concurrency control: methods, performance, and...
TRANSCRIPT

Concurrency Control: Methods, Performance, and AnalysisALEXANDER THOMASIAN
IBM T. J. Watson Research Center, 30 Saw Mill River Road, Hawthorne, NY 10532
Standard locking (two-phase locking with on-demand lock requests and blockingupon lock conflict) is the primary concurrency control (CC) method for centralizeddatabases. The main source of performance degradation with standard locking isblocking, whereas transaction (txn) restarts to resolve deadlocks have a secondaryeffect on performance. We provide a performance analysis of standard locking thataccurately estimates its performance degradation leading to thrashing. We nextintroduce two sets of methods to cope with its performance limitations. Restart-oriented locking methods selectively abort txns to increase the level of concurrencyfor active txns with respect to standard locking in high-contention environments.For example, the running-priority method aborts blocked txns based on theessential blocking principle, which only allows blocking by active txns. The wait-depth-limited (WDL) method further minimizes wasted processing by basing abortdecisions on the progress made by a txn. Restart waiting serves as a load-controlmechanism by deferring the restart of an aborted txn until conflicting txns haveleft the system. These two methods have performance superior to other restart-oriented methods and standard locking in high-contention environments. In two-phase processing methods an aborted txn may continue its first phase of executionin “virtual” mode, that is, without requesting any locks, prefetching data for itssecond execution phase. The second execution phase is shorter since no disk I/O isrequired, resulting in a lower effective degree of txn concurrency and less datacontention. This method is effective provided access invariance prevails; that is,txns access the same set of objects in the second phase as they did in the first. Theoptimistic die method is appropriate for the first phase and the optimistic killmethod for further phases. Lock preclaiming instead of the optimistic kill methodin the second phase prevents further restarts, which is a weak point of theoptimistic CC method due to the quadratic effect, that is, the probability of failedvalidation increases as the square of txn size. Several two-phase processingmethods are described and shown to outperform restart-oriented locking methodsin high-contention environments provided adequate hardware resources areavailable. This tutorial reviews CC methods based on standard locking, restart-oriented locking methods, two-phase processing methods including optimistic CC,and hybrid methods (combining optimistic CC and locking) in centralized systems.Its main goals are as follows: (i) succinctly specify CC methods of interest; (ii)describe models for performance evaluation of CC methods, including new modelsthat alleviate some of the shortcomings of models used in earlier studies; (iii)compare the performance of CC methods; (iv) list insights gained from analytic andsimulation studies; (v) review methods to relieve the level of lock contention:special methods for indices and aggregate data; modified txn structures; andrelaxed levels of consistency for queries; (vi) survey performance evaluation studiesof CC methods; (vii) illustrate the applicability of basic analytic methods to
Permission to make digital / hard copy of part or all of this work for personal or classroom use is grantedwithout fee provided that the copies are not made or distributed for profit or commercial advantage, thecopyright notice, the title of the publication, and its date appear, and notice is given that copying is bypermission of the ACM, Inc. To copy otherwise, to republish, to post on servers, or to redistribute tolists, requires prior specific permission and / or a fee.© 1998 ACM 0360-0300/98/0300–0070 $5.00
ACM Computing Surveys, Vol. 30, No. 1, March 1998

evaluating the performance of CC methods; and (viii) suggest areas of furtherinvestigation.
Categories and Subject Descriptors: D.4.8 [Operating Systems]: Performance—Modeling and prediction; stochastic analysis; simulation. H.2.4 [DatabaseManagement] Systems—transaction processing
General Terms: Algorithms, Performance
Additional Key Words and Phrases: Adaptive methods, concurrency control,deadlocks, data contention, flow diagrams, load control, Markov chains, optimisticconcurrency control, queueing network models, restart-oriented locking methods,serializability, thrashing, two-phase locking, two-phase processing, wait depthlimited methods
CONTENTS
INTRODUCTION1. MODELING AND ANALYSIS OF TRANSACTION
PROCESSING SYSTEMS1.1 Transaction Model1.2 Database Access Model1.3 Computer System Model
2 STANDARD LOCKING AND ITS PERFORMANCE2.1 Lock Conflicts and Deadlocks2.2 A Performance Analysis of Dynamic Locking2.3 Performance Analyses of Static Locking2.4 Performance Analyses of Dynamic Locking2.5 On More Realistic Lock-Contention Models2.6 Methods to Improve Locking Performance
3. RESTART-ORIENTED LOCKING METHODS3.1 Description of Restart-Oriented Locking Meth-
ods3.2 Performance Comparison of Restart-Oriented
Locking Methods3.3 Performance Analysis of the Running-Priority
Method4. TWO-PHASE PROCESSING METHODS AND AC-
CESS INVARIANCE4.1 Optimistic Concurrency Control4.2 Mechanisms Used by Two-Phase Processing
Methods4.3 Description and Performance of Two-Phase Pro-
cessing Methods4.4 Performance Analysis of Optimistic Concurency
Control Methods5. CONCLUSIONSGLOSSARYAPPENDIX: NOTATIONREFERENCES
INTRODUCTION
The requirement for concurrency control(CC)1 arose two decades ago to ensurecorrectness when a shared database is
updated by multiple transactions (txn)sconcurrently [Gray and Reuter 1992].Txn concurrency or multiprogrammingis required to take advantage of multi-ple processors and CPU-I/O overlap toattain high txn throughputs.
The universally accepted correctnesscriterion for processing txns against adatabase is serializability; that is, theinterleaved execution of a set of concur-rent txns is tantamount to a serial exe-cution [Date 1983; Bernstein et al. 1987;Gray and Reuter 1992]. This correctnesscriterion is not acceptable for some ap-plications (e.g., stock trading bids mayhave a FCFS (first-come, first-served)processing requirement [Peinl et al.1988]. Such specialized systems are notconsidered in this tutorial. Standardlocking (i.e., strict two-phase locking(2PL) with on-demand lock requests andthe general waiting method on lock con-flict) is almost exclusively used by cur-rent database management systems(DBMS)s [Date 1983; Bernstein et al.1987; Gray and Reuter 1992]. Strict2PL requires locks to be released onlywhen the txn is committed or aborted,since this prevents cascading aborts[Bernstein et al. 1987; Gray and Reuter1992]. Cascading aborts occur when atxn accesses an object modified by anuncommitted txn, which aborts after re-leasing the lock. Standard locking withsome deviations is used in most com-mercial DBMSs [Date 1983; Gray andReuter 1992].
We are mainly concerned with CCmethods for centralized high-perfor-1 Abbreviations are summarized in the Glossary.
Concurrency Control • 71
ACM Computing Surveys, Vol. 30, No. 1, March 1998

mance txn processing systems. Due tothe high level of txn concurrency (re-quired for attaining higher txn through-puts) and increasing txn complexity,both of which result in an increase inthe probability of lock conflict, the per-formance of such systems may be lim-ited by lock contention. In the case ofstandard locking this is in the form oftxn blocking due to lock conflicts, whichmay lead to a thrashing behavior inwhich the majority of txns in the systemare blocked. Various techniques to re-duce the level of lock contention areintroduced in this article, but our em-phasis is on restart-oriented lockingmethods and two-phase processingmethods [Franaszek et al. 1992].
Restart-oriented locking methods al-low some txns encountering lock con-flicts to be blocked, but reduce the levelof lock contention by aborting other txnsencountering or causing lock conflicts.Aborted txns are restarted by the sys-tem at a later time without user inter-vention. Restart-oriented locking meth-ods that limit the level of txn blockingare called wait-depth-limited methods.The wait-depth-limited (WDL) methodbelongs to this category, since it takesinto account txn progress in decidingwhich txn among a set of conflictingtxns to abort [Franaszek et al. 1992].Two-phase processing methods executetxns in two (or multiple) phases takingadvantage of the fact that txn re-execu-tion may not require disk I/O providedan adequately sized database buffer isavailable and access invariance prevails[Franaszek et al. 1990; Franaszek et al.1992].
Two other widely discussed methodsare optimistic CC (OCC) [Kung andRobinson 1981] and time-stamp order-ing (TSO) methods [Ceri and Pelagatti1984; Cellary et al. 1988], but the latterare more appropriate in distributed da-tabases and are known to have a poorperformance otherwise [Ryu and Tho-masian 1986]. In fact, OCC methods areviable execution modes for two-phasetxn processing, as in the case of utiliz-ing the optimistic die and kill methods
in the first and second phases, respec-tively [Franaszek et al. 1992].
A brief review of analytical modelingof a typical computer system model isprovided to determine baseline txn per-formance due to hardware resource con-tention, that is, ignoring the effect ofdata contention. We also outline theperformance analyses of several CCmethods to illustrate the applicability ofanalytic techniques. Insights gainedfrom analytic solutions are giventhroughout the article. The analysis ofstandard locking is expected to be ofinterest to all readers, but otherwise theanalyses of restart-oriented lockingmethods and OCC methods and surveysof analytic studies can be skipped with-out loss in continuity.
Readers are expected to be familiarwith basic DBMS and CC concepts.There are texts dealing with CC in da-tabases and their performance [Bern-stein et al. 1987; Tay 1987; Cellary etal. 1988; Kumar 1995; Thomasian1996a], which are complemented by thisarticle. This tutorial/survey should be ofvalue to researchers interested in theperformance of database systems, espe-cially CC methods, designers of high-performance txn processing systems,and professionals concerned with tuningthe performance of txn processing sys-tems. There is also material for re-searchers interested in analyzing theperformance of CC methods.
This article is organized as follows. InSection 1 we describe the txn executionmodel, the database access model, andthe computer system model. In Section2 we analyze the performance of thestandard locking method, discuss itsthrashing behavior, and describe load-control methods to prevent thrashing.Analyses of locking methods are nextreviewed. We then introduce a more re-alistic locking model, which is followedby a discussion of some of the shortcom-ings of locking models. Finally, we de-scribe some recently proposed methodsto reduce the level of lock contention.
In Section 3 we provide a succinctdescription of restart-oriented locking
72 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

methods, including wait-depth-limitedmethods and the WDL method. The per-formance of these and several othermethods is compared through simula-tion and we outline the analysis of thesymmetric running priority method. InSection 4 we describe OCC methods andvarious validation options. A specifica-tion of mechanisms utilized by two-phase processing methods is followed bythe description of representative two-phase processing methods. Simulationresults to evaluate the performance oftwo-phase processing methods againsteach other and with other methods arereported. Finally, we discuss analyticsolutions for OCC methods in Section4.4.
In Section 5 we summarize the majorpoints of the earlier sections of the arti-cle. We next discuss difficulties in devel-oping analytic models for predictingperformance degradation due to lockingin operational txn processing systems.Finally, several areas requiring furtherinvestigation and some new areaswhere CC is an issue are listed.
The notation required for analyzingthe performance of CC methods is intro-duced in Section 1 and summarized inthe Appendix.
1. MODELING AND ANALYSIS OFTRANSACTION PROCESSING SYSTEMS
We describe models for evaluating theperformance of txn processing systemsas affected by hardware and data re-source contention. Hardware resourcecontention has the primary effect onperformance, whereas data contentionhas a secondary effect. Relatively ab-stract models, both from the viewpointof data and hardware resource conten-tion, are used in performance analysesand simulation studies of CC methods.These models are not detailed enoughfor predicting the performance of “real”txn processing systems, but are deemedadequate for the performance compari-son of CC methods.
Sections 1.1 through 1.3 describe thetxn, database access, and computer sys-
tem models. The reader is referred toChapter 2 in Thomasian [1996a] for amuch more detailed discussion of ana-lytic and simulation methods to evalu-ate the performance of CC methods.
1.1 Transaction Model
Transaction Execution Steps. Single-level or flat txns, as opposed to multi-level txns [Gray and Reuter 1992], andrelatively short update txns, ratherthan batch update txns or read-onlyqueries, are of main interest in thisstudy (other txn structures are dis-cussed in Elmagarmid [1992] and Ra-mamithram and Chrisanthis [1996]).Techniques to cope with the lock conten-tion between long-running read-onlyqueries and short update txns are dis-cussed in Section 2.5. A txn accessing kdatabase objects consists of k 1 1 exe-cution steps, numbered 0–k. Each stepinvolves CPU processing and disk ac-cesses. The last k steps begin with adatabase call, which leads to an accessto a single database object, after anappropriate lock on the object has beenacquired. The completion of the laststep leads to txn commit (i.e., the writ-ing of log records onto stable storage)after which the locks held by the txn arereleased [Date 1983; Bernstein et al.1987; Gray and Reuter 1992]. Loggingof commit data onto disk adds to the txnresponse time and the holding time oflocks, but logging time can be reducedby providing a nonvolatile RAM (ran-dom access memory) for this purpose[Franaszek et al. 1992]. The number ofobjects accessed by a txn is referred toas txn size. A system may process mul-tiple txn classes, where txn class k isdenoted by Ck. Txn class is determinedby its size in this work, although othertxn characteristics may be used for thispurpose.
Transaction arrival process. Txnsoriginate from a finite number ofsources (say S), which may correspondto bank tellers generating txns after athink time with a mean Z; that is, the
Concurrency Control • 73
ACM Computing Surveys, Vol. 30, No. 1, March 1998

arrival rate with M txns already at thesystem is L(M) 5 (S 2 M)/Z. We con-sider one-shot txns, such that the user isnot involved after the txn is submitted;that is, there are no intervening userthink times [Agrawal et al. 1987a]. Qua-sirandom arrivals with exponentiallydistributed think times lead to analyti-cally tractable models [Kleinrock 1975].A truncated exponential distribution isadopted in txn processing benchmarksto avoid very long think times [Gray1993].
A system with a sufficiently large S isconsidered to be open with a txn arrivalrate independent of the number of txnsat the system. The txn arrival processin an open system is usually assumed tobe Poisson with an arrival rate l [Klein-rock 1975]. The mean response timecharacteristic (i.e., the mean txn re-sponse time R(l) versus l) can be usedfor the performance comparison of CCmethods in this case.
A system with S 5 M sources is con-sidered to be closed when Z 5 0. Acompleted txn is then immediately re-placed by a new txn so that the degreeof txn concurrency in the system is al-ways M. The seemingly unrealisticclosed model is quite useful in compar-ing the performance of CC methods be-cause: (i) the solution of a closed modelcan be used as a submodel in perfor-mance evaluation of a system with ex-ternal arrivals [Lazowska et al. 1984];(ii) it is easier to estimate the peakperformance of CC methods by simulat-ing a closed rather than an open model,which is due to the variability of thenumber of txns in an open model. Theperformance of a closed system with Mtxns can be specified by its throughputT(M), whereas T(M), M $ 1 is referredto as its effective throughput character-istic (ETC). It follows from Little’s re-sult (that the mean number of requestsin a system is equal to the product ofthe arrival rate of requests and themean time they spend in the system[Kleinrock 1975; Lazowska et al. 1984])that the mean residence time of txns inthe system is R(M) 5 M/T(M).
A frequency-based model specifies thefraction fk of txns in Ck processed by thesystem. In an open system the arrivalrate of txns in Ck is lk 5 lfk, 1 # k #K, where K is the largest txn size. Notethat ¥k51
K fk 5 1 with fk . 0 for txnsizes being processed by the system andfk 5 0 otherwise. The mean number oftxns in Ck is M# k 5 lkRk according toLittle’s result, where Rk is the meanresponse time of txns in Ck.
In a closed system we may specify thedegree of txn concurrency Mk of txns inCk. A frequency-based model is also ap-plicable in this case, with a completedtxn being immediately replaced by anew txn in Ck with probability fk. Thethroughput for txn completions in Ck isa fraction of fk of T(M); that is, Tk(M) 5fkT(M), 1 # k # K. The performancecomparison of CC methods with a fre-quency-based closed system simply re-quires the comparison of their ETCs[Ryu and Thomasian 1987; Thomasian1993], and an open model requires thecomparison of the mean-response-timecharacteristics, which are more difficultto obtain (see the hierarchical solutionmethod in Section 1.3).
1.2 Database Access Model
The granule is the unit of data at whichCC is applied to the database. A granulemay be associated with multiple data-base objects; for example, a page-levellock applies to all the records in a page[Gray and Reuter 1992]. The effect ofgranularity of locking on performancehas been considered in several studies(see, e.g., Tay [1987]). A finer level ofgranularity of locking incurs more over-head, but reduces the level of lock con-tention. For example, the frequency oflock conflicts in processing short txns islowered with record- rather than page-level locking, whereas a query accessinga relational table should preferably usetable-level locking since with record-and even page-level locking it wouldincur a tremendous overhead [Gray andReuter 1992; Thomasian 1996a]. Tech-niques to resolve the lock contention
74 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

between txns and read-only queries arediscussed in Section 2.6.
We consider a database with D ob-jects that are locked in exclusive andshared mode. This simple locking modelcan be justified by the fact that we aremainly concerned with short txns.
Most studies assume that databaseobjects are accessed with uniform prob-abilities. Nonuniformity of database ac-cess is captured by the hot-spot modeland the b 2 c rule [Tay 1987]; that is, afraction b (resp., 1 2 b) of txn accessesare to a fraction c (resp., 1 2 c) of thedatabase.
A homogeneous database accessmodel is postulated in most studiessuch that all txn classes follow the samelock-request pattern (see Section 2.1). Amore realistic database access model fortxn processing with multiple txn classesand multiple database regions is basedon the heterogeneous database accessmodel, which is elaborated in Section2.5.
Sequential database access has beenconsidered in some early simulationstudies of static locking (see Chapter 4in Tay [1987]) and is analyzed in Ryuand Thomasian [1988]. Database accesspatterns or granule placements are re-viewed in Langer and Shum [1982].
Performance analyses of CC methodscan be classified according to whetherthe objects accessed and locks obtainedby a txn are distinct or not, which arereferred to as without- and with-re-placement options [Langer and Shum1982]. Analyses in the former case leadto expressions with binomial coeffi-cients, which can be approximated accu-rately by simpler expressions for thewith-replacement option (see the ex-pression for probability of data conflictin Section 4.4). When the number oflock requests by a txn (say k) is muchsmaller than D, then even if locks arereplaced, the chances that a txn willrequest the same lock are very small.This is why expressions for the proba-bility of data conflict for with- and with-out-replacement options yield indistin-guishable results. Expressions for the
with-replacement option are preferable,since they are easier to evaluate [Tho-masian 1996a].
1.3 Computer System Model
A queueing network model (QNM) de-termines the execution time of txns inthe computer system by taking into ac-count its processing time at the variousdevices of the computer system, as wellas queueing effects. The processing timeat the CPU is determined by txn path-length and CPU speed. Disk processingtime is determined by the disk accesstime and the number of disk I/Os, whichis affected by the miss ratio of the data-base buffer [Gray and Reuter 1992]. Thebuffer hit ratio of a workload is a func-tion of its buffer space allocation andthe buffer management policy, includ-ing the buffer replacement policy, forexample, least recently used, LRU[Gray and Reuter 1992].
The infinite-resource model is usefulin comparing the performance limits ofCC methods [Franaszek and Robinson1985; Ryu and Thomasian 1987; Tay1987; Thomasian 1993]. According tothis model, each txn has its own virtualprocessor and its execution time is inde-pendent of the number of txns beingexecuted concurrently. The mean resi-dence time of txns in the system is thenr(M) 5 c and the system throughput ist(M) 5 M/c, M $ 1.
A finite-resource model allows thelevel of hardware resource contention tobe varied to determine its effect on over-all performance [Thomasian and Ryu1986; Agrawal et al. 1987; Franaszek etal. 1992; Thomasian 1993]. This is espe-cially important when comparing theperformance of restart-oriented CCmethods with blocking-oriented CCmethods (such as standard locking),where the former introduce wasted pro-cessing (processing not leading to thesuccessful completion of a txn), whereasthe latter may result in system under-utilization due to blocked txns.
Figure 1 shows a set of user terminalsaccessing a computer system with the
Concurrency Control • 75
ACM Computing Surveys, Vol. 30, No. 1, March 1998

central server QNM, where the centralserver is the CPU and the peripheralservers are the disks. The probabilitythat a txn completes after the currentCPU burst and a response is sent to auser terminal is p0. The number of vis-its to the CPU follows the geometricdistribution Pk 5 p0(1 2 p0)k21, k $ 1,with the mean equal to 1/p0. After com-pleting CPU processing, a txn accessesthe nth disk with probability pn suchthat the mean number of visits to disk nis pn/p0. This simple model for txn tran-sitions does not lend itself to modelingfixed-size txns. This is accomplished bymaking txn transitions at the comple-tion of CPU processing dependent onthe state of the txn [Irani and Lin 1979;Thomasian 1982].
QNMs can be analyzed to determinethe response time of txns as affected byhardware resource contention [Klein-rock 1975; Lazowska et al. 1984]. Prod-uct-form QNMs constitute a small sub-set of QNMs, since several strictrequirements need to be met for a QNMto be product-form (e.g., the service timedistribution at nodes with the FCFSdiscipline is exponential [Lazowska etal. 1984]). Performance measures suchas throughput, device utilizations, andmean queue lengths can be computedefficiently for a product-form QNM us-ing the mean service demands of txns atits nodes. The mean service demand of atxn at a node is the product of the meannumber of visits the txn makes to thenode and the mean service time per
Figure 1. Central server queueing model.
76 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

visit. For a given txn arrival rate themean residence time at the nodes of anopen QNM can be computed separately,as if the arrival process to each nodewere Poisson [Kleinrock 1975]. In thecase of a closed QNM, the convolution ormean-value analysis algorithm [La-zowska et al. 1984] can be used to ob-tain the system throughput characteris-tic (STC) t(m), 1 # m # Mmax, whereMmax is the maximum degree of txnconcurrency.
The device with the highest utiliza-tion in a QNM is referred to as thebottleneck device. It is the first to be sat-urated as the arrival rate (resp., the num-ber of txns) is increased in an open (resp.,closed) system. The maximum through-put is given by tmax 5 1/X9bottleneck,where X9bottleneck 5 max(X1/m1, . . . ,XN/mN), with Xn being the mean servicedemand and mn the number of serversat node n [Kleinrock 1975; Lazowska etal. 1984].
A realistic computer system model fortxn processing cannot be adequatelyrepresented by a product-form QNM, forexample, nonexponential service timesat disks with a FCFS discipline, CPUpriorities, and txn blocking due to lockconflicts [Franaszek et al. 1992].
Hierarchical solution method. Thehierarchical solution method is useful inevaluating the performance of txn pro-cessing systems with external arrivals,which cannot be solved directly as openmodels although the underlying QNM isproduct-form, for example, due to con-straints on the degree of txn concur-rency or lock conflicts in static locking[Thomasian and Ryu 1983; Thomasian1985] (see Section 2.3). The theoreticaljustification for this solution method isthe decomposition or aggregation princi-ple in QNMs [Lazowska et al. 1984]. Forexample, the computer subsystem inFigure 1 can be replaced by an aggre-gate or flow-equivalent service center[Lazowska et al. 1984]. In the case of asingle job-type (txn class) the aggregateserver is state-dependent with a com-
pletion rate given by the STC (t(M),M $ 1).
The processing of txns with Poissonarrivals can be represented by a birth–death model, with states correspondingto the number of txns at the system (M)[Kleinrock 1975]. The birth rate at allstates is l and the death rate at state Mis t(M). The birth–death model has asolution provided tmax . l, where tmax isthe maximum attainable throughput. Asystem with quasirandom arrivals canbe represented with a birth–deathmodel with S 1 1 states and arrivalrates L(M) 5 (S 2 M)/Z, 0 # M # S.
Multiple txn classes that have differ-ent processing requirements can bespecified as different job types in QNMterminology. The flow-equivalent ser-vice center in the case of two job types isspecifiable as t1(M1, M2), t2(M1, M2),M1 $ 0, M2 $ 0. Such flow-equivalentservers have been utilized in the analy-ses in Potier and LeBlanc [1983], Tho-masian [1985], and Thomasian [1993a].
In a single-txn-class system with datacontention, the ETC (T(M), M $ 1)rather than the STC (t(M), M $ 1)should be used in the analysis.
Performance degradation due to CCMethods. This degradation is due totxn blocking, restarts, or both. In thefollowing discussion any overheads as-sociated with txn blocking and abortsare ignored. The following cases arepossible.
(1) CC methods with no (or negligible)wasted processing. Standard lockingwith dynamic lock requests meetsthis criterion, since txn aborts toresolve deadlocks are rare and txnblocking due to lock conflicts incursa negligible overhead. An analysismay yield the mean number of ac-tive (versus blocked) txns M# a in asystem with M txns [Tay et al.1985]. Provided that the STC is nothighly discontinuous, the effectivethroughput is given by T(M) .t(M# a). Interpolation can be usedwhen M# a is not an integer.
Concurrency Control • 77
ACM Computing Surveys, Vol. 30, No. 1, March 1998

