contour detection on mobile platforms - par...
TRANSCRIPT

1/26
Contour Detection on Mobile Platforms
Bor-Yiing Su, [email protected]
Prof. Kurt Keutzer, [email protected]
Parallel Computing Lab,
University of California, Berkeley

2/26
Category of This Work
2
Personal
Health
Image
Retrieval
Hearing,
MusicSpeech
Parallel
Browser
Design Patterns/Motifs
Sketching
Legacy
CodeSchedulers
Communication &
Synch. Primitives
Efficiency Language Compilers
Legacy OS
Multicore/GPGPU
OS Libraries & Services
RAMP Manycore
Hypervisor
Corr
ectn
ess
Composition & Coordination Language (C&CL)
Parallel
Libraries
Parallel
Frameworks
Static
Verification
Dynamic
Checking
Debugging
with Replay
Directed
TestingAutotuners
C&CL Compiler/Interpreter
Efficiency
Languages
Type
Systems
Dia
gnosin
g P
ow
er/
Perf
orm
ance

3/26
Outline
Motivation
Revisiting the Image Contour Detector: Damascene
Parallelizing Damascene on Multiple Platforms
Conclusion

4/26
What will future visual applications
look like?
Interact with images
Computer needs to understand images to provide image
interaction services
• Summarize information from the images
• Location aware services
• Optical character recognition
Interact with image parts through touchpad interfaces
Augmented reality

5/26
CBIR on a Mobile Platform
Goal: meeting end user’s requirements
Improving detection rate (accuracy), response time (speed), and battery
life (energy)
Our work: using Damascene as a case study to understand the capability of
modern mobile platforms in terms of:
Execution time
Power consumption
Choice of computation platform

6/26
Outline
Motivation
Revisiting the Image Contour Detector: Damascene
Parallelizing Damascene on Multiple Platforms
Conclusion

7/26
Image Contour Detection
State-of-the-art algorithm which achieves the highest accuracy: gPb
M. Maire, P. Arbeláez, C. Fowlkes, and J. Malik. Using contours to detect
and localize junctions in natural images. CVPR, pp. 1–8, June 2008.
Image Human Generated
Contours
Machine Generated
Contours

8/26
Computation Flow of Damascene
CombineNon-max
SuppressionIntervening
Contour
Combine,
Normalize
Contours

9/26
Outline
Motivation
Revisiting the Image Contour Detector: Damascene
Parallelizing Damascene on Multiple Platforms
Targeting Platforms
Performance on Desktop Platforms
• On Nvidia GTX480 GPU
• On Intel Nehalem Core i7 920 Quad-Core CPU
Performance on Mobile Platforms
• On ARM v7 Quad-Core Processor
• On MSM8655 Single-Core Snapdragon with NEON Support
Execution Time Analysis
Power Analysis
Conclusion

10/26
Desktop Platforms
Fermi GTX 480 Nelalem Core i7 920
Specifications GTX 480
CUDA Cores 480
Processor Clock 1.4 GHz
SP FLOPS 1.35 T
Memory Bandwidth 177.4 GB/s
Memory Size 1.5 GB
L1 Cache + Shared
Memory64 kB per SM
L2 Cache 768 kB
Specifications Core i7 920
Cores 4
Processor Clock 2.66 GHz
SP FLOPS 42.56 G
Memory Bandwidth 25.6 GB/s
L1 Cache 64 kB per core
L2 Cache 1MB per core
L3 Cache 8 MB

11/26
Mobile Platforms
ARM Cortex A9 Snapdragon MSM8655
Specifications Cortex A9
Cores 4
Processor Clock 800 MHz
SIMD Width (NEON) 128 bits
DMIPS 8000
L1 Cache 32 kB
L2 Cache 512 kB
Memory Bandwidth N.A.
Specifications MSM 8655
Cores 1
Processor Clock 1 GHz
SIMD Width (NEON) 128 bits
DMIPS 2100
L1 Cache 32 kB
L2 Cache 256 kB
Memory Bandwidth N.A.

