characterizing ls-dyna performance on sgi systems ... ls-dyna ® performance on sgi systems using...
TRANSCRIPT

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside
MPI Profiling Tool
AuthorsDr. Olivier Schreiber*, Tony DeVarco**, Scott Shaw***
Abstract SGIは、統合計算、ストレージ、遠隔可視化ソリューションを製造業のお客様に提供し、複数のコンピュータアーキテクチャ、すなわちマルチノード分散メモリプロセッサ・クラスタと共有メモリプロセッサシステムを有効に活用し、システム全体の管理工数と費用を削減します。LS-DYNAは単一コードベースに複数のソルバが統合されています。
この文書では、次の方法でLS-DYNAの陽解法ソルバのプロファイルを取得します。MPI分析ツールにはSGI MPInsideを使用しました。SGI MPInsideは、通常の通信プロファイリングの特徴を分析して「オンザフライ」モデリングを行い、最新のインテル® Xeon®プロセッサ、インターコネクトファブリックとミドルウェア、SGI MPIライブラリ、およびLS-DYNAソースコードで利用できる様々なアップグレードの潜在的な性能向上を予測します。また、プロファイルに基づくSGI MPIのMPIplaceコンポーネントの使い方を説明し、SGIシステム上でのランク間転送時間を最小化して、TopCrunchの
「Car2car」標準ベンチマークにおいて最大10%、シミュレーション実行時間を削減できることを示します。
* Senior Applications Engineer** Director Manufacturing Solutions*** Principal Applications Engineer

W H I T E P A P E R
I N D E X
1.0 SGIシステムについて 11.1 SGI® Rackable® スタンダードデプス・クラスタ 11.2 SGI® ICE™ XA システム 21.3 SGI® UV™ 3000 31.4 SGI パフォーマンスツール 31.5 SGI システム管理ツール 41.6 リソースおよびワークロードのスケジューリング 41.7 SGI® VizServer® (NICE DCV) 4
2.0 LS-DYNA 62.1 使用バージョン 62.2 LS-DYNAの並列処理機能 6
2.2.1 基本的なハードウェアとソフトウェアの概念 62.2.2 並列処理の背景 62.2.3 分散メモリ並列計算の実装 72.2.4 並列処理のメトリックス 7
2.3 並列実行制御 82.3.1 実行手順 82.3.2 ノードとコア全体のMPIタスクとOpenMPスレッドアロケーションの実行コマンド 9
2.4 チューニング 92.4.1 入出力とメモリ 92.4.2 高密度プロセッサ上で利用可能なコアの一部を使用 102.4.3 インテル® Hyper-threading 102.4.4 インテル® ターボブースト 102.4.5 SGI Performance Suite MPI と SGI PerfBoost 112.4.6 SGI Accelerate LibFFiO 11
3.0 ベンチマークの説明 113.1 Car2car 113.2 Car2carのチューニング 12
4.0 MPInside 124.1 MPInside 概要 124.2 MPInside 技術 124.3 MPInside の使い方 13
4.3.1 MPInside コマンド 134.3.2 MPInside の出力 13
4.3.2.1 Timing Table 13
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool

W H I T E P A P E R
4.3.2.2 Bytes Sent Table 134.3.2.3 Number of “Send” Calls Table 144.3.2.4 Bytes Received Table 144.3.2.5 Number of “Recv” Calls Table 144.3.2.6 その他の出力 14
4.3.2.6.1 Number of requests distribution 144.3.2.6.2 Times Distribution 15
4.3.2.7 転送行列 154.4 MPInsideが取り扱う情報 15
4.4.1 一般事項 154.4.2 MPIファンクションの略称 164.4.3 更に進んだ機能 16
4.5 MPInsideでの推定 174.6 ロードバランス対策 184.7 Car2car Topcrunch ベンチマークのケーススタディ 18
4.7.1 基本プロファイリング 184.7.2 一括持ちプロファイリング 194.7.3 送信遅延時間プロファイリング 204.7.4 完璧なインターコネクトプロファイリング 21
4.8 SGI MPIplace プロファイルに基づいたMPI用配置ツール 214.8.1 概要 224.8.2 Car2Car Topcrunch ベンチマークのケーススタディ 23
5.0 まとめ 246.0 参考文献 24
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 1
W H I T E P A P E R
1.0 SGIシステムについてこの文書に記載したベンチマークを実行するために、SGI®Rackable™スタンダードデプス・クラスタ、SGI®ICE™ X統合ブレードクラスタ、SGI®UV™ 2000共有メモリシステム等のSGIシステムを使用しました。これらは世界で最も難しい計算課題を解決するために使用されているサーバと同じものです。これらの各サーバプラットフォームは、共有メモリ並列(SMP)モードと分散メモリ並列(DMP)モードのLSTC LS-DYNAをサポートしています[1]。
1.1 SGI®Rackable™スタンダードデプス・クラスタSGI® Rackable™スタンダードデプス、ラックマウントC2112-4GP3 2Uエンクロージャは、4ノードと64スロット(サーバ当たり16スロット)で最大4TBのメモリをサポートしています。また、2Uにつき最大144コアをサポートし、FDR InfiniBand、14コアインテル® Xeon®プロセッサE5-2600 v3シリーズと2133 MHz DDR4メモリを搭載して、TCO削減のためにSUSE® Linux® Enterprise ServerまたはRed Hat® Enterprise Linuxで動作します(図1)。
図 1: Overhead View of SGI Rackable Server with the Top Cover Removed

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 2
W H I T E P A P E R
1.2 SGI®ICE™XAシステムSGI® ICE™ XAは、世界最速の商用分散メモリ型スーパーコンピュータのひとつです。この性能のリーダーシップは、研究所や顧客サイトで証明されており、その中には世界最大かつ最速の純粋なInfiniBand計算クラスタを採用しているサイトもあります。インテル® Xeon®プロセッサE5-2600 v3シリーズ単独での計算ノード、またはインテル® Xeon®プロセッサおよびインテル® Xeon Phi™コプロセッサとNvidia®Compute GPUから成る計算ノードを構成できます。SUSE® Linux® Enterprise ServerとRed Hat®Enterprise Linux上で稼働するSGI ICE XAは、ラック当たり191テラフロップスを超える性能を発揮でき、36ノードから数万ノードまでの構成が可能です。
SGI ICE XAは、システムのオーバーヘッドと通信のボトルネックが最小になるよう設計されており、例えば、LS-DYNA topcrunch.orgのベンチマークでは2,000コアを超えるスケーラビリティを提供し、6年間連続で最高の地位を確保しています。SGI ICE Xは、スイッチとシングルプレインあるいはデュアルプレインのFDRインフィニバンドインターコネクトを選択することにより、さまざまなトポロジーで構成できます。統合されたブレード設計により、ラックレベルでの冗長電源と、空冷(現在ICE Xには空冷ラックがありますがICE XAにはありません)、もしくは冷水か温水による水冷が選択可能で、ストレージや可視化機能を追加することも可能です(図2にICE Xのラックとブレードのエンクロージャを示します)。
この文書では次のSGI ICE XAの構成を使用しました。
• 576ノード(13,824コア)
• インテル® Xeon® 12コア 2.6Ghz E5-2690 v3
• Hypercubeインターコネクトで統合したMellanox® Technologies ConnectX®業界標準インフィニバンドFDR
• コア当たり128GBのRAM、メモリ速度2133MHz
• Altair® PBS Professional
• SLESまたはRHEL, SGI Performance Suite
図 2: SGI ICE X Cluster with Blade Enclosure

