cse 3302 programming languages lecture 2: syntax
TRANSCRIPT

CSE 3302 L2 Spring 2011 1
CSE 3302Programming Languages
Lecture 2: Syntax
(based on slides by Chengkai Li)
Leonidas FegarasUniversity of Texas at Arlington

CSE 3302 L2 Spring 2011 2
How do we define a PL?
• Specifying a PL:– Syntax: the form (structure) of a program– Semantics: the meaning of a program– Pragmatics: the implementation of a PL
• Need a precise definition, without ambiguity– Given a program, there is only one unique interpretation
• Purpose:– For language designers: Convey the design principles of the language– For language implementers: Define precisely what is to be implemented– For language programmers: Describe the language that is to be used
• How to describe?– Natural language: ambiguous– Formal methods: very precise, used extensively (especially for syntax)

CSE 3302 L2 Spring 2011 3
Scanning and Parsing
Lexical Structure: The structure of tokens (words)scanning phase (lexical analysis) : recognize tokens from characters
Syntactical Structure: The structure of programsparsing phase (syntax analysis) : determine the syntactic structure
AST: Abstract Syntax Tree
scanner parser
get token
token
source file
get next character AST

CSE 3302 L2 Spring 2011 4
Scanning
• A scanner groups input characters into tokens
input token value identifier x equal =
identifier x star *x = x * (acc+123) left-paren ( identifier acc plus + integer 123 right-paren )
• Tokens are typically represented by numbers
CSE 3302 L2 Spring 2011 5
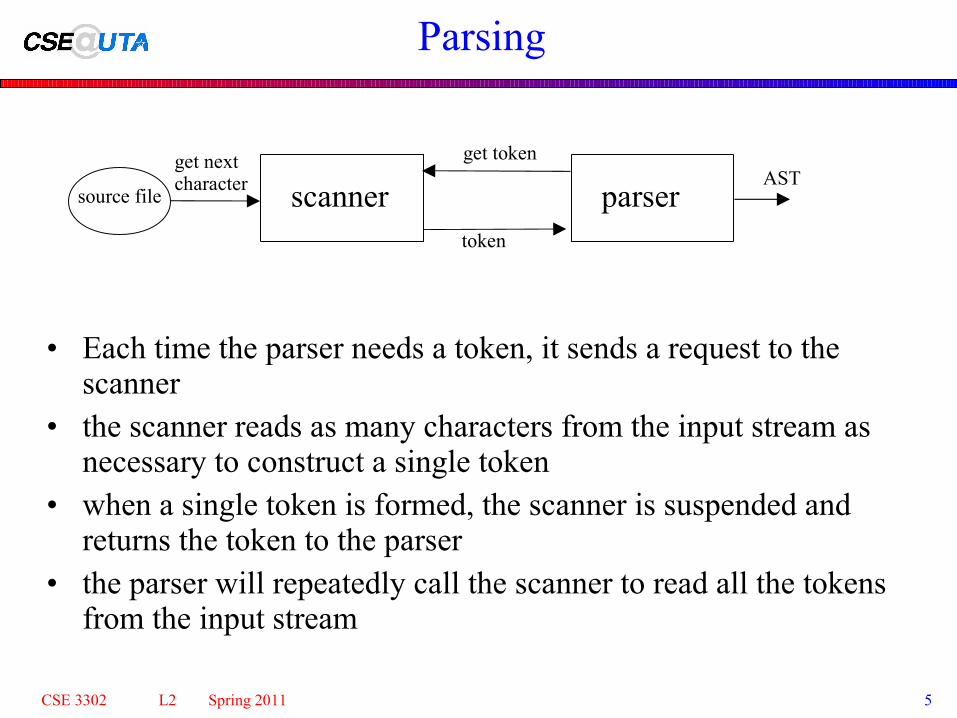
Parsing
• Each time the parser needs a token, it sends a request to the scanner
• the scanner reads as many characters from the input stream as necessary to construct a single token
• when a single token is formed, the scanner is suspended and returns the token to the parser
• the parser will repeatedly call the scanner to read all the tokens from the input stream
scanner parser
get token
token
source file
get next character AST

