cs390s, week 3: buffer overflows, part 2 pascal meunier, ph.d., m.sc., cissp january 24, 2007...
Post on 21-Dec-2015
212 views
TRANSCRIPT

CS390S, Week 3: Buffer Overflows, Part 2Pascal Meunier, Ph.D., M.Sc., CISSPJanuary 24, 2007Developed thanks to the support of Symantec Corporation,NSF SFS Capacity Building Program (Award Number 0113725) and the Purdue e-Enterprise CenterCopyright (2004, 2007) Purdue Research Foundation. All rights reserved.

Part II: Topics
Problems (cont.)– Incorrect Specification of Bounds
Malicious sizes Calling sizeof on pointers
– Deficient Error Checking
Correct code and Solutions Exploit prevention mechanisms
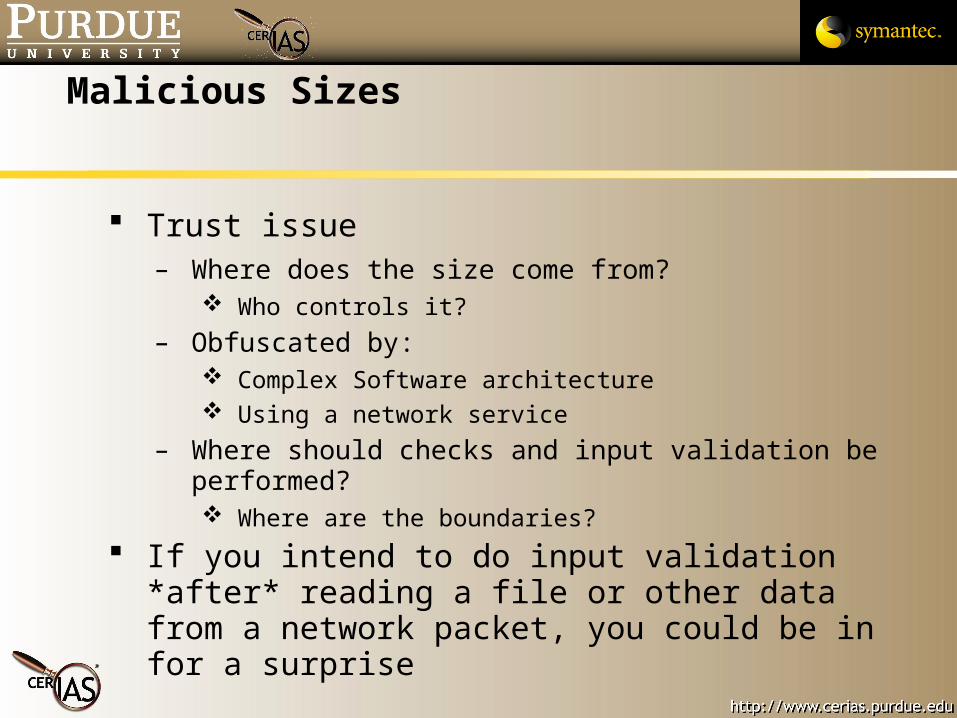
Malicious Sizes
Trust issue– Where does the size come from?
Who controls it?
– Obfuscated by: Complex Software architecture Using a network service
– Where should checks and input validation be performed? Where are the boundaries?
If you intend to do input validation *after* reading a file or other data from a network packet, you could be in for a surprise

Example: Reading a file (.RAR)
Consider this header structure, with a fixed-size array to contain a name:
#define NM 1024struct StreamHeader:SubBlockHeader{
uint UnpSize; byte UnpVer; byte Method; uint StreamCRC; ushort StreamNameSize; byte StreamName[NM];};

The RawRead Class
The RawRead class abstracts reading from a file, by first reading into a cache. Then bytes are read as needed to provide values:
bool RawRead::Get(unsigned short &Field){ if ((m_ReadPos + 1) < m_Data.Size()) { Field = m_Data[m_ReadPos] + (m_Data[m_ReadPos + 1]*LEFT_8); m_ReadPos += 2; return true; } return false;}

