cs 152 computer architecture and engineering lecture 22 ...cs152/sp08/lectures/l22-final.pdfcs 152...
TRANSCRIPT

CS 152 Computer Architecture
and Engineering
Lecture 22: Final Lecture
Krste AsanovicElectrical Engineering and Computer Sciences
University of California, Berkeley
http://www.eecs.berkeley.edu/~krste
http://inst.cs.berkeley.edu/~cs152
5/6/2008 2
CS152-Spring!08
Today’s Lecture
• Review entire semester– What you learned
• Follow-on classes
• What’s next in computer architecture?

5/6/2008 3
CS152-Spring!08
The New CS152 Executive Summary(what was promised in lecture 1)
The processor yourpredecessors built inCS152
What you’llunderstand andexperiment with inthe new CS152
Plus, the technologybehind chip-scalemultiprocessors(CMPs)
5/6/2008 4
CS152-Spring!08
From Babbage to IBM 650

5/6/2008 5
CS152-Spring!08
IBM 360: Initial Implementations
Model 30 . . . Model 70
Storage 8K - 64 KB 256K - 512 KB
Datapath 8-bit 64-bit
Circuit Delay 30 nsec/level 5 nsec/level
Local Store Main Store Transistor Registers
Control Store Read only 1µsec Conventional circuits
IBM 360 instruction set architecture (ISA) completelyhid the underlying technological differences betweenvarious models.
Milestone: The first true ISA designed as portablehardware-software interface!
With minor modifications it still survives today!
5/6/2008 6
CS152-Spring!08
Microcoded Microarchitecture
Memory(RAM)
Datapath
µcontroller
(ROM)
AddrData
zero?busy?
opcode
enMemMemWrt
holds fixedmicrocode instructions
holds user programwritten in macrocode
instructions (e.g.,MIPS, x86, etc.)

5/6/2008 7
CS152-Spring!08
Implementing Complex Instructions
ExtSel
A B
RegWrt
enReg
enMem
MA
addr addr
data data
rsrtrd
32(PC)31(Link)
RegSel
OpSel ldA ldB ldMA
Memory
32 GPRs+ PC ...
32-bit RegALU
enALU
Bus
IR
busyzero?Opcode
ldIR
ImmExt
enImm
2
ALUcontrol
2
3
MemWrt
32
rsrtrd
rd ! M[(rs)] op (rt) Reg-Memory-src ALU op M[(rd)] ! (rs) op (rt) Reg-Memory-dst ALU op M[(rd)] ! M[(rs)] op M[(rt)] Mem-Mem ALU op
5/6/2008 8
CS152-Spring!08
From CISC to RISC
• Use fast RAM to build fast instruction cache of user-visible instructions, not fixed hardware microroutines
– Can change contents of fast instruction memory to fit whatapplication needs right now
• Use simple ISA to enable hardwired pipelinedimplementation
– Most compiled code only used a few of the available CISCinstructions
– Simpler encoding allowed pipelined implementations
• Further benefit with integration– In early ‘80s, can fit 32-bit datapath + small caches on a single chip
– No chip crossings in common case allows faster operation
5/6/2008 9
CS152-Spring!08
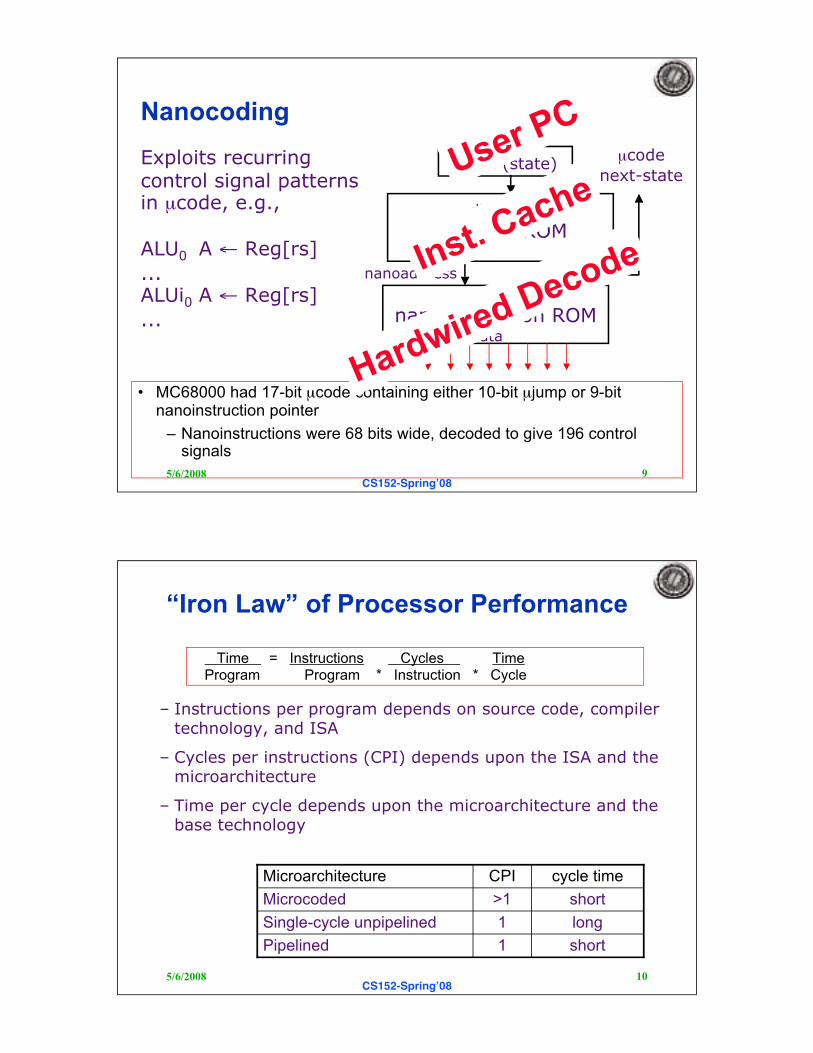
Nanocoding
• MC68000 had 17-bit µcode containing either 10-bit µjump or 9-bitnanoinstruction pointer
– Nanoinstructions were 68 bits wide, decoded to give 196 controlsignals
µcode ROM
nanoaddress
µcode
next-state
µaddress
µPC (state)
nanoinstruction ROMdata
Exploits recurringcontrol signal patternsin µcode, e.g.,
ALU0 A ! Reg[rs]
...ALUi0 A ! Reg[rs]
...
User PC
Inst. Cache
Hardwired Decode
5/6/2008 10
CS152-Spring!08
“Iron Law” of Processor Performance
Time = Instructions Cycles Time Program Program * Instruction * Cycle
– Instructions per program depends on source code, compilertechnology, and ISA
– Cycles per instructions (CPI) depends upon the ISA and themicroarchitecture
– Time per cycle depends upon the microarchitecture and thebase technology
short1Pipelined
long1Single-cycle unpipelined
short>1Microcoded
cycle timeCPIMicroarchitecture

