computing trends using graphic processor in hep · computing trends using graphic processor in hep...
TRANSCRIPT

Computing trends using graphic processor in HEP
Computing trends using graphic processor in HEP
Mihai NICULESCU1,2, Sorin-Ion ZGURA2
1 – University of Bucharest, Faculty of Physics, Romania2 – Institute of Space Sciences, Bucharest-Magurele
FCAL Workshop, Predeal 29 May – 1 June 2011

Summary
● The problem & solutions● CUDA● CERN & CUDA● GSI & CUDA● ISS & CUDA● Conclusions

HEP Problem
1-2 PBPB / month
200 000000 events

Current Effort
● Monte Carlo tools (which link theory and experiment)
● Detector simulation frameworks● Algorithmic and statistical analysis tools● Data processing frameworks and algorithms● Grid middleware● Data production and management systems ● Underlying data persistency and database
infrastructure.

Possible Solution: GPGPU
1 TFLOPS ~ 20 times typical multicore CPU1 TFLOPS ~ 20 times typical multicore CPU
OpenCL
Less popular: ClearSpeed, BrookGPU, AMD Stream Computing, and Sh

GPU vs CPU

Why is GPU so fast?

CUDACompute Unified Device Architecture
Requirements:ISA(Instruction Set Architecture)NV driverCUDA Toolkit(CUDA SDK)
CUDA ToolKit:●nvcc C compiler●CUFFT + CUBLAS libraries●Cuda Profiler●Nv gdb●CUDA Runtime●Programming manual
CUDA SDK:●Lots of examples
● Mandelbrot● Nbody● Fluids● ...
●Dev easy

CUDAProgramming Model
GPU is a computing device:- coprocessor for the CPU (host)- own memory (DRAM)- many threads in parallel (>1000)- SPMD – single program, multiple data

CUDAExecution Model
●Defines execution domain●Runs an algorithm on all domain

Example: C vs CUDA

CERN & CUDAFAST TRIGGERING & PATTERN RECOGNITION IN THE RICH DETECTOR
NA62 Experiment

NA62 Experiment - continued
● 3 algorithms for ring finding ● matrix of 1000 PMT● NVIDIA Tesla C1060 1 GPU GT200, 240 cores,
4 GB DDR3, 800 MHz bandwidth of 102GB/s. ∼
Algorithm Time (μs)
GHT 85
OPMH 139
ODMH 12.4

CERN & CUDACERN Summer school 2010 integration of CUDA in AliRoot
ALICE Experiment
●Building System: Using FindCuda.cmake●AliCudaROOT interface
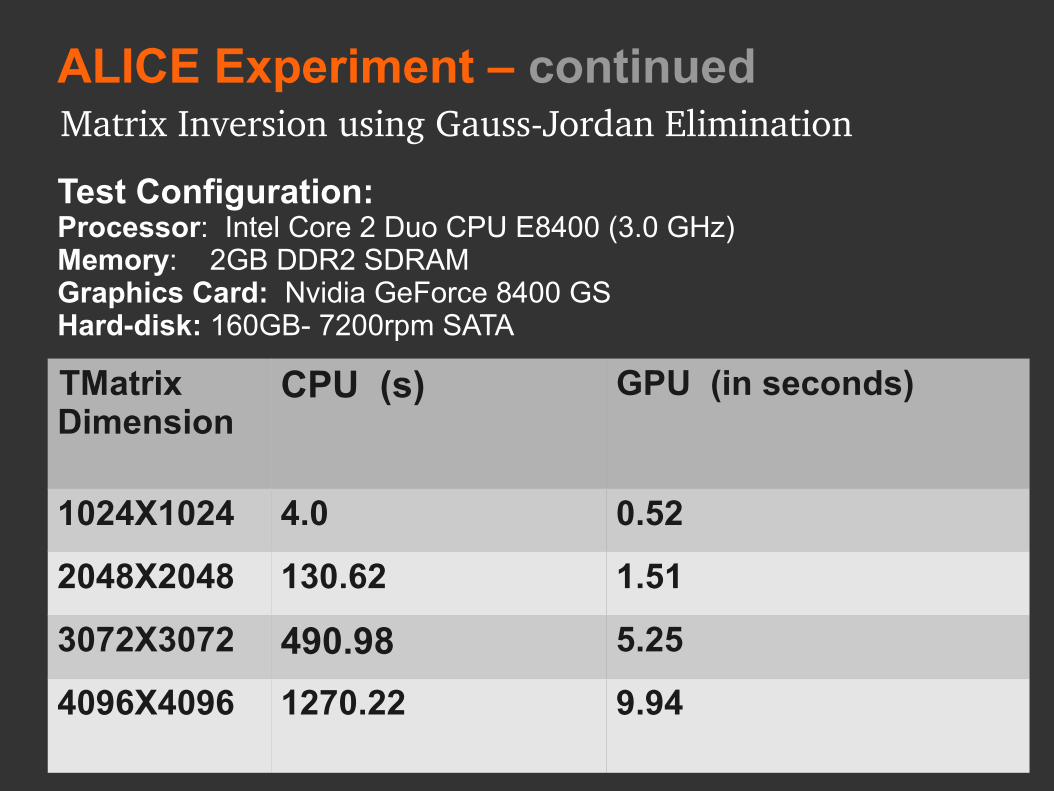
TMatrix Dimension
CPU (s) GPU (in seconds)
1024X1024 4.0 0.52
2048X2048 130.62 1.51
3072X3072 490.98 5.25
4096X4096 1270.22 9.94
Test Configuration:Processor: Intel Core 2 Duo CPU E8400 (3.0 GHz) Memory: 2GB DDR2 SDRAM Graphics Card: Nvidia GeForce 8400 GSHard-disk: 160GB- 7200rpm SATA
ALICE Experiment – continuedMatrix Inversion using GaussJordan Elimination

