computational models of discourse: texttilingcsporled/compdisc/slides/texttiling.pdf ·...
TRANSCRIPT

Computational Models of Discourse:TextTiling
Caroline Sporleder
Universitat des Saarlandes
Sommersemester 2009
13.05.2009
Caroline Sporleder [email protected] Computational Models of Discourse

Text Segmentation
. . . indentification of (sub-)topic shifts
Caroline Sporleder [email protected] Computational Models of Discourse

Text Segmentation
Example
Penicillin is a group of beta-lactam antibiotics used in the treatmentof bacterial infections caused by susceptible, usually Gram-positive,organisms. The discovery of penicillin is usually attributed to Scot-tish scientist Sir Alexander Fleming in 1928. Fleming noticed a haloof inhibition of bacterial growth around a contaminant blue-greenmold Staphylococcus plate culture. Fleming concluded that themold was releasing a substance that was inhibiting bacterial growthand lysing the bacteria. Common adverse drug reactions associatedwith use of the penicillins include: diarrhea, nausea, rash, urticaria,and/or superinfection (including candidiasis).
Caroline Sporleder [email protected] Computational Models of Discourse

Text Segmentation
Example
Penicillin is a group of beta-lactam antibiotics used in the treatmentof bacterial infections caused by susceptible, usually Gram-positive,organisms. The discovery of penicillin is usually attributed to Scot-tish scientist Sir Alexander Fleming in 1928. Fleming noticed a haloof inhibition of bacterial growth around a contaminant blue-greenmold Staphylococcus plate culture. Fleming concluded that themold was releasing a substance that was inhibiting bacterial growthand lysing the bacteria. Common adverse drug reactions associatedwith use of the penicillins include: diarrhea, nausea, rash, urticaria,and/or superinfection (including candidiasis).
Caroline Sporleder [email protected] Computational Models of Discourse

Identifying Sub-Topic Boundaries
Why not simply use paragraph boundaries or section headings?
not all paragraph boundaries reflect topic changes(Stark 1988)
paragraphing conventions are genre-dependent(e.g., news texts)
subsections often too large
⇒ segmentation into multi-paragraph units
Applications
hypertext display
information retrieval
text summarisation
Caroline Sporleder [email protected] Computational Models of Discourse

Identifying Sub-Topic Boundaries
Why not simply use paragraph boundaries or section headings?
not all paragraph boundaries reflect topic changes(Stark 1988)
paragraphing conventions are genre-dependent(e.g., news texts)
subsections often too large
⇒ segmentation into multi-paragraph units
Applications
hypertext display
information retrieval
text summarisation
Caroline Sporleder [email protected] Computational Models of Discourse

Identifying Sub-Topic Boundaries
Why not simply use paragraph boundaries or section headings?
not all paragraph boundaries reflect topic changes(Stark 1988)
paragraphing conventions are genre-dependent(e.g., news texts)
subsections often too large
⇒ segmentation into multi-paragraph units
Applications
hypertext display
information retrieval
text summarisation
Caroline Sporleder [email protected] Computational Models of Discourse

Sub-Topic Segmentation
Methods
find linguistic markers for “topic-shift”
adverbial clauses and prosodic markers (Brown & Yule, 1983)
certain (discourse) markers: oh, well, ok, however (Litman &Passonneau, 1995)
pronoun reference structure (Passonneau & Litman, 1993)
tense and aspect (Webber 1987)
distribution of lexical chains
distribution of lexical items (Hearst 1997) (for expositorytexts)
Caroline Sporleder [email protected] Computational Models of Discourse

Sub-Topic Segmentation
Methodsfind linguistic markers for “topic-shift”
adverbial clauses and prosodic markers (Brown & Yule, 1983)
certain (discourse) markers: oh, well, ok, however (Litman &Passonneau, 1995)
pronoun reference structure (Passonneau & Litman, 1993)
tense and aspect (Webber 1987)
distribution of lexical chains
distribution of lexical items (Hearst 1997) (for expositorytexts)
Caroline Sporleder [email protected] Computational Models of Discourse

Sub-Topic Segmentation
Methodsfind linguistic markers for “topic-shift”
adverbial clauses and prosodic markers (Brown & Yule, 1983)
certain (discourse) markers: oh, well, ok, however (Litman &Passonneau, 1995)
pronoun reference structure (Passonneau & Litman, 1993)
tense and aspect (Webber 1987)
distribution of lexical chains
distribution of lexical items (Hearst 1997) (for expositorytexts)
Caroline Sporleder [email protected] Computational Models of Discourse

TextTiling (Hearst, 1997)
Main Hypothesis“. . . when [a] subtopic changes, a significant proportion of thevocabulary changes as well.” (Hearst, 1997, p. 40)
⇒ related to segmentation with lexical chains but “shallower”(thus easier to compute)
Caroline Sporleder [email protected] Computational Models of Discourse

Text Structure Types (Skorochod’ko 1972)
Compute word overlap between sentences and look at distributionof highly connected sentences:
chained
ringed
monolithic
piecewise
Caroline Sporleder [email protected] Computational Models of Discourse

TextTiling (Hearst, 1997)
Example:
Stargazer text (life on earth and other planets)
Segments:
1 Intro: search for life in space (paragraphs 1–3)
2 The moon’s chemical composition (4–5)
3 How early earth-moon proximity shaped the moon (6–8)
4 How the moon helped life evolve on earth (9–12)
5 Improbability of the earth-moon system (13)
6 Binary/trinary star systems make life unlikely (14–16)
7 The low probability of nonbinary/trinary systems (17–18)
8 Properties of earth’s sun that facilitate life (19–20)
9 Summary (21)
Caroline Sporleder [email protected] Computational Models of Discourse

Distribution of Terms
Distribution of terms in Stargazer (Hearst 1997, p. 42)
Caroline Sporleder [email protected] Computational Models of Discourse

Distribution of Terms
frequent terms (e.g., moon): main topic
less frequent but uniformly distributed terms (scientist):neutral
terms that cluster (binary): indicative of sub-topic boundaries
⇒ need to find clusters
Caroline Sporleder [email protected] Computational Models of Discourse

Comparing adjacent text blocks
AimDetermine which sentence boundaries correspond to sub-topicboundaries.
compute lexical score for the gap between pairs of text blocks.
text blocks contain k adjacent sentences and act as movingwindows
low lexical scores preceded and followed by high lexical scoresmay indicate topic shifts
Lexical ScoreThree possibilities:
dot product of word vectors (tf.idf weighting found not towork so well)
vocabulary introduction
lexical chains
Caroline Sporleder [email protected] Computational Models of Discourse

Comparing adjacent text blocks
Hearst (1997), p. 44:
Caroline Sporleder [email protected] Computational Models of Discourse

The TextTiling Algorithm
Three main steps:1 Tokenisation:
tokenisationstop word removalstemmingsplitting text in equal-size “pseudo-sentences” (tokensequences)
2 Computing Lexical Scoreset block size k (i.e., size of moving window) ≈ avg.paragraph lengthcompute score
3 Boundary Identificationassign a depth score to each token sequence gap i (find peakat left hand side l and peak at right hand side r ,depth − score(i) = score(l)− score(i) + score(r)− score(i))smooth scoresminor heuristics for boundary assignment (prevent boundariesthat are too close, mover boundaries to paragraph breaks)sort boundary scores and assign top n boundaries
Caroline Sporleder [email protected] Computational Models of Discourse

Determining Boundaries
Hearst (1997), p. 51
Caroline Sporleder [email protected] Computational Models of Discourse
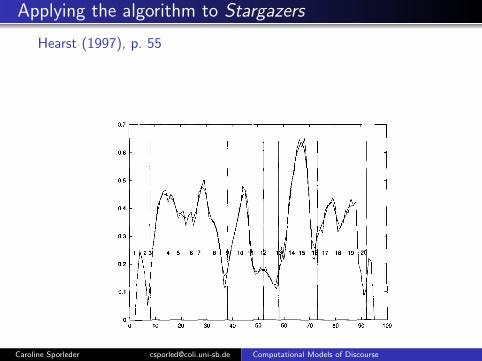
Applying the algorithm to Stargazers
Hearst (1997), p. 55
Caroline Sporleder [email protected] Computational Models of Discourse

Evaluation
Manually created gold standard
seven annotators for 12 articles
inter-annotator agreement: kappa score of .647
Kappa Score
K = P(A)−P(E)1−P(E)
where P(A) is the proportion of times that the annotators agreeand P(E ) the proportion of times that they would be expected toagree by chance.
Caroline Sporleder [email protected] Computational Models of Discourse

Evaluation
Algorithm parameters
block/window size
number of words in a token sequence
smoothing parameters
number of boundaries to assign
⇒ ideally optimise on development set
Caroline Sporleder [email protected] Computational Models of Discourse

Evaluation
Hearst (1997), p. 56
Caroline Sporleder [email protected] Computational Models of Discourse

And after TextTiling?
Other work on text segmentation
mostly also based on lexical overlap, e.g., Choi (2000): cosinebetween word vectors of adjacent sentences plus comparisonof ranks
typically evaluated on artificial data sets (join different textsand attempt to find the boundaries)
What do you think about evalutation on artificial data sets?
Caroline Sporleder [email protected] Computational Models of Discourse