CSE 3302 L2 Spring 2011 6
Tasks of a Scanner
• A typical scanner:– recognizes the keywords of the language
• these are the reserved words that have a special meaning in the language, such as the words class, while, if, ... in Java
• they cannot be redefined (as variables, etc)
– recognizes special characters, such as ( and ), or groups of special characters, such as := and ==
– recognizes identifiers• predefined identifiers: have initial meaning and allow redefinition
– eg, String, Object, Integer in Java
– recognizes constants: integers, reals, decimals, strings, etc– ignores whitespaces (tabs, blanks, etc) and comments
– recognizes and processes special directives (such as the #include "file" directive in C) and macros

CSE 3302 L2 Spring 2011 7
Scanner Generators
• Input: a scanner specification– describes every token using Regular Expressions (REs)
eg, the RE [az][azAZ09]* recognizes all identifiers with at least one alphanumeric
letter whose first letter is lower-case alphabetic– handles whitespaces and resolve ambiguities
• Output: the actual scanner• Scanner generators compile regular expressions into efficient
programs (finite state machines)– eg, lex, flex, JLex

CSE 3302 L2 Spring 2011 8
Regular Expressions
• are a very convenient form of representing (possibly infinite) sets of strings, called regular sets
Name REepsilon εsymbol a
concatenation ABselection A | B
repetition A*
Shortcuts: A+ = AA* A? = A|ε [a-z] = (a|b|...|z)
• eg, the RE (a | b)*aa represents the infinite set{“aa”,“aaa”,“baa”,“abaa”, ... }
–

CSE 3302 L2 Spring 2011 9
Examples
for-keyword = forletter = [a-zA-Z]digit = [0-9]identifier = letter (letter | digit)*sign = + | - | εinteger = sign (0 | [1-9]digit*)decimal = integer . digit*real = (integer | decimal) E sign digit+

CSE 3302 L2 Spring 2011 10
Disambiguation Rules
• longest match (substring) rule: from all tokens that match the input prefix, choose the one that matches the most characters
• rule priority: if more than one token has the longest match, choose the one listed first
Examples:for8 is it the for-keyword, the identifier “f”, the identifier “fo”, the identifier “for”, or the identifier “for8”? Use rule 1: “for8” matches the most characters.for is it the for-keyword, the identifier “f”, the identifier “fo”, or the identifier “for”? Use rule 1 & 2: the for-keyword and the “for” identifier have the longest match but the for-keyword is listed first.

CSE 3302 L2 Spring 2011 11
Whitespaces
• Principle of longest match requires that tokens are separated by whitespace
• Whitespace (token delimiters):– blanks, newlines, and tabs are ignored, except when they
separate tokens– an exception: FORTRAN
• DO 99 I = 1.10 (the same as DO99I=1.10)• DO 99 I = 1, 10
• Free-format language: the format has no effect on the program structure– Most languages are free format– One exception: python– Haskell uses Indention Syntax to denote structure (optional)
• greatly reduces the amount of junk syntax in the language, such as '{', '}', and ';'

CSE 3302 L2 Spring 2011 12
Parser
• A parser recognizes sequences of tokens according to some grammar and generates Abstract Syntax Trees (ASTs)
• A context-free grammar (CFG) has– a finite set of terminals (tokens)– a finite set of nonterminals from which one is the start symbol– and a finite set of productions of the form:
A → X1 X2 ... Xnwhere A is a nonterminal and each Xi is either a terminal or
nonterminal symbol
scanner parser
get token
token
source file
get next character AST

CSE 3302 L2 Spring 2011 13
Context-Free Grammars
• Example of grammar rules (productions):
(1) sentence → noun-phrase verb-phrase .
(2) noun-phrase → article noun(3) article → a | the
(4) noun → girl | dog
(5) verb-phrase → verb noun-phrase(6) verb → sees | pets

CSE 3302 L2 Spring 2011 14
Languages produced by Grammars
Language: the set of strings (of terminals) that can be generated from the start symbol by derivation:
sentence
⇒ noun-phrase verb-phrase . (rule 1)
⇒ article noun verb-phrase . (rule 2)
⇒ the noun verb-phrase . (rule 3)
⇒ the girl verb-phrase . (rule 4)
⇒ the girl verb noun-phrase . (rule 5)
⇒ the girl sees noun-phrase . (rule 6)
⇒ the girl sees article noun . (rule 2)
⇒ the girl sees a noun . (rule 3)
⇒ the girl sees a dog . (rule 4)

CSE 3302 L2 Spring 2011 15
Context-Free Grammars (CFG)
• Context-Free Grammars (CFG)– Noam Chomsky, 1950s– They define context-free languages
• Four components:– terminals, nonterminals, one start symbol, productions
• Left-hand side of a production is always one single nonterminal:– The nonterminal is replaced by the corresponding right-hand side, no
matter where the nonterminal appears– i.e., there is no context in such replacement/derivation
• Context-sensitive grammars– aX → b– cX → d
• Why context-free?

