data mining - columbia university topic 1: introduction to data mining instructor: chris volinsky 1
TRANSCRIPT

Data Mining - Columbia University
Topic 1:Introduction to Data Mining
Instructor: Chris Volinsky
1

Intro
• Who am I?
• Who are you?
Data Mining - Columbia University 2
Data Mining - Columbia University
Class Schedule
• Sept 8 – December 8• No class Election Day or Thanksgiving
• Syllabus:
www.research.att.com/~volinsky/DataMining/Columbia2011/Columbia2011.html
My email: [email protected] phone: 973-360-8644My office hours: by appointment before or after class
3

Class Assessment
• 30% HW– Due every two weeks– 1st HW due next Thursday September 15– No late HW accepted
• 40% Tests– Midterm and Final
• 30% Data Mining Project– Proposal due in October– Project due Tuesday Dec 13
Data Mining - Columbia University 4

Data Mining - Columbia University
Course Objectives
• Direct Objectives:– To learn data mining techniques– To see their use in real-world/research applications– To understand limitations of standard statistical
techniques in data mining applications– To get an understanding of the methodological
principles behind data mining– To be able to read about data mining in the popular
press with a critical eye– To implement & use data mining models using
statistical software
5

Data Mining - Columbia University
Data Analysis Project
• The goal of data mining is to find interesting patterns in data. You will be required to:– Define a scientific question of interest– Collect a data set n>1000 (probably online)– Prepare the data set properly– Analyze the data using appropriate models– Write a 10-20 page report on your analysis (graphics
included)
• Project proposals (1/2 -1 page) will be due in early October.
• “Volunteers” to present projects in class for extra credit.
• Finished reports will be due December 13.
6

Data Mining - Columbia University
Data Mining Software
7
• Software– Can use any software you like – must know how to input,
manipulate, graph, and analyze data. – Preferred: R– Also: SAS, Weka, SPSS, Systat, Enterprise Miner, JMP, Minitab,
Matlab, SQL Server– Maybe not: Excel, C
• What is R?– Open source statistical software grown out of S/Splus– www.r-project.org– Many user-contributed packages at CRAN (cran.r-project.org)– Active, helpful user community (help lists, bulletin boards, etc)– R Tutorials available online (see class website and CRAN)– Great graphics (with a bit of a learning curve)
• Other useful tools: Perl/Python, AWK, Shell scripts

Data Mining - Columbia University
Resources• Data mining is a new field and as such, does not have
authoritative texts (yet).• This class draws from many sources, best are
– “Elements of Statistical Learning” Hastie, Tibshirani, and Friedman
– “Handbook of Data Mining” Hand, Mannila and Smyth – “Interactive and Dynamic Graphics for Data Analysis” Cook and
Swayne– “Data Mining – Practical Machine Learning Tools and
Techniques” Witten and Frank– Also good class notes available from other classes:
• David Madigan, Columbia• Di Cook, Iowa State• Padhraic Smyth, UC Irvine• Jiawei Han, Simon Fraser
– see class web site for pointers to these notes, or just Google them!)
• Also a few good books which teach stats/DM through R:– “The R Book” Crawley– “A Handbook of Statistical Analyses Using R” Evirtt and Hothorn– “Modern Applied Statistics Using S-Plus” Venables and Ripley
8

Data Mining - Columbia University
Course Outline• Each ‘unit’ covers two lectures• Units:
– Intro to Data Mining– Data exploration and visualization– Data Mining Concepts– Regression Topics– Classification and Supervised Learning– Clustering and Unsupervised Learning– Text Mining and Information Retrieval– Web Mining– Social Networks – Assorted Topics
• Advanced Classification – Neural networks, Support Vector machines
• Ensemble methods• Recommender Systems• Fraud
9

Data Mining - Columbia University
What is Data Mining?
• Not well defined….• No one can agree on what data mining is! In
fact the experts have very different descriptions:
– “finding interesting structure (patterns, statistical models, relationships) in data bases”. - Fayyad, Chaduriand
– “the nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.” - Fayyad
– “a knowledge discovery process of extracting previously unknown, actionable information from very large data bases” – Zorne
– “a process that uses a variety of data analysis tools to discover patterns and relationships in data that may be used to make valid predictions.”--- Edelstein
10

