cloud storage survey -...
TRANSCRIPT

Cloud storage survey
Version 1.1 Date 17th November Purpose Survey of cloud storage services provided by different providers Status In-progress Author Xiaoming Gao, Pranav Shah, Adarsh Yoga, Abhijeet Kodgire and Xiaogang Ni

Table of Contents
1 Introduction ........................................................................................... 3
2 Taxonomy .............................................................................................. 4
3 Commercial cloud Storage ...................................................................... 5
3.1 Amazon Cloud Storage Provider ....................................................................................................... 5
3.1.1 Amazon S3.................................................................................................................................. 5
3.1.2 Amazon EBS ............................................................................................................................... 6
3.1.3 Amazon SimpleDB ...................................................................................................................... 7
3.1.4 Amazon RDS .............................................................................................................................. 8
3.2 Microsoft Cloud Storage Provider ..................................................................................................... 9
3.2.1 Windows Azure Blob ................................................................................................................... 9
3.2.2 Windows Azure Table .................................................................................................................. 9
3.2.3 Windows SQL Azure ................................................................................................................. 10
4 Academic Cloud Storage ....................................................................... 10
4.1 Eucalyptus .................................................................................................................................... 10
4.2 Nimbus Cumulus ........................................................................................................................... 12
4.3 OpenNebula .................................................................................................................................. 13
4.4 OpenStack ..................................................................................................................................... 14
4.5 Hadoop Distributed File Systems (HDFS) ........................................................................................ 15
4.6 HBase ........................................................................................................................................... 15
5 Conclusion and Future Work ................................................................ 16
6 Acknowledgement ................................................................................ 16
7 References ............................................................................................ 16

Abstract Cloud Storage Systems have been under research and development for a long time in both industrial and
academic world, exemplified by Amazon Simple Storage Service (S3) [1], Amazon Elastic Block Store
[2], Nimbus Cumulus [3], Hadoop Distributed File System (HDFS) [4], etc. These systems provide
extendable storage solutions to both cloud applications and virtual machine instances hosted in clouds,
and thus play an important role in cloud computing environments, especially for solving data intensive
computing problems. However, there has been no comprehensive taxonomy and description about these
systems, and users may find it hard to choose appropriate services for their specific use cases or problems.
This report will present our work on a survey of cloud storage systems. We investigated commercial
products for cloud storage services such as Amazon Web Services [5] and Windows Azure Platform [6],
and proposed taxonomy for these storage services. Each category of services in the taxonomy has their
specific targeted use cases. For example, while object storage services are suitable for storing VM images
and large files, block storage services are mainly used to extend the disk space of running VM instances.
Based on this taxonomy, we surveyed existing open-source cloud computing systems, including Nimbus
[3], Eucalyptus [8], OpenNebula [9], OpenStack [10], and identified the type of storage services provided
by these systems. Moreover, we tried to analyze the architecture and implementation details of their
storage systems, and compare them in terms of functionality, reliability, and scalability.
This report will describe our taxonomy, demonstrate typical use cases of each type of cloud storage
systems, and present our analysis on the storage services provided by both commercial and academic
cloud platforms. We hope our work can provide both a detailed reference for cloud users, which can help
them choose the proper services for their problems, and a good starting point for researchers interested in
this area.