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 3
W H I T E P A P E R
1.3 SGI®UV™3000SGI UV 3000サーバは最大256ソケット(4,096コア)で構成されます。シングル・システム・イメージで64TBのグローバル共有メモリをサポートしているので、インメモリ・データベースから多様なデータ集約型アプリケーションや、数値計算HPCアプリケーションに対して、SGI UVの能力を最大限引き出せます。しかも、なじみのあるLinux OS [2]でプログラミングでき、複雑な通信アルゴリズムを搭載するためにソフトウェアを書き換える必要はありません。TCOは、ひとつのシステムを管理するだけなので低くなります。ワークフローと全体の時間は、データを移動させることなくひとつのシステム上でプリプロセッシングやポストプロセシング、ソルバ、可視化を稼働させることで高速化できます(図3)。
ジョブのメモリは、マルチユーザーに対する異機種混合のワークロード環境での柔軟性を最大限にするために、コアの配置とは独立にアロケートされます。一方クラスタ上では問題を分解しなければならず、多数のノードを利用する必要があります。SGI UVは、多くのメモリを必要とする問題を利用可能なアプリケーションライセンスを用いてあらゆる数のコアで実行することができ、しかもメモリリソース不足によるジョブの中断をあまり気にする必要がありません。
図 3: SGI UV CAE workflow running LSTC applications
1.4 SGIパフォーマンスツール最新のMPI準拠ライブラリと標準Linuxディストリビューションを活用して、SGI® Performance Suite(図4)は、HPCアプリケーションの飛躍的な高速化と規模の拡大を加速させます。機能豊富なツール群はアプリケーションの配置を最適化し、再コンパイルせずにランタイムでアプリケーションのチューニングを可能にし、最大70%まで性能を高めることができます。細粒度の指標がMPI分析を容易にします。チェックポイントリスタート機能が生産性を高めます。さらに標準Linuxディストリビューション上の特別なカーネルを使わずに、ハード・リアルタイム・パフォーマンスが実現できます。世界に誇るアプリケーションの専門知識と相まって、SGIはLinuxを次のレベルに引き上げます。詳細は、 http://www.sgi.com/products/software/ をご覧ください。
図 4: SGI Performance Suite Components

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 4
W H I T E P A P E R
1.5 SGIシステム管理ツールベアメタル・プロビジョニングとメモリ障害回避、365日24時間のシステムモニタリング、タスク自動化、革新的な電力最適化などを通して、SGI® Management Suiteは、生産性の最大化と高い投資対効果の実現を支援します。アドミニストレータは、ずば抜けた速度でのシステム導入とアップグレード、積極的なシステムの健全性とエネルギー消費の管理、高いサービスレベルの常時提供ができるので、ユーザーは間断なく短い時間により多くのジョブを走らせることが可能になります。詳細は、http://www.sgi.com/products/software/smc.html をご覧ください。
1.6 リソースおよびワークロードのスケジューリング リソースとワークロードのスケジューリングにより、大規模で複雑なアプリケーション、ダイナミックで予測できないワークロードを管理し、限られた計算リソースを最適化することができます。SGIは、複数のソリューションを提供し、お客様のニーズに的確にお応えします。
Altair Engineering PBS Professional®は、SGIのあらゆるクラスタとサーバに対して技術計算のスケーリングを行うSGI推奨ワークロード管理ツールです。
特長
• ポリシー主導型のワークロード管理。生産性を向上し、サービスレベルを満たし、ハードウェアとソフトウェアのコストを最小限に抑えます。
• ワークロード主導自動ダイナミックプロビジョニング等の機能について、SGI Management Centerとの統合業務
• Altair PBS Professional Power Awarenessは、SGI Management Center 3とジョブレベルの電力管理を統合します。
AdaptiveComputingMoab®HPCスイート・ベーシックエディション
Adaptive Computing Moab® HPCスイートは、スケーラブルなシステム上でのワークロードに対するインテリジェント予測スケジューリングを可能にします。
• クラスタワークロードのスケジューリング、管理、モニタリング、報告を統合するポリシーに基づいたHPCワークロードマネージャ
• TORQUEリソースマネージャ同梱
1.7 SGI®VizServer®(NICEDCV)SGI VizServer (NICE DCV)は、Webベースのポータルを介して技術ユーザーにリモート3Dモデリングツールを提供し、GPUとリソースの共有および安全なデータの保存を可能にします。(図5)
図 5: SGI VizServer workflow

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 5
W H I T E P A P E R
企業のサーバにインストールされたSGI VizServer (NICE DCV)は、企業のプライベートネットワークに組み込まれたSaaSとして、LS-PrePostのリモート可視化機能を提供できます。LS-PrePostソフトウェアを、使いやすいWebインターフェースでアクセスできるので、エンドユーザーが容易に利用できます。このソリューションは、直感的なヘルプとガイダンスを提供しており、経験の少ないユーザーが複雑なITプロセスに邪魔されることなく生産性を最大にできます。
SGIVizServer(NICEDCV):• 技術者に優しいセルフサービスポータル : 技術者は、セルフサービスポータルを使って、LS-PrePostアプリ
ケーションとWebブラウザで設定したデータにアクセスできます。ユーザーの企業データ漏洩防止とITマネージャの使用履歴管理を保証するセキュリティ、モニタリング、管理も提供します。技術者は、自分のローカルクライアントに個別のLS-PrePostソフトウェアをインストールする必要はなく、WebブラウザからLS-PrePostアプリケーションとデータに直接アクセスします。
• リソース制御と抽象レイヤ : リソース制御と抽象レイヤは、ポータル内部に隠されており、エンドユーザーからは見えません。ユーザーの使い心地を損なうことなく、ジョブのスケジューリング、遠隔可視化、リソースプロビジョニング、相互ワークロード、分散データ管理を処理します。このレイヤは、ブラウザからのユーザーの要求を翻訳し、可視化やHPCタスクを遂行するために必要なリソースの割り当てを支援します。このレイヤは、マルチサイトWANでの実装だけでなく、単一SGI RackableクラスタやSGI UVサーバ上で稼働するスケーラブルなアーキテクチャーを持っています。
• 計算とストレージリソース : SGI VizServer (NICE DCV)は、企業が既に持っている、または新規購入したSGI業界標準リソースを活用します。対象リソースには、ホスト・アプリケーション・バイナリ、モデル、中間結果に必要なストレージだけでなく、サーバ、HPCスケジューラ、メモリ、グラフィックス・プロセッシング・ユニット(GPU)、可視化サーバなどがあります。これらは全てリソース制御と抽象レイヤを介してWebベースのポータルでアクセスし、エンドユーザーの必要に応じてミドルソフトウェアにより提供されます。
NICE DCVとEnginFrameソフトウェアは、共通技術標準に従って構築されています。このソフトウェアは、ネットワークを大幅にアップグレードすることなく、企業独自のセキュアなエンジニアリングクラウドを作成できるように、ネットワークインフラに順応できます。また、このソフトウェアでは、技術アプリケーションとデータの両方がプライベートクラウドまたはデータセンタに留まるので、データの安全が確保され、データを転送する必要性を排除し、ワークステーション上で閲覧できます。これらのソリューションは、シンプル、セルフサービス、ダイナミック、スケーラブルというクラウド・コンピューティングの一番の特長を備えています。その上、ユーザーがどこにいても、エンドユーザーへHPC機能を提供するだけでなく、3D可視化もできるほど強力です。

