computer-assisted topic classification for mixed-methods social science research
TRANSCRIPT

This article was downloaded by: [Laurentian University]On: 18 September 2013, At: 23:59Publisher: RoutledgeInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: MortimerHouse, 37-41 Mortimer Street, London W1T 3JH, UK
Journal of Information Technology & PoliticsPublication details, including instructions for authors and subscription information:http://www.tandfonline.com/loi/witp20
Computer-Assisted Topic Classification for Mixed-Methods Social Science ResearchDustin Hillard a , Stephen Purpura b & John Wilkerson ca Department of Electrical Engineering, University of Washingtonb Information Science, Cornell Universityc University of WashingtonPublished online: 11 Oct 2008.
To cite this article: Dustin Hillard , Stephen Purpura & John Wilkerson (2008) Computer-Assisted Topic Classificationfor Mixed-Methods Social Science Research, Journal of Information Technology & Politics, 4:4, 31-46, DOI:10.1080/19331680801975367
To link to this article: http://dx.doi.org/10.1080/19331680801975367
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information (the “Content”) containedin the publications on our platform. However, Taylor & Francis, our agents, and our licensors make norepresentations or warranties whatsoever as to the accuracy, completeness, or suitability for any purpose ofthe Content. Any opinions and views expressed in this publication are the opinions and views of the authors,and are not the views of or endorsed by Taylor & Francis. The accuracy of the Content should not be reliedupon and should be independently verified with primary sources of information. Taylor and Francis shallnot be liable for any losses, actions, claims, proceedings, demands, costs, expenses, damages, and otherliabilities whatsoever or howsoever caused arising directly or indirectly in connection with, in relation to orarising out of the use of the Content.
This article may be used for research, teaching, and private study purposes. Any substantial or systematicreproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in anyform to anyone is expressly forbidden. Terms & Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions

Journal of Information Technology & Politics, Vol. 4(4) 2007Available online at http://jitp.haworthpress.com
© 2007 by The Haworth Press. All rights reserved.doi:10.1080/19331680801975367 31
WITP
Computer-Assisted Topic Classification for Mixed-Methods Social Science Research
Hillard, Purpura, and Wilkerson Dustin HillardStephen PurpuraJohn Wilkerson
ABSTRACT. Social scientists interested in mixed-methods research have traditionally turned tohuman annotators to classify the documents or events used in their analyses. The rapid growth of digi-tized government documents in recent years presents new opportunities for research but also new chal-lenges. With more and more data coming online, relying on human annotators becomes prohibitivelyexpensive for many tasks. For researchers interested in saving time and money while maintaining confi-dence in their results, we show how a particular supervised learning system can provide estimates of theclass of each document (or event). This system maintains high classification accuracy and provides accu-rate estimates of document proportions, while achieving reliability levels associated with human efforts.We estimate that it lowers the costs of classifying large numbers of complex documents by 80% or more.
KEYWORDS. Topic classification, data mining, machine learning, content analysis, informationretrieval, text annotation, Congress, legislation
Technological advances are making vastamounts of data on government activity newlyavailable, but often in formats that are of limitedvalue to researchers as well as citizens. In thisarticle, we investigate one approach to trans-forming these data into useful information.“Topic classification” refers to the process ofassigning individual documents (or parts of doc-uments) to a limited set of categories. It iswidely used to facilitate search as well as in thestudy of patterns and trends. To pick an example
of interest to political scientists, a user of theLibrary of Congress’ THOMAS Web site (http://thomas.loc.gov) can use its Legislative IndexingVocabulary (LIV) to search for congressionallegislation on a given topic. Similarly, a user of acommercial Internet service turns to a topic clas-sification system when searching, for example,Yahoo! Flikr for photos of cars or Yahoo!Personals for postings by men seeking women.
Topic classification is valued for its ability tolimit search results to documents that closely
Dustin Hillard is a Ph.D. candidate in the Department of Electrical Engineering, University of Washington.Stephen Purpura is a Ph.D. student in Information Science, Cornell University.John Wilkerson is Associate Professor of Political Science at the University of Washington.This project was made possible with support of NSF grants SES-0429452, SES-00880066,
SES-0111443, and SES-00880061. An earlier version of the paper was presented at the Coding Across theDisciplines Workshop (NSF grant SES-0620673). The views expressed are those of the authors and not theNational Science Foundation. We thank Micah Altman, Frank Baumgartner, Matthew Baum, Jamie Callan,Claire Cardie, Kevin Esterling, Eduard Hovy, Aleks Jakulin, Thorsten Joachims, Bryan Jones, David King,David Lazer, Lillian Lee, Michael Neblo, James Purpura, Julianna Rigg, Jesse Shapiro, and RichardZeckhauser for their helpful comments.
Address correspondence to: John Wilkerson, Box 353530, University of Washington, Seattle, WA 98195(E-mail: [email protected]).
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

32 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
match the user’s interests, when compared toless selective keyword-based approaches. How-ever, a central drawback of these systems istheir high costs. Humans—who must be trainedand supervised—traditionally do the labeling.Although human annotators become somewhatmore efficient with time and experience, themarginal cost of coding each document doesnot really decline as the scope of the projectexpands. This has led many researchers to ques-tion the value of such labor-intensiveapproaches, especially given the availability ofcomputational approaches that require muchless human intervention.
Yet there are also good reasons to cling to aproven approach. For the task of topic classifi-cation, computational approaches are usefulonly to the extent that they “see” the patternsthat interest humans. A computer can quicklydetect patterns in data, such as the number ofE’s in a record. It can then very quickly orga-nize a dataset according to those patterns. Butcomputers do not necessarily detect the patternsthat interest researchers. If those patterns areeasy to objectify (e.g., any document that men-tions George W. Bush), then machines willwork well. The problem, of course, is that manyof the phenomena that interest people defy sim-ple definitions. “Bad” can mean good—orbad—depending on the context in which it isused. Humans are simply better at recognizingsuch distinctions, although computerized meth-ods are closing the gap.
Technology becomes increasingly attractiveas the size and complexity of a classificationtask increase. But what do we give up in termsof accuracy and reliability when we adopt aparticular automated approach? In this article,we begin to investigate this accuracy/efficiencytradeoff in a particular context. We begin bydescribing the ideal topic classification systemwhere the needs of social science researchersare concerned. We then review existing appli-cations of computer-assisted methods in politi-cal science before turning our attention to amethod that has generated limited attentionwithin political science to date: supervisedlearning systems.
The Congressional Bills Project (http://www.congressionalbills.org) currently includes
approximately 379,000 congressional billtitles that trained human researchers haveassigned to one of 20 major topic and 226subtopic categories, with high levels of inter-annotator reliability.1 We draw on this corpusto test several supervised learning algorithmsthat use case-based2 or “learning by example”methods to replicate the work of human anno-tators. We find that some algorithms performour particular task better than others. How-ever, combining results from individualmachine learning methods increases accuracybeyond that of any single method, and provideskey signals of confidence regarding theassigned topic for each document. We thenshow how this simple confidence estimatecan be employed to achieve additional classifi-cation accuracy more efficiently than wouldotherwise be possible.
