constrained optimization for validation-guided conditional random field learning minmin chen ,...
TRANSCRIPT

Constrained Optimization for Validation-Guided Conditional
Random Field Learning
Minmin Chen , Yixin Chen , Michael Brent , Aaron Tenney
Washington University in St. Louis104/19/23 KDD 2009
Presented by: Qiang Yang, HKUST

Conditional Random Fields
Conditional Random Fields (Lafferty, McCallum& Pereira 2001)Probabilistic model for sequential data segmentation and
labeling
2
1 1 2
GA T
1 2
C G
LabelingSequence
ObservationSequence
04/19/23 KDD 2009
FEATURE

Applications
Natural Language ProcessingLafferty J., McCallum A.& Pereira F. 2001Sha F. & Pereira F. 2003Sarawagi S. & Cohen W. W. 2005
Computer VisionSminchisescu C., Kanaujia A. & Metaxas D. 2006Vishwanathan S. V. N. et al. 2006
BioinformaticsCulotta A., Kulp D. & McCallum A. 2005 Gross, S. S. et al. 2007
304/19/23 KDD 2009

Challenges and Related Work
OverfittingLikelihood training Overfitting
Model flexibility Large feature set OverfittingRelated Work
Regularization (Sha 2003, Vail 2007)Smoothing methods (Newman 1977, Rosenfeld 1996)Regularization with a Gaussian prior works as well as or better
than smoothing methods, but the regularization parameter is hard to tune
04/19/23 KDD 2009 4

Motivation of Proposed Work
Cross-validation is often used to estimate the accuracy of a classifier and to select models. Generally, the performance on the validation set is strongly correlated to the performance of the trained model on the unseen data
Constraints prescribing the performance of the trained model on the validation set are used to guide the learning process and avoid the model from fitting freely and tightly to the training data
04/19/23 KDD 2009 5
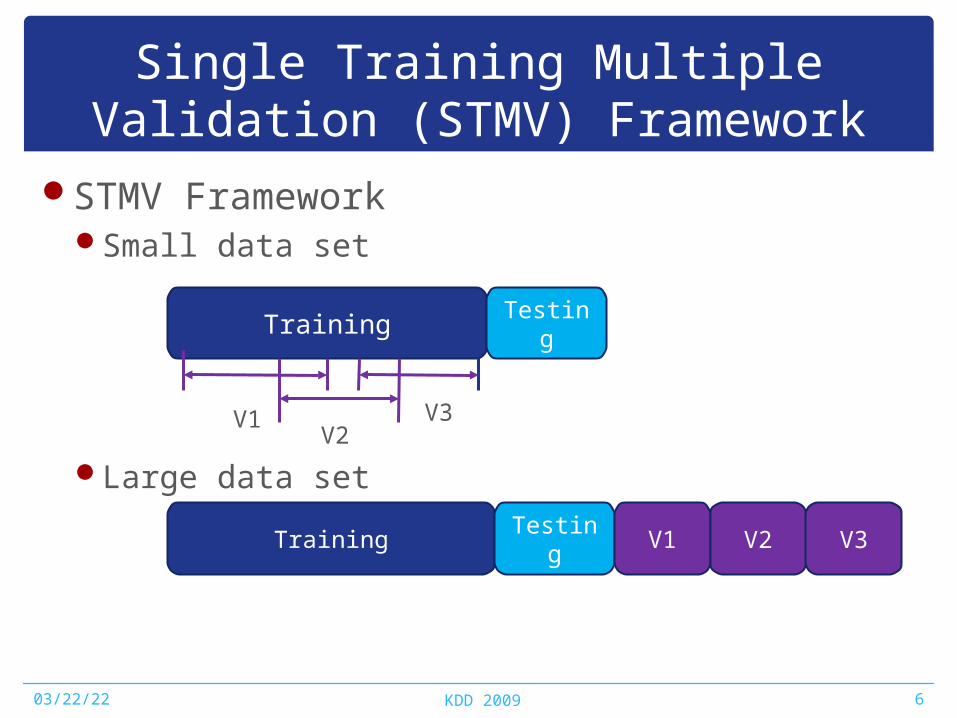
Single Training Multiple Validation (STMV) Framework
STMV FrameworkSmall data set
Large data set
04/19/23 KDD 2009 6
Training Testing
V1V2
V3
Training Testing V1 V2 V3

Constrained Formulation
Where
Constraints prescribing the difference of scores to ensure the model take consideration of the performance on the validation sets
04/19/23 KDD 2009 7
Original objective : maximize the log likelihood of the labeling
sequence given the observation sequence of the training data
Score of a specific labeling sequence y for an observation
sequence x
Score of the most likely sequence found by Viterbi under current
model for validation sequence v(j)
Score of real labeling sequence for validation sequence v(j)