5/6/2008 11
CS152-Spring!08
5-Stage Pipelined Execution
time t0 t1 t2 t3 t4 t5 t6 t7 . . . .instruction1 IF1 ID1 EX1 MA1 WB1
instruction2 IF2 ID2 EX2 MA2 WB2
instruction3 IF3 ID3 EX3 MA3 WB3
instruction4 IF4 ID4 EX4 MA4 WB4
instruction5 IF5 ID5 EX5 MA5 WB5
Write-Back(WB)
I-Fetch(IF)
Execute(EX)
Decode, Reg. Fetch(ID)
Memory(MA)
addr
wdata
rdataDataMemory
we
ALU
ImmExt
0x4
Add
addrrdata
Inst.Memory
rd1
GPRs
rs1rs2
wswdrd2
we
IRPC
5/6/2008 12
CS152-Spring!08
Pipeline Hazards
• Pipelining instructions is complicated by HAZARDS:– Structural hazards (two instructions want same hardware resource)
– Data hazards (earlier instruction produces value needed by laterinstruction)
– Control hazards (instruction changes control flow, e.g., branches orexceptions)
• Techniques to handle hazards:– Interlock (hold newer instruction until older instructions drain out of
pipeline)
– Bypass (transfer value from older instruction to newer instruction assoon as available somwhere in machine)
– Speculate (guess effect of earlier instruction)
• Speculation needs predictor, prediction check, andrecovery mechanism

5/6/2008 13
CS152-Spring!08
Exception Handling 5-Stage Pipeline
PCInst.Mem D Decode E M
DataMem W+
IllegalOpcode
Overflow Data addressExceptions
PC addressException
AsynchronousInterrupts
ExcD
PCD
ExcE
PCE
ExcM
PCM
Cause
EPC
Kill DStage
Kill FStage
Kill EStage
SelectHandlerPC
KillWriteback
CommitPoint
5/6/2008 14
CS152-Spring!08
Processor-DRAM Gap (latency)
Time
!Proc 60%/year
DRAM7%/year
1
10
100
1000
1980
1981
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
DRAM
CPU
1982
Processor-MemoryPerformance Gap:(grows 50% / year)
Perf
orm
ance “Moore’s Law”
Four-issue 2GHz superscalar accessing 100ns DRAM couldexecute 800 instructions during time for one memory access!

5/6/2008CS152-Spring!08
Common Predictable Patterns
Two predictable properties of memory references:
– Temporal Locality: If a location is referenced it islikely to be referenced again in the near future.
– Spatial Locality: If a location is referenced it is likelythat locations near it will be referenced in the nearfuture.
Memory Reference Patterns
Donald J. Hatfield, Jeanette Gerald: Program
Restructuring for Virtual Memory. IBM Systems Journal
10(3): 168-192 (1971)
Time
Mem
ory
Ad
dre
ss (
on
e d
ot
per
access)
TimeTime
SpatialLocality
Temporal Locality