1 Introduction Cloud technologies having been developing fast, of which one important branch is cloud storage systems.
Different providers and cloud infrastructures are publishing new storage services from time to time, and
this generally happens in both commercial and academic world. For example, Amazon Relational
Database Service (RDS) [7] became available just in 2010, Microsoft started providing Windows Azure
Drive Service [11] (also known as XDrive) just several weeks before this report is written, and Nimbus
also started providing the Cumulus service in 2010. On the other hand, there is a lack of clear taxonomy
and summary about all the different types of cloud storage services. As a result, cloud users always find it
hard or time consuming to select the right storage services for their applications when trying to utilize
cloud resources to support their projects.
This project proposes taxonomy of cloud storage systems. Moreover, based on this taxonomy, we provide
a detailed survey about storage services from both commercial cloud providers and academic cloud
platforms, covering various aspects of them, including the categories they belong to, declared level of
quality of service (QoS), pricing models, system architecture, and implementation details. As will be
shown by our work, despite of the rich set of services provided in the field, the performance of most
storage services are not very satisfactory yet. Besides, a significant amount of work on storage services is
still needed for academic cloud infrastructures.
Since the area is producing updates in a weekly or even daily manner, this work will by no means be a
complete overview of the whole world of cloud storage systems. However, we hope this piece of work
could serve as an initial reference to help cloud users in choosing the appropriate storage services for their
applications. Furthermore, the challenges in storage systems of academic clouds presented in this report
will hopefully uncover some interesting research opportunities to the academic community.
The rest of this report is organized as follows. Section 2 will present our taxonomy of cloud storage
systems. Based on this taxonomy, Section 3 and 4 will provide a detailed survey of storage services in
both commercial and academic clouds. Section 5 will conclude and prospect our future work.
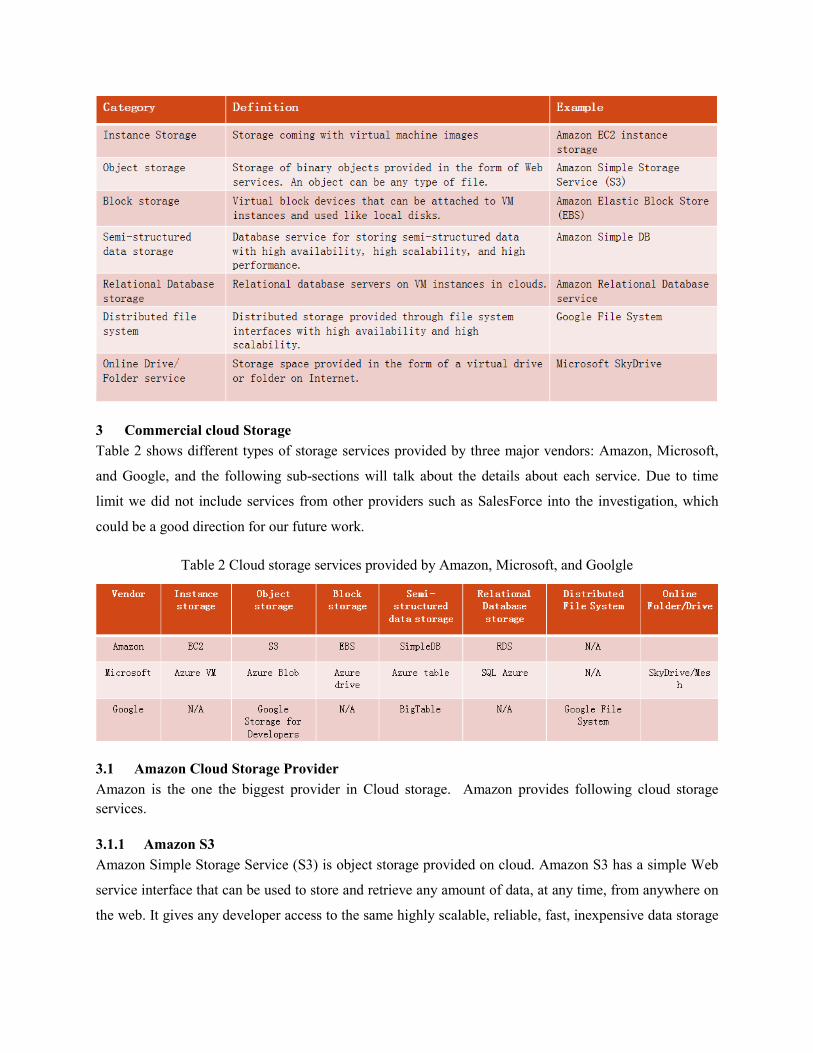
2 Taxonomy Table 1 shows our taxonomy for the cloud storage services, including the definition and examples of each
category in the taxonomy. The examples shown here are from commercial cloud providers because we
generated the taxonomy based on initial investigation of commercial cloud services, but actually the
services provided by academic cloud infrastructures also fall into this same set of categories, as will be
shown in Section 4.
Table 1 Cloud Storage Taxonomy
3 Commercial cloud Storage Table 2 shows different types of storage services provided by three major vendors: Amazon, Microsoft,
and Google, and the following sub-sections will talk about the details about each service. Due to time
limit we did not include services from other providers such as SalesForce into the investigation, which
could be a good direction for our future work.
Table 2 Cloud storage services provided by Amazon, Microsoft, and Goolgle
3.1 Amazon Cloud Storage Provider Amazon is the one the biggest provider in Cloud storage. Amazon provides following cloud storage services.
3.1.1 Amazon S3 Amazon Simple Storage Service (S3) is object storage provided on cloud. Amazon S3 has a simple Web
service interface that can be used to store and retrieve any amount of data, at any time, from anywhere on
the web. It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage

infrastructure that Amazon uses to run its own global network of web sites. The service aims to maximize
benefits of scale and to pass those benefits to developers.
Objects are the fundamental entities stored in Amazon S3. Each object in a bucket can contain up to 5 TB
of data. Objects consist of object data and metadata. The data portion is opaque to Amazon S3. The
metadata is a set of name-value pairs that describe the object. These include some default metadata such
as the date last modified and standard HTTP metadata such as Content-Type. The developer can also
specify custom metadata at the time the Object is stored. Each object is stored and retrieved using a
unique developer-assigned key. A key is the unique identifier for an object within a bucket. Every object
in a bucket has exactly one key. Because the combination of a bucket, key, and version ID uniquely
identify each object, Amazon S3 can be thought of as a basic data map between "bucket + key + version"
and the object itself.
Amazon S3 achieves high availability by replicating data across multiple servers within Amazon's data
centers. After a "success" is returned, the data is safely stored. However, information about the changes
might not immediately replicate across Amazon S3.
Some of the features provided by Amazon S3 are as follows.
1. It provides versioning of object. It enables user to keep multiple versions of an object in one bucket.
2. Customers can store their data using the Amazon S3 Reduced Redundancy Storage (RRS) option. RRS enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy than Amazon S3's standard storage.
3. The Amazon S3 architecture is designed to be programming language-neutral, using amazons supported interfaces to store and retrieve objects. Amazon S3 provides a REST and a SOAP interface.
3.1.2 Amazon EBS Amazon Elastic Block Store (EBS) provides block level storage volumes those can be attached to EC2
instances. Amazon EBS volumes are persistent storage that persists independently from the life of an EC2
instance.
Amazon EBS allows you to create storage volumes from 1 GB to 1 TB that can be mounted as devices by
Amazon EC2 instances. Multiple volumes can be mounted to the same instance. Storage volumes behave
like raw, unformatted block devices, with user supplied device names and a block device interface. You
can create a file system on top of Amazon EBS volumes, or use them in any other way you would use a
block device (like a hard drive).
Amazon EBS volumes are placed in a specific Availability Zone, and can then be attached to instances
also in that same Availability Zone. Each storage volume is automatically replicated within the same
Availability Zone. This prevents data loss due to failure of any single hardware component. Amazon EBS

