clipper: a low-latency online prediction serving system: spark summit east talk by dan crankshaw
TRANSCRIPT

Daniel CrankshawSpark Summit East
February 2017
A Low-Latency Online Prediction Serving System
Clipper

BigData
Big Model
Training
Learning
Timescale: minutes to daysSystems: offline and batch optimizedHeavily studied ... major focus of the AMPLab

BigData
Big Model
Training
Application
Decision
Query
?
Learning Inference
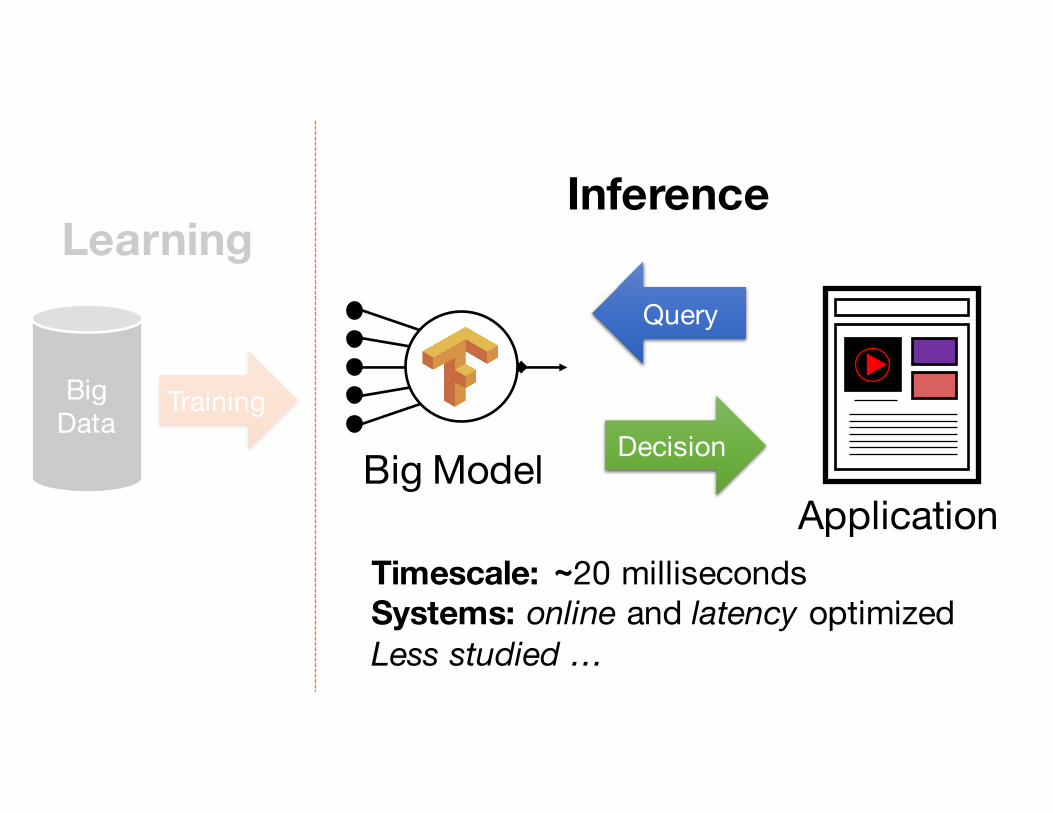
BigData
Training
LearningInference
Big ModelApplication
Decision
Query
Timescale: ~20 millisecondsSystems: online and latency optimizedLess studied …

BigData
Big Model
Training
Application
Decision
Query
Learning Inference
Feedback

BigData
Training
Application
Decision
Learning Inference
Feedback
Timescale: hours to weeksSystems: combination of systemsLess studied …

BigData
Big Model
Training
Application
Decision
Query
Learning Inference
Feedback

BigData
Big Model
Training
Application
Decision
Query
Learning Inference
Feedback
Responsive(~10ms)
Adaptive(~1 seconds)

Example: Fraud Detection

Serving Predictions Today
BigData
Big Model
Training
Offline Batch System
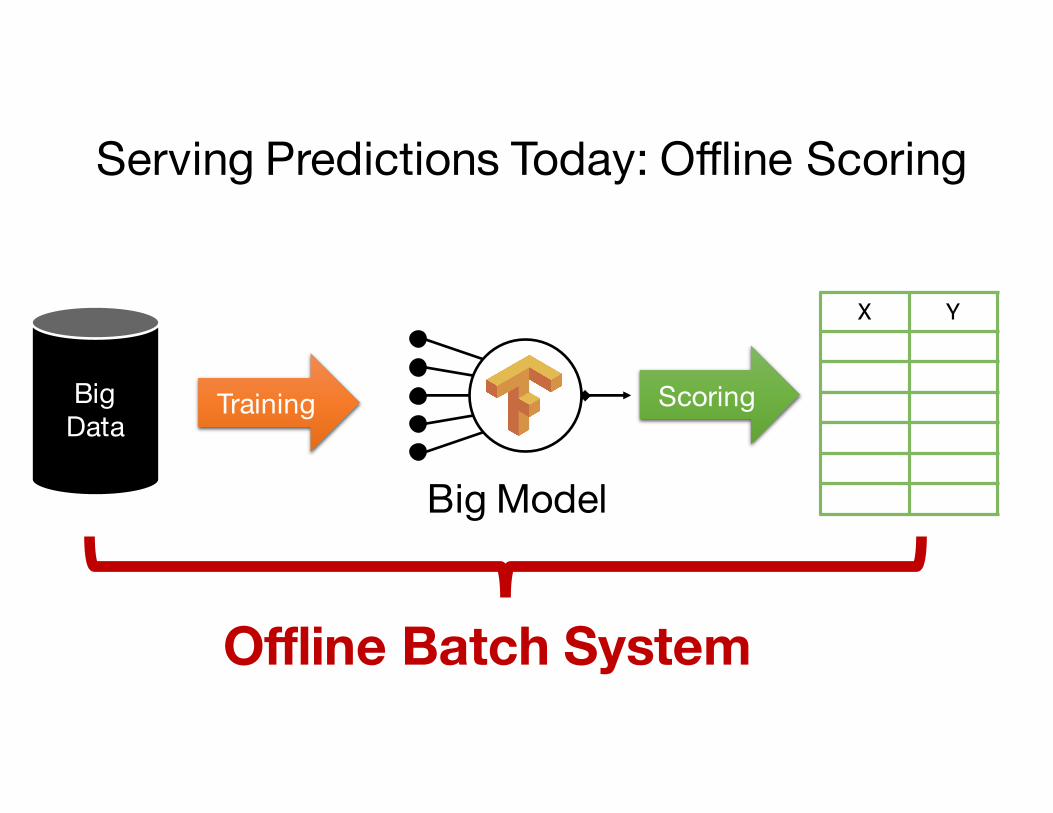
BigData
Big Model
Training
Offline Batch System
Scoring
X Y
Serving Predictions Today: Offline Scoring

