d02.1 requirements and good practices for a big …...dg digit unit.d.1 d02.1 requirements and good...
TRANSCRIPT

DG DIGIT
Unit.D.1
D02.1 REQUIREMENTS AND GOOD PRACTICES
FOR A BIG DATA TEST INFRASTRUCTURE
ISA2 action 2016.03 – Big Data for Public Administrations
“Big Data Test Infrastructure”
Specific contract n°406 under Framework Contract n° DI/07172 – ABCIII
July 2017

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 04/07/2017 Doc. Version:3.0 1 / 85
This study was carried out for the ISA2 Programme by KPMG Italy.
Authors:
Lorenzo CARBONE
Simone FRANCIOSI
Silvano GALASSO
Pavel JEZ
Valerio MEZZAPESA
Alessandro TRAMONTOZZI
Stefano TURCHETTA
Specific Contract No: 406
Framework Contract: DI/07172
Disclaimer
The information and views set out in this publication are those of the author(s) and do not
necessarily reflect the official opinion of the Commission. The Commission does not guarantee the
accuracy of the data included in this study. Neither the Commission nor any person acting on the
Commission’s behalf may be held responsible for the use which may be made of the information
contained therein.
© European Union, 2017

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 04/07/2017 Doc. Version:3.0 2 / 85
Document Control Information
Settings Value
Document Title: D02.1 Requirements and good practices for a Big Data Test Infrastructure
Project Title: ISA2 Action 2016.03 – Big Data for Public Administrations – Big Data Test Infrastructure
Document Authors:
Lorenzo CARBONE Simone FRANCIOSI Silvano GALASSO Pavel JEZ Valerio MEZZAPESA Alessandro TRAMONTOZZI Stefano TURCHETTA
Commission Project Officer:
Marco FICHERA – European Commission – DIGIT D.1
External Contractor Project Manager:
Lorenzo CARBONE
Doc. Version: 3.0
Sensitivity: Internal
Date: 4 July 2017
Revision History
The following table shows the development of this document.
Version Date Description Created by Reviewed by
0.1 March 2017 Proposal of a Table of Contents for the Report
Simone FRANCIOSI Pavel JEZ Valerio MEZZAPESA Alessandro TRAMONTOZZI Stefano TURCHETTA
Lorenzo CARBONE Silvano GALASSO
1.0 30 May 2017 First release shared with PO
Simone FRANCIOSI Pavel JEZ Valerio MEZZAPESA Alessandro TRAMONTOZZI Stefano TURCHETTA
Lorenzo CARBONE Silvano GALASSO
2.0 06 June 2017
Full draft version to be shared with ISA Coordination Group
Simone FRANCIOSI Pavel JEZ Valerio MEZZAPESA Alessandro TRAMONTOZZI Stefano TURCHETTA
Lorenzo CARBONE Silvano GALASSO
3.0 04 July 2017
Final version refined with MSs’ feedbacks
Simone FRANCIOSI Pavel JEZ Valerio MEZZAPESA Alessandro TRAMONTOZZI Stefano TURCHETTA
Lorenzo CARBONE Silvano GALASSO

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 04/07/2017 Doc. Version:3.0 3 / 85
TABLE OF CONTENTS
EXECUTIVE SUMMARY .................................................................................................................. 7
1. INTRODUCTION .............................................................................................................................. 9
1.1. Objectives of the document .................................................................................................. 11
1.2. Structure of the document .................................................................................................... 12
2. CONTEXT .................................................................................................................................... 14
2.1. The ISA2 programme and the Action 2016.03 “Big Data for Public Administrations”.............. 14
2.2. The CEF Programme .............................................................................................................. 17
2.3. The “European Cloud Initiative” communication ................................................................... 19
3. METHODOLOGY FOLLOWED ............................................................................................................ 22
4. DATA COLLECTION RESULTS ............................................................................................................. 28
4.1. Emerging business needs among Member States in the Big Data field .................................. 28
4.2. Collected Big Data Pilots at EU and National level ................................................................. 31
4.2.1. Criteria for the analysis of Big Data pilots ................................................................ 34
4.2.2. Overview of collected Big Data pilots ....................................................................... 41
4.2.3. Emerging business needs from the analysis of existing Big Data Pilots ..................... 43
5. BIG DATA USE CASES IN SCOPE FOR THE BIG DATA TEST INFRASTRUCTURE ................................................ 47
5.1. Long-list of Big Data use cases: factsheets ............................................................................. 47
5.1.1. Predictive analysis .................................................................................................... 47
5.1.2. Route-traceability / flow monitoring ........................................................................ 48
5.1.3. Web analysis (scraping / monitoring) ....................................................................... 48
5.1.4. Text analysis ............................................................................................................ 48
5.1.5. Descriptive analysis .................................................................................................. 49
5.1.6. Time-series analysis ................................................................................................. 49
5.1.7. Social media analysis ............................................................................................... 50
5.1.8. IoT and smart city .................................................................................................... 50
5.1.9. Network analysis...................................................................................................... 50
5.1.10. Population / customer segmentation ....................................................................... 51
5.1.11. Image processing ..................................................................................................... 51
5.1.12. IoT security .............................................................................................................. 51
5.1.13. Applying bioinformatics to genetic data ................................................................... 52
5.2. Short list of Big Data use cases: Prioritisation of use cases in scope for the Big Data Test Infrastructure ........................................................................................................................ 52
6. BUSINESS AND TECHNICAL REQUIREMENTS FOR THE DESIGN OF THE BIG DATA TEST INFRASTRUCTURE............. 55
6.1. Business requirements .......................................................................................................... 55
6.2. Technical requirements ......................................................................................................... 56
6.2.1. Framework for the identification of the technical requirements ............................... 56
6.2.2. Infrastructure ........................................................................................................... 58
6.2.3. Governance and Security.......................................................................................... 59
6.2.4. Data Ingestion / Storage .......................................................................................... 60

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 04/07/2017 Doc. Version:3.0 4 / 85
6.2.5. Data Elaboration ...................................................................................................... 61
6.2.6. Data Consumption ................................................................................................... 62
7. DESIGN OF THE FUTURE BIG DATA TEST INFRASTRUCTURE ..................................................................... 63
7.1. Good practices and recommendations for the design of the future Big Data Test Infrastructure ................................................................................................................ 63
7.2. Next steps of the study ......................................................................................................... 84
8. LIST OF ANNEXES .......................................................................................................................... 85

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 04/07/2017 Doc. Version:3.0 5 / 85
TABLE OF FIGURES
Figure 1 – Narratives of the Big Data Test Infrastructure ............................................................... 10
Figure 2 – The CEF soGOFA model ................................................................................................. 19
Figure 3 – Methodological approach followed under TASK 1 ......................................................... 22
Figure 4 - Adopted Methodology for the overall study .................................................................. 26
Figure 5 – Member States on-board for Task 1 of the study .......................................................... 29
Figure 6 – Big Data initiatives classified by policy domain .............................................................. 41
Figure 7 – Big Data initiatives classified by Big Data use case......................................................... 42
Figure 8 – Final priority for the identified Big Data use cases ......................................................... 53
Figure 9 – Framework used to classify the Technical requirements ............................................... 57
Figure 10 – Yearly data flow estimates for satellites Sentinel 1-3 as well as MODIS and Landsat 8 64
Figure 11 – JEO-DPP processing components ................................................................................ 65
Figure 12 – The "Sandbox" high-level architecture ........................................................................ 70
Figure 13 - ANAC Cloudera cluster................................................................................................. 71
Figure 14 – Oozie workflows in the ANAC case .............................................................................. 72
Figure 15 – ESTAT cluster high-level architecture .......................................................................... 74
Figure 16 – Example of the crowd monitoring in ArenA................................................................. 76
Figure 17 – Overview of the KAVE services .................................................................................... 76
Figure 18 – Node connections for the BigData@Polito cluster ...................................................... 79
TABLE OF TABLES
Table 1 – Methodology followed for Task 1 of the study ............................................................... 25
Table 2 – Emerging business needs among Member States in the Big Data field ........................... 31
Table 3 – Targeted interviews with EU DGs / Public Institutions .................................................... 32
Table 4 – Entire list of attributes used to classify the existing Big Data initiative ........................... 40
Table 5 – Emerging business needs from existing Big Data pilots................................................... 46
Table 6 – Predictive analysis factsheet .......................................................................................... 47
Table 7 – Route traceability / flow monitoring factsheet ............................................................... 48
Table 8 – Web analysis (scraping / monitoring) factsheet .............................................................. 48
Table 9 – Text analysis factsheet ................................................................................................... 48
Table 10 – Descriptive analysis factsheet ...................................................................................... 49
Table 11 – Time-series analysis factsheet ...................................................................................... 49

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 04/07/2017 Doc. Version:3.0 6 / 85
Table 12 – Social media analysis factsheet .................................................................................... 50
Table 13 – IoT and Smart city factsheet ......................................................................................... 50
Table 14 – Network analysis factsheet .......................................................................................... 50
Table 15 – Population / customer segmentation factsheet............................................................ 51
Table 16 – Image processing factsheet .......................................................................................... 51
Table 17 – IoT security factsheet ................................................................................................... 51
Table 18 – Applying bioinformatics to a genetic data factsheet ..................................................... 52
Table 19 – Detailed view of the use cases prioritisation ................................................................ 54
Table 20 – Business Requirements ................................................................................................ 56
Table 21 – Technical Requirements for the Infrastructure .............................................................. 59
Table 22 – Technical Requirements for the Governance and Security Area .................................... 60
Table 23 – Technical Requirements for the Data ingestion / storage area ..................................... 61
Table 24 – Technical Requirements for the Data elaboration area ................................................. 62
Table 25 – Technical Requirements for the Data consumption area ............................................... 62

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/20177 / 85 Doc. Version:2.0
EXECUTIVE SUMMARY
This document has been issued under the ISA2 Action 2016.03 – Big Data for Public
Administrations – Big Data Test Infrastructure, with the aim of providing a description of the
outcomes of the activities performed so far in the context of the study “Big Data Test
Infrastructure”.
The main objective of this study is to identify the main key features and design the architecture of
a “Big Data Test Infrastructure”, which the European Commission (EC) will make available to other
EC DGs, Member States’ Public Administrations and EU Institutions in order to:
1. Facilitate the launch of pilot projects on Big Data, data analytics or text mining, by
providing the infrastructure and software tools needed to start a small project;
2. Foster the sharing of various data sources across policy domains and organisations to
support better policy-making;
3. Support Public Administrations through the creation of a Big Data community around best
practices, methodologies and artefacts (algorithms, analytical models, pilots output, etc.) on
Big Data for policy-making.
More in detail, within this document (TASK 1 of the overall study) a description of the relevant Big
Data use cases and business/technical requirements for the future Big Data Test Infrastructure is
provided together with a description of the methodological approach followed.
Therefore under TASK 01 of the aforementioned study, the following main outcomes have been
achieved:
Identification of a set of relevant initiatives on the Big Data field performed by EU public
administrations and EU Institutions that make use of Big Data infrastructures to launch
and execute pilot projects on Big Data / Analytics (e.g. server clusters with scalable storage
and computing capacity, usage of Analytics tools, etc.);
Detailed description of each of the relevant initiatives, considering both business needs
(supported use cases, success factors, etc.) and technology aspects (e.g. architecture,
adopted tools, etc.);
Establishment of bilateral communications with the owners of each identified Big Data
pilot and with the national contact points of the Member States (nominated by the ISA
Coordination Group Members);

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/20178 / 85 Doc. Version:2.0
Identification of relevant Big Data use cases to be supported by the future Big Data Test
Infrastructure;
Definition of business and technical requirements for the future Big Data Test
Infrastructure;
Identification of good practices and recommendations for the design of the architecture
of the future Big Data Test Infrastructure to be performed during TASK 2 and TASK 3 of the
overall Study.
As a result, this document outlines Member States’ needs in the Big Data field and clearly defines
the Big Data use cases to be supported by the future Big Data Test Infrastructure and a set of
business and technical requirements that will guide the design of the Big Data Test Infrastructure.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/20179 / 85 Doc. Version:2.0
1. INTRODUCTION
The amount of data generated worldwide keeps increasing at an astounding pace, by 40% each
year, and forecasts expect it to rise 30-fold between 2010–2020. Since non-interoperable means
are being used to describe data generated in the public sector, most of this data cannot be re-used.
Previous studies have already investigated Big Data and data analytics initiatives launched by EU
Public Administrations (PAs) and EU Institutions (EUIs) both at European and National level. Indeed,
their focus was geared towards studying the potential or added value of Big Data analytics to help
public authorities at all levels of government and in different domains in reaching their goals, as
well as towards capturing valuable lessons learned and best practices of mature public
organisations to inspire peers while helping them in further use of Big Data analytics and to become
more insight-driven. That being said, despite the various use cases covered by these
aforementioned studies, the adoption of some analytics technologies in public administrations is
still lacking. At the moment, several Cloud environments exist in the European Commission but no
Big Data infrastructure is available to any PA or EUI with a full stack of technologies
(infrastructure in terms of storage and computing capacity, analytics tools and test datasets) to test
the value of new ways of processing Big Data and display its benefits to their management.
Providing these analytics technologies to PAs and EUIs would both significantly increase the
adoption of analytics technologies and encourage users to initiate research and test projects in the
Big Data field, and as a result boost innovation and R&D (Research and Development).
Therefore, the ISA2 Action 2016.03 – “Big Data for Public Administrations” aims to address the use
of Big Data within PAs to support better decision-making.1 The study “Big Data Test Infrastructure”,
launched at the beginning of January 2017 under the above-mentioned activities, aims at filling the
gap within PAs in the Big Data field, providing the design of a centralised European Big Data Test
Infrastructure to be used by any PA and EUI in Europe.
1 https://ec.europa.eu/isa2/sites/isa/files/library/documents/isa2-work-programme-2016-summary_en.pdf

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201710 / 85 Doc. Version:2.0
Indeed, the purpose of this study is to identify the main key features of the “Big Data Test
Infrastructure” and design its architecture, which the European Commission (EC) will make
available to any interested EC DGs, PAs and EUIs in Europe in order to:
1. Facilitate the launch of pilot projects on Big Data, data analytics or text mining, by
providing the infrastructure and the software tools needed to start a pilot project;
2. Foster the sharing of various data sources across policy domains and organisations to
support better policy-making; and
3. Support PAs through the creation of a Big Data community around best practices,
methodologies and artefacts (big data algorithms, analytical models, pilots’ outputs, etc.) on
Big Data for policy-making.
A cross-border aggregation of data through a ready-to-use Big Data Test infrastructure would allow
and increase the adoption of meaningful analytics services that will benefit the European and
National PAs / EUIs and the European Union as a whole.
The following examples will facilitate readers to understand the potential of this Big Data Test
Infrastructure:
Figure 1 – Narratives of the Big Data Test Infrastructure

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201711 / 85 Doc. Version:2.0
The entire “Big Data Test Infrastructure” study is structured in accordance with the following three
main tasks:
The objective of this document is to report the final results of Task 1.
1.1. OBJECTIVES OF THE DOCUMENT
As anticipated in the Introduction, the objective of this document (outcome of TASK 1 of the
overall study) is to describe the identified business and technical requirements and good
practices for setting-up a Big Data Test Infrastructure to be used by EU Institutions and EU Public
Administrations to launch pilot projects on Big Data.
The identified set of business and technical requirements will guide TASK 3, providing key features
and main functionalities of the future Big Data Test Infrastructure, and the identified good
practices will provide useful recommendations and guidelines for the design phase of the
infrastructure, resulting from the analysis of relevant European initiatives addressing the use of Big
Data Infrastructures.
A further objective of this document is to describe the identified and prioritised Big Data use cases
to be supported by the future Big Data Test Infrastructure.
The main objectives of this document can therefore be summarised as follows:
Identification of Big Data use cases to be supported by
the future Big Data Test Infrastructure, through the
analysis of Member States’ needs and of relevant Big
Data pilot projects in Europe
Quick reference: Chapter 5

