cs224d: deep nlp lecture 13: convolutional neural networks ... · cs224d: deep nlp lecture 13:...
TRANSCRIPT


Overviewoftoday
• FromRNNstoCNNs
• CNNVariant1:Simplesinglelayer• Application:Sentenceclassification• Moredetailsandtricks• Evaluation• Comparisonbetweensentencemodels:BoV,RNNs2,CNNs
• CNNVariant2:Complexmultilayer
5/12/16RichardSocher

FromRNNstoCNNs
5/12/16RichardSocher
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
2.53.8
5.56.1
13.5
15
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
4.53.8
5.56.1
13.5
15
2.53.8

FromRNNstoCNNs
5/12/16RichardSocher
• Recursiveneuralnetsrequireaparsertogettreestructure
• Recurrentneuralnetscannotcapturephraseswithoutprefixcontextandoftencapturetoomuchoflastwordsinfinalvector
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
2.53.8
5.56.1
13.5
15
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
4.53.8
5.56.1
13.5
15
2.53.8

FromRNNstoCNNs
5/12/16RichardSocher
• RNN:Getcompositionalvectorsforgrammaticalphrasesonly
• CNN:Whatifwecomputevectorsforeverypossiblephrase?• Example:“thecountryofmybirth”computesvectorsfor:
• thecountry,countryof,ofmy,mybirth,thecountryof,countryofmy,ofmybirth,thecountryofmy,countryofmybirth
• Regardlessofwhetheritisgrammatical• Wouldn’tneedparser• Notverylinguisticallyorcognitivelyplausible

Whatisconvolutionanyway?
5/12/16RichardSocher
• 1ddiscreteconvolutiongenerally:
• Convolutionisgreattoextractfeaturesfromimages
• 2dexampleà• Yellowshowsfilterweights• Greenshowsinput
StanfordUFLDLwiki

FromRNNstoCNNs
5/12/16RichardSocher
• Firstlayer:computeallbigramvectors
• SamecomputationasinRNNbutforeverypair
• Thiscanbeinterpretedasaconvolutionoverthewordvectors
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
2.53.8
5.56.1
13.5
15

FromRNNstoCNNs
5/12/16RichardSocher
• Nowmultipleoptionstocomputehigherlayers.• Firstoption(simpletounderstandbutnotnecessarilybest)• Justrepeatwithdifferentweights:
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
2.53.8
5.56.1
13.5
15
23.5
45.5
13.5

FromRNNstoCNNs
5/12/16RichardSocher
• Firstoption(simpletounderstandbutnotnecessarilybest)
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
2.53.8
5.56.1
13.5
15
23.5
45.5
13.5
23.5
45.5

FromRNNstoCNNs
5/12/16RichardSocher
• Firstoption(simpletounderstandbutnotnecessarilybest)
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
2.53.8
5.56.1
13.5
15
23.5
45.5
13.5
23.5
45.5
33.5