also provides the ability to create point-in-time snapshots of volumes, which are persisted to Amazon S3.
These snapshots can be used as the starting point for new Amazon EBS volumes, and protect data for
long-term durability. The same snapshot can be used to instantiate as many volumes as you wish.
Features provided by Amazon EBS are as follows:
1. Amzon EBS provides you point-in-time checkpoints for backup and recovery. And these
checkpoints are incremental (copy-on-write), EBS does not store whole data of your volume but
only the data that is modified sincs your last ckeckpoint. Amazon EBS uses S3 for storing the
checkpoints.
2. The latency and throughput of Amazon EBS volumes is designed to be significantly better than
the Amazon EC2 instance stores in nearly all cases. Also Amazon EBS provide user to improve
the performance in following way.
One can attach multiple volumes to one instance and create logical stripe volume; this stripe
volume increases the volume performance to great extent.
3. Because Amazon EBS servers are replicated within a single Availability Zone, mirroring data
across multiple Amazon EBS volumes in the same Availability Zone will not significantly
improve volume durability. However, Amazon EBS provides you to create point-in-time
checkpoint that stored on Amazon S3 and automatically copied across multiple availability
zones. So one who is more concerned about the durability can create consistent checkpoints more
frequently.
3.1.3 Amazon SimpleDB Amazon simpleDB [12] is semi-structured database. It is a non-relational DB that offloads the work of
database administration. Developers simply store and query data items via web services requests, and
Amazon SimpleDB does the rest. Unbound by the strict requirements of a relational database, Amazon
SimpleDB is optimized to provide high availability, ease of scalability, and flexibility with little or no
administrative burden. Behind the scenes, Amazon SimpleDB creates and manages multiple
geographically distributed replicas of your data automatically to enable high availability and data
durability. You can change your data model on the fly, and data is automatically indexed for you. With
Amazon SimpleDB, you can focus on application development without worrying about infrastructure
provisioning, high availability, software maintenance, schema and index management, or performance
tuning.
Amazon SimpleDB provides a simple web services interface to create and store multiple data sets, query
your data easily, and return the results. Your data is automatically indexed, making it easy to quickly find
the information.
Features provided by Amazon EBS are as follows:

1. It is very simple to use. The service allows you to quickly add data and easily retrieve or edit that
data through a simple set of API calls. Accessing these capabilities through a web service also
eliminates the complexity of maintaining and scaling these operations.
2. It is very flexible. It is not necessary to pre-define all of the data formats you will need to store;
simply add new attributes to your Amazon SimpleDB data set when needed, and the system will
automatically index your data accordingly.
3. It is very scalable. Amazon SimpleDB allows you to easily scale your application.You can
quickly create new domains as your data grows or your request throughput increases. Currently,
you can store up to 10 GB per domain and you can create up to 100 domains.
4. SimpleDb is very reliable and fast. Amazon SimpleDB provides quick, efficient storage and
retrieval of your data to support high performance web applications. The service runs within
Amazon's high-availability data centers to provide strong and consistent performance.
3.1.4 Amazon RDS Amazon Relational Database Service (Amazon RDS) is a web service that makes it easy to set up,
operate, and scale a relational database in the cloud. Amazon RDS gives you access to the full capabilities
of a familiar MySQL database. This means the code, applications, and tools you already use today with
your existing MySQL databases work seamlessly with Amazon RDS.
Amazon RDS automatically patches the database software and backs up your database, storing the
backups for a user-defined retention period and enabling point-in-time recovery. Amazon RDS makes it
easy to use replication to enhance availability and reliability for production databases and to scale out
beyond the capacity of a single database deployment for read-heavy database workloads. Features
provided by Amazon EBS are as follows:
a. The automated backup feature of Amazon RDS enables point-in-time recovery for your DB
Instance. Amazon RDS will backup your database and transaction logs and store both for a user-
specified retention period. This allows you to restore your DB Instance to any second during your
retention period, up to the last five minutes.
b. DB Snapshots are user-initiated backups of your DB Instance. These full database backups will
be stored by Amazon RDS until you explicitly delete them. You can create a new DB Instance
from a DB Snapshot whenever you desire.
c. Amazon RDS provides two distinct but complementary replication features that can be used in
conjunction to gain enhanced database availability, protect your latest database updates against