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201712 / 85 Doc. Version:2.0
Identification of a set of business and technical
requirements that will guide the design of the future Big
Data Test Infrastructure
Quick reference: Chapter 6
Identification of good practices coming from Big Data
infrastructures set up by public administrations at
national level, in order to provide useful guidelines and
recommendations for the design of the future Big Data
Test Infrastructure
Quick reference: Chapter 7
1.2. STRUCTURE OF THE DOCUMENT
This document represents the final deliverable of TASK 1 of the overall study related to the Big Data
Test Infrastructure. This document contains seven main sections, structured according to the
approach to the study, as listed below:
• Introduction – presents the entire study and its main objectives (Chapter 1);
• Context – outlines the context of the study, pointing out the ISA2 Programme and the ISA2
Action 2016.03 – “Big Data for Public Administrations”, the CEF funding Programme and
the European Cloud Initiative (Chapter 2);
• Methodology followed – this section introduces the methodological approach used for
TASK 1, highlighting the steps adopted (Chapter 3);
• Data collection results – describes the outcomes of the Data Collection activities in terms
of desk research, targeted interviews with key stakeholders and bilateral conferences with
Member States (Chapter 4);
• Big Data use cases in scope for the Big Data Test Infrastructure – describes the identified
Big Data use cases to be supported by the future Big Data Test Infrastructure, and the

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201713 / 85 Doc. Version:2.0
adopted prioritisation parameters (Chapter 5);
• Business and technical requirements for the design of the Big Data Test Infrastructure –
presents the final version of the business and technical requirements, which will be used
for the design of the infrastructure (TASK 3 of the study). In addition, this chapter sets out
the framework adopted for the classification of the technical requirements (Chapter 6);
• Design of the future Big Data Test Infrastructure – this final chapter provides
recommendations and guidelines that are useful for the design of the infrastructure
expected under TASK 3 of the study (Chapter 7).
In addition to these chapters, this document includes the following annexes:
• Annex 1 Minutes of targeted interviews – minutes of the interviews conducted with EC
DGs and EU Institutions;
• Annex 2 Big Data pilots gathered during the data collection phase – overview of all the Big
Data pilots undertaken with business and technical information;
• Annex 3 Minutes of the bilateral conferences with Member States – interview guide and
minutes of each bilateral conference conducted with national contact points nominated by
the ISA Coordination Group;
• Annex 4 Business and technical requirements – Excel file containing the detailed
information on the Big Data use cases, the identified business and technical requirements,
and the emerging business needs resulting from the analysis of Member States needs and
conducted pilots.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201714 / 85 Doc. Version:2.0
2. CONTEXT
2.1. THE ISA2 PROGRAMME AND THE ACTION 2016.03 “BIG DATA FOR PUBLIC
ADMINISTRATIONS”
Nowadays, European Public Administrations are expected to provide efficient and effective
electronic cross-border or cross-sector interactions between not only PAs but also between PAs
and both citizens and businesses without any disruption. By implementing and executing the ISA2
Programme (commonly referred to as ISA2) from 1 January 2016 to 31 December 2020, the EC
finances thirty-five (35) clusters of actions2 with an operational financial envelope of
approximately EUR 131 million. This programme will continue to ensure that Member States (MSs)
are provided with high-quality, fast, simple and low-cost interoperable digital services.
By supporting and developing new actions and interoperability solutions, the Council and the
European Parliament ensure that ISA2 will contribute to increasing interoperability that will in turn
advance the services offered, cut overall costs and result in a better-functioning internal market.
Under ISA2, the Presidency will prioritise actions and develop provisions to prevent any overlaps
and promote full coordination and consistency with other EU programmes (Connecting Europe
Facility Programme, DSM Strategy).
The 5-year ISA2 Programme 2016–2020 has been developed as a follow-up to its predecessor ISA, which ran from
2010 to 2015. Still managed by the ISA Unit (up to 2016, DIGIT.B6, now DIGIT.D1) of DG Informatics of the EC, the
ISA2 Programme will focus on specific aspects such as ensuring correct coordination of interoperability activities at
EU level; expanding the development of solutions for public administrations according to businesses’ and citizens’
needs; proposing updated versions of tools that boost interoperability at EU and national level, namely the
European Interoperability Framework (EIF) and the European Interoperability Strategy (EIS); the European
Interoperability Reference Architecture (EIRA) and a cartography of solutions: the European Interoperability
Cartography (EIC).
With the adoption of ISA2, the EC commits to developing necessary IT services and solutions for the advancement of
public-sector innovation and digital public service delivery to citizens and businesses.
In order to remain in line with the European DSM Strategy, ISA2 monitors and supports EIF implementation in
Europe.
ISA is also well aligned with the Connecting Europe Facility Programme (CEF Programme), the Union’s funding
instrument for trans-European networks in the fields of transport, energy and telecommunications. The CEF
supports the deployment and operation of key cross-border digital services. ISA2 supports the quality improvement
of selected services and brings them to the operational level required to become a CEF service. It is also one of the
enabler and contributor programmes for public-sector innovation in Europe.
2 See: https://ec.europa.eu/isa2/dashboard/isadashboard

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201715 / 85 Doc. Version:2.0
The ISA2 Programme currently covers 35 actions, in which the “Big Data for Public
Administrations” represents the third, namely Action 2016.03. ISA2 is structured in such a way
that actions are grouped into packages of similar policy areas, which are agreed by the
Commission and Member States. Action 2016.03 belongs to the package “access the data / data
sharing / open data” under which the ISA2 programme funds actions to help open up national data
repositories, facilitate the reuse of data across borders and sectors, and widen access to data
created by the public sector.3
Phase 1 of this Action is aimed at carrying out a landscape analysis in order to identify: (i) the
requirements and challenges of PAs in Europe and the Commission in the context of Big Data; (ii)
ongoing initiatives and best practices in these areas, including an assessment of the tools and
solutions that these initiatives have implemented; and (iii) synergies and areas of cooperation with
the policy DGs and the MSs in this domain. Furthermore, phase 1 also intends to execute some
pilots that showcase the usefulness and policy benefits that Big Data can bring.
This action will continue to build upon the results of phase 1, focusing on the following activities:
Track 1: continue with the identification of further opportunities and areas of interest
whereby the use of Big Data could help improve working methods as well as ensure better
policy-making for policy DGs as well as Member States' Public Administrations;
Track 2: continue the implementation of already identified pilots through generalising the
developed functionalities and thus extending their use to policy agnostic contexts in order
to maximise the benefit and return on investment of the proposed solution;
Track 3: launch a new wave of pilots in specific domains, which hold a potential for later
being generalised and scaled-up to be made available to different services agnostic of their
specific policy area.
Moreover, in order to encourage the use of Big Data tools, under the same action, ISA2 funded
some Big Data pilots which may motivate PAs. Two of these pilots are reported on below:
Transpositions Big Data Pilot4
In order to support the compliance checks carried out by Commission staff on national measures
transposing EU directives, it was necessary to implement a proof of concept (PoC) to showcase the
benefits and feasibility of applying text-mining techniques.
3 See: https://ec.europa.eu/isa2/sites/isa/files/isa2_2017_work_programme_summary.pdf 4 See: https://joinup.ec.europa.eu/asset/isa_bigdata/asset_release/transpositions-big-data-pilot#download-links

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201716 / 85 Doc. Version:2.0
The objectives of the PoC showcasing the use of Big Data in the procurement domain, in
cooperation with DG GROW are as follows:
To prove the usefulness of Big Data and the policy benefits that it can bring;
To demonstrate the use of natural language analysis techniques to check the compliance of the
transpositions sent by the European Member States related to EU directives.
In the context of the PoC, one directive and its respective national transpositions will be analysed,
with the objective of supporting the manual checks currently undertaken by European Commission
staff.
Scientific Health Papers Text Mining Pilot5
In order to fulfil the requirements of identification of concrete Big Data and open knowledge
opportunities and requirements in PAs set out by the ISA action 1.22, it was necessary to execute a
PoC showcasing the use of Big Data in the EC research domain. The PoC intends to demonstrate
the use of text mining techniques used on large amounts of unstructured research health papers
from several data sources as a means of identifying areas of interest for additional input to
consider prior to launching calls for grants.
The execution was undertaken in cooperation with DG RTD in order to prove the usefulness and
policy benefit that Big Data can contribute.
Recently ISA2 funded other Big Data pilots, for example one with the Municipality
of Madrid.
The ISA2 Action 2016.03 is a natural continuation of the ISA Action (1-22) “Big Data and Open
Knowledge for Public Administrations”, carried out in the context of the 2010–2015 ISA
programme. It aimed at identifying “the challenges and opportunities that Member States and the
Commission face in the context of Big Data and open knowledge [and] to create synergies and
cooperation between the Commission and Member States, leading to more effective and informed
actions by public administrations”.6 Under this action, a study by Deloitte was conducted on
Big Data entitled “Big Data Analytics for Policy Making”7 and the initiative “Big Data Test
Infrastructure” represents a technical follow-up of this Deloitte report. The final report places
specific attention on Big Data and data analytics initiatives launched by European PAs in order to
5 See: https://joinup.ec.europa.eu/asset/isa_bigdata/asset_release/scientific-health-papers-text-mining-pilot 6 See: http://ec.europa.eu/isa/actions/01-trusted-information-exchange/1-22action_en.htm 7 See: https://joinup.ec.europa.eu/asset/isa_bigdata/document/big-data-analytics-policy-making-report

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201717 / 85 Doc. Version:2.0
provide insights. The study first analyses the added value of Big Data analytics to assist public
authorities at all levels of government and in different domains to achieve their goals. Second, it
captures valuable lessons learned and best practices of mature public organisations to inspire
peers and to help them along the journey to use Big Data analytics and to become more insight
driven. The study gathered over 100 cases, of which 10 were selected, where PAs mine Big Data or
use data analytics to gain better insights and increase their impact. These cases covered a wide
range of different data sources and types of analytics as well as policy domains and levels of
government, to conduct more in-depth case studies and to gather key lessons learned from the
use of Big Data and data analytics within these public authorities.
Based on all use cases and best practices, Deloitte’s study developed several recommendations
addressed to any public organisation that is willing to work with data analytics and Big Data. All
these useful insights are published in the above-mentioned final report: “Big Data Analytics for
Policy Making”.
2.2. THE CEF PROGRAMME
The Connecting Europe Facility (CEF) represents a key EU funding instrument that promotes
growth, jobs and competitiveness through targeted infrastructure investment at the European
level. CEF aims to support the development of high-performing, sustainable and efficiently
interconnected trans-European networks in the fields of transport, energy and digital services. The
programme’s investments fill the missing links in Europe's energy, transport and digital backbone.8
CEF’s benefits are multiple for citizens from the EU MSs, especially within the following sectors:
Transport: travel will be easier and more sustainable;
Energy: Europe’s energy security will be enhanced, while enabling wider use of
renewables;
Telecom: cross-border interaction between public administrations, businesses and citizens
will be facilitated;
Economy: the CEF offers financial support to projects through innovative financial
instruments such as guarantees and project bonds. These instruments create significant
leverage in their use of EU budget and act as a catalyst to attract further funding from the
8 See: https://ec.europa.eu/inea/en/connecting-europe-facility

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201718 / 85 Doc. Version:2.0
private sector and other public sector actors.
Moreover, in order to facilitate the delivery of digital public services across borders, the EU MSs
have created interoperability agreements with the aim to deploy trans-European Digital Service
Infrastructures (the DSIs) to be run by CEF Digital.9 This programme supports the provision of basic
and re-usable digital services, known as the CEF building blocks,10 such as eDelivery, eID,
eSignature and eInvoicing. The CEF building blocks can be combined with each other, adopting a
Service Oriented Architecture approach, and integrated with more complex services (e.g. eJustice).
Building blocks denote the basic digital service infrastructures, which are key enablers to be
reused in more complex digital services.11
The CEF building blocks offer basic capabilities that can be used in any European project, and they
can be combined and used in projects in any domain or sector at European, national or local level.
The building blocks are based on existing formalised technical specifications and standards.
The main goals of the CEF building blocks are listed below:
Facilitating the adoption of common technical specifications by PAs;
Ensuring interoperability between IT systems so that citizens, businesses and
administrations can benefit from seamless digital public services wherever they may be in
Europe;
Facilitating the adoption of common technical specifications by projects across different
policy domains with minimal (or no) adaptation by providing services and sometimes
sample software.
The CEF Regulation and the CEF Principles set the context and objectives for the CEF Programme
and define the conditions for providing funding to current and future Building Block DSIs. Each DSI
is implemented through its Service Offering. The soGOFA model describes the four aspects
(Governance, Operations, Financing and Architecture) that need to be managed to deliver this
Service Offering:
9 See: https://ec.europa.eu/cefdigital/wiki/display/CEFDIGITAL/CEF+Digital+Home 10 See: https://ec.europa.eu/cefdigital/wiki/display/CEFDIGITAL/CEF+building+blocks 11 See: https://ec.europa.eu/cefdigital/wiki/display/CEFDIGITAL/CEF+Definitions

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201719 / 85 Doc. Version:2.0
Figure 2 – The CEF soGOFA model
Currently preparations are ongoing for the next CEF funding Programme, in particular the
prioritisation of the CEF candidate Building Blocks by the members of the CEF Expert Group based
on their national needs. As a result, some candidate(s) will become part of the CEF Programme,
requiring a strong Governance of the delivery of those candidates among Member States.
The future “Big Data Test Infrastructure” is in line with the above-mentioned CEF Regulation and
principles and the future infrastructure will be designed around the four aspects of the soGOFA
model.
In order to participate in this programme, DG DIGIT.D1 prepared, with KPMG support, a list of
deliverables to describe the Big Data Test Infrastructure (i.e. a Maturity form, Synopsis and
Narratives document) and the candidate received strong interest from several Member States in
the prioritisation process (MSs representatives of the so-called CEF Expert Group), officially
entering the short-list of candidate building blocks. The final selection process is ongoing and the
candidate building block has already been presented to the CEF Expert Group during a webinar
session.
2.3. THE “EUROPEAN CLOUD INITIATIVE” COMMUNICATION
In line with the Digital Single Market (DSM), the European Cloud Initiative aims at maximising the
growth potential of the European digital economy. The European Cloud Initiative is based on three
defined goals which are considered as pillars of the initiative:12
• Developing a secure, open environment for the scientific community for storing, sharing and
12 http://ec.europa.eu/newsroom/dae/document.cfm?doc_id=15266

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201720 / 85 Doc. Version:2.0
re-using scientific data and results, namely the European Open Science Cloud (EOSC);
• Deploying the underpinning super-computing capacity, the fast connectivity and the high-
capacity Cloud solutions needed via a European Data Infrastructure (EDI);
• Expanding the user base to the public sector and to industry, creating solutions and
technologies that will benefit all areas of the economy and society.
Below, a closer look is taken at each of the three aforementioned pillars:
1. European Open Science Cloud
It aims to give Europe a global lead in scientific data infrastructures, to ensure that European
scientists reap the full benefits of data-driven science. Practically, it will offer 1.7 million European
researchers and 70 million professionals in science and technology a virtual environment with free
at the point of use, open and seamless services for storage, management, analysis and re-use of
research data, across borders and scientific disciplines.
2. European Data Infrastructure (EDI)
The EDI, once fully implemented, will underpin the European Open Science Cloud and will allow
fully unlocking the value of Big Data and digital by default. The EDI will contribute to the
digitalisation of industry, to develop European platforms for new, strategic applications and to
foster industrial innovation.
In addition, the EDI will support the EU to rank among the world's top supercomputing powers by
realising exascale supercomputers around 2022, based on EU technology, which would rank the EU
in the top 3 places worldwide. The EUDAT will gather the necessary resources and capabilities, to
close the chain from research and development to the delivery and operation of the exascale
computing HPC systems co-designed between users and suppliers.
3. Widening access and building trust
The user base of the EOSC and of the EDI will be widened to the public sector, for instance through
large-scale pilots involving eGovernment and public sector stakeholders, and by progressively
opening the EDI to users from industry and the public sector in order to cover the whole European
dimension.
The ultimate aim is that the EOSC will ensure that public data is fully discoverable, accessible and
exploitable by scientists, policymakers and businesses.
This will give the public cheaper, faster, better and interconnected public services and improved
policy making based on affordable and secure computer- and data-intensive services.
Indeed, the EDI will focus on widening the user base of digital infrastructures (and High