12/26
Damascene on GTX 480
• Bryan Catanzaro, Bor-Yiing Su, Narayanan Sundaram, Yunsup Lee, Mark Murphy, and Kurt Keutzer,
"Efficient, High-Quality Image Contour Detection," in International Conference on Computer Vision
(ICCV-2009), pp. 2381-2388, Kyoto Japan, September 2009.
Routine Execution Time (ms)
Preprocess 0.789
Textons 129
Localcues 733
Intervening 14.12
Lanczos Solver 800
Poseprocess 7.96
Total 1706
The starting implementation
Image size used for benchmarking: 321 x 481 pixels

13/26
Porting to the CPU Platform
Porting the original CUDA implementation to serial C
implementation
Using our revised algorithms from the CUDA implementation
Using pthread to parallelize routines that execute more than 1
second on a 321 x 481 image
Exploring coarse grained parallelism on CPU instead of fine
grained parallelism on GPU
Setting compiler flags to vectorize the code, but not using SSE
intrinsics manually
Resulting in 10%-20% performance gain
Image size used for benchmarking
The same as the image used in GPU benchmarking
• 321 x 481 pixels

14/26
Performance on Core i7 920
RoutinesNumber of Used Threads
1 2 4
texton 2.99 1.45 0.75
localcues 18.93 9.44 5.26
intervene 3.01 1.54 1.01
Lanczos 11.10 6.13 4.71
Total 38.32 20.27 13.48
RoutinesNumber of Threads
1 2 4
texton 1 2.06 4.00
localcues 1 2.01 3.60
intervene 1 1.95 2.97
Lanczos 1 1.81 2.36
Total 1 1.89 2.84
Execution Time (s) Scalability on Number of Threads
Not all kernels scale linearly on the number of threads
Some computations are bounded by memory bandwidth
Compiler vectorization works better on single thread
Not all routines in Damascene are parallelized

15/26
Porting to the ARM Cortex A9
Quad-Core Processor
Code base
The same as the CPU pthread code
Compiler flags
None: not using any compiler flags
fpu: -march=armv7-a -mfloat-abi=softfp -mfpu=neon
All: -O3 -ftree-vectorize
Neonize: using the NEON intrinsics manually
16/26
Performance on the ARM Cortex A9
Quad-Core Processor
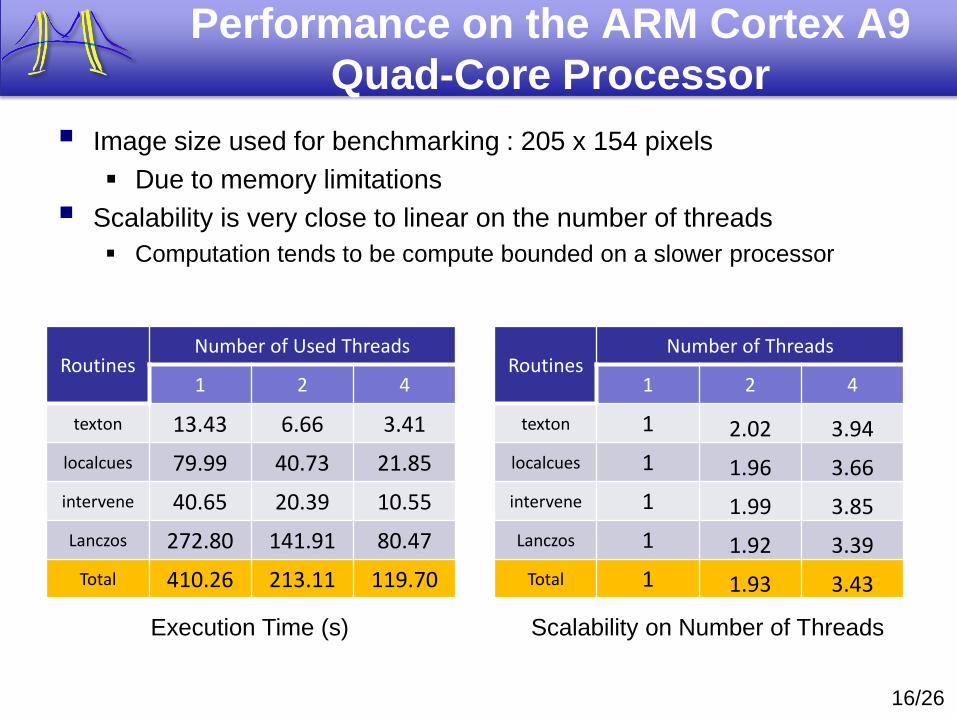
Image size used for benchmarking : 205 x 154 pixels
Due to memory limitations
Scalability is very close to linear on the number of threads
Computation tends to be compute bounded on a slower processor
RoutinesNumber of Used Threads
1 2 4
texton 13.43 6.66 3.41
localcues 79.99 40.73 21.85
intervene 40.65 20.39 10.55
Lanczos 272.80 141.91 80.47
Total 410.26 213.11 119.70
RoutinesNumber of Threads
1 2 4
texton 1 2.02 3.94
localcues 1 1.96 3.66
intervene 1 1.99 3.85
Lanczos 1 1.92 3.39
Total 1 1.93 3.43
Execution Time (s) Scalability on Number of Threads

