current topics in information access: image retrieval chad carson eecs department uc berkeley sims...
Post on 21-Dec-2015
213 views
TRANSCRIPT

Current Topics in Information Access:
Image Retrieval
Chad Carson
EECS Department
UC Berkeley
SIMS 296a-3
December 2, 1998

Outline
• Background– What do collections look like?
– What do users want?
• Sample image retrieval systems– Piction: retrieve photos (of people) based on captions
– WebSeek: Web search based (mostly) on text
– QBIC: retrieve general photos using content, text
– Blobworld: rely exclusively on image content
• Discussion

Image collections are diverse

What are the tasks?
• Large, diverse image collections are common
• Text is sometimes unreliable or unavailable
• Users want “things,” not “stuff”– More than overall image properties
– Traditional object recognition won’t work
– Two choices: • Rely on text to identify objects
• Look at regions (objects or parts of objects)

Large-scale systems: simple features
• Mainly overall color and texture, plus text
• Some segmentation
• QBIC [Flickner et al. ’95]
• WebSeek [Smith and Chang ’96]
• Virage [Gupta and Jain ’97]
• Photobook [Pentland et al. ’96]
• ImageRover [Sclaroff et al.’97]
• WebSeer [Frankel et al. ’96]

Other approaches
• Iconic matching [Jacobs et al. ’95]– Match user sketch to coarse representation
– Look at overall image layout
• Spatial relationships [Lipson et al. ’97]– Relationships between superpixels for querying and
classification
• Region-based approach [Ma & Manjunath ’98]– Semi-automatic segmentation

Classical object recognition won’t work
• Match geometric object model to image points
• Doesn’t apply to our domain– Designed for fixed, geometric objects
– Relies on clean segmentation
• Survey: Binford ’82

Sample image retrieval systems
• Piction– News photos of people
– Relies heavily on text
– Captions guide image understanding
• WebSeek– Index images and videos on the Web
– Relies heavily on text
– Some content-based searching

Sample image retrieval systems (cont’d.)
• QBIC– General image/video collections
– Use both content and textual information
– User labeling is important
• Blobworld– Relies exclusively on image content
– Find images regions corresponding to objects
– Querying based on regions’ color, texture, simple shape

Piction: retrieval based on captions
• Collection: several hundred news photographs, mostly of people
• Use captions to identify who’s in the picture and where, then find matching faces
• Relies heavily on text

NLP derives constraints from caption
• Determine four types of information:– Object classes:
Which proper-noun complexes (PNCs) are people?
– Who/what is in the picture:Which people are in the picture? Which aren’t?
– Spatial constraints:Where are these people in the picture?
– Significant visual characteristics:What do they look like (gender, hair color, glasses, etc.)?

Use constraints in image interpretation
• Example:“Lillian Halasinski of Dunkirk stands with a portrait of Mother Mary Angela Truszkowka at a news conference in the Villa Maria Convent on Doat Street.”
First find frame, then look for faces inside and outside

Image understanding: locate and describe faces
• Locate human faces by finding three contours (hairline, left contour of face, right contour of face)
• Look at multiple scales
• Confirm by looking for face-specific features
• Neural net discriminates between male and female

Discussion
• How well does the NLP module work?– “Tom Smith and his wife Mary Jane prepare for the visit
of President Clinton on Tuesday”
• How well does the face finder work?
• Does this system really need to use image content?– How much would we get from captions alone?

WebSeek: search for images on the Web
• Collection: 500,000 Web images and videos
• Filename and surrounding text determine subject
• Simple content-based techniques– Global color histograms
– Color in localized regions
Collect and process images and videos
• Retrieve image or video
• Store visual features and textual information
• Generate icon (motion icon) to represent image (video) compactly

Classify images based on associated text
• Extract terms– URL: http://www.host.com/animals/dogs/poodle.gif
– Alt text: <img src=URL alt=“picture of poodle”>
– Hyperlink text: <a href=URL>Sally the poodle</a>
• Map terms to subjects using a semi-automatically constructed key-term dictionary
• Store terms, location in subject taxonomy

Content-based information
• Extract information from image– Global color histogram
– Size, location, relationship of color regions
• Automatically determine image type:– Color photo, color graphic, gray image, B&W image
• Use content-based information when browsing within category hierarchy

Discussion
• How good is the text-based classification?
• Can we always count on having text?
• How much does the content-based information add in this case?

