cmsc 22200 computer architecture lecture 12: … 22200 computer architecture lecture 12: multi-core...
TRANSCRIPT

CMSC 22200 Computer Architecture Lecture 12: Multi-Core
Prof. Yanjing Li University of Chicago

Administrative Stuff ! Lab 4
" Due: 11:49pm, Saturday " Two late days with penalty
! Exam I " Grades out on Thursday
2

Where We Are in Lecture Schedule ! ISA ! Uarch
" Datapath, control " Single cycle, multi cycle
! Pipelining: basic, dependency handling, branch prediction ! Advanced uarch: OOO, SIMD, VLIW, superscalar ! Caches
! Multi-core
! Virtual memory, DRAM, …
3

Lecture Outline ! Multi-core
" Motivation " Overview and fundamental concepts
! Challenges for programmers
! Challenges for computer architects
4

Paradigm Shift: Single-Core to Multi-Core

Microarchitecture: before early/mid-2000’s
6
! Pushing for single-core performance ! Clock frequency scaling (“free” from technology scaling)
! Fast memory access: on-chip caches
! Exploiting instruction level parallelism (ILP) ! Pipelining (branch prediction, deep pipeline) ! Superscalar ! Out-of-order processing ! SIMD ! …

Microarchitecture: after early/mid-2000’s ! Focus on task-level parallelism
" Multi-core era " Proliferation of CMP (chip multi-processor)
7 Image source: Intel

Why Single-Core to Multi-Core? ! “Power wall”
" Beyond what’s allowed by technology scaling ! More complexity # more transistors # more power ! Higher clock rate # more switching # more power
" What limits power? ! Cooling
! No more large benefits from ILP " Diminishing returns " Degrees of ILP is limited " Pallock’s rule: the complexity of all the additional logic
required to find parallel instructions dynamically is approximately proportional to the square of the number of instructions that can be issued simultaneously.
8
[Olukutun Queue 05]

Multi-Core Benefits
9
! Performance " Latency (execution time) " Throughput
! Power
! Others " Complexity, yield, reliability…
! What are the tradeoffs?

Power Benefits of Multi-Core
10
! N units at frequency F/N consume less power than 1 unit at frequency F
! (Dynamic) power modeled as α * C * V2 * F
! Assume same workload, uarch, technology # α * C is constant
! Lower F # lower V (linear) # cubic reduction in Power
Switching activity
capacitance
voltage
frequency

Multi-Core Fundamentals
11

Task-Level Parallelism ! Different �tasks/threads� executed in parallel
" Contrast with ILP, or data parallelism (SIMD)
! How to create “tasks”? " Partition a single problem into multiple related tasks (threads)
! Explicitly: parallel programming
" Run many independent tasks (processes) together ! Easy when there are many processes
" Cloud computing workloads
! Does not improve the performance of a single task
12

Computers to Exploit Task-Level Parallelism ! Two types: loosely coupled vs. tightly coupled
! Loosely coupled " No shared global memory address space " Multicomputer network (e.g., datacenters, HPCs) " Data sharing is explicit, e.g., via message passing
! Tightly coupled " Shared global memory address space " E.g., Multi-core processors, multithreaded processors " Data sharing is implicit (through memory)
! Operations on shared data require synchronization
13

Tightly Coupled/Shared Memory Processors
14
! Logical view
! Many possible physical implementations " Levels of caches; uniform memory access (UMA) vs. non
uniform memory access (NUMA)

Brief Introduction to Parallel Programming

How Do Programmers Leverage Multi-Core Benefits?
! Given a single problem, cannot just rely on compilers or hardware to improve performance like how it was done in the past
! Programmers must explicitly partition the problem into multiple related tasks (threads) " Different programming models
! Pthreads ! OpenMP ! ...
" Some programs easy to partition; others are more difficult " How to guarantee correctness?
16

Example
CPU 1 CPU2 Ld r1, x Ld r1, x
Add r1, r1, 1 Add r1, r1, 1 St r1, x St r1, x
17
! Unpredictable results, called race conditions, can happen if we don’t control access to shared variables ! A concurrency problem; can occur in single processors
also
! E.g., “x++” from multiple threads ! assume x is initialized to 0. What is the value of x after
the following execution?

