cis 270 - december '99 introduction to parallel architectures dr. laurence boxer niagara...
TRANSCRIPT

CIS 270 - December '99
Introduction to Parallel Architectures
Dr. Laurence Boxer
Niagara University

CIS 270 - December '99
Parallel Computers
•Purpose - speed
•Divide a problem among processors
•Let each processor work on its portion of problem in parallel (simultaneously) with other processors
•Ideal - if p is the number of processors, get solution in 1/p of the time used by a computer of 1 processor
•Actual - rarely get that much speedup, due to delays for interprocessor communications

CIS 270 - December '99
0
2
4
6
8
10
12
14
16
18
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Series1
Series2
Series3
-
5
10
15
20
25
30
35
Series1
Series2
Graphs of relevant functions
Series 1:
Series 2:
Series 3:
y n
y n
y n
log2
Series 1:
Series 2:
y n
y n
n
log
{ , , , , , , }
2
128 256 512 640 768 896 1024

CIS 270 - December '99
Architectural issues
•Communications diameter - how many communication steps are necessary to send data from processor that has it to processor that needs it - large is bad
•Bisection width - how many wires must be cut to cut network in half - measure of how fast massive amounts of data can be moved through network - large is good
•Degree of network - important to scalability (ability to expand number of processors) - large is bad
Limitations on speed:
Limitation on expansion:

CIS 270 - December '99
PRAM - Parallel Random Access Machine
•Shared memory yields fast communications
•Source processor writes data to memory
•Destination processor reads data from memory
( )1•Fast communications make this model theoretical ideal for fastest possible parallel algorithms for given # of processors
•Impractical - too many wires if lots of processors
Any processor can send data to any other processor in time as follows:

CIS 270 - December '99
Suppose Since each time step cuts the number
of active data values in half, after steps, the number
of active data values is Hence, problem is
solved when
n
i
n
i k n
k
ik i
2
22
2
.
.
log .

CIS 270 - December '99
Notice the tree structure of the previous algorithm:
CIS 270 - December '99
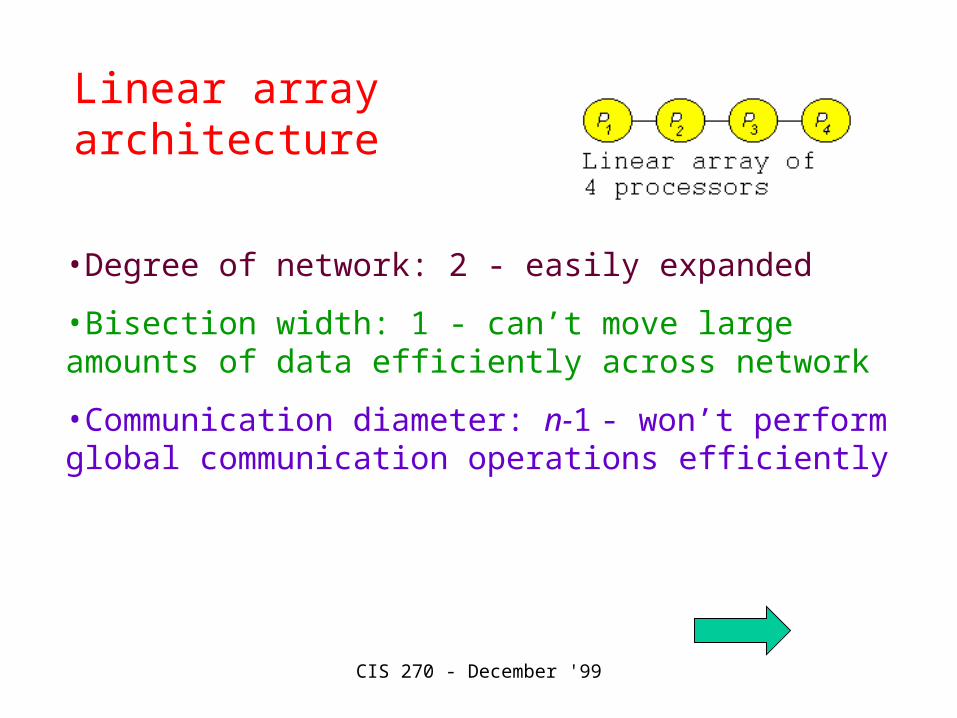
Linear array architecture
•Degree of network: 2 - easily expanded
•Bisection width: 1 - can’t move large amounts of data efficiently across network
•Communication diameter: n-1 - won’t perform global communication operations efficiently

CIS 270 - December '99
Total on linear array:
•Assume 1 item per processor
•Communications diameter implies
( )n time required
•Since this is the time required to total n items on a RAM, there is no asymptotic benefit to using a linear array for this problem

CIS 270 - December '99
Input-based sorting on a linear array
•The algorithm illustrated is a version of Selection Sort - each processor selects the smallest value it sees and passes others to the right.
•Time is proportional to communication diameter, ( )n
This is somewhat faster than the RAM sorting time of
(not via Selection Sort), but in using
processors, the speedup factor of is disappointing.
( log )
log
n n n
n2
2

