data cleaning and transformation helena galhardas dei ist (based on the slides: “a survey of data...
Post on 21-Dec-2015
214 views
TRANSCRIPT

Data Cleaning and Transformation
Helena GalhardasDEI IST
(based on the slides: “A Survey of Data Quality Issues in Cooperative Information Systems”, Carlo Batini, Tiziana Catarci, Monica Scannapieco, 23rd International Conference on Conceptual Modelling (ER 2004))

Agenda
Introduction Data (Quality) Problems Data Cleaning and Transformation Data Quality
(Data Quality) Dimensions Techniques
Object Identification Data integration/fusion
Tools

When materializing the integrated data (data warehousing)…
DataExtraction
DataLoading
DataTransformation ... ...
SOURCE DATA
TARGET DATA
ETL: Extraction, Transformation and Loading
70% of the time in a datawarehousing project is spent with the ETL process

Why Data Cleaning and Transformation?Data in the real world is dirty
incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data
e.g., occupation=“”
noisy: containing errors or outliers (spelling, phonetic and typing errors, word transpositions, multiple values in a single free-form field)
e.g., Salary=“-10”
inconsistent: containing discrepancies in codes or names (synonyms and nicknames, prefix and suffix variations, abbreviations, truncation and initials)
e.g., Age=“42” Birthday=“03/07/1997” e.g., Was rating “1,2,3”, now rating “A, B, C” e.g., discrepancy between duplicate records

Why Is Data Dirty? Incomplete data comes from:
non available data value when collected different criteria between the time when the data was
collected and when it is analyzed. human/hardware/software problems
Noisy data comes from: data collection: faulty instruments data entry: human or computer errors data transmission
Inconsistent (and redundant) data comes from: Different data sources, so non uniform naming
conventions/data codes Functional dependency and/or referential integrity violation

Why is Data Quality Important?Activity of converting source data into target data without
errors, duplicates, and inconsistencies, i.e.,
Cleaning and Transforming to get…
High-quality data!
No quality data, no quality decisions! Quality decisions must be based on good quality data (e.g.,
duplicate or missing data may cause incorrect or even misleading statistics)
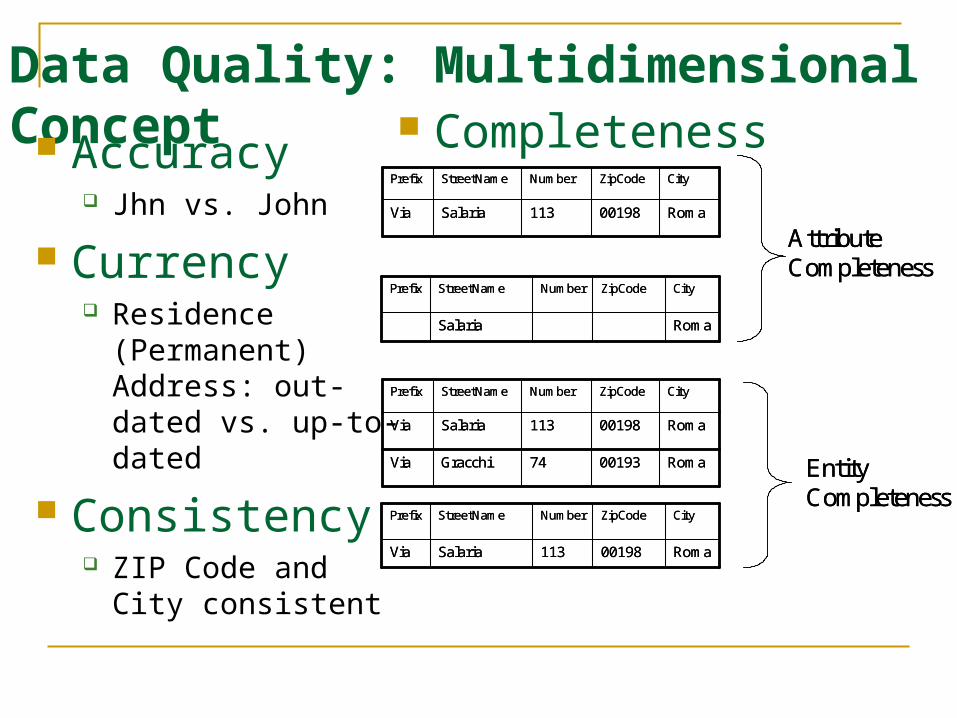
Data Quality: Multidimensional Concept Accuracy
Jhn vs. John
Currency Residence
(Permanent) Address: out-dated vs. up-to-dated
Consistency ZIP Code and City
consistent
Roma00198113SalariaVia
CityZipCodeNumberStreetNamePrefix
RomaSalaria
CityZipCodeNumberStreetNamePrefix
AttributeCompleteness
Roma00198113SalariaVia
Roma0019374GracchiVia
CityZipCodeNumberStreetNamePrefix
Roma00198113SalariaVia
CityZipCodeNumberStreetNamePrefix
EntityCompleteness
Roma00198113SalariaVia
CityZipCodeNumberStreetNamePrefix
RomaSalaria
CityZipCodeNumberStreetNamePrefix
AttributeCompleteness
Roma00198113SalariaVia
Roma0019374GracchiVia
CityZipCodeNumberStreetNamePrefix
Roma00198113SalariaVia
CityZipCodeNumberStreetNamePrefix
EntityCompleteness
Completeness

8
Application contexts
Eliminate errors and duplicates within a single source E.g., duplicates in a file of customers
Integrate data from different sources E.g.,populating a DW from different operational data stores
Migrate data from a source schema into a different fixed target schema E.g., discontinued application packages
Convert poorly structured data into structured data E.g., processing data collected from the Web

Types of information systems
Distribution
Heterogeneity
Autonomy
no semi totally
yes
yes
P2PSystems
DWSystems
Monolithic
CISs

Types of data Many authors
Structured Semi structured Unstructured
[Shankaranaian et al 2000] Raw data Component data Information products
[Bouzenghoub et al 2004] Stable, Long term changing Frequently changing
[Dasu et al 2003] Federated data, that
come form different heterogeneous sources
Massive high dimensional data
Descriptive data Longitudinal data,
consisting in time series Web data
[Batini et al 2003] Elementary data Aggregated data

