cross media publishing von lehrmaterialien mit xml schema ...tschnied/diplomarbeit.pdf · cross...
TRANSCRIPT

Cross Media Publishingvon Lehrmaterialien mit
XML Schema & XSL-Transformationen
Diplomarbeitvon
Tanja Schniederberend
betreut vonProf. Dr. Oliver Vornberger
Akad. Dir. Klaus Brauer
Fachbereich Mathematik/InformatikUniversität Osnabrück
11.06.2003

1
Vorwort
Diese Diplomarbeit entstand an der Universität Osnabrück im Fachbereich Mathema-tik/Informatik. Sie bildet den schriftlichen Teil der Diplomprüfungen für meinen Ab-schluss als Diplom Systemwissenschaftlerin.
Danksagung
An dieser Stelle möchte ich allen, die mich bei der Erstellung dieser Diplomarbeitunterstützt haben, danken.
• Herrn Prof. Dr. Oliver Vornberger und Akad. Dir. Klaus Brauer für die Betreuungder Arbeit
• Ralf Kunze, Olaf Müller und Ingo Reckers für konstruktive Vorschläge und dasKorrekturlesen der Arbeit
• Maren Schniederberend für weitere Korrekturanmerkungen
• Friedhelm Hofmeyer für die Bereitstellung eines Computers und der benötigtenSoftware
Warenzeichen
Alle in dieser Arbeit genannten Unternehmens- und Produktbezeichnungen sind in denmeisten Fällen geschützte Marken- oder Warenzeichen. Die Wiedergabe von Marken-oder Warenzeichen in dieser Diplomarbeit berechtigt auch ohne besondere Kennzeich-nung nicht zu der Annahme, dass diese als frei von Rechten Dritter zu betrachtenwären. Alle erwähnten Marken- oder Warenzeichen unterliegen uneingeschränkt denländerspezifischen Schutzbestimmungen und den Besitzrechten der jeweiligen einge-tragenen Eigentümer.

I
Inhaltsverzeichnis
1 Einleitung 1
1.1 Aufgabenstellung. . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Aufbau der Arbeit. . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 XML Schema 3
2.1 Basis: XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Entstehung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Grundlagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 Definition einfacher Datentypen und Elemente. . . . . . . . . . . . . 8
2.5 Definition komplexer Datentypen und Elemente. . . . . . . . . . . . 11
2.6 Namensräume. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.7 Techniken zur Wiederverwendung und Strukturierung. . . . . . . . . 17
3 XSLT 20
3.1 Entstehung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2 Basis: XML-Dokument. . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2.1 Aufbau des Konzeptbaumes. . . . . . . . . . . . . . . . . . 21
3.2.2 Bewegung im Konzeptbaum. . . . . . . . . . . . . . . . . . 22
3.3 Grundlagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Datenabhängige Verarbeitung. . . . . . . . . . . . . . . . . . . . . . 28
3.5 Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.6 Erweiterungsfunktionen. . . . . . . . . . . . . . . . . . . . . . . . . 36
4 XSL-FO 41
4.1 Entstehung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2 Grundlagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3 Seitendefinition. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.4 Inhalte einer Seite. . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.5 Generierung mit XSLT. . . . . . . . . . . . . . . . . . . . . . . . . 48
4.6 Formatierer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50

II
5 SVG 52
5.1 Entstehung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2 Grundlagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.3 Darstellungsobjekte. . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.4 Animationen und Interaktionen. . . . . . . . . . . . . . . . . . . . . 57
6 Allgemeines Konzept 61
6.1 Begriffsdefinitionen und Zusammenhänge. . . . . . . . . . . . . . . 61
6.2 Vollständiger Arbeitsablauf aus Anwendersicht. . . . . . . . . . . . 63
6.3 Anforderungen an die Dokumenteingabe. . . . . . . . . . . . . . . . 66
6.4 Anforderungen an die Dokumentstruktur. . . . . . . . . . . . . . . . 67
6.5 Anforderungen an die Ausprägungen. . . . . . . . . . . . . . . . . . 68
7 Dokumentstruktur 70
7.1 Existierende Datenformate. . . . . . . . . . . . . . . . . . . . . . . 70
7.1.1 Textbeschreibende Datenformate. . . . . . . . . . . . . . . . 70
7.1.2 Datenformate zur Beschreibung von Lehrmaterialien. . . . . 71
7.1.3 Bewertung der Datenformate. . . . . . . . . . . . . . . . . . 72
7.2 Beschreibung inklusive Ausprägungskriterien. . . . . . . . . . . . . 73
7.2.1 Semantische Objekte. . . . . . . . . . . . . . . . . . . . . . 74
7.2.2 Strukturelle Objekte. . . . . . . . . . . . . . . . . . . . . . 74
7.2.3 Darstellungsstrukturen. . . . . . . . . . . . . . . . . . . . . 75
7.2.4 Erweiterungen elementarer Einheiten. . . . . . . . . . . . . 76
7.2.5 Zusatzinformationen für die Ausprägungen. . . . . . . . . . 76
7.3 Realisierungsvorgaben. . . . . . . . . . . . . . . . . . . . . . . . . 76
8 Realisierung 78
8.1 Dateneingabe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
8.2 Datenformat in XML Schema. . . . . . . . . . . . . . . . . . . . . 80
8.2.1 Elemente. . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
8.2.2 Beziehungen der Elemente. . . . . . . . . . . . . . . . . . . 84
8.2.3 Zusatzinformationen für die Ausprägungen. . . . . . . . . . 87
8.3 Generierung der Ausgabe mit XSLT. . . . . . . . . . . . . . . . . . 90
8.3.1 Folgerungen der Struktur. . . . . . . . . . . . . . . . . . . . 90
8.3.2 Sprachunterstützung. . . . . . . . . . . . . . . . . . . . . . 95

III
8.3.3 Flexibilität der Stylesheet Prozessoren. . . . . . . . . . . . . 97
8.3.4 MathML . . . . . . . . . . . . . . . . . . . . . . . . . . . .100
8.4 Verschiedene Ausprägungen. . . . . . . . . . . . . . . . . . . . . . 102
8.4.1 Allgemeine Bestimmmung von Ausprägungen mit XSLT. . . 103
8.4.2 Skript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .105
8.4.3 Präsentation. . . . . . . . . . . . . . . . . . . . . . . . . . .106
9 Anwendung 109
9.1 Beispieldokument. . . . . . . . . . . . . . . . . . . . . . . . . . . .109
9.2 Skript in XHTML . . . . . . . . . . . . . . . . . . . . . . . . . . . .111
9.3 Skript in PDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .112
9.4 Präsentation in SVG. . . . . . . . . . . . . . . . . . . . . . . . . .113
10 Ausblick 115
A Schemata der Dokumente 117
B Ausprägungstransformationen 119
C Testseiten verschiedener Formatierer 120
D Literaturverzeichnis 124
Erklärung

IV
Abbildungsverzeichnis
1 Einordnung von XML. . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 XML-Dokument als Konzeptbaum. . . . . . . . . . . . . . . . . . . 22
3 Funktion von XSLT. . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 Selektierte Elemente im Konzeptbaum. . . . . . . . . . . . . . . . . 27
5 Ausgabe mit Saxon. . . . . . . . . . . . . . . . . . . . . . . . . . . 38
6 Ausgabe mit Xalan. . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7 Ablauf zur Erstellung von Formaten aus XML-Daten. . . . . . . . . 42
8 Regionen einer Seite in XSL-FO. . . . . . . . . . . . . . . . . . . . 44
9 Formatierung von Text in XSL-FO. . . . . . . . . . . . . . . . . . . 47
10 Zeile mit Grafikinhalt in XSL-FO . . . . . . . . . . . . . . . . . . . 48
11 Einfache grafische Objekte in SVG. . . . . . . . . . . . . . . . . . . 54
12 Pfad in SVG. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
13 Pfadorientierter Text in SVG. . . . . . . . . . . . . . . . . . . . . . 56
14 Zeitpunktaufnahmen einer Animation in SVG. . . . . . . . . . . . . 58
15 Interaktion in SVG . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
16 Ein Dokument liefert verschiedene Inhaltsdarstellungen. . . . . . . . 62
17 Arten der Inhaltsdarstellungen. . . . . . . . . . . . . . . . . . . . . 63
18 Arbeitsablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
19 Allgemeine Datenstruktur. . . . . . . . . . . . . . . . . . . . . . . . 73
20 Struktur eines Kapitels. . . . . . . . . . . . . . . . . . . . . . . . . 75
21 Definition des Kapitels. . . . . . . . . . . . . . . . . . . . . . . . . 83
22 Zusammenhang der Textgruppen. . . . . . . . . . . . . . . . . . . . 84
23 Gruppenzusammenhänge. . . . . . . . . . . . . . . . . . . . . . . . 87
24 Ausschnitt XHTML mit MathML . . . . . . . . . . . . . . . . . . . 103
25 Beispielkapitel in XHTML . . . . . . . . . . . . . . . . . . . . . . . 112
26 Beispielskript in XHTML. . . . . . . . . . . . . . . . . . . . . . . . 113
27 Beispielskript als PDF . . . . . . . . . . . . . . . . . . . . . . . . . 114
28 Beispielpräsentation in SVG. . . . . . . . . . . . . . . . . . . . . . 114
29 Testseite mit XEP. . . . . . . . . . . . . . . . . . . . . . . . . . . .121
30 Testseite mit XSL Formatter. . . . . . . . . . . . . . . . . . . . . . 122
31 Testseite mit FOP. . . . . . . . . . . . . . . . . . . . . . . . . . . .123

1
1 Einleitung
Lehrmaterialien werden über unterschiedliche Medien und an verschiedene Adressa-ten verteilt. Dabei werden sowohl Medien wie Tafeln, Folien oder Papier benutzt, alsauch seit jüngerer Zeit der Computer. Alle diese Medien müssen auf unterschiedlicheArt behandelt werden. Zusätzlich werden auch unterschiedliche Informationen auf denMedien verbreitet. Die Folien unterstützen eher stichwortartig ein Thema, das vorge-tragen wird, und das Papier liefert die Möglichkeit die vorgetragenen Informationenausführlich an die Lernenden zu verteilen. Die Tafel wird hingegen häufig zur Ent-wicklung einer Thematik verwendet. Es werden damit zu einem Thema unterschied-liche Detaillierungsgrade beschrieben, die auf verschiedene Arten verbreitet werdenkönnen. Ein Dozent muss deshalb zur Zeit mehrere Dokumente in unterschiedlichenFormaten erstellen und pflegen, um eine Thematik für verschiedene Adressatenkrei-se und Medien aufzubereiten. Damit werden dieselben Informationen vielfach erzeugtund können nicht wiederverwendet werden. Ein Weg zur Lösung dieser Problematiksoll in dieser Diplomarbeit aufgezeigt werden.
1.1 Aufgabenstellung
UnterCross Media Publishingversteht man die Verbreitung von einem Inhalt auf un-terschiedlichen Medien. Dabei ist der Inhalt nur ein einziges Mal zu spezifizieren undwird durch Automatismen so aufbereitet, dass er sowohl in elektronischer als auch ingedruckter Form veröffentlicht werden kann. Dieser Gedanke ist auf die verschiede-nen Formen von Lehrmaterialien, wie beispielsweise Skript und Präsentation, anzu-wenden. Deshalb müssen aus einem inhaltlichen Dokument unterschiedliche Formateerzeugt werden.
Die ganze Verarbeitung soll aber nicht nur die Ausgabe eines einmal festgelegten In-haltes auf unterschiedlichen Medien, sondern auch die Aufbereitung für verschiedeneAdressatenkreise ermöglichen. Damit wird ein Inhalt in zwei Richtungen interpretiert,einmal inhaltlich anhand des Adressaten und einmal technisch anhand des einzuset-zenden Mediums. Damit werden vielfältige Verbreitungsarten ermöglicht.
Die Aufgabenstellung umfasst die Konzeptionierung und Machbarkeitsanalyse anhandeiner Implementation des Cross Media Publishing, angewendet auf den Spezialfall derLehrmaterialien unter Einsatz von XML Schema und XSL-Transformationen. Zur Be-schreibung der zugrunde liegenden Struktur für die Lehrmaterialien ist XML Schemaeinzusetzen, da XML Schema eine zentrale Rolle in der Zukunft von XML spielenwird. "XML Schema is poised to play a central role in the future of XML processing,especially in Web services [...]" [SKO2003]. Aufbauend auf dieser Grundlage müssendie verschiedenen Publikationswege beschrieben werden können. Die dafür notwendi-gen Voraussetzungen werden mit XSL-Transformationen abgedeckt.

2
1.2 Aufbau der Arbeit
In den ersten Kapiteln werden die technischen Grundlagen verschiedener XML-An-wendungen (XML Schema, XSLT, XSL-FO und SVG) erläutert, die für die spätereRealisierung von Bedeutung sind. Ergänzt werden die Erläuterungen durch kurze Bei-spiele, die die Funktionsweise der einzelnen XML-Anwendungen, unabhängig vonder weiteren Betrachtung, anhand des Quellcodes deutlich machen sollen. Die zentra-len Rollen nehmen dabei XML Schema und XSLT ein. Im Gegensatz dazu werden zuXSL-FO und SVG nur die grundsätzlichen Möglichkeiten erläutert.
Auf die technischen Grundlagen folgt das Konzept zum Cross Media Publishing. An-hand der Vorgaben, die aus dem Konzept resultieren, werden die Anforderungen an dieDokumenteingabe, die Dokumentstruktur und die Ausprägungen festgehalten. Die-se Anforderungen werden mit den existierenden Datenformaten verglichen und dieStruktur des verwendeten Datenformates wird erläutert.
Aufbauend auf diesem theoretischen Ansatz wird die konkrete Realisierung behandelt.Dazu werden die theoretischen Anforderungen des Konzeptes in eine praktische Um-setzung gebracht. Die Dateneingabe beschäftigt sich mit den Anforderungen an einenEditor unter dem Gesichtspunkt des eingesetzten Formates. Die Realisierung der Do-kumentstruktur und der weitere Generierungsprozess wird anhand von beispielhaftenCodeauszüge dargestellt.
Die beispielhafte Betrachtung des gesamten Prozesses von einem Dokument bis hin zumehreren Ausprägungen rundet die Ausführungen ab. Der im Anschluss betrachteteAusblick stellt weitere Ideen und Vorstellungen zur Weiterentwicklung des Konzeptevor.

3
2 XML Schema
XML Schema ist eine XML-Anwendung, mit der neue XML-Anwendungen definiertwerden. Um die Funktionsweise von XML Schema zu verstehen und anwenden zukönnen, sollten grundlegende XML Kenntnisse vorhanden sein. Das folgende Kapi-tel soll zunächst einen kurzen Überblick über XML liefern. Für ein tiefer gehendesVerständnis sei auf die dementsprechende Fachliteratur verwiesen, z.B. [Har2000a,Har2000b].
2.1 Basis: XML
Die eXtensible Markup Language(XML) wurde 1998 in erster Version vom W3C[W3CXML] als Empfehlung verabschiedet. XML ist eine Metasprache, die es ermög-licht anhand von Auszeichnungen, sogenannten Tags, neue Markup-Sprachen zu defi-nieren. Auf diese Weise definierte Sprachen werdenXML-Anwendungengenannt.
XML ist aus derStandard Generalized Markup Language(SGML) entstanden. SGMList bereits 1986 als Metasprache zur Dokumentenbeschreibung [ISO8879] standardi-siert worden. Mit SGML werden Vorschriften geliefert, um neue Auszeichnungsspra-chen zu definieren. 1990 ist aus den Ideen von SGML die erste Version von HTMLentstanden und seit der Version 2.0 im Jahr 1995 wird HTML auch durch SGML defi-niert. Während sich allerdings HTML weit verbreitet hat, wird SGML nur von einemsehr eingeschränkten Benutzerkreis, beispielsweise von Verlagen, verwendet. Das istinsbesondere der hohen Komplexität und einer mehrere hundert Seiten langen Definiti-on von SGML [Hof1998] zu verdanken. Zur Verringerung dieser Komplexität und zurVerkürzung der Definition des Standards ist XML entstanden1. XML ist ebenfalls eineMetasprache, vgl. Abbildung1. Die wesentlichen Ideen von SGML wurden in XMLaufgegriffen und erschwerende Eigenschaften abgeschafft. So verstößt beispielsweisedie aus HTML bekannte Möglichkeit Tags wegzulassen, wenn sie aus dem Zusam-menhang klar hervorgehen, gegen die Regeln von XML. Das stellt eine Vereinfachungin dem Sinne dar, dass keine Rückschlüsse auf die Struktur eines Dokumentes anhanddes Kontextes gemacht werden müssen. Dadurch wird besonders die Entwicklung vonAnwendungsprogrammen erleichtert. Dokumente, die gültige XML-Dokumente lie-fern, sind somit auch automatisch gültige SGML-Dokumente. XML stellt also einevereinfachte Teilmenge von SGML dar, mit der Ausnahme, dass die bei SGML ge-forderte Angabe einerDocument Type Definition(DTD) in XML-Dokumenten ver-nachlässigt werden kann, vgl. [Bry2001, Kapitel 4.1.1]. XML-Dokumente, die keineDTD angeben, sind somit keine gültigen SGML-Dokumente. Ansonsten ist XML auf-wärtskompatibel zu SGML. Zur weiteren Unterscheidung vgl. [Cla1997]. Aus dieserEntwicklung stammt die optische Ähnlichkeit von HTML- und XML-Dokumenten,die sich in der Auszeichnung anhand von Tags ausdrückt.
1Zu den weiteren Anforderungen an XML siehe [Beh2000, S.389].

4
� �� �� �� �� �� �� �� �
� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �
� � � � � � � �� � � � � � � �
� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �
� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �
� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �� � � � � � � �
Met
aspr
ache
n
SGML
XML
HTML
XHTML
SVG
MathML
definieren
XSLT
Abbildung 1:Einordnung von XML
Der Zweck, mit XML eine Metasprache zu entwickeln, die sich einer hohen Benutzungerfreut, ist gelungen. Schon heute werden zahlreiche XML-Anwendungen, beispiels-weiseXHTML, SVG, MathML und XSLT, definiert und benutzt. In [Zap2002] wirdeine große Anzahl von XML-Anwendungen nach Einsatzgebieten sortiert dargestellt,wobei sich die Liste kontinuierlich verlängert.
In XML werden strukturierte Informationen beschrieben, die mit Tags ausgezeichnetwerden. Derartige Dokumente müssen die von XML aufgestellten Grundregeln befol-gen. Erfüllt ein XML-Dokument die folgenden acht Regeln, so gilt es alswell formed(wohlgeformt), vgl. [Har2000a, S.179 ff.]:
1. Der Anfang des Dokumentes startet mit einer XML-Deklaration:
<?xml version="1.0"?>
2. Zu jedem öffnenden Tag gibt es ein schließendes Tag:
<TAG> inhalt </TAG>
3. Leere Elemente können in der folgenden Kurzform notiert sein:
<LEERES_ELEMENT/>
Diese Notation ist gleichbedeutend mit:
<LEERES_ELEMENT></LEERES_ELEMENT>
4. Das Wurzelelement des Dokumentes muss alle anderen Elemente enthalten.

5
5. Elemente können ineinander verschachtelt, dürfen aber nicht verzahnt sein:
richtig ist:
<ELEMENT1><ELEMENT2></ELEMENT2></ELEMENT1>
falsch ist:
<ELEMENT1><ELEMENT2></ELEMENT1></ELEMENT2>
6. Alle Attribute müssen in Anführungszeichen stehen.
7. Die Zeichen< und& sind geschützte Zeichen und dürfen nur für den Beginn vonTags bzw. Entity2-Referenzen eingesetzt werden.
8. Es dürfen nur die vordefinierten Entity-Referenzen& , ' , < ,> , " benutzt werden.
Basierend auf diesen Grundlagen sind mittlerweile zahlreiche XML-Anwendungenentstanden. Die für die weitere Arbeit entscheidenen Anwendungen, werden in denfolgenden Kapiteln ausführlich behandelt.
2.2 Entstehung
Die erste Möglichkeit zur Beschreibung von neuen XML-Anwendungen wurde mittelsDTD’s geliefert, vgl. Kapitel2.1. Durch die schnelle Verbreitung von XML wurdenschnell die Grenzen von DTD’s erreicht. DTD’s liefern keine Möglichkeit Datentypenzu definieren, da sie nur mit Einschränkungen auf den benutzbaren Zeichen arbeiten.Ebenso ist die Wiederverwendbarkeit eingeschränkt, da keine global eindeutigen Na-men vergeben werden können. Aus diesen Gründen wurde nach einer Möglichkeitgesucht, die Datentypen der Elemente und Attribute eines XML-Dokumentes genauerzu definieren, um somit ihre Wiederverwendbarkeit und Interoperabilität zu erhöhen.Das alles sollte mit einer Sprache erreicht werden, die auch in XML geschrieben wird.
Aus diesen wesentlichen Anforderungen ist am 02.05.2001 vom W3C die erste undzur Zeit aktuelle Empfehlung von XML Schema in drei Teilen verabschiedet worden.Der Leitfaden zu XML Schema inXML Schema Part 0: Primer[W3CXSDa] und diezwei maßgeblichen EmpfehlungenXML Schema Part 1: Structures[W3CXSDb] undXML Schema Part 2: Datatypes[W3CXSDc]. XML Schema ist demnach eine XML-Anwendung, mit der neue XML-Anwendungen beschrieben werden können.
2Ein Entity ist eine Speichereinheit eines XML-Dokumentes. Diese sind beliebig groß und kön-nen Text oder Binärdaten enthalten. Mittels Entity-Referenzen kann ihr Inhalt in ein XML-Dokumenteingefügt werden, vgl. [Har2000a, S.293 ff.]

6
In vielen Fällen wird allerdings zur Zeit noch mit DTD’s gearbeitet, da sie von vie-len Tools umfangreicher unterstützt werden als XML Schema. Auf Dauer werden sichaber die erweiterten Möglichkeiten von XML Schema im Vergleich zu DTD’s durch-setzen. So resultieren aus der Anforderung zur Definition eigener Datentypen in XMLSchema neue Ideen dieses Wissen über den Inhalt eines Elementes oder Attributesauch in die weiteren Verarbeitungsschritte einzubringen. Beispielsweise ist angedachtin einer weiteren Version von XSLT, vgl. Kapitel3, den Zugriff auf die Datentypen zuermöglichen.
2.3 Grundlagen
XML-Dokumente müssen nicht mit einer DTD oder einem Schema verknüpft sein.Das bedeutet, dass sie auch ohne Angabe einer Definition, sei es nun eine DTD oderein Schema, existieren und auf ihre Wohlgeformtheit überprüft werden können, vgl.Kapitel 2.1. Allerdings lassen sich ohne Angabe einer Definition keine Prüfungen be-züglich der Struktur des Dokumentes vornehmen. Diese können nur gemacht werden,wenn das Dokument auf eine DTD oder ein Schema verweist. Die darin spezifiziertenAngaben zu der Struktur des XML-Dokumentes, werden anhand eines XML-Parsers3
getestet. Ist das XML-Dokument nach der vorgegebenen Struktur der DTD oder desSchemas aufgebaut, so nennt man esgültig. Diese Gültigkeitsprüfung nennt man auchValidierung. Da diese Prüfung erst in einem zweiten Schritt erfolgen kann, ist die Vor-aussetzung, dass es sich um ein wohlgeformtes Dokument handelt.
Da XML Schema die Struktur von XML-Dokumenten beschreibt, sollen im Folgen-den nur noch gültige Dokumente betrachtet werden. Auf dieser Grundlage bauen auchdie weiteren Verarbeitungsschritte auf. Um den Anforderungen an ein wohlgeformtesXML-Dokument gerecht zu werden, ist der äußere Rahmen für jedes XML-Schemaim wesentlichen gleich:
<?xml version="1.0" encoding="UTF-8"?><xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">...</xs:schema>
In der ersten Zeile handelt es sich um die standardmäßige XML-Deklaration. Diesewurde hier um das Attributencoding ergänzt, mit dem der Zeichensatz des gesamtenDokumentes angegeben werden kann. Als nächstes folgt das Wurzelelement, das diegesamten weiteren Elemente enthalten muss. Für die Definition eines XML Schemasmuss dieses dasschema-Element sein. Zur eindeutigen Identifizierung wird ihm mit
3Ein XML-Parser ist ein Programm, das ein XML-Dokument einliest und dadurch den Zugriff aufden Inhalt und die Struktur des Dokumentes ermöglicht. Eine Überprüfung der Gültigkeit ist für denParser nicht zwingend erforderlich, doch bedingt ein erfolgreiches Einlesen die Wohlgeformtheit desDokumentes.

7
demxmlns -Attribut der Namensraumhttp://www.w3.org/2001/XMLSche-mazugewiesen. Auf Namensräme wird in Kapitel2.6noch explizit eingegangen. Diegängige Notation für Schema-Elemente ist das Präfixxs , das im weiteren verwendetwird. In den folgenden Beispielen wird dieses Präfix gefolgt von einem Doppelpunktbenutzt und damit die Zugehörigkeit der Elemente zur Schemadefinition festgelegt.Eigenen Definitionen wird dieses Präfix nicht vorangestellt, wodurch sie immer leichtzu erkennen sind.
In den äußeren Rahmen werden nun die Definitionen für die neue XML-Anwendungeingebettet. Die einfachste Art ist das Hinzufügen eines neuen Elementes. Dazu müs-sen der Name und der Typ angegeben werden.
Beispiel 2.3.1:Ein Element mit dem Namendatum vom Typ date läßt sich folgendermaßen be-schreiben:<xs:element name="datum" type="xs:date"/>
Ein auf einen einfachen Typ eingeschränktes Element, kann nur den Inhalt aufnehmen,der durch die Typangabe spezifiziert wurde. Diese Einschränkung ist vergleichbar mitTypfeldern einer Datenbank. Es können also keine weiteren Elemente in dem Elemententhalten sein.
Beispiel 2.3.2:Dasdatum -Element aus dem vorangegangenen Beispiel würde etwa folgendermaßenin einem XML-Dokument zum Einsatz kommen:<datum>2003-05-31</datum>
Neben den bereits in XML Schema existierenden einfachen Datentypen, vgl. Tabelle1, lassen sich auch eigene Datentypen definieren. Diese Technik soll im Folgendenerläutert werden.
Datentyp Beispiel für gültigen Inhalt
string alle textuellen Inhalte inkl. Leerzeichenlanguage en de en-USanyURI http://www.uos.detime 18:00:30gMonthDay --05-30 --12-01 --01-31integer 123 -987 0double 4.56 5.6e7 INFboolean true 1 0
Tabelle 1: Häufig benutzte Datentypen in XML Schema.

8
2.4 Definition einfacher Datentypen und Elemente
Wie es in gängigen Programmiersprachen der Fall ist, lassen sich neue Datentypendefinieren. Dazu dienen die bereits existierenden Datentypen als Grundlage. Hierfürgibt es drei grundsätzliche Möglichkeiten, die zum Einsatz kommen können:
• Einschränkungen:Festlegung einer Teilmenge von gültigen Werten aus der ursprünglichen Werte-menge
• Listen:Durch Leerzeichen getrennte Aufzählungen eines Typs
• Vereinigungen:Kombination verschiedener Datentypen zu einem neuen Typ
Allen diesen Typ-Definitionen können auch bereits selbst erzeugte Datentypen zugrun-de liegen, woraus sich beliebige Kombinationsmöglichkeiten ergeben. Eine Ausnahmebildet hierbei die Liste, da keine Liste von Listen erzeugt werden kann.
Die einzelnen Definitionsmöglichkeiten sind durch die unterschiedlichen Umsetzungs-arten sehr flexibel. So lässt sich bespielsweise eine Einschränkung durch
• Aufzählungslisten gültiger Werte
• Angabe von Minimal- oder Maximalwerten
• Muster
• Längenbegrenzung der einzugebenden Zeichen
realisieren. Einige dieser Umsetzungsarten sollen in den folgenden Beispielen demon-striert werden.
Beispiel 2.4.1:Verschiedene Arten von Einschränkungen:
1. Ein einfacher Datentypgrafikformat , der durch Einschränkungen vonxs:string nur noch bestimmte Werte (gif , jpg odereps ) annehmen darf:
<xs:simpleType name="grafikformat"><xs:restriction base="xs:string">
<xs:enumeration value="gif"/><xs:enumeration value="jpg"/><xs:enumeration value="eps"/>
</xs:restriction></xs:simpleType>

9
2. Für einen Typartikelnummer , der auf einer ganzen Zahl zwischen 1 und999999 beruht, sind verschiedene Definitionen möglich. In diesem Beispiel wirddie 0 ausgeschlossen, während die 999999 mit in den Wertebereich aufgenom-men wird:
<xs:simpleType name="artikelnummer"><xs:restriction base="xs:integer">
<xs:minExclusive value="0"/><xs:maxInclusive value="999999"/>
</xs:restriction></xs:simpleType>
3. Ein Beispiel zur Benutzung von Mustern, ist die Einschränkung von URI’s4 aufausschließlich per FTP (File Transfer Protocol) erreichbare Daten. Diese be-ginnen stets mitftp:// , gefolgt von einer beliebigen Zeichenkette. Hier wirdbeispielhaft ein Datentyp namensftpURI erzeugt, der vonxs:anyURI ab-stammt:
<xs:simpleType name="ftpURI"><xs:restriction base="xs:anyURI">
<xs:pattern value="ftp://.*"/></xs:restriction>
</xs:simpleType>
Beispiel 2.4.2:Listen und Vereinigungen:
1. Es lassen sich auch neue Datentypen durch Listen erzeugen, wie hier zumBeispiel eineformatliste von den in Beispiel 2.4.1(1) erzeugten Gra-fikformaten. Gültige Elemente zu diesem Datentyp würden immer mit Leer-zeichen die einzelnen Listeneinträge voneinander trennen, beispielsweise"gif gif jpg" oder "eps jpg gif" , wobei die Anzahl der Einträgekeine Rolle spielt.
<xs:simpleType name="formatliste"><xs:list itemTyp="grafikformat"/>
</xs:simpleType>
4Mit einem Uniform Resource Identifier(URI) werden alle Arten von Namen und Adressen be-schrieben, die auf Quellen im Web hinweisen. Der bekannteste Einsatz von URI’s sindUniform Re-source Locator(URL), die eine Teilmenge der URI’s darstellen. Weiter reichende Informationen dazusind in [W3CURI] zu finden.

10
2. Durch die Vereinigung vom positiven und negativen Integerdatentyp lässt sichein neuer Datentyp erstellen, der alle Integerwerte mit Ausnahme der Null ak-zeptiert. Mit dieser Definition wirdIntegerOhneNull vom Typunion . Umdie Datentyp-Eigenschaft beizubehalten, dass es sich um Elemente des Typs In-teger handelt, muss eine derartige Definition als Restriktion auf dem Integer-Typvorgenommen werden.
<xs:simpleType name="IntegerOhneNull"><xs:union memberTypes="xs:positiveInteger
xs:negativeInteger"/></xs:simpleType>
Von diesen eigens definierten Datentypen lassen sich genauso Elemente erzeugen, wiees von den vorgegebenen Typen der Fall ist. Allerdings ist es nicht immer nötig extraeinen eigenen Datentyp zu kreieren, wenn dieser für einen sehr speziellen Fall benötigtwird und keine weitere Verwendung findet. Dafür besteht immer die Möglichkeit einElement mit direkter Typdefinition zu erzeugen, so dass dieser nicht speziell benanntwird und nur lokal in dem Element existiert.
Beispiel 2.4.3:Ein gruss -Element, das verschiedene Begrüßungsarten (hallo , morgen oderservus ) enthalten darf, wird nur einmal benötigt. Deshalb bietet sich hierfür einelokale Definition des Elementes an. Diese Definition ist im wesentlichen mit den vor-hergehenden Typdefinitionen identisch, nur wird kein Name für den Typ vergeben unddas Element enthält kein Attribut, das auf den Typ verweist.
<xs:element name="gruss"><xs:simpleType>
<xs:restriction base="xs:string"><xs:enumeration value="hallo"/><xs:enumeration value="morgen"/><xs:enumeration value="servus"/>
</xs:restriction></xs:simpleType>
</xs:element>
Einfache Datentypen beschreiben somit ausschließlich den Inhalt eines einzigen Ele-mentes und machen keine Aussage zu der Struktur des Dokumentes. Dazu werdenkomplexe Elemente und Datentypen definiert.

11
2.5 Definition komplexer Datentypen und Elemente
Einfache Datentypen haben keinen Einfluß auf die Beziehung der Elemente unterein-ander. Die Struktur, die das Auftreten der Elemente bestimmt, wird durch komplexeDatentypen definiert. Sie beschreiben die Struktur eines Dokumentes anhand der insie geschachtelten Elemente und ihrer Reihenfolge. So gibt es Elemente, die sich ausanderen zusammensetzen lassen. Bei dieser Art der Strukturbeschreibung gibt es dreiverschiedene Möglichkeiten:
1. Dieall -Umgebung besitzt keine Reihenfolge. Alle aufgezählten Elemente kön-nen somit in beliebiger Reihenfolge auftauchen. Es besteht nur die Möglichkeitein Element als optional zu deklarieren. Angaben über ein mehrfaches Auftreteneines Elementes sind allerdings nicht möglich.
2. In einersequence lässt sich die Reihenfolge der Elemente oder auch andererInhalte wie Gruppen (in Kapitel2.7folgt eine genauere Beschreibung) festlegenund die Häufigkeit bestimmen. Elemente können dabei genau einmal auftreten,optional sein oder auf einen beliebig großen Wert bis zu unendlich hin festgesetztwerden. Standardmäßig müssen Elemente genau einmal auftreten. Sequenzenbieten die Möglichkeit ineinander geschachtelt zu werden. Dadurch ist es auchmöglich Sequenzen von Sequenzen zu bilden.
3. Die letzte Möglichkeit Elemente zu schachteln, ist die Auswahl mit dem Ele-mentchoice . Hierbei lassen sich verschiedene Elemente, Gruppen oder auchSequenzen angeben, die wahlweise benutzt werden können. Auch daschoice -Element lässt sich ineinander schachteln. Innerhalb dieser Umgebung könnenden Elementen beliebige Werte für die Anzahl ihres Auftretens mitgeben wer-den.
Beispiel 2.5.1:Eine Adresse setzt sich aus verschiedenen Elementen (dem Namen der Person, derStraße, der Postleitzahl und der Stadt) zusammen. Die Adresse ist als Sequenz reali-siert, wodurch die Elemente in der angegebenen Reihenfolge vorkommen müssen undmit Ausnahme der optionalen Straße nur genau einmal auftreten dürfen.
<xs:element name="adresse"><xs:complexType>
<xs:sequence><xs:element name="name" type="xs:string"/><xs:element name="strasse" type="xs:string"
minOccurs="0"/><xs:element name="PLZ" type="xs:nonNegativeInteger"/><xs:element name="Stadt" type="xs:string"/>
</xs:sequence></xs:complexType>
</xs:element>

12
Dieses Beispiel lässt sich anstatt mit einer Sequenz auch ohne weiteres unter Verwen-dung desall -Elementes realisieren. Das liegt daran, dass zum einen die Reihenfolgevernachlässigbar ist und zum anderen die auftretenden Elemente maximal einmal vor-kommen dürfen.
Solche Definitionen lassen sich sowohl direkt in Elementen vornehmen, als auch inbenannten komplexen Datentypen. Wird diese Definition in einem Datentyp realisiert,so lässt er sich für unterschiedliche Elemente wiederverwenden. Das findet auf diegleiche Art statt, wie es auch bei Elementen eines einfachen Typs der Fall ist, indemder Name des Typs im entsprechenden Attribut angegeben wird.
Bei der Definition komplexer Datentypen unterscheidet man grundsätzlich drei ver-schiedene Arten von komplexen Inhalten. Die eine Art beruht auf der Erweiterungoder Einschränkung einfacher oder komplexer Typen. In Kapitel2.4wurden nur einfa-che Typen definiert, die keine Elemente oder Attribute enthalten können. Diese einfa-chen Typen können nun als Grundlage eines neuen komplexen Typs dienen. Durch dassimpleContent -Element wird der einfache Typ innerhalb der komplexen Typde-finition referenziert. Auf dieser Basis können nun spezielle komplexe Merkmale demTyp hinzugefügt werden. In diesem Fall lässt sich der ursprünglich einfache Typ umeines oder mehrere Attribute zu einem komplexen Datentypen ergänzen.
Beispiel 2.5.2:Zur Angabe eines Bildes soll neben der URI mit Hilfe eines Attributes das Formateingetragen werden. Dazu reicht es einen Datentyp zu schaffen, der auf einem einfa-chen Typ, nämlich derxs:anyURI , beruht und diesen durch eine Erweiterung umein Attribut des zuvor definierten einfachen Typengrafikformat ergänzt.
<xs:complexType name="bild"><xs:simpleContent>
<xs:extension base="xs:anyURI"><xs:attribute name="format" type="grafikformat"/>
</xs:extension></xs:simpleContent>
</xs:complexType>
Ein Element mit dem Namengrafik von diesem Typbild würde in einer Beispie-lausprägung des Schemas etwa folgendermaßen aussehen:
<grafik format="jpg">C:/bild.jpg</grafik>
Auf diese Art erzeugte Datentypen sind zwar komplex, aber lassen sich auch wiederals Grundlage für andere Datentypen imsimpleContent benutzen. Damit lassen