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201721 / 85 Doc. Version:2.0
Performance Computing – HPC), which will, as a result, provide easier access via the Cloud both to
researchers in key scientific disciplines and to the long tail of science. Industry, particularly SMEs
without in-house capabilities and public authorities (e.g. smart cities and transport) will benefit
from Cloud-based and easy-to-use HPC resources, applications and analytics tools.
Potential synergies can be explored between the EOSC, the EDI and the Big Data Test Infrastructure.
Considering the EOSC and EDI long-term goals (2022 and 2025), the Big Data Test Infrastructure
could support the third pillar “Widening the user base”, for instance, by providing services to
Member States in the short term, thus fostering the take up of (big) data technologies in PAs.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201722 / 85 Doc. Version:2.0
3. METHODOLOGY FOLLOWED
This section provides a description of the overall methodological approach (represented in Figure
3) applied in order to guarantee the achievement of the objectives of TASK 1:
Figure 3 – Methodological approach followed under TASK 1
Step 1.1
Data Collection
Activities
In order to ensure a consistent and reliable identification of Big Data use
cases and related business and technical requirements for the Big Data
Test Infrastructure, the study started identifying and analysing relevant
Big Data pilot projects performed at EU Level (European Commission
DGs and EU Institutions) and at National level (public administrations in
Europe).
Therefore, the aim of this step has been to obtain detailed data both via
accurate desk research and directly from the owners of the Big Data pilot
projects.
Desk research on Big Data pilots at EU and National level has been
performed considering the following data source categories:
Similar studies conducted by the European Commission or third
parties. All material available such as sources/existing documents
and results related to other ISA actions (e.g. Interoperability Test
Bed) has been consulted;
Big Data Pilots/PoC already delivered at European level and at
National level;
Big Data projects funded by the European Commission (e.g. FP7 or

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201723 / 85 Doc. Version:2.0
H2020);
KPMG credentials/experience and Competence Centre in the Data
& Analytics area.
The desk research activities resulted in the identification of a long list of
Big Data pilot projects at EU and National level. In order to ensure the
reliability of the information collected through Desk research activities,
the team complemented it with a primary data collection phase through
dedicated bilateral interviews with the owners of each Big Data pilot.
All the information on relevant Big Data pilots/projects has been
collected in an Excel template structured according to the following
categories:
General information – General information about the Big Data
project under analysis;
Business information – Business needs in terms of project
objective(s), addressed Big Data use cases, applicable Policy
Domains, level of Government, Key Success Factors and KPIs;
stakeholders and end-users, status of the project;
Technical information – Technical information related to the Big
Data pilot in terms of technologies, infrastructure, tools, etc.
In order to identify good practices among the collected Big Data pilots, a
set of assessment criteria was defined and agreed with the EC Project
Officer.
Step 1.2
Analysis and
Identification of use
cases and draft
requirements
The objective of this step has been to develop a first draft version of Big
Data use cases and business/technical requirements for the future Big
Data Test Infrastructure, including a draft version of good practices
based on the detailed analysis of the Big Data pilots collected during the
Data Collection activities performed under Step 1.1.
The analysis of collected initiatives, pilots and business needs focused on

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201724 / 85 Doc. Version:2.0
the preliminary identification of Big Data good practices and related
use cases that help to solve specific business challenges among PAs.
The identification and classification of Big Data use cases were followed
by an initial prioritisation of these cases in order to select the most
relevant to be supported by the Big Data Test Infrastructure
(i.e. “demand-driven approach”). The prioritisation process is described
in detail in Chapter 5.
Starting from the identified Big Data use cases, a set of business and
technical requirements has been identified and classified according to a
tailored requirements framework. This framework has been structured
in specific functional areas that represent the high-level architecture of
the future Big Data Test Infrastructure (e.g. data ingestion/storage,
data elaboration, data consumption).
Step 1.3
Refinement and
Validation process
The identified list of prioritised Big Data use cases and related business
and technical requirements have been refined through a structured
refinement and validation process that involved the Member States.
Member States have been included through the activation of the ISA
Coordination Group (ISA CG): each interested national member of the
ISA CG nominated a national contact point to be involved during the
whole study.
Our team organized several bilateral conferences with these national
contact points in order to gather national business needs for the future
Big Data Test Infrastructure. This step was fundamental for the
consolidation process of the first draft of use cases and requirements
produced under Step 1.2. Indeed, during these bilateral conferences
several new Big Data use cases were identified based on Member
States’ needs, while other Big Data pilots/projects performed at National
level were collected.
Based on the significant amount of collected feedback from the national

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201725 / 85 Doc. Version:2.0
contact points of the Member States, a webinar with all the interested
Member States has been organised to present the results of the study,
as well as to collect any additional useful feedback in a structured way.
Step 1.4
Report on final
requirements and
good practices
The final step of TASK 1 has been the delivery of this Report “D02.01
Requirements and good practices for a Big Data Test Infrastructure”
based on the consolidated results of TASK 1:
List of the relevant Big Data Use Cases to be supported by the future
Big Data Test Infrastructure;
List of business and technical requirements that will guide the design
of the Big Data Test Infrastructure;
List of identified good practices and recommendations to be used
during the design of the Big Data Test Infrastructure (TASK 3).
Table 1 – Methodology followed for Task 1 of the study
As described above, the methodological approach adopted for TASK 1 of the study focused on the
identification and consolidation of the requirements that will guide the design of a future Big Data
Infrastructure based on Member States’ needs. In order to provide a clear picture of the overall
methodological approach defined for the complete study, the following figure highlights the main
relationships connecting the three Tasks of the study.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201726 / 85 Doc. Version:2.0
Figure 4 - Adopted Methodology for the overall study
As highlighted in Figure 4 above, two main information sources are used:
Existing Big Data Initiatives: existing Big Data initiatives, project and pilots (both at European
and at National level) collected during the Data Collection phase. All the projects collected were
useful to have a broader picture of what has already been implemented in Europe and of all the
Big Data use cases of interest to key stakeholders;
Member States: involvement of Member States through the ISA Coordination Group, in order
to gather the national business requirements regarding Big Data and to collect information on
existing Big Data pilots at National level.
All the information collected has been fundamental in the identification of the so-called “Long-List
of Use Cases”, which includes a list of high level use cases related to the Big Data field
(e.g. predictive analysis, web analysis, image processing, etc.). The wide variety of use cases makes
it difficult to implement them all in one single platform (e.g. applying bioinformatics to genetic data
and text analysis). Therefore, a prioritisation process has been conducted, which led to a so-called
“Short-list of Use Cases” in scope for the Big Data Test Infrastructure.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201727 / 85 Doc. Version:2.0
Finally, a list of Business and Technical Requirements has been identified and consolidated to
support the implementation of Big Data pilots in the area of the identified Big Data use cases.
TASK 3 is focused on the design of the Big Data Test Infrastructure based on the identified
requirements, good practices / recommendations and data exchange APIs available at EU level
(to be identified under TASK 2 of the study).

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201728 / 85 Doc. Version:2.0
4. DATA COLLECTION RESULTS
This section aims at summarising the following main outcomes of the Data Collection phase
performed during TASK 1:
Identification of emerging business needs in the Big Data field from the interested
Member States, through bilateral conferences performed with each national contact point.
The involvement of the interested Member States provided useful input for the
identification of business and technical requirements for a future Big Data Test
Infrastructure.
Identification of a list of relevant Big Data pilots performed at EU and National level,
through structured desk research activities and in-depth interviews with the owners of the
pilots in order to deepen business and technical aspects of the pilots.
The technical analysis of these pilot projects provided useful information for the design of
the future Big Data infrastructure in terms of “sizing” of the infrastructure (storage and
computing capacity), addressed Big Data use cases, main technologies used, main
architecture principles followed (e.g. adoption of only open source software, scalable
infrastructure, etc.), good practices and recommendations.
The following paragraphs provide a summary of the results of the above-mentioned data collection
activities.
4.1. EMERGING BUSINESS NEEDS AMONG MEMBER STATES IN THE BIG DATA FIELD
The strong involvement of many Member States has been a success factor for TASK 1 of the study
and in particular for a clear identification of business needs at National level for the future Big Data
Infrastructure.
The involvement of Member States has been achieved through activation of the ISA Coordination
Group: a formal email communication has been sent to ISA Coordination Group members in order
to identify national contact points to be involved during the study through bilateral conferences.
Eight MSs have participated actively during Task 1 of the initiative and this participation is foreseen
to continue for the duration of the entire project. MSs on-board so far are: Czech Republic, Estonia,
Hungary, Malta, Norway, Slovenia, Spain, and Portugal. In addition, the Netherlands requested to

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201729 / 85 Doc. Version:2.0
participate in the process beginning in a more passive role in order to have more time to determine
their business needs.
Figure 5 – Member States on-board for Task 1 of the study
Bilateral conferences were conducted with each of the participating MSs, where DIGIT and KPMG
presented the initiative in detail and collected constructive business requirements. The virtual
meetings were based on a format which included a structured presentation followed by an open
discussion between attendees guided by experts, which proved to be a very efficient and effective
format for presenting the project and gathering the expectations and feedback from
Member States. In this context, the Webinar mode increased the participation rate of attendees
since their geographical distribution would have precluded their physical participation.
The following paragraphs detail all the business needs gathered during the bilateral conferences.
As indicated earlier, the project secured strong interest from several Member States involved
through the ISA coordination Group.
The table below shows the final results with regard to the collected business needs which are being
taken into account for the identification of the requirements (see chapter 6). Each need is described
with the following attributes:

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201730 / 85 Doc. Version:2.0
• ID: a simple identifier, useful to link the needs to the requirements;
• Topic: a simple classification of the need;
• Member States: the list of Member States which have stated the need during the bilateral
conferences;
• Need description: the description of the need.
ID Topic Member States Need description
1 Open Data access
Estonia There is a need to define a structured process/methodology to access and deal with Open Data.
2 Data format Estonia
It is necessary to share common standard data formats and interpretation in order to understand the real value in using Big Data.
3 Knowledge
Estonia Hungary Spain Slovenia
It is necessary to arrange for regular training of managers in PAs and of people on the policy-making side in general in order to acquire Big Data skills and allow them to understand the potential of Data Analytics tools and methodologies.
4 Data integration
Estonia
It is necessary to integrate datasets from different data sources and to access integrated data from an analytical environment in order to provide the opportunity to experiment and discover useful and interesting correlations among data.
5 Privacy and security
Estonia
It is necessary to have a functional environment allowing access to sensitive and confidential data at a raw level in order to perform analytics on fine-grained data.
6 Privacy and security
Hungary, Malta, Czech Republic
It is necessary to allow the use of MSs physical infrastructure in order to host the Big Data test infrastructure or to complement it, for example in order to be compliant with specific national data privacy and security policies (e.g. national data cannot be moved outside the national border).
7 Privacy and security
Hungary, Spain
It is necessary to perform a normalization of the legislation on the use of national PAs data at European level (data handling, analysis and storage of data) in order to create direct data interfaces with PAs and Institutions.
8 Licensing Malta, Spain
It is necessary to implement the Big Data Test infrastructure through free/open-source software in order to avoid licensing costs.
9 Support Malta It is necessary to have a Big Data team to support PAs in launching Big Data experiments and pilots.
10 Community Malta, Norway, Spain
It is necessary to create a Big Data community to share Big Data artefacts among European and National Public Administrations / Public Institutions, in order to share, in addition, projects’ results, methodologies, best practices, datasets and, in general, Big Data know-how and other Big Data experiences.
11 Infrastructure scalability
Spain It is necessary to use a scalable Cloud platform in order to perform pilots at different scales and maturity levels.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201731 / 85 Doc. Version:2.0
ID Topic Member States Need description
12 Collaboration Slovenia
It is necessary to create an environment (e.g. with collaboration tools) which allows data owners and technicians (e.g. data scientists) working closely together to obtain results, through continuous interpretation and validation of interim results.
13 Privacy and security
Slovenia
It is necessary to allow the masking or aggregating of sensitive data in order to perform analysis which is compliant with data privacy and security concerns.
14 Infrastructure integration
Spain It is necessary to integrate or interact with other Big Data infrastructures (i.e. providing or consuming data or services).
15 Code/analytics migration support
Spain It is necessary to allow the import code/scripts/analytics from other Big Data or Business Intelligence projects already developed
Table 2 – Emerging business needs among Member States in the Big Data field
4.2. COLLECTED BIG DATA PILOTS AT EU AND NATIONAL LEVEL
As anticipated in Chapter 3, in order to collect information on existing Big Data projects / pilots at
EU and National level which used a Big Data Infrastructure, the team undertook various data
collection activities which can be summarised in the following two steps:
1. A preliminary collection – Long-list of Big Data pilots: in this first step the team gathered
information on several existing projects / pilots in the Big Data field through desk research,
targeted interviews with key stakeholders and analysis of technical public information or
data provided by the owners. Information was collected on the following types of initiatives:
Big Data Pilots/projects implemented at European level (already delivered or ongoing).
Information on these initiatives was collected and further analysed through targeted
interviews with key stakeholders of EU DGs and European Institutions which also could
be potential users of the future Big Data Test Infrastructure. The main objectives of the
Interviews were to collect information on Big Data and Data Analytics pilots; deepen the
need for an IT Infrastructure supporting stakeholders business needs and gather
information on relevant Big Data Use cases the future Big Data Test Infrastructure could
support. The results of these interviews are briefly summarised in the following table:

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201732 / 85 Doc. Version:2.0
Category Stakeholder Main insights
EU
Statistics
Office
ESTAT
Implementing the ESS Big Data Action Plan, Big Data training courses,
developing Data Science Skills and pilot projects related to the smart
statistics field of expertise. They have tested an interesting platform called
“Sandbox” and conducted research with their Big Data Cluster. Both are
further analysed in Chapter 7.
EC JRC
Implementing several Big Data projects in different areas: text mining,
remote sensing, data mining / machine learning, semantic analysis,
IoT security, etc. It was productive for the data collection phase in terms of
the number of Big Data pilots with different Big Data use cases.
Implementing an interesting pilot with ESA: Earth Observation and
Social Sensing Big Data pilot project. Further information on this pilot can be
found in Chapter 7.
EC DG CNECT
Potential synergies between the EDI and the Big Data Test Infrastructure.
Considering that EDI has a long-term goal (by 2025), the Big Data Test
Infrastructure could support the third pillar “Widening the user base”, for
instance by providing services to Member States in the short term, thus
fostering the take up of (Big) Data technologies in public administrations.
EC DG RTD Implementing Big Data projects on fraud detection and on a text and data
mining tool. Their actual need is to scale-up their Big Data infrastructure.
EU Public
Institution EASA
Implementing a Big Data PoC for the Data4Safety programme. They will soon
publish a call for tender to acquire a Big Data platform. In the meantime,
their need is to test Big Data tools on different use cases and there could be
synergies with the future Big Data Test Infrastructure.
Table 3 – Targeted interviews with EU DGs / Public Institutions
Big Data Pilots/projects implemented at National level (already delivered or ongoing),
information on such initiatives was also collected through the bilateral conferences with
MSs;
Big Data projects funded by the EC (e.g. FP7 or H2020);
KPMG credentials/experience and Competence Centre in the Data and Analytics area,
including relevant projects in the private sector.
2. Technical drill down – Short-list of Big Data pilots: starting from the long-list of projects
identified in the previous step, the team singled out a subset of relevant initiatives to be

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201733 / 85 Doc. Version:2.0
analysed more comprehensively in terms of technical features of the Big Data Infrastructure
used for execution of the pilots. These cases are identified as Good practices in the present
study. All recommendations / guidelines collected are useful for the design of the Big Data
Test Infrastructure to be performed under Task 3 of the study. This technical information
was collected directly in a long-list EXCEL template (i.e. Annex 2), detailed in Chapter 7.
The long-list and short-list information is described more fully in the following paragraph 4.2.1.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201734 / 85 Doc. Version:2.0
4.2.1. CRITERIA FOR THE ANALYSIS OF BIG DATA PILOTS
This section describes the criteria used for the analysis of the Big Data projects/pilots identified
during the Data Collection phase. For each project analysed, we used a structured template in order
to gather various data to support the analysis. At the minimum, register and business information
was collected for all the pilots, while for the relevant initiatives to be further analysed in Chapter 7,
Technical Information was collected for the Big Data Infrastructure used.
All the information on relevant Big Data pilots/projects has been collected in an Excel template
structured according to the following sections:
Long-list information – as anticipated, this section has been completed for all the projects
collected:
General information – General information about the Big Data project under
analysis (i.e. register information such as name and description of the initiative);
Business information – Business needs in terms of project objective(s), addressed
Big Data use cases and Policy Domains, level of Government, Key Success Factors and
KPIs; stakeholders and end-users, status of the project;
Short-list information – as anticipated, this section has been completed for a subset of
relevant projects detailed in Chapter 7:
Technical information – Technical information related to the Big Data pilot in terms
of technologies, infrastructure, tools, etc.
Architecture dimension – this section indicates the infrastructure and software used
to implement the Big Data project/pilot;
Operation dimension – this section describes how the service is provided
(i.e. on-premises or in-Cloud);
Governance and Skills dimension – this section illustrates the specific skills required
for implementation of the Big Data pilot and how to launch the pilot.
The following Table 4 describes in detail the aforementioned attributes both for the long-list and
short-list pilots.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201735 / 85 Doc. Version:2.0
Big Data projects – Long-list and short-list information
Scope Category Category Description Criterion (and sub-
criterion) Criterion Description Possible values
Long-list information
BD Project information
General information about the Big Data project.
Public Organisation The name of the Institution that leads the project.
free-text response
Country The country of the organisation. To choose from the list of all the European countries
Initiative / Action The name of the related Big Data initiative/action.
free-text response
Project Title The title of the project free-text response
Project Description A description of the project. free-text response
Business Needs This criterion assesses the business needs of the owner of the project in terms of project objective(s), addressed Use Cases, applicable Policy Domains, level of Government, Key Success Factors and KPIs.
Project Objectives / Needs This criterion assesses the main objectives / needs of the Big Data project.
free-text response
Addressed Use Cases The main use cases addressed by the project (e.g. text mining, sentiment analysis, predictive maintenance, fraud-detection)
free-text response
Policy Domain The main policy domain for which the project is applicable. NB: the source of the policy domains list is taken from the report "Big Data analytics for policy-making" (Deloitte)
To choose from Agricultural, Consumer, Cultural/Education, Energy, Environmental, Financial/Fiscal/Economic, Health, Home and Justice Affairs, Housing/Real Estate, Humanitarian/Development, Industrial, Regional, Security, Social, Statistics/Population/Cadastral, Transport, Various policies
Government Level This criterion assesses the level of government of the project. NB: the source of the Government Levels list is taken from the report "Big Data analytics for policy-making" (Deloitte)
To choose from: - EU - Supranational (e.g. UN, World Bank, UNECE, etc.) - National - Regional - Local
Key Success Factors The most relevant (technical) features / choices of the project that brought it success.
free-text response