CSE 3302 L2 Spring 2011 16
Backus-Naur Form (BNF)
• A meta language used to describe CFG• Introduced by John Backus/Peter Naur: for describing the syntax
of Algol60• BNF is formal and precise
E → ID | NUM | E * E | E / E | E + E | E - E | ( E ) ID → a | b |…|z NUM → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9

CSE 3302 L2 Spring 2011 17
Example #2
• An example that describes statements: S → if E then S else S | begin S L | print E L → end | ; S L E → NUM = NUM NUM → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9

CSE 3302 L2 Spring 2011 18
Example #3
• Expressions with terms and factors:
E → E + T
| E - T | T
T → T * F
| T / F | F
F → num
| id

CSE 3302 L2 Spring 2011 19
Derivations
• Notation:– terminals: t, s, ...– nonterminals: A, B, ...– symbol (terminal or nonterminal): X, Y, ...– sequence of symbols: a, b, ...
• Given a production:A ::= X
1 X
2 ... X
n
the form aAb => aX1 X2 ... Xnb is called a derivation
• eg, using the production T ::= T * F we getT / F + 1 x => T * F / F + 1 x
• Leftmost derivation: when you always expand the leftmost nonterminal in the sequence
• Rightmost derivation: ... rightmost nonterminal

CSE 3302 L2 Spring 2011 20
Parse Tree
• Given the derivations used to parse an input sequence, a parse tree has– the start symbol as the root– the terminals of the input sequence as leaves
– for each production A ::= X1 X
2 ... X
n used in a derivation, a node A with
children X1 X
2 ... X
n
E
E T
T T F
F F
id(x) + num(2) * id(y)
From Example #3:E => E + T => E + T * F => T + T * F => T + F * F => T + num * F => F + num * F => id + num * F => id + num * id => x + 2 * y

CSE 3302 L2 Spring 2011 21
Abstract Syntax Tree (AST)
• Abstract Syntax Tree: Removes ``unnecessary’’ terminals and nonterminals but still completely determines syntactic structure
• A parse tree is not an AST– A parse tree is tedious: all terminals and nonterminals in a
derivation are included in the tree
+
*x
y z
E
E T
T T F
F F
id(x) + num(2) * id(y)
AST:

CSE 3302 L2 Spring 2011 22
AST Example
If-statement
if ( expr ) stmt else stmt
If-statement
expr stmt stmt

CSE 3302 L2 Spring 2011 23
What is Parsing?
• Given a grammar and a token string:– determine if the grammar can generate the token string
– ie, is the string a legal program in the language?
• ... or Better:– construct a parse tree for the token string

CSE 3302 L2 Spring 2011 24
What’s significant about a parse tree?
A parse tree gives a unique syntactic structure
• Leftmost vs rightmost derivation• There is only one leftmost derivation and one rightmost
derivation for a parse tree

CSE 3302 L2 Spring 2011 25
Exampleexpr → expr + expr | expr ∗ expr | ( expr ) | number
number → number digit | digit
digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9expr
expr
number
digit
3
*
expr
number
digit
4
expr
number
digit
5
expr
+
parse tree leftmost derivationexpr
number
digit
5
number
digit
3
number
digit
4
exprexpr *
+expr expr

CSE 3302 L2 Spring 2011 26
What’s significant about parse tree?
A parse tree has a unique meaning• It provides a basis for semantic analysis• Syntax-directed semantics: semantics are attached to
syntactic structure– eg, attribute grammars
expr
expr1 expr2+
expr.val = expr1.val + expr2.val

CSE 3302 L2 Spring 2011 27
Language vs Grammar vs Parser
• Chomsky Hierarchy
• A language can be described by multiple grammars, while a grammar defines only one language
• A grammar can be parsed by multiple parsers, while a parser accepts one grammar, thus one language
• Goal: design a language that allows a simple grammar and an efficient parser– Given a language, we should construct a grammar that allows
fast parsing– Given a grammar, we should build an efficient parser