(2) CC methods with restarts but noblocking. OCC methods fall into thiscategory. The system efficiency isthe fraction of useful processing inthe system and can be expressed asT(M)/t(M) (see Section 3.3 for amore detailed discussion).
(3) CC methods with blocking and re-starts. The running priority methodand WDL belong to this category[Franaszek and Robinson 1985; Fra-naszek et al. 1992]. Since thewasted processing is due to activetxns, the system efficiency is definedas T(M# a)/t(M# a). The method withthe highest efficiency in this casemay not be the method maximizingM# a and attaining the maximumthroughput with an infinite resourcemodel (see Section 3.2).
Separation of hardware and data-resource contention. The separation ofhardware and data contention is a de-sirable property, since it allows the STCto be computed only once. This separa-tion is possible if the data contentionoverhead is insignificant or is indepen-dent of the level of lock contention.Wasted processing, as in the case ofrestart-oriented locking methods, allowsthis separation provided the aforemen-tioned conditions are met [Tay et al.1985; Tay 1987; Thomasian 1992,1995a].
The overhead associated with differ-ent CC methods is comparable [Robin-son 1984]. This overhead may be in-cluded in the processing associated withtxn steps, but there is a dependence onthe level of data contention; for exam-ple, a lock request leading to a conflictand txn blocking requires additionalCPU processing due to a context switch.In static locking extra processing is re-quired to check for the eligibility ofblocked txns for activation [Potier andLeBlanc 1980; Thomasian and Ryu1983] (see Section 2.3). Txn aborts re-quire extra processing to undo txn’s up-dates and restart the txn.
Lock contention depends on lock hold-ing times, which are affected by hard-
ware resource contention, whereashardware-resource contention is deter-mined by the number of active txns andthe processing requirements for txnsteps, which are affected by the lock-contention level. An iterative solutioncombining the analysis of the hardware-resource-contention model with the da-ta-contention model is therefore re-quired [Ryu and Thomasian 1990a].
2. STANDARD LOCKING AND ITSPERFORMANCE
In standard locking, locks are usuallyrequested on demand, which is referredto as dynamic locking (DL), whereas inStatic Locking (SL) locks for all data-base objects required for the executionof a txn are assumed to be known apriori and are requested before the txnbegins its execution. Strict 2PL withlocks released at txn completion time isconsidered in this study, but some vari-ations to strict 2PL are discussed inSection 2.6.
The general waiting (GW) method, ac-cording to which a txn making a con-flicting lock request2 is blocked await-ing the release of the lock, is susceptibleto encountering a deadlock, where twotxns are blocked indefinitely awaitingthe release of each other’s locks. Dead-locks are resolved by aborting one of thetxns in a deadlock cycle according to oneof the victim selection policies [Agrawalet al. 1987b]:
(1) the txn that is the current blocker;(2) a random blocker (i.e., one of the
txns involved in the deadlock cycle);(3) the txn with the minimum number
of locks;(4) the youngest txn; and
2 A lock conflict occurs when the requested lock isheld in an incompatible mode by another txn orthere is a pending lock request in an incompatiblemode for it; for example, the lock is held in sharedmode and there is an exclusive lock request pend-ing for it when another txn requests a shared lockon it. Lock compatibility tables are given in Date[1983], Bernstein et al. [1987], and Gray andReuter [1992].
78 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

(5) the txn with the minimum amountof work.
It follows from simulation results re-ported in Agrawal et al. [1987b] that thedeadlock resolution policy has little ef-fect on the maximum attainablethroughput of the standard lockingmethod.
Cyclic restarts occur when restartedtxns have lock conflicts with txns withwhich they have had lock conflicts be-fore and this leads to repeated dead-locks. Cyclic restarts are a possibilitywith policies (1) and (2), whereas policy(4) guarantees that they are prevented.Policies (3) and (5) are pseudostable inthat they tend to prevent cyclic restarts,but do not guarantee this. Restart wait-ing prevents cyclic restarts by delayingthe restart of an aborted txn until theconflicting txns have left the system.This method is adopted in simulationstudies reported in Ryu and Thomasian[1990a], Thomasian and Ryu [1991],Franaszek et al. [1992], and Thomasian[1993, 1997a].
Only shared and exclusive locks areconsidered, since we are concerned withlock contention among relatively shorttxns (as noted in Section 1.2). A txnholding a shared lock on an objectshould promote it to an exclusive lockbefore it can update the object. Dead-locks will arise if this action is taken bymore than one txn holding a shared lockon the same object; 97% of deadlocks ina database prototype were due to suchlock promotion [Date 1983]. When theupdating of an object is a possibility,txns can prevent deadlocks by acquiringupdate locks, since they are compatibleonly with shared locks, not with eachother and exclusive locks [Date 1983;Gray and Reuter 1992]. The analysis ofDB2 traces for several workloads re-veals that approximately 90% of exclu-sive locks are obtained directly [Singhaland Smith 1997]. This can be used as ajustification for not considering lockpromotion and update locks.
The simulation study for validating
analytic solutions detects and resolvesdeadlocks immediately. Some systemscarry out deadlock detection on a peri-odic basis [Gray and Reuter 1992],which is more appropriate for distrib-uted databases, since extra messagesare required for deadlock detection[Ceri and Pelagatti 1984]. Timeouts aresuitable for deadlock resolution in dis-tributed systems and shared-nothingarchitectures, but this method has thedrawback that the timeout interval isdifficult to determine [Jenq et al. 1989].
This section is organized as follows.In Section 2.1 we derive the probabilityof lock conflict, probability of deadlock,and the mean blocking time per lockconflict with respect to an active txn. InSection 2.2 we analyze the performanceof DL and demonstrate its thrashingbehavior. In Sections 2.3 (resp., 2.4) wesurvey analytic solutions for SL (resp.,DL). In Section 2.5 we introduce a het-erogeneous database access model. Wealso discuss some shortcomings of cur-rent locking models from the viewpointof evaluating the performance of txnprocessing systems. Finally, in Section2.6 variations to standard locking aredescribed.
2.1 Lock Conflicts and Deadlocks
We first analyze a system with fixed txnsizes and then extend the analysis tovariable txn sizes. A closed system withM txns is considered in both cases.
Analysis of dynamic locking withfixed-size transactions with identicalper-step processing times. The meantxn response time is the sum of its meanexecution time and the mean blockingtimes when it encounters a lock conflict.The increase in txn response time dueto restarts to resolve deadlocks is ig-nored, since the frequency of deadlockstends to be small [Thomasian and Ryu1991] (also see discussion in Section2.2). The mean blocking time per step isu 5 PcW, where Pc is the probability oflock conflict (per lock request) and W is
Concurrency Control • 79
ACM Computing Surveys, Vol. 30, No. 1, March 1998

the mean waiting time (per lock con-flict). Noting that there is no blocking inthe first step, the mean txn responsetime is R(M) 5 (k 1 1)s(M# a) 1 kPcWand the effective txn throughput isT(M) 5 M/R(M).
The mean number of locks (L# ) heldper txn is the ratio of the mean time-space of locks held by txns and themean txn response time. In a systemwith no lock contention L# 5 k/2, and L#. k/2 is a good approximation for asystem with lock contention [Ryu andThomasian 1990a]. When all lock re-quests are exclusive the probability oflock conflict (Pc) for the ith lock requestis
Pc 5
Mean number of locksheld by other txns
Number of database locksnot held by the txn
5N# 2 i
D 2 i.
~M 2 1!L#
D.
~M 2 1!k
2D,
(2.1)
where N# . (M 2 1)L# is the meannumber of locks held by the other M 2 1txns in the system, where each txn con-tributes an average number of locks. Wehave taken advantage of the fact thattxn size k($i) tends to be much smallerthan the database size (D), so that thedependence of Pc on the txn step hasbeen ignored [Tay 1987; Ryu and Tho-masian 1990a; Thomasian 1993]. Theprobability that a txn encounters a lockconflict is
Pw 5 1 2 ~1 2 Pc!k . kPc
.~M 2 1!k2
2D. (2.2)
The approximation is justified by thefact that Pc tends to be small (e.g., lessthan 0.001). The probability that twotxns are involved in a two-way deadlock
is [Gray and Reuter 1992]
PD~2! 5 Pr@T1 3 T2#Pr@T2 3 T1#
z ~number of candidates for T2!
5Pw
2
M 2 1.
~M 2 1!k4
4D2. (2.3)
Similar expressions apply to multi-way deadlocks, but since Pw is verysmall, PD(i) for i . 2 is negligibly smallso that PD 5 ¥i$2 PD(i) . PD(2). Amore accurate expression for PD(2) isobtained in the following.
The fraction of time txns are blockedin the system (b) is the ratio of txnblocking time and its mean responsetime, which is equal to the fraction ofblocked txns in the system:
b 5kPcW
R~M!5
M# b
M. (2.4)
The equality follows from Little’s resultby multiplying the numerator and de-nominator of the first fraction by T(M).
In a system with a low lock-conten-tion level, most lock conflicts are withactive txns. The mean waiting time W1can be obtained by noting that the prob-ability of lock conflict increases with thenumber of locks ( j) that the (active) txnholds [Thomasian and Ryu 1991]:
W1 5 Oj51
k 2j
k~k 1 1!@~k 2 j!~s~M# a! 1 u!
1 s9~M# a!] 5k 2 1
3@s~M# a! 1 u#
1 s9~M# a!, (2.5)
where k(k 1 1)/2 is a normalizationconstant and s(M# a) is the mean dura-tion of txn steps, which is determinedby analyzing or simulating the corre-sponding QNM with M# a active txns. Theterm in brackets is the mean remainingprocessing time after a lock conflict oc-curs at the jth step of txn execution and
80 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

s9(M# a) is the mean residual processingtime of the step in which the lock con-flict occurred [Kleinrock 1975].3 A simi-lar expression is derived in Tay et al.[1985] and Tay [1987]. The fraction oftime that a txn is blocked by an activetxn is A 5 W1/R(M). In the case offixed-size txns, it follows from Eq. (2.5)that A . 1/3.
Eq. (2.3) does not take into accountthe fact that T1 should be in the blockedstate for a deadlock to occur. In the caseof two-way deadlocks, the fraction oftime the other txn is blocked is A . 1/3,which leads to P9D(2) . PD(2)/3 [Tho-masian and Ryu 1991], where PD(2) isgiven by Eq. (2.3). The analysis in Mas-sey [1986] yields 2P9D(2), and that inTay et al. [1985] and Tay [1987] yields4/3P9D(2).
Analysis of dynamic locking withvariable-size transactions. We distin-guish txn classes based on their size, asdetermined by the number of requestedlocks. As stated in Section 1.1, the frac-tion of txns requesting k locks is de-noted by fk, 1 # k # K with ¥k51
K fk 5 1,where K denotes the largest txn size.The ith moment of the number of re-quested locks is Ki 5 ¥k51
K kifk.The mean response time for txns in
Ck is Rk(M) 5 (k 1 1)s(M# a) 1 kPcW,from which the mean response timeover all txn classes is given as
R~M! 5 Ok51
K
Rk~M! fk 5 r~M# a! 1 K1PcW,
(2.6)
where r(M# a) 5 (K1 1 1)s(M# a). It fol-lows from Eq. (2.4) that b 5 K1PcW/R(M) in the case of variable size txns,hence
R~M! 5 r~M# a!/~1 2 b!, (2.7)
which also applies to fixed-size txns.The effective throughput can be ob-tained from the STC T(M) . t(M# a),since the wasted processing due todeadlocks is negligibly small.
Pc is determined by the mean numberof locks held by a txn, which is affectedby the distribution of txn size. It followsfrom M# k/M 5 fkRk(M)/R(M) that M# k .Mkfk/K1.4 The mean number of locksheld per txn is then
L# 51
MO
k51
K
L# kM# k .1
MO
k51
K k
2M# k
.1
2K1O
k51
K
k2fk 5K2
2K1
. (2.8)
In the case of the geometric distribu-tion fk 5 q(1 2 q)k21, k $ 1. SinceK1 5 1/q it follows that setting q 5 1/Kyields K1 5 K and L# . K, as opposed toL# . K/2 for fixed-size txns; that is, Pcfor this distribution is twice that forfixed txn sizes [Thomasian and Ryu1991].
The probability of deadlock per txn isaffected by the third moment of txn size[Thomasian and Ryu 1991]; for exam-ple, this probability is an order of mag-nitude higher for geometrically distrib-uted txn sizes with the same mean asfixed-size txns.
A 5 W1/R(M) can be expressed asfollows [Thomasian and Ryu 1991; Tho-masian 1993].
A 5W1
R~M!.
K3 2 K1
3K1~K2 1 K1!,
(2.9)
which ignores the residual delay in thestep in which the lock conflict occurred.
Validation against simulation hasshown the accuracy of the analysis inestimating the preceding variables for
3 s9(M# a) equals s(M# a)/2 when the processing timeis fixed, 2s(M# a)/3 when it is uniformly distributed[Tay 1987], and s(M# a) when it is exponentiallydistributed, which is due to the memoryless prop-erty of this distribution [Kleinrock 1975].
4 The approximation is due to the fact that txnresponse times in the numerator and denominatorare proportional to k 1 1 and K1 1 1, rather thank and K1, respectively.
Concurrency Control • 81
ACM Computing Surveys, Vol. 30, No. 1, March 1998

fixed- and variable-size txns [Thoma-sian and Ryu 1991].
2.2 A Performance Analysis of DynamicLocking
We analyze the performance of DL firstwith identical and then different per-step processing times. Factors contrib-uting to thrashing are then discussed.
The effect of deadlocks on system per-formance is ignored in this analysissince deadlocks tend to be rare (asshown in Section 2.1) and taking thiseffect into account requires a rathercomplicated analysis, as in Ryu andThomasian [1990a]. Ignoring thewasted processing due to txn restarts toresolve deadlocks is justifiable by thefact that it constitutes a small fractionof the total processing cost [Thomasian1993]. According to Eq. (2.3), the proba-bility of deadlock increases with thefourth power of txn size, which is aweakness of the analysis for longertxns; that is, the mean response timefor these txns is underestimated whenthe lock-contention level is high.
Analysis with identical per-step pro-cessing times. Txn blocking can bespecified by a waits-for graph (WFG),which is a directed graph with nodesrepresenting txns and edges the waits-for relationship. In a system with onlyexclusive lock requests, the WFG is adirected tree, with each blocked txnpointing to an active txn or anotherblocked txn holding the requested lock(see, e.g., Tay et al. [1985] and Tay[1987]). The system state can be repre-sented by a forest of trees, where thenodes with out-degree zero representactive txns. Active txns are consideredto be at the roots of the trees and aredesignated to be at level zero, txnsblocked by active txns are at level one,txns blocked by level-one-blocked txnsare at level two, and so on. The numberof levels by which blocked txns are re-moved from active txns or their level inthe tree is referred to as their waitdepth.
If shared locks in addition to exclu-sive locks are considered, the WFG is nolonger a directed tree but rather a di-rected acyclic graph, since a txn mightbe blocked by multiple active txns hold-ing the same shared lock. The evolutionof the WFG depends on the lock-sched-uling policy. FCFS scheduling assuresfairness and a threshold scheduler forlocks will increase the degree of concur-rency in processing shared-lock re-quests [Thomasian and Nicola 1993].5
This results in an increase of the maxi-mum throughput at which such re-quests can be processed by the system[Thomasian and Nicola 1993]. NonFCFSscheduling of lock requests is not con-sidered further at this point, but lockpriorities are considered in Section 4.
Simulation studies show that the waitdepth tends to be limited to a few levelsfor reasonable simulation parameters(e.g., txn sizes much smaller than data-base size) so we first consider the casewhen a txn is blocked either by an ac-tive txn or a txn that is blocked (byanother active txn). The probability ofbeing blocked by an active (resp.,blocked) txn is 1 2 b (resp., b) and themean blocking time is W1 (resp., W2 51.5W1).6 More generally, the probabilitythat the effective level of blocking of a
5 The threshold scheduler processes shared-lockrequests without regard for enqueued exclusive-lock requests, until the number of exclusive-lockrequests exceeds a prespecified threshold. At thispoint, in-progress shared lock requests are pro-cessed to completion and further shared lock re-quests are enqueued. All exclusive-lock requestsare processed next, before the system reverts toprocessing shared-lock requests. The cycle re-peats. This scheme requires timeouts to avoidlong delays in processing lock requests of eithertype.6 This is informally justified as follows. Consider atxn T2 that has a lock conflict with a blocked txnT1; for example, T2 3 T1 3 T0. T2 encounters itslock conflict with T1 at a time distributed uni-formly over the time T1 was blocked by T0, hencethe extra delay is 0.5W1. T2 may have beeninitially blocked by T1, which became blocked at alater time with T0, resulting in the WFG T2 3 T13 T0 as before. It can be argued that T2 hadcompleted one half of its waiting time when T1was blocked.
82 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

txn (as opposed to its initial level ofblocking) is i, is approximated byPb(i) 5 bi21, i . 1 and Pb(1) 5 1 2b 2 b2 2 b3 . . .. The mean waitingtime at level i . 1 is approximated byWi 5 (i 2 0.5)W1. The mean overallwaiting time (W) is a weighted sum ofdelays incurred by txns blocked at dif-ferent levels:
W 5 Oi$1
Pb~i!Wi
5 W1F 1 2 Oi$1
bi 1 Oi.1
~i 2 0.5!bi21G .
(2.10)
We define nc 5 K1Pc as the meannumber of lock conflicts per txn. Multi-plying both sides by nc/R(M) and defin-ing a 5 ncA (with A 5 W1/R(M)) andsince b 5 ncW/R(M), we have
b 5 a~1 1 0.5b 1 1.5b2 1 2.5b3 1 . . .!.(2.11)
At low lock-contention levels b . a,such that M# a . M(1 2 a). The approx-imation R(M) . r(M)/(1 2 a) for closedsystems or R(l) . r(l)/(1 2 a) for opensystems has been used in numerous per-formance studies of txn processing sys-tems. A better approximation for b canbe obtained by substituting b with a onthe RHS of Eq. (2.10) [Thomasian andRyu 1991].
We can obtain a closed-form expres-sion for the series in Eq. (2.11) by as-suming that it is infinite, since it con-verges for b , 1, leading to
b3 2 ~1.5a 1 2!b2
1 ~1.5a 1 1!b 2 a 5 0. (2.12)
It is stated in Tay [1990] that “As yet,there are no proposed measures for theresource requirements of a given con-currency control algorithm.” Note thata, which is the product of the meannumber of lock conflicts per txn and themean waiting time per lock conflict(with respect to active txns) normalized
by mean txn response time, is a singlemetric that determines the level of lockcontention for standard locking. Twodifferent systems will have the samelock contention level as long as theyhave the same a.
The cubic equation has an algebraicsolution that yields 0 # b1 , b2 # 1 andb3 $ 1 for a # a* 5 0.226 and a singleroot b3 . 1 for a . a*. a* can be used asan indicator of whether the system isoperating in the thrashing region. Thesmallest root b1 for a # a* determinessystem performance.
Two cases are possible when the STC(t(m), m $ 1) is a nondecreasing func-tion, before it attains a fixed value dueto the saturation of the bottleneck re-source (see Section 1.3): the system ishardware-resource-bound (e.g., the pro-cessor saturates while the level of lockcontention in the system is low), or thesystem is data-contention-bound andthrashes before the hardware resourcebound is attained. In the latter case, theeffective throughput T(M) increaseswith M and the peak throughput is at-tained when M# a 5 M(1 2 b) is at itsmaximum. Plotting M# a versus b for sev-eral txn size distributions, it is observedthat M# a is maximized at b . 0.3 [Tho-masian 1993]. This is also verified fromdM# a/da 5 0, which yields a 5 0.2135with a corresponding b . 0.3. The ETC(T(M)), M $ 1) increases with M,reaches a peak at a corresponding to M,at which point M# a and hence T(M) .t(0.7M) (assuming infinite hardware re-sources) reach their maximum.
If we subject the system to quasiran-dom arrivals (see Section 1.1), then theintersection point of L(M) 5 (S 2 M)/Z,1 # M # S with the ETC T(M), 1 #M # S, corresponds to the equilibriumpoint of the system, where the txn ar-rival rate is equal to the completionrate. There may be one intersectionpoint in the stable or thrashing region,or two points, in which case the systemis bistable [Tay 1987; Thomasian 1993].
The value of a can be used for loadcontrol, that is, preventing thrashing bylimiting the number of txns activated in
Concurrency Control • 83
ACM Computing Surveys, Vol. 30, No. 1, March 1998