SingleLayerCNN
• Asimplevariantusingoneconvolutionallayerandpooling• BasedonCollobertandWeston(2011)andKim(2014)
“ConvolutionalNeuralNetworksforSentenceClassification”• Wordvectors:• Sentence: (vectorsconcatenated)• Concatenationofwordsinrange:• Convolutionalfilter: (goesoverwindowofhwords)• Couldbe2(asbefore)higher,e.g.3:
5/12/16RichardSocher
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1746–1751,October 25-29, 2014, Doha, Qatar. c�2014 Association for Computational Linguistics
Convolutional Neural Networks for Sentence Classification
Yoon KimNew York [email protected]
AbstractWe report on a series of experiments withconvolutional neural networks (CNN)trained on top of pre-trained word vec-tors for sentence-level classification tasks.We show that a simple CNN with lit-tle hyperparameter tuning and static vec-tors achieves excellent results on multi-ple benchmarks. Learning task-specificvectors through fine-tuning offers furthergains in performance. We additionallypropose a simple modification to the ar-chitecture to allow for the use of bothtask-specific and static vectors. The CNNmodels discussed herein improve upon thestate of the art on 4 out of 7 tasks, whichinclude sentiment analysis and questionclassification.
1 IntroductionDeep learning models have achieved remarkableresults in computer vision (Krizhevsky et al.,2012) and speech recognition (Graves et al., 2013)in recent years. Within natural language process-ing, much of the work with deep learning meth-ods has involved learning word vector representa-tions through neural language models (Bengio etal., 2003; Yih et al., 2011; Mikolov et al., 2013)and performing composition over the learned wordvectors for classification (Collobert et al., 2011).Word vectors, wherein words are projected from asparse, 1-of-V encoding (here V is the vocabularysize) onto a lower dimensional vector space via ahidden layer, are essentially feature extractors thatencode semantic features of words in their dimen-sions. In such dense representations, semanticallyclose words are likewise close—in euclidean orcosine distance—in the lower dimensional vectorspace.
Convolutional neural networks (CNN) utilizelayers with convolving filters that are applied to
local features (LeCun et al., 1998). Originallyinvented for computer vision, CNN models havesubsequently been shown to be effective for NLPand have achieved excellent results in semanticparsing (Yih et al., 2014), search query retrieval(Shen et al., 2014), sentence modeling (Kalch-brenner et al., 2014), and other traditional NLPtasks (Collobert et al., 2011).
In the present work, we train a simple CNN withone layer of convolution on top of word vectorsobtained from an unsupervised neural languagemodel. These vectors were trained by Mikolov etal. (2013) on 100 billion words of Google News,and are publicly available.1 We initially keep theword vectors static and learn only the other param-eters of the model. Despite little tuning of hyper-parameters, this simple model achieves excellentresults on multiple benchmarks, suggesting thatthe pre-trained vectors are ‘universal’ feature ex-tractors that can be utilized for various classifica-tion tasks. Learning task-specific vectors throughfine-tuning results in further improvements. Wefinally describe a simple modification to the archi-tecture to allow for the use of both pre-trained andtask-specific vectors by having multiple channels.
Our work is philosophically similar to Razavianet al. (2014) which showed that for image clas-sification, feature extractors obtained from a pre-trained deep learning model perform well on a va-riety of tasks—including tasks that are very dif-ferent from the original task for which the featureextractors were trained.
2 Model
The model architecture, shown in figure 1, is aslight variant of the CNN architecture of Collobertet al. (2011). Let xi 2 Rk be the k-dimensionalword vector corresponding to the i-th word in thesentence. A sentence of length n (padded where
1https://code.google.com/p/word2vec/
1746
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
1.1

SinglelayerCNN
• Convolutionalfilter: (goesoverwindowofhwords)• Note,filterisvector!• Windowsizehcouldbe2(asbefore)orhigher,e.g.3:• TocomputefeatureforCNNlayer:
5/12/16RichardSocher
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
1.1

SinglelayerCNN
• Filterwisappliedtoallpossiblewindows(concatenatedvectors)
• Sentence:
• Allpossiblewindowsoflengthh:
• Resultisafeaturemap:
5/12/16RichardSocher
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
1.1 3.5 … 2.4
??????????
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747

SinglelayerCNN
• Filterwisappliedtoallpossiblewindows(concatenatedvectors)
• Sentence:
• Allpossiblewindowsoflengthh:
• Resultisafeaturemap:
5/12/16RichardSocher
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
the countryof my birth
0.40.3
2.33.6
44.5
77
2.13.3
1.1 3.5 … 2.4
00
00

SinglelayerCNN:Poolinglayer
• Newbuildingblock:Pooling• Inparticular:max-over-timepoolinglayer• Idea:capturemostimportantactivation(maximumovertime)
• Fromfeaturemap
• Pooledsinglenumber:
• Butwewantmorefeatures!
5/12/16RichardSocher
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747

Solution:Multiplefilters
• Usemultiplefilterweightsw
• Usefultohavedifferentwindowsizesh
• Becauseofmaxpooling,lengthofc irrelevant
• Sowecanhavesomefiltersthatlookatunigrams,bigrams,tri-grams,4-grams,etc.
5/12/16RichardSocher
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747

Multi-channelidea
• Initializewithpre-trainedwordvectors(word2vecorGlove)
• Startwithtwocopies
• Backprop intoonlyoneset,keepother“static”
• Bothchannelsareaddedtoci beforemax-pooling
5/12/16RichardSocher

