data-ed webinar: a framework for implementing nosql, hadoop
TRANSCRIPT

• Big Data could know us better than we knowourselves– Dan
Gardner
• We'll see this as the time in history whthe world's information wastransformed frominert, passive statand put into aunified system thbrings thatinformation alive– Michael Nielsen
ow have ace to enme the
of ournowledgerse, one anonstantly e,figuresto matcheedshael S. one
at
A Framework for ImplementingNoSQL, Hadoop
• N • Today a street stall in Mumbai can access moreb information, maps, statistics, academic papers, pricen trends, futures markets, and data than a U.S.c President could only a few decades ago– – Juan Enriquez
ot everything that can e counted counts, and ot everything that ounts can be countedAlbert Einstein
Big Data and NoSQL continue to make headlines everywhere.However, most of what has been written about these topics is focused on the hardware, services, and scale out. But what about a Big Data and NoSQL Strategy, one that supports your business strategy? Virtually every major organization thinking about these data platforms is faced with the challenge of figuring out the appropriate approach and the requirements. This presentation will provide guidance on how to think about and establish realistic Big Data management plans and expectations. We will introduce aframework for evaluating the various choices when it comes to implementing and succeeding with Big Data/NoSQL and showhow to demonstrate a sample use case.Takeaways:• A Framework for evaluating Big Data techniques• Deciding on a Big Data platform – How do you know which one
is a good fit for you?• The means by which big data techniques can complement
existing data management practices• The prototyping nature of practicing big data techniques• The distinct ways in which utilizing Big Data can generate
business valueDate: Time: Presenter:
June 9, 20152:00 PM ET/11:00 AM PTPeter Aiken, Ph.D. & Josh Bartels
• Soon we will salt the oceans, the land, and the skwith uncounted numbers of sensors invisible to theyes but visible to one another
• We n – Esther Dysonchanbeco centerown kunive that crecon itselfour n– Mic
Mal
• We've reached a tipping point in history: today more ydata is being manufactured by machines, servers, eand cell phones, than by people– Michael E. Driscoll
• Every century, a new technology-steam power, electricity, atomic energy, or microprocessors-has swept away the old world with a vision of a new one.Today, we seem to be entering the era of Big Data– Michael Coren
1Copyright 2015 by Data Blueprint Slide #

Shannon Kempe
Executive Editor at DATAVERSITY.net
2Copyright 2015 by Data Blueprint Slide #

Steven MacLauchlan• 10 years of experience in Application
Development and Data Modeling with a focus on Healthcare solutions.
• Delivers tailored data management solutions that provide focus on data’s business value while enhancing clients’ overall capability to manage data
• Certified Data Management Professional (CDMP)
• Computer Science degree from Virginia Commonwealth University
• Most recent focus: Understanding emerging data modeling trends and how these can best be leveraged for the Enterprise.
3Copyright 2015 by Data Blueprint Slide #

Get Social With Us!
Live Twitter FeedJoin the conversation! Follow us:
@datablueprint@paikenAsk questions and submit your comments: #dataed
Like Us on Facebookwww.facebook.com/
datablueprintPost questions and commentsFind industry news, insightful
content
and event updates.
Join the GroupData Management &
Business IntelligenceAsk questions, gain insightsand collaborate with fellow
data management professionals
4Copyright 2015 by Data Blueprint Slide #

Peter Aiken, Ph.D.• 30+ years in data management• Repeated international recognition• Founder, Data Blueprint (datablueprint.com)
• Associate Professor of IS (vcu.edu)
• DAMA International (dama.org)
• 9 books and dozens of articles• Experienced w/ 500+ data
management practices• Multi-year immersions:
– US DoD– Nokia– Deutsche Bank– Wells Fargo– Walmart– …
• DAMA International President 2009-2013
• DAMA International Achievement Award 2001 (with Dr. E. F. "Ted" Codd
• DAMA International Community Award 2005
PETERAIKEN WITH JUANITA BILLINGSF O R EW O RD B Y J O H N B O TTEG A
MONETIZINGDATA M AN AGEM EN T
Unlocking the Value in Your Organization’s Most Important Asset.
The Case for the Chief ta fficerRecasting uite erageYour Most aluable A
Peter Aiken andMichael Gorman
5Copyright 2015 by Data Blueprint Slide #

Josh Bartels• Data management consultant and
leader– Over (10) years of experience– Multiple industries (Finance, Defense,
Insurance)• Certifications
– Certified Data Management Professional (CDMP)
– Project Manager (PMP)– Data Vault 2.0 Practitioner (CDVP2)
• Education– Masters in Business Administration– Masters in Information Systems
• Current Efforts– focus on the creation and migration to
new data platforms for clients in thefinancial and insurance industries.
6Copyright 2015 by Data Blueprint Slide #

Presented by Peter Aiken, Ph.D., Josh Bartels, Steven MacLauchlan
A Framework for Implementing NoSQL, Hadoop
Demystifying Big Data 2.0: Developing the Right Approach for Implementing Big Data Techniques
7Copyright 2015 by Data Blueprint Slide #

A Framework for Implementing NoSQL, HadoopDemystifying Big Data 2.0: Developing the Right Approach for Implementing Big Data Techniques
• Big Data Context– We are using the wrong vocabulary to discuss this topic
• More Precise Definitions– Framework– Non Von Neuman Architectures– Hadoop/Nosql
• Big Data– Historical Perspective
• Big Data Approach– Crawl, Walk, Run
• Framework Examples– Social– Operational BWB
• Take Aways and Q&ATweeting now at: #dataed
8Copyright 2015 by Data Blueprint Slide #

A Framework for Implementing NoSQL, HadoopDemystifying Big Data 2.0: Developing the Right Approach for Implementing Big Data Techniques
• Big Data Context– We are using the wrong vocabulary to discuss this topic
• More Precise Definitions– Framework– Non Von Neuman Architectures– Hadoop/Nosql
• Big Data– Historical Perspective
• Big Data Approach– Crawl, Walk, Run
• Framework Examples– Social– Operational BWB
• Take Aways and Q&ATweeting now at: #dataed
10Copyright 2015 by Data Blueprint Slide #

Myth #1: Big Data has a clear definition
Fact:• The term is used so often
and in many contexts that its meaning has becomevague and ambiguous
• Industry experts andscientists often disagree
http://articles.washingtonpost.com/2013-08-16/opinions/41416362_1_big-data-data-crunching-marketing-analytics
10Copyright 2015 by Data Blueprint Slide #

Big Data (has something to do with Vs - doesn't it?)
• Volume– Amount of data
• Velocity– Speed of data in and out
• Variety– Range of data types and sources
• 2001 Doug Laney
• Variability– Many options or variable interpretations confound analysis
• 2011 ISRC
• Vitality–A dynamically changing Big Data environment in which analysis and predictive models
must continually be updated as changes occur to seize opportunities as they arrive• 2011 CIA
• Virtual– Scoping the discussion to only include online assets
• 2012 Courtney Lambert
• Value/Veracity• Stuart Madnick (John Norris Maguire Professor of Information Technology, MIT Sloan School of Management & Professor of Engineering Systems, MIT School of Engineering)
11Copyright 2015 by Data Blueprint Slide #