5/6/2008 17
CS152-Spring!08
Causes for Cache Misses
• Compulsory: first-reference to a block a.k.a. cold
start misses- misses that would occur even with infinite cache
• Capacity: cache is too small to hold all data needed by the program- misses that would occur even under perfect replacement policy
• Conflict: misses that occur because of collisions due to block-placement strategy
- misses that would not occur with full associativity
5/6/2008 18
CS152-Spring!08
A Typical Memory Hierarchy c.2006
L1 DataCache
L1Instruction
CacheUnified L2
Cache
RF Memory
Memory
Memory
Memory
Multiportedregister file
(part of CPU)
Split instruction & dataprimary caches(on-chip SRAM)
Multiple interleavedmemory banks
(DRAM)
Large unified secondary cache(on-chip SRAM)
CPU
5/6/2008 19
CS152-Spring!08
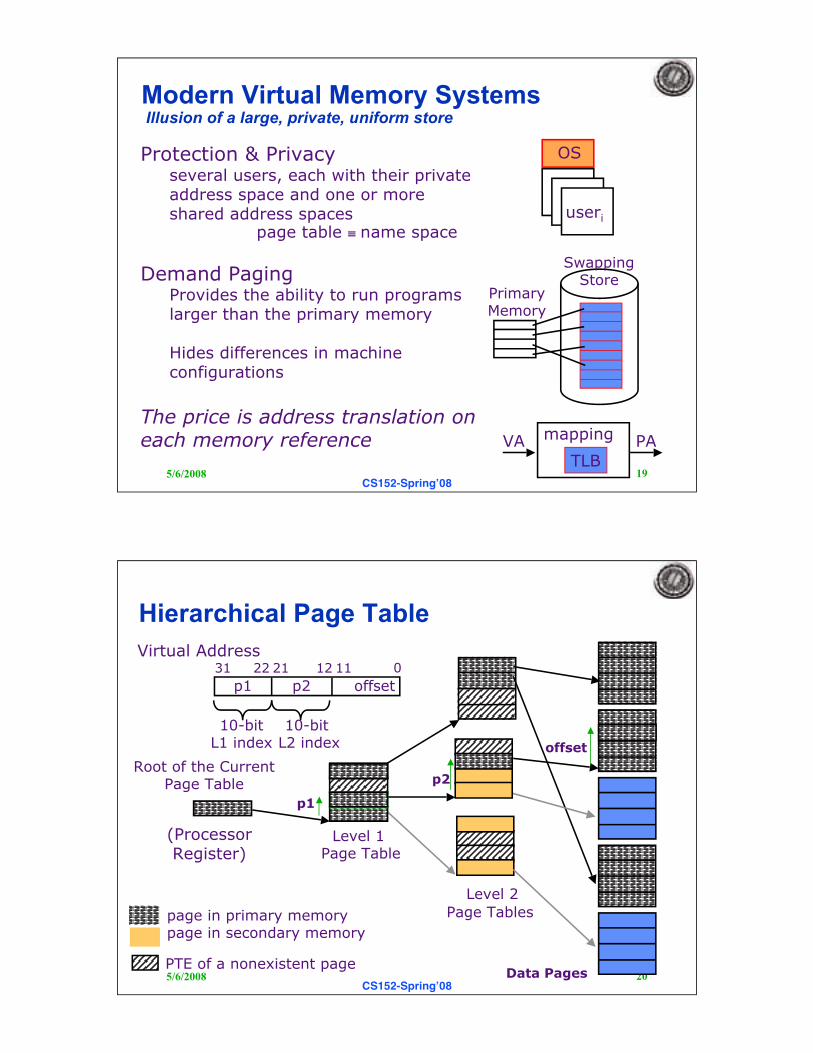
Modern Virtual Memory Systems Illusion of a large, private, uniform store
Protection & Privacyseveral users, each with their privateaddress space and one or moreshared address spaces
page table " name space
Demand PagingProvides the ability to run programslarger than the primary memory
Hides differences in machineconfigurations
The price is address translation oneach memory reference
OS
useri
PrimaryMemory
SwappingStore
VA PAmapping
TLB
5/6/2008 20
CS152-Spring!08
Hierarchical Page Table
Level 1 Page Table
Level 2
Page Tables
Data Pages
page in primary memory page in secondary memory
Root of the CurrentPage Table
p1
offset
p2
Virtual Address
(ProcessorRegister)
PTE of a nonexistent page
p1 p2 offset
01112212231
10-bitL1 index
10-bit L2 index
5/6/2008 21
CS152-Spring!08
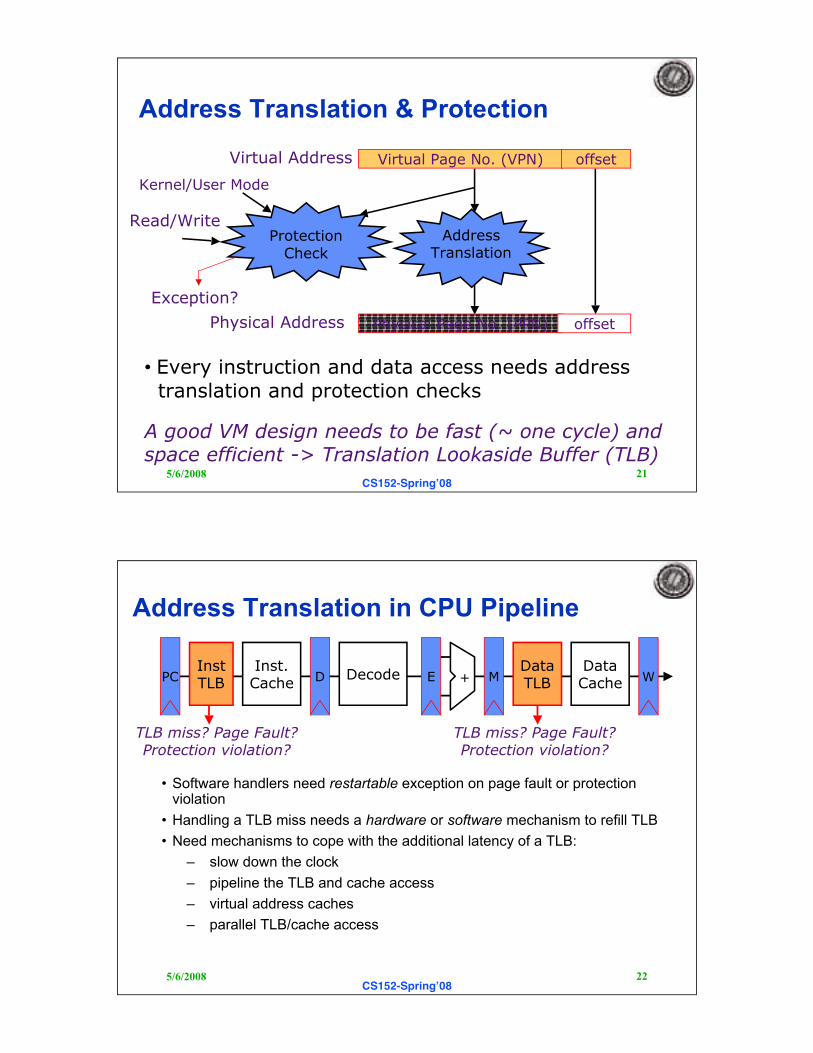
Address Translation & Protection
• Every instruction and data access needs address
translation and protection checks
A good VM design needs to be fast (~ one cycle) andspace efficient -> Translation Lookaside Buffer (TLB)
Physical Address
Virtual Address
AddressTranslation
Virtual Page No. (VPN) offset
Physical Page No. (PPN) offset
ProtectionCheck
Exception?
Kernel/User Mode
Read/Write
5/6/2008 22
CS152-Spring!08
Address Translation in CPU Pipeline
• Software handlers need restartable exception on page fault or protectionviolation
• Handling a TLB miss needs a hardware or software mechanism to refill TLB
• Need mechanisms to cope with the additional latency of a TLB:
– slow down the clock
– pipeline the TLB and cache access
– virtual address caches
– parallel TLB/cache access
PCInstTLB
Inst.Cache D Decode E M
DataTLB
DataCache W+
TLB miss? Page Fault?Protection violation?
TLB miss? Page Fault?Protection violation?