Overloaded Get Function
This overload allows reading strings of variable size (note the memcpy call):
bool RawRead::Get(byte *pField, int Size){
if (pField) {
if ((m_ReadPos+Size) <= m_Data.Size()
&& m_Data.Size() > m_ReadPos) {
memcpy(pField, &m_Data[m_ReadPos], Size);
m_ReadPos += Size;
return true;
}
}
return false;
}

Can you spot the bad practice and the vulnerability?
int Archive::ReadHeader(){
RawRead *pRaw;
//(several lines deleted)…
case STREAM_HEAD:
*(SubBlockHeader *)&StreamHead = SubBlockHead;
pRaw->Get(StreamHead.UnpSize);
pRaw->Get(StreamHead.UnpVer);
pRaw->Get(StreamHead.Method);
pRaw->Get(StreamHead.StreamCRC);
pRaw->Get(StreamHead.StreamNameSize);
pRaw->Get((byte *)StreamHead.StreamName,
StreamHead.StreamNameSize);
StreamHead.StreamName[StreamHead.StreamNameSize] = 0;
break;
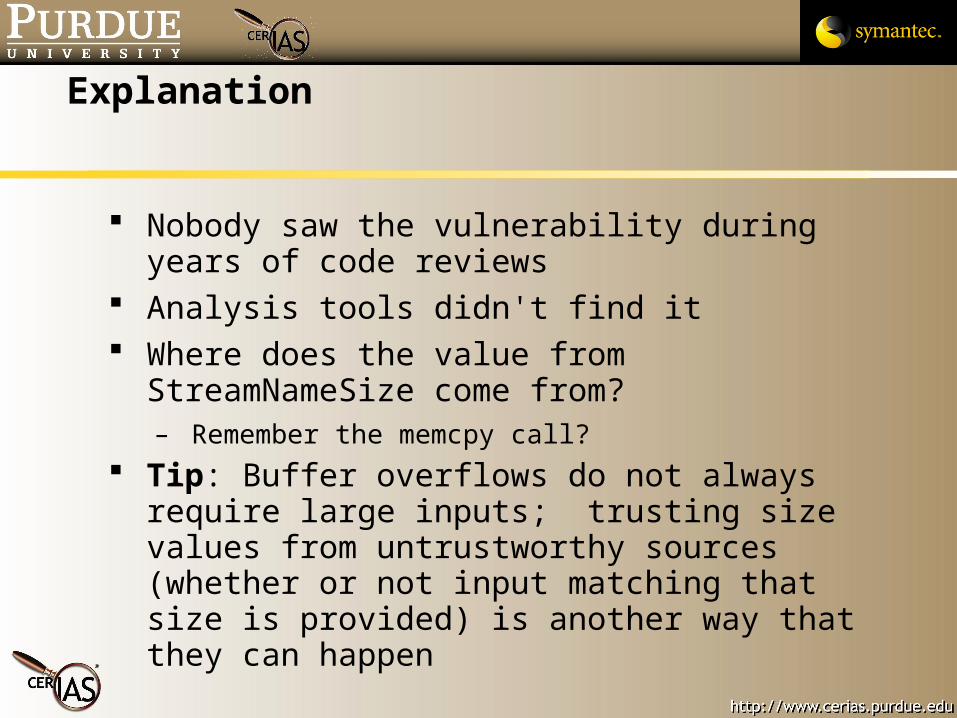
Explanation
Nobody saw the vulnerability during years of code reviews
Analysis tools didn't find it Where does the value from StreamNameSize come
from?– Remember the memcpy call?
Tip: Buffer overflows do not always require large inputs; trusting size values from untrustworthy sources (whether or not input matching that size is provided) is another way that they can happen

Calling sizeof on Pointers
What's the difference between an array and a pointer?– C performs implicit conversions of arrays into pointers!– Can you pass an array to a function?
void print_size(char parameter[]) { printf("Sizeof(parameter): '%d'\n", sizeof(parameter)); strncpy(parameter, "A witty saying", sizeof(parameter)); parameter[sizeof(parameter)-1] = '\0'; printf("The copied string is: %s\n", parameter);}

Summary
Using sizeof on a pointer instead of an array returns the size of the pointer– yet using strlen may be unsafe unless it is known that the
argument is a constant string or a NUL-terminated buffer.
The function strnlen (and several other string functions) can’t be used unless the size of the buffer is known already.
Forcing NUL-termination by setting the last element of the buffer to NUL also requires knowing its size, and has the danger of creating a bus error if in fact the program tries to modify a constant string.
Suggestion: pass the sizes of buffers along with the pointers.

