cloudera development kit (cdk): hadoop application development made easier
TRANSCRIPT

11
Headline Goes HereSpeaker Name or Subhead Goes Here
Cloudera Developer Kit:Hadoop Application Development Made Easier
E. Sammer | Engineering ManagerMay 2013

22
“[I]t’s not enough to just build a scalable and stable system; the system also has to be easy enough for thousands of internal developers of all types and all skill levels to use.”
http://gigaom.com/data/how-disney-built-a-big-data-platform-on-a-startup-budget/

3
Hadoop is incredibly powerful
3

4
Hadoop is incredibly flexible
4

5
Hadoop is incredibly low-level
5

6
Hadoop is incredibly complex
6

7
A typical system (zoom 100:1)
7

8
A typical system (zoom 10:1)
8

9
A typical system (zoom 5:1)
9

10
What you actually care about
Getting data from A to BUsing it later
10

11
Infrastructure details
Serialization, file formats, and compressionMetadata capture and maintenanceDataset organization and partitioningDurability and delivery guaranteesWell-defined failure semanticsPerformance and health instrumentation
11

12
Cloudera Development Kit
Make Hadoop accessible to the enterprise developerCodify expert patterns and practicesMake the “right thing” easy and obviousAddress the most common cases
Let developers focus on business logical, not infrastructure
12

13
Cloudera Development Kit
An open source set of libraries, guides, and examples for building data-oriented systems and applicationsProvides higher level APIs atop existing components of CDHSupports piecemeal adoption via loosely coupled modules
13

14
CDK Data Module
High level APIs for interacting with datasets in HDFSConfiguration-based format and schema managementConsistent data model and serialization semanticsMetadata system integration and supportAutomatic dataset partitioning and file management
14
1515
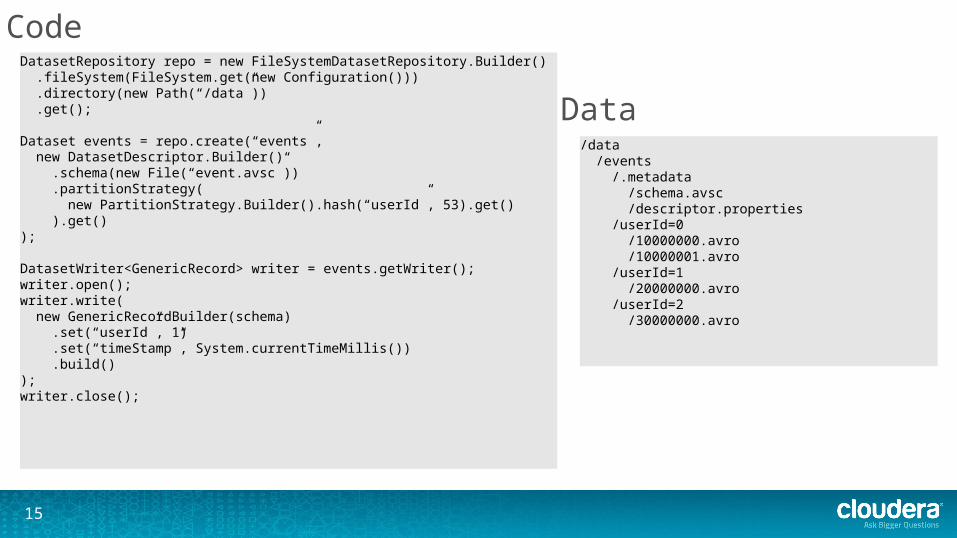
DatasetRepository repo = new FileSystemDatasetRepository.Builder() .fileSystem(FileSystem.get(new Configuration())) .directory(new Path(“/data”)) .get();
Dataset events = repo.create(“events”, new DatasetDescriptor.Builder() .schema(new File(“event.avsc”)) .partitionStrategy( new PartitionStrategy.Builder().hash(“userId”, 53).get() ).get());
DatasetWriter<GenericRecord> writer = events.getWriter();writer.open();writer.write( new GenericRecordBuilder(schema) .set(“userId”, 1) .set(“timeStamp”, System.currentTimeMillis()) .build());writer.close();
/data /events /.metadata /schema.avsc /descriptor.properties /userId=0 /10000000.avro /10000001.avro /userId=1 /20000000.avro /userId=2 /30000000.avro
Code
Data

16
Under development
Configuration-based record transformation and filtering engineData pipeline deployment, discovery, and management
Working with customers, partners, and the community on new modules and features
16

17
Getting started
CDK code repo: github.com/cloudera/cdkCDK example repo: github.com/cloudera/cdk-examplesBinary artifacts available from Cloudera’s Maven repositoryMailing list: groups.google.com/a/cloudera.org/d/forum/cdk-dev
17

18
• Submit questions in the Q&A panel
• Watch this webinar on-demand at http://cloudera.com
• Follow Cloudera @Cloudera
• Follow Cloudera Engineering @ClouderaEng
• Thank you for attending!
Learn more about the CDKhttp://cloudera.com/cdk
CDK on GitHub http://cloudera.github.io/cdk/
docs/0.2.0/

1919