EGovScientific
DataWebData
…
Research areas in DQ systems
Application Domains
Research areas
Models
Measurement/Improvement Techniques
Dim
en
sions
Measurement/Improvement Tools and Frameworks M
eth
od
olo
gie
s
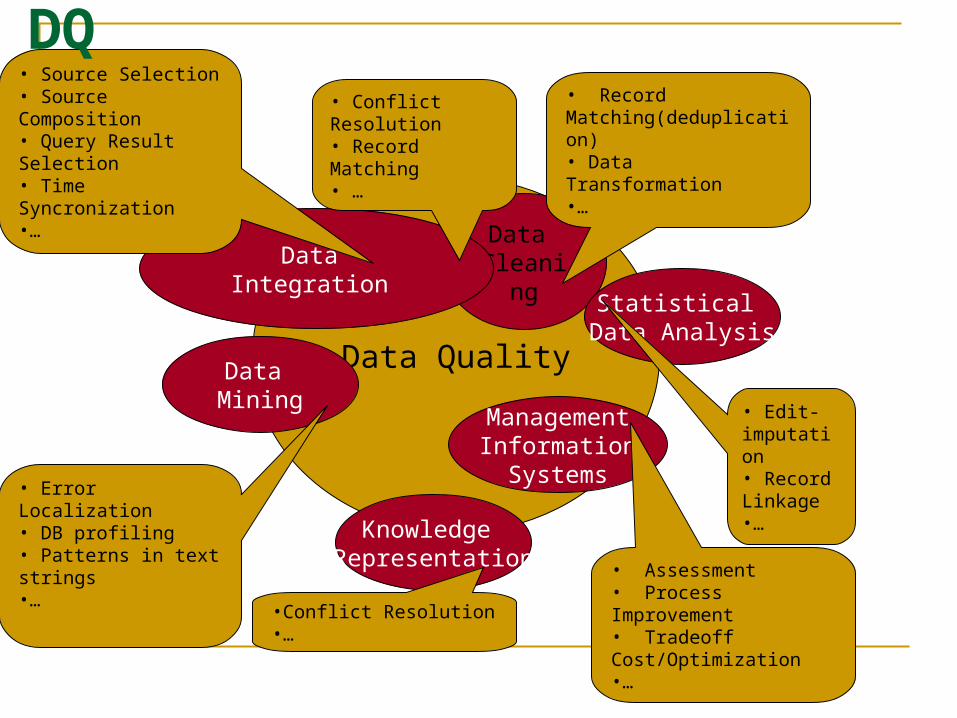
Data Quality
Data Cleanin
g
Data Integration
Data Mining
Statistical Data Analysis
ManagementInformation
Systems
• Record Matching(deduplication)• Data Transformation •…
• Error Localization• DB profiling• Patterns in text strings•…
• Conflict Resolution• Record Matching• …
• Source Selection• Source Composition• Query Result Selection• Time Syncronization•…
• Assessment• Process Improvement• Tradeoff Cost/Optimization•…
Knowledge Representation
Research issues related to DQ
• Edit-imputation • Record Linkage•…
•Conflict Resolution•…

Data Quality
Data Integration
Data Cleanin
g
Data Mining
Statistical Data Analysis
ManagementInformation
Systems
Knowledge Representation
Research issues mainly addressed in the book

Existing technology
Ad-hoc programs written in a programming language like C or Java or using an RDBMS proprietary language Programs difficult to optimize and maintain
RDBMS mechanisms for guaranteeing integrity constraints Do not address important data instance problems
Data transformation scripts using an ETL
(Extraction-Transformation-Loading) or data quality tool
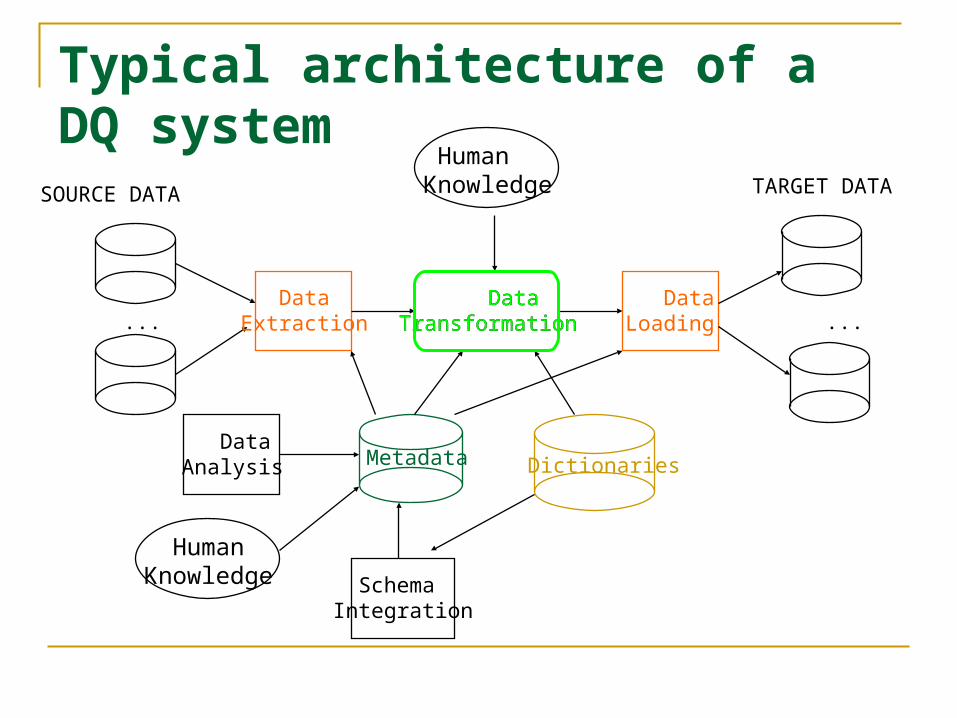
Typical architecture of a DQ system
HumanKnowledge
HumanKnowledge
DataExtraction
DataLoading
DataTransformation
Metadata Dictionaries DataAnalysis
SchemaIntegration
... ...
SOURCE DATA TARGET DATA
DataTransformation

Data Quality Dimensions

Traditional data quality dimensions Accuracy Completeness Time-related dimensions: Currency, Timeliness,
and Volatility Consistency
Schema quality dimensions are also defined Their definitions do not provide quantitative
measures so one or more metrics have to be associated For each metric, one or more measurement methods
have to be provided regrading: (i) where the measurement is taken; (ii) what data are included; (iii) the measurement device; and (iv) the scale on which results are reported.

Accuracy Closeness between a value v and a value v’, considered
as the correct representation of the real-world phenomenon that v aims to represent. Ex: for a person name “John”, v’=John is correct, v=Jhn is
incorrect Syntatic accuracy: closeness of a value v to the elements
of the corresponding definition domain D Ex: if v=Jack, even if v’=John , v is considered syntactically correct Measured by means of comparison functions (e.g., edit distance)
that returns a score Semantic accuracy: closeness of the value v to the true
value v’ Measured with a <yes, no> or <correct, not correct> domain Coincides with correctness The corresponding true value has to be known

Ganularity of accuracy definition Accuracy may refer to:
a single value of a relation attribute an attribute or column a relation the whole database
Example of metric to quantify data accuracy: Ratio calculated between accurate values and the
total number of values.

Completeness “The extent to which data are of sufficient
breadth, depth, and scope for the task in hand.” Three types:
Schema completeness: degree to which concepts and their properties are not missing from the schema
Column completeness: measure of the missing values for a specific property or column in a table.
Population completeness: evaluates missing values with respect to a reference population

Completeness of relational data The completeness of a table characterizes the extent
to which the table represents the real world. Can be characterized wrt:
The presence/absence and meaning of null values Ex: Person(name, surname, birthdate, email), if email is null may
indicate the person has no mail (no incompleteness), email exists but is not known (incompletenss), is is not known whether Person has an email (incompleteness may not be the case)
Validity of open world assumption (OWA) or closed world assumption (CWA) OWA: cannot state neither the truth or falsity of facts not
represented in the tuples of a relation CWA: only the values actually present in a relational table and no
other values represent facts of the real world.