17/26
Porting to the Single Core
Snapdragon Processor
Development environment: Android NDK
Code base
The same as the serial CPU implementation: Not using pthread
Compiler flags
None: not using any compiler flags
fpu: -march=armv7-a -mfloat-abi=softfp -mfpu=neon
All: -O3 -ftree-vectorize
Neonize: using the NEON intrinsics manually

18/26
Benchmarking the Lanczos
Eigensolver
The Lanczos iterative solver is composed of spmv, saxpy, sdot and
snrm2 kernels
All these kernels are memory bounded
Manually NEONize the kernels result in a performance gain of
7%-3x
Sparse Matrix Pattern

19/26
Performance on the Snapdragon
Processor
Image size used for benchmarking : 205 x 154 pixels
Due to memory limitations
Setting all compiler flags delivers a 6x speedup on the contour
detection computation
It is essential to get the compiler flags right on floating point
computations
Routine Flag_None Flag_All Ratio
texton 106.45 5.19 20.51
localcues 395.81 52.15 7.59
intervene 13.81 6.55 2.11
Lanczos 830.48 151.75 5.47
Total 1358.89 217.04 6.26
Execution Time (s)
Compiler Flags None vs. All

20/26
Execution Time Analysis
Image size used for benchmarking : 205 x 154 pixels
Implementations
Snapdragon: single core, 4-way SIMD, compiler vectorization
Cortex A9: quad-core, 4-way SIMD, compiler vectorization
Nehalem: quad-core, 4-way SIMD, compiler vectorization
Fermi: 15 cores, 16-way SIMD, dual issue, manual vectorization
Routin
e
Snapdr
agon
Cortex
A9
Nehale
mFermi
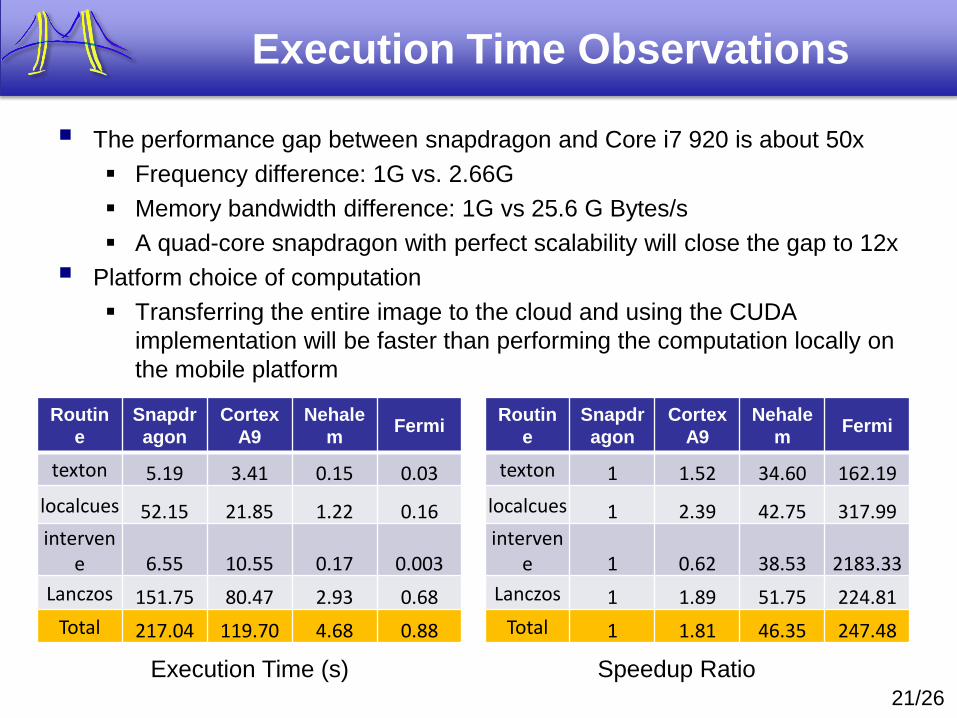
texton 5.19 3.41 0.15 0.03
localcues 52.15 21.85 1.22 0.16
intervene 6.55 10.55 0.17 0.003
Lanczos 151.75 80.47 2.93 0.68