What is Data Mining
• From Zaiane:– Data Mining, also popularly known as Knowledge Discovery in
Databases (KDD)...
– The Knowledge Discovery in Databases process comprises of a few steps leading from raw data collections to some form of new knowledge. The iterative process consists of the following steps:
• Data cleaning: ... • Data integration: ... • Data selection: ... • Data transformation: ... • Data mining: it is the crucial step in which clever techniques are applied
to extract patterns potentially useful. • Pattern evaluation: ... • Knowledge representation: ...
Data Mining - Columbia University 11

What is Data Mining?
• What does the authority say? – Data mining is the process of extracting hidden patterns from
data.
– Data mining is the process of discovering new patterns from large data sets involving methods from statistics and artificial intelligence but also database management.
• Hand, Mannila, Smyth:– “data mining is the analysis of (often large) observational data sets to find
unsuspected relationships and to summarize the data in novel ways that are both understandable and useful to the data owner”
• Isn’t that the same as statistics?
Data Mining - Columbia University 12

Data Mining - Columbia University
Data Mining vs. Statistics
• Snark: Data Mining = Statistics + Marketing
• Statistics is known for:– well defined hypotheses used to learn about a– specifically chosen population studied using– carefully collected data providing inferences with– well known properties.
• Data mining isn’t that careful. It is:– data driven discovery of– models and patterns from– massive and– observational data sets
13

Data Mining - Columbia University
Data Mining v. Statistics
• Traditional statistics– first hypothesize, then collect data, then analyze– often model-oriented (strong parametric models)– Focused on understanding
• Data mining (also Machine Learning): – few if any a priori hypotheses– data is usually already collected a priori– analysis is typically data-driven not hypothesis-driven– Often algorithm-oriented rather than model-oriented– Focused on prediction
• But– statistical ideas are very useful in data mining, e.g., in validating whether
discovered knowledge is useful – Increasing overlap at the boundary of statistics and DM– Cultures could learn from each other– Very powerful when used together
14

Data Mining - Columbia University
Data Mining Enablers
• Explosion of data• Fast and cheap computation and storage
– Moore’s Law: processing doubles every two years– Disk storage doubles every 9 months– Database technology
• Competitive pressure in business– Data has value! Successes are widely publicized
• Commercial products• SAS, SPSS, Google Analytics, IBM, Oracle
– Open Source products• Weka • R
• Don’t need a data mining expert to do data mining!
15

Data Mining - Columbia University
Data-Driven Discovery
• Observational data– cheap relative to experimental data
• Examples: – Retail stores, airlines, etc– Amazon, Google, etc– Do iPhone users use more data than Android
users?• makes sense to leverage available, observational
data
– What are the perils of observational data?– Easy to do pseudo-experiments– Observational data can also help in
hypothesis formulation.
16

Data Mining - Columbia University
Data Mining: Confluence of Multiple Disciplines
Data Mining
Database Technology
Statistics
OtherDisciplines
InformationScience
MachineLearning Visualization
Different fields have different views of what data mining is(also different terminology!)
17

Data Mining - Columbia University
Data Data Data
• It’s all about the data - where does it come from?– www– NASA– Business processes/transactions– Telecommunications and networking– Medical imagery– Government, census, demographics
(data.gov!)– Sensor networks, RFID tags– sports
18

Data Mining - Columbia University
Types of Data: Flat File or Vector Data
• Rows = objects• Columns = measurements on objects
– Represent each row as a p-dimensional vector, where p is the dimensionality
• In efffect, embed our objects in a p-dimensional vector space• Both n and p can be very large in data mining (also p>>n)• Matrix can be quite sparse
n
p
19

Data Mining - Columbia University
Types of Data: TextData
Word IDs
TextDocuments
20
ObamaObama
“The Help”“The Help”
Can be represented as a sparse matrix