Metrics for quantifying completeness (1) Model without null values with OWA
Need a reference relation r’ for a relation r, that contains all the tuples that satisfy the schema of r
C(r) = |r|/|ref(r)| Ex: according to a registry of Lisbon municipality,
the number of citizens is 2 million. If a company stores data about Lisbon citizens for the purpose of its business and that number is 1,400,000 then C(r) = 0,7

Metrics for quantifying completeness (2) Model with null values with CWA: specific definitions for different granularities: Values: to capture the presence of null values for
some fields of a tuple Tuple: to characterize the completeness of a tuple
wrt the values of all its fields: Evaluates the % of specified values in the tuple wrt the
total number of attributes of the tuple itself Ex: Student(stID, name, surname, vote, examdate) (6754, Mike, Collins, 29, 7/17/2004) vs (6578, Julliane,
Merrals, NULL, 7/17/2004)

Metrics for quantifying completeness (3) Attribute:to measure the number of null values of
a specific attribute in a relation Evaluates % of specified values in the column
corresponding to the attribute wrt the total number of values that should have been specified.
Ex: For calculating the average of votes in Student, a notion of the completeness of Vote should be useful
Relations: to capture the number of null values of a specific attribute in a relation Measures how much info is represented in the relation
by evaluating the content of the info actually available wrt the maximum possible content, i.e., without null values.

Time-related dimensions Currency: concerns how promptly data are updated
Ex: if the residential address of a person is updated (it corresponds to the address where the person lives) then it is updated
Volatility: characterizes the frequency with which data vary in time EX: Birth dates (volatility zero) vs stock quotes (high degree of
volatility) Timeliness: expresses how current data are for the task
in hand Ex: The timetable for university courses can be current by
containing the most recent data, but it cannot be timely if it is available only after the start of the classes.

Metrics of time-related dimensions Last update metadata for currency
Straightforward for data types that change with a fixed frequency
Length of time that data remain valid for volatility
Currency + check that data are available before the planned usage time for timeliness

Consistency
Captures the violation of semantic rules defined over a set of data items, where data items can be tuples of relational tables or records in a file Integrity constraints in relational data
Domain constraints, Key, inclusion and functional dependencies
Data edits: semantic rules in statistics

Evolution of dimensions Traditional dimensions are Accuracy,
Completeness, Timeliness, Consistency
1. With the advent of networks, sources increase dramatically, and data become often “found data”.
2. Federated data, where many disparate data are integrated, are highly valued
3. Data collection and analysis are frequently disconnected.
As a consequence we have to revisit the concept of DQ and new dimensions become fundamental.

Other dimensions Interpretability: concerns the documentation
and metadata that are available to correctly interpret the meaning and properties of data sources
Synchronization between different time series: concerns proper integration of data having different time stamps.
Accessibility: measures the ability of the user to access the data from his/her own culture, physical status/functions, and technologies availavle.

Techniques
Relevant activities in DQ Techniques for record
linkage/object identification/record matching
Techniques for data integration

Relevant activities in DQ

Relevant activities in DQ Record Linkage/Object identification/Entity
identification/Record matching Data integration
Schema matching Instance conflict resolution Source selection Result merging Quality composition
Error localization/Data Auditing Data editing-imputation/Deviation detection
Profiling Structure induction
Data correction/data cleaning/data scrubbing Schema cleaning Tradeoff/cost optimization

Record Linkage/Object identification/ Entity identification/Record matchingGiven two tables or two sets of tables,
representing two entities/objects of the real world, find and cluster all records in tables referring to the same entity/object instance.

Data integration (1)
1. Schema matchingTakes two schemas as input and
produces a mapping between semantically correspondent elements of the two schemas

Data Integration (2)2. Instance conflicts resolution & merging
Instance level conflicts can be of three types:representation conflicts, e.g. dollar vs. eurokey equivalence conflicts, i.e. same real world
objects with different identifiersattribute value conflicts, i.e. instances
corresponding to same real world objects and sharing an equivalent key, differ on other attributes

Data Integration (3)
3. Result merging: it derives from the combination of individual answers into one single answer returned to the user
For numerical data, it is often called fused answer and a single value is returned as an answer, potentially differing from each of the alternatives

Data Integration (4)4. Source selection
Querying a multidatabase with different sources characterized by different qualities
5. Quality compositionDefines an algebra for composing data
quality dimension values

Error localization/Data Auditing
Given one/two/n tables or groups of tables, and a group of integrity constraints/qualities (e.g. completeness, accuracy), find records that do not respect the constraints/qualities.
Data editing-imputation Focus on integrity constraints
Deviation detection data checking that marks deviations as possible
data errors

Profiling
Evaluating statistical properties and intensional properties of tables and records
Structure induction of a structural description, i.e. “any form of regularity that can be found”

Data correction/data cleaning/data scrubbing
Given one/two/n tables or groups of tables, and a set of identified errors in records wrt to given qualities, generates probable corrections (deviation detection) and correct the records, in such a way that new records respect the qualities.

Schema cleaning
Transform the conceptual schema in order to achieve or optimize a given set of qualities (e.g. Readability, Normalization), while preserving other properties (e.g. equivalence of content)

Tradeoff/cost optimization
Tradeoff – When some desired qualities are conflicting (e.g. completeness and consistency), optimize such properties according to a given target
Cost – Given a cost model, optimize a given request of data quality according to a cost objective coherent with the cost model

Techniques for Record Linkage/
Object identification/Entity identification/
Record matching

Techniques for record linkage/object identification/record matching Introduction to techniques General strategies Details on specific steps Short profiles of techniques [Detailed description] [Comparison]

Introduction to techniques

An example
The same business as represented in the three most important business data bases in central agencies in Italy: - CC Chambers of Commerce- INPS Social security - INAIL Accident Insurance
Id Name Type of activity Address City
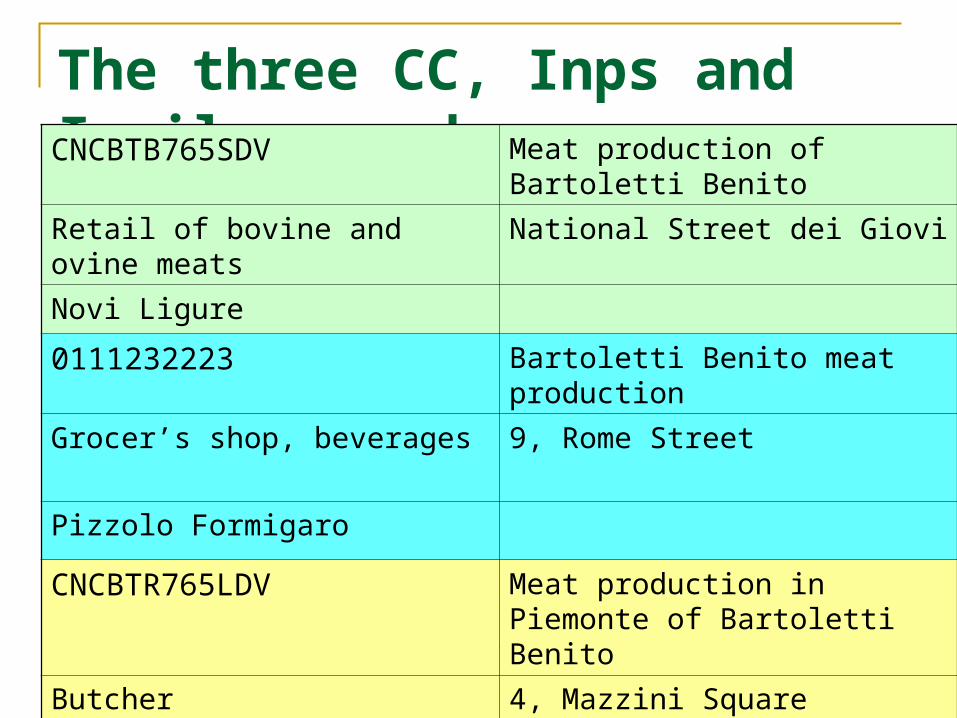
The three CC, Inps and Inail recordsCNCBTB765SDV Meat production of Bartoletti
Benito
Retail of bovine and ovine meats National Street dei Giovi
Novi Ligure
0111232223 Bartoletti Benito meat production
Grocer’s shop, beverages 9, Rome Street
Pizzolo Formigaro
CNCBTR765LDV Meat production in Piemonte of Bartoletti Benito
Butcher 4, Mazzini Square
Ovada