TOPIC CLASSIFICATION FOR SOCIAL SCIENCE DOCUMENT
RETRIEVAL
Social scientists are interested in topic clas-sification for two related reasons: retrievingindividual documents and tracing patterns andtrends in issue-related activity. Mixed-methodstudies that combine pattern analyses withcase-level investigations are becoming stan-dard, and linked examples are often critical topersuading readers to accept statistical find-ings (King, Keohane, & Verba, 1994). In SoftNews Goes to War, for example, Baum (2003)draws on diverse corpora to analyze media cov-erage of war (e.g., transcripts of “EntertainmentTonight,” the jokes of John Stewart’s “TheDaily Show,” and network news programs).
Keyword searches are fast and may be effec-tive for the right applications, but effective key-word searches can also be difficult to constructwithout knowing what is actually in the data. Asearch that is too narrow in scope (e.g., “renew-able energy”) will omit relevant documents,while one that is too broad (e.g., “solar”)will generate unwanted false positives. In fact,most modern search engines, such as Google,consciously reject producing a reasonably
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

Hillard, Purpura, and Wilkerson 33
comprehensive list of results related to a topicas a design criterion.3
Many political scientists rely on existingdatabases where humans have classified events(decisions, votes, media attention, legislation)according to a predetermined topic system (e.g.,Jones & Baumgartner, 2005; Poole &Rosenthal, 1997; Rohde, 2004; Segal & Spaeth,2002). In addition to enabling scholars to studytrends and compare patterns of activity, reliabletopic classification can save considerableresearch time. For example, Adler and Wilkerson(2008) wanted to use the Congressional BillsProject database to study the impact of congres-sional reforms. To do this, they needed to tracehow alterations in congressional committeejurisdictions affected bill referrals. The fact thatevery bill during the years of interest had alreadybeen annotated for topic allowed them to reducethe number of bills that had to be individuallyinspected from about 100,000 to “just” 8,000.
Topic classification systems are also widelyused in the private sector and in government.However, a topic classification system createdfor one purpose is not necessarily suitable foranother. Well-known document retrieval sys-tems such as the Legislative Indexing Vocabu-lary of the Library of Congress’ THOMASWeb site allow researchers to search for docu-ments using preconstructed topics (http://thomas.loc.gov/liv/livtoc.html), but the THOMASLegislative Indexing Vocabulary is primarilydesigned to help users (congressional staff,lobbyists, lawyers) track down contemporarylegislation. This contemporary focus creates thepotential for “topic drift,” whereby similar docu-ments are classified differently over time as users’conceptions of what they are looking for change.4
For example, “women’s rights” did not existas a category in the THOMAS system untilsometime after 1994. The new category likelywas created to serve current users better, butearlier legislation related to women’s rights wasnot reclassified to ensure intertemporal compa-rability. Topic drift may be of little concernwhere contemporary search is concerned, but itis a problem for researchers hoping to comparelegislative activity or attention across time. Ifthe topic categories are changing, researchersrisk confusing shifts in the substance of legisla-
tive attention with shifts in coding protocol(Baumgartner, Jones, & Wilkerson, 2002).
So, what type of topic classification systembest serves the needs of social scientists? If thegoals are to facilitate trend tracing and docu-ment search, an ideal system possesses the fol-lowing characteristics. First, it should bediscriminating. By this we mean that the topiccategories are mutually exclusive and span theentire agenda of topics. The search requires thatthe system indicate what each document is pri-marily about, while trend tracing is made moredifficult if the same document is assigned tomultiple categories. Second, it should beaccurate. The assigned topic should reflect thedocument’s content, and there should be a sys-tematic way of assessing accuracy. Third, theideal system should be reliable. Pattern andtrend tracing require that similar documents beclassified similarly from one period to the next,even if the terminology used to describe thosedocuments is changing. For example, civil rightsissues have been framed very differently fromone decade to the next. If the goal is to comparecivil rights attention over time, then the classifi-cation system must accurately capture attentiondespite these changing frames. Fourth, it shouldbe probabilistic. In addition to discriminating adocument’s primary topic, a valuable topicsystem for search should also identify thosedocuments that address the topic even thoughthey are not primarily about that topic. Finally, itshould be efficient. The less costly the system isto implement, the greater its value.
Human-centered approaches are attractivebecause they meet most of these standards.Humans can be trained to discriminate the mainpurpose of a document, and their performancecan be monitored until acceptable levels ofaccuracy and reliability are achieved. However,human annotation is also costly. In this article,we ask whether supervised machine learningmethods can achieve similar levels of accuracyand reliability while improving efficiency.
We begin by contrasting our approach toseveral computer-assisted categorization meth-ods currently used in political science research.Only supervised learning systems have thepotential to address the five goals of topic clas-sification described above.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

34 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
COMPUTER ASSISTED CONTENT ANALYSIS IN POLITICAL SCIENCE
Content-analysis methods center on extract-ing meaning from documents. Applications ofcomputer-assisted content analysis methodshave developed slowly in political science overthe past four decades, with each innovationadding a layer of complexity to the informationgleaned from the method. Here we focus on aselected set of noteworthy projects that serve asexamples of some of these important develop-ments (see Table 1).
Data comparison, or keyword matching, wasthe first search method ever employed on digi-tal data. Keyword searches identify documentsthat contain specific words or word sequences.Within political science, one of the mostsophisticated is KEDS/TABARI (Schrodt,Davis, & Weddle, 1994; Schrodt & Gerner,1994). TABARI turns to humans to create a setof computational rules for isolating text andassociating it with a particular event category.Researchers use the resulting system to analyzechanging attention in the international media orother venues.
Systems based on keyword searching canmeet the requirements for a solid topic classifi-cation system. Keyword search systems such asTABARI can be highly accurate and reliablebecause the system simply replicates codingdecisions originally made by humans.5 If thesystem encounters text for which it has not beentrained, it does not classify that text. Keywordsearch systems can also be discriminating,because only documents that include the searchterms are labeled. The system can also be prob-abilistic, by using rules to establish whichdocuments are related to a topic area.
However, for nonbinary classification tasks,achieving the ability to be both discriminatingand probabilistic can be expensive, because thesystem requires explicit rules of discriminationfor the many situations where the text toucheson more than one topic. For example, the topic“elderly health care issue” includes subjectsthat are of concern to non-seniors (e.g., healthinsurance, prevention). Effective keywordsearches must account for these contextual fac-tors, and at some point other methods mayprove to be more efficient for the same level ofaccuracy.
TABLE 1. Criteria for Topic Classification and the Appropriateness of Different Computer-Assisted Content Analysis Methods
Criteria Method
Unsupervised Learning (without
human intervention)
Keds/Tabari Wordscores Hopkins and King, 2007
Supervised Learning
System for topic classification
Partial Yes No Partial Yes
Discriminates the primary subject of a document?
Yes No No No Yes
Document level accuracy is assessed
No No Yes No Yes
Document level reliability is assessed?
