comp 3503 / 5013 dynamic neural networks daniel l. silver march, 2014 1
TRANSCRIPT

1
Comp 3503 / 5013Dynamic Neural Networks
Daniel L. SilverMarch, 2014

2
Outline
• Hopfield Networks• Boltzman Machines• Mean Field Theory• Restricted Boltzman Machines (RBM)

3
Dynamic Neural Networks
• See handout for image of spider, beer and dog• The search for a model or hypothesis can be
considered the relaxation of a dynamic system into a state of equilibrium
• This is the nature of most physical systems– Pool of water– Air in a room
• Mathematics is that of thermal-dynamics– Quote from John Von Neumann

4
Hopfield Networks
• See hand out

5
Hopfield Networks
• Hopfield Network video intro– http://www.youtube.com/watch?v=
gfPUWwBkXZY– http://faculty.etsu.edu/knisleyj/neural/
• Try these Applets:– http://lcn.epfl.ch/tutorial/english/hopfield/html/i
ndex.html– http://www.cbu.edu/~pong/ai/hopfield/
hopfieldapplet.html

6
Hopfield Networks
Basics with Geoff Hinton:• Introduction to Hopfield Nets– http://www.youtube.com/watch?v=YB3-Hn-inHI
• Storage capacity of Hopfield Nets– http://www.youtube.com/watch?v=O1rPQlKQBLQ

7
Hopfield Networks
Advanced concepts with Geoff Hinton:• Hopfield nets with hidden units– http://www.youtube.com/watch?v=bOpddsa4BPI
• Necker Cube – http://www.cs.cf.ac.uk/Dave/JAVA/boltzman/
Necker.html• Adding noise to improve search– http://www.youtube.com/watch?v=kVgT2Eaa6KA

8
Boltzman Machine
- See Handout - http://www.scholarpedia.org/article/Boltzmann_machine
Basics with Geoff Hinton• Modeling binary data– http://www.youtube.com/watch?v=MKdvJst8a6k
• BM Learning Algorithm – http://www.youtube.com/watch?v=QgrFsnHFeig

9
Limitations of BMs
• BM Learning does not scale well• This is due to several factors, the most important
being:– The time the machine must be run in order to collect
equilibrium statistics grows exponentially with the machine's size = number of nodes• For each example – sample nodes, sample states
– Connection strengths are more plastic when the units have activation probabilities intermediate between zero and one. Noise causes the weights to follow a random walk until the activities saturate (variance trap).

10
Potential Solutions
• Use a momentum term as in BP:
• Add a penalty term to create sparse coding (encourage shorter encodings for different inputs)
• Use implementation tricks to do more in memory – batches of examples
• Restrict number of iterations in + and – phases• Restrict connectivity of network
wij(t+1)=wij(t) +ηΔwij+αΔwij(t-1)
11
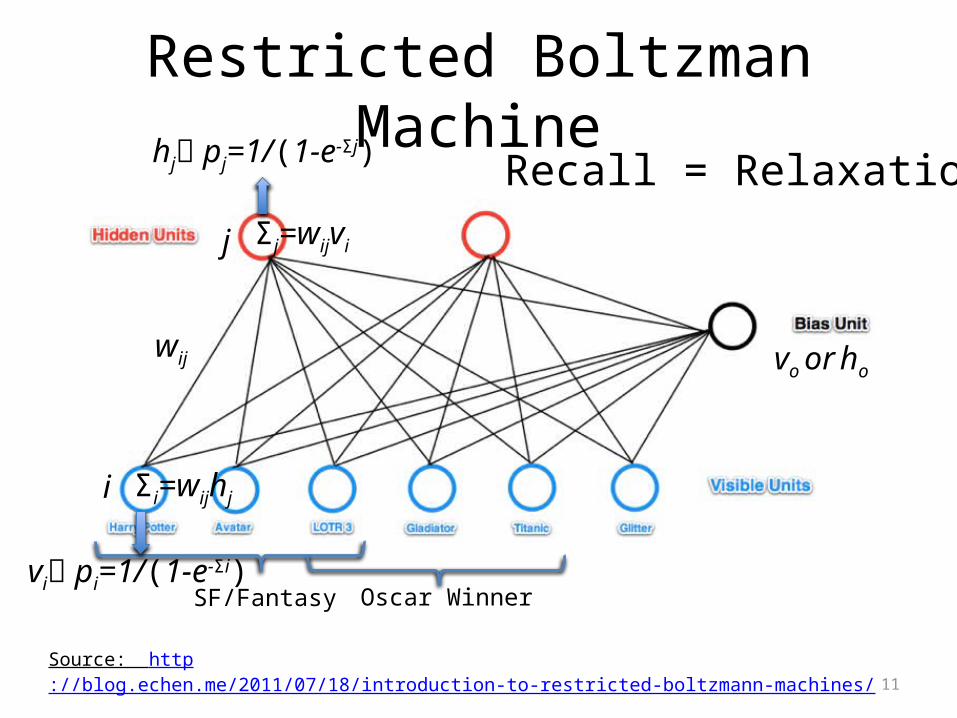
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
wij
j
i
Σj=wijvi
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Recall = Relaxation
Σi=wijhj
vo or ho

