database management 8. course. query types equality query – each field has to be equal to a...
TRANSCRIPT

Database Management
8. course

Query types
• Equality query– Each field has to be equal to a constant
• Range query– Not all the fields have to be equal to a constant– Example• Simple key, age>20• Composite key, age=20, sal can be anything• Composite key, age>20, sal>3000

Indexes

Indexes
• To speed up not supported operations• Collection of data entries to speed up search• Rid=pointer to the entries

How to organize data?
• Hash data entries on the search key• Build a data structure that direct a search for
data entries– Tree-based

Properties of indexes

Clusered vs. unclustered
• Clustered– Ordering of data is similar to ordering of indexes
(data sorted by the search key on every page)– Expensive
• Unclustered– Random ordering of data


Dense vs. sparse
• Dense:– It contains at least one data entry for every search
key that appears in the data file– Useful optimization techniques rely on it
• Sparse– Contains one entry for each page in the data file– Much smaller

Example

Primary vs. secondary
• Primary– Index on a set of fields that includes primary key
• Secondary– Not primary index
• Unique– Contains a key candidate
• Do not get confused about the literature!– Primary: <k,rid>– Secondary: <k, list of rids>

Simple vs .composite
• Contains several fields

Tree-structured indexing

Tree-structured indexing
• Supports equality and range search• ISAM (indexed sequential access method):– Static structure, for rarely changed files– Does not adjust to changes in the file– Data is on the tree leaves (pages) and overflow
pages• B tree, B+ tree– Dynamic, for often changed files– When insert or delete, it is balanced

ISAM
• Let’s assume a sorted file:– File of Students sorted by gpa– Range search: students with gpa > 3.0– Logarithmic search, then sequential read– Big file time consuming search
• Pre idea– Second file that stores the key of the 1st records
of the pages and a pointer to the page


• Binary search in the second index file• Sequential search in the found page• Disadvantage: expensive insert and delete

ISAM idea
• Recursive index file structure– Create a 3rd file from the 2nd index file which
stores the 1st key of every page– Create a 4th file from the 3rd index file which
stores the 1st key of every page– Etc.– Continue until the file fits on one page– If several inserts: overflow pages are added (index
structure is static)

• Sequential file storage:1st main advantage:Fast search!
• Structure:

Example
• Search value: 27*

Insert 23*, 48*, 41*, and 42*

Delete 42*, 51*, and 97*
• 51* remains in the index, empty pages are kept

• F: no. of children per index• N: no. of leaf pages• Search time (no overflow): logFN• 2nd main advantage: When a page is
requested by a transaction, it gets locked– Queue: transactions waiting for the same page
• But! The index pages remain free (searching remains possible)

B-trees
• ISAM: long overflow chain might occur• Dynamic structure• Balanced tree– Internal nodes: direct the search– Leaf nodes: contain data entries
• Doubly linked structures by pointers• Insert and delete keep it balanced

Example

Properties
• Order of a B+ tree: d• Every node contains m entries where
d ≤ m ≤ 2d (in the root 1 ≤ m ≤ 2d)

• Format of a node:
• Non-leaf nodes contain m+1 pointers• Only leaf nodes contain data entries (if they
are not separated)