No No Yes No Yes
Indicate secondary topics? No No No No YesEfficient to implement Yes, integrating
document level accuracy and reliability checks makes the process similar to supervised learning
Yes, but costs rise with scope of task
Yes, costs decline with scope of task
Yes, costs decline with scope of task
Yes, costs decline with scope of task
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

Hillard, Purpura, and Wilkerson 35
Unsupervised approaches, such as factoranalysis or agglomerative clustering, have beenused for decades as an alternative to keywordsearching. They are often used as a first step touncovering patterns in data including documentcontent (Hand, Mannila, & Smyth, 2001). In arecent political science application, Quinn,Monroe, Colaresi, Crespin, and Radev (2006)have used this approach to cluster rhetoricalarguments in congressional floor speeches.
Unsupervised approaches are efficientbecause typically they do not require humanguidance, in contrast to data comparison or key-word methods. They also can be discriminatingand/or probabilistic, because they can producemutually exclusive and/or ranked observations.Consider the simplest case of unsupervisedlearning using agglomerative clustering—near-exact duplicate detection. As a researcher, ifyou know that 30% of the documents in a dataset are near-exact duplicates (99.8% of textcontent is equivalent) and each has the sametopic assigned to it, it would be inefficient toask humans to label all of these documents.Instead, the research would use an unsupervisedapproach to find all of the clusters of duplicates,label just one document in the cluster, and thentrust the labeling approach to assign labels tothe near-exact duplicate documents.6
But, to assess the accuracy and reliability ofunsupervised methods on more complex contentanalysis questions, humans must examine thedata and decide relevance. And once researchersbegin to leverage information from humanexperts to improve accuracy and reliability(achieve a higher match with human-scored rele-vance) in the data generation process, the methodessentially evolves into a hybrid of the super-vised learning method we focus on here.
Another semi-automated method, similar tothe method proposed in this article, is the super-vised use of word frequencies in Wordscores(www.wordscores.com). With Wordscores,researchers select model training “cases” thatare deemed to be representative of oppositeends of a spectrum (Laver, Benoit, & Garry,2003). The software then orders other docu-ments along this spectrum based on their simi-larities and differences to the word frequenciesof the end-point model documents. Wordscores
has been used to locate party manifestos andother political documents of multiple nationsalong the same ideological continuum.
This method can be efficient because itrequires only the human intervention requiredto select training documents and conduct vali-dation. Wordscores is also probabilistic,because it can produce ranked observations.And the method has been shown to be accurateand reliable. However, its accuracy and reliabil-ity are application dependent, in that the ranksWordscores assigns to documents will makesense only if the training documents closelyapproximate the user’s information retrievalgoal. Its small number of training documentslimits the expression of the user’s informationneeds. That is, Wordscores was not designed toplace events in discrete categories.
Application-independent methods for con-ducting algorithmic content analysis do notexist. The goal of such a system would be togenerate discriminative and reliable results effi-ciently and accurately for any content analysisquestion that might be posed by a researcher.There is a very active community of computerscientists interested in this problem, but, todate, humans must still select the propermethod for their application. Many NaturalLanguage Processing (NLP) researchers believethat an application-independent method willnever be developed (Kleinberg, 2002).7
As a part of this search for a more generalmethod, Hopkins and King recently havedeveloped a supervised learning method thatgives, as output, “approximately unbiased andstatistically consistent estimates of the propor-tion of all documents in each category” (Hopkins& King, 2007, p.2). They note that “accurateestimates of these document category propor-tions have not been a goal of most work in theclassification literature, which has focusedinstead on increasing the accuracy of individualdocument classification” (ibid). For example, aclassifier that correctly estimates 90% of thedocuments belonging to a class must estimateincorrectly that 10% of those documents belongto other classes. These errors can bias estimatesof class proportions (e.g., the proportion of allmedia coverage devoted to different candi-dates), depending on how they are distributed.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

36 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
Like previous work (Purpura & Hillard,2006), the method developed by Hopkins andKing begins with documents labeled byhumans, and then statistically analyzes wordfeatures to generate an efficient, discrimina-tive, multiclass classification. However, theirapproach of estimating proportions is notappropriate for the researchers interested inmixed-methods research requiring the abilityto analyze documents within a class. Despitethis limitation, mixed-methods researchersmay still want to use the Hopkins and Kingmethod to validate estimates from alternativesupervised learning systems. Because it is theonly other method (in the political science lit-erature) of those mentioned that relies onhuman-labeled training samples, it does offera unique opportunity to compare the predic-tion accuracy of our supervised learningapproach in our problem domain to anotherapproach (though the comparison must berestricted to proportions).
SUPERVISED LEARNING APPROACHES
Supervised learning (or machine learningclassification) systems, have been the focus ofmore than 1,000 scholarly publications in thecomputational linguistics literature in recentyears (Breiman, 2001; Hand, 2006; Mann,Mimno, & McCallum, 2006; Mitchell, 1997;Yang & Liu, 1999). These systems have beenused for many different text annotation pur-poses but have been rarely used for this purposein political science.
In this discussion, we focus on supervisedlearning systems that statistically analyze termswithin documents of a corpus to create rules forclassifying those documents into classes. Touncover the relevant statistical patterns, annota-tors mark a subset of the documents in the corpusas being members of a class. The researcher thendevelops a “document representation” that drawson this “training set” to accurately machine anno-tate previously unseen documents in the corpusreferred to as the “test set.”
Practically, a document representation canbe any numerical summary of a document in
the corpus. Examples might include a binaryindicator variable, which specifies whetherthe document contains a picture, a vectorcontaining “term weights” for each word inthe document, or a real number in the interval(i.e., 0, infinity) that represents the cost of pro-ducing the document. Typically, a criticalselection criterion is empirical system perfor-mance. If a human can separate all of the doc-uments in a corpus perfectly by asking, forexample, whether a key e-mail addressappears, then a useful document representationwould be a binary indicator variable specify-ing whether the e-mail address appears in eachdocument. However, for classification tasksthat are more complex, simplicity, calculationcost, and theoretical justifications are also rel-evant selection criteria.
Our document representation consists of avector of term weights, also known as featurerepresentation, as documented in Joachims(1998). For the term weights, we use both tf*idf(term frequency multiplied by inverse docu-ment frequency) and a mutual informationweight (Purpura & Hillard, 2006). The mosttypical feature representation first applies Por-ter stemming to reduce word variants to a com-mon form (Porter, 1980), before computingterm frequency in a sample divided by theinverse document frequency (to capture howoften a word occurs across all documents in thecorpus) (Papineni, 2001).8 A list of commonwords (stop words) also may be omitted fromeach text sample.
Feature representation is an importantresearch topic in itself, because differentapproaches yield different results dependingon the task at hand. Stemming can bereplaced by a myriad of methods that performa similar task—capturing the signal in thetransformation of raw text to numeric repre-sentation—but with differing results. Infuture research, we hope to demonstrate howalternative methods of preprocessing and fea-ture generation can improve the performanceof our system.
For topic classification, a relatively compre-hensive analysis (Yang & Liu, 1999) finds thatsupport vector machines (SVMs) are usuallythe best performing model. Purpura and Hillard
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

Hillard, Purpura, and Wilkerson 37
(2006) applied a SVM model to the corpusstudied here with high fidelity results. We areparticularly interested in whether combiningthe decisions of multiple supervised learningsystems can improve results. This combinedapproach is known as ensemble learning (Brill& Wu, 1998; Curran, 2002; Dietterich, 2000).Research indicates that ensemble approachesyield the greatest improvements over a singleclassifier when the individual classifiers per-form with similar accuracy but make differenttypes of mistakes.