Extended Saddle Point (ESP) Theory
Extended Saddle Point Theory (Wah & Chen 2005)Introduces a necessary and sufficient condition on the
Constrained Local Minimum (CLM) of a constrained nonlinear programming problem in a continuous, discrete, or mixed space
Offer several salient advantages over previous constraint handling theory• Does not require the constraints to be differentiable or in closed form• Satisfied over an extended region of penalty values• Necessary and sufficient
04/19/23 KDD 2009 8

Extended Saddle Point (ESP) Search Algorithm
Extended Saddle Point Search AlgorithmTransform the constrained formulation into a penalty form where Outer loop updates the extended penalty values Inner loop minimizes
ChallengesEfficient calculation of the gradient of the penalty function• The first term of the constraint is determined by the most likely sequence
found by the Viterbi Algorithm. • Change of the parameter W can result in a very different sequence
non-differentiable
04/19/23 KDD 2009 9
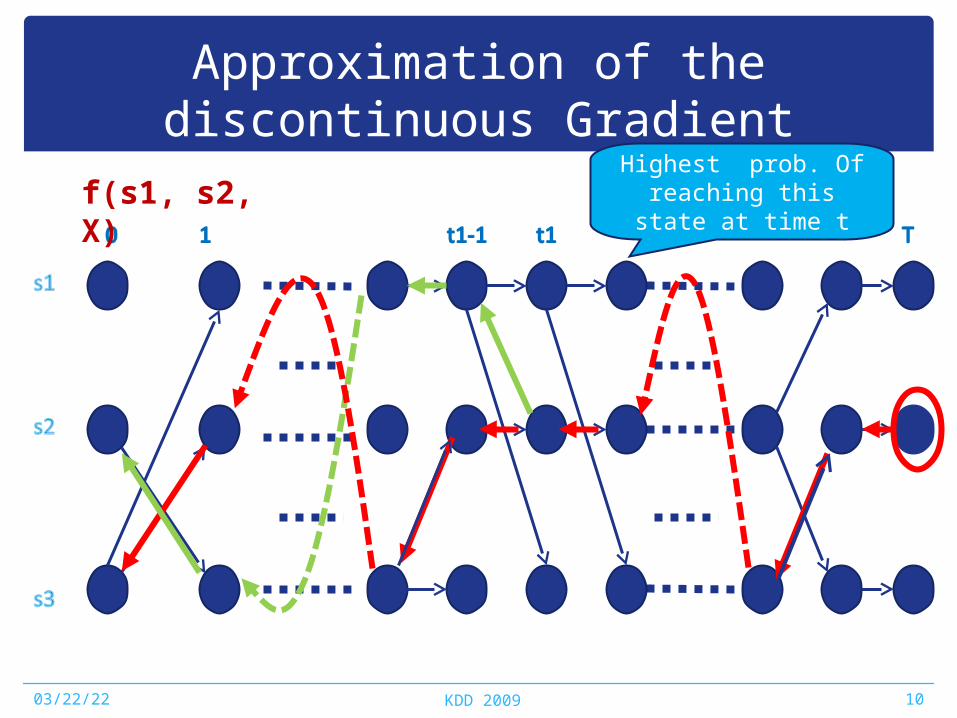
Approximation of the discontinuous Gradient
04/19/23 KDD 2009 10
Highest prob. Of reaching this state at time tf(s1, s2, X)