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201736 / 85 Doc. Version:2.0
Big Data projects – Long-list and short-list information
Scope Category Category Description Criterion (and sub-
criterion) Criterion Description Possible values
Key Performance Indicator This criterion assesses which KPIs are used to evaluate the project success (e.g. decrease in maintenance cost, increased public approval rate, increase in the institution processing speed)
free-text response
Stakeholders and end-users
This criterion assesses the stakeholders involved in the Big Data-related project (beneficiaries and private/public organisations involved in the project)
Stakeholders involved This sub-criterion assesses which stakeholders were involved in the development of the project.
Public organisation(s), Public Administration Body (National/Regional/Local administrative levels), Academia, University, Public Research Organisation, Private company(ies), Large Enterprise, SME, Other
End-Users Category and Geographical Coverage
The sub-criterion assesses the End-Users of the project in terms of category and geographical coverage.
Categories: - Public Administration - Private Organisation - Citizen Geographical coverage: - EU - More than one EU nation - National - Regional - Local
Project Status This criterion assesses the overall project status in terms of status of development of the Big Data project, duration, issues and challenges/barriers encountered.
Status The current status of the project. To choose from: - planned - ongoing - completed
Year The year of the project. Date field
Duration [m] The duration of the project in months.
To choose from: - 0-3 months - 3-6 months - 6-12 months - >12 months

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201737 / 85 Doc. Version:2.0
Big Data projects – Long-list and short-list information
Scope Category Category Description Criterion (and sub-
criterion) Criterion Description Possible values
Challenges and Issues Challenges and issues that the project owner faced and how they were overcome. For example regarding Budget, Resources, Expertise, Technical / Functional, Other challenges/issues faced during the project.
free-text field
Short-list information
Technical Features
This criterion assesses: - Infrastructure: if the pilot/project uses a Big Data infrastructure. - Licensing: whether the project only uses free software or also commercial software is needed. - Data and Connectors: information about the data sources, types, and data exchange APIs. - Storage: data storage information. - Computing: the computing features of the project. - Visualization: features and functionalities of the visualization tools. - Privacy and Security: information regarding privacy and security constraints that the project must adhere to.
Tools Software Modules
Whether the used software modules (like Python, MATLAB, Web services) are free or commercial.
Names of the software modules / tools and the licensing type (free/commercial). Ex: Python (free)
Platforms Whether the used platform (such as Cloudera, Hortonworks, Pivotal) are free or commercial.
Names of the platforms and relative licensing type (free/commercial). Ex: Cloudera (free)
Data exchange APIs
Data Sources From which sources data was collected. NB: the source of the data sources list is taken from the report "Big Data analytics for policy-making" (Deloitte)
Multiple-choice selection among: - Business App - Public web/Social media - Machine log - Sensor
Developed / re-used data exchange API
Which data exchange APIs were developed or reused by third parties.
free-text response
Data Type What type of data was collected. To choose among Structured, Semi-structured, Unstructured, Multiple
Storage Database Type What type of databases were used. To choose among SQL, NoSQL, NewSQL, Multiple
Back-end Software
Which database or other back-end products were used (e.g. OracleDB, HDFS, Mesos, Hive, Neo4J).
free-text response
Data Volume The target volume of data stored and that will be stored in the databases.
To choose from: - 0-10 GB - 10-100 GB - 100GB - 1TB - >1TB

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201738 / 85 Doc. Version:2.0
Big Data projects – Long-list and short-list information
Scope Category Category Description Criterion (and sub-
criterion) Criterion Description Possible values
Data Ingestion How the data is ingested into the databases.
Multiple-choice selection among: - Batch - Near real-time - Real-time - Manual
Computing ETL Complexity Level
The complexity of the data processing operations.
To choose from: - Low (e.g. filters, concatenations) - Medium (e.g. denormalization) - High (e.g. complex aggregate functions)
Computing Infrastructure
If data must be processed batch or streaming.
To choose from: - Batch - Streaming - Both
Data Analytics Level
The level / complexity of the data analytics conducted. NB: the source of the policy domains list is taken from the report "Big Data analytics for policy-making" (Deloitte)
To choose from: - Descriptive - Diagnostic - Predictive - Prescriptive
Machine Learning Branch
If applicable, what class of Machine Learning algorithms used.
Multiple-choice selection among: - Supervised - Unsupervised - Semi-supervised - Reinforcement
Data Analytics Software
The software / libraries used for conducting the analyses (e.g. Python, R, KNIME, RapidMiner, Spark, H2O).
free-text response
Visualization Used Software / tools
The name(s) of the software used for visualization (e.g. PowerBi, QlikView, dedicated Web app, etc.)
free-text response
Mobile Access If mobile access of the visualization tool is needed.
Yes or No.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201739 / 85 Doc. Version:2.0
Big Data projects – Long-list and short-list information
Scope Category Category Description Criterion (and sub-
criterion) Criterion Description Possible values
Visualization Algorithms
The categories of the data visualization techniques, from the simplest to the most complex.
Multiple-choice selection among: - Spatial layout (e.g. charts, plots, trees) - Abstract or summary (e.g. binning and clustering) - Interactive or real-time
Data Export Formats
The most useful data export formats (e.g. Excel, CSV, txt, PDF).
free-text response
Privacy and Security
Data Location The location of data stored and managed by the Cloud service and/or infrastructure provider/Data Centre.
To choose from: - Data stored only with the Member States Public Authority - Data stored/managed in the country of the Cloud provider - Data stored cross-country (multiple sites)
Data Privacy The data privacy policies that the project must adhere to.
free-text response
Infrastructure Security
The security constraints that must be satisfied by the infrastructure.
free-text response
Architecture dimension
This criterion assesses the Architecture of the platform used for the project/pilot
Big Data Infrastructure
If the pilot/project runs on a Big Data infrastructure (e.g. Cloudera, Hortonworks)
Possible values: - Yes - No
Architecture/solution building blocks
The logical architecture used to run the project/pilot
free-text response
Operations dimension
This criterion assesses the operations dimension of the project/pilot.
Infrastructure Type If the infrastructure is on-premise or on the Cloud.
To choose from: - On-premise - Public Cloud - Private Cloud - Hybrid Cloud - Community Cloud
Maturity Level The solidity of the project (e.g. if the project is a study report, a PoC, or a more consolidated project).
To choose from: - Study/Report - PoC - Small-Scale project - Large-Scale project - Operational platform/service

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 06/06/201740 / 85 Doc. Version:2.0
Big Data projects – Long-list and short-list information
Scope Category Category Description Criterion (and sub-
criterion) Criterion Description Possible values
Governance and Skills dimension
This criterion assesses the governance and skills needed for the project.
Governance This sub-criterion assesses the service request procedure
free-text response
Team skills The team skills / profiles needed for implementation of the project (e.g. System Administrator, Data Engineer, Data Scientist, Business Analyst)
free-text response
Project Financing
This criterion assesses the budget of the project
Funding Sources This sub-criterion evaluates the funding sources of the project.
To choose from: - EU financing - National/Regional financing - Private financing
Table 4 – Entire list of attributes used to classify the existing Big Data initiative

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 41 / 85
4.2.2. OVERVIEW OF COLLECTED BIG DATA PILOTS
This paragraph contains some relevant statistics concerning the long-list Big Data pilots collected
during the data collection phase. The long-list of almost 50 cases was categorised according to the
Criteria detailed in the previous paragraph and all the cases used a Big Data Infrastructure.
Concerning the policy domain, the entire list includes Big Data projects coming from a wide range
of different areas. This reflects the fact that applications of Big Data and data analytics are possible
in various domains. As shown in Figure 6 below, ‘Statistics/Population/Cadastral’ and ‘Transport’
and ‘Security’ are the policy domains with more European /National cases. Frequently however, the
initiatives do not cover only a single domain but more than one simultaneously since the same
Big Data Platform is used to correlate data coming from different policy domains contributing to the
solution of problems whose correlation with the analysed policy domains was originally hidden and
/ or unclear. All the other policy domains are represented by between one and five cases.
Figure 6 – Big Data initiatives classified by policy domain
With regard to the addressed Big Data Use Cases (further detailed in Chapter 5), as shown in the
next figure, ‘Predictive analysis’ is the more appealing use case for the Public Sector while use cases

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 42 / 85
relative to Internet of Things (IoT) or bioinformatics seem to be more relevant for the Private
sector. In addition, ‘Descriptive Analysis’ and ‘Route-traceability / flow monitoring’ are well
represented by 10 Big Data projects. Finally, ‘Web Analysis’ (i.e. web scraping and web monitoring)
and ‘Text Analysis’ concluded the list of more relevant Big Data use cases.
Figure 7 – Big Data initiatives classified by Big Data use case
This is an overview of the Big Data pilots collected during the collection phase but also, thanks to
the strong collaboration with MSs, additional Big Data projects were collected for each Member
States. For example, in Spain there are currently 21 initiatives whose output is a system that covers
one or more usual Big Data use cases, using well-known Big Data technologies, as described by the
following pictures:

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 43 / 85
Further comments about the Spanish Big Data initiatives are as follows:
1. Many PAs are using Big Data technologies as an alternative to Business Intelligence
technologies to make a descriptive analysis, not using more advanced analytics.
2. There are two additional initiatives to develop a Big Data Infrastructures:
SocialBigData-CM: an initiative carried out by three Universities of Madrid and a group
of private and public enterprises, to provide Big Data services to a network of
researchers in the area of social transformations;
Aragón Smart Open Region: an initiative carried out by the region of Aragón to provide
Big Data services to the regional PAs.
3. Based on these use cases, the majority of the 21 initiatives could be potentially under the
scope of the Big Data Test Infrastructure.
4.2.3. EMERGING BUSINESS NEEDS FROM THE ANALYSIS OF EXISTING BIG DATA PILOTS
With regard to emerging business needs among MSs, data collection activities described in the
previous paragraphs have indicated additional business needs which are taken into account for
identification of the requirements (see Chapter 6).
The following table shows the final results of the collected business needs, each described with the
following attributes:
• ID: an identifier of the business need obtained through the analysis of the Big Data pilots.
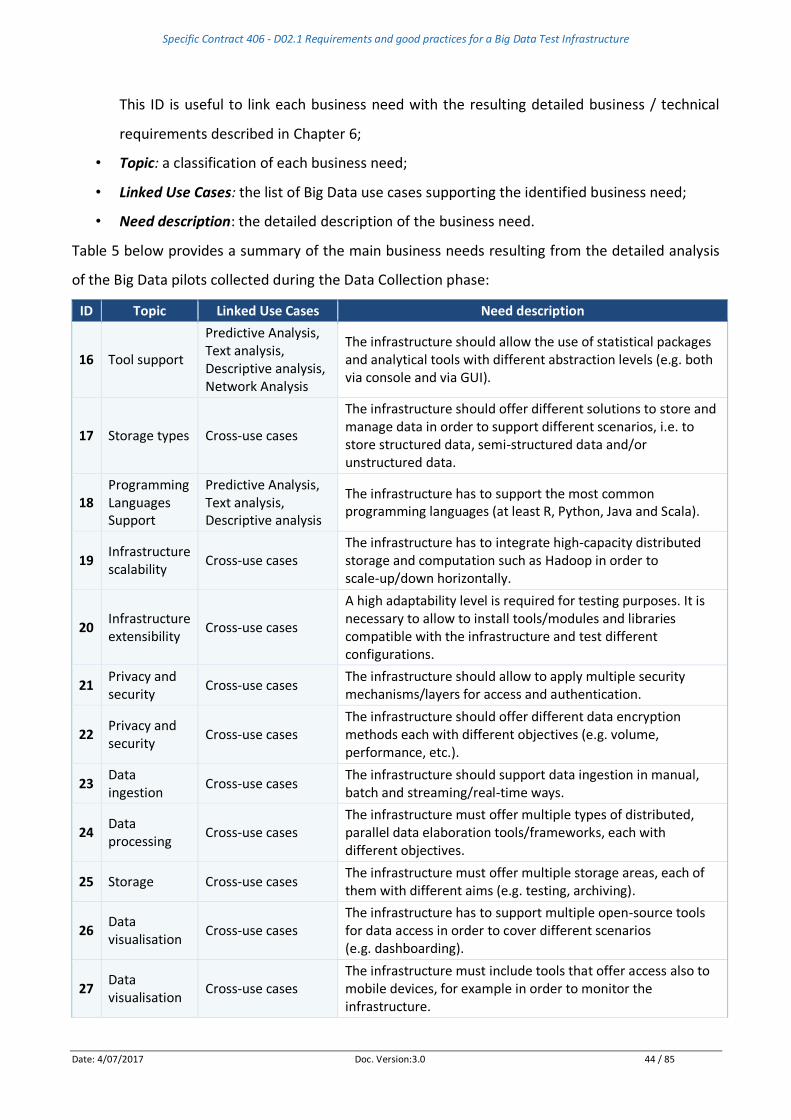
Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 44 / 85
This ID is useful to link each business need with the resulting detailed business / technical
requirements described in Chapter 6;
• Topic: a classification of each business need;
• Linked Use Cases: the list of Big Data use cases supporting the identified business need;
• Need description: the detailed description of the business need.
Table 5 below provides a summary of the main business needs resulting from the detailed analysis
of the Big Data pilots collected during the Data Collection phase:
ID Topic Linked Use Cases Need description
16 Tool support
Predictive Analysis, Text analysis, Descriptive analysis, Network Analysis
The infrastructure should allow the use of statistical packages and analytical tools with different abstraction levels (e.g. both via console and via GUI).
17 Storage types Cross-use cases
The infrastructure should offer different solutions to store and manage data in order to support different scenarios, i.e. to store structured data, semi-structured data and/or unstructured data.
18 Programming Languages Support
Predictive Analysis, Text analysis, Descriptive analysis
The infrastructure has to support the most common programming languages (at least R, Python, Java and Scala).
19 Infrastructure scalability
Cross-use cases The infrastructure has to integrate high-capacity distributed storage and computation such as Hadoop in order to scale-up/down horizontally.
20 Infrastructure extensibility
Cross-use cases
A high adaptability level is required for testing purposes. It is necessary to allow to install tools/modules and libraries compatible with the infrastructure and test different configurations.
21 Privacy and security
Cross-use cases The infrastructure should allow to apply multiple security mechanisms/layers for access and authentication.
22 Privacy and security
Cross-use cases The infrastructure should offer different data encryption methods each with different objectives (e.g. volume, performance, etc.).
23 Data ingestion
Cross-use cases The infrastructure should support data ingestion in manual, batch and streaming/real-time ways.
24 Data processing
Cross-use cases The infrastructure must offer multiple types of distributed, parallel data elaboration tools/frameworks, each with different objectives.
25 Storage Cross-use cases The infrastructure must offer multiple storage areas, each of them with different aims (e.g. testing, archiving).
26 Data visualisation
Cross-use cases The infrastructure has to support multiple open-source tools for data access in order to cover different scenarios (e.g. dashboarding).
27 Data visualisation
Cross-use cases The infrastructure must include tools that offer access also to mobile devices, for example in order to monitor the infrastructure.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 45 / 85
ID Topic Linked Use Cases Need description
28 Infrastructure monitoring
Cross-use cases The infrastructure must include tools that offer monitoring and managing of the services and resources used by the pilot.
29 Data export Cross-use cases The infrastructure has to allow the possibility to export data in multiple formats (e.g. txt, csv, xlsx, pptx, etc.).
30 Data cleaning
Web Analysis (scraping / monitoring), IoT and Smart City, Social media analysis
The data has to support tools for data cleaning, for example in order to normalise different datasets to a unique format.
31 Data processing
Predictive Analysis, Text analysis, Descriptive analysis, Network Analysis
The infrastructure must support multiple types of statistical and machine learning software, modules and tools in order to cover different scenarios (e.g. text analysis, data clustering, etc.).
32 Data visualisation
Time-series analysis, Route-traceability / flow-monitoring, Network Analysis
The infrastructure has to support interactive real-time data visualisation tools, for example in order to allow users to deal with streaming data.
33 Performance
Image processing, Predictive Analysis, Applying bioinformatics to genetic data
The infrastructure has to support tools and technologies to assure high performance computing (e.g. in image processing).
34 Privacy and security
Cross-use cases The infrastructure has to allow the definition of multiple user roles with different authorisation and permission levels.
35 Privacy and security
Cross-use cases The infrastructure has to allow import users definition/profiling from other systems (e.g. with LDAP synchronisation).
36 Privacy and security
Cross-use cases The infrastructure must allow the definition of data ownership and visibility based on different user profiles/groups.
37 Data quality Cross-use cases
The infrastructure must support tools for the evaluation of data quality at least in three main steps: 1-Input – when the data is acquired, or in the process of being acquired. 2-Throughput – any point in the business process in which data is transformed, analysed or manipulated. This might also be referred to as ‘process quality’. 3-Output – the reporting of quality with statistical outputs derived from Big Data sources.
38 Data format Cross-use cases There is a necessity to create a shared repository of standard ontologies and data formats.
39 Infrastructure scalability
Cross-use cases The infrastructure has to support the project maturity lifecycle, from a single PoC to a fully operational system.
40 Privacy and security
Cross-use cases
There is a necessity to allow use of the platform without the transfer of sensitive data (for privacy and security policies), since frequently it is not possible to transfer data outside the EU and furthermore it is not possible to reveal data outside the system.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 46 / 85
ID Topic Linked Use Cases Need description
41 Data ingestion
Web Analysis (scraping / monitoring), IoT & Smart City, Social media analysis
There is a necessity to support the integration of data coming from different sources often very different from each other. There is a necessity to cater for the easy integration of developed connectors in the infrastructure.
42 Licensing Cross-use cases
The infrastructure should be composed as far as possible of open-source modules and tools, avoiding licensing costs. For the operation of such modules / tools there is the necessity to have continued software maintenance and the availability of technical and commercial support.
43 Community Cross-use cases The infrastructure has to support tools which facilitate the sharing of studies, report results, statistical models, feedback on data and processes validation among infrastructure users.
44 Knowledge Cross-use cases There should be a methodology/process to acquire and spread knowledge and skills related to Big Data.
45 Migration support
Cross-use cases There is a necessity to allow the transmission of pilot data from a test environment to a production environment in order to support project scale-up.
46 Privacy and security
Population / customer segmentation
The infrastructure must support the anonymity of data, and /or aggregate data, due to the fact that privacy constraints related to data sets often limit the personnel authorized to access and treat the data, and in order to allow files to be moved outside the physical boundaries of a single organisation.
47 Partnership Cross-use cases There is the necessity for a framework for partnership arrangements in Big Data projects, with operational guidelines for forging Big Data partnership agreements.
48 Infrastructure configuration
Cross-use cases There is the necessity to provide for control over how the infrastructure components installation is set-up and configured.
49 Infrastructure service level
Cross-use cases Even though it will be a test infrastructure, it is necessary that the infrastructure will ensure pre-defined service levels (it could be useful to define a service-level agreement (SLA)).
Table 5 – Emerging business needs from existing Big Data pilots