Defining Big Data• Big Data are high-volume, high-velocity, and/or high-variety
information assets that require new forms of processing toenable enhanced decision making, insight discoveryand process optimization.
– Gartner 2012• Big data refers to datasets whose size is beyond the ability of
typical database software tools to capture, store, manage, and analyze.– IBM 2012
• An all-encompassing term for any collection of data sets so large and complex that it becomes difficult to process using on-hand data management tools or traditional dataprocessing applications– Wikipedia 2014
• Shorthand for advancing trends in technology that open the door to a new approachto understanding the world and making decisions.
– NY Times 2012• The broad range of new and massive data types that have appeared over the last
decade– Tom Davenport 2014
• Data of a very large size, typically to the extent that its manipulation and management present significant logistical challenges.”
– Oxford English Dictionary 2014• Big data is about putting the "I" back into IT.
– Peter Aiken 2007
12Copyright 2015 by Data Blueprint Slide #

Big Data Techniques• New techniques available to impact the productivity (order of
magnitude) of any analytical insight cycle that compliment, enhance, or replace conventional (existing) analysis methods
• Big data techniques are currently characterized by:– Continuous, instantaneously
available data sources– Non-von Neumann
Processing (defined later in the presentation)– Capabilities approaching
or past human comprehension– Architecturally enhanceable
identity/security capabilities– Other tradeoff-focused data processing
• So a good question becomes "where in our existing architecture can we most effectively apply Big Data Techniques?"
13Copyright 2015 by Data Blueprint Slide #

Big Data Technologies by themselves, are a One Legged Stool
Governance is the major meansof preventing over reliance on one legged stools!
14Copyright 2015 by Data Blueprint Slide #

The Big Data LandscapeCopyright Dave Feinleib, bigdatalandscape.com
15Copyright 2015 by Data Blueprint Slide #

Rela%onal zoneMicroso^
Non+rela%onalzone
Lotus Notes
Objec/vity
MarkLogic
Ac/anVersant
InterSystemsCaché
McObject
Starcounter
ArangoDB
Founda/onDB
Neo4J
InfiniteGraphCloudant
RethinkDBCouchDB
BerkeleyDBRavenDB LevelDB
Oracle NoSQL
RiakCouchbase
Redis
Handlersocket
Cassandra.ioGoogle App
Engine DatastoreGoogle Cloud
Datastore
Accumulo
YarcDataCassandra
HBase
Verizon Splice
Machine
FirebirdAc/an IngresSAP Sybase ASE
EnterpriseDB
SQLServer
MySQL
InformixExasol
MariaDB Oracle IBMDatabase DB2
SAPHANA
Database.com
AWS RDSClearDB
Google Cloud SQLHP Cloud RDB
for MySQLFathomDB
StormDBRackspaceCloudDatabases
Azure SQLDatabase
TeradataAster
Oracle Big DataAppliance
SciDB HPCC
Cloudera
HortonworksMapR IBMBigInsights
ZeWaset
NGDATA
LucidWorksBig Data
InfochimpsMetamarkets
MetascaleMortarData
Al/scale
Rackspace
Qubole
Voldemort
TokuDB
CortexDB Aerospike
RainStor
IBM PureDatafor Analy/cs
SQream
Teradata
Kogni/o
LucidDBKx Systems
Ac/an MatrixIBM InfoSphere
ParStreamSAP Sybase IQ
HP Ver/caPivotal Greenplum
MonetDBLogicBlox
SpaceCurve
XtremeDataMetamarkets Druid
Ac/an Vector
MySQL ClusterClustrix ScaleDB
ScaleBase
ScaleArcTesora
CodeFutures
Con/nuent
Datomic
CockroachDBJustOneDB
TransLa[c e
NuoDB
Drizzle
Pivotal GemFire XD
Zimory Scale
GaleraDeepDB
FairCom MemSQL GenieDB
Infobright
FlockDB
AllegrographHypergraphDB
AffinityDB MongoDB
SPARQLBASEGiraph
Trinity MemCachier
Redis LabsMemcachedCloud
BitYota
IronCache
Grid/cache zoneMemcached
Ehcache
ScaleOutSo^ware
IBMeXtreme
ScaleOracle
Coherence
GigaSpaces XAPGridGain
PivotalGemFire
CloudTran
InfiniSpan
Hazelcast
OracleExaly/cs
Oracle EndecaServer A[ v io
Elas/csearch
Towardsenterprise search
Lucene/Solr
IBM InfoSphereData Explorer
SumoLogic
A TowardsE*discovery
DatabaseTamino
XML Server
DocumentumxDB
UniData
UniVerse
Adabas
OrientDB
Ipedo XML
ObjectStore
AWSElas/Cache
IBM IMS
WakandaDB
Sparksee
https://E 451research.com/
dashboard/dpa©2014by 451ResearchLLC.
All rights reserved
HyperDex
TIBCOAc/veSpaces
Titan
BigMemory
FatDB
GrapheneDB
Hypertable
Al/base HDB
Al/base XDB
JumboDB
Stardog
Data caching
Data grid
Search
Appliances
Inememory
Stream processing
Redshi1010data
GoogleBigQuery
AWS
TempoIQ
InfluxDBWebScaleSQL
2
D
E
D
Red Hat JBossData Grid
654
Iris CouchMongoLab
Compose
Redis LabsRedis Cloud
ObjectRocketAzure DocumentDB
TokuMXCloudBird
1 3
AWS DynamoDB
RedisGreenRedisetoego
AWS SimpleDB
AWS Elas/Cachewith Redis
MagnetoDB
ObjectRocketRedis
Databricks/SparkOracle BigData Cloud
SQLite
Ac/an PSQLProgress OpenEdge
Oracle TimesTensolidDB
HerokuPostgres
TreasureData
vFabric PostgresPostgreSQL
Percona
SAP Sybase SQL Anywhere
Presto Impala JethroData
IBMBig SQL CitusDB Hadapt
PivotalHD/HAWQ
DataStaxEnterprise
Sqrrl Enterprise
Microso^HDInsight
HPAutonomy
OracleExadata
IBMPureData
ApacheDrill
SQL ServerPDW
ApacheTajo
ApacheHive
MammothDB
SRCH2
TIBCOLogLogic
Splunk
TowardsSIEM
LogglyLogentries
InfiniSQL
Savvis
So^layer
xPlentyTrafodion
MariaDB Enterprise
Apache StormApache S4
IBMInfoSphereStreams
TIBCOStreamBaseAWSKinesis
SQLStreamDataTorrent
FeedzaiSo^ware AG
GuavusLokad
Data Platforms
MapOctober 2014
Key:General purpose
Specialist analy/ceaseaeServiceBigTables
GraphDocument Keyvalue stores Keyvalue directaccessHadoop
MySQL ecosystem
Advancedclustering/shardingNewSQL databases
OpenStack Trove
MySQLFabricSpider
A
B
C
TeSystems
B
C
2 43 5
PostgreseXL
Azure Google CloudDataflowSearch
1 6
VoltDB
AWS EMR
GoogleCompute
Engine
Stra/o
16Copyright 2015 by Data Blueprint Slide #