ClassificationafteroneCNNlayer
• Firstoneconvolution,followedbyonemax-pooling
• Toobtainfinalfeaturevector:(assumingmfiltersw)
• Simplefinalsoftmax layer
5/12/16RichardSocher
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
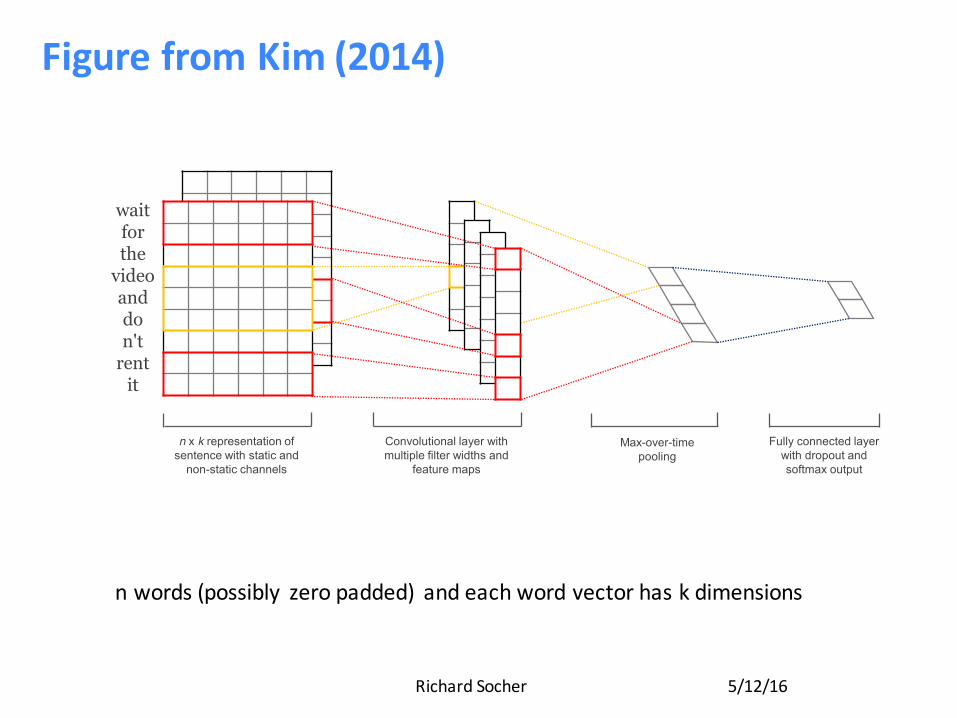
FigurefromKim(2014)
wait for the
video and do n't
rent it
n x k representation of sentence with static and
non-static channels
Convolutional layer with multiple filter widths and
feature maps
Max-over-time pooling
Fully connected layer with dropout and softmax output
Figure 1: Model architecture with two channels for an example sentence.
necessary) is represented as
x1:n = x1 � x2 � . . .� xn, (1)
where � is the concatenation operator. In gen-eral, let xi:i+j refer to the concatenation of wordsxi,xi+1, . . . ,xi+j . A convolution operation in-volves a filter w 2 Rhk, which is applied to awindow of h words to produce a new feature. Forexample, a feature ci is generated from a windowof words xi:i+h�1 by
ci = f(w · xi:i+h�1 + b). (2)
Here b 2 R is a bias term and f is a non-linearfunction such as the hyperbolic tangent. This filteris applied to each possible window of words in thesentence {x1:h,x2:h+1, . . . ,xn�h+1:n} to producea feature map
c = [c1, c2, . . . , cn�h+1], (3)
with c 2 Rn�h+1. We then apply a max-over-time pooling operation (Collobert et al., 2011)over the feature map and take the maximum valuec = max{c} as the feature corresponding to thisparticular filter. The idea is to capture the most im-portant feature—one with the highest value—foreach feature map. This pooling scheme naturallydeals with variable sentence lengths.
We have described the process by which one
feature is extracted from one filter. The modeluses multiple filters (with varying window sizes)to obtain multiple features. These features formthe penultimate layer and are passed to a fully con-nected softmax layer whose output is the probabil-ity distribution over labels.
In one of the model variants, we experimentwith having two ‘channels’ of word vectors—one
that is kept static throughout training and one thatis fine-tuned via backpropagation (section 3.2).2
In the multichannel architecture, illustrated in fig-ure 1, each filter is applied to both channels andthe results are added to calculate ci in equation(2). The model is otherwise equivalent to the sin-gle channel architecture.
2.1 Regularization
For regularization we employ dropout on thepenultimate layer with a constraint on l2-norms ofthe weight vectors (Hinton et al., 2012). Dropoutprevents co-adaptation of hidden units by ran-domly dropping out—i.e., setting to zero—a pro-portion p of the hidden units during foward-backpropagation. That is, given the penultimatelayer z = [c1, . . . , cm] (note that here we have m
filters), instead of using
y = w · z + b (4)
for output unit y in forward propagation, dropoutuses
y = w · (z � r) + b, (5)
where � is the element-wise multiplication opera-tor and r 2 Rm is a ‘masking’ vector of Bernoullirandom variables with probability p of being 1.Gradients are backpropagated only through theunmasked units. At test time, the learned weightvectors are scaled by p such that ˆ
w = pw, andˆ
w is used (without dropout) to score unseen sen-tences. We additionally constrain l2-norms of theweight vectors by rescaling w to have ||w||2 = s
whenever ||w||2 > s after a gradient descent step.
2We employ language from computer vision where a colorimage has red, green, and blue channels.
1747
5/12/16RichardSocher
nwords(possibly zeropadded) andeachwordvectorhaskdimensions