CSE 3302 L2 Spring 2011 28
Ambiguity
• Ambiguous grammar: There can be multiple parse trees for the same token string– multiple leftmost derivations.
• Why is it bad?– Multiple interpretations => no unique meaning

CSE 3302 L2 Spring 2011 29
Ambiguity
• Is this ambiguous?
• How about this?
• How to resolve ambiguity?– Rewrite the grammar to avoid ambiguity
number → number digit | digit
digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
expr → expr - expr | number

CSE 3302 L2 Spring 2011 30
Example of Ambiguity: Precedenceexpr → expr + expr | expr ∗ expr | ( expr )
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
expr
expr
3 *
expr
4
expr
5
expr
+
parse tree 1
Two different parse tress for expression 3+4*5
expr
expr
5
expr *
parse tree 2
+
3
expr
4
expr

CSE 3302 L2 Spring 2011 31
Eliminating Ambiguity for Precedence
• Establish “precedence cascade”– use different structured names for different
constructs, adding grammar rules– higher precedence = lower in cascade
expr → expr + expr | term
term → term ∗ term | ( expr ) | number
expr → expr + expr | expr ∗ expr | ( expr ) | number

CSE 3302 L2 Spring 2011 32
Example of Ambiguity: Associativity
expr → expr - expr | ( expr ) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
expr
expr
5 -
expr
2
expr
1
expr
-
parse tree 1
Two different parse tress for expression 5-2-1
expr
expr
1
expr -
parse tree 2
-
5
expr
2
expr
expr.val = 4 expr.val = 2
it is right-associative, which is against common practice in integer arithmetic
it is left-associative, which is what we usually assume

CSE 3302 L2 Spring 2011 33
Eliminating Ambiguity for Associativity
• left-associativity: left-recursion
expr → expr - term | term
term → (expr) | number
expr → expr - expr | ( expr ) | number
• right-associativity: right-recursion
expr → expr = expr | a | b | c
expr → term = expr | term
term → a | b | c

CSE 3302 L2 Spring 2011 34
Putting all Together
expr → expr - expr | expr / expr | ( expr ) | number
number → number digit | digit
digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
expr → expr - term | term
term → term / factor | factor
factor → ( expr )| number
number → number digit | digit
digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
We want to make minus left-associative and division to have higher precedence than minus

CSE 3302 L2 Spring 2011 35
Example of Ambiguity: dangling-else
stmt → if( expr ) stmt
| if( expr ) stmt else stmt
| other-stmtTwo different parse trees for “if( expr ) if( expr ) stmt else stmt”
stmt
stmt
(expr)
if
if stmt
(expr)
parse tree 1 parse tree 2
stmt else
stmt
(expr)
if
if stmt
(expr) stmtstmt else

CSE 3302 L2 Spring 2011 36
Eliminating Dangling-Else
stmt → matched_stmt | unmatched_stmtmatched_stmt → if( expr ) matched_stmt else matched_stmt
| other-stmtunmatched_stmt → if( expr ) stmt
| if( expr ) matched_stmt else unmatched_stmt
• “else” may occur in both matched_stmt and unmatched_stmt• The statement before “else” must be a matched statement
– Thus, the “else” will not match any “if” inside that statement, otherwise there will be more than one parse tree

CSE 3302 L2 Spring 2011 37
EBNF
• Repetition { }
• Option [ ]
expr → expr - term | term
if-stmt → if ( expr ) stmt
| if ( expr ) stmt else stmt
if-stmt → if ( expr ) stmt [ else stmt ]
number → digit | number digit number → { digit }
signed-number → sign number
| number signed-number → [ sign ] number
expr → term {− term}

CSE 3302 L2 Spring 2011 38
Syntax Diagrams
• Often drawn based on EBNF, not BNF
• Example: If-statement
if
elsestatement
expression
statement
( )if-statement

CSE 3302 L2 Spring 2011 39
Parsing
• Parsing:– Determine if a grammar can generate a given token string– ... or better, construct a parse tree for the token string
• Two ways of constructing the parse tree– Top-down (from root towards leaves)
• Can be constructed more easily by hand
– Bottom-up (from leaves towards root)• Can handle a larger class of grammars
• Parser generators tend to use bottom-up methods