Data Mining - Columbia University
128.195.36.195, -, 3/22/00, 10:35:11, W3SVC, SRVR1, 128.200.39.181, 781, 363, 875, 200, 0, GET, /top.html, -, 128.195.36.195, -, 3/22/00, 10:35:16, W3SVC, SRVR1, 128.200.39.181, 5288, 524, 414, 200, 0, POST, /spt/main.html, -, 128.195.36.195, -, 3/22/00, 10:35:17, W3SVC, SRVR1, 128.200.39.181, 30, 280, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.195.36.101, -, 3/22/00, 16:18:50, W3SVC, SRVR1, 128.200.39.181, 60, 425, 72, 304, 0, GET, /top.html, -, 128.195.36.101, -, 3/22/00, 16:18:58, W3SVC, SRVR1, 128.200.39.181, 8322, 527, 414, 200, 0, POST, /spt/main.html, -, 128.195.36.101, -, 3/22/00, 16:18:59, W3SVC, SRVR1, 128.200.39.181, 0, 280, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:54:37, W3SVC, SRVR1, 128.200.39.181, 140, 199, 875, 200, 0, GET, /top.html, -, 128.200.39.17, -, 3/22/00, 20:54:55, W3SVC, SRVR1, 128.200.39.181, 17766, 365, 414, 200, 0, POST, /spt/main.html, -, 128.200.39.17, -, 3/22/00, 20:54:55, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:55:07, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:55:36, W3SVC, SRVR1, 128.200.39.181, 1061, 382, 414, 200, 0, POST, /spt/main.html, -, 128.200.39.17, -, 3/22/00, 20:55:36, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:55:39, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:56:03, W3SVC, SRVR1, 128.200.39.181, 1081, 382, 414, 200, 0, POST, /spt/main.html, -, 128.200.39.17, -, 3/22/00, 20:56:04, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:56:33, W3SVC, SRVR1, 128.200.39.181, 0, 262, 72, 304, 0, GET, /top.html, -, 128.200.39.17, -, 3/22/00, 20:56:52, W3SVC, SRVR1, 128.200.39.181, 19598, 382, 414, 200, 0, POST, /spt/main.html, -,
…5115
1111115151115177777777
1113333333131113332232
…User 5User 4User 3User 2User 1
Transactional Data
Can be represented as a time series:
21
Date stamped events (weblogs, phone calls):

128.200.39.17, -, 3/22/00, 20:55:07, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.200.39.17, -, 3/22/00, 20:55:36, W3SVC, SRVR1, 128.200.39.181, 1061, 382, 414, 200, 0, POST, /spt/main.html, -, 128.200.39.17, -, 3/22/00, 20:55:36, W3SVC, SRVR1, 128.200.39.181, 0, 258, 111, 404, 3, GET, /spt/images/bk1.jpg, -, 128.195.36.195, -, 3/22/00, 10:35:11, W3SVC, SRVR1, 128.200.39.181, 781, 363, 875, 200, 0, GET, /top.html, -, 128.195.36.195, -, 3/22/00, 10:35:16, W3SVC, SRVR1, 128.200.39.181, 5288, 524, 414, 200, 0, POST, /spt/main.html, -, 128.195.36.195, -, 3/22/00, 10:35:17, W3SVC, SRVR1, 128.200.39.181, 30, 280, 111, 404, 3, GET, /spt/images/bk1.jpg, -, …,
Types of Data: Relational Data
128.195.36.195, Doe, John, 12 Main St, 973-462-3421, Madison, NJ, 07932114.12.12.25,Trank, Jill, 11 Elm St, 998-555-5675, Chester, NJ, 07911…
07911, Chester, NJ, 07954, 34000, , 40.65, -74.1207932, Madison, NJ, 56000, 40.642, -74.132…
Data Mining - Columbia University
• Most large data sets are stored in relational data sets• Special data query language: SQL• Oracle, MSFT, IBM• Good open source versions: MySQL, PostGres
22
Data Mining - Columbia University
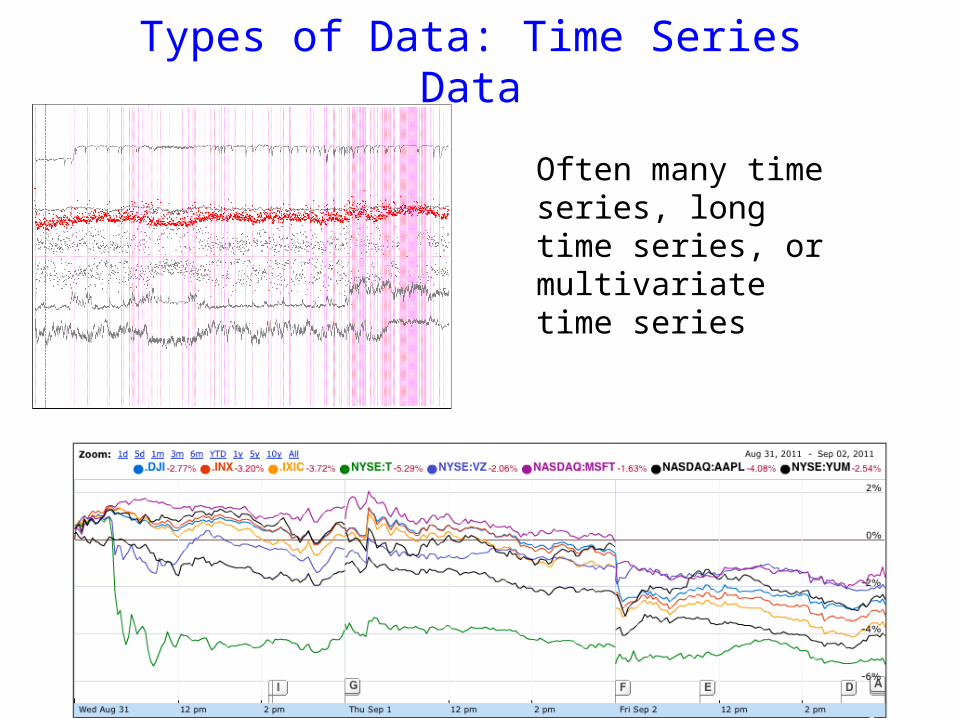
Types of Data: Time Series Data
Often many time series, long time series, or multivariate time series
23