5/6/2008 23
CS152-Spring!08
Concurrent Access to TLB & Cache
Index L is available without consulting the TLB# cache and TLB accesses can begin simultaneously
Tag comparison is made after both accesses are completed
Cases: L + b = k L + b < k L + b > k
VPN L b
TLB Direct-map Cache 2L
blocks2b-byte block
PPN Page Offset
=hit?
DataPhysical Tag
Tag
VA
PA
VirtualIndex
k
5/6/2008 24
CS152-Spring!08
CS152 Administrivia
• Lab 4 competition winners!
• Quiz 6 on Thursday, May 8– L19-21, PS 6, Lab 6
• Last 15 minutes, course survey– HKN survey
– Informal feedback survey for those who’ve not done it already
• Quiz 5 results



5/6/2008 30
CS152-Spring!08
Complex Pipeline Structure
IF ID WB
ALU Mem
Fadd
Fmul
Fdiv
Issue
GPR’sFPR’s

5/6/2008 31
CS152-Spring!08
Superscalar In-Order Pipeline
• Fetch two instructions per cycle;issue both simultaneously if oneis integer/memory and other isfloating-point
• Inexpensive way of increasingthroughput, examples includeAlpha 21064 (1992) & MIPSR5000 series (1996)
• Same idea can be extended towider issue by duplicatingfunctional units (e.g. 4-issueUltraSPARC) but register fileports and bypassing costs growquickly
Commit
Point
2PC
Inst.Mem D
DualDecode X1 X2
DataMem W+GPRs
X2 WFadd X3
X3
FPRs X1
X2 Fmul X3
X2FDiv X3
Unpipelined
divider
5/6/2008 32
CS152-Spring!08
Types of Data Hazards
Consider executing a sequence ofrk ! (ri) op (rj)
type of instructions
Data-dependencer3 ! (r1) op (r2) Read-after-Write r5 ! (r3) op (r4) (RAW) hazard
Anti-dependencer3 ! (r1) op (r2) Write-after-Read r1 ! (r4) op (r5) (WAR) hazard
Output-dependencer3 ! (r1) op (r2) Write-after-Write r3 ! (r6) op (r7) (WAW) hazard