Serving Predictions Today: Offline Scoring
X Y
Application
Decision
Query
Look up decision in KV-Store
Online Serving System

Serving Predictions Today: Offline Scoring
X Y
Application
Decision
Query
Look up decision in KV-Store
Online Serving System
Problems:Ø Requires full set of queries ahead of time
Ø Small and bounded input domainØ Wasted computation and space
Ø Can render and store unneeded predictionsØ No feedback and costly to update

Serving Predictions Today: Online Scoring
Application
Decision
Query
Render prediction with model in real-time
Online Serving System
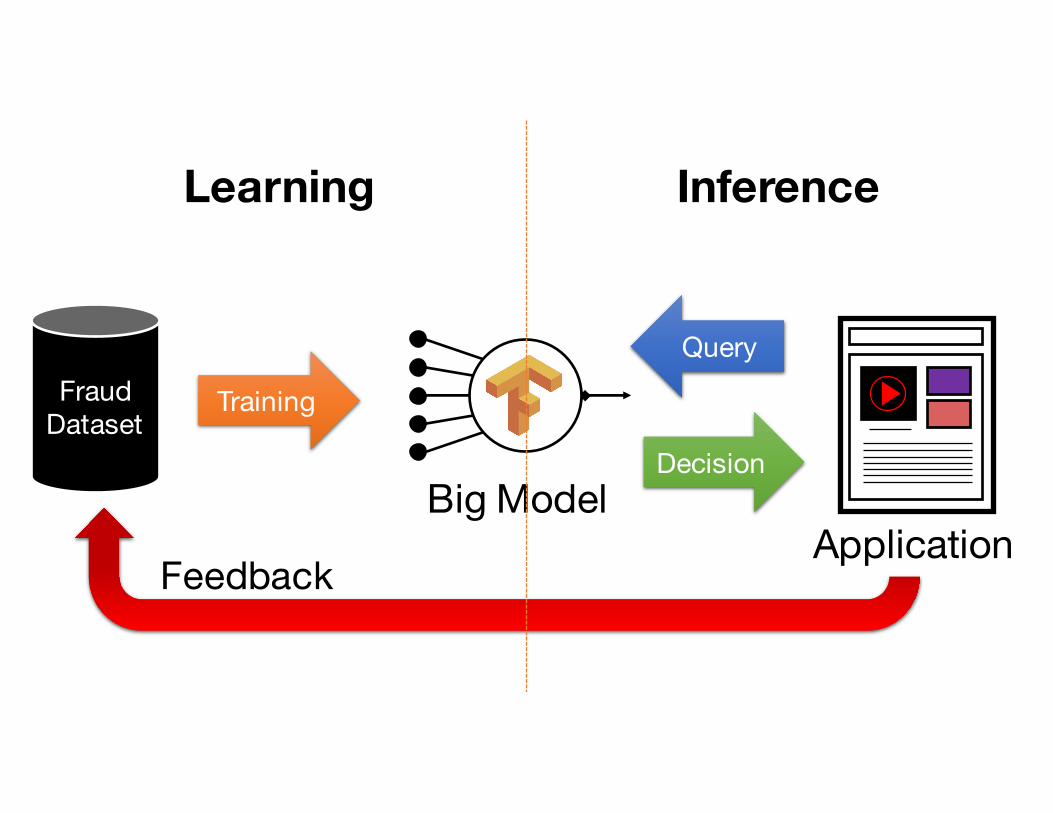
FraudDataset
Big Model
Training
Application
Decision
Query
Learning Inference
Feedback
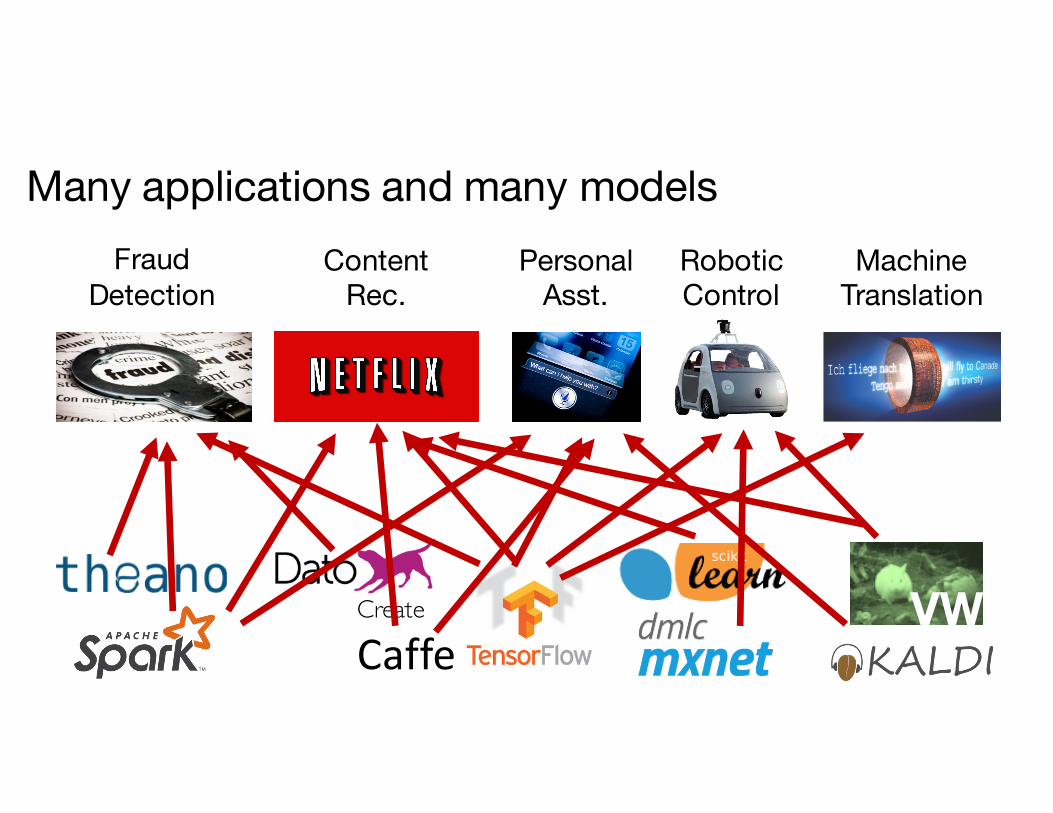
???
ContentRec.
FraudDetection
PersonalAsst.
RoboticControl
MachineTranslation
Create VWCaffe
Many applications and many models
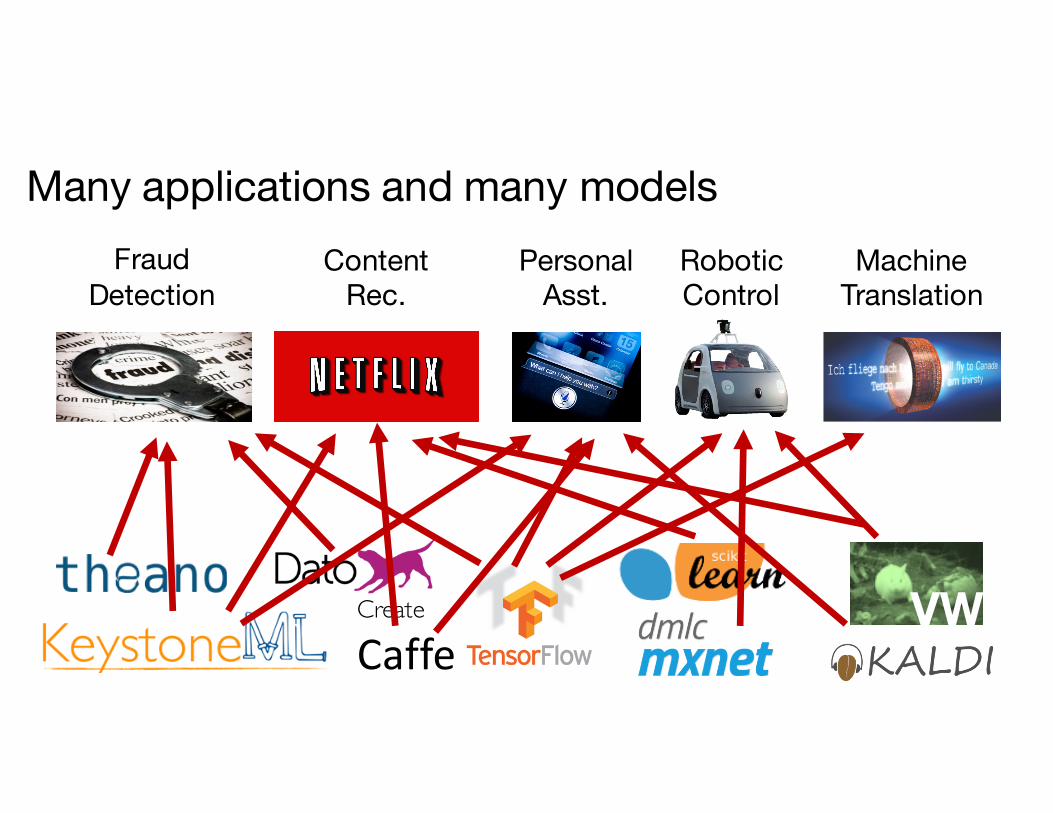
Many applications and many models
???
ContentRec.
FraudDetection
PersonalAsst.
RoboticControl
MachineTranslation
Create VWCaffe

Can we decouple models and applications?
???
ContentRec.
FraudDetection
PersonalAsst.
RoboticControl
MachineTranslation
Create VWCaffe

Requirements • System cannot stand in way of independent evolution of applications
models, empowers• enables separate evolution, development
• From perspective of data scientist• Ease of application evolution
• model rollout• application deployment• support for wide range of frameworks that data scientists• improve accuracy, use cutting edge techniques, frameworks• experiment with models in predictions
• Don’t have to worry about applications (performance• Frontend developer
• Stable, reliable, performant APIs (need systems that meet their SLOs)• scale system, hardware to meet application demands
• Don’t worry about models (oblivious to underlying)

Requirements• Decouple applications from models and allow them to evolve
independently from each other• The Data Scientist perspective: focus on making accurate
predictions• Support many models, frameworks• Simple deployment and online experimentation• (Mostly) oblivious to system performance and workload demands
• The Frontend Dev perspective: focus on building reliable, low-latency applications• Provide stable, reliable, performant APIs (need systems that meet their
SLOs)• scale system, hardware to meet application demands
• Oblivious to the implementations of the underlying models