Record linkage and its evolution towards object identification in databases ….
Crlo Batini BtiniCarlo55 54
Record linkageFirst record and second record represent the same aspect of reality?
Object identification in databasesFirst group of records and second group of records represent the same aspect of reality?
Crlo Batini Pescara Pscara Itly Europe
Carlo Batini Pscara Pscara Italy Europe

Type of data considered (Two) formatted tables
Homogeneous in common attributes Heterogeneous
Format (Full name vs Acronym) Semantics (e.g. Age vs Date of Birth) Errors
(Two) groups of tables Dimensional hierarchy
(Two) XML documents

…and object identification in semistructured documents
<country> <name> United States of America </name><cities> New York, Los Angeles, Chicago
</cities><lakes>
<name> Lake Michigan </name></lakes>
</country>
<country> United States <city> New York </city>
<city> Los Angeles </city><lakes>
<lake> Lake Michigan </lake></lakes>
</country>
are the sameobject?
and

Relevant steps
A
B
Input files
A x B
InitialSearch space
Possiblematched
S’, Subset of A x B
Reduced searchSpace S’
Blockingmethod
Match
Unmatch
Assignment
Decision model

General strategy and phases (1)0. Preprocessing
Standardize fields to compare and correct simple errors
1. Estabilish blocking method (also called searching method) Given the search space S = A x B of the two files, find a new
search space S’ contained in S, to apply further steps.
2. Choose comparison function Choose the function/set of rules that express the distance
between pairs of records in S’
3. Choose decision model Choose the method for assigning pairs in S’ to M, the set of
matching records, U the set of unmatching records, and P the set of possible matches
4. Check effectiveness of method

General strategy and phases (2)- [Preprocessing]
- Estabilish a blocking method
- Compute comparison function
- Apply decision model
- [Check effectiveness of method]

Paradigms used in Techniques Empirical – heuristics, algorithms,
simple mathematical properties Statistical/probabilistic – properties and
formalisms in the areas of probability theory and Bayesian networks
Knowledge based – formalisms and models in knowledge representation and reasoning

General strategy – probabilistic methods
[Preprocessing] Establish blocking method Compute comparison function Compute probabilities and thresholds
With training setWithout training set
[Check effectiveness of method]

General strategy - knowledge based methods
[Preprocessing] Establish blocking method Get domain knowledge Choose transformations/rules Choose most relevant rules Apply rules using a knowledge based
engine [Check effectiveness of method]
General strategy -hierarchical structures/tree structures- [Preprocessing]
- Structure traversal- Estabilish blocking/filtering method- Compute comparison function- Apply local/global decision model - [Check effectiveness of method]
Crlo Batini Pescara Pscara Itly Europe
Carlo Batini Pscara Pscara Italy Europe

Details on specific steps

Preprocessing Error correction (with the closest value in the domain)
E.g. Crlo Carlo Elimination of stop words
Of, in, …. Standardization
E.g.1 Bob Robert E.g.2
Mr George W Bush
George Bush
Mr George W Bush
George Bush

Types of Blocking/Searching methods (1) Blocking - partition of the file into mutually exclusive blocks.
Comparisons are restricted to records within each block.
Blocking can be implemented by: Sorting the file according to a block key (chosen
by an expert). Hashing - a record is hashed according to its
block key in a hash block. Only records in the same hash block are considered for comparison.

61
String distance filtering
S1 S2
maxDist = 1
John Smith
John Smit
Jogn Smith
John Smithe
length
length- 1
length
length + 1
editDistance

Type of Blocking/Searching methods (2) Sorted neighbour or Windowing – moving a
window of a specific size w over the data file, comparing only the records that belong to this window
Multiple windowing - Several scans, each of which uses a different sorting key may be applied to increase the possibility of combining matched records
Windowing with choice of key based on the quality of the key

Window scanning
S
n
Window scanning
S
n
Window scanning
S
n
May loose some matches

Comparison functionsType Example
Identity ‘Batini’ = ‘Batini’
Simple distance ‘Batini’ similar to ‘Btini’
Complex distance ‘Batini’ similar to ‘Btaini’
Error driven dis-tance(Soundex)
Hilbert similar to Heilbpr
Frequency weighted distance
1. Smith is more frequent than Zabrinsky
2. In IBM research, IBM less frequent than research
Transformation John Fitzgerald Kennedy Airport
Acronym JFK Airport
Rule (Clue) Seniors appear to have one residence in Florida or Arizona and another in the Midwest or Northeast regions of the country

More on comparison functions/ String comparators (1)Hamming distance - counts the number of mismatches
between two numbers or text strings ( fixed length strings)
Ex: The Hamming distance between 00185 and 00155 is 1, because there is one mismatch
Edit distance - the minimum cost to convert one of the strings to the other by a sequence of character insertions, deletions and replacements. Each one of these modifications is assigned a cost value.
Ex: the edit distance between “Smith” and “Sitch” is 2, since “Smith” is obtained by adding “m” and deleting “c” from “Sitch”.

More on comparison functions/ String comparators (2)Jaro’s algorithm or distance finds the number of common
characters and the number of transposed characters in the two strings. J distance accounts for insertions, deletions, and transpositions.
A common character is a character that appears in both strings within a distance of half the length of the shorter string. A transposed character is a common character that appears in different positions.
Ex: Comparing “Smith” and “Simth”, there are five common characters, two of which are transposed
Scaled Jaro string comparator:f(s1, s2) = (Nc/lengthS1+Nc/lengthS2+0,5Nt/Nc)/3,
Where Nc is the nb of comon characters between the two strings and Nt is the number of transpositions

More on comparison functions – String comparators (3)N-grams comparison function forms the set of all
the substrings of length n for each string. The distance between the two strings is defined as square radix of the sum of differences among the number of occurrences of the substring x in the two strings a and b, respectively.
Soundex code clusters together names that have similar sounds. For example, the Soundex code of “Hilbert” and “Heilbpr” is similar.