Deficient Error Checking
Language designers typically overload return values with error values to simplify the calling interface– An error is signified by a nonsensical return value
e.g., -1 when a positive integer is expected– Possibly converted to a large positive number by using an
unsigned variable...
– Returned values may be semantically incorrect and cause bugs and crashes
– Programmers need to check returned values at every step of the way In theory, you always should In practice, it's done only on calls that the programmer thinks
can fail (i.e., rarely)

Gets, fgets
char * gets(char *str);– Buffer "str" can be overflowed– Can return NULL in a number of cases
Is str NUL-terminated if a read error occurs?
char * fgets(char * str, int size, FILE * stream);– Buffer "str" is not NUL-terminated if an I/O error occurs– If an error occurs, returns NULL– If end-of-file occurs before any characters are read,
returns NULL also (and buffer is unchanged)– Callers must use feof(3) and ferror(3) to determine which
occurred.

Other Unsafe Functions: sprintf family
int sprintf(char *s, const char *format, /* args*/ ...);– Buffer "s" can be overflowed
int snprintf(char *s, size_t n, const char *format, /* args*/ ...);– Does not guarantee NUL-termination of s on some
platforms (Microsoft, Sun)– MacOS X: NUL-termination guaranteed– Which is it on the class server? Check with "man
sprintf"
int vsprintf(char * str, const char * format, va_list ap);– Buffer "str" can be overflowed
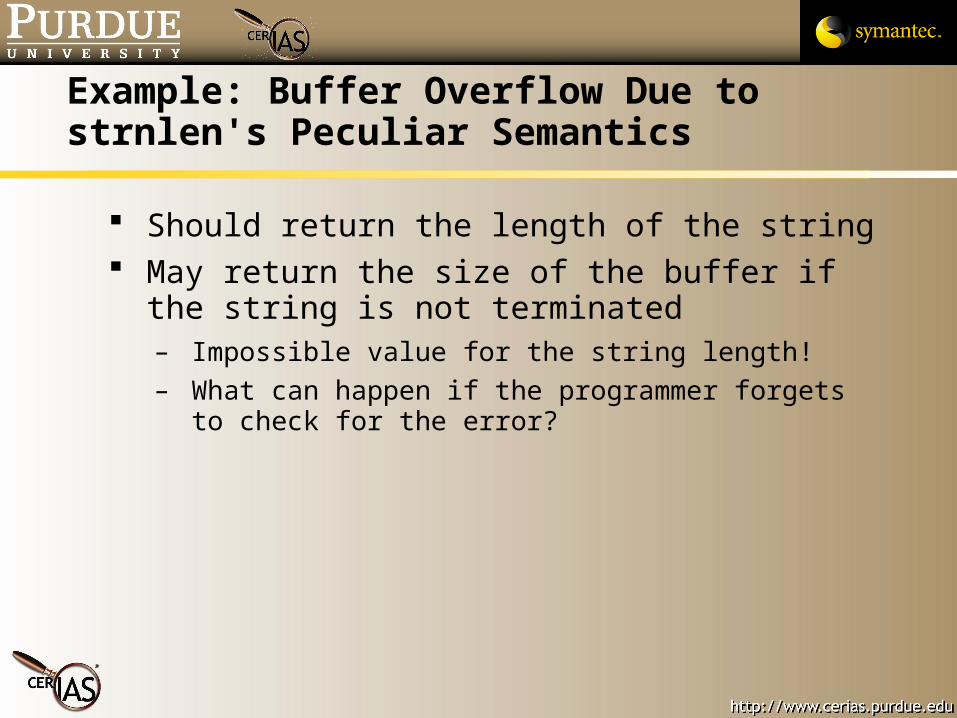
Example: Buffer Overflow Due to strnlen's Peculiar Semantics
Should return the length of the string May return the size of the buffer if the string is not
terminated– Impossible value for the string length!– What can happen if the programmer forgets to check for
the error?