Trickstomakeitworkbetter:Dropout
• Idea:randomlymask/dropout/setto0someofthefeatureweightsz
• CreatemaskingvectorrofBernoullirandomvariableswithprobabilityp(ahyperparameter)ofbeing1
• Deletefeaturesduringtraining:
• Reasoning:Preventsco-adaptation(overfitting toseeingspecificfeatureconstellations)
5/12/16RichardSocher

Trickstomakeitworkbetter:Dropout
• Attrainingtime,gradientsarebackpropagated onlythroughthoseelementsofzvectorforwhichri =1
• Attesttime,thereisnodropout,sofeaturevectorszarelarger.• Hence,wescalefinalvectorbyBernoulliprobabilityp
• Kim(2014)reports2– 4%improvedaccuracyandabilitytouseverylargenetworkswithoutoverfitting
5/12/16RichardSocher

Anotherregularizationtrick
• Somewhatlesscommon
• Constrainl2 normsofweightvectorsofeachclass(rowinsoftmax weightW(S))tofixednumbers(alsoahyperparameter)
• If ,thenrescaleitsothat:
5/12/16RichardSocher

Allhyperparameters inKim(2014)
• Findhyperparameters basedondev set• Nonlinearity:reLu• Windowfiltersizesh=3,4,5• Eachfiltersizehas100featuremaps• Dropoutp=0.5• L2constraintsforrowsofsoftmax s=3• MinibatchsizeforSGDtraining:50• Wordvectors:pre-trainedwithword2vec,k=300
• Duringtraining,keepcheckingperformanceondev setandpickhighestaccuracyweightsforfinalevaluation
5/12/16RichardSocher

