coupling between asr and mt in speech-to- speech translation arthur chan prepared for advanced...
Post on 18-Dec-2015
234 views
TRANSCRIPT

Coupling between ASR and MT in Speech-to-
Speech Translation
Arthur Chan
Prepared for Advanced Machine Translation Seminar

This Seminar (~35 pages) Introduction (6 slides) Ringger’s categorization of Coupling between ASR
and NLU (7 slides) Interfaces in Loose Coupling
• 1 best and N-best (5 slides)• Lattices/Confusion Network/Confidence Estimation (9
slides)• Results from literature (4 slides)
Tight Coupling• Ney’s Theory and 2 methods of Implementation (4 slides)• ( Sorry, no FST approaches will be discussed)
Many Bonus Material at the back

History of this presentation
V1:• Draft finished in Mar 1st
• Tanja’s comment: • Direct modeling could be skipped.
• We could focus on telling why/ASR
• Generates the current outputs
• Issues in MT searching could be ignored.

History of this presentation (cont.) V2 – V4:
• Followed Tanja’s comment and finished in Mar 19th .
• Reviewer’s comment
• Too long (70 pages)• Ney’s search formulation is too difficult to follow
V5 – V6• Significantly trimmed down the presentation
• Moved a lot of things to the backup section. V7
• Incorporated some comments from Alon, Stephan and the class.

4 papers on Coupling of Speech-to-Speech Translation
H. Ney, “Speech translation: Coupling of recognition and translation,” in Proc. ICASSP, 1999.
S.Saleem, S. C. Jou, S. Vogel, and T. Schultz, “Using word lattice information for a tighter coupling in speech translation systems,” in Proc. ICSLP, 2004.
V.H. Quan et al., “Integrated N-best re-ranking for spoken language translation,” in In EuroSpeech, 2005.
N. Bertoldi and M. Federico, “A new decoder for spoken language translation based on confusion networks,” in IEEE ASRU Workshop, 2005.
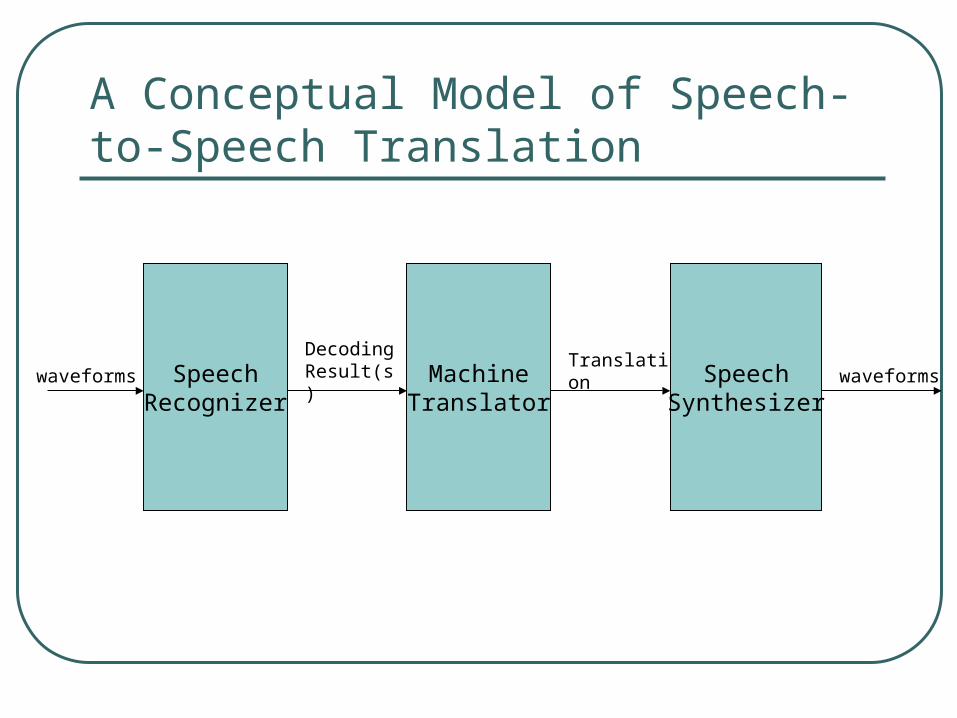
A Conceptual Model of Speech-to-Speech Translation
SpeechRecognizer
MachineTranslator
SpeechSynthesizer
waveforms
DecodingResult(s)
Translationwaveforms