the system. Since the value of a cannotbe estimated directly, the critical valueof the mean number of lock conflicts pertxn (nc 5 a/A) can be used for thispurpose, provided A is known. In thecase of fixed-size txns A . 1/3 and nc .0.64, as opposed to nc . 0.75 observedfrom simulation results [Tay et al. 1985;Tay 1987]. In the case of the geometricdistribution, A . 1 according to Eq.(2.9) and nc . 0.21. In general, thevalue of A computed from this equationusing the first three moments of txnsize distribution (Ki, 1 # i # 3) can beused to estimate nc. Also the criticalvalue of the probability of lock conflictper lock request Pc 5 nc/K1 is an easy-to-use metric for detecting thrashing.
Note that the variability of txn sizehas a major effect on system perfor-mance; for example, in a system withinfinite resources the peak txn through-put with a (truncated) geometric distri-bution is a factor of three smaller thanthe peak throughput with fixed-sizetxns [Thomasian 1993]. In fact thevalue of a for fixed-size txns is one sixthof the a for geometrically distributedtxns with the same mean size.
This analysis is shown to be quiteaccurate through validation, except atthe highest contention level at the ex-treme cases (i) small M and large k(large txns); and (ii) large M and smallk. The problem in the first case is that(i) the analysis with mean values is notapplicable to a system with a few txns;(ii) the analysis does not take into ac-count the fact that a single txn mayblock multiple txns; that is, the waitdepth is over-estimated by the analysis.Not surprisingly, the analysis underes-timates the performance in this case. Adetailed analysis to estimate W is un-dertaken in Tay et al. [1985] and Tay[1987]. The accuracy of global perfor-mance measures estimated by this anal-ysis is comparable to the analysis inthis section, which is based on Thoma-sian [1993].
Analysis with different per-step pro-cessing times. The mean processing
time of the ith step of a txn in Ck isdenoted by si
k(M# a), 0 # i # k, 1 # k #K, where M# a is the vector of the meannumber of txns in different classes andsteps, which determines the duration oftxn steps. The mean txn response timecan be obtained from Eq. (2.6), once Pc,W, and M# a are determined.
The probability of lock conflict with ablocked txn with identical per-step pro-cessing times can be approximated by b,since active and blocked txns approxi-mately hold the same number of locks[Ryu and Thomasian 1990a]. When txnsteps have different processing timesthis probability is approximated by r .L# b/L# , where L# 5 L# a 1 L# b with L# a andL# b denoting the mean number of locksheld by active and blocked txns, respec-tively, which can be computed as
L# a 5 Ok51
K
fk Oi51
k iski ~M# a!
R~M!,
L# b 5 Ok51
K
fk Oi51
k ~i 2 1!PcW
R~M!. (2.13)
The conflict ratio, which is defined asthe ratio of the total number of locksheld by txns and the total number oflocks held by active txns [Moenkebergand Weikum 1992; Weikum et al. 1994],is related to r as conflict ratio 5 1/(1 2r) or conversely r 5 1 2 1/conflict ratio.
The probability that a txn is blockedat level i is approximated by Pb(i) 5ri21, i . 1 with Pb(1) 5 1 2 r/(1 2 r).The probability of lock conflict is givenby Eq. (2.1). The mean waiting timewith one level of blocking can be ex-pressed as follows by noting Eq. (2.5) fora single txn class.
W1 51
HO
k51
K
fk Oi51
k
iski ~M# a!
z F Oj51
k
skj ~M# a! 1 ~k 2 i! PcWG . (2.14)
84 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

The normalization constant is H 5¥k51
K fk ¥i51k isk
i (M# a). The term in thebrackets is the mean waiting time in-curred when a txn has a lock conflictwith an active txn in Ck in its ith pro-cessing step (we have assumed that txnsteps have an exponential distribution).
The mean waiting time of a txnblocked at level i is approximated byWi 5 (i 2 0.5)Wi, i . 1 as before.Similarly to Eq. (2.10) we have
W 5 W1~1 1 0.5r 1 1.5r2 1 2.5r3
1 . . .!. (2.15)
Since r , 1, a closed-form approxima-tion for the preceding series can be ob-tained assuming that it is infinite; wehave
W 5 W1F1 10.5r~1 1 r!
~1 2 r!2 G . (2.16)
Multiplying both sides of the equationby K1Pc/R(M) yields
b 5 aF1 10.5r~1 1 r!
~1 2 r!2 G . (2.17)
Note that in addition to a, the parame-ter r is required for the analysis in thiscase.
To simplify the discussion, we assumethat the durations of txn steps are givenand are independent of M# a. An iterativesolution is required in this case, whichproceeds as follows. Initialize W 5 0;compute R(M), L# a, L# b, and r; computeW from Eq. (2.16). Repeat the iterationstep until convergence is attained withrespect to W. The iteration converges ina few cycles and predicts system perfor-mance up to the peak throughput quiteaccurately.
Investigations with the numerical so-lution and simulation results obtainedby varying the duration of the last txnstep, which has the most impact onlock-holding times, lead to 0.2 , r ,0.3, where the lower (resp., upper) limitis attained when the duration of the laststep is very long (resp., equal to others).
This range of values for r corresponds to1.25 , conflict ratio , 1.43, which isconsistent with results in Moenkeberg[1992]. Similarly to the case of txnswith identical per-step processingtimes, M# a is maximized at b . 0.3.
Factors affecting thrashing. In thecase of txns with identical per-step pro-cessing times, the system load is deter-mined by a 5 K1PcA, where Pc in-creases linearly with the mean numberof txns in the system provided that theeffective database size remains fixed.The load in a system with different per-step processing times is similarly af-fected by a.
There is an inherent variability in thenumber of txns in an open system withPoisson arrivals, although the txn ar-rival rate (l) is fixed. This may tempo-rarily lead to a . 0.226 and possiblythrashing. Load control can be appliedby limiting the degree of txn concur-rency to (M# max), which can be deter-mined through analysis or simulationfor a specific workload. This is not adesirable approach, since the variabilityin the workload processed by the systemmay lead to system underutilization orthrashing behavior.
One method to reduce the degree oftxn concurrency is for txns to incurfewer disk accesses, since disk accesstimes are significantly longer than CPUprocessing times. This can be partiallyaccomplished by increasing the size ofthe database buffer to achieve a higherhit ratio, but a point of diminishingreturns is soon reached. The main stor-age database paradigm, such as in IMSFastpath [Gray and Reuter 1992], elim-inates disk I/O altogether for smallerdatabases, except for logging purposes.
Given a fixed overall processing ca-pacity, it is advantageous to have asmaller number of fast processorsrather than a larger number of slowprocessors, since aside from multipro-cessing effects (effective total processingcapacity due to cache interference, stor-age access conflicts, and OS lock con-flicts), a higher degree of txn concur-
Concurrency Control • 85
ACM Computing Surveys, Vol. 30, No. 1, March 1998

rency (with a higher data-contentionlevel) is required in the latter case toattain the same throughput.
Analytic and simulation results showthat the mean number of active txns(M# a) is maximized at b . 0.3 at adegree of txn concurrency M, regardlessof whether the per-step processingtimes are identical. This provides a veryeasy-to-use paradigm for load control,except in the case of the heterogeneousdatabase-access model in Section 2.5. Inthe case of an infinite-resource model,as we increase the number of txns in thesystem the throughput remains flat be-yond M, since M# a remains the same andthe number of blocked txns increases. Itis lock conflicts with blocked txns thatcause a snowball effect leading tothrashing; that is, it is best not to in-crease the number of txns beyond thepoint at which the peak throughput isattained.
The susceptibility of a system tothrashing is affected by the variabilityin the txn mix in the form of txn sizes,read-only versus update txns, and so on.A system with fixed-size txns (withidentical per-step processing times) mayrun at the critical value a* or evenhigher values of a* for a long time (i.e.,large number of txn completions) beforethrashing occurs, whereas a systemwith the geometric txn size distributionmay thrash for values below a* [Thoma-sian 1993]. In a simulation study re-ported in Thomasian [1993], the num-ber of txn completions to thrashingdecreases as the variance of txn size isincreased for the same mean txn size.
2.3 Performance Analyses of StaticLocking
The identities of all required locks areassumed to be known a priori in SL,which is only possible at a coarse gran-ularity of locking (e.g., locks for rela-tional tables [Date 1983]). The identi-ties of requested locks depend on thetxn’s input parameters and the state ofthe database, the latter of which is notknown a priori but can be determined
by preexecuting txns (see Section 4).The execution of a txn with SL isstarted only when all locks have beenacquired. The strict FCFS and nonstrictFCFS txn scheduling policies for SL areconsidered in Thomasian and Ryu[1983]. With strict FCFS the queue ofblocked txns is scanned when new locksbecome available upon the completion ofa txn and txns are activated in strictFCFS order; that is, a txn in the queuecannot be activated if txns preceding itin the queue have not been activated.Strict FCFS scheduling can also be im-plemented by allowing an arriving txnto acquire available locks and enqueue-ing lock requests for unavailable locks,both by an atomic action, to preventdeadlocks with other txns arriving si-multaneously [Galler and Bos 1983].
A nonstrict FCFS scheduler scansblocked txns in FCFS order, but txns atthe head of the queue are bypassed iftheir lock requests cannot be fully satis-fied. The fact that there are no partialallocations of locks to txns improvesperformance by precluding unnecessarylock conflicts among newly arriving txnsand blocked txns. An arriving txn canstart execution immediately if its lockrequests are satisfied, that is, if it doesnot have a lock conflict with currentlyactive txns. Otherwise, this txn is en-queued in FCFS order. The starvationproblem of the nonstrict FCFS policy,that a txn requesting a large number oflocks may be bypassed repeatedly, canbe rectified by reverting to a strictFCFS policy.
The strict FCFS policy, unlike thenonstrict policy, does not satisfy the es-sential blocking property that a txn canonly be blocked by an active txn doing“useful work,” leading to its commit[Franaszek and Robinson 1985]. It isnot surprising therefore that a strictFCFS policy is outperformed by the lat-ter policy as quantified in Thomasianand Ryu [1983]. Note that even betterperformance could be attained withstrict essential blocking [Franaszek etal. 1992], which differs from essentialblocking in that it requests locks only
86 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

when they are required, that is, on de-mand locking.
Assuming that fine-granularity lock-ing is possible with SL, it entails anincreased lock holding time as comparedto DL. Incremental SL is a form of DLwhere locks are requested in quick suc-cession at the beginning of txn execu-tion. It is therefore not surprising thatDL outperforms incremental SL [Tay etal. 1985; Tay 1987]. More generally, DLoutperforms SL for lower degrees of txnconcurrency, which is due to the shorterlock-holding times and lower lock con-tention in DL, but it is outperformed bySL when it thrashes [Tay et al. 1985;Thomasian and Ryu 1986; Tay 1987].This is because with a nonstrict SLmethod the number of txns eligible forexecution increases as more txns aremade available for execution; that is,the system throughput increases up tothe saturation of the bottleneck re-source.
There have been a large number ofperformance studies of atomic SL [Po-tier and LeBlanc 1980; Galler and Bos1983; Thomasian and Ryu 1983; Morrisand Wong 1985; Tay et al. 1985; Thoma-sian 1985; Tay 1987; Ryu and Thoma-sian 1988; Thomasian and Ryu 1989].An analysis of SL using a hierarchicalsolution method appears in Potier andLeBlanc [1980], which is flawed in itsprobabilistic analysis of txn conflicts[Langer and Shum 1982; Thomasian1996a]. The analyses in Thomasian andRyu [1983] and Morris and Wong[1985], although tedious, accurately es-timate the performance of SL.
The analysis in Galler and Bos [1983]uses heuristic approximations, but theresults are not accurate in all cases. Asimplified analysis of SL in Tay [1987]turns out to be inaccurate in a fewhigh-contention cases considered inMorris and Wong [1985]. This analysisis extended in Thomasian and Ryu[1989] and applied to the following cas-es: (i) different distributions for txn pro-cessing time; (ii) multiple txn classes;(iii) shared and exclusive lock requests;and (iv) query and update txns.
2.4 Performance Analyses of DynamicLocking
In Sections 2.1 and 2.2 we described ananalytic solution method for DL. Com-prehensive reviews of analytic solutionsfor DL also appear in Tay [1987], Ryuand Thomasian [1990a], and Thomasianand Ryu [1991]. Solution methods forDL roughly belong to one of the follow-ing categories.
—Analytic solutions based on QNMs ex-tend the hardware-resource-conten-tion model to incorporate lock conten-tion [Irani and Lin 1979; Thomasian1982]. A central-server model (seeSection 1.3) is utilized to representhardware resource contention and Dpseudoservers to represent the lock-contention delays for the D databaselocks, which are only visited whenthere is a lock conflict. The mean ser-vice time at the nodes is the meanwaiting time (W), which is not knowna priori but can be expressed as afraction of the mean txn residencetime (R(M)) in the closed system withM txns (this model is also used in thefollowing studies). An iterative solu-tion is proposed in Thomasian [1982],since R(M) is not known a priori.
—The analytic solution method in Tayet al. [1985] and Tay [1987] is basedon “flow diagrams,” which are definedin Section 3.3. The mean waiting timeper lock conflict (W) is estimated by adetailed analysis [Tay et al. 1985; Tay1987]. The analysis of a closed systemwith M txns leads to a cubic equationin the mean number of active txns(M# a), with three roots in the intervals(2`, M(1 2 k2L/3), (M(1 2 k2L/3),(M(1 2 k2L/6)), and (M(1 2 k2L/3),1 `), for k2L , 1.5, where L 5 M/D.The second root is the only one ofinterest. The second term inside theparentheses can be expressed as k2L/F . PcW/R(M), with Pc given by Eq.(2.1). For the upper (resp., lower)bound, W/R(M) 5 1⁄3 (resp., 2⁄3), withan arithmetic mean W/R(M) 5 1⁄2(rather than 1/2.25 in the author’s
Concurrency Control • 87
ACM Computing Surveys, Vol. 30, No. 1, March 1998

earlier works [Tay 1990]), which coin-cides with the approximation used inThomasian [1982].
—The analysis in Section B in Thoma-sian and Ryu [1991] allows variabletxn sizes and different processingtimes for txn steps, which are ob-tained from an underlying QNM.Only two levels of txn blocking withcurrently active txns and txns thatare blocked by active txns are consid-ered. Simulation results show thatthis analysis is quite accurate up torelatively high lock-contention levels,but cannot predict peak throughputin systems with infinite resources,that is, at very high levels of txnconcurrency. A similar analysis ispresented in Yu et al. [1993].
—An analytic solution based on aMarkov chain model whose statesrepresent the number of active txns( J) in a closed system with M txnsappears in Ryu and Thomasian[1990a]. The holding time in eachstate is determined by analyzing theQNM of the underlying computer sys-tem model. At the completion of astep a txn requests a new lock orcommits. A lock request may result inthe transition J 3 J, J 3 J 2 1, andJ 3 I, I $ J depending on whetherthe lock request is successful, unsuc-cessful with blocking, or unsuccessfulwith an abort to resolve the deadlockcaused by its lock request (the locksreleased by an aborted txn may acti-vate other txns). This analysis thusassumes that the txn causing thedeadlock is aborted to resolve a dead-lock, because a more sophisticatedlock-conflict resolution method, whichtakes into account the progress madeby txns, as in WDL, is much moredifficult to analyze [Thomasian 1992].A multilevel solution method isadopted that facilitates bottom-upvalidation and allows modifications tosome levels of the analysis withoutaffecting others (e.g., a different lockconflict model can be adopted). It isalso based on very few approxima-
tions and takes into account dead-locks, unlike almost all other analysesof DL [Tay et al. 1985; Thomasian1993].
2.5 On More Realistic Lock-ContentionModels
Most performance studies of CC meth-ods are concerned with a homogeneousdatabase access model, as defined inSection 1.2 and analyzed in Sections 2.1and 2.2. Furthermore, our discussion sofar has been concerned with exclusivelock requests. We introduce the effectivedatabase-size paradigm for dealing withshared as well as exclusive locks andnonuniform database accesses in thecontext of the homogeneous model. Aminor variation from this model is thedistinction made between update andquery txns, where the latter only re-quest locks in shared mode [Tay 1987].A forerunner of the TPC-C benchmark[Gray 1993] is described and simulatedin Jenq et al. [1989], which representsthe more realistic heterogeneous data-base-access model. We briefly describethis model and propose a table-drivenload-control method for it, since load-control methods for the homogeneousdatabase access model are ineffective inthis case [Thomasian 1996b]. We nextdiscuss the issue of characterizing txnclasses through inspection of txn code ormonitoring txn execution. Finally, welist some possible shortcomings of thestandard locking models in the contextof relational databases.
Shared and exclusive locks and non-uniform database accesses. The effec-tive database size paradigm (EDSP)provides an elegant approach for deal-ing with shared and exclusive lock re-quests and nonuniform database ac-cesses in the case of the GW method[Tay et al. 1985; Tay 1987]. It is shownthat shared and exclusive lock requeststo a database of size D can be replacedwith exclusive lock requests to a data-base of size Deff 5 D/(1 2 s2), where sdenotes the fraction of lock requests
88 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

that are in shared mode. In the case ofthe nonuniform database-access model,where a fraction b of database accessesare to a fraction c of the database, it isshown in Tay et al. [1985] and Tay[1987] that Deff 5 D/[b2/c 1 (1 2 b)2/(1 2 c)]. EDSP in the context of restart-oriented locking methods is discussed inSection 3.2.
Heterogeneous database access model.A closed system with M txns in J txnclasses and I database regions is consid-ered. Txns in class j (Cj) have a fre-quency fj and in their nth step (denotedby Cj,n) access database region i (denot-ed by Di) with probability gj,n,i. Thiscan be represented by a bipartite graph,where one set of nodes represents txnsteps and the other set the database
regions; that is, Cj,nO¡gj, n, i
Di .The analytic solution method in Sec-
tions 2.1 and 2.2 is extended in Thoma-sian [1996b] to analyze this model. Val-idation results show this analysis to beacceptably accurate in predicting sys-tem performance up to high levels oflock contention, but not the peakthroughput with an infinite resourcemodel.
Simulation studies of two systemswith four and eight txn classes and fivedatabase regions (with other parame-ters varied randomly over several ex-periments) reveal that the critical valueof r (as defined in Section 2.2) varies inthe range (0.211–0.376) in the first sys-tem and (0.245–0.376) in the other[Thomasian 1996b]. Conflict ratios areobserved to be in the range (1.26–1.60)based on the experimental results re-ported in Weikum et al. [1994], which isconsistent with these figures. In spite ofthe concurrence of these results, thereis no guarantee that the range of valuesof r will hold in other environments.Furthermore, even if the precedingrange of critical values for r is generallyapplicable, it is too wide to be useful forload control.
Consider a system whose txns belongto two disjoint sets from the viewpoint
of accesses to database regions: txns inone set have a high level of lock conten-tion, whereas the txns in the other setdo not. The thrashing of txns in the firstset will lead to an overall thrashingbehavior in the system, because due tothe frequency-based model completedtxns in the second set are replaced bytxns in the first set. We can preventthrashing by restricting the number oftxns in the two sets to M1 and M2 withM1 1 M2 5 M, so that the txns in thesecond set will not be affected by thetxns in the first set.
As an example of load control basedon the composition of txns in the sys-tem, consider a system with two (inter-fering) txn classes. The maximumthroughput attained by the two classesis T1(M1, 0) and T2(0, M2). Let usassume that txns in C1 have a higherpriority and the system is guaranteed torun T91(. . .) (, T1(M1, 0)) txns in C1.Load control is achievable by providinga table T1(M1, M2) for various composi-tions of txn classes to determine themaximum degree of concurrency fortxns in C2 to guarantee the throughputfor txns in C1 [Thomasian 1996b]. Thismethod is more flexible than the onediscussed in Weikum et al. [1994],which sets limits on the degree of con-currency for txn classes and their com-binations by adding one txn class at atime to the txn mix. The problem withthe table-driven approach is the diffi-culty of generating a table for a systemwith a large number of txn classes. Itshould be noted that the number of txnclasses contributing to lock contentionmay be rather small and it may bepossible to aggregate several txn classesinto one class to reduce the number oftxn classes to be considered. This re-mains an area for further investigation.
Characterization of transaction work-loads. Txns in the same txn class mayhave a different execution sequencebased on the input data to the txn andthe state of the database. For example,98% of debit txns are processed nor-mally, whereas 2% result in an over-
Concurrency Control • 89
ACM Computing Surveys, Vol. 30, No. 1, March 1998

