coarse-to-fine efficient viterbi parsing
DESCRIPTION
Coarse-to-Fine Efficient Viterbi Parsing. Nathan Bodenstab OGI RPE Presentation May 8, 2006. Outline. What is Natural Language Parsing? Data Driven Parsing Hypergraphs and Parsing Algorithms High Accuracy Parsing Coarse-to-Fine Empirical Results. What is Natural Language Parsing?. - PowerPoint PPT PresentationTRANSCRIPT

Coarse-to-Fine Efficient Viterbi Parsing
Nathan BodenstabOGI RPE Presentation
May 8, 2006

2
Outline
• What is Natural Language Parsing?
• Data Driven Parsing
• Hypergraphs and Parsing Algorithms
• High Accuracy Parsing
• Coarse-to-Fine
• Empirical Results

3
What is Natural Language Parsing?
• Provides a sentence with syntactic information by hierarchically clustering and labeling its constituents.
• A constituent is a group of one or more words that function together as a unit.

4
What is Natural Language Parsing?
• Provides a sentence with syntactic information by hierarchically clustering and labeling its constituents.
• A constituent is a group of one or more words that function together as a unit.

5
Why Parse Sentences?
• Syntactic structure is useful in– Speech Recognition– Machine Translation– Language Understanding
• Word Sense Disambiguation (ex. “bottle”)• Question-Answering• Document Summarization

6
Outline
• What is Natural Language Parsing?
• Data Driven Parsing
• Hypergraphs and Parsing Algorithms
• High Accuracy Parsing
• Coarse-to-Fine
• Empirical Results

7
Data Driven Parsing
• Parsing = Grammar + Algorithm• Probabilistic Context-Free Grammar
P(children=[Determiner, Adjective, Noun] | parent=NounPhrase)

8
• Find the maximum likelihood parse tree from all grammatically valid candidates.
• The probability of a parse tree is the product of all its grammar rule (constituent) probabilities.
• The number of grammatically valid parse trees increases exponentially with the length of the sentence.
Data Driven Parsing

9
Outline
• What is Natural Language Parsing?
• Data Driven Parsing
• Hypergraphs and Parsing Algorithms
• High Accuracy Parsing
• Coarse-to-Fine
• Empirical Results

10
Hypergraphs
• A directed hypergraph can facilitate dynamic programming (Klein and Manning, 2001).
• A hyperedge connects a set of tail nodes to a set of head nodes.
Standard Edge Hyperedge

11
Hypergraphs

12
The CYK Algorithm
• Separates the hypergraph into “levels”• Exhaustively traverses every hyperedge, level by level

13
The A* Algorithm
• Maintains a priority queue of traversable hyperedges• Traverses best-first until a complete parse tree is found
Pri
ori
ty Q
ueu
e

14
Outline
• What is Natural Language Parsing?
• Data Driven Parsing
• Hypergraphs and Parsing Algorithms
• High Accuracy Parsing
• Coarse-to-Fine
• Empirical Results