C2 DataStax Enterprise C6 HPVer/ca B5 Microso SQL Server PDW C4 ScaleDB hWps://451research.com/dashboard/dpa
17Copyright 2015 by Data Blueprint Slide #
INDEX D6 D2 B3 C6
1010data Accumulo Ac/anIngres Ac/anMatrix
A2C3D4C1C4
DataTorrent Datomic DeepDB DocumentumxDB Drizzle
B6D2E1C2B4
HPCCHyperDex HypergraphDB Hypertable IBM Big SQL
D6D2E2A3B4
MonetDB MongoDB MongoLab MortarData MySQL
E3B6A3A2C5
ScaleOutSo^ware SciDBSo^layer So^wareAG solidDB
B5 Ac/an PSQL E5 Ehcache A5 IBM BigInsights C4 MySQL Cluster D6 SpaceCurveC6 Ac/an Vector A1 Elas/csearch B4 IBM DB2 C4 MySQL Fabric C1 SparkseeE1 Ac/an Versant B3 EnterpriseDB E6 IBM eXtreme Scale C1 Neo4J E1 SPARQLBASED1 Adabas C4 CodeFutures D1 IBM IMS B2 NGDATA C4 SpiderC2 Aerospike C4 CodeFutures C6 IBM InfoSphere C3 NuoDB B3 Splice MachineE1 AffinityDB E2 Compose B2 IBM InfoSphere Data Explorer E1 Objec/vity B2 SplunkE1 Allegrograph D4 Con/nuent A2 IBM InfoSphere Streams E2 ObjectRocket B3 SQLiteD3 Al/base HDB C2 Couchbase B4 IBM PureData D2 ObjectRocket Redis A2 SQLStreamD3 Al/base XDB D2 CouchDB B6 IBM PureData for Analy/cs D1 ObjectStore B6 SQreamA3 Al/scale D5 Database.com B5 Impala C5 OpenStack Trove B2 Sqrrl EnterpriseB4 Apache Drill A5 Databricks/Spark E6 InfiniSpan A5 Oracle Big Data Appliance A1 SRCH2B4 Apache Hive C2 DataStax Enterprise C3 InfiniSQL A5 Oracle Big Data Cloud B2 StarcounterA2 Apache S4 A2 DataTorrent E1 InfiniteGraph E5 Oracle Coherence D1 StardogA2 Apache Storm C3 Datomic D6 InfluxDB B4 Oracle Database C5 StormDBB3 Apache Tajo D4 DeepDB C4 Infobright A1 Oracle Endeca Server A6 Stra/oB2 ArangoDB E2 DocumentDB A3 Infochimps B4 Oracle Exadata B1 Sumo LogicA1 A[vio C1 Documentum xDB B5 Informix B6 Oracle Exaly/cs A3 TeSystemsE2 AWS DynamoDB C5 Drizzle E1 Intersystems Caché D2 Oracle NoSQL C1 Tamino XML
ServerE4 AWS Elas/Cache E5 Ehcache C1 Ipedo XML Database C5 Oracle TimesTen D6 TempoIQE2 AWS Elas/Cache with Redis A1 Elas/csearch E2 Iris Couch C1 OrientDB B6 TeradataA4 AWS EMR B3 EnterpriseDB E4 IronCache C6 ParStream B6 Teradata AsterA2 AWS Kinesis C5 Exasol B5 JethroData B3 Percona C4 TesoraD5 AWS RDS C3 FairCom D2 JumboDB E4 Pivotal GemFire E4 TIBCO
Ac/veSpacesD6 AWS Redshi^ C2 FatDB C3 JustOneDB D6 Pivotal Greenplum B1 TIBCO LogLogicE2 AWS SimpleDB D5 FathomDB C6 Kogni/o B5 Pivotal HD/HAWQ A2 TIBCO
StreamBaseE2 Azure DocumentDB A2 FeedZai C6 Kx Systems D3 Pivotal SQLFire D1 TitanB2 Azure Search B3 Firebird D2 LevelDB B3 PostgreseXL C4 TokuDBD5 Azure SQL Database D1 FlockDB B1 Logentries B3 PostgreSQL D2 TokuMXD2 BerkeleyDB C2 Founda/onDB B1 Loggly B4 Presto B3 TrafodionE4 BigCache D4 Galera D6 LogicBlox C5 Progress OpenEdge D3 TransLa[ceE4 BigMemory C4 GenieDB A2 Lokad A3 Qubole A4 Treasure DataD6 BitYota E4 GigaSpaces XAP E2 Lotus Notes A3 Rackspace E1 TrinityC2 Cassandra E1 Giraph A1 Lucene/Solr C5 Rackspace Cloud Databases C1 UniDataD2 Cassandra.io D5 Google BigQuery C6 LucidDB B6 RainStor C1 UniVerseB5 CitusDB D2 Google App Engine Datastore B2 LucidWorks Big Data D2 RavenDB A3 VerizonD5 ClearDB A2 Google Cloud Dataflow E2 MagnetoDB E6 Red Hat JBoss Data Grid B3 vFabric PostgresE2 Cloudant D2 Google Cloud Datastore B4 MammothDB C2 Redis D2 VoldemortD2 CloudBird C5 Google Cloud SQL A4 MapR E3 Redis Labs Memcached Cloud C3 VoltDBA5 Cloudera A4 Google Compute Engine B3 MariaDB E2 Redis Labs Redis Cloud D1 WakandaDBE5 CloudTran D1 GrapheneDB B3 MariaDB Enterprise E2 Redisetoego D5 WebScaleSQLC4 Clusrix E3 GridGain B2 MarkLogic E2 RedisGreen A3 xPlentyC3 CockroachDB A2 Guavus D1 McObject D2 RethinkDB B6 XtremeDataC4 CodeFutures B5 Hadapt E5 Memcached C2 Riak C1 YarcDataD2 Compose C2 Handlersocket E3 MemCachier B5 SAP HANA A4 ZeWasetD4 Con/nuent E5 Hazelcast C3 MemSQL B3 SAP Sybase ASE D4 Zimory ScaleB2 CortexDB C2 HBase A3 Metamarkets C6 SAP Sybase IQC2 Couchbase C5 Heroku Postgres C6 Metamarkets Druid B3 SAP Sybase SQL AnywhereD2 CouchDB A5 Hortonworks A5 Metascale A3 SavvisD5 Database.com A1 HP Autonomy A5 Microso^ HD Insight C4 ScaleArcA5 Databricks/Spark D5 HP Cloud RDB for MySQL B5 Microso^ SQL Server C4 ScaleBase

Myth #2: Everyone should invest in Big Data
Fact:• Not every company will
benefit from Big Data• It depends on your size
and your ability– Local pizza shop vs.
state-wide or national chain
18Copyright 2015 by Data Blueprint Slide #

Big Data can create significant financial value across sectors
• Some (not all)companies cantake advantageof Big Data tocreate value if they want tocompete
20Copyright 2015 by Data Blueprint Slide #

A Framework for Implementing NoSQL, HadoopDemystifying Big Data 2.0: Developing the Right Approach for Implementing Big Data Techniques
• Big Data Context– We are using the wrong vocabulary to discuss this topic
• More Precise Definitions– Framework– Non Von Neuman Architectures– Hadoop/Nosql
• Big Data– Historical Perspective
• Big Data Approach– Crawl, Walk, Run
• Framework Examples– Social– Operational BWB
• Take Aways and Q&ATweeting now at: #dataed
20Copyright 2015 by Data Blueprint Slide #

Big Data = Big Spending• Enterprises are spending wildly on Big Data but don’t
know if it’s worth it yet (Business Insider, 2012)• Big Data Technology Spending Trend:• 83% increase over the next 3 years (worldwide):
– 2012: $28 billion– 2013: $34 billion– 2016: $232 billion
• Caution:– Don’t fall victim to SOS (Shiny Object
Syndrome)– A lot of money is being invested but
is it generating the expected return?– Gartner Hype Cycle suggests results
are going to be disappointing http://www.businessinsider.com/enterprise-big-data-spending-2012-11#ixzz2cdT8shhehttp://www.inc.com/kathleen-kim/big-data-spending-to-increase-for-it-industry.html
http://www.gartner.com/DisplayDocument?id=2195915&ref=clientFriendlyUrl
21Copyright 2015 by Data Blueprint Slide #