Example, d=2

SearchThe value
nodepointer points at

Insert
• Find the leaf where it belongs, insert there• Recursively call the insertion to the proper
child node• When the leaf or the node is full then split it• The new leaf needs a parent node with a
pointer to it (newchildentry)
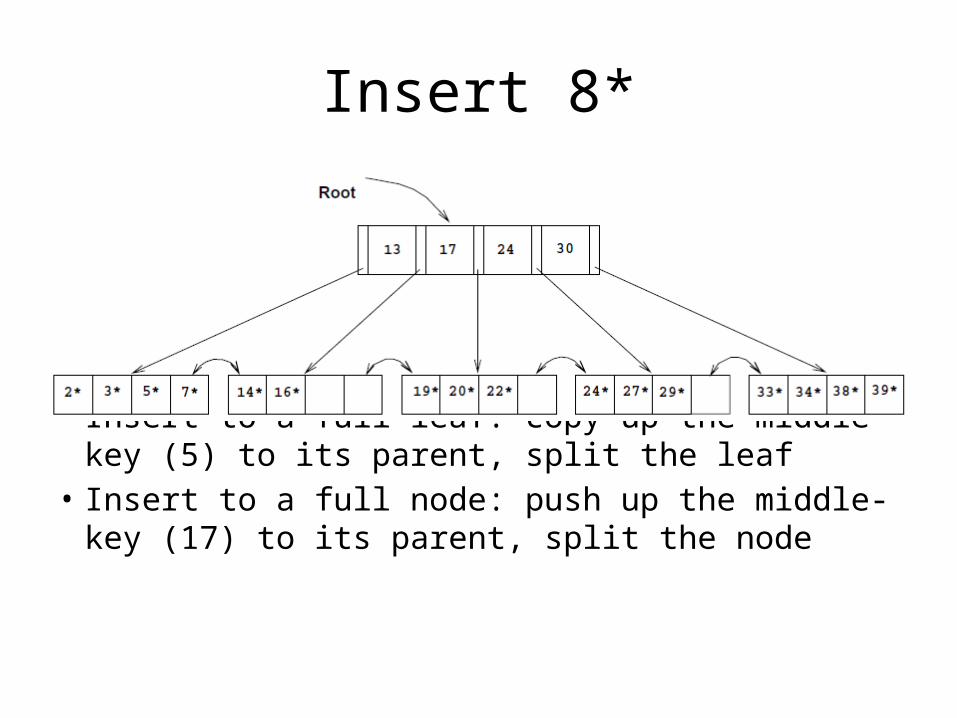
Insert 8*
• Insert to a full leaf: copy up the middle-key (5) to its parent, split the leaf
• Insert to a full node: push up the middle-key (17) to its parent, split the node


Result


&(value) = address of value

Alternatives
• Sibling: a node immediately to the left or right of the node that has the same parent
• Possibility: try to reorganize entries with a sibling before splitting the node– Replace a parent key with another copied up key
• If the sibling is full, then split node• In average it is worthy to redistribute
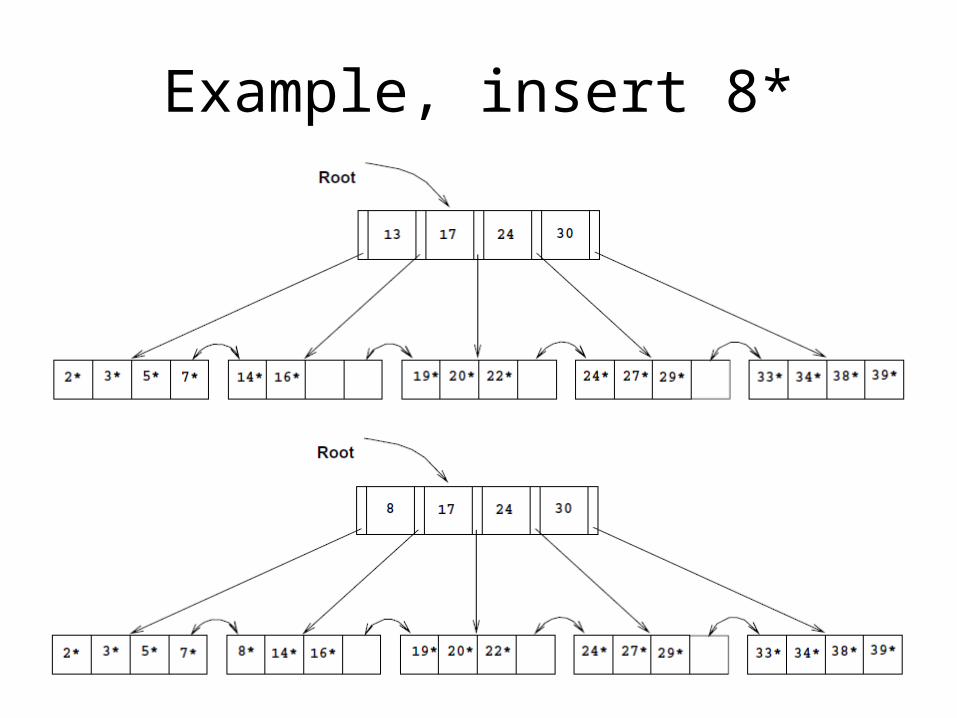
Example, insert 8*