5/6/2008 33
CS152-Spring!08
Fetch: Instruction bits retrievedfrom cache.
Phases of Instruction Execution
I-cache
FetchBuffer
IssueBuffer
Func.Units
Arch.State
Execute: Instructions and operands sentto execution units .When execution completes, all results andexception flags are available.
Decode: Instructions placed in appropriateissue (aka “dispatch”) stage buffer
ResultBuffer Commit: Instruction irrevocably updates
architectural state (aka “graduation” or“completion”).
PC
5/6/2008 34
CS152-Spring!08
Pipeline Design with Physical Regfile
FetchDecode &Rename
Reorder BufferPC
BranchPrediction
Update predictors
Commit
BranchResolution
BranchUnit
ALU MEMStoreBuffer
D$
Execute
In-Order
In-OrderOut-of-Order
Physical Reg. File
kill
kill
kill
kill
5/6/2008 35
CS152-Spring!08
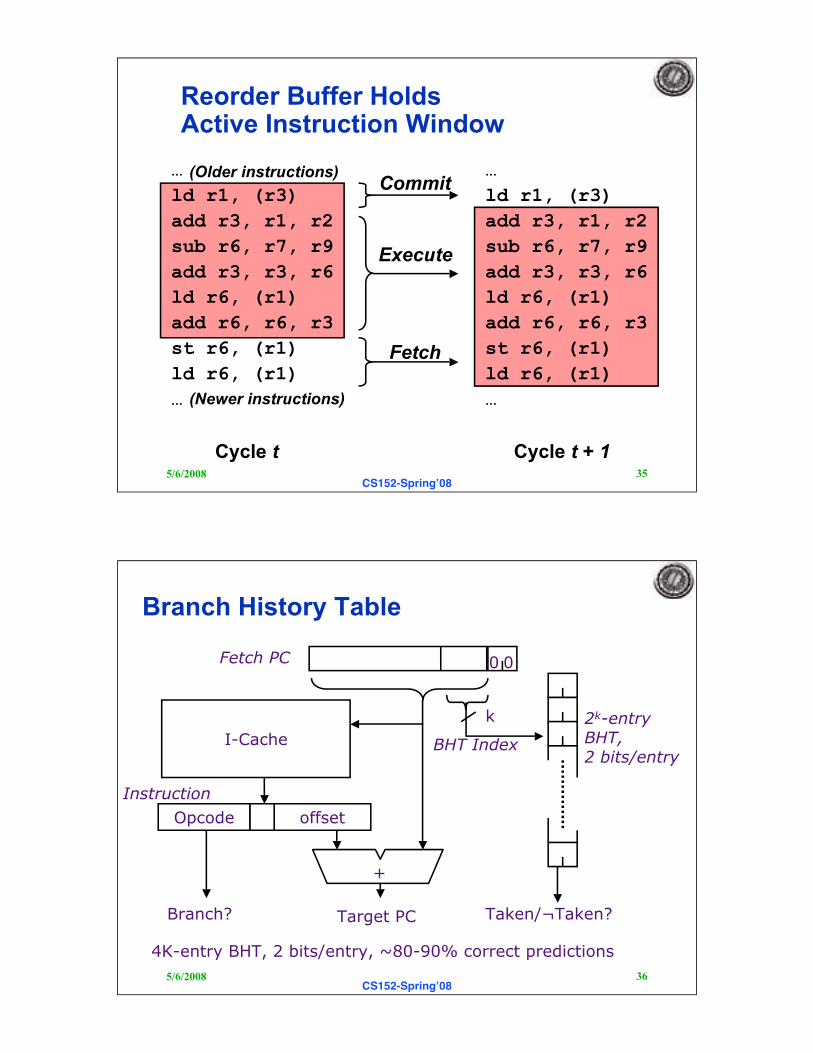
Reorder Buffer HoldsActive Instruction Window
…
ld r1, (r3)
add r3, r1, r2
sub r6, r7, r9
add r3, r3, r6
ld r6, (r1)
add r6, r6, r3
st r6, (r1)
ld r6, (r1)
…
(Older instructions)
(Newer instructions)
Cycle t
…
ld r1, (r3)
add r3, r1, r2
sub r6, r7, r9
add r3, r3, r6
ld r6, (r1)
add r6, r6, r3
st r6, (r1)
ld r6, (r1)
…
Commit
Fetch
Cycle t + 1
Execute
5/6/2008 36
CS152-Spring!08
Branch History Table
4K-entry BHT, 2 bits/entry, ~80-90% correct predictions
0 0Fetch PC
Branch? Target PC
+
I-Cache
Opcode offset
Instruction
k
BHT Index
2k-entryBHT,2 bits/entry
Taken/¬Taken?

5/6/2008 37
CS152-Spring!08
Two-Level Branch PredictorPentium Pro uses the result from the last two branchesto select one of the four sets of BHT bits (~95% correct)
0 0
kFetch PC
Shift inTaken/¬Takenresults of eachbranch
2-bit global branchhistory shift register
Taken/¬Taken?
5/6/2008 38
CS152-Spring!08
Branch Target Buffer (BTB)
• Keep both the branch PC and target PC in the BTB• PC+4 is fetched if match fails• Only taken branches and jumps held in BTB• Next PC determined before branch fetched and decoded
2k-entry direct-mapped BTB(can also be associative)
I-Cache PC
k
Valid
valid
Entry PC
=
match
predicted
target
target PC

5/6/2008 39
CS152-Spring!08
Combining BTB and BHT• BTB entries are considerably more expensive than BHT, but can
redirect fetches at earlier stage in pipeline and can accelerateindirect branches (JR)
• BHT can hold many more entries and is more accurate
A PC Generation/Mux
P Instruction Fetch Stage 1
F Instruction Fetch Stage 2
B Branch Address Calc/Begin Decode
I Complete Decode
J Steer Instructions to Functional units
R Register File Read
E Integer Execute
BTB
BHTBHT in laterpipeline stagecorrects whenBTB misses apredictedtaken branch
BTB/BHT only updated after branch resolves in E stage
5/6/2008 40
CS152-Spring!08
Check instructiondependencies
Superscalar processor
Sequential ISA Bottleneck
a = foo(b);
for (i=0, i<
Sequentialsource code
Superscalar compiler
Find independentoperations
Scheduleoperations
Sequentialmachine code
Scheduleexecution