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 6
W H I T E P A P E R
2.0 LS-DYNA2.1 使用バージョン
LS-DYNA/MPP ls971 R3.2.1以降。R4.2.1では、現象を短い時間間隔でシミュレートする場合、座標の配列が倍精度でコード化されるため、25% (neon)から35%(car2car)の性能劣化を招きます。
コンパイラ: Fortran: EM64Tベースのアプリケーションに対してインテル® Fortranコンパイラ 11.1。
MPI: IBM Platform MPI、インテルMPI、Open MPIおよびSGI MPI。
2.2 LS-DYNAの並列処理機能2.2.1 基本的なハードウェアとソフトウェアの概念
システムのハードウェアコンポーネントとそれらを用いて行う実際の演算とを識別することが大切です。 以下にハードウェア側の概念を示します。
1. コア: 算術演算を行う中央演算装置(CPU)
2. プロセッサ: ソケットで取り付けられ、4個、6個、8個、またはそれ以上のコアを持つ半導体素子
3. ノード: ひとつのネットワークインターフェースとアドレスに関連付けられたホスト
現在の技術では、ノードはエンクロージャにラックマウントされたシャーシやブレード内のボード上に実装されています。ボードは2つまたはそれ以上のソケットを備えています。 以下にソフトウェア側の概念を示します。
1. プロセス: 自分自身のアドレス空間を持つ実行ストリーム
2. スレッド: 他のスレッドとアドレス空間を共有する実行ストリーム
従って、システムで解を計算するために生成されたプロセスとスレッドが、プロセッサとコアのハードウェア階層に応じて、ノード上に異なる方法で配置されるので注意が必要です。
2.2.2 並列処理の背景科学技術計算分野での並列計算には、2つのパラダイムが存在し、個別に実装されるか、場合によりハイブリッドコードとして組み合わされます。共有メモリ並列計算(SMP)は、1980年代に出現し、同時に「DOループ」やメモリ共有スレッドによるサブルーチン生成といった技法の開発をもたらしました。このパラダイムでは、並列化効率は、「DOループの粒度」と呼ばれるデータアクセスに対する算術演算の相対的重要性に影響されます。1990年代の後半に、分散メモリ並列計算(DMP)処理が導入され、より粗い粒度の並列計算設計により、性能向上に対して極めて適切であることが実証されました。その後、DMPはMPIアプリケーション・プログラミング・インタフェースに統合されました。また、その間に、共有メモリ並列計算によるOpenMP™ (オープンマルチプロセシング)とPthread標準APIを介した効率の良い実装により、並列化済みの数値演算ライブラリが追加されました。

Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 7
W H I T E P A P E R
DMPプログラムとSMPプログラムは、制約がありますが、いずれも共通に利用できる2種類のハードウェアシステム上で実行できます。
• 単一のメモリアドレス空間とオペレーティングシステムの単一インスタンスを共有する複数のコアを持つ共有メモリシステムあるいはシングルノード
• 独立したローカルメモリアドレス空間とオペレーティングシステムのノード別専用インスタンスを有するノードで構成される、分散メモリシステム(クラスタとしても知られる)
注:単一メモリ空間であるため、SMPプログラムはクラスタを跨って実行することはできません。逆に、DMPプログラムは、共有メモリシステムで完全かつ適切に実行することができます。SMPに比べてDMPはより粗い粒度を有するため、共有メモリシステムでは、一見した名前の示唆するものがどのようなものであっても、SMPではなくDMPを実行することが望まれます。また、SMPとDMPの処理は一体化でき、その処理モードは「ハイブリッドモード」と呼ばれます。
2.2.3 分散メモリ並列計算の実装分散メモリ並列計算は、取り組む問題に対して領域分割を使って実装されます。それぞれの業界が関わる物理的現象に応じて、領域とは、形状、有限要素、行列、周波数、荷重条件、または陰解法の右辺などとして現れます。通信コストによる並列処理の非効率性は、パーティション分割によって作られた境界の影響を受けます。ロードバランシングも、全てのMPIプロセスが解法中に同じ計算量をこなし、同時に終了するために重要です。計算リソース全体にわたるMPIプロセスの配置は、「ランク」または「ラウンドロビン」アロケーションを使って、各アーキテクチャーに適応させることができます。
2.2.4 並列処理のメトリックス「プログラムの並列プロセス数を増やすことで実現できる高速化は、逐次処理部分の逆数に制約される」というアムダールの法則は、以下の公式で表わされます(この公式においてPは並列化できるプログラムの割合、1-Pは逐次処理部分の割合で、Nは計算で用いるプロセス数です)。
アムダールスピードアップ = 1/[(1-P)+P/N]
導出メトリックス: 効率 = アムダールスピードアップ/N
アプリケーションの並列化可能部分はCPU速度への依存度が高く、オーバヘッドタスクから構成される逐次処理部分は、RAM速度やI/O帯域幅への依存度が高いという経験的事実から、傾向が推測できます。従って、より高速なCPUのシステムで実行されるアプリケーションは、1-Pの逐次処理部分が大きいほど、そしてPの並列処理部分が小さいほど、アムダールスピードアップが低下します。このことは、この事例で示すようにシステムBがシステムAより高速なCPUを有するといった、ハードウェア構成の相違に誤った評価を生みます。
N System a elapsed seconds System B elapsed seconds
1 1000 810
10 100 90
Speedup 10 9