Experiments
Model MR SST-1 SST-2 Subj TREC CR MPQACNN-rand 76.1 45.0 82.7 89.6 91.2 79.8 83.4
CNN-static 81.0 45.5 86.8 93.0 92.8 84.7 89.6CNN-non-static 81.5 48.0 87.2 93.4 93.6 84.3 89.5
CNN-multichannel 81.1 47.4 88.1 93.2 92.2 85.0 89.4
RAE (Socher et al., 2011) 77.7 43.2 82.4 � � � 86.4
MV-RNN (Socher et al., 2012) 79.0 44.4 82.9 � � � �RNTN (Socher et al., 2013) � 45.7 85.4 � � � �DCNN (Kalchbrenner et al., 2014) � 48.5 86.8 � 93.0 � �Paragraph-Vec (Le and Mikolov, 2014) � 48.7 87.8 � � � �CCAE (Hermann and Blunsom, 2013) 77.8 � � � � � 87.2
Sent-Parser (Dong et al., 2014) 79.5 � � � � � 86.3
NBSVM (Wang and Manning, 2012) 79.4 � � 93.2 � 81.8 86.3
MNB (Wang and Manning, 2012) 79.0 � � 93.6 � 80.0 86.3
G-Dropout (Wang and Manning, 2013) 79.0 � � 93.4 � 82.1 86.1
F-Dropout (Wang and Manning, 2013) 79.1 � � 93.6 � 81.9 86.3
Tree-CRF (Nakagawa et al., 2010) 77.3 � � � � 81.4 86.1
CRF-PR (Yang and Cardie, 2014) � � � � � 82.7 �SVMS (Silva et al., 2011) � � � � 95.0 � �
Table 2: Results of our CNN models against other methods. RAE: Recursive Autoencoders with pre-trained word vectors fromWikipedia (Socher et al., 2011). MV-RNN: Matrix-Vector Recursive Neural Network with parse trees (Socher et al., 2012).RNTN: Recursive Neural Tensor Network with tensor-based feature function and parse trees (Socher et al., 2013). DCNN:Dynamic Convolutional Neural Network with k-max pooling (Kalchbrenner et al., 2014). Paragraph-Vec: Logistic regres-sion on top of paragraph vectors (Le and Mikolov, 2014). CCAE: Combinatorial Category Autoencoders with combinatorialcategory grammar operators (Hermann and Blunsom, 2013). Sent-Parser: Sentiment analysis-specific parser (Dong et al.,2014). NBSVM, MNB: Naive Bayes SVM and Multinomial Naive Bayes with uni-bigrams from Wang and Manning (2012).G-Dropout, F-Dropout: Gaussian Dropout and Fast Dropout from Wang and Manning (2013). Tree-CRF: Dependency treewith Conditional Random Fields (Nakagawa et al., 2010). CRF-PR: Conditional Random Fields with Posterior Regularization(Yang and Cardie, 2014). SVMS : SVM with uni-bi-trigrams, wh word, head word, POS, parser, hypernyms, and 60 hand-codedrules as features from Silva et al. (2011).
to both channels, but gradients are back-propagated only through one of the chan-nels. Hence the model is able to fine-tuneone set of vectors while keeping the otherstatic. Both channels are initialized withword2vec.
In order to disentangle the effect of the abovevariations versus other random factors, we elim-inate other sources of randomness—CV-fold as-signment, initialization of unknown word vec-tors, initialization of CNN parameters—by keep-ing them uniform within each dataset.
4 Results and Discussion
Results of our models against other methods arelisted in table 2. Our baseline model with all ran-domly initialized words (CNN-rand) does not per-form well on its own. While we had expected per-formance gains through the use of pre-trained vec-tors, we were surprised at the magnitude of thegains. Even a simple model with static vectors(CNN-static) performs remarkably well, giving
competitive results against the more sophisticateddeep learning models that utilize complex pool-ing schemes (Kalchbrenner et al., 2014) or requireparse trees to be computed beforehand (Socheret al., 2013). These results suggest that the pre-trained vectors are good, ‘universal’ feature ex-tractors and can be utilized across datasets. Fine-tuning the pre-trained vectors for each task givesstill further improvements (CNN-non-static).
4.1 Multichannel vs. Single Channel ModelsWe had initially hoped that the multichannel ar-chitecture would prevent overfitting (by ensuringthat the learned vectors do not deviate too farfrom the original values) and thus work better thanthe single channel model, especially on smallerdatasets. The results, however, are mixed, and fur-ther work on regularizing the fine-tuning processis warranted. For instance, instead of using anadditional channel for the non-static portion, onecould maintain a single channel but employ extradimensions that are allowed to be modified duringtraining.
1749
5/12/16RichardSocher

Problemwithcomparison?
• Dropoutgives2– 4%accuracyimprovement• Severalbaselinesdidn’tusedropout
• Stillremarkableresultsandsimplearchitecture!
• DifferencetowindowandRNNarchitectureswedescribedinpreviouslectures:pooling,manyfiltersanddropout
• IdeascanbeusedinRNN2stoo• Tree-LSTMsobtainbetterperformanceonsentencedatasets
5/12/16RichardSocher

• FixedtreeRNNsexploredincomputervision:Socher etal(2012):“Convolutional-RecursiveDeepLearningfor3DObjectClassification”
5/12/16RichardSocherLecture1,Slide 26

