dedu: building a deduplication storage system over cloud computing this paper appears in : computer...
TRANSCRIPT

DeDu: Building a Deduplication Storage system over Cloud computing
This paper appears in : Computer Supported Cooperative work in Design(CSCWD) ,2011 15th InternationalData of Conference: 8-10 June 2011Author(s): Zhe Sun, Jun Shen, Fac. of inf., Univ. of Wollongong, Wollongong, NSW, Australia Jianming Yong, Fac. of bus., Univ. of Southern Queensland, Toowoomab, QLD ,Australia
Speaker: Yen-Yi Chen MA190104Date:2013/05/28

Outline
• Introduction• Two issues to be addressed• Deduplication• Theories and approaches • System design• Simulations and Experiments• Conclusions

Introduction
• 雲端運算興起、分散式系統架構• 資訊爆炸、資料海量• 儲存設備成本上升• 增加資料傳輸與減緩佔用網路頻寬

Introduction
• System name: DeDu• Front-end: deduplication application• Back-end: Hadoop Distributed File System
• HDFS• HBase

Two issues to be addressed
• How does the system identify the duplication? *hash function-MD5 and SHA-1
• How does the system manage the data? *HDFS and HBase

Deduplication
A C
B A
C
B
C
CA
AB
A
A
A
B
B
C
C
B
Data Store Data StoreData Store
a a
a
c
b
b
1. Data chunks are evaluated to determine a unique signature for
each
2. Signature values are compared to identify all
duplicates
3.Duplicate data chunks are replaced
with pointes to a single stored chunk. Saving
storage space
類別 File-level Block-level
重複資料比對層級 檔案 區塊
重複資料比對範圍 整個指定磁碟區 整個指定磁碟區
優點對單一檔案的容量刪減效果最好
可跨檔案比對,也能比對不同檔案底層的重複部份
缺點對已編碼檔案無效,對完全相同的兩份檔案仍會重複儲存
較消耗處理資源
重複資料刪檢比例 1:2~1:5 1:200甚至更高

Theories and approaches
A. The architecture of source data and link filesB. Architecture of deduplication cloud storage system
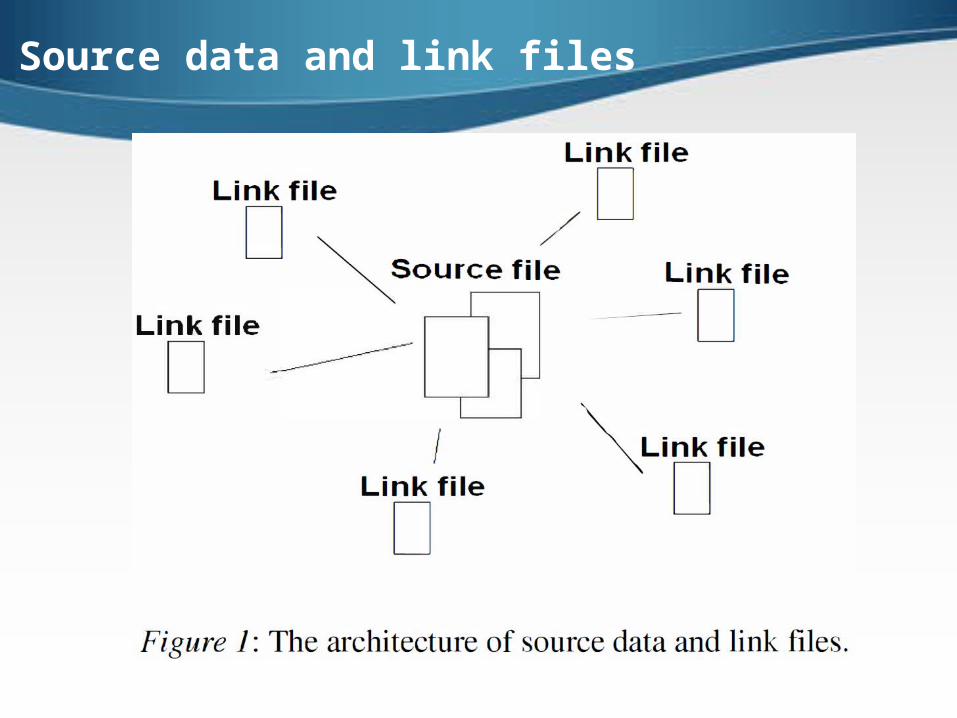
Source data and link files

Deduplication Cloud storage system

System design
A. Data organisationB. Storage of the filesC. Access to the filesD. Deletion of files