5/6/2008 41
CS152-Spring!08
VLIW: Very Long Instruction Word
• Multiple operations packed into one instruction
• Each operation slot is for a fixed function
• Constant operation latencies are specified
• Architecture requires guarantee of:– Parallelism within an instruction => no cross-operation RAW check
– No data use before data ready => no data interlocks
Two Integer Units,Single Cycle Latency
Two Load/Store Units,Three Cycle Latency Two Floating-Point Units,
Four Cycle Latency
Int Op 2 Mem Op 1 Mem Op 2 FP Op 1 FP Op 2Int Op 1
5/6/2008 42
CS152-Spring!08
Scheduling Loop Unrolled Code
loop: ld f1, 0(r1)
ld f2, 8(r1)
ld f3, 16(r1)
ld f4, 24(r1)
add r1, 32
fadd f5, f0, f1
fadd f6, f0, f2
fadd f7, f0, f3
fadd f8, f0, f4
sd f5, 0(r2)
sd f6, 8(r2)
sd f7, 16(r2)
sd f8, 24(r2)
add r2, 32
bne r1, r3, loop
Schedule
Int1 Int 2 M1 M2 FP+ FPx
loop:
Unroll 4 ways
ld f1
ld f2
ld f3
ld f4add r1 fadd f5
fadd f6
fadd f7
fadd f8
sd f5
sd f6
sd f7
sd f8add r2 bne
5/6/2008 43
CS152-Spring!08
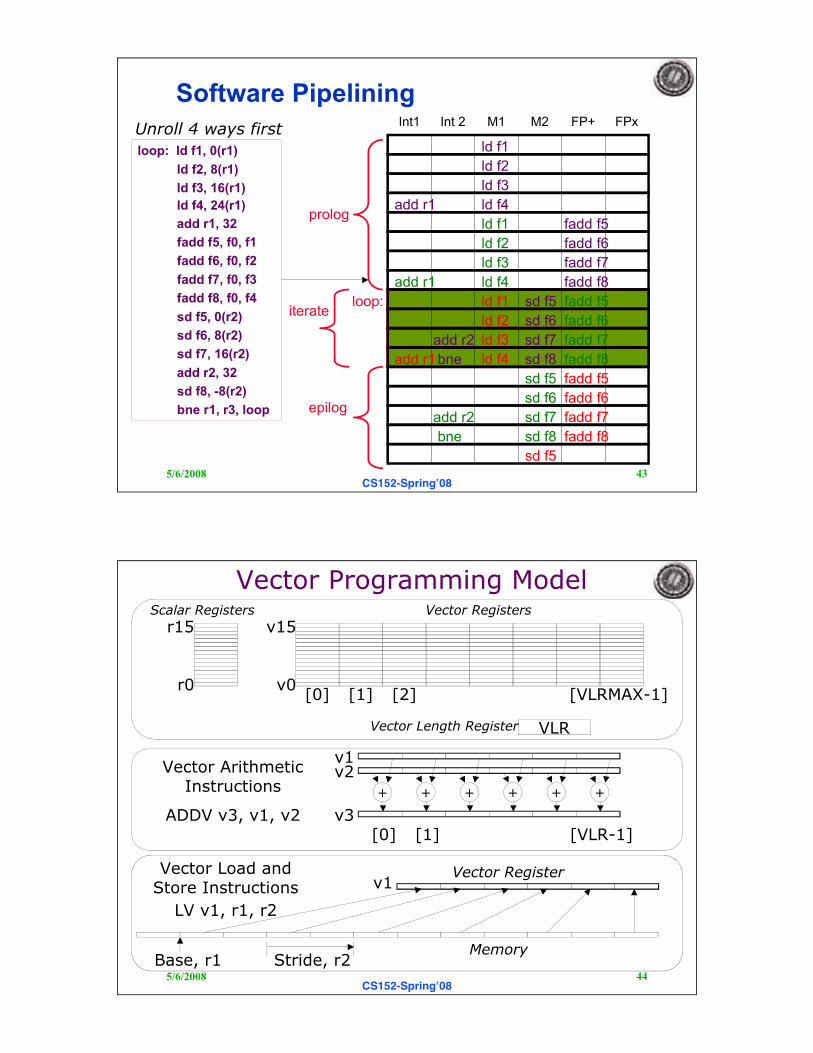
Software Pipelining
loop: ld f1, 0(r1)
ld f2, 8(r1)
ld f3, 16(r1)
ld f4, 24(r1)
add r1, 32
fadd f5, f0, f1
fadd f6, f0, f2
fadd f7, f0, f3
fadd f8, f0, f4
sd f5, 0(r2)
sd f6, 8(r2)
sd f7, 16(r2)
add r2, 32
sd f8, -8(r2)
bne r1, r3, loop
Int1 Int 2 M1 M2 FP+ FPxUnroll 4 ways first
ld f1
ld f2
ld f3
ld f4
fadd f5
fadd f6
fadd f7
fadd f8
sd f5
sd f6
sd f7
sd f8
add r1
add r2
bne
ld f1
ld f2
ld f3
ld f4
fadd f5
fadd f6
fadd f7
fadd f8
sd f5
sd f6
sd f7
sd f8
add r1
add r2
bne
ld f1
ld f2
ld f3
ld f4
fadd f5
fadd f6
fadd f7
fadd f8
sd f5
add r1
loop:iterate
prolog
epilog
5/6/2008 44
CS152-Spring!08
Vector Programming Model
+ + + + + +
[0] [1] [VLR-1]
Vector ArithmeticInstructions
ADDV v3, v1, v2 v3
v2v1
Scalar Registers
r0
r15Vector Registers
v0
v15
[0] [1] [2] [VLRMAX-1]
VLRVector Length Register
v1Vector Load and
Store Instructions
LV v1, r1, r2
Base, r1 Stride, r2Memory
Vector Register
5/6/2008 45
CS152-Spring!08
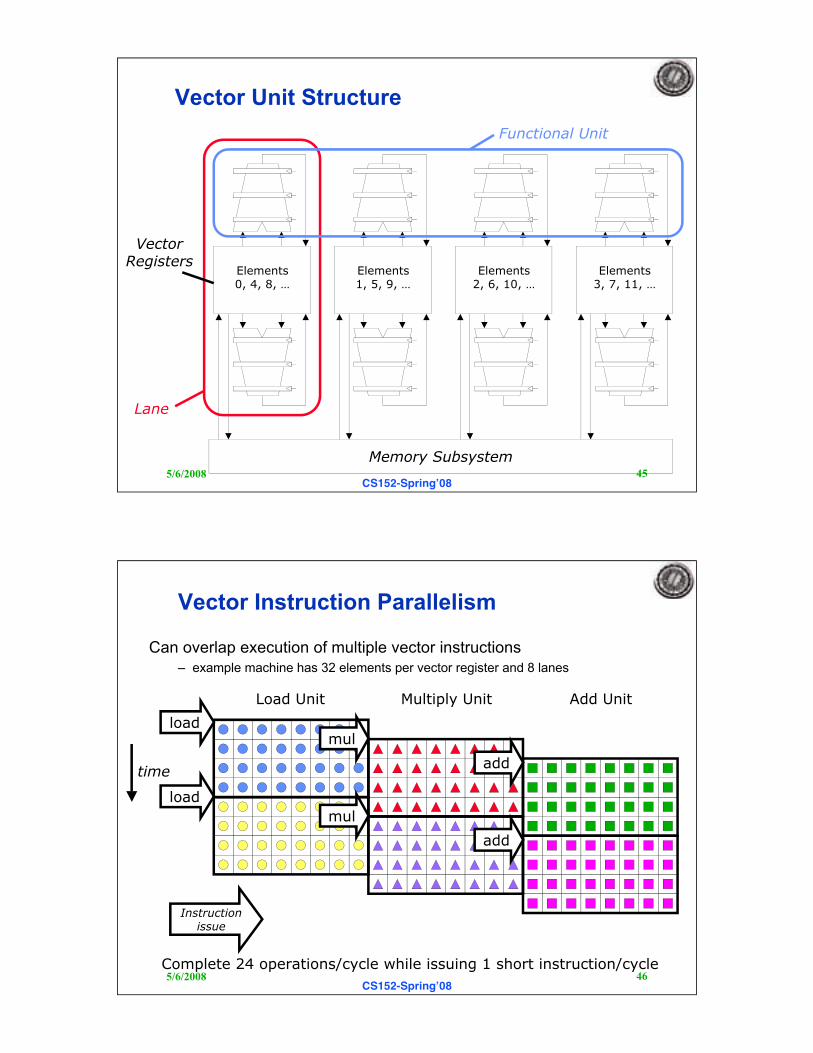
Vector Unit Structure
Lane
Functional Unit
VectorRegisters
Memory Subsystem
Elements0, 4, 8, …
Elements1, 5, 9, …
Elements2, 6, 10, …
Elements3, 7, 11, …
5/6/2008 46
CS152-Spring!08
load
Vector Instruction Parallelism
Can overlap execution of multiple vector instructions– example machine has 32 elements per vector register and 8 lanes
loadmul
mul
add
add
Load Unit Multiply Unit Add Unit
time
Instructionissue
Complete 24 operations/cycle while issuing 1 short instruction/cycle