More on comparison functions – String comparators (4)TF-IDF (Token Frequency-Inverse Document
Frequency) or cosine similarity assigns higher weights to tokens appearing frequently in a document (TF weight) and lower weights to tokens that appear frequently in the whole set of documents (IDF weight).
Widely used for matching strings in documents

Main criteria of useHamming distance Used primarily for numerical fixed size fields
like Zip Code or SSN
Edit distance Can be applied to variable length fields. To achieve reasonable accuracy, the modifications costs are tuned for each string data set.
Jaro’s algorithm and
Winkler’s improvement
The best one in several experiments
N - grams Bigrams (n = 2) effective with minor typographical errors
TF-IDF Most appropriate for text fields or documents
Soundex code Effective for dictation mistakes

Techniques(probabilistic, knowledge based, empirical)

List of techniquesName Main Reference Type of strategy
Fellegy and Sunter family [Fellegi 1969] probabilistic
[Nigam 2000] [Nigam 2000] probabilistic
Cost based [Elfeky 2002] probabilistic
Induction [Elfeky 2002] probabilistic
Clustering [Elfeky 2002] probabilistic
Hybrid [Elfeky 2002] probabilistic
1-1 matching [Winkler 2004] probabilistic
Bridging file [Winkler 2004] probabilistic
Delphi [Ananthakr. 2002] empirical
XML object identification [Weis 2004] empirical
Sorted Neighbour and variants [Hernandez 1995]
[Bertolazzi 2003]
empirical
Instance functional dependencies [Lim et al 1993] Knowledge based
Clue based [Buechi 2003] Knowledge based
Active Atlas [Tejada 2001] Knowledge based
Intelliclean and SN variant [Low 2001] Knowledge based

Added techniquesName Main Reference Type of strategy
Approximate string join [Gravano 2001]
empirical
Text join [Gravano 2003]
empirical
Flexible string matching [Koudas 2004] empirical
Approximate XML joins [Guha 2002] empirical

Empirical techniques

Sorted Neighbour searching method
1. Create Key: Compute a key K for each record in the list by extracting relevant fields or portions of fields. Relevance is decided by experts.
2. Sort Data: Sort the records in the data list using K
3. Merge: Move a fixed size window through the sequential list of records limiting the comparisons for matching records to those records in the window. If the size of the window is w records, then every new record entering the window is compared with the previous w – 1 records to find “matching” records

SNM: Create key
Compute a key for each record by extracting relevant fields or portions of fields
Example:
First Last Address ID Key
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456

SNM: Sort Data
Sort the records in the data list using the key in step 1
This can be very time consuming O(NlogN) for a good algorithm, O(N2) for a bad algorithm
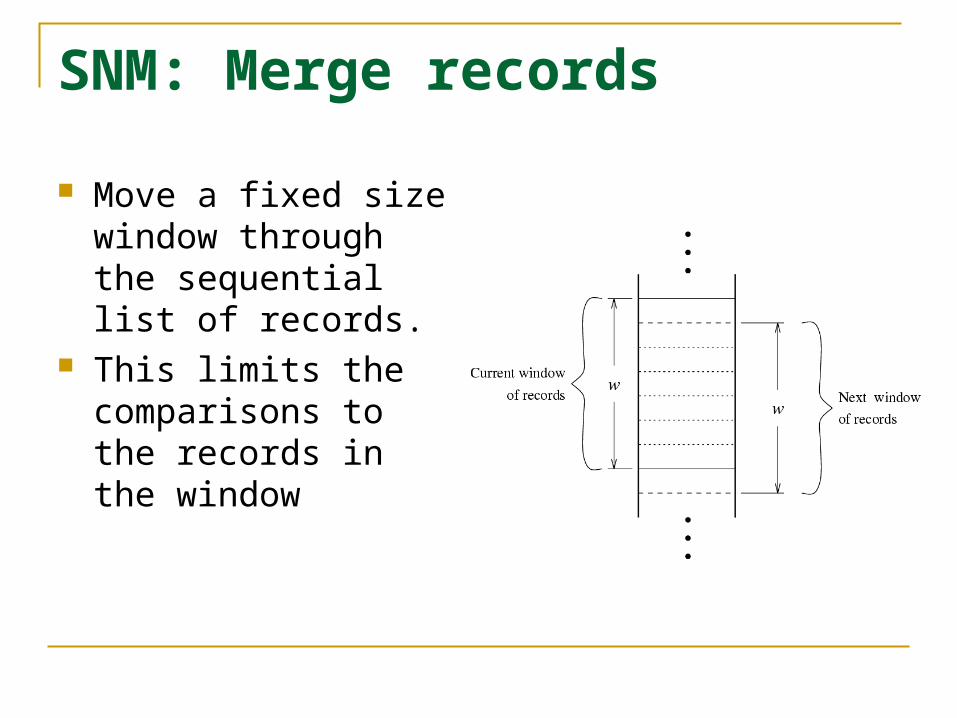
SNM: Merge records
Move a fixed size window through the sequential list of records.
This limits the comparisons to the records in the window

SNM: Considerations
What is the optimal window size while Maximizing accuracy Minimizing computational cost
Execution time for large DB will be bound by Disk I/O Number of passes over the data set

Selection of Keys
The effectiveness of the SNM highly depends on the key selected to sort the records
A key is defined to be a sequence of a subset of attributes
Keys must provide sufficient discriminating power
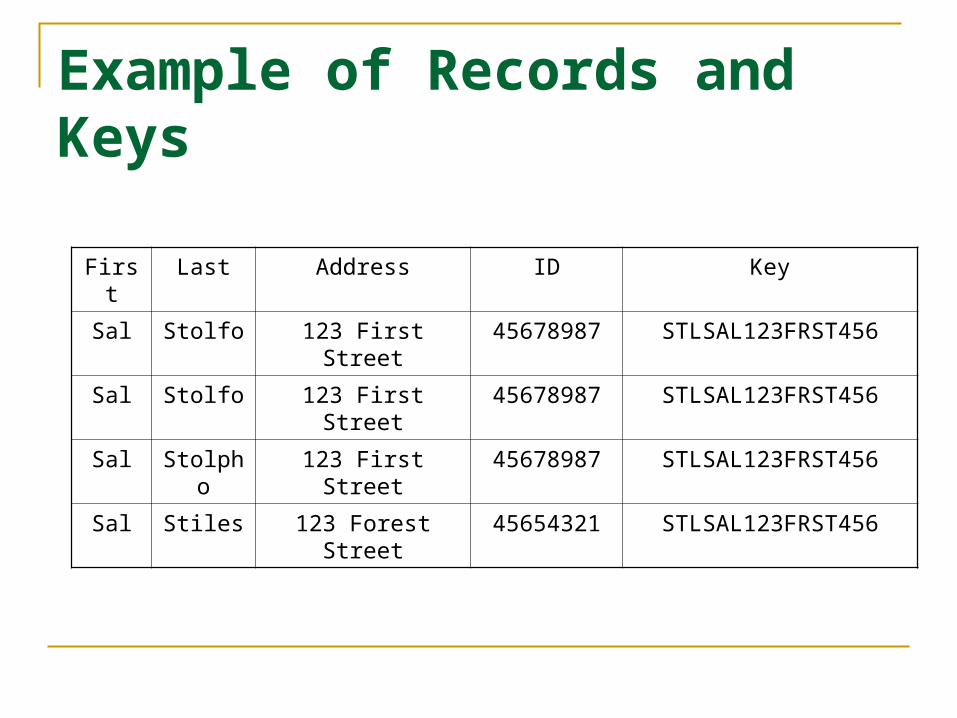
Example of Records and Keys
First Last Address ID Key
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456
Sal Stolpho 123 First Street 45678987 STLSAL123FRST456
Sal Stiles 123 Forest Street 45654321 STLSAL123FRST456

Equational Theory
The comparison during the merge phase is an inferential process
Compares much more information than simply the key
The more information there is, the better inferences can be made

Equational Theory - Example Two names are spelled nearly identically and
have the same address It may be inferred that they are the same person
Two social security numbers are the same but the names and addresses are totally different Could be the same person who moved Could be two different people and there is an
error in the social security number

A simplified rule in English
Given two records, r1 and r2
IF the last name of r1 equals the last name of r2,
AND the first names differ slightly,
AND the address of r1 equals the address of r2
THEN
r1 is equivalent to r2

The distance function
A “distance function” is used to compare pieces of data (usually text)
Apply “distance function” to data that “differ slightly”
Select a threshold to capture obvious typographical errors. Impacts number of successful matches and
number of false positives

Examples of matched records
SSN Name (First, Initial, Last) Address
334600443
334600443
Lisa Boardman
Lisa Brown
144 Wars St.
144 Ward St.
525520001
525520001
Ramon Bonilla
Raymond Bonilla
38 Ward St.
38 Ward St.
0
0
Diana D. Ambrosion
Diana A. Dambrosion
40 Brik Church Av.
40 Brick Church Av.
789912345
879912345
Kathi Kason
Kathy Kason
48 North St.
48 North St.
879912345
879912345
Kathy Kason
Kathy Smith
48 North St.
48 North St.