13
sich auch Einschränkungen realisieren, die nicht durch die Restriktionen auf einen ein-fachen Typ abgebildet werden können. Beispielsweise lässt sich ein zuvor erweiterterTyp in seiner Zeichenanzahl eingeschränken oder seine hinzugefügten Attribute lassensich als verboten deklarieren. Liegt der Definition eines komplexen Datentyps ein ein-facher Typ zugrunde, so beziehen sich seine komplexen Eigenschaften ausschließlichauf die Ergänzung um Attribute. Komplexe Typen können daher nicht als Grundlagevon Attributen dienen. Diese werden ausschließlich durch einfache Typen erzeugt.
Eine weitere Möglichkeit komplexe Typen zu erzeugen besteht in der Beschreibungder Struktur. Wie schon im Beispiel 2.5.1 gezeigt, lassen sich Elemente aus anderenElementen zusammensetzen. Das kann mit und ohne Reihenfolge realisiert werden.Bei dieser grundsätzlichen Art der Strukturbeschreibung ist die Angabe, dass es sichum einen komplexen Inhalt handelt, nicht nötig. Erst wenn ein komplexer Datentyperweitert oder eingeschränkt werden soll, muss das festgelegt werden. Diese Verän-derungen sind sehr ähnlich zu denen bei einfachen Typen. Mit Erweiterungen lassensich Elemente, Gruppen oder Attribute zu einem Typ hinzufügen. Allerdings betrifftdies nur das Anhängen an das Ende des zugrunde liegenden Datentyps. Eine Um-strukturierung der vorhandenen Elemente bezüglich ihrer Reihenfolge läßt sich nichtrealisieren. Durch Restriktionen können Elemente oder Attribute in ihrem Auftreteneingeschränkt werden. Hierbei ist stets zu berücksichtigen, dass ein Element des resul-tierenden Datentyps auch nach dem Typ gültig sein muss, der die Grundlage gelieferthat. Das bedeutet, dass kein Element oder Attribut verboten werden kann, welcheszuvor zwingend erforderlich war. Es können also nur Einschränkungen auf optionaleEigenschaften getroffen werden.
Beispiel 2.5.3:Die Einschränkung des komplexen Datentypsadresse aus Beispiel 2.5.1 auf denNamen der Person, Postleitzahl und Adresse ist ein typisches Beispiel für Restriktio-nen. Das zuvor optionale Element Strasse fällt hier weg. Jedes Element vom neuenTyp nameort ist somit auch nach dem alten Typadresse gültig. Die anderen Ele-mente mussten alle aufgezählt werden und durften nicht wegfallen, da bei ihnen keineAngaben zur Anzahl des Auftretens gemacht wurden und somit der Standard besagt,dass diese Elemente genau einmal auftreten müssen.
<xs:complexType name="nameort"><xs:complexContent>
<xs:restriction base="adresse"><xs:sequence>
<xs:element name="name" type="xs:string"/><xs:element name="PLZ" type="xs:nonNegativeInteger"/><xs:element name="Stadt" type="xs:string"/>
</xs:sequence></xs:restriction>
</xs:complexContent></xs:complexType>

14
Eine letzte Möglichkeit einen Typ zu erzeugen liegt in der Kombination von einfachenund komplexen Elementeigenschaften. Dazu lässt sich bei einem komplexen Daten-typen dasmixed -Attribut auf true setzen. Ein komplexer Datentyp, dermixedist,kann neben den angegebenen Elementen auch einfachen Text enhalten. Ein Elementdiesen Typs ist dadurch frei in seiner Kombination aus Elementen und beliebigem Text.
Beispiel 2.5.4:Zur Definition eines beliebigen Textes mit Elementen wird das Attributmixed einge-setzt. So wird dasboldtext Element als komplex definiert, das aus Text besteht undoptional auch ein bis beliebig vielebold -Elemente enthalten kann.
<xs:element name="boldtext"><xs:complexType mixed="true">
<xs:choice minOccurs="0" maxOccurs="unbounded"><xs:element name="bold" type="xs:string"/>
</xs:choice></xs:complexType>
</xs:element>
Die folgende beispielhafte Ausprägung des oben definierten Elementesboldtext ,wird von einem XML-Parser als gültig validiert:
<boldtext>Hier steht <bold>ein Element</bold> im Textund ein zweites <bold>ist hier</bold>und es geht weiter...
</boldtext>
2.6 Namensräume
Um die Wiederverwendbarkeit und Kombinationsmöglichkeiten einmal geschriebenerSchemata zu erhöhen, müssen diese über eindeutige Bezeichnungen verfügen. Erst da-durch wird gewährleistet, dass bei der Benutzung fremder Elemente nicht eigene De-finitionen zerstört werden, weil beispielsweise Elemente gleichen Namens verwendetwurden. Um diese Bedingungen zu erfüllen, sind Namensräume eingefügt worden. EinNamensraum ist vergleichbar mit dem Namen eines Java-Paketes, zu dem verschiede-ne Elemente bzw. Klassen gehören. Allerdings ist im Unterschied dazu der Namens-raum eine reine Identifikationsbezeichnung, während der Paketname auch Informatio-nen zu der Verzeichnisstruktur der Klassen liefert. Um die Eindeutigkeit zu gewähr-leisten, ist es aber üblich eine eigene URL anzugeben. Namensräume sind eine XML-weite Erfindung [W3CXMLNS] um verschiedene XML-Anwendungen voneinander

15
zu unterscheiden. Gerade die Verwendung von Namensräumen innerhalb von XMLSchema stellen einen großen Vorteil im Vergleich zu einer DTD dar, vgl. [Vli2002,S.153 ff.].
XML Schema benutzt für jedes Element einen Namensraum. Dieser kann entwederexplizit angegeben oder durch einmalige Angabe als Standardnamensraum für alleElemente festgesetzt werden. Nur durch die Vergabe von Namensräumen können diebenutzten Elemente überhaupt identifiziert und damit ein Dokument als gültig validiertwerden. Schon in der Vorlage für XML-Schema-Dokumente auf Seite6 wurde durchden Namensraum die Schemadefinition vom W3C identifiziert. Es ist damit genaufestgelegt um welche Elemente es sich handelt und das Dokument kann anhand diesesNamensraumes als gültige XML-Anwendung validiert werden.
Der Namensraum eines Elementes oder auch Attributes wird durch dasxmlns -Attri-but (XML -NameSpace) festgelegt. Wird direkt in einem Element perxmlns -Attributauf einen Namensraum verwiesen, so gilt dieser Namensraum für das Element undalle seine Kinderelemente. Nur wenn ein Kindelement auf einen neuen Namensraumreferenziert, so wird diese Vererbungsachse unterbrochen. Mit dieser Regel spart mansich grundsätzlich eine Menge Schreibarbeit, allerdings wird es somit auch nötig seinimmer wieder den Namensraum zu ändern. Um dies zu erleichtern, lassen sich Prä-fixe vergeben, die als abkürzende Schreibweise gedacht sind. Mittels dieses Zusatzesan demxmlns -Attribut, getrennt durch einen Doppelpunkt, wird diese Abkürzungdefiniert.
Beispiel 2.6.1:Mit xmlns:xs="http://www.w3.org/2001/XMLSchema" lässt sich derNamensraum für die Schemadefinition mitxs: abkürzen, wie das in den vorherigenBeispielen schon geschehen und auch allgemein üblich ist. Dennoch ist diese Abkür-zung beliebig wählbar und stattxs könnte auchschema oder irgendeinwortbenutzt werden.
Der aktuelle Namensraum, für den die Elemente eines Schemas geschrieben werden,kann durch die Verwendung destargetNamespace -Attributes in demschema-Tag für alle Elemente gesetzt werden. Ob dieser aber auch der Namensraum ist, indem die Elemente geschrieben werden, hängt von demxmlns -Attribut ab. Ist diesesmit demtargetNamespace identisch, so brauchen für die Elemente keine Präfixebenutzt werden. Weichen die Namensräume voneinander ab, so sind sie mittels einesPräfixes voneinander abzugrenzen und darüber erreichbar.
Beispiel 2.6.2:Ein Schema, das den Namensraumhttp://www.aktuellerRaum.de be-schreibt und in dem die drei ElementeName, Stadt undAdresse definiert werden,muss sich aber nicht in dem aktuellen Namensraum befinden. Der beschreibende Na-mensraum ist hier mit dem Präfixakt versehen und die Elemente müssen somit auchbei Referenzierungen aufeinander dieses Präfix benutzen, um wiedergefunden zu wer-

16
den. Der aktuelle Namensraum, der hier ohne Präfix angesprochen werden kann, ist derder Schemabeschreibung, nämlichhttp://www.w3.org/2001/XMLSchema .Deshalb konnten hier alle Elemente, die aus der Schemadefinition stammen, ohne einPräfix, wie in den Beispielen zuvor geschehen, benutzt werden.
<?xml version="1.0" encoding="UTF-8"?><schema targetNamespace="http://www.aktuellerRaum.de"
xmlns:akt="http://www.aktuellerRaum.de"xmlns="http://www.w3.org/2001/XMLSchema">
<element name="Name" type="string"/><element name="Stadt" type="string"/><element name="Adresse">
<complexType><all>
<element ref="akt:Name"/><element ref="akt:Stadt"/>
</all></complexType>
</element></schema>
Es können beliebig viele Namensräume angegeben und deren Elemente benutzt wer-den. Es gibt aber auch die Möglichkeit auf einen Namensraum zu verzichten, um beimZusammenfügen mehrerer Schemata einen einheitlichen Namensraum verwenden zukönnen. Dazu besteht die Möglichkeit Elemente und auch Attribute alsunqualifiedzu deklarieren und sie damit keinem Namensraum zuzuordnen. Der für ein Schema zubenutzende Standard kann durch dieelementFromDefault - undattribute-FromDefault -Attribute des Schema-Tags aufqualified bzw. unqualifiedgesetzt werden. Dennoch lässt sich das für jedes Element oder Attribut in seiner De-finition ändern. In den meisten Fällen ist es üblich Elemente alsqualified festzu-legen, um sie eindeutig einem Namensraum zuzuordnen. Attribute werden häufig alsunqualified festgelegt, da sie stets in Zusammenhang mit einem Element auftre-ten. Da Elemente meistens einen Namensraum besitzen, ist für Attribute selber keineigener Namensraum zwingend notwendig. Für globale Elemente und Attribute erüb-rigt sich diese Frage sowieso, da diese immerqualified sein müssen.

17
2.7 Techniken zur Wiederverwendung und Strukturierung
Neben der Wiederbenutzbarkeit von Datentypen gibt es auch die Möglichkeit einmaldefinierte Elemente oder Attribute wieder zu verwenden. Das gilt für alle Elementeund Attribute, die global definiert sind. Global bedeutet, dass sie direkt unterhalb desschema-Elementes spezifiziert wurden. Diese Elemente und Attribute sind im ge-samten Schema sichtbar und lassen sich von beliebigen Stellen aus über ihren Namenreferenzieren. Für Elemente und Attribute lokaler Definitionen gilt das nicht. Sie lassensich ausschließlich an der Position benutzen, an der sie definiert werden. Im Gegen-satz zu Datentypen müssen Elementen und Attributen immer Namen gegeben werden,unabhängig davon ob sie global oder lokal definiert sind. Diese Namen werden in demXML-Dokument für die Auszeichnung benutzt.
Eine weitere Möglichkeit zur Strukturierung und Wiederverwendung von verschiede-nen Elementen wird durch die Anwendung von Gruppen geliefert. Mit ihnen lassensich verschiedene Elemente zusammenfassen. Dabei sind die gleichen Mechanismenzu verwenden wie bei komplexen Datentypen, also Sequenzen, Wahlmöglichkeitenund dasall -Modell. Diese Gruppen können nur global erzeugt werden und sind somitan beliebiger Stelle im Schema referenzierbar. Mittels Gruppen lassen sich dement-sprechend gleiche Strukturen einmal definieren und beliebig oft wiederverwenden.Änderungen werden dadurch einfacher machbar, indem sie nur einmal in der Grup-pe vorgenommen werden müssen.
Diese Technik zur Gruppierung existiert auch für Attribute. Es können Attributgrup-pen definiert werden, die verschiedene Attribute auflisten. Da Attribute keine Strukturbeinhalten, werden in Attributgruppen die Attribute in Form einer Liste aufgeführt.Soll ein Element alle Attribute einer Attributgruppe per Definition zugewiesen be-kommen, so lässt sich diese Gruppe referenzieren. Es lassen sich dadurch spezielleAttributgruppen erstellen, die von mehreren Elementen genutzt werden und somit denEinbau von Änderungen erleichtern.
Beispiel 2.7.1:Eine Nachricht wird definiert, die mittels der Referenz auf eine Attributgruppeeinganginfo Attribute hinzugeliefert bekommt. Die Attributeart und datumwerden ebenfalls erst definiert und mittels Referenz in die Attributgruppe integriert.Das Datum ist dabei als zwingend gekennzeichnet, während die Art optional ist. Bei-spielhafte Ausprägungen könnten die folgenden sein:
<nachricht datum="2003-05-01">text 1</nachricht><nachricht art="mail" datum="2003-05-02">text</nachricht>
In der Attributgruppe wurde noch eine Dokumentation eingefügt. Sie ist in derannotation zu finden. Mittels desdocumentation -Elements ist die für den Be-trachter des Schemas lesbare Dokumentation eingetragen.

18
<xs:attribute name="art" type="xs:string"/><xs:attribute name="datum" type="xs:date"/>
<xs:attributeGroup name="einganginfo"><xs:annotation>
<xs:documentation>Diese Gruppe enthaelt alle Eingangsinformationen
</xs:documentation></xs:annotation><xs:attribute ref="art" use="optional"/><xs:attribute ref="datum" use="required"/>
</xs:attributeGroup>
<xs:element name="nachricht"><xs:complexType>
<xs:simpleContent><xs:extension base="xs:string">
<xs:attributeGroup ref="einganginfo"/></xs:extension>
</xs:simpleContent></xs:complexType>
</xs:element>
Ein Schema kann schnell sehr komplex und für den Leser unübersichtlich werden.Um das zu vermeiden, gibt es die Möglichkeit zur Dokumentation. Es werden zweiverschiedene Arten von Dokumentationen unterschieden. Die Dokumentation der Ele-mente, Attribute, etc. für den Anwender (vgl. Beispiel 2.7.1) und die Dokumentationfür den Prozessor. Diese Informationen können durch unterschiedliche Elemente aus-einandergehalten werden, die jeden beliebigen Inhalt enthalten können. Somit lassensich für den Anwender jegliche Beschreibungen in lesbarer und leicht verständlicherForm einfügen und für den Prozessor Zusatzinformationen einbinden, die er für einespezielle Verarbeitung benötigt. Diese Zusatzinformationen hängen von dem Einsatz-gebiet der definierten XML-Anwendung ab, werden aber für eine einfache Verarbei-tung nicht benötigt. Aufgrund dieser Dokumentationsmöglichkeiten lassen sich ausden Schemadefinitionen automatisch geeignete Dokumentationen generieren.
Für das Aufteilen und Zusammenfügen verschiedenartiger Schemata spielen beson-ders Namensräume eine große Rolle. Für diese Möglichkeit der Strukturierung gibt esdrei verschiedene Arten:
1. Mittels include können Schemata eingefügt werden, die den gleichen oder garkeinentargetNamespace besitzen wie das Schema, in das sie eingefügt wer-den. Alle Elemente und Attribute bekommen somit den gleichen Namensraum

19
zugewiesen. Auf diese Weise hinzugefügte Definitionen werden genauso behan-delt, als wenn sie in dem Schema selber eingegeben worden wären. Hierbei mussmit besonderer Vorsicht auf die Namensvergabe der Elemente, Attribute und Da-tentypen geachtet werden, damit diese sich nicht gegenseitig überschreiben.
2. Ähnlich zum Einfügen ganzer Schemata arbeitetredefine . Es können aller-dings nur einzelne Typen oder Gruppen aus dem anderen Schema eingefügt wer-den, die mittels gültigen Veränderungen (Restriktionen oder Erweiterungen, sie-he Kapitel2.4) überdefiniert werden.
3. Zum Importieren eines Schemas wird dasimport -Element verwendet. Hiermitwird lediglich der Speicherort des Namensraumes des Schemas angegeben, umeinem Parser die Möglichkeit zu geben, die Definition des importierten Schemaszu finden und das Dokument auch anhand dieses Schemas zu validieren.
Eine weitere Möglichkeit zur Strukturierung bilden Substitutionsgruppensubsti-tutiongroup . Durch Angabe der Zugehörigkeit eines Elements zu einer solchenGruppe, lässt es sich durch ein anderes Element dieser Substitutionsgruppe ersetzen.Innerhalb eines gültigen XML-Dokumentes spielt es dann keine Rolle mehr, welchesElement eingesetzt wird, solange es zu der Substitutionsgruppe gehört. Speziell fürdiesen Einsatz lassen sich auch abstrakte Elemente definieren, die nicht im XML-Dokument auftauchen dürfen. Ein solches Element kann sinnvoll als Grundlage vonSubstitutionsgruppen dienen, da es nur die Aufgabe eines Platzhalters erfüllt. Die-se Technik bietet einen besonderen Ansatz zur objektorientierten Modellierung einesSchemas. Allerdings ist dabei der Typ des Elements, das die Grundlage für die Substi-tutionsgruppe bildet, zu beachten. Abhängig davon dürfen nur gültige Erweiterungenoder Einschränkungen auf diesem Datentyp der Substitutionsgruppe hinzugefügt wer-den. Es ist also nicht möglich einen Platzhalter für beliebige Elemente zu definieren.

20
3 XSLT
Die eXtensible Stylesheet Language for Transformation(XSLT) ist eine XML-Anwen-dung zur Transformation von XML-Dokumenten. Sie ermöglicht Auswertungen undUmstrukturierungen von XML-Daten und ist dadurch speziell für die Umwandlungeiner XML-Anwendung in eine andere geeignet. Es werden zudem auch andere Da-tenformate als Ergebnis einer XSL-Transformation unterstützt, so dass mit XSLT allewesentlichen Konvertierungen von XML-Daten vorgenommen werden können. Diedazu erforderlichen Grundlagen werden im Folgenden erläutert.
3.1 Entstehung
Am Anfang der Entwicklung stand die XML-AnwendungeXtensible Stylesheet Lan-guage(XSL), die für Umstrukturierungen und grafische Aufbereitungen von XML-Daten entwickelt wurde. Schnell ergaben sich verschiedene Anwendungsgebiete, sodass die Sprache in zwei Einsatzbereiche unterteilt wurde. Der eine Teil beschäftigtsich mit dem Layout der Datendarstellung. Daraus ist die weiterhin unter dem NamenXSL oder auch XSL-FO bekannte XML-Anwendung entstanden. Weitere Erklärun-gen zu XSL-FO werden in Kapitel4 vorgenommen. Der andere Teil kümmert sich umdie Struktur, die die XML-Daten besitzen und den Möglichkeiten auf diese StrukturEinfluß zu nehmen. Aus diesem Anwendungsbereich ist XSLT entstanden.
Als offizielle Empfehlung ist XSLT in der Version 1.0 [W3CXSLT] am 16.11.1999vom W3C veröffentlicht worden. XSLT beschäftigt sich ausschließlich mit der Trans-formation von XML-Dokumenten und es sollen keine Angaben zum Layout gemachtwerden. So kann XSLT eingesetzt werden um XML-Dokumente eines Formates in dieStruktur eines anderen XML-Formates umzuwandeln oder aber auch um ein HTML-oder Text-Dokumente zu generieren. Bei diesen letzten beiden Möglichkeiten wird dieStruktur der XML-Daten durchbrochen und die Strukturierung geht verloren. WelcheMöglichkeit eingesetzt wird, muss somit in Abhängigkeit der zu lösenden Aufgabeentschieden werden.
Es wird kontinuierlich an der Weiterentwicklung von XSLT gearbeitet. Die angedachteVersion 1.1 ist allerdings nicht über den Stand eines Arbeitsdokumentes hinaus gekom-men und so wird nun bereits an der Version 2.0 gearbeitet. Diese wird einige wichtigeVeränderungen bieten, die am Ende des Kapitels noch angedeutet werden, da einigeAufgabenstellungen sonst nicht zu bewältigen wären. Da diese Version aber noch unterBearbeitung und damit in Veränderung ist, werden diese angedachten Techniken nurmit speziellem Hinweis an den Beispielen eingesetzt. An den Grundlagen wird sichkeine wesentliche Änderung ergeben, weshalb diese versionsneutral sein sollten.

21
3.2 Basis: XML-Dokument
Die genaue Definition der Struktur eines XML-Dokumentes ist teilweise in XSLTund teilweise in XPath beschrieben. XPath ist eine W3C-Spezifikation [W3CXPATH]zum Bewegen und Adressieren von Inhalten in XML-Dokumenten. Dazu wird mittelsXPath ein Konzept beschrieben, das ein XML-Dokument als Baum mit vielen Kno-ten auffasst. Dieses Modell wird nicht nur in XSLT benutzt, sondern dient auch alsGrundlage für XPointer [W3CXPointer] und XQuery [W3CXQuery]. Der hierbei be-schriebene Baum ist ähnlich dem Baum, der im DOM beschrieben wird. DOM stehtfür DocumentObject Model und stellt neben SAX, derSimple API for XML, eineWeiterverarbeitungsmöglichkeit für XML-Dokumente bereit. SAX arbeitet ereignis-orientiert, während DOM einen Baum im Speicher aufbaut. Diese unterschiedlichenArten der Verarbeitung sind hauptsächlich für die XSLT-Prozessoren und ihre spezifi-schen Erweiterungen (vgl. Kapitel3.6) wichtig, sollen für die weitere Betrachtung derXSL-Transformationen aber keine weitere Beachtung finden. Wichtig ist allein dasVerständnis für die Unterscheidung, dass ein DOM zwar dem vom XSLT benutztenBaum ähnelt, aber die beiden nicht identisch sind. Ein DOM beinhaltet beispielsweiseauch Knoten, die Leerzeichen enthalten, während diese im XPath-Modell nicht auf-treten dürfen. Weitere Unterschiede zu den beiden Modellen sind in [W3CXPATH,Kapitel 5] und [Kay2001, S.56 ff., S.570 ff.] aufgeführt und ausführlicher beschrie-ben.
Im folgenden Kapitel soll der Konzeptbaum, der XSLT zugrunde gelegt wird, beschrie-ben werden. Anschließend wird in Kapitel3.2.2die Bewegung innerhalb dieses Bau-mes erläutert.
3.2.1 Aufbau des Konzeptbaumes
Das XML-Dokument wird als Konzeptbaum von Knoten aufgefasst. Der Beginn desBaumes startet mit der Wurzel bzw. dem Wurzelknoten, der alle weiteren Knoten ent-hält. Die Wurzel entspricht keinem Element in dem betrachteten XML-Dokument,sondern repräsentiert das Dokument als Ganzes. Sie enthält genau einen Elementkno-ten. Dieser Knoten stimmt mit dem ersten Element des Dokumentes überein und die-ser muss alle weiteren Elemente enthalten. Darunter können in beliebiger Anzahl undTiefe die weiteren Knoten enthalten sein, die ihrerseits weiter verzweigen können. Ab-bildung2 zeigt einen beispielhaften Baum in der XSLT-Ansicht. Die hier eingefügteDarstellung der einzelnen Elemente soll in weiteren Beispielen wieder benutzt werden.
Neben dem Wurzelknoten unterscheidet man sechs weitere Knotenarten (Text-, Ele-ment-, Attribut-, Kommentar-, Verarbeitungsanweisungs- und Namensraumknoten).Sie repräsentieren ihren jeweiligen Typ im XML-Dokument. Textknoten werden fürden letztendlich in einem Element enthaltenen Inhalt, der nur aus Text und nicht ausweiteren Elementen besteht, benutzt. Für jeden Typ einer Angabe im XML-Dokumenterscheint also ein eigener Knoten in dem Konzeptbaum. Nur Attribute und Namens-

22
räume werden in dem XML-Dokument gleichermaßen aufgeführt und trotzdem imBaum als unterschiedliche Knotenarten behandelt.
Wert
PID
Text
Inhalt
URIPräfix
WertName
*Name
*Name
URIPräfix
*Name
URIPräfix
Inhalt
Wert
PID
WertName
Inhalt
*Name
URIPräfix
*Name
URIPräfix
WertName
WertName
Text
Attributknoten
WURZEL
Namensraumknoten
Kommentar
Textknoten
Prozessor Anweisung
Elementknoten
Abbildung 2:XML-Dokument als Konzeptbaum
Die Beziehungen der Knoten untereinander sind in der Abbildung2 durch Linien ge-kennzeichnet. So ist die Wurzel der Elternknoten des darunter liegenden Elementes,dem Kindknoten der Wurzel. Diese Eltern-Kind-Beziehung gilt im allgemeinen füralle Knoten, mit Ausnahme der Attribut- und Namensraumknoten. Deren Eltern sindihre jeweiligen Elementknoten, zu denen sie gehören. Sie sind aber nicht über die Be-ziehung Kind von ihrem Elternknoten aus ansprechbar. Genauere Auswirkungen be-züglich dieser Unterscheidung werden in Kapitel3.3 deutlich. Ein derart aufgebauterBaum liefert die Grundlage, auf der nun die Bewegungen innerhalb der Verarbeitungund die Transformationen aufbauen.
3.2.2 Bewegung im Konzeptbaum
Die Knoten in der Baumansicht des XML-Dokumentes stehen also in genau definier-ten Eltern-Kind-Beziehungen zueinander. Um anhand dieser Beziehungen bestimm-te Knoten zu finden, können verschiedene Wege innerhalb des Baumes abgeschrittenwerden. Einige werden hier aufgeführt, für eine ausführliche Liste siehe [Vli2002, S.54ff.]. Die folgenden Regeln beziehen sich immer auf den alsKontextknotenbenanntenaktuellen Knoten.
• Die child-Achse beinhaltet alle Kinder des Kontextknotens. Sie liefert die Kno-ten, die ohne Angabe eines weiteren Pfades im aktuellen Kontext enthalten sind.Sie bildet somit die Standardachse.

23
• Mit der descendant-Achse lässt sich diechild-Achse in die Tiefe weiterverfol-gen. Das heisst, in ihr sind nicht nur die Kinderknoten des aktuellen Kontextesenthalten, sondern auch seine Kinder und die Kinder der Kinder usw.
• Mittels derparent-Achse kann auf den Elternknoten des aktuellen Kontextkno-tens zugegriffen werden.
• Alle Eltern und deren Eltern werden mit derancestor-Achse eines Knotens ab-gesucht.
• Die attribute-Achse liefert alle Attribute des aktuellen Kontextes. Dies ist dieeinzige Möglichkeit auf Attribute zuzugreifen.
• Da Namensräume ebenfalls nicht über die anderen Achsen erreicht werden kön-nen, gibt es dienamespace-Achse. Sie liefert den Namensraumknoten, der zudem aktuellen Kontext gehört.
• Mittels derpreceding-Achse lassen sich alle Knoten der gleichen Ebene vor demaktuellen, mit derfollowing-Achse nach dem aktuellen Knoten erfassen. DieseAchse kann auch auf die Knoten mit dem gleichen Elternknoten eingeschränktwerden. (preceding-sibling- undfollowing-siblingAchse)
Das sind die wesentlichen Möglichkeiten um sich durch den Baum zu bewegen. Es las-sen sich in Einzelfällen noch einige wichtige Unterscheidungen treffen, beispielsweiseob der aktuelle Knoten zu der Auswahl dazu gehören soll oder nicht. Desweiteren las-sen sich einige häufig benutzte Achsen abkürzen, so steht@für dieattribute-Achse und.. für die Eltern. Sollen keine Einschränkungen bei der Suche nach Knoten bezüg-lich einer dieser Achsen gemacht werden, so erlaubt der Einsatz von// eine beliebigeAnzahl und Art von Knoten, die an seiner Stelle auftauchen dürfen. Natürlich lassensich neben diesen relativen Einschränkungen auch absolute vornehmen. Dazu wird derPfad für die Knoten fest anhand der Elementnamen auf der Suchachse vorgegeben.Alle Bewegungsschritte innerhalb des Baumes lassen sich je nach Aufgabenstellungbeliebig kombinieren.
3.3 Grundlagen
Mit XSLT lassen sich Vorlagen definieren, die die Ausgabe der Transformation be-schreiben und auf bestimmte Knoten des Baumes angewendet werden. Die Auswahldieser Knoten findet als Mustererkennung statt. Das bedeutet, dass es Regeln gibt, diedie Knoten erfüllen müssen, um dann mittels einer Vorlage verarbeitet zu werden. Die-se Selektierung findet anhand von XPath-Ausdrücken statt. Einer der einfachsten Aus-drücke ist beispielsweise/ , der den Wurzelknoten des XML-Dokumentes auswählt,oder. für den aktuellen Knoten. Die weiteren Möglichkeiten zur Knotenauswahl an-hand der Achsen wurden bereits in Kapitel3.2.2erläutert.

24
Die grundsätzliche Funktionsweise von XSLT ist in Abbildung3 dargestellt. Eingangssteht ein Baum, der aus der Betrachtung einer XML-Datei hervorgegangen ist (sie-he Kapitel3.2.1). Mittels XSLT lässt sich dieser Baum umformen. Elemente lassensich einfügen, löschen oder ihre Position lässt sich verändern. Der dadurch erzeugteErgebnisbaum wird zum Ende der Bearbeitung in den meisten Anwendungsfällen inein Dokument geschrieben. Das ist allerdings nicht zwingend notwendig und alleinabhängig von der Art der Verarbeitung.
XML−Dokument
XSLT
Ergebnisbaum
Abbildung 3:Funktion von XSLT
Zur Ausführung der XSL-Transformation wird ein XSLT-Prozessor benötigt. Mit ihmwerden die Transformationen auf die XML-Daten angewendet. Es gibt viele verschie-dene XSLT-Prozessoren, die bekanntesten sind Xalan, Saxon, MSXML und XDK.
Xalan entstammt dem Apache XML-Projekt [ApacXalan] und ist frei verfügbar. Erwird häufig eingesetzt, besonders wegen seiner hohen Standardgenauigkeit.
Saxon ist ebenfalls frei verfügbar [KaySaxon]. Er ist sehr aktuell und beinhaltet auchFunktionen, die noch nicht im Standard enthalten sind, aber in zukünftige Ver-sionen eingehen sollen. Dies ist wohl mit seiner Entwicklung als Einzelprojektvon Michael Kay zu begründen, der Mitautor der XSLT-Arbeitspapiere ist. Sa-xon gilt zur Zeit als der schnellste XSLT-Prozessor.
MSXML ist das von Microsoft gelieferte XML-Paket [MSXML], das auch einenXSLT-Prozessor beinhaltet. Dieses Paket ist ebenfalls frei verfügbar und kannin den Internet Explorer von Microsoft integriert werden. Damit ist es möglichXML-Dokumente direkt im Browser anzusehen, auf die beim Aufruf die ange-gebene XSL-Transformation angewendet wird. Die Funktionalitäten sind aller-dings nicht auf dem neuesten Stand.
XDK steht für Oracle’sXML Developer’sK it [OracleXDK]. Es beinhaltet ein kom-plettes XML-Paket samt Parser und XSLT-Prozessor, das kostenlos herunterzu-laden ist.
Im Weiteren werden hauptsächlich Xalan und Saxon Anwendung finden. Xalan bevor-zugt zum Testen aller Standardfunktionalitäten und Saxon zum Experimentieren mitneuen XSLT-Versionen.

25
Ein XSLT-Stylesheet beginnt, da es sich dabei um ein XML-Dokument handelt, stetsmit der XML-Deklaration, gefolgt von dem Stylesheet-Tag mit der Namensrauman-gabe zur XSLT-Definition und einer Versionsnummer. Eine einfache Vorlage, die denWurzelknoten auswählt und seinen ganzen Inhalt ausgibt, sieht somit folgendermaßenaus:
<?xml version="1.0" encoding="UTF-8"?><xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"><xsl:template match="/">
<xsl:value-of select="."/></xsl:template>
</xsl:stylesheet>
Mittels destemplate -Elementes werdenTemplates(Vorlagen) definiert, die bei denElementen Anwendung finden, die die Regeln desmatch -Attributes erfüllen. Das istin diesem Fall nur die Wurzel. Auf sie wird somit diese Vorlage angewendet, indemsie als aktueller Knoten betrachtet wird und von ihr aus die weiteren Verarbeitungs-hinweise ausgeführt werden. In diesem Fall wird nun dasvalue-of -Element ange-wendet. Das gibt alle textuellen Inhalte des aktuellen Knotens und aller seiner Kinderaus. Angewendet auf ein XML-Dokument wirft dieses Stylesheet alle Tags heraus undliefert nur die Inhalte der Elemente aneinandergereiht. Dies ist die Grundlage für je-des Stylesheet. In dieses Grundgerüst werden zur speziellen Bearbeitung eines XML-Dokumentes weitere Vorlagen eingebaut.
Das obige Stylesheet erzeugt bei den meisten XSLT-Prozessoren standardmäßig einXML-Dokument. Das ist genau dann die korrekte Vorgehensweise, wenn beispielswei-se ein XML-Dokument einer XML-Anwendung in ein XML-Dokument einer anderenumgewandelt werden soll. Doch das ist nicht die einzige Anwendungsmöglichkeit fürXSLT. Es können auch andere Ausgabeformate wie HTML oder Text erzeugt werden.Um dies zu ermöglichen, muss die Struktur des Ausgabebaumes der Transformationzerbrochen werden. Dafür gibt es die Möglichkeit das Format der Ausgabe mit demoutput -Element zu bestimmen. Auch weitere Angaben zu diversen Einstellungenwie Versionsnummer und Encoding. können damit realisiert werden. Um also nichtvon den Einstellungen des jeweiligen XSLT-Prozessors abhängig zu sein, sollten dieseAngaben immer mit demoutput -Element gemacht werden.
Für eine konkrete Bearbeitung eines bestimmten XML-Dokumentes und um exakteRegeln zu definieren, ist die Struktur des Dokumentes wichtig (vgl. Kapitel3.2). Sokönnen Elementknoten anhand ihres Namens selektiert und Vorlagen auf sie angewen-det werden. Mittels einemmatch auf den Namen des Elements werden alle Elementedieses Namens, die sich direkt in dem aktuellen Kontext befinden, gefunden. UnterHinzunahme eines relativen oder absoluten Pfades (vgl. Kapitel3.2.2), können vomaktuellen Kontext ausgehend, Knoten an beliebigen Stellen in dem XML-Dokument

26
gefunden werden. Da bei relativen Pfaden die Ergebnisse je nach aktueller Positionvariieren können, ist es wichtig immer über den aktuellen Kontext in Kenntnis zu sein.
Wenn die Richtung der Suche festgelegt ist, können die Elemente anhand weitererKriterien ausgewählt werden. Das kann anhand des Namens des Elementes oder durchAbfrage bestimmter Eigenschaften gemacht werden. Dabei brauchen nicht nur abso-lute Werte festgelegt werden, auch verschiedene Wildcards sind einsetzbar. So steht*für jeden beliebigen Elementknoten, mit@lassen sich Attributknoten in Kombinationmit ihrem Namen ansprechen und die Funktionnode() liefert alle Knoten inner-halb des aktuellen Kontextes zurück. Damit sind also neben Element- und Attribut-knoten auch Text-, Kommentar-, Namensraum- und Verarbeitungsanweisungsknotengemeint. Bestimmte Eigenschaften eines Knotens außer seinem Namen und seiner Po-sition lassen sich über Prädikate abfragen. Dazu werden der Pfad- und Namensangabespezifizierende Ausdrücke in eckigen Klammern ([] ) angehängt. In einem derartigenAusdruck wird mittels Zahlen das Element bestimmt, das unter den genannten Vor-bedingungen an der jeweiligen Position auftritt. Desweiteren können innerhalb desAusdruckes Funktionen wie beispielsweiselast() für die Auswahl des letzten Ele-mentes genutzt werden. Kombinationen aus Funktionen, Werten und Vergleichsope-rationen liefern dadurch weitreichende Möglichkeiten Bedingungen zu schreiben, diedie Selektion bestimmen. Ausführliche Erläuterungen hierzu sind in Kapitel3.5 auf-geführt.
Beispiel 3.3.1:
1. Das company -Element, das unterhalb der Wurzel sitzt, wird nach allenfiliale -Elementen, die wiederumverkaeufer -Elemente besitzen, abge-sucht. Es werden jedoch nur dieverkaeufer -Elemente zurückgeliefert, de-renUmsatz -Attribut einen Wert kleiner100 besitzt. Wenn diese Suchabfragein einem Attribut, wie beispielsweise demmatch destemplate -Elementes,auftaucht, muss das<-Zeichen durch\&lgt; ersetzt werden. In Abbildung4ist dargestellt, welche Elemente mit diesem Ausdruck in einem beispielhaftenBaum erfasst werden.
/company/filiale/verkaeufer[@Umsatz < 100]
2. Alle ersten Elemente innerhalb des Baumes, sollen gefunden werden. Hierbeisind die doppelten Anführungsstriche durch einfache zu ersetzen, da die doppel-ten schon zur Bezeichnung des Attributes genutzt werden, in dem der Ausdruckeingefügt wird. Diese Abfrage ist somit auf ein beliebiges XML-Dokument an-wendbar, weil keine Angaben zu Struktur und Namen der Elemente gemachtwurden.
//*[position()=’1’]

27
3. Sollen unabhängig von ihrer Position nurverkaeufer -Elemente gefundenwerden, die ein AttributUmsatz mit dem Wert 99 besitzen, so ist dies eineMöglichkeit dafür:
//verkaeufer[@Umsatz=’99’]
Umsatz95
*verkaeufer
Umsatz97
*verkaeufer
*filiale
100Umsatz
*verkaeufer
*filiale
*verkaeufer
WURZEL
*company
99Umsatz
UmsatzUmsatz110 99
*verkaeufer
*verkaeufer
Abbildung 4: Die blau umrahmten Verkäufer werden von Beispiel 3.3.1 (1) selektiert. MitBeispiel 3.3.1 (3) werden die gelben Elemente ausgewählt.
Auf alle Knoten, die durch die festgelegten Regeln ausgewählt wurden, werden nun dieinnerhalb destemplate -Elements angegebenen Vorlagen angewendet. Hierbei las-sen sich im wesentlichen wieder Elemente und Attribute für den Ergebnisbaum erzeu-gen, die an verschiedene Bedingungen geknüpft sind. Es lassen sich auch die weiterenVerarbeitungsschritte innerhalb des nun aktuellen Kontextes beschreiben. Das bedeu-tet, dass der gerade betrachtete Knoten nun der aktuelle ist. Durch den Aufruf seinerKinder oder anderer Elemente lassen sich diese ebenfalls bearbeiten und auswertenoder ihre Vorlagen aufrufen.
Soll einfach der Wert eines Knotens in den Ausgabebaum übernommen werden, solässt sich dieser mittels desvalue-of -Elementes direkt dort hinein ausgeben. Hier-bei geht allerdings die Eigenschaft, dass es sich um einen Knoten gehandelt hat, ver-loren. Um dem entgegen zu wirken, lässt sich ein Knoten mittelscopy in den Ergeb-nisbaum kopieren. Dabei bleibt seine Struktur und sein Namensraumknoten erhalten,nicht jedoch Kinder- oder Attributknoten. Um auch diese mitzukopieren und damitganze Teilbäume vom Startdokument in das Ergebnis mit zu übernehmen, gibt es nochdie Möglichkeit innerhalb voncopy-of einen Knoten zu selektieren und alle unterihm hängenden Knoten mit zu erfassen.
Es lassen sich aber auch eigene, neue Knoten erzeugen, die in den Ergebnisbaumeingefügt werden. Dazu dienen die je nach Knotenart zu verwendenden Elemente

