classification part 3: artificial neural networks bmtry 726 4/15/14
TRANSCRIPT

Classification Part 3: Artificial Neural Networks
BMTRY 7264/15/14

Last ClassLast class we discussed
(1) Problems with linear classification methods
-As with regression, we have a hard time including a large number of covariates especially if n is small
-linear boundary may not really be an appropriate choice for separating our classes
(2) We introduced the concept of Artificial Neural Networks- Extract linear combinations of inputs as derived features and
then model the outcome (classes) as a nonlinear function of these features-They are really nonlinear statistical models but with pieces that
are familiar to us already

Artificial Neural Networks (ANNs)ANNs modeled after the brain so often refer to features/outputs as neurons
ANNs consist of(1) A set of observed input features(2) A set of derived features(3) A set of outcomes we want to explain/predict(4) Weights on connections between inputs, derived features, and
outcomes
The simplest (and perhaps most common) type of ANN is a feed-forward ANN
This means data feed forward through the network with no cycles or loops

ANNsRecall our generic example of an ANN from last class
(1) Xi , i=1,2,…,p are the observed
features/inputs
(2) Zm , m=1,2,…,M, are the derived
features -referred to as the “hidden” layer
(3) Yk , k=1,2,…,K, are the outputs
-Classification: classes we want to model using observed features X
-Regression: Y could be a continuous
Y1 Y2 YKY1
Z2Z1 Z3 ZM
X2X1 X3 XpXp-1
…
…
…

ANNsHidden LayerZm represent hidden features derived by applying an activation function to linear combinations of the observed features
Common activation functions include
Y1 Y2 YKY1
Z2Z1 Z3 ZM
X2X1 X3 XpXp-1
…
…
…
'0 , 1, 2,...,m m mZ v m M α X
11
1 if 0
0 if 0
ve
vsign v
v
sigmoid v
radial basis function

ANNs
Output
Outputs (i.e. predicted Y’s) come from applying a non-linear function to linear combinations of derived features Zm
Some examples of gk(T)
Y1 Y2 YKY1
Z2Z1 Z3 ZM
X2X1 X3 XpXp-1
…
…
…
0 1 2'
k k k
k k
T Z , k , ,...,K
Y f g T
β
X
1
softmax useif
identity use for regression ANNs
Tk
K Tkl
ek e
k k
g T v sigmoid
g T T

ANNsConsider the expression for the derived features Zm
Parameters a0m represent “bias” like we described for LDA
- recall the “bias” defined location of a decision boundary
Parameters am define linear combinations of X’s for derived features Zm and can be thought of as weights
-i.e. how much influence a particular input variable Xi has on the
derived feature Zm
0 1 2'm m mZ , m , ,...,M α X

ANNsNow consider the expression for the output values Yk
Parameters b0k represent another “bias” parameter
- These also help define locations of decision boundaries
Parameters bk define linear combinations of derived features Zm also represent weights -i.e. how much influence a particular derived feature Zm have on the
output
We can add these “weights” into the graphic representation of our ANN
0
0 1 2
'k k k
'k k k k k k
T
Y g T g , k , ,...,K
β Z
β Z

Y1 Y2 YKY1
Z2Z1 Z3 ZM
X2X1 X3
XpXp-1
…
…
…
aMp
b13
b1M b21b22 b23
b3M bK1
bK2 bK3
bKM
b11
a21a11
b12
a3p

Simple Example of Feed-Forward ANN
Consider a simple example:-4 input variables (i.e. our Xi’s)
-3 derived features (i.e. our Zm’s)
-2 outcomes (i.e. our Yk’s)
Let’s look at the graphic representation of this ANN…

Simple Example of Feed-Forward ANN
Four inputs: X1, X2, X3, and X4 (i.e. observed features in the data)
Y1
Y2
Y1
Z2
Z1
Z3
X2
X1
X3
X4
Three derived features in the hidden layer: Z1, Z2, and Z3
Two outputs: Y1 and Y2 (i.e. possible classes in the data)

Simple Example of Feed-Forward ANN
Y1
Y2
Y1
Z2
Z1
Z3
X2
X1
X3
X4
First consider the connection between observed features X and derived features in the hidden layer, Z1, Z2, and Z3
We can add the “weights” for each of the X’s for the derived features to our graphical representation
0'
m m mZ α X
a11
a12a13
a21
a22
a23
a31
a32
a33
a41
a42
a43