unplanned outages, and scale beyond the capacity constraints of a single DB Instance for read-
heavy database workloads. Multi-AZ Deplyments and Read Replicas are two replication features.
3.2 Microsoft Cloud Storage Services
Microsoft is one the biggest cloud storage provider. Microsoft provides following cloud storage services:
3.2.1 Windows Azure Blob Microsoft Azure Blob [6] provides object storage on cloud. Azure Blob is Distributed Storage for large
data items. Each item can be up to 50GB.Azure Blob provides user distributed storage system. One can
use Azure Blob by creating containers. Each container consists of blobs and each blob is made up of
blocks. All access to Windows Azure Blob is done through a standard HTTP REST PUT/GET/DELETE
interface. Azure blob can be used to store any kind of data on cloud.
Features provided by Microsoft Azure Blob are as follows:
1. Blob containers provide the level of access control for user blob data for sharing purposes. For
instance, one can set a container to be Public readable so that everyone can read all the contents
of that container.
2. Another common use of blob containers is that some applications use a separate blob container
for each of their notion of application users. In this case, the blob container abstraction provides a
grouping mechanism for the applications, and allows the applications to manage each group
independently.
3.2.2 Windows Azure Table Microsoft Azure Table [6] is structured storage offered by Microsoft can be used to maintain the service
state. Structured storage is provided in the form of Tables, which contain a set of Entities, which contains
a set of named Properties. It Supports for LINQ, ADO .NET Data Services and REST. Features provided
by Microsoft Azure Table are as follows:
1. It supports massively scalable tables in the cloud. The system efficiently scales your tables by
automatically load balancing partitions to different servers as traffic grows. It supports a rich set
of data types for properties and can be accessed via ADO.NET Data Services and REST.
2. A compile time type checking is provided via ADO.NET Data Services which allows you to use
Windows Azure Table just as you would use a structured table. This includes supporting features
like pagination, optimistic concurrency and continuation for long running queries.

3.2.3 Windows SQL Azure SQL Azure Database [6] is a cloud database service from Microsoft. SQL Azure provides web-facing
database functionality as a utility service.TDS is protocol which is used to connect to cloud based
database. SSL is required when client connects to TDS endpoint to ensure security. Queries are
formulated in Transact-SQL language. It provides exactly similar relational database model for database
programmers. Features provided by Windows SQl Azure are as follows:
1. Manageablity : low administrative overhead as compared to on premise database.
2. Low-Friction Provisioning: you can provision your data-storage needs in minutes and respond
rapidly to changes in demand as compared to on premise database.
3. High Availability: The service replicates multiple redundant copies of your data to multiple
physical servers to ensure data availability and load balancing.
4. Scalability: A key advantage of the cloud computing model is the ease with which you can scale
your solution.
5. Developer Empowerment: SQL Azure is built on top of the TSQL language and is designed to be
compatible with SQL Server with a few changes, so developers can use their existing knowledge
and skills. This reduces the cost and time that is usually associated with creating a cloud-based
application.
4 Academic Cloud Storage Table 2 shows the different types of storage services from several major academic cloud platforms. The
following sub-sections will discuss the details related to each service.
Table 2 Storage services provided by academic cloud platforms
4.1 Eucalyptus Eucalyptus is an open source cloud computing platform that was originally developed at the University of
California at Santa Barbara. It implements Infrastructure as a Service in the forms of virtual machines and
virtual disk volumes, and provides Web service interfaces that are compatible with Amazon EC2, EBS,
and S3. Correspondingly, VM instances come with a certain amount of instance storage; Eucalyptus EBS
is an implementation of a block storage service; and Eucalyptus S3 provides object storage service.

The architecture of Eucalyptus is shown in Figure 1. The Cloud Controller, Cluster Controller, and Node
Controller are used to implement the EC2 functionalities. To support the storage functionalities, there is a
central Walrus service component which answers the clients' requests to the EBS interface and S3
interface, and there is one storage controller in each cluster managed by Eucalyptus, which manages the
storage server in that cluster. Walrus completes clients' requests by coordinating the operations of storage
controllers in all clusters.
Figure 1 Eucalyptus architecture
Eucalyptus uses its S3 service for virtual machine image management. When a user requests a virtual
machine (VM) instance based on a specific image through the EC2 interface, the Cloud Controller will
first contact the Cluster Controllers to decide which node the VM should be deployed at, and then
corresponding node controller will request the S3 interface of Walrus to transfer that image to local
storage of the physical node, and then launch the VM using the locally stored image. Different Eucalyptus
deployment may provide different sizes of VM instances, leading to different amounts of instance storage
space.
Figure 2 Eucalyptus EBS implementation