FAIR/GSI & CUDA FairRoot
FairRoot used by CBM & PANDA from GSI: Building System Using FindCuda.cmake FairCuda: ROOT interface
integration of CUDA in FairRoot

FAIR/GSI & CUDA PANDA experiment
Track fitting algorithms: a helix fit based on the work of Chernov et. al. task using the FairCuda interface
Track & vertex fitting

FAIR/GSI & CUDA PANDA experiment
Results: comparison between GPU and CPU time gain almost a factor 70 x

FAIR/GSI & CUDA CBM experiment
CBM experiment is a dedicated fixed target heavy ion experiment. Kalman filter parallelized based track fitting algorithm (SSE,Cell)
Porting the Kalman Filter

CBM experiment continued
Competitive fitting speed on GPU Common source with SIMD version for algorithmic part Can be embedded into other GPU code Can be run standalone
Results

ISS & CUDA Analysis & Viewer app for UrQMD
data Input: UrQMD data Input: UrQMD GUI interface (Qt4) GUI interface (Qt4) storage: SQLite storage: SQLite analysis & plotting: ROOT analysis & plotting: ROOT processing env: CUDA processing env: CUDA vizualization: OpenGL vizualization: OpenGL
Flow parameters analysis & 3D vizualition
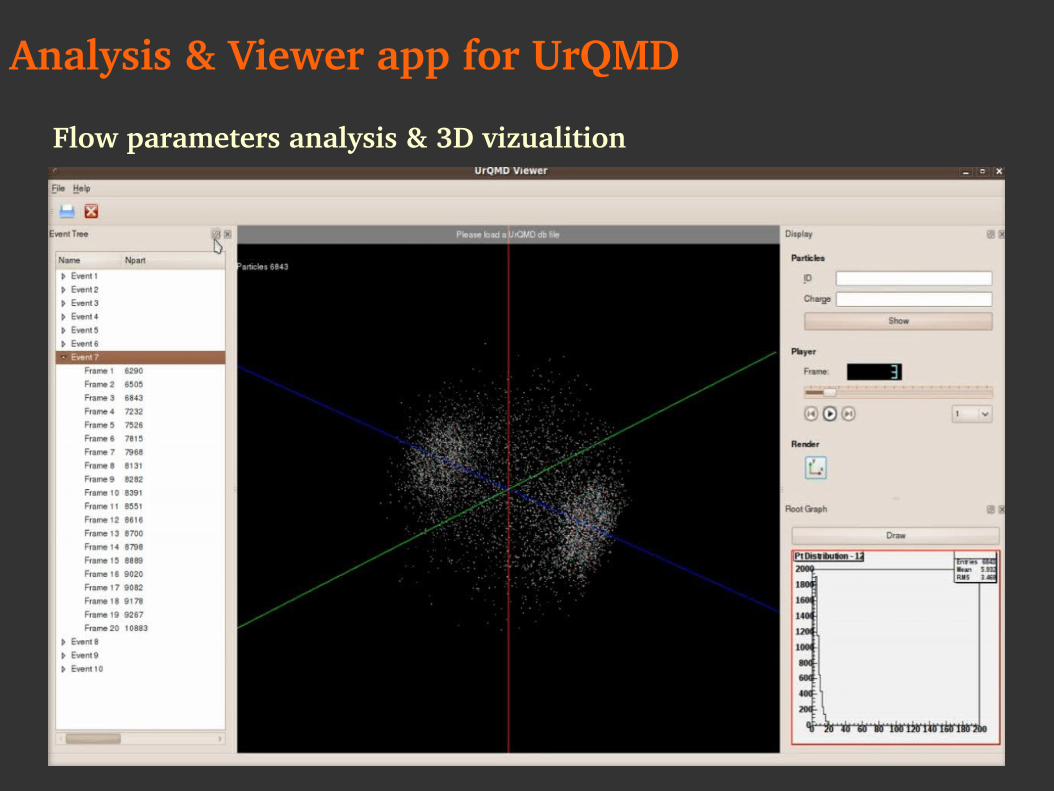
Flow parameters analysis & 3D vizualition
Analysis & Viewer app for UrQMD
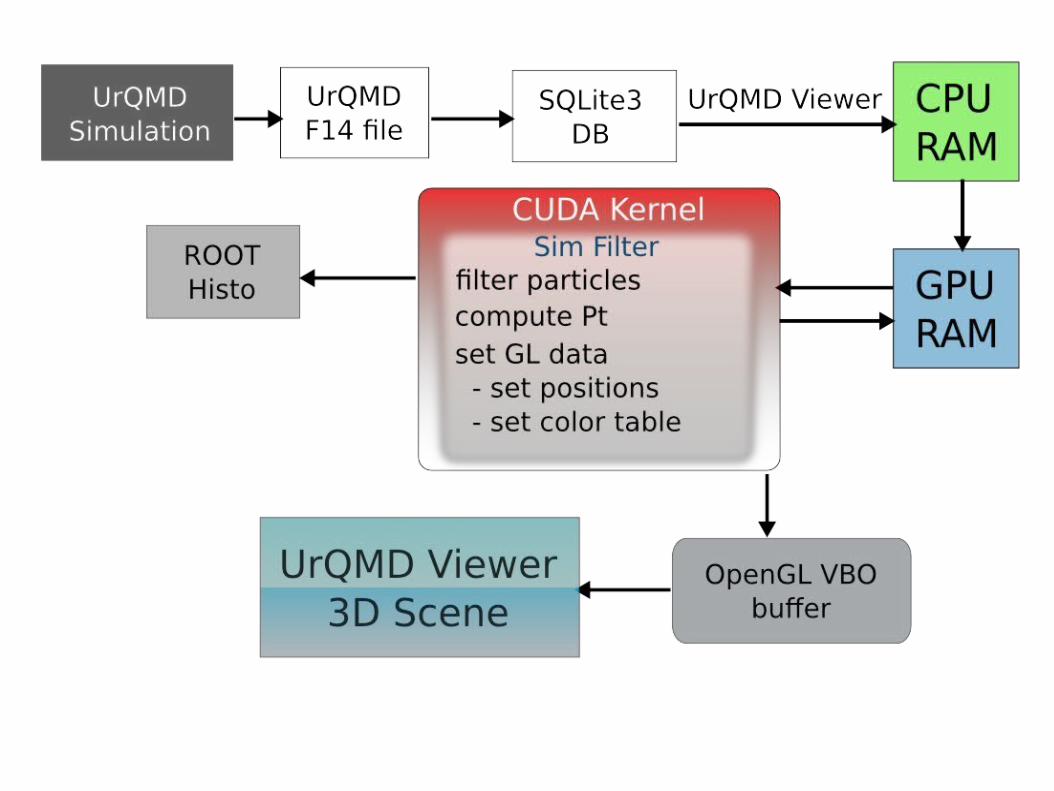

