deep web under the guidance of prof. pushpak bhattacharyya presented by - jayanta das (11305r012)...
Post on 18-Dec-2015
219 views
TRANSCRIPT

Deep Web
Under the guidance of Prof. Pushpak Bhattacharyya
Presented by -Jayanta Das (11305R012)Souvik Pal (113059003)Subhro Bhattacharyya (113059005)
(Group 4)

Introduction
What is Deep Web

Introduction: What is Deep Web
• Modern Internet: Most effective source of information.
• Most popular search engine: Google• In 2008, Google added Trillionth (1012) web
link to their index database!• Stores several billion documents!• Despite many a times we are not satisfied
with the search results.– 43 % users reports dissatisfaction about the results

Real Life Example

Motivation: Why Deep Web
• Then why Google fails?• Most of the Web's information is buried far
down on dynamically generated sites.– Traditional web crawler cannot reach there.– Large portion of data are literally ‘un-explored’ • Quest for exploration of unknown – a human instinct
– Need for more specific information stored in databases• Can only be obtained if we have access to the database
containing the information.

Evolution of Deep Web
• Early Days: static html pages, crawlers can easily reach
• In mid-90’s: Introduction of dynamic pages, that are generated as a result of a query.
• In 1994: Jill Ellsworth used the term “Invisible Web” to refer to these websites.
• In 2001, Bergman coined it as “Deep Web”

Measuring the Deep Web (1)
• “… when you can measure what you are speaking about, and express it in numbers, you know something about it…” – Lord Kelvin
• First Attempt: Bergman (2000 )– Size of surface web is around 19 TB– Size of Deep Web is around 7500 TB – Deep Web is nearly 400 times larger than the
Surface Web

Measuring the Deep Web (2)
• In 2004 Mitesh classified the deep web more acurately
• Most of the html forms are found either on the fist hop or 2nd hop from the home page

Measuring the Deep Web (3)
• Unstructured: Data objects as unstructured media (text, images, audio, video)– e.g www.cnn.com
• Structured: data objectsas structured “relational”records with attribute-value pairs.

Deep Resources• Dynamic Web Pages
– returned in response to a submitted query or accessed only through a form
• Unlinked Contents– Pages without any backlinks
• Private Web– sites requiring registration and login (password-protected resources)
• Limited Access web– Sites with captchas, no-cache pragma http headers
• Scripted Pages– Page produced by javascrips, Flash, AJAX etc
• Non HTML contents– Multimedia files e.g. images o videos

Approach towards crawling
Deep Web

Timeline: How it all started!
• 2001: Raghavan et al -> Hidden Web Exposer– domain specific human assisted crawler
• 2002: Stumbleupon used Human Crawler– human crawlers can find relevant links that
algorithmic crawlers miss.
• 2003: Bergman introduced LexiBot– used for quantifying the deep web
• 2004: Yahoo! Content Acquisition Program– paid inclusion for webmasters

Time line contd…
• 2005: Yahoo! Subscriptions– Yahoo started searching subcription only sites• eg WSJ
• 2005: Notulas et. al. -> Hidden Web Crawler– automatically generated meaningful queries to
issue against search form
• 2005: Google site map– Allows webmasters to inform search engines
about urls on their websites that are available for crawling.

Present Deep Web Search Scenario
• Federated Search• Google’s surfacing

Federated Search
• Federated search is the process of performing a real-time search of multiple diverse and distributed sources from a single search page, with the federated search engine acting as intermediary.
• Why federated?– Content from different sources are combined
instead of searching the sources one at a time.

Federated Search: Properties (1)
• Real Time– Fed search occurs live and results are current.
• Diverse and Distributed Sources– Multiple sources present in different locations in
the web are serached. Sources are diverse in nature containing text, documents, pdfs, ppts etc.

Federated Search: Properties (2)
• Single Search page– Fed search engines provide a single point of
searching.
• Fed Search engine acts as intermediary– User does not communicate directly with the
content sources when performing searches. The search engine does it on the user’s behalf.

Federated Search Method
• Works by filling out forms on web pages.
• The search engine is programmed with the knowledge of each form that it has to search.
• It knows how to fill out the form, press the ‘submit’ button and retrieve the results.