RelationshipbetweenRNNsandCNNs
• CNN RNN
5/12/16RichardSocher

RelationshipbetweenRNNsandCNNs
• CNN RNN
5/12/16RichardSocher

RelationshipbetweenRNNsandCNNs
• CNN RNN
• StridesizeflexibleinCNNs,RNNs“weightedaveragepool”• Tying(sharing)weightsoffiltersinsidevs acrossdifferentlayers• CNN:multiplefilters,additionallayertype:max-pooling• Balancedinputindependentstructurevs inputspecifictree
5/12/16RichardSocher
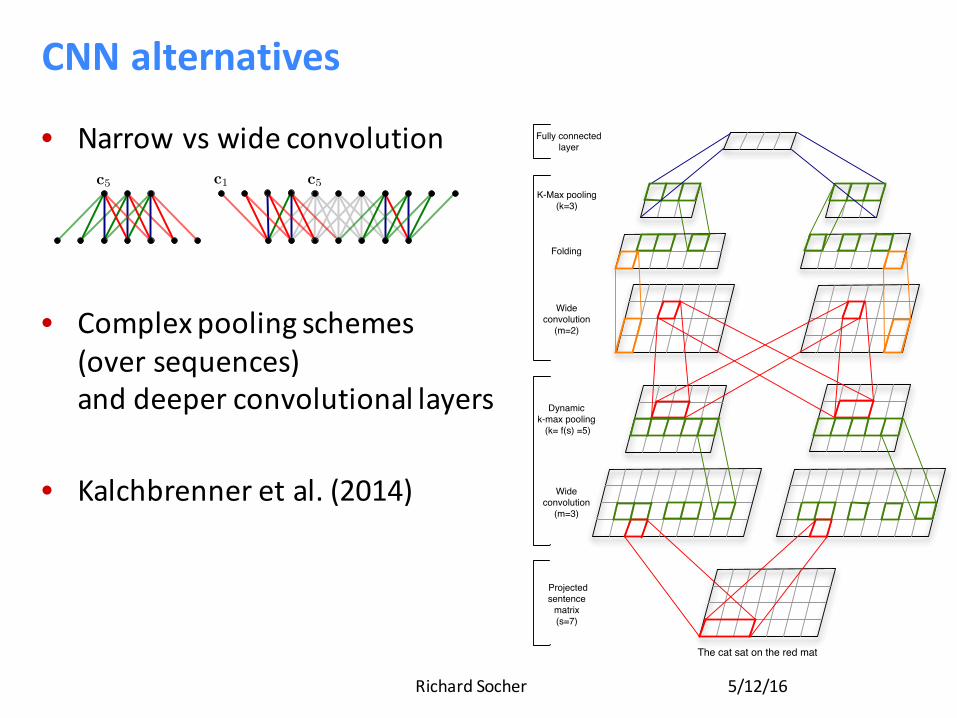
CNNalternatives
• Narrowvs wideconvolution
• Complexpoolingschemes(oversequences)anddeeperconvolutionallayers
• Kalchbrenner etal.(2014)
5/12/16RichardSocher
layer to the network, the TDNN can be adopted asa sentence model (Collobert and Weston, 2008).
2.1 Related Neural Sentence ModelsVarious neural sentence models have been de-scribed. A general class of basic sentence modelsis that of Neural Bag-of-Words (NBoW) models.These generally consist of a projection layer thatmaps words, sub-word units or n-grams to highdimensional embeddings; the latter are then com-bined component-wise with an operation such assummation. The resulting combined vector is clas-sified through one or more fully connected layers.
A model that adopts a more general structureprovided by an external parse tree is the RecursiveNeural Network (RecNN) (Pollack, 1990; Kuchlerand Goller, 1996; Socher et al., 2011; Hermannand Blunsom, 2013). At every node in the tree thecontexts at the left and right children of the nodeare combined by a classical layer. The weights ofthe layer are shared across all nodes in the tree.The layer computed at the top node gives a repre-sentation for the sentence. The Recurrent NeuralNetwork (RNN) is a special case of the recursivenetwork where the structure that is followed is asimple linear chain (Gers and Schmidhuber, 2001;Mikolov et al., 2011). The RNN is primarily usedas a language model, but may also be viewed as asentence model with a linear structure. The layercomputed at the last word represents the sentence.
Finally, a further class of neural sentence mod-els is based on the convolution operation and theTDNN architecture (Collobert and Weston, 2008;Kalchbrenner and Blunsom, 2013b). Certain con-cepts used in these models are central to theDCNN and we describe them next.
2.2 ConvolutionThe one-dimensional convolution is an operationbetween a vector of weights m 2 Rm and a vectorof inputs viewed as a sequence s 2 Rs. The vectorm is the filter of the convolution. Concretely, wethink of s as the input sentence and s
i
2 R is a sin-gle feature value associated with the i-th word inthe sentence. The idea behind the one-dimensionalconvolution is to take the dot product of the vectorm with each m-gram in the sentence s to obtainanother sequence c:
cj
= m|sj�m+1:j (1)
Equation 1 gives rise to two types of convolutiondepending on the range of the index j. The narrowtype of convolution requires that s � m and yields
s1 s1ss ss
c1 c5c5
Figure 2: Narrow and wide types of convolution.The filter m has size m = 5.
a sequence c 2 Rs�m+1 with j ranging from mto s. The wide type of convolution does not haverequirements on s or m and yields a sequence c 2Rs+m�1 where the index j ranges from 1 to s +m � 1. Out-of-range input values s
i
where i < 1
or i > s are taken to be zero. The result of thenarrow convolution is a subsequence of the resultof the wide convolution. The two types of one-dimensional convolution are illustrated in Fig. 2.
The trained weights in the filter m correspondto a linguistic feature detector that learns to recog-nise a specific class of n-grams. These n-gramshave size n m, where m is the width of thefilter. Applying the weights m in a wide convo-lution has some advantages over applying them ina narrow one. A wide convolution ensures that allweights in the filter reach the entire sentence, in-cluding the words at the margins. This is particu-larly significant when m is set to a relatively largevalue such as 8 or 10. In addition, a wide convo-lution guarantees that the application of the filterm to the input sentence s always produces a validnon-empty result c, independently of the width mand the sentence length s. We next describe theclassical convolutional layer of a TDNN.
2.3 Time-Delay Neural Networks