Prediction-Serving System:Ø Decouple applications from models and allow them to
evolve independently from each otherØ The Frontend Dev perspective: focus on building reliable,
low-latency applicationsØ Provide stable, reliable, performant APIs to meet SLAs
Ø scale system, hardware to meet application demandsØ Oblivious to the implementations of the underlying models
Ø The Data Scientist perspective: focus on making accurate predictionsØ Support many models and frameworks simultaneouslyØ Simple deployment and online experimentationØ (Mostly) oblivious to system performance and workload demands
Requirements

Clipper
Predict FeedbackRPC/REST Query Interface
Applications
create_application()deploy_model()
Management REST APIreplicate_model()inspect_instance()
From the Frontend Dev perspective

From the Data Scientist perspective
class ModelContainer:def __init__(model_data)def predict_batch(inputs)
Implement Model API:

From the Data Scientist perspective
class ModelContainer:def __init__(model_data)def predict_batch(inputs)
Implement Model API:
Ø Implemented in many languagesØ PythonØ JavaØ C/C++Ø RØ …

From the Data Scientist perspective
Model implementation packaged in container
Model Container (MC)
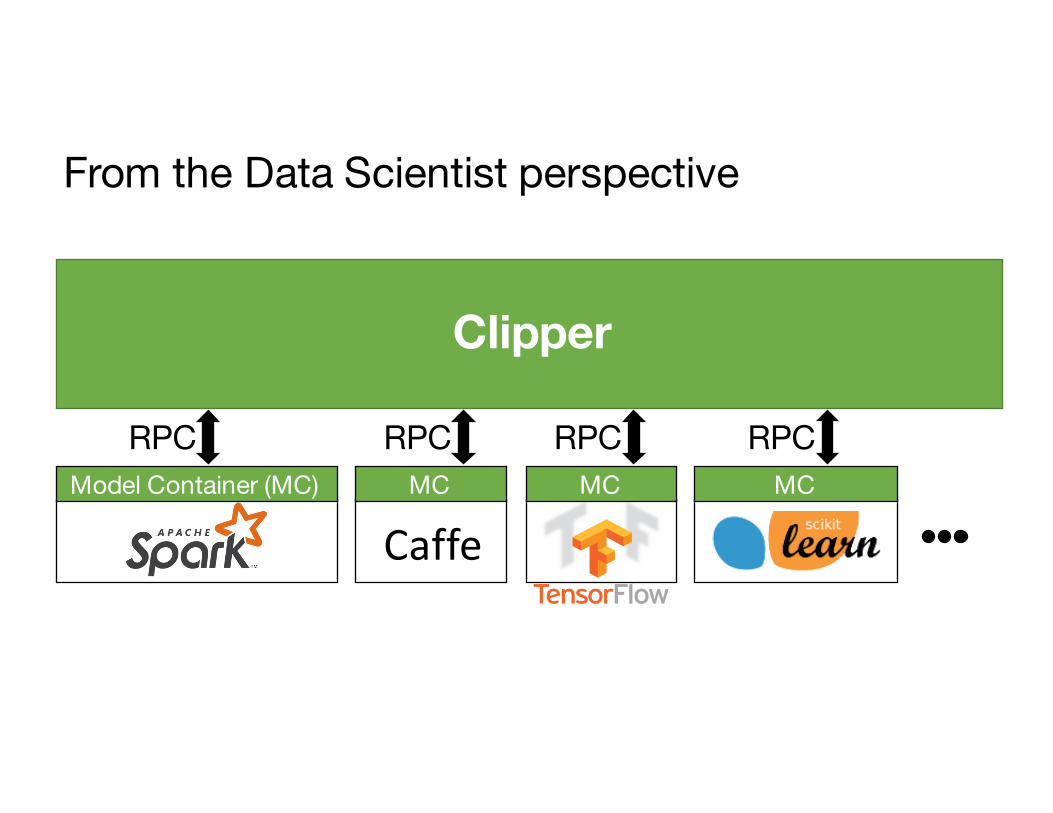
Clipper
CaffeMC MC MC
RPC RPC RPC RPC
From the Data Scientist perspective
Model Container (MC)

Clipper
Predict FeedbackRPC/REST Interface
Model Container (MC)
CaffeMC MC MC
RPC RPC RPC RPC
From the data scientist perspective
Applications
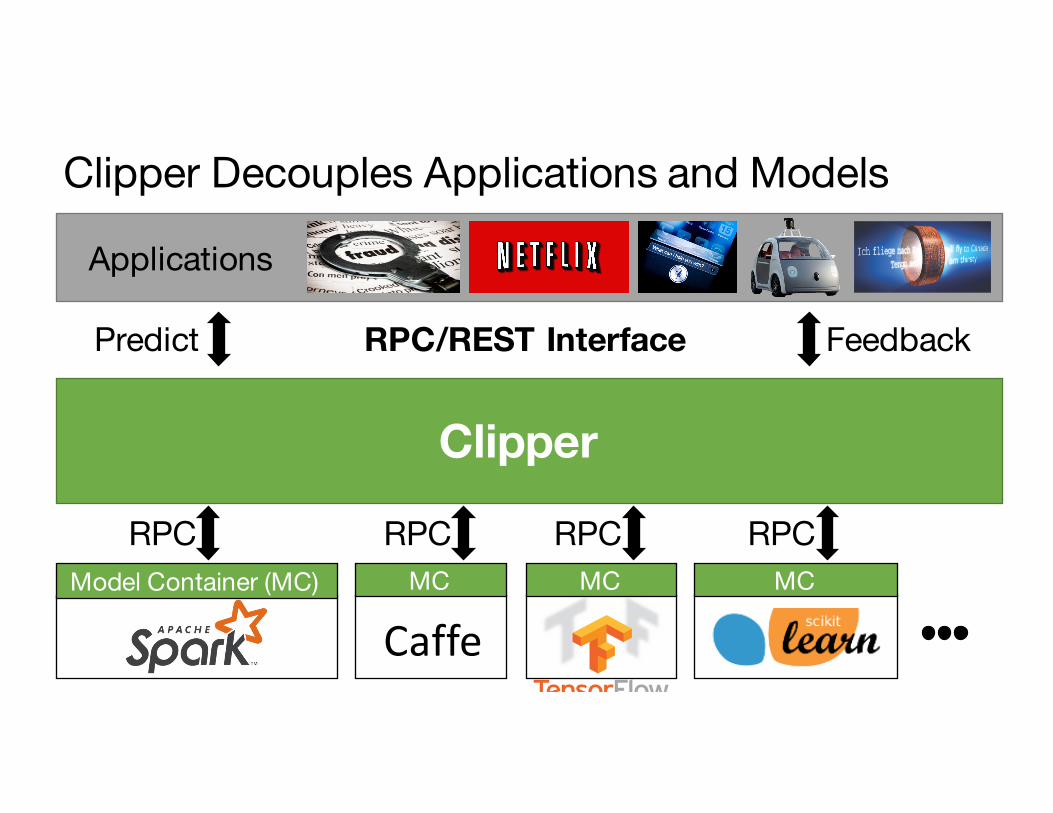
Clipper
Predict FeedbackRPC/REST Interface
CaffeMC MC MC
RPC RPC RPC RPC
Clipper Decouples Applications and Models
Applications
Model Container (MC)