Simple Example of Feed-Forward ANNConsider the first derived feature Z1
It is created by applying our activation function, s, to a linear combination of out observed features
If our activation function is sigmoid it takes the form
Thus we can see that our derived feature Z1 takes the form:
Y1
Y2
Y1
Z2
Z1
Z3
X2
X1
X3
X4
'01 1
'1 01 1
01 11 1 12 2 13 3 14 4
1
1 exp
v
Z v
X X X X
α X
α X
1
1 vv
e
a11
a12
a13
a14

Simple Example of Feed-Forward ANN
Given the form of the activation function, it is easy to write out the form of each of our three derived features Z1, Z2, and Z3
01 11 1 12 2 13 3 14 4
02 21 1 22 2 23 3 24 4
03 31 1 32 2 33 3 34 4
'1 01 1
'2 02 2
'3 03 3
1
1
1
1
1
1
X X X X
X X X X
X X X X
Ze
Ze
Ze
α X
α X
α X

Simple Example of Feed-Forward ANN
Y1
Y2
Y1
Z2
Z1
Z3
X2
X1
X3
X4
'
0
'0
, 1, 2,...,k k k
k k k k k k
T k K
f g T g
β Z
X β Z
Now that we have the form of our derived features, Z1, Z2, and Z3, we can now consider the connections between our derived features and out outputs Yk
Again we can add the “weights” to the graphical representation of our ANN
b11
b12
b21
b22
b31
b32

Simple Example of Feed-Forward ANN
Y1
Y2
Y1
Z2
Z1
Z3
X2
X1
X3
X4
1
k
k
T
k K T
l
eg T
e
b11
b12
b21
b22
b31
b32
Consider the first output class Y1
It is created by applying an output function, gk(T), to a linear combination of the derived features
Since the activation function is sigmoid, it makes sense for the our output function to be the softmax function
Thus we can see that our first output Y1 takes the form:
01 11 1 21 2 31 3
01 11 1 21 2 31 3 02 12 1 22 2 32 31 1
Z Z Z
Z Z Z Z Z Z
eY g T
e e

Simple Example of Feed-Forward ANN
Given the form of the output function, it is easy to write out the form of the two outputs Y1 and Y2
01 11 1 21 2 31 3
01 11 1 21 2 31 3 02 12 1 22 2 32 3
02 12 1 22 2 32 3
01 11 1 21 2 31 3 02 12 1 22 2 32 3
1 1 1
2 2 2
ˆ
ˆ
Z Z Z
Z Z Z Z Z Z
Z Z Z
Z Z Z Z Z Z
eY g T
e e
eY g T
e e

Feed-Forward ANN
Denote complete set of weights, q, for the ANN as
Goal: estimate weights such that the model fits well
Fitting well means minimizing loss function or error
For regression can use sum-of-squared error loss
For classification we can use either the sum-of squared error or the deviance (also known as cross-entropy)
0
0
, ; 1, 2,..., 1 weights
, ; 1, 2,..., 1 weights
m m
k k
m M M p
k K K M
α
β
2
1 1
K N
ik k ik iR y f x
θ
1 1log
N K
ik k ii kR y f x
θ

Fitting a Feed-Forward ANN
Purpose of learning is to estimate parameters/weights for connections in the model (i.e. am and bk) that allow model to reproduce the provided patterns of inputs and outputs
ANN learns function of arbitrary complexity from examples (i.e. the training data)
Complexity depends on the number of hidden neurons
Once network trained can use it to get the expected outputs with incomplete/slightly different data

Fitting a Feed-Forward ANN
Basic idea of the learning phase:
Back Propagation for learning the parameters/ weights in a feed-forward ANN (one method) -Provide observed inputs and outputs to the network, -Calculate estimated outputs -back propagating the calculated error -Repeat process iteratively for a specified number of iterations
Under back propagation, weights are updated using the gradient descent method -Follow steepest path of error function in order to minimize it