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 8
システムAとシステムBは、たとえシステムBが全体にわたってより高速な基本性能を有する場合でも、それぞれの並列スピードアップは10と9で表わされます。この問題は、システムの最も遅い逐次処理時間によってスピードアップを正規化することで解決できます。
Speedup 10 11.11
特定データセットの数値計算において、プロセッサ数の増加につれて経過実行時間が減少する場合、ストロングスケーリングを示すと言います。データセットのサイズを増加させながら数値計算をする場合、プロセッサ数も増加させると経過実行時間が一定の範囲内になる場合、ウィークスケーリングを示すと言います。
最終的には、特にひとつのシステムで複数のジョブを同時に実行する場合、スループットのメトリックスが適しています。
ジョブ数/時間/システム= 3600/(ジョブ経過時間)
ここで、システムとは、全体でひとつのユニットとしてセットアップされた、シャーシ、ラック、ブレード、あるいは任意のハードウェアです。
2.3 並列実行制御2.3.1 実行手順
実行手順において以下が保証されなければなりません。
1. ノードやノード内のソケット間で実行するプロセスやスレッドを設定します。
2. ノード容量内に収まるようにプロセスメモリをアロケートします。
3. ノードやネットワークそれぞれで適切なスクラッチファイルを使用します。
バッチスケジューラやリソースマネージャは、1つまたは複数の計算ノードで実行されるようにフロントエンドのログインノードからジョブをディスパッチします。以下はジョブ登録スクリプトの概要です。
1. ディレクトリをバッチスケジューラでアロケートされた最初の計算ノード上のローカル・スクラッチ・ディレクトリに変更します。
2. 全ての入力ファイルをこのディレクトリに上書きします。
3. バッチスケジューラでアロケートされた他の計算ノード上に、並列ローカル・スクラッチ・ディレクトリを作成します。
4. 最初の計算ノード上のアプリケーションを起動します。実行ファイル自体は、主解析実行の最初と最後で、起動ノードと他のノード間の伝播やさまざまなファイルの収集を実行できます。開始スクリプトでは、d3plot*のような出力ファイルを非同期に消去し、スクラッチ・ディレクトリを開放することもできます。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 9
2.3.2 ノードとコア全体のMPIタスクとOpenMPスレッドアロケーションの実行コマンドLS-DYNAでは、プロセス、スレッド、および関連するメモリの配置は、実行コマンド内の次に示すキーワードで行います[1]。
• -np: 分散メモリ並列計算ジョブで使用するMPIプロセスの総数
• ncpu=: SMP OpenMPスレッド数
• memory, memory2: MPIプロセス用にアロケートするメモリサイズ(ワード単位) (ワードは実行ファイルが単精度では4バイト、倍精度では8バイトです。)
1. ピュアMPIモード : 全部または一部のコアを使用 mpirun -np #MPIprocesses HybridExec inputFile ncpu=1 #MPIprocesses=#nodes x #CoresPerNode
2. ハイブリッドモード : MPIプロセスとスレッドの混合 mpirun -np #MPIprocesses HybridExec inputFile ncpu=#ThreadsPerProcess #MPIprocesses x ncpu = total#Threads = #nodes x #CoresPerNode
3. SMPモード(スレッドのみ): mpirun -np 1 HybridExec inputFile ncpu=#CoresOn1Node
4. SMPのみで実行可能なSMPモード(スレッドのみ): SMPexec inputFile ncpu=#CoresOn1Node
2.4 チューニング2.4.1 入出力とメモリ
バッチ環境で最良の実行時間を達成するには、入出力ファイルのディスクアクセスを計算ノードに最も近い高性能ファイルシステムで行う必要があります。高性能ファイルシステムとして、インメモリ・ファイルシステム(/dev/shm)、ダイレクト・アタッチ・ストレージ(DAS)ファイルシステム、またはネットワーク・アタッチ・ストレージ(NAS)ファイルシステムの何れかを用いることができます。ディスクレス計算環境では、インメモリ・ファイルシステムとネットワーク・アタッチ・ストレージ・ファイルシステムのみが選択可能です。ネットワーク・アタッチ・ストレージ(NAS)ファイルシステムを有するクラスタ計算環境では、アプリケーションMPI通信とNFSトラフィックの分離により、スクラッチファイルに対する最適なNFS I/Oスループットを実現できます。図7にファイルシステム体系を示します。
図 6: Example filesystems for Scratch Space