Data organisation

Storage of the files
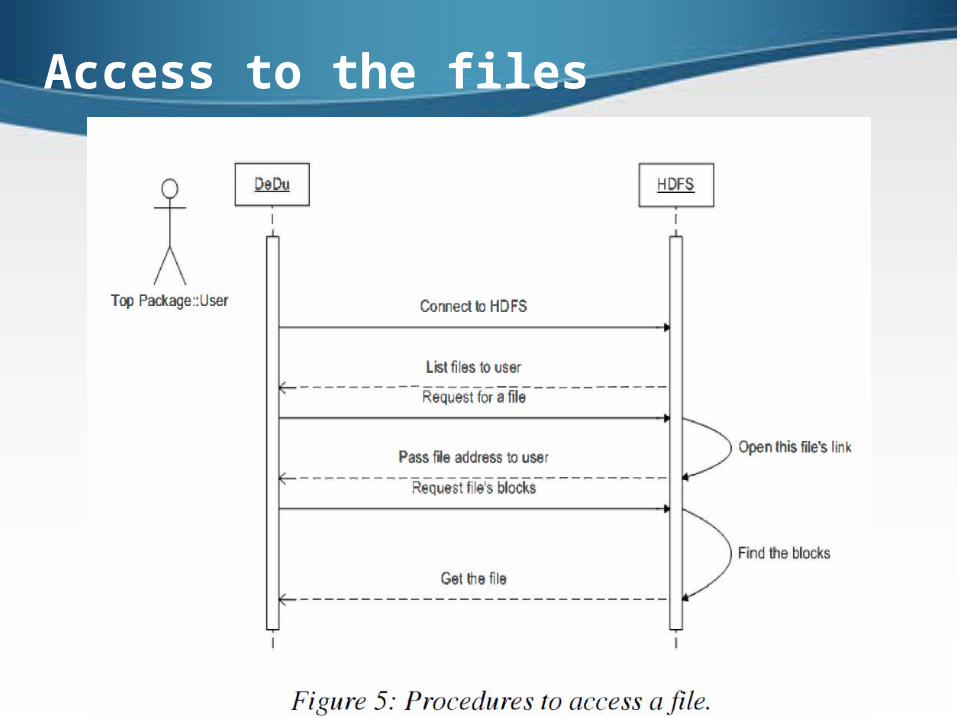
Access to the files
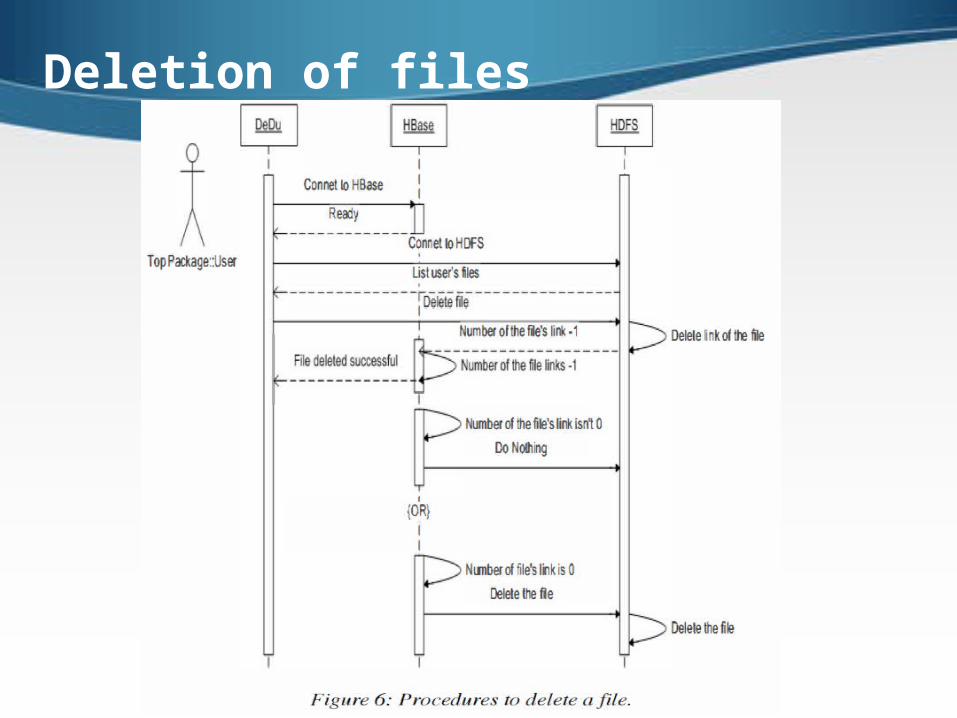
Deletion of files
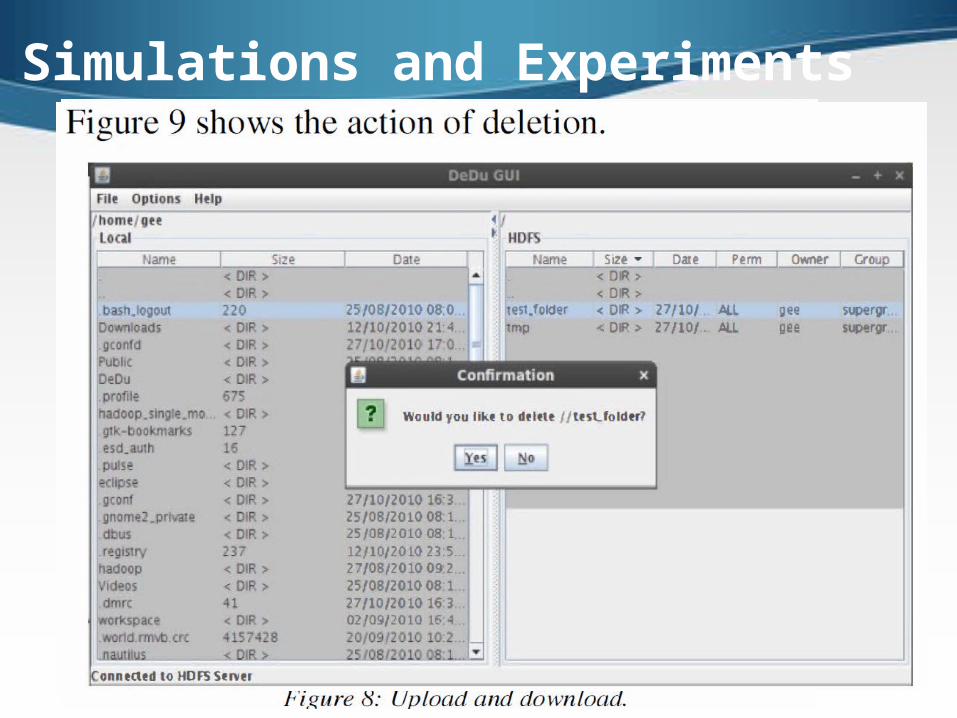
Simulations and Experiments
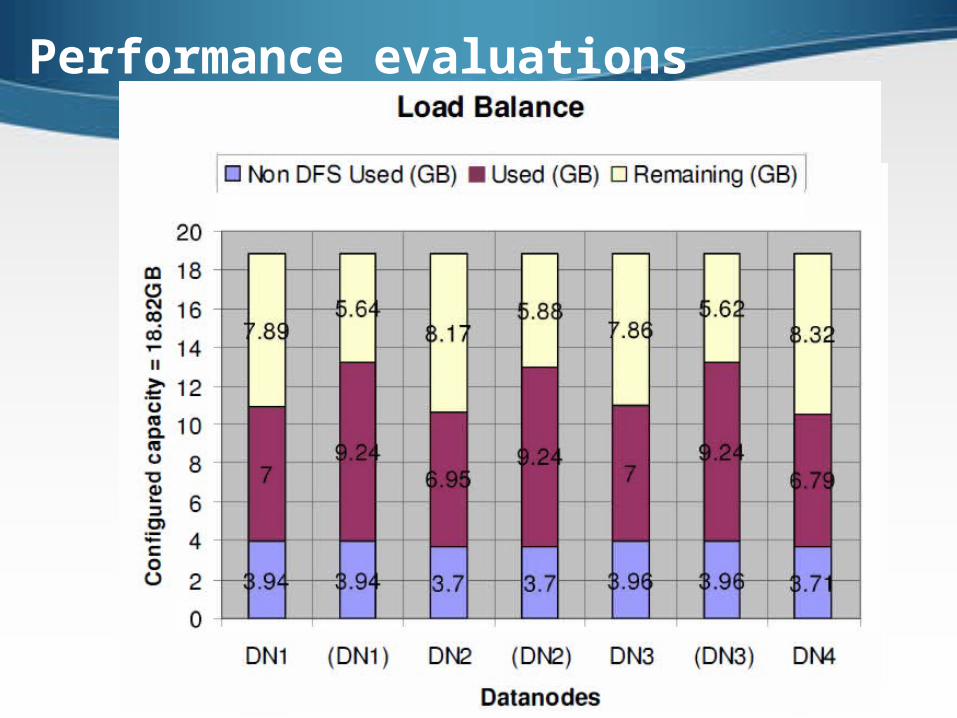
Performance evaluations

Conclusions
• 1. The fewer the data nodes, the writing efficiency is high; but the reading efficiency is low;• 2. The more data nodes, the writing efficiency is low, but reading efficiency is hight;• 3. single file is big, the time to calculate hash values becomes higher ; but transmission cost is low;• 4.single file is small, the time to calculate hash
values becomes lower ; but transmission cost is high.

Thanks for your listening