Example Code
char buffer1[BUFF_SIZE]; // setup buffer to not contain any NULsmemset(buffer1, 66, BUFF_SIZE);// Attempt to concatenate a string to buffer1 WRONG!free_length = (sizeof(buffer1) -1) - strnlen(buffer1, sizeof(buffer1));copy_length = MIN(free_length, strlen(large_string));strncat(buffer1, large_string, copy_length);
Causes a segmentation fault!

Tips
Wrap functions with problematic corner cases with your own functions to avoid code duplication and reduce the likelihood that you will forget to handle those cases
When you design your own functions, return semantically safe default values when an error happens, and communicate the error through a parameter (passed by reference)– This is not a license to ignore error conditions, but rather a
guarantee that if you or someone using your functions forget to check for errors or mistakenly believe that errors can't happen at that point, the severity of the bug will be likely reduced.

Correct Code and Solutions
Suggestions Safe unbounded write Safe bounded operations Function replacements Wide and multibyte strings Languages and libraries

Suggestions
Reduce complexity by being systematic– Standardize on the same string library
Don't want to have to include 5 different string libraries in a product because every module uses a different one
– Always compare string lengths Convert buffer sizes to maximum string lengths
– Pass buffer size information with every pointer
Be aware of implied or explicit trust Abort safely by respecting program invariants
– Try to always terminate strings– Return safe values
Check for errors and special cases

Safe Unbounded Copies (Contrived ;)
– int main() { const char * first_string = "A witty saying proves nothing. (Voltaire)"; char buffer1[83]; int error_code; size_t bytes_copied; bytes_copied = copies_galore( first_string, strlen(first_string) +1, buffer1, sizeof(buffer1), &error_code );

Main (cont.)
– // example of demultiplexing errors and data: // we want to know both if an error occurred, // and how many bytes were copied before it // occurred. if (error_code != 0) { printf("Error(s) no. %d occurred.\n", error_code); } printf("We copied %d characters!\n", bytes_copied); return error_code;}

Copies_galore: Declaration and Setup
– #include "string.h"size_t copies_galore (char *s1, size_t s1_size, char *b1, size_t b1_size, int *error_code) // error_code is ORed with a power of 2 // for each possible error{ char * dyn_buf; size_t free_length; size_t copy_length; size_t s1_length; size_t copied_bytes = 0; size_t b1_length;
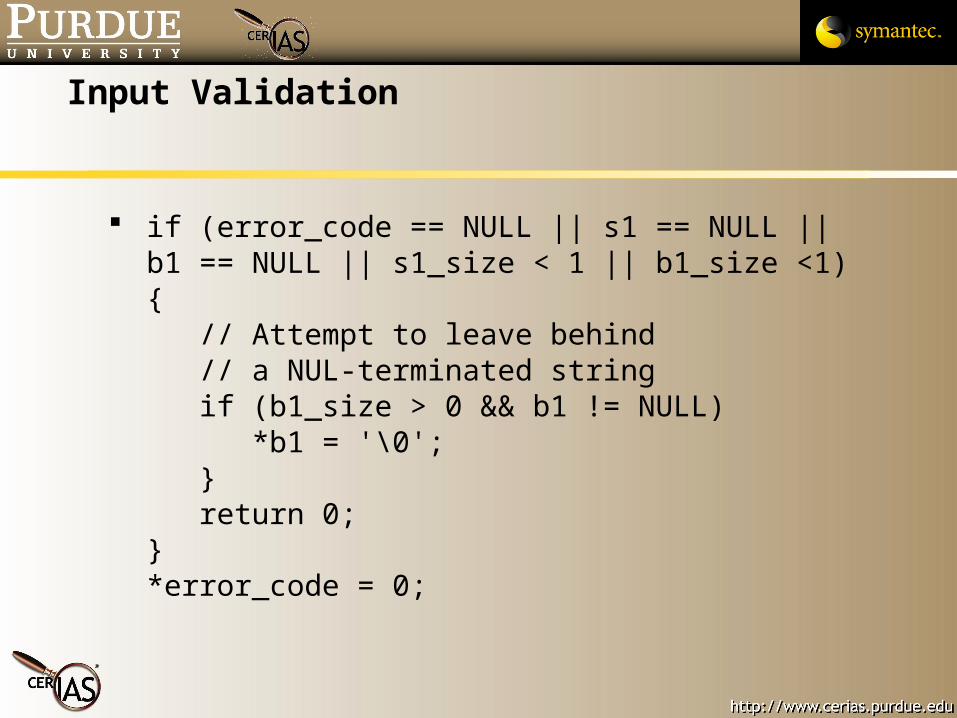
Input Validation
if (error_code == NULL || s1 == NULL || b1 == NULL || s1_size < 1 || b1_size <1) { // Attempt to leave behind // a NUL-terminated string if (b1_size > 0 && b1 != NULL) *b1 = '\0'; } return 0;}*error_code = 0;