Motivation of Tight Coupling between ASR and MT
One best of ASR could be wrong MT could be benefited from wide range of
supplementary information provided by ASR• N-best list
• Lattice
• Sentenced/Word-based Confidence Scores
• E.g. Word posterior probability
• Confusion network
• Or consensus decoding (Mangu 1999) MT quality may depend on WER of ASR (?)

Scope of this talk.
SpeechRecognizer
MachineTranslator
SpeechSynthesizer
waveforms
1-best?
Translationwaveforms
Lattice?
N-best?
Confusion network?
Loose Coupling/Tight Coupling

Topics Covered Today
The concept of Coupling
• “Tightness” of coupling between ASR and Technology X. (Ringger 95)
Two questions:• What could ASR provide in loose coupling?
• Discussion of interfaces between ASR and MT in loose coupling
• What is the status of tight coupling?
• Ney’s Formulation

Topics not covered
Direct Modeling• Use both features in ASR and MT
• Some referred as “ASR and MT unification”
FST approaches• [V7: I only read two papers and couldn’t do the
justcice.]
Implication of the MT search algorithms on the coupling
Generation of speech from text.

The Concept of Coupling

Classification of Coupling of ASR and Natural Language Understanding (NLU)
Proposed in Ringger 95, Harper 94 3 Dimensions of ASR/NLU
• Complexity of the search algorithm• Simple N-gram?
• Incrementality of the coupling• On-line? Left-to-right?
• Tightness of the coupling• Tight? Loose? Semi-tight?
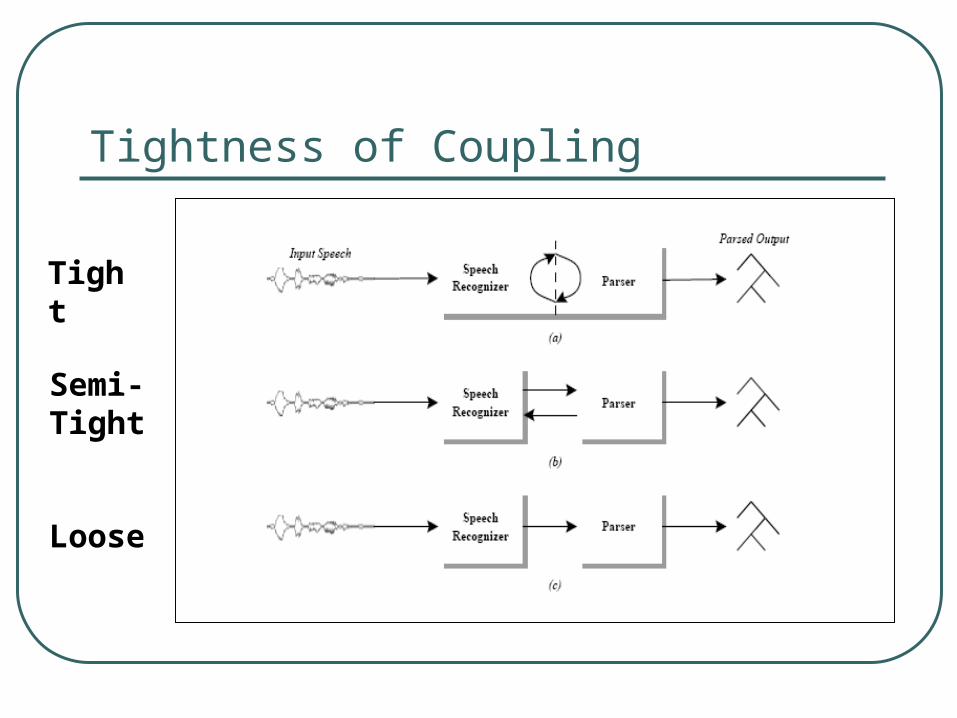
Tightness of Coupling
Tight
Semi-Tight
Loose

