decision problems
TRANSCRIPT

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 1/43
Autonomous Mobile Systems
The Markov Decision ProblemValue Iteration and Policy Iteration
Cyrill Stachniss Wolfram Burgard

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 2/43
What is the problem?
Consider a non-perfect system.
Actions are performed with a probability
less then 1. What is the best action for an agent
under this constraint?
Example: a mobile robot does notexactly perform the desired action.
Uncertainty about performing actions!

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 3/43
Example (1)
Bumping to wall “reflects” to robot.
Reward for free cells -0.04 (travel-cost).
What is the best way to reach the celllabeled with +1 without moving to –1 ?

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 4/43
Example (2)
Deterministic Transition Model:move on the shortest path!

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 5/43
Example (3)
But now consider the non-deterministictransition model (N / E / S / W):
(desired action)
What is now the best way?

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 6/43
Example (4)
Use a longer path with lower probability tomove to the cell labeled with –1.
This path has the highest overall utility!

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 7/43
Deterministic Transition Model
In case of a deterministic transition modeluse the shortest path in a graph structure.
Utility = 1 / distance to goal state.
Simple and fast algorithms exists(e.g. A*-Algorithm, Dijsktra).
Deterministic models assume a perfect
world (which is often unrealistic).
New techniques need for realistic,
non-deterministic situations.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 8/43
Utility and Policy
Compute for every state a utility: “What is the usage (utility) of this statefor the overall task?”
A Policy is a complete mapping formstates to actions (“In which state shouldI perform which action?”).

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 9/43
Markov Decision Problem (MDP)
Compute the optimal policy in anaccessible, stochastic environment with
known transition model.
Markov Property:
The transition probabilities depend onlythe current state and not on the history
of predecessor states.
Not every decision
problem is a MDP.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 10/43
The optimal Policy
Probability of reaching state j form state i with action a.
Utility of state j .
If we know the utility we can easilycompute the optimal policy.
The problem is to compute the correct
utilities for all states.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 11/43
The Utility (1)
To compute the utility of a state we haveto consider a tree of states.
The utility of a state depends on theutility of all successor states.
Not all utility functions can be used.
The utility function must have the
property of separability. E.g. additive utility functions:
(R = reward function)

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 12/43
The Utility (2)
The utility can be expressed similar tothe policy function:
The reward R(i) is the “utility” of the stateitself (without considering the successors).

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 13/43
Dynamic Programming
This Utility function is the basis for “dynamic programming”.
Fast solution to compute n-step decisionproblems.
Naive solution: O(|A|n).
Dynamic Programming: O(n|A||S|).
But what is the correct value of n?
If the graph has loops:

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 14/43
Iterative Computation
Idea:
The Utility is computed iteratively:
Optimal utility:
Abort, if change in the utility is below a
threshold.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 15/43
The Value Iteration Algorithm
8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 16/43
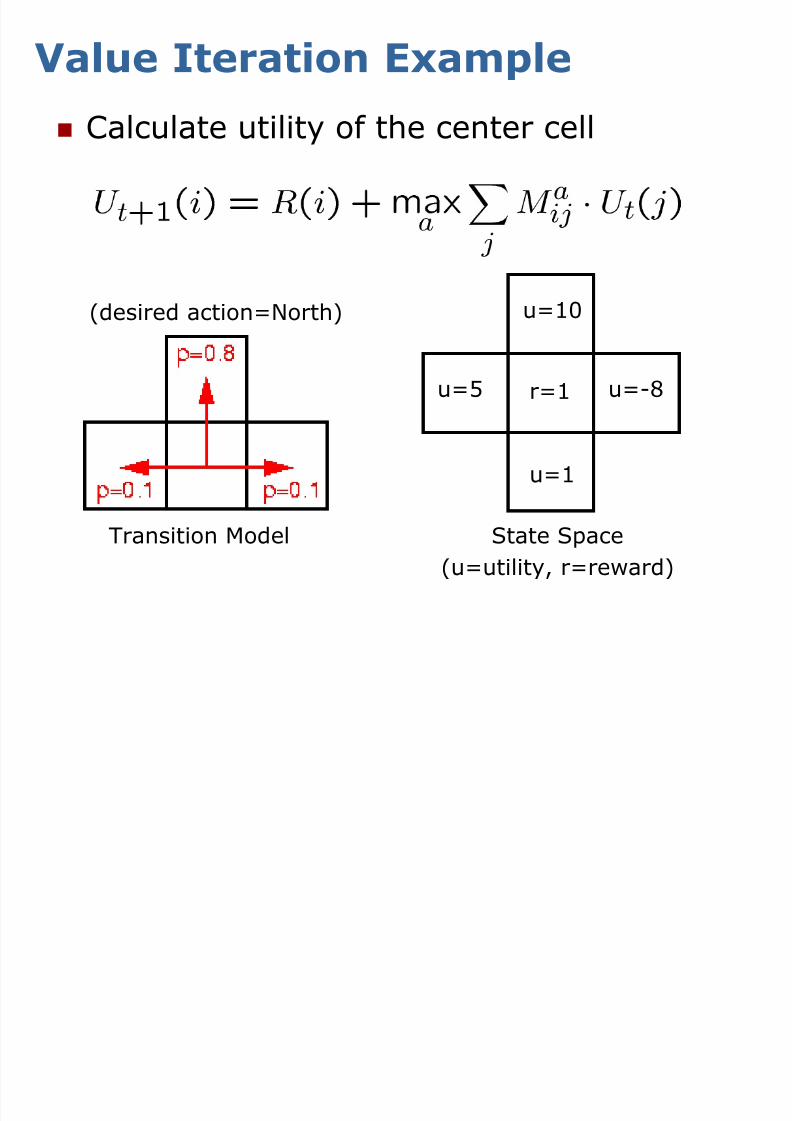
Value Iteration Example
Calculate utility of the center cell
u=10
u=-8u=5
u=1
r=1
(desired action=North)
Transition Model State Space
(u=utility, r=reward)
8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 17/43
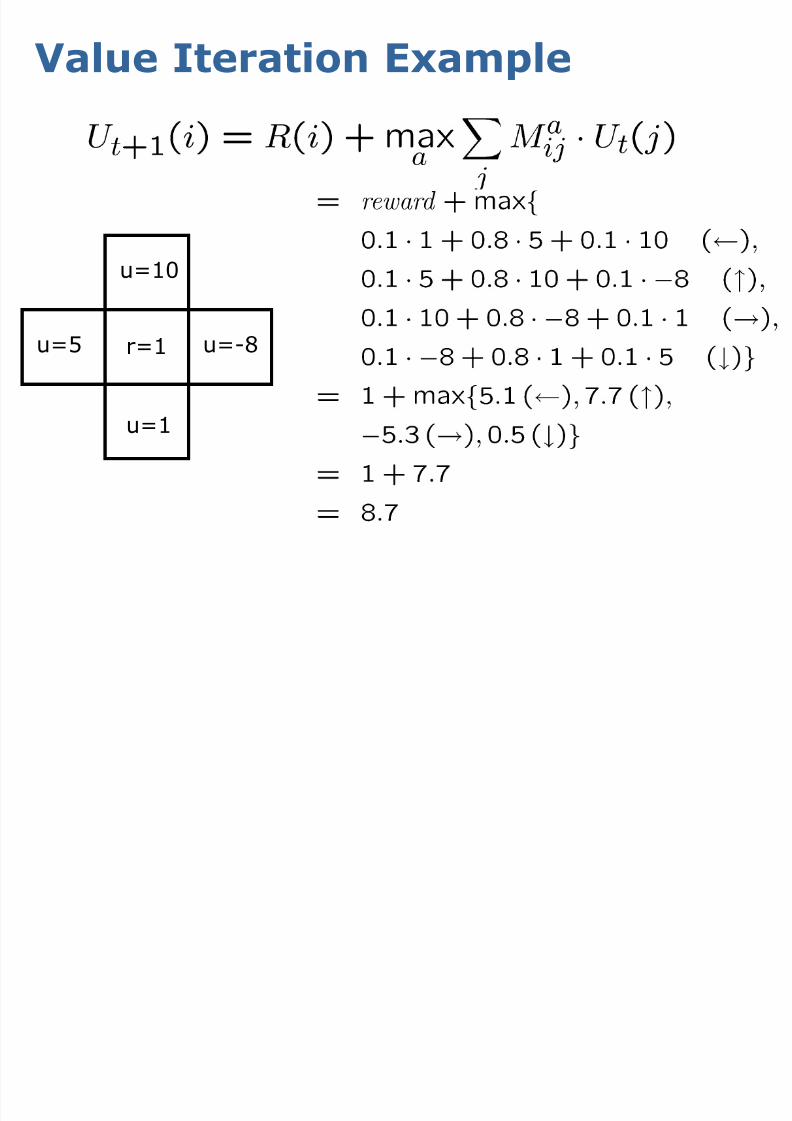
Value Iteration Example
u=10
u=-8u=5
u=1
r=1

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 18/43
From Utilities to Policies
Computes the optimal utility function.
Optimal Policy can easily be computedusing the optimal utility values:
Value Iteration is an optimal solution tothe Markov Decision Problem!