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 10
コア当たりのシステムメモリを増やせば増やすほど、I/O効率改善用のLinuxカーネル・バッファキャッシュだけでなく解析計算にもメモリを割り当てることができ、システムの性能向上が図れます。SGIのフレキシブルファイルI/O(FFIO)は、SGI Accelerateにバンドルされたリンクレスライブラリ(アプリケーションへのリンクを必要としないライブラリ)です。このFFIOは、ユーザー定義のI/Oバッファキャッシュを実装することで、I/Oが集中した複数のジョブやプロセスの実行時に、オペレーティングシステムのスラッシングを回避します。これは、DASやNASストレージサブシステムを用いる共有メモリ並列システムやクラスタ計算環境で有効です。FFIOは、ユーザーページキャッシュを独立させるので、ジョブやプロセスはLinuxカーネル・ページキャッシュと競合しません。つまり、ディスクへの同期コールは最小にすべきですが、FFIOは、ディスクとストレージサブシステム間の同期コール数を反映したeie_closeの同期値や非同期値によりエコーバックされる、システムコール数とI/O操作数を最小にし、大型ジョブやI/O集中ジョブに対する性能を向上させます(参考資料[2]:第7章フレキシブルファイルI/O)。
2.4.2 高密度プロセッサ上で利用可能なコアの一部を使用計算システムの見方には2つあります。1つは、調達費用を決めるノードで見る方法、もう1つは、スループットの決定要因であるコアで見る方法です。プロセッサは価格、クロックレート、コア数およびメモリ帯域幅が異なるので、ターンアラウンドタイムやスループットの最適化基準を選択する場合は、利用可能なすべてのコアで実行しているか、一部のコアで実行しているかに依存します。ライセンス料は、システムに実存する物理コア数ではなく、同時に実行するスレッドやプロセスの数に応じて算出されるため、利用可能なコアを一部しか使用していない場合には、ライセンスコストの削減にはつながりませんが、性能向上を実現できる可能性があります。部分的に使用しているノード間でのスレッドやプロセスの配置は、コア間の共有リソースの存在を考慮して行う必要があります。
2.4.3 インテル®Hyper-threadingインテルHyper-threading(HT)は、マルチスレッドやマルチプロセスのアプリケーションで、性能向上を図れるインテル® Xeon®プロセッサファミリの機能です。この機能を活用することで、ユーザーはノード毎で利用可能な物理コア数の2倍のOpenMPスレッドやMPIプロセスを実行することができます(オーバサブスクリプション)。
LS-DYNAでは、2ノードを超える場合、2倍に増えたMPIプロセス間通信による損失で、Hyper-threadingによる効果が相殺されてしまいます。
2.4.4 インテル®TurboBoost インテル®ターボブーストは、インテル® Xeon®プロセッサファミリの機能で、プロセッサの熱設計枠により制約される制御限界内で、コアの動作周波数を引き上げて性能を向上させます。起動モードは、MPIプロセス、OpenMPスレッドまたはPthreadの実行中のある時点で動作しているコア数の関数になります。ターボブーストは、定格動作周波数に対する最大動作周波数の比率まで、少数のコアの性能を改善できます。ターボブーストは、多くのコアが使われると、動作中のコアが少ない場合とは異なり、全てのコアの動作周波数を高めることはできません。例えば、3.0GHzが定格動作周波数の場合、1つか2つのコアが動作中であれば、コアの動作周波数は3.3GHzに上昇しますが、3つか4つのコアが動作中であれば、その動作周波数は最大でも3.2GHzまでしか上昇しません。計算タスクに関しては、ターボブーストを使用すると実行時間が改善されることが多いので、プロセッサ以外の他の性能ボトルネックが原因ですべての利点が失われるとしても、ターボブーストを有効にしておくことが最善です。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 11
2.4.5 SGIPerformanceSuiteMPIとSGIPerfBoostMPIランクをプロセッサコアに結合する機能は、利用可能な複数のノード、ソケットまたはコア環境で性能を制御する上で重要です。参考資料[3] には「3.1.2 CPUアフィニティとコア設定の計算費用対効果、・・・HP-MPIは現時点ではCPUアフィニティとコア設定の機能を提供して、MPIランクの発行元であるプロセッサのコアにMPIランクを結合している。SMPスレッドを含む子スレッドも同様に同一プロセッサのコアに結合することができるが、異なるプロセッサには結合できない。さらに、SMPスレッドに対するコア設定は、システムデフォルトで行われるが、ユーザーはそれを明示的に制御することはできない。・・・」と記載されています。
対照的に、SGI MPIは、「omplace」オプションで、各ノード内のハイブリッドMPIプロセス、OpenMPスレッドおよびPthreadを正確に配置できます。SGI MPIにバンドルされたPerfBoost機能は、IBM Platform MPI、インテルMPI、OpenMPIの各コールを、リンクレスでSGI MPIコールに変換します。
2.4.6 SGIAccelerateLibFFIOLS-DYNA/MPP/Explicitの場合、I/Oは集中せず、また設定がSGI MPIで行えるため、libFFIOが必要とされないことも珍しくありません。しかし、LS-DYNA/MPP/Implicitの場合、大きなI/Oを含むため、libFFIOはNASや低速ファイルシステムでの帯域幅の競合を相殺することができます。
3.0 ベンチマークの説明ベンチマークには、ジョージワシントン大学のNational Crash Analysis Center(NCAC)で作成され、TopCrunch
(http:www.topcrunch.org)で公開されている3つのデータセットを使用しました。TopCrunchプロジェクトは、高性能コンピュータシステムと技術計算ソフトウェアの集約した性能動向を追跡するために開始されました。人工的なベンチマークを使用するのではなく、実際の工学計算ソフトウェアアプリケーションであるLS-DYNA/Explicitを実データと共に使用しました。2008年から、SGIはこの3つのデータセットで最高性能の地位を確保しています。測定基準は最小経過時間で、各プロセッサの全てのコアを使用しなければならないというルールです。
LS-DYNA/Implicit [4]、[5]も参考資料[8][9]に掲載されています。
3.1 Car2car車両2台の傾斜正面衝突(図7)。車両モデルは、250万要素のNCACミニバンモデルに基づいています。シミュレーションでは、最初から最後までのステップで、201,854,976バイトのd3plotファイルと101,996,544バイトのd3plot[01-25]ファイルを26回(2,624MB)書き込みました。
図 7: Car2car

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 12
3.2 Car2carチューニング倍精度を単精度にすると性能に影響します。選択したLS-DYNAのバージョンもまたR3.2.1まで戻すと結果に影響します。その後、その他の点は自動分解で結果を改善できます。インテル®ターボブーストとデュアルレールでさらに性能が改善します。最終結果は単精度、R3.2.1、ユーザー指定の分解、ターボブーストモードおよびデュアルレールをすべて使用したものです。
4.0 MPInside4.1 MPInside概要
MPInsideは、高性能MPI環境であるSGI MPIで、mpiplaceと共に利用できるMPIプロファイリングツールです[10]。MPInsideは、例えば、MPIの送受信が対として同期実行されていない場所を見つけ出して情報を提供でき、MPIアプリケーション開発者にとって自分のアプリケーションの最適化に役立ちます。
4.2 MPInsideTerminologyMPI通信は、同期する必要がない送受信で構成されています。「送信遅延時間」(Send Late Time、SLT)とは、ひとつのプロセスのMPI_Recvコールから、メッセージが来る予定のプロセスのMPI_Sendコールまでの遅延と定義します。データの実転送にかかる時間は、転送時間(Transfer Time、Tt)と呼ばれます。SLTとTtの合計をファンクション時間
(Function time、FT)と定義します。「受信遅延時間」(Receive Late Time)とは、ブロックされたMPI_sendコールから、最終的な遠隔受信プロセスのMPI_Recvコールまでの遅延と定義します。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 13
上記の例では、MPI_Recvがブロックされたファンクションなので、ファンクション待ち時間FWTはFT時間と等しくなります。しかし、MPI_Irecvのようなブロックされないファンクションの場合には、FWTは、このファンクションに対応する
(MPIの意味で)要求を「終了」するMPI_Waitファンクションの時間になります。
ブロックされない受信(MPI_Irecv、MPI_Recv_init)は、アプリケーションに通信と計算の重複実行を可能にします。通常、通信時間は転送時間と見なされますが、実際にはMPI_Irecvを使うと、アプリケーションは送信遅延時間中にも有用な計算を行うことが可能です。この送信遅延時間は、アプリケーションがMPI_Wait、MPI_Test等を使ってブロックされない受信を完了させようと試行する間、継続する可能性があります。この場合、計算と重複した送信遅延時間はカウントされません。WaitやTestでブロックされた要求、または遅れてしまった要求を終了させるのに要した時間として、アプリケーションから明白な送信遅延時間だけがカウントされます。
4.3 MPInsideの使い方4.3.1 MPInsideコマンド
MPInsideのコマンドは、アプリケーションの変更や再リンクの必要がまったくなく、mpirunコマンドでターゲットアプリケーション実行ファイルの前に引数として挿入するだけです。
4.3.2 MPInsideの出力実行終了時、略記形式のラベルで表したMPIファンクションを複数の列とし、各ランクにつき一行で記載した5つの表を、ASCIIファイルに出力します。
4.3.2.1 TimingTable>>>> Communication time totals (s) 0 1<<<<
CPU Compute MPI_Init w_MPI_Recv Recv w_MPI_Waitall Waitall
0 868.484133 0.000232 0 322.801183 0 0
1 654.365446 0.000213 0 326.385665 0 0.348279
2 645.987836 0.000189 0 337.04429 0 0.270488
3 634.765585 0.000189 0 339.249457 0 0
4 648.41097 0.000214 0 333.377204 0 0
5 657.331095 0.000185 0 322.48984 0 0
4.3.2.2 BytesSentTable:>>>> Bytes sent <<<<
CPU Compute MPI_Init w_MPI_Recv Recv w_MPI_Waitall Waitall
0 ------ 0 0 0 0 0
1 ------ 0 0 0 0 0
2 ------ 0 0 0 0 0
3 ------ 0 0 0 0 0
4 ------ 0 0 0 0 0