Building an equational theory The process of creating a good equational
theory is similar to the process of creating a good knowledge-base for an expert system
In complex problems, an expert’s assistance is needed to write the equational theory

Transitive Closure
In general, no single pass (i.e. no single key) will be sufficient to catch all matching records
An attribute that appears first in the key has higher discriminating power than those appearing after them If an employee has two records in a DB with SSN
193456782 and 913456782, it’s unlikely they will fall under the same window

Transitive Closure
To increase the number of similar records merged Widen the scanning window size, w Execute several independent runs of the SNM
Use a different key each time Use a relatively small window Call this the Multi-Pass approach

Transitive Closure
Each independent run of the Multi-Pass approach will produce a set of pairs of records
Although one field in a record may be in error, another field may not
Transitive closure can be applied to those pairs to be merged

Multi-pass Matches
Pass 1 (Lastname discriminates)KSNKAT48NRTH789 (Kathi Kason 789912345 )KSNKAT48NRTH879 (Kathy Kason 879912345 )
Pass 2 (Firstname discriminates)KATKSN48NRTH789 (Kathi Kason 789912345 )KATKSN48NRTH879 (Kathy Kason 879912345 )
Pass 3 (Address discriminates)48NRTH879KSNKAT (Kathy Kason 879912345 )48NRTH879SMTKAT (Kathy Smith 879912345 )

Transitive Equality ExampleIF A implies B
AND B implies C
THEN A implies C
From example:789912345 Kathi Kason 48 North St. (A)
879912345 Kathy Kason 48 North St. (B)
879912345 Kathy Smith 48 North St. (C)

KB techniques -Types of knowledge considered
Paper Name of technique
Type of knowledge
[Lim et al 1993]
Instance level funct. dependencies
Instance level functional dependencies
[Low et al 2001]
Intelliclean Rules for duplicate identification and for merging records
[Tejadaa 2001]
Active Atlas Importance of the different attributes for deciding a mapping
Transformations among values that are relevant for the mappings
[Buechi et al 2003]
Clue based Clues, i.e domain dependent properties of data to be linked

Intelliclean [Low 2001]
Two files/knowledge based Exploits rules (see example) for duplicate
identification and for merging records. Rules are fed into an expert system engine The pattern matching and rule activation
mechanisms make use of an efficient method for comparing a large collection of patterns to a large collection of objects.

Example of rule

Intelliclean Sorted Neighbour Two files/knowledge based Improves multi pass SN by
attaching a confidence factor to rules and applying selectively the transitive closure.

probabilistic techniques

Fellegi and Sunter family Two files/ probabilistic
Compute in some way conditional probabilities of matching/not matching based on an agreement pattern (comparison function).
Establish two thresholds for deciding matching and non matching, based on a priori error bounds on false matches and false nonmatches.
Also called error based techniques Pros: well founded technique; widely applied, tuned and
optimized. Cons: in most cases, needed training data for good estimates.

Fellegi and Sunter RL family of models - 1For the two data sources A and B the set of pairs A x B
is mapped in two sets, M (matched) where a = b and U (unmatched) otherwise.
Having in mind that it is always better to classify a record pair as a possible match than to falsely decide on its matching status, a third set P, called possible matched, is defined. In the case that a record pair is assigned to P, a domain expert should manually examine this pair.
The problem, then, is to determine in which set each record pair belongs to, in presence of errors.
A comparison function C compares values of pairs of records, and produces a comparison vector.

Fellegi and Sunter RL family of models - 2
We may then assign a weight for each component of the record pair, calculating the composite weight and comparing the weight against two thresholds T1 and T2, and assigning M, U, or P (not assigned) according to the relative value of the composite weight (CW) wrt the two thresholds. In other words:- If CW > T2 then designate pair as a match M- If CW < T1 then designate pair as an unmatched U- Otherwise designate as not assigned.

Fellegi and Sunter RL family of models - 3The thresholds can be estimated by a priori error
bounds on false matches and false non matches.
This is the reason why the model is called error-based
Fellegi and Sunter proved that this decision procedure is optimal,in the sense that, fixed the rates of false matches and false non matches, the clerical review region is minimized.

Fellegi and Sunter RL family of models - 4The procedure has been investigated under different
assumptions, and for different comparison functions.
This is the reason of the name family of models.
E.g. When the comparison function is a simple agree/disagree pattern for three variables, if the variables are independent ( independence assumption), we may express the probabilities that the record match/not match as product of elementary probabilities, and solve the system of equations in closed form.

More on independence assumption Independence assumption - To make computation more tractable, FS made a conditional independence assumption that corresponds to the naïve Bayesian assumption for BN:
P (agree on first name Robert, agree on last name Smith/C1) =
P (agree on first name George/C1) P( agree on last name Smith/C1).
Under this assumption FS provided a method for computing the probabilites in the 3 variable case. Winkler developed a variant of the EM algorithm for a more general case.
Nigam 2000 has shown that classification decision rules based on Naïve BN (independence assumption) work well in practice.
Dependence assumption – Varying authors have observed that the computed probabilities do not even remotely correspond to the true underlying probabilities.

Expectation maximization model An expectation-maximization (EM) algorithm is an
algorithm for finding maximum likelihood estimates of parameters (in our case, probabilities of match and not match) in probabilistic models, where the model depends on unobserved (latent) variables.
EM alternates between performing an expectation (E) step, which computes the expected value of the latent variables, and a maximization (M) step, which computes the maximum likelihood estimates of the parameters given the data and setting the latent variables to their expectation.

Agenda
Introduction Data (Quality) Problems Data Cleaning and Transformation Data Quality
(Data Quality) Dimensions Techniques
Object Identification Data integration/fusion
Tools

Tools – table of contents DQ problems revisited Generic functionalities Tool categories Addressing data quality problems

Existing technology
How to achieve data quality Ad-hoc programs RDBMS mechanisms to guaranteeing
integrity constraints Data transformation scripts using a data
quality tool

Data quality problems (1/3)
Schema level data quality problems prevented with better schema design, schema translation and integration.
Instance level data quality problems errors and inconsistencies of data that are not prevented at schema level

Schema level data quality problems Avoided by an RDBMS
Missing data – product price not filled in Wrong data type – “abc” in product price Wrong data value – 0.5 in product tax (iva) Dangling data – category identifier of product does not exist Exact duplicate data – different persons with same ssn Generic domain constraints – incorrect invoice price
Not avoided by an RDBMS Wrong categorical data – countries and corresponding states Outdated temporal data – just-in-time requirement Inconsistent spatial data – coordinates and shapes Name conflicts – person vs person or person vs client Structural Conflicts - addresses
Data quality problems (2/3)