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 19/43
Convergence “close-enough”
Different possibilities to detectconvergence:
RMS error – root mean square error
Policy Loss
…

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 20/43
Convergence-Criteria: RMS
CLOSE-ENOUGH(U,U’) in the algorithm can
be formulated by:

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 21/43
Example: RMS-Convergence

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 22/43
Example: Value Iteration
1. The given environment.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 23/43
Example: Value Iteration
1. The given environment. 2. Calculate Utilities.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 24/43
Example: Value Iteration
1. The given environment. 2. Calculate Utilities.
3. Extract optimal policy.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 25/43
Example: Value Iteration
1. The given environment. 2. Calculate Utilities.
3. Extract optimal policy. 4. Execute actions.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 26/43
Example: Value Iteration
The Utilities. The optimal policy.
(3,2) has higher utility than (2,3). Whydoes the polity of (3,3) points to the left?

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 27/43
Example: Value Iteration
The Utilities. The optimal policy.
(3,2) has higher utility than (2,3). Whydoes the polity of (3,3) points to the left?
Because the Policy is not the gradient!It is:

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 28/43
Convergence of Policy and Utilities
In practice: policy converges faster thanthe utility values.
After the relation between the utilities are
correct, the policy often does not changeanymore (because of the argmax).
Is there an algorithm to compute theoptimal policy faster?

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 29/43
Policy Iteration
Idea for faster convergence of the policy:
1. Start with one policy.2. Calculate utilities based on the current
policy.
3. Update policy based on policy formula.
4. Repeat Step 2 and 3 until policy is
stable.

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 30/43
The Policy Iteration Algorithm
l i i i ( )

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 31/43
Value-Determination Function (1)
2 ways to realize the function VALUE-DETERMINATION.
1st way: use modified Value Iteration with:
Often needs a lot if iterations to converge(because policy starts more or lessrandom).
V l D t i ti F ti (2)

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 32/43
Value-Determination Function (2)
2nd way: compute utilities directly. Givena fixed policy, the utilities obey the eqn:
Solving the set of equations is oftenthe most efficient way for small statespaces.
V l D t i ti E l

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 33/43
Value-Determination Example
Policy Transition Probabilities
V l /P li It ti E l

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 34/43
Value/Policy Iteration Example
Consider such a situation.How does the optimalpolicy look like?
V l /P li It ti E l

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 35/43
Value/Policy Iteration Example
Consider such a situation.How does the optimal
policy look like?
Try to move from (4,3)
and (3,2) by bumping tothe walls. Then entering(4,2) has probability 0.
What’s next? POMDPs!

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 36/43
What’s next? POMDPs!
Extension to MDPs.
POMDP = MDP in not or only partly
accessible environments.
State of the system is not fully observable.
“Partially Observable MDPs”. POMDPs are extremely hard to compute.
One must integrate over all possible statesof the system.
Approximations MUST be used.
We will not focus on POMDPs in here.
Approximations to MDPs?

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 37/43
Approximations to MDPs?
For real-time applications even MDPs arehard to compute.
Are there other way to get the a good
(nearly optimal) policy?
Consider a “nearly deterministic” situation.
Can we use techniques like A*?
MDP Approximation in Robotics

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 38/43
MDP-Approximation in Robotics
A robot is assumed to be localized.
Often the correct motion commands
are executed (but no perfect world!). Often a robot has to compute a path
based on an occupancy grid.
Example for the path planning task:
Goals: Robot should not collide.
Robot should reach the goal fast.
Convolve the Map!

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 39/43
Convolve the Map!
Obstacles are assumed to be biggerthan in reality.
Perform a A* search in such a map.
Robots keeps distance to obstacles andmoves on a short path!
Map Convolution

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 40/43
Map Convolution
Consider an occupancy map. Than theconvolution is defined as:
This is done for each row and each
column of the map.
Example: Map Convolution

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 41/43
Example: Map Convolution
1-d environment, cells c0, …, c5
Cells before and after 2 convolution runs.
A* in Convolved Maps

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 42/43
A* in Convolved Maps
The costs are a product of path lengthand occupancy probability of the cells.
Cells with higher probability (e.g.caused by convolution) are shunnedby the robot.
Thus, it keeps distance to obstacles.
This technique is fast and quite reliable.
Literature

8/3/2019 Decision Problems
http://slidepdf.com/reader/full/decision-problems 43/43
Literature
This course is based on:
Russell & Norvig: AI – A Modern Approach
(Chapter 17, pages 498-)