Total 217.04 119.70 4.68 0.88
Routin
e
Snapdr
agon
Cortex
A9
Nehale
mFermi
texton 1 1.52 34.60 162.19
localcues 1 2.39 42.75 317.99
intervene 1 0.62 38.53 2183.33
Lanczos 1 1.89 51.75 224.81
Total 1 1.81 46.35 247.48
Execution Time (s) Speedup Ratio
21/26
Execution Time Observations
The performance gap between snapdragon and Core i7 920 is about 50x
Frequency difference: 1G vs. 2.66G
Memory bandwidth difference: 1G vs 25.6 G Bytes/s
A quad-core snapdragon with perfect scalability will close the gap to 12x
Platform choice of computation
Transferring the entire image to the cloud and using the CUDA
implementation will be faster than performing the computation locally on
the mobile platform
Routin
e
Snapdr
agon
Cortex
A9
Nehale
mFermi
texton 5.19 3.41 0.15 0.03
localcues 52.15 21.85 1.22 0.16
intervene 6.55 10.55 0.17 0.003
Lanczos 151.75 80.47 2.93 0.68
Total 217.04 119.70 4.68 0.88
Routin
e
Snapdr
agon
Cortex
A9
Nehale
mFermi
texton 1 1.52 34.60 162.19
localcues 1 2.39 42.75 317.99
intervene 1 0.62 38.53 2183.33
Lanczos 1 1.89 51.75 224.81
Total 1 1.81 46.35 247.48
Execution Time (s) Speedup Ratio
22/26
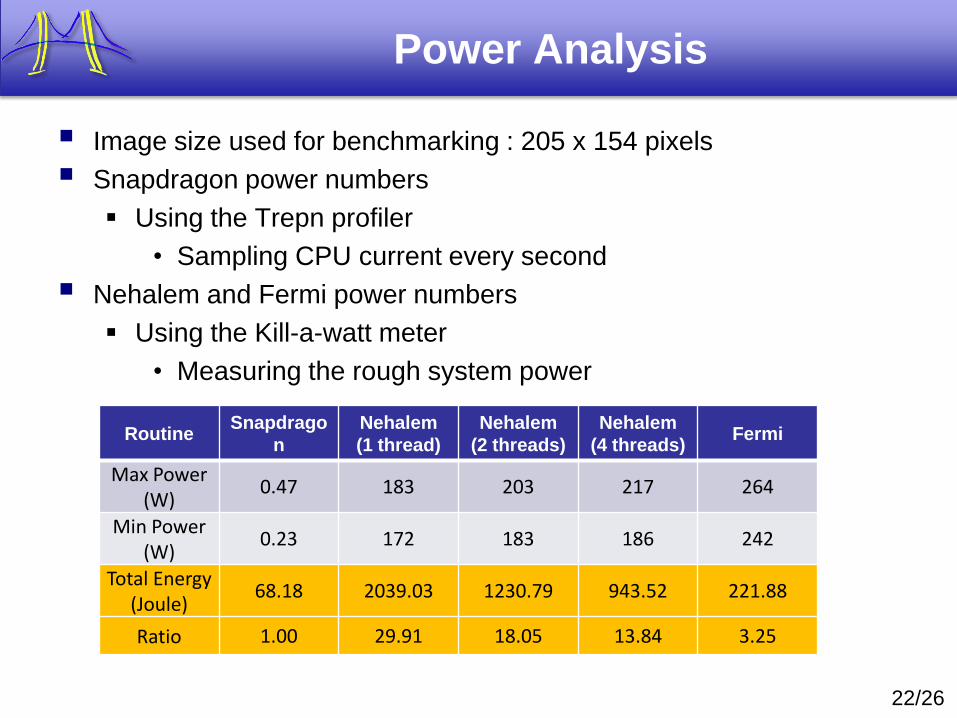
Power Analysis
Image size used for benchmarking : 205 x 154 pixels
Snapdragon power numbers
Using the Trepn profiler
• Sampling CPU current every second
Nehalem and Fermi power numbers
Using the Kill-a-watt meter
• Measuring the rough system power
RoutineSnapdrago
n
Nehalem
(1 thread)
Nehalem
(2 threads)
Nehalem
(4 threads)Fermi
Max Power (W)
0.47 183 203 217 264
Min Power (W)
0.23 172 183 186 242
Total Energy (Joule)
68.18 2039.03 1230.79 943.52 221.88
Ratio 1.00 29.91 18.05 13.84 3.25