Illustration of Gradient Descent
w1
w0
R(q)
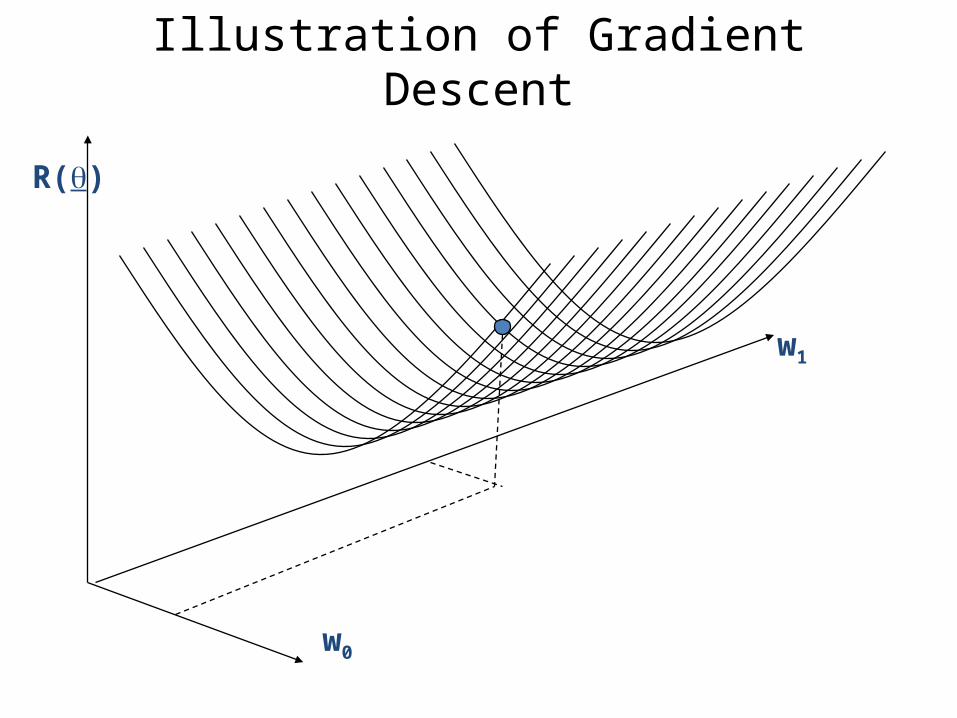
Illustration of Gradient Descent
w1
w0
R(q)

Illustration of Gradient Descent
w1
w0
R(q)
Direction of steepestdescent = direction ofnegative gradient

Illustration of Gradient Descent
w1
w0
R(q)
Original point inweight space
New point inweight space

Back Propagation
(1) Initialize weights with random values (generally (1,-1))
(2) For a specified number of training iterations do: For each input and ideal (expected) output pattern i. Calculate the actual output from the input ii. Calculate output neurons error iii. Calculate hidden neurons error iv. Calculate weights variations (delta)
v. Adjust the current weight using the accumulated deltas
(3) Iterate until some chosen stopping point

Back-Propagation using Gradient Descent
i. Calculate the actual output from the input (rth iteration)
1 2 301 11 21 31
1 2 302 12 22 321 2 301 11 21 31
1 1 101 11 21 31' ' '
1 exp 1 exp 1 exp01 1 02 2 03 3
1 1 1ˆ
r r r r
r r r rZ Z Zr r r r
r r r r
r r r r r r
Z Z Zr r
Z Z Z
eY g T
e e
e
α X α X α X
1 1 10 1 2 3' ' '
1 exp 1 exp 1 exp01 1 02 2 03 3
1
r r r rk k k kr r r r r r
K
ke
α X α X α X

Back Propagation Using Gradient Descent
ii. Calculate output neurons erroriii. Calculate hidden neurons error
Based on out choice of model fit/error function (e.g. SSE)
Write in terms of the weights….
2
1 1ˆ
N K
ik iki kR y y

Back-Propagation using Gradient Descent
Goal is to minimize the error term so take the partial derivative with respect to the weights
This must be done of each weight in the ANN
Start with the weights in our hidden layer variables
2
1 1
M p
ik k km mj ijm ji
km km
y g xR

Back-Propagation Using Gradient Descent
For SSE…
Use chain rule and write in terms of predicted y, Tk, and then bkm
2
1 1
ˆ
ˆ
M p
ik k km mj ijm ji
km km
i i ik k
km ik k km
y g xR
R R y T
y T

Back-Propagation Using Gradient Descent
For SSE…
2
0 1 1
ˆˆ2
ˆ ˆ
ˆˆ ˆ1
... ...
ˆ ˆ ˆ2 1
Tk
T Tk hh k
ik iki
ik ikik ik
ee e
ikik ik
k k
k k i km m kM Mkmi
km km
iik ik ik ik mi
km
y yRy y
y y
yy y
T T
z z zTz
Ry y y y z