Figure 2 shows the implementation of Eucalyptus EBS. On the storage server, virtual volumes are created
in the form of files or LVM [13] volumes on users' demands. When a user requests to attach a volume to a
VM instance, the volume will first be exported as an ATA over Ethernet [15] (AoE) target on the storage
server. The physical node where the VM instance is deployed will then try to discover the AoE target.
After the discovery is complete, virtual AoE devices will be created on the physical node, and the
corresponding node controller will be able to execute the local hypervisor administration commands to
attach the virtual AoE device as a virtual block device to the specified VM instance. After the attachment
is completed, the user will be able to use the virtual volume as if it was a local disk on his/her VM
instance. Volume detachment is done with a corresponding reverse sequence of operations.
In a typical Eucalyptus configuration, e.g., that of the india.futuregrid.org site of FutureGrid [], there is
one storage server for each cluster. As a result, the storage server could create a problem of single point of
failure for EBS volumes in that cluster. Moreover, since the bandwidth and storage space of the storage
server is shared among all nodes in the cluster, the scalability of Eucalyptus EBS is limited.
4.2 Nimbus Cumulus Nimbus is an open-source toolkit focused on providing Infrastructure-as-a-Service (IaaS) capabilities to
the scientific community. To achieve this they focus on 3 main goals:
1. Allow providers to build clouds
a) Private clouds (privacy, expense considerations)
b) Workspace Service: open source EC2 implementation
2. Allow users to use cloud computing
a) Do whatever it takes to enable scientists to use IaaS
b) Context Broker: turnkey virtual clusters
c) IaaS Gateway: interoperability
3. Allow developers to experiment with Nimbus
a) For research or usability/performance improvements
b) Community extensions and contributions

Figure 1 Nimbus Architecture
The Nimbus Workspace Service provides an implementation of a compute cloud allowing users to lease
computational resources by deploying virtual machines (VMs) on those resources. A complementary tool,
Cumulus, provides an implementation of a quota-based storage cloud. Cumulus is designed for scalability
and allows providers to configure multiple storage cloud implementations. Cumulus is basically a storage
software for clouds that allows remote users to store objects using the widespread S3 protocol. It is
compatible with Amazan S3 Rest API with small exceptions and it work seamlessly with clients such as
s3cmd and boto. It also offers administrators extra functionality such as ability to specify disk quotas.
Figure 2 Who uses Nimbus [3]
4.3 OpenNebula OpenNebula is a fully open-source toolkit to build any type of IaaS cloud: private, public and hybrid.
The design of OpenNebula mainly addresses the requirements of businesses use cases from leading
companies and across multiple industries, such as Hosting, Telecom, eGovernment, Utility Computing
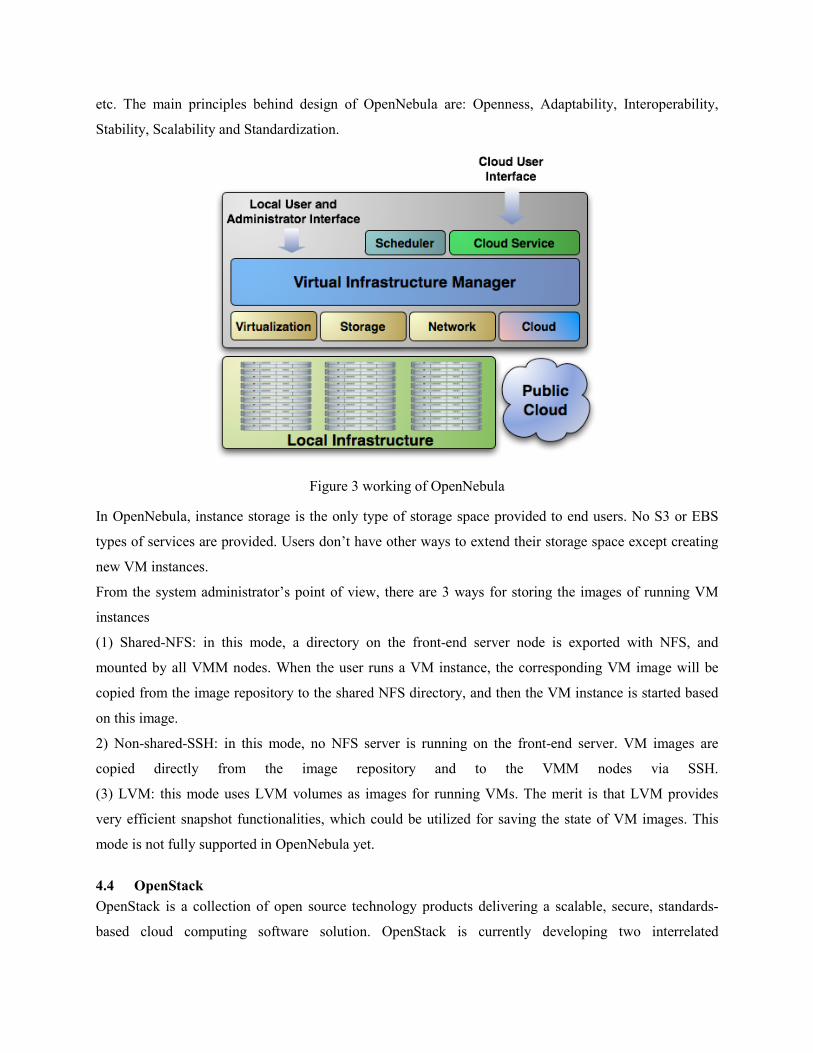
etc. The main principles behind design of OpenNebula are: Openness, Adaptability, Interoperability,
Stability, Scalability and Standardization.
Figure 3 working of OpenNebula
In OpenNebula, instance storage is the only type of storage space provided to end users. No S3 or EBS
types of services are provided. Users don’t have other ways to extend their storage space except creating
new VM instances.
From the system administrator’s point of view, there are 3 ways for storing the images of running VM
instances
(1) Shared-NFS: in this mode, a directory on the front-end server node is exported with NFS, and
mounted by all VMM nodes. When the user runs a VM instance, the corresponding VM image will be
copied from the image repository to the shared NFS directory, and then the VM instance is started based
on this image.
2) Non-shared-SSH: in this mode, no NFS server is running on the front-end server. VM images are
copied directly from the image repository and to the VMM nodes via SSH.
(3) LVM: this mode uses LVM volumes as images for running VMs. The merit is that LVM provides
very efficient snapshot functionalities, which could be utilized for saving the state of VM images. This
mode is not fully supported in OpenNebula yet.
4.4 OpenStack OpenStack is a collection of open source technology products delivering a scalable, secure, standards-
based cloud computing software solution. OpenStack is currently developing two interrelated