28
attribute , element , comment und text . Der Inhalt, der auf diese Art neu er-zeugten Knoten in dem Ausgabebaum, kann durch fixe Werte, Selektion bestimmterKnoten und ihrer Werte oder auch Berechnungen auf den Werten, innerhalb des jewei-ligen Elementes eingefügt werden.
Beispiel 3.3.2:Es soll ein Element mit dem Namenausgabe erzeugt werden, das ein Attribut na-mensatrid mit dem Wert1 besitzt. Der Inhalt des Elementes setzt sich aus demWert des Knotensknoten , wenn ein solcher im aktuellen Kontext vorliegt, und demTextnormaler Text zusammen.
<xsl:element name="ausgabe"><xsl:attribute name="atrid">
<xsl:text>1</xsl:text></xsl:attribute><xsl:value-of select="knoten"/><xsl:text>normaler Text</xsl:text>
</xsl:element>
Für den Fall, dass kein Knoten namensknoten vorliegt, würde in der Ausgabe diesesElement eingefügt werden:
<ausgabe atrid="1">normaler Text</ausgabe>
Hierdurch lassen sich komplett neue Elemente und Attribute definieren.
3.4 Datenabhängige Verarbeitung
Nicht jeder Knoten des Ausgangsdokumentes soll einfach übernommen werden. Essollen nur solche mit bestimmten Eigenschaften, Zusammenfassungen in Form derAnzahl des Auftretens oder die Ergebnisse von Berechnungen kombinierter Werte inden Ergebnisbaum eingetragen werden.
Wurde ein ausgewählter Knoten zum aktuellen Kontext gemacht, so werden auf ihnRegeln bezüglich seiner Weiterverarbeitung angesetzt. Hierbei lassen sich Entschei-dungen mittelsif -Abfragen bei nur einem Test, oderchoose bei mehreren Überprü-fungen vornehmen. Damit lassen sich Verzweigungen in Abhängigkeit vom Eingangs-dokument realisieren. Beiif -Anweisungen muss anhand destest -Attributes, daseinen Wahrheitsausdruck, alsotrue oderfalse , enthalten muss, eine Auswertungvorgenommen werden. Diese Auswertung entscheidet darüber, ob die weiteren Ar-beitsschritte innerhalb des Elementes überhaupt durchgeführt werden sollen. Es stehtkeineelse -Abfrage zur Verfügung, wie das in gängigen Programmiersprachen der

29
Fall ist. Dafür verwendet man die Wahlmöglichkeit mittels deschoose -Elementes.Innerhalb dieses Elementes lassen sich ein bis beliebig vielewhen-Abfragen einfü-gen, die ebenso wie dieif -Abfrage mittels einestest -Attributes festlegen lassen,ob ihr Inhalt ausgeführt werden soll. Vergleichbar mitswitch-case -Konstrukten inanderen Sprachen, lässt sich auch innerhalb vonchoose ein otherwise -Fall defi-nieren, der immer dann zum Einsatz kommt, wenn keiner der zuvor in denwhen-Testsabgefragten Fälle mittrue ausgewertet wurde.
Beispiel 3.4.1:Wenn der Knoten des aktuellen Kontextes sich an erster Position befindet, wirderstens ausgegeben, ist er der letzte unter seinen Geschwistern der gleichen Ebe-ne, so liefert diese Abfrageletztens . Sollte keiner dieser beiden Fälle zutreffen, sowird nächstens in den Ergebnisbaum eingefügt.
<xsl:choose><xsl:when test="position()=1">
<xsl:text>erstens</xsl:text></xsl:when><xsl:when test="last()">
<xsl:text>letztens</xsl:text></xsl:when><xsl:otherwise>
<xsl:text>nächstens</xsl:text></xsl:otherwise>
</xsl:choose>
Während sich Verzweigungen in XSLT nicht wesentlich von gängigen Programmier-sprachen unterscheiden, so gibt es allerdings keine abzählbaren Schleifen, wie bei-spielsweisewhile oderfor -Schleifen. Dasfor-each -Element erfüllt einen etwasanderen Zweck. Es ist abhängig davon wie häufig das Eingangsdokument durchlaufenwird. So lässt sich bei ihm über einselect -Attribut ein XPath-Ausdruck angeben,der dafür sorgt, dass der gesamte Inhalt desfor-each auf jedes Element angewen-det wird, das mittels des Ausdruckes erreicht wird. Es ist hierbei zu beachten, dass dasElement, auf den der Inhalt angewendet wird, zu dem aktuellen Kontext während derVerarbeitung wird.
Beispiel 3.4.2:Innerhalb des aktuellen Kontextes soll für jedentest -Knoten der Wert seineswert -Knotens ausgegeben werden.
<xsl:for-each select="test"><xsl:value-of select="wert"/>
</xsl:for-each>

30
Es existieren auch Variablen in XSLT, doch lassen sich diese nur einmal initialisierenund nicht wieder verändern. In ihnen können Werte, Knoten oder auch gesamte Bäu-me gespeichert werden. Dasvariable -Element kann entweder über dasselect -Attribut den Wert der Variablen zuweisen oder über seinen Inhalt. Der Name hier-für wird mittels desname-Attributes angegeben. Die Sichtbarkeit einer Variablen be-schränkt sich auf das Element, in dem sie erzeugt wurde. Globale Variablen sind dem-nach nur solche, die unterhalb desstylesheet -Elementes definiert wurden. Alleanderen sind lokale Variablen innerhalb des jeweiligen Kontextes. Auf Variablen kanninnerhalb ihrer Sichtbarkeit durch die Verknüpfung des Dollarzeichens$ mit dem Va-riablennamen innerhalb von anderenselect - odertest -Attributen zugegriffen wer-den. Zur Ausgabe des gespeicherten Wertes in dem Ergebnisbaum dient beispielsweisedie Kombination desvalue-of -Elementes mit demselect -Attribut, das den Wertder Variablen an der entsprechenden Stelle einfügt.
Beispiel 3.4.3:Eine Variable namensvar mit dem Inhalt des aktuellen Kontextknotens lässt sich aufzwei Arten erzeugen:
1. <xsl:variable name="var"><xsl:value-of select="."/>
</xsl:variable>
2. <xsl:variable name="var" select"."/>
Der Zugriff auf den Wert der Variablen ist immer gleich. In diesem Beispiel wird derWert einfach ausgegeben:
<xsl:value-of select="$var"/>
Bei einer einfachen Abfrage, wie in dem obigen Beispiel, unterscheidet sich die Artder Definition einer Variablen nicht. Doch die kurze Schreibweise kommt schnell anihre Grenzen. So lassen sich innerhalb desselect -Attributes keine anderen XSLT-Elemente aufrufen und ihr Rückgabewert speichern. Das lässt sich nur im Inhalt desvariable -Elementes durchführen.
Um innerhalb der Verarbeitung eines Elementes, die Verarbeitung anderer Elemente,beispielsweise seiner Kinder, anzustoßen, und damit die Reihenfolge der Verarbei-tung innerhalb des Baumes zu bestimmen, wird dasapply-templates -Elementbenutzt. Diesem Element läßt sich optional mittelsselect - Attribut mitteilen, wel-che Knoten als nächstes zu behandeln sind. Die dementsprechenden Vorlagen werdendann an dieser Stelle aufgerufen. Um unterschiedliche Vorlagen für gleiche Knoten

31
nur an verschiedenen Stellen in der Verarbeitung zu ermöglichen, können den Vorla-gen mittels desmode-Attributes verschiedene Modi zugewiesen werden. Diese Modikönnen bei dem Aufruf einer Vorlage mittelsapply-templates alsmode-Attributangegeben werden. Damit lassen sich verschiedenartige Behandlungen der Knoten zuunterschiedlichen Bearbeitungszeitpunkten festlegen.
Eine andere Möglichkeit Vorlagen aufzurufen ist mit dem Elementcall-templategegeben. Damit lassen sich mit Namen versehene Vorlagen bearbeiten. Dazu ist derVorlage ein Name durch dasname-Attribut mitzugeben. Über den Namen ist die Vor-lage eindeutig identifizierbar und über die Angabe imname-Attribut des aufrufendenElements wird sie an der aufrufenden Position bearbeitet. So können auch Vorlagenerstellt werden, die unabhängig vom selektierten Knoten aufgerufen werden könnenund deren aktueller Kontext sich somit nicht ändert.
Beispiel 3.4.4:Innerhalb der Vorlage, die auf die Wurzel des Dokumentes angewendet wird, wird dieVorlage mit Nameninfo aufgerufen. Dieser Aufruf kann an beliebigen Stellen mitanderen Vorlagen wiederholt werden und alle Verarbeitungsanweisungen, die in ihrdefiniert werden, brauchen nur an einer Stelle festgeschrieben werden.
<xsl:template match="/"><xsl:call-template name="info"/>
</xsl:template>
<xsl:template name="info"><xsl:text>Hier Infos einfügen!</xsl:text>
</xsl:template>
Einige wichtige Aufgaben lassen sich allerdings erst durch das Hinzufügen von Pa-rametern realisieren. So können Vorlagen erzeugt werden, die Parameter benutzen,indem einparam -Element direkt am Anfang der Vorlage definiert wird. Innerhalb derVorlage kann auf diesen Parameter dann wie auf eine Variable zugegriffen werden.Zur Übergabe eines Wertes an den Parameter, wird beim Aufruf der Vorlage der Wertmit demwith-param -Element übergeben. Auch globale Parameter sind möglich.Ihre Initialisierung erfolgt allerdings prozessorabhängig, beispielsweise bei Komman-dozeilenaufruf mittels Wertübergabe an den Parameternamen.
Eine Kombination von Vorlagenaufrufen mit Parametern kann dazu benutzt werdenProbleme zu lösen, die eigentlich die Verwendung einer Schleife erfordern würden.Da diese in XSLT nicht existieren, sind zur Lösung derartiger Aufgabenstellungenrekursive Techniken einzusetzen.

32
Beispiel 3.4.5:Ein klassisches Beispiel für Rekursion ist die Berechnung der Fakultät. Um diese mitXSLT zu berechnen, wurde in der hier verwendeten Vorlage der Wert der zugrunde-liegenden Berechnung direkt in dem Stylesheet angegeben. Das Ergebnis der Vorlageist somit unabhängig von dem XML-Dokument, auf das diese angewendet wird. Inder Vorlage für die Wurzel wird einergebnis -Element erzeugt, das zum Inhalt denWert derfakultaet -Vorlage mit Startparametera=5 besitzt. Die aufgerufene Vor-lage testet, ob der übergebene Parameter größer Null ist. Wenn dieses der Fall ist, sowird die gleiche Vorlage nochmals mit dem um eins reduzierten Parameterwert auf-gerufen. Das zurückgelieferte Ergebnis, mit dem Parameterwert multipliziert, liefertdann das Ergebnis. Als Abbruchbedingung für die Rekursion wird1 zurückgeliefert,wenn der Parameter kleiner oder gleich eins ist.
<xsl:template match="/"><xsl:element name="ergebnis">
<xsl:call-template name="fakultaet"><xsl:with-param name="a" select="’5’"/>
</xsl:call-template></xsl:element>
</xsl:template>
<xsl:template name="fakultaet"><xsl:param name="a"/><xsl:if test="$a > 1">
<xsl:variable name="erg"><xsl:call-template name="fakultaet">
<xsl:with-param name="a" select="$a - 1"/></xsl:call-template>
</xsl:variable><xsl:value-of select="$a * $erg"/>
</xsl:if><xsl:if test="$a <= 1">
<xsl:value-of select="’1’"/></xsl:if>
</xsl:template>
Durch Einsatz und Kombination dieser oben aufgeführten Möglichkeiten erreicht XSLTdie Mächtigkeit viele geforderte Aufgaben zu lösen. Es sind noch einige weitere Ele-mente dafür von Nutzen. Ein Beispiel hierfür ist dassort -Element, mit dem sichElemente nach bestimmten Eigenschaften innerhalb vonapply-templates oderfor-each -Elementen sortieren lassen. Damit wird die Reihenfolge, in der die ge-fundenen Knoten abgearbeitet werden, festgelegt.

33
Zur Auswertung bestimmter Elemente, auch über verschiedene Ebenen hinweg, dientdasnumber -Element. Mit ihm können Knoten oder auch Werte gezählt, weiter be-rechnet und formatiert ausgegeben werden. Eine typische Anwendung für dasnum-ber -Element ist die Durchnummerierung der Knoten anhand ihrer Position im Baum.Eine andere Möglichkeit, wenn es um die Formatierung von Werten für die Ausgabegeht, liefert dasdecimal-format -Element. Mit diesem Element lassen sich For-matierungsregeln definieren, die an unterschiedlichen Stellen innerhalb des Stylesheetswieder aufgerufen werden können, wenn numerische Werte in den Ergebnisbaum über-nommen werden müssen.
Eine eindeutige Indizierung von bestimmten Elementen anhand festgelegter Eigen-schaften, lässt sich mit demkey -Element erreichen. Durch diesen Index können bei-spielsweise Querverweise innerhalb des Baumes erzeugt werden. Auf einen derart er-zeugten Schlüssel, der nur global existieren kann, kann innerhalb des gesamten Doku-mentes zugegriffen und die dazugehörigen Elemente abgefragt werden.
Um Struktur und Übersichtlichkeit in großen Stylesheets zu erreichen, lassen sich dieseauf verschiedene kleinere Stylesheets aufteilen. Auch die Wiederverwertbarkeit wirddurch diese Modularisierung gewährleistet. Es gibt zwei Möglichkeiten verschiedeneXSLT’s zusammenzufügen,import undinclude . Beide können nur alsTop-Level-Element, also direkt unterhalb desstylesheet -Elementes, eingesetzt werden. Solldasimport -Element benutzt werden, so muss dieses direkt an erster Position inner-halb desstylesheet -Elementes auftreten. Mit ihm lassen sich andere Stylesheetsimportieren, deren Vorlagen allerdings eine niedrigere Priorität besitzen, als es stan-dardmäßig üblich ist. Allen Vorlagen werden Prioritäten mitgegeben. Diese ergebensich aus der Genauigkeit des XPath-Ausdruckes, mit dem sie erstellt werden. Somitwird immer die Vorlage auf einen Knoten angewendet, deren Ausdruck diesen am ex-aktesten getroffen hat. Um in einzelnen Fällen selber Einfluss darauf zu nehmen, lässtsich die Priorität einer Vorlage auch von außen festlegen. Importierte Vorlagen werdensomit immer nur zuletzt angewendet, wenn keine mit höherer Priorität auf den Knotenpassen.
Das Einfügen von Stylesheets mittelsinclude ist an jeder beliebigen Stelle unter-halb desstylesheet -Elementes möglich. Alle eingefügten Vorlagen besitzen diegleiche Priorität, wie die direkt definierten Vorlagen. Besonders zur Aufteilung aufunterschiedliche Dateien bei großen Mengen an Vorlagen, wird diese Methode ver-wendet.
3.5 Funktionen
Wie in Kapitel 3.3 schon ansatzweise erwähnt, stellt XSLT bzw. XPath auch einigeFunktionen zur Verfügung. Diese dienen als Unterstützung zur Definition der Bedin-gungen, die innerhalb vonselect odertest -Attributen festgeschrieben werden.
XPath, als Grundlage der Baumstruktur, liefert neben den verschiedenen möglichen

34
Achsen (siehe Kapitel3.2.2) auch verschiedenartige Funktionalitäten zur genauerenSpezifikation bestimmter Eigenschaften. Es lassen sich mittels Knotentests bestimmteSorten von Knoten finden und unterscheiden, so zum Beispiel Text- oder Kommen-tarknoten. Funktionen zur Bearbeitung von Nummern sorgen dafür, dass verschiedeneKnoten umgewandelt und mit ihnen mathematische Operationen durchgeführt werdenkönnen. So lassen sich Knotenmengen mitcount durchzählen oder auch einfach nurihre Werte auf beliebige Art und Weise kombinieren. Hierfür stehen gängige Opera-toren wie+, - , * , div odermod bereit. Auch Wahrheitsaussagen lassen sich durchOperatoren wie=, < >, and oderor und den dazugehörigen Funktionen bearbeiten.Mit der boolean() -Funktion lassen sich alle möglichen Objekte in Wahrheitswerteumwandeln undnot() dient zur Invertierung der Wahrheitswerte. Diese Wahrheits-aussagen werden besonders bei Tests benötigt, vgl. Kapitel3.4.
Eine weitere wichtige Gruppe von Funktionen dienen der Stringverarbeitung. Abfra-gen bezüglich der Länge von Strings und dem Auftreten bestimmter Zeichenfolgen andefinierten Positionen im String sind besonders für Tests sinnvoll. Das Zerteilen vonStrings und das Zusammenfügen und Umwandeln von Zeichen ermöglichen auch einespezifizierte Stringbearbeitung.
Diese gängigen Operationen und Funktionen anderer Programmiersprachen, werdendurch speziell auf die Baumstruktur abgestimmte Funktionen ergänzt. Zur Auswahlbestimmter Knoten liefert XPath den Zugriff auf ein Element an einer bestimmtenPosition (position() ). Es lassen sich eindeutige ID’s zu Knoten erzeugen und diesean anderer Stelle wiederfinden (id() ) bzw. verweisen. Auch die Informationen überden Namen oder den Namensraum eines Knotens, lassen sich abfragen und stehen sozur weiteren Verarbeitung zur Verfügung.
Für die Benutzung der Funktionen ist die Unterscheidung nach ihrer Spezifikation inXPath oder XSLT nicht entscheidend. Während XPath allerdings eher die grundsätzli-chen Operationen zur Verfügung stellt, liefern die in XSLT definierten Funktionen spe-zifische Funktionalitäten in Abhängigkeit des Umfangs der eigenen Sprache. So wirdmit der Funktioncurrent() der aktuelle Knoten geliefert, in dem gerade die Vera-beitung stattfindet. Das ist sehr ähnlich dem per XPath spezifizierten aktuellen Knoten(. ) und somit sind diese beiden auch in den meisten Fällen identisch. Allerdings wirdder XPath-Ausdruck erst innerhalb seines gesamten Ausdrucks ausgewertet, das heißtder XSLT-Prozessor befindet sich in der Verarbeitung des XPath-Ausdrucks. Wenndieser ihn bis zu der Stelle, an der der. -Ausdruck ausgewertet wird, zu einem ande-ren Element umgeleitet hat, so wird an der nun für den Prozessor aktuellen Stelle, derAusdruck ausgewertet. Anders ist das bei der Verarbeitung dercurrent() -Funktion.Diese gehört zu XSLT und wird somit einzeln ausgewertet. Sollte diese innerhalb ei-nes XPath-Ausdruckes benutzt werden, so steht ihr Ergebnis schon vor Bearbeitungdes Ausdruckes fest. Dadurch kann es passieren, dass diese beiden Ausdrücke an be-stimmten Stellen unterschiedliche Ergebnisse liefern.

35
Beispiel 3.5.1:In den meisten Fällen liefern die Ausdrücke. undcurrent() die gleichen Ergeb-nisse. Beide liefern den Wert des aktuellen Knotens zurück. Innerhalb der Auswertungeines XPath-Ausdrucks kann das jedoch variieren. Mit Benutzung dercurrent() -Funktion wird nur dann der Inhalt des Elementes zurückgeliefert, wenn der aktuelleKnoten einid -Attribut hat. Die Benutzung von. wird immer den Inhalt des erstenElementes zurückliefern, das bei der Suche nach einem Element mitid -Attribut ge-funden wird.
Identische Ausgabe:<xsl:value-of select="current()"/>
<xsl:value-of select="."/>
Unterschiedliche Ergebnisse:<xsl:value-of select="//*[@id=current()/@id]"/>
<xsl:value-of select="//*[@id=./@id]"/>
Damit mit XSLT Auswertungen über verschiedene Dateien gemacht werden können,muss es die Möglichkeit geben mehrere Dokumente gleichzeitig zu bearbeiten. Mittelsder document() -Funktion kann auf andere XML-Dokumente zugegriffen werden.Innerhalb dieser Dokumente kann beliebig navigiert und gearbeitet werden, wie esauch in dem Ausgangsdokument der Fall ist. Eine Unterstützung von Dokumenten, dienicht XML-basierend sind, ist auf diese Art nicht machbar. Eine Möglichkeit, diesesProblem zu lösen, wird in Kapitel3.6erläutert.
Einige XSLT-Funktionen dienen als Spezifizierungsfunktionen für bestimmte Elemen-te. Das ist beispielsweise bei dem schon in Kapitel3.4 erwähntendecimal-for-mat -Element der Fall. Innerhalb dieses Elementes wird eine Formatierungsregel de-finiert, die innerhalb des Stylesheets an beliebigen Stellen wieder verwendet werdenkann. Dazu wird mittels derformat-number() -Funktion auf sie zugegriffen unddie angegebenen Zahlen werden nach den festgelegten Regeln formatiert ausgegeben.Ebenso arbeitet auch diekey() -Funktion mit einem Element zusammen. Mittels deskey -Elementes lassen sich Schlüssel erzeugen, die mit derkey() -Funktion wiederabgerufen werden können. Bei der Schlüsselerzeugung handelt es sich um einen ein-fachen Zugriff auf eine bestimmte ausgewählte Menge von Knoten. Diese eindeutigenSchlüssel erzeugen damit einen neuen Zusammenhang zwischen Elementen, die in dieausgewählten Knotenmengen gehören. Eine einfachere Zugriffsart ist über die Eindeu-tigkeit eines jeden Elements möglich. So lässt sich für jedes Element eine eindeutigeID generieren (generate-id() ), die innerhalb des gesamten Dokumentes gültigist. Zu jedem Zeitpunkt der Verarbeitung des XML-Dokumentes mit dem Stylesheetist die erzeugte ID eines Elementes gleich, allerdings kann sie bei einem erneuten Auf-ruf des Stylesheets oder eines anderen XSLT-Prozessors variieren.

36
Wichtige Informationen zum verarbeitenden XSLT-Prozessor, lassen sich durch diesystem-property() -Funktion zur Laufzeit abfragen. Die Versionsnummer zeigtan, welcher Stand von XSLT unterstützt wird. Auch Name und URL des XSLT-Pro-zessors lassen sich abfragen. Dies ist besonders wichtig, da XSLT zwar eine vom W3Cverabschiedete Empfehlung ist, aber dennoch nicht alle XSLT-Prozessoren alle Funk-tionalitäten implementieren, siehe auch Kapitel3.3. Durch Bereitstellung der Syste-meigenschaften lassen sich somit Vorlagen erstellen, die abhängig vom eingesetztenProzessor, verschiedene Verarbeitungsanweisungen ausführen. Die XSLT-Prozessorenkönnen auch noch weitere Systemeigenschaften unterstützen, aber die sind von jedemeinzelnen XSLT-Prozessor abhängig und nicht standardisiert.
Damit die Auswahl der Verarbeitungsschritte nicht vom Namen des eingesetzten Pro-zessors abhängig ist, gibt es die Möglichkeit die Erreichbarkeit von bestimmten Ele-menten oder Funktionen abzufragen. Das lässt sich mit den XSLT-Funktionenele-ment-available() undfunction-available() erreichen. Die Recherchenim Rahmen dieser Diplomarbeit haben ergeben, dass zur Zeit nicht alle XSLT-Pro-zessoren diese Funktionen unterstützen. Das erschwert die Arbeit besonders flexibleund fehlerresistente Stylesheets zu schreiben. Einen großen Einfluß hat dieses auf dieMöglichkeit Erweiterungen zu den Standard-Funktionen zu schreiben. Auf diese Er-weiterungsfunktionen soll im nächsten Kapitel näher eingegangen werden.
3.6 Erweiterungsfunktionen
Viele Funktionalitäten, die sich im Gebrauch von XSLT als notwendig erweisen, sindnoch nicht in der ersten Version der Spezifikation enthalten. Um derartigen Proble-men und damit Unzulänglichkeiten in der Benutzung vorzubeugen, ist das Schreibenvon Erweiterungsfunktionen im Standard vorgesehen. Hiermit erhält der Benutzer dieMöglichkeit, eigene, problemspezifische Funktionen in einer beliebigen Programmier-sprache zu implementieren und in das Stylesheet einzubinden. Diese angedachte Fle-xibilität geht leider in der ersten Version von XSLT auf Kosten der Abhängigkeit vomXSLT-Prozessor (siehe Kapitel3.5). So ist in der Spezifikation der Einsatz und dieBenutzung von Erweiterungsfunktionen nicht eindeutig definiert. Verschiedene XSLT-Prozessoren arbeiten somit unterschiedlich und benötigen eigens auf sie abgestimmteAngaben, um Erweiterungen ausführen zu können. Neben den bereits in Kapitel3.5er-läuterten Funktionenelement-available() und function-available()existiert noch eine weitere Möglichkeit die Funktionalität des Stylesheets zu garan-tieren. Das ist mittels desfallback -Elementes möglich, indem direkt beim erstenAuftauchen eines nicht erreichbaren Elementes oder einer nicht erreichbaren Funktionin den durchfallback definierten Verarbeitungsfall gesprungen wird. Damit wirdauf jeden Fall die Ausführung der innerhalb desfallback -Elementes stehenden An-weisungen garantiert.

37
Beispiel 3.6.1:Einsatz eines Erweiterungselementes:Zur Ausgabe des Ergebnisses einer XSL-Transformation in mehrere Dokumen-te liefert Xalan eine entsprechende Erweiterung. Der Namensraum und sein Prä-fix redirect wird wie üblich angegeben. Allgemein ist dieser für den XSLT-Prozessor unwichtig, doch Xalan benutzt diesen Namensraum bei Erweiterungenzum Auffinden der Klasse, in der die Erweiterungen implementiert sind. Mittels desextension-element-prefixes -Attributes wird dem Prozessor mitgeteilt, mitwelchem Präfix Erweiterungselemente versehen sind. Es soll eine HTML-Ausgabeerzeugt werden. Um festzustellen, ob der Prozessor dasredirect:write -Elementkennt, wird dieelement-available -Funktion eingesetzt. Ist dies der Fall, so kanndas Dokument auf mehrere Dateien aufgeteilt werden. Dafür werden für alle vorhan-denen Elemente die Vorlagen mit dem Modeviele aufgerufen. In dieser Vorlagewird die Ausgabe jeweils in eine Datei umgeleitet, die mittels dergenerate-id() -Funktion einen eindeutigen Namen erhält. Sollte das Element unbekannt sein und so-mit kein Splitten auf verschiedene Dateien durchgeführt werden, so wird eine HTML-Seite erzeugt und in diese werden alle Werte der Reihe nach eingefügt.
<?xml version="1.0"?><xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"xmlns:redirect="org.apache.xalan.xslt.extensions.Redirect"extension-element-prefixes="redirect">
<xsl:output method="html" encoding="iso-8859-1"/>
<xsl:template match="/"><xsl:choose>
<!-- Schreiben in mehrere Dateien wird unterstuetzt --><xsl:when test="element-available(’redirect:write’)">
<!-- Alle Elemente im viele-Modus bearbeiten--><xsl:apply-templates select="*" mode="viele"/>
</xsl:when><!-- Das Schreiben laesst sich nicht aufteilen --><xsl:otherwise>
<!-- Erzeuge eine HTML-Seite, die alles enthaelt --><html><head><title>
<xsl:value-of select="text()"/></title></head><body><h1><xsl:value-of select="text()"/></h1>
<xsl:apply-templates select="*"/><hr/>© Tanja Schniederberend
</body></html>
</xsl:otherwise></xsl:choose>
</xsl:template>
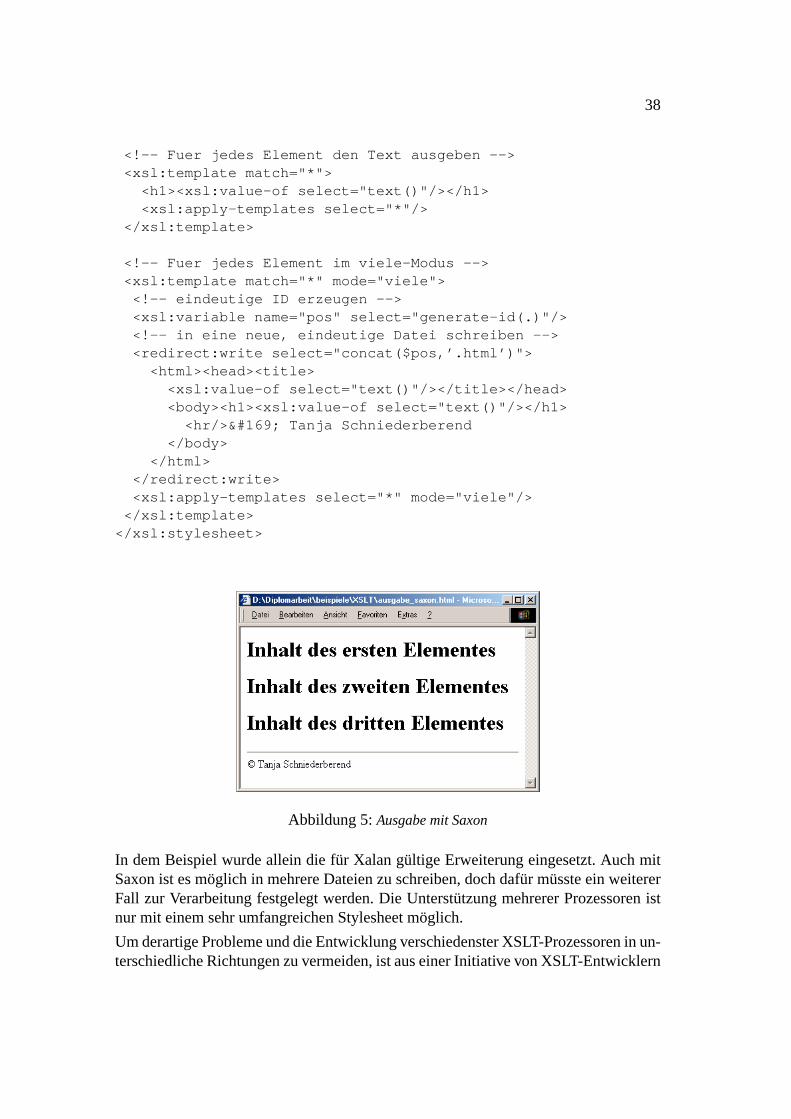
38
<!-- Fuer jedes Element den Text ausgeben --><xsl:template match="*">
<h1><xsl:value-of select="text()"/></h1><xsl:apply-templates select="*"/>
</xsl:template>
<!-- Fuer jedes Element im viele-Modus --><xsl:template match="*" mode="viele">
<!-- eindeutige ID erzeugen --><xsl:variable name="pos" select="generate-id(.)"/><!-- in eine neue, eindeutige Datei schreiben --><redirect:write select="concat($pos,’.html’)">
<html><head><title><xsl:value-of select="text()"/></title></head><body><h1><xsl:value-of select="text()"/></h1>
<hr/>© Tanja Schniederberend</body>
</html></redirect:write><xsl:apply-templates select="*" mode="viele"/>
</xsl:template></xsl:stylesheet>
Abbildung 5:Ausgabe mit Saxon
In dem Beispiel wurde allein die für Xalan gültige Erweiterung eingesetzt. Auch mitSaxon ist es möglich in mehrere Dateien zu schreiben, doch dafür müsste ein weitererFall zur Verarbeitung festgelegt werden. Die Unterstützung mehrerer Prozessoren istnur mit einem sehr umfangreichen Stylesheet möglich.
Um derartige Probleme und die Entwicklung verschiedenster XSLT-Prozessoren in un-terschiedliche Richtungen zu vermeiden, ist aus einer Initiative von XSLT-Entwicklern

39
(a) Das erste Element, das alle weiterenElemente, aber keinen Text enthält
(b) erstes Kindelement
(c) zweites Kindelement (d) drittes Kindelement
Abbildung 6:Ausgabe mit Xalan in verschiedene Dateien
das EXSLT-Projekt ("E" steht für extensions - Erweiterungen)[EXSLT] entstanden.Wesentliche Aufgabe des Projektes ist die Dokumentation, wie Erweiterungen benutztwerden sollen, und die Angabe von Funktionen, die ein Prozessor unterstützen soll.Zum aktuellen Stand unterstützen zwar nur einige wenige Prozessoren diese Erwei-terungen, aber dafür sind es die häufig eingesetzten, dazu gehören Xalan und Saxon.Wie weit sich dieses Projekt auf Dauer durchsetzt ist allerdings fraglich, zumal selbstdie eben genannten Prozessoren nicht jede Erweiterung unterstützen. Wichtig ist aber,dass die innerhalb dieses Projektes definierten Erweiterungsfunktionen mit in die Dis-kussion um die Version 2.0 von XSLT aufgenommen wurden. Zwei häufig benötigteFunktionen, wie das Lesen aus Textdateien und das Schreiben in mehrere Ausgabedo-kumente, wurde bislang nur als Erweiterung der einzelnen Prozessoren implementiert,sind aber durch den hohen Bedarf mit in die Diskussion der Anforderungsliste an dienächste XSLT-Version aufgenommen worden. Die Aufnahme und Standardisierungderartiger Funktionen wird in der Zukunft wieder für eine hohe Unabhängigkeit vonden Prozessoren sorgen und eine Vereinfachung der Entwicklung mit sich ziehen.
Bereits zum aktuellen Stand des Arbeitspapiers zur Version 2.0 von XSLT unterstütztSaxon in der Version 7.4 wichtige Funktionen, wie das Ausgeben in mehrere Doku-mente, anhand der Vorgaben des Arbeitspapieres. Innerhalb dieser Entwicklungsphasekann sich natürlich noch einiges ändern. Dennoch ist daraus eine Tendenz zu erkennen.Weitere Beispiele für neue Funktionalitäten von XSLT sind die Ergänzung um XQuery,eine XML-basierte Datenabfragesprache, und die Unterstützung von Datentypen aus

40
XML-Dokumenten, wenn diese anhand eines XML Schemas definiert wurden. Bei derErstellung von Stylesheets, die mehrere Prozessoren unterstützen, ist es somit um sowichtiger auf die Version des unterstützten XSLT zu achten und diese Versionen zuunterscheiden.