Back-Propagation Using Gradient Descent
Repeat this idea for the input weights…
1 1
1ˆ ˆ ˆ1 1
M p
ik k km mj ijm ji
mj mj
Kiik ik ik ik km mi mi ijk
mj
y g xR
Ry y y y z z x

Back Propagation Using Gradient Descent
ii. Calculate output neurons error -this comes from the derivative of the hidden layer weights
iii. Calculate hidden neurons error -this comes from the derivative of the input weights
1
1
ˆ ˆ ˆ2 1
ˆ ˆ ˆ2 1
ˆ ˆ ˆ1 1
ˆ ˆ ˆ1 1
iik ik ik ik mi
km
ki ik ik ik ik
Kiik ik ik ik km mi mi ijk
mj
K
mi ik ik ik ik km mi mik
Ry y y y z
y y y y
Ry y y y z z x
s y y y y z z

Back Propagation
iv. Calculate weights variations (delta)-Just the derivatives of our error function with respect to the weights
1
1
For hidden layer/derived features
ˆ ˆ ˆ2 1
For the input features
ˆ ˆ ˆ1 1
ˆ ˆ ˆ1 1
iik ik ik ik mi
km
Kiik ik ik ik km mi mi ijk
mj
K
mi ik ik ik ik km mi mik
Ry y y y z
Ry y y y z z x
s y y y y z z

Learning Rate
• We also want to scale the step sizes the algorithm takes
• This “scale” value is also known as the learning rate and controls how far we descend on the gradient
• In general it is a constant selected by the user
• This learning rate, gr, is multiplied by the derivatives

Update at the r+1 Iteration
1 1
1 1&
1,2,..., number observations
1,2,..., number inputs
1,2,..., number hidden units
1,2,..., number classes
N Nr r r ri ikm km r mj mj rr ri i
km mj
R R
i N
j p
m M
k K
v. Add the weights variations to the accumulated delta

Back Propagation
In forward pass current weights fixed and predicted values come from these weight
In backward pass errors are estimated and used calculate the gradient to update the weights
Learning rate gr often taken to be fixed though it can be optimized to minimize the error at each iteration
One important note, since the gradient descent algorithm requires taking derivatives, the activation, output, and error functions must be differentiable w.r.t. the weights

Considerations When Fitting ANNs
Training ANNs is a bit of an art form and there are things that must be taken into consideration
Considerations when training network (1) Choice of starting weights
-Over-fitting-Scaling inputs-Number of hidden layers-Multiple minima

Considerations When Fitting ANNs
Training ANNs is a bit of an art form and there are things that must be taken into consideration
Considerations when training network (1) Choice of starting weights
-If weights are near 0, the operative part of sigmoid function approximately linear-Initial weights generally chosen to be near 0 so that the model nearly linear-Model becomes progressively more non-linear as weights increase

Considerations When Fitting ANNs(2) Over-fitting -Often NNs have too many weights and over fit the data using global minimum of error function R(q) -One solution is weight decay, which is analogous to ridge regression
2 2
2 21 1
Penalized error function:
Where: km ml
km mlkm ml
R J
J
θ θ
θ

Considerations When Fitting ANNs(3) Scaling inputs -As with any of the other methods we’ve discussed, if inputs have very
different scales, can greatly impact quality of model-Best to standardize inputs prior to training the model
(4) Number of hidden layers -Typically have between 5-100 units-Generally better to have too many hidden units-Too few results in less model flexibility -If too many, some can be shrunk to 0 with appropriate regularization
(5) Multiple minima-R(q) non-convex and has many local minima-Thus final solution is dependent on choice of starting weights-Try number random starting points picking one with lowest penalized error-Or average prediction over collection of networks (more on that later)

A Couple of Extra PointsModels do not have to have a hidden layer
-A model with no hidden layers is called a perceptron-If we are using the sigmoid activation function, this is VERY similar to multinomial logistic regression-If using identity link, this is VERY similar to linear regression
By the same token, models can have more than one hidden layer-We may decide to have 5 hidden layers, each with different numbers of derived features
Not all features must be connected-this is equivalent to placing zero weight on
-connection between an input and a derived features-connection between derived feature and output

A Classic ProblemThe US post office needs to be able to sort mail using handwritten zip codes on letters
There are too many letters to sort by hand… can we develop a NN to recognize the numbers in a zip code?