Experimental Results : Gene Prediction
Find out the protein coding regions and associated components
Apply our STMV framework and ESP search algorithm on CONTRAST, a state-of-the-art gene predictor
Data set:Fruit fly genome, 27,463 genes, evenly divided into 4 setsFeature set includes around 33,000 features
Compare performance to original CONTRAST, and CONTRAST with regularizationGene, exon, nucleotide level sensitivity and specificity
04/19/23 KDD 2009 11
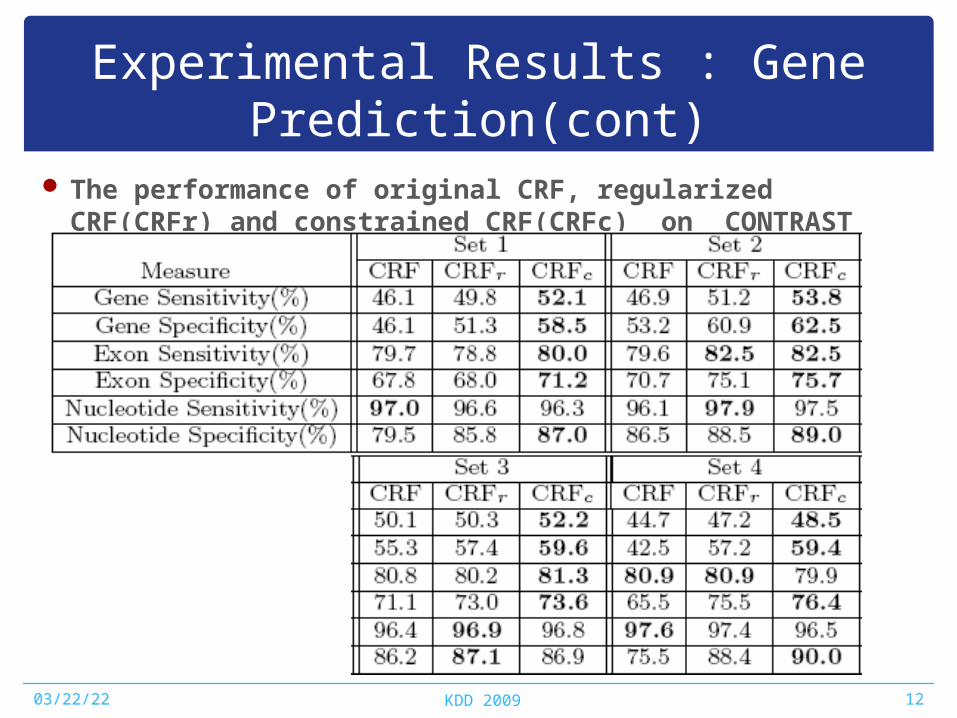
Experimental Results : Gene Prediction(cont)
The performance of original CRF, regularized CRF(CRFr) and constrained CRF(CRFc) on CONTRAST
04/19/23 KDD 2009 12

Experimental Result: Stock Price Prediction
Predict if tomorrow’s stock price will raise or fall comparing to today’s, based on historical data;
Preprocessing techniques to smooth out the noise in the raw data
Date set:1741 stocks from NASDAQ and NYSEEach contains stock prices from 2002-02-01 to 2007-09-12Feature set includes 2,000 features
Predict on day T+1:Training Sequence : day 1 ~ TValidation Sequence: day T-V+1 ~ T (V = 100)
04/19/23 KDD 2009 13
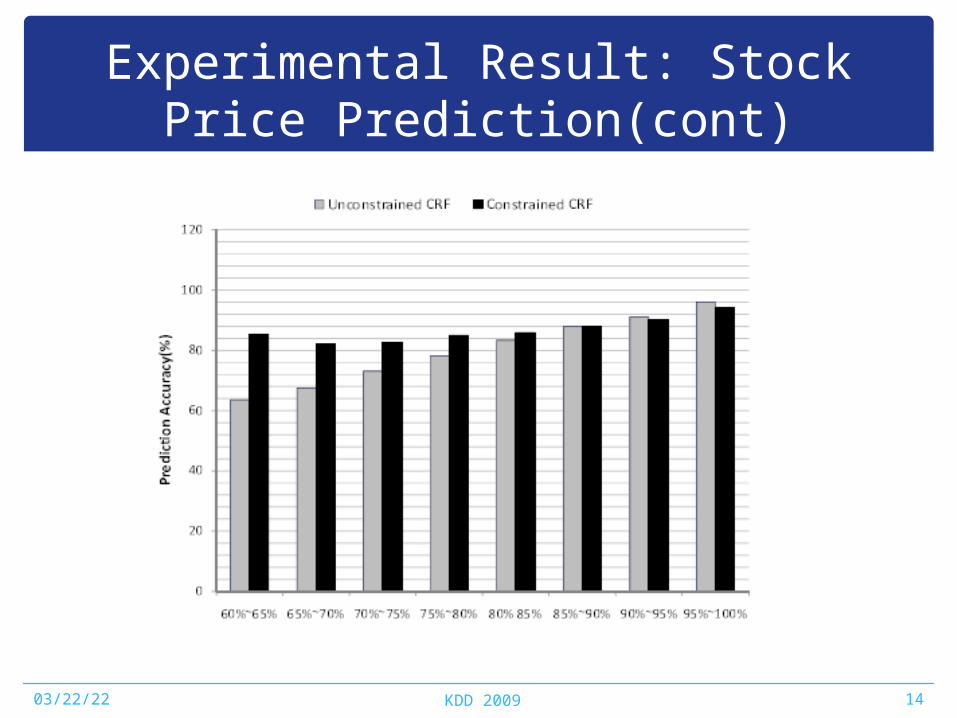
Experimental Result: Stock Price Prediction(cont)
04/19/23 KDD 2009 14

Conclusion
A Single Training Multiple Validation (STMV) frameworkIntegrate validation into the training process by modeling the
validation quality as constraints in the problem formulationEffectively avoid overfitting of CRF models
Approximation SchemeEfficiently approximate the discontinuous gradient of our
constrained formulation Extended Saddle Point (ESP) search algorithm
Robustly find a constrained local minimum for our constrained formulation
04/19/23 KDD 2009 15