Coordinating Access to Shared Data (I)
! Locks: simple primitive to ensure updates to single variables occur within a critical section " Many variations (spinlocks, semaphores, …)
18
CPU 1 CPU2 LOCK x … Ld r1, x LOCK x
Add r1, r1, 1 wait St r1, x wait
UNLOCK x lock acquired Ld r1, x
Add r1, r1, 1 …

Locks: Performance vs. Correctness
! Few locks (coarse-grain locking) " E.g., use one lock for an entire shared array + Easy to write -- Poor performance )processors spend a lot of time stalled
waiting to acquire locks) ! Many locks (fine-grain locking)
" E.g., use one lock for each element in a shared array + Good performance (minimize contention to locks) -- More difficult to write -- Higher chance of incorrect program (deadlock)
! Need to consider the tradeoffs very carefully ! Privatize as much as possible to avoid locking!
19

Coordinating Access to Shared Data (II)
! Barriers: globally get all processors to the same point in program " Divides a program into easily-understood phases
20

Barrier Example
For i = 1 to N A[i] = (A[i] + B[i] ) * C[i] sum = sum + A[i]
For i = 1 to N // independent operations A[i] = (A[i] + B[i] ) * C[i]
For i = 1 to N // reduction sum = sum + A[i]
21
BARRIER

Barriers: Pros and Cons + Generally easy to reason about # easy to debug
+ Reduces the need for locks (no lock for the variable “sum”)
-- Overhead - Fast processors are stalled waiting at the barrier
22

Performance Analysis
23

Parallel Speedup ! Speedup with P cores = t1/tp
" t1 and tp: execution time using a single core and p cores, respectively
24

Parallel Speedup Example ! a4x4 + a3x3 + a2x2 + a1x + a0
! Assume add/mul operations take 1 cycle and no communication cost
! How fast is this with a single core? " Assume no pipelining or concurrent execution of instructions
! How fast is this with 3 cores?
25

Superlinear Speedup ! Can speedup be greater than N with N processing
elements?
! Unfair comparisons " Compare best parallel algorithm to wimpy serial algorithm
! Cache/memory effects " More processors # more caches # fewer misses " Sometimes, to eliminate cache effects, dataset is also
increased by a factor of N
26
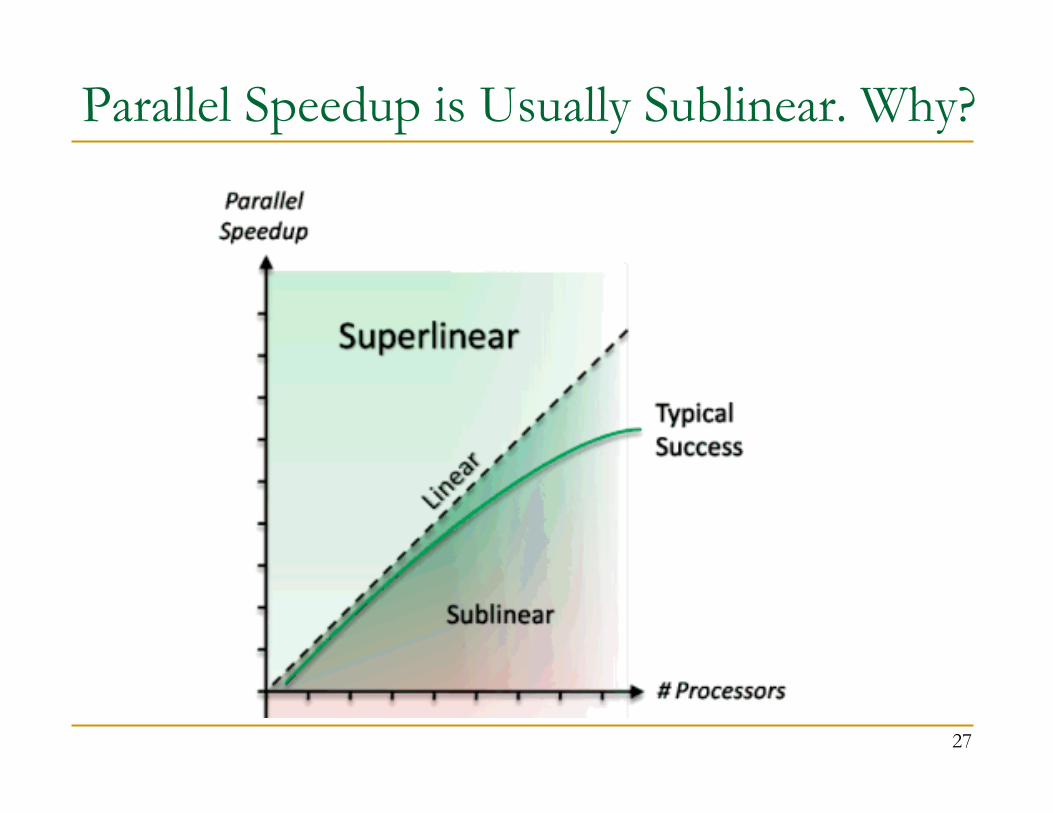
Parallel Speedup is Usually Sublinear. Why?
27