draft requiring additional processing(e.g., to check credit limits, etc.). Thiscase can be specified by two subclasseswith respective frequencies. More com-plex txns may not lend themselves to asimple classification of their subclassesbased on inspecting txn code, and themonitoring of txn execution is requiredfor this purpose. In effect, each txn sub-class is characterized by its frequencyand the sequence of database calls madeby the subclass is deterministic. Thenumber of txn subclasses is determinedby all possible paths from the initial tothe final state(s) of the txn, which maybe quite large, even if there are no cy-cles in its execution. The frequency of atxn subclass is the probability associ-ated with the path. This system can beanalyzed by extending the solutionmethod in Thomasian [1996b].
Other extensions to lock-contentionmodels. This discussion is in the con-text of relational DBMSs because oftheir popularity.
—Relational models provide locking atmultiple granularity levels, intentlocks, and cursor locks [Date 1983;Gray and Reuter 1992]. A better un-derstanding of the locking behavior oftxn processing systems is required forspecifying realistic locking models foranalysis (see e.g., Singhal and Smith[1997]).
—Determining lock-conflict probabili-ties with a rather complex lock-com-patibility matrix, as in the case ofrelational DBMSs (see e.g., Date[1983] and Gray and Reuter [1992]),is a challenging problem, especially athigher lock-contention levels.
—A large number of specialized lockingmethods with provisions for recoveryhave been developed for operations onindex structures [Mohan and Levine1992]. Performance evaluation of CCmethods for index structures such asB1 trees has been an area of researchactivity by itself. A survey of previouswork and a simulation study appearin Srinivasan and Carey [1993]. Ana-
lytic methods to compare the perfor-mance of several locking methods forB* trees are presented in Johnsonand Shasha [1993].
—It is postulated that an on-demandlocking scheme requests one lock at atime, but this is not necessarily so. Adatabase call may entail accesses tomultiple records and the txn may onlyproceed after all of the requestedlocks are acquired.
—Most performance studies of CCmethods postulate data accesses uni-formly distributed over a databasewhose size (D) is given. In fact, only asubset of database objects is accessedat any one time, usually with nonuni-form probabilities [Singhal and Smith1997]. Given the probability of lockconflict (Pc), the database size D canbe estimated using Eq. (2.1), aftertaking into account that a fraction sof lock requests is in shared mode.
—A possible weakness of performancestudies of CC methods is that thedatabase size (D) remains fixed as thedegree of txn concurrency (M) or thetxn arrival rate (l) is increased. Thisis not so for some applications such asbanking, as exemplified by the TPC-Aor TPC-B benchmarks [Gray 1993],where the number of bank recordsincreases in proportion to the numberof its clients.
—Schedulers for txn processing systemstake into account several factors,mainly based on txn response-timeobjectives, but also to control the lock-contention level. Briefly, an IMS txnhas a type and multiple txn typesmay belong to a class. Txn classes areassigned to “message-processing re-gions” such that each region can pro-cess several txn classes and a classmay be processable at several regions.There may be a different processor-priority level associated with eachclass in a region. The effect of txnscheduling on the level of lock conten-tion has not been taken into accountin performance studies.
90 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

2.6 Methods to Improve LockingPerformance
The concurrent processing of long read-only queries for decision support appli-cations and short update txns intro-duces conflicts between the twoworkloads, especially when the formerfollows a strict 2PL paradigm. One ap-proach is to run queries at a reducedlevel of consistency of 1 and 2, whichimplies reading uncommitted data andobtaining shared locks only for the du-ration of the read, respectively [Date1983; Gray and Reuter 1992]. The latterensures cursor stability but does notguarantee repeatable reads, which re-quires shared locks with strict 2PL[Date 1983; Gray and Reuter 1992].There is a significant degree of conten-tion between cursor locks and exclusivelocks, according to Singhal and Smith[1997], which results in a slowdown ofquery processing and wasted system re-sources (e.g., allocated buffer space). Alarge number of versioning methodshave been proposed to address this is-sue, as reviewed in Bober and Carey[1992] and Mohan et al. [1992b]. Thesimulation study in Bober and Carey[1992] shows that versioning (at therecord rather than page level) allowsimproved performance for query pro-cessing, and Mohan et al. [1992b] pre-sents a transient versioning method inthe ARIES framework [Mohan et al.1992a].
The nested txn paradigm offers moredecomposable execution units and finer-grained control over concurrency andrecovery than flat txns [Moss 1985;Gray and Reuter 1992]. The decomposi-tion of units of work into subtasks andtheir appropriate distribution in a com-puter system is a prerequisite for in-tratxn parallelism [Haerder and Ro-thermel 1993]. Multilevel txns arerelated to nested txns, but are morespecialized [Weikum 1991; Gray andReuter 1992]. For example, txns holdlong-term record-level locks (more gen-erally object-level locks [Weikum andHasse 1993]), whereas page-level locks
are held by subtxns for the duration ofoperations on records. Compensatingoperations for subtxns are provided forrollback recovery. An implementation ofmultilevel txns and a performance eval-uation using synthetic benchmarks isreported in Weikum and Hasse [1993].
Ordered sharing allows a flexiblelock-compatibility matrix (amongshared and exclusive lock requests) aslong as operations are executed in thesame order as locks are acquired[Agrawal et al. 1994]. Thus it introducesrestrictions on how the program realiz-ing the txn is written; for example, theacquisition of an exclusive lock on anobject should be followed immediatelyby its update. A txn T2 may obtain ashared lock on an object locked in exclu-sive mode by T1 (i.e., read the valuewritten by T1) but this will result indeferring T2’s commit to after T1’s com-mit. Simulation results show that thereis an improvement in performance withrespect to standard locking that can beascribed to the reduced txn waiting timewith respect to standard locking[Agrawal et al. 1994].
Altruistic locking allows txns to do-nate previously locked objects, oncethey are done with them but before theobject is unlocked [Salem et al. 1994].Another txn may lock a donated object,but to ensure serializability it shouldremain in the wake of the original txn(i.e., accesses to objects should be or-dered). Cascading aborts, which are apossibility when the donated object waslocked exclusively, can be preventedwith strict 2PL. This makes the ap-proach more suitable for read-only que-ries or long-running txns updating fewrecords.
The proclamation-based model for co-operating txns is described in Jagadishand Shmuelli [1992], which in additionto its original motivation can be used toreduce the level of lock contention. Thismethod is different from altruistic lock-ing in that a txn, instead of releasing itslock on an object (that it is not going tomodify again), proclaims one or morepossible values for the object, which can
Concurrency Control • 91
ACM Computing Surveys, Vol. 30, No. 1, March 1998

be accessed by other txns. Txns inter-ested in the object can proceed withtheir execution according to the pro-claimed value(s). Note that this methodhas similarities to the polyvaluesmethod in Montgomery [1978] (see Sec-tion 4.3).
Increment/decrement locks are oneapproach to relieve the level of lockcontention for aggregate values [Grayand Reuter 1992], but there is no check-ing of the value, for example, that it isnegative. The escrow method [O’Neil1986] is a generalization of the fieldcalls approach in IMS Fastpath [Grayand Reuter 1992], where the minimum,current, and maximum values of an ag-gregate variable are made available toother txns. Let us assume that a bank-ing account with a current balance of$1,000 has a credit txn for $100 and adebit txn for $200 in progress. Then thebalance is represented by ($800, $1,000,$1,100). The final balance is $900 ifboth txns are successful. A debit txn for$500 need not be delayed awaiting thecompletion or abort of either or bothtxns, since there are adequate funds inthe account in either case.
The synchronization technique andscheduling policy described in Bayer[1986] allows simultaneous processingof a batch txn and short update txns. A“random” batch txn updates databaserecords only once in each run (convert-ing them from old to new records) andthe updates are independent of the or-der in which they are carried out. Thereis a conflict if a short txn needs toaccess old and new records. Since theblocking delay is not tolerable for shorttxns, the batch txn may update the re-quired old records and make them avail-able to short txns after intermediatecommit points [Date 1983; Bayer 1986].
Lock-holding time by long-lived txnscan be reduced by using intermediatecommit points according to the sagasparadigm [Garcia-Molina 1987; Grayand Reuter 1992]. A long-lived txn T isviewed as a set of subtxns T1, . . . , Tnthat are executed sequentially and canbe committed individually at their com-
pletion. However, the abort of subtxn Tjresults in the undoing of the updates ofall preceding subtxns from a semanticpoint of view through compensatingsubtxns C1, . . . Cj21. Compensating txnsconsult the log to determine the param-eters to be used for undoing the updatesof aborted txns.
A method for chopping txns intosmaller txns to reduce the level of lockcontention and to increase the level oftxn concurrency, while preserving cor-rectness, is presented in Shasha et al.[1995], which also reviews relatedworks. Preserving correctness requiresknowledge about the set of txns that arerunning concurrently with the txn to bechopped. Examples of correct and incor-rect “choppings” are given in the paperand are not repeated here; suffice it tosay that the critical steps that may failshould be executed first. Simulation re-sults show a significant improvement inperformance when a long-running txn(say a batch update) is chopped intosmaller txns, but this is at the cost of anincreased number of commits with theassociated overhead [Shasha et al.1995]. A related study that extendsFarag and Ozsu [1989] and Korth andSpeegle [1994] appears in Ammann etal. [1997].
Semantics-based CC methods relyupon the semantics of txns (see, e.g.,Garcia-Molina [1983]) or semantics ofobjects [Weihl 1988; Badrinath and Ra-mamithram 1992]. Txn semantics is uti-lized in Garcia-Molina [1983] and Cel-lary et al. [1988], where txns areclassified into types and a compatibilityset is associated with different types. Asemantics-based CC method for objectsis based on commutativity of operations.Recoverability of operations is an exten-sion of this concept, which allows aninvoked operation to proceed when it isrecoverable with respect to an uncom-mitted operation [Badrinath and Ra-mamithram 1992]. Various operationson stacks and tables belong to this cate-gory. The two methods based on com-mutativity of operations presented inWeihl [1988] differ in that one method
92 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

uses intention lists and the other usesundo logs. This work is extended inLynch [1994]. Object-oriented DBMSsallow a higher degree of txn concur-rency than provided by simple lockingfor operations on abstract data types[Skarra and Zdonik 1989; Ozsu 1994]. Amore detailed discussion of these topicsappears in Ramamithram and Chrisan-this [1996].
3. RESTART-ORIENTED LOCKINGMETHODS
Restart-oriented locking methods com-bine blocking and aborts (followed bysystem-initiated restarts) to cope withthe performance limitations of standardlocking. We first describe restart-ori-ented locking methods, various optionsfor restarting aborted txns, and the is-sue of resampling of lock requests forrestarted txns with respect to the origi-nal txns. Section 3.2 provides a perfor-mance comparison of restart-orientedlocking methods based on simulation re-sults reported in Thomasian [1997a].The modeling of shared locks, in addi-tion to exclusive locks and hot-spots, isalso discussed in this section. Finally, inSection 3.3 we review analytic studies ofrestart-oriented locking methods andanalyze a representative method.
3.1 Description of Restart-OrientedLocking Methods
The wait depth is the distance (d) of ablocked txn from active txns at the rootnodes of the respective acyclic WFG.Only exclusive locks are considered ini-tially to simplify the discussion, inwhich case WFGs are directed trees. Aconcise specification of some well-knownrestart-oriented locking methods is asfollows:
—According to the no-waiting (NW)[Tay et al. 1985b] or the immediaterestart method [Agrawal et al. 1987a]a txn TA that has a lock conflict witha txn TB is aborted. The WFG TA 3TB is temporarily formed and re-duced. The wait depth is d 5 0.
—The asymmetric running priority(RPA) method [Franaszek and Robin-son 1985] aborts TB in the WFG TA 3TB 3 TC when TA becomes blockedby TB, which is already blocked byTC. This action is expected to improvesystem performance, since it partiallyfulfills the strict essential blockingproperty [Franaszek et al. 1992] (seeSection 2.3).It is possible that TB, which was ac-tive at the time TA became blocked byit, may become blocked by TC at alater time. When TC is active, theSymmetric RP (RPS) method [Fra-naszek et al. 1992] guarantees thatthe wait depth does not exceed one byaborting a txn such as TB, which isblocking other txns when it encoun-ters a lock conflict. The wait depth ismaintained at d 5 1 in this case.7
Adaptive methods are desirable inthat they adjust the wasted process-ing due to txn aborts to match theexcess processing capacity of the sys-tem. An adaptive RP method onlyaborts a txn at d 5 1 blocking b $ 1txns, where the txn breadth b is thenumber of txns blocked by it [Fra-naszek et al. 1991a] (this adaptivemethod is used in the context of atwo-phase processing method in Sec-tion 4.4). Wasted processing can bereduced by increasing the value of bor by aborting a txn only when itswait depth d . 1 [Franaszek et al.1992]. It is also meaningful to considera combination of rules based on thewait depth and breadth (e.g., (i) if d . 1and b $ 1, and (ii) if d 5 1 and b . 1).
—The asymmetric cautious waiting(CWA) method [Hsu and Zhang 1992]aborts TA when it is blocked by TB,which is itself blocked by TC as in
7 There are two alternatives to ensure this. Thefirst method checks whether a txn TA encounter-ing a lock conflict is blocking other txns; if so, it isaborted. Next it is checked whether TB blockingTA is blocked itself, and if TB is in the blockedstate, it is aborted. Simulation results have shownthat changing the ordering of these two tests haslittle effect on overall performance.
Concurrency Control • 93
ACM Computing Surveys, Vol. 30, No. 1, March 1998

TA 3 TB 3 TC. The symmetric CW(CWS) method first checks if TA isblocking other txns, as in (TX, TY,. . . , TZ) 3 TA 3 TB, and abortsthem when TA becomes blocked. Thewait depth is maintained at d 5 1with CWS.Symmetric and asymmetric RP andCW are deadlock-free [Franaszek andRobinson 1985; Hsu and Zhang 1992].
—The WDL(d), d $ 1 family of methodslimits the wait depth of blocked txnsto d, taking into account txn progressin deciding which txn to abort toachieve this goal [Franaszek et al.1992]. They are a subset of wait-depth-limited methods, which onlylimit the wait depth (such as RPS orCWS). The WDL(1) or WDL method ismainly of interest [Franaszek et al.1992], since it attains high perfor-mance at the cost of relatively littlewasted processing. Conflicts are re-solved by comparing the length of thetxns involved in the conflict. Thelength L(TA) of a txn TA is a functionof the progress made by the txn (e.g.,the number of locks held by TA [Fra-naszek et al. 1992]). The modifiedWDL (MWDL) method [Thomasian1992] is based on two slightly differ-ent rules from WDL [Franaszek et al.1992] such that the comparison of txnlengths is always confined to two txnsat a time.Consider a lock request by TA thatcauses a lock conflict with TB result-ing in a transient WFG [(TX, TY, . . . ,TZ) 3]TA 3 TB[3 TC]. The followingrules are applied when a lock conflictoccurs with the MWDL method.
(1) If TA, which is blocking someother txns, has a lock conflict withTB, and then if L(TA) , L(TB), abortTA, else abort TB.8
WDL makes the comparisonL(TA) , max(L(TB), L(TX), . . . ,L(TZ)) when TA is blocking txns (TX,TY, . . . , TZ) [Franaszek et al. 1992].
(2) If TA, which is not blocking anyother txns, has a lock conflict withTB, which is itself blocked by an ac-tive txn (TC), if L(TB) # L(TC), thenabort TB, else abort TC.WDL makes the comparison L(TB) #max(L(TA), L(TC)) [Franaszek et al.1992].Although the WDL family of methodsallows wait depths greater than one,a wait depth of one yields improvedperformance [Franaszek et al. 1992;Thomasian 1997a] without requiringexcessive extra processing.
—The wound-wait (WW) method[Rosenkrantz et al. 1978] blocks txnTA requesting a lock held by TB if TAis not older than TB; otherwise TB isaborted. A variant of WW, similarly toRPA, wounds TB only if it is blocked(at the site where the conflict oc-curred in a distributed database).
—The wait-die (WD) method [Rosen-krantz et al. 1978] allows a youngertxn to wait if it is blocked by an oldertxn; otherwise the txn encountering alock conflict is aborted.Txn age is determined by the arrival-time timestamp. Both WW and WDmethods are deadlock-free [Rosen-krantz et al. 1978], but similarly tothe CWA and RPA methods allow anunlimited wait depth. The WW andWD methods are intended as low-costdeadlock-prevention mechanisms indistributed database environmentsfrom the viewpoint of the number ofmessages involved. The WW outper-forms WD according to the simulationresults in [Agrawal et al. 1987b],which is the reason it is not consid-ered in Section 3.2.
NW, CW, WD, and the method inChesnais et al. [1983] (see Section 3.3)are nonpreemptive methods [Hsu andZhang 1992], in that the txn encounter-
8 We could have used L(TA) . L(TB) instead ofL(TA) $ L(TB) for the else condition and a tie-breaking rule for equality (e.g., abort the youngertxn). This extra complication is not justified, sinceit is not expected to result in an improvement inperformance.
94 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

ing a lock conflict is aborted, whereasRP and WW are preemptive methodsaccording to this definition. A classifica-tion is also possible based on txn at-tributes used in determining the txn tobe aborted (if any). Txn timestamps inthe case of the WW and WD methodsare static attributes that are assigned atthe beginning of txn execution (txntimestamps are reassigned for each in-stance of txn execution in the case of theTSO method). WDL uses a dynamic at-tribute (i.e., the number of locks cur-rently held by a txn).
Transaction aborts and restarts.We distinguish between these twoterms, which have been used inter-changeably. Txn abort occurs first and atxn releases its locks and stops its exe-cution or continues executing in virtual-execution mode (see Section 4.2).Aborted txns whose execution is stoppedand txns in virtual-execution mode com-pleting their execution are automati-cally restarted by the system. Cyclicrestarts or livelocks need to be prevent-ed: (i) to reduce the wasted processingincurred in this manner, and (ii) to en-sure txn completion within a finite timeinterval. The following methods to pre-vent cyclic restarts are complementaryto those in the introduction to Section 2.
(1) Restart waiting can be easily imple-mented in a centralized system bydelaying the restart of an abortedtxn until all txns that have con-flicted with it are completed [Ryuand Thomasian 1990b; Franaszek etal. 1992].
(2) Random delays or conflict avoidancedelays [Agrawal 1987a,b; Tay 1987],which are introduced before a txn isrestarted after its abort, do notguarantee that cyclic restarts willbe prevented. The drawback of ap-plying this method is the difficultyof determining the duration of ran-dom delays, especially in the case ofvariable-size txns.
(3) Immediate restarts are possible in asystem with a backlog of txns, such
that an aborted txn is set aside andis replaced by a new txn with adifferent script [Tay et al. 1985;Agrawal et al. 1987a], which is de-fined as the sequence of objects ac-cessed by the txn. Another interpre-tation is that the restarted txnrequests a different set of locks fromits prior execution; that is, the txndoes not exhibit access invariance[Franaszek et al. 1990, 1992]. Thisis referred to as lock resampling orfake restarts, as opposed to no lockresampling.
The restart waiting-no lock resam-pling combination of options is mainlyof interest. No lock resampling occurswith access invariance across successiveexecutions of a restarted txn and is ex-pected not to affect the level of lockcontention in the system when txn re-starts occur, although this is not so forlock resampling which favors methodsintroducing more txn restarts. The re-start waiting method is straightforwardto implement and allows a fair compar-ison.
Lock resampling is an inherent short-coming of the analytic solution methodsthat results in overestimating systemperformance by an extent that dependson the frequency of txn restarts. Thiseffect is quantified in the case of theNW method in Agrawal et al. [1987a].Resampling also applies to lockingmodes, the class of restarted txns, andtxn processing times. Resampling re-sults in an unfair advantage to methodswith more frequent restarts, since thiscreates a bias of the completed txns inthe system towards txns with the char-acteristics: (i) a higher fraction ofshared lock requests, (ii) fewer accessesto hot-spots, and (iii) smaller txn sizes.
3.2 Performance Comparison of Restart-Oriented Locking Methods
There have been several simulationstudies of restart-oriented locking meth-ods, most notably Agrawal et al. [1987b]and Franaszek et al. [1992]. We summa-
Concurrency Control • 95
ACM Computing Surveys, Vol. 30, No. 1, March 1998