Instance level data quality problems Single record
Missing data in a not null field – ssn:-9999999 Erroneous data – price:5 but real price:50 Misspellings: José Maria Silva vs José Maria Sliva Embedded values: Prof. José Maria Silva Misfielded values: city: Portugal Ambiguous data: J. Maria Silva; Miami Florida,Ohio
Multiple records Duplicate records: Name:José Maria Silva, Birth:01/01/1950 and
Name:José Maria Sliva, Birth:01/01/1950 Contradicting records: Name:José Maria Silva, Birth:01/01/1950
and Name:José Maria Silva, Birth:01/01/1956 Non-standardized data: José Maria Silva vs Silva, José Maria
Data quality problems (3/3)

Generic functionalities (1/2) Data sources – extract data from different and
heterogeneous data sources Extraction capabilities – schedule extracts; select
data; merge data from multiple sources Loading capabilities – multiple types,
heterogeneous targets; refresh and append; automatically create tables
Incremental updates – update instead of rebuild from scratch
User interface – graphical vs non-graphical Metadata repository – stores data schemas and
transformations

Generic functionalities (2/2)
Performance techniques – partitioning; parallel processing; threads; clustering
Versioning – version control of data quality programs Function library – pre-built functions Language binding – language support to define new
functions Debugging and tracing – document the execution;
tracking and analyzing to detect problems and refine specifications
Exception detection and handling – set of input rules for which the execution of data quality program fails
Data lineage – identifies the input records that produced a given data item
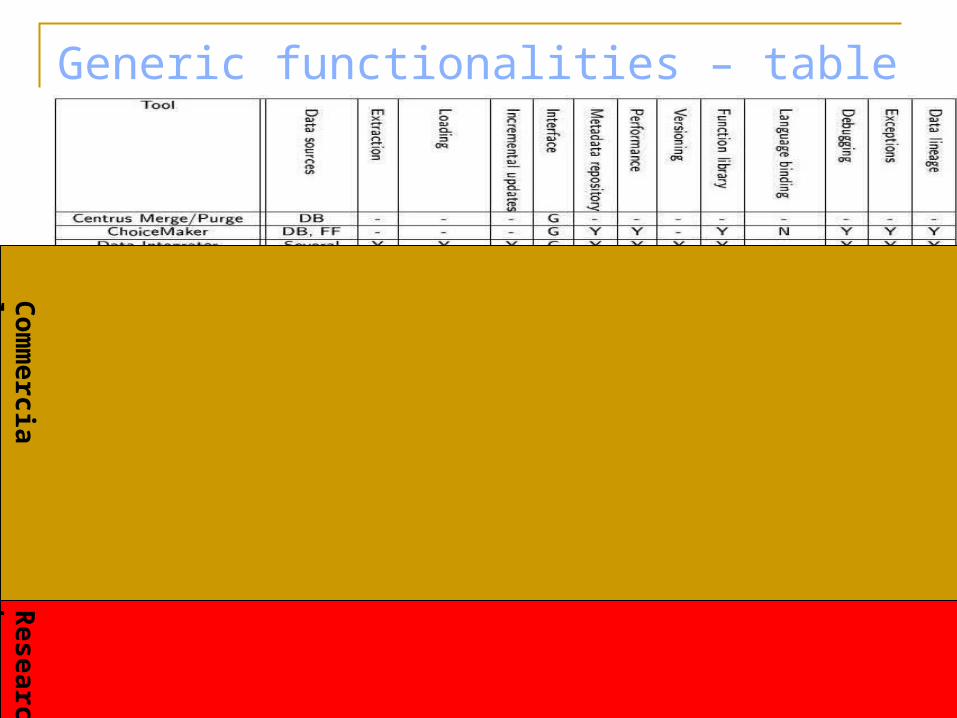
Generic functionalities – table of tools
Commercial
Research
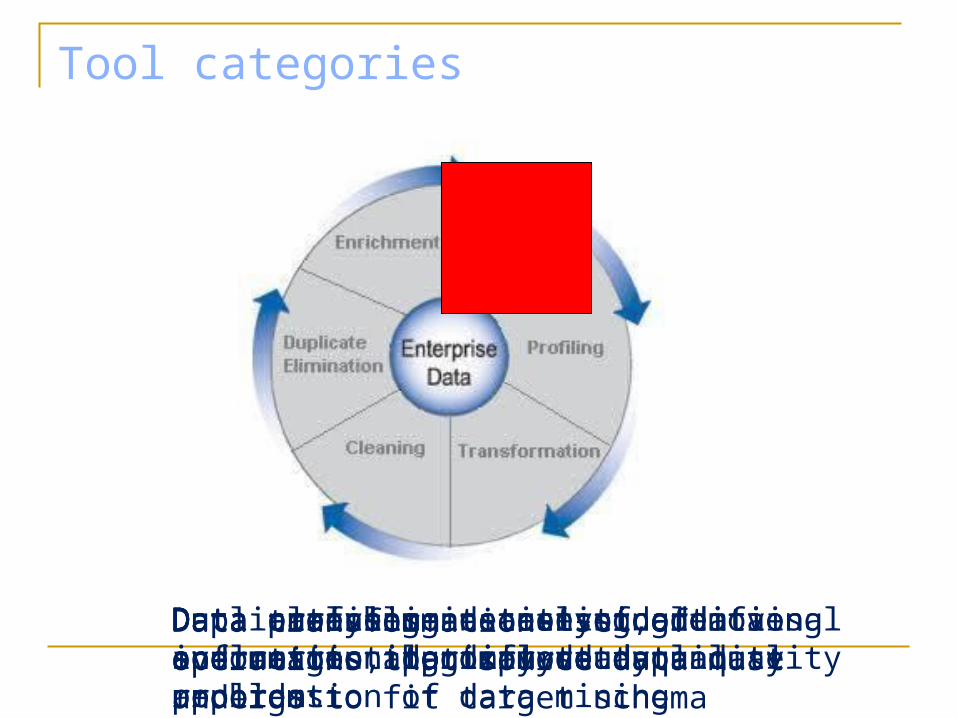
Tool categories
Data analysis – statistical evaluation, logical study and application of data mining algorithms to define data patterns and rules
Data profiling – analysing data sources to identify data quality problemsData transformation– set of operations that source data must undergo to fit target schemaData cleaning– detecting, removing and correcting dirty dataDuplicate elimination– identifies and merges approximate duplicate recordsData enrichement– use of additional information to improve data quality
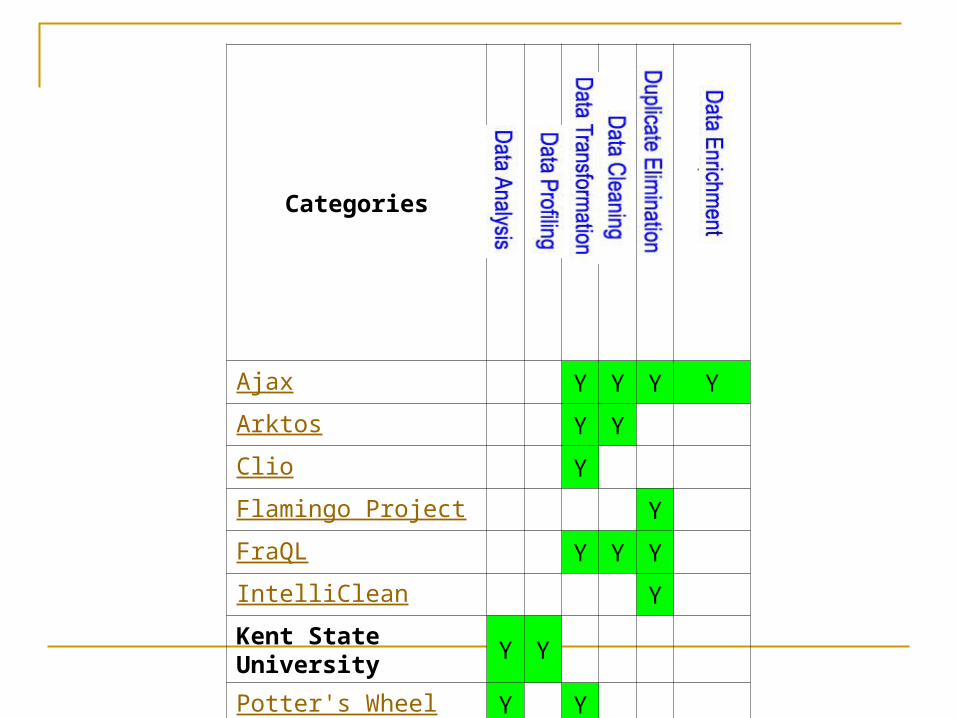
Categories
Ajax Y Y Y Y
Arktos Y Y
Clio Y
Flamingo Project Y
FraQL Y Y Y
IntelliClean Y
Kent State University Y Y
Potter's Wheel Y Y
Transcm Y