Limits of Parallel Speedup
28

I. Serial Bottleneck: Amdahl’s Law ! α: Parallelizable fraction of a program ! N: Number of processors
" Amdahl, �Validity of the single processor approach to achieving large scale computing capabilities,� AFIPS 1967.
! As N goes to infinity, speedup = 1/(1-α) " α = 99% $ max speedup = 100
! Maximum speedup limited by serial portion: Serial bottleneck
29
Speedup = 1
+ (1 – α) α N

Sequential Bottleneck ! Observations
" Diminishing returns for adding more cores " Speedup remains small until α is large
30
0
50
100
150
200
0 0.
04
0.08
0.
12
0.16
0.
2 0.
24
0.28
0.
32
0.36
0.
4 0.
44
0.48
0.
52
0.56
0.
6 0.
64
0.68
0.
72
0.76
0.
8 0.
84
0.88
0.
92
0.96
1
N=10
N=100
N=1000
α (parallel fraction)

Why the Sequential Bottleneck? ! Parallel machines have the
sequential bottleneck
! Main cause: Non-parallelizable operations on data (e.g. non-parallelizable loops)
for ( i = 0 ; i < N; i++) A[i] = (A[i] + A[i-1]) / 2
! Other causes: " Single thread prepares data and
spawns parallel tasks (usually sequential)
" Repeated code 31

What Else Can be a Bottleneck?
Solve(SubProblem);
C2
C1
B
E
A
D1
D2
A,E: Amdahl’s serial part
C1,C2: Critical SectionsD: Outside critical section
B: Parallel Portion
Lock (X)SubProblem = PQ.remove();
Unlock(X);
Unlock(X) PQ.insert(NewSubProblems);Lock(X)
NewSubProblems = Partition(SubProblem);If(problem solved) break;
while (problem not solved)
. . .
PrintSolution();
ForEach Thread:
SpawnThreads();InitPriorityQueue(PQ);
LEGEND
32
! In Amdahl’s law, Parallelizable code is “perfect”, i.e., no overhead
C2

II. Bottlenecks in Parallel Portion ! Synchronization: Operations manipulating shared data
cannot be parallelized " Locks / barrier synchronization " Communication: Tasks may need values from each other - Causes thread serialization when shared data is contended
! Load Imbalance: Parallel tasks may have different lengths " E.g., due to imperfect parallelization (e.g., 103 elements, 10 cores) - Reduces speedup in parallel portion
! Resource Contention: Parallel tasks can share hardware resources, delaying each other - Additional latency not present when each task runs alone
33

Remember: Critical Sections
! Enforce mutually exclusive access to shared data ! Only one thread can be executing it at a time ! Contended critical sections make threads wait # threads
causing serialization can be on the critical path
34
Each thread: loop { Compute lock(A) Update shared data unlock(A) }
N
C

Remember: Barriers
! Synchronization point ! Threads have to wait until all threads reach the barrier ! Last thread arriving to the barrier is on the critical path
35
Each thread: loop1 { Compute } barrier loop2 { Compute }

Parallel Programming is Challenging ! Getting parallel programs to work correctly AND ! Optimizing performance in the presence of bottlenecks
! Much of parallel computer architecture is about " Making programmer’s job easier in writing correct and high-
performance parallel programs " Designing techniques that overcome the sequential and
parallel bottlenecks to achieve higher performance and efficiency
36