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 14
4.3.2.3 Numberof“Send”CallsTable:>>>> Calls sending data <<<<
CPU Compute MPI_Init w_MPI_Recv Recv w_MPI_Waitall Waitall
0 ------ 1 0 0 0 0
1 ------ 1 0 0 0 239981
2 ------ 1 0 0 0 239981
3 ------ 1 0 0 0 0
4 ------ 1 0 0 0 0
4.3.2.4 BytesReceivedTable:>>>> Bytes received <<<<
CPU Compute MPI_Init w_MPI_Recv Recv w_MPI_Waitall Waitall
0 ------ 0 0 28953401700 0 0
1 ------ 0 0 28939575772 0 0
2 ------ 0 0 20038927680 0 0
3 ------ 0 0 19903973196 0 0
4 ------ 0 0 13668688376 0 0
4.3.2.5 Numberof“Recv”CallsTable:>>>> Calls receiving data <<<<
CPU Compute MPI_Init w_MPI_Recv Recv w_MPI_Waitall Waitall
0 ------ 0 0 14208346 0 0
1 ------ 0 0 13966079 0 239981
2 ------ 0 0 14222841 0 239981
3 ------ 0 0 17384042 0 239981
4 ------ 0 0 15638825 0 239981
4.3.2.6 その他の出力ファンクション呼び出しをメッセージサイズの区分にて、次の数量に応じてヒストグラム表示したものを出力します。
4.3.2.6.1 Numberofrequestsdistribution:>>> Rank 0 Sizes distribution <<<
Sizes Recv Send Isend Irecv
65536 0 106 0 48558469
32768 0 38 0 0
16384 0 22 4356 0
[...]
128 489344 1199947 248494 1199934
64 1208805 1679905 245879 719961
32 487218 720068 2531 239989
0 3616833 3927 3636521 0

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 15
4.3.2.6.2 TimesDistribution:>>> Rank 0 Size distribution times<<<
Sizes Recv Send Isend Irecv
65536 0 0.357941 0 30.856745
32768 0 0.001294 0 0
16384 0 0.000713 0.002428 0
8192 16.060919 1.945468 0.005868 0
4.3.2.7 転送行列各ランクを行と列とした、次の3つの値も生成します。
• TIME(i,j): ランク「i」がランク「j」からデータを受信するのに要した合計時間
• SIZE(i,j): ランク「i」からランク「j」へのデータ転送量
• REQUEST(i,j): 上記の転送に使ったコール数
4.4 MPInsideが取り扱う情報4.4.1 一般事項
MPInsideは、受信側で規定したサイズではなく、物理的に転送されたバイト数を報告します。
MPI_BcastやMPI_Alltoallのような一括操作については、転送はブロードキャスト元に対して送信を割り当て、操作に関わる他のランクについては受信として割り当てます。
報告されるサイズは、バッファサイズに該当ファンクションに関わったランクの数を乗じて計算されます。
MPInsideで測定する「Compute(計算)」時間は、そのランクが費やした時間で、プロファイリングされたMPIコールに寄与しない時間です。時間にはI/O時間を含みますが、MPINSIDE_SHOW_READ_WRITEが設定されている場合は別 に々測定されます。その場合、libc I/Oファンクション、すなわちread()、write、open、およびMPI_File_read_at()のようなMPI_File_xxxの読み込みまたは書き込みMPI I/Oファンクションの、文字数と直接コールの回数はひとつの表で報告されます。
I/O待ちやシステム待ちのような通信に関係しない時間も、オープンソースのperfツールとoprofileツール、またはオープンソースではないインテル® VTune™プロファイリングツールを組み合わせて使用することにより補足可能で、計算時間をさらに掘り下げることができます。
先に述べたように、あるランクは、他のランクが追いつくのを待つために、MPIコールでブロックされる場合があります。これは、MPI_Allreduceのような一括操作の場合で、このようなMPI一括ファンクションのほんの少しの時間が、最後のランクの完了時点への到着待ちに費やされます。このようなタイミング調整不良のコストを評価するために、全ランクを同期する各MPI一括ファンクションの前にMPI_Barrierコールを挿入すると、その経過時間を記録し、これにより一括操作の待ち時間だけを計測できます。それに続くMPI一括ファンクションで表示されるのは、データの物理的転送時間とその処理時間です。この報告機能は、MPINSIDE_EVAL_COLLECTIVE_WAITで起動します。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 16
データの表とヒストグラムでは、「b_xxx」の列が「xxx」MPI一括ファンクションに対応するMPI_barrier時間を示し、「xxx」の列が残りの時間を示しています。
一括以外の操作については、MPINSIDE_EVAL_SLTを設定すると、MPInsideは、Recv-Waitイベントに関連した遅延(SLT)である、全ての送信コールに対する時間を計測します。そのような時間は、表内でw_xxxと示され、xxxはMPI_WaitまたはMPI_Recvとなります。xxxはMPI_Irecvにはなりません。なぜなら、最後のファンクションに対する送信遅延時間は、存在してもMPI_Waitのようなファンクションで考慮されているからです。
どちらのプロファイリングモードも有効になっていない場合(ベーシックモード)、対応するMPIコールで費やした時間として表示されます。
一括待ち(Collective Wait)モードとSLTモードが有効な場合、MPIコールで費やした時間は、さらに転送時間(Tt)と待ち時間に分割されます。待ち時間は、計算負荷の不均衡またはOS関係の外乱によるものです。
MPI_SendまたはMPI_IsendとMPI_Waitの対では、受信遅延時間は「遅れた」受信が主原因です。十分なバッファを確保すれば、その影響は最小にできます。
一方、MPI_RecvまたはMPI_IrecvとMPI_Waitの対での待ち時間は、対応する送信者が遅れている場合、ゼロにはなりません(送信遅延時間、SLT)。この待ち時間は、どんなバッファを準備しても避けることができません。従ってモニタリングではより重要になります。
要約すると、w_MPI_Recv、b_Bcastおよびb_Allreduce列での時間は全て待ち時間で、Recv、BcastおよびAllreduce列での時間は全て物理的転送時間です。合計経過時間は、「Compute」列と全てのMPI列を合計したものです。
4.4.2 MPIファンクションの略称b_<Collective_function>: MPINSIDE_EVAL_COLLECTIVE_WAITを設定している場合、<Collective_function>の前にMPI_Barrierを意図的に挿入したことを示します。一括ファンクション(Collective_function)の合計時間はb_<Collective_function> + <Collective_function>となります。
w_<receive_or_wait_func>: 対応するMPI_RecvまたはMPI_Waitに対して、送信が遅れたことによる時間を考慮する意図的な待ちファンクションを示します。
4.4.3 さらに進んだ機能測定する代わりに、MPInsideは、「完璧なインターコネクト」を仮定した通信モデルを使って報告することもできます。この漸近値で、特定のアプリケーションと実行事例について、通信ハードウェアやライブラリを強化することに意味があるかどうかを判断できます。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 17
「完璧な」プロファイルとは、RecvとBcastの時間を消し去ることはなく、残りは、MPIコール引数の引き渡し、スタックのプッシュとポップ動作、メモリの配置と開放のためのlibmpiでのオーバーヘッドです。さらに重要なのは、RecvやBcastの相手の、ひとつもしくは複数のランクが追いつくことを待っている時間です。これらの時間は、SLTや一括待ち時間とほぼ同等ですが、転送時間なしだとランクが同期しやすくなるので短くなることもあります。
4.5 MPInsideでの推定MPInside表のw_MPI_Recv列での大きな時間は、Recvにおける送信遅延時間(SLT)に相当しています。
MPInside表のb_Bcast列での大きな時間は、Bcastが実際に開始される前の同期待ち時間に相当しています。
完璧なインターコネクトモードでのRecvとBcastの0でない時間は、送信遅延時間(SLT)や一括待ち時間で示したのと同様に、RecvやBcastの相手のひとつもしくは複数のランクが追いつくのを待っている時間とほぼ同等ですが、計算区間ごとに転送時間なしだとランク同士が同期しやすくなるので短くなることもあります。
上記3つの症状は、計算時間でも同様の異常が見られた場合、ロードバランスの不均衡に起因していると推定されます。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 18
4.6 ロードバランス対策MPInsideのデータをもとに、領域分割を分析またはLSTCで対策して、ロードバランスの不均衡を低減できます。改善できない場合、MPI_Ibcast(MPT 2.10以降)またはMPI_Irecvを使って計算と通信を重複させたり、より多くのデータがないと作業を実行できなくなるまでブロックを遅らせたりすることが役立ちます。IbcastやIrecvからの要求に対する周期的なMPI_Test*で、さらに重複させることができます。SGI MPIには、要求があると一回進む独立した進捗スレッドがあります。MPI_Testは進捗エンジンを「キック」して完了を再度確認させます。
4.7 Car2carTopcrunchベンチマークのケーススタディ4.7.1 基本プロファイリング
SGI MPInsideを実行し、基本プロファイリングを取得して、計算時間とMPIコールに関係する1,992個のMPIプロセス全体にわたって、積層図を作成しました。図8のY軸は、ランク0から1,991の全範囲に対する経過時間を表しています。
薄紫、青、濃紺の帯は、全てのランクにわたって、実行時間の約半分弱が計算時間であり、通信時間の大部分がRecvコールとBcastコールに費やされることを示しています。
図 8: mpinside_basic_f2501_stats.xls