41
4 XSL-FO
Die eXtensible Stylesheet Language Formatting Objects(XSL-FO) ist eine XML-Anwendung zur grafischen Aufbereitung von XML-Dokumenten. Hierbei steht be-sonders die Möglichkeit ein druckbares Format zu liefern im Vordergrund. XSL-FOist somit eine XML-basierte Beschreibung für das Erscheinungsbild gedruckter Doku-mente, dessen Funktionsweise in diesem Kapitel näher erläutert wird.
4.1 Entstehung
Zur grafischen Aufbereitung von XML-Dokumenten wurde anfangs dieeXtensibleStylesheet Language(XSL) entwickelt. Da sich eine Aufteilung in zwei wesentlicheAnwendungsbereiche, Layout und Strukturierung, abzeichnete, wurde die Sprache die-sen Anforderungen angepasst. Aus dem Strukturierungsaspekt ist XSLT entstandenund die auf das Layout konzentrierte Sprache XSL ist geblieben. Da allerdings ausder Geschichte heraus noch häufig Verwechslungen zwischen diesen Bezeichnungenauftreten, nennt man XSL zur Herausstellung des Formatierungsaspektes im allgemei-nen Gebrauch XSL-FO. Dies erklärt auch das Präfixfo , das für die Namensrauman-gabe benutzt wird und sich weitestgehend etabliert hat. Die endgültige Empfehlung[W3CXSLFO] ist in erster Version am 15.10.2001 vom W3C verabschiedet worden.Mit XSL-FO sollen Möglichkeiten geliefert werden, um druckbare Dokumente ausstrukturierten XML-Daten zu erzeugen. Dazu lassen sich die darzustellenden Seitenunabhängig vom letztendlich erzeugten Format definieren. Es existieren mehrere ver-schiedene Formatierer, die unterschiedliche Formate oder ihre Beschreibung generie-ren können. Die meisten Formatierer unterstützen Formate wie PostScript und PDF,einige aber auch RTF oder TeX. Alle diese Formate sind für die Ausgabe auf demDrucker geeignet, nur bei der Generierung mittels TeX wird noch ein Zwischenschritteingelegt. Dieser Schritt sorgt dafür, dass der Formatierer keine Kenntnis über die Zei-chensetzung benötigt, sondern ausschließlich eine Abbildung der in XSL-FO beschrie-benen auf die in TeX beschriebenen Daten machen muss. In Anbetracht der Aktualitätdieser XML-Anwendung ist das eine Möglichkeit, die bei einigen Formatierern nochfehlerhafte Zeichensetzung zu umgehen und auf ein bereits langjährig erfahrenes Sy-stem auszuweichen. Darauf wird in Kapitel4.6noch näher eingegangen.
Zur Festlegung des Erscheinungsbildes von HTML-Elementen werden häufigCasca-ding Style Sheets(CSS) [W3CCSS] verwendet. Dies ist eine eigene Sprache, die aufdie Formatierung von HTML-Elementen spezialisiert ist. Mit ihrer Hilfe können unteranderem Fonts und Farben definiert werden. CSS hat großen Einfluß auf die Entste-hung von XSL-FO gehabt. Viele Eigenschaften, die mit CSS definiert werden können,wurden in XSL-FO übernommen. Die Syntax unterscheidet sich zwar, zumal CSS kei-ne XML-Anwendung ist, aber die Attribute sind ähnlich. So kann in beiden Sprachenbeispielsweise die Schriftgröße mit demfont-size -Element gesetzt werden. Die

42
Einflüsse sind auch aus der Definition von XSL-FO ersichtlich, die mehrfach auf dieDefinition von CSS verweist.
4.2 Grundlagen
XSL-FO beschreibt den Seitenaufbau, wie beispielsweise Größe, Position, Rahmen,Zeilenabstände, benutzte Schriftarten und Farben. Um die XML-Daten, die in einedruckreife Datei überführt werden sollen, in dieses Format zu bringen, werden siemeistens mittels XSLT in ein gültiges XSL-FO-Dokument umgeformt (vgl. Abbil-dung7). XSLT fungiert dabei im wesentlichen als Variable für den Inhalt. Die Daten,die den Inhalt bilden, werden mit XSLT an den Stellen in dem XSL-FO-Dokumenteingefügt, an denen sie mittels XSL-FO zur Ausgabe bearbeitet werden sollen. Für dieweitere Betrachtung der Funktionsweise von XSL-FO reicht es daher aus, die Datenfest in das FO-Dokument hineinzuschreiben. Die XSL-Transformation, die diese Dateieigentlich erzeugt, also im wesentlichen die Textpassagen in die XSL-FO Auszeich-nungen integriert, wird in Kapitel3 beschrieben. Ein Beispiel zu der Zusammenarbeitvon XSL-FO und XSLT wird in Kapitel4.5behandelt.
XSL−Transformation
Formatierer
PSDokumentXSL−FO−
DokumentXML−
Abbildung 7:Ablauf zur Erstellung von Formaten aus XML-Daten
Der Aufbau eines XSL-FO-Dokumentes ist immer gleich. Zu Beginn werden die Sei-ten definiert. Dabei werden die Größe, die Ränder und die beschreibbaren Regionenfestgelegt. Darauf folgen optional Deklarationen, wie die Bestimmung eines einzu-setzenden Farbprofils. Im Anschluß folgt die Beschreibung des gesamten Inhalts undaller seiner Eigenschaften, wie Position, Fonts und Farben. Der folgende Code zeigtden grundlegenden Aufbau eines XSL-FO-Dokumentes:
<?xml version="1.0" encoding="UTF-8"?><fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">
<!-- Seiten definieren --><fo:layout-master-set>
...</fo:layout-master-set>

43
<!-- optional Deklarationen --><fo:declarations>
...</fo:declarations>
<!-- Seiten benutzen , Inhalt einfügen --><fo:page-sequence master-reference="seitenverweis">
...</fo:page-sequence>
...
</fo:root>
Es können beliebig vielepage-sequence -Elemente eingefügt werden, während nurein layout-master-set -Element existieren darf, in dem alle Seitendefinitionenenthalten sein müssen. Dasdeclarations -Element ist optional und nur dann an-zuwenden, wenn das vorhandene in ein anderes Farbprofil geändert wird. Deshalb wirdes in den weiteren Beispielen vernachlässigt.
4.3 Seitendefinition
Jedes XSL-FO-Dokument besteht aus mindestens einer Seite. Diese muss imLayout-Master-Setdefiniert werden. Dazu wird die Seitengröße angegeben, die Ränder werdenabgesteckt und die beschreibbaren Regionen werden festgelegt.
Beispiel 4.3.1:Es soll eine einfache DIN A4 Seite definiert werden. Der Rand nach oben und untenbeträgt 2cm und der nach rechts und links 2,5cm. Innerhalb der Seite wird imRegion-bodyder Hintergrund auf grau gesetzt.
<fo:simple-page-master master-name="einfach"page-height="29.7cm" page-width="21cm"margin-top="2cm" margin-bottom="2cm"margin-left="2.5cm" margin-right="2.5cm">
<fo:region-body background-color="grey"/></fo:simple-page-master>
Der Region-bodystellt die eigentliche Schreibzone des Dokumentes dar. Neben ihmlassen sich aber noch vier weitere Regionen definieren. Nur in diesen Regionen kannInhalt eingefügt werden. Die anderen Regionen liegen über, unter, links und rechtsvomRegion-body. Sie eignen sich somit besonders für alle festen Angaben, wie Kopf-

44
oder Fußzeilen, Seitenzahlen oder Titel. In Abbildung8 wird der Aufbau einer Seitemit den Regionen dargestellt (vgl. [Paw2002, S.34]). Die Ränder wurden zuvor mittelsdermargin -Attribute bei der Seitendefinition festgelegt. Die Elemente zur Seitende-finition werden alle nur über ihre Attribute festgelegt, der Inhalt dieser Elemente bleibtleer.
margin−top
margin−buttom
margin−right
margin−left
Region−before
Region−after
Region−endR
egion−start
Region−body
Abbildung 8:Die zu definierenden Regionen einer einzelnen Seite in XSL-FO.
Die Veränderungen, die an einer Seite vorgenommen werden können, sind aber nochviel weitreichender. Die absoluten und relativen Richtungen der Seitenelemente kön-nen bestimmt werden. Dadurch ist es möglich die Regionen so zu drehen, dass sie aufdem Kopf oder auf der Seite liegen. Gleichzeitig lässt sich auch noch die Schreibrich-tung bestimmen. Standardmäßig ist diese von links nach rechts und von oben nachunten definiert. Aber sie lässt sich auch auf rechts nach links und auf unten nach obenfestlegen.
Die ganzen Angaben bezogen sich auf die Definition einer einzelnen Seite. Wennnun aber mehrere Seiten erzeugt werden, so müssen diese auch beschrieben werdenkönnen. Das wird beispielsweise durch die Anwendung mehrerer einzelner Seitenrealisiert. Diese Seiten können alle gleich aufgebaut sein oder jede einzeln definiertwerden. Doch das reicht noch nicht aus. So kann im Vorfeld häufig nichts über dieMenge des Inhaltes gesagt werden und wie dieser über verschiedene Seiten verteiltwerden soll. Um trotzdem zu berücksichtigen, dass beispielsweise alle linken Seiten

45
anders aussehen als alle rechten oder die erste anders als die restlichen, lassen sichSeiten-Sequenzendefinieren. Mit ihnen wird die Reihenfolge, Häufigkeit und Auswahlder einzelnen Seiten festgelegt. So lassen sich Bedingungen ähnlich demchoose -Element in XSLT definieren, anhand derer eine bestimmte einzelne Seite benutzt wird.Die Bedingungen sind abhängig von der Seitenposition, beispielsweise ob es sich umdie erste oder letzte Seite handelt, dem Auftreten der Seite, an gerader oder ungeraderStelle, und dem eventuell auf einer Seite vorhanden fliessenden Inhalt.
Beispiel 4.3.2:Eine Sequenz von Seiten, die für die erste Seite eine definierte Titelseite aufruft und fürdie restlichen die eben schon definierte Beispielseiteeinfach , wird folgendermaßenerstellt:
<fo:page-sequence-master master-name="viele"><fo:repeatable-page-master-alternatives>
<fo:conditional-page-master-referencemaster-reference="titel" page-position="first"/>
<fo:conditional-page-master-referencemaster-reference="einfach" page-position="rest"/>
</fo:repeatable-page-master-alternatives></fo:page-sequence-master>
4.4 Inhalte einer Seite
Die zuvor definierten Seiten können nun mit Inhalt gefüllt werden. Das wird innerhalbderpage-sequence -Elemente gemacht. Diese referenzieren auf den Master einereinfachen oder einer Sequenz von Seiten. Da auch mehrere Seiten-Sequenzen benutztwerden können, müssen diese untereinander abgestimmt werden. Dafür gibt es bei je-der neu eingefügten Sequenz die Möglichkeit, die Seitennummerierungen anzupassenoder den Beginn auf einer geraden oder ungeraden Seite festzulegen.
Die Seitengrundlage ist damit festgelegt. Durch Referenzen auf die definierten Regio-nen der Seite kann in diese der Inhalt eingefügt werden. Dabei wird fließender undfester Inhalt unterschieden. Fester Inhalt wird direkt auf einer Seite platziert, währendsich fließender Inhalt je nach Aufteilung durch den Formatierer über verschiedene Sei-ten verteilen lässt. Übersteigt der fließende Text allerdings die im Sequenz-Master de-finierte Anzahl der Seiten, so kommt es zu einer Fehlermeldung. Es sollte also schonbei der Master-Definition darauf geachtet werden, dass die Anzahl der gesamten Seitennicht beschränkt ist und somit immer ausreichend Seiten zur Verfügung stehen.
Zum Platzieren und Definieren des Inhaltes gibt es viele Möglichkeiten der Gestaltung.Sie hängen mit dem Bearbeitungsmodell des Formatierers zusammen. Alle Objekte,

46
die der Formatierer in einer Seite platzieren muss, werden in ein Rechteck gesteckt,dasArea genannt wird. Diese Area ist nicht unbedingt mit den einzelnen definiertenInhalten einer Seite identisch. Der fließende Inhalt kann beispielsweise in einem Ele-ment definiert sein, aber nicht auf eine Seite passen. Somit wird er getrennt und inmehrere Areas aufgeteilt. Dieser Arbeitsschritt des Formatierers ist bei der Definiti-on aller Inhalte zu berücksichtigen, da so zusammenhängende Einträge mit gleicherFormatierung auch getrennt werden können.
Die Areas können ineinander geschachtelt werden. Damit entsteht ein ganzer Baumineinander liegender Areas. Verschiedene Objekte können auch zu Areas zusammen-geschlossen werden. Angaben hierzu lassen sich genauso über Attribute realisieren wiedas Aufteilen auf unterschiedliche Seiten. Zwei wesentliche Typen von Areas werdenim Folgenden benutzt:Inline-Areasund Block-Areas. Inline-Areas beschäftigen sichmit allem, was innerhalb einer Zeile angeordnet oder platziert werden kann. Block-Areas sind zusammengehörige Teile, die in einem Dokument platziert werden soll.
Blöcke sind ineinander schachtelbar. Sie können aus einfachen Textpassagen, Listen,Tabellen oder auch Grafiken bestehen. Allein mittels demblock-container -Ele-ment definierte Blöcke sind absolut innerhalb einer Area positionierbar, ansonstenist die Positionierung relativ vorzunehmen. Die einfachste Benutzung einesblock -Elements stellt das Einfügen von Text dar. Alle Eigenschaften (Fonts, Abstände vonZeilen oder Rändern, Hintergrund, etc.) lassen sich in den Attributen desblock -Elementes setzen. Für Größenangaben stehen dabei verschiedene Maßeinheiten zurVerfügung, zum Beispiel Pixel, Zoll oder Zentimeter. Bei geschachtelten Blöcken wer-den die Eigenschaften weiter vererbt. Blöcke können somit alsContaineranderer Ele-mente dienen und diese auch kombinieren, beispielsweise eine Grafik in den Hinter-grund legen und den Text darüber. Auch Fußnoten lassen sich einfügen und Blöckenkönnen ID’s mitgegeben werden. Anhand der ID’s lassen sich an anderer Stelle Ver-weise auf diese Blöcke erstellen, wodurch Links und Seitenzahlenverweise innerhalbdes Textes ermöglicht werden.
Beispiel 4.4.1:Es wird fließender Inhalt imRegion-Bodyeiner Seite definiert. Der Inhalt besteht auseinfachen Blöcken, die ineinander geschachtelt sind und nur Text enthalten. Die At-tribute der Blöcke bestimmen die Textausrichtung, die Schriftgröße und den Abstandzueinander.
<fo:flow flow-name="xsl-region-body"><fo:block text-align="left" font-size="22pt">
Inhalt<fo:block space-before="6pt" font-size="16pt">
Ein Block im Block</fo:block>
</fo:block></fo:flow>

47
Abbildung 9:Der gerenderte Inhalt zweier Block-Abschnitte aus Beispiel 4.4.1
Listen und Tabellen stellen auch Blöcke dar, die in den beschriebenen Arten benutztwerden können. Sie lassen sich aber auch noch exakter formatieren. Beispiele hierfürsind dasListenlabelund sein Abstand zum eigentlichen Listeninhalt oder die Tabel-lenbeschriftung in Bezug auf die eigentliche Tabelle. Diese Beschriftung wird nebendem Tabellenkopf und dem Tabellenkörper angegeben und bildet mit ihnen zusammeneinen eigenen Block. Die Inhalte dieser Beschreibungen können wiederum in andereBlöcke integriert sein.
Eine kleinere Einheit innerhalb von Blöcken stellen dieinline -Elemente dar. Wäh-rend sich für Blöcke allgemeine Eigenschaften setzen lassen, bieteninline -Ele-mente die Möglichkeit direkt in einer Zeile Veränderungen vorzunehmen. So lassensich mit ihrer Hilfe einzelne Wörter oder Textpassagen unterstreichen, kursiv oder fettdrucken. Dieinline -Elemente können auf Zeichen- und Wortabstände Einfluß neh-men, können Zeilenleerräume mit Zeilenführern füllen, wie den Linien einer Zeilein einem Inhaltsverzeichnis, und innerhalb einer Zeile Grafiken einfügen. Natürlichkönnen auch ininline -Elementen alle Arten von Farb- und Fontveränderungen vor-genommen werden.
Beispiel 4.4.2:Zum Einfügen einer Grafik innerhalb einer Zeile, wird dasinline -Element verwen-det. Hier wird innerhalb eines mit Text gefüllten Blockes eine externe GIF-Datei ein-gefügt. Durch Festsetzung der Höhe und der zu benutzenden Skalierungsfunktion wirddie Grafik an die Zeilenhöhe angepasst. Das Ergebnis ist in Abbildung10zu sehen.
<fo:block space-before="20pt" font-size="16pt">Eine Grafik in einer Zeile<fo:inline>
<fo:external-graphic height="16pt" scaling="uniform"src="url(smile.gif)"/>
</fo:inline>gefolgt von ein wenig Text.
</fo:block>

48
Abbildung 10:Formatierte Grafik in einer Zeile
Die elementarste Ebene, auf der Darstellungskriterien festgelegt werden können, sindeinzelne Zeichen. Das ist allgemein gebräuchlich um einzelne Zeichen hoch oder tiefzu stellen. Es lassen sich auf dieser Ebene aber auch Zeichen drehen oder ihre Farbeoder Größe verändern.
Die Liste der einzelnen Formatierungsmöglichkeiten für jedes Element ist sehr lang.Überall können die eben beschriebenen Eigenschaften anhand von Attributen verän-dert und dem Zweck angepasst werden. Auch die Benutzung der Elemente ist beliebigtief schachtelbar und ihr Einsatz in fließendem und statischem Inhalt möglich. Im fol-genden Kapitel wird in einem Beispiel dargestellt, wie die Kombination aus XSLT undXSL-FO zur druckreifen Darstellung von XML-Daten führt.
4.5 Generierung mit XSLT
Die Daten, die mit XSL-FO ausgegeben werden sollen, werden im allgemeinen mittelsXSLT in dieses Format gebracht. Der grundsätzliche Aufbau sieht so aus, dass in derVorlage für das Wurzeldokument der allgemeine Rahmen und alle Seitendefinitionengesetzt werden. Dann werden abhängig vom Inhalt verschiedene Vorlagen aufgerufen,die eventuell ganze Seiten mit Inhalt füllen oder die entsprechenden Daten in ein XSL-FO-Element einfügen. In vielen Fällen können die statischen Inhalte direkt bestimmtwerden und nur die fließenden werden über verschiedeneTemplate-Aufrufe festgelegt.
Der Aufbau dieses XSLT-Dokumentes stellt natürlich nur eine mögliche Variante dar.Wie bei anderen XSL-Transformationen ist der Aufbau abhängig von dem zu Grundeliegenden XML-Dokument. Die Kombination aus XSLT und XSL-FO zeigt aber deut-lich, wie die Zusammenarbeit funktioniert und bildet ein Beispiel für ein Dokument,in dem die Elemente zweier Namensräume benutzt werden.
Beispiel 4.5.1:
<?xml version="1.0"?><xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"xmlns:fo="http://www.w3.org/1999/XSL/Format" version="1.0">
<xsl:output method="xml"/>

49
<!-- Grundgeruest in der Wurzelvorlage --><xsl:template match="/">
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"><fo:layout-master-set>
...</fo:layout-master-set><fo:page-sequence master-reference="title">
<!-- Der Autor als statischer Inhalt unten auf der Seite --><fo:static-content flow-name="xsl-region-after">
<fo:block font-size="12pt" text-align="center"><xsl:value-of select="//Autor"/>
</fo:block></fo:static-content>
<!-- Der fliessende Inhalt im Seitenkoerper --><fo:flow flow-name="xsl-region-body">
<fo:block font-size="24pt" text-align="center"><!-- bestehend aus allen selektierten Daten -->
<xsl:value-of select="//daten"/></fo:block>
<!-- und einzelnen Bloecken fuer jede Person --><xsl:for-each select="//person">
<fo:block font-size="20pt" text-align="center"><!-- der Inhalt wird durch andere Templates bestimmt -->
<xsl:apply-templates select="//persinfo"/></fo:block>
</xsl:for-each></fo:flow>
</fo:page-sequence></fo:root>
</xsl:template>
<xsl:template match="persinfo"><xsl:value-of select="name"/>
</xsl:template>
</xsl:stylesheet>
Die Ideen für den Einsatz von XSL-FO gehen noch weiter. So könnten die beschrie-benen Seiten nicht nur mittels eines Formatierers umgewandelt und gedruckt werden,auch eine Integration in Browser wäre denkbar. Es wäre auch möglich mittels XSL-FObezüglich des Layouts beschriebene XML-Daten direkt grafisch im Browser darzustel-len und dadurch einen qualitativ hochwertigeren Ausdruck zu erzeugen.

50
4.6 Formatierer
Die Qualität des Ausdrucks eines Dokumentes, das mit XSL-FO beschrieben wurde,hängt natürlich wesentlich vom eingesetzten Formatierer ab. Leider werden nicht al-le XSL-FO-Eigenschaften von allen Formatierern unterstützt. Viele halten sich zwaran den Standard, sind allerdings noch so jung, das ausgefallene Elemente oder Attri-bute des Standards noch nicht implementiert sind. Auch der Umfang der extern ein-bindbaren Dateien ist sehr unterschiedlich. Abhängig vom Formatierer werden somitverschiedene Grafikformate unterstützt, wobei jedes Format mit der Angabe seinesMIME-Types möglich wäre. So ist auch die Integration von SVG-Grafiken machbar,aber in den meisten Fällen nicht realisiert. Ein Formatierer könnte anhand der Größeeinfach ein schwarzes Rechteck für die Fläche liefern, deren Inhalt von einem anderenProzess bearbeitet wird. Somit braucht der Formatierer kein Wissen über jeden Typ zubesitzen und die Darstellung der SVG-Grafik kann einem anderen Prozess überlassenwerden.
Die folgenden Angaben sollen einen kurzen Überblick über die verbreitetsten Forma-tierer geben. Welcher Formatierer sich für die endgültige Umsetzung am besten eignet,muss im Einzelfall entschieden werden. Eine ausführliche Liste von Anwendungenrund um XSL ist beim W3C [W3CXSL] abrufbar.
XEP ist ein kommerzielles Produkt der Firma RenderX [renderx] mit Sitz in Ka-lifornien. Die aktuelle Version 3.4 beruht auf der XSL-FO-Empfehlung vom15.10.2001. Es sind verschiedene Versionen für Entwickler, Server und auch ko-stenlos zum Testen oder für akademische Zwecke verfügbar. XEP ermöglicht dieGenerierung von PDF und PS, fügt aber im Fall der Testversion einen Stempelauf jeder Seite oder in der akademischen Version eine Anmerkung in den No-tizen des Dokumentes ein. Deweiteren können eigene Elemente von RenderXergänzt werden, die beispielsweise Dokumentinformationen oder Lesezeichendem generierten PDF hinzufügen können.
FOP ist aus dem Apache Projekt entstanden und damit frei verfügbar [fop]. FOP istin Java geschrieben, die aktuelle Versionsnummer ist 0.20.5 und erzeugt wer-den diverse Formate, wie PDF, PS, SVG und TXT. Allerdings wird die besteUnterstützung, in der auch noch einige XSL-FO-Attribute unbehandelt bleiben,für PDF geliefert. Das generierte SVG ist für die Weiterverwendung nicht zugebrauchen.
XSL Formatter ist ein kommerzielles Produkt von Antenna House Inc. [antenna] inTokyo. Aktuell ist der XSL Formatter, beruhend auf der W3C Empfehlung fürXSL-FO, als Version 2.5 für Windows und in der Version 2.0 für Linux erhält-lich. Er ist in C++ geschrieben, generiert PDF und besticht besonders durchseine Geschwindigkeit bei der Generierung. Der XSL Formatter lässt sich zuTestzwecken kostenlos herunterladen, doch wird auch hier auf jede Seite derFirmenname platziert.

51
PassiveTexstellt frei verfügbar TeXMakros bereit, die dazu gedacht sind XSL-FO-Daten auf eine TeX-Beschreibung zu mappen und daraus dann PDF zu erzeu-gen. Das Copyright [Rah2003] liegt bei Sebastian Rahtz von der Oxford Uni-versity. Der Vorteil der Lösung zur Formatierung TeX zu benutzen, liegt in derSatzkenntnis von TeX. TeX beherrscht sowohl die Worttrennung als auch ma-thematische Formeln und kann damit eine gleichmäßige Darstellung erzeugen.
Die Ergebnisse einer Testseite, die die Unterschiede der Formatierung der Tools FOP,XEP und XSL Formatter zeigen, sind im AnhangC zu finden.

52
5 SVG
Scaleable Vector Grafics(SVG) ist eine XML-Anwendung zur Beschreibung zweidi-mensionaler Vektorgrafiken, die sowohl Animationen als auch Interaktionen mit demBenutzer unterstützt. Das Einsatzgebiet für SVG-Grafiken liegt hauptsächlich im In-ternet. Die folgenden Erläuterungen sollen eine grobe Vorstellung davon liefern, wasSVG-Grafiken leisten können.
5.1 Entstehung
Die erste Empfehlung für SVG wurde am 04.09.2001 vom W3C verabschiedet. Wäh-rend der Erstellung dieser Diplomarbeit ist jedoch eine neuere Version 1.1 [W3CSVG]am 14.01.2003 veröffentlicht worden. Neben dieser Version wurde gleichzeitig aucheine spezielle Version für Mobile Endgeräte verabschiedet: SVG Tiny & SVG Basic[W3CSVGT]. Damit wurden die Grundlagen geschaffen, um den Einsatz von SVGnicht nur auf das Internet zu begrenzen, sondern auch auf die mobile Kommunikationauszudehnen.
Zur Darstellung von SVG-Grafiken wird ein spezialisierter Betrachter (Viewer) benö-tigt. Da SVG auf XML beruht, soll dieser im Rahmen des Mozilla-Projektes [Mozilla]direkt in den Browser integriert werden. Die Entwicklung von SVG ist noch recht jung,weshalb bespielsweise elementare Elemente wie Text noch nicht vollständig integriertsind und dadurch neben der offiziellen Version noch ein Zusatzpaket installiert werdenmuss. Für andere Browser, wie beispielsweise den Internet Explorer von Microsoft,wird allerdings ein Plug-In benötigt. Das verbreitetste Plug-In ist der SVG-Viewervon Adobe [AdoSVG], der nicht nur für unterschiedlichste Plattformen zur Verfügungsteht, sondern auch die Unterstützung der meisten Elemente von SVG-Grafiken liefert.Die aktuelle Version 3.0 ist vom November 2001 und ist sowohl für Windows 98 bisXP, Mac 8.6 bis 10.1, Linux und Solaris 8 verfügbar. Es stehen aber auch eigenständi-ge Betrachter zur Verfügung, zum Beispiel die auf Java basierenden Viewer von IBModer Apache. Der aktuelle Stand der Entwicklung dieser und weiterer SVG-Betrachterkann beim W3C unter [W3CSVGImpl] abgefragt werden. Für die weitere Betrachtungwird der gängige Viewer von Adobe als Plug-In für den Internet Explorer eingesetzt.
5.2 Grundlagen
Da SVG auf XML basiert, beginnt eine SVG-Datei mit der gleichen XML-Deklarationwie alle XML-Anwendungen. Darauf folgt das Wurzelelementsvg , das alle weiterenElemente enthält. Eine Vorlage für SVG-Grafiken sieht demnach folgendermaßen aus:

53
<?xml version="1.0" encoding="UTF-8"?><svg xmlns="http://www.w3.org/2000/svg"
height="600" width="800">...
</svg>
Die Größenangabe ist optional, mit ihr kann die Größe der Grafik festgelegt werden.Standardmäßig werden für Größenangaben immer Pixel benutzt. Es sind allerdingsauch andere absolute Angaben wiemmoder relative Angaben in%vom äußeren Be-zugsrahmen möglich. Auf diese Art lassen sich auch alle weiteren Elemente der Grafikpositionieren.
Die SVG-Grafik kann direkt in einem Viewer geöffnet werden. Häufig sollen aberdie Grafiken in eine HTML-Seite integriert werden. Dazu lassen sie sich mittels des<embed>- oder<object> -Tags in das HTML-Dokument einfügen. Das<embed>-Tag entspricht nicht dem Standard des W3C und gilt als veraltet, wird allerdings voneinigen Browsern besser unterstützt als das<object> -Tag. Das<object> -Tag istdas offizielle Tag zum Einfügen externer Medien in HTML-Dokumente und wird vomW3C empfohlen. Nur mit dem<object> -Tag lassen sich auch Ersatzdarstellungendefinieren. Diese Ersatzdarstellungen werden angezeigt, wenn der angegebene MIME-Type, für SVG ist dasimage/svg+xml , nicht korrekt wiedergegeben werden kann[Spo2001, S. 32 ff.], [Wat2001, Kapitel 10].
<embed src="datei.svg" type="image/svg+xml"/>
<object src="datei.svg" type="image/svg+xml"><img src="ersatz.gif"/>
</object>
Die Grundlage der SVG-Grafik bildet die Zeichenfläche, auf der sie erstellt wird. Indieser können durch ein Koordinatensystem alle Elemente genau platziert werden. DerNullpunkt wird dabei in die obere linke Ecke gelegt, die positive x-Achse verläuftnach rechts und die positive y-Achse nach unten. Die Längen der Achsen sind nichtbeschränkt, deshalb können auch Elemente platziert werden, die nicht sichtbar sind.Der sichtbare Ausschnitt aus dem Koordinatensystem beginnt im Nullpunkt und en-det an den Achsenabschnitten, die durch Angabe der Breite und Höhe des SVG-Tagsfestgelegt wurden. Die sichtbare Fläche wird auchViewportgenannt.

54
5.3 Darstellungsobjekte
Die einfachsten Objekte, die auf der Zeichenfläche platziert werden können, sind Recht-ecke, Kreise, Ellipsen, Polygone, Linien und Polylinien5. Sie alle lassen sich durchAngabe ihrer spezifischen Punkte erzeugen. Darunter ist beispielsweise für einen Kreisder Mittelpunkt und der Radius zu verstehen, für ein Rechteck sind das der Startpunkt,die Breite und die Höhe. Die Reihenfolge der Definitionen bestimmt, welches Elementoben liegt. Das ist bei übereinander angeordneten Objekten immer das zuletzt ange-gebene. Ist die Position und Größe der Objekte festgelegt, so lassen sich noch anhandvon Attributen Farbeinstellungen definieren. Farben können dabei mit ihrem Namen,in RGB-Werten oder per Hexadezimalcode festgelegt werden.
Beispiel 5.3.1:Das Rechteck beginnt bei (x,y)=(50,50), mit Breite 50 und Höhe 30 Pixel. Es soll blaugefüllt werden. Der Kreis liegt direkt im Ursprung, hat einen Radius von 50 Pixel undwird grün dargestellt. Die Abbildung11zeigt das Ergebnis im SVG Viewer.
<rect x="50" y="50" width="50" height="30"style="fill:rgb(0,0,255)" />
<circle cx="0" cy="0" r="50"style="fill:rgb(0,200,150)" />
Abbildung 11:Darstellung eines Rechtecks und Kreises in SVG
Zur Beschreibung von Formen, die nicht durch einfache Objekte abgebildet werdenkönnen, lassen sich Pfade definieren. Pfade sind sehr flexibel und geeignet um jeglicheFormen abzubilden. Sie bestehen aus einer Aneinanderreihung von Streckenabschnitt,die durch unterschiedliche Beschreibungen entstehen. So lässt sich eine absolute Posi-tion bestimmen, beispielsweise für den Startpunkt, gerade Linien, Teilabschnitte vonEllipsen oder auch verschiedene Arten von Bezierkurven. Geschlossene Pfade bilden
5Polylinien bestehen aus aneinandergereihten Linien.

55
somit völlig neue Figuren, die wie andere Objekte gefüllt werden können. Die An-gaben zur Definition der Pfade können in absoluten Werten, ausgedrückt durch großeBuchstaben, und in relativen Werten mittels kleinen Buchstaben vorgenommen wer-den. Eine einmal definierte Form lässt sich somit bei Verwendung relativer Pfade durchdie Änderung der absoluten Position einfach verschieben.
Beispiel 5.3.2:Es soll eine gewellte Linie mittels eines Pfades definiert werden. Mittels desid -Attributes wird der Namewelle vergeben. Die Definition findet imd-Attributstatt. Mit Mx y wird der Startpunkt der Linie auf(x, y) = (50, 100) gesetzt.qdx1 dy1 dx dy definiert eine quadratische Bezierkurve mittels relativer Koordi-naten. Sie beginnt beim Startpunkt, endet bei(xe, ye) = (x+dx, y+dy) = (150, 100)und die Krümmung wird durch den Kontrollpunkt(x1, y1) = (x + dx1, y + dy1) =(100, 150) festgelegt. Der Endpunkt liefert automatisch den neuen Startpunkt für dienächste Kurve. Da Pfade standardmäßig nicht dargestellt werden, ist der Rand diesesPfades mit demstyle -Attribut auf blau und seine Füllung auf leer gesetzt worden.Das Ergebnis ist in Abbildung12zu sehen.
<path id="welle"d="M50 100 q50 50 100 0 q50 -50 100 0 q50 50 100 0"style="stroke:rgb(0,0,255);fill:none"/>
Abbildung 12:Eine gewellte Linie, die mittels einer Pfadbeschreibung erzeugt wurde.
Ein weiteres wichtiges Element stellt Text dar, der sich auch beliebig positionierenlässt. Die besondere Art der Verwendung von Text in SVG gegenüber anderen zweidi-mensionalen Grafikformaten stellt einen wesentlichen Vorteil von SVG dar. Text wirdals reiner Text eingefügt und auch als Text belassen. Somit können SVG-Grafikenauch nach ihrem textuellen Inhalt durchsucht werden und sind so für Suchmaschineninteressant. Der Text kann beliebig formatiert werden, sowohl bezüglich seiner Farbeals auch seines Schrifttyps. Dazu dienen sehr ähnliche Beschreibungen wie bei CSS.

56
Soll nicht der ganze Text verändert, sondern nur ein bestimmter Inhalt angepasst wer-den, so lassen sich mittelstspan -Elementen auch einzelne Formatierungen innerhalbdes Text-Objektes vornehmen. Damit lässt sich beispielsweise ein einzelner Buchstabehoch oder tief stellen. Zur Ausrichtung des gesamten Textes können Pfade verwendetwerden. Sie werden mittelstextPath -Element in den Text eingefügt und die Grund-linie des Textes wird am Pfad ausgerichtet.
Beispiel 5.3.3:Der Text wird im Schrifttyp Arial, Schriftgröße 24 und blau dargestellt. Da der Textentlang eines Pfades laufen soll, muss er nicht positioniert werden. Dafür wird ihmein textPath -Element mitgegeben. Das besteht aus einem Link zu dem Pfad, derzur Ausrichtung verwendet werden soll. In diesem Fall ist das die in Beispiel 5.3.2definierte Welle. Anhand dieser schlängelt sich der Text, der noch für das WortTexteine grüne Färbung enthält, vgl. Abbildung13.
<textstyle="font-family:Arial;font-size:24;fill:rgb(0,0,255)"><textPath xlink:href="#welle">
Das ist <tspan style="fill:green">Text</tspan> aufeinem Pfad...
</textPath></text>
Abbildung 13:An einem Pfad orientierter Text
Wie schon in Beispiel 5.3.3 bei Pfaden gezeigt, lassen sich Elemente, denen eine IDzugewiesen wurde, über diese referenzieren. Das funktioniert für jedes beliebige Ele-ment, also auch für Text. Damit lassen sich diese Elemente einfach wiederbenutzen.Weiterhin können neue Symbole erstellt werden, die in Form ihrer Definition in derGrafik nicht auftauchen, aber an verschiedenen Stellen über dasuse -Element einge-fügt und formatiert werden. Diese Verweise beschränken sich nicht nur auf Elemen-te innerhalb einer SVG-Datei, sondern lassen sich auch durch XLink (XML Linking

57
Language) auf externe Dateien ausweiten. Dadurch ist es beispielsweise möglich ei-ne Symboldatei anzulegen, die in unterschiedlichen Grafiken benutzte Darstellungendefiniert.
Es lassen sich auch Grafiken anderer Formate in SVG-Grafiken einfügen. So sorgt dasimage -Element dafür, das beispielsweise auch gif, jpg und png Grafiken integriertwerden können. Sie können nicht nur der einfachen Darstellung dienen, sondern auchdie Grundlage für Füllmuster bilden. Diese können neben Farben zum Füllen von Ob-jekten benutzt werden. Farbverläufe sind eine weitere Möglichkeit um Objekte zu fül-len. Durch Attribute lässt sich auch ein Wert für den Alphakanal mit angeben, der überdie Transparenz eines Objektes entscheidet. Um den optischen Eindruck von Schattenund Licht zu bekommen, können Filter eingesetzt werden. Neben den existierendenlassen sich auch beliebige Filter neu definieren. Damit können verschiedenartige Ef-fekte erzielt werden, wie beispielsweise auch das Verschmieren von Rändern.
Elemente, die sich aus verschiedenen Objekten zusammensetzen, lassen sich zu Grup-pen zusammenfassen. Damit werden sie in der Gruppe platziert und ausgerichtet. Inder Gruppe entsteht ein eigenes Koordinatensystem, auf das sich alle Elemente derGruppe beziehen. Dieses stimmt standardmässig mit dem Ausgangskoordinatensy-stem der Zeichenfläche überein, kann aber geändert werden. Mittels destransform -Attributes lassen sich verschiedene Arten von Transformationen auf die Gruppe an-wenden. Sie beschreiben beispielsweise die neue Position oder Skalierung des neuenim Bezug zum alten Koordinatensystem. Mehrere Transformationen, wie Verschiebenund Drehen können nicht nur alleine vorgenommen werden, sondern lassen sich auchin einer Transformationsmatrix zusammenfassen.
Weiter unterstützt werden noch Titel und Beschreibungselemente, die innerhalb jedesElements angewendet werden können. Mit ihnen lässt sich der Titel der SVG-Grafikoder eine Beschreibung des Elementes festlegen. Objekte die nur definiert werden,aber nicht erscheinen sollen, lassen sich innerhalb desdefs -Elementes erzeugen. Da-mit existiert dieses Objekt während der Verarbeitung der SVG-Grafik und lässt sichan anderen Stellen referenzieren. Das Einfügen desdefs -Elementes ist nur direktunterhalb dessvg -Elements möglich.
5.4 Animationen und Interaktionen
Eine wichtige Eigenschaft von SVG-Grafiken stellt die Möglichkeit zur Animationdar. Animationen finden in SVG zeitorientiert statt, das heißt die Angabe einer Ani-mation wird mit einer zeitlichen Dauer versehen. Dabei können zwei verschiedeneArten von Animationen verwendet werden. Die erste beeinflusst die Eigenschaften inForm von Attributen eines Elementes, die verändert werden können. So lassen sichbeispielsweise Farbwerte fließend ineinander verändern und Größen- oder Transfor-mationsangaben, die in verschiedenen Attributen angegeben werden, kontinuierlich zuneuen Werten umformen. Die zweite Möglichkeit ist die Festlegung von Pfaden, ent-lang der sich Objekte bewegen lassen.

58
Beispiel 5.4.1:Ein Kreis soll entlang eine Pfades bewegt werden und dabei seine Farbe ändern. DieBewegung wird mit demanimateMotion -Element auf 8 Sekunden entlang des an-gegebenen Pfades festgesetzt. Innerhalb der ersten 4 Sekunden, ändert sich die Farbevon blau zu rot. Nach dieser Zeit wird für weitere 4 Sekunden die Farbe wieder ent-gegengesetzt zu blau verwandelt. Das Ergebnis ist ansatzweise der Abbildung14 zuentnehmen.
<circle cx="50" cy="100" r="16" style="fill:blue"><animateMotion dur="8s"
path="M0 0 q50 50 100 0 q50 -50 100 0 q50 50 100 0"/><animateColor dur="4s" from="blue" to="red"
attributeName="fill"/><animateColor dur="4s" from="red" to="blue" begin="4s"
attributeName="fill"/></circle>
(a)Beginn der Animation (b) Mitten in der Animation
Abbildung 14:Verschiedene Zeitpunktaufnahmen einer Animation aus Beispiel 5.4.1
Es unterstützt nicht jeder SVG-Betrachter alle grafischen Möglichkeiten, die in SVGgegeben werden. Damit allerdings keine unerwünschten Effekte oder Fehler bei derDarstellung der Objekte auftreten, gibt es die Möglichkeit die Funktionen des Viewersabzufragen. Für dasswitch -Element existieren verschiedene Attribute, die bei Un-terstützung durch den Viewer den Grafikcode in dem Element ausführen lassen. Solltedieses nicht der Fall sein, so wird der Code nicht für die Grafik verwendet. Dadurchkann beispielsweise abgefragt werden, ob Animationen oder nur statische Elementeunterstützt werden. Auch die Überprüfung, ob externe Dateien erreichbar sind, lässtsich vornehmen, um die Elemente nur in diesem Fall darzustellen.
Die einfachste Art in Interaktion mit dem Benutzer der Grafik zu treten, ist das Einfü-gen eines Hyperlinks. Das funktioniert ähnlich zu HTML, indem in eina-Element die

59
darzustellenden Angaben des Links eingefügt werden und einxlink:href -Attributdie anzusteuernde URL, sowohl intern als auch extern, zugewiesen bekommt.
Eine richtige Verarbeitung der Benutzereingaben wird allerdings erst durch die Ma-nipulationsmöglichkeiten mittels ECMA-Script erlaubt. DieEuropean Computer Ma-nufacturers Association[ECMA] ist eine internationale Standardisierungsorganisationfür Informations- & Kommunikationstechnologien. 1999 wurde von ihr ECMA-Scriptals Standard für JavaScript und JScript verabschiedet. ECMA-Script dient zur Defini-tion von Funktionen, die bei bestimmten Eingabebefehlen des Anwenders aufgerufenwerden. Innerhalb dieser Funktionen können Elemente und auch Attribute gelöscht,verändert oder neu in die SVG-Grafik eingefügt werden. Das ganze beruht auf derSichtweise einer SVG-Grafik als DOM. Mittels des DOM wird einApplication Pro-gramming Interface(API) bereitgestellt, mit dem einzelne Elemente im Dokument-Baum gefunden und bearbeitet werden können. Hierbei spielt besonders die Vergabeeindeutiger ID’s für die Elemente eine wichtige Rolle, da diese die Elemente identifi-zieren.
Beispiel 5.4.2:Es wird ein Text erzeugt, der auf einen Mausklick reagiert. Dafür wird demonclick -Attribut eine Funktion mit dem Eventevt als Parameter zugewiesen. Die Funktionwird innerhalb desscript -Elementes definiert. Dazu wird vom übergebenen Eventder Auslöser und dessen Vaterdokument abgefragt. Dieses Gesamtdokument kann nunanhand einer ID nach einem bestimmten Element durchsucht werden. Zu dem Ele-ment wird nun das Attributstyle abgerufen und in Abhängigkeit seines Wertes neugesetzt. Dadurch wird beim ersten Klick auf den Ausgangstext der zuvor unsichtbareText sichtbar gemacht und beim nächsten Klick wieder unsichtbar. Angedeutet wirddieses Beispiel in Abbildung15dargestellt.
<defs><script type="text/ecmascript">
<![CDATA[function zeige(evt){
var doc =evt.getTarget().getOwnerDocument();var newtext =doc.getElementById("zeig");var attri =newtext.getAttribute("style");if(attri=="visibility:hidden"){
newtext.setAttribute("style","visibility:inherit");}else{
newtext.setAttribute("style","visibility:hidden");}
}]]>
</script></defs>

60
<text x="20" y="40" onclick="zeige(evt)"style="font-family:Arial;font-size:24;fill:rgb(0,0,255)">Weitere Informationen
</text><text id="zeig" x="50" y="60" style="visibility:hidden">
Alles was Sie zu Interaktion wissen sollten.</text>
(a)Startgrafik
(b) Nach einem Klick auf den Text
Abbildung 15:Interaktion mit dem Benutzer
Da SVG-Dateien reine Textdateien sind, lassen sie sich durch Kompression noch inihrer Dateigröße reduzieren. Aus diesem Grunde unterstützt SVG die Komprimierungmittels zip, so dass das Datenvolumen zur Übertragung sinkt und nur die Entschlüsse-lung vor der Darstellung ein wenig Prozessorleistung auf Benutzerseite erfordert.