rize here the results of a simulationstudy with the restart waiting-no lockresampling options (justified in the pre-vious section) and exclusive lock re-quests to compare the performance ofeight methods: GW, NW, CWS, RPS andRPA, WDL, MWDL, and WW [Thoma-sian 1997]. The simulation parametersare: database size D 5 16,384, txn sizeK 5 16, txn steps have identical expo-nential distributions. The number oftxns is varied to obtain the peakthroughput for different hardware re-source contention levels, which is at-tained by varying the number of proces-sors in the system (P).
—GW outperforms other methods forsmaller values of P, but achieves itsmaximum throughput at M . 78 withM# a 5 55 active txns; that is, GW canutilize at most P 5 55 processors.Note also that there is little differencein the peak throughput attained bydifferent methods at P 5 50, since thelevel of lock contention is low.
—NW is outperformed by GW at P 550, but NW outperforms GW by al-most 20% at P 5 100 and its through-put continues to increase up to P 5250. NW with the immediate restart-lock resampling option is susceptibleto thrashing due to repeated restarts.
—CWS introduces a significant im-provement in performance over NWthat is due to the reduction in wastedprocessing. This is also the case forthe CWA method [Hsu and Zhang1992]. Simulation results show thatthe CWS and CWA methods have acomparable performance (differing bya few percentage points) and as wouldbe expected CWS outperforms (is out-performed by) CWA for small (resp.,large) values of P, since CWA intro-duces fewer aborts than CWS.
—The RPS method outperforms CWS inall cases, which is attributable to thefact that aborting a blocked txn in thecase of RPS results in an increase inthe number of active txns from oneactive txn in TA 3 TB 3 TC to twoactive when TB is aborted and is set
aside, whereas an aborted txn in thecase of CWS just starts restart wait-ing, since an immediate restart willlead to repeated conflicts and aborts[Hsu and Zhang 1992].For smaller values of P, RPA outper-forms not only RPS but also the WDLand MWDL methods, which is attrib-utable to the fact that RPA results inless wasted processing than the othermethods, such that it can maximizethe useful processing in the system.
—The WDL [Franaszek et al. 1992] andthe MWDL [Thomasian 1992] meth-ods outperform others (includingRPA) at higher processing capacities.The peak throughput attained bythese two methods is almost a factorof four higher than that attained byGW and 20% higher than RPA. Theseresults concur with simulation resultsin Fanaszek et al. [1992]. It is inter-esting to note that MWDL, in spite ofits relative simplicity with respect toWDL, attains a performance veryclose to it.
—WW, although outperforming GW forhigher values of P, is outperformed byall other methods except NW. Thefact that txns are blocked in times-tamp order results in very little dropin peak throughput, once it is at-tained. In effect, unnecessary restartsare avoided and the restart-waitingoption is not required in this case.
The method with the maximum effec-tive throughput for a given P maximizesthe number of processors doing usefulwork (say Pu). Thus for intermediatevalues of P, RPA outperforms WDL,since it attains a higher Pu. However, asP is increased, WDL and MWDL utilizemore processors (up to P 5 500) andattain a higher Pu than RPA [Thoma-sian 1993].
A simulation with a synthetic work-load and a lock trace is used in Weikumet al. [1994] to compare the performanceof several load-control methods, espe-cially those based on conflict ratios (seeSection 2.2). WDL is shown to have asuperior performance in all cases but
96 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

one, which is an accelerated syntheticworkload. The main reason for the suc-cess of WDL according to this study isits smaller lock-waiting time with re-spect to other methods. Note that re-start waiting in the case of WDL servesthe role of load control.
Synthesizing methods that will maxi-mize system throughput for a given setof system parameters remains an openproblem. Guidelines for this purpose areas follows.
(1) From the viewpoint of data conten-tion, it should conform with the es-sential blocking property [Fra-naszek and Robinson 1985] andminimize wasted lock-holding time,which affects system performancewhen lock utilizations are high (e.g.,locks on hot-spots).9
(2) From the viewpoint of hardware re-source contention it should mini-mize wasted processing by associat-ing a higher priority level with txnsthat have acquired more processingthan others [Franaszek et al. 1992]and exhibit adaptiveness to systemload, for example, by reducing thenumber of txn aborts when the sys-tem is overloaded [Franaszek et al.1991a].
(3) From the viewpoint of reducing txnresponse times, care should betaken not to abort txns that arenear completion but have not yetentered the commit phase. This en-tails a reduction in lock-holdingtime and wasted processing, whichare both almost doubled when a txnnear its completion is aborted. Theprogress made by a txn towards itscompletion can be deduced from itstype in some cases (a system withcanned txn classes). The perfor-mance of a system that takes into
account txn progress with respect toits completion in deciding whichtxns to abort requires further inves-tigation.
Adaptive methods balance the reductionin lock contention with wasted process-ing. Minimizing the wasted processingup to a point where the bottleneck re-source in the system (e.g., the proces-sors) is almost fully utilized is a goodstrategy, since this tends to maximizethe useful processing in the system.This was verified through simulation ofthe two-phase processing method inFranaszek et al. [1991a] (see Section4.3), which is based on the adaptive RPmethod in Section 3.1.
Given that the future lock requestsare known a priori, an “optimal” policycan be used to determine the best possi-ble performance, for example, the mini-mum mean response time for a giventhroughput, against which other meth-ods can be gauged. Unfortunately, anoptimal policy for this purpose is com-putationally very expensive. In con-trast, the optimal policy for minimizingthe miss ratio in paging virtual-memorysystems is to simply replace the pagereferenced furthest in the future, pro-vided the trace of page requests isknown.
The performance of methods based onOCC and access invariance is comparedto the WDL method in Section 4.4.
The effect of shared locks and hot-spots on performance. It is importantto determine if the relative performanceof the restart-oriented locking methodsalso holds in the presence of shared aswell as exclusive locks and hot-spots. Astraightforward extension of RPA withshared locks restarts all txns holdingthe requested lock in shared mode if atleast one of them needs to be abortedbecause it is blocked. This method out-performs the GW method in a systemwith infinite resources according to thesimulation results in Thomasian [1993],but this may not be true in a systemwith limited hardware resources.
EDSP (introduced in Section 2.4) is
9 To see why this is so, consider the followingexample. The throughput of a system with a sin-gle hot-spot can be maximized by minimizing thewasted lock holding time on the hot-spot. Thus thetxn holding this lock cannot be aborted or blocked;that is, txns that get in its way (by holding locksrequired by it) are aborted.
Concurrency Control • 97
ACM Computing Surveys, Vol. 30, No. 1, March 1998

expected to be applicable to wait-depth-limited methods, since they maintain asubset of the WFG for the GW method,but this is not always so. For example,according to Corollary 5.2 in Tay et al.[1985b], EDSP for shared and exclusivelocks for NW with lock resampling holdsonly for sufficiently low levels of lockcontention. This problem is consideredfurther in Hsu and Zhang [1995] in thecontext of NW and CWA, which are“equal-chance abort policies”; that is,the probability of txn abort upon a lockrequest is independent of its currentstate. The data-flow balance principle isused in the context of the hot-spot data-base access model to show that the ef-fective database size (Deff) is an increas-ing function of M and that EDSPunderestimates Deff (overestimates thelock conflict probability) by estimatingDeff at M 5 0. This is because EDSPdoes not take into account the lock-resampling effect. This analysis is oflimited applicability, since it deals withthe less realistic lock-resampling op-tion.
It follows from simulation results inThomasian [1993] that EDSP providesan acceptably accurate approximationfor the no-lock-resampling option, in-cluding no resampling of locking modes.For example, in the case of the NWmethod with frequent aborts, simula-tion results obtained by applying EDSPto shared and exclusive locks are indis-tinguishable from the results for theoriginal model; also, very close resultsare obtained with the hot-spot model.From these experiments, it is conjec-tured that EDSP applies approximatelyto the NW and CWA methods for whichthe txn making the lock request isaborted. This is attributed to the factthat the expected mix of the modes oflocks held by txns in the system is af-fected negligibly in this case. However,there is the second-order effect that atxn making an exclusive lock requesthas a higher probability of lock conflictthan when it makes a shared lock re-quest.
In the case of RPA, it is observed from
simulation results that the throughputobtained by applying EDSP to the hot-spot model matches the original modelquite well. The peak system throughputis typically overestimated by 5%. EDSPis less accurate in the case of RPA whenapplied to a system with shared andexclusive locks. This is attributable tothe fact that the composition of txns inthe system is affected when txns areaborted as a result of a lock conflict (asin the case of multiple txns holding alock in shared mode, which is requestedin exclusive mode, being aborted be-cause one of them is blocked).
3.3 Performance Analysis of the RunningPriority Method
We briefly review earlier analytic stud-ies of restart-oriented locking methodsand outline the analysis of a nontrivialwait-depth-limited method by analyzingthe performance of the RPS method.
Review of earlier analytic studies.A method according to which a txn en-countering a lock conflict repeats itsrequest L times before it is aborted isdescribed in Chesnais et al. [1983]. AMarkov-chain model representing theprogress of a single txn is used to ana-lyze system performance. Numerical re-sults with the immediate restart-lockresampling option and the infinite-re-source assumption lead to the conclu-sion that the best performance is at-tained at L 5 0, that is, the NWmethod. Comprehensive studies of NWand GW using flow diagrams appear inTay et al. [1985b] and Tay et al.[1985a], respectively (see also Tay[1987]). It is shown in Tay et al. [1985a]that the NW method outperforms GWwhen there are infinite resources, but atlower degrees of txn concurrency NW isoutperformed by GW (by at most 5%).Another study [Ryu and Thomasian1990b] concludes that GW outperformsNW in its nonthrashing region, unlessthere are infinite resources and the im-mediate restart-lock resampling optionis in effect. The flow-diagram method of
98 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998
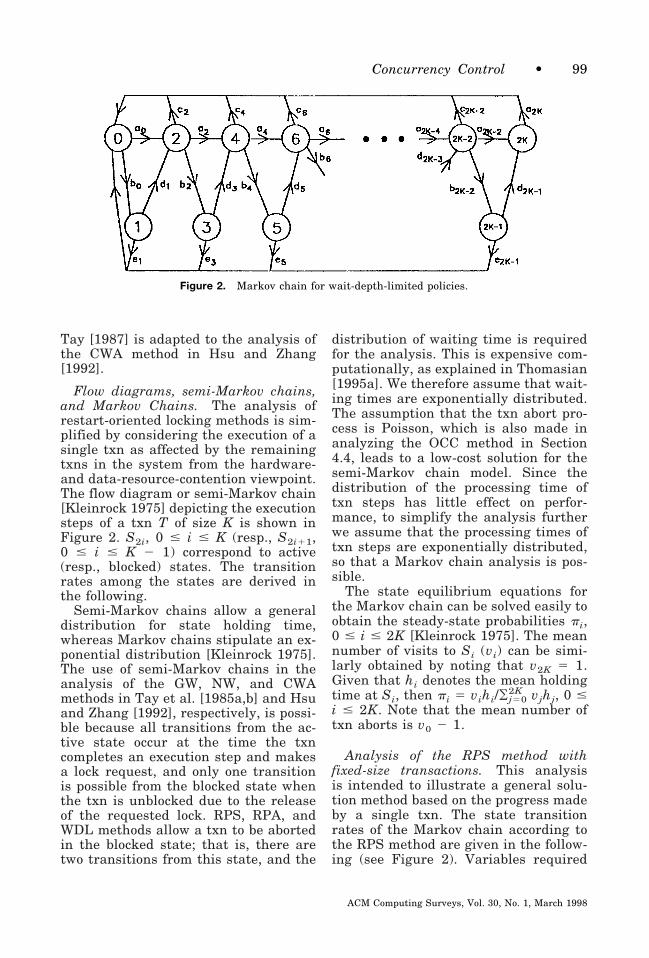
Tay [1987] is adapted to the analysis ofthe CWA method in Hsu and Zhang[1992].
Flow diagrams, semi-Markov chains,and Markov Chains. The analysis ofrestart-oriented locking methods is sim-plified by considering the execution of asingle txn as affected by the remainingtxns in the system from the hardware-and data-resource-contention viewpoint.The flow diagram or semi-Markov chain[Kleinrock 1975] depicting the executionsteps of a txn T of size K is shown inFigure 2. S2i, 0 # i # K (resp., S2i11,0 # i # K 2 1) correspond to active(resp., blocked) states. The transitionrates among the states are derived inthe following.
Semi-Markov chains allow a generaldistribution for state holding time,whereas Markov chains stipulate an ex-ponential distribution [Kleinrock 1975].The use of semi-Markov chains in theanalysis of the GW, NW, and CWAmethods in Tay et al. [1985a,b] and Hsuand Zhang [1992], respectively, is possi-ble because all transitions from the ac-tive state occur at the time the txncompletes an execution step and makesa lock request, and only one transitionis possible from the blocked state whenthe txn is unblocked due to the releaseof the requested lock. RPS, RPA, andWDL methods allow a txn to be abortedin the blocked state; that is, there aretwo transitions from this state, and the
distribution of waiting time is requiredfor the analysis. This is expensive com-putationally, as explained in Thomasian[1995a]. We therefore assume that wait-ing times are exponentially distributed.The assumption that the txn abort pro-cess is Poisson, which is also made inanalyzing the OCC method in Section4.4, leads to a low-cost solution for thesemi-Markov chain model. Since thedistribution of the processing time oftxn steps has little effect on perfor-mance, to simplify the analysis furtherwe assume that the processing times oftxn steps are exponentially distributed,so that a Markov chain analysis is pos-sible.
The state equilibrium equations forthe Markov chain can be solved easily toobtain the steady-state probabilities pi,0 # i # 2K [Kleinrock 1975]. The meannumber of visits to Si (vi) can be simi-larly obtained by noting that v2K 5 1.Given that hi denotes the mean holdingtime at Si, then pi 5 vihi/¥j50
2K vjhj, 0 #i # 2K. Note that the mean number oftxn aborts is v0 2 1.
Analysis of the RPS method withfixed-size transactions. This analysisis intended to illustrate a general solu-tion method based on the progress madeby a single txn. The state transitionrates of the Markov chain according tothe RPS method are given in the follow-ing (see Figure 2). Variables required
Figure 2. Markov chain for wait-depth-limited policies.
Concurrency Control • 99
ACM Computing Surveys, Vol. 30, No. 1, March 1998

for analyzing the Markov chain are de-rived later.
(1) S2 j 3 S2 j12 with rate a2 j, 0 # j #K 2 1 designates successful lockrequests, and S2K 3 S0 with ratea2K 5 mK corresponds to the comple-tion of a txn. The probability that atxn T encountering a lock conflict atS2 j is blocking another txn is givenby Qj. Let Pa (resp., Pb) denote theprobability of lock conflict with anactive (resp., blocked) txn, with Pc 5Pa 1 Pb. We have a2 j 5 [(1 2 Pc) 1Pb(1 2 Qj)]mj 5 (1 2 Pa 2 PbQj)mj,0 # j # K 2 1. Pa, Pb, and Qj arederived in the following.
(2) S2 j 3 S2 j11 with rate b2 j, 1 # j #K 2 1 designates unsuccessful lockrequests leading to txn blocking. Tis blocked only if it is not blockingany other txns, and hence b2 j 5Pa(1 2 Qj)mj, 0 # j # K 2 1.
(3) S2 j 3 S0 with rate c2 j 5 PcQjmj,1 # j # K 2 1 corresponds to txnaborts.
(4) S2 j11 3 S2 j12 with rate d2 j11, 0 #j # K 2 1. The waiting time for theacquisition of a lock (due to comple-tion or abort of the txn holding thelock) is approximated by an expo-nential distribution W(t) 5 1 2e2nt, t $ 0, with n 5 1/W.
(5) S2 j11 3 S0 with rate e2 j11, 0 # j #K designates the abort of T, whichoccurs when T9, which is not block-ing other txns, requests a lock heldby T. We assume that the processaccording to which T is aborted atS2 j11 is Poisson with rate vj (seeEq. (3.4)).
The probability of lock conflict with ac-tive (resp., blocked) txns is Pa . (M 21)L# a/D (resp., Pb . (M 2 1)Lb/D), whereL# a 5 ¥j51
K jp2 j (resp., L# b 5 ¥j51K21jp2 j11)
is the mean number of locks held byactive (resp., blocked) txns. The fractionof blocked txns in the system is given byb(5 ¥j51
K p2 j21). As in the case of stan-dard locking (see Section 2.1), the meannumber of active and blocked txns isgiven by M# a 5 M(1 2 b) and M# b 5 Mb,
respectively. The mean number of locksheld per txn is L# 5 L# a 1 L# b and hencePc . (M 2 1)L# /D. The probability thatan active txn T at S2 j is blocking atleast one of the M# b blocked txns in thesystem is approximated by
Qj 5 1 2 @1 2 j/~ML# a!#M# b, 1 # j # K,
(3.1)
where j/(ML# a) is the probability thatanother txn is blocked by the target txnat S2 j (the denominator denotes themean number of locks held by activetxns).
The mean waiting time Wj due to alock conflict with an active txn at S2 j isWj 5 ¥l.2i
2K n9lhl. Visit ratios with re-spect to S2 j are obtained as follows:v92 j 5 1, v92i11 5 b2iv92i, and v92i12 5(a2i 1 b2id2i11)v92i, j # i # K. Thistakes into account lock acquisition bytxn completion or abort. The mean hold-ing time in Sl is hl 5 si 5 1/mi, whenl 5 2i, j # i # K. The residual process-ing time in S2 j equals the processingtime in that step, since the per-stepprocessing times are exponentially dis-tributed [Kleinrock 1975]. The mean de-lay in the blocked state Sl is the ex-pected value of the minimum of twoexponential distributions hl 5 1/(vi 1n) with l 5 2i 1 1, j # i # K 2 1[Kleinrock 1975]. The mean waitingtime is given by
W 5 Oj51
K
qjWj , (3.2)
where qj is the probability of lock con-flict with an active txn at S2 j. The prob-ability qj equals the time-space productof the number of locks held at S2 j andtheir holding time: qj 5 jp2 j/H, whereH 5 ¥j51
K jp2 j is a normalization con-stant. The rate of lock requests by theother txns in the system is
l 5 S1 21
MDT~M! Ol50
K21
v2l~1 2 Ql!.
(3.3)
100 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

The summation takes into account theincrease in the rate of requested locksdue to txn restarts and the fact thatlock conflicts due to txns that are block-ing other txns do not have an effect,since these txns are aborted upon lockconflict.
The rate at which a txn at S2 j11 isaborted is proportional to the number oflocks that it holds:
vj 5 jl/D, 0 # j # K 2 1. (3.4)
The mean txn response time is R(M) 5¥j50
K v2 jsj 1 ¥j50K21 v2 j11/(n 1 vj). Txn
throughput is given by T(M) 5 M/R(M)or alternatively by T(M) 5 MmKp2K.Some of the parameters required for theanalysis are not known a priori; hencean iterative solution is required, whichtends to converge in a few cycles.
Validation with infinite resourcesshows the analysis of the RPS methodto be quite accurate up to very high lockcontention levels, but to underestimatepeak throughput by 8%, which is par-tially attributable to the fact that theanalysis does not take into account thepossibility of multiple txns being un-blocked when another txn is aborted[Thomasian 1995a].
Outline of the analysis of GW and NWmethods. In the case of the NWmethod, there are only two transitiontypes: a2 j 5 mj(1 2 Pa), 0 # j # K 2 1and c2 j21 5 mjPa, 0 # j # K. It can beeasily shown that p2 j 5 p0(1 2 Pa) j,1 # j # K. Multiplying both sides ofthis equation by M yields the meannumber of txns in different states, asobtained by the analysis of flow dia-grams in Tay et al. [1985b] and Tay[1987]. The analysis in this case is tan-tamount to solving a polynomial equa-tion in q 5 1 2 Pa, which can bederived from the last equation notingthat Pa . N# /D, where N# 5 M ¥j51
K jpjis the mean number of locks held in thesystem. The polynomial has a uniqueroot in the range (0,1) [Tay 1987].
In the case of GW there are threetransition types, provided that as in Tay
et al. [1985a] we ignore the effect ofdeadlocks: a2 j 5 mj(1 2 Pc), 0 # j #K 2 1, b2 j 5 mjPc, 0 # j # K, and d2 j21 5n 5 1/W, 1 # j # K. The state equilib-rium equations are given by p2 j21 5(mPc/n)p2 j22, 1 # j # K and p2 j 5p0 5 [1 1 K(1 1 mPc/n)]21, 1 # j # K.Active states and blocked states haveequal probabilities, since the probabilityof a txn encountering a lock conflict isindependent of its step and the possibil-ity of abort to resolve deadlocks is ig-nored. System performance in this casedepends on Pc and n 5 1/W. Multiplelevels of txn blocking need to be consid-ered to estimate W in this case [Tay etal. 1985a; Thomasian and Ryu 1991;Thomasian 1993c].
Analysis of RPS with variable trans-action sizes. The analysis of the fre-quency-based model of the NW methodin Tay et al. [1985b] and Tay et al.[1987] uses different transition pointsfrom a single flow-diagram to denotetxn completions. This analysis does notensure conservation of txn class fre-quencies; that is, the fraction of txnscompleted by the system differs fromthe original frequencies in a mannerfavoring shorter txns, which have ahigher probability of success thanlonger txns. The analysis for a singletxn class can be extended to multipleclasses with the frequency-based modelby using a separate Markov chain perclass in the analysis, as is done in Tho-masian [1992, 1995a]. A system with agiven number of txns in two classes isanalyzed by a simple extension of theanalysis for a single txn class in Tay etal. [1985b] and Tay [1987].
4. TWO-PHASE PROCESSING METHODSAND ACCESS INVARIANCE
The first phase of txn execution maylead to its commit, but even if it is notsuccessful its execution to completionprefetches data from disk for the secondexecution phase of the txn. Two-phaseprocessing methods increase thechances of successfully re-executing
Concurrency Control • 101
ACM Computing Surveys, Vol. 30, No. 1, March 1998

txns, if necessary, by allowing a shorterprocessing time for txns in the secondphase and a lower effective degree oftxn concurrency in this and furtherphases, provided that the databasebuffer is large enough to retain pagesaccessed by txns and access invarianceprevails [Franaszek et al. 1992]. Accessinvariance can be at the logical or phys-ical level. In the first case a txn accessesthe same logical objects (e.g., records)and in the second case the same physi-cal objects (e.g., blocks) are accessedupon re-execution [Franaszek et al.1990, 1992]. OCC methods are wellsuited for two-phase processing, as isshown in the following discussion. Mul-tiphase processing is possible withOCC, since txn completion in the secondexecution phase is not guaranteed.
The restart-oriented methods dis-cussed in Section 3 also benefit fromaccess invariance to some degree; thatis, a restarted txn can usually accesspages from the database buffer result-ing from a txn’s prior execution (up tothe point of the txn’s abort), but unliketwo-phase processing no attempt ismade to continue the execution of anaborted txn.
Section 4.1 is a brief introduction toOCC and its validation options. Mecha-nisms for two-phase txn processing aredescribed in Section 4.2, followed in Sec-tion 4.3 by a description of txn schedul-ing methods and their relative perfor-mance with respect to each other andother methods. In Section 4.4 we outlineanalytic solution methods for OCC.
4.1 Optimistic Concurrency Control
Optimistic CC (OCC) is a major alterna-tive to locking [Kung and Robinson1981; Robinson 1982a], but is less suit-able than locking in meeting the re-quirements of DBMSs for high-perfor-mance txn processing [Haerder 1984;Mohan 1992]. However, there have beenmany prototyping efforts (see Thoma-sian and Rahm [1990] for a partial list),numerous proposals for improved algo-rithms [Menasce and Nakanishi 1982;
Robinson 1984; Haerder 1984; Fra-naszek et al. 1992], and several analy-ses of OCC performance [Menasce andNakanishi 1982; Moenkeberg and Wei-kum 1985; Ryu and Thomasian 1987].
The execution of a txn with OCC com-prises the following phases [Kung andRobinson 1981].
(1) During the read phase txns accessdatabase objects, possibly updatinga subset of these objects. A “clean”or committed copy of requested ob-jects is made available to txns fromthe database buffer in this phase,and dirty copies of the same objectsmay exist in the private workspaceof other txns. Reciprocally, the up-dates (prewrites) of txns during theread phase do not affect the data-base buffer, but only the txn’s pri-vate workspace.
(2) The validation phase is required toensure serializability by checkingfor data conflicts as described in thefollowing. Data conflicts are re-solved by aborting txns that failtheir validation.
(3) A read-only txn is considered com-pleted after a successful validation,and a txn that has updated someobjects during the write phase ini-tiates commit processing by writingthe log records onto disk and thenexternalizes updated objects to thedatabase buffer.
The validation method described inKung and Robinson [1981] has theshortcoming of unnecessarily abortingtxns, which is rectified in Robinson[1984]. The implementation describedin Menasce and Nakanishi [1982] andRyu and Thomasian [1987] requires theassociation with “active” database ob-jects of a timestamp t(O) that indicatesthe time at which object O was lastupdated. Let t(O, T) denote the timethat object O was read by tnx T. Thefollowing two rules are required for thecorrect execution of a txn T.
102 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