Algorithms
We will test the performance of four alterna-tives: Naïve Bayes, SVM, Boostexter, andMaxEnt.
Naïve Bayes
Our Naïve Bayes Classifier uses a decisionrule and a Bayes probability model with strongassumptions of independence of the features(tf*idf). Our decision rule is based on MAP(maximum a posteriori), and it attempts toselect a label for each document by selectingthe class that is most probable. Our implemen-tation of the Naïve Bayes comes from therainbow toolkit (McCallum, 1996).
The SVM Model
The SVM system builds on binary pair-wise classifiers between each pair of catego-ries, and chooses the one that is selectedmost often as the final category (Joachims,1998). Other approaches are also common(such as a committee of classifiers that testone vs. the rest), but we have found that theinitial approach is more time efficient withequal or greater performance. We use a lin-ear kernel, Porter stemming, and a featurevalue (mutual information) that is slightlymore detailed than the typical inverse docu-ment frequency feature. In addition, weprune those words in each bill that occur lessoften than the corpus average. Further detailsand results of the system are described inPurpura and Hillard (2006).
Boostexter Model
The Boostexter tool allows for features of asimilar form to the SVM, where a word can beassociated with a score for each particular textexample (Schapire & Singer, 2000). We use thesame feature computation as for the SVMmodel, and likewise remove those words thatoccur less often than the corpus average. Underthis scenario, the weak learner for each iterationof AdaBoost training consists of a simple ques-tion that asks whether the score for a particularword is above or below a certain threshold. TheBoostexter model can accommodate multicate-gory tasks easily, so only one model need belearned.
The MaxEnt Model
The MaxEnt classifier assigns a document toa class by converging toward a model that is asuniform as possible around the feature set. Inour case, the model is most uniform when it hasmaximal entropy. We use the rainbow toolkit(McCallum, 1996). This toolkit provides across validation feature that allows us to selectthe optimal number of iterations. We providejust the raw words to rainbow, and let it runword stemming and compute the feature values.
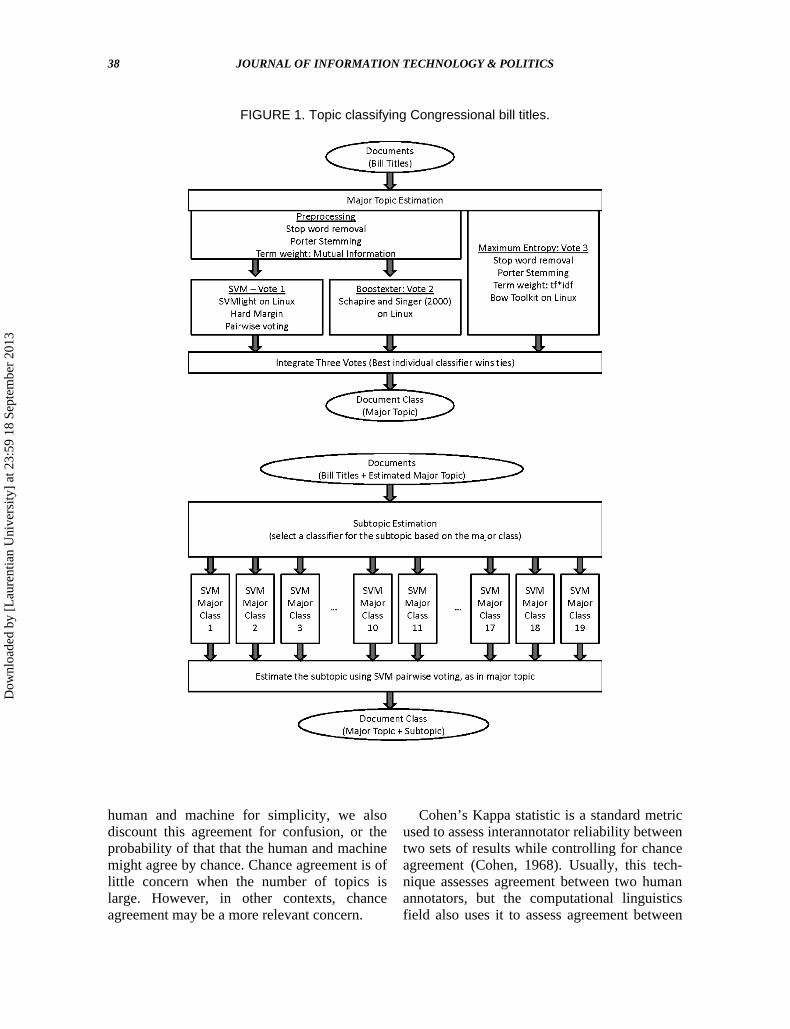
Figure 1 summarizes how we apply thissystem to the task of classifying congres-sional bills based on the word features oftheir titles. The task consists of two stages. Inthe first, we employ the ensemble approachdeveloped here to predict each bill’s majortopic class. Elsewhere, we have demonstratedthat the probability of correctly predicting thesubtopic of a bill, given a correct predictionof its major topic, exceeds .90 (Hillard,Purpura, & Wilkerson, 2007; Purpura &Hillard, 2006). We leverage this valuableinformation about likely subtopic class in thesecond stage by developing unique subtopicdocument representations (using the threealgorithms) for each major topic.9
Performance Assessment
We assess the performance of our automatedmethods against trained human annotators.Although we report raw agreement between
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13
38 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
human and machine for simplicity, we alsodiscount this agreement for confusion, or theprobability of that that the human and machinemight agree by chance. Chance agreement is oflittle concern when the number of topics islarge. However, in other contexts, chanceagreement may be a more relevant concern.
Cohen’s Kappa statistic is a standard metricused to assess interannotator reliability betweentwo sets of results while controlling for chanceagreement (Cohen, 1968). Usually, this tech-nique assesses agreement between two humanannotators, but the computational linguisticsfield also uses it to assess agreement between
FIGURE 1. Topic classifying Congressional bill titles.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

Hillard, Purpura, and Wilkerson 39
human and machine annotators. Cohen’s Kappastatistic is defined as:
In the equation, p(A) is the probability of theobserved agreement between the two assess-ments:
where N is the number of examples, and I() isan indicator function that is equal to 1 whenthe two annotations (human and computer)agree on a particular example. P(E) is theprobability of the agreement expected bychance:
where N is again the total number of examplesand the argument of the sum is a multiplica-tion of the marginal totals for each category.For example, for category 3—health—theargument would be the total number of bills ahuman annotator marked as category 3 multi-plied by the total number of bills the computersystem marked as category 3. This multiplica-tion is computed for each category, summed,and then normalized by N2.
Due to bias under certain constraintconditions, computational linguists also useanother standard metric, the AC1 statistic, toassess interannotator reliability (Gwet, 2002).The AC1 statistic corrects for the bias ofCohen’s Kappa by calculating the agreementby chance in a different manner. It has a sim-ilar form:
but the p(E) component is calculateddifferently:
where C is the number of categories, and πc isthe approximate chance that a bill is classifiedas category c:
In this study we report just AC1 because thereis no meaningful difference between Kappaand AC1.10 For annotation tasks of this levelof complexity, a Cohen’s Kappa or AC1 statis-tic of 0.70 or higher is considered to be verygood agreement between annotators (Carletta,1996).