Who wrote this … ?
23
Copyright 2015 by Data Blueprint
• In considering any newsubject, there isfrequently a tendencyfirst to overrate what we find to be alreadyinteresting orremarkable, andsecondly - by a sort of natural reaction - to undervalue the truestate of the case.
• Augusta Ada King, Countess of Lovelace - aka Ada Lovelace, publisher of the first computing program

Gartner Five-phase Hype Cyclehttp://www.gartner.com/technology/research/methodologies/hype-cycle.jsp
Peak of Inflated Expectations: Early publicity produces a number of success stories—often accompanied by scores of failures. Somecompanies take action; many do not.
Trough of Disillusionment: Interest wanes as experiments and implementations fail to deliver. Producers of thetechnology shake out or fail. Investments continue only if the surviving providers improve their products to thesatisfaction of early adopters.
Technology Trigger: A potential technology breakthrough kicks things off. Early proof-of-concept stories and media interesttrigger significant publicity. Often no usable products exist and commercial viability is unproven.
Slope of Enlightenment: More instances of how the technology can benefit the enterprise start to crystallize and become more widely understood. Second- and third-generation products appear from technology providers. More enterprises fund pilots;conservative companies remain cautious.
Plateau of Productivity: Mainstream adoption starts totake off. Criteria for assessing provider viability are moreclearly defined. The technology’s broad market applicability and relevance are clearly paying off.
23Copyright 2015 by Data Blueprint Slide #

Gartner Hype Cycle
"A focus on big data is not a substitute for thefundamentals of information management."
24Copyright 2015 by Data Blueprint Slide #

2012 Big Data in Gartner’s Hype Cycle
25Copyright 2015 by Data Blueprint Slide #

2013 Big Data in Gartner’s Hype Cycle
26Copyright 2015 by Data Blueprint Slide #

2014 Big Data in Gartner’s Hype Cycle
27Copyright 2015 by Data Blueprint Slide #
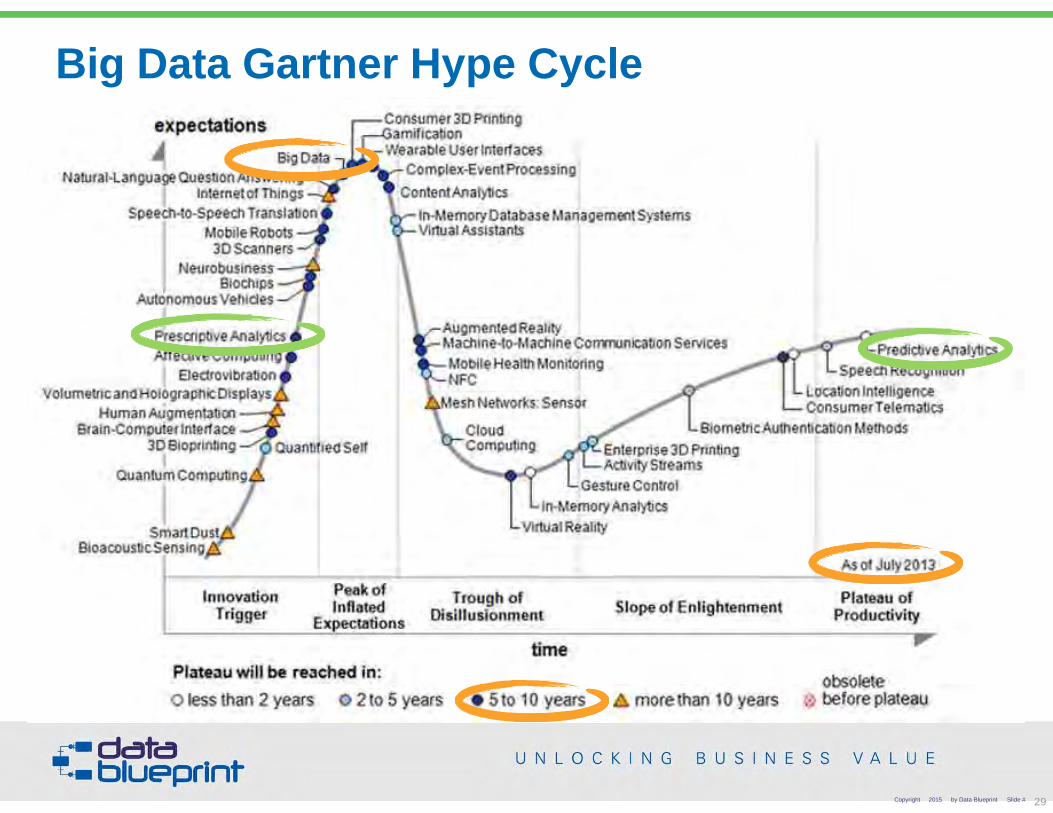
Big Data Gartner Hype Cycle
Copyright 2015 by Data Blueprint Slide # 29

Myth #3: Big Data is innovative
Fact:• Big Data techniques are
innovative• ROI and insights depend
on the size of the businessand the amount of dataused and produced, e.g.– Local pizza place vs. Papa
John’s– Retail
29Copyright 2015 by Data Blueprint Slide #

My Barn must pass a foundation inspection
• Before further construction can proceed• No IT equivalent in most organizations
30Copyright 2015 by Data Blueprint Slide #

Frameworks• A system of ideas
for guiding analyses
• A means of organizing project data
• Data integration priorities decision making framework
• A means of assessing progress
8 31Copyright 2015 by Data Blueprint Slide #

"There’s now a blurring between the storage world and the memory world"
• Faster processors outstripped not only the hard disk, but mainmemory– Hard disk too slow– Memory too small
• Flash drives remove both bottlenecks– Combined Apple and Yahoo have
spend more than $500 million to date
• Make it look like traditional storage or more systemmemory– Minimum 10x improvements– Dragonstone server is 3.2 tb flash
memory (Facebook)
• Bottom line - new capabilities!
8 32Copyright 2015 by Data Blueprint Slide #

Non-von Neumann Processing/Efficiencies• von Neumann
bottleneck (computer science)– "An inefficiency inherent in
the design of any von Neumann machine that arises from the fact that most computer time is spent in moving information between storage and the central processing unit rather than operating on it"[http://encyclopedia2.thefreedictionary.com/von+Neumann+bottleneck]
• Michael Stonebraker– Ingres (Berkeley/MIT)– Modern database
processing is approximately 4% efficient
• Many big data architectures are attempts to address this, but:– Zero sum game– Trade characteristics
against each other• Reliability• Predictability
– Google/MapReduce/ Bigtable
– Amazon/Dynamo– Netflix/Chaos Monkey– Hadoop– McDipper
• Big data techniques exploit non-von Neumann processing
8 33Copyright 2015 by Data Blueprint Slide #

m
• Decomposition• Reassembly
– not optional!
8 34Copyright 2015 by Data Blueprint Slide #