5/6/2008 47
CS152-Spring!08
Multithreading
How can we guarantee no dependencies betweeninstructions in a pipeline?
-- One way is to interleave execution of instructionsfrom different program threads on same pipeline
F D X M W
t0 t1 t2 t3 t4 t5 t6 t7 t8
T1: LW r1, 0(r2)T2: ADD r7, r1, r4T3: XORI r5, r4, #12T4: SW 0(r7), r5T1: LW r5, 12(r1)
t9
F D X M W
F D X M W
F D X M W
F D X M W
Interleave 4 threads, T1-T4, on non-bypassed 5-stage pipe
Prior instruction ina thread alwayscompletes write-back before nextinstruction insame thread readsregister file
5/6/2008 48
CS152-Spring!08
Multithreaded Categories
Tim
e (p
roce
ssor
cyc
le) Superscalar Fine-Grained Coarse-Grained Multiprocessing
Simultaneous
Multithreading
Thread 1
Thread 2
Thread 3
Thread 4
Thread 5
Idle slot

5/6/2008 49
CS152-Spring!08!085/6/2008 49
CS152-Spring
Power 4
SMT in Power 5
2 fetch (PC),
2 initial decodes
2 commits
(architected
register sets)
5/6/2008 50
CS152-Spring!08
A Producer-Consumer Example
The program is written assuminginstructions are executed in order.
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rhead
process(R)
Producer Consumertail head
RtailRtail Rhead R