12
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
wij
j
i
Σj=wijvi
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Recall = Relaxation
Σi=wijhj
vo or ho

13
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
j
i
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Σi=wijhj
vo or ho
Oscar Winner SF/FantasyRecall = Relaxation
wij
Σj=wijvi

14
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
j
i
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Σi=wijhj
vo or ho
Oscar Winner SF/FantasyRecall = Relaxation
wij
Σj=wijvi
15
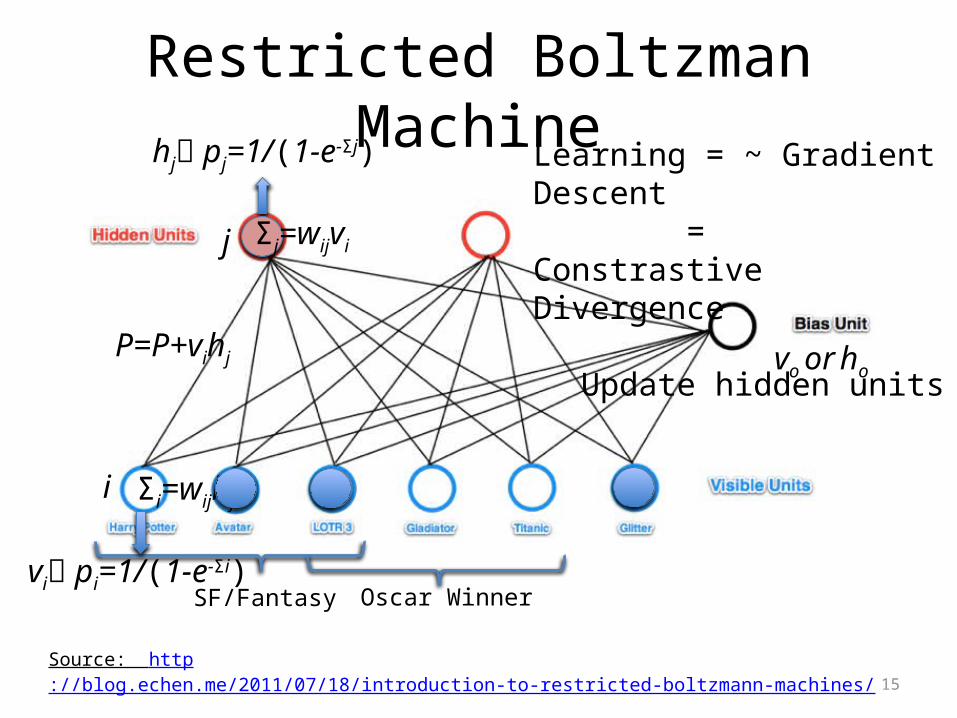
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
j
i Σi=wijhj
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Learning = ~ Gradient Descent = Constrastive Divergence
Update hidden units
P=P+vihj vo or ho
Σj=wijvi
16