Clipper Generalizes Models Across ML Frameworks
Clipper
ContentRec.
FraudDetection
PersonalAsst.
RoboticControl
MachineTranslation
Create VWCaffe

DEMO

ClipperCreate VWCaffeKey Insight:
The challenges of prediction serving can be addressed between end-user applications and machine learning frameworks
As a result, Clipper is able to:Ø hide complexity
Ø by providing a common prediction interface to applicationsØ bound latency and maximize throughput
Ø through caching, adaptive batching, model scaleoutØ enable robust online learning and personalization
Ø through model selection and ensemble algorithmswithout modifying machine learning frameworks or end-user applications

ClipperAs a resultØ hide complexity
Ø by providing a common prediction interface to applicationsØ bound latency and maximize throughput
Ø through caching, adaptive batching, model scaleoutØ enable robust online learning and personalization
Ø through model selection and ensemble algorithmswithout modifying machine learning frameworks or end-user applications
Clipper Decouples Applications and Models

ChallengesØ Managing heterogeneity everywhere
Ø different types of models (different software, different resource requirements) in a production environment
Ø Different application performance requirementsØ workloads, latencies
Ø Scheduling (space-time resource management)Ø Where and when to send prediction queries to models
Ø Latency-accuracy tradeoffsØ Marginal utility of allocating additional resources
Ø How to use feedback to improve accuracy in real-time
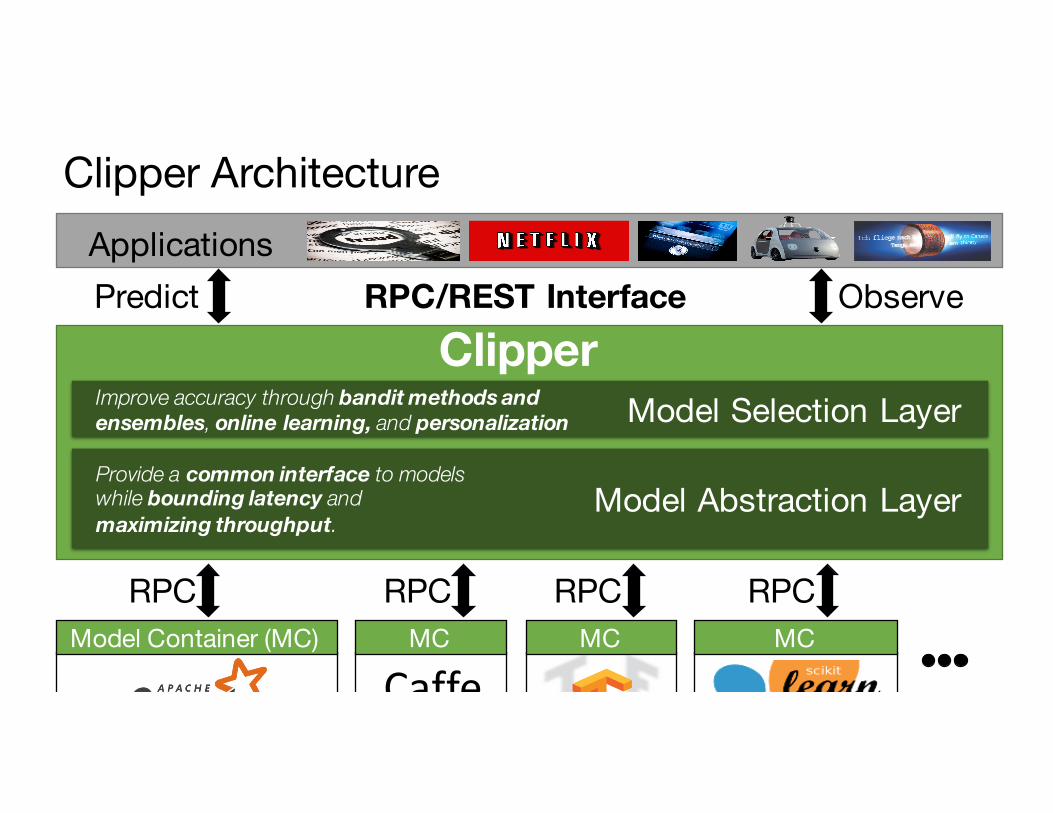
Clipper Architecture
Clipper
Caffe
ApplicationsPredict ObserveRPC/REST Interface
MC MC MCRPC RPC RPC RPC
Model Abstraction LayerProvide a common interface to modelswhile bounding latency and maximizing throughput.
Model Selection LayerImprove accuracy through bandit methods and ensembles, online learning, and personalization
Model Container (MC)
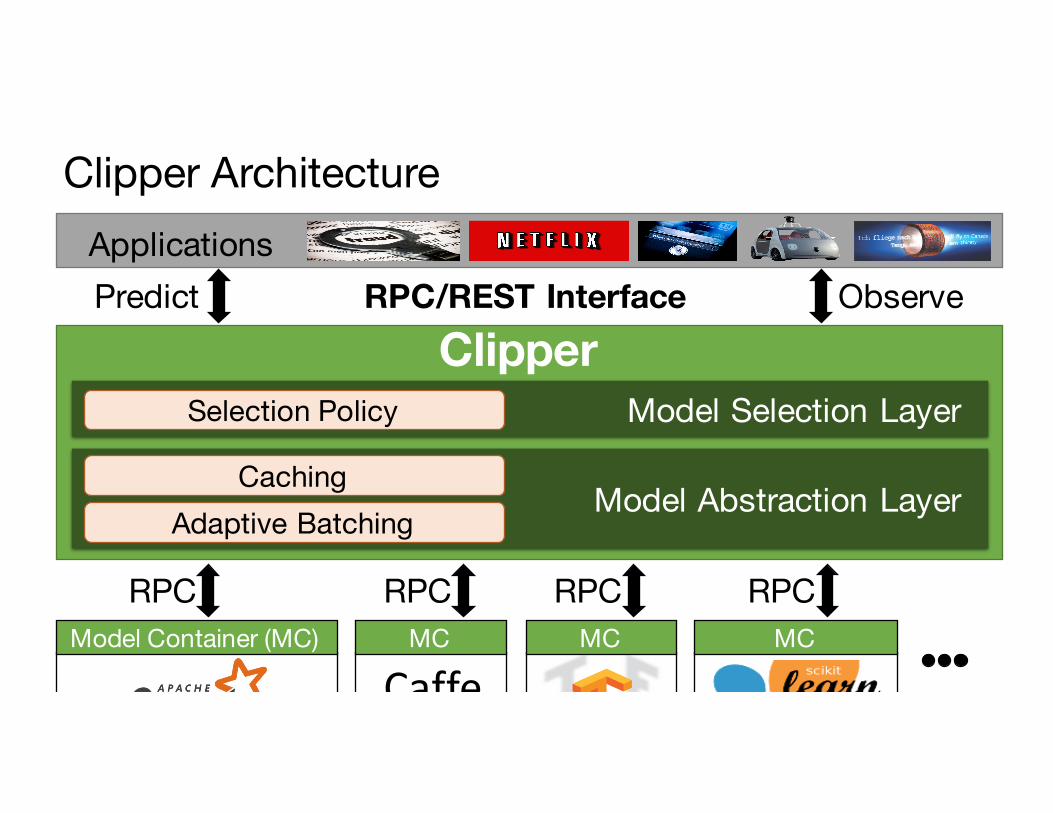
Clipper Architecture
Clipper
Caffe
ApplicationsPredict ObserveRPC/REST Interface
MC MC MCRPC RPC RPC RPC
Model Selection LayerSelection Policy
Model Abstraction LayerCaching
Adaptive Batching
Model Container (MC)