61
6 Allgemeines Konzept
Vielfach müssen zu einem Themenbereich verschiedene Arten von Dokumenten er-stellt werden. Der Dozent benutzt die Tafel, Folien oder den Beamer für die Vermitt-lung von Lehrstoff in seiner Vorlesung. Das Vorlesungsskript wird in gedruckter oderelektronischer Form dem Hörer zugängig gemacht. Die gleichen Informationen wer-den also nicht nur durch verschiedene Medien, sondern auch in unterschiedlichen In-haltsdarstellungen verteilt. Für die Erstellung und Pflege dieser Dokumente bedeutetdies, dass die Informationen mehrfach erzeugt und geändert werden müssen, um einenkonsistenten Inhalt zu garantieren. Um diesem redundanten Arbeitsaufwand entgegenzu wirken, soll die Verwaltung dieser gesamten Informationen in einem Dokument er-möglicht werden. Aus diesem Dokument lassen sich automatisiert verschiedene Aus-prägungen generieren. Im Folgenden wird ein Konzept, das diesen Gedanken vertieftund die Grundlagen für die Umsetzung einer derartigen Arbeitsunterstützung liefert,erläutert.
6.1 Begriffsdefinitionen und Zusammenhänge
Es soll ein Dokument erstellt werden, das die Inhalte beschreibt, die automatisch inverschiedene Inhaltsdarstellungen verwandelt werden können. Dieses Dokument wirdim Folgenden auchQuelldokumentgenannt. Mit diesem Dokument ist dabei keine ein-zelne Datei gemeint, denn der Inhalt kann sich auch über mehrere Dateien erstrecken,sondern ein systematischer Zusammenschluss von Informationen. Das Dokument spie-gelt demnach die Struktur der Daten wieder, die zu einem bestimmten Themengebietbeschrieben werden sollen. Zu diesem Zweck muss dem Quelldokument ein speziel-les Format zugrunde liegen, mit dem die Beziehungen der Daten untereinander fest-gehalten werden können. Aus der Kombination von Daten und Struktur entsteht einDokument, welches die Inhalte zu einem bestimmten Thema zusammenfasst.
Zur Erstellung des Dokumentes müssen bestimmte Regeln eingehalten werden. Darumkümmert sich eineAnwendung, die den Autor in der Dokumenteingabe unterstützensoll. Unter einer Anwendung ist in diesem Fall ein Programm zu verstehen, das dieStruktur eines Quelldokumentes beherrscht und die Dokumenteingabe erleichtert. Eshandelt sich dabei also um einen auf die Struktur des Quelldokumentes eingerichtetenEditor.
Aus den Daten, die in dem Quelldokument beschrieben sind, sollen verschiedene In-haltsdarstellungen erstellt werden können. Es gibt zwei unterschiedliche Aspekte derInhaltsdarstellung, einen inhaltlichen und einen technischen. Der inhaltliche Aspektbezieht sich auf die Auswahl der Informationen des Quelldokumentes, die für dieDarstellung von Bedeutung sind. Eine Inhaltsdarstellung, der der inhaltliche Aspektzugrunde liegt, wird im FolgendenAusprägunggenannt. Der technische Aspekt derInhaltsdarstellung ist für die Darstellung der Ausprägung in einem bestimmten Daten-format zuständig. Er lässt sich anhand desFormatesunterscheiden.

62
Unterschiedliche Ausprägungen ermöglichen es, dass abhängig von der Verwendungder Inhalte eine diverenzierte inhaltliche Tiefe dargestellt werden kann. Beispielswei-se werden Themen in einem Skript detaillierter beschrieben als in einer Präsentationvorgetragen. Das heisst, der Ausschnitt der Daten, der für die Erstellung der Ausprä-gung verwendet wird, kann variieren. Dabei können einzelne Daten ausgewählt undandere vernachlässigt werden. Durch die Variation von Umfang und Detaillierungs-grad können somit verschiedene Aspekte der Thematik fokusiert werden. Verschiede-ne Ausprägungen der Daten stellen den gleichen Sachverhalt in unterschiedlicher Artund Inhaltstiefe dar. Beispielhafte Ausprägungen wären etwa ein Skript bzw. Lehrbuchund eine Präsentation bzw. ein Notizzettel.
Die definierten Begriffe sollen im Folgenden im Zusammenhang betrachtet werden:Ein Quelldokument wird zu einem bestimmten Thema erstellt. Das ganze Dokumentlässt sich zum größten Teil beispielsweise in Form eines Skriptes darstellen, vgl. Ab-bildung 16. Auf der gleichen Thematik baut nun ein Vortrag auf, der durch einigetextuelle Auszüge aus dem Dokument unterstützt werden soll. Dafür sind jedoch nichtdie Inhalte auf einer derart detaillierten Art und Weise darzustellen, wie es in einemSkript der Fall ist. Dennoch behandeln beide Ausprägungen die selbe Thematik. Somitändert sich lediglich die Inhaltstiefe und die Art der Darstellung.
http://www....
Skript
Dokument
Vortrag
blabla...
Ausprägungen
Papier
Computer
Mensch
Präsentationsmedien
Abbildung 16:Aus einem Dokument lassen sich verschiedene Ausprägungen generieren, diewiederum für unterschiedliche Präsentationsmedien zur Verfügung stehen.
Die in Abbildung 16 aufgeführten Ausprägungen, Skript und Vortrag, sind die ge-bräuchlichsten. Aus diesem Grund werden sie im Folgenden weiter spezifiziert undimplementiert, so dass sie als anschauliche Beispiele herangezogen werden können.

63
Für jede Ausprägung, die aus dem Dokument generiert werden kann, existiert eineStandardausprägung. Das heißt, dass aufgrund der Daten des Quelldokumentes derGenerierungsschritt zu einer Ausprägung führt, ohne dass dafür zusätzliche Informa-tionen herangezogen werden müssen. Die Informationen die zur Anpassung einer Aus-prägung in das Dokument eingefügt werden können, werden im Folgenden alsZusatz-informationenbezeichnet.
In der bisherigen Betrachtung wurde noch nicht über dasPräsentationsmediument-schieden, das zur Ansicht der Ausprägung herangezogen werden soll. Das Präsentati-onsmedium sollte dem jeweiligen Verwendungszweck angemessen ausgesucht werdenkönnen. Die wichtigsten Präsentationsmedien sind das gedruckte Exemplar und dieDarstellung am Computer. Daraus resultieren die Anforderungen nicht nur verschie-dene Ausprägungen generieren zu können, sondern auch die jeweiligen Formate, diefür die unterschiedlichen Präsentationsmedien notwendig sind. Die Tabelle in Abbil-dung17stellt diese beiden Arten der Inhaltsdarstellung gegenüber.
Abbildung 17:Gegenüberstellung der verschiedenen Arten von Inhaltsdarstellungen für einDokument
6.2 Vollständiger Arbeitsablauf aus Anwendersicht
Die Arbeitsweise zur Erstellung eines Dokumentes und seiner Ausprägungen soll imFolgenden anhand eines Beispielszenarios erläutert werden.
Die Benutzung eines Systems, welches die geforderten Eigenschaften besitzt, soll fürden Anwender in der Summe eine Arbeitserleichterung darstellen. Deshalb muss ei-

64
ne Anwendung existieren, die den Dozenten bereits bei der Dokumenteingabe unter-stützt. Die Präsentation dient häufig als erste schriftliche Form des Inhaltes zu einemneuen Themengebiet. Der Dozent muss durch das System in die Lage versetzt werden,dieses Themengebiet mittels Stichworten in eine geeignete, präsentationsfähige Formzu bringen. Während für die Erstellung einer Präsentation heutzutage häufigPower-Point von Microsoft verwendet wird, sollte eine derart leichte Bedienungsweise auchfür das hier beschriebene System möglich sein. Die Eingabe unterscheidet sich dabeiallerdings in der Art der Angaben, die benötigt werden. Beispielsweise sind keine Lay-outbeschreibungen vorzunehmen, sondern es ist eine reine Inhaltseingabe erforderlich.Der Inhalt muss allerdings strukturiert werden. Das bedeutet, dass die Reihenfolge unddie Zusammengehörigkeit der Daten feststehen muss. Damit unterscheidet sich die Ar-beitsweise des Anwenders von der bisherigen. Aber dafür sollte nach einer Eingewöh-nungsphase weniger Aufwand für die Generierung der Ausprägungen gegenüber derbisherigen Arbeitsweise notwendig sein.
Aus der Eingabe der inhaltlich strukturierten Daten in das Quelldokument lässt sich au-tomatisiert eine erste Präsentation in einer Standardausprägung generieren. Entsprichtdie Standardausprägung nicht dem gewünschten Ergebnis, so wird die Präsentationin weiteren Iterationsschritten durch Anpassungen der Struktur und des Inhaltes desQuelldokumentes geändert, bis die gewünschte Form erreicht ist.
Das so entstandene Quelldokument, soll nun um Notizen zu den jeweiligen Stichwör-tern ergänzt werden. Diese Notizen müssen an den entsprechenden Positionen in dasDokument eingetragen werden können. Natürlich dürfen diese Ergänzungen die ur-sprüngliche Ausprägung, in diesem Fall die Präsentation, nicht verändern. Es könnenaber neue Detaillierungsebenen hinzufügt werden, die für neue Ausprägungen benötigtwerden. So vergrößert sich sukzessive der Datenbestand, der nun beispielsweise zweiverschiedene Ausprägungen beliefert, die Präsentation und eine um Notizen erweiterteDarstellung.
Die in der Präsentation vorhandenen Daten sollen nicht nur den Dozenten in der Ver-mittlung seiner Lehrinhalte unterstützen, sondern auch den Hörern zur Verfügung ge-stellt werden. Dafür lässt sich ein anderer Generierungsschritt auf das Quelldokumentanwenden, der ein Standardskript erzeugt. Allerdings reicht die stichwortartige Infor-mationssammlung in den meisten Fällen für eine sinnvolle Darstellung noch nicht aus.Angereichert durch detailliertere Beschreibungen entsteht somit ein Skript entlang derPräsentationsunterlagen. Dabei werden nicht nur neue Daten hinzugefügt, sondern esmüssen unter Umständen auch einige Zusatzinformationen geändert werden, so dassnicht alle Daten in der neuen Ausprägung Skript erscheinen.
Durch die Erweiterung einer Präsentation wird also ein Skript erstellt. Aber das istnicht die einzig denkbare Vorgehensweise, mit der ein Dokument erstellt werden kann.So ist unter anderem auch der umgekehrte Weg möglich. Aus einem Quelldokument,das erzeugt wurde um ein Skript zu generieren, kann im nachhinein eine Präsenta-tion generiert werden. Dazu muss nur die Präsenations-Standardausprägung auf dasQuelldokument angewendet werden, wodurch ein erster Vorschlag für die Präsenta-

65
tion erzeugt wird. Das Ergebnis kann als Grundlage für die weitere Bearbeitung derneuen Ausprägung dienen, indem einzelne Inhalte ausgewählt und andere vernachläs-sigt oder ergänzt werden.
Diese Beispielszenarien liefern eine grobe Vorstellung über die Arbeitsweise zur Er-stellung von Dokumenten. Wie verschieden die Ergebnisse auch am Ende ausfallen,so wiederholen sich doch die Arbeitsschritte in jeder Vorgehensweise. Das gilt auchfür die Bearbeitung der Ausprägungen, die je nach Verwendungszweck variieren kön-nen. Abbildung18stellt den verallgemeinerten Arbeitsfluss dar. Die einzelnen Schrittelassen sich dabei folgendermaßen zusammenfassen:
• Erstellen eines neuen Dokumentes (häufig unter Berücksichtigung einer bestimm-ten Ausprägung)
• Hinzufügen von Informationen zu einem Dokument
... zur Ergänzung der schon vorhandenen Ausprägung
... zur Vorbereitung auf eine neue Ausprägung
... zur Darstellungsabstimmung der einzelnen Ausprägungen
• Generierung verschiedener Ausprägungen
Abbildung 18:Arbeitsablauf von der Erstellung eines Dokumentes bis zur Erzeugung mehre-rer Ausprägungen

66
6.3 Anforderungen an die Dokumenteingabe
Die Informationseingabe zur Erstellung des Quelldokumentes muss strukturiert erfol-gen. Es müssen Angaben zu den Informationen eingegeben werden, die ihre Funkti-on innerhalb des Dokumentes beschreiben. Beispielsweise besteht die Eingabe einerPräsentation in erster Linie aus Titeln der einzelnen Folien und den dazugehörigenStichwörtern. Daneben sollen natürlich auch andere Inhalte wie Grafiken oder Tabel-len eingefügt werden können. Die Strukturierung der Daten findet in der Form statt,dass Zusammenhänge hinzugefügt werden müssen, die beschreiben, welche Folien zueinem Kapitel oder welche Stichwörter zu einem Titel gehören. Bei der Eingabe ist dieAusprägungsart zu beachten, die der Autor eingeben möchte. Beispielsweise ist dieGliederung nach Kapiteln zur Beschreibung eines Skriptes intuitiver, als bei der Ein-gabe einer Präsentation. Da aber diese Strukturen den Grundstock der Daten liefern,ist eine Unterstützung bei der Strukturierung besonders wichtig. Um die strukturier-te Eingabe zu ermöglichen muss ein Editor Bedingungen und Anforderungen an dieStruktur vorgeben und überprüfen können. Die Struktur der Daten kann den Anwenderbeispielsweise durch die Arbeitsabläufe bei der Dateneingabe leiten.
Ein Quelldokument soll als Grundlage vieler Ausprägungen dienen. Damit werden dieInhalte auf verschiedene Arten dargestellt. Um das zu ermöglichen, muss dem An-wender eine andere Darstellung bei der Dokumenteingabe präsentiert werden, als esdie Ausprägung später zeigt. Deshalb müssen Abhängigkeiten zwischen dem Quell-dokument und der Ausprägung in dem Editor unterstützt werden. Ist beispielsweisedie erste Ausprägung erzeugt, so sollte ein Mechanismus existieren, der es ermöglicht,dass der Autor die zu korrigierende Stelle in der Ausprägung markiert und an die pas-sende Stelle in den Bearbeitungsmodus überführt wird. Das ist besonders wichtig, dastandardmäßig bestimmte Daten nur in einigen Ausprägungen sichtbar sind.
Im Bearbeitungsmodus kann der Autor dazu übergehen Anpassungen an den Ausprä-gungen vorzunehmen. So werden standardmäßig keine Grafiken mit in die Präsentati-on übernommen. Der Autor muss aber in die Lage versetzt werden, diese Einstellungfür einzelne Grafiken zu ändern. Er kann einzelne Objekte auswählen und sie für wei-tere Ausprägungen darstellbar machen. Deshalb werden die Änderungen nicht in derOriginalsicht sondern im Bearbeitungsmodus des Quelldokumentes erfolgen, da dieOriginalsicht hohe technische Fähigkeiten des Autoren voraussetzt und schnell un-übersichtlich wird. Auch gegenüber der Ausprägungssicht hat der BearbeitungsmodusVorteile. Ein Einfügen innerhalb einer beliebigen Ausprägung hätte zur Folge, dassdort nicht verfügbare Daten, die allerdings im Quelldokument vorhanden sind, nichtnachträglich sichtbar gemacht werden könnten. Es würde also auf eine vielfältige Da-tensammlung der verschiedenen Ausprägungen hinauslaufen. Der Bearbeitungsmodusist daher als spezielle Ansicht für den Editor wüschenswert, der allen Inhalten desQuelldokumentes eine bestimmte Darstellung zuweist und die Inhalte hervorhebt, diefür die aktuell zu erstellende Ausprägung von Bedeutung sind. Die Ausprägungen soll-ten schon während der Bearbeitung als Ergebnisvorschlag zur Verfügung stehen.

67
6.4 Anforderungen an die Dokumentstruktur
Die Erzeugung eines Dokumentes und seiner Ausprägungen ist nur mit Anwendungs-unterstützung möglich. Daher muss die Dokumentgrundlage aus einer maschinenles-baren Datenbeschreibung bestehen, die automatisch interpretiert werden kann.
Der Informationsgehalt, der aus den Daten gezogen werden kann, ist abhängig von derStruktur des Dokumentes und den interpretierbaren Datenauszeichnungen. Erst durchdie Struktur und die inhaltlichen Auszeichnungen wird eine automatisierte Verarbei-tung der Inhalte möglich. Für das Datenformat bedeutet das, dass es nur vorgegebeneAbhängigkeiten von Objekten erlauben darf, wodurch die Struktur der Daten regle-mentiert wird.
Abhängig von der Dokumentstruktur sollen Standardausprägungen generiert werden.Diese können nur definiert werden, wenn die Struktur Aussagen über die Zusammen-hänge liefert. Dazu müssen neben der Gruppierung der Informationen zu thematischenBlöcken auch inhaltliche Auszeichnungen gemacht werden können. So können belie-bige Ausprägungen aufgrund der Dokumentstruktur und der inhaltlichen Auszeich-nungen definiert werden.
Um die Anpassung der Standardausprägung zu ermöglichen, muss das Dokument mitZusatzinformationen versehen werden können, die die Generierung der Ausprägungbeeinflussen. Dabei handelt es sich um Auszeichnungen, die Informationen markieren,die abweichend von der standardmäßigen Ausprägung aufgenommen oder weggelas-sen werden sollen. Beispielsweise sollen nicht alle Grafiken eines Skriptes auch inder Präsentation erscheinen, so dass einzelne Grafiken per Auszeichnung ausgewähltwerden müssen.
Das Quelldokument soll allerdings die Grundlage aller Ausprägungen bilden. Die zu-grunde liegende Dokumentstruktur muss das unterstützen, indem sie unabhängig vonden Ausprägungen ist. Aus diesem Grund müssen die Zusatzinformationen über alleAusprägungen im Dokument festgehalten werden können. Das ermöglicht, dass diethematischen Inhalte für jede Ausprägung unterschiedlich verbunden werden können.
Die Bearbeitung des Dokumentes erfolgt nicht in seiner Ausprägung. Um dennocheinen Rückschluss von der Ausprägung auf die ursprünglichen Inhalte des Quelldoku-mentes ziehen zu können, gibt es prinzipiell zwei Möglichkeiten:
1. Die Generierung der Ausprägung ist umkehrbar.
2. Die Elemente sind eindeutig identifizierbar.
Im ersten Fall muss aus den Generierungsanweisungen der Ausprägung eine eindeuti-ge Zuordnung zwischen Quelldokument und Ausprägung hervorgehen. Nur damit sinddie zugrunde liegenden Daten des Quelldokumentes rekonstruierbar. Im zweiten Fallfindet eine eindeutige Identifizierung der Daten in dem Quelldokument und abhängigdavon in der Ausprägung statt. Die Daten lassen sich somit über ihre Identifizierungreferenzieren.

68
Die Generierung diverser Ausprägungen und die Unterstützung unterschiedlicher Prä-sentationsmedien, stellt die Inhalte auf verschiedene Arten dar. Damit werden für ei-ne Ausprägung unterschiedliche Formatierungen vorgenommen. Die Formatierungensollen nicht im Dokument gespeichert werden. Alle Angaben bezüglich des Layoutswerden bei der Generierung der Ausprägungen vorgenommen. Das Dokument um-fasst somit nur die inhaltlichen Informationen inklusive der Zusatzinformationen. Diegrafische Gestaltung liegt damit nicht beim Autor, sondern in dem späteren Generie-rungsprozess. Damit wird erreicht, dass der Autor das Dokument lediglich inhaltlichbefüllen muss.
Zum Ausschöpfen der Vorteile, die die Unterstützung verschiedener Präsentationsme-dien bietet, sollen in dem Dokument auch unterschiedliche Medien, beispielsweiseFilm, Grafiken und Ton, integriert werden können. Ob das Format der Medien aufeinem bestimmten Präsentationsmedium abbildbar ist, muss die Generierung der Aus-prägung berücksichtigen. Es kann beispielsweise kein Film auf Papier dargestellt wer-den. Die erforderlichen Informationen, die für die Anpassung der Ausprägung an einausgewähltes Präsentationsmedium benötigt werden, sind in den Dokumentdaten zuverankern.
Für den Einsatz im Lehrmittelbereich muss das Dokument neben dem üblichen Zei-chensatz auch verschiedene Fachspezifika beherrschen. Beispielsweise reicht der Stan-dardzeichensatz zur Beschreibung mathematischer oder chemischer Formeln ebensowenig aus, wie zur Darstellung von Musiknoten.
In welcher Form die Dateien gespeichert und verwaltet werden, ist in dieser Betrach-tung vernachlässigt worden, da es für die Grundlage des Aufbaus der Daten und ihrerweiteren Verarbeitung keine Rolle spielt. Allerdings soll die Unterstützung von ver-teilten Dateien in der Dokumentstruktur berücksichtigt werden.
6.5 Anforderungen an die Ausprägungen
Eine Ausprägung muss aus den Dokumentdaten generiert werden können. Es wer-den also abhängig von der Dokumentstruktur Regeln definiert, welche Inhalte für dieAusprägung von Bedeutung sind. Diese Regeln müssen unabhängig vom thematischenInhalt nur durch die Struktur und Zusatzinformationen beschreibbar sein. Damit wirdgarantiert, dass sie auf alle Quelldokumente angewendet werden können.
Zur Definition einer Ausprägung müssen Vorgaben gemacht werden, wie die Inhal-te dargestellt werden sollen. Es werden im Folgenden zwei Arten von Ausprägungennäher betrachtet, die Präsentation und das Skript. Das Skript zeigt standardmäßig alledarstellbaren Inhalte an, die in dem Dokument eingegeben wurden. Die Präsentationberuht im Standard auf bestimmten Teilen des Quelldokumentes. Die Titel dienen alsFolienüberschriften und markierte Schlüsselwörter als Listenpunkte der Folie. Diesebeiden Annahmen stellen nur einen ersten Ansatz zur Erzeugung der Standardausprä-gungen dar, auf dem weiter aufgebaut werden kann, vgl. Kapitel8.3. Dazu müssen die

69
Elemente anhand ihrer Zusatzinformationen überprüft und dementsprechend in eineAusprägung übernommen werden. So lassen sich beispielsweise auch Grafiken oderTabellen in eine Präsentation einfügen.
Jede Ausprägung sollte als Standardausprägung generiert werden können. Das bedeu-tet, dass sie schon in Abhängigkeit der Struktur des Quelldokumentes eine erste Dar-stellung liefert. Das ist die einzige Möglichkeit ohne Zusatzangaben für die Ausprä-gung ein Ergebnis aus der Generierung zu bekommen.
Die Erstellung einer Ausprägung für ein Präsentationsmedium, muss alle benötigtenLayoutangaben den Dokumentdaten hinzufügen. Hinzu kommt die Entscheidung wel-che Medientypen eingebunden werden. In dem Generierungsschritt müssen desweite-ren alle Angaben über die Navigation eingearbeitet werden. Beispielsweise sollte einePräsentation immer nur in einer bestimmten Reihenfolge ablaufen. Ein Skript hat inder gedruckten Fassung ebenfalls eine sequentielle Reihenfolge, kann aber, wenn esam Computer publiziert wird, über Querverweise verfügen und bekommt damit einevernetzte Darstellung. In erster Version sollte allerdings eine Standardnavigation er-zeugt werden. Spätere Änderungen können durch ergänzende Möglichkeiten in derAusprägungsgenerierung vorgenommen werden.

70
7 Dokumentstruktur
Die Basis der Realisierung stellt die Konzeption der Struktur des Quelldokumentes dar.Die Struktur muss alle Informationen bereitstellen, die für die Generierung der Ausprä-gungen benötigt werden. Im Folgenden werden existierende Formate untersucht undanhand der im Konzept gestellten Anforderungen eigene Lösungsansätze vorgestellt.Diese Lösungsansätze stellen die grundsätzlichen Vorgaben für die Realisierung dar.
7.1 Existierende Datenformate
Die bereits existierenden Formate zur Beschreibung von darzustellenden Inhalten un-terteilen sich im wesentlichen in zwei unterschiedliche Kategorien. Zum einen in diereinen Textformate, die sich mit dem Schreiben von Büchern, Artikeln oder auchOnline-Inhalten etc. beschäftigen. Zum anderen existieren seit neuerer Zeit auch struk-turierte Formate zur Beschreibung von Lehrmaterialien, die sich im wesentlichen aufdie inhaltliche Weiterverwendung und didaktische Modulbildung ausgerichtet haben.
7.1.1 Textbeschreibende Datenformate
Textbeschreibende Datenformate haben sich auf die Art der Ausprägung konzentriert.Sie lassen in Abhängigkeit der zu erstellenden Ausprägung bestimmte Inhalte zu. Soexistieren in den meisten Formaten Standarddokumente, anhand denen die Strukturdes Inhaltes vorgegeben wird. Beispielsweise setzt sich ein Buch aus verschiedenenKapiteln zusammen, die aus einem Titel und dem eigentlichen Inhalt bestehen. EinArtikel kann neben dem Titel hingegen beispielsweise nur kurze Textpassagen, denenweitere Einschränkungen zugrunde gelegt werden, enthalten. Diese Dokumente sindsomit nicht ohne weiteres von einer Ausprägung in eine andere überführbar. Das giltsowohl für etablierte Formate wieTeX, als auch fürDocBookoder das proprietäretbook. Desweiteren wird in diesen Formaten besonders die Beschreibung des Layoutsin das Dokument mit aufgenommen.
DocBookundtbookliegen beide als XML-basierte Formate vor, die zur Beschreibungvon textuellen Dokumenten entstanden sind.DocBookist ein von derOrganization forthe Advancement of Structured Information Standards(OASIS) veröffentlichter Stan-dard [OASIS] zur Dokumentenbeschreibung, der ursprünglich in SGML verabschiedetwurde. Dieser Standard ist inzwischen auf XML übertragen worden. Als Grundla-ge dient eine DTD, ein Schema ist noch in Bearbeitung. Mit über 300 Elementen istder Umfang sehr komplex und die Verschachtelung der Elemente sehr tief. Bei jederNeueingabe eines Dokumentes wird die Auswahl der zu erstellenden Ausprägung, bei-spielsweise eines Buches oder Artikels, vorangestellt.tbookist ein Format, das aus derAnforderung entstanden ist, TeX in XML nachzubilden [Brotbook]. Es existieren auch

71
bei tbookunterschiedliche Dokumente, die je nach Art der Ausprägung nicht zueinan-der kompatibel sind. Besondere Unterstützung wird beitbookdem Layout gewidmet,das direkt in die Daten eingepflegt werden muss.
Andere Formate, wie etwa MicrosoftsDOC-Format, erlauben sogar die Erstellung vonDokumenten, die keine strukturellen Angaben enthalten, sondern allein über Forma-tierungsanweisungen ihre endgültig dargestellte Struktur zugewiesen bekommen.
7.1.2 Datenformate zur Beschreibung von Lehrmaterialien
Die Unterstützung zur Entwicklung von Lehrmitteln durch darauf ausgerichtete For-mate ist noch relativ jung. Es hat sich noch kein eindeutiger Standard zur expliziten Be-schreibung von Lehrmaterialien etabliert. Zur konzeptionellen Beschreibung von ein-zelnen Lerninhalten gibt es den vomInstitute of Electrical and Electronics Engineers(IEEE) verabschiedeten StandardLOM. Für einige Realisierungen im Lehrmaterialien-Umfeld dient dieser Standard als Grundlage. Andere Standards aus dem ähnlichenUmfeld, wie beispielsweise Computer Based Training, werden im Folgenden nichtweiter betrachtet.
Bei Learning Object Metadata(LOM) handelt es sich um einen Standard [LOM] zurkonzeptionellen Beschreibung von Lerninhalten. Es werden die Informationen fest-gelegt, die zur Beschreibung von einzelnen Lernobjekten angegeben werden müssen.In den Standard sind Teile der Beschreibung aus dem Dublin-Core Projekt [Dublin]und Ariadne Projekt [Aria] eingeflossen. In Dublin Core wurde ein Standardvokabularzur Beschreibung von allgemeinen Ressourcen festgelegt, vgl. [Schö2001]. Der Bezugzu Lehrmaterialien wurde erst im Ariadne Projekt hergestellt. Dabei handelt es sichum ein Europäisches Projekt zur Erstellung einesKnowledge Pool Systems, in demmit Metadaten versehene Lernobjekte verteilt verwaltet und wiederverwendet werdenkönnen [Duval]. Einen weiteren Einfluss hatte dasInstructional Management SystemProjekt [IMS]. Dabei handelt es sich um ein US-Projekt, das sich mit der gleichen The-matik zur Beschreibung von Lernobjekten beschäftigt hat und viele Mitarbeiter, die ander Entwicklung von LOM teilgenommen haben, beinhaltete.
Mit LOM wurde die Beschreibung der Informationen, die zu einem Lernobjekt gehö-ren, festgeschrieben. Dabei kann sich diese Beschreibung sowohl auf digitale wie auchauf nicht digitale Lehrmaterialien stützen. Die Beschreibungen, die für ein einzelnesLernobjekt vorgenommen werden können, werden in neun unterschiedlichen Katego-rien ( wie generelle, geschichtliche, technische und rechtliche Angaben) durch weitereEigenschaften verfeinert. Damit lassen sich zu jedem Objekt über 40 Eigenschaftenbeschreiben. Es gehören zur Kategorie generelle Angaben beispielsweise Titel, Spra-che und Beschreibung. Da es sich bei LOM um ein hierachisches Modell handelt,werden auch Verweise zu anderen Lernobjekten als Relation in die Beschreibung desObjektes eingebettet. Die verschiedenen Kategorien werden in [Duval] in einer Grafikveranschaulicht.

72
Es werden in LOM nur die Informationen standardisiert, die ein Lernobjekt besitzt.Dazu zählen nicht die Sprache oder Kodierung, in der diese Informationen gespeichertwerden. Damit ist es möglich den Standard in unterschiedlichen Sprachen umzusetzen.Desweiteren lässt "[...] die derzeitige Spezifikation von Metadaten durch LOM keineadäquate Repräsentation von didaktischen Konzepten [...]" [Ade2000] zu. Mit LOMwerden demnach nur die zugrunde liegenden "Bausteine" spezifiziert.
Die Bausteine können verwendet werden, um darauf ein semantisches Modell aufzu-bauen. So werden Lehrmaterialien aus verschiedenen Lernobjekten zusammengestellt,die nur im Zusammenhang einen sinnvollen Lehrgehalt bekommen. Da auf dieser Ebe-ne der Beschreibung von Lehrmaterialien verschiedene Sprachen entwickelt, aber nochkeine standardisiert wurde, hat das CEN/ISSS (European Committee for Standardiza-tion / Information Society Standardization System) den VergleichSurvey of Educa-tional Modelling Languages (EMLs)[CEN2002] durchgeführt. Als EML wird in denVergleich eine Sprache aufgefasst, die aus der pädagogischen Perspektive mit seman-tischen Informationen und Zusammenhängen Inhalte und Prozesse von Lerninhaltenbeschreibt.
In dem Vergleich werden sechs verschiedene Sprachen gegenübergestellt, von denenalle in XML oder SGML beschrieben wurden. Zwei der untersuchten Sprachen be-nutzen LOM-Objekte und eine dritte Sprache ermöglicht über Erweiterungen die In-tegration von LOM. Alle Sprachen sind mit besonderer Rücksicht auf die Wieder-verwendbarkeit ihrer beschriebenen Inhalte entwickelt worden. Dennoch sind sie alleprinzipiell sehr verschieden und Übereinstimmungen der Sprachen müssen noch wei-ter untersucht werden. Nur zwei der sechs Sprachen erfüllen wirklich die Forderungnach der Integration pädagogischer Methoden. Daraus ist OUNL-EML [OUNL] vonder Open University of the Netherlands als einzige Sprache hervorgegangen, die vie-len internationalen Standards gerecht wird und für eine mögliche Standardisierung inFrage kommen könnte. Eine Besonderheit kommt noch derLearning Material MarkupLanguage[LMML ] zu, die als einzige auch die Integration mehrerer XML-basierterSprachen wie MathML und SMIL erlaubt.
Es wird allerdings in naher Zukunft keine standardisierte Sprache zur Beschreibungvon Lehrmaterialien geben.
7.1.3 Bewertung der Datenformate
Die verschiedenen Datenformate haben in ihrem Einsatz unterschiedliche Vorzüge.Die textbeschreibenden sind sehr intuitiv und bilden jeweils eine Ausprägung gut ab.Allerdings sind sie nicht als Grundlage eines Dokumentes für verschiedene Ausprä-gungen geeignet und erfüllen nicht die Anforderungen an die Trennung von Contentund Layout.
Die Sprachen zur Beschreibung von Lehrmaterialien sind sehr unterschiedlich auf-gebaut. Sie liefern unterschiedliche Ansätze zur Beschreibung von Lehrinhalten. Sie

73
sind alle tief strukturiert, weshalb sie wesentliche Informationen für unterschiedlicheAusprägungen bereitstellen. Für die Erstellung von Dokumenten und zur Generierungvon Ausprägungen für unterschiedliche Adressatenkreise lässt nur OUNL-EML ver-schiedene Instanziierungen der gleichen Ausprägung zu. Allerdings ist die Integrationvon fachlichem Material anderer XML-Anwendungen nur in LMML möglich. Nebeneinem fehlenden Standard sind desweiteren in diesen Strukturen keine Zusatzinforma-tionen integriert, die für die Anpassung der Ausprägungen benötigt werden.
Für die weitere Umsetzung wird eine eigene Dokumentstruktur entwickelt, die ver-schiedene Aspekte der anderen Sprachen zusammenfügt und eigene Aspekte integriert.Die Strukturierung der Informationen und semantischen Auszeichnungen stellt einenersten Aspekt dar. Mit Hinblick auf die Erstellung der Dokumente liefert die einfacheEingabe von textuellen Daten in einer fortlaufenden Struktur einen weiteren Gesichts-punkt. Als letztes fließen die ausprägungsrelevanten Informationen in die Dokument-struktur ein.
7.2 Beschreibung inklusive Ausprägungskriterien
Aus den Anforderungen an die Dokumentstruktur soll im Folgenden im Vergleichzu den existierenden Formaten die realisierte Dokumentstruktur beschrieben werden.Grundlage für die Realisierung bilden die Beschreibungen der Lehrmaterialien. Da-zu liegen verschiedene Möglichkeiten vor, wie die Informationen strukturiert werden,vgl. Abbildung19. Resultiert die Struktur aus den Eigenschaften der verwendeten In-halte, so spricht man vonsemantischen Objekten. Beispielsweise ergibt sich aus ei-ner Definition der Bezug zwischen dem Fachausdruck und seiner Erläuterung. Lassensich die Strukturen durch Schachtelungen von Inhalten abbilden, so werden diese imFolgenden alsstrukturelle Objektebezeichnet. Zum Beispiel kann ein Kapitel weite-re Unterkapitel enthalten, die ihrerseits weitere Abschnitte enthalten. Auf diese Artlassen sich inhaltliche Abhängigkeiten zwischen den Elementen modellieren. Objektezur Beschreibung vonDarstellungsstrukturen, wie zum Beispiel Listen und Tabellen,bilden eine letzte Form der strukturbildenden Daten.
Definition Beispiel
SemantischeObjekte
Lehrstoff
Darstellungs−Strukturen
Tabelle Liste
StrukturelleObjekte
Kapitel Abschnitte
Abbildung 19:Allgemeine Datenstruktur

74
Gefüllt werden die verschiedenen zur Verfügung stehenden Objekte mit elementarenEinheiten. Dazu gehören Text, Grafiken oder Multimedia-Objekte, wie beispielsweiseFilmen, Ton oder Applets.
Texte sind die einfachste Einheit, die jedes Präsentationsmedium akzeptieren muss.Für Grafiken ist das nicht immer der Fall, beispielsweise kann es bei Online-Inhaltenvorkommen, dass der Browser keine Grafiken darstellt. Daher muss für Grafiken dieAngabe von Alternativtext ermöglicht werden.
Für multimediale Objekte müssen ebenfalls Regeln definiert werden, wie sie auf deneinzelnen Präsentationsmedien zu behandeln sind. Dem Inhalt ist zu entnehmen, ob sieübersprungen oder alternativ behandelt werden, wenn sie von dem Präsentationsmedi-um nicht dargestellt werden können. Für nicht druckbare Inhalte, wie beispielsweiseFilme, existieren deshalb zusätzliche Angaben, wie beschreibende Texte oder Grafi-ken, die Alternativen zu dem Objekt erlauben.
7.2.1 Semantische Objekte
Die semantischen Auszeichnungen stellen die wesentlichen Informationsobjekte dar.Sie beschreiben exakt, welche Informationen sie kapseln. Mit welchen Elementarein-heiten sie dies erreichen, ist nicht von Bedeutung. Dazu gehören auf oberer Ebenegenauso Definitionen, bestehend aus dem zu erläuternden Term und einer Erklärung,wie auch Beispiele, denen keine weitere Unterteilung zugrunde liegen muss.
Auf tieferer Ebene von semantischen Objekten befinden sich Schlüsselwörter. Sie kön-nen benutzt werden um den Inhalt eines einfachen Textes anhand dieser Wörter knappund präzise wiederzugeben. Um verschiedene Gewichtungen der Textinhalte zu er-möglichen, lassen sich neben den Schlüsselwörtern auf dieser Ebene auch einzelneObjekte markieren. In einer gedruckten Ausprägung könnte sich diese Markierungdurch eine andere Darstellung erkennen lassen.
Eine weitere Art von semantischen Objekten sind Zitate. Sie können durch ihre Ver-bindung zu verschiedenen Literaturangaben zur Einordnung des Dokumentes in Bezugzu anderen Dolumenten benutzt werden.
7.2.2 Strukturelle Objekte
Strukturen, die über die Verschachtelung von Objekten entstehen, sind wohl die ge-bräuchigsten. So werden textuelle Informationen immer mit einem Titel überschriebenund je nach Umfang in verschiedene Kapitel oder auch nur einzelne Absätze aufgeteilt.Ein Kapitel besteht wiederum aus einem Titel, einer optionalen Beschreibung und demeigentlichen Inhalt, vgl. Abbildung20. Dieser Inhalt setzt sich aus den semantischenObjekten der oberen Ebene, strukturellen Objeken, sowie den Darstellungsstrukturenzusammen. Desweiteren können auch direkt Grafiken und multimediale Objekte ein-

75
gebunden werden, da der Informationsgehalt dieser Objekte variieren kann. So kannbeispielsweise in einem Film die ganze Thematik eines Kapitels enthalten sein.
Abbildung 20:Struktur eines Kapitels
Durch die Baumstruktur ergibt sich eine immer detaillierter werdende inhaltliche Be-schreibung eines Themas. Als weiteres Strukturobjekt spielen dabei die Absätze einewichtige Rolle. Absätze können neben textuellen Inhalten auch verschiedenste Ele-mente enthalten. Dazu gehören bis auf die Kapitel selber alle Objekte, die in demInhalt eines Kapitels auftreten können, ergänzt um die semantischen Objekte untererEbenen. Desweiteren lassen sich auch alle Elementareinheiten einschließlich ihrer Er-weiterungen in die Absätze integrieren. Absätze besitzen somit wenig Restriktionengegenüber ihrem Inhalt. Das ist besonders wichtig, da sie neben dem Einfügen vonText auch zur Gruppierung von Inhalten dienen. Damit lassen sich zusammengehörigeTeile des Inhaltes eines Kapitels auszeichnen.
7.2.3 Darstellungsstrukturen
Bei der Verwendung von grafischen Auszeichnungen vermischt sich der Strukturie-rungsanspruch mit dem grafischen Layout. Eine Unterscheidung, welche Angaben zurgrafischen Gestaltung und welche noch zur Strukturbildung gehören, lässt sich hieroft nicht eindeutig festlegen. Beispielsweise stellt eine Tabelle strukturierte Informa-tionen dar, dient aber auch der grafischen Gestaltung der Inhalte. Um das Prinzip derTrennung von Content und Layout aufrecht zu erhalten, besitzen Tabellen daher keineEigenschaften zur gestalterischen Definition. Sie bestehen einfach aus einem optio-nalen Tabellenkopf und einer beliebigen Anzahl Zeilen. Beide, sowohl Tabellenkopfals auch Zeile, sind Reihenfolgen von einzelnen Zellen, die die eigentlichen Inhaltebeinhalten.
Listen sind im wesentlichen ähnlich zu Tabellenzeilen, da sie aus einer Reihe vonEinträgen bestehen. Da auch die Angabe, ob es sich um eine nummerierte Liste oderpunktuelle Aufzählung handelt, von inhaltlicher Bedeutung sein kann, wird diese An-gabe hinzugefügt.