Time Series: Ebay Data
Data Mining - Columbia University
Jank, Shmueli, et al (2005)
24

Data Mining - Columbia University
Types of Data: Image Data
25
Data Mining - Columbia University
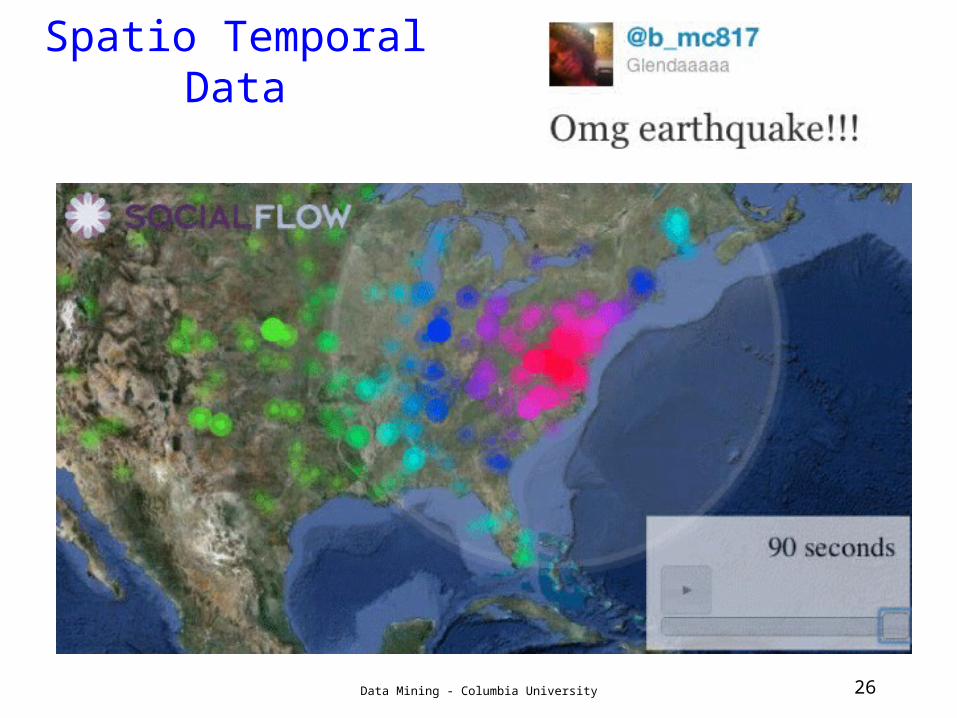
Spatio Temporal Data
• http://senseable.mit.edu/nyte/movies/nyte-globe-encounters.mov-encounters.mov
26

