J. Ohm, “Advanced packet-video coding based on layered VQ and SBC techniques,” IEEE
Trans. Circ. Syst. for Video Tech., vol. 3, no. 3, pp. 208—221, June 1993.
[18] H. Brusewitz, “Motion compensation with triangles,” Proc. 3rd Int. Conf. 64-kbit Coding of
Moving Video, Sep 1990.
[19] G.J. Sullivan and Baker R.L., “Motion compensation for video compression using control grid
interpolation,” Proc. Int. Conf. Acoust. Speech and Sig. Proc., pp. 2713—2716, May 1991.
[20] V. Seferdis and M. Ghanbari, “General approach to block-matching motion estimation,”
Optical Engineering., vol. 32, no. 7, pp. 1464—1474, Jul 1993.
[21] Y. Nakaya and H. Harashima, “Motion compensation based on spatial transformations,” IEEE
Trans. Circ. Syst. for Video Tech., vol. 4, pp. 339—367, Jun 1994.
[22] C.L. Huang and Hsu C.Y., “A new motion compensation method for image sequence coding
using hierarchical grid interpolation,” IEEE Trans. Circ. Syst. for Video Tech., , no. 4, pp.
42—52, Feb 1994.
[23] M.J. Weinberger, G. Seroussi, and G. Sapiro, “LOCO-I: A low complexity, context-based,
lossless image compression algorithm,” Proc. IEEE Data Compression Conf. (Snowbird), pp.
140—149, April 1996.
35