76
7.2.4 Erweiterungen elementarer Einheiten
Einfache Texte sind die wichtigste Form elementarer Einheiten. Sie können aber nebenden inhaltlichen Informationen auch besondere Auszeichnungen zu den Daten enthal-ten. So werden beispielsweise mit Links keine Strukturen, Semantiken oder Darstel-lungsstrukturen beschrieben, sondern nur Texte mit bestimmten Eigenschaften. Hiermit der Eigenschaft, dass es sich um einen Verweis handelt. Es handelt sich um Er-weiterungen auf der elementaren Einheit Text. Sie können damit in fast allen Objektenauftreten, in denen auch Text benutzt wird. Eine Ausnahme bildet beispielsweise derText selber, der den Verweis beschreibt. Die gleichen Aussagen gelten auch für Fuß-noten.
Zur direkten Unterstützung von fachspezifischen Sprachen, müssen diese ebenfalls di-rekt in die Texte eingebunden werden können. Das heißt, sie müssen in dem Formatintegriert werden, in dem sie ihre eigene Struktur beibehalten können. In vielen Dar-stellungen werden beispielsweise mathematische Formeln als Grafiken eingebunden.Dabei gehen wichtige Informationen über den Inhalt verloren, da Grafiken nicht imnachhinein wieder ihren Inhalt in beschreibender Sprache vermitteln können. Das istfür eine gedruckte Ausgabe unwesentlich, aber zur Unterstützung anderer Präsenta-tionsmedien (z.B. Computer) oder nachträglicher Änderungen spielt es eine wichtigeRolle. So lassen sich nur korrekt beschriebene Daten weiterverarbeiten und beispiels-weise in eine Sprachausgabe für Blinde umformen. Deshalb werden mathematischeObjekte direkt in alle Texte integriert.
7.2.5 Zusatzinformationen für die Ausprägungen
Desweiteren müssen noch Zusatzinformationen für die unterschiedlichen Ausprägun-gen hinzugefügt werden. Diese Zusatzinformationen sollen einzelne Datenobjekte füreinzelne Ausprägungen freischalten oder sperren. Dabei muss beachtet werden, dasssie für unterschiedliche Ausprägungen verschiedene Inhalte besitzen können. Aus die-sem Grund wird für jede Ausprägung eine Standardinformation zu den betrachtetenObjekten hinzugefügt. Um Anpassungen an den Ausprägungen zu machen, lassen sichnun einzelne Objekte markieren. Das geschieht indem das Element mit einer weiterenEigenschaft versehen wird, die für die jeweilige Ausprägung die Abweichungen vomStandard kenntlich macht. Damit lässt sich jede neue Instanz der Ausprägung auf derBasis der Standardausprägung aufbauen.
7.3 Realisierungsvorgaben
Zur Beschreibung von Daten, die mit zusätzlichen Informationen bestückt und anhandvon Kriterien strukturiert werden sollen, eignet sich eine Metasprache wie XML. Inder derzeitigen Entwicklung derartiger Thematiken (DocBook, tbook, LMML, etc.)wird ebenfalls häufig XML zur Umsetzung verwendet. Auch fachspezifische Daten

77
können in XML beschrieben werden. Beispiele hierfür sind MathML für mathema-tische Daten, CML für chemische Daten und verschiedene XML-Anwendungen zurBeschreibung von Musiknoten. Durch die Bestrebungen viele Fachsprachen in XMLauszudrücken, wird in Zukunft die Integration weiterer Formate wesentlich erleichtert.
Auch die Ausgabe von XML-Daten wird in unterschiedlichen XML-Anwendungenbehandelt und auf verschiedenen Medien erprobt. Da eine Umwandlung von einerXML-Anwendung in eine andere mit einer XSL-Transformation vorgenommen wer-den kann, vgl. Kapitel3. XHTML dient beispielsweise der statischen Darstellung undSVG der animierten und interaktiven Darstellung am Computer. XSL-FO und die dar-auf angesetzten Formatierer ermöglichen die Erstellung von druckbaren Erzeugnis-sen. Somit sind beim Einsatz von XML die besten Voraussetzungen zur Unterstüt-zung vieler Präsentationsmedien gegeben. Die Möglichkeiten der unterschiedlichenXML-Anwendungen, die eingesetzt werden, sind vielfältig und durch die gemeinsameGrundsprache XML leicht verknüpfbar. Ebenso wird durch den hohen Verbreitungs-grad von XML, der sich auch durch eine breite Unterstützung bei den Ausgabegerätenwiederspiegelt, ein grosses Einsatzgebiet abgedeckt.
In Anbetracht der Aktualität der Entwicklung liegt es nahe XML Schema anstatt ei-ner DTD zur Beschreibung der Dokumentstruktur einzusetzen. XML Schema liefertbesondere Vorteile, die für die weitere Entwicklung von Bedeutung sind. So könnenin XML Schema Dokumentationsmöglichkeiten verwendet werden, die ein Editor zurBeschreibung der Elemente oder Attribute verwenden kann. Damit kann dem Autoreine gute Unterstützung bei der Bearbeitung von Dokumenten gegeben werden. Zuweiteren Vorteilen von XML Schema gegenüber DTD’s vgl. Kapitel2.2.
Da XML-Dateien nicht binär kodiert sind, sondern für jeden Menschen lesbar vorlie-gen, sind sie mit jedem Editor zu bearbeiten. Daher können die Dokumente in demFall, dass der Editor die geforderten Ansprüche noch nicht unterstützt, auch mit einfa-chen Editoren erstellt werden.

78
8 Realisierung
Aufbauend auf dem allgemeinen Konzept in Kapitel6 und der daraus in Kapitel7 ab-geleiteten Dokumentstruktur soll im Folgenden die Umsetzung der vorangegangenenAnforderungen erläutert werden. Dazu werden zunächst die existierenden Möglichkei-ten zur Dateneingabe beleuchtet und im Anschluss wird die weitere Implementationdargestellt. Dabei werden die gestellten Forderungen an die Dokumentstruktur mittelsXML Schema umgesetzt und durch XSLT in verschiedene Ausprägungen und Formateüberführt.
8.1 Dateneingabe
Da XML bereits weit verbreitet ist, ist die Unterstützung mit Programmen zur Daten-eingabe von XML-Anwendungen schon vielfach gegeben. Aber aufgrund der Aktuali-tät der Entwicklung muss auf Komfort und Einfachheit noch weitestgehend verzichtetwerden. Da es sich bei XML um einen offiziellen Standard handelt, muss aber keineProduktbindung auf Dauer erfolgen. Die Auswahl der Programme kann somit nach ei-genem Ermessen und abhängig von der zukünftigen Entwicklung erfolgen. Im Folgen-den soll der Funktionsumfang zu einigen aktuellen Programmen aufgelistet werden.
XMLSpy ist ein kommerzielles und kostenpflichtiges Anwendungsprogramm von Al-tova zur Bearbeitung von XML, das besonders für Techniker geeignet ist. Eswerden sowohl DTD als auch XML Schema unterstützt, allerdings werden diesenicht automatisch während der Eingabe validiert. Für die Dateneingabe wurdedazuAuthenticentwickelt, das durch eine einfache Eingabe in Formularform fürLaien geeignet ist. Allerdings beruht die Eingabemaske auf einem eigenen Da-tenformat, das nur dann zu erstellen ist, wenn die Transformationen mit demdazugehörendenStylesheet Designererzeugt wurden. Externe XSL Transfor-mationen können nicht integriert werden und es können nicht alle Elementtypenwie beispielsweisemixed-ContentModelle, eingefügt werden. Desweiteren tre-ten in dem integrierten Schemavalidator noch einige Fehler in der Validierungder Elemente auf. So werden gemixte Elemente bestehend aus Text und weiterenElementen ebenso wie die Struktur von ineinander geschachtelten Elementen inspeziellen Fällen falsch validiert, getestet in Version 5 Release 3. Auch automa-tisch generierte Beispieldateien zu einem Schema sind nicht gültig.
XMetal kann als Testversion von Corel bezogen werden. Ansonsten ist auch XMetalein kommerzielles und kostenpflichtiges Tool, aktuell in der Version 4 verfüg-bar, das zuvor von SoftQuad entwickelt wurde und von Corel aufgekauft wurde.XMetal ist speziell für die Eingabe und Transformation von SGML, XML undXHTML Dokumenten geeignet. Dementsprechend bietet es neben der reinenCode-Ansicht auch die Möglichkeit das Dokument in einer grafischen Ansicht

79
durch eigene definierte Darstellungen der einzelnen Elemente oder in der Tag-Ansicht mit einem Verschachtelungsbaum anzusehen. Auch eine Preview desresultierenden Dokumentes ist möglich. Die Unterstützung von XML Schemaist allerdings noch ein wenig lückenhaft, so werden beispielsweise in der gete-steten Version 3 keine importierten Schemata unterstützt.
Epic ist ein kommerzieller und kostenpflichtiger Editor von Arbortext, der über weitmehr Funktionen als die reine Dokumenteingabe verfügt. Er ist bereits früherzur Eingabe von SGML-Dokumenten entstanden und daher sehr komfortabel.Leider konnte dieser Editor nicht umfangreich getestet werden, da dieser nichtals Testversion mit Schemaunterstützung zur Verfügung steht.
Die meisten Editoren scheitern an der einfachen Benutzung. Es werden neben derfarbig markierten Darstellung als XML-Dokument häufig nur baumartige Darstellun-gen ermöglicht. Zwar lässt sich diese Ansicht in vielen Fällen durch verschiedeneFormatierungsanweisungen anpassen, aber zur einfachen Benutzung durch den Laienfehlen noch weitere Unterstützungen. Einige unterstützen dabei verschiedene XML-Anwendungen in der Darstellung, wie XHTML oder XSL-FO. Für einen breiten Ein-satz, der auch Laien die Möglichkeit der Dokumenteingabe ermöglichen soll, solltendie Editoren noch weiter entwickelt werden.
Eine weitere Möglichkeit zum besseren Verständnis der Elemente bei der Datenein-gabe liefern die Dokumentationen. Zur Beschreibung der Elemente des XML Sche-mas werden diese benutzt, damit sie dem Anwender die Bedeutung der Elemente auf-zeigen können. Durch den Einsatz in Editoren, die eine Auswertung der Dokumen-tation vornehmen, lässt sich die Benutzbarkeit für den Endanwender beispielsweisedurchToolTip-Texteerleichtern. Derartige Unterstützungen werden in den aktuellenProgrammen noch nicht angeboten.
Die Darstellung des Dokumentes bei der Dateneingabe ist jedoch nicht das einzigeProblem. XMetal oder Epic sind bereits als SGML-Editoren entstanden und daher sehrgut auf DTD’s angepasst. XML Schema ist im Vergleich dazu noch sehr neu und seineUnterstützung ist nicht vollständig oder fehlerfrei gegeben. Daher können zum Test,ob ein Dokument dem gegebenen Schema auch entspricht, verschiedeneValidatoreneingesetzt werden. Dazu werden XML-Parser beauftragt ein Dokument einzulesen undanhand der Fehlermeldungen des Parsers ist die Gültigkeit des XML-Dokumentes ab-zulesen.
XSV ist ein vom W3C genutzterXML SchemaValidator, der vom W3C zum Down-load als Kommandozeilenprogramm oder als online-Anwendung frei zur Verfü-gung gestellt wird. Er wird kontinuierlich weiterentwickelt und hält sich relativgenau an den Standard. Dennoch sind einige kleine Fehler bei Spezialfällen desStandards enthalten. Beispielsweise akzeptiert er Gruppen mitall -Umgebung,die als optional deklariert ist.

80
Schematron Validatorvon Topologi ist eigentlich für die Validierung von Schema-tron, einem anderen regelbasierenden Schema zur Beschreibung von XML-Da-teien, entstanden. Er beherrscht aber auch XML Schema und ist über eine kleineOberfläche zur Auswahl der zu validierenden Dateien zu steuern. Er scheitertallerdings an verteilten XML Schemata.
Xerces-J ist ein javabasierender XML-Parser aus dem Apache Projekt. Er ist frei ver-fügbar und in eigene Implementierungen zu integrieren. Über mitgelieferte Bei-spielprogramme lässt sich als Nebeneffekt auch der benutzte Parser einstellen.Damit kann der Parser angewiesen werden, auch das XML Schema, auf dem daseinzulesende Dokument basiert, zu validieren. Von den getesteten Validatoren,ob integriert in einen Editor oder alleinstehend, ist dieser der exakteste gewesen.
Eine umfassende Liste von Anwendungen, die XML Schema benutzen und prüfen, istunter [W3CXSD] zu finden.
8.2 Datenformat in XML Schema
Die in Kapitel7.2beschriebende Dokumentstruktur wird in XML Schema umgesetzt.Dazu werden zunächst die Elemente beschrieben, die dazu notwendig sind. Anschlie-ßend werden diese Elemente zueinander in Beziehung gebracht. Die weiteren Voraus-setzungen für die späteren Ausprägungen werden dann im Anschluß hinzugefügt.
8.2.1 Elemente
Die Festlegung der Elemente, die in dem Dokument benutzt werden können, erfolgt inbestimmten Gruppen. Die Gruppen dienen der Strukturierung und der Wiederbenutz-barkeit der Elemente. Sie sind in dem erzeugten Dokument nicht sichtbar.
Auf unterster Ebene innerhalb von textuellen Inhalten stehen dietext.elements .Sie können überall dort eingesetzt werden, wo einfacher Text benutzt werden soll. Sieunterteilen sich weiter in drei Gruppen:
• text.inline.elements sind alle Elemente, die innerhalb eines Textes auf-tauchen können und weitere Angaben zu ihrem Inhalt machen. Dazu gehörenFussnotenfootnote , Links link und Zitatecitation .
• text.marker.elements sind semantische Auszeichner für Wörter oderTextpassagen. Mit ihnen können innerhalb des Textes Worte gewichtet werden.Ein Schlüsselwortkeyword ist dabei sehr eng an die Bedeutung des gesam-ten Textes gelehnt. Zur gewichteten Bewertung von Textpassagen oder Wörternwurden weitere Abstufungen festgelegt. So wird ein neu verwendeter Ausdruck,der allerdings nicht den Charakter einer neuen Definition besitzt, mitnewterm

81
bezeichnet. Er bestimmt eine aus dem Zusammenhang hervorgehende Textpas-sage. Auf Definitionen wird später noch eingegangen. Dasmarker -Elementist im Unterschied zu einem Schlüsselwort eine mögliche Auszeichnung um dieWichtigkeit einer Textpassage zu markieren.
• def.math ist eine reine Definitionsgruppe. Mit ihrer Hilfe wird einmath -Element eingefügt, das alle Inhalte von MathML enthalten kann. Auf MathMLwird in Kapitel 8.3.4näher eingegangen. Wie beliebige Elemente aus anderenNamensräumen, hier aus MathML, in dieses Element eingefügt werden können,wird im Code-Beispiel1 dargestellt.
Code-Beispiel 1:Das Einfügen aller beliebigen Elemente aus dem Namensraum von MathML wirdmit dem xs:any -Element und der Angabe des Namensraumes für MathML er-reicht. Durch die Angabe der Bearbeitungsartstrict , lax oder skip improcessContents -Attribut wird festgelegt, ob eine Validierung zwingend, even-tuell oder gar nicht stattfinden soll. In diesem Beispiel wurde die Artlax gewählt,da damit der Prozessor angewiesen wird nach einer Definition für die eingefügten Ele-mente zu suchen, um sie zu validieren. Sollte die Suche erfolglos bleiben, so wird keineValidierung vorgenommen, aber dennoch kann das restliche Dokument weiter behan-delt werden und es wird kein Fehler gemeldet. Da die Unterstützung von MathMLvielfach noch nicht gegeben ist, kann für derartige Formate eine Ersatzgrafik verwen-det werden.
<xs:element name="math"><xs:complexType>
<xs:sequence><xs:any namespace="http://www.w3.org/1998/Math/MathML"
processContents="lax"minOccurs="0" maxOccurs="unbounded"/>
<xs:group ref="def.graphic" minOccurs="0"/></xs:sequence>
</xs:complexType></xs:element>
Neben den Gruppen existiert auch noch eincode -Element, das vergleichbar zu MathMLdie Position einer "Fachsprache der Informatik" einnimmt. Innerhalb dieses Elemen-tes wird nur Textxs:string eingegeben, weshalb Leerzeichen, Tabulator-Einrückerund Zeilenumbrüche erhalten bleiben. Damit lassen sich Code-Auszüge in die Texteintegrieren. Eine weitere Möglichkeit liefert noch die Angabe einer Datei mittels desfilelocation -Attributes. Der Inhalt descode -Elementes wird vernachlässigt unddie angegebene Datei an seiner Stelle in das Dokument integriert.

82
Aufbauend auf dem Text werden folgende Gruppierungen für die verschiedenen Ele-mente vorgenommen:
• content.text.structure.elements fasst alle Elemente zusammen,die die Inhalte durch Darstellungsstrukturen beschreiben. Tabellentable lie-fern über die Struktur anhand von zwei Kriterien den größten Informationsge-winn. Listenlist strukturieren hingegen nur anhand eines Kriteriums.
• content.text.semantic.elements ist die Gruppe für alle Elementemit rein semantischer Inhaltsauszeichnung. So sagen Beispieleexample oderDefinitionendefinition nichts über die Form des Inhaltes aus. In Beispielenkönnen etwa Texte, Tabellen, Listen und Grafiken gekapselt werden. Definitio-nen sind dagegen weiter in den zu definierenden Term, der nur textuelle Inhalteoder mathematische Zeichen besitzen darf, und die eigentliche Erläuterung dazuaufgeteilt.
• content.text.media.elements beinhaltet alle Elemente, die zur Inte-gration verschiedener Medien benötigt werden. Dazu gehören beispielsweiseGrafikengraphic , Appletsapplet und weitere externe Objekteobject .
Diese gesamten Elemente dienen zur Beschreibung des Inhaltes der einzelnen Kapitelchapter . Ein Kapitel besteht aus einem Titeltitle , einem optionalen Ersetzungs-titel substitutetitle , einer optionalen Zusammenfassungabstract und demInhalt content . Ein Titel besteht aus reinem Text ergänzt um Textelemente und istdamit wie eine Zusammenfassung, die nur textuelle Inhalte über das Kapitel liefert,vom gemixten Typelementtext . Das gleiche gilt auch für den Ersetzungstitel, aufden in Kapitel8.2.3näher eingegangen wird. In Abbildung21 sind die Elemente ei-nes Kapitels dargestellt. Daschapter - und dascontent -Element sind komplexeTypen, die nur Elemente beinhalten.
Eine weitere wichtige Strukturierung kann mittels Absätzenpara vorgenommen wer-den. Sie bilden zum einen Textbausteine, die alle textauszeichnenden Elemente enthal-ten und zum anderen die strukturellen, semantischen oder Multimedia-Objeke. Damitlassen sich Inhalte gruppieren, was für die Generierung der Ausprägungen von Bedeu-tung ist.
Das gesamte Dokumentlecture ist prinzipiell nichts anderes als ein Kapitel mitUnterkapiteln. Allerdings kommen noch einige allgemeine Informationen hinzu, diefestgelegt werden müssen. Zu den allgemeinen Informationen eines Dokumentes zäh-len zwingend die Autorenauthor , zusammengefasst in dem Elementauthorship .Desweiteren können noch ein Untertitelsubtitle und ein Datumdate hinzugefügtwerden. Zum Einfügen von Inhalt-, Grafik- und Tabellenverzeichnissen, wie auch demGlossar stehen jeweils die entsprechenden Elemente zur Verfügung. Diese sind nichtweiter von Bedeutung, da ihre Inhalte automatisch aus den dazugehörigen Elemen-ten erstellt werden können. Die Elemente funktionieren damit als reine Markierungen,

83
Abbildung 21:Definition des Kapitels - Grafische Ausgabe in XMLSpy
die angeben ob ein Verzeichnis erstellt werden soll. Das Literaturverzeichnis funktio-niert prinzipiell gleich, doch müssen die im Text eingefügten Verweise noch mit ihrenQuellen in Verbindung gebracht werden. Dazu können verschiedene Einträge in demLiteraturverzeichnis gemacht werden, die den Verweisen zugeordnet werden.
Um die Quellenangaben für mehrere Dokumente nutzen zu können, lässt sich das Lite-raturverzeichnis in eine eigene Datei schreiben und in dembibliography -Elementüber dasfilelocation -Attribut einfügen. Dieses Attribut steht für unterschiedli-che Elemente zur Verfügung, beispielsweise das oben erwähntecode -Element, denenes dadurch ermöglicht werden soll auch externe Dateien zu integrieren. Diese Datei-en müssen natürlich auch nach dem Schema gültig sein. Nur dascode -Element unddasmath -Element bilden hierbei eine Ausnahme, da es sich beim Code nicht um einXML-Dokument handeln muss und die mathematischen Formeln in einem externenNamensraum geschrieben wurden.
Das lecture -Element verfügt neben diesen Angaben auch noch über ein Sprach-Attribut language , mit dem die Sprache für das gesamte Dokument festgelegt wird.Es handelt sich dabei um eine Pflichtangabe, was durch die folgende Definition fest-gelegt wurde:
<xs:attribute name="language" type="xs:language"use="required"/>
Damit sind die wesentlichen Elemente des Quelldokumentes beschrieben. Die Strukturder Elemente und ihre Abhängigkeiten werden im folgenden Kapitel beschrieben.

84
8.2.2 Beziehungen der Elemente
Da an allen Stellen, an denen Text eingefügt werden darf, dieser auch weitere Elemen-te enthalten kann, wurden abhängig davon verschiedene Datentypen eingeführt. EinBeispiel ist der Datentypelementtext , der als "mixed"-Typ definiert ist und damitneben Text auch die Elemente der Gruppetext.elements in beliebiger Häufigkeitund Reihenfolge enthalten kann. Der Datentypelementcodetext ist quasi dergleiche Datentyp wieelementtext nur erweitert um dascode -Element. Abbil-dung22stellt diese Gruppen und Datentypen im Zusammenhang dar. Deweiteren gibtes noch den Datentypmarkedtext , der auf die gleiche Weise alle Markierungsele-mente integriert, undmathtext , in dem neben Text noch mathematische Elementeauftreten dürfen.
Abbildung 22:Zusammenhang der Textgruppen und die darauf basierenden Datentypen
Die Elemente der Gruppetext.elements dürfen auch geschachtelt werden. Damitwird es möglich in einer Fußnote einen Link oder in einem Schlüsselwort ein mathe-matisches Element zu benutzen. Da XML Schema keine Möglichkeit zur Überprüfungvon Bedingungen besitzt, sind hierfür teilweise neue Definitionen nötig. Die einfacheSchachtelung von einem Link in einer Fußnote ist sinnvoll einzusetzen, während einetiefere Verschachtelung auf Probleme stößt. Wird beispielsweise dem Link, der sichin der Fußnote befindet, noch eine Fußnote angehängt, so ist diese nicht interpretier-bar. Derartige tiefe Verschachtelungen sollten ausgeschlossen werden. Deshalb sinddiese Elemente in verschiedenen Kontexten nicht einfach referenziert, sondern werdeninnerhalb der Definition anderer Elemente neu definiert.
Code-Beispiel 2:Eine Fußnote besteht aus Text, der verschiedene Elemente beinhalten kann. Dazu wer-den in die Gruppetext.marker.elements mathematische Zeichen, Code undZitate über Referenzen eingebunden. Daslink -Element muss wie oben erläutert neudefiniert werden. Dazu wurde die eigentliche Definition mit dem Unterschied über-nommen, dass der dargestellte Text nur vom Typmarkedtext ist.

85
<xs:element name="footnote"><xs:annotation>
<xs:documentation>insert a footnote at this position
</xs:documentation></xs:annotation>
<!-- Mischung aus Text und Elementen --><xs:complexType mixed="true">
<xs:sequence minOccurs="0" maxOccurs="unbounded"><xs:group ref="text.marker.elements" minOccurs="0"
maxOccurs="unbounded"/><!-- Neudefinition des Links --><xs:element name="link" minOccurs="0"
maxOccurs="unbounded"><xs:complexType>
<xs:all><xs:element name="uri" type="xs:anyURI"/><xs:element name="text" type="markedtext"/>
</xs:all><xs:attributeGroup ref="pres:standard.out"/><xs:attributeGroup ref="script:standard.in"/>
</xs:complexType></xs:element><xs:group ref="def.math" minOccurs="0"
maxOccurs="unbounded"/><xs:group ref="def.citation" minOccurs="0"
maxOccurs="unbounded"/><xs:element ref="code" minOccurs="0"
maxOccurs="unbounded"/></xs:sequence><xs:attributeGroup ref="pres:standard.out"/><xs:attributeGroup ref="script:standard.in"/>
</xs:complexType></xs:element>
Da in dem zweiten Code-Beispiel die Gruppen und Elemente bezüglich ihrer Häufig-keit des Auftretens auf Null bis unendlich gesetzt wurden, sind die Elemente optional.Durch die Angabe der gleichen Attribute in der Sequenz, ist die Sequenz beliebighäufig wiederholbar. Dadurch ist die durch eine Sequenz vorgegebene Reihenfolgeabgeschaltet und die Elemente lassen sich in beliebiger Reihenfolge und Häufigkeitwiederholen.

86
Abschnittepara werden auf die gleiche Weise definiert. Sie können neben Text auchweitere Elemente enthalten, wodurch sie bestimmte Zusammengehörigkeiten struktu-rieren. So lassen sich Auszeichnungen der Gruppetext.elements im Text vorneh-men und über die Gruppecontent.text.elements alle weiteren inhaltlichenElemente wie Grafiken, Definitionen oder auch Tabellen einbinden. Für Abschnitte istdie Reihenfolge in der sie eingegeben und interpretiert werden identisch.
Die Darstellungsstrukturen der Gruppecontent.text.structure.elementsmüssen in eine Struktur gebracht werden, die eine aneinandergereihte Eingabe der In-halte ermöglicht. Die Reihenfolge der Eingabe entspricht der späteren Ausgabe. Listenbestehen auslistitem -Elementen, die die einzelnen Einträge der Liste bestimmen.Diese können Elemente der Gruppetext.elements , Code oder weitere Listen ent-halten.
Tabellen werden in Form ihrer Zeilen beschrieben. Es lässt sich optional zu einer Ta-belle eine Legende für die Beschreibung der Tabelle und ein Tabellenkopf hinzufü-gen. Der Tabellenkopf besteht aus der gleichen Beschreibungsart, wie die weiterenTabellenzeilen. Die Anzahl der Tabellenzeilen kann zwischen einer und beliebig vie-len variieren. Die Zeilen werden übercelldata -Elemente gefüllt, die neben Textbis auf semantische Strukturen und Tabellen alle Elemente enthalten können. Mit derAuszeichnung als Tabellenkopf wird die besondere Stellung einer Zeile in Bezug aufdie gesamte Tabelle ausgedrückt. Tabellen sollen der reinen Strukturierung ihres In-haltes dienen und keine Layoutgestaltung vornehmen. Daher sind sie nicht ineinanderschachtelbar.
Für die Elemente zur semantischen Inhaltsauszeichnungcontent.text.seman-tic.elements sind die erlaubten Inhalte verschieden. Während in einem Beispielexample alle Elemente bis auf die semantischen der eigenen Gruppe auftreten dür-fen, sind Definitionendefinition wesentlich eingeschränkter. Sie bestehen aus ei-nem Termterm , der neben Text noch mathematische Elemente enthalten kann undeinem erläuternden Textcomment dazu.
Die Elemente der Gruppecontent.text.media.elements setzen sich alle ausihren notwendigen Angaben zusammen. Eine Grafikgraphic besteht beispielsweiseauslabel , uri undalternative . Ein Appletapplet kann über alle dazugehö-rigen Angaben verfügen und einobject hat die Wahl zwischen Uri und MIME-TypeAngabe oder Klassenangabe mit Parametern.
Die zuvor beschriebenen Gruppencontent.text.structure.elements , con-tent.text.declaration.elements , content.text.media.elementsbilden zusammengenommen diecontent.text.elements -Gruppe, siehe Abbil-dung23. Darin sind alle Elemente enthalten, die im eigentlichen Inhalt eines Kapitelsauftreten dürfen. Andere Elemente, die nicht dazu gehören, wären etwa Titel, Zusam-menfassungen oder Autorenangaben.
Der Content eines Kapitels wird durch die Elemente der Gruppecontent.ele-ments bestimmt, die sich aus der Gruppecontent.text.elements und dem

87
chapter -Element zusammensetzt. Die Erweiterung um die Kapitel ist für die Erstel-lung von geschachtelten Kapiteln mit Unterkapiteln notwendig. Abbildung23 stelltdie gesamten Elemente dar, die in demcontent eines Kapitels auftreten können undwie sie in Gruppen strukturiert sind.
Abbildung 23:Gruppenzusammenhänge
Diese Art der Strukturierung ermöglicht die einfache Erweiterung um Elemente. Sollzum Beispiel ein neues Medienelement integriert werden, so muss dieses nur in derGruppecontent.text.media.elements eingehängt werden und es kann anallen Positionen auftauchen, an denen die anderen Medien auch auftauchen dürfen.
Einen weiterer Vorteil, der aus der Verwendung von Gruppen resultiert, ist, dass glo-bale Gruppen nicht instanziiert werden dürfen. Das bedeutet, dass ein Dokument, wel-ches mit dem Element einer globalen Gruppe beginnt, nicht gültig ist. Das unterschei-det sich von der Verwendung globaler Elemente. Alle global definierten Elemente kön-nen als Startelement für ein gültiges Dokument dienen. Um die Gültigkeit für einfacheElemente zu verhindern, wurden sie in Gruppen definiert.
8.2.3 Zusatzinformationen für die Ausprägungen
Es gibt zwei verschiedene Ansätze um die Informationen zu gewinnen, die für dieAusprägungen notwendig sind. Zum einen über die Struktur und zum anderen über dieZusatzinformationen.
Die Struktur wird durch die Schachtelung der Elemente realisiert. Beispielsweise nimmtdaspara -Element eine ganz besondere Stellung ein. Mit ihm lassen sich verschiedeneInhalte zusammen gruppieren. Wie diese Strukturen in der weiteren Verarbeitung zurGenerierung der Ausprägungen genutzt werden, spielt für das Schema keine Rolle.

88
Da die Struktur alleine nicht ausreicht und auch Sonderfälle ermöglicht werden müs-sen, lassen sich die meisten Elemente über Attribute steuern. Diese Attribute sind ineinem eigenen Schemastamp.xsd definiert. Zur Markierung einer Standardausprä-gung gehört dason-Attribut. Dieses kann nur einen der boolschen Wertetrue oderfalse annehmen. Damit wird markiert, ob ein Element in der Standardausprägung er-scheinen soll. Die Festlegung dieses Wertes ermöglicht eine Ausprägungsgenerierungaus dem Quelldokument ohne weitere Angaben zu der Ausprägung zu machen. Al-lerdings sollen zu einer Ausprägung auch verschiedene Ausprägungsinstanzen ermög-licht werden. So wird beispielsweise nicht nur eine Standardausprägung Präsentationerzeugt, sondern es müssen auch Abstufungen bezüglich des Präsentationsinhaltes vor-genommen werden können. Hierfür muss das zweite Attributdelta gesetzt werden,das die Informationen über viele verschiedene Ausprägungsinstanzen enthalten kannund dafür als eine Liste von Strings definiert ist. Jede Ausprägungsinstanz muss miteinem Namen versehen werden, der in die entsprechende Liste derdelta -Attributeder Elemente eingetragen werden muss. Das muss bei allen Elementen gemacht wer-den, die abweichend von der Standardausprägung zu behandeln sind. Dadurch werdendiese Elemente zusätzlich aufgenommen oder vernachlässigt. Bei der Namenswahl istzu beachten, dass Listen nur über Leerzeichen als Trennungssymbole verfügen.
Code-Beispiel 3:Der einfache Datentypdeltalist beruht auf einer Liste von Strings. Mit ihm wirddas Attributdelta erzeugt. Der Beispielcode zeigt die einfache Definition von bei-den.
<xs:simpleType name="deltalist"><xs:list itemType="xs:string"/>
</xs:simpleType><xs:attribute name="delta" type="deltalist"/>
Die aus den Kombinationen der beiden Attribute resultierenden Konstellationen sind inder Tabelle2 für eine beispielhafte Ausprägungsinstanz mit dem Namenspezielldargestellt. Dason-Attribut markiert dabei, ob ein Element zur Standardausprägunggehört. Dasdelta -Attribut notiert immer die Abweichungen für eine Ausprägungs-instanz vom Standard einer bestimmten Ausprägung.
Der Vorteil dieser etwas komplexen Attributangaben liegt in der Erzeugung der Stan-dardausprägung. Anhand der Definitionen der Regeln, welche Elemente des Quell-dokumentes in eine Standardausprägung einfließen sollen, lassen sich die Attributesetzen. Bei den jeweiligen Elementen, die in eine Standardausprägung einfließen, wirdschon im Schema dason-Attribut für diese Ausprägung per default auftrue ge-setzt. Damit lässt sich für jedes Element schon bei der Schemadefinition genau einon-Attribut, das die Standardausprägung bestimmt, setzen. Werden nun für einzelne

89
on delta Darstellung?
true Jatrue speziell Neinfalse Neinfalse speziell Ja
Tabelle 2: Konstellationen aus der Kombination deson- und desdelta -Attributesfür die Ausprägungsinstanzspeziell
Ausprägungsinstanzen Abweichungen davon festgelegt, so sind diese in demdelta -Attribut zu machen. Daher ist es weiterhin möglich trotz der hinzugefügten Angabenfür eine bestimmte Ausprägungsinstanz noch die Standardausprägung zu generieren.Ebenfalls lassen sich so weitere Instanzen festlegen, die auch auf der Standardausprä-gung aufbauen können, da nur die Unterschiede zu dieser festgehalten werden müssen.Daher muss für diese nicht mit einer vollständig neuen Auswahl begonnen werden.
Da immer beide Attribute zu einem Element definiert werden müssen, werden die At-tribute durch Referenzen auf Attributgruppen den Elementen hinzugefügt. Die Attri-butgruppen beinhalten beide Attribute, doch mit unterschiedlichendefault -Angaben.Die Gruppestandard.in setzt für Elemente die zur Standardausprägung gehö-ren den default-Wert vonon auf true , die Gruppestandard.out setzt entge-gengesetzt auf false, wie das Code-Beispiel4 zeigt. Die Verwendung vondefault -Angaben ist allerdings nur sehr eingeschränkt zu verwenden. Diese Eingaben werdennicht zwangsläufig von einem Editor oder Validator hinzugefügt, vgl. [Oba2002]. Des-halb muss in der weiteren Verarbeitung dieser Fall berücksichtigt werden.
Code-Beispiel 4:Diese Attributgruppe soll von Elementen eingesetzt werden, die standardmäßig nichtin der Ausprägung erscheinen sollen, denen aber die Möglichkeit gegeben werden soll,nachträglich aufgenommen zu werden. Daher wird dason-Attribut per Voreinstellungauf false gesetzt.
<xs:attributeGroup name="standard.out"><xs:attribute ref="on" default="false"/><xs:attribute ref="delta"/>
</xs:attributeGroup>
Damit wurden die Attribute beschrieben, die für eine Ausprägung und ihre verschiede-nen Instanzen gesetzt werden können. Es sollen jedoch mehrere Ausprägungen ermög-licht werden, weshalb diese Attribute für jede Ausprägung eigenständig ermöglichtwerden müssen. Deshalb wird das Schemastamp.xsd für jede neue Ausprägung