Network Data: Physical Network
Data Mining - Columbia University 27

Data Mining - Columbia University
Network Data: Derived Social Network
Algorithms for estimating relative importance in networks S. White and P. Smyth, ACM SIGKDD, 2003.
28

Social Network: Real social network
Data Mining - Columbia University 29
HP Labs email network500 people, 20k relationships

Data Mining - Columbia University
Examples of Data Mining Successes
• Market Basket (WalMart)• Recommender Systems (Amazon.com)• Fraud Detection in Telecommunications
(AT&T)• Target Marketing / CRM• Financial Markets• DNA Microarray analysis (or is it?)• Web Traffic / Blog analysis
30

Data Mining - Columbia University
Examples of Data Mining Successes
• Google is a company built on data mining• PageRank mined the web to build better
search• Google as spell checker• Google as ad placer• Google as news aggregator• Google as face recognizer
31

Data Mining - Columbia University
The Data Mining Process
• Often called KDD - Knowledge Discovery in Databases
• Analysis is just one part of the process– Data collection and storage– Data cleaning– Data sampling– Analysis– Decision making
32

Data Mining - Columbia University
Different Data Mining Tasks
• Exploratory Data Analysis
• Descriptive Modeling
• Predictive Modeling
• Discovering Patterns and Rules
• + others….
33

Data Mining - Columbia University
Exploratory Data Analysis
• Before you model – what do you do?• Must check your data
– Compute summary statistics: range, max, min, mean, median, variance, skewness,..
– Missing values, outliers, skewness, etc– What types of variables do you have?
• Visualization is widely used– 1d histograms– 2d scatter plots– Higher-dimensional methods
• Simple exploratory analysis can be extremely valuable– Always “look” at your data before applying any data
mining algorithms
34

Data Mining - Columbia University
Example of Exploratory Data Analysis
35
Languages of the World Wide Web – Google Research Blog July, 2011

Data Mining - Columbia University
Descriptive Modeling
• Goal is to build a “descriptive” model – e.g., a model that could simulate the data if
needed– models the underlying process
• Examples:– Density estimation:
• estimate the joint distribution P(x1,……xp)
– Cluster analysis:• Find natural groups in the data
– Dependency models among the p variables• Learning a Bayesian network for the data
36

Data Mining - Columbia University
Example of Descriptive Modeling
Anemia Group
Control Group
Hemoglobin vs. cell volume
37

Data Mining - Columbia University
Example of Descriptive Modeling
Anemia Group
Control Group
38

Data Mining - Columbia University
Predictive Modeling
• Predict one variable Y given a set of other variables X– Here X could be a p-dimensional vector
– Classification: Y is categorical– Regression: Y is real-valued
• In effect this is function approximation, learning the relationship between Y and X
• In data mining, the emphasis is on predictive accuracy, not on understanding the model
39

Data Mining - Columbia University
Predictive Modeling: Fraud Detection
• Telecommunications fraud detection– Fraud costs companies US$ Billions per year– very few transactions are fraudulent, but they are costly
• Approach– For each transaction estimate “fraudiness”.– Based on known fraud AND known user behavior– High probability cases investigated by fraud police
• Example models:– Credit card usage profiling– anomaly detection– guilt by association
40

Data Mining - Columbia University
Pattern Discovery
• Goal is to discover interesting “local” patterns in the data rather than to characterize the data globally
• given market basket data we might discover that• If customers buy wine and bread then they buy cheese with
probability 0.9• These are known as “association rules”• This was how data mining was born.• But I don’t like it
• Other examples:– Astronomy– Finance
41