technologies: OpenStack Compute and OpenStack Object Storage. We studied OpenStack Object Storage
which is software for creating redundant, scalable object storage using clusters of commodity servers to
store terabytes or even petabytes of data. OpenStack can prove beneficial for Corporations, service
providers, VARS, SMBs, researchers, and global data centers looking to deploy large-scale cloud
deployments for private or public clouds. The main features of OpenStack Object Storage are: Access
control lists for stored objects, Public containers so that headers can control link access to objects and
Extensible statistics.
OpenStack Object Storage is not a file system or real-time data storage system, but rather a long term
storage system for a more permanent type of static data the can be retrieved, leveraged, and then updated
if necessary. Primary examples of data that best fit this type of storage model are virtual machine images,
photo storage, email storage, backup archiving, and so on. Objects are written to multiple hardware
devices in the data center, with the OpenStack software responsible for ensuring data replication and
integrity across the cluster. Storage clusters can scale horizontally by adding new nodes. Should a node
fail, OpenStack works to replicate its content from other active nodes. Because OpenStack uses software
logic to ensure data replication and distribution across different devices, inexpensive commodity hard
drives and servers can be used in lieu of more expensive equipment.
4.5 Hadoop Distributed File Systems (HDFS) HDFS is classified as distributed file Systems. HDFS provides file system functionalities such as file
read/write, file/directory creation and deletion, etc. HDFS provides file system API in Java, but the
semantics are not totally compatible with Posix standards. It also provides some extra functionalities,
such as listing the blocks of a file, to upper level applications or platforms such as the Hadoop
MapReduce framework. HDFS achieve file data reliability by storing multiple replica for file blocks, and
users can configure the reliability level by specifying different values for the replica number parameter.
HDFS can scale to thousands of servers, and is being used to store 25 PB of data in Yahoo.
4.6 HBase HBase [14] is classified as semi-structured database storage. It is basically a column oriented, multi-
dimensional database storage. It is indexed with row keys and column keys. There is no SQL, no joins
and no query engine. It provides support using JAVA API, as well as a Restful Web service gateway. It is
built on top of HDFS and therefore is as reliable as HDFS. Its main feature is high availability and high
performance. It can support structure with billions of rows * millions of rows. It can be good for
applications that require semi-structured data and needs flexible data schema or large scale storage.