15
High(er) Accuracy Parsing
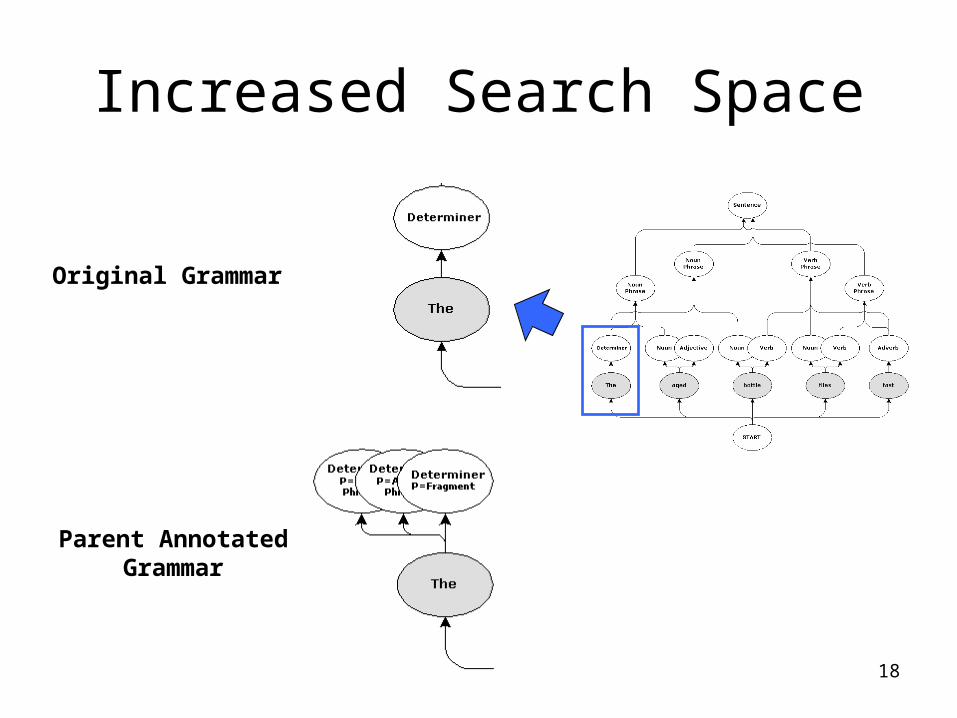
• Modify the Grammar to include more context• (Grand) Parent Annotation (Johnson, 1998)
P(children=[Determiner, Adjective, Noun] | parent=NounPhrase, grandParent=Sentence)

16
Increased Search Space
Original Grammar
Parent AnnotatedGrammar

17
Increased Search Space
Original Grammar
Parent AnnotatedGrammar
18
Increased Search Space
Original Grammar
Parent AnnotatedGrammar

19
Increased Search Space
Original Grammar
Parent AnnotatedGrammar

20
Increased Search Space
Original Grammar
Parent AnnotatedGrammar

21
Grammar Comparison
65
70
75
80
85
90
Ac
cu
rac
y %
• Exact Inference with the CYK algorithm becomes intractable.• Most algorithms using Lexical models resort to greedy search strategies.• We want to find the globally optimal (Viterbi) parse tree for these high- accuracy models efficiently.

22
Outline
• What is Natural Language Parsing?
• Data Driven Parsing
• Hypergraphs and Parsing Algorithms
• High Accuracy Parsing
• Coarse-to-Fine
• Empirical Results

23
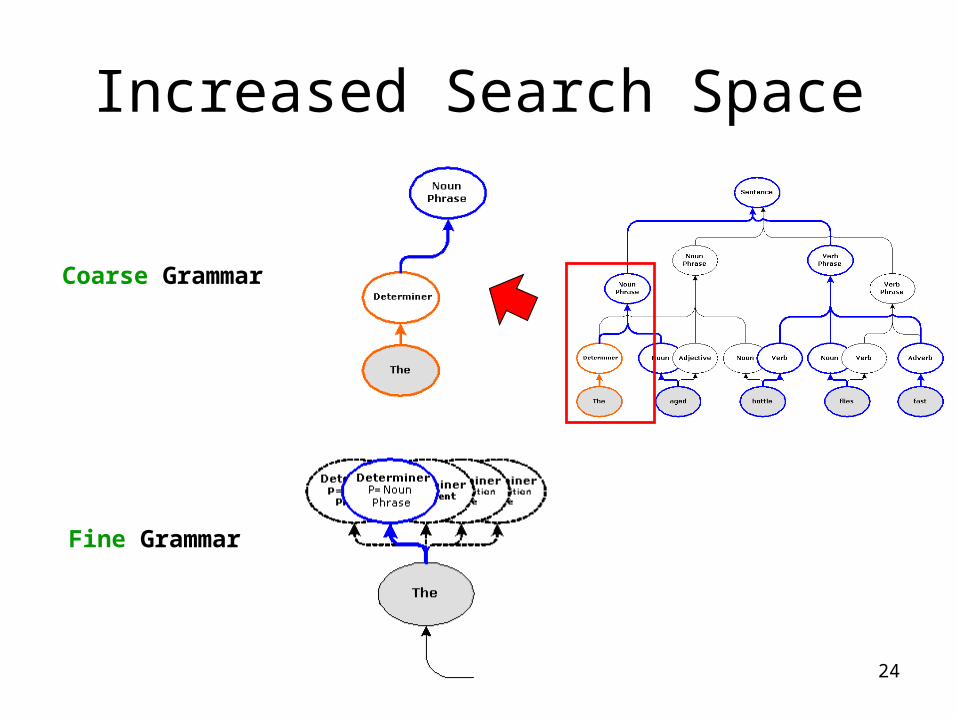
Coarse-to-Fine• Efficiently find the optimal parse tree of a large, context-enriched
model (Fine) by following hyperedges suggested by solutions of a simpler model (Coarse).
• To evaluate the feasibility of Coarse-to-Fine, we use – Coarse = WSJ– Fine = Parent
65
70
75
80
85
90
Acc
ura
cy %
24
Increased Search Space
Coarse Grammar
Fine Grammar