Delete
• Find leaf, delete• Recursively call the deletion to the proper
child node• If the node is on minimal occupancy then
redistribute or merge with a sibling (oldchildentry)
• Update parent
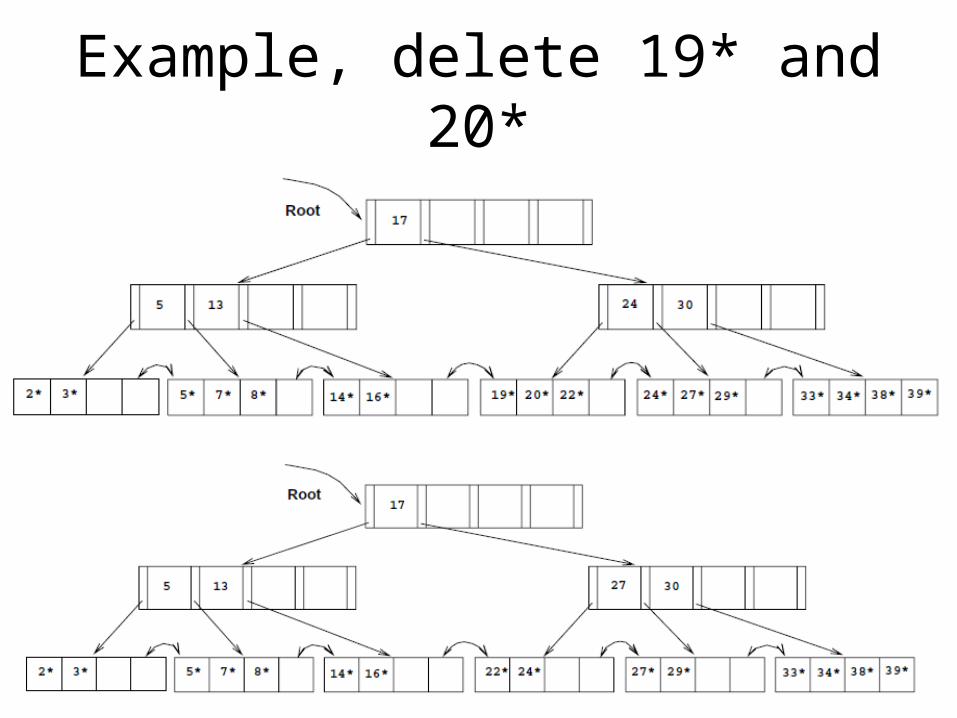
Example, delete 19* and 20*

Delete 24*

• 17* is pulled down

Alternative, delete 24*
Redistribution of entries between non-leaf-level pages



Duplicates
• Several entries with the same key• Use overflow pages• Treat like a normal entry and some of the
leaves contain values with the same key• Search: search for the left-most data (tricky)• Helps: rid is the part of the search key

B+ trees in practice
• Size of the B+ tree depends on the search key size
• Reduce the key!• Helps if e.g. not all the search key value is
stored

Prefix key compression
• Check the largest value in the subtree (Davey Jones) which is smaller than the value of the actual key (David Smith)
• Store e.g. as many letters as the subelement can be differentiated from the actual one (4)