Model Container (MC)
Caffe
Correction LayerCorrection Policy
MC MC MCRPC RPC RPC
Model Abstraction LayerCaching
Adaptive Batching
Provide a common interface to models while
RPC

Correction LayerCorrection Policy
Model Container (MC)RPC
CaffeMC
RPCMC
RPCMC
RPC
Model Abstraction LayerCaching
Adaptive Batching
Common Interface à Simplifies Deployment: Ø Evaluate models using original code & systemsØ Models run in separate processes as Docker containers
Ø Resource isolation

Correction LayerCorrection Policy
Model Abstraction LayerCaching
Adaptive Batching
Model Container (MC)RPC
CaffeMC
RPCMC
RPCMC
RPCMC
RPCMC
RPC
Common Interface à Simplifies Deployment: Ø Evaluate models using original code & systemsØ Models run in separate processes as Docker containers
Ø Resource isolationØ Scale-out
Problem: frameworks optimized for batch processing not latency

A single page load may generatemany queries
Adaptive Batching to Improve ThroughputØ Optimal batch depends on:
Ø hardware configurationØ model and frameworkØ system load
Clipper Solution:
be as slow as allowed…
Ø Inc. batch size until the latency objective is exceeded (Additive Increase)
Ø If latency exceeds SLO cut batch size by a fraction (Multiplicative Decrease)
Ø Why batching helps:
HardwareAcceleration
Helps amortizesystem overhead
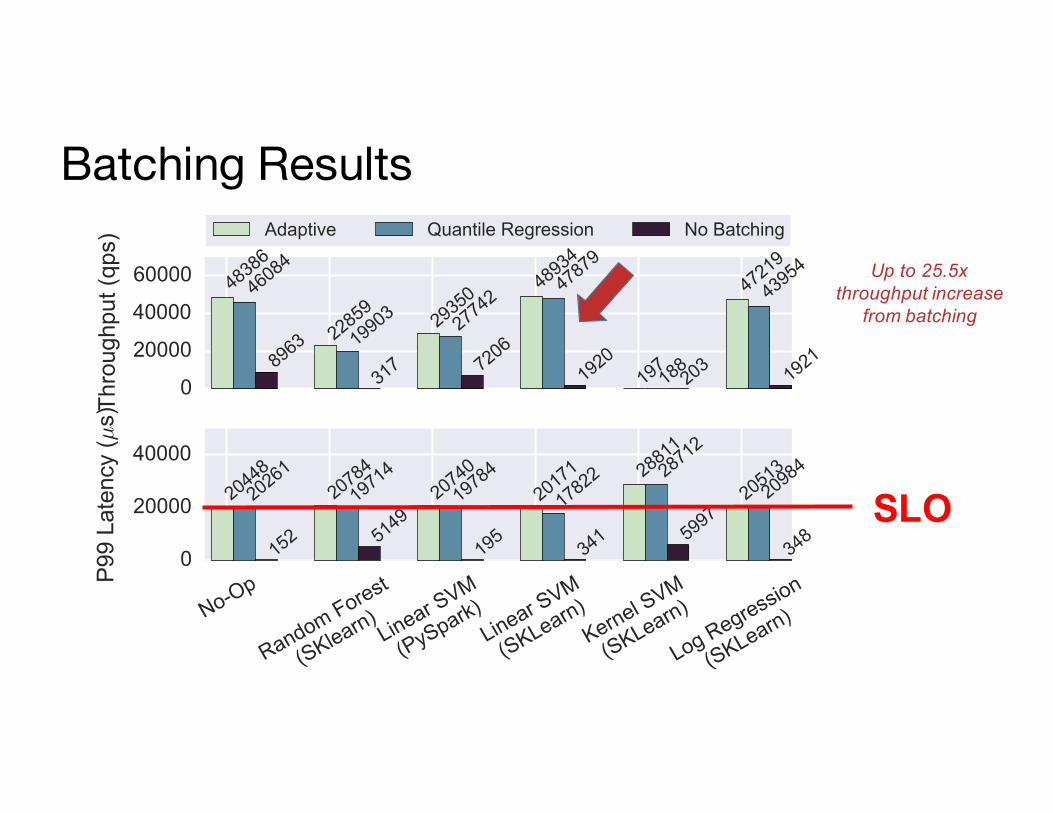
Batching Results
SLO
Up to 25.5x throughput increase
from batching
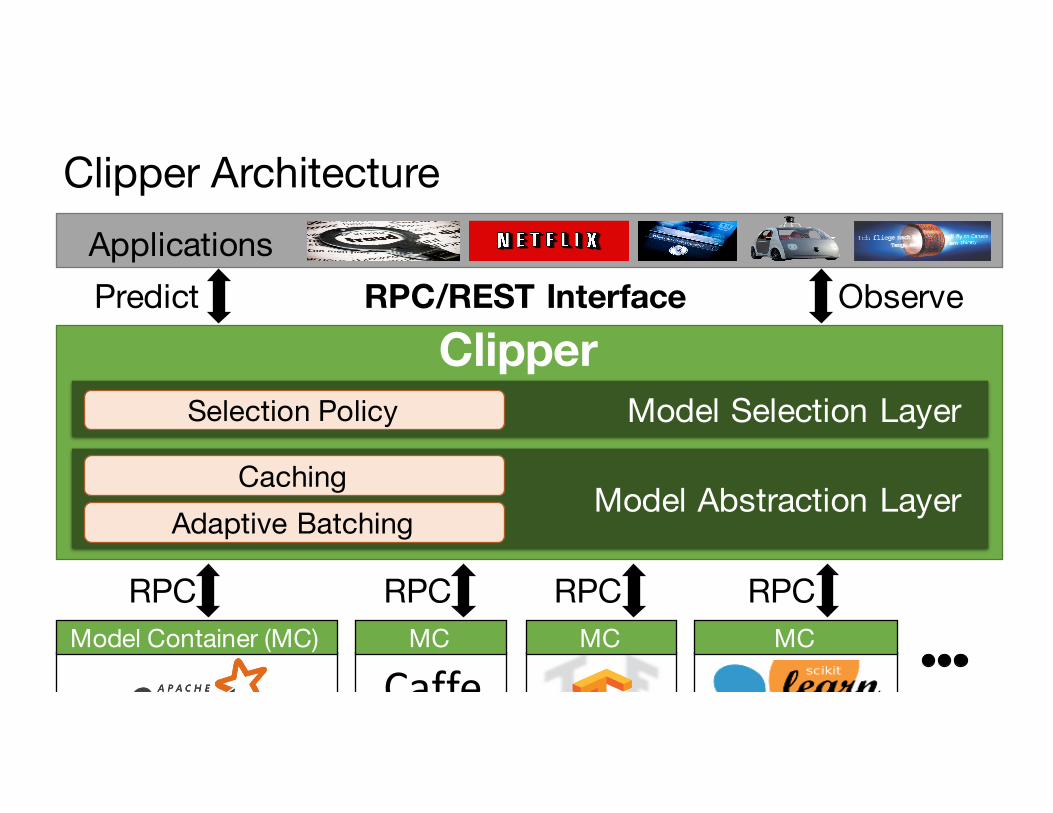
Clipper Architecture
Clipper
Caffe
ApplicationsPredict ObserveRPC/REST Interface
Model Container (MC) MC MC MCRPC RPC RPC RPC
Model Selection LayerSelection Policy
Model Abstraction LayerCaching
Adaptive Batching
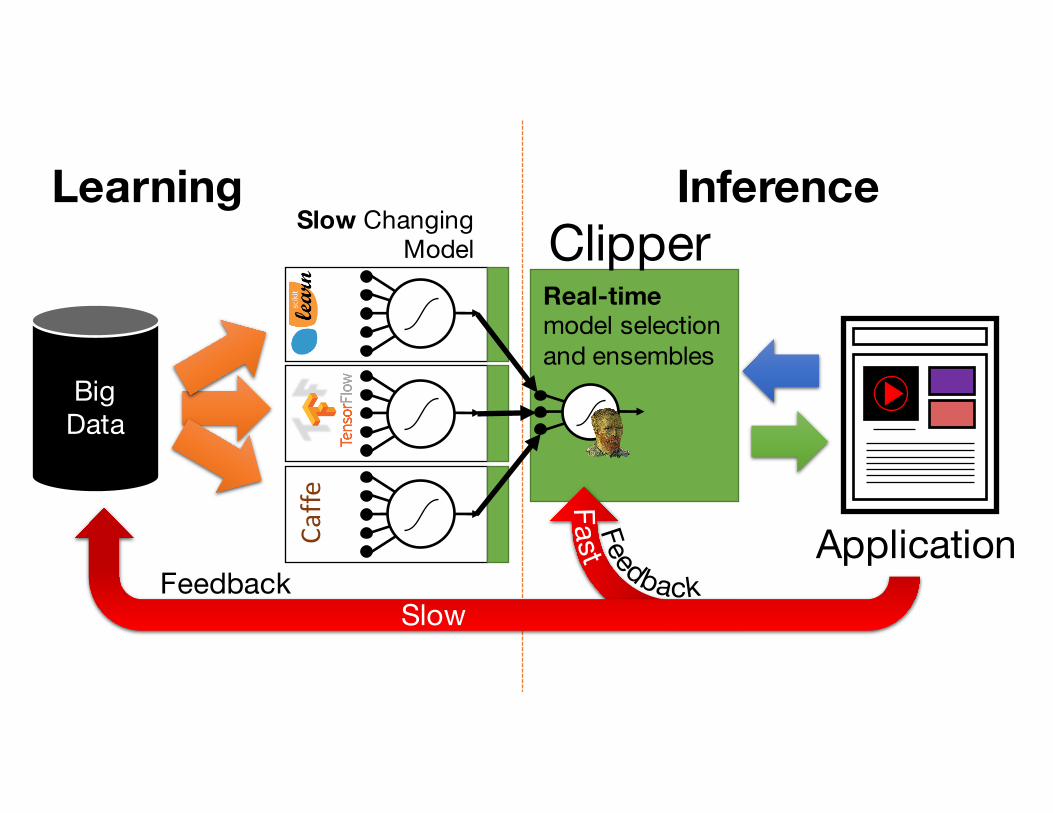
Caffe
BigData
Application
Learning Inference
FeedbackSlow
Slow ChangingModel
Real-time model selection and ensembles
Clipper
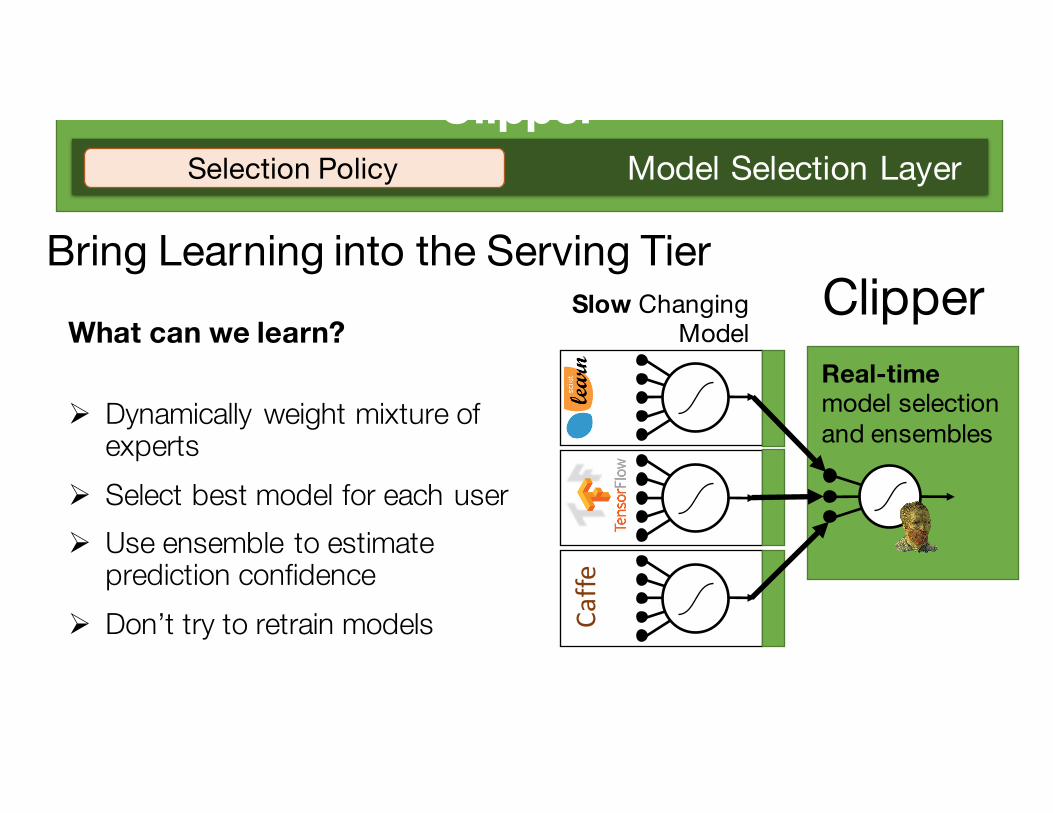
ClipperModel Selection LayerSelection Policy
Caffe
Slow ChangingModel
ClipperBring Learning into the Serving Tier
What can we learn?
Ø Dynamically weight mixture of experts
Ø Select best model for each userØ Use ensemble to estimate
prediction confidenceØ Don’t try to retrain models
Real-time model selection and ensembles

Road MapØ Open source on GitHub: https://github.com/ucbrise/clipper
Ø Kick the tires, try out our tutorialØ Alpha release in mid-April
Ø Focused on reliability and performance for serving single-model applicationsØ First class support for Scikit-Learn and Spark models, arbitrary Python functionsØ Coordinating initial set of features with RISE Lab sponsors and collaborators
Ø After alpha releaseØ Support for selection policies and multi-model applicationsØ Model performance monitoring to detect and correct accuracy degradationØ New task scheduler design to leverage model and resource heterogeneity
“Clipper: A Low-Latency Online Prediction Serving System” [NSDI ‘17]https://arxiv.org/abs/1612.03079