Notes:
Semi-tight coupling could appear as• Feedback loop between ASR and Technology
X for the whole utterance of speech
• Or Feedback loop between ASR and Technology X for every frame.
The Ringger framework• A good way to understand how speech-based
system is developed

Example 1: LM Someone asserts that ASR has to be used
with 13-grams. • In tight-coupling,
• A search will be devised to search for the best word sequence with best acoustic score + 13 gram likelihood
• In loose coupling• A simple search will be used to generate some outputs
(N-best list, lattice etc.), • 13-gram will then use to rescore the output.
• In semi-tight coupling• 1, A simple search will be used to generate results• 2, 13 gram will be applied at the word-end only (but
exact history will not be stored)

Example 2: Higher order AM
Segmental model assume obs. probability is not conditionally independent.
Someone assert that segmental model is better than just HMM. • Tight coupling: Direct search of the best word
sequence using segmental model.
• Loose coupling: Use segmental model to rescore
• Semi-tight coupling: Hybrid HMM-Segmental model algorithm?

Summary of Coupling between ASR and NLU

Implication on ASR/MT coupling
Generalize many systems• Loose coupling
• Any system which uses 1-best, n-best, lattice, or other inputs for 1-way module communication
• (Bertoldi 2005)
• CMU System (Saleem 2004)
• Tight coupling• (Ney 1999)
• Semi-tight coupling• (Quan 2005)

Interfaces in Loose Coupling:1-best and N-best

Perspectives ASR outputs
• 1-best results• N-best results• Lattice• Consensus network. • Confidence scores
How ASR generate these outputs? Why they are generated? What if there are multiple ASRs?
• (and what if their results are combined?) Note : we are talking about state-lattice now, not
word-lattice.

Origin of the 1-best.
Decoding of HMM-based ASR= Searching the best path in a huge HMM-state
lattice.
1-best ASR result• The best path one could find from
backtracking.
State Lattice in ASR (Next page)


Note on 1-best in ASR Most of the time 1-best Word Sequence Why?
• In LVCSR, storing the backtracking pointer table for state sequence takes a lot of memory (even nowadays)
• [Compare this with the number of frames of score one need to be stored]
Usually a backtrack pointer storing • The previous words before the current word
Clever structure dynamically allocate back-tracking pointer table.

What is N-best list?
Traceback not only from the 1st -best, also from the 2nd best and 3rd best, etc.
Pathway:• Directly from search backtrack pointer table
• Exact N-best algorithm (Chow 90)
• Word pair N-best algorithm (Chow 91)
• A* search using Viterbi score as heuristic (Chow 92)
• Generate lattice first, then generate N-best from lattice

Interfaces in Loose Coupling:Lattice, Consensus Network and Confidence Estimation

What is Lattice?
A word-based lattice A compact representation of state-lattice
• Only word node (or link) are involved
Difference between N-best and Lattice• Lattice could be compact representation of N-
best list.
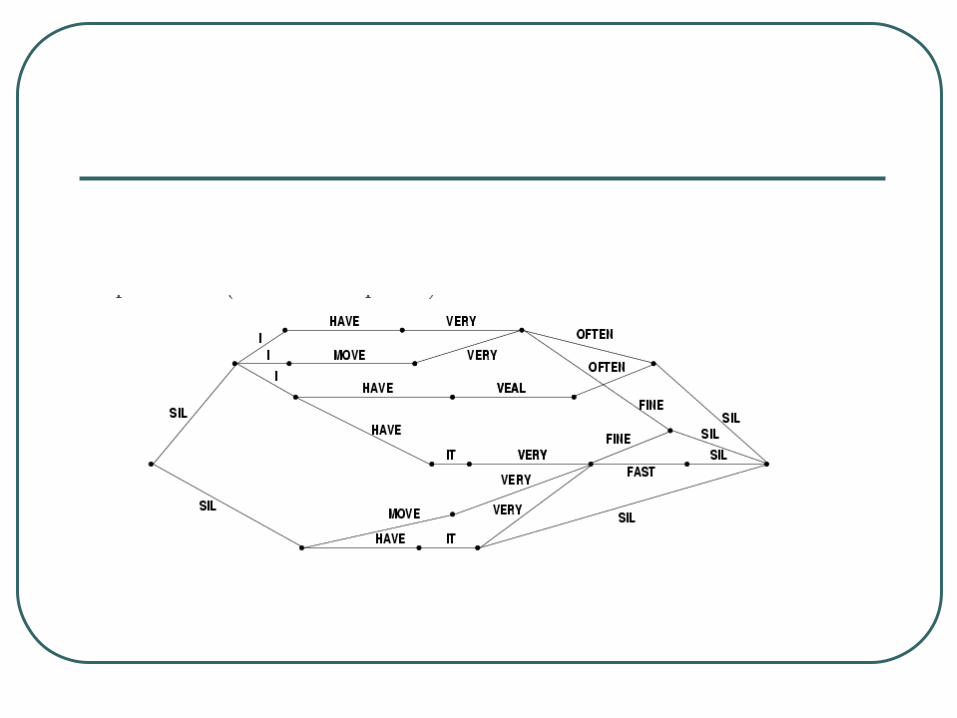