Bulk-loading a B+ tree
• Insertion into B+ trees– The tree already exsist, I insert sg into it– The tree is newly created for a file and I start to
build it with insertions (algorithm-based, always start from the root) time consuming
• Bulk-loading– How to build a B+ tree for a file efficiently
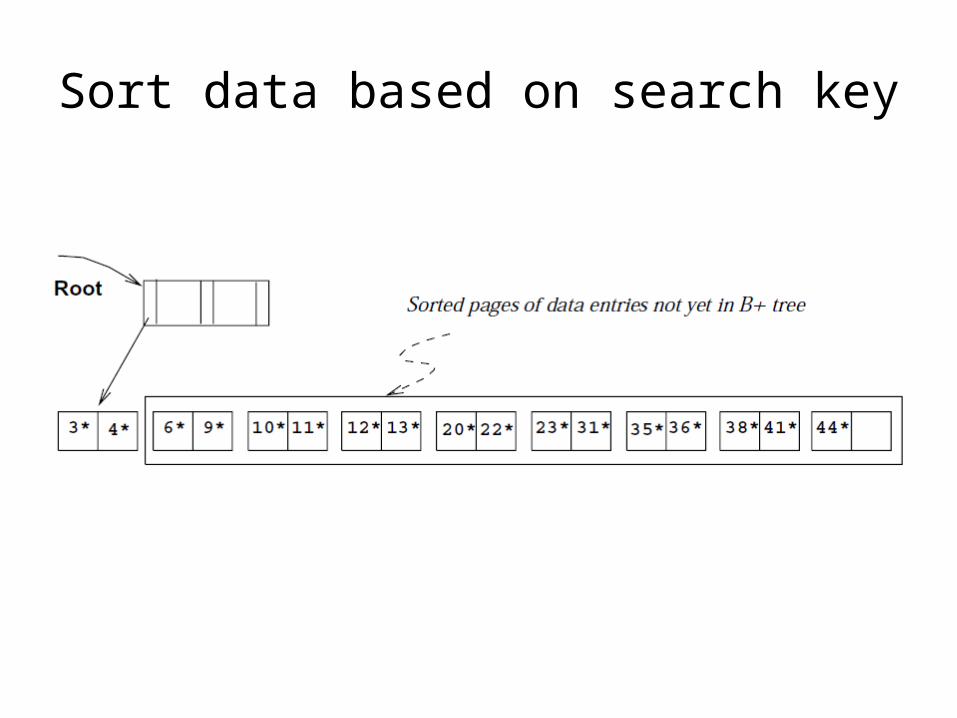
Sort data based on search key

Fill root
• Lowest values are given to the root until the page is full

Split root
• Create new root

Redistribute
• E.g. shift left every entry
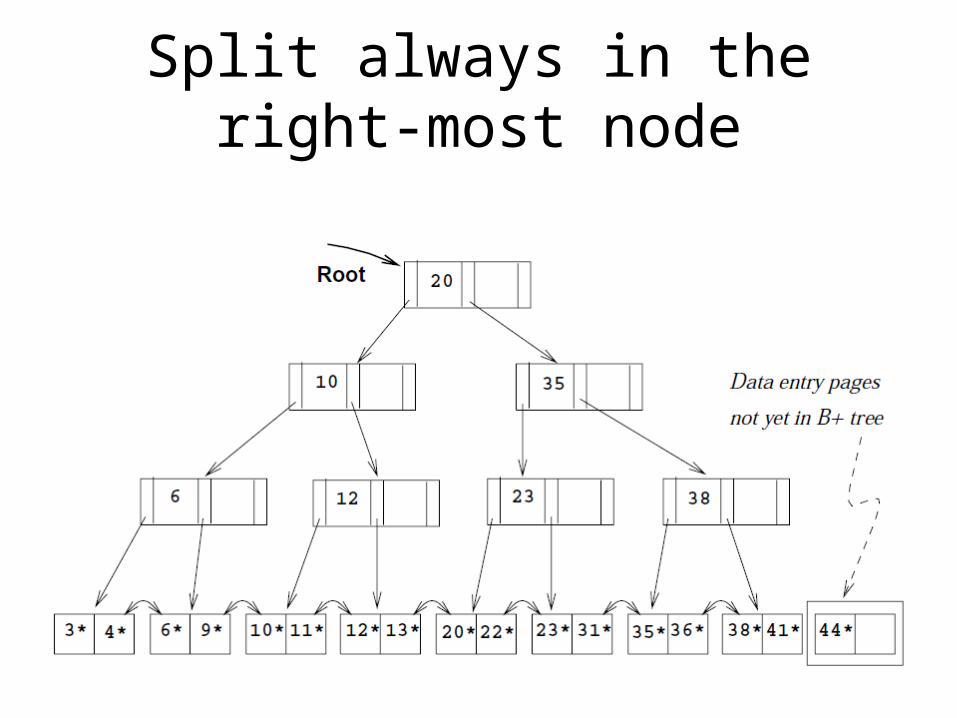
Split always in the right-most node

The order concept
• The rule, d denotes the minimal occupancy (number of records) of a node, is sometimes skipped and replaced by physical space criterion (nodes must be kept al least half-full)– Non-leaf node contains more data than a leaf node,
since a search key does not need as much space as a data record
– Search key contains string: variable size records and index entries
– Records with same search key: varible size storing

Effect of insert and delete
• With splits, merges, and redistributions data may get to another page
• Rid changes

Thank you for your attention!