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 47 / 85
5. BIG DATA USE CASES IN SCOPE FOR THE BIG DATA TEST INFRASTRUCTURE
This chapter provides the result of the joint analysis of both business needs coming from existing
Big Data pilots and from Member States. This analysis has led to the identification of a long-list of
Big Data use cases further prioritised in order to identify the short-list of Big Data use cases to be
supported by the future Big Data Test Infrastructure.
5.1. LONG-LIST OF BIG DATA USE CASES: FACTSHEETS
This paragraph provides the long-list of the identified Big Data use cases. For each use case, a
detailed factsheet has been drafted containing the following information:
Use case – the title of the use case;
Description – a brief description of the use case;
Linked Big Data projects – a brief description of the identified Big Data projects at EU or
National level that implement the use case through a Big Data Infrastructure, useful to
provide the reader with a clear understanding of practical implementation of the use case;
Related Technologies – an overview of the main technologies used for implementation of
the identified Big Data projects.
5.1.1. PREDICTIVE ANALYSIS
Use case Description Linked Big Data projects
PREDICTIVE ANALYSIS
Variety of statistical techniques (e.g. predictive modelling, machine learning) that analyse current and historical facts to make predictions about future or unknown events.
Traffic/Weather analysis for the NL government, which makes use of a Big Data platform to analyse traffic and weather data in order to predict the effect of weather on traffic congestion and vehicle density. Fraud Analytics at the Lithuanian Customs, where an advanced analytics solution has been deployed that uses highly accurate prediction models to sort through enormous volumes of customs-related data and profile which types of activities have the greatest probability of corresponding with illegal or fraudulent operations.
Related Technologies
HortonWorks Platform, NoSQL Databases, Spark, Anaconda (Python), Root (C++), Notebook, Jupiter, R.
Table 6 – Predictive analysis factsheet

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 48 / 85
5.1.2. ROUTE-TRACEABILITY / FLOW MONITORING
Use case Description Linked Big Data projects
ROUTE-TRACEABILITY
/ FLOW MONITORING
Whatever concerns the tracking and detection of objects through the use of sensors (e.g. GPS, mobile phone signals, road cameras) or any other types of data usable for this purpose.
Mobile Phone Data, which investigates and enables access to mobile phone data as a source in order to infer information about day-time populations and migrations and to produce official statistics.
Related Technologies
HortonWorks Platform, SQL Databases, Spark.
Table 7 – Route traceability / flow monitoring factsheet
5.1.3. WEB ANALYSIS (SCRAPING / MONITORING)
Use case Description Linked Big Data projects
WEB ANALYSIS
(SCRAPING / MONITORING)
Gathering information from websites, involving data scraping (using bot or web-crawler) and data parsing to extract the unorganised web data as well as converting data from APIs into a manageable format.
Web Scraping for Job Vacancy Statistics, which explores a mix of sources including job portals, job adverts on enterprise websites, and job vacancy data from third-party sources in order to produce estimates in the domain of job vacancies, testing different approaches under different conditions.
Related Technologies
HortonWorks/Cloudera Platform, NoSQL Databases, data exchange API, SAS, Anaconda (Python), Root (C++).
Table 8 – Web analysis (scraping / monitoring) factsheet
5.1.4. TEXT ANALYSIS
Use case Description Linked Big Data projects
TEXT ANALYSIS
Using natural language processing to analyse unstructured text data, deriving patterns and trends, possibly extracting the text content and evaluating and interpreting the output data.
DG RTD – Text and data mining tool, in which an internal system has been developed to perform text and data mining on research data (EC internal documents, external data such as publications, patents, studies, etc.), in order to classify, correlate and explore/discover knowledge.
Related Technologies
HortonWorks Platform, NoSQL Databases, Spark, Anaconda (Python), Root (C++), Notebook, Jupiter, R.
Table 9 – Text analysis factsheet

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 49 / 85
5.1.5. DESCRIPTIVE ANALYSIS
Use case Description Linked Big Data projects
DESCRIPTIVE ANALYSIS
Use of statistics to quantitatively describe or summarise features of a collection of information. Such descriptions may be either quantitative, i.e. summary statistics, or visual, i.e. simple-to-understand graphs.
ANAC - Big Data Cooperational System, a Big Data platform that gathers, combines and stores public contracts data while also providing statistics for fraud detection. Database for the European Network of Cancer Registries, which has developed a pan-European cancer information system that will facilitate the monitoring of cancer incidence and mortality in the EU and will provide regular information on the burden of cancer in Europe.
Related Technologies
HortonWorks Platform, NoSQL Databases, Spark, Python, C/C++, Notebook, Jupiter, R, Java, MatLab.
Table 10 – Descriptive analysis factsheet
5.1.6. TIME-SERIES ANALYSIS
Use case Description Linked Big Data projects
TIME-SERIES ANALYSIS
Comprises methods for analysing time series data in order to extract meaningful statistics and other characteristics of the data.
CASSANDRA (Computer ASSisted ANalysis using Dynamic Regression Algorithms), in which time series modelling techniques have been applied in order to “nowcast” the KPI value and to identify potential structural breaks in the data series. The case of Predictive Modelling, Time Series Analytics for Facility usage of Ministry of Public Administration of Republic Slovenia which makes use of big data platform to analyse when employees utilize government facilities by visualization the statistical patterns of employee working time and identifying opportunities for financial and sustainability savings.
Related Technologies
HortonWorks Platform, NoSQL Databases, Spark, Python, C/C++, Notebook, Jupiter, R, Java, MatLab.
Table 11 – Time-series analysis factsheet

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 50 / 85
5.1.7. SOCIAL MEDIA ANALYSIS
Use case Description Linked Big Data projects
SOCIAL MEDIA ANALYSIS
Gathering data from blogs and social media websites and analysing data to make business decisions.
Mixed Emotion, in which social media comments (and also other sources) have been explored, through a Big Data platform, to produce and perceive emotions in everyday interactions in order to track customer / user behaviour and satisfaction.
Related Technologies
HortonWorks/Cloudera Platform, NoSQL Databases, data exchange API, Python, Java.
Table 12 – Social media analysis factsheet
5.1.8. IOT AND SMART CITY
Use case Description Linked Big Data projects
IoT and SMART CITY
Gather relevant information on the usage of several interconnected devices (Internet of Things environment) in a Smart City context.
Amsterdam Innovation Arena – Data Driven Operator, the Amsterdam Arena is one of the largest sporting and entertainment venues; for their innovation organisation an integrated data management policy and system has been established in order for them to become a more data driven operator for venues and fan experiences.
Related Technologies
Azure Cloud, HortonWorks Platform, NoSQL Databases, Spark, Anaconda (Python), Root (C++), Qlik Dashboard.
Table 13 – IoT and Smart city factsheet
5.1.9. NETWORK ANALYSIS
Use case Description Linked Big Data projects
NETWORK ANALYSIS
Investigating any structures through the use of network and graph theories, characterising networked structures in terms of nodes and the ties, edges, or links (relationships or interactions) that connect them.
Transport for London data analytics, where traffic information and users data have been examined in order to provide better customer service with regard to travel and the performance of the bus and road network.
Related Technologies
HortonWorks Platform, Graph Databases, Gephi, Circos
Table 14 – Network analysis factsheet

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 51 / 85
5.1.10. POPULATION / CUSTOMER SEGMENTATION
Use case Description Linked Big Data projects
POPULATION / CUSTOMER
SEGMENTATION
Dividing a broad population into sub-groups of consumers based on some types of shared characteristics such as common needs, interests, similar lifestyles or even similar demographic profiles.
Sandbox experiment – Mobile Phones, where phone data coming from different sources has been analysed to define clusters of different types of "users" (business-personal-scholar), for example based on call patterns and social behaviour. Developing Employee profiles of Ministry of Public Administration of Republic Slovenia which makes use of big data platform to analyse and segment employees into relevant groups based on multiple internal datasets.
Related Technologies
HortonWorks Platform, NoSQL Databases, Spark, Anaconda (Python), Root (C++), Notebook, Jupiter, R.
Table 15 – Population / customer segmentation factsheet
5.1.11. IMAGE PROCESSING
Use case Description Linked Big Data projects
IMAGE PROCESSING
Computational operations using any form of signal processing for which the input is an image, a series of images, or a video; the output of image processing may be either an image or a set of characteristics or parameters related to the image.
JRC Earth Observation and Social Sensing Big Data Pilot Project, a Big Data platform that includes tools to process and analyse the massive Earth Observation image stream in order to monitor the dynamic of human settlements through multi-temporal high-resolution maps.
Related Technologies
Distributed Platform, NoSQL Databases, Spark, Python, C/C++, MatLab, Jupiter, Java.
Table 16 – Image processing factsheet
5.1.12. IOT SECURITY
Use case Description Linked Big Data projects
IoT SECURITY
Safeguarding connected devices and networks in the Internet of Things since security has often not been considered in the IoT product design.
ARMOUR – Large-Scale Experiments of IoT Security and Trust, a Big Data platform that enables the piloting and testing of security of IoT devices in order to define and compare different privacy and security solutions for different scenarios.
Related Technologies
No technological information collected for the relevant projects identified so far
Table 17 – IoT security factsheet

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 52 / 85
5.1.13. APPLYING BIOINFORMATICS TO GENETIC DATA
Use case Description Linked Big Data projects
APPLYING BIOINFORMATICS TO GENETIC DATA
The use of computational biology, in terms of macromolecules applying “informatics” techniques to understand/organise the information associated with analysing genetic data.
Bioinformatics CCSIS and Next Generation Sequencing for Novel analytical Methods, a platform that includes a database and several bioinformatics tools to mine biological Big Data integrated from many sources.
Related Technologies
No technologies information collected for the relevant projects identified so far
Table 18 – Applying bioinformatics to a genetic data factsheet
5.2. SHORT LIST OF BIG DATA USE CASES: PRIORITISATION OF USE CASES IN SCOPE FOR THE
BIG DATA TEST INFRASTRUCTURE
The long-list of Big Data use cases described in the previous paragraph has been prioritised in order
to identify the Big Data use cases meeting Member States’ prerequisites and therefore to be
supported by a first release of the future Big Data Test Infrastructure. The prioritisation process has
been conducted in accordance with two main steps:
• Step 1 – Preliminary prioritisation – this step has been implemented in order to generate
an initial prioritisation of the Big Data use cases (HIGH, MEDIUM, LOW priority) based on
the following criteria:
Cardinality, in terms of number of identified Big Data projects that implement the
specific use case;
Feasibility of implementation, in terms of ease of implementation of the specific
use case (e.g. a project that implements the use case “applying bioinformatics to
genetic data” usually requires an ad-hoc solution in terms of Big Data infrastructure /
data analytics tools);
National coverage, in terms of use cases implemented through Big Data pilots
performed by at least one Member State.
• Step 2 – Member States prioritisation: this step envisaged an overall refinement of the
preliminary prioritisation with the interested Member States. During the bilateral
conferences, each national contact point has been able to provide its use cases

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 53 / 85
prioritisation based on national business needs.
Results of Step 1 of the preliminary prioritisation process are reported below:
Figure 8 – Final priority for the identified Big Data use cases

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 54 / 85
The table below provides a detailed overview of the final results of the prioritisation process based on the feedback provided so far by each
national contact point. The HIGH priority use cases are included in the short-list for the Big Data Test Infrastructure.
Use Case Name Preliminary
Priority ESTONIA SPAIN SLOVENIA MALTA
CZECH REPUBLIC
HUNGARY (N.A.)
PORTUGAL (N.A.)
NORWAY (N.A.)
Final Priority
PREDICTIVE ANALYSIS High No
interest High High Medium High ND ND ND High
ROUTE-TRACEABILITY / FLOW MONITORING High
No interest
No interest
No interest
Medium High ND ND ND Medium
WEB ANALYSIS (SCRAPING / MONITORING) High Medium High High High High ND ND ND High
TEXT ANALYSIS High High No
interest No
interest High High ND ND ND High
DESCRIPTIVE ANALYSIS High No
interest No
interest High Medium High ND ND ND High
TIME-SERIES ANALYSIS High No
interest No
interest High Medium High ND ND ND High
SOCIAL MEDIA ANALYSIS High No
interest High High High High ND ND ND High
IoT & SMART CITY Medium No
interest No
interest No
interest Low Medium ND ND ND Low
NETWORK ANALYSIS Medium High High High Medium Medium ND ND ND High
POPULATION / CUSTOMER SEGMENTATION Medium Medium
No interest
No interest
Medium Medium ND ND ND Medium
IMAGE PROCESSING Low Low No
interest No
interest Low Low ND ND ND Low
IoT SECURITY Low No
interest No
interest No
interest Medium Low ND ND ND Low
APPLYING BIOINFORMATICS TO GENETIC DATA Low
No interest
No interest
No interest
Low Low ND ND ND Low
Table 19 – Detailed view of the use cases prioritisation