CSE 3302 L2 Spring 2011 40
Top-Down Parser
• Recursive-descent parser: – A special kind of top-down parser: single left-to-right scan, with one lookahead
symbol
– Backtracking (trial-and-error) may happen
• Predictive parser: – The lookahead symbol determines which production to apply, without
backtracking
• Will use the example:E ::= E + T | E - T | TT ::= T * F | T / F | FF ::= num | id

CSE 3302 L2 Spring 2011 41
Top-down Parsing
• It starts from the start symbol of the grammar and applies derivations until the entire input string is derived
• Example that matches the input sequence id(x) + num(2) * id(y)E => E + T use E ::= E + T => E + T * F use T ::= T * F
=> T + T * F use E ::= T => T + F * F use T ::= F => T + num * F use F ::= num => F + num * F use T ::= F => id + num * F use F ::= id => id + num * id use F ::= id
• You may have more than one choice at each derivation step:• my have multiple nonterminals in each sequence• for each nonterminal in the sequence, may have many rules to choose from
• Wrong predictions will cause backtracking• need predictive parsing that never backtracks

CSE 3302 L2 Spring 2011 42
Bottom-up Parsing
• It starts from the input string and uses derivations in the opposite directions (from right to left) until you derive the start symbol
• Previous example:id(x) + num(2) * id(y)<= id(x) + num(2) * F use F ::= id<= id(x) + F * F use F ::= num<= id(x) + T * F use T ::= F<= id(x) + T use T ::= T * F
<= F + T use F ::= id<= T + T use T ::= F<= E + T use E ::= T<= E use E ::= E + T
• At each derivation step, need to recognize a handle (the sequence of symbols that matches the right-hand-side of a production)
• Also known as shift-reduce parsing

CSE 3302 L2 Spring 2011 43
Predictive Parsing
• The goal is to construct a top-down parser that never backtracks• Always leftmost derivations
– left recursion is bad!
• We must transform a grammar in two ways:– eliminate left recursion– perform left factoring
• These rules eliminate most common causes for backtracking although they do not guarantee a completely backtrack-free parsing

CSE 3302 L2 Spring 2011 44
Left Recursion Elimination
• For example, the grammarA ::= A a | b
recognizes the regular expression ba*.• But a top-down parser may have hard time to decide which rule
to use• Need to get rid of left recursion:
A ::= b A'A' ::= a A' |
ie, A' parses the RE a*.• The second rule is recursive, but not left recursive

CSE 3302 L2 Spring 2011 45
Left Recursion Elimination (cont.)
• For each nonterminal X, we partition the productions for X into two groups:– one that contains the left recursive productions– the other with the rest
That is:X ::= X a1
...X ::= X an
where a and b are symbol sequences.• Then we eliminate the left recursion by rewriting these rules into:
X ::= b1 X'
...X ::= bm X'
X ::= b1
...X ::= bm
X' ::= a1 X'
...X' ::= an X'
X' ::=

CSE 3302 L2 Spring 2011 46
Example
E ::= E + T | E - T | TT ::= T * F | T / F | FF ::= num | id
E ::= T E'E' ::= + T E' | - T E' |T ::= F T'T' ::= * F T' | / F T' |F ::= num | id

CSE 3302 L2 Spring 2011 47
Left Factoring
• Factors out common prefixes:X ::= a b1
...X ::= a bn
• becomes:X ::= a X'X' ::= b1
...X' ::= bn
• Example:E ::= T + E | T - E | T
E ::= T E'E' ::= + E | - E |

CSE 3302 L2 Spring 2011 48
Recursive Descent Parsing
E ::= T E'
E' ::= + T E'
| - T E'
|
T ::= F T'
T' ::= * F T'
| / F T'
|
F ::= num
| id
static void E () { T(); Eprime(); }static void Eprime () { if (current_token == PLUS) { read_next_token(); T(); Eprime(); } else if (current_token == MINUS) { read_next_token(); T(); Eprime(); };}static void T () { F(); Tprime(); }static void Tprime() { if (current_token == TIMES) { read_next_token(); F(); Tprime(); } else if (current_token == DIV) { read_next_token(); F(); Tprime(); };}static void F () { if (current_token == NUM || current_token == ID) read_next_token(); else error();}