More on research DQ toolsReference Name Main features
[Raman et al 2001]
Potter’s wheel
Tightly integrates transformations and discrepancy/anomaly detection
[Caruso et al 2000]
Telcordia’s tool
Record linkage tool parametric wrt to distance functions and matching functions
[Galhardas et al 2001]
Ajax Declarative language based on five logical transformation operators
Separates a logical level and a physical level
[Vassiliadis 2001]
Artkos Covering all aspects of ETL processes (architecture, activities, quality management) with a unique metamodel
[Elfeky et al 2002]
Tailor Framework for existing and new techniques analysis and comparison
[Buechi et al 2003]
Choicemaker Uses clues that allows rich expression of the semantics of data
[Low et al 2001]
Intelliclean See section on techniques

Data Fusion
Instance conflict resolution

Instance conflicts resolution & merging Occur due to poor data quality
Errors exist when collecting or entering data Sources are not updated
Three types: representation conflicts, e.g. dollar vs. euro key equivalence conflicts, i.e. same real world
objects with different identifiers attribute value conflicts, i.e. instances
corresponding to same real world objects and sharing an equivalent key, differ on other attributes

ExampleEmpId Name Surname Salary Email
arpa78 John Smith 2000 [email protected]
eugi 98 Edward Monroe 1500 [email protected]
ghjk09 Anthony Wite 1250 [email protected]
treg23 Marianne Collins 1150 [email protected]
EmpId Name Surname Salary Email
arpa78 John Smith 2600 [email protected]
eugi 98 Edward Monroe 1500 [email protected]
ghjk09 Anthony White 1250 [email protected]
dref43 Marianne Collins 1150 [email protected]
Key conflicts
Attributeconflicts

Techniques
At design time or query time, even if actual conflicts occur at query time
Key conflicts require object identification techniques
There are several techniques for dealing with attribute conflicts

General approach for solving attribute-level conflicts Declaratively specify how to deal with
conflicts: Set of conflict resolution functions
E.g., count(), min(), max(), random(), etc Set of strategies to deal with conflicts
Correspond to diff. Tolerance degrees Query model that takes into account posible
conflicts directly Use SQL directly or extensions to it.

Conflict resolution and result merging: list of proposals SQL-based conflict resolution (Naumann et al 2002) Aurora (Ozsu et al 1999) Fan et al 2001 FraSQL-based conflict resolution (Sattler et al 2003) FusionPlex (Motro et al 2004) OOra (Lim et al 1998) DaQuinCIS (Scannapieco 2004) (Wang et al 2000) ConQuer (Fuxman 2005) (Dayal 1985)

Conflict resolution and result merging: list of proposals SQL-based conflict resolution (Naumann et al
2002) Aurora (Ozsu et al 1999) Fan et al 2001 FraSQL-based conflict resolution (Sattler et al 2003) FusionPlex (Motro et al 2004) OOra (Lim et al 1998) DaQuinCIS (Scannapieco 2004) (Wang et al 2000) ConQuer (Fuxman 2005) (Dayal 1985)

Declarative (SQL-based) data merging with conflicts resolution [Naumann 2002] Problem: Merging data in an integrated database or in a query against multiple sources
Solution: proposal of a set of resolution functions (e.g. MAX,
MIN, RANDOM; GROUP, AVG, LONGEST) declarative merging of relational data sources by
common queries through: Grouping queries Join queries (divide et impera) nested joining (one at a time, hierarchical)

Declarative (SQL-based) data merging with conflicts resolution [Naumann 2002] Problem: Merging data in an integrated database or in a query against multiple sources
Solution: proposal of a set of resolution functions (e.g. MAX,
MIN, RANDOM; GROUP, AVG, LONGEST) declarative merging of relational data sources by
common queries through: Grouping queries Join queries (divide et impera) nested joining (one at a time, hierarchical)

Grouping queriesSELECT isbn, LONGEST(title), MIN(price)FROM booksGROUP BY isbn
If multiple sources involved with potential duplicates:SELECT books.isbn,LONGEST(books.title), MIN(books.price)FROM (
SELECT * FROM books1UNIONSELECT * FROM books2) AS books
GROUP BY books.isbn
Advantages: good performance
Inconvenient: user-defined aggregate functions not supported by most RDBMS

Join queries (1) Dismantle a query result that merges multiple
sources into different parts, resolve conflicts within each part, and union them to a final result.
Partitions the union of the two sources into : The intersection of the two:
Query 1
SELECT books1.isbn, LONGEST(books1.title, books2.title),
MIN(books1.price, books2.price)
FROM books1, books2
WHERE books1.isbn = books2.isbn

Join queries (2)
Query 2a
SELECT isbn, title, price
FROM books1
WHERE books1.isbn NOT IN
(SELECT books1.isbn,
FROM books1, books2
WHERE books1.isbn = books2.isbn)
)
Advantages: Use of built-in scalar functions available by RDBMS
Query 2b
SELECT isbn, title, price
FROM books1
WHERE books1.isbn NOT IN
(SELECT books2.isbn,
FROM books2
)
Inconvs: Length and complexity of queries
The part of books 1 that does not intersect with books2 (Query 2a or 2b) and vice-versa

Advantages and inconvenients
Pros: the proposal considers the usage of SQL, thus exploiting capabilities of existing database systems, rather than proposing proprietary solutions
Cons: limited applicability of conflict resolution functions that often need to be domain-specific

References
“Data Quality: Concepts, Methodologies and Techniques”, C. Batini and M. Scannapieco, Springer-Verlag, 2006.
“Duplicate Record Detection: A Survey”, A. Elmagarmid, P. Ipeirotis, V. Verykios, IEEE Transactions on Knowledge and Data Engineering, Vol. 19, no. 1, Jan. 2007.
“A Survey of Data Quality tools”, J. Barateiro, H. Galhardas, Datenbank-Spektrum 14: 15-21, 2005.
“Declarative data merging with conflict resolution”, F. Naumann and M. Haeussler, IQ2002.