Copy From a Fixed String to a Buffer: Checks
– // Don't do this: s1[s1_size - 1] = '\0';// to make a call to strlen safe. // You'll get a bus error if s1 is a constant string!// The following code is safe whether s1 is a// constant string or a buffers1_length = strnlen(s1, s1_size);if (s1_length == s1_size) { *error_code = 1; printf("%s\n", "Source is not NUL-terminated");} else {

Copy From a Fixed String to a Buffer: Copy
// convert b1_size to length
// to compare length against length
if (s1_length > (b1_size - 1)) {
*error_code = *error_code | 2;
printf("%s\n", "Buffer1 is too small");
} else {
// return value is not checked
// because it is simply b1
strcpy(b1, s1);
printf("Copied string: '%s'\n", b1);
copied_bytes = copied_bytes + s1_length;
}
}

Dynamic Memory Allocation: Checks
b1_length = strnlen(b1, b1_size); if (b1_length == b1_size) { // note that this could happen // if b1 was not copied to // earlier! *error_code = *error_code | 4; printf("%s\n", "b1 was not NUL-terminated"); return copied_bytes; }

Dynamic Memory Allocation: Allocation
– // allocation takes a size so it's length+1 dyn_buf = (char *) malloc(b1_length + 1); if (dyn_buf == NULL) { printf("Error allocating memory\n"); *error_code = *error_code | 8; } else {
Why is the calculation "b1_length + 1" safe?

Dynamic Memory Allocation: Copy
strcpy(dyn_buf, b1); printf("Dynamically allocated string: %s\n", dyn_buf); copied_bytes = copied_bytes + b1_length;

Concatenation
free_length = (b1_size - 1) - b1_length;
// we know that this call to strlen is safe,
// otherwise use strnlen as above
copy_length = strlen(dyn_buf);
printf("Copy length: %u\n", copy_length);
if (free_length >= copy_length) {
strcat(b1, dyn_buf);
printf("Concatenated string: '%s'\n", b1);
printf("Length of concatenated string: %u\n",
strlen(b1));
copied_bytes = copied_bytes + copy_length;
} else {

Copies Galore: End
– *error_code = *error_code | 16; printf("%s\n", "Copy could not be done."); } // free dynamically allocated memory! free(dyn_buf); } return copied_bytes;}

Safe Bounded Operations: No Truncation
int main()
{
const char * first_string = "A witty saying
proves nothing. (Voltaire)";
int BUFF_SIZE = 40;
char buffer[BUFF_SIZE];
if (strlen(first_string)+1 > BUFF_SIZE) {
buffer[0] = '\0';
printf("%s\n", "Buffer is too small, string
cannot be copied");
} else {

No Truncation (cont)
// return value is not checked because it is
simply buffer
// last argument is # of bytes to copy
// including NUL byte
strncpy(buffer, first_string,
strlen(first_string)+1);
printf("Copied string: '%s'\n", buffer);
}
return 0;
}
Note how strncpy and strcpy are interchangeable without loss
of safety; strncpy doesn't provide an advantage when truncation
is undesirable