One of Data Blueprint's Big Data Clusters
8 35Copyright 2015 by Data Blueprint Slide #
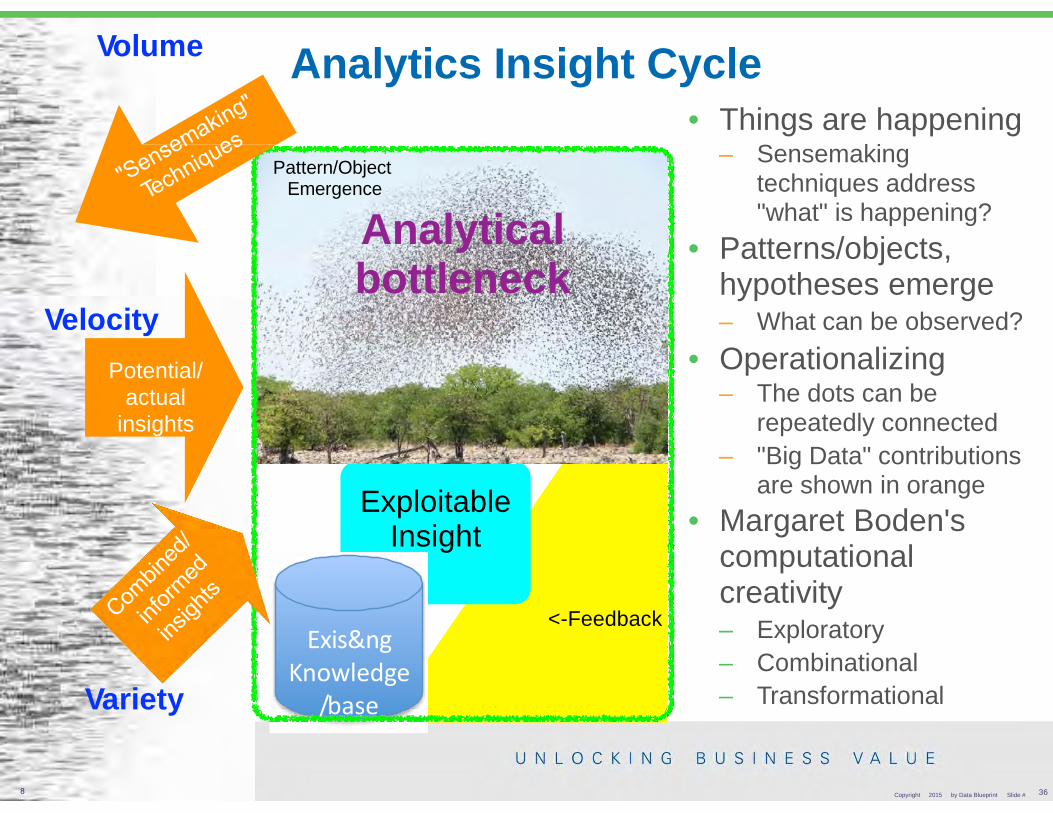
<-Feedback
ExploitableInsight
• Patterns/objects, hypotheses emerge– What can be observed?
• Operationalizing– The dots can be
repeatedly connected
Analytics Insight Cycle
Exis&ng Knowledge
/base
• Things are happening– Sensemaking
techniques address "what" is happening?
• Patterns/objects, hypotheses emerge– What can be observed?
• Operationalizing– The dots can be
repeatedly connected– "Big Data" contributions
are shown in orange• Margaret Boden's
computational creativity– Exploratory– Combinational– Transformational
Volume
Variety
VelocityPotential/
actual insights
Pattern/Object Emergence
Analytical bottleneck
8 36Copyright 2015 by Data Blueprint Slide #

Big Data: Two prominent use cases• Sandwich offers a good analogy
of the big data and existingtechnologies
• Landing Zone (less expensive)– Especially useful in cases were data
is highly disposable
• Existing technologies are the– Contents sandwiched and
complemented landing zone and archival capabilities
• Archiving/Offloading (less needfor structure)– "Cold" transactional and analytic
dataAdapted from Nancy Kopp:http://ibmdatamag.com/2013/08/relishing-the-big-data-burger/
Landing Zone
Archiving Offloading
Existing Data Architectural
Processing
8 37Copyright 2015 by Data Blueprint Slide #

What is NoSQL?• Commonly interpreted as "Not Only SQL• Broad class of database management technologies that
provide a mechanism for storage and retrieval of data that doesn’t follow traditional relational database methodology.
• Motivations– Simplicity of design– Horizontal scaling– Finer control over availability of the data.
• The data structures used by NoSQL databases differ fromthose used in relational databases, making someoperations faster in NoSQLand others faster in relational databases.
8 38Copyright 2015 by Data Blueprint Slide #

What is Hadoop?• A data storage and processing
system, that runs on clusters of commodity servers.• Able to store any kind of data in its native format.• Perform a wide variety of analyses and transformations.• Store terabytes, and even petabytes, of data
inexpensively.• Handles hardware and system failures automatically,
without losing data or interrupting data analyses.• Critical components of Hadoop:
– HDFS- The Hadoop Distributed File System is the storage systemfor a Hadoop cluster, responsible for distribution of data across theservers.
– Mapreduce- The inner workings of Hadoop that allows for distributed and parallel analytical job execution.
40Copyright 2015 by Data Blueprint Slide #

Why NoSQL? Why Hadoop?• Large number of users (read: the internet)
• Rapid app development and deployment
• Large number of mission critical writes (sensors/etc)
• Small, continuous reads and writes, especially where“Consistency” is less important (social networks)
• Hadoop solves the hard scaling problems caused by largeamounts of complex data.
• As the amount of data in a cluster grows,new servers can be added to a Hadoopcluster incrementally and inexpensivelyto store and analyze it.
40Copyright 2015 by Data Blueprint Slide #

Hadoop Use Cases in the Real World• Risk Modeling
• Customer Churn Analysis
• Recommendation Engine
• Ad Targeting
• Point of Sale Transaction Analysis
• Social Sentiment on Social Media
• Analyzing network data to predict failure
• Threat analysis
• Trade Surveillance
41Copyright 2015 by Data Blueprint Slide #

http://blogs.informatica.com/perspectives/uk/2011/08/09/hadoop-enriches-data-science-part-2-of-hadoop-series/
42Copyright 2015 by Data Blueprint Slide #

44
Copyright 2015 by Data Blueprint
• Data analysis struggles with the social– Your brain is excellent at social cognition - people can
• Mirror each other’s emotional states• Detect uncooperative behavior• Assign value to things through emotion
– Data analysis measures the quantity of social interactions but not the quality• Map interactions with co-workers you see during work days• Can't capture devotion to childhood friends seen annually
– When making (personal) decisions about social relationships, it’s foolish to swap the amazing machinein your skull for the crude machine on your desk
• Data struggles with context– Decisions are embedded in sequences and contexts– Brains think in stories - weaving together multiple
causes and multiple contexts– Data analysis is pretty bad at
• Narratives / Emergent thinking / Explaining
• Data creates bigger haystacks– More data leads to more statistically significant
correlations– Most are spurious and deceive us– Falsity grows exponentially greater amounts of data
we collect
• Big data has trouble with big problems– For example: the economic stimulus debate– No one has been persuaded by data to switch sides
• Data favors memes over masterpieces– Detect when large numbers of people take an instant
liking to some cultural product– Products are hated initially because they are unfamiliar
• Data obscures values– Data is never raw; it’s always structured according to
somebody’s predispositions and values
Some Big Data Limitations

Myth #4: Big Data is just another IT project
Copyright 2013 by Data Blueprint
Fact:• Big Data is not your typical IT
project– Does not answer typical IT questions– Trend analysis, agile, actionable, etc.– Fundamentally different approach
• Big Data Projects are exploratory• Big Data enables new capabilities• Big Data can be a disruptive
technology• It might sound simple but that
doesn’t mean it’s easy• Beware of SOS (Shiny Object
Syndrome)
44

http://articles.washingtonpost.com/2013-08-16/opinions/41416362_1_big-data-data-crunching-marketing-analytics
Copyright 2013 by Data Blueprint
Myth #4: Big Data is new
Fact:• The term originated in the Silicon
Valley in the 1990s• The concept has been used
previously– 800 year old linguistic datasets– Use in sciences in 1600s– Kepler, Sloan Digital Sky Survey,
Statisticians’ view
• Much harder to leverage Big Data when you lack appropriatetechniques
45