How lattice is generated?
From the decoding backtracking pointer table• Only record all the links between word nodes.
From N-best list• Become a compact representation of N-best
• [sometimes spurious link will be introduced]
Some complicated issue• Triphone contexts
• Cause a lot of complicated issue
• When lattice is too large
• You want to trim it.

Conclusions on lattices
Lattice generation itself could be a complicated issue
Sometimes, what post-processing stage (e.g. MT) will get is pre-filtered, pre-processed results.

Confusion Network and Consensus Hypothesis
Confusion Network:• Or “Sausage Network”.
• Or “Consensus Network”

Special Properties
More “local” than lattice• One can apply simple criteria to find the best
results
• E.g. “consensus decoding” is to apply word-posterior probability on confusion network.
More tractable • In terms of size

Note on Consensus Network:
Note:• Time information might not be preserved in confusion
network
• The similarity function directly affect the final output of the consensus network.
Other ways to generate confusion network• From the N-best list
• Using Rover.
• A mixture of voting and adding confidence of word

Confidence Measure
Anything other than likelihood which could tell whether the answer is useful
E.g.• Word posterior probability
• P(W|A)
• Usually compute using lattices
• Language model backoff mode
• Other posterior probabilities (frame, sentence)

Interfaces in Loose Coupling:Results from the Literature

General Note
Coupling in SST is still pretty new Papers are chosen according to whether
some outputs have been used• Other techniques such as direct modeling
might be mixed into the papers.

N-best list (Quan 2005)
Using N-best list for reranking• Interpolation weights of AM and TM are then
optimized.
Summary:• Reranking gives improvements.