90
in ein anderes Schema includiert (include ). In stamp.xsd sind daher die Attri-bute ohne Namensraum beschrieben worden. Für jede Ausprägung, die in das Doku-ment eingefügt werden soll, wird nun ein eigenes Schema mit eigenem Namensraumerstellt. Das Schema für die Ausprägung Präsentationpresentation.xsd wirdebenso wie die vollständigestamp.xsd im AnhangA aufgeführt. Die definiertenAttribute nehmen damit immer den Namensraum des Schemas an, von dem sie inclu-diert werden. Damit sind für verschiedene Ausprägungen die Attribute immer gleich,nur der Namensraum, kenntlich gemacht durch das Präfix, variiert.
Die Integration der Attributgruppen für die Ausprägungen Präsentation mit dem Präfixpres und Skript mit dem Präfixscript ist schon in dem Code-Beispiel2 definiertworden. Die Benutzung in einem XML-Dokument des Schemas könnte folgenderma-ßen aussehen:
<footnote pres:on="false" pres:delta=""script:on="true" script:delta="">
Der Text, der in der Fußnote erscheint.</footnote>
Diese Angaben sind für fast alle Elemente machbar. Für einige Elemente sind sie al-lerdings nicht sinnvoll, beispielsweise bei einzelnen Elementangaben wie der URI zueiner Grafik. Dabei ist nur die Funktionalität für die gesamten Grafikinformationenwünschenswert, damit diese für spezielle Ausprägungen ausgewählt werden können.
Eine besondere Stellung für die diversen Ausprägungen kommt noch den Titeln derKapitel zu. Diese dürfen stets nur einmal auftreten. Damit können keine unterschied-lichen Angaben für verschiedene Ausprägungen gemacht werden. Um dennoch unter-schiedliche Titel zu erlauben, wurde den Kapiteln noch ein Substitutionstitelsub-stitutetitle mitgegeben. Dieser wird standardmäßig nicht eingesetzt, aber erkann bei unterschiedlichen Ausprägungen als Ersatz für den eigentlichen langen Titeldienen.
8.3 Generierung der Ausgabe mit XSLT
Die diversen Ausprägungen aus dem Quelldokument lassen sich mittels XSLT erzeu-gen. Dabei sind verschiedene Formate denkbar. Im folgenden sollen einige grundsätz-liche Transformationen zur Generierung der Ausprägungen erläutert werden, die sichauf verschiedene Formate erweitern lassen. Zum einfachen Verständnis wird in derBeschreibung die Generierung anhand von XHTML-Seiten erläutert.
8.3.1 Folgerungen der Struktur
Anhand der Struktur, die das Dokument besitzt, lassen sich Gewichtungen festlegen,die als Grundlage einer Ausprägung dienen. So wurden Schlüsselwörter als präzise

91
Stichwörter zur knappen Beschreibung einer Textpassage definiert und werden dement-sprechend innerhalb des Textes durch Fettdruck hervorgehoben. An anderer Stelle wer-den sie gegebenenfalls als Ersatz für den gesamten Text fungieren.newterm undmarker sind Abschwächungen dazu, die in einigen Ausprägungen teilweise gar nichtauftreten. Innerhalb des Textes werden sie nun als kursiv und unterstrichen dargestellt.
Code-Beispiel 5:Die Schlüsselwörter werden in der Standardausprägung zu XHTMLfett dargestellt. Der Namensraum für die Elemente wurde mitxmlns:lec="http://www-lehre.inf.uos.de/ tschnied/lecture"bekannt gemacht. Um auf bestimmte Elemente zugreifen zu können, müssen sie des-halb alle mit demlec -Präfix aufgerufen werden. Da in einem Schlüsselwort-Elementauch andere Elemente enthalten sein können, werden alle seine Kinderelementemittels desapply-templates -Elementes aufgerufen und abgearbeitet. Da dieeingefügten Werte keine Leerzeichen enthalten, wird durch dastext -Elementabschließend noch ein Leerzeichen angehängt.
<xsl:template match="lec:keyword"><b><xsl:apply-templates/></b><!-- Einfuegen eines Leerzeichens --><xsl:text> </xsl:text>
</xsl:template>
Derartige Vorlagen, die für jedes mögliche Element existieren, erlauben die Verarbei-tung des Dokumentes in der Reihenfolge, in der die Informationen eingegeben wurden.Das ist aber nicht immer gewünscht. So ist an einigen Stellen in dem Dokument dieReihenfolge bestimmter Einträge beliebig, aber die Darstellung soll immer gleich aus-fallen. Ein Kapitel zum Beispiel besteht aus einem Titel, gegebenenfalls Ersetzungs-titel, Content und optionaler Zusammenfassung. Da diese alle nur maximal einmalauftreten dürfen, ist die Reihenfolge nicht wesentlich aber für die Darstellung sehrentscheidend. Der Titel soll immer als Überschrift und nicht als Unterschrift verwen-det werden. Um derartige Reihenfolgen für die Ausprägung zu berücksichtigen, ist dieVerarbeitung der Elemente in einer vorgegebenen Reihenfolge vorzunehmen. Deshalbwird in einer Kapitelvorlage erst der Titel und dann in Abhängigkeit der Position derContent und die Zusammenfassung ausgewertet. Die Bearbeitung der Fußnoten ist ne-ben den im Text erscheinenden Zahlen auch erst am Ende der Ausgabe vorzunehmen.Dazu wird im Fall einer Ausgabe in mehrere Dateien die Bearbeitung der Fußnotenauch erst am Schluss eines Kapitels vorgenommen.
Code-Beispiel 6:Für jedes Kapitel soll eine HTML-Seite erzeugt werden. Die HTML-Seite besteht im-mer aus dem Titel des Kapitels, gefolgt von dem Content oder einer optionalen Zusam-menfassung. Sind diese ganzen Informationen verarbeitet, so müssen noch die Inhalte

92
zu den Fußnoten angehängt werden. Das geschieht über den Aufruf einer Vorlage fürFußnoten mit einem dafür vorgesehenen Modusannotation . Da die Fußnoten be-liebig tief in anderen Elementen geschachtelt sein können, werden sie unabhängig vonihrer Verzweigungsstruktur alle aufgerufen, bis auf die, die sich in weiteren Unter-kapiteln befinden. Dazu werden in der vorgeschaltetenfor-each -Anweisung allechapter -Elemente aussortiert. Diese Fußnoten werden erst bei der Bearbeitung dereigenen Kapitel eingefügt.
<!-- Bearbeitung des Titels --><h1 align="left">
<xsl:apply-templates select="lec:title"/></h1><!-- Aufruf der Vorlagen fuer den Content und das Abstract --><xsl:apply-templates select="lec:content | lec:abstract"/><!-- Fussnoten wenn vorhanden --><xsl:if
test="content/*[not(local-name()=’chapter’)]//lec:footnote"><p>
<xsl:for-eachselect="lec:content/*[not(local-name()=’chapter’)]"><xsl:apply-templates
select=".//lec:footnote" mode="annotation"/></xsl:for-each>
</p><hr/>
</xsl:if>
Eine größere Aufgabe kommt der Nummerierung der Kapitel und den damit verbun-denen Links innerhalb eines Dokumentes zu. Die Nummerierung verläuft dabei ganzeinfach mittels desnumber -Elements.
<xsl:number level="multiple" count="lec:chapter" format="1"/>
Damit wird über beliebig viele Ebenen gezählt und zwar nur allechapter -Elemente.Die Formatierung kann zusätzlich noch angegeben werden und wird hier standardmä-ßig mit einem Punkt getrennt. Mögliches Beispiel wäre etwa8.3.1 . Auf diese Artlassen sich auch Verweise zu den Kapiteln innerhalb des Dokumentes realisieren. Al-lerdings ist es meistens nicht sinnvoll nur eine Datei zu generieren, da die Aufteilung inmehrere Dateien erhöhte Übersichtlichkeit bietet. Auch hierfür können die Nummerie-rungen der Kapitel herangezogen werden, da sie in der benutzten Art eine eindeutigeIdentifizierung bilden. Auf das Aufteilen auf mehrere Dateien wird in Kapitel8.3.3weiter eingegangen.

93
Bei der Aufteilung in mehrere Dateien muss auch eine Navigation eingebaut werden.Die Navigation soll sich für diese Ausprägung entlang der eingegebenen Dokument-struktur bewegen. Daher ist für jede Seite der Vorgänger und ein Nachfolger zu be-stimmen und zu referenzieren. Der Vorgänger ist dabei immer das in der Reihenfolgevorher aufgetretene Kapitel. Ist dieses auf der gleichen Gliederungsebene, so kann ein-fach auf die um eins reduzierte aktuelle Kapitelnummer verwiesen werden. Sollte dasVorgängerkapitel allerdings Unterkapitel besitzen, so stellt das letzte Unterkapitel desVorgängerkapitels den Vorgänger dar. Dazu muss das vorhergehende Kapitel rekursivimmer sein letztes Unterkapitel aufrufen, bis es bei dem der tiefsten Ebene angelangtist. Dieses unterste Kapitel bildet dann den Vorgänger. Ist gar kein Kapitel als Vorgän-ger des aktuellen Kapitels vorhanden, so ist das übergeordnete Kapitel als Vorgängereinzusetzen. Diese Bestimmung des Vorgängers entspricht einer rückwärts gelesenenpreorder-Traversierung der Kapitel im Baum. Die Realisierung wird in XSLT mittelsRekursion durchgeführt. Das folgene Beispiel beschreibt diese Umsetzung für die Be-stimmung des Vorgängers.
Code-Beispiel 7:Die Bestimmung wird überall anhand der Nummerierung der Kapitel durchgeführt.Dazu muss immer mittels desfor-each -Elementes in den jeweiligen Kontext ge-wechselt werden, auch wenn im Fall der Eltern nur ein Knoten in Frage kommt. Fürdie Suche nach dem letzten Unterkapitel eines vorherigen Kapitels wird eine extra Vor-lageget_last_child_pos aufgerufen, die rekursiv sich selber aufruft und immerweiter in die Tiefe absteigt.
<!-- Vorlage zur Bestimmung des Vorgaengers --><xsl:template name="get_back_pos">
<xsl:choose><!-- auf der selben Ebene ist ein vorheriges Kapitel --><xsl:when test="preceding-sibling::chapter">
<!-- merke die aktuelle Kapitelnummer --><xsl:variable name="actual_pos">
<xsl:number level="single" count="chapter"/></xsl:variable><!-- wechsle den Kontext zu den Eltern --><xsl:for-each select="parent::content">
<!-- wechsle den Kontext zu dem vorherigen Kapitel --><xsl:for-each select="chapter[number($actual_pos) -1]">
<!-- bestimme das letzte Unterkapitel des Vorgaengers --><xsl:call-template name="get_last_child_pos"/>
</xsl:for-each></xsl:for-each>
</xsl:when><!-- sonst waehle den Elternknoten --><xsl:otherwise>
<xsl:for-each select="parent::content">

94
<xsl:for-each select="parent::chapter"><xsl:number level="multiple" count="chapter" format="1"/>
</xsl:for-each></xsl:for-each>
</xsl:otherwise></xsl:choose>
</xsl:template>
<!-- Kapitelnummer des tiefsten und letzten Kapitels --><xsl:template name="get_last_child_pos">
<!-- wenn Unterkapitel da sind --><xsl:if test="content/chapter">
<!-- im letzten Kapitel weiter suchen --><xsl:for-each select="content/chapter[last()]">
<xsl:call-template name="get_last_child_pos"/></xsl:for-each>
</xsl:if><!-- sonst ist das aktuelle Kapitel das gesuchte --><xsl:if test="not(content/chapter)">
<xsl:number level="multiple" count="chapter" format="1"/></xsl:if>
</xsl:template>
Es wurden keine Anforderungen zu der Speicherungsart der Daten vorgenommen, den-noch sollte die Möglichkeit gegeben werden die Daten verteilt zu speichern und nichtin einer Datei verwalten zu müssen. Zum Einfügen verteilter Dateien werden dieseüber Attributangaben der Elemente, für die sie eingefügt werden sollen, spezifiziert.Die Auswertung wird in XSLT mittels derdocument -Funktion vorgenommen. Dazuwird die URI der einzubindenen Datei aus dem Attribut an diedocument -Funktionübergeben und auf diese Elemente kann dann genauso zugegriffen werden, wie auf dieElemente des eigenen Dokumentes. Dadurch lässt sich beispielsweise das Literaturver-zeichnis aus einer externen Datei beziehen oder innerhalb des Dokumentes verwalten.Der externe Bezug erhält dabei den Vorrang. Auf welche Art ein solches Verzeichnisverwaltet werden soll, hängt auch von der sonstigen Datenverwaltung ab, die hier nichtnäher betrachtet werden soll.
Code-Beispiel 8:Durch Angabe einerfilelocation als Attribut desbibliography -Elementes,werden die Daten aus der externen Datei bezogen. Dem Test, ob diese Angabe existiert,folgt die Zuweisung des Zugriffs auf dieses Dokument in einer Variablenitems .Dadurch muss der Zugriff auf die Datei nur einmal gemacht werden und an spätererStelle kann über die Variable in der Baumstruktur der Datei navigiert werden.

95
<!-- Attribut filelocation existiert --><xsl:if test="@filelocation">
<!-- Zugriff auf die Datei in Variable speichern --><xsl:variable name="items"
select="document(@filelocation)"/><ul>
<!-- fuer jeden Eintrag im Literaturverzeichnis --><xsl:for-each select="$items/bibliography/item">
<!-- ... Bearbeitung einfuegen ... --></xsl:for-each>
</ul></xsl:if>
Derartige Bearbeitungsschritte können beispielsweise auch für das Zusammenziehenmehrerer getrennt gespeicherter Kapitel zu einem Dokument benutzt werden. Dafürwurden einige Elemente, wie daschapter - oder example -Element, global defi-niert und mit demfilelocation -Attribut versehen. So lassen sich auch Defini-tionen oder Beispiele in einer gesonderten Datei speichern. Diese Vorgehensweise istaber nur für XML-basierte Daten möglich. In dieser XSL-Transformation wird auchvorausgesetzt, dass es sich nur um nach dem Schema gültige XML-Dokumente han-delt. Andere Dokumente müssten aufgrund ihrer Datenstruktur verarbeitet werden. FürDateien, die keine XML-Dateien sind, ist das nicht so einfach zu lösen. Eine typischesBeispiel für die Notwendigkeit andere Dateien einzulesen, ist die Integration von Bei-spielcode. So kann an diversen Stellen zwar Code, der alle seine Leerzeichen, Tabs undZeilenumbrüche beibehält, in ein XML-Dokument integriert werden, aber dieser mussdirekt in dem XML-Dokument eingefügt werden. Mittels derdocument -Funktionist das aus einer externen nicht-XML-Datei nicht möglich. Derartige Anwendungenkönnen nur über eigene Erweiterungsfunktionen gelöst werden. In dem aktuellen Ar-beitspapier zu XSLT 2.0 [W3CXSLTb] ist bereits eineunparsed-text -Funktionaufgenommen, die abhängig von der übergebenen URI eine Datei einliest und denInhalt als String und ohne weitere Verarbeitung direkt in den Ergebnisbaum einfügt.Damit lassen sich in der Zukunft beispielsweise externe Codeauszüge einfügen.
8.3.2 Sprachunterstützung
Ein weiterer Einsatz derdocument -Funktion dient der Unterstützung von verschie-denen Sprachen. Über die Angabe der Sprache als Attribut des lecture-Elementes wirddie richtige Auswahl der durch die Transformation hinzugefügten Bezeichnungen ge-wählt. Diese Bezeichnungen werden in einer externen Datei language.xml gespeichertund ihr Zugriff wird durch diedocument -Funktion realisiert. Für jede Variable ist indieser Datei ein Element gespeichert, das für jede gültige Sprache ein Element mit dem

96
entsprechenden Namen enthalten kann. Zur Unterstützung von Deutsch und Englischsieht der Beginn der Datei folgendermaßen aus:
<language><table_of_contents>
<de>Inhaltsverzeichnis</de><en>Table of contents</en>
</table_of_contents><content>
<de>Inhalt</de><en>Content</en>
</content>...
</language>
Die Erweiterung um eine Sprache erfolgt durch die Angabe eines dementsprechendenSprachelementes in jeder Variablen und beim Hinzufügen einer neuen Variablen mussnur auf die festzulegenden Sprachen geachtet werden. Um diese nun auch innerhalbdes Stylesheets verwenden zu können, müssen XSLT-Variablen erzeugt und die Werteeingelesen werden. Die damit verbundenen Initialisierungen der Variablen werden ineiner externen XSL-Datei (variable.xsl) vorgenommen, die mittelsinclude in daseigentliche Stylesheet eingefügt wird. Das folgende Beispiel zeigt einen Ausschnittder Datei variable.xsl für die Initialisierung einer Variablen.
Code-Beispiel 9:Die Sprachauswahl für das Dokument wird demlanguage -Attribut deslecture -Elementes entnommen. Der Zugriff auf die Sprachdatei wird einmal vorgenommenund in einer Variablen gemerkt. Zur Initialisierung der Variablen wird dieser Zugriffmit Angabe der Variablen auf die Sprachdatei gemacht und der Wert für die angegebe-ne Sprache eingesetzt.
<!-- auswaehlen der aktuellen Sprache --><xsl:variable
name="language" select="/lec:lecture/@language"/>
<!-- Zugriff auf die Elemente in der Sprachdatei --><xsl:variable name="lang_vars"
select="document(’language.xml’)/language"/>
<!-- Variable fuers Inhaltsverzeichnis --><xsl:variable name="inhaltsverzeichnis">
<!-- passendes Element nach Elementen durchsuchen --><xsl:for-each select="$lang_vars/table_of_contents">

97
<!-- initialisieren mit dem Wert des Elementes,das der Sprachangabe entspricht -->
<xsl:value-of select="*[local-name()=$language]"/></xsl:for-each>
</xsl:variable><!-- ... weitere Variablen -->
8.3.3 Flexibilität der Stylesheet Prozessoren
Der Einsatz von XML-Dokumenten als Grundlage für die Daten und XSLT zur Gene-rierung der Ausgabe, hält sich an einen Standard, der nicht von etwaigen Programmenabhängig macht. Doch das gilt nur, solange auch die XSLT-Prozessoren sich alle anden Standard halten und diesen vollständig abdecken. In Anbetracht der Aktualitätvon XSLT ist das jedoch nicht ganz der Fall. Zum einen ist die Unterstützung nicht beiallen Prozessoren vollständig gegeben, wie auch schon in Kapitel3.5 angesprochen,und zum anderen fehlen wichtige Funktionen. Darunter fallen die Ausgabe in mehrereDateien und die Integration von Dateien, die nicht auf XML basieren. Um derartigeFunktionalitäten zu erreichen müssen Erweiterungsfunktionen eingesetzt werden, dieallerdings abhängig von dem eingesetzten XSLT-Prozessor sind, vgl. Kapitel3.6.
Für die Realisierung wurde die Unterstützung von Xalan zur Ausgabe in mehrere Da-teien benutzt. Ebenso wurde für den Fall, dass ein anderer Prozessor eingesetzt wird,eine Abfrage eingebaut, die dann die Ausgabe in eine einzelne Datei umlenkt, wie esmit den Standardfunktionalitäten von XSLT möglich ist. Auch mit der Unterstützungvon Saxon wurde experimentiert, der in seiner aktuellen Version schon einige Funk-tionalitäten der Diskussion um XSLT 2.0 unterstützt, die aber noch nicht standardisiertsind. Die dementsprechenden Elemente sind noch nicht in anderen XSLT-Prozessorenverfügbar, weshalb diese einen Fehler melden. Die Aufteilung auf mehrere Dateienwurde deshalb mit Xalan umgesetzt, der sich sehr genau an den Standard hält.
Code-Beispiel 10:Beispiel zum Aufteilen auf Dateien und Abfang von Prozessoren Der Test, ob dasvon Xalan unterstützte Schreiben in externe Dateien aufgerufen werden kann, findetanhand der Verfügbarkeit desredirect:write -Elementes statt und wird in derVariablenxalan_redirect abgespeichert. Anhand dieses Testergebnisses werdenan unterschiedlichen Stellen verschiedene Ausgaben erstellt. So wird wie schon inBeispiel 3.6.1 beschrieben die Ausgabe auf eine oder mehrere Dateien verteilt. Wichtigist dabei die unterschiedliche Behandlung einiger Elemente zu berücksichtigen, wiebeispielsweise Links innerhalb des Dokumentes oder Fußnoten.
<xsl:variable name="xalan_redirect"select="element-available(’redirect:write’)"/>

98
<xsl:template match="/"><xsl:choose>
<!-- Der Xalan unterstuetzt das Aufteilen in mehrere Dateiendurch ein eigenes Element -->
<xsl:when test="$xalan_redirect"><!-- Startseite schreiben --><redirect:write select="’index.xhtml’">
<!-- Der Seitenkopf bleibt gleich --><xsl:processing-instruction name="xml-stylesheet">
<xsl:text>href="insert/mathmlstyle/mathml.xsl"type="text/xsl"</xsl:text>
</xsl:processing-instruction><html>
<head><title>
<xsl:value-of select="lec:lecture/lec:title"/></title>
<link rel="stylesheet" type="text/css" href="format.css"/></head><!-- Seitenkörper mit Inhalt --><body>
<!-- Beginn der Seite ist immer gleich --><xsl:call-template name="firstside"/>
<!-- Abstrakt und gesamten Inhalt aufrufen --><xsl:apply-templates select="lec:lecture/lec:abstract |
lec:lecture/lec:content"/><!-- Fussnoten, die nicht in Unterkapiteln stecken --><xsl:if test="lec:lecture/lec:content/*
[not(local-name()=’chapter’)]//lec:footnote |lec:lecture/*[not(local-name()=’content’)]//lec:footnote">
<p><xsl:apply-templates select="lec:lecture/lec:content/*
[not(local-name()=’chapter’)]//lec:footnote |lec:lecture/*[not(local-name()=’content’)]//lec:footnote" mode="annotation"/>
</p><hr/>
</xsl:if><!-- Seitennavigation einfügen--><xsl:call-template name="navigation">
<xsl:with-param name="back" select="’’"/><xsl:with-param name="next" select="’inhalt’"/>
</xsl:call-template>

99
</body></html>
</redirect:write><!-- Verarbeitung des Inhaltsverzeichnisses --><!-- ... --><!-- Verarbeitung des Literaturverzeichnisses --><!-- ... -->
</xsl:when><!-- Prozessor kann nur in eine Datei schreiben --><xsl:otherwise>
<!-- Seitenkopf einfügen, siehe oben --><!-- ... --><html xmlns="http://www.w3.org/1999/xhtml">
<head><!-- ... --></head><body>
<!-- Erste Seite aufbauen --><xsl:call-template name="firstside"/><!-- Alle Inhalte zur Verarbeitung aufrufen --><xsl:apply-templates select="lec:lecture/lec:abstract |
lec:lecture/lec:content |lec:lecture/lec:bibliography |lec:lecture/lec:table_of_contents |lec:lecture/lec:content/lec:chapter"/>
<!-- Alle Fussnoten an die Seite anhaengen --><p>
<xsl:apply-templates select="//lec:footnote"mode="annotation"/>
</p><hr/>
</body></html>
</xsl:otherwise></xsl:choose>
</xsl:template>
Beim Verteilen der Ausgabe auf mehrere Dateien ist zu beachten, dass diese unter-schiedliche Bezeichnungen haben. Wird beispielsweise beim Aufruf des Prozessorszur Generierung eine Dateiindex.xhtml angegeben, so kollidiert diese mit dervon dem Stylesheet erzeugtenindex.xhtml -Datei. Werden derartige gleichzeitigschreibende Zugriffe auf eine Datei gemacht, so können Daten verloren gehen.

100
8.3.4 MathML
MathML ist eine XML-Anwendung zur Beschreibung von mathematischen Formeln.Durch die Kombination von XHTML und MathML lassen sich mathematische For-meln auch in Textseiten darstellen. Da es sich um eine XML-Anwendung handelt, istdie Integration in XHTML über die Namensraumspezifikation möglich. Da allerdingsnicht alle Browser MathML darstellen können, sind dafür eventuell Plug-Ins erforder-lich. Das ist auch der Grund, weshalb verschiedene Möglichkeiten existieren, um eineDarstellung der MathML-Elemente zu erzwingen. Beispielsweise lässt sich ein Sty-lesheet, sowohl XSLT als auch CSS, referenzieren, das zur Darstellung von MathMLgenutzt werden soll.
Mozilla verfügt ab der Version 0.9.5, Netscape ab Version 7.0, über einen integrierten,nativen MathML-Renderer. Das bedeutet, dass ohne weitere Angaben die mit MathMLdefinierten Elemente darstellbar sind. Dazu müssen unter Umständen nur geeignetemathematische Fonts herunter geladen werden. Die früheren Versionen Mozilla 0.9.4und Netscape 6.1 unterstützen dahingegen nur die Darstellung mathematischer For-meln mittels XSLT.
Mit der Verwendung von XSLT ist eine Möglichkeit gegeben, um MathML auch imMS Internet Explorer darzustellen. Dieser unterstützt ab Version 6.0 die aktuelle XSLTEmpfehlung 1.0. Die älteren Versionen 5.0 und 5.5 wurden mit einem XSLT-Prozessorausgeliefert, der anhand des Arbeitspapieres zur Entwicklung der XSLT-Empfehlungarbeitet. Um diese Browser auch empfehlungstauglich zu machen, muss MSXML 3.0,ein von Microsoft geschriebenes XML-Paket mit XSLT-Prozessor, instaliert werden.So lassen sich die vom W3C bereitgestellten XSL-Transformationen einsetzen und dieElemente darstellen.
Für den Internet Explorer existieren noch weitere Plug-Ins, die zur Darstellung vonMathML benutzt werden können. Allerdings interpretiert der Internet Explorer dasMathML-Element und seinen Inhalt nicht in einer XHTML-Seite. Nur innerhalb einerXML-Datei mit dementsprechender Dateiendungxml wird dasmath -Element wei-ter verarbeitet. Das W3C beschreibt die aktuelle Unterstützung aller Browser und dieProblematiken dabei in [W3CMathML].
MathML ist in zwei unterschiedliche Definitionsarten unterteilt. Die eine Art dient derBeschreibung der Darstellung (presentation-MathML), die andere des mathematischenInhaltes (Content-MathML). Der Unterschied wird an dem folgenden, allgemein be-nutzten Beispiel erläutert.
Beispiel 8.3.1:Die Beschreibung der Formel(a + b)2 kann auf zwei Arten erfolgen. Die Präsenta-tionsbeschreibung erfolgt anhand der resultierenden Darstellung, indem die Formelin der Reihenfolge der Ausführung von innen nach außen beschrieben wird. Hierbeibeginnt das mit dem Hochstellenmsup einer Zahlmn zu dem Term in Klammernmfenced . Die Angabe, welche Klammern benutzt werden sollen ist optional, macht

101
aber den Verwendungszweck deutlich. Der innere Term besteht aus Variablenmi , diemit einem Operatormoverknüpft sind.
<msup><mfenced open="(" close=")">
<mi>a</mi><mo>+</mo><mi>b</mi>
</mfenced><mn>2</mn>
</msup>
Die inhaltliche Beschreibung entspricht der preoder-Traversierung eins Baumes. Da-zu werden inapply -Elementen die auszuführenden Teile der Formel eingefasst. Diebeginnt mit der Beschreibung, dass ein Exponentpower zu dem folgenden Element,das aus einer weiteren Formel besteht, existiert. Die Operanden besitzen in dieser Dar-stellung alle eigene Elemente, so auch derplus -Operator, dem zwei Variablencifolgen. Im Anschluß wird nun der Exponent zu der inneren Formel als Zahlenwertcnfestgelegt.
<apply><power/><apply>
<plus/><ci>a</ci><ci>b</ci>
</apply><cn>2</cn>
</apply>
Die inhaltliche Beschreibung ist nicht direkt auf die Darstellung zu übertragen, wes-halb diese Formelbeschreibung auch nicht gleichermaßen gut dargestellt werden kann.Die Unterstützung der Präsentationsbeschreibung ist weitaus häufiger gegeben, da beiihr keine inhaltliche Interpretation vorgenommen werden muss.
Zum Einbinden in XHTML spielt es keine Rolle in welcher Form MathML verwendetwurde. Dazu werden folgende Angaben vom W3C empfohlen [W3CMathML]:
• Die Angabe eines Stylesheets zur Darstellung der MathML-Elemente.
<?xml-stylesheet type="text/xsl"href="http://www.w3.org/Math/XSL/mathml.xsl"?>

102
• Da der Internet Explorer standardmäßig in den Sichterheitseinstellungen das La-den von Stylesheets fremder Server verbietet, sollte eine lokale Kopie dieserStylesheets auf dem gleichen Server hinterlegt werden und auf diese verwiesenwerden.
<?xml-stylesheet type="text/xsl"href="insert/mathmlstyle/mathml.xsl"?>
• Soll genau festgelegt werden, welche Möglichkeit zum Rendern der mathema-tischen Formeln benutzt werden soll, so kann dieses optional über Preferenzeneingestellt werden.
• Das Einfügen der MathML-Beschreibung sollte direkt in dem XHTML-Doku-ment erfolgen. Dazu wird die Beschreibung in einemmath -Element mit Na-mensraumangabe vorgenommen:
<math xmlns="http://www.w3.org/1998/Math/MathML">
Diese Angaben sind in der XSL-Transformation der Ausgabedatei hinzuzufügen. DieNamensraumangabe für dasmath -Element wird einfach in die Ausgabe mit hinein-geschrieben. Der Stylesheet-Verweis muss allerdings direkt zu Begin jeder XHTML-Datei vor demhtml -Tag vorgenommen werden. Da es sich hierbei um eineProcessing-Instructionhandelt, also um eine Anweisung, die das Verarbeitungsprogramm, hier derBrowser, ausführen soll, muss diese auch als eine solche definiert werden. Der folgen-de Ausdruck liefert das gewüschte Ergebnis:
<xsl:processing-instruction name="xml-stylesheet"><xsl:text>href="insert/mathmlstyle/mathml.xsl"
type="text/xsl"</xsl:text>
</xsl:processing-instruction>
Die Darstellung zweier mathematischer Formeln mit Mozilla ist in Abbildung24 zusehen. Die Formeln wurden hellrot hervorgehoben. Der Ausschnitt ist aus dem Bei-piel entstanden, das in Kapitel9 weiter erläutert wird. Der Internet Explorer bearbeitetallerdings die Datei anhand der Dateiendung, weshalb er sie nicht als XML-Datei in-terpretiert und die Formeln nicht anzeigt.
8.4 Verschiedene Ausprägungen
Um aus dem Dokument unterschiedliche Ausprägungen zu erzeugen, müssen ausrei-chend Informationen aus dem Inhalt hervorgehen. Das geschieht zum einen durch die

103
Abbildung 24:Ausschnitt XHTML mit MathML
Struktur der Elemente und darauf festgelegten Regeln, die für jede Ausprägung de-finiert werden müssen, und zum anderen durch die Zusatzinformationen des Autors.Diese Angaben werden durch Attribute zu den jeweiligen Elementen hinzugefügt.
Zur Erzeugung von verschiedenen Ausprägungen müssen zuerst die Regeln festgelegtwerden, anhand denen die Ausprägungen bestimmt werden sollen. Das wird im Fol-genden beispielhaft für ein Skript und eine Präsentation durchgeführt.
8.4.1 Allgemeine Bestimmmung von Ausprägungen mit XSLT
Die Festlegung welche Informationen in einer Ausprägung erscheinen sollen, werdenanhand von Attributen vorgenommen, wie es bereits in Kapitel8.2.3vorgestellt wurde.Die weitere Verarbeitung der Zusatzinformationen muss im Stylesheet vorgenommenwerden. Da nicht vorausgesetzt werden kann, dass alledefault-Werte gesetzt wurden,da das abhängig von dem Editor beziehungsweise Validator ist, der verwendet wird,muss die Grundlogik der einzelnen Ausprägungen mit in der Transformation berück-sichtigt werden. Für die Betrachtung des Skriptes heisst das, dass alle Elemente dar-gestellt werden, wenn keinscript -Attribut ausgewertet werden muss, und für diePräsentation, dass nur Titel und Schlüsselwörter aufgenommen werden.
Code-Beispiel 11:Das folgende Template kann auf jedes beliebige Element angewendet werden, wenngetestet werden soll, ob das Element in dieser Ausprägung dargestellt werden soll.Dazu muss einfach bei der Verarbeitung einer Vorlage zu einem Element diese Ab-frage vorangestellt werden. Die Abfrage berücksichtigt im ersten Test, ob überhauptein script:on -Attribut existiert. Ist dies nicht der Fall, so wird das Element über-nommen. Existiert das Attribut, so muss es in Verbindung mit demscript:delta -Attribut anhand der Tabelle2 ausgewertet werden.

104
<xsl:template match="*" mode="scripttest"><!-- Elemente ohne Auspraegungsattribute erscheinen --><xsl:if test="not(@script:on)">true</xsl:if><!-- Element wird per Standard dargestellt --><xsl:if test="@script:on=’true’"><xsl:choose>
<!-- überpruefe delta bezueglich der auspraegung --><xsl:when test="@script:delta">
<xsl:variable name="del" select="string(@script:delta)"/><!-- wenn delta existiert, die Liste durchsuchen --><xsl:if test="contains($del, $ausinstanz)">false</xsl:if><xsl:if
test="not(contains($del, $ausinstanz))">true</xsl:if></xsl:when><xsl:otherwise>true</xsl:otherwise>
</xsl:choose></xsl:if><!-- Element nicht im Standard --><xsl:if test="@script:on=’false’">
<xsl:choose><!-- überpruefe delta bezueglich der auspraegung --><xsl:when test="@script:delta">
<xsl:variable name="del" select="string(@script:delta)"/><!-- wenn delta existiert, die Liste durchsuchen --><xsl:if test="contains($del, $ausinstanz)">true</xsl:if><xsl:if
test="not(contains($del, $ausinstanz))">false</xsl:if></xsl:when><xsl:otherwise>false</xsl:otherwise>
</xsl:choose></xsl:if>
</xsl:template>
Dieses Template, beziehungsweise sein Pendant zur Abfrage der Zugehörigkeit zurPräsentationsausprägung, kann in jedem Stylesheet unverändert wiederverwendet wer-den, da es nur der Abfrage eines Wahrheitsausdruckes entspricht.
Ob eine Unterstützung der verschiedenen Multimedia-Objekte in den Formaten derAusprägungen gegeben ist, muss in jedem Fall speziell entschieden werden. So kannin der Generierung von HTML-Dateien sowohl ein Applet oder eine Grafik eingebettetwerden, auch mit den eventuellen Ersatzdarstellungen, während zur Generierung vonPDF über XSL-FO keine Applets verwendet werden können. Daher kann in der Ver-arbeitung von XML-Daten zu XSL-FO direkt eine Ersatzdarstellung benutzt werdenund das Applet wird vernachlässigt.

105
8.4.2 Skript
Das komplette Skript sollte sowohl zu XHTML-Seiten als auch in eine druckbare Formmittels PDF aufbereitet werden. Die wesentlichen Verarbeitungsschritte dafür wurdenin den vorhergehenden Kapiteln zur XHTML-Generierung dargestellt. Für die Ver-arbeitung vieler Inhalte bleiben die in XSL-FO sehr ähnlich, nur dass die speziellenXSL-FO-Elemente statt der XHTML-Tags gesetzt werden müssen und über einzelneausprägungsspezifische Unterstützungen entschieden werden muss.
Ein wesentlicher Unterschied liegt in dem Hinzuziehen von Layoutinformationen. InXHTML können diese entweder direkt in den Tags angegeben oder mittels CSS auchextern festgelegt werden. Dazu wird einfach ein Link zu der entsprechenden CSS-Datei in die XHTML-Ausgabedateien integriert. Eine Änderung des Layouts auf derBasis von CSS-Informationen kann somit leicht von außen vorgenommen werden. Da-mit besteht die Möglichkeit mit spezifischen Designs die Ausgabe ohne Veränderungenan den Transformationen mit verschiedenem Layout zu versehen.
In XSL-FO werden die Layoutinformationen mittels Attributen den einzelnen Elemen-ten hinzugefügt. Um einige allgemeine Informationen für alle Elemente zu verwendenund eine spätere Anpassung zu erleichtern, können die layoutspezifischen Attributein von XSLT zur Verfügung gestelltenattribute-set -Elementen definiert und anden verwendeten Stellen integriert werden.
Code-Beispiel 12:Die Verwendung vonattribute-set ’s ermöglicht die Einstellung von Attribut-werten, die an verschiedenen Stellen wieder benutzt werden. Hier wird ein Rahmendefiniert, der nur aus dem unteren Strich des Rechtecks besteht. Diese Attribute wer-den für denstandard-header, der derRegion-beforeentspricht, benutzt, um eine Liniezur Abgrenzung der restlichen Seite zu ziehen. Es müssen dabei mehrere Werte gesetztwerden, da ansonsten für die nicht gesetzten Werte die Standardwerte gelten und damitdort Linien gezeichnet werden würden.
<xsl:attribute-set name="underline-border">
<xsl:attribute name="border-before-style">solid</xsl:attribute><xsl:attribute name="border-after-style">solid</xsl:attribute><xsl:attribute name="border-start-style">solid</xsl:attribute><xsl:attribute name="border-end-style">solid</xsl:attribute><xsl:attribute name="border-before-width">0mm</xsl:attribute><xsl:attribute name="border-after-width">.1mm</xsl:attribute><xsl:attribute name="border-start-width">0mm</xsl:attribute><xsl:attribute name="border-end-width">0mm</xsl:attribute>
</xsl:attribute-set>

106
Derartige Attribute lassen sich für alle möglichen Formatierungsanweisungen festle-gen und in eine externe Datei auslagern. Diese ist dann einfach zu verändern oder zuersetzen.
Eine Problematik stellt die Integration von MathML in XSL-FO dar. Durch die Rück-führung von XSL-FO auf TeX beispielsweise mit PassiveTex wird die Bearbeitungder mathematischen Formeln in TeX vorgenommen. Damit wird eine hohe Qualitätder Formeldarstellung erlangt. Der XSL Formatter von Antenna House unterstützt dasEinbinden von MathML als Grafik oder direkt und benötigt den MathML Player zumRendern. Auf die gleiche Art können auch SVG-Grafiken integriert werden, die miteinem SVG Viewer gerendert werden. SVG wird auch von FOP mit unterstützt undstellt nach dem aktuellen Stand die bessere Unterstützung dar. Daher ist noch nicht zurdirekten Integration von MathML zu raten, sondern der Umweg über Grafiken vorzu-nehmen, indem MathML als SVG oder GIF gerendert und in XSL-FO eingebundenwird.
Für die weitere Realisierung wurde FOP benutzt, da dieser frei verfügbar ist und damitkeine Sicherheitsmechanismen integriert hat, wie das bei den anderen Formatierernder Fall ist, beispielsweise das Fehlen jeder ungeraden Seite mit Begin der elften Seite.Dennoch gibt es bei der Verwendung einige Nachteile, wie die fehlende MöglichkeitLeerzeichen zu behalten, siehe auch AnhangC.
8.4.3 Präsentation
Die Präsentationsdarstellung der XML-Daten soll in einem animierbaren Format rea-lisiert werden. Dazu bietet sich SVG an, da es nicht nur animiert sondern auch XML-basierend ist.
Bei der Realisierung sind allerdings einige Schwachstellen von SVG aufgedeckt wor-den. So gibt es in SVG keine Möglichkeit wie etwa in HTML oder XSL-FO Textebeliebiger Länge vernünftig darzustellen. So können die Texte zwar beliebig lang sein,aber sie werden nicht umgebrochen und damit in dem Fall unvollständig angezeigt.Auch die Anzahl der Texte, die auf eine Seite passen, müsste im Vorfeld von Hand be-rechnet werden. In den Anforderungen an einen neuen SVG-Standard in der Version1.2 oder 2.0 [W3CSVGR] sind aus dem hohen Bedarf an derartige Manipulationsmög-lichkeiten für Texte auch die Forderungen nach Textumbrüchen und Positionierungs-eigenschaften wie zentrieren eingegangen. Erst mit Unterstützung dieser Funktionali-täten kann eine ansprechende Präsentation mit SVG erzeugt werden.
In der Umsetzung werden die Daten, die auf jeweils einer Folie erscheinen sollen,innerhalb einer Gruppe dort positioniert und als unsichtbar deklariert. Damit werdenalle Folien erstellt und nur die erste Folie mit dem Titel und dem Autor wird als erstessichtbar eingefügt und dargestellt.