Web Form example
A web form that a normal search engine cannot crawl . This involves fillingin the textbox, clicking ‘search’ and retreiving the results.
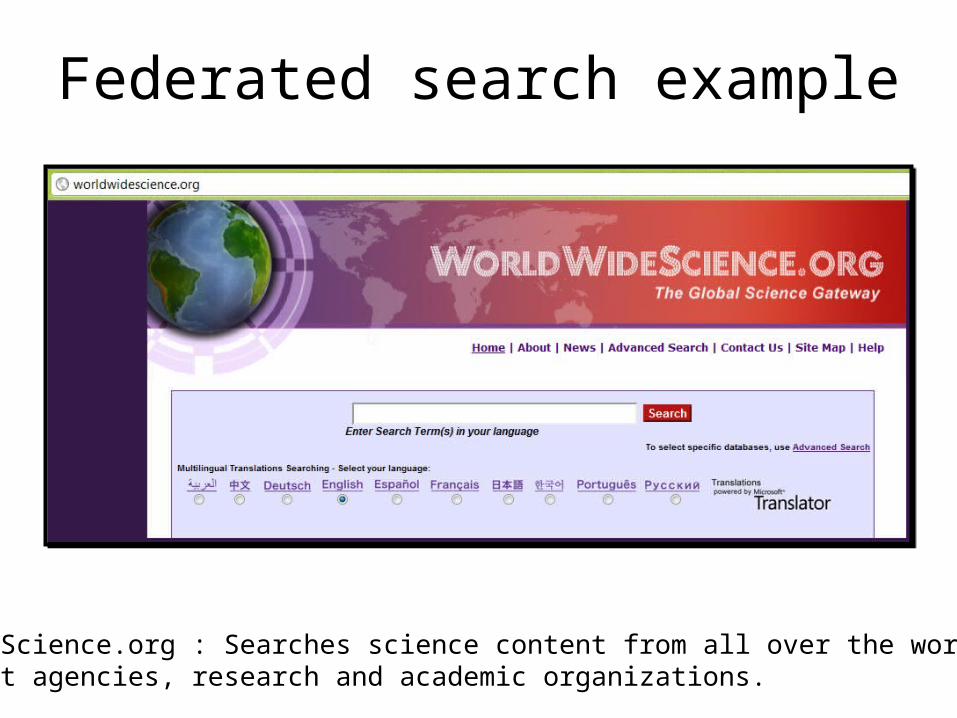
Federated search example
WorldWideScience.org : Searches science content from all over the world, from government agencies, research and academic organizations.

Incremental search : Federated search engines do not wait for results from all sources.To improve response time results are displayed in chunks while the search continues in the background. When a new result set is available the user is prompted.
Fed Search In Action

Metasearch vs Fed Search• Metasearch is similar to federated search.• Here the search engine searches other search
engines in real time.• Even though they search the underlying
search engine in real time, the underlying search engines may not have the most current information as they themselves are crawlers.
• It is NOT a Deep Web Seach!– People often confuse between Meta Search and
Fed Search

Metasearch example

Federated Search (Advantages)
• Efficiency, Time SavingsInstead of querying many search engines one at a time , the federated search engine does it on the user’s behalf
• Quality of resultssearches only authoritative sources since it has been programmed to do so.
• Most Current contentSearches in real time.

Federated Search (Challenges)
• Aggregation– The process of combining search results from
different sources in some helpful way eg: sorting by date,title,author
• Ranking– Displaying results relevant to search
• De-duplication– A federated search engine may retreive the same
result from multiple resources

Google’s reasons to move away from Fed Search
• Federated search works quite well when it is restricted to one domain.
• In case of general search involving multiple domains it is not as effective. – Number of domains is extremely large – Defining boundary of domain difficult. – Mapping a query to a domain difficult– Dependent on latency of deep web sources.