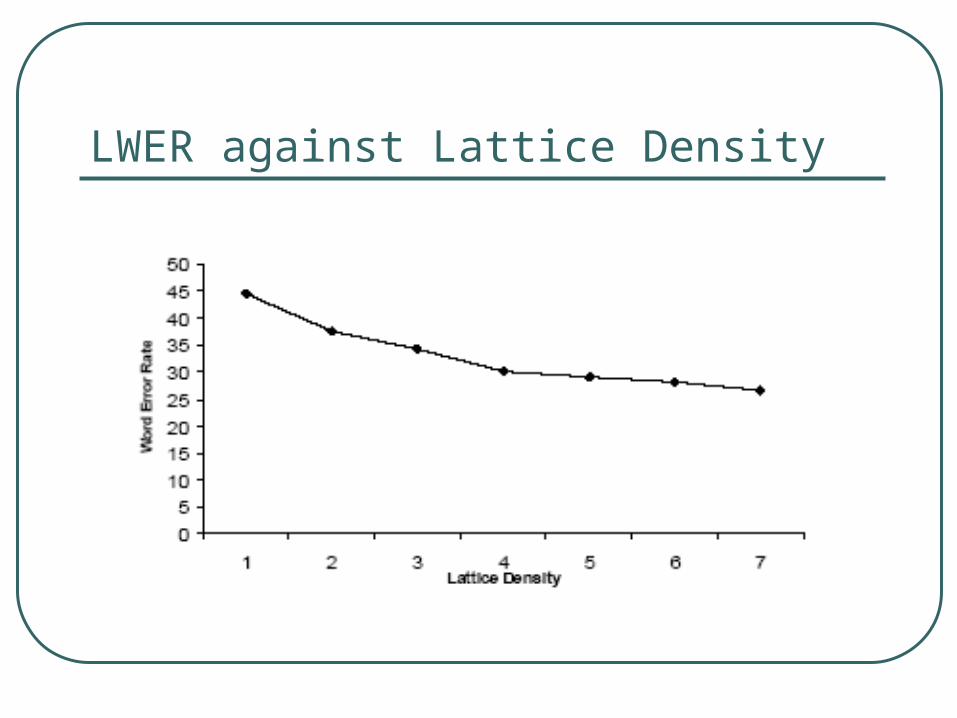
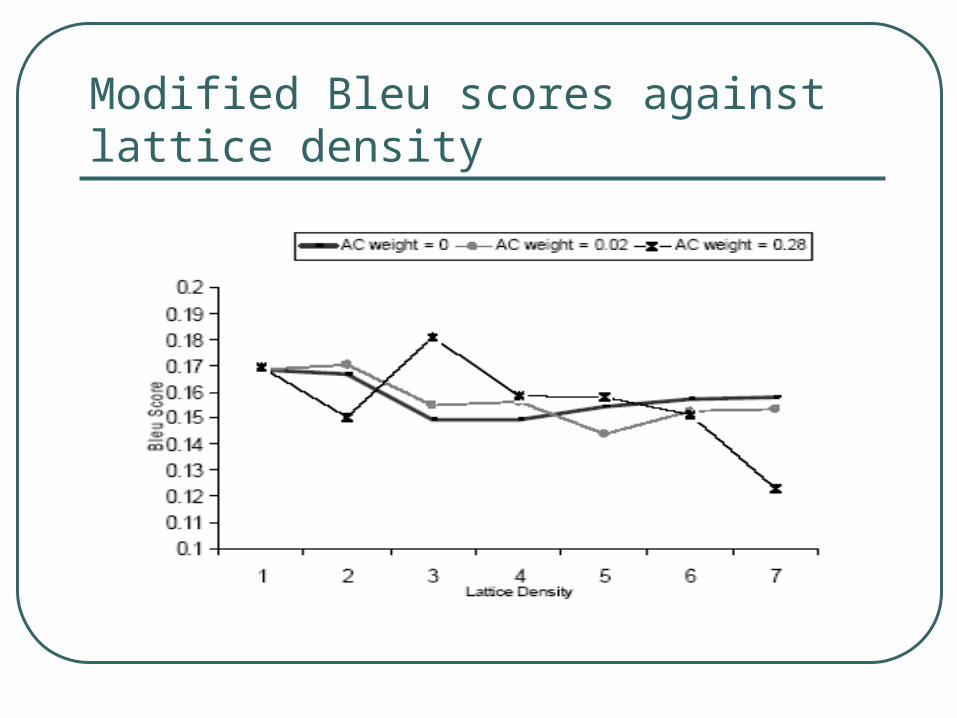
Lattices: CMU results (Saleem 2004)
Summary of results• Lattice word error rate improved when lattice
density improves
• Lattice density and Weight on Acoustic scores turns out to be an important parameter to tune• Too large and small could hurt.

Consensus Network
Bertoldi 2005 is probably the only work on confusion-network based method
Summary of results:• When direct modeling is applied
• Consensus Network doesn’t beat N-best method.
• Author argues for speed and simplicity of the algorithm

Confidence: Does it help?
According to Zhang 2006, Yes. • Confidence Measure (CM) filtering is used to
filter out unnecessary results in N-best
• Note: The approaches used is quite different.

Conclusion on Loose Coupling
SR could give a rich set of outputs. It seems that it is still an unknown what type of
output should be used in pipeline. Currently, it seem to lack of comprehensive
experimental studies on which method is the best.
Usage of confusion network and confidence estimation seem to be under-explored.