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 55 / 85
6. BUSINESS AND TECHNICAL REQUIREMENTS FOR THE DESIGN OF THE
BIG DATA TEST INFRASTRUCTURE
This chapter provides a summary of the identified business and technical requirements for
setting-up a Big Data Test Infrastructure to be used by EU Institutions and EU Public Administrations
to launch pilot projects on Big Data. All the business and technical requirements were derived from
the emerging business needs described in Chapter 4 and from the short-list of use cases.
6.1. BUSINESS REQUIREMENTS
Business requirements are related to business objectives, vision and goals. The Business
requirements typically define a very high level requirement that is not linked to a specific functional
area. However, this high level requirement guarantees that the needs extracted from the data
collection are satisfied.
Each requirement is described according to the following attributes:
• ID: a simple identifier;
• Short-name: a synthetic name useful to identify the requirement;
• Description: the requirement description;
• Link to the needs: identifiers of the collected business needs described in Chapter 4 from
which the requirement is derived.
BUSINESS REQUIREMENTS
ID Short-name Description Link to
the needs
1 Open data access
There is a need to define a structured process/methodology to access and deal with open data
1
2 Data format standardisation
It is necessary to share common standard data formats and interpretation (e.g. creating a shared repository) in order to understand the real value of using Big Data
2, 38
3 Spreading Big Data Knowledge
It is necessary to have a methodology/process (e.g. regular training) to acquire and spread knowledge and skills related to Big Data, especially for managers in PAs and for people working on the policy-making side in general to allow them to understand the potential of Data Analytics tools and methodologies.
3, 44

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 56 / 85
BUSINESS REQUIREMENTS
ID Short-name Description Link to
the needs
4 Access sensitive data at raw level
It is necessary to have a functional environment allowing access to sensitive and confidential data at raw level in order to perform analytics on fine-grained data. At the same time, private data should stay securely stored within the system without transfer to third countries. Special attention should be given to personal data protection according to the legal requirements.
5, 40
5 Normalization of data-related EU legislation
It is necessary to execute a normalization of legislation on the use of national PAs data at European level (data handling, analysis and storage of the data) in order to create direct data interfaces with PAs and EU Institutions.
7
6
Adoption of free/ open-source SW
It is necessary to implement the Big Data Test infrastructure of free/open-source software modules and tools as widely as possible in order to avoid licensing costs. It is also necessary to have continuous software maintenance for these modules/tools and availability of technical and commercial support.
8, 42
7
Technical Support on Big Data piloting
It is necessary to have a Big Data team to support Public Administrations in launching Big Data experiments and pilots. This support should go beyond purely technical support and should offer know-how, seminars, hands-on tutoring, etc.
9
8 Sharing of Big Data artefacts
It is necessary to create a Big Data community to share Big Data artefacts among European Public Administrations and Public Institutions, and disseminate project results, methodologies, best practices, datasets and, in general, Big Data Know-how and other Big Data experiences.
10, 43
9 Community and collaboration tools
It is necessary to create an environment (e.g. with web platform for dissemination of good practices, collaborative tools and operational guidelines) which allows various data owners and technicians (e.g. data scientists) working closely together to exchange knowledge and experiences, and to gain results through continuous interpretation and validation of interim results within a framework of Big Data partnership.
12, 47
Table 20 – Business Requirements
6.2. TECHNICAL REQUIREMENTS
A technical requirement focuses on the technical aspects that a system must fulfil; it may either
cover aspects related to functionality that the system should offer (i.e. functional type such as
data import/export) or be related to behaviour of the system in certain situations
(i.e. non-functional type such as reliability, scalability or availability).
6.2.1. FRAMEWORK FOR THE IDENTIFICATION OF THE TECHNICAL REQUIREMENTS
In order to classify the technical requirements emerging from both the Member States and the

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 57 / 85
analysis of existing Big Data pilots, a conceptual framework has been defined: it describes a
high-level Big Data architecture, composed of the main dimensions related to Big Data acquisition,
storage, processing and analysis, with an additional dimension related to governance.
Figure 9 – Framework used to classify the Technical requirements
The framework is structured according to the logical areas described below:
Data Sources: this area relates to the different nature and types of data sources,
for example web-pages, traditional databases, documents, IoT devices, enterprise systems.
It is important to classify them according to some type of dimension: internal vs external,
the amount of data, push or pull acquisition, structured/semi-structured/unstructured data.
Other specific dimensions could be helpful in different domains/scenarios.
Data Ingestion / Storage: this includes anything related to the acquisition of data
(for instance the frequency of the ingestion tasks, batch or real-time ingestion), how it is
stored and organised in the infrastructure (for example relational database, distributed file
system, different storage areas) and non-functional aspects such as capability to scale

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 58 / 85
or latency;
Data Elaboration: this includes anything related to data processing, the type of elaboration
(for example from simple ETL to advanced machine learning algorithms), if the elaboration is
performed in batch, (near) real-time or hybrid mode;
Data Consumption: this includes anything related to data expending, for example for
reporting and visualisation, data exploration, analytical and dynamic queries,
export datasets;
Governance and Security: this includes anything related to the provision, management or
monitoring of the infrastructure and also the privacy and security of both the infrastructure
and the data;
Infrastructure: this area covers aspects related to the technology stacks, including storage,
and the servers’ computing and networking capacity.
The following paragraphs provide a classification of the technical requirements for each of the
aforementioned areas. Each requirement is described according to the following attributes:
• ID: a simple identifier;
• Short-name: a synthetic name useful to identify the requirement;
• Description: the requirement description;
• Supported Use Cases: the Big Data use cases supported by the requirement;
• Link to the needs: identifiers of the collected business needs described in Chapter 4
from which the requirement is derived.
6.2.2. INFRASTRUCTURE
TECHNICAL REQUIREMENT – Infrastructure
ID Short-name Description Supported Use Cases
Link to the needs
10 Infrastructure scalability
It is necessary to use a scalable infrastructure with high capacity distributed storage and computation in order to scale-up/down or horizontally and perform a pilot at different scale and maturity levels
Cross-use cases 11, 19
11 Infrastructure extensibility
A high adaptability level is required for testing purposes. This is necessary to enable the installation of tools/modules and libraries compatible with the infrastructure and test different configurations
Cross-use cases 20

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 59 / 85
TECHNICAL REQUIREMENT – Infrastructure
ID Short-name Description Supported Use Cases
Link to the needs
12 High Performance Computing
The infrastructure has to support tools and technologies to assure high performance computing (e.g. in image processing)
Image processing, Predictive Analysis, Applying bioinformatics to genetic data
33
13 Project’s life-cycle support
The infrastructure has to support the project maturity life-cycle, from a single PoC to a fully operational system
Cross-use cases 39
14 Infrastructure service level
Even though it will be a test infrastructure, it is necessary that the infrastructure ensures pre-defined service levels (it could be useful to define an SLA)
Cross-use cases 49
15 Infrastructures integration
It is necessary to integrate or interact with other Big Data infrastructures (i.e. providing or consuming data or services).
Cross-use cases 14
Table 21 – Technical Requirements for the Infrastructure
6.2.3. GOVERNANCE AND SECURITY
TECHNICAL REQUIREMENT – Governance and Security
ID Short-name Description Supported Use Cases
Link to the needs
16 Privacy and Security
It is necessary to allow the use of MSs physical infrastructure in order to host the Big Data test infrastructure or to complement it, for example in order to be compliant with specific national data privacy and security policies (e.g. national data cannot be moved outside the national border)
Cross-use cases 6
17 Data Masking and Anonymisation
The infrastructure has to support data hiding (e.g. masking) and making anonymous and/or aggregate data because privacy constraints on data sets (e.g. the new GDPR 13in force starting from May 2018) often limit the personnel authorised to access and treat the data and in order to allow files to be moved outside the physical boundaries of a single organisation being compliant with data privacy and security concerns.
Population/ customer segmentation
13, 46
18 Infrastructure Privacy and security
The infrastructure should support the application of multiple security mechanisms/layers for access and authentication
Cross-use cases 21
13 General Data Protection Regulation (GDPR) EU/2016/679

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 60 / 85
TECHNICAL REQUIREMENT – Governance and Security
ID Short-name Description Supported Use Cases
Link to the needs
19 Data Privacy and security
The infrastructure should offer different data encryption methods each of them with different aims (e.g. volume, performance, etc.)
Cross-use cases 23
20 Data visualisation
The infrastructure has to include tools offering access also to mobile devices, for example in order to monitor the infrastructure
Cross-use cases 27
21 Infrastructure monitoring
The infrastructure has to include tools offering monitoring and managing of the services and resources used by the pilot
Cross-use cases 28
22 User Roles The infrastructure has to allow the definition of multiple user roles with different authorisation and permission levels
Cross-use cases 34
23 User Profiling Synchronisation
The infrastructure has to allow import user definition/profiling from other systems (e.g. with LDAP synchronisation)
Cross-use cases 35
24 Data Ownership The infrastructure has to allow definition of data ownership and visibility based on different user profiles/groups
Cross-use cases 36
25 Data quality
The infrastructure has to support tools to evaluate data quality at least for three main steps: 1- Input – when the data is acquired, or in the process of acquisition 2- Throughput – any point in the business process in which data is transformed, analysed or manipulated. This might also be referred to as ‘process quality’ 3- Output – the reporting of quality with statistical outputs derived from Big Data sources
Cross-use cases 37
26 Migration support
It is necessary to allow the export of pilot/data from the test environment to a production environment in order to support project scale-up
Cross-use cases 45
27 Infrastructure configuration
It is necessary to obtain authorization to have control over how the infrastructure components installation are set-up and configured
Cross-use cases 48
Table 22 – Technical Requirements for the Governance and Security Area
6.2.4. DATA INGESTION / STORAGE
TECHNICAL REQUIREMENT – Data Ingestion / Storage
ID Short-name Description Supported Use Cases
Link to the needs

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 61 / 85
TECHNICAL REQUIREMENT – Data Ingestion / Storage
ID Short-name Description Supported Use Cases
Link to the needs
28 Data Connectors
It is necessary to support the integration of data coming from different sources, often quite dissimilar between themselves, in a single analytical environment. It is necessary to allow the easy integration of developed connectors in the infrastructure.
Web Analysis, IoT and Smart City, Social media analysis
4, 41
29 Storage Types
The infrastructure should offer different solutions to store and manage data in order to support different scenarios, i.e. to store structured data, semi-structured data and/or unstructured data
Cross-use cases 17
30 Data ingestion Types
The infrastructure should support data ingestion in manual, batch and streaming/real-time ways
Cross-use cases 23
31 Multiple Storage Areas
The infrastructure must offer multiple storage areas, each of them with different objectives (e.g. testing, archiving)
Cross-use cases 25
Table 23 – Technical Requirements for the Data ingestion / storage area
6.2.5. DATA ELABORATION
TECHNICAL REQUIREMENT – Data Elaboration
ID Short-name Description Supported Use Cases
Link to the needs
32 Tool support The infrastructure should allow the use of statistical packages and analytical tools with different abstraction levels (e.g. both via console and via GUI)
Predictive Analysis, Text analysis, Descriptive analysis, Network Analysis
4, 16
33 Programming Languages Support
The infrastructure must support the most common programming languages (at least R, Python, Java and Scala)
Predictive Analysis, Text analysis, Descriptive analysis
18
34 Data processing
The infrastructure has to offer multiple types of distributed, parallel data elaboration tools/frameworks, each of them with a different objective
Cross-use cases 24
35 Data cleaning The infrastructure must support tools for data cleaning, for example in order to normalise different datasets to a unique format
Web Analysis, IoT and Smart City, Social media analysis
30

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 62 / 85
TECHNICAL REQUIREMENT – Data Elaboration
ID Short-name Description Supported Use Cases
Link to the needs
36 Advanced Analytics
The infrastructure must support multiple types of statistical and machine learning software, modules and tools in order to cover different scenarios (e.g. text analysis, data clustering, etc.)
Predictive Analysis, Text analysis, Descriptive analysis, Network Analysis
31
37 Code/analytics migration support
The infrastructure has to allow the import of code/scripts/analytics from other Big Data or Business Intelligence projects already developed
Cross-use cases 15
Table 24 – Technical Requirements for the Data elaboration area
6.2.6. DATA CONSUMPTION
TECHNICAL REQUIREMENT – Data Consumption
ID Short-name Description Supported Use Cases
Link to the needs
38 Data Access The infrastructure must support multiple open-source tools for data access in order to cover different scenarios (e.g. dashboarding)
Cross-use cases 26
39 Data export The infrastructure has to allow the export of data in multiple formats (e.g. txt, csv, xlsx, pptx, …)
Cross-use cases 29
40 Data visualisation
The infrastructure must support interactive real-time data visualisation tools, for instance in order to allow users to deal with streaming data
Time-series analysis, Route-traceability/flow monitoring, Network Analysis
32
Table 25 – Technical Requirements for the Data consumption area

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 63 / 85
7. DESIGN OF THE FUTURE BIG DATA TEST INFRASTRUCTURE
This chapter represents a bridge between Task 1 and Task 3 of the study. Indeed, during Task 1,
a subset of the existing Big Data pilots were identified (all with interesting Big Data infrastructures)
to be further analysed in order to provide useful recommendations and guidelines for the future
design of the Big Data test infrastructure.
7.1. GOOD PRACTICES AND RECOMMENDATIONS FOR THE DESIGN OF THE FUTURE BIG DATA
TEST INFRASTRUCTURE
This chapter provides a detailed description of relevant cases of Big Data Infrastructures set-up by
European and National PAs and EUIs to launch Big Data pilots. Furthermore, based on the
identified business and technical requirements (see Chapter 6), a set of relevant recommendations
and guidelines are provided to support the design of the future Big Data Test Infrastructure, taking
into consideration the following three dimensions of the soGOFA model (see Chapter 2.2):
Architecture dimension: this section indicates the infrastructure and software used to
implement the Big Data project/pilot;
Operation dimension: this section describes how the service is provided (on-premises or
in-Cloud);
Governance and Skills dimension: this section delineates the specific skills required for
implementation of the Big Data pilot and how to launch the pilot.
The Financing dimension (the fourth dimension of the soGOFA model) is not taken into account as
it is not relevant at this point of the study. In fact, this section is more focused on reporting
relevant European cases in order to gather useful insights for the design of the future Big Data Test
Infrastructure (Task 3 of the study).