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 19
4.7.2 一括持ちプロファイリング図9は、一括待ちモードを有効にすることで、前のグラフのBcastコールが、実際にはランク同期のためにbarrierのような時間で構成されることを示しており、Bcasts自身はその時間の1%です。
図 9: mpinside_collectivewait_f2501_stats.xls

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 20
4.7.3 送信遅延時間プロファイリング図10は、送信遅延時間モードを有効にしても、Recv時間に影響がなく、w_MPI_Recv部分を大きく減少させないことを示しており、送信遅延時間の遅延が大きくないことを示したものです。
図 10: mpinside_slt_f2501_stats.xls
W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 21
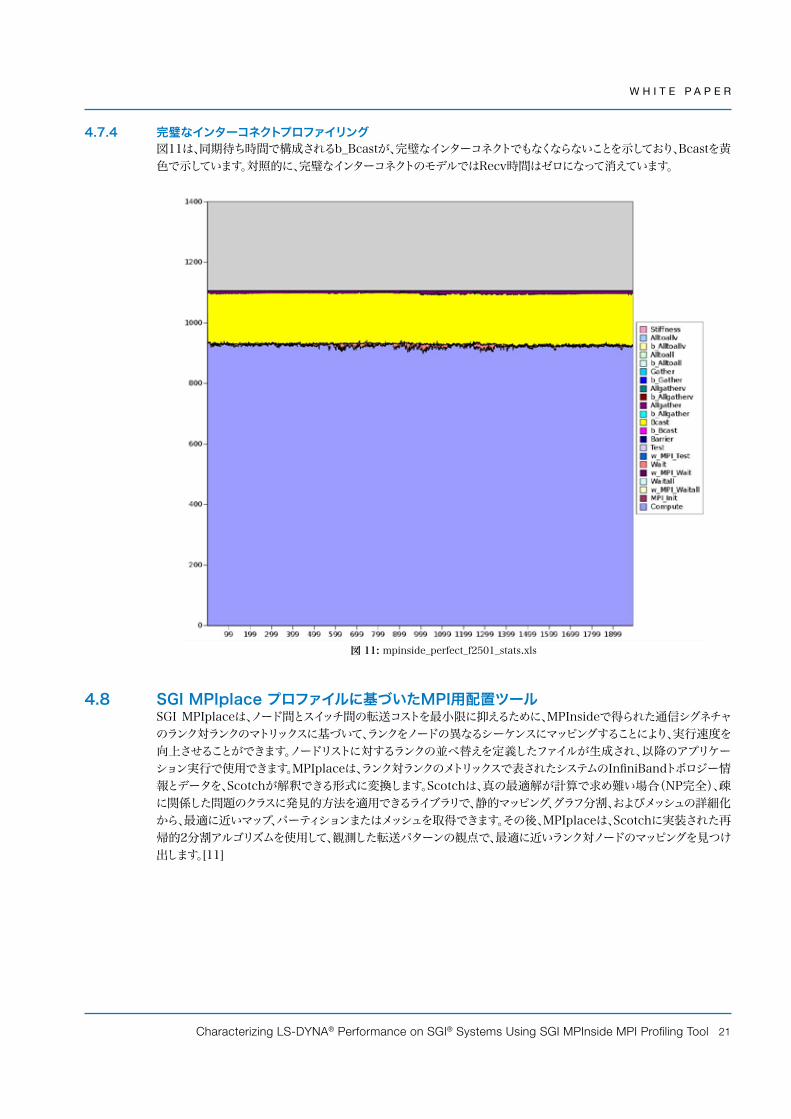
4.7.4 完璧なインターコネクトプロファイリング図11は、同期待ち時間で構成されるb_Bcastが、完璧なインターコネクトでもなくならないことを示しており、Bcastを黄色で示しています。対照的に、完璧なインターコネクトのモデルではRecv時間はゼロになって消えています。
図 11: mpinside_perfect_f2501_stats.xls
4.8 SGIMPIplaceプロファイルに基づいたMPI用配置ツールSGI MPIplaceは、ノード間とスイッチ間の転送コストを最小限に抑えるために、MPInsideで得られた通信シグネチャのランク対ランクのマトリックスに基づいて、ランクをノードの異なるシーケンスにマッピングすることにより、実行速度を向上させることができます。ノードリストに対するランクの並べ替えを定義したファイルが生成され、以降のアプリケーション実行で使用できます。MPIplaceは、ランク対ランクのメトリックスで表されたシステムのInfiniBandトポロジー情報とデータを、Scotchが解釈できる形式に変換します。Scotchは、真の最適解が計算で求め難い場合(NP完全)、疎に関係した問題のクラスに発見的方法を適用できるライブラリで、静的マッピング、グラフ分割、およびメッシュの詳細化から、最適に近いマップ、パーティションまたはメッシュを取得できます。その後、MPIplaceは、Scotchに実装された再帰的2分割アルゴリズムを使用して、観測した転送パターンの観点で、最適に近いランク対ノードのマッピングを見つけ出します。[11]

