cs246 search engine bias. junghoo "john" cho (ucla computer science)2 motivation “if you...
Post on 20-Dec-2015
218 views
TRANSCRIPT

CS246
Search Engine Bias

Junghoo "John" Cho (UCLA Computer Science) 2
Motivation
“If you are not indexed by Google, you do not exist on the Web” --- news.com article
People “discover” pages through search engines Top results: many users Bottom results: no new users
Are we biased by search engines?

Junghoo "John" Cho (UCLA Computer Science) 3
Research issues
Are we biased by search engines? Impact of Search Engines on Page Popularity
Can we avoid search engine bias? Page Quality: In Search of Unbiased Web
Ranking Shuffling a Stacked Deck: The Case for Partially
Randomized Ranking of Search Engine Results

Junghoo "John" Cho (UCLA Computer Science) 4
Questions to Address
Are the rich getting richer? Web popularity evolution experiments
How much bias do search engines introduce? Web user models and popularity evolution
analysis
Any potential solution to the problem? Less biased ranking metric Introducing randomness to search results

Junghoo "John" Cho (UCLA Computer Science) 5
Web Evolution Experiment
Collect Web history data Is “rich-get-richer” happening?
From Oct. 2002 until Oct. 2003 154 sites monitored
Top sites from each category of Open Directory
Pages downloaded every week All pages in each site A total of average 4M pages every week (65GB)

Junghoo "John" Cho (UCLA Computer Science) 6
“Rich-Get-Richer” Problem
Construct weekly Web-link graph From the downloaded data
Partition pages into 10 groups Based on initial link popularity Top 10% group, 10%-20% group, etc.
How many new links to each group after a month? Rich-get-richer More new links to top groups

Junghoo "John" Cho (UCLA Computer Science) 7
Result: Simple Link Count
After 7 months 70% of new links to the top 20% group No new links to bottom 60% groups

Junghoo "John" Cho (UCLA Computer Science) 8
Result: PageRank
After 7 months Decrease in PageRank for bottom 50% pages Due to normalization of PageRank

Junghoo "John" Cho (UCLA Computer Science) 9
Impact of Search Engines
Yes, the rich seems to get richer, but is it because of search engine? Even further, is it really a “bias”?
Study of bias from search engine is necessary

Junghoo "John" Cho (UCLA Computer Science) 10
Search Engine Bias
What we mean by bias? What is the ideal ranking?
How do search engines rank pages?

Junghoo "John" Cho (UCLA Computer Science) 11
What is the Ideal Ranking?
Rank by intrinsic “quality” of a page? Very subjective notion
Different quality judgment on the same page Can there be an “objective” definition?

Junghoo "John" Cho (UCLA Computer Science) 12
Page Quality Q(p)
The probability that an average Web user will like page p if he looks at it
In principle, we can measure Q(p) by1. showing p to all Web users and2. counting how many people like it
p1: 10,000 people, 8,000 liked it, Q(p1) = 0.8 p2: 10,000 people, 2,000 liked it, Q(p2) = 0.2
Democratic measure of quality When consensus is hard to reach, pick the one
that more people like

Junghoo "John" Cho (UCLA Computer Science) 13
PageRank: Practical Ranking
A page is “important” if many pages link to it Not every link is equal A link from an “important” page matters more than
others PR(pi) = (1 - d) + d [PR(p1)/c1 + · · · +
PR(pm)/cm]
Random-Surfer Model When users follow links randomly, PR(pi) is the
probability to reach pi

Junghoo "John" Cho (UCLA Computer Science) 14
PageRank vs. Quality
PageRank ~ Page quality if everyone is given equal chance
High PageRank high quality To obtain high PageRank, many people should
look at the page and like it.
Low PageRank low quality? PageRank is biased against new pages
How much bias for low PageRank pages?

Junghoo "John" Cho (UCLA Computer Science) 15
Measuring Search Engine Bias
Ideal experiment: Divide the world into two groups The users who do not use search engines The users who use search engines very heavily Compare popularity evolution
Problem: Difficult to conduct in practice

Junghoo "John" Cho (UCLA Computer Science) 16
Theoretical Web-User Model
Let us do theoretical experiments! Random-surfer model
Users follow links randomly Never use serach engine
Search-dominant model Users always start with a search engine Only visit pages returned by search engine
Compare popularity evolution

Junghoo "John" Cho (UCLA Computer Science) 17
Basic Definitions
Simple popularity P(p,t) Fraction of Web users who like p at time t E.g., 100,000 users, 10,000 like p, P(p,t)=0.1
Visit popularity V(p,t) # users that visit p in a unit time
Awareness A(p,t) Fraction of Web users who are aware of p E.g, 100,000 users, 30,000 aware of p, A(p,t)=0.3
P(p,t) = Q(p) A(p,t)