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 64 / 85
Figure 10 – Yearly data flow estimates for satellites Sentinel 1-3 as well as MODIS and Landsat 8
JRC – EU “JRC Earth Observation & Social Sensing Big Data Pilot Project (EO&SS@BigData)”
Policy domain
Environment Addressed use cases
Image processing, Descriptive Analysis
Project Status
Ongoing 2015–2018
Project description & objectives
The Earth Observation and Social Sensing Big Data (EO&SS@BD) pilot project was launched on 1 January 2015 as a response to the need for JRC to pursue a dedicated approach to 'Big Data' and to address the volume, variety, and velocity of the data flows originating from the EU Copernicus programme. As a result, the setting up of a JRC prototype platform for Big Data storage, management, processing, and analysis was initiated in 2016. Its specifications are primarily based on the requirements of the JRC Knowledge Production units. During the period 2017–2018, the prototype Joint Earth
Observation Data and Processing Platform (JEODPP) will be further developed and scaled-up to fulfil the needs of the Knowledge Production units and to serve as a precursor to the Joint Earth Observation Data and Processing Centre (JEODPC). This precursor centre will contribute to the establishment of a European Big Data Centre at JRC as stated in the Communication from the Commission on the European Cloud Initiative (COM(2016) 178 final). In addition, the EO&SS@BD multi-year pilot project contributes to JRC collaboration with international institutions, in particular with CERN, ESA, and EUSC. The major goal of the project is to provide a re-usable platform for storing and processing of Earth Observation [EO] and Social Sensing data at JRC, while acquiring technical skills in this field of expertise.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 65 / 85
Architecture dimension
The JEODPP architecture consists of processing servers accessing the data provided by a series of storage servers and their directly attached storage in a distributed file system environment orchestrated by a management and meta data server mapping the logical file names and paths to their physical location. The I/O bottleneck typically observed with network attached storage is avoided by considering appropriate high-speed server inter-communication topology (switched fabric in fibre channel). This topology has the best scalability compared to arbitrated loop and point-to-point alternatives. Storage servers are automatically populated with the data requested by the applications. For instance, the automatic download of Sentinel-2A data is achieved by using a time-based job scheduler launching OpenSearch and OpenData (ODat) scripts taking into account user requirements (geographical areas, cloud coverage, seasonality, etc.). Processing can be performed at various levels:
Low-level batch processing orchestrated by a dedicated workload manager;
High-level interactive processing and visualisation through web browser client;
Intermediate level access through remote desktop connection.
The current platform architecture is at prototype level and uses all open-source software/tools (C/C++, IPython, Matlab, JAVA, SLURM, QGIS, Jupyter) and is already able to batch daily TBs of structured (metadata) and unstructured data (high resolution satellite images). The prototype has 200–300 TB of net storage using a DFS developed by CERN, ~200 CPU cores of processing capacity and a connectivity of 10 Gb Ethernet with a dedicated switch.
Data from the Copernicus programme are all open and so there are no privacy and security concerns, the system provide a simple authentication system.
Operational dimension
On-premises In-Cloud Hybrid The prototype is currently hosted on the JRC server farm (“on-premises”), but in order to scale-up, JRC is taking into consideration several Cloud providers
Possibility for the future scale-up of the infrastructure
Possibility for the future scale-up of the infrastructure
Governance and Skills dimension
How to launch pilot projects Specific Skills
Following conclusion of the experimental phase, the platform would be accessible by any JRC unit through a formal request which should describe the addressed use cases to be
The main technical skills required are related to image processing and High-Performance computing.
Figure 11 – JEO-DPP processing components

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 66 / 85
implemented.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
Full involvement of the final users during the entire project life-cycle, including design phase of the prototype platform;
The use of open-source software/tools that have continued software maintenance and the availability of technical and commercial support;
For the Data Storage component, JRC used the following criteria to identify their Distributed File System (DFS): the availability of technical/commercial support, future continuous software maintenance, reusability of the DFS for different policy domains’ projects, innovative/European solution, and the right compromise of performance, flexibility of extension, usability and manageability and with a high level of security.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 67 / 85
CONSIP / AgID – ITA “Procurement of a Big Data platform through a framework contract for Italian PAs”
Policy domain
Cross-policy Addressed use cases
Descriptive analysis, Text Analysis, Predictive analysis, Web analysis
Project Status
Ongoing
Project description & objectives
This project is related to an Italian call for tender entitled SPCloud divided into the following four work packages:
Lot.1: Cloud computing services;
Lot.2: Digital identity management services and application security;
Lot.3: Interoperability of services for data and application cooperation (Open/Big Data);
Lot.4: Implementation services and management of portals and online services.
This study focuses only on Lot.3 related to the request and procurement, through a framework contract, of a Big Data platform for any Italian Public Administration. This platform enables the running of Big Data projects supporting different use cases/policy domains with the possibility to acquire optional services. The service includes the activities, methodologies and tools to support the PA’s data analysis of internal (i.e. implementing connectors among the PA’s internal system and the Big Data platform) and external sources (e.g. social network data, open data, etc.), with the aim of identifying trends, hidden patterns and new correlations between data in order to support the administration's decision-making and improve the efficiency of internal administrative processes. The formulation and implementation of the analysis model can belong to one of the following categories of analysis: Data Mining: includes classic analysis of data mining that uses both machine learning techniques
and statistical methods. Graph mining techniques are also included;
Stream Processing: includes real-time analytics, stream-analytics and complex event processing. These analyses are often used for scientific and environmental surveys (e.g. by sensors), in the field of Smart City, in fraud detection and security attack systems. This category of analysis must be able to process data dynamically (i.e. in real-time or near real-time);
Text analysis: analysis of unstructured textual data that includes natural language processing, sentiment analysis and trend analysis.
Architecture dimension
The infrastructure is provided in-Cloud by the provider “service centre” (i.e. provider facilities). The technical specification of the Big Data platform depends on the administrative requirements but the call for tender establishes minimum requirements and guidelines depending on the specific Big Data use case the customer has to implement: a “General Purpose” cluster (just one node with low specifications for a small-scale prototype), a “CPU-intensive” cluster (with 5 nodes with at least 16 core CPU each, 32 BG Ram minimum, for an intensive use of the CPU, for example for “text analysis”), a “RAM-intensive” cluster (with 5 nodes with at least 8-16 core CPU each, 64-128 BG Ram minimum, for in-memory real-time processing).
To implement Big Data analysis, providers make substantial use of open-source software.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 68 / 85
Operational dimension
On-premises In-Cloud On-premises: in this mode the tender provider implements all the activities related to installation, configuration and deployment of the system chosen by the administration using the infrastructure and any software licenses made available by the administration.
As-a-service: in this mode the platform identified by the administration is provided by the tender supplier with its in Cloud infrastructure (“Services Centre”). In this mode the provider ensures the activation/management of the platform (hardware and software) in a transparent way including specific security requirements and granting the resources segregation at its Cloud infrastructure. In addition, this mode includes real-time monitoring of the service, a help desk and technical support H24x7. The imprint of the software provided by the tenderer is mainly open-source, while in the “on-premises” mode the Administration will provide the eventually licensed software.
Governance and Skills dimension
The service is supplied by the provider as a project and it is structured in the following phases:
Preliminary Assessment: evaluation of the administrative requirements for the analysis of Big Data and assessment for identification of the Big Data platform to be requested and acquired through a framework contract;
Activation of the platform: activation of the Big Data platform both in “on-premises” and “as-a-service” mode;
Support for Big Data Analysis: acquisition of data from internal sources/external administration (both structured and unstructured data), formulation and implementation of the analysis model, and running of the implemented solution.
The Public Administration/Institution can acquire the entire process required by the service in question, or can select a subset of the phases, to be activated depending on specific requirements. In addition, other optional services such as the operative running/advanced configuration of the platform can be activated.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
This project could be a guide in terms of the governance model adopted to provide the service. As reported in the “Governance dimension”, the service is structured as a project and includes a preliminary assessment by the provider to help the administration to identify the sizing and tools of the Big Data platform. This is very useful with regard to the lack of Big Data skills in the public sector.
Providers make extensive use of open-source software.
Identification of different Infrastructures (working nodes for processing and storage) based on the Big Data use cases to be implemented

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 69 / 85
UNECE – EU “SANDBOX”
Policy domain
Cross-policy Addressed use cases
Web analysis, Descriptive analysis, Network analysis
Project Status
2013–2016
Project description and objectives
In 2014, the UNECE High-Level Group for the Modernisation of Official Statistics (HLG-MOS) initiated a project to create a “Sandbox”, a web-based collaborative environment, hosted in Ireland by ICHEC (Irish Centre for High-End Computing) to better understand how to use the power of "Big Data" to support the production of official statistics.
In this project, more than 40 experts from national and international statistical organisations worked to identify and tackle the main challenges of using Big Data sources for official statistics. The countries involved were: Austria, France, Germany, Hungary, Ireland, Italy, Mexico, the Netherlands, Poland, Serbia, Russian Federation, Slovenia, Spain, Sweden, Switzerland, Turkey, United Arab Emirates, United Kingdom, and United States of America. The international organisations involved were: Eurostat, UNECE (United Nations Economic Commission for Europe), UNSD (United Nations Statistics Division), and OECD (Organisation for Economic Co-operation and Development).
The sandbox is a flexible environment supporting various activities, including:
1. Conducting experiments and pilots in different policy domains – The sandbox can be used for experiments involving creating and evaluating new software programmes, developing new methodologies and exploring the potential of new data sources. This use case extends the current role of the sandbox beyond Big Data, and encompasses all types of data sources;
2. Testing – Setting up and testing of statistical pre-production purposes is also possible in the sandbox, including simulating complete workflows and process interactions;
3. Training – The sandbox can be used as a platform for supporting training courses. It can run special software for high performance computing which cannot be installed or run on standard computers. Non-confidential demonstration datasets can be uploaded and shared, facilitating shared training activities across organisations. The sandbox environment also provides statisticians with opportunities for self-learning, e-learning and learning by doing;
4. Supporting the implementation of the Common Statistical Production Architecture (CSPA) – The sandbox can be used as a statistical laboratory where researchers can jointly develop and test new CSPA-compliant software;
5. Data hub – The sandbox also provides a shared data repository, subject to confidentiality constraints. It can be used to share non-confidential data sets that cover multiple countries, as well as public-use micro-data sets.
During the experimental phase, several small-scale pilots were implemented in different policy domains and supporting different Big Data use cases such as population/customer segmentation analysis using mobile phone data, descriptive analysis using smart meter data, web analysis scraping and monitoring data from Wikipedia and Enterprise websites, network analysis to link

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 70 / 85
trade data.
Architecture dimension
During 2015, the Sandbox infrastructure has been updated with greater capability but with fewer nodes in order to ease the maintenance and the upgrading of the platform as newer versions and components of the Hadoop ecosystem become available. The cluster consisted of separate admin and login nodes as well as
4 compute/data nodes each with 2 x Intel Xeon E5-2650 v3 10-core processors for processing, 128 GB RAM for in-memory processing, a 4 x 4TB disk for data storage and a FDR Infiniband (56 Gbit) for the connection among nodes. The installed platform is the Hortonworks Data platform with the HDFS (Hadoop Distributed File System) for storage, Hadoop MapReduce for processing and Rhadoop for data elaboration.
Operational dimension
On-premises
The infrastructure is hosted “on-premises” at the ICHEC data centre but it can be accessed through a web client.
Governance dimension
Any organisation producing official statistics can subscribe to the sandbox, as a service for the international statistical community, on a non-profit basis. However, users will be required to pay an annual subscription to cover the costs of technical support, hardware upgrades and installation of software. In order to subscribe, organisations are requested to send an expression of interest (a simple e-mail) to [email protected]. Future users are requested to agree to standard terms of use, receiving also an invoice for the annual subscription fee (currently EUR 10,000) from the National University of Ireland, Galway (which provides financial administration services to ICHEC). In addition, a seat on the Strategic Advisory Board will be provided to each subscriber.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
Provide several features that facilitate the approach to Big Data and data science.
An infrastructure for Big Data processing ready for use at a low subscription cost;
Software already installed and proved/tested;
Shared datasets instantly available;
Tools and materials for capacity-building.
Driven by the community.
Offers a seat on the Strategic Advisory Board to each subscriber.
Figure 12 – The "Sandbox" high-level architecture

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 71 / 85
ANAC – ITA “Big Data Cooperational System”
Policy domain
Home and justice affairs
Addressed use cases
Descriptive Analysis
Project Status
Finished
Project description and objectives
ANAC, the Italian anti-corruption national authority, gathers a wide range of information about public contracts in order to monitor them during their life-cycle. In order to enable ANAC to analyse such information and also share such data with other PAs, it is necessary to create a system able to continuously gather information from different sources and at the same time combine this diverse information. The analytical and cooperation needs of internal and external actors require an evolution of Business Intelligence tools, with a consequent revision of the architectural model, conceived as a structured analytical solution and defined according to a specific set of business requirements. These needs can be managed by adopting modern technologies that enable the concept of Self Service analysis. Switching from an Enterprise BI to a Self Service BI environment enables business users to have the required analysis flexibility, while allowing IT to control the quality and validity of the data. In addition, implementing this solution through Big Data technology can be considered to be an enabling factor for responding and overcoming all the criticalities associated with performance, data volumes, and the analytic capabilities to be managed.
Architecture dimension
ANAC has an on premise Cloudera cluster composed of seven nodes, respectively:
1 x head node (1CPU 8 core, 32 GB RAM, 300 GB HDD)
3 x master nodes (1CPU 8 core, 32 GB RAM, 2 x 80 GB SSD)
3 x worker nodes (1CPU 8 core, 64 GB RAM, 6 x 300 GB HDD)
The operating system of each node is Red Hat 6 (x86_64). The Hadoop installation is based on Cloudera (CDH 5.9).
The head node is dedicated to the execution of the Cloudera Manager; the other services of the Cloudera platform are distributed among master nodes and worker nodes according to the services logical architecture.
The most relevant services used are the following:
Zookeeper, for maintaining configuration information, naming, providing distributed synchronisation, and providing group services;
YARN, to provide resource management and a central platform to deliver consistent operations, security, and data governance tools across clusters;
Figure 13 - ANAC Cloudera cluster

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 72 / 85
HDFS, the highly fault-tolerant distributed file system used to store data across the cluster nodes;
SPARK, the fast and general engine for large-scale in-memory data processing, used as an execution engine instead of the MapReduce framework in order to obtain better performance for Hive queries;
HIVE, the software that facilitates reading, writing, and managing large datasets residing in distributed storage using SQL;
SQOOP, for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases;
OOZIE, the workflow scheduler system to manage Apache Hadoop jobs supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system-specific jobs (such as Java programmes and shell scripts);
HUE, is the open source web GUI that permits easy interaction with Apache Hadoop and Cloudera components (e.g. Hive, Oozie, etc.).
Assessments and tests have been conducted both on cluster available resources and on jobs that would be performed in order to correctly configure the infrastructure parameters and to choose the right execution framework.
Four main Oozie workflows have been developed as listed below:
Full import, to get all available data from data sources (SQL Sqerver);
Delta import, to get only new or changed data since the last import;
Full export, to export all available data from the data lake;
Delta export, to export only new or changed data since the last export.
Both Full import and Delta import apply massive ETL on obtained data in order to produce de-normalised data; such data can be accessed from BI tools (e.g. HUE Notebook, Zeppelin, etc.) in order to perform analysis.
Operational dimension
On-premises In-Cloud Hybrid
The system is hosted on the ANAC server infrastructure (“on-premises”)
Because of privacy and security policy the system cannot be hosted on a Cloud infrastructure
Because of privacy and security policy the system cannot be hosted on a hybrid infrastructure
Figure 14 – Oozie workflows in the ANAC case

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 73 / 85
Governance and skills dimension
How to launch pilot projects Specific Skills
Other enabled PAs can access and perform analytics only on data they are authorised for.
The main technical skills required are related to infrastructure administration and configuration and Cloudera components knowledge.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
Depending on the infrastructure available, resources and job types, in order to achieve the best performance and efficient resource consumption it is important to:
Correctly configure all the cluster parameters related to the job execution (default values are often not suitable);
Choose the right execution framework (MapReduce vs Spark vs etc.).