5 Conclusion and Future Work Several attractive features are offered by academic cloud providers, and suit scientific applications nicely.
Among those, elastic resource provisioning enables applications to expand and relax computing instances
as needed to scale and save costs respectively. Affordable and reliable persistent storage are also
amenable to supporting the data deluge that is often present in scientific applications. But the academic
cloud systems are not providing a rich set of storage services so far. On the other hand, the marketplace
for commercial cloud storage services is already a hotly contested space – there are literally dozens of
companies fighting it out in a variety of different verticals. Our taxonomy of cloud storage services
attempts to classify some of them, and breaks them down according to functionality, targeted cloud users,
use cases, and focuses on different features.
Since storage itself is rapidly becoming a commodity (courtesy of providers like Amazon S3, Rackspace,
Microsoft Azure, and Google), the features, performance, and price of services is where end users will
have to make their choices. For example, one costs less but another may offer more value. One direction
for our future work is to include more emerging services from other providers, such as SalesForce,
DropBox, and Box.net, to our survey scope. We will also work on performance tests for commercial
storage services and complete more investigation on design and implementation details of open source
cloud storage systems, such as node membership management in clustered storage backend, and so on.
We believe further investigation can uncover more challenges and research opportunities for researchers
in the cloud community.
6 Acknowledgement We would like to thank Prof. Qiu for her insight to our work, and for encouraging us to submit our work
as a poster to CloudCom2010. We also would like to thank the FutureGrid group for presenting many
interesting and informative talks during the classes, and we got the answers of some questions in this
report from them. Finally, we would like to thank all the classmates for their interests on our work and
helpful suggestions.
7 References [1] Amazon S3, http://aws.amazon.com/s3/.
[2] Amazon EBS, http://aws.amazon.com/ebs/.
[3] Nimbus project, http://www.nimbusproject.org/.
[4] K. Shvachko, H. Kuang, S. Radia, R. Chansler, " The Hadoop Distributed File System", Proceedings
of IEEE MSST 2010, Incline Village, NV, USA, May 2010.
[5] Amazon Web Services, http://aws.amazon.com/.
[6] Windows Azure Platform, http://www.microsoft.com/windowsazure/.

[7] Amazon RDS, http://aws.amazon.com/rds/.
[8] D. Nurmi, R. Wolski, C. Grzegorczyk, G. Obertelli, S. Soman, L. Youseff, D. Zagorodnov, "The
Eucalyptus Open-Source Cloud-Computing System", Proceedings of CCGRID 2009, Shanghai, China,
May 2009.
[9] B. Sotomayor, R. S. Montero, I.M. Llorente, I. Foster, " Virtual Infrastructure Management in Private
and Hybrid Clouds", J. IEEE Internet Computing, vol. 13, no. 5, Sept.-Oct. 2009.
[10] OpenStack, http://openstack.org/.
[11] Windows Azure Drive, http://blogs.msdn.com/b/windowsazure/archive/2010/02/02/beta-release-of-
windows-azure-drive.aspx.
[12] Amazon SimpleDB, http://aws.amazon.com/simpledb/.
[13] LVM, http://tldp.org/HOWTO/LVM-HOWTO/.
[14] HBase, http://hbase.apache.org/.
[15] S. Hopkins, B. Coile, “The ATA over Ethernet Protocol Specification”, Technical Report, The
Brantley Coile Company, Inc., February 2009.