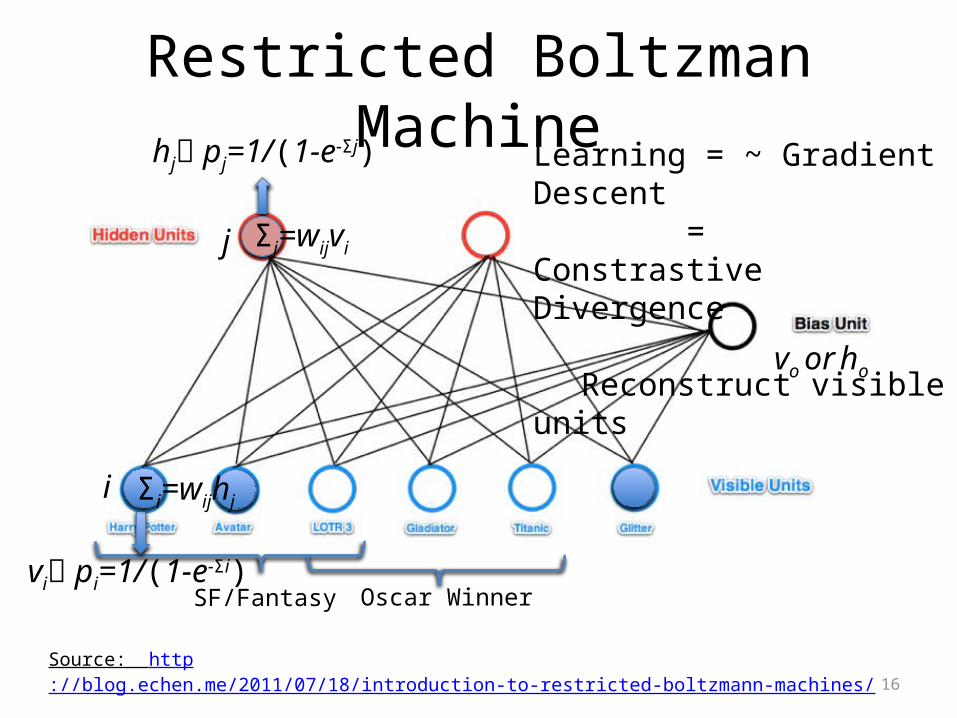
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
j
i
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Learning = ~ Gradient Descent = Constrastive Divergence
Reconstruct visible units
vo or ho
Σj=wijvi
Σi=wijhj
17
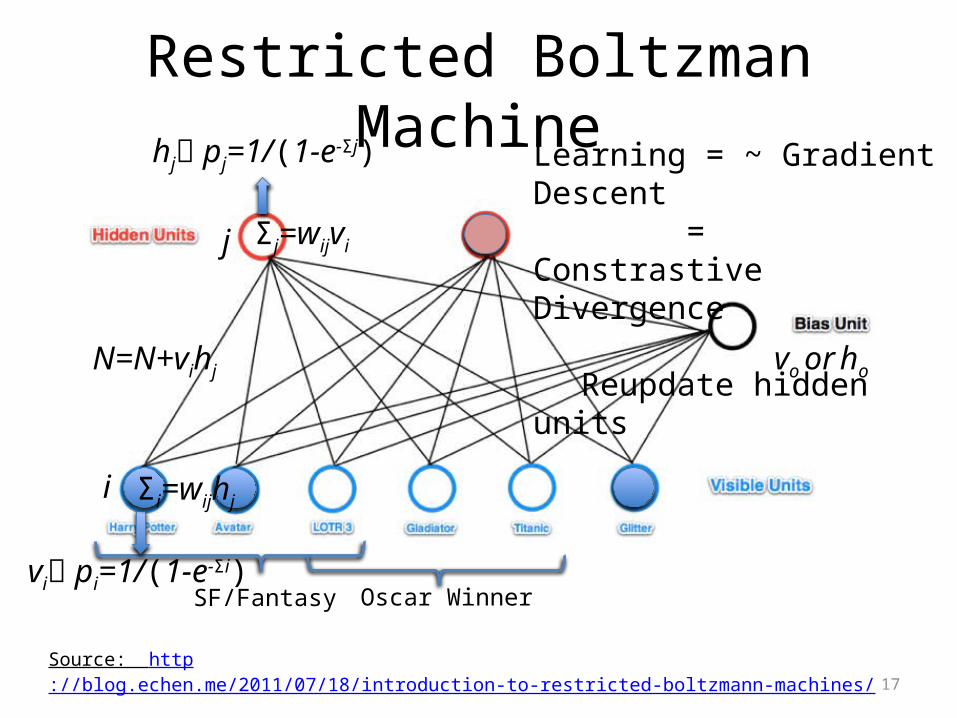
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
j
i
Σj=wijvi
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Learning = ~ Gradient Descent = Constrastive Divergence
Reupdate hidden units
vo or ho
Σi=wijhj
N=N+vihj
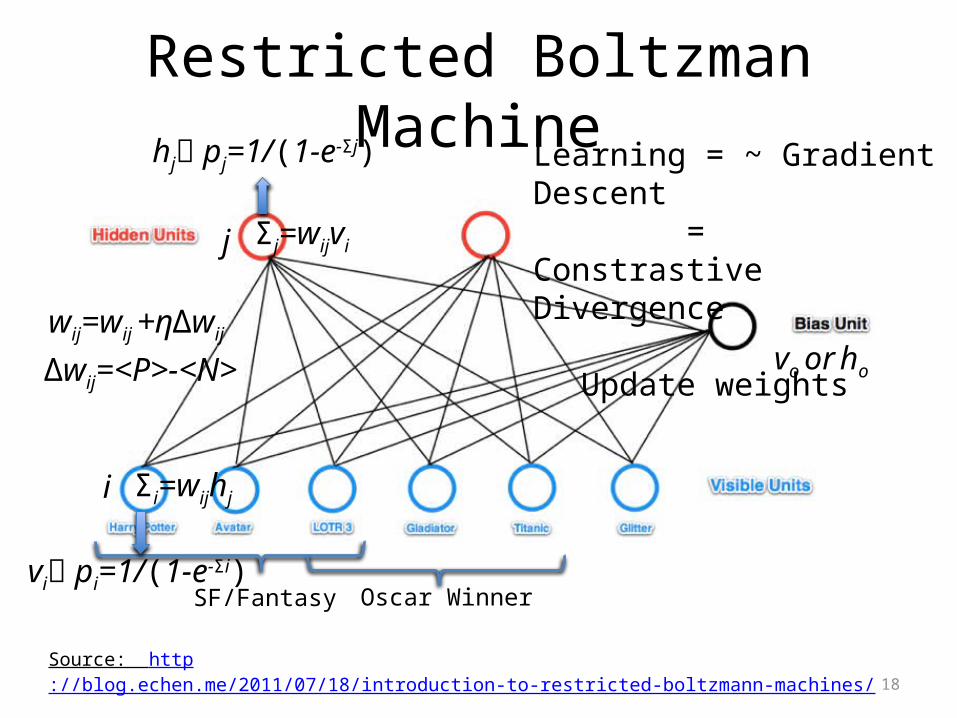
18
Restricted Boltzman Machine
Source: http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
SF/Fantasy Oscar Winner
Δwij=<P>-<N>
j
i
Σj=wijvi
hj pj=1/(1-e-Σj)
vi pi=1/(1-e-Σi)
Σi=wijhj
vo or ho
wij=wij +ηΔwij
Learning = ~ Gradient Descent = Constrastive Divergence
Update weights

19
Restricted Boltzman Machine
• RBM Overview:– http
://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
• Wikipedia on DLA and RBM:– http://en.wikipedia.org/wiki/Deep_learning
• RBM Details and Code:– http://www.deeplearning.net/tutorial/rbm.html

20
Restricted Boltzman Machine
Geoff Hinton on RBMs:• RBMs and Constrastive Divergence Algorithm– http://www.youtube.com/watch?v=fJjkHAuW0Yk
• An example of RBM Learning– http://www.youtube.com/watch?v=Ivj7jymShN0
• RBMs applied to Collaborative Filtering– http://www.youtube.com/watch?v=laVC6WFIXjg

21
Additional References
• Coursera course – Neural Networks fro Machine Learning:– https://class.coursera.org/neuralnets-2012-001/
lecture• ML: Hottest Tech Trend in next 3-5 Years– http://www.youtube.com/watch?v=b4zr9Zx5WiE