Comments about Consensus Network
From Stephan:• Reasons not using consensus networks *now*
• 1, the consensus network might occasionally give spurious links in each sausage segment.
• 2, lattices from the ASR teams could change from time to time. MT teams need time to consume them.
From Alon, Ralf and Stephan:• There are not much big reasons not to use consensus
network because essentially it is just another type of network.

Tight Coupling : Theory and Practice

Theory (Ney 1999)
Baye’s Rule
Introduce f as hidden var.
Baye’s Rule
Assume x doesn’t depend on target lang.
Sum to Max

Layman point of view
Three factors• Pr(e) : target language model
• Pr(f|e) : translation model
• Pr(x|f) : acoustic model
• Note: assumption has been made only the best matching f for e is used.

Comparison with SR
In SR:• Pr(f) : Source language model
In Tight coupling• Pr(f|e), Pr(e) : Translation model and Target
language model

Algorithmic Point of View
Brute Force Method: Instead of incorporating LM into standard Viterbi algorithm• Incoporating P(e) and P(f|e)
• => Very complicated
The backup slides in the presentation has detail about Ney’s implementations.

Experimental Results in Matusov, Kanthak and Ney 2005
Summary of the results• Translation quality is only improved by tight
coupling when the lattice density is not high.
• Same as Saleem 2004, incorporation of acoustic scores help.

Conclusion: Possible Issues of tight coupling
Possibilities:• In SR, source n-gram LM is very closed to the best
configuration.
• The complexity of the algorithm is too high, approximation is still necessary to make it work.
• When the criterion in tight coupling is used. It is possible that the LM and the TM need to be jointly estimated.
• The current approaches still haven’t really implement tight-coupling
• There might be bugs in the programs.

Conclusion
Two major issues in coupling of SST is discussed• In loose coupling:
• Consensus network and Confidence scoring is still not fully utilized
• In tight coupling:• The approach seem to be haunted by very high
complexity of search algorithm construction

Discussion
Ian: It could be quite difficult to characterize a relationship of WER and BLEU.
Alan ask: Why not jointly optimize translation model and acoustic model?• Arthur: direct modeling could be useful
• Stephan: (rephrase) will it really help?
The End. Thanks.

Literature 2006 Ruiqiang Zhang, Genichiro Kikui. Integration of Speech Recognition and
Machine Translation: Speech Recognition Word Lattice Translation. Speech Communication. Vol.48, Issues 3-4
H. Ney, “Speech translation: Coupling of recognition and translation,” in Proc. ICASSP, 1999.
E. Matusov, S.Kanthak, and H. Ney, “On the integration of speech recognition and statistical machine translation,” in Proc. InterSpeech, 2005.
S.Saleem, S. C. Jou, S. Vogel, and T. Schultz, “Using word lattice information for a tighter coupling in speech translation systems,” in Proc. ICSLP, 2004.
V.H. Quan et al., “Integrated N-best re-ranking for spoken language translation,” in In EuroSpeech, 2005.
N. Bertoldi and M. Federico, “A new decoder for spoken language translation based on confusion networks,” in IEEE ASRU Workshop, 2005.
L. Mangu, E. Brill, & A. Stolcke, Finding consensus in speech recognition: word error minimization and other applications of confusion networks, Computer Speech and Language 14(4), 373-400., (2000)
E. Ringger, A Robust Loose Coupling for Speech Recognition and Natural Language Understanding, 1995

Backup Slides

Saleem’s results
LWER against Lattice Density
Modified Bleu scores against lattice density

Optimal density and score weight based on Utterance Length.

Some Lattice-specific Issue

How lattice is generated when there are phone contexts at the word end?
Very complicated when phonetic context is involved• Not only word-end needs to be stored but also
the phone contexts.
• Lattice has the word identity as well as contexts
• Lattice can become very large.

How this is resolved?
Some used only approximate triphone to generate lattice in first stage (BBN)
Some generate lattice even with full CD-phones but convert it back to no-context lattices (RWTH)
Use the lattice with full CD phone contexts (RWTH)

What ASR folks do when lattice is still too large?
Use some criteria to prune the lattice. Example Criteria
• Word posterior probability
• Application of another LM or AM, then filtering.
• General confidence score
• Maximum lattice density• (number of words in lattice/number of words)
Or generate an even more compact representation than lattices• E.g. consensus network.