The Bills of Mortality was an Early Data Collection
47Copyright 2015 by Data Blueprint Slide #

Mortality Geocoding
Where is it happening?
Copyright 2015 by Data Blueprint
47
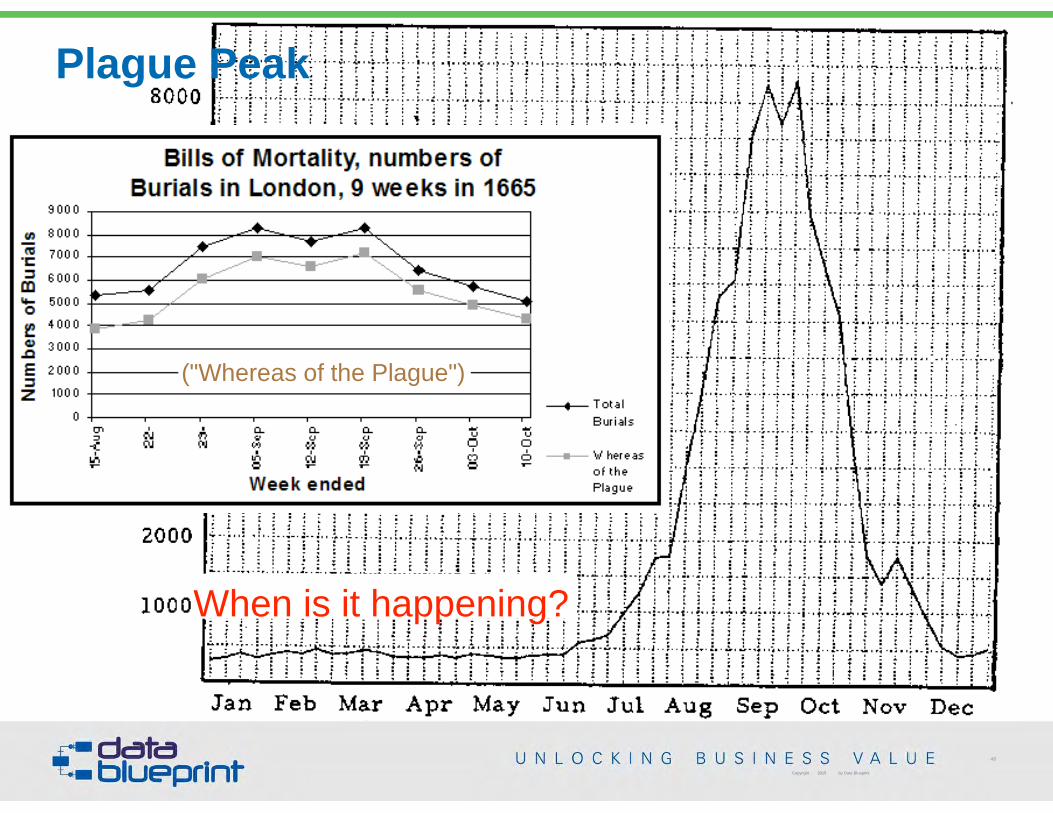
("Whereas of the Plague")
Plague Peak
When is it happening?
Copyright 2015 by Data Blueprint
48

Black Rats or Rattus Rattus
Why is it happening?
50
Copyright 2015 by Data Blueprint

What Will Happen? What will happen?
51
Copyright 2015 by Data Blueprint

Formalizing Data Management• Defend the Realm:
The authorized history of MI5by Christopher Andrew
• World War I• 1914• At war with much
of Europe• 14,000,000 Germans living
in the United Kingdom• How to efficiently and
effectively manageinformation on that manyindividuals?
• The Security Service is responsible for "protecting the UK against threats to national security fromespionage, terrorism and sabotage, from the activities of agents of foreign powers, and from actions intended to overthrow or undermine parliamentary democracy by political, industrial or violent means."
51Copyright 2015 by Data Blueprint Slide #

“As a final thought, how about a machine that would send, via closed-circuit television, visual andoral information needed immediately at high-levelconferences or briefings? Let’s say that a group of senior officers are contemplating a covert actionprogram for Afghanistan. Things go well untilsomeone asks “Well, just how many schools arethere in the country, and what is the literacy rate?” No one in the room knows. (Remember, this is animaginary situation). So the junior member present dials a code number into a device at one end of thetable. Thirty seconds later, on the screen overhead, a teletype printer begins to hammer out therequired data. Before the meeting is over, the group has been given, through the same method, thenames of countries that have airlines intoAfghanistan, a biographical profile of the Soviet ambassador there, and the Pakistani order of battlealong the Afghanistan frontier. Neat, no?”
• Predicted use of not justcomputing in theintelligence community
• Also forecastpredictiveanalytics
• Accompanyingprivacychallenges
52Copyright 2015 by Data Blueprint Slide #

A Framework for Implementing NoSQL, HadoopDemystifying Big Data 2.0: Developing the Right Approach for Implementing Big Data Techniques
• Big Data Context– We are using the wrong vocabulary to discuss this topic
• More Precise Definitions– Framework– Non Von Neuman Architectures– Hadoop/Nosql
• Big Data– Historical Perspective
• Big Data Approach– Crawl, Walk, Run
• Framework Examples– Social– Operational BWB
• Take Aways and Q&ATweeting now at: #dataed
53Copyright 2015 by Data Blueprint Slide #

http://articles.washingtonpost.com/2013-08-16/opinions/41416362_1_big-data-data-crunching-marketing-analytics
Copyright 2013 by Data Blueprint
Myth #6: Big Data provides all the Answers
Fact:• Big Data does not mean the end of
scientific theory• Be careful or you’ll end up with
spurious correlations– Don’t just go fishing for correlations and
hope they will explain the world
• To get to the WHY of things, you need ideas, hypotheses and theories
• Having more data does not substitute for thinking hard, recognizing anomalies and exploringdeep truths
• You need the right approach
54