Case Study:Google’s Crawling

Case Study: Google’s crawling (1)
• Two approaches for Deep Web Crawling:–Virtual Integration–Surfacing
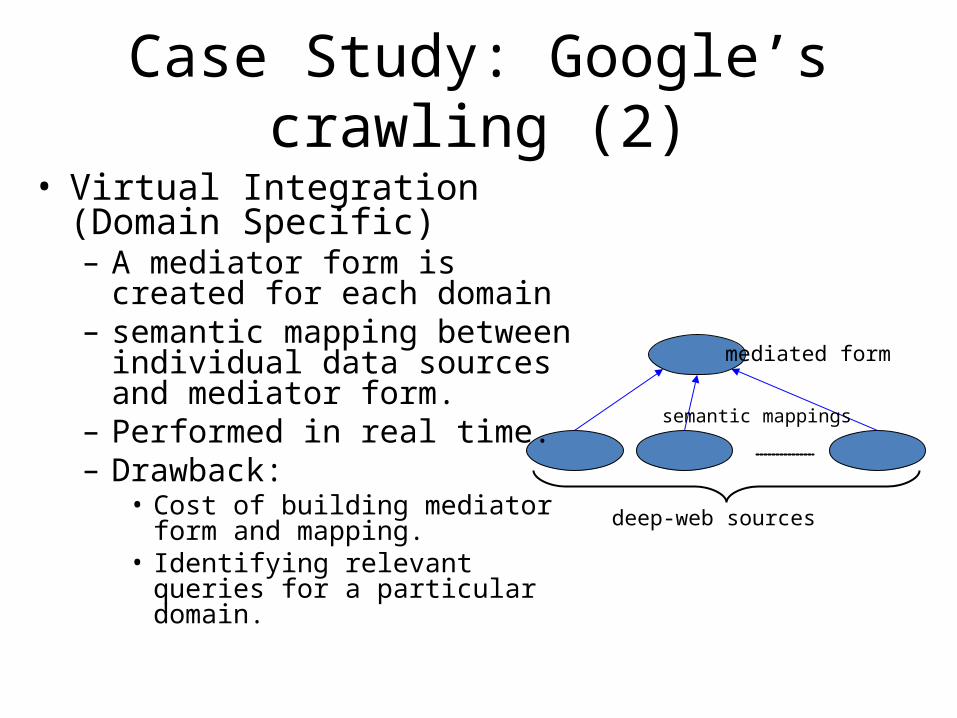
mediated form
deep-web sources
semantic mappings
Case Study: Google’s crawling (2)• Virtual Integration (Domain
Specific)– A mediator form is created for each
domain– semantic mapping between
individual data sources and mediator form.
– Performed in real time.– Drawback:
• Cost of building mediator form and mapping.
• Identifying relevant queries for a particular domain.

Case Study: Google’s crawling (3)
• Surfacing:– Precomputes most relevant form values for
‘interesting’ html forms– Resulting urls are generated offline and indexed– Helps in retaining exsiting infrustructure while
inclusion of Deep Web– Covers maximum web pages while bounding the
total number of web form submissions– GET vs POST method

Case Study: Google’s crawling (4)
• Challenges:– Which form inputs to fill– Appropiate values to those inputs
• Google’s approach:– Selecting wild card for form submission• Some fields are mandetory
– Query template– Testing with all possible values in select menu– Predicting form values from datatypes

Subconcious Mind and Deep Web
• Inspiration behind exploration of deep web
• Analogy– Iceberg example– Real life example

References(1)1. Wikipedia,
http://en.wikipedia.org/wiki/Deep_web2. Bergman, Michael K , "The Deep Web: Surfacing Hidden Value". The Journal of
Electronic Publishing , August 2001
3. Alex Wright, "Exploring a 'Deep Web' That Google Can’t Grasp". The New York Times. Sept 23, 2009.http://www.nytimes.com/2009/02/23/technology/internet/23search.html?th&emc=th
4. Jesse Alpert & Nissan Hajaj, “We knew the web was big…”, 2008http://googleblog.blogspot.com/2008/07/we-knew-web-was-big.html
5. He, Bin; Patel, Mitesh; Zhang, Zhen; Chang, Kevin Chen-Chuan ,"Accessing the Deep Web: A Survey". Communications of the ACM (CACM), May 2007

References(2)6. Madhavan, Jayant; David Ko, Łucja Kot, Vignesh Ganapathy, Alex Rasmussen, Alon
Halevy, Google’s Deep-Web Crawl, 2008
7. Maureen Flynn-Burhoe, "Timeline of events related to the Deep Web" ,2008, http://papergirls.wordpress.com/2008/10/07/timeline-deep-web/
8. Darcy Pedersen, "Federated Search Finds Content that Google Can’t Reach Part I of III" , 2009,http://deepwebtechblog.com/federated-search-finds-content-that-google-can’t-reach-part-i-of-iii/
9. Darcy Pedersen, "A Federated Search Primer – Part II of III" , 2009, http://deepwebtechblog.com/a-federated-search-primer-part-ii-of-iii/
10. Darcy Pedersen, "A Federated Search Primer – Part IIIof III" , 2009, http://deepwebtechblog.com/a-federated-search-primer-part-iii-of-iii/

THANK YOU