A TDNN convolves a sequence of inputs s with aset of weights m. As in the TDNN for phonemerecognition (Waibel et al., 1990), the sequence sis viewed as having a time dimension and the con-volution is applied over the time dimension. Eachsj
is often not just a single value, but a vector ofd values so that s 2 Rd⇥s. Likewise, m is a ma-trix of weights of size d⇥m. Each row of m isconvolved with the corresponding row of s and theconvolution is usually of the narrow type. Multi-ple convolutional layers may be stacked by takingthe resulting sequence c as input to the next layer.
The Max-TDNN sentence model is based on thearchitecture of a TDNN (Collobert and Weston,2008). In the model, a convolutional layer of thenarrow type is applied to the sentence matrix s,where each column corresponds to the feature vec-
tor wi
2 Rd of a word in the sentence:
s =
2
4w1 . . . ws
3
5 (2)
To address the problem of varying sentencelengths, the Max-TDNN takes the maximum ofeach row in the resulting matrix c yielding a vectorof d values:
cmax
=
2
64max(c1,:)
...max(c
d,:)
3
75 (3)
The aim is to capture the most relevant feature, i.e.the one with the highest value, for each of the drows of the resulting matrix c. The fixed-sizedvector c
max
is then used as input to a fully con-nected layer for classification.
The Max-TDNN model has many desirableproperties. It is sensitive to the order of the wordsin the sentence and it does not depend on externallanguage-specific features such as dependency orconstituency parse trees. It also gives largely uni-form importance to the signal coming from eachof the words in the sentence, with the exceptionof words at the margins that are considered fewertimes in the computation of the narrow convolu-tion. But the model also has some limiting as-pects. The range of the feature detectors is lim-ited to the span m of the weights. Increasing m orstacking multiple convolutional layers of the nar-row type makes the range of the feature detectorslarger; at the same time it also exacerbates the ne-glect of the margins of the sentence and increasesthe minimum size s of the input sentence requiredby the convolution. For this reason higher-orderand long-range feature detectors cannot be easilyincorporated into the model. The max pooling op-eration has some disadvantages too. It cannot dis-tinguish whether a relevant feature in one of therows occurs just one or multiple times and it for-gets the order in which the features occur. Moregenerally, the pooling factor by which the signalof the matrix is reduced at once corresponds tos�m+1; even for moderate values of s the pool-ing factor can be excessive. The aim of the nextsection is to address these limitations while pre-serving the advantages.
3 Convolutional Neural Networks withDynamic k-Max Pooling
We model sentences using a convolutional archi-tecture that alternates wide convolutional layers
K-Max pooling(k=3)
Fully connected layer
Folding
Wideconvolution
(m=2)
Dynamick-max pooling (k= f(s) =5)
Projectedsentence
matrix(s=7)
Wideconvolution
(m=3)
The cat sat on the red mat
Figure 3: A DCNN for the seven word input sen-tence. Word embeddings have size d = 4. Thenetwork has two convolutional layers with twofeature maps each. The widths of the filters at thetwo layers are respectively 3 and 2. The (dynamic)k-max pooling layers have values k of 5 and 3.
with dynamic pooling layers given by dynamic k-max pooling. In the network the width of a featuremap at an intermediate layer varies depending onthe length of the input sentence; the resulting ar-chitecture is the Dynamic Convolutional NeuralNetwork. Figure 3 represents a DCNN. We pro-ceed to describe the network in detail.
3.1 Wide Convolution
Given an input sentence, to obtain the first layer ofthe DCNN we take the embedding w
i
2 Rd foreach word in the sentence and construct the sen-tence matrix s 2 Rd⇥s as in Eq. 2. The valuesin the embeddings w
i
are parameters that are op-timised during training. A convolutional layer inthe network is obtained by convolving a matrix ofweights m 2 Rd⇥m with the matrix of activationsat the layer below. For example, the second layeris obtained by applying a convolution to the sen-tence matrix s itself. Dimension d and filter widthm are hyper-parameters of the network. We let theoperations be wide one-dimensional convolutionsas described in Sect. 2.2. The resulting matrix chas dimensions d⇥ (s+m� 1).