CIS 270 - December '99
Mesh architecture
•Square grid of processors
•Each processor connected by communication link to N, S, E, W neighbors
•Degree of network: 4 - makes expansion easy - can introduce adjacent meshes and connect border processors

CIS 270 - December '99
For a mesh:
bisection width is
n n
n
Application: sorting
Could have initial data all in “wrong half” of mesh, as shown.
Since all n items must get to correct half-mesh, time required to sort is
In 1 time unit, amt. of data that can cross into correct half of mesh:
n
nnn /

CIS 270 - December '99
In a
mesh, each of these steps takes
time. Hence, time for broadcast is
nn
n
n

CIS 270 - December '99
Semigroup operation (e.g., total) in mesh
1. “Roll up” columns in parallel, totaling each column in last row by sending data downward.
2. Roll up last row to get total in a corner.
3. Broadcast total from corner to all processors. nTime:
nTime:
nTime:

CIS 270 - December '99
Previous algorithm could run in approximately half the time by gathering total in a center, than corner, processor.
Mesh total algorithm - continued
nHowever, running time is still
i.e., still approximately proportional to communication diameter (with smaller constant of proportionality).

CIS 270 - December '99
Hypercube
•Number n of processors is a power of 2
•Processors are numbered from 0 to n-1
•Connected processors are those whose binary labels differ in exactly 1 bit. Note binary labels have bits.
Communication diameter:
Degree of network:
Bisection width:
log
log
log
/
2
2
2
2
n
n
n
n
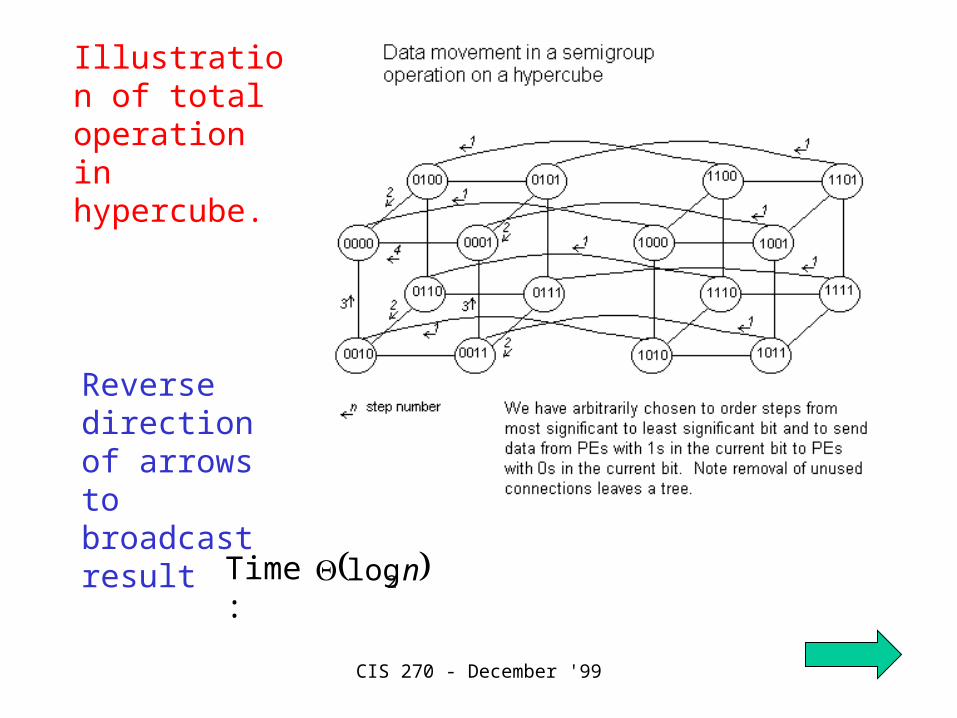
CIS 270 - December '99
Illustration of total operation in hypercube.
Reverse direction of arrows to broadcast result
Time: n2log

CIS 270 - December '99
Coarse-grained parallelism
•Most of previous discussion was of fine-grained parallelism - # of processors comparable to # of data items
•Realistically, few budgets accommodate such expensive computers - more likely to use coarse-grained parallelism with relatively few processors compared with # of data items.
•Coarse grained algorithms often based on each processor boiling its share of data down to single partial result, then using fine-grained algorithm to combine these partial results

CIS 270 - December '99
Example: coarse-grained totalSuppose n data are distributed evenly (n/p per processor among p processors)
1. In parallel, each processor totals its share of the data. Time: Θ(n/p)
2. Use a fine-grained algorithm to add the partial sums (total residing in one processor) and broadcast result to all processors. In case of mesh, time: p
Total time for mesh:
p
p
n
Since p
np , this is Θ(n/p) - optimal.

CIS 270 - December '99
More info:
Algorithms Sequential and Parallel
by
Russ Miller and Laurence Boxer
Prentice-Hall, 2000
(available December, 1999)