Corpus: The Congressional Bills Project
The Congressional Bills Project (http://www.congressionalbills.org ) archives informa-tion about federal public and private billsintroduced since 1947. Currently the databaseincludes approximately 379,000 bills. Research-ers use this database to study legislative trendsover time as well as to explore finer questionssuch as the substance of environmental billsintroduced in 1968, or the characteristics of thesponsors of environmental legislation.
Human annotators have labeled each bill’stitle (1973–98) or short description (1947–72)as primarily about one of 226 subtopics origi-nally developed for the Policy Agendas Project(http://www.policyagendas.org ). These subtop-ics are further aggregated into 20 major topics(see Table 2). For example, the major topic ofenvironment includes 12 subtopics correspond-ing to longstanding environmental issues,including species and forest protection,recycling, and drinking water safety, amongothers. Additional details can be found online athttp://www.policyagendas.org/codebooks/top-icindex.html.
The students (graduate and undergraduate)who do the annotation train for approxi-mately three months as part of a year-long
k = p A p E
p E
( ) ( )
1 ( )
−−
p AN
I Human Computern nn
N
( )1
( )1
==
==∑
p EN
HumanTotal
ComputerTotalc
cc
C
( )1 (
)21
= ∑×
=
ACp A p E
p E1
( ) ( )
1 ( )= −
−
p EC c c
c
C
( )1
1( (1
1
=−
−=p p ))∑
p cc cHumanTotal ComputerTotal
N= +( )/2
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

40 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
commitment. Typically, each student anno-tates 200 bills per week during the trainingprocess. To maintain quality, interannotatoragreement statistics are regularly calculated.Annotators do not begin annotation in earnestuntil interannotator reliability (including amaster annotator) approaches 90% at themajor topic level and 80% at the subtopiclevel.11 Most bills are annotated by just oneperson, so the dataset undoubtedly includesannotation errors.
However, it is important to recognize thatinterannotator disagreements are usually legiti-mate differences of opinion about what a bill isprimarily about. For example, one annotatormight place a bill to prohibit the use of live
rabbits in dog racing in the sports and gamblingregulation category (1526), while another mightlegitimately conclude that it is primarily aboutspecies and forest protection (709). The factthat interannotator reliability is generally high,despite the large number of topic categories,suggests that the annotators typically agree onwhere a bill should be assigned. In a review of asmall sample, we found that the distributionbetween legitimate disagreements and actualannotation errors was about 50/50.
EXPERIMENTS AND FINDINGS
The main purpose of automated text classifi-cation is to replicate the performance of humanlabelers. In this case, the classification task con-sists of either 20 or 226 topic categories. Weexploit the natural hierarchy of the categoriesby first building a classification system todetermine the major category, and then buildinga child system for each of the major categoriesthat decides among the subcategories withinthat major class, as advocated by Koller andSahami (1997).
We begin by performing a simple randomsplit on the entire corpus and use the first subsetfor training and the second for testing. Thus,one set of about 190,000 labeled samples isused to predict labels on about 190,000 othercases.
Table 3 shows the results produced whenusing our text preprocessing methods and fouroff-the-shelf computer algorithms. With 20major topics and 226 subtopics, a randomassignment of bills to topics and subtopicscan be expected to yield very low levels of
TABLE 2. Major Topics of the Congressional Bills Project
1 Macroeconomics2 Civil Rights, Minority Issues, Civil Liberties3 Health4 Agriculture5 Labor, Employment, and Immigration6 Education7 Environment8 Energy
10 Transportation12 Law, Crime, and Family Issues13 Social Welfare14 Community Development and Housing Issues15 Banking, Finance, Domestic Commerce16 Defense17 Space, Science, Technology, Communications18 Foreign Trade19 International Affairs and Foreign Aid20 Government Operations21 Public Lands and Water Management99 Private Legislation
TABLE 3. Bill Title Interannotator Agreement for Five Model Types
SVM MaxEnt Boostexter Naïve Bayes Ensemble
Major topic N = 20 88.7% (.881) 86.5% (.859) 85.6% (.849) 81.4% (.805) 89.0% (.884)Subtopic N = 226 81.0% (.800) 78.3% (.771) 73.6% (.722) 71.9% (.705) 81.0% (.800)
Note. Results are based on using approximately 187,000 human-labeled cases to train the classifier to predict approxi-mately 187,000 other cases (that were also labeled by humans but not used for training). Agreement is computed bycomparing the machine’s prediction to the human assigned labels. (AC1 measure presented in parentheses).
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

Hillard, Purpura, and Wilkerson 41
accuracy. It is therefore very encouraging tofind high levels of prediction accuracy acrossthe different algorithms. This is indicative of afeature representation—the mapping of text tonumbers for analysis by the machine—that rea-sonably matches the application.
The ensemble learning voting algorithm com-bines the best of the four (SVM, MaxEnt, andBoostexter) marginally improves interannotatoragreement (compared to SVM alone) by 0.3%(508 bills). However, combining informationfrom three algorithms yields important addi-tional information that can be exploited to lowerthe costs of improving accuracy. When the threealgorithms predict the same major topic for abill, the prediction of the machine matches thehuman-assigned category 94% of the time (seeTable 4). When the three algorithms disagree bypredicting different major topics, collectively themachine predictions match the human annotationteam only 61% of the time. The AC1 measureclosely tracks the simple accuracy measure, sofor brevity we present only accuracy results inthe remaining experiments.
PREDICTING TO THE FUTURE: WHEN AND WHERE SHOULD
HUMANS INTERVENE?
A central goal of the Congressional BillsProject (as well as many other projects) is toturn to automated systems to lower the costs oflabeling new bills (or other events) as opposedto labeling events of the distant past. The previ-ous experiments shed limited light on the valueof the method for this task. How different areour results if we train on annotated bills fromprevious Congresses to predict the topics ofbills of future Congresses?
From past research we know that topic driftacross years can be a significant problem.Although we want to minimize the amount oftime that the annotation team devotes to examin-ing bills, we also need a system that approaches90% accuracy. To address these concerns, weadopt two key design modifications. First, weimplement a partial memory learning system.For example, to predict class labels for the bills
of the 100th Congress (1987–1988), we onlyuse information from the 99th Congress, pluswhatever data the human annotation team hasgenerated for the 100th as part of an activelearning process. We find that this approachyields results equal to, or better than, what canbe achieved using all available previous train-ing data.
The second key design decision is that weonly want to accept machine-generated classlabels for bills when the system has high confi-dence in the prediction. In other cases, we wishto have humans annotate the bills, because wehave found that this catches cases of topic driftand it minimizes mistakes. One implication ofTable 4 is that the annotation team may be ableto trust the algorithms’ prediction when allthree methods agree and limit its attention tothe cases of disagreement where they disagree.But we need to confirm that the results are com-parable when we use a partial memory learningsystem.