Read O. Copy object O into T’s localworkspace. In case there is no time-stamp associated with an object, itstimestamp is set to the current timet(O) 5 Clock. Also set t(O, t) 5 Clock.
Validate T. For all objects O accessedby the txn, check in a critical sectionwhether t(O, T) $ t(O):
—If the condition is not true for anyobject, then abort T.
—Otherwise commit T and external-ize all objects O in the write setafter setting t(O) 5 Clock.
Validation may be carried out in a criti-cal section serializing the validationprocess, which may become a bottleneckat high txn volumes. Performance canbe improved by acquiring exclusivelocks on all accessed objects by anatomic action (static locking with strictFCFS policy; see Section 2.3).
The OCC method can append accessentries (similarly to locks in standardlocking) to linked lists associated withhash classes identifying accessed ob-jects. Access entries are used at txncommit time in identifying conflictedtxns and marking them as “injured.”According to the kill or broadcast com-mit method, a txn is aborted “rightaway,” but in fact txn abort is usuallydeferred until its next interaction withthe CC manager. According to the die orsilent commit option, an injured txn isaborted only at the end of its execution[Robinson 1984; Ryu and Thomasian1987]. No validation is required at thecompletion of the read phase when a txnis already injured; its access entries aredeleted and the txn is aborted. Other-wise
(1) The relevant access entries arelocked by an atomic action. The txnis simply delayed if there is a lockconflict until the required access en-tries are unlocked.
(2) The access entries of objects up-dated by the txn are used to injuretxns that have accessed the sameobjects.
(3) The txn writes its log records, exter-nalizes updated objects, and deletesaccess entries.
Aborted txns can be restarted rightaway, since the conflicting txns havecommitted and left the system; that is,no further conflicts will occur.
Both OCC and 2PL are inefficientwhen txns update database hot-spots.Locking has been extended with fieldcalls in IMS FastPath to deal with ag-gregate variables constituting hot-spots[Gray and Reuter 1992]. The similaritybetween OCC and field calls consideredin Gray and Reuter [1992] is repeatedhere in the context of an inventory con-trol application [O’Neil 1987]. A txnfirst tests that enough items are avail-able (e.g., QOH $ Request_size) to sat-isfy the Request_size for a certain orderand again before txn commit. If the first(resp., second) test fails, then the txnfollows an alternate path (resp., isaborted). This method is similar to OCCin that the object is not updated afterthe first test, but only after the secondtest is successful. Only one out of Mtxns accessing the QOH succeeds withOCC, whereas all M txns will succeedwith the field-calls approach, as long asthe current value of QOH exceeds thesum of Request_sizes.
4.2 Mechanisms Used by Two-PhaseProcessing Methods
In this section we describe mechanismsassociated with txn scheduling methodsthat take advantage of access invari-ance.
(1) Transaction phases. A txn phase isan instance of its execution. Thefirst execution phase of a txn maylead to txn commit, but even when itis unsuccessful (e.g., the txn fails itsvalidation), it serves the role ofpriming the database buffer. Weonly distinguish among the execu-tion in the first phase, which usu-ally requires disk I/O, and furtherphases, which do not (provided ac-cess invariance prevails).
Concurrency Control • 103
ACM Computing Surveys, Vol. 30, No. 1, March 1998

(2) Running modes. We consider threerunning modes:—Virtual Execution (VE). This exe-
cution mode is intended for deter-mining the script of a txn (i.e., theset of objects accessed by the txn).Txn type and the input data to thetxn provide some informationabout the future behavior of a txn,but this also depends on the stateof the database. VE can be used topredict the data blocks accessedby a txn with some degree of cer-tainty, by running a txn withoutinvoking CC. The “pipelined” txnprocessing scheme in Reuter[1985] is based on VE in the firstphase and serialized execution(SE), which may be considered adegenerate form of CC, in the sec-ond phase. One thread in a mul-tithreaded experimental txn-pro-cessing system executes txns inSE mode, whereas other threadsare used for execution in VE mode[Li and Naughton 1988].—Optimistic die and kill methods
are applicable.—Locking. DL (dynamic locking)
and SL (static locking) or lockpreclaiming are relevant for thesecond phase (see Section 4.3),since they do not introduce anytxn restarts (this is almost truein the case of DL), whereas re-start-oriented locking methods,such as RP (running priority),are appropriate for the firstphase.
An “aborted” txn releases its locks. Ifthe txn is in its second phase it beginsrestart waiting, and first-phase txnscontinue their execution in the weakerVE or optimistic modes. In the lattercase objects accessed/updated by “abort-ed” txns are copied into the txn’s privateworkspace.Switching from a weaker to a strongermode, such as VE 3 OCC, VE 3 lock-ing, or OCC 3 locking, is more difficult.Consider switching an uninjured txn
running in optimistic mode to lockingmode, as considered in Franaszek et al.[1991a] (see Section 4.3). Upgrading theaccess entries of a txn to locks mayresult in other txns being injured andtxn updates being externalized at thispoint.
(3) Locking priorities. A two-phase pro-cessing method should specify howdata conflicts are resolved amongtxns in the same and differentphases.Locks are given a higher prioritythan access entries, since: (i) txns inoptimistic mode are much more sus-ceptible to aborts than txns withstandard locking; and (ii) the opti-mistic mode is used in the firstphase and is followed by the lockingmode in further phases. We nextconsider lock conflicts.—No locking priorities. Lock re-
quests are handled in FCFS order,regardless of the phase of the txnmaking the lock request.
—Nonpreemptive locking priorities.Lock requests by second-phasetxns are given a higher prioritythan first-phase txns.
—Preemptive locking priorities. Lockrequests by txns in the second orfurther phases are given preemp-tive priority with respect to locksheld by first-phase txns. A txnthat loses a lock in the first phasemay continue running in virtualexecution mode.
(4) Transaction spawning. In additionto simply blocking a txn when itencounters a lock conflict, it is pos-sible to spawn a subtxn [Franaszeket al. 1992]. The subtxn that is pro-vided with a private workspace runsin VE mode prefetching data re-quired for the main txn’s execution.
(5) Checkpointing at the transactionlevel. This type of checkpointing canbe used to reduce the wasted pro-cessing caused by txn aborts. Check-pointing in OCC is discussed in Sec-tion 4.3.
104 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

(6) CPU priorities. Txns in phase twohave preemptive CPU priority withrespect to txns in phase one, be-cause it is important to minimizethe holding time for locks and accessentries in this phase (see Section4.3). Note that the execution time oftxns in the first phase is dominatedby disk I/O time and little is lost byhaving a lower CPU priority level inthis phase. A txn in the first phasewill run at an even lower prioritylevel after it is conflicted; for exam-ple, the priority level of a txn run-ning in optimistic die mode is low-ered after a conflict.
Integrated CC and CPU scheduling[Franaszek et al. 1991b]. This para-digm is based on matching the numberof executing txns with the availability ofhardware resources in the system (e.g.,CPU utilization). For example, txns inthe system are prioritized based onwhether they are runnable in the fol-lowing categories: (1) standard locking;(2) RP, that is, txns not runnable byGW, but runnable with RP, for example,txn TC in the WFG TC 3 TB 3 TA; (3)the optimistic method, where all txnsare runnable. Txns in category (1) runat priority level i (1 is the highest prior-ity level). When the CPU is underuti-lized because there are no txns such asTA to run, the scheduler will first runtxns such as TC. This seems to requirethe abort of TB, but this is not requiredif a private workspace paradigm isadopted, which facilitates running inoptimistic mode as well. If the CPU isstill not fully utilized after running txnssuch as TC, the scheduler will run alltxns, including txns such as TB. Con-versely, more conservative running op-tions are adopted when the CPU is fullyutilized. Further investigations are re-quired to ascertain the viability of thismethod.
4.3 Description and Performance of Two-Phase Processing Methods
In this section we describe txn schedul-ing methods utilizing the mechanisms
in Section 4.2. VE and the optimistic diemethod are suitable for execution in thefirst phase, because they serve the pur-pose of prefetching data for the secondexecution phase. Lock or data conten-tion is less of a problem in the secondphase, since the mean number of txnsexecuting in this phase, which deter-mines the effective degree of txn concur-rency, tends to be an order of magnitudesmaller than the number of txns in thefirst phase. Hence the method used inthe second phase has little effect onperformance. However, to reduce thevariability of txn response times, lock-ing methods should be used in prefer-ence to OCC methods, since locking(with lock preclaiming and preemptivelock priorities for second-phase txnswith respect to second-phase txns) dis-allows repeated txn aborts, whereasOCC allows restarts of second-phasetxns by first-phase txns.
A list of viable two-phase processingmethods is specified as “p1/p2-p29 . . . ,”where p1 is the CC method used inphase 1 and p2,p29, . . . are the CCmethods used in phase 2. In case a txnis aborted in phase 2, it is usually re-executed with the same CC method, butthis is not always the case, for example,when access invariance is violated [Tho-masian and Ryu 1990; Thomasian1997b]. Representative two-phase pro-cessing methods are as follows:
(1) VE/SE-DL-SL-optimistic kill. SEruns txns serially in the secondphase, whereas the other methodsallow concurrent txn processing inthis phase.
(2) Optimistic die/kill. The optimisticdie method in the first phase servesthe purpose of data prefetching,even though the txn has been con-flicted, but its repeated use in fur-ther phases is not justifiable, sinceit no longer serves this purpose. Op-timistic kill, on the other hand, min-imizes wasted processing in latterphases.
(3) Optimistic kill/kill. The optimistickill method is appropriate for the
Concurrency Control • 105
ACM Computing Surveys, Vol. 30, No. 1, March 1998

first phase in the following cases: (i)txns are not access-invariant; (ii)the database is main-storage-resi-dent or few disk accesses are re-quired due to a high buffer hit ratio;and (iii) wasted processing cannotbe tolerated due to limited process-ing capacity. The preceding com-ments about txn validation priori-ties also apply in this case.
(4) Optimistic die/DL-SL. These are ex-amples of hybrid CC methods, whichhave the advantage with respect tooptimistic die/kill that second-phasetxns have priority with respect tofirst-phase txns; that is, lock re-quests conflicting with access en-tries result in a fatal injury to thecorresponding first-phase txn, un-less the txn making the lock requestis aborted later to resolve a dead-lock. Lock preclaiming in the secondphase according to SL ensures thatrepeated aborts, which are inherentin OCC methods, are alleviated[Thomasian and Rahm 1990; Tho-masian 1997b] (the advantage ofthis method is noted in Lynch et al.[1994]).
(5) RPA_VE/DL-SL. A txn in the firstphase may be aborted due to theRPA (asymmetric RP) paradigm ordue to lock preemption by a second-phase txn, since lock requests bytxns in the second phase have apreemptive priority with respect tolocks held by first-phase txns. Afirst-phase txn conflicted in thismanner copies objects protected byits locks into a private workspace,releases its locks, and rather thanbeing aborted, continues running inVE mode. A first-phase txn (runningin RPA mode) is blocked when it hasa lock-conflict with an active orblocked second-phase txn, becauselock requests by second-phase txnshave a higher priority than first-phase txns.We use this context to elaborate ontxn spawning at this point. Thereare two possibilities when a con-
flicted txn (say T) spawns a subtxnthat starts running in VE mode.—T is unblocked before the spawned
subtxn completes its execution.There are two choices: abort thespawned subtxn or run thespawned subtxn to the end, sothat no spawning will be requiredif the txn is blocked again. This isso provided access invariance pre-vails.
—The spawned subtxn completeswhile T is still blocked. In thiscase T is switched from the first tothe second phase. In case T isblocked by a first-phase txn andprovided that lock requests by sec-ond-phase txns have a preemptivepriority with respect to first-phasetxns, then the first-phase txn isaborted releasing its locks. If T isblocked by a second-phase txn, itwill remain blocked until this txncompletes.
Simulation results indicate that txnspawning does not improve perfor-mance with respect to RP-VE/DL forthe range of modeling parametersconsidered [Franaszek et al. 1992].Txn spawning has been adopted forreal-time txn processing inBestavros and Braoudakis [1995].
The branching txn paradigm [Burgerand Thanisen 1992] in the context ofmultiversion locking provides for twoinstances of txn execution based on theold and new value of the locked vari-able. “Branch-restriction policies” arerequired, since otherwise the number oftxns in the system grows exponentially,leading to thrashing due to resourceexhaustion.
Polyvalues provide a similar capabil-ity for coping with failures in a distrib-uted database environment through abookkeeping tool described in Montgom-ery [1978]. With two pending txns T1and T2 there are three polyvalues forthe bank account balance (Binit 2 W1 2W2, T1, T2), (Binit 2 W1, T1 ¬ T2), and(Binit 2 W2, ¬ T1, T2), where Binitstands for initial bank balance, W for
106 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

withdrawal, and Ti (resp., ¬Ti) indi-cates the commit (resp., abort) of txn Ti.Thus items remaining locked due to thefailure of a commit coordinator can beaccessed conditionally by other txns.Note that no branching is required bytxns, which just require the balance toexceed a certain value. The escrow par-adigm generalizes and formalizes poly-values in the case of aggregate variables[O’Neil 1986].
The issue of accessing different ver-sions of an object arises in the context ofhybrid CC methods as well [Thomasianand Rahm 1990; Thomasian 1997b]. Thealternatives are
(1) access committed data;(2) access exclusively locked but uncom-
mitted objects from the databasebuffer or the private workspace.Such objects may be modified again(i.e., do not necessarily reflect theversion to be committed); and
(3) block access until all exclusive locksheld on the object are released.
Simulation results show little differencebetween the performance attained bythe first and third methods in the con-text of an optimistic die/SL hybridmethod [Thomasian 1997b].
Performance comparison of two-phaseprocessing methods. We summarizethe simulation results in Franaszek etal. [1992], which considers a multipro-cessor with a large database buffer. Theload on the disks is assumed to be bal-anced and the number of disks is chosensuch that all disks have a 20% utiliza-tion when the processors are 75% uti-lized. Disk utilization is based on abuffer hit ratio of 62.5% when all txnscommit at the end of their first execu-tion phase. The database buffer is largeenough to ensure that txns running intheir second phase can access data re-quested in the first phase from thebuffer. Each txn requests 16 locks onthe average, of which 25% are to hot-spots. The comparison of CC methods isbased on their ETC (T(M), M $ 1), that
is, which CC method attains the maxi-mum effective throughput.
(1) The VE/DL-SL method provides alower bound to the ETC attainableby two-phase processing methods.There is no difference between theperformance attained by using theDL and SL methods in the secondphase, since there are few txns inthis phase at any time and there islittle lock contention. SL is prefera-ble to DL in that it prevents txnaborts due to deadlocks. In a high-data-contention system with ade-quate hardware resources, VE/DLoutperforms standard locking,which also follows from the numeri-cal results obtained from the analy-sis in Thomasian and Ryu [1991].
(2) The optimistic die/kill method out-performs the optimistic kill/killmethod in a system with adequatehardware resources and access in-variance, but this is not so in asystem with limited hardware re-sources [Franaszek et al. 1990,1992]. This is because executingtxns to the end ensures their suc-cessful re-execution if access invari-ance prevails, since txn executiontime without disk I/O tends to bevery short. The optimistic kill/killmethod also exhibits the prefetchingeffect up to the point of txn abort,while wasting less processing.
(3) The optimistic die/kill method out-performs the RP_VE/SL-DL methodin high-contention systems with ad-equate hardware resources and viceversa. The main reason is that theRP_VE running mode results in lesswasted processing in the first phasethan the OCC die policy.
One observation about two-phase pro-cessing methods is that their perfor-mance follows the same pattern at veryhigh lock-contention levels, which is de-termined by the bottleneck hardwareresource. This is because very few txnscan commit successfully at the end oftheir first execution phase and hence
Concurrency Control • 107
ACM Computing Surveys, Vol. 30, No. 1, March 1998

both phases of almost all txns are exe-cuted. Two-phase processing methodsmay outperform the WDL method inhigh-data-contention systems with ade-quate hardware resources [Franaszek1992]. However, this is not always so;for example, the WDL method outper-forms the optimistic die/SL method in asystem with a main storage database(no prefetching required) and a largenumber of processors [Franaszek 1992],but is outperformed by the optimistickill method in this case.
An adaptive method to improve theperformance of two-phase processingmethods is described in Franaszek[1991a]. Txns are initially run in opti-mistic die/kill mode and once the bottle-neck resource (e.g., the processors) be-comes fully utilized (due to increasedload) a more conservative method suchas RPA is invoked. Further saturationof CPU utilization may lead to the adap-tive variant of RPA described in Section3.1. Simulation results in Franaszek[1991a] show that the improvement inperformance due to adaptive methodscan be significant.
Checkpointing in optimistic concur-rency control. The effect of checkpointsor volatile savepoints [Gray and Reuter1992]) by individual txns are investi-gated in the context of the optimistickill method in Thomasian [1995b].Checkpointing is appropriate for OCCsince: (i) it solely uses aborts to resolvedata conflicts and (ii) checkpointing isfacilitated by the private workspaceparadigm (i.e., the updates of abortedtxns need not be undone). There is atradeoff between checkpointing over-head and the saved processing due topartial rollbacks, which allows a txn toresume execution from the checkpointpreceding access to the data item to bereleased.
Numerical results obtained from ananalytic solution for the optimistic killmethod with checkpointing show that itis not effective if database objects areaccessed uniformly, even if checkpoint-ing overhead is low and a checkpoint is
taken before each data access [Thoma-sian 1995b]. This is because the proba-bility with which a data object is con-flicted is proportional to the length oftime since it was accessed, so that ob-jects accessed at the beginning of txnexecution are more susceptible to con-flict than those accessed towards itscompletion. In the case where onecheckpoint is to be taken, numericalresults show that the mean responsetime and wasted processing are mini-mized if the checkpoint is taken after 1⁄3of objects required by a txn are accessed(this number may not be known a pri-ori), which implies that only 1⁄3 of thetxn’s processing is saved. Performancecan be improved if accesses to hot-spotsare deferred to the end of txn executionand a checkpoint is taken prior to theseaccesses, because objects held for ashort duration of time are less vulnera-ble to conflicts and most of txn’s pro-cessing is preserved if a data conflictoccurs. This may be accomplished byrewriting the txn program, but thistends to be very costly.
Improving the performance of optimis-tic concurrency control. The distinctionbackward-oriented and forward-ori-ented validation in OCC is made inHaerder [1984], where the former corre-sponds to the validation method de-scribed in Section 4.1. In forward-ori-ented OCC a txn checks whether itswrite set conflicts with the read sets oftxns in their read phase and the txncommits and “the write-sets are onlypropagated if they do not conflict withcurrent read sets of all other activetxns.” Thus forward-oriented validationin OCC provides opportunities for per-formance improvement as follows.
(1) Defer txn commit when there is aconflict. A case when deferring txnvalidation results in a potentiallyimproved performance is as follows.An object modified by the validatedtxn has been read by another txn.Deferring the introduction of themodified object into the database al-
108 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