107
Code-Beispiel 13:Für die Folie des Inhaltes werden alle Titel zusammen in den Text einer Gruppe ein-gefasst. Zu Begin der Präsentation ist diese Gruppe unsichtbar. Alle in ihr enthaltenenElemente wie der Text besitzen die Sichtbarkeitseigenschaftinherit , das bedeutet,dass sie die Sichtbarkeit ihrer übergeordneten Gruppe erben. Über die Nummerierungaller Knoten im Dokument kann die Nummer als ID für den Text verwendet werden,da sie eindeutig ist. Die ID’s dienen zum Wiederfinden der verschiedenen Folien inder weiteren Verarbeitung und damit der Abfolge der Präsentation. Ein durchsichtigesRechteck wird über die gesamte Gruppe gelegt, um auf einen Mausklick reagieren zukönnen.
<!-- Inhaltsverzeichnis in einer Gruppe --><g style="font-family:Verdana" visibility="hidden">
<!-- Bestimmung der ID anhand der Knotenposition --><xsl:variable name="textid">
<xsl:number count="*" level="any"/></xsl:variable><!-- Knotenposition als ID-Attribut setzen --><xsl:attribute name="id"><xsl:value-of select="$textid"/></xsl:attribute>
<!-- Durchsichtiges Rechteck zum Klicken --><rect width="800" height="600" fill="blue"
visibility="visibile" opacity="0"><!-- Funktion bestimmen, die bei Klick aufgerufen wird
mit Uebergabe des ausloesenden Events, der aktuellen ID,der folgenden ID und der maximalen Knoten im Baum -->
<xsl:attribute name="onclick">clicked(evt,’<xsl:value-ofselect="$textid"/>’,’<xsl:value-of select="$textid +1"/>’,’<xsl:value-of select="$nodenr"/>’)</xsl:attribute>
</rect>
<!-- Text einfuegen mit geerbter Sichtbarkeit --><text x="5%" y="10%" fill="blue" style="font-size:20"
visibility="inherit"><!-- Textzeile fuer die Ueberschrift --><tspan style="font-size:25" visibility="inherit">
<xsl:value-of select="$inhaltsverzeichnis"/></tspan><!-- Alle Titel einfuegen --><xsl:apply-templates
select="/lec:lecture/lec:content//lec:title"mode="list-of-content"/>
</text></g>

108
Alle Inhalte wurden zudem mit einer Funktion versehen, die bei einem Klick auf denText aufgerufen wird. Diese Funktion kümmert sich um die Darstellung der neuenFolie, indem diese sichtbar und die alte unsichtbar gemacht wird. Die Definition derFunktion wird in dem zu Begin der SVG-Datei stehendenscript -Tag innerhalb ei-nesCDATA-Abschnittes mittels ECMA-Script vorgenommen.
Code-Beispiel 14:Die clicked -Funktion soll immer dann aufgerufen werden, wenn auf einen Textoder ein Bild geklickt wurde und die nächste Folie sichbar gemacht werden soll. Dazuwird rekursiv nach der nächsten vorhandenen ID im SVG-Baum gesucht. Wenn diesegefunden wurde, wird der alte Text unsichtbar und der neue sichtbar gemacht, indemdie dazugehörigen Attribute gesetzt werden.
<script type="text/ecmascript"><![CDATA[//beim Klick newtextid-Element fuer textid-Element setzen
aufhoeren bei maxcountfunction clicked(evt,textid,newtextid,maxcount) {
var newText = svgDocument.getElementById(newtextid);//neues text-Element gefundenif(newText) {
var oldText = svgDocument.getElementById(textid);newText.setAttribute(’visibility’,’visible’);oldText.setAttribute(’visibility’,’hidden’);
} else {var newid = parseInt(newtextid)+1;if(maxcount > newid) {
clicked(evt,textid,newid,maxcount);}
}}
]]></script>
Das Ergebnis und die Funktionsweise der Anwendung ist am besten in dem Beispielzu sehen, das im folgenden Kapitel beschrieben wird.

109
9 Anwendung
Im Anschluss an die Realisierung soll nun ein Beispieldokument, das die in dem XMLSchema definierte Struktur enthält, betrachtet werden. Daran werden die verschiede-nen Transformationen getestet und Auszüge aus der Darstellung als XHTML-, PDF-und SVG-Datei gezeigt.
9.1 Beispieldokument
Als Beispieldokument wird ein Auszug vom Computergrafikskript von Olaf Müllerund Ralf Kunze aus dem Sommersemester 2002 verwendet. Dieses wurde in einigenTeilen ein wenig überarbeitet um die verschiedenen Funktionen in dem Zusammen-spiel von XML Schema und XSLT zu verdeutlichen.
Auszug eines Kapitels aus dem Beispieldokument:
<chapter><title>Definition</title><content>
<definition pres:on="true"><term pres:on="false" script:on="true" script:delta="test">
Grafische Datenverarbeitung</term><comment>
Der Begriff <newterm>Grafische Datenverarbeitung</newterm>umfaßt<para>
<keyword pres:on="true">generative Computergrafik</keyword>Erzeugung künstlicher Bilder aus einer Beschreibung:<list>
<item>Eingabe der Beschreibung</item><item>Manipulation der Beschreibung</item><item>Ausgabe des zur Beschreibung gehörigen Bildes</item>
</list><keyword pres:on="true">Bildverarbeitung</keyword>
Bildveränderung, so daß der Informationsgehalt leichtererkennbar wird:
<list><item>Veränderung von Bilddaten (z.B. Drehung)</item><item>Verbesserung von Bilddaten (z.B. Kontrasterhöhung)</item><item>Vereinfachung von Bilddaten (z.B. Farbreduzierung)</item>
</list><keyword pres:on="true">Mustererkennung</keyword>
Analyse von Bilddaten durch Zerlegung in bekannte graphische

110
Objekte:<list>
<item>z.B. wo verläuft die Straße?</item><item>z.B. um welchen Buchstaben handelt es sich?</item>
</list></para>
</comment></definition><para>
In dieser Vorlesung geht es ausschließlich um generativeComputergrafik!
</para></content>
</chapter>
Die Gültigkeit des Dokumentes anhand des vorgegebenen Schemas wurde mit demXSV und Xerces-J getestet. Beide prüfen die XML-Datei anhand des Schemas, das inder Datei mittels desxsi:schemaLocation -Attributes angegeben ist.
Der Aufruf mittels XSV erfolgt im eigenen Verzeichnis durch:
> xsv cgteil1.xml
Ein gekürzter Auszug des Ergebnisses der Validierung mit eingebauten Kommentaren:
<?xml version=’1.0’?><xsv xmlns=’http://www.w3.org/2000/05/xsv’
docElt="{http://www-lehre.inf.uos.de/~tschnied/lecture}lecture"instanceAssessed="true" instanceErrors="0"rootType="[Anonymous]" schemaErrors="0"schemaLocs="http://www-lehre.inf.uos.de/~tschnied/lecture ->lecture.xsd" target="file:///D:/Programme/XSV/cgteil1.xml"validation="strict"version="XSV 2.2-4 of 2003/01/21 23:23:04">
<!-- Das Schema und das XML-Dokument sind fehlerfrei --><!-- Die Schemadateien, die hinzugeladen werden -->
<schemaDocAttempt URI="file:///D:/Programme/XSV/lecture.xsd"namespace="http://www-lehre.inf.uos.de/~tschnied/lecture"outcome="success" source="schemaLoc"/>
<schemaDocAttempt URI="file:///D:/Programme/XSV/markedtext.xsd"namespace="http://www-lehre.inf.uos.de/~tschnied/lecture"outcome="success" source="include"/>
<!-- ... gleiches gilt für die Auspraegungsschemata .. --><!-- ... presentation.xsd ... stamp.xsd ... script.xsd -->
<schemaDocAttempt URI="http://www.w3.org/1998/Math/MathML"namespace="http://www.w3.org/1998/Math/MathML"

111
outcome="failure" source="new namespace"><notASchema filename="http://www.w3.org/1998/Math/MathML">
couldn’t open</notASchema>
</schemaDocAttempt><!-- Suche nach einem Schema zur Validierung fuer MathML --><!-- ist fehlgeschlagen -->
<XMLMessages>Error: can’t find address for host "www.w3.org"in http URL "http://www.w3.org/1998/Math/MathML"
</XMLMessages></xsv>
Zwar ist in der obigen Ausgabe ein Fehler aufgetreten, da keine Validierung der Math-ML-Elemente vorgenommen werden konnte, aber dennoch ist das Schema und dieXML-Instanz fehlerfrei. Das liegt an der Definition desprocessContents auflax bei den MathML-Elementen, siehe Kapitel8.2.1. Damit wird im XSV zwar dieseMeldung ausgegeben, aber das Dokument trotzdem als gültig erkannt, während beimEinsatz von Xerces keine Meldung dazu ausgegeben wird.
Zur Validierung kann beim Xerces-J einfach ein mitgeliefertes Beispielprogramm auf-gerufen werden, bei dem die entsprechenden Prüfungseigenschaften des Parsers an-gestellt werden. Für den mitgelieferten SAX-Parserorg.apache.xerces.par-sers.SAXParser funktioniert das beispielsweise mit einem Zählprogramm für dieElemente und Attribute:
> java sax.Counter -np -v -s -f -dv -m cgteil1.xml
cgteil1.xml: 1820 ms, 743920 bytes(433 elems, 810 attrs, 0 spaces, 35224 chars)
Dabei muss natürlich Java und der Xerces korrekt installiert sein und die Xerces-jar-Dateien müssen auf dem Klassenpfad liegen.
9.2 Skript in XHTML
Auf das gültige Dokument soll eine XSL-Transformation angewendet werden, die dar-aus XHTML erzeugt. Da einige Erweiterungsfunktionen von Xalan genutzt wurden,wird dieser auch zur Transformation verwendet. Der Prozessor wird mit der XML-Datei, dem zu verwendenden Stylesheet und der Ausgabedatei aufgerufen:
java org.apache.xalan.xslt.Process -IN cgteil1.xml-xsl lecture.xslt -out cgnew.html

112
Abbildung 25:Beispielkapitel in XHTML
Xalan erzeugt für jedes Kapitel einzelne XHTML-Dateien. In Abbildung25 ist dieXHTML-Seite für das oben beispielhaft gezeigte Kapitel dargestellt.
Die Verwendung von Saxon 7 erzeugt aus der Transformation eine einzelne XHTML-Datei mit allen Inhalten. Für mehrere Ausgaben müsste die Transformation mittels derim Working Draft zu XSLT 2.0 benutzten Elemente zur Mehrfachausgabe umgeschrie-ben werden. In Abbildung26ist der entstandene Ausschnitt für das gleiche Kapitel wiezuvor dargestellt, der mit folgendem Aufruf erzeugt wird:
java -jar saxon7.jar -o cg.xhtml cgteil1.xml lecture.xslt
9.3 Skript in PDF
Zur Generierung der FO-Datei wird wieder eine XSL-Transformation angewendet,wie das bereits in dem vorherigen Kapitel beschrieben wurde. Die Verwendung vonErweiterungsfunktionen zur Generierung vieler Ausgabedateien ist zur Erzeugung vonXSL-FO nicht notwendig, weshalb die Wahl des Prozessors entfällt.
java org.apache.xalan.xslt.Process -IN cgteil1.xml-xsl folecture.xsl -out lecture.fo
Die daraus entstandene FO-Datei kann direkt an den Formatierer übergeben werden,der daraus eines seiner unterstützten Formate, wie hier PDF, generiert. Dabei über-nimmt der Formatierer automatisch die Bestimmung der einzelnen Seiten. Der Aufrufvon FOP setzt Java voraus, sowie Xalan und Xerces als XSLT-Prozessor und XML-Parser. Die weiteren benutzten Dateien sind dem Klassenpfad zu entnehmen.

113
Abbildung 26:Beispielskript in XHTML
java -cp build\fop.jar;lib\batik.jar;lib\logkit-1.0.jar;lib\avalon-framework-cvs-20020315.jar; lib\jimi-1.0.jarorg.apache.fop.apps.Fop -fo lecture.fo -pdf lecture.pdf
[INFO] FOP 0.20.4[INFO] building formatting object tree[INFO] [1][INFO] [1][ERROR] property - "white-space" is not implemented yet.[INFO] [2][INFO] [3]
...[INFO] Parsing of document complete, stopping renderer
Das mit FOP erzeugte Ergebnis als PDF-Ausgabe ist der Abbildung27zu entnehmen.
9.4 Präsentation in SVG
Die Erzeugung von SVG besteht wiederum nur aus einer einzigen Transformation, mitder die SVG-Datei direkt erzeugt wird. Dabei macht es keinen Unterschied welcherProzessor benutzt wird. Für den Xalan liefert der folgende Aufruf die Abbildung28.
java org.apache.xalan.xslt.Process -IN cgteil1.xml-xsl presentation.xsl -out presentation.svg

114
Abbildung 27:Beispielskript als PDF
Abbildung 28:Beispielpräsentation in SVG

115
10 Ausblick
Die Definition eines XML Schemas für die Beschreibung von Lehrmaterialien ist sehrkomplex. Es haben sich dabei einige Diskussionspunkte aufgetan und verschiedeneEinschränkungen ergeben.
Eine wesentliche Einschränkung in der Definition ist durch das Fehlen von Bedin-gungen in XML Schema aufgetreten. Dadurch lassen sich keine Abhängigkeiten derVerzweigungstiefen der Elemente modellieren. Für eine Einschränkung der Eingabeauf die wirklich sinnvollen Strukturkonstellationen ist das aber unabdingbar. Derarti-ges lässt sich beispielsweise durch die Integration anderer Schema-Sprachen oder mitProgrammiersprachen lösen, vgl. [Extend]. Auch eine Überprüfung durch ein XSLT-Stylesheet ist möglich, allerdings kann dieses erst im nachhinein angewendet werdenund nicht schon bei der Eingabe Elemente verbieten.
Im konkreten Einsatz eines solchen Konzeptes zur Verwaltung von Informationen istjedoch auch eine gesonderte Analyse über die Verwendung eines Content Manage-ment Systems voranzustellen. Damit würde der Nutzen aus den derart gewonnenenInformationen für einen größeren Benutzerkreis ersichtlich. So lassen sich Querver-weise zwischen verschiedenen Themen realisieren und einmal erstellte Informationenauch von verschiedenen Benutzern wiederverwenden. Durch die Unterstützung derElemente mit Linkeigenschaften wird dafür die Grundlage geliefert, so lassen sichbeispielsweise einzelne Kapitel in verschiedene Dateien aufteilen.
Für die unterschiedlichen Elemente des Schemas sind einige Möglichkeiten bezüglichihrer Restriktionen zu überdenken. So ist beispielsweise die Trennung von Content undLayout ein oberstes Ziel gewesen, doch ist dieses nicht immer eindeutig einzuordnen.Beispielsweise besitzen Tabellen durch ihre Struktur einen hohen Informationsgehalt,jedoch können zu viele Einstellungskriterien, wie beispielsweise das Weglassen vonLinien, eher dem Layout zugeordnet werden.
Aufgaben oder Tests sind weitere Objekte, die unterstützt werden sollten. Sie fallenunter die Kategorie der semantischen Objekte und können speziell für eLearning-Ausprägungen sinnvoll sein. Ihre Logik bezieht sich auf die Kombination von Fragenund Antworten, die in ihrer Komplexität von einfachen Multiple-Choice-Aufgaben bishin zu Freitext variieren können. Dazu sind die weiteren Bearbeitungsschritte zu be-rücksichtigen.
Eine Erhöhung der Komplexität für den Anwender stellt auch das Einfügen von unter-schiedlichen Detaillierungsstufen dar. Diese können durch das Festlegen neuer Aus-prägungsinstanzen umgesetzt werden. Es ist allerdings auch eine gleiche Ausprägungs-instanz für unterschiedliche Adressatenkreise z.B. für Anfänger, Standard oder Exper-ten denkbar. Die Eingabe der Daten würde damit jedoch stark erschwert werden.
Als weitere Unterstützung von offiziellen Standards ist eine vollständige Beschreibungeinzelner Elemente mittels der LOM-Spezifikation denkbar. Allerdings sollte dabei derhohe Aufwand für die Dateneingabe berücksichtigt werden und die Beschreibung nur

116
optional einzugeben sein.
Zur Unterstützung externer Literaturverzeichnisse, ist die Integration von BibTeX-Verzeichnissen denkbar. Damit können schon vorhandene Informationen und Erfah-rungen weiter genutzt werden. Dementsprechend kann die Einbeziehung der Literatur-angaben in Abhängigkeit der Quellangaben erfolgen, die auch in dem Quelldokumentverwendet werden oder die durch Einträge imbibliography -Element bestimmtwerden.
Die eingesetzten Stylesheets sind durch die Benutzung von Erweiterungsfunktionenfür eine optimale Ausgabe mittels der Verwendung von Xalan ausgelegt. Durch eineweitere Unterstützung anderer XSLT-Prozessoren oder die Verwendung zukünftigerElemente aus der XSLT 2.0 Spezifikation, die zur Zeit nur als Arbeitspapier vorliegt,lassen sich die Stylesheets auf andere Prozessoren übertragen. Damit ist die Flexibilitätbezüglich des Einsatzes der unterschiedlichen Prozessoren wieder hergestellt.
Ebenfalls wird die Aufteilung der Stylesheets in unterschiedliche Dateien zum aktuel-len Zeitpunkt in einigen XSLT-Prozessoren noch nicht einwandfrei unterstützt. Daherwurde auf ein weiteres Aufspalten der Transformationsdateien verzichtet. Damit ließensich auch die einzelnen Transformationen zusammenfassen und parameterabhängig zuden verschiedenen Ausprägungen steuern.
Durch die Trennung von Content und Layout lässt sich die Gestaltung der Inhalte mitverschiedenen Darstellungen vornehmen. So lassen sich verschiedene Designs für diegleichen Ausprägungen benutzten und die gleichen Inhalte lassen sich mit speziellenLayouts unterschiedlicher Lehrinstitutionen darstellen.
Eine mögliche neue Ausprägung kann beispielsweise als Überblick über alle Lehrma-terialien erzeugt werden, indem die Informationen einzelner Dokumente zusammenge-fasst werden. Damit lassen sich direkt alle behandelten Thematiken zusammengefasstdarstellen. Auch eine Bewertung der Inhalte kann vorgenommen werden, etwa anhandder Häufigkeit des Auftretens in unterschiedlichen Ausprägungen.
Auch weitere Ausprägungen für mobile Endgeräte sind denkbar. So sind schon XML-Anwendungen speziell für diese standardisiert worden, beispielsweise XHTML Basicoder SVG mobile. Aus diesem Grund ist eine Unterstützung allein durch die Definitionund Implementation einer weiteren Ausprägung machbar.

117
A Schemata der Dokumente
Das aus der Umsetzung entstandene Schema teilt sich in fünf Dateien auf. Drei bezie-hen sich auf die Ausprägungen und die zwei weiteren auf die Beschreibung des ge-samten Inhaltes. Zunächst werden die ausprägungsspezifischen Schemata aufgeführt.
Das Grundschemastamp.xsd, bildet für jede Ausprägungsart die Basis. Die Quelle istauf der beigefügten CD unterAnwendung/Schemazu finden und sieht folgenderma-ßen aus:
<?xml version="1.0" encoding="UTF-8"?><xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="unqualified"attributeFormDefault="unqualified"><xs:simpleType name="deltalist"><xs:annotation>
<xs:documentation>a listtype for the names of a presentation other then thestandard one</xs:documentation>
</xs:annotation><xs:list itemType="xs:string"/></xs:simpleType><xs:attribute name="on" type="xs:boolean" default="true"><xs:annotation>
<xs:documentation>markes the element to be in the standard presentation or not</xs:documentation>
</xs:annotation></xs:attribute><xs:attribute name="delta" type="deltalist"><xs:annotation>
<xs:documentation>markes the element to be in an presentation that isn’t thestandard, if the standard also exists this marks that itschouldn’t be in the presentation</xs:documentation>
</xs:annotation></xs:attribute><xs:attributeGroup name="standard.out"><xs:annotation>
<xs:documentation>for elements that only in some singlemoments will be inserted (instead of "standard.in")</xs:documentation>
</xs:annotation><xs:attribute ref="on" default="false"/>

118
<xs:attribute ref="delta"/></xs:attributeGroup><xs:attributeGroup name="standard.in"><xs:annotation>
<xs:documentation>all attributes of this group are requiredto insert an element in the presentation
</xs:documentation></xs:annotation><xs:attribute ref="delta"/><xs:attribute ref="on"/></xs:attributeGroup>
</xs:schema>
Die Schemata der einzelnen umgesetzten Ausprägungen ergeben sich aus der Integra-tion des Basisschemas und der Vergabe eines Namensraumes. Da diese bis auf dieNamensvergabe somit gleich aussehen, ist hier das Beispiel für die Präsentationpre-sentation.xsd aufgelistet.
<?xml version="1.0" encoding="UTF-8"?><xs:schema
targetNamespace="http://www-lehre.inf.uos.de/~tschnied/presentation"xmlns="http://www-lehre.inf.uos.de/~tschnied/presentation"xmlns:xs="http://www.w3.org/2001/XMLSchema"elementFormDefault="qualified"attributeFormDefault="unqualified">
<xs:include schemaLocation="stamp.xsd"/>
</xs:schema>
Die Aufteilung des gesamten Schemas bezieht sich neben den Ausprägungen noch aufdie Ebenen, der Elementintegration. Alle Elemente, die ausschließlich innerhalb vonTexten auftreten, sind in der Dateimarkedtext.xsddefiniert.
Die Datei lecture.xsd beschreibt das ganze Schema, indem sie die zuvor genanntenSchemata zusammenfügt und alle Strukturelemente definiert. Die gesamten Quellensind unterAnwendung/Schemaauf der CD wiederzufinden.

119
B Ausprägungstransformationen
Die kompletten XSL-Transformationen um XHTML, XSL-FO und SVG zu erzeu-gen sind auf der beigefügten CD unterAnwendung/XSLT zu finden. Dabei dient dielecture.xslzur Erzeugung von XHTML-Dateien in der Script-Ausprägung undfolec-ture.xsl erzeugt die dazugehörige XSL-FO-Datei. Zur Generierung der Präsentations-Ausprägung in SVG wirdpresentation.xslverwendet. Alle XSL-Transformationenbenutzen zur Sprachunterstützung die invariable.xsl definierten und mit den Wertenauslanguage.xmlinitialisierten Variablen.

120
C Testseiten verschiedener Formatierer
Die Qualität der verschiedenen Formatierer für XSL-FO-Dokumente ist sehr verschie-den. In Kapitel4.6 wurden die verbreitetsten kurz vorgestellt. Die folgenden Testsei-ten sollen einen kurzen Überblick über ihre Qualität und die Unterschiede liefern. Daskann allerdings nicht in aller Ausführlichkeit geschehen, da beispielsweise vom XSLFormatter in der Testversion keine Grafiken oder von FOP allgemein keine Tabellenmit Überschriften unterstützt werden.

121
Testseite
zur Generierung von PDFFließtext kann überall stehen. Er wird auf unterschiedliche Arten dargestellt. Die getesteten FormatiererXEP, FOP und XSL Formatter beherschen alle keine Trennung für Wörter, weshalb die Zeilen alle aufdie angegebene Breite zurechtgezogen werden. An dieser Stelle kommt der Vorteil der Generierungmittels TeX zum Tragen. TeX beherrscht die Trennung, wodurch das Erscheinungsbild viel flüssiger undgleichmäßiger wirkt.
Getestet wurden:• FOP• XEP• XSL Formatter
Ein Wort das über eine Zeile geht wird überall verschieden behandelt. Das ist problematisch wenn keineTrennung möglich ist:
EinWortdasübereineZeilegehtwirdüberallverschiedenbehandeltdasistproblematischwennkeineTrennungmöglichist.
Nicht alle Formatierer unterstützen Leerzeichen:
<HTML> <HEAD> <TITLE>HTML Titel</TITLE> </HEAD> <BODY> HTML Körper </BODY></HTML>
Testbild als GIF
Eine fixe Tabelle ohne Beschriftung:
XSL FormatterXEPFOP
kommerziellkommerziellopen source
Eine Tabelle mit Beschriftung:Darstellung einer Tabelle mit variabler Breite
XSL FormatterXEPFOP
unterstütztunterstütztvariable Tabellen werden nichtunterstützt
1© Tanja Schniederberend
XSL•FORenderX
Abbildung 29:Testseite mit XEP

122
Testseite
zur Generierung von PDFFließtext kann überall stehen. Er wird auf unterschiedliche Arten dargestellt. Die getesteten FormatiererXEP, FOP und XSL Formatter beherschen alle keine Trennung für Wörter, weshalb die Zeilen alle aufdie angegebene Breite zurechtgezogen werden. An dieser Stelle kommt der Vorteil der Generierungmittels TeX zum Tragen. TeX beherrscht die Trennung, wodurch das Erscheinungsbild viel flüssigerund gleichmäßiger wirkt.
Getestet wurden:• FOP• XEP• XSL Formatter
Ein Wort das über eine Zeile geht wird überall verschieden behandelt. Das ist problematisch wennkeine Trennung möglich ist:
EinWortdasübereineZeilegehtwirdüberallverschiedenbehandeltdasistproblematischwennkeineTrennungmöglichist.
Nicht alle Formatierer unterstützen Leerzeichen:
<HTML> <HEAD> <TITLE>HTML Titel</TITLE> </HEAD> <BODY> HTML Körper </BODY></HTML>
Testbild als GIF
Eine fixe Tabelle ohne Beschriftung:
FOP XEP XSL Formatter
open source kommerziell kommerziell
Eine Tabelle mit Beschriftung:Darstellung einer Tabelle mit variabler Breite
FOP XEP XSL Formatter
variable Tabellen werden nichtunterstützt
unterstützt unterstützt
1© Tanja Schniederberend
Antenna House XSL Formatter (Evaluation) http://www.antennahouse.com/
Abbildung 30:Testseite mit dem XSL Formatter

123
Testseite
zur Generierung von PDF
Fließtext kann überall stehen. Er wird auf unterschiedliche Arten dargestellt. Die getesteten Formatierer XEP,FOP und XSL Formatter beherschen alle keine Trennung für Wörter, weshalb die Zeilen alle auf die angegebeneBreite zurechtgezogen werden. An dieser Stelle kommt der Vorteil der Generierung mittels TeX zum Tragen.TeX beherrscht die Trennung, wodurch das Erscheinungsbild viel flüssiger und gleichmäßiger wirkt.
Getestet wurden:• FOP• XEP• XSL Formatter
Ein Wort das über eine Zeile geht wird überall verschieden behandelt. Das ist problematisch wenn keineTrennung möglich ist:
EinWortdasübereineZeilegehtwirdüberallverschiedenbehandeltdasistproblematischwennkeineTrennungmöglichist.
Nicht alle Formatierer unterstützen Leerzeichen:
<HTML> <HEAD> <TITLE>HTML Titel</TITLE> </HEAD> <BODY> HTMLKörper </BODY> </HTML>
Testbild als GIF
Eine fixe Tabelle ohne Beschriftung:
FOP XEP XSL Formatter
open source kommerziell kommerziell
Eine Tabelle mit Beschriftung:
1© Tanja Schniederberend
Abbildung 31:Testseite mit FOP

124
D Literaturverzeichnis
Aufgrund der Aktualität der in dieser Diplomarbeit eingesetzten Techniken, sind vieleInformationen noch nicht in Büchern zu finden. Deshalb beziehen sich die meistenLiteraturverweise auf Web-Seiten, deren Erreichbarkeit und Inhalt sich schnell ändernkönnen. Zum Zeitpunkt der Erstellung dieser Diplomarbeit (Stand: 01.06.2003) warendie Quellen unter den hier aufgeführten Links erreichbar.
Literatur
[Ade2000] Adelsberger, Heimo H., Prof. Dr.; DIN/VAWi-Workshop: Di-daktische Modellierung; Universität Essen, Wirtschaftsin-formatik der Produktionsunternehmen;http://elm.wi-inf.uni-essen.de/en/standard/din_didactics.html; aktualisiert: 10/2000
[AdoSVG] Adobe; Adobe SVG Zone; http://www.adobe.com/svg/; 2001
[antenna] Antenna House; Antenna House XSL Formatter Home;http://www.antennahouse.com/; aktualisiert: 03/2003
[ApacXalan] Apache; xml.apache.org; http://xml.apache.org;aktualisiert: 03/2003
[Aria] Ariadne; ARIADNE Foundation for the European Knowledge Pool;http://www.ariadne-eu.org/; aktualisiert: 2002
[Beh2000] Behme, Henning;Mintert , Stefan;XML in der Praxis - Professionel-les Web-Publishing mit der Extensible Markup Language; Addison-Wesley; München; 1.Aufl.; 2000
[Brotbook] Bronger, Torsten;The tbook system for XML Authoring;http://tbookdtd.sourceforge.net/; aktualisiert: 05/2003
[Bry2001] Bry , Francois; Skript Markup-Sprachen und semistrukturierteDaten; Ludwig-Maximilians-Universität München, Lehr- und For-schungseinheit für Programmier- und Modellierungssprachen;http://www.pms.informatik.uni-muenchen.de/lehre/markupsemistrukt/01ss/unterlagen/markup-skript/index.html; 2001
[Cla1997] Clark , James;Comparison of SGML and XML;http://www.w3.org/TR/NOTE-sgml-xml-971215; W3C Note;NOTE-sgml-xml-971215; 1997
[CEN2002] CEN/ISS; Survey of Educational Modelling Languages (EMLs);http://www.cenorm.be/isss/Workshop/LT/eml-version1.pdf; 2002

125
[Dublin] Dublin Core Metadata Initiative ; Dublin Core Metadata Initiative;http://dublincore.org/; aktualisiert: 05/2003
[Duval] Duval, Erik; Learning Technology Standardization: Too many?Too few?; http://www.rz.uni-frankfurt.de/neue_medien/standardisierung/duval_text.pdf
[ECMA] ECMA International ; ECMA International - StandardizingInformation and Communication Systems;http://www.ecma-international.org/
[EXSLT] EXSLT ; EXSLT - community extensions to XSLT;http://www.exslt.org; aktualisiert: 01/2003
[Extend] xFront ; Extending XML Schemas;http://www.xfront.com/ExtendingSchemas.html;aktualisiert: 02/2003
[fop] Apache Software Foundation; FOP; xml.apache.org/fop;aktualisiert: 05/2003
[Har2000a] Harold , Elliotte R.; Die XML-Bibel, MITP-Verlag; Bonn; 1.Aufl.;2000
[Har2000b] Harold , Elliotte R.;Means, W. Scott;XML in a Nutshell; O’Reilly;Sebastopol (USA); 1.Aufl.; 2001
[Hof1998] Hofmann, Thomas; SGML/XML; http://th-o.de/sgml/index2.htm;1998
[IMS] IMS Global Learning Consortium, Inc. ; IMS Global LearningConsortium, Inc.; http://www.imsproject.org/; aktualisiert: 2003
[ISO8879] International Standardization Organization ; ISO 8879;http://www.iso.ch; aktualisiert: 03/2003
[ISO/IEC] ISO/IEC JTC1 SC36; ISO/IEC JTC1 SC36 Home Page;http://jtc1sc36.org/index.html; aktualisiert: 03/2003
[Kay2001] Kay, Michael;XSLT Programmer’s Reference; Wrox Press;Birmingham; 2.Aufl.; 2001
[KaySaxon] Kay Michael H.;SAXON The XSLT Processor;http://saxon.sourceforge.net/; aktualisiert: 05/2003
[LMML] IFIS ; LMML; http://www.lmml.de; aktualisiert: 01/2003
126
[LOM] IEEE Learning Technology Standards Committee (LTSC);Learning Object Metadata (LOM) Standard;http://ltsc.ieee.org/wg12/; 2002
[Mozilla] Mozilla Organisation; Mozilla SVG Project;http://www.mozilla.org/projects/svg/; aktualisiert: 03/2003
[MSXML] MSDN Library ; MSXML 4.0 SDK;http://msdn.microsoft.com/library/default.asp?url=/library/en-us/xmlsdk/htm/sdk_intro_6g53.asp; 2003
[OASIS] OASIS; OASIS DocBook TC; http://www.oasis-open.org/docbook/;08/2002
[Oba2002] Obasanjo, Dare;W3C XML Schema Design Patterns: Avoiding Com-plexity; http://www.xml.com; 11/2002
[OracleXDK] Oracle; XML Developer’s Kit;http://otn.oracle.com/tech/xml/xdkhome.html; aktualisiert: 2003
[OUNL] Open University of the Netherlands; Educational Modelling Lan-guage; http://eml.ou.nl
[Paw2002] Pawson, Dave;XSL-FO; O’Reilly; Sebastopol (USA); 1.Aufl.; 2002
[Rah2003] Rahtz, Sebastian;PassiveTeX;http://www.tei-c.org.uk/Software/passivetex/; 03/2003
[renderx] RenderX; RenderX; http://www.renderx.com; aktualisiert: 05/2003
[Schö2001] Schönfeld, Jochen;LOM-IMS-Ariadne - Metadaten fürWeb-basiertes Lernen; Technische Universität Berlin;http://cis.cs.tu-berlin.de/Lehre/WS-0001/Sonstiges/wbl-pages/Material/ausarbeitungen/sem_ws00-01_rk_jc_wbt_metadaten.pdf;2001
[SKO2003] Skonnard, Aaron;Understanding XML Schema; MSDN Library;http://msdn.microsoft.com/library/en-us/dnxml/html/understandxsd.asp; 2003
[Spo2001] Spona, Helma;Das Einsteigerseminar SVG - Webgrafiken mit XML;vmi-Buch; Bonn; 1.Aufl.; 2001
[Tid2002] Tidwell , Doug;XSLT; O’Reilly; Köln; 1.Aufl.; 2002
[Vli2002] Vlist , Eric van der;XML Schema; O’Reilly; Sebastopol (USA);1.Aufl.; 2002

127
[Wat2001] Watt , Andrew H.;Designing SVG Web Graphics; New Riders Pu-blishing; 1.Aufl.; 2001
[W3C] World Wide Web Consortium ; World Wide Web Consortium;http://www.w3.org; aktualisiert: 06/2003
[W3CCSS] W3C Recommendation; Cascading Style Sheets, level 2;http://www.w3.org/TR/REC-CSS2/; 1998
[W3CMathML] W3C Math Working Group ; Putting mathematics on the Web withMathML; http://www.w3.org/Math/XSL/Overview.html; aktualisiert:03/2003
[W3CSVG] W3C Recommendation; Scalable Vector Graphics (SVG) 1.1 Spe-cification; http://www.w3.org/TR/SVG11/; 2003
[W3CSVGImpl] W3C; SVG Implementations; http://www.w3.org/Graphics/SVG/SVG-Implementations.htm8#viewer; aktualisiert: 01/2003
[W3CSVGR] W3C Working Draft ; SVG 1.1/1.2/2.0 Requirements;http://www.w3.org/TR/SVG2Reqs/; 04/2002
[W3CSVGT] W3C Recommendation; Mobile SVG Profiles: SVG Tiny and SVGBasic; http://www.w3.org/TR/SVGMobile/; 2003
[W3CURI] World Wide Web Consortium ; Web Naming and Addressing Over-view (URIs, URLs, ...); http://www.w3.org/Addressing/; aktualisiert:07/2002
[W3CXML] W3C Recommendation; Extensible Markup Language (XML) 1.0;2.Aufl.; http://www.w3.org/TR/REC-xml; 2000
[W3CXMLNS] W3C Recommendation; Namespaces in XML;http://www.w3.org/TR/REC-xml-names/; 1999
[W3CXPATH] W3C Recommendation; XML Path Language (XPath); Version 1.0;http://www.w3.org/TR/xpath; 1999
[W3CXPointer] W3C Recommendation; XPointer Framework;http://www.w3.org/TR/xptr-framework/; 2003
[W3CXQuery] W3C Working Draft ; XQuery 1.0: An XML Query Language;http://www.w3.org/TR/xquery/; 2003
[W3CXSD] W3C; XML Schema; http://www.w3.org/XML/Schema; aktualisiert:01/2003

128
[W3CXSDa] W3C Recommendation; XML Schema Part 0: Primer;http://www.w3.org/TR/xmlschema-0/; 2001
[W3CXSDb] W3C Recommendation; XML Schema Part 1: Structures;http://www.w3.org/TR/xmlschema-1/; 2001
[W3CXSDc] W3C Recommendation; XML Schema Part 2: Datatypes;http://www.w3.org/TR/xmlschema-2/; 2001
[W3CXSL] W3C; The Extensible Stylesheet Language (XSL);http://www.w3.org/Style/XSL/; aktualisiert: 01/2003
[W3CXSLFO] W3C Recommendation; Extensible Stylesheet Language (XSL);Version 1.0;http://http://www.w3.org/TR/xsl/; 2001
[W3CXSLT] W3C Recommendation; XSL Transformations (XSLT); Version 1.0;http://www.w3.org/TR/xslt; 1999
[W3CXSLTb] W3C Working Draft ; XSL Transformations (XSLT) Version 2.0;http://www.w3.org/TR/xslt20/; 05/2003
[Zap2002] Zap Think ; Key XML Specifications and Standards;http://www.zapthink.com/reports/poster.html; 2002

Erklärung
Hiermit erkläre ich, dass ich meine Diplomarbeit
"Cross Media Publishingvon Lehrmaterialien mit
XML Schema & XSL-Transformationen"
selbstständig angefertigt und keine anderen Quellen und Hilfsmittel, außer denen inder Arbeit angegebenen, benutzt habe.
Osnabrück, 11.06.2003 .................................Tanja Schniederberend