For the purposes of these experiments, wewill focus on predicting the topics of bills fromthe 100th Congress to the 105th Congress usingonly the bill topics from the previous Congressas training data. This is the best approximationof the “real world” case that we are able to con-struct, because (a) these congressional sessionshave the lowest computer/human agreement ofall of the sessions in the data set, (b) the 105thCongress is the last human-annotated session,and (c) the first production experiment with livedata will use the 105th Congress’ data to pre-dict the class labels for the bills of the 106thCongress. The results reported in Table 5 are at
TABLE 4. Prediction Success for 20 Topic Categories When Machine Learning Ensemble
Agrees and Disagrees
Methods Agree Methods Disagree
correct 94% 61%incorrect 6% 39%cases 85% 15%(N of Bills) (158,762) (28,997)
Note. Based on using 50% of the sample to train thesystems to predict to the other 50%.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13
42 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
the major topic only. As mentioned, the proba-bility of correctly predicting the subtopic of abill, given a correct prediction of major topicclass, exceeds 0.90 (Hillard et al., 2007; Pur-pura & Hillard, 2006).
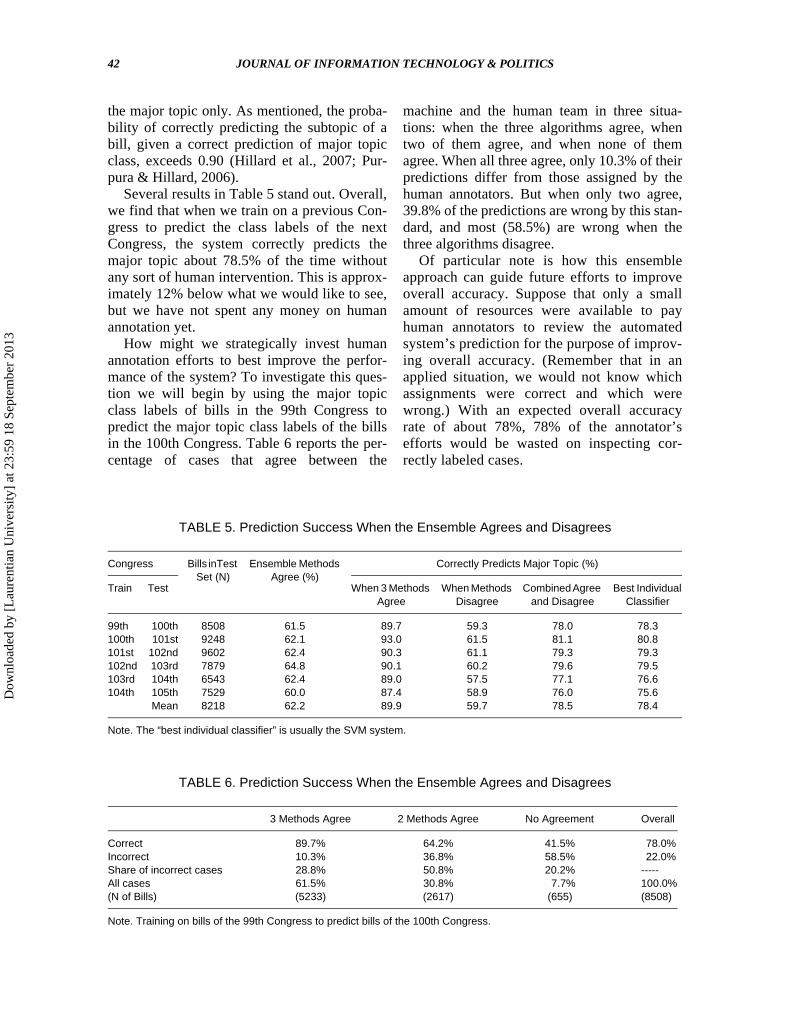
Several results in Table 5 stand out. Overall,we find that when we train on a previous Con-gress to predict the class labels of the nextCongress, the system correctly predicts themajor topic about 78.5% of the time withoutany sort of human intervention. This is approx-imately 12% below what we would like to see,but we have not spent any money on humanannotation yet.
How might we strategically invest humanannotation efforts to best improve the perfor-mance of the system? To investigate this ques-tion we will begin by using the major topicclass labels of bills in the 99th Congress topredict the major topic class labels of the billsin the 100th Congress. Table 6 reports the per-centage of cases that agree between the
machine and the human team in three situa-tions: when the three algorithms agree, whentwo of them agree, and when none of themagree. When all three agree, only 10.3% of theirpredictions differ from those assigned by thehuman annotators. But when only two agree,39.8% of the predictions are wrong by this stan-dard, and most (58.5%) are wrong when thethree algorithms disagree.
Of particular note is how this ensembleapproach can guide future efforts to improveoverall accuracy. Suppose that only a smallamount of resources were available to payhuman annotators to review the automatedsystem’s prediction for the purpose of improv-ing overall accuracy. (Remember that in anapplied situation, we would not know whichassignments were correct and which werewrong.) With an expected overall accuracyrate of about 78%, 78% of the annotator’sefforts would be wasted on inspecting cor-rectly labeled cases.
TABLE 5. Prediction Success When the Ensemble Agrees and Disagrees
Congress Bills inTest Set (N)
Ensemble Methods Agree (%)
Correctly Predicts Major Topic (%)
Train Test When 3 Methods Agree
When Methods Disagree
Combined Agree and Disagree
Best Individual Classifier
99th 100th 8508 61.5 89.7 59.3 78.0 78.3100th 101st 9248 62.1 93.0 61.5 81.1 80.8101st 102nd 9602 62.4 90.3 61.1 79.3 79.3102nd 103rd 7879 64.8 90.1 60.2 79.6 79.5103rd 104th 6543 62.4 89.0 57.5 77.1 76.6104th 105th 7529 60.0 87.4 58.9 76.0 75.6
Mean 8218 62.2 89.9 59.7 78.5 78.4
Note. The “best individual classifier” is usually the SVM system.
TABLE 6. Prediction Success When the Ensemble Agrees and Disagrees
3 Methods Agree 2 Methods Agree No Agreement Overall
Correct 89.7% 64.2% 41.5% 78.0%Incorrect 10.3% 36.8% 58.5% 22.0%Share of incorrect cases 28.8% 50.8% 20.2% -----All cases 61.5% 30.8% 7.7% 100.0%(N of Bills) (5233) (2617) (655) (8508)
Note. Training on bills of the 99th Congress to predict bills of the 100th Congress.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13
Hillard, Purpura, and Wilkerson 43
A review of just 655 bills where the threemethods disagree (i.e., less than 8% of the sam-ple) can be expected to reduce overall annota-tion errors by 20%. In contrast, inspecting thesame number of cases when the three methodsagree would reduce overall annotation errors byjust 3.5%. If there are resources to classifytwice as many bills (just 1,310 bills, or about15% of the cases), overall error can be reducedby 32%, bumping overall accuracy from 78% to85%. Coding 20% of all bills according to thisstrategy increases overall accuracy to 87%.