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 22
4.8.1 概要A. 性能ベースラインに対してMPT有りでアプリケーションを実行します。
B. 転送メトリックスを生成するためにMPINSIDE_MATRICES=PLA:-B:Sと指定し、MPTとMPInside有りでアプリケーションを実行します。
C. ステップBのメトリックスとノードリストを使用してMPIplaceを実行し、ノードリストと共にランクの並べ換えを生成します。例えば、ノードリストがn001、n002、n003で、24コアの多重度の場合、以下のように記録されます。
n003
n002
n002
n002
n002
n002
n002
n002
n003
n003
n003
n003
[...]
D. D. MPTとランクの並べ替え有りで再度アプリケーションを実行し、性能を向上させます。従って、mpirunコマンドでは、並べ替えられたノードリストを使用することになります。
mpirun -v n003 1, n002 1, n002 1, n002 1,
n002 1, n002 1, n002 1, n002 1, n003 1, n003 1, n003 1, n003 1, n003 1, n003 1,
n003 1, n003 1, n003 1, n003 1, n003 1, n003 1, n003 1, n003 1, n003 1, n003 1,
n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n002 1,
n002 1, n002 1, n002 1, n002 1, n002 1, n002 1, n002 1, n003 1, n003 1, n003 1,
n003 1, n003 1, n003 1, n003 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1,
n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n001 1, n002 1,
n002 1, n002 1, n002 1, n002 1, n002 1, n002 1, n002 1, n002 1
omplace -vv -c 0-23
mpp971_s_R3.2.1_Intel_linux86-64_sgimpt i=neon.refined.rev01.k ncpu=1 memory=40m p=pfile
memory2=4m
修正されたノードに対するランクのマッピングが表示されます。wrank grank lrank pinning node name cpuid
0 0 0 yes n003 0
8 1 1 yes n003 1
9 2 2 yes n003 2
10 3 3 yes n003 3
11 4 4 yes n003 4
12 5 5 yes n003 5
13 6 6 yes n003 6
14 7 7 yes n003 7
15 8 8 yes n003 8
16 9 9 yes n003 9
17 10 10 yes n003 10

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 23
あるいは、分かりやすくするために並べ替えると以下のようになります。wrank grank lrank pinning node name cpuid
0 0 0 yes n003 0
1 24 0 yes n002 0
2 25 1 yes n002 1
3 26 2 yes n002 2
4 27 3 yes n002 3
5 28 4 yes n002 4
6 29 5 yes n002 5
7 30 6 yes n002 6
8 1 1 yes n003 1
9 2 2 yes n003 2
4.8.2 Car2CarTopcrunchベンチマークのケーススタディ24コア 83ノードにおいて1,992ランクを使用し、モデルを下記の条件で実行しました。
A. 性能ベースラインに対してMPT 2.12ベータ版で実行されたLS-DYNA経過時間: 3,222秒(0時間53分42秒)。239,981サイクル
B. メトリックス生成用、MPT 2.12ベータ版、MPInside3.6.6ベータ版で実行されたLS-DYNA経過時間: 3,492秒(0時間58分12秒)。239,981サイクル
C. 並べ替えファイル生成のためのmpiplace$ head mpiplace_perm
936
937
1560
1561
1562
1563
1564
1565
1566
1567
[...]
Elapsed: 56.18 sec.
D. mpiplace_permとmpirun有りでMPT 2.12ベータ版で実行された、MPInside無しのLS-DYNA経過時間: 2,992秒(0時間49分52秒)。239,981サイクル
これは7%の向上です。
この7%の性能改善は、領域分割によるロードバランスのチューニングを加味したものになります。ベースラインの実行に領域分割を使用しない場合は、MPInsideとmpiplaceを用いた性能向上は、7%に対して10%に上昇します。
5.0 まとめ陽解法ソルバをMPI分析ツールSGI MPInsideを使って調査し、通常の通信プロファイリングの特徴を分析して「オンザフライ」モデリングを行い、最新のインテル® Xeon® CPU、インターコネクトとミドルウェア、MPIライブラリ、および実装したLS-DYNAソースコードで利用できる様々なアップグレードの潜在的な性能向上を予測しました。ランク間転送時間を最小化するために、プロファイルに基づくmpiplaceコンポーネントを実行して、この分野での利点がさっそくもたらされていることを示し、今後さらなる取り組みが期待されます。

W H I T E P A P E R
Characterizing LS-DYNA® Performance on SGI® Systems Using SGI MPInside MPI Profiling Tool 24
6.0 参考文献1. LS-DYNA®, KEYWORD USER’S MANUAL, VOLUME I, Appendix O, August 2012, Version
971 R6.1.0.
2. SGI. Linux Application Tuning Guide. Silicon Graphics International, California, 2009.
3. Yih-Yih Lin and Jason Wang. “Performance of the Hybrid LS-DