comparative performance evaluation of cache-coherent numa and coma architectures per stenstrom,...
TRANSCRIPT

Comparative Performance Evaluation of Cache-Coherent
NUMA and COMA Architectures
Per Stenstrom, Truman Joe and Anoop Gupta
Presented by Colleen Lewis

Overview
• Common Features
• CC-NUMA
• COMA
• Cache Misses
• Performance Expectations
• Simulation & Results
• COMA-F

Common Features
CC-NUMA COMA
DASH Alewife DDM KSR1
• Large-scale multiprocessors
• Single address space
• Distributed main memory
• Directory-based cache coherence
• Scalable interconnection network
• Examples:

Cache-Coherent Non-Uniform-Memory-Access Machines
• Network independent
• Write-invalidate cache coherence protocol
• 2 hop miss
• 3 hop miss
CC-NUMA

COMA Cache-Only Memory Architectures
• Attraction memory – per-node memory acts as secondary/tertiary cache
• Data is distributed and mobile• Directory is dynamically distributed in a
hierarchy • Combining – can optimize multiple reads
– LU - 47%, Barnes Hut - 6%, remaining < 1%
• Reduces the average cache latency• Increased overhead for directory structure
COMA

Cache Misses
Cold miss
Capacity miss
Coherence miss
Which architecture has lower latency?
CC-NUMA COMA

Figure 1
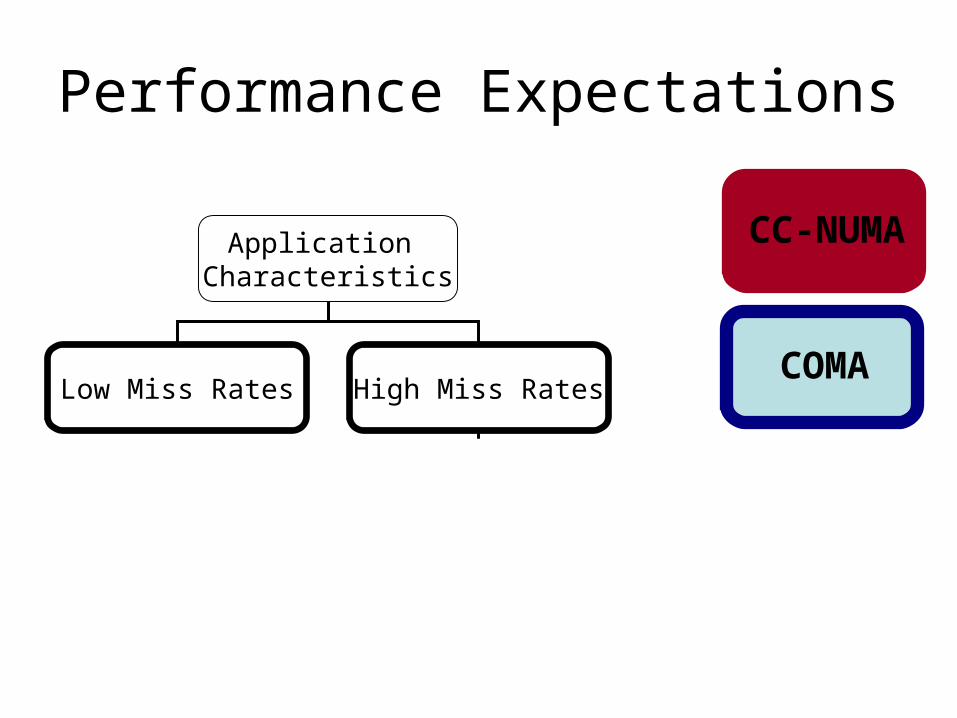
Performance Expectations
Application Characteristics
Low Miss Rates High Miss Rates
Mostly Coherence Misses
Mostly CapacityMisses
Coarse Grained Data Access
Fine GrainedData Access
CC-NUMA
COMA

Simulation
• 16 processors
• Cache lines = 16 bytes
• Cache size of 4 Kbytes – (Small – to force capacity misses)

Results
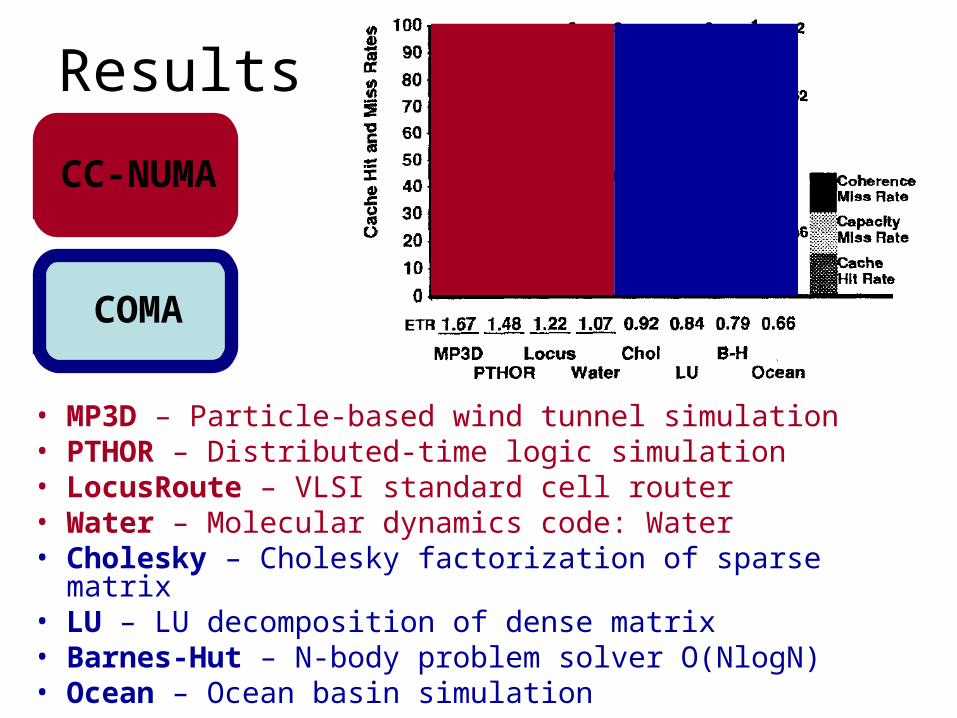
Results
• MP3D – Particle-based wind tunnel simulation• PTHOR – Distributed-time logic simulation• LocusRoute – VLSI standard cell router• Water – Molecular dynamics code: Water• Cholesky – Cholesky factorization of sparse matrix• LU – LU decomposition of dense matrix• Barnes-Hut – N-body problem solver O(NlogN)• Ocean – Ocean basin simulation
CC-NUMA
COMA

Page Migration – Page Size• Introduces additional overhead• Node hit rate increases as page size decreases
– Reduces false sharing– Fewer pages accessed by multiple processors
• Likely won’t work if data chunks are much smaller than pages (example - LU)
• NUMA-M performs better for Cholesky

Initial Placement
• Implemented as page migration with a max of 1 time that a page can be migrated
• LU does significantly better
• Ocean does the same for single vs. multiple migrations
• Requires increased work for compiler and programmer

Cache Size/Network Variations
• Cache Size Variations– Increasing the cache size causes coherence misses
to dominate– With 64KB cache, CC-NUMA (without migration) is
better for everything except Ocean.
• Network Latency Variations– Even with aggressive implementations of directory
structure, COMA can’t compensate in applications with significant coherence miss rate

COMA-F
• Data directory information has a home node (CC-NUMA)
• Supports replication and migration of data blocks (COMA-H)
• Attempts to reduce the coherence miss penalty
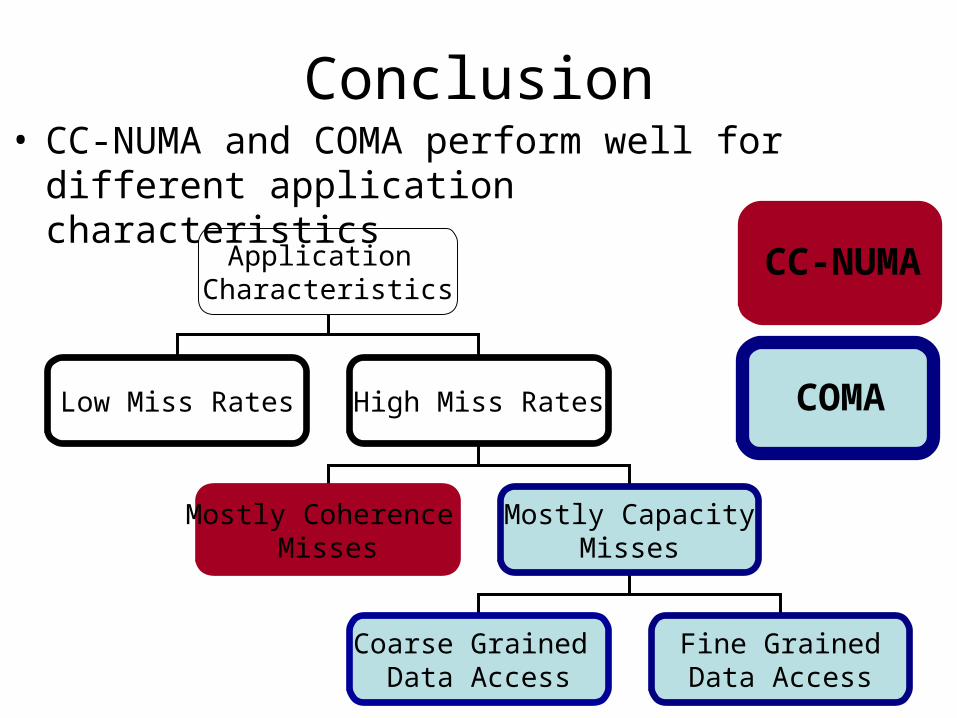
Conclusion
Application Characteristics
Low Miss Rates High Miss Rates
Mostly Coherence Misses
Mostly CapacityMisses
Coarse Grained Data Access
Fine GrainedData Access
CC-NUMA
COMA
• CC-NUMA and COMA perform well for different application characteristics