In the political science literature, the mostappropriate alternative approach for validatingthe methods presented here is the one recentlyadvocated by Hopkins and King (2007). Whiletheir method, discussed earlier, does not predictto the case level and is therefore inadequate forthe goals we have established in this work. Wecan compare estimates of proportions by apply-ing our software and the ReadMe softwaremade available by Hopkins and King (http://gking.harvard.edu/readme/) to the same dataset.We trained the ReadMe algorithm and the bestperforming algorithm of our ensemble (SVM)on the human-assigned topics of bills of the
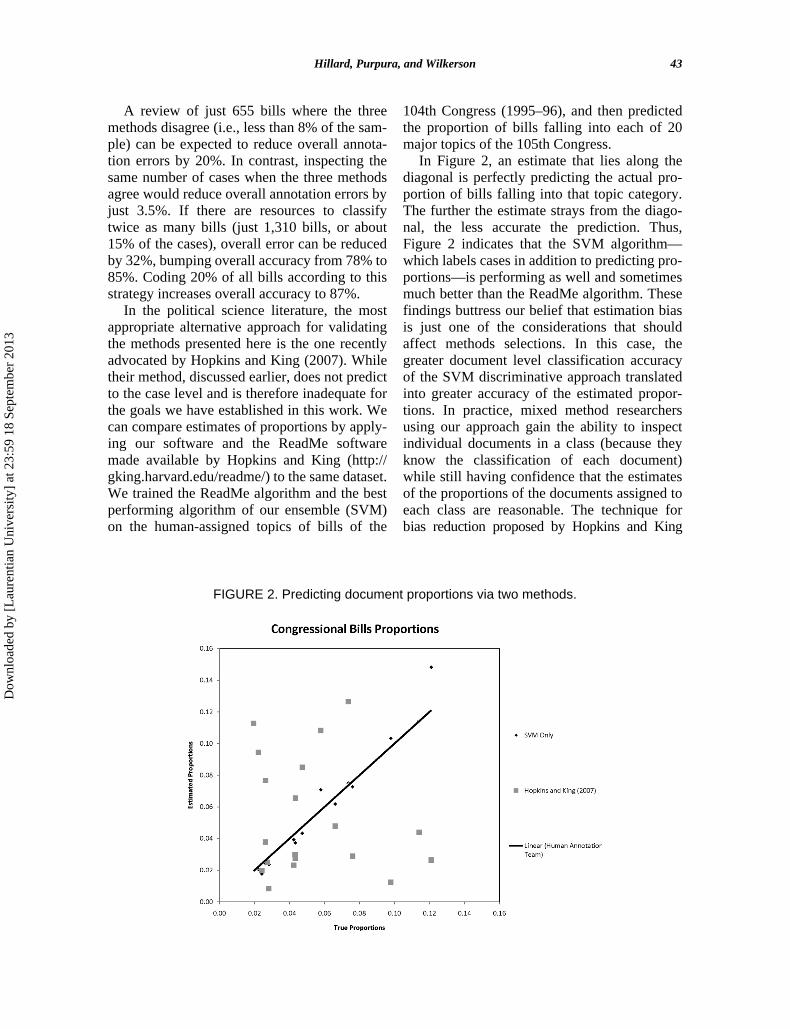
104th Congress (1995–96), and then predictedthe proportion of bills falling into each of 20major topics of the 105th Congress.
In Figure 2, an estimate that lies along thediagonal is perfectly predicting the actual pro-portion of bills falling into that topic category.The further the estimate strays from the diago-nal, the less accurate the prediction. Thus,Figure 2 indicates that the SVM algorithm—which labels cases in addition to predicting pro-portions—is performing as well and sometimesmuch better than the ReadMe algorithm. Thesefindings buttress our belief that estimation biasis just one of the considerations that shouldaffect methods selections. In this case, thegreater document level classification accuracyof the SVM discriminative approach translatedinto greater accuracy of the estimated propor-tions. In practice, mixed method researchersusing our approach gain the ability to inspectindividual documents in a class (because theyknow the classification of each document)while still having confidence that the estimatesof the proportions of the documents assigned toeach class are reasonable. The technique forbias reduction proposed by Hopkins and King
FIGURE 2. Predicting document proportions via two methods.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

44 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
could then be used as a postprocessing step—potentially further improving proportionpredictions.
CONCLUSIONS
Topic classification is a central componentof many social science data collectionprojects. Scholars rely on such systems to iso-late relevant events, to study patterns andtrends, and to validate statistically derivedconclusions. Advances in information technol-ogy are creating new research databases thatrequire more efficient methods for topic clas-sifying large numbers of documents. Weinvestigated one of these databases to find thata supervised learning system can accuratelyestimate a document’s class as well as docu-ment proportions, while achieving the highinter-annotator reliability levels associatedwith human efforts. Moreover, compared tohuman annotation alone, this system lowerscosts by 80% or more.
We have also found that combining infor-mation from multiple algorithms (ensemblelearning) increases accuracy beyond that ofany single algorithm, and also provides keysignals of confidence regarding the assignedtopic for each document. We then showed howthis simple confidence estimate could beemployed to achieve additional classificationaccuracy.
Although the ensemble learning methodalone offers a viable strategy for improvingclassification accuracy, additional gains can beachieved through other active learning inter-ventions. In Hillard et al. (2007), we show howconfusion tables that report classification errorsby topic can be used to target follow-up inter-ventions more efficiently. One of the conclusionsof that research was that stratified samplingapproaches can be more efficient than randomsampling, especially where smaller trainingsamples are concerned. In addition, much of thecomputational linguistics literature focuses onfeature representations and demonstrates thatexperimentation in this area is also likely tolead to improvements. The Congressional BillsProject is in the public domain (http://www.
congressionalbills.org). We hope that this workinspires others to improve upon it.
We appreciate the attraction of less costlyapproaches such as keyword searches, cluster-ing methodologies, and reliance on existingindexing systems designed for other purposes.Supervised learning systems require high-quality training samples and active humanintervention to mitigate concerns such as topicdrift as they are applied to new domains (e.g.,new time periods), but it is also important toappreciate where other methods fall short as faras the goals of social science research areconcerned. For accurately, reliably, and effi-ciently classifying large numbers of complexindividual events, supervised learning systemsare currently the best option.
NOTES
1. http://www.congressionalbills.org/Bills_Reliability.pdf
2. We use case-based to mean that cases (examplesmarked with a class) are used to train the system. This isconceptually similar to the way that reference cases areused to train law school students.
3. Google specifically rejects use of recall as adesign criterion in their design documents, available athttp://www-db.stanford.edu/˜backrub/google.html
4. Researchers at the Congressional Research Ser-vice are very aware of this limitation of their system,which now includes more than 5,000 subject terms. How-ever, we have been reminded on more than one occasionthat THOMAS’s primary customer (and the entity thatpays the bills) is the U.S. Congress.
5. TABARI does more than classify, but at its heart itis an event classification system just as Google (at itsheart) is an information retrieval system.
6. If we were starting from scratch, we would employthis method. Instead, we use it to check whether near-exact duplicates are labeled identically by both humansand software. Unfortunately, humans make the mistake ofmislabeling near-exact duplicates more times than we careto dwell upon, and we are glad that we now have comput-erized methods to check them.
7. Many modern popular algorithmic NLP text clas-sification approaches convert a document into a mathe-matical representation using the bag of words method.This method reduces the contextual information availableto the machine. Different corpus domains and applicationsrequire more contextual information to increase effective-ness. Variation in the document pre-processing (includingmorphological transformation) is one of the key methods
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

Hillard, Purpura, and Wilkerson 45
for increasing effectiveness. See Manning and Shütze(1999) for a helpful introduction to this subject.
