decisiontree-110906040745-phpapp01
TRANSCRIPT

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 1/30
R. AkerkarTMRF, Kolhapur, India
1R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 2/30
Introduction
A classification scheme which enerates a tree and
a set of rules from given data set.
e set o recor s ava a e or eve op ngclassification methods is divided into two disjointsubsets – a trainin set and a test set .
The attributes of the records are categorise into twotypes:
r u es w ose oma n s numer ca are ca e numer caattributes.
Attributes whose domain is not numerical are called theca egor ca a r u es.
2R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 3/30
Introduction
A decision tree is a tree with the followin ro erties:
An inner node represents an attribute. An edge represents a test on the attribute of the father
.
A leaf represents one of the classes.
Construction of a decision tree
Based on the training data
op- own s ra egy
3R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 4/30
Decision TreeExample
The data set has five attributes. There is a special attribute: the attribute class is the class label. The attributes, temp (temperature) and humidity are numerical
attributes Other attributes are categorical, that is, they cannot be ordered.
Based on the training data set, we want to find a set of rules toknow what values of outlook, temperature, humidity and wind,
4R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 5/30
Decision Tree
Example
We have five leaf nodes. In a decision tree, each leaf node represents a rule.
We have the following rules corresponding to the tree given inFigure.
, . RULE 2 If it is sunny and the humidity is above 75%, then do not play. RULE 3 If it is overcast, then play. RULE 4 If it is rainy and not windy, then play. s ra ny an w n y, en on p ay.
5R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 6/30
Classification
The classification of an unknown in ut vector is done b
traversing the tree from the root node to a leaf node. A record enters the tree at the root node.
,node the record will encounter next.
This process is repeated until the record arrives at a leafno e.
All the records that end up at a given leaf of the tree areclassified in the same way.
There is a unique path from the root to each leaf.
The path is a rule which is used to classify the records.
6R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 7/30
In our tree, we can carry out the classificationfor an unknown record as follows.
Let us assume, for the record, that we know
do not know the value of class attribute) as
outlook= rain; temp = 70; humidity = 65; and = .
7R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 8/30
We start from the root node to check the value of the attributeassociated at the root node.
This attribute is the splitting attribute at this node.
For a decision tree, at every node there is an attribute associatedwith the node called the splitting attribute.
In our example, outlook is the splitting attribute at root.
Since for the given record, outlook = rain, we move to the right-
most child node of the root. At this node, the splitting attribute is windy and we find that for
the record we want classify, windy = true.
Hence, we move to the left child node to conclude that the class
label Is "no play ".
8R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 9/30
The accuracy of the classifier is determined by the percentage of thetest ata set t at s correct y c ass e .
We can see that for Rule 1 there are two records of the test data setsatisfying outlook= sunny and humidity < 75, and only one of theseis correctly classified as play.
Thus, the accuracy of this rule is 0.5 (or 50%). Similarly, theaccuracy of Rule 2 is also 0.5 (or 50%). The accuracy of Rule 3 is0.66.
RULE 1
If it is sunny and the humidity is not above 75%, then play.
9R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 10/30
Concept of Categorical Attributes Consider the following training
data set.
There are three attributes,namely, age, pincode and class.
The attribute class is used for
class label.
The attribute age is a numeric attribute, whereas pincode is a categorical
one.
oug e oma n o p nco e s numer c, no or er ng can e e neamong pincode values.
You cannot derive any useful information if one pin-code is greater thanano er p nco e .
10R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 11/30
Figure gives a decision tree for the
.
The splitting attribute at the root is
here is pincode = 500 046. Similarly, for the left child node, the
s littin criterion is a e < 48 thesplitting attribute is age).
Although the right child node has At root level, we have 9 records.The associated s littin criterion isthe same attribute as the splittingattribute, the splitting criterion isdifferent.
pincode = 500 046.
As a result, we split the recordsinto two subsets. Records 1, 2, 4, 8,
and 9 are to the left child note andremaining to the right node.
The process is repeated at every
node.
11R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 12/30
Advantages and Shortcomings of Decision
Tree Classifications A decision tree construction process is concerned with identifying
the splitting attributes and splitting criterion at every level of the tree.
Major strengths are:
Decision tree able to generate understandable rules.
They are able to handle both numerical and categorical attributes.
They provide clear indication of which fields are most important for.
Weaknesses are:
.each node, each candidate splitting field is examined before its best splitcan be found.
Some decision tree can only deal with binary-valued target classes.
12R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 13/30
Iterative Dichotomizer (ID3) Quinlan (1986)
Each node corresponds to a splitting attribute
Each arc is a possible value of that attribute.
At each node the splitting attribute is selected to be the mostinformative among the attributes not yet considered in the path from
the root.
Entropy is used to measure how informative is a node.
The algorithm uses the criterion of information gain to determine the
goo ness o a sp . The attribute with the greatest information gain is taken as
the splitting attribute, and the data set is split for all distinct.
13R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 14/30
Training DatasetThis follows an example from Quinlan’s ID3
age income student credit_rating buys_computer
<=30 hi h no fair no
The class label attribute,buys_computer , has two distinctvalues.
<=30 high no excellent no
31…40 high no fair yes
>40 medium no fair yes
>40 low yes fair yes
Thus there are two distinctclasses. (m =2)
Class C1 corresponds to yes
>40 low yes excellent no
31…40 low yes excellent yes
<=30 medium no fair no
<=30 low yes fair yes
.
There are 9 samples of class yes and 5 samples of class no .
> me um yes a r yes<=30 medium yes excellent yes
31…40 medium no excellent yes
31…40 high yes fair yes
14R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 15/30
Extractin Classification Rules from Trees
Represent the knowledge in
the form of IF-THEN rules
One rule is created for each
Each attribute-value pair
along a path forms aconjunction
The leaf node holds the class
rediction
Rules are easier for humans
to understand
What are the rules?
15R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 16/30
Solution (Rules)
IF age = “<=30” AND student = “no ” THEN buys_computer = “no ”
IF age = “<=30” AND student = “yes ” THEN buys_computer = “yes ”
IF age = “31…40” THEN buys_computer = “yes ”
IF age = “>40” AND credit_rating = “excellent ” THEN
buys_computer = “yes ”
IF age = “<=30” AND credit_rating = “fair ” THEN buys_computer =
“no ”
16R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 17/30
Algorithm for Decision Tree Induction
Basic algorithm (a greedy algorithm)
Tree is constructed in a top-down recursive divide-and-conquermanner
At start, all the training examples are at the root
Attributes are categorical (if continuous-valued, they arediscretized in advance)
Examples are partitioned recursively based on selected attributes
Test attributes are selected on the basis of a heuristic orstatistical measure (e.g., information gain)
Conditions for stopping partitioning
All sam les for a iven node belon to the same class
There are no remaining attributes for further partitioning – majority voting is employed for classifying the leaf
There are no sam les left
17R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 18/30
Attribute Selection Measure: Information
.
S contains si tuples of class Ci for i = {1, …, m} information measures info re uired to classif an
arbitrary tuple
….information is encoded in bits .s
slog
s
s) ,...,s ,ss I(
im
i
im21 2
1
entropy of attribute A with values {a1,a2,…,av}
)s ,...,s( I s...s
E(A) mj j
vmj j
11
information gained by branching on attribute A
E(A))s ,...,s , I(sGain(A) m 21
18R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 19/30
Entropy Entropy measures the homogeneity (purity) of a set of examples. It gives the information content of the set in terms of the class labels of
the examples. Consider that you have a set of examples, S with two classes, P and N. Let
the set have p instances for the class P and n instances for the class N. So the total number of instances we have is t = p + n. The view [p, n] can
be seen as a class distribution of S.
The entropy for S is defined as Entropy(S) = - (p/t).log2(p/t) - (n/t).log2(n/t)
Example: Let a set of examples consists of 9 instances for class positive,and 5 instances for class negative.
Answer: p = 9 and n = 5. So Entropy(S) = - (9/14).log2(9/14) - (5/14).log2(5/14)
= -(0.64286)(-0.6375) - (0.35714)(-1.48557) = (0.40982) + (0.53056) = 0.940
19R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 20/30
EntropyThe entropy for a completely pure set is 0 and is 1 for a set with
equa occurrences or o e c asses.
i.e. Entropy[14,0] = - (14/14).log2(14/14) - (0/14).log2(0/14)
= - . og - . og
= -1.0 - 0
= 0
i.e. Entropy[7,7] = - (7/14).log2(7/14) - (7/14).log2(7/14)
= - (0.5).log2(0.5) - (0.5).log2(0.5)
= - (0.5).(-1) - (0.5).(-1)= 0.5 + 0.5
= 1
20R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 21/30
Attribute Selection by Information Gain
Class P: buys_computer = “yes”
Class N: buys_computer = “no”
)0,4(14
4)3,2(
14
5)( I I age E
I(p, n) = I(9, 5) =0.940
Compute the entropy for age :
age pi ni I(pi, ni)
694.0)2,3(
14
I
means “age <=30” has 5
out of 14 samples, with 2 yes's
and 3 no’s. Hence
<=30 2 3 0.971
30…40 4 0 0
>
)3,2(14
I
02.0incomeGain
246.0)(),()( age E n p I ageGainage income s tudent c redit_ra ting buys_computer
<=30 high no fair no
<=30 high no excellent no
31…40 high no fair yes
>40 medium no fair yes ,
048.0)_(
151.0)(
ratingcredit Gain
student Gain>40 low yes fair yes>40 low yes excellent no
31…40 low yes excellent yes
<=30 medium no fair no
<=30 low yes fair yes
<=30 medium yes excellent yes
31…40 medium no excellent yes
31…40 high yes fair yes>40 medium no excellent no
Since, age has the highest information gainamong the attributes, it is selected as the
test attribute. 21R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 22/30
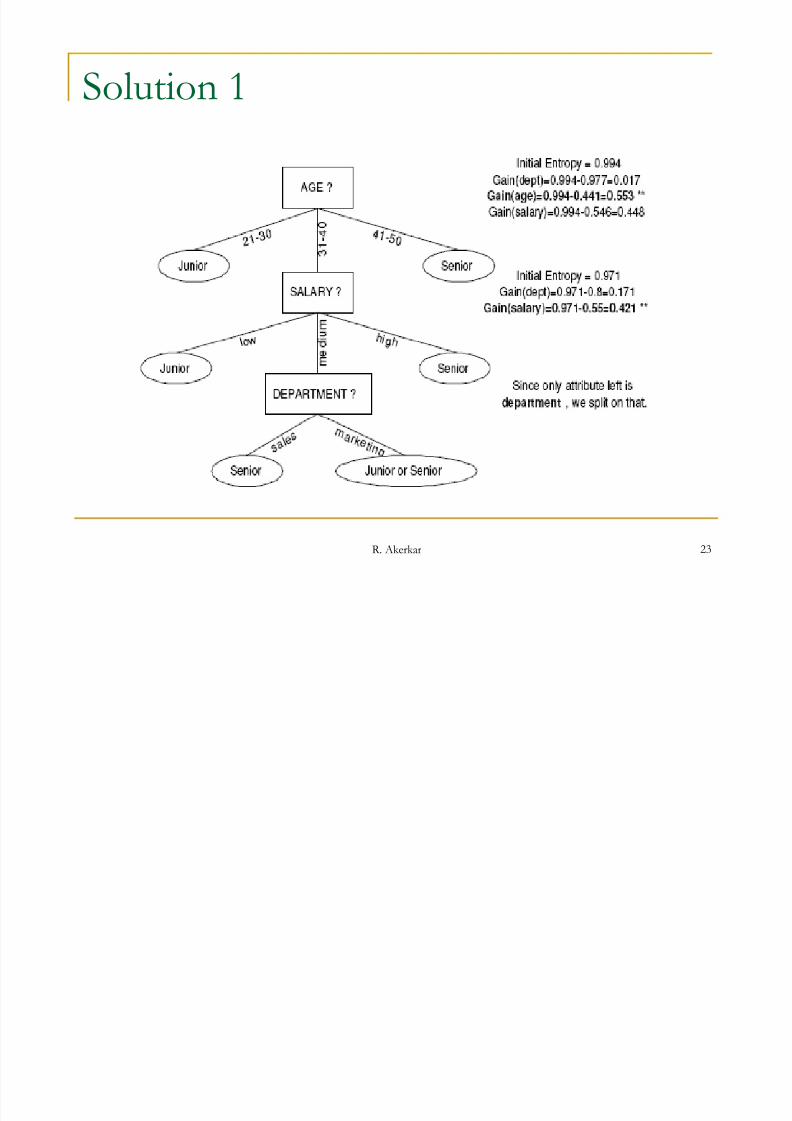
Exercise 1
The following table consists of training data from an employee .
Let status be the class attribute. Use the ID 3 algorithm to construct a
decision tree from the given data .
22R. Akerkar
8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 23/30
Solution 1
23R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 24/30
Other Attribute Selection Measures
,
All attributes are assumed continuous-valued
attribute
May need other tools, such as clustering, to get thepossible split values
Can be modified for categorical attributes
24R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 25/30
Gini Index (IBM IntelligentMiner)
If a data set T contains examples from n classes, gini index, gini (T ) isn
where p j is the relative frequency of class j in T.
j
p jg n
1
(
respectively, the gini index of the split data contains examples from n classes, the gini index gini (T ) is defined as
)()()(2
21
1T gini
N
N T gini
N
N T gini split
The attribute provides the smallest gini split (T ) is chosen to split the node(need to enumerate all possible splitting points for each attribute ).
25R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 26/30
Exercise 2
26R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 27/30
Solution 2
SPLIT: Age <= 50 ---------------------- | High | Low | Total -------------------- S1 (left) | 8 | 11 | 19
S2 (right) | 11 | 10 | 21 -------------------- For S1: P(high) = 8/19 = 0.42 and P(low) = 11/19 = 0.58 = = = = . . Gini(S1) = 1-[0.42x0.42 + 0.58x0.58] = 1-[0.18+0.34] = 1-0.52 = 0.48 Gini(S2) = 1-[0.52x0.52 + 0.48x0.48] = 1-[0.27+0.23] = 1-0.5 = 0.5 Gini-Split(Age<=50) = 19/40 x 0.48 + 21/40 x 0.5 = 0.23 + 0.26 = 0.49
= ---------------------- | High | Low | Total -------------------- S1 (top) | 18 | 5 | 23
-------------------- For S1: P(high) = 18/23 = 0.78 and P(low) = 5/23 = 0.22 For S2: P(high) = 1/17 = 0.06 and P(low) = 16/17 = 0.94 Gini(S1) = 1-[0.78x0.78 + 0.22x0.22] = 1-[0.61+0.05] = 1-0.66 = 0.34
- - -= - . . . . = - . . = - . = . Gini-Split(Age<=50) = 23/40 x 0.34 + 17/40 x 0.11 = 0.20 + 0.05 = 0.25
27R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 28/30
Exercise 3
,
the data among the two split points? Why?
28R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 29/30
Solution 3
Intuitively Salary <= 65K is a better split point since it produces`` <= ,
results in more mixed partitions (i.e., just look at the distributionof Highs and Lows in S1 and S2).
More formally, let us consider the properties of the Gini index .If a partition is totally pure, i.e., has all elements from the same
class, then gini (S) = 1-[1x1+0x0] = 1-1 = 0 (for two classes).
On the other hand if the classes are totally mixed, i.e., bothclasses have equal probability then
= - . . + . . = - . + . = . .
In other words the closer the gini value is to 0, the better the. .
29R. Akerkar

8/3/2019 decisiontree-110906040745-phpapp01
http://slidepdf.com/reader/full/decisiontree-110906040745-phpapp01 30/30
Avoid Overfittin in Classification Overfittin : An induced tree ma overfit the trainin data
Too many branches, some may reflect anomalies due to noiseor outliers
Poor accurac for unseen sam les
Two approaches to avoid overfitting
Prepruning: Halt tree construction early—do not split a node if
this would result in the goodness measure falling below athreshold
Difficult to choose an appropriate threshold
Postpruning: Remove branches from a “fully grown” tree—get a
sequence o progress ve y prune trees Use a set of data different from the training data to decide
which is the “best pruned tree”
30R. Akerkar