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 74 / 85
EUROSTAT – EU “Eurostat Big Data cluster”
Policy domain
Statistics/ Population/ Cadastral
Addressed use cases
Web Analysis (Scraping/Monitoring) Route-traceability/ flow monitoring
Project Status
Ongoing
Project description & objectives
The Eurostat Task Force on Big Data (TF.BD) was created in January 2014 to coordinate the follow-up of the requirements of the Scheveningen Memorandum. In this context, the TF.BD launched several pilot projects on the use of Big Data sources for official statistics. Until January 2016, TF.BD pilot projects were run exclusively on the UNECE Big Data Sandbox, which is a platform maintained by the Irish Centre for High-End Computing and shared with other NSIs working on Big Data and official statistics. To overcome some limitations of this shared platform, an internal Big Data cluster has been designed at Eurostat for usage by the TF.BD. The purpose of the Eurostat Big Data cluster is to provide a distributed storage and computation platform to run internal pilot projects on the use of Big Data sources for official statistics. Two of the most relevant projects that have used the Eurostat Big Data cluster are the following:
Web Scraping for Job Vacancy Statistics: the aim of this pilot is to demonstrate through concrete estimates which approaches (techniques, methodology, etc.) are the most suitable to produce statistical estimates in the domain of job vacancies and under which conditions these approaches can be used in the ESS. The aim is not to develop a system suitable for production. The pilot will focus on feasibility and will explore a mix of sources including job portals, job adverts on enterprise websites, and job vacancy data from third-party sources, from which collected data may be acquired;
Mobile Phone Data: the potential of mobile phone data as a data source for official statistics is beyond any debate. The overall objective of the FPA is to exploit this rich source to produce estimates of day-time population as a mature official statistics product.
Architecture dimension
The logical architecture of the Eurostat cluster is shown in the following image:
The cluster is composed of 6 nodes connected to a high capacity network switch reserved for intra-cluster data transfer. Each node can be accessed via SSH and can access to the Internet for data download. Ambari, Hue, PostgreSQL/PostGIS and RStudio are available respectively on individual nodes. Some storage space on node 6 is reserved for home repository. Two external network drives are used for backups. The 6 nodes are identical. The specifications are the following:
Processor: 2 x Intel Xeon E5-2620 V2 6 cores 2.1 GHz
RAM: 141 GB (+ 39GB swap)
Disk: 6TB (2 x 300GB + 6 x 900 GB)
Figure 15 – ESTAT cluster high-level architecture

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 75 / 85
Connectivity: 2 x 10 GB/s Ethernet
The operating system of each node is Red Hat 6 (x86_64). The Hadoop installation is based on Hortonworks HDP3 distribution version 2.3.2.0-2950. Only a selection of the distribution modules is installed: Hadoop (version 2.7.1), YARN (version 2.7.1), Pig (version 0.15.0), Hive (version 1.2.1), Tez (version 0.7.0), Spark (version 1.4.1), HBase (version 1.1.2), Storm (version 0.10.0), Falcon (version 0.6.1), Hue (version 2.6.1-2950), Ambari (version 2.1-377), Zookeeper (version 3.4.6), Oozie (version 4.2.0), Mahout (version 0.9.0.2.3.2).
In addition to the Hadoop software, the following software is installed to support the execution of the pilot projects:
Python (versions 2.6 and 2.7), installed on all nodes.
R (version 3.3.1), installed on all nodes. Packages RHadoop, SparkR and Sparklyr are used to deploy and execute Spark jobs written in R programming language.
RStudio server (version 0.99.489), installed on node 6.
GDAL (version 1.9.2), installed on all nodes.
PostgreSQL/PostGIS (version 9.3.13), installed on node 5.
Operational dimension
On-premises In-Cloud Hybrid The system is hosted on the Eurostat server infrastructure (“on-premises”)
The cluster is dedicated to Eurostat internal use only.
The cluster is dedicated to Eurostat internal use only.
Governance and skills dimension
How to launch pilot projects Specific Skills
The cluster is dedicated to Eurostat internal use only (Eurostat and NSIs).
The main technical skills required are related to infrastructure administration and configuration, Hortonworks components knowledge, experience with statistical software/tools/library.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
It is important to have high capacity distributed storage and computation to perform advanced analytics and statistics;
It is important to have a high adaptability level for testing purposes, allowing, for example, to install new libraries on-demand and test different configurations.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 76 / 85
Figure 17 – Overview of the KAVE services
City of Amsterdam – NL
“Amsterdam innovation ArenA – Data Driven Operator”
Policy domain
Cultural/ Education
Addressed use cases
Predictive Analytics, Smart City & IoT
Project Status
Ongoing since 2016
Project description and objectives
The pilot project Amsterdam ArenA – Data Driven Operator has been ongoing since March 2016. Amsterdam ArenA is a technology frontrunner, so they are always looking for the next big innovation in order to bring new solutions and technologies to an ever-changing world. The Amsterdam ArenA owns and operates one of the largest sporting and entertainment venues in Europe. For this innovative organisation, they strive to establish an integrated data management policy and system. The goal is to become a more data-driven operator for venues and fan experiences. The data environment should aim at generating insights from the data through (advanced) analytics. This project is part of a larger development of the Amsterdam Zuidoost area and the desire of the municipality of Amsterdam to implement, in practice, technologies related to the so-called Smart City. The desire for flexible data storage in combination with an ambition to make more use of data analysis in areas of customer service, has led to the implementation of a storage and analysis solution using flexible Big Data techniques: KAVE on Microsoft AZURE. The KAVE on AZURE can deal with unstructured data, and thus is ready for any external sources. It has centralised data governance, and there is a single point of truth for data definitions, data quality, data management, etc. This solution also offers the required flexibility for data analysts to perform any type of analysis and makes it easy to reuse existing data couplings and insights. The example analysis on the data collected by ArenA and stored in KAVE is the crowd management and monitoring using Wi-Fi signals from smartphones.
Architecture dimension
The core of the ArenA architecture is a Hadoop data lake, which consists of a series of storage servers and their directly attached storage in a distributed file system environment orchestrated by a management and meta data server mapping the logical file names and paths to their physical location. The data can be processed in a batch or real-time using the associated computing element. Processing can be also performed at various levels:
Low level batch processing orchestrated by a dedicated workload manager (using technologies such as YARN and Apache Spark);
High level interactive processing and visualisation through web browser client;
Intermediate level access through remote desktop connection.
Figure 16 – Example of the crowd monitoring in ArenA

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 77 / 85
The data ingested by the platform are also of various types and formats:
Structured (databases) vs unstructured (data from sensors);
Static vs streamed.
The current platform (KAVE) has been successfully deployed before. KAVE is a Hadoop distribution built upon the Hortonworks Data Platform and other proven technology. By leveraging open source technology and integrating them through a common security technology a rich and powerful environment is created. Currently KAVE contains components such as: HDP (Hadoop, hive, spark, etc.), FreeIPA (LDAP, Kerberos, etc.), MongoDB, Storm, Jenkins, SonarQUBE, Gitlabs, Anaconda (Python), R, Root, VNC. The underlying operating system is CentOS. Due to the combination of Hadoop technology Microsoft Azure hardware, this architecture can deal with any size of input data stream and its storage capacity is limited only by the budget. Also, the solution is extremely modular – only the services which are necessary for the given task are deployed and every KAVE can be tailored to suit the needs of a given project. The data lake has a sophisticated system of data governance that allows the sharing of data between various entities (internal data, universities, external partners, public institutions, etc.) with clear establishment of data ownership and access rights. All users of all services are authenticated against one central database and have different data access roles depending on their needs. In addition, all communication between users and the data lake is encrypted with SSL. All data access and protection procedures are formalised, documented and audited when needed. All procedures also comply with private data protection regulation.
Operational dimension
On-premises In-Cloud Hybrid The scalability requirements prevent hosting on premises
Whole infrastructure is hosted in Microsoft Azure Cloud
Possibility for future scale-up of the infrastructure
Governance and skills dimension
How to launch pilot projects Specific Skills
Following conclusion of the experimental phase, more services and users will be added to the platform to allow for growth of the whole Smart City ecosystem
The main technical skills required are System Administrator, Data Engineer, Data Scientist, Business Analyst and Front-end developer
Recommendations and guidelines for the design of the Big Data Test Infrastructure
Full involvement of the final users during the entire project life-cycle, including the design phase of the prototype platform. This was especially important in this case as many stakeholders were involved;
In order for the organisation to become truly data-driven, all its parts need to change/adapt. It is therefore crucial to have support from top-level management, and the implementing organisation(s) should be responsible solely to the top management in order to avoid inherent resistance from the various departments of the organisation that is endeavouring to become data-driven;
Hadoop as a solution was chosen because of the availability of technical/commercial support, future continued software maintenance, widespread and growing user expertise

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 78 / 85
with it, the best functioning solution for a given budget, and the right compromise with regard to performance, flexibility of extension, usability and manageability and with a high level of security;
Design and formalise data governance upfront and then update the rules during the project if it proves necessary;
Use a granular and modular computing platform that can grow together with the project and can be easily scaled up and out.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 79 / 85
Politecnico di Torino – ITA
“BigData@Polito Cluster”
Policy domain
Cross-policy Addressed use cases
Cross-use case Project Status
Ongoing
Project description and objectives
The BigData laboratory is a joint research project supported by the Politecnico di Torino (PoliTO), thanks to an agreement involving the following departments:
DAUIN, Department of Control and Computer Engineering
DET, Department of Electronics and Telecommunications
DIGEP, Department of Management and Production Engineering
DISMA, Department of Mathematical Sciences "Giuseppe Luigi Lagrange" The mission of the BigData@Polito laboratory is to provide an opportunity to exploit computing capabilities offered by Big Data technologies. The laboratory offers the opportunity to access and acquire experience on a Big Data Cluster, running state of the art software. The BigData@Polito laboratory provides a useful platform for:
Research projects
Joint research collaboration among research groups
Partnership between research groups of the Politecnico di Torino and companies, external institutions or entities
Finally, the laboratory provides a significant opportunity for education. Students have direct access to learn how to utilise Big Data technologies that nowadays play an important role in every analysis for companies and research centres. Access is available to all researchers (from any area) who are interested in using and getting their hands on Big Data computing technologies, paving the way for collaboration between research centres, companies and external institutions. Access to the cluster is available to any professor or researcher of any research group at the Politecnico di Torino. External companies or researchers who show interest in the BigData@polito laboratory can also access it.
Architecture dimension
The cluster of the Big Data laboratory was initially composed of about 10 nodes and was available to few users.
A new version of the cluster, the first scale-up, consists of a group of nodes, organised on two racks:
30 worker nodes – storage available 768 TB, memory 2TB (8GB per computing core)
18 nodes - single node maximum storage available 36 TB
12 nodes provided by the previous BigData cluster bought in 2013 – Single node maximum storage available 10 TB
3 master nodes still provided by Dell Figure 18 – Node connections for the BigData@Polito cluster

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 80 / 85
1 device for storage provided by QNAP – 40TB RAID-6
4 switch 48-port layer 2, used to interconnect all nodes of the cluster, provided by Dell
Uninterruptible Power Supply
The rack cooling of the cluster is based on a closed-architecture solution, an energy efficient method where the cooling unit is integrated on the side the rack without affecting the temperature of the room where the two racks are situated. By way of this approach the air can circulate only inside the rack and not within the whole room. This is an advantage for the cluster because it can be easier to maintain the desired temperature to control the two racks and reduce energy wastage.
Each node of the BigData@Polito cluster runs a Cloudera distribution on Linux Ubuntu. The Cloudera distribution is based on the open source Apache Hadoop framework for Big Data distributed applications. The Apache Hadoop ecosystem includes Apache open source projects for data management such as YARN and HDFS (Hadoop Distributed File System), governance/integration like Falcon, Flume and Sqoop, operations like Ambari, Oozie and ZooKeeper, data access such as Hive, Pig, Mahout, Storm, Spark. This is only a sub-list and new projects can be included in the future.
There will be a further cluster infrastructure scale-up to support neural network projects and to extend access to a bigger user base. In order to implement this scale-up, specific BigData hardware will be included in the cluster and also a hybrid model (on-premises + Cloud) will be considered.
Operational dimension
On-premises In-Cloud Hybrid All services of the BigData@Polito laboratory are accessible only from inside the Politecnico network or through VPN
- As part of the next scale-up step a hybrid solution will be considered.
Governance and skills dimension
How to launch pilot projects Specific Skills
All services of the BigData@Polito laboratory are accessible only from inside the Politecnico network. Wi-Fi users might need to use the Politecnico VPN to access some Web interfaces. To interact with the system it is necessary to be authenticated to the BIGDATA.POLITO.IT Kerberos Realm. This is done automatically when using the Access Gateway, otherwise the system must be configured as a Kerberos client.
The main technical skills required are related to infrastructure administration and configuration and Cloudera components knowledge, which can be acquired via dedicated courses.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
It is important to frequently (about every 2 years) upgrade and update cluster hardware and software infrastructure;
Having both dedicated training courses and access to the Big Data cluster is fundamental to acquiring specific skills and to experiencing what has been learned;
It is important to perform several test to correctly configure the Cloudera platform’s parameters in order to optimise components performance.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 81 / 85

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 82 / 85
Ministry of Public Administration -SLO
“BigData pilot for HR efficiency”
Policy domain
Cross-policy Addressed use cases
Descriptive Analysis, Time-Series Analysis
Project Status
Finished
Project description & objectives
One of the fundamental tasks of the within Ministry of Public Administration of the Republic Slovenia (hereafter MPA) is to establish efficient public administration. Therefore, the MPA implemented several activities, such as functional analysis, creating a data dictionary and renovation of registers, portal of open data, data warehouse and business intelligence.
The pilot project - Big Data Analysis for HR efficiency has been established as part of the development oriented strategy supporting ICT as an enabler for development of data driven Public
Administration in Slovenia. It has been run within MPA in collaboration with EMC Dell as an external partner. This pilot project has been launched aiming to learn what big data tool installed on the Slovenian Governmental Cloud Infrastructure could enable in terms of research of HR data of our ministry to improve our efficiency.
Therefore, anonymized internal data sources containing time management, HR database, Finance database and Public Procurement had been combined with external resources using postal codes of employees and weather data to identify potentials for improvement and possible patterns of behaviour.
This pilot project confirmed that using big data tools could provide an effective and solid basis for predicting process, planning policies and decision-making process on all managerial levels in public administration based on existing internal data sources combined with some external data.
Gained experience showed that big data analytics could help improve the efficiency of MPA in decision-making by using different statistical and quantitative analysis. The results showed that there is considerable potential for improvement in the field of HR and lowering costs in the field of public procurement within MPA.
MPA will continue with this project, first to spread the gained experience and knowledge of big data tools among its employees and share it to other ministries and administrative authorities within the Slovenian Public Administration.
Architecture dimension
Architecture for the pilot project was rather small dimensions and consisted of two data servers and two working stations (see Picture).
Technical specifications of the each data server are: 16 CPU, 48 GB RAM, 590 GB disk, Linux Centos 7, Jupiter, Python, RStudio, R Language, ORACLE database; technical specification of the two work stations:
2 CPU, 16 GB RAM, 250 GB disc, MS Windows, MS Power BI 16 CPU, 50 GB RAM, 250 GB disc, MS Windows, MS Power BI

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 83 / 85
The focus an emphasis were not on the amount of data (there were only 20GB), but on exploring what big data tools could enable and what experiences and lessons learned could be gained. Therefore, the hardware configuration was of modest capacity, but could be upgraded if necessary. The main goal was to gain experience in data preparation, to understand the content of the data in close collaboration with data owners, to conduct pseudo-anonymisation and to learn data analysis methods and techniques to interpret results. Furthermore, Big Data Platform laboratory was designed in MPA to provide environment based on R- Studio, R language and Python (all open-source software) This is planned to be spread to other governmental agencies in the future.
Operational dimension
On-premises Since some databases contained personal data, analysis had been performed within MPA premises on MPA IT infrastructure under strict security rules.
Governance & skills dimension
How to launch pilot projects Specific Skills
Project started with several introductory workshops aiming to select adequate data resources for further analysis as follows: data on employee’s time management (Codeks), ISPAP – salaries data, HR data and finance data (MFERAC) and data on public procurement. Crucial was close collaboration between data owners and big data experts. Very important phases were initial interviews, meta data creation, ongoing cooperation and data interpretation during analysis.
The Big Data tools and analytics tools used were Jupyter, Python, R language and Power BI for the presentation of the results. Several statistical techniques were used such as: Random Forest, Topic modelling, Z-Score Normalization, Multivariate Statistical, linear regression analysis and Log data transformation. Very important was good knowledge of the content of the data (data owners together with technicians).
Knowledge related to database administration and data masking techniques.
Knowledge of some programming languages (R, Python).
Knowledge of artificial intelligence, statistical and data mining methods of data analysis.
Recommendations and guidelines for the design of the Big Data Test Infrastructure
Data compliance with current privacy legislations, using data masking / substitution / anonymisation and eliminating some sensitive data from the analysis.
Regular training of manager also in the Big Data field of expertise in order to enhance the important collaboration among business and technicians.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 84 / 85
7.2. NEXT STEPS OF THE STUDY
As anticipated in the Introduction, the overall study is structured in three main tasks. The next
steps of the study will then be the following:
Task 2 – Analysis of Interoperable Data Ontologies and Data Exchange APIs: the main
purpose of this task is to identify and assess existing interoperable data ontologies and
data exchange APIs available at EU level and at Member State level in different policy
areas, and classify them according to different criteria (e.g. policy area, feasibility for
cross-border transactions, technical maturity, etc.). Those APIs will be used in the future
Big Data Test Infrastructure through built-in connectors in order to exchange and collect
data to be further analysed with Big Data techniques, with the aim of supporting
decision-making processes in different policy areas. Research, open source and EU PAs'
projects are in scope of the study while proprietary/commercial APIs and datasets are out
of scope.
Task 3 – Design of the Big Data Test Infrastructure: the objective of this task is to produce
the architectural design of the Big Data Test Infrastructure, as well as the governance and
operational model, based on the requirements and good practices collected during Task 1.
Indeed, this task will also take into account the results achieved during previous activities
of the ISA2 action 2016.03 – Big Data for Public Administrations and will take into
consideration and further elaborate the framework used for the classification of the
Technical Requirements.

Specific Contract 406 - D02.1 Requirements and good practices for a Big Data Test Infrastructure
Date: 4/07/2017 Doc. Version:3.0 85 / 85
8. LIST OF ANNEXES
ANNEX 1: MINUTES OF TARGETED INTERVIEWS
ANNEX 2: BIG DATA PILOTS GATHERED DURING DATA COLLECTION PHASE
ANNEX 3: MINUTES OF THE BILATERAL CONFERENCES WITH MEMBER STATES
ANNEX 4: BUSINESS AND TECHNICAL REQUIREMENTS