23/26
Power Observations
Race to halt principle is well applied on the desktop platforms
Mobile platforms are about 400x more power efficient than desktop
platforms
Although the execution time on the mobile platform is about 50x
(compared to CPU) to 250x (compared to GPU) slower, it still
consumes the least amount of energy
As long as the image uploading and the results downloading energy
is smaller than the computation energy, we should keep the
computation on the cloud
RoutineSnapdrago
n
Nehalem
(1 thread)
Nehalem
(2 threads)
Nehalem
(4 threads)Fermi
Max Power (W)
0.47 183 203 217 264
Min Power (W)
0.17 172 183 186 242
Total Energy (Joule)
68.18 2039.03 1230.79 943.52 221.88
Ratio 1.00 29.91 18.05 13.84 3.25

24/26
Outline
Motivation
Revisiting the Image Contour Detector: Damascene
Parallelizing Damascene on Multiple Platforms
Conclusion

25/26
Conclusion
Execution time
Our hand optimized CUDA code still delivers the best performance
Our CPU implementation achieves linear scalability on ARM Cortex A9, but not
on Core i7 920
• The computation tends to be more compute bounded on the slower ARM
Cortex A9, but more memory bounded on the faster Core i7 920
The gap between single core snapdragon and quad core Core i7 920 is about
50x
Power
Race to halt principle is well applied on the desktop platforms
Snapdragon is about 400x more power efficient than desktop platforms
Although Snapdragon is about 50x – 250x slower than the desktop platforms, it
still consumes less energy
Platform choice of computation
Damascene is very computationally intensive and has lots of data parallelism
• Uploading the entire image to the cloud will be better than performing the
computations locally on the mobile platform in terms of both total execution
time and energy consumption
With the advancement of mobile technologies, this decision might be changed in
the future

26/26
Future Work
Include network bandwidth scenarios
Data transmission latency model
Data transmission power consumption model
Include input pre-processing analysis
Image down sampling
Image compression rate
Port the entire object recognition system onto mobile platforms
Client-cloud co-design
Revisit the object recognition system from the perspective of client-
cloud co-design
Try out other object recognition systems that are less computationally
intensive on the mobile platforms

27/26
Thank You