Data Mining - Columbia University
Example of Pattern Discovery
• IBM “Advanced Scout” System– Bhandari et al. (1997)– Every NBA basketball game is annotated,
• e.g., time = 6 mins, 32 seconds event = 3 point basket player = Michael Jordan
• This creates a huge untapped database of information
– IBM algorithms search for rules of the form “If player A is in the game, player B’s scoring rate increases from 3.2 points per quarter to 8.7 points per quarter”
42

Data Mining - Columbia University
Data Mining Pitfalls
• Is data mining always necessary– Just because you have a terabyte doesn’t
mean you need to use it.
• Privacy concerns– Differ by country, industry, application,
generation
• Meaningfulness of patterns unclear– Rhine paradox– Terrorism– DM has a lot to learn from statistics!
43

Data Mining - Columbia University
Rhine Paradox
• David Rhine: parapsychologist who studied ESP (he was a believer!)
• He devised an experiment where subjects were asked to guess 10 hidden cards --- red or blue.
• Reported: 1 in 1000 people have ESP
• He told these people they had ESP and called them in for another test of the same type.
• What do you think happened?• What is the conclusion?
44

Data Mining - Columbia University
Data Mining Pitfalls
• PR Problems: data mining as a four letter word?
– ...increasingly people’s data is at risk. The old ways ...are still at use like dumpster diving, stealing from mailboxes, physical theft, and credit card receipt copying. New tactics include disparate techniques of phishing, email fraud, data mining, spam, key-logging and an array of other technological processes. - Steven D. Domenikos, IdentityTruth, 2008
– One place oversight is sorely lacking is in the whole matter of data mining. ...What have they contributed? Not a single case comes to mind in which security services apprehended a terrorist following identification by data mining. ...that huge database will be out there, win or lose, for some government agency to divert to its purposes or some hacker to turn to private gain or crime. - John Prados, TomPaine.com
45

Data Mining - Columbia University
Fighting Terrorism in the US
• US Government is widely known to be collecting lots of data on Americans and using data mining to look for patterns consistent with terrorist activity.
• Bruce Schneier, Wired Magazine, “Why Data Mining Won’t Stop Terror”:
• Assume:– 1 in 100 false positive (99% precision)– 1 in 1000 false negative– 1 trillion events (phone calls, credit card transactions,
emails) per day – 10 are really terrorist plots
• Then:– 1 billion false alarms for every true plot uncovered– 27 million leads daily– Even if 99.9999% precision = 2,750 false alarms
46

Data Mining v. Privacy
• There is often tension between data mining and personal privacy:
• http://www.aclu.org/pizza/images/screen.swf
• Now, some case studies….
Data Mining - Columbia University 47
Risk v. Reward in Data Mining
More data about more people in fewer places
48Data Mining - Columbia University

The risks of research
My own personal story:or…how a paper published in JCGS leads
me to be connected to FBI wiretapping.
2001-2005: Publish papers on “Communities of Interest” – using social networks and “Guilt by association” to catch fraud
9 September 2007: NYT lead story “F.B.I. Data Mining Reached Beyond Initial Targets” – discusses FBI techniques COI and GBA
23 October 2007: Blogosphere erupts: “How AT&T Provides the FBI with Terror Suspect Leads”
49Data Mining - Columbia University

The Good, The Bad, and the Maybe
• The question remains: how do we effectively leverage sensitive personal data for research purposes?
• Three case studies can give insight– Netflix Prize– AOL search dataset– Barabasi mobile study
50Data Mining - Columbia University

Case Study 1: AOL Search Data
• August 4, 2006: AOL releases 20M search terms by anonymized users ‘for research purposes’. – Why?
• Within hours, uproar on the blogs– “The utter stupidity of this is staggering” -
TechCrunch
• August 7: AOL removes data, issues apology– “this was a screw-up, and we are angry”– “an innocent enough attempt to reach out to
the research community”• August 9: NYT front page story
– Identifies Thelma Arnold, 62 year old widow
51Data Mining - Columbia University