lows the other txn to validate suc-cessfully. Consider T1, which isready to commit, having modifiedobject A to A9. T2, which is in itsread phase, may have read A andused it to modify B to B9. DeferringT1’s commit to after T2’s commitresults in the serialization orderT1 3 T2.
(2) A validating txn that conflicts withother txns may commit suicide, al-though it has not been injured ear-lier, since this action is expected toimprove overall performance (e.g.,by reducing wasted processing).
Deferring the commit of a txn makesit vulnerable to conflicts with othertxns. In addition, a txn’s suicide to saveanother txn may be in vain, since theconflicting txn may be aborted after all.A dependency graph can be constructedamong a set of txns to dynamically de-termine a commit ordering (differentfrom the order in which txn executionsare completed), which may improve per-formance with respect to basic OCC.Similarly to serialization graph testing[Bernstein et al. 1987], this is at thecost of added space and complexity. Thevalidation scheme based on “intervals oftimestamps” is intended to improve thesuccess rate in a distributed databaseenvironment [Boksenbaum et al. 1987].
4.4 Performance Analysis of OptimisticConcurrency Control Methods
Analytic modeling methods for OCC andinsights gained from previous studiesare outlined in this section. The analy-ses of OCC methods are based on Mena-sce and Nakanishi [1982], Moenkebergand Weikum [1985], and Ryu and Tho-masian [1987].
An Analytic solution for optimisticconcurrency control. The first paperdealing with the analysis of OCC con-siders the die method with static dataaccess; that is, all objects required by atxn are accessed at the beginning of txnexecution [Menasce and Nakanishi1982]. We simplify the discussion by
considering a closed system with Mtxns.
The probability of a data conflict in adatabase with size D when the commit-ting (resp., conflicting) txn is updatingm (resp., accessing n) data objects,which are accessed with uniform proba-bilities, is given by
f~n, m! 5 1 2 S D 2 nm DY S D
m D . 1
2 ~1 2 n/D!m . nm/D.
In the case of fixed-size txns with size k,where all k accessed objects are up-dated, c 5 f(k, k) . k2/D [Franaszeket al. 1992].
A key observation from the precedingequation (and the simple analysis inFranaszek et al. [1992]) is that theprobability of txn abort increases withthe square of its size, which is referredto as the quadratic effect in Franaszeket al. [1992]. Thus when txn steps haveequal processing times, the probabilityof conflict with an optimistic die (resp.,kill) method increases proportionally tok2/D (resp., k2/(2D)). It is observed fromnumerical results in Ryu and Thoma-sian [1987] that in a system with vari-able txn sizes the wasted processing isdominated by the largest txn sizes.
The system is represented by aMarkov-chain model whose states (Sj)specify the number of txns ( j) that cancomplete successfully. The transitionrates of the Markov chain are obtainedby solving the QNM of the underlyingcomputer system to obtain the STCt(M), M $ 1. The state transitions areaffected by the probability that a com-mitting txn at Sj conflicts with l txnsfrom the remaining j 2 1 txns, which isgiven by
S j 2 1l Dcl~1 2 c!j212l.
The analysis in Menasce and Nakan-ishi [1982] underestimates the mean re-sponse times attained by OCC [Morrisand Wong 1985] because OCC favors
Concurrency Control • 109
ACM Computing Surveys, Vol. 30, No. 1, March 1998

the successful validation of txns withshorter processing times. The process-ing times of restarted txns, which areassumed to be exponentially distributedin the Markov-chain analysis, are resa-mpled when a txn is restarted. Themean execution times of txns completedby the system tends to be less than theintended average. It can be argued,however, that the processing times oftxn phases vary from one execution toanother and that txns with shorter exe-cution times have a higher probabilityof success.
We next outline the analysis in Mor-ris and Wong [1985]. Txn processingtimes are postulated to be exponentiallydistributed (with mean 1/m) and the ef-fect of hardware resource contention isspecified by the processing rate s(M)such that txns proceed with rate ms(M).Let u denote the system efficiency orthe fraction of time the system spendsdoing useful work. Then the txn comple-tion rate is T(M) 5 ums(M). A keyassumption used in the analysis is thatrunning txns observe the commits ofother txns as a Poisson process withrate l 5 (1 2 1/M)ums(M). The rate atwhich a txn is conflicted is then g 5 lc.The probability of a data conflict for atxn with processing time x is q 5 1 2e2gxM/s(M). Provided that the executiontime of a txn is not resampled (it re-mains equal to x), the number of itsexecutions in the system follows a geo-metric distribution Pj 5 q(1 2 q)j21,j $ 1 with a mean J# (x) 5 1/q 5 egxM/s(M).The analysis in Menasce and Nakanishi[1992] assumes that the number of txnexecutions (J) is independent of txn ex-ecution time (X) and hence E[J X] 5 J#X# .
The system efficiency can be specifiedas the ratio of the mean execution timeof a txn and its residence time in thesystem:
u 5E@ xM/s~M!#
E@ xMegxM/s~M!/s~M!#
5*0
` xe2m xdx
*0` xe2~m2gM/s~M!! xdx
5 @1 2 ~M 2 1!cu!]2.
gM/s(M) , m is required for the denom-inator to converge. Solving the qua-dratic equation yields one acceptableroot: u 5 (1 1 2a 2 =1 1 4a)/4a2 .1 2 2a, where a 5 (M 2 1)c is small,such that higher terms in expanding(1 1 4a)1/2 can be ignored.
This study similarly to Menasce andNakanishi [1982] considers the relativeperformance of SL and the optimisticdie method. SL (with the FCFS withskip option; see Section 2.3) outper-forms the optimistic die method,whereas the more efficient optimistickill method (with static data access) hasa performance indistinguishable fromSL in a system with infinite resources[Thomasian and Ryu 1986], where thewasted processing time due to txn re-starts does not affect the processingtime of other txns.
These analyses are extended in sev-eral directions in Ryu and Thomasian[1987]. Numerical results show that thetxn-processing-time distribution affectsthe overall performance. The analysis ofthe kill method with exponential pro-cessing times yields u 5 (1 1 a)21 .1 2 a, which indicates that the diemethod is twice as inefficient as the killmethod. The analysis of OCC with dy-namic (on demand) object accesses takesinto account the fact that the conflictrate varies according to the number ofdata objects that have been accessed.The analysis of a system with multipletxn classes, where class is determinedby txn size, considers each class sepa-rately to ensure that the fraction of txnsin the stream of completed txns is thesame as in the arrival stream (see Sec-tion 3.3). The analysis can be extendedto take into account the variability intxn processing times across executions(e.g., due to the prefetching effect). Also,different methods can be modeled fordifferent phases (e.g., optimistic die in
110 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

the first phase and optimistic kill orlocking in the second phase).
5. CONCLUSIONS
The performance of an abstract stan-dard locking model is analyzed in thisarticle to provide an understanding offactors leading to its performance deg-radation. Restart-oriented lockingmethods relieve lock contention by se-lectively aborting txns, and two-phaseprocessing methods reduce the data con-tention level in systems with access in-variance by shortening the holding timeof locks or access entries by prefetchingthe data required for txn execution inthe second phase, if it is required. Wesummarize the conclusions of previoussimulation and analytic studies regard-ing the relative performance of CCmethods and survey methods applicableto the analysis of standard locking, re-start-oriented locking methods, andOCC.
Conclusions based on simulation andanalytic studies regarding the relativeperformance of CC methods can be sum-marized as follows.
(1) Standard locking is desirable in low-lock-contention environments, sinceit introduces a minimal amount ofextra processing by aborting txnsonly to resolve deadlocks. The levelof lock contention is expected to below in relational DBMSs fine-tunedfor txn processing applications [Mo-han et al. 1992a].
(2) Given that there are no robust load-control methods to prevent thrash-ing, especially in environments withvarying workloads, restart-orientedmethods such as the WDL methodwith restart-waiting provide aneasy-to-implement solution to thisproblem. In fact, simulation resultsshow that WDL attains a muchhigher txn throughput than stan-dard locking and most other meth-ods in a high-lock-contention envi-ronment.
(3) Two-phase processing methods arebeneficial in systems with longertxn response times due to disk I/Oor remote accesses, resulting inhigher degrees of txn concurrencyand hence higher data contention.Simulation results show that two-phase methods result in signifi-cantly improved performance withrespect to standard locking, as wellas restart-oriented locking methodssuch as WDL, provided adequatehardware resources are available.Specialized software can be used toreduce the overhead of executingtxns in the second phase [Reuter1985]. In addition, provisions needto be made to reduce the overhead ofundoing the updates of aborted txns,which also applies to restart-ori-ented locking methods.
Key insights derived from analyticand simulation studies are summarizedas follows.
(1) The single metric a (defined in Sec-tion 2.2) uniquely determines thelock-contention level in a standardlocking system with the homoge-neous txn access model and identi-cal per-step processing times. Thesystem thrashes beyond the criticalvalue a* 5 0.226, which is just be-yond the point where the maximumthroughput in a system with infiniteresources is attained. The meannumber of active txns (M# a) is maxi-mized at the point where 30% oftxns are blocked (b . 0.3), whichholds for various txn size distribu-tions and txns with different per-step processing times [Thomasian1993].In a system with finite resources themaximum throughput is determinedby the bottleneck resource (see Sec-tion 1.3), which is usually at a rela-tively low txn-concurrency level re-sulting in a low lock-contentionlevel.
(2) Factors leading to thrashing are (i)a sudden increase in the number of
Concurrency Control • 111
ACM Computing Surveys, Vol. 30, No. 1, March 1998

activated txns; (ii) although thelimit on the degree of txn concur-rency to prevent thrashing is notexceeded, an undesirable composi-tion of txns is activated (e.g., allactivated txns are long); and (iii)there is a temporary increase in thenumber of accesses to hot-spots.
(3) For txns of size k and identical per-step processing times, the probabil-ity of lock conflict (Pc) (resp., theprobability of deadlock per txn(PD)), is proportional to k2 (resp.,k4) [Gray and Reuter 1992]. Fortxns with a variable number of lockrequests, Pc depends on the secondmoment of requested locks (see Eq.(2.8) for the mean number of locksheld per txn) and PD depends on thethird moment of txn size [Thoma-sian and Ryu 1991]. Thus the vari-ability of txn size has a major effecton the lock-contention level.
(4) The mean waiting time for a lockheld by an active txn (W1) is onethird of txn’s mean residence time,provided that txns have a fixed sizeand locks are requested uniformlyover its residence time (see Eq.(3.5)). The mean waiting time perlock request (W) is a weighted sumof the probability of being blocked atlevel i (Pb(i)) and the associatedmean waiting time (Wi). It followsfrom Eq. (2.10) that W . 1.8W1 atthe point where the mean number ofactive txns (M# a) is maximized atb 5 0.3.In the case of variable-size txns withidentical steps, W1 is proportional tothe third moment of the number ofrequested locks. It follows that thevariability of txn size has a majoreffect on the performance degrada-tion due to lock contention in thiscase.
(5) When the per-step processing timesare different, in addition to a, thefraction of lock conflicts withblocked txns (r) is a useful measureof lock contention in standard lock-ing. Experimentation shows that as
the level of lock contention is varied0.2 # r # 0.3 [Thomasian 1996b],which is consistent with the conflict-ratio metric equal to (1 2 r)21
[Moenkeberg and Weikum 1992].Similarly to txns with identical per-step processing times, M# a in thiscase is also maximized at b . 0.3.
(6) For the heterogeneous database-ac-cess model r was observed to varyover a wider range than for the ho-mogeneous database-access model.Although concurring with experi-mental results in Weikum et al.[1994], the wider range of values forr makes it less useful for load con-trol.
(7) Restart-oriented locking methodsreduce the level of lock contention atthe cost of additional processing. Ina lock-contention-bound system sig-nificant increases in the maximumthroughput attainable by the systemare possible. The WDL [Franaszeket al. 1992] and MWDL [Thomasian1992; 1997] methods outperformRPS; because they cause less wastedprocessing than RPS. This is accom-plished through heuristics that takeinto account txn progress. The RPAmethod can outperform both WDLand MWDL methods in a systemwith limited hardware resources be-cause it results in less wasted pro-cessing than both of the precedingmethods and RPS.Adaptive methods that vary thewait depth and breadth to maximizeCPU utilization, without saturatingit, tend to improve system perfor-mance.
(8) Optimistic CC methods are suscepti-ble to abort according to a quadraticeffect; that is, the probability of anunsuccessful validation increases asthe square of txn size [Franaszek etal. 1992]. Numerical results basedon the performance analysis in Ryuand Thomasian [1987] show that ina system with variable txn sizesmost of the wasted processing is dueto the larger txn sizes.
112 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

(9) Two-phase txn-processing methodsreduce the effective level of txn con-currency to attain higher txnthroughputs. Thus even if the firstexecution phase of a txn is unsuc-cessful, it has the beneficial effect ofprefetching the data from disk,which can be used by the secondexecution phase provided access in-variance prevails.
There has been little work on analyz-ing the performance of txn processingsystems taking into account lock-con-tention effects. This is due to the diffi-culty of characterizing txn processingsystems from the lock-contention view-point, rather than the inability to de-velop appropriate methods for perfor-mance evaluation (a simulation studycan be used when analysis is not possi-ble). The locking analysis in Thomasian[1996b] (see Section 2.5), with appropri-ate extensions (e.g., to take into accountspecialized locking methods for indexstructures), might lend itself to “an-swering engineering questions” [Tay1990], for example, predicting the effectof lock contention on the performance ofa txn-processing system. Analytic re-sults need be validated against mea-surement results rather than just simu-lations.
Statistics on lock-contention levelsare provided by most DBMSs, but themeasurement data are not sufficientlydetailed and cannot be easily correlatedwith other events in the system. Fur-thermore, additional information is re-quired about the database, txns pro-cessed by the system, and txnscheduling to synthesize a realistic lock-contention model. Some of this informa-tion is proprietary in nature and notavailable externally.
Some additional topics related to CCare as follows.
CC in “advanced database applica-tions” or “unconventional txn manage-ment” is an area of current interest[Barghouti and Kaiser 1991; Elmagar-mid 1992; Ramamithram and Chrisan-this 1996]. Alternative txn models such
as sagas, altruistic locking, cooperatingtxns, and txn chopping, which were dis-cussed in Section 2.6, are a step in thisdirection. Some of the associated prob-lems have to do more with schedulingand coordinating related activities,rather than CC, such as in the case ofworkflow models [Khoshafian and Buck-iewicz 1995].
Real-time txns or databases are an-other area of current research. VariousCC methods have been evaluated to de-termine their suitability for real-timetxn processing and many new CC meth-ods have been proposed [Ramamithram1993]. These include methods based onaccess invariance, because it providesan opportunity to preanalyze the objectsrequired by the txn for its second phaseexecution [O’Neil et al. 1995] and hy-brid methods (see Section 4.3) [Huanget al. 1991]. Txn spawning for improv-ing performance in real-time systemshas been considered in Bestavros andBraoudakis [1995].
Active databases provide timely re-sponses to time-critical events and thisis accomplished by providing event-con-dition-action rules to be specified for theDBMS. A performance evaluation of ac-tive databases that takes into accountlocking effects and distinguishes be-tween external and rule-managementtasks is reported in Carey et al. [1991].
CC in distributed databases is cov-ered in an early tutorial [Bernstein andGoodman 1981] and several texts [Date1983; Ceri and Pelagatti 1984; Bern-stein et al. 1987; Cellary et al. 1988]. Infact, some early CC methods, such asTSO, WW, and WD methods, were in-tended for distributed databases. Stan-dard locking with two-phase commit isthe main approach used for CC and toensure atomicity. The number of mes-sages required for txn execution is quiteimportant in this case [Ceri and Pel-agatti 1984]. This includes the numberof messages required for deadlock detec-tion and two-phase commit. Methods toreduce the number of messages for com-mit processing are discussed in Sama-ras et al. [1995].
Concurrency Control • 113
ACM Computing Surveys, Vol. 30, No. 1, March 1998

Numerous CC methods have beenconsidered for distributed databases.The tradeoff between the number ofmessages and the information availableto minimize the wasted processing dueto txn aborts is explored for severalvariations of the distributed WDLmethod in Franaszek et al. [1993]. Amethod based on access invariance thatuses OCC in the first phase and lockpreclaiming in the second phase is dis-cussed in Thomasian and Rahm [1990]and Thomasian [1998] (these papersalso discuss earlier works in OCC indistributed databases). A comprehen-sive simulation study of several CCmethods for distributed databases is re-ported in Carey and Livny [1991]. Anexample of an approach based on allo-cating fractions of aggregate values tothe nodes of a distributed system isdescribed in Thomasian [1994] (this pa-per also surveys related work on thistopic).
In addition to multiprocessors,shared-nothing and shared-disk sys-tems are of current interest for txn pro-cessing. In shared-nothing systems thedata are partitioned to balance the load(e.g., by using hashing on primary keysin a relational database). From theviewpoint of CC these systems behaveas distributed databases, although someoptimizations are possible, for example,broadcast capability to all processors fortwo-phase commit. The simulation of apreliminary version of the TPC-Cbenchmark on a shared-nothing systemappears in Jenq et al. [1989].
In shared-disk or data-sharing sys-tems multiple computers have access toa set of shared disks. Txns are routed tocomputers to achieve a balanced loadand to attain a higher database bufferhit ratio [Rahm 1993]. In addition toconcurrency control, there is the issue ofcoherency control for the contents ofdatabase buffers across systems [Rahm1993]. Similar problems arise in client-server systems, which are addressed ina simulation study reported in Carey etal. [1991].
Multidatabase txn management deals
with distributed heterogeneous DBMSs,possibly with different CC and txn re-covery methods. Local txns are run un-der the control of a local DBMS, and amultidatabase system is provided to runglobal txns. The multidatabase systemis to accomplish its task with minimalmodifications to the operation of thesystem [Breitbart et al. 1992]. As notedin Breitbart et al. [1992], most researchto date has been concerned with how torun txns in a heterogeneous environ-ment, with no attention paid to perfor-mance issues: for example, how muchmore expensive will it be to run txnswhen each box runs a different CC pro-tocol? A hierarchical architecture formultidatabase systems is described inMehrotra et al. [1997] and techniquesfor CC in such systems are developed.
Glossary
CC concurrency controlCPU central processing unitCWA cautious
waiting—asymmetric [Hsuand Zhang 1992]
CWS cautiouswaiting—symmetric[Thomasian 1997a]
DBMS data base managementsystem
DL dynamic lockingEDSP effective database size
paradigmETC effective throughput
characteristicFCFS first-come, first-served
GW general waiting method(i.e., standard locking)
MWDL modified wait-depth-limited method [Thomasian1992]
NW no waitingOCC optimistic CC [Kung and
Robinson 1981]QNM queueing network modelRPA running
priority—asymmetric[Franaszek and Robinson1985]
RPS runningpriority—symmetric[Franaszek et al. 1992]
SE serialized execution
114 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

SL static lockingSTC system-throughput
characteristicTSO time-stamp ordering
methodTxn Transaction
VLDB Very large data basesWDL wait-depth limited
[Franaszek et al. 1992]WD wait-die [Rosenkrantz et
al. 1978]WFG waits-for graph
WW wound-wait [Rosenkrantzet al. 1978]
2PL two-phase locking
Appendix: Notation
a Mean number of lock conflictsper txn times the normalizedwaiting time for single-levelblocking (a 5 K1PcA with A 5W1/R(M)).
b Fraction of txns in the blockedstate (b 5 K1PcW/R(M) 5M# b/M).
Ck Txns in class k that request klocks.
D Number of data items andassociated locks in thedatabase.
fk Fraction of txns in class k (Ck)that also request k locks.
K Largest txn size or maximumnumber of locks requested pertxn.
Ki ith moment of the number ofrequested locks.
L# a(L# b) Mean number of locks held by atxn while it is active (blocked)(L# 5 L# a 1 L# b).
L# k Mean number of locks held bytxns in Ck.
M Number of txns in the closedsystem.
M# a(M# b) Mean number of active(blocked) txns in the system(M# a 5 (1 2 b) M and M# b 5bM).
M Multiprogramming level thatmaximizes the number of activetxns in the system (M# a) andpotentially system throughput.
nc Mean number of lock conflictsper txn (nc 5 K1Pc).
Pc Probability of lock conflict perlock request (Pc . (M 2 1)L# /D).
PD(i) Probability that a txnencounters a deadlock of cyclelength i.
rk(M) Mean response time for a txn inCk as determined by hardware-resource contention only.
r(M) Mean response time over all txnclasses as determined byhardware-resource contentiononly (r(M) 5 ¥k51
K rk(M) fk).Rk(M) Mean response time for txns in
Ck (Rk(M) 5 (k 1 1)s(M# a) 1kPcW).
R(M) Mean response time over all txnclasses (R(M) 5 ¥k51
K
Rk(M) fk).r Conflict ratio, which is the
fraction of lock conflicts thatare with blocked txns.
s(M# a) Mean processing time of a txnstep with M# a active txns in thesystem.
t(M) System throughput with M txnsas determined by hardware-resource contention. t(M), M $1 is referred to as thethroughput characteristic.
T(M) Txn throughput with M txns inthe system as affected byhardware-resource and lockcontention. T(M), M $ 1 isreferred to as the effectivethroughput characteristic of thesystem.
W1 Mean txn waiting time due to alock conflict with an active txn.
W Mean txn waiting time due to alock conflict.
REFERENCES
AGRAWAL, D., EL ABBADI, A., AND LANG, A. E.1994. The performance of protocols based onlocks with ordered sharing. IEEE Trans.Knowl. Data Eng. 6, 5 (Oct.), 805–818.
AGRAWAL, R., CAREY, M. J., AND LIVNY, M. 1987a.Concurrency control performance modeling:Alternatives and implications. ACM Trans.Database Syst. 12, 4 (Dec.), 609–654.
AGRAWAL, R., CAREY, M. J. AND MCVOY, L. W.1987b. The performance of alternative strate-gies for dealing with deadlocks in databasemanagement systems. IEEE Trans. Softw.Eng. 13, 12 (Dec.), 1348–1363.
AMMANN, P., JAJODIA, S., AND RAY, I. 1997. Ap-plying formal methods to semantic-based de-composition of transactions. ACM Trans. Da-tabase Syst. 22, 2 (June), 215–254.
BADRINATH, B. R. AND RAMAMITHRAM, K. 1992.
Concurrency Control • 115
ACM Computing Surveys, Vol. 30, No. 1, March 1998