CNNapplication:Translation
• Oneofthefirstsuccessfulneuralmachinetranslationefforts
• UsesCNNforencodingandRNNfordecoding
• Kalchbrenner andBlunsom (2013)“RecurrentContinuousTranslationModels”
5/12/16RichardSocherRCTM IIRCTM I
P( f | e )
P( f | m, e )
e
e
e
F
T
S
S
csm
cgm
icgm
E
F g
g
Figure 3: A graphical depiction of the two RCTMs. Arrows represent full matrix transformations while lines arevector transformations corresponding to columns of weight matrices.
represented by Eei
. For example, for a sufficientlylong sentence e, gram(Ee
2) = 2, gram(Ee3) = 4,
gram(Ee4) = 7. We denote by cgm(e, n) that matrix
Eei
from the CSM that represents the n-grams of thesource sentence e.
The CGM can also be inverted to obtain a repre-sentation for a sentence from the representation ofits n-grams. We denote by icgm the inverse CGM,which depends on the size of the n-gram represen-tation cgm(e, n) and on the target sentence lengthm. The transformation icgm unfolds the n-gramrepresentation onto a representation of a target sen-tence with m words. The architecture correspondsto an inverted CGM or, equivalently, to an invertedtruncated CSM (Fig. 3). Given the transformationscgm and icgm, we now detail the computation of theRCTM II.
4.2 RCTM II
The RCTM II models the conditional probabilityP (f|e) by factoring it as follows:
P (f|e) = P (f|m, e) · P (m|e) (9a)
=
mY
i=1
P (f
i+1|f1:i,m, e) · P (m|e) (9b)
and computing the distributions P (f
i+1|f1:i,m, e)
and P (m|e). The architecture of the RCTM IIcomprises all the elements of the RCTM I togetherwith the following additional elements: a translationtransformation Tq⇥q and two sequences of weightmatrices (Ji
)2is
and (Hi
)2is
that are part ofthe icgm
3.The computation of the RCTM II proceeds recur-
sively as follows:
Eg
= cgm(e, 4) (10a)Fg
:,j = �(T ·Eg
:,j) (10b)
F = icgm(Fg
,m) (10c)h1 = �(I · v(f1) + S · F:,1) (10d)
h
i+1 = �(R · hi
+ I · v(fi+1) + S · F:,i+1) (10e)
o
i+1 = O · hi
(10f)
and the conditional distributions P (f
i+1|f1:i, e) areobtained from o
i
as in Eq. 4. Note how each re-constructed vector F:,i is added successively to thecorresponding layer h
i
that predicts the target wordf
i
. The RCTM II is illustrated in Fig. 3.
3Just like r the value s is small and depends on the lengthof the source and target sentences in the training set. SeeSect. 5.1.2.

Modelcomparison
• BagofVectors:Surprisinglygoodbaselineforsimpleclassificationproblems.Especiallyiffollowedbyafewlayers!
• WindowModel:Goodforsinglewordclassificationforproblemsthatdonotneedwidecontext
• CNNs:goodforclassification,unclearhowtoincorporatephraselevelannotation(canonlytakeasinglelabel),needzeropaddingforshorterphrases,hardtointerpret,easytoparallelizeonGPUs
5/12/16RichardSocher

Modelcomparison
• RecursiveNeuralNetworks:mostlinguisticallyplausible,interpretable,providemostimportantphrases(forvisualization),needparsetrees
• RecurrentNeuralNetworks:Mostcognitivelyplausible(readingfromlefttoright),notusuallythehighestclassificationperformancebutlotsofimprovementsrightnowwithgates(GRUs,LSTMs,etc).
• Bestbutalsomostcomplexmodels:Hierarchicalrecurrentneuralnetworkswithattentionmechanismsandadditionalmemoryà Lastweekofclass:)
5/12/16RichardSocher

Nextweek:
• Guestlecturesnextweek:
• Speechrecognitionandstateoftheartmachinetranslation
5/12/16RichardSocher