Case Study 1: AOL Search Data
• What’s the big deal?– Ego searches make it easy to figure out who you are – combined with
porn or illegal queries can make for serious privacy violations.
• What went wrong– Not well thought out : risk >> reward– Poor internal controls on public data release– Lack of understanding of subject matter– Lack of understanding of anonymizing data
• Fallout– CTO + at least two others fired– Data still out in the public
• Is it ethical to study?
– Inspiration for bad drama “purple lilac," "happy bunny pictures,” "square dancing
steps” "cut into your trachea," "pee fetish,” "Simpsons incest."
“purple lilac," "happy bunny pictures,” "square dancing
steps” "cut into your trachea," "pee fetish,” "Simpsons incest."
52Data Mining - Columbia University

Case Study 2: Netflix Prize
• October 2006: Netflix releases anonymized movie ratings from its customer base– 100M ratings, 500K customers (<10% of all
data)• Random integer as user ID• "some of the rating data for some customers in the
training and qualifying sets have been deliberately perturbed in one or more of the following ways: deleting ratings; inserting alternative ratings and dates; and modifying rating dates”
• 2007: Shock paper claiming de-anonymization of Netflix Prize data
53Data Mining - Columbia University

Case Study 2: Netflix Prize
• Narayanan and Shmatikov (2008)– “The adversary with a small amount of background
knowledge about an individual…can identify with high probability that individual’s record in the data and learn…sensitive attributes”
– Claim that Netflix’ data sanitization not relevant– Accuse Netflix of violating Video Privacy Protection Act
of 1988– Details:
• With aux info on 8 movies, where 2 can be wrong, and dates are known within 14 days; 99% de-anonymization
– Aux info can be gotten via web sites, water coolers, etc
• People might be willing to give away some ratings, but not others
54Data Mining - Columbia University

Case Study 2: Netflix Prize
• Much ado about nothing– Although paper is technically correct, dates are key
• Without dates, you must know 8 movies, all outside of the top 500 to get over 80% chance of de-anonymization
• Auxiliary data very hard to come by• No known cases discovered
• Netflix did it right– Consulted with top machine learning experts – 0 < risk << reward– Investment in quality data and expertise
mitigated risk
55Data Mining - Columbia University

Case Study 3: Barabasi Mobile Study
• Gonzalez, Hidalgo and Barabasi (2008)– Article in Nature outlines study on human mobility patterns
• 100000 individuals selected randomly from dataset of 6 million• Unidentified country (unclear if the researchers knew)• Cell tower location at start of call• 206 individuals were “pinged” every two hours for a week
– Findings• “humans follow simple, reproducible patterns”• Sample finding: Nearly three-quarters of those studied mainly
stayed within a 20-mile-wide circle for half a year.• Results “could impact all phenomena driven by human
mobility, from epidemic prevention to emergency response and urban planning.”
56Data Mining - Columbia University

Case Study 3: Barabasi Mobile Study
• Uproar ensued over ‘secret tracking’ of cell phone users– Blowback of negative feedback to Nature and scientists– Study would be “illegal in the US”– Approval from ONR review board and Northeastern review
board. Barabasi did not check with an “ethics panel”
• Response– Hidalgo: “the data could be misused”, but we were “not
trying to do evil things. We are trying to make the world a little better.”
– Northeastern and Nature backed the research– Continues to be referenced as an example of dangerous
research– Risk and reward both very high
57Data Mining - Columbia University

Research Concepts - Privacy• How do we guarantee that data is private?
– “quasi-identifiers” – combinations of attributes within the data that can be used to identify individuals.
– E.g. 87% of the population of the United States can be uniquely identified by gender, date of birth, and 5-digit zip code
– Datasets are “k-anonymous” when for any given quasi-identifier, a record is indistinguishable from k-1 others.
• But, one step further, maybe all k have a given sensitive attribute!– The distribution of target values within a group is referred to as “l-
diversity”.
• Ways to ‘fuzz’ data to increase anonymity and diversity:– Generalize / summarize the data : bin size, aggregate counts– Suppress or delete data– Perturb data
• Balance between privacy and utility is a hot research topic
Data Mining - Columbia University 58

Data Mining and Ethics
• Privacy is not the only issue – data mining brings up ethical issues as well
• Can you use sexual and/or racial information for profiling?– Medical diagnosis?– Loan payments?– What about proxies for these things?
• Best practices:– Full disclosure– Full transparency– Limited access to data– Opt-out– But: can we use data for the public good without informing
everyone?
Data Mining - Columbia University 59