Semantics-based concurrency control: Beyondcommutativity. ACM Trans. Database Syst.17, 1 (March), 163–199.
BARGHOUTI, N. S. AND KAISER, G. E. 1991. Con-currency control in advanced database appli-cations. ACM Comput. Surv. 23, 3 (Sept.),269–317.
BAYER, R. 1986. Consistency of transactionsand random batch. ACM Trans. DatabaseSyst. 11, 4 (Dec.), 397–404.
BERNSTEIN, P. A. AND GOODMAN, N. 1981. Con-currency control in distributed database sys-tems. ACM Comput. Surv. 13, 2 (June), 185–221.
BERNSTEIN, P., HADZILACOS, V., AND GOODMAN, N.1987. Concurrency Control and Recovery inDatabase Systems. Addison-Wesley, Reading,MA.
BESTAVROS, A. AND BRAOUDAKIS, S. 1995. Value-cognizant speculative concurrency control.Proceedings of the 21st International Confer-ence on Very Large Data Bases (Zurich, Swit-zerland, Sept.) 122–133.
BOBER, P. M. AND CAREY, M. J. 1992. On mixingqueries and transactions via multiversionlocking. Proceedings of the Eighth Interna-tional Conference on Data Engineering(Tempe, AZ, Feb.), 535–545.
BOKSENBAUM, C., CART, M., FERRIE, J., AND PONS,J. F. 1987. Concurrent certification by in-terval of timestamps in distributed databasesystems. IEEE Trans. Softw. Eng. 13, 4(April), 409–419.
BREITBART, Y., GARCIA-MOLINA, H., AND SILBERS-CHATZ, A. 1992. Overview of multidatabasetransaction management. Int. J. Very LargeData Bases 1, 181–239.
BURGER, A. AND THANISCH, P. 1994. Branchingtransactions: A transaction model for paralleldatabase systems. In Directions in Databases:Proceedings of the Twelfth British NationalConference on Databases, BNCOD 12 (Guild-ford, UK, July), D. S. Bowers, Ed., 121–136.
CAREY, M. J. AND LIVNY, M. 1991. Conflict de-tection tradeoffs for replicated data. ACMTrans. Database Syst. 16, 4 (Dec.), 703–746.
CAREY, M. J., JAUHARI, R., AND LIVNY, M. 1991.On transaction boundaries in active databas-es: A performance perspective. IEEE Trans.Knowl. Data Eng. 3, 3 (Sept.), 320–336.
CAREY, M. J., FRANKLIN, M. J., LIVNY, M., AND SHE-KITA, E. J. 1991. Data caching tradeoffs inclient server DBMS architectures. In Proceed-ings of the 1991 ACM SIGMOD InternationalConference on Management of Data (Denver,CO, May) 357–366.
CELLARY, W., GELENBE, E., AND MORZY, T. 1988.Concurrency Control in Distributed Data-bases. North-Holland.
CERI, S. AND PELAGATTI, G. 1984. Distributed
Databases—Principles and Systems. McGraw-Hill, New York.
CHESNAIS, A., GELENBE, E., AND MITRANI, I. 1983.On the modeling of parallel access to shareddata. Commun. ACM 26, 3 (March), 198–202.
DATE, C. J. 1983. An Introduction to DatabaseSystems, Vol. II. Addison-Wesley, Reading,MA.
ELMAGARMID, A. K. 1992. Database TransactionModels for Advanced Applications. Morgan-Kaufmann, San Mateo, CA.
FARRAG, A. A. AND OZSU, M. T. 1989. Using se-mantic knowledge of transactions to increaseconcurrency. ACM Trans. Database Syst. 14, 4(Dec.), 503–525.
FRANASZEK, P. AND ROBINSON, J. T. 1985. Limi-tations of concurrency in transaction process-ing. ACM Trans. Database Syst. 10, 1(March), 1–28.
FRANASZEK, P. A., HARITSA, J. R., ROBINSON, J. T.,AND THOMASIAN, A. 1993. Distributed con-currency control based on limited wait depth.IEEE Trans. Parallel Distrib. Syst. 4, 11(Nov.), 1246–1264.
FRANASZEK, P., ROBINSON, J. T., AND THOMASIAN,A. 1990. Access invariance and its use inhigh contention environments. In Proceedingsof the Sixth International Conference on DataEngineering (Los Angeles, Feb.), 47–55.
FRANASZEK, P. A., ROBINSON, J. T., AND THOMASIAN,A. 1991a. Adaptive concurrency controlscheme for transaction processing. IBM Tech.Disclosure Bull. 33, 9 (Feb.), 29–30.
FRANASZEK, P. A., ROBINSON, J. T., AND THOMASIAN,A. 1991b. Integrated concurrency control/CPU scheduling. IBM Tech. Disclosure Bull.33, 9 (Feb.), 37–40.
FRANASZEK, P., ROBINSON, J. T., AND THOMASIAN,A. 1992. Concurrency control for high con-tention environments. ACM Trans. DatabaseSyst. 17, 2 (June), 304–345.
GALLER, B. I. AND BOS, L. 1983. A model oftransaction blocking in databases. Perform.Eval. 3, 95–122.
GARCIA-MOLINA, H. 1983. Using semantic knowl-edge for transaction processing in a distributeddatabase. ACM Trans. Database Syst. 8, 2(June), 186–213.
GARCIA-MOLINA, H. AND SALEM, K. 1987. Sagas.In Proceedings of the 1987 SIGMOD Confer-ence on Management of Data (San Francisco,May), 249–259.
GRAY, J. N., Ed. 1993. The Benchmark Hand-book for Transaction Processing Systems, 2nded. Morgan-Kaufmann, San Mateo, CA.
GRAY, J. N. AND REUTER, A. 1992. TransactionProcessing: Concepts and Facilities. Morgan-Kaufmann, San Mateo, CA.
HAERDER, T. 1984. Observations on optimisticconcurrency control schemes. Inf. Syst. 9, 2,111–120.
116 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

HAERDER, T. AND ROTHERMEL, K. 1993. Con-currency control issues in nested transac-tions. Int. J. Very Large Data Bases 2, 39–74.
HSU, M. AND ZHANG, B. 1992. Performance eval-uation of cautious waiting. ACM Trans. Data-base Syst. 17, 3 (Sept.), 477–512.
HSU, M. AND ZHANG, B. 1995. Modeling perfor-mance impact of hot spots. In Performance ofConcurrency Control Mechanisms in Central-ized Database Systems, V. Kumar, Ed. Pren-tice-Hall, Englewood Cliffs, NJ, Chapter 7,148–164.
HUANG, J., STANKOVIC, J. A., RAMAMITHRAM, K.,AND TOWSLEY, D. 1991. Experimental eval-uation of real-time optimistic concurrencycontrol schemes. In Proceedings of the Seven-teenth International Conference on Very LargeData Bases (Barcelona, Sept.), 35–46.
IRANI, K. B. AND LIN, H. L. 1979. Queueing net-work models for concurrent transaction pro-cessing in database systems. In Proceedings ofthe 1979 ACM SIGMOD International Confer-ence on Management of Data (Boston, June),134–142.
JAGADISH, H. V. AND SHMUELLI, O. 1992. A proc-lamation based model for cooperating transac-tions. In Proceedings of the Eighteenth Inter-national Conference on Very Large Data Bases(Vancouver, Canada, August), 265–276.
JENQ, B. C., TWICHELL, B. C., AND KELLER, T. W.1989. Locking performance in a shared noth-ing parallel database machine. IEEE Trans.Knowl. Data Eng. 1, 4 (Dec.), 530–543.
JOHNSON, T. AND SHASHA, D. 1993. The perfor-mance of concurrent B-tree algorithms. ACMTrans. Database Syst. 18, 1 (March), 51–101.
KHOSHAFIAN, S. AND BUCKIEWICZ, M. 1995. In-troduction to Groupware, Workflow, andWorkgroup Computing. John Wiley, NewYork.
KLEINROCK, L. 1975. Queueing Systems, Vol. I:Theory. John Wiley, New York.
KORTH, H. F. AND SPEEGLE, G. 1994. Formal as-pects of concurrency control in long durationtransaction systems using the NT/PV model.ACM Trans. Database Syst. 19, 3 (Sept.), 492–535.
KRISHNAKUMAR, N. AND BERNSTEIN, A. J. 1994.Bounded ignorance: A technique for increas-ing concurrency in a replicated system. ACMTrans. Database Syst. 19, 4 (Dec.), 586–625.
KUMAR, V., Ed. 1995. Performance of Concur-rency Control Mechanisms in Centralized Da-tabase Systems. Prentice-Hall, Upper SaddleRiver, NJ.
KUNG, H. T. AND ROBINSON, J. T. 1981. On opti-mistic concurrency control methods. ACMTrans. Database Syst. 6, 2 (June), 213–226.
LANGER, A. M. AND SHUM, A. W. 1982. The dis-tribution of granule accesses made by data-
base transactions. Commun. ACM 25, 11(Nov.), 831–832.
LAZOWSKA, E. D., ZAHORJAN, J., GRAHAM, G. S., ANDSEVCIK, K. C. 1984. Quantitative SystemPerformance: Computer System Analysis Us-ing Queueing Network Models. Prentice-Hall,Upper Saddle River, NJ.
LI, K. AND NAUGHTON, J. F. 1988. Multiprocessormain memory transaction processing. In Pro-ceedings of the International Symposium onDatabases in Parallel and Distributed Sys-tems (Austin, TX, Dec.), 177–187.
LYNCH, N., MERRITT, M., WEIHL, W., AND FEKETE,A. 1994. Atomic Transactions. Morgan-Kaufmann, San Mateo, CA.
MASSEY, W. 1986. A probabilistic analysis ofdatabase systems. In Proceedings of Perfor-mance 86 and ACM SIGMETRICS 1986 JointConference (Raleigh, NC, May), 141–146.
MEHROTRA, S., KORTH, H. F., AND SILBERSCHATZ, A.1997. Concurrency control in hierarchicalmultidatabase systems. Int. J. Very LargeData Bases 6, 157–172.
MENASCE, D. A. AND NAKANISHI, T. 1982. Opti-mistic versus pessimistic concurrency controlmechanisms in database management sys-tems. Inf. Syst. 7, 1, 13–27.
MOENKEBERG, A. AND WEIKUM, G. 1992. Perfor-mance evaluation of an adaptive and robustload control method for the avoidance of datacontention thrashing. In Proceedings of theEighteenth International Conference on VeryLarge Data Bases (Vancouver, Canada, Aug.),432–443.
MOHAN, C. 1992. Less optimism about optimis-tic concurrency control. In Proceedings of theSecond International Workshop on ResearchIssues on Data Engineering (Tempe, AZ,Feb.), 199–204.
MOHAN, C. AND LEVINE, F. 1992. ARIES/IM: Anefficient and high concurrency index manage-ment method using write-ahead logging. InProceedings of the 1992 ACM SIGMOD Inter-national Conference on Management of Data(San Diego, June), 371–380.
MOHAN, C., HADERLE, D., LINDSAY, B., PIRAHESH,H., AND SCHWARTZ, P. 1992a. ARIES: Atransaction recovery method supporting finegranularity locking and partial rollbacks us-ing write-ahead locking. ACM Trans. Data-base Syst. 17, 1 (March), 94–162.
MOHAN, C., PIRAHESH, H., AND LORIE, R. 1992b.Efficient and flexible methods for transientversioning of records to avoid locking by read-only transactions. In Proceedings of the 1992ACM SIGMOD International Conference onManagement of Data (San Diego, June), 124–133.
MONTGOMERY, W. A. 1978. Robust concurrencycontrol for a distributed information system.MIT-LCS-TR-207, MIT, Lab. for ComputerScience, Cambridge, MA. (Dec.).
Concurrency Control • 117
ACM Computing Surveys, Vol. 30, No. 1, March 1998

MORRIS, R. J. T. AND WONG, W. S. 1985. Perfor-mance analysis of locking and optimistic con-currency control algorithms. Perform. Eval. 5,2, 105–118.
MOSS, J. E. B. 1985. Nested Transactions: AnApproach to Reliable Distributed Computing.MIT Press, Cambridge, MA.
O’NEIL, P. E. 1986. The escrow transactionmethod. ACM Trans. Database Syst. 11, 4(Dec.), 405–430.
O’NEIL, P. E., RAMAMITHRAM, K., AND PU, C.1995. A two-phase approach to predictabilityscheduling real-time transactions. In Perfor-mance of Concurrency Control Methods inCentralized Database Systems V. Kumar, Ed.,Prentice-Hall, Englewood Cliffs, NJ, 494–522.
OZSU, M. T. 1994. Transaction models and trans-action management in object-oriented data-base management systems. In Advances inObject-Oriented Database Systems. A. Dogac,M. T. Ozsu, A. Biliris, and T. Sellis, Eds.Springer-Verlag, New York, 147–184.
PEINL, P., REUTER, A., AND SAMMER, H. 1988.High contention in a stock trading database:A case study. In Proceedings of the 1988 ACMSIGMOD International Conference on Man-agement of Data (Chicago, June), 260–268.
POTIER, D. AND LEBLANC, P. 1980. Analysis oflocking policies in database management sys-tems. Commun. ACM 23, 10 (Oct.), 584–593.
PU, C. AND LEFF, A. 1991. Replica control indistributed databases: An asynchronous ap-proach. In Proceedings of the 1991 ACM SIG-MOD International Conference on Manage-ment of Data (Denver, CO, May), 377–386.
RAHM, E. 1993. Empirical performance evalua-tion of concurrency and coherency control pro-tocols for database sharing systems. ACMTrans. Database Syst. 18, 2 (June), 333–377.
RAMAMITHRAM, K. 1993. Real-time databases.Distrib. Parallel Databases 1, 199–226.
RAMAMITHRAM, K. AND CHRISANTHIS, P. K. 1996.Advances in Concurrency Control and Trans-action Processing. IEEE Computer SocietyPress, Los Alamitos, CA.
REUTER, A. 1985. The transaction pipeline pro-cessor. In International Workshop on HighPerformance Transaction Systems (PacificGrove, CA, Sept.).
ROBINSON, J. T. 1982a. Design of concurrencycontrols for transaction processing systems.Tech. Rep. CMU-CS-82-114, Ph.D. Thesis,Computer Science Dept., Carnegie-MellonUniversity, Pittsburgh, PA.
ROBINSON, J. T. 1982b. Experiments with trans-action processing on a multiprocessor. IBMRes. Rep. RC 9725, Yorktown Heights, NY,Dec.
ROBINSON, J. T. 1984. Separating policy fromcorrectness in concurrency control design.Softw. Pract. Exper. 14, 9 (Sept.), 827–844.
ROSENKRANTZ, D. J., STEARNS, R. E., AND LEWIS,P. M., II. 1978. System level concurrencycontrol for distributed database systems. ACMTrans. Database Syst. 3, 2 (June), 178–198.
RYU, I. K. AND THOMASIAN, A. 1987. Perfor-mance evaluation of centralized databaseswith optimistic concurrency control. Perform.Eval. 7, 3, 195–211.
RYU, I. K. AND THOMASIAN, A. 1988. Per-formance analysis of centralized databaseswith static locking. Unpublished rep., IBMT. J. Watson Research Center, Hawthorne,NY.
RYU, I. K. AND THOMASIAN, A. 1990a. Analysisof database performance with dynamic lock-ing. J. ACM 37, 3 (July), 491–523.
RYU, I. K. AND THOMASIAN, A. 1990b. Per-formance analysis of dynamic locking with theno-waiting policy. IEEE Trans. Softw. Eng.16, 7 (July), 684–698.
SALEM, K., GARCIA-MOLINA, H., AND SHANDS, J.1994. Altruistic locking. ACM Trans. Data-base Syst. 19, 1 (March), 117–165.
SAMARAS, G., BRITTON, K., CITRON, A., AND MOHAN,C. 1995. Two-phase commit optimizationsin a commercial distributed environment. Dis-trib. Parallel Databases, 325–360.
SHASHA, D., LLIRBAT, F., SIMON, E., AND VALDURIEZ,P. 1995. Transaction chopping: Algorithmsand performance studies. ACM Trans. Data-base Syst. 20, 3 (Sept.), 325–363.
SINGHAL, M. 1991. Performance analysis of thebasic timestamp ordering algorithm viaMarkov modeling. Perform. Eval. 12, 17–41.
SINGHAL, V. AND SMITH, A. J. 1997. Analysis oflocking behavior in three real database sys-tems. Int. J. Very Large Data Bases 6, 40–52.
SKARRA, A. H. AND ZDONIK, S. B. 1989. Con-currency control and object-oriented data-bases. In Object-Oriented Concepts, Data-bases, and Applications. W. Kim and F. H.Lochovski, Eds., ACM Press, New York, 395–421.
SRINIVASAN, V. AND CAREY, M. J. 1993. Per-formance of B1 tree concurrency control algo-rithms. Int. J. Very Large Data Bases 2, 361–406.
TAY, Y. C. 1987. Locking Performance in Cen-tralized Databases. Academic Press, Orlando,FL.
TAY, Y. C. 1990. Issues in modeling locking per-formance. In Stochastic Analysis of Computerand Communication Systems, H. Takagi, Ed.,North-Holland, New York, 631–658.
TAY, Y. C., GOODMAN, N., AND SURI, R. 1985a.Locking performance in centralized data-bases. ACM Trans. Database Syst. 10, 4(Dec.), 415–462.
TAY, Y. C., SURI, R., AND GOODMAN, N. 1985b. Amean value performance model for locking in
118 • A. Thomasian
ACM Computing Surveys, Vol. 30, No. 1, March 1998

databases: The no-waiting case. J. ACM 32, 3(July), 618–651.
THOMASIAN, A. 1982. An iterative solution tothe queueing network model of a DBMS withdynamic locking. In Proceedings of the Thir-teenth Computer Measurement Group Confer-ence (San Diego, Dec.), 252–261.
THOMASIAN, A. 1985. Performance evaluation ofcentralized databases with static locking.IEEE Trans. Softw. Eng. 11, 2 (April), 346–355.
THOMASIAN, A. 1988. Distributed optimisticconcurrency control methods for high-perfor-mance transaction processing. IEEE Trans.Knowl. Eng. 10, 1 (Jan./Feb.), 2–18.
THOMASIAN, A. 1992. Performance analysis oflocking policies with limited wait depth. InProceedings of Performance 92 and ACM SIG-METRICS Joint Conference (Newport, RI,June), 115–127.
THOMASIAN, A. 1993. Two-phase locking and itsthrashing behavior. ACM Trans. DatabaseSyst. 18, 4 (Dec.), 579–625.
THOMASIAN, A. 1994. A fractional data alloca-tion method for distributed databases. In Pro-ceedings of the Third International Conferenceon Parallel and Distributed Information Sys-tems (Austin, TX, Sept.), 168–175.
THOMASIAN, A. 1995a. Performance analysis oflocking policies with limited wait depth. Per-form. Eval. (submitted). Also IBM Res. Rep.RC 19977, Hawthorne, NY, March.
THOMASIAN, A. 1995b. Checkpointing for opti-mistic concurrency control methods. IEEETrans. Knowl. Data Eng. 7, 2 (April), 332–339.
THOMASIAN, A. 1996a. Database ConcurrencyControl: Methods, Performance, Analyses.Kluwer Academic, Boston.
THOMASIAN, A. 1996b. On realistic modelingand analysis of lock contention. Inf. Syst. 21,5, 409–430.
THOMASIAN, A. 1997. A performance compari-son of locking policies with limited waitdepth. IEEE Trans. Knowl. Data Eng. 8, 2(May/June), 421–434.
THOMASIAN, A. 1998. Distributed optimisticconcurrency control methods for high perfor-mance transaction processing. IEEE Trans.Knowl. Data Eng. 10, 1 (Jan/Feb.), 2–18.
THOMASIAN, A. AND NICOLA, V. 1993. Per-formance evaluation of a threshold policy forscheduling readers and writers. IEEE Trans.Computers 42, 1 (Jan.), 83–98.
THOMASIAN, A. AND RAHM, E. 1990. A new dis-tributed optimistic concurrency controlmethod and a comparison of its performancewith two-phase locking. In Proceedings of1990 International Conference on DistributedComputing Systems (Paris, May), 294–301.
THOMASIAN, A. AND RYU, I. K. 1983. A decompo-sition solution to the queueing network modelof the centralized DBMS with static locking.In Proceedings of the ACM SIGMETRICSConference (Minneapolis, MN, Aug.), 82–92.
THOMASIAN, A. AND RYU, I. K. 1986. Per-formance comparison of concurrency controlmethods for shared centralized databases.Unpublished rep., IBM T. J. Watson ResearchCenter, Hawthorne, NY.
THOMASIAN, A. AND RYU, I. K. 1989. A recursivesolution method to analyze the performance ofstatic locking systems. IEEE Trans. Softw.Eng. 15, 10 (Oct.), 1147–1156.
THOMASIAN, A. AND RYU, I. K. 1991. Performanceanalysis of two-phase locking. IEEE Trans.Softw. Eng. 17, 5 (May), 386–402.
WEIHL, W. E. 1988. Commutativity based CCfor abstract data types. IEEE Trans. Comput-ers 37, 12 (Dec.), 1488–1505.
WEIKUM, G. 1991. Principles and realizationstrategies of multilevel transaction manage-ment. ACM Trans. Database Syst. 16, 4(March), 132–180.
WEIKUM, G., HASSE, C., MOENKEBERG, A., AND ZAB-BACK, P. 1994. The COMFORT automatictuning project. Inf. Syst. 19, 5, 381–432.
YU, P. S., DIAS, D. M., AND LAVENBERG, S. S.1993. On modeling database concurrencycontrol. J. ACM 40, 4 (Sept.), 831–872.
Received March 1995; revised March 1997; final revision accepted November 1997
Concurrency Control • 119
ACM Computing Surveys, Vol. 30, No. 1, March 1998