Ney 99’s Formulation of SST’s Search.

Assumptions in Modeling
Alignment Models (HMM)
Acoustic Modeling• Speech Recognizer will produce a word graph.
• Each link with word hypothesis covers the portion of acoustic scores. (notation is confusing in paper)

Lexicon Modeling
Further assumption from standard IBM* models• Target word is assumed to be dependent on
previous word
• So, in fact, source LM is actually there.

First Implementation: Local Average Assumptions
Local Average Assumptions
P(x|e) is used to capture the local characteristic of the acoustic.

Justification of Using Average Local Assumption
Rephrased from Author (p.3 para 2)• Lexicon modeling and language modeling will
cause f_{j-1}, f_{j}, f_{j+1} appear in the math. In another words
• It is too complicated to carry out
• Computation advantage: the local score could be obtained just from the word graph but before translation• => Full translation strategy could still be carried out

Computation of P(x|e)
Make use of best source sequence Also refer to Wessel 98,
• A commonly used word posterior probability algorithm for lattice• A forward-backward like procedure is used
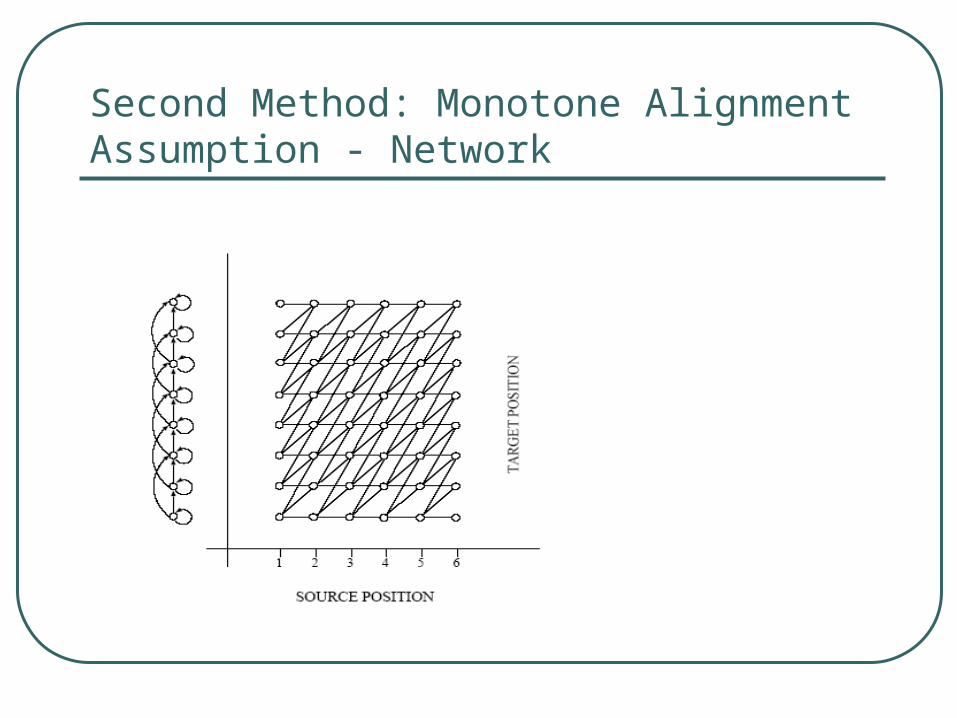
Second Method: Monotone Alignment Assumption - Network

Monotone Alignment Assumption – Formula for Text Input
Close-formed solution exist form DP O(JE^2)

Monotone Alignment Assumption – Formula for Speech Input
DP: O(JE^2F^2)

How to make Monotone Assumptions work?
Words needs to be reordered• As part of search strategy.
Does acoustic model assumption used?• i.e. Are we talking about word lattice or still
state lattice?• Don’t know, seems like we are actually talking
about word lattice.
• Supported by Matusov 2005