Copyright 2013 by Data Blueprint55

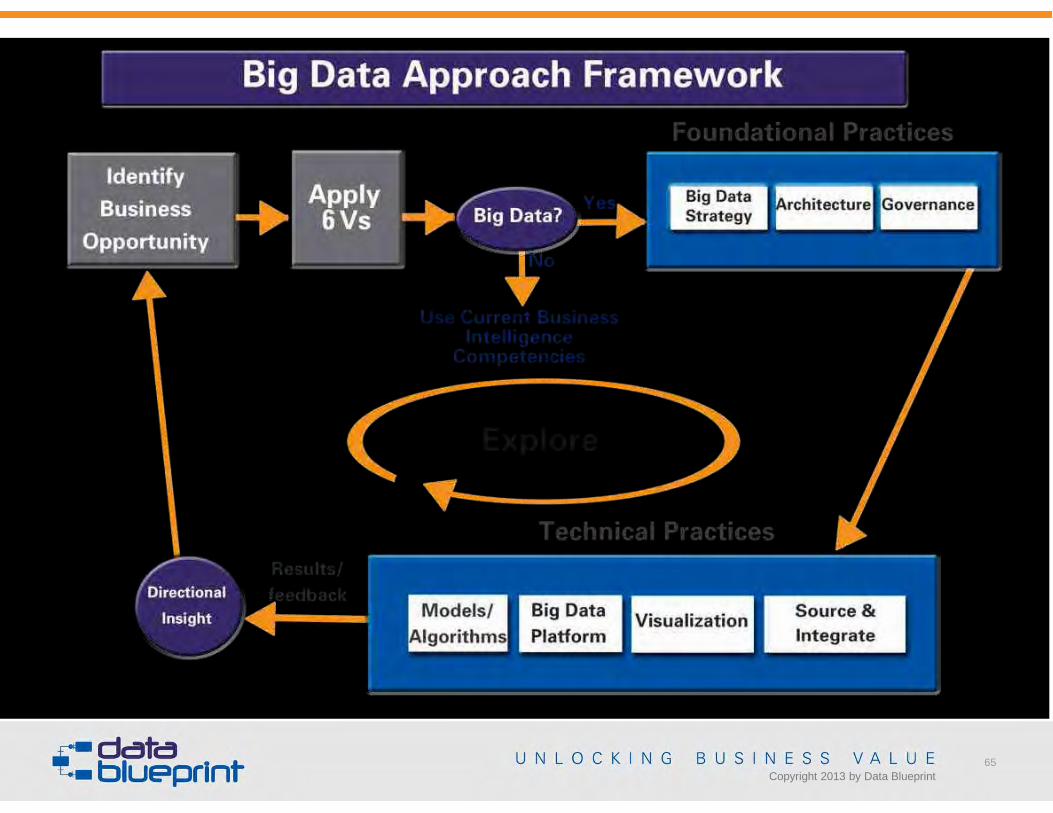
• Identify business opportunity
Copyright 2013 by Data Blueprint
• How can data be leveraged inexploring– External market place
• Analyze opportunities and threats– Internal efficiencies
• Analyze strengths and weaknesses
56

Example: 2012 Olympic Summer Games
Copyright 2013 by Data Blueprint
1. Volume: 845 million FB users averaging 15 TB+ of data/day
2. Velocity: 60 GB of data per second3. Variety: 8.5 billion devices connected4. Variability: Sponsor data, athlete data, etc.5. Vitality: Data Art project “Emoto”6. Virtual: Social media
57

• Based on my 6 V analysis, do I need a Big Data solution
Copyright 2013 by Data Blueprint
or does my current BI solution address my businessopportunity?– Do the 6 Vs indicate general Big Data characteristics?– What are the limitations of my current Bi environment?
(Technology constraint)– What are my budgetary restrictions? (Financial constraint)– What is my current Big Data knowledge base? (Knowledge
constraint)
58

• MUST have bothFoundational andTechnical practiceexpertise
60Copyright 2013 by Data Blueprint

Copyright 2013 by Data Blueprint60

• Data Strategy
Copyright 2013 by Data Blueprint
• Data Governance
• Data Architecture
• Data Education
61

• Data Quality
Copyright 2013 by Data Blueprint
• Data Integration
• Data Platforms
• BI/Analytics
62

• Needs to be actionable• Generally well understood by
business• Document what has been learned
Copyright 2013 by Data Blueprint63

• Perfect results are not necessary
• Reiterate and refine• Iterative process to
reach decision point• Use as feedback for
next exploration
Copyright 2013 by Data Blueprint64
Copyright 2013 by Data Blueprint65

Myth #7: You need Big Data for Insights
Fact:• Distinction between Big Data and
doing analytics– Big Data is defined by the technology stack
that you use– Big Data is used for predictive and
prescriptive analytics
• Use existing data for reporting, figureout bottlenecks and optimize current business model
• Understand how is your datastructured, architected and stored
Copyright 2013 by Data Blueprint66

A Framework for Implementing NoSQL, HadoopDemystifying Big Data 2.0: Developing the Right Approach for Implementing Big Data Techniques
• Big Data Context– We are using the wrong vocabulary to discuss this topic
• More Precise Definitions– Framework– Non Von Neuman Architectures– Hadoop/Nosql
• Big Data– Historical Perspective
• Big Data Approach– Crawl, Walk, Run
• Framework Examples– Social– Operational BWB
• Take Aways and Q&A
68Copyright 2015 by Data Blueprint Slide #
Tweeting now at: #dataed

Social Sentiment Analysis• One of the burgeoning areas
for use of Big Data / Hadoopplatforms.
• Allows for the landing of multiple sources of unstructured data. (Twitter, Facebook, Linked In, etc.)
• Data than can be analyzed with algorithms looking for keywords that determinepositive/negative feedback
Copyright 2013 by Data Blueprint69

Operational Use• Utilize real time pricing data from multiple sources to dynamically
update the pricing for books in the Amazon Marketplace.• Ingested data from multiple sources looking for real time changes
in price.• Would apply predictive model to determine best price point and set
price of their books on the marketplace.• Increased conversion rate, but created a race to the bottom
situation if not monitored
Copyright 2013 by Data Blueprint79
Healthcare Example: Patient Data
Copyright 2013 by Data Blueprint
• Clinical data:– Diagnosis/prognosis/treatment
– Genetic data
• Patient demographic data• Insurance data:
– Insurance provider
– Claims data
• Prescriptions & pharmacy information• Physical fitness data
– Activity tracking through smartphone apps & social media
• Health history• Medical research data
70

http://www.forbes.com/sites/xerox/2013/09/27/big-data-boosts-customer-loyalty-no-really/
Copyright 2013 by Data Blueprint
Retail Example: Loyalty Programs & Big Data• Companies need to understand current wants and needs AND
predict future tendencies• Customer -> Repeat Customer -> Brand Advocate• Customer loyalty programs & retention strategies
– Track what is being purchased and how often
– Coupons based on purchasing history
– Targeted communications, campaigns & special offers
– Social media for additional interactions
– Personalize consumer interactions
• Customer purchase history influencesproduct placements– Retailers rapidly respond to consumer demands
– Product placements, planogram optimization, etc.
71

References
Copyright 2013 by Data Blueprint
• The Human Face of Big Data, Rick Smolan & Jennifer Erwitt, First Edition edition (November 20, 2012)
• McKinsey: Big Data: The next frontier for innovation, competition and productivity (http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation?p=1)
• The Washington Post: Five Myths about Big Data (http://articles.washingtonpost.com/2013-08-16/opinions/41416362_1_big-data-data-crunching-marketing-analytics)
• Gartner: Gartner’s 2013 Hype Cycle for Emerging Technologies Maps Out Evolving Relationship Between Humans and Machines (http://www.gartner.com/newsroom/id/2575515)
• The New York Times | Opinion Pages: What Data Can’t Do (http://www.nytimes.com/2013/02/19/opinion/brooks-what-data-cant-do.html?_r=1&)
• CIO.com: Five Steps for How to Better Manage Your Data (http://www.cio.com.au/article/429681/five_steps_how_better_manage_your_data/)
• Business Insider: Enterprises Aren’t Spending Wildly on ‘Big Data’ But Don’t Know If It’s Worth It Yet (http://www.businessinsider.com/enterprise-big-data-spending-2012-11#ixzz2cdT8shhe)
• Inc.com: Big Data, Big Money: IT Industry to Increase Spending (http://www.inc.com/kathleen-kim/big-data-spending-to-increase-for-it-industry.html)
• Forbes: Big Data Boosts Customer Loyalty. No, Really. (http://www.forbes.com/sites/xerox/2013/09/27/big-data-boosts-customer-loyalty-no-really/)
72