8. Although the use of features similar to tf*idf (termfrequency multiplied by inverse document frequency)dates back to the 1970’s, we cite Papineni’s literaturereview of the area.
9. Figure 1 depicts the final voting system used topredict the major and subtopics of each Congressional Bill.The SVM system, as the best performing classifier, is usedalone for the subtopic prediction system. However, whenresults are reported for individual classifier types (SVM,Boostexter, MaxEnt, and Naïve Bayes), the same classifiersystem is used to predict both major and subtopics.
10. Cohen’s Kappa, AC1, Krippendorf’s Alpha, andsimple percentage comparisons of accuracy are all reason-able approximations for the performance of our systembecause the number of data points and the number of cate-gories are large.
11. See http://www.congressionalbills.org/BillsReliability.pdf
REFERENCES
Adler, E. S., & Wilkerson, J. (2008). Intended conse-quences? Committee reform and jurisdictional changein the House of Representatives. Legislative StudiesQuarterly, 33(1), 85–112.
Baum, M. (2003). Soft news goes to war: Public opinionand American foreign policy in the new media age.Princeton NJ: Princeton University Press.
Baumgartner, F., Jones, B. D., & Wilkerson, J. (2002).Studying policy dynamics. In F. Baumgarter & B. D.Jones (Eds.), Policy dynamics (pp. 37–56). Chicago:University of Chicago Press.
Breiman, L. (2001). Statistical modeling: The two cul-tures. Statistical Science, 16(3), 199–231.
Brill, E. & Wu, J. (1998). Classifier combination forimproved lexical disambiguation. In Proceedings ofthe COLING-ACL ’98 (pp. 191–195). Philadelphia,PA: Association for Computational Linguistics.
Carletta, J. (1996). Assessing agreement on classificationtasks: The Kappa statistic. Computational Linguistics,22(2), 249–254.
Cohen, J. (1968). Weighted Kappa: Nominal scale agree-ment with provision for scaled disagreement or partialcredit. Psychological Bulletin, 70(4), 213–220.
Curran, J. (2002). Ensemble methods for automatic the-saurus extraction. Proceedings of the conference onempirical methods in natural language processing(pp. 222–229). Morristown, NJ: Association for Com-putational Linguistics.
Dietterich, T. (2000). Ensemble methods in machine learn-ing. Lecture Notes in Computer Science, 1857, 1–15.
Gwet, K. (2002). Kappa statistic is not satisfactory forassessing the extent of agreement between raters.
Statistical Methods for Inter-rater Reliability Assess-ment, 1(April), 1–6.
Hand, D. (2006). Classifier technology and the illusion ofprogress. Statistical Science, 21(1), 1–14.
Hand, D., Mannila, H., & Smyth, P. (2001). Principles ofdata mining (adaptive computation and machine learn-ing). Cambridge, MA: MIT Press.
Hillard, D., Purpura, S., & Wilkerson, J. (2007). An activelearning framework for classifying political text. Pre-sented at the annual meetings of the Midwest PoliticalScience Association, Chicago, April.
Hopkins, D., & King, G. (2007). Extracting systematicsocial science meaning from text. Unpublished manu-script (Sept. 15, 2007), Center for Basic Research,Harvard University.
Joachims, T. (1998). Text categorization with supportvector machines: Learning with many relevant fea-tures. In Proceedings of the European conference onmachine learning (pp. 137–142). Chemnitz, Germany:Springer.
Jones, B. D., & Baumgartner, F. B. (2005). The politics ofattention: How government prioritizes problems.Chicago: University of Chicago Press.
King, G., Keohane, R. O., & Verba, S. (1994). Designingsocial inquiry: Scientific inference in qualitativeresearch. Princeton, NJ: Princeton University Press.
Kleinberg, J. (2002). An impossibility theorem for cluster-ing. Proceedings of the 2002 Conference on Advances inNeural Information Processing Systems, 15, 463–470.
Koller, D., & Sahami, M. (1997). Hierarchically classify-ing documents using very few words. In Proceedingsof the Fourteenth International Conference onMachine Learning, 170-78. San Francisco, CA: D. H.Fisher, & E. Morgan Publishers.
Laver, M., Benoit, K., & Garry, J. (2003). Estimating thepolicy positions of political actors using words as data.American Political Science Review, 97(2), 311–331.
Mann, G., Mimno, D., & McCallum, A. (2006). Biblio-metric impact measures and leveraging topic analysis.Proceedings of the ACM/IEEE-CS Joint Conference onDigital Libraries (pp. 65–74). New York: Associationfor Computer Machinery.
Manning, C., & Shütze, H. (1999). Foundations of statisti-cal natural language processing. Cambridge, MA:MIT Press.
McCallum, A. (1996). Bow: A toolkit for statisticallanguage modeling, text retrieval, classification andclustering. Available at http://www.cs.cmu.edu/mccallum/bow
Mitchell, T. (1997). Machine learning. New York:McGraw-Hill.
Papineni, K. (2001). Why inverse document frequency?In Proceedings of the North American Chapter ofthe Association for Computational Linguistics(pp. 1–8). Morristown, NJ: Association for Comput-ing Machinery.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13

46 JOURNAL OF INFORMATION TECHNOLOGY & POLITICS
Poole, K., & Rosenthal, H. (1997). Congress: A political-economic history of roll call voting. New York: OxfordUniversity Press.
Porter, M. F. (1980). An algorithm for suffix stripping.Program, 16(3), 130–137.
Purpura, S., & Hillard, D. (2006). Automated classifica-tion of congressional legislation. In Proceedings of theInternational Conference on Digital GovernmentResearch (pp. 219–225). New York: Association forComputer Machines.
Quinn, K., Monroe, B., Colaresi, M., Crespin, M., &Radev, D. (2006). An automated method of topic-coding legislative speech over time with application tothe 105th–108th U.S. Senate. Presented at the AnnualMeetings of the Society for Political Methodology,Seattle, WA.
Rohde, D. W. (2004). Roll call voting data for theUnited States House of Representatives, 1953–2004.Compiled by the Political Institutions and PublicChoice Program, Michigan State University, East
Lansing, MI. Available at http://crespin.myweb.uga.edu/pipcdata.htm
Schapire, R. E., & Singer, Y. (2000). Boostexter: A boost-ing based system for text categorization. MachineLearning, 39(2/3), 135–168.
Schrodt P., Davis, S., & Weddle, J. (1994). Political Science:KEDS—a program for the machine coding of event data.Social Science Computer Review, 12(4), 561–587.
Schrodt, P., & Gerner, D. (1994). Validity assessment of amachine-coded event data set for the Middle East,1982–92. American Journal of Political Science, 38(3),825–844.
Segal, J., & Spaeth, H. (2002). The Supreme Court and theattitudinal model revisited. Cambridge, England: Cam-bridge University Press.
Yang, Y., & Liu, X. (1999). A re-examination of text cate-gorization methods. Proceedings of the ACM-SIGIRConference on Research and Development in Informa-tion Retrieval. San Francisco, New York: Associationfor Computer Machinery.
Dow
nloa
ded
by [
Lau
rent
ian
Uni
vers
ity]
at 2
3:59
18
Sept
embe
r 20
13