Junghoo "John" Cho (UCLA Computer Science) 18
Random-Surfer Model
Popularity-equivalence hypothesis V(p,t) = r P(P,t) (r: proportionality constant) Rationale: PageRank is visit popularity under the
random-surfer model
Random-visit hypothesis A visit done by any user with equal probability Simplifying assumption

Junghoo "John" Cho (UCLA Computer Science) 19
Random-Surfer Model: Analysis
Current popularity P(p,t) Number of visitors from V(p,t) = r P(p,t) Awareness increase ∆A(p,t) Popularity increase ∆P(p,t) New popularity P(p,t+1)
Formal analysis: Differential equation
)(]1[),( 0),(
pQetpPt
dttpPn
r

Junghoo "John" Cho (UCLA Computer Science) 20
Random-Surfer Model: Result
The popularity of page p evolves over time as
Q(p): quality of p P(p,0): initial popularity of p at time zero N: total number of Web users R: proportionality constant
tpQn
r
epPpQ
pQtpP
)(]1
)0,()(
[1
)(),(

Junghoo "John" Cho (UCLA Computer Science) 21
Random-Surfer Model: Popularity Evolution
5 20 25 30 35
0.2
0.4
0.6
0.8
1.0
Infant Expansion Maturity
Popularity
Time1510
Q(p)=1 P(p,0)=10^-8 r/n = 1

Junghoo "John" Cho (UCLA Computer Science) 22
Search-Dominant Model
V(p,t) ~ P(p,t)? For i th result, how many clicks? For PageRank P(p,t), what ranking? Empirical measurements
New Visit-popularity hypothesis V(p,t) = r P(p,t)9/4
Random-visit hypothesis
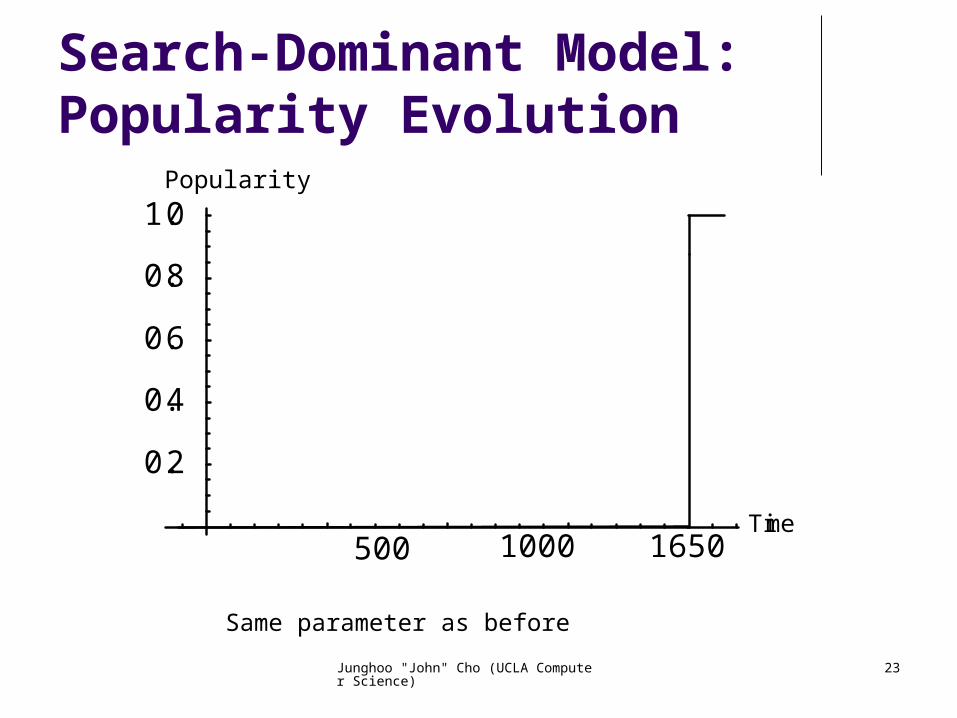
Junghoo "John" Cho (UCLA Computer Science) 23
Search-Dominant Model: Popularity Evolution
500 1000 1650Time
0.2
0.4
0.6
0.8
1.0Popularity
Same parameter as before