Truncating Copy: Setup
– #define MIN(a,b) (((a) <= (b)) ? (a) : (b))#include "string.h"int main(){ const char * first_string = "A witty saying proves nothing. (Voltaire)"; size_t BUFF_SIZE = 75; // 41 characters + 33 (copy) + 1 for NUL size_t copy_length; // "length" implies string size_t free_length; char buffer1[BUFF_SIZE]; char buffer2[34]; // copy 33 characters

Truncating Copy: From Constant to Buffer
– // Source is guaranteed to be NUL-terminated strncpy(buffer1, first_string, BUFF_SIZE-1); buffer1[BUFF_SIZE-1] = '\0'; printf("Copied string: '%s'\n", buffer1);

Truncating Copy: Buffer to Buffer
– // Source might not be NUL-terminated// copy length must be <= size of destination -1// this assumes buffers of at least 1 byte// sizes should be checked if not obviously correct copy_length = MIN(sizeof(buffer1) -1, sizeof(buffer2) - 1);strncpy(buffer2, buffer1, copy_length);// Postcondition: destination must be NUL-terminatedbuffer2[copy_length] = '\0';printf("Copied buffer to buffer: '%s'\n", buffer2);

Concatenation
// Precondition: destination must be NUL-terminated
// or call to strlen replaced with strnlen with
// appropriate checks to avoid integer underflow
// copy length must be <= length left in destination
free_length = sizeof(buffer1)-1 - strlen(buffer1);
copy_length = MIN(free_length, sizeof(buffer2) - 1);
printf("Copy size: %u\n", copy_length);
strncat(buffer1, buffer2, copy_length);
printf("Concatenated string: '%s'\n", buffer1);
printf("Length of concatenated string: '%u'\n",
strlen(buffer1));
return 0;
}

Safely Using snprintf
int main(){ char * first_string = "A witty saying proves nothing. (Voltaire)"; int BUFF_SIZE = 42; char buffer1[BUFF_SIZE]; int length_copied;
length_copied = snprintf(buffer1, BUFF_SIZE, "%s", first_string);

Checks for snprintf
– if (length_copied < 0) { // safely terminate buffer1 if it is used later // regardless of the error buffer1[0] = '\0'; printf("%s\n", "An output error occurred"); } else { if (length_copied >= BUFF_SIZE) { buffer1[BUFF_SIZE -1] = '\0'; printf("%s\n", "string was truncated"); } printf("Copied string: '%s'\n", buffer1); } return 0;}

Wide Character Strings
Defining a macro to calculate element sizes can help the situation (as wide-character codes have a fixed number of bytes per character):
– #define ELEMSIZE(s) (sizeof(s)/sizeof(s[0]))
An example safe copy using wcsncpy is (assuming that pUnvalidatedInput points to a valid string):
– wchar_t buffer[20] = {0};wcsncpy(buffer, pUnvalidatedInput, ELEMSIZE(buffer)-1);

Visual Studio _countof Macro
Windows programmers may be used to a similar _countof macro.
Microsoft has improved the _countof macro in Visual Studio 2005, to cause a compile-time error in C++ if a non-array is passed. This helps prevent the common problem of using sizeof on a pointer (resulting in 4 or 8 bytes) when a buffer size was desired instead.

Languages and Libraries
Pitfall: Using many libraries simultaneously– std::string– CString– CComBSTR– _bstr_t– etc...
Bugs happen due to different usage conventions, and conversion issues
Safestr
Free library available at: http://zork.org Features:
– Works on UNIX and Windows– Buffer overflow protection– String format protection– "Taint-tracking" (à la Perl's taint mode)
Limitations and differences:– Does not handle multi-byte characters– License: binaries must reproduce a copyright notice– NUL characters have no special meaning– Must use their library functions all the time (but conversion
to regular "C" strings is easy)

Microsoft Strsafe
Null-termination guaranteed Option for using either number of characters or
bytes (for Unicode character encoding), and disallowing the other
Option to treat truncation as a fatal error Define behavior upon error
– Output buffer set to "" or filled
Option to prevent information leaks– Pad rest of buffer
However, correct calculations still needed– e.g., wcsncat requires calculating the remaining space in
the destination string...