Data Management MaturityJuly 14, 2015 @ 2:00 PM ET/11:00 AM PT
Trends in Data ModelingAugust 11, 2015 @ 2:00 PM ET/11:00 AM PT
Sign up here:www.datablueprint.com/webinar-scheduleor www.dataversity.net
Upcoming Events
Copyright 2013 by Data Blueprint73

10124 W. Broad Street, Suite CGlen Allen, Virginia 23060 804.521.4056

Copyright 2013 by Data Blueprint77
Potential Tradeoffs:CAP theorem: consistency, availability and partition-tolerance
Small datasets can be both consistent & available
Partition (Fault)
Tolerance
AvailabilityConsistency
Atomicity Consistency IsolationDurability
Basic Availability Soft-stateEventual consistency

Additional Context
Copyright 2013 by Data Blueprint76

http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation?p=1
Copyright 2013 by Data Blueprint
5 Ways in which Data creates Business Value1. Information is transparent
and usable at much higher frequency
2. Expose variability and boost performance
3. Narrow segmentation of customers and moreprecisely tailored productsor services
4. Sophisticated analytics andimproved decision-making
5. Improved development of the next generation of products and services
77

• We are at an inflection point: Thesheer volume of data generated, stored, and mined for insights hasbecome economically relevant to businesses, government, andconsumers (McKinsey)
• We believe the same important principles still apply:
– What problem are you trying to solve foryour business? Your solution needs to fityour problem
– Doing data for (big) data’s sake is not goingto solve any problems
– Risk of spending a lot of money on chasingBig Data that will realize little to no returns -especially at this hype cycle stage
http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation?p=1
Why the Big Deal about Big Data?
80Copyright 2013 by Data Blueprint

http://www.cio.com.au/article/429681/five_steps_how_better_manage_your_data
Copyright 2013 by Data Blueprint
Business InformationMarket: $1.1 Trillion aYear• Enterprises spend an
average of $38 million on information/year
• Small and mediumsized businesses on average spend$332,000
79

Take Aways-Big Data Context
Copyright 2013 by Data Blueprint
• Technology continues to evolve at increasing speeds
• Big Data is here– We have the potential to
create insights• Spend wisely & strategically:
– Big Data is not going to solveall your problems.
• Fact:– Big Data is not for everyone
• Fact:– Lack of a clear definition
• Hype Cycle:– Current: Peak of Inflated Expectations– Soon: Trough of Disillusionment
80

Take Aways: Big Data Challenges Today
Copyright 2013 by Data Blueprint
• Fact: Big Data techniques are innovative but “Big Data” is not
• Challenges are both foundational andtechnical, today as well as in 1600s
• Technology continues to advance rapidly (4 Vs)
• Challenges associated with Big Data are not new:– Well-known foundational data management issues– Need to align data and business with rapidly
changing environment– Duplicity, accessibility, availability– Foundational business issues
81

Take Aways-Approach: Crawl, Walk, Run
Copyright 2013 by Data Blueprint
• Crawl:– Identify business opportunity and
determine whether you truly needa Big Data solution
• Walk:– Apply a combination of
foundational and technical data management practices.Document your insights and make sure they are actionable
• Run:– Recycle and explore. Staying
agile allows you to be exploratory.
82

Take Aways-Design Principles: Foundational & Technical
Copyright 2013 by Data Blueprint
• Foundational data management principles still apply
• Beware of SOS (Shiny Object Syndrome)
• You must have a data strategy beforeyou can have a Big Data strategy
• Fact: You don’t need Big Data to gaininsights
• Big Data integration requirements evolvefrom your strategy
• Fact: Bigger Data is not always better
83

Take Aways: In Summary
Copyright 2013 by Data Blueprint
• Big data techniques are innovativebut “Big Data” is not
• Big Data characteristics: 6 Vs– Volume, Velocity, Variety, Variability, Vitality,
Virtual
• Approach: Crawl-Walk-Run• Big Data challenges require solutions
that are based on foundational andtechnical data management practices
• Beware of SOS (Shiny ObjectSyndrome):– Spend wisely and strategically– Big Data is not going to solve all your
problems
84

Foundational Practice: Data Strategy• Your data strategy must
align to your organizational business strategy and operating model
• As the market place becomes more data-driven, a data-focused business strategy is an imperative
• Must have data strategy before you have a Big Data strategy
Copyright 2013 by Data Blueprint85

Data Strategy Considerations• What are the questions that
you cannot answer today?• Is there a direct reliance on
understanding customer behavior to drive revenue?
• Do you have information overload and are you trying to find the signal in the noise?
• Which is more important:– Establishing value from current
data assets/data reporting?– Exploring Big Data
opportunities?
Copyright 2013 by Data Blueprint86

Foundational Practice: Data Architecture• Common vocabulary expressing
integrated requirements ensuringthat data assets are stored, arranged, managed, and used insystems in support of organizational strategy [Aiken2010]
• Most organizations have data assets that are not supportive of strategies
• Big question:– How can organizations more
effectively use their information architectures to support strategy implementation?
90Copyright 2013 by Data Blueprint

Data Architecture Considerations• Does your current architecture for
BI and analytics support Big Data?• Are you getting enough value out of
your current architecture?• Can you easily integrate and share
information across your organization?
• Do you struggle to extract the valuefrom your data because it is toocumbersome to navigate andaccess?
• Are you confident your data isorganized to meet the needs of your business?
Copyright 2013 by Data Blueprint88

Technical Practice: Data Integration• A data-centric
organization requires unified data
• Integrating data across organizational silos creates new insights
• It is also the biggest challenge
• Big Data techniques can be used to complement existing integration efforts
Copyright 2013 by Data Blueprint89

Data Integration Considerations• The complexity of your data
integration challenge depends onthe questions you’re trying toanswer
• Integration requirements for Big Data are dependent on the types of questions you’re asking:– Integration here may be more fuzzy than
discrete– Integration is domain-based (based on
time, customer concept, geographic distribution)
• Those requirements should evolvefrom your strategy
Copyright 2013 by Data Blueprint90

Technical Practice: Data Quality• Quality is driven by fit for purpose
considerations• Big Data quality is different:
– Basic– Availability– Soft-state– Eventual consistency
• Directional accuracy is the goal• Focus on your most important data
assets and ensure our solutionsaddress the root cause of any qualityissues – so that your data is correctwhen it is first created
• Experience has shown that organizations can never get in front of their data quality issues if they only usethe ‘find-and-fix’ approach
Copyright 2013 by Data Blueprint91

Data Quality Considerations• Big Data is trying to be
predictive• What are the questions you
are trying to answer?– What level of accuracy are you
looking for?– What confidence levels?– Example: Do I need to know
exactly what the customer isgoing to buy or do I just need toknow the range of products he/ she is going to choose from?
Copyright 2013 by Data Blueprint92

Technical Practice: Data Platforms• Do you want to measure
critical operational processperformance?
• No one data platform can answer all your questions. Thisis commonly misunderstood and often leads to very expensive, bloated andineffective data platforms.
• Understanding the questionsthat need to be asked and howto build the right data platformor how to optimize an existing one
Copyright 2013 by Data Blueprint93

Data Platforms Considerations• Commonalities between most big data
stacks with file storage, columnar store, querying engine, etc.
• Big data stack generally looks the same until you get into appliances– Algorithms are built into appliance
themselves, e.g. Netezza, Teradata, etc.)
• Ask these questions:– Do you want insights on your
customer’s behavior?– Do you need real-time customer
transactional information?– Do you need historical data or just
access to the latest transactions?– Where do you go to find the single
version of the truth about your customers?
Copyright 2013 by Data Blueprint94