QBIC: image content plus annotation
• Collections:– General collections
– Video clips
– Fabric samples
– etc.
• Retrieval based on color, texture, shape, sketch
• Relies (sometimes) on human annotation of image or objects

Populating the database
• Use any available text (title, subject, caption, etc.)
• User selects and labels important regions
• Store information about image content
• Extract key frames and describe video content

Video processing
• Detect shots– Pan over skyline pan over Bay zoom to bridge
• Generate representative frames– Capture all the background from the shot in one image
• Extract motion layers to facilitate segmentation

Query based on text and content
• Textual information: title, subject, object labels
• Global image properties: color and texture
• Object properties: color and shape
• Sketch: use the sketch as a template to find matches

Discussion
• QBIC’s shape description doesn’t capture the essence of objects, just the appearance of one view
• How much does QBIC rely on textual information?

Blobworld: represent image regions
• We want to find objects look for coherent regions

• Expectation-Maximization (EM)– Assign each pixel to a Gaussian in color/texture space
segmentation
• Model selection: Minimum Description Length– Prefer fewer Gaussians if performance is comparable
Group pixels into regions

Describe regions’ color, texture, shape
• Color– Color histogram within region
• Texture– Contrast and directionality
stripes vs. spots vs. smooth
• Shape– Fourier descriptors of contour

Querying: let user see the representation
• Current systems act like black boxes– User can’t see what the computer sees
– It’s not clear how parameters relate to the image
• User should interact with the representation– Helps in query formulation
– Makes results understandable
– Minimizes disappointment
Sample queries
• Query in collection of 10,000 images
• Shape gives lower precision, closer matches
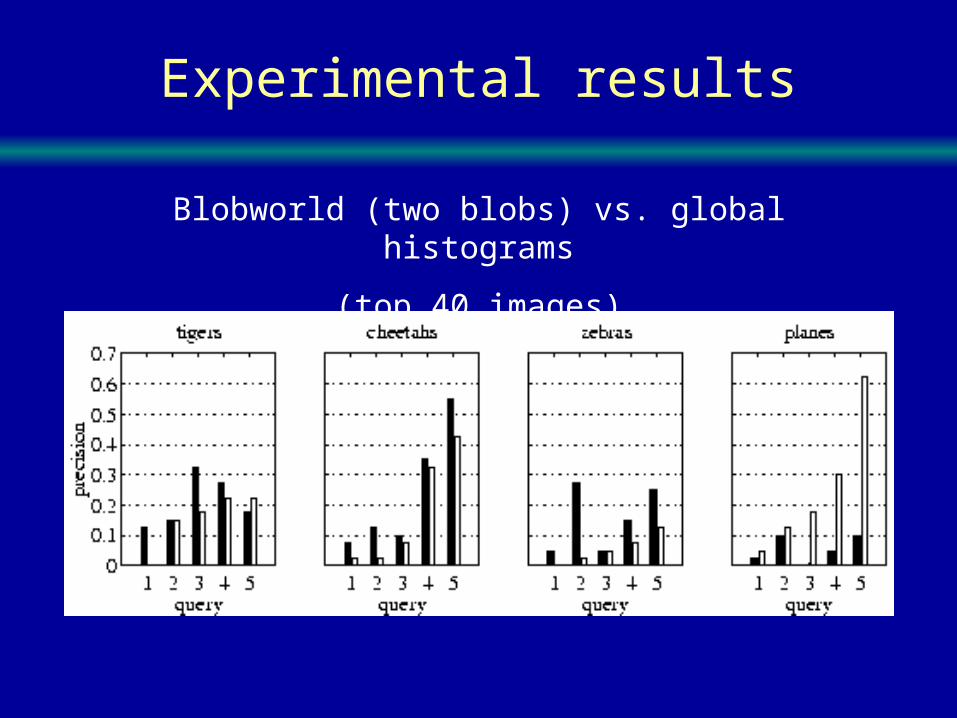
Experimental results
Blobworld (two blobs) vs. global histograms
(top 40 images)

Blobworld vs. global histograms
• Distinctive objects (tigers, cheetahs, zebras):– Blobworld does better
• Distinctive scenes (airplanes):– Global histograms do better
– Adding blob size would help ( “large blue blob”)
• Others:– Both do somewhat poorly, but Blobworld has room to
grow (shape, etc.)

Discussion
• How much can we accomplish using image content alone?– Today
– In the future

Overall Discussion
• What are the tasks?
• Who are the actual users?
• What can we expect of the users?
• How much can we (should we) rely on text?
• How useful is content-based information?
• How good will image understanding need to be before it’s generally useful?