5/6/2008 51
CS152-Spring!08
Sequential ConsistencyA Memory Model
“ A system is sequentially consistent if the result ofany execution is the same as if the operations of allthe processors were executed in some sequential order, and the operations of each individual processorappear in the order specified by the program”
Leslie Lamport
Sequential Consistency = arbitrary order-preserving interleavingof memory references of sequential programs
M
P P P P P P
5/6/2008 52
CS152-Spring!08
Sequential Consistency
Sequential consistency imposes more memory orderingconstraints than those imposed by uniprocessorprogram dependencies ( )
What are these in our example ?
T1: T2:Store (X), 1 (X = 1) Load R1, (Y) Store (Y), 11 (Y = 11) Store (Y’), R1 (Y’= Y)
Load R2, (X) Store (X’), R2 (X’= X)
additional SC requirements
5/6/2008 53
CS152-Spring!08
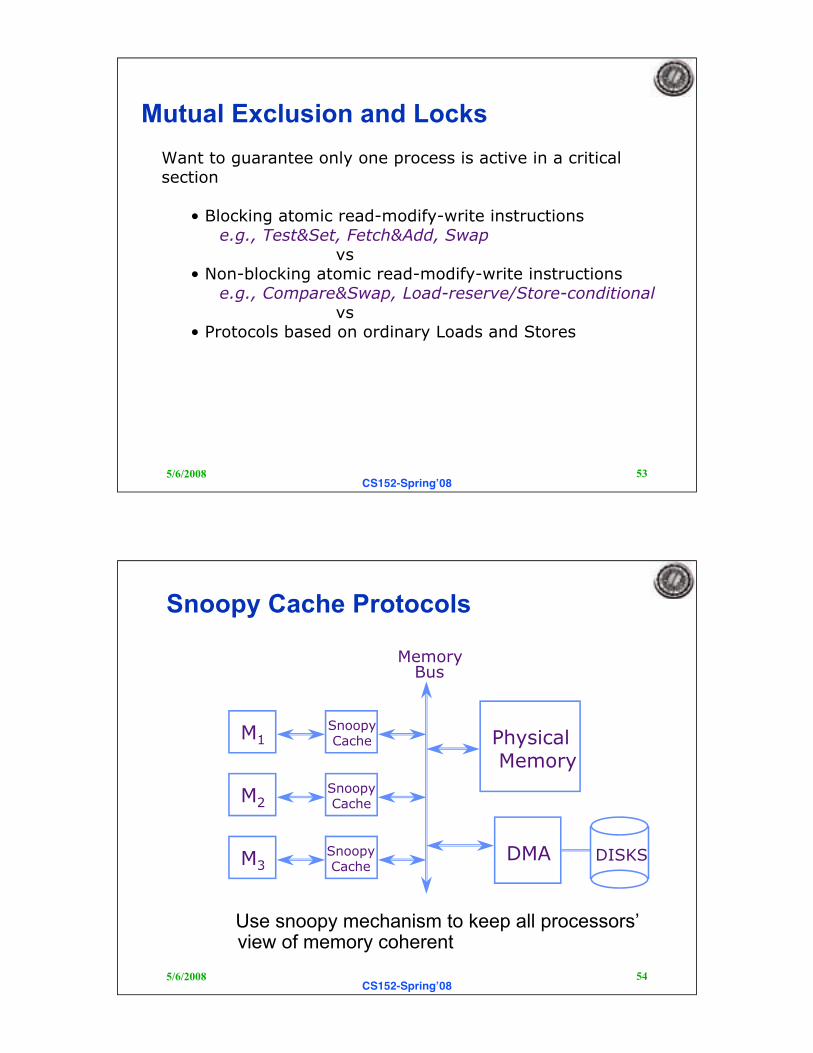
Mutual Exclusion and Locks
Want to guarantee only one process is active in a criticalsection
• Blocking atomic read-modify-write instructionse.g., Test&Set, Fetch&Add, Swap
vs• Non-blocking atomic read-modify-write instructions
e.g., Compare&Swap, Load-reserve/Store-conditionalvs
• Protocols based on ordinary Loads and Stores
5/6/2008 54
CS152-Spring!08
Snoopy Cache Protocols
Use snoopy mechanism to keep all processors’view of memory coherent
M1
M2
M3
Snoopy Cache
DMA
Physical Memory
Memory Bus
Snoopy Cache
Snoopy Cache
DISKS

5/6/2008 55
CS152-Spring!08
MESI: An Enhanced MSI protocol increased performance for private data
M E
S I
M: Modified ExclusiveE: Exclusive, unmodifiedS: Shared I: Invalid
Each cache line has a tag
Address tag
state bits
Write miss
Other processorintent to write
Read miss,shared
Other processorintent to write
P1 write
Read by any processor
Other processor reads
P1 writes back
P1 readP1 writeor read
Cache state inprocessor P1
P 1 in
tent
to w
rite
Read miss,not shared
5/6/2008 56
CS152-Spring!08
Basic Operation of Directory
• k processors.
• With each cache-block in memory:k presence-bits, 1 dirty-bit
• With each cache-block in cache:1 valid bit, and 1 dirty (owner) bit• ••
P P
Cache Cache
Memory Directory
presence bits dirty bit
Interconnection Network
• Read from main memory by processor i:
• If dirty-bit OFF then { read from main memory; turn p[i] ON; }
• if dirty-bit ON then { recall line from dirty proc (cache state toshared); update memory; turn dirty-bit OFF; turn p[i] ON; supplyrecalled data to i;}
• Write to main memory by processor i:
• If dirty-bit OFF then {send invalidations to all caches that have theblock; turn dirty-bit ON; supply data to i; turn p[i] ON; ... }

5/6/2008 57
CS152-Spring!08
Directory Cache Protocol(Handout 6)
• Assumptions: Reliable network, FIFO messagedelivery between any given source-destination pair
CPU
Cache
Interconnection Network
DirectoryController
DRAM Bank
DirectoryController
DRAM Bank
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
DirectoryController
DRAM Bank
DirectoryController
DRAM Bank
5/6/2008 58
CS152-Spring!08
Performance of Symmetric Shared-MemoryMultiprocessors
Cache performance is combination of:
1. Uniprocessor cache miss traffic
2. Traffic caused by communication– Results in invalidations and subsequent cache misses
• Adds 4th C: coherence miss– Joins Compulsory, Capacity, Conflict
– (Sometimes called a Communication miss)

5/6/2008 59
CS152-Spring!08
Intel “Nehalem”(2008)
• 2-8 cores
• SMT (2 threads/core)
• Private L2$/core
• Shared L3$
• Initially in 45nm
5/6/2008 60
CS152-Spring!08
Related Courses
CS61C CS 152
CS 258
CS 150
Basic computer
organization, first look
at pipelines + caches
Computer Architecture,
First look at parallel
architectures
Parallel Architectures,
Languages, Systems
Digital Logic Design
Strong
Prerequisite
CS 194-6
New FPGA-based
Architecture Lab Class
CS 252
Graduate Computer
Architecture,
Advanced Topics

5/6/2008 61
CS152-Spring!08
Advice: Get involved in research
E.g.,
• RADLab - data center
• ParLab - parallel clients
• Undergrad research experience is the most importantpart of application to top grad schools.
5/6/2008 62
CS152-Spring!08
End of CS152
• Thanks for being such patient guinea pigs!– Hopefully your pain will help future generations of CS152 students

5/6/2008 63
CS152-Spring!08
Acknowledgements
• These slides contain material developed andcopyright by:
– Arvind (MIT)
– Krste Asanovic (MIT/UCB)
– Joel Emer (Intel/MIT)
– James Hoe (CMU)
– John Kubiatowicz (UCB)
– David Patterson (UCB)
• MIT material derived from course 6.823
• UCB material derived from course CS252