Microsoft
Visual Studio 2005 has a new series of safe string manipulation functions– strcpy_s()– strncpy_s()– strncat_s()– strnlen()– etc...
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dncode/html/secure05202002.asp
Visual Studio 2005 (as of Beta 1) by default issues deprecation warnings on strcpy, strncpy, etc… Say goodbye to your old friends, they're too dangerous!

Libraries Trade-off
Usually buffer management problems are traded for memory management problems (memory leaks)
Features to look for:– License that allows its use without legal headaches
terms and fees
– Garbage collection– Ease-of-use (by contrast to ease of making mistakes)– Portability– Performance– Internationalization capabilities– Training and experience

Derivative Languages
Cyclone is a dialect of C that guarantees the safety of operations that could, for example, result in buffer overflows
Fat pointers automatically include size information Static safety analysis Garbage collection available if desired

Preventing Buffer Overflows Without Programming
Idea: make the heap and stack non-executable– Because many buffer overflow attacks aim at executing
code in the data that overflowed the buffer
Doesn't prevent "return into libc" overflow attacks– Because the return address of the function on the stack
points to a standard "C" function (e.g., "system"), this attack doesn't execute code on the stack
e.g., ExecShield for Fedora Linux (used to be RedHat Linux)

A Typical Stack Exploit (386 architecture)
The stack contains:– Parameters (arguments) to function– Return Address– Local variables– Anything pushed on the stack
addr[100+] overwrites the return address
addr[0] typicallycontains exploitcode
Return address ischosen to point at exploitcode!
Arguments
Return Address
Low Addresses
High Addresses
Stack grows this way
addr[99]
addr[0]

Canaries on a Stack
Add a few bytes containing special values between variables on the stack and the return address.
Before the function returns, check that the values are intact.– If not, there's been a buffer overflow!
Terminate program
If the goal was a Denial-of-Service then it still happens– At least the machine is not compromised
If the canary can be read by an attacker, then a buffer overflow exploit can be made to rewrite them– e.g., see string format vulnerabilities

Canary Implementations
StackGuard Stack-Smashing Protector (SSP)
– Formerly ProPolice– gcc modification– Used in OpenBSD– http://www.trl.ibm.com/projects/security/ssp/
Windows: /GS option for Visual C++ .NET These can be useful when testing too!

Protection Using Virtual Memory Pages
Page: A chunk (unit) of virtual memory POSIX systems have three permissions for each
page.– PROT_READ– PROT_WRITE– PROT_EXEC
Idea: manipulate and enforce these permissions correctly to defend against buffer overflows– Make injected code non-executable

OpenBSD
PROT_* purity (correct enforcement of permissions for pages in VM system; i386 and PowerPC architectures limit this)
W^X (write permission is exclusive of execute)– Data shouldn't need to be executed!– Limits also self-modifying (machine) code
.rodata (read-only data is enforced to be read-only on a separate page)

Windows Execution Protection
"NX" (No Execute) Windows XP service pack 2 feature
– Somewhat similar to POSIX permissions
Requires processor support– AMD64– Intel Itanium

Question
A buffer overflow is not exploitable if:
a) It happens in the heap
b) It happens in the stack
c) It happens where memory is not executable
d) None of the above

Question
A buffer overflow is not exploitable if:
a) It happens in the heap
b) It happens in the stack
c) It happens where memory is not executable
d) None of the above

Question
Making some memory locations non-executable protects against which variants of buffer overflow attacks?
a) Code in the overwritten data
b) Return into libc
c) Variable corruption

Question
Making some memory locations non-executable protects against which variants of buffer overflow attacks?
a) Code in the overwritten data
b) Return into libc
c) Variable corruption

Questions or Comments?

Pascal Meunier
Contributors:Jared Robinson, Alan Krassowski, Craig Ozancin, Tim Brown, Wes Higaki, Melissa Dark, Chris Clifton, Gustavo Rodriguez-Rivera