Junghoo "John" Cho (UCLA Computer Science) 24
Comparison of Two Models
Time to final popularity 66 times increase!
Expansion stage Random surfer: 12 time units Search dominant: non existent
5 20 25 30 35
0.2
0.4
0.6
0.8
1.0
Infant Expansion Maturity
Popularity
Time1510 500 1000 1650
Time
0.2
0.4
0.6
0.8
1.0Popularity
Random-surfer model
Search-dominant model

Junghoo "John" Cho (UCLA Computer Science) 25
Reducing the Bias?
Many possibilities! Can we measure quality? Will randomness help?
Show some random pages in search results Give a new page a chance

Junghoo "John" Cho (UCLA Computer Science) 26
Measuring Quality: Basic Idea
Quality: probability of link creation by a new visitor
Assuming the same number of visitors Q(p) # of new links (or popularity increase)
Quality estimatorQ(p) = P(p)

Junghoo "John" Cho (UCLA Computer Science) 27
Measuring Quality: Problem (1)
Different number of visitors to each page More visitors to more popular pages How to account for # of visitors?
Quality estimatorQ(p) = P(p) / P(p)
Idea: PageRank = # of visitors Divide by current PageRank

Junghoo "John" Cho (UCLA Computer Science) 28
Measuring Quality: Problem (2)
No more new links to very popular pages Everyone already knows them P(p) / P(p) ~ 0 for well-known pages How to account for well-known pages?
Quality estimatorQ(p) = P(p) / P(p) + C P(p)
Idea: P(p) = Q(p) when everyone knows p Use P(p) to measure Q(p) for well-known pages

Junghoo "John" Cho (UCLA Computer Science) 29
Quality Estimator: Theory
Under the random-surfer model, Q(p) is
Essentially the same as the previous formula
Q(p) = P(p) / P(p) + CP(p)
),(),(
/),()( tpP
tpP
dttpPd
r
npQ

Junghoo "John" Cho (UCLA Computer Science) 30
Is Quality Estimator Effective?
How to measure its effectiveness? Implement it to a major search engine? Any other alternatives?
Idea Pages eventually obtain deserved popularity
(however long it may take…) “Future” PageRank ~ Q(p)

Junghoo "John" Cho (UCLA Computer Science) 31
Quality Estimator: Evaluation
Q(p) as a predictor of future PageRank Compare the correlations of
Current Q(p) with future PageRank Current PageRank with future PageRank
Does Q(p) predicts future PageRank better?
PR’(p)Q(p)PR(p) ?
Experiments Download Web multiple times with long interval

Junghoo "John" Cho (UCLA Computer Science) 32
Quality Estimator: Evaluation
Compare relative error
Result For Q(p): err(p) = 0.45 For PR(p): err(p) = 0.74 Q(p) is significantly better than PR(p)
)(for )('/)()('
)(for )('/)()(')(
pPRpPRpPRpPR
pQpPRpQpPRperr

Junghoo "John" Cho (UCLA Computer Science) 33
Quality Estimator: Detail

Junghoo "John" Cho (UCLA Computer Science) 34
Randomization
Let us give new pages a chance to prove themselves Introduce randomness in search results Say, 10% of results are randomly selected from new pages
Why is randomization good? New high-quality pages will be promoted quickly But is it really important?
Counter argument Most new pages are bad Why should users bother looking at them?

Junghoo "John" Cho (UCLA Computer Science) 35
Average Quality Per Click
Bottom line: User’s satisfaction Make sure users like the pages they click
Tradeoff of randomization Positive: High-quality new pages will become
popular more quickly Improvement in search quality
Negative: Randomly selected pages are likely to be of low quality Decrease in search quality

Junghoo "John" Cho (UCLA Computer Science) 36
Exploration/Exploitation Tradeoff

Junghoo "John" Cho (UCLA Computer Science) 37
Joke Experiments (1)
Ranked list of jokes Users click on a link and read a joke Provide positive or negative feedback “Simulated search”
Two ranked lists and user groups1. Popularity-based: ranked by # of positive votes
2. Popularity + randomization
1000 users participated

Junghoo "John" Cho (UCLA Computer Science) 38
Joke Experiments (2)
Ranking determines the popularity evolution of jokes Compare the evolution and evaluate
Evaluation metric Fraction of positive user votes
Result Popularity only: 0.2 Popularity + randomization: 0.35

Junghoo "John" Cho (UCLA Computer Science) 39
More Analytical Study
Based on search-dominant user model But pages get created and deleted over time
In most cases, 10-20% randomization is helpful Optimal randomness depends on exact
parameter settings

Junghoo "John" Cho (UCLA Computer Science) 40
Summary
Search engine bias Do search engines make popular pages more
popular?
Experimental and analytical study Strong possibility
Possible solutions Less biased ranking metric Randomization in search results