Results:
NVIDIA graphic board GeForce 9600 GT (8 processors ) with 1GB DRAM at 900MHz and 64 cores at 1.6GHz. cluster of 16 CPUs CORE 2 DUO at 2.2GHz and 2GB RAM per core.
interaction GeForce 9600 GT (MB/seconds)
16 Intel Core2Duo 2.2GHz (MB/seconds)
pp 30 4
AuAu 37 6
Analysis & Viewer app for UrQMD – continued

Conclusions
much interest in GPU CUDA
CUDA familiar programming concepts, but ...
performance boost orders of magnitude
cool price
diverse parallel algorithms

References Amir Farbin , Emerging Computing Technologies in High Energy Physics ,
http://arxiv.org/abs/0910.3440v1
NVIDIA http://developer.nvidia.com/object/cuda.html
M. Al-Turany , Optimization of HEP codes on GPUs , Eur. Phys. J. Plus (2011) 126: 1
Gianluca Lamanna, Gianmaria Collazuol and Marco Sozzi , GPUs for fast triggering and pattern matching at the CERN experiment NA62 , http://www.sciencedirect.com/science/article/pii/S0168900210022011
Subhankar Biswas , GPUs for accelerating compute-intensive tasks in the AliRoot Framework , CERN Summer School 2010, http://indico.cern.ch/getFile.py/access?contribId=3&resId=0&materialId=slides&confId=99464
M. Al-Turany , F. Uhlig , R. Karabowicz , GPU’s for event reconstruction in the FairRoot
Framework , Journal of Physics: Conference Series 219 (2010) 042001 , doi:10.1088/1742-6596/219/4/042001
M. Bach, S. Gorbunov, I. Kisel , V. Lindenstruth, and U. Kebschull, Porting a Kalman filter based track fit to NVIDIA CUDA , GSI SCIENTIFIC REPORT 2008 , http://www.gsi.de/scirep2008/PAPERS/FAIR-EXPERIMENTS-38.pdf
Matthias Bach , SIMT Kalman Filter - High throughput track fitting , 2010-06-11 , https://www.gsi.de/documents/DOC-2010-Jun-125-1.pdf
A.JIPA , C.M. MITU, M. NICULESCU,S.I ZGURA, DATA ANALYSIS AND 3D EVOLUTION IN HIGH ENERGY PHYSICS USING GRAPHIC PROCESSOR , Conferinta Nationala de Fizica 2010, Iasi,