25
Coarse-to-Fine
Build Coarse hypergraph

26
Coarse-to-Fine
Choose a Coarse hyperedge

27
Coarse-to-FineReplace the Coarse hyperedge with Fine hyperedge (modifies probability)

28
Coarse-to-Fine
Propagate probability difference

29
Coarse-to-Fine
Repeat until optimal parse treehas only Fine hyperedges

30
Upper-Bound Grammar
• Replacing a Coarse hyperedge with a Fine hyperedge can increase or decrease its probability.
• Once we have found a parse tree with only Fine hyperedges, how can we be sure it is optimal?
• Modify the probability of Coarse grammar rules to be an upper-bound on the probability of Fine grammar rules.
nParentAPNn
,|max
nPFineNn
Coarse APAP max
where N is the set of non-terminals and is a grammar rule.A

31
Outline
• What is Natural Language Parsing?
• Data Driven Parsing
• Hypergraphs and Parsing Algorithms
• High Accuracy Parsing
• Coarse-to-Fine
• Empirical Results

32
ResultsComputational Time
0.001
0.01
0.1
1
10
100
5 7 9 11 13 15 17 19 21 23 25
Sentence Length
Tim
e (s
eco
nd
s)
CTF
CYK
A*
Search Guidance
1
10
100
1000
10000
100000
1000000
10000000
5 7 9 11 13 15 17 19 21 23 25
Sentence Length
Hy
pe
red
ge
s T
rav
ers
ed
CYK
A*
CTF

33
Summary & Future Research
• Coarse-to-Fine is a new exact inference algorithm to efficiently traverse a large hypergraph space by using the solutions of simpler models.
• Full probability propagation through the hypergraph hinders computational performance. – Full propagation is not necessary; lower-bound of log2(n)
operations.
• Over 95% reduction in search space compared to baseline CYK algorithm.– Should prune even more space with higher-accuracy (Lexical)
models.

34
Thanks

35
Choosing a Coarse HyperedgeTop-Down vs. Bottom-Up

36
Top-Down vs. Bottom-UpComputational Time Comparison
0
10
20
30
40
50
60
70
80
90
100
5 7 9 11 13 15 17 19 21 23 25
Sentence Length
Tim
e (s
eco
nd
s)
CTF Top-Down
CTF Bottom-Up
Search Guidance Comparison
0
50000
100000
150000
200000
250000
300000
5 7 9 11 13 15 17 19 21 23 25
Sentence Length
Hyp
ered
ges
Tra
vers
ed
CTF Top-Down
CTF Bottom-Up
• Top-Down• Traverses more hyperedges• Hyperedges are closer to the root• Requires less propagation (1/2)
• Bottom-Up• Traverses less hyperedges• Hyperedges are near the leaves (words) and shared by many trees• True probability of trees isn’t know at the beginning of CTF

37
Coarse-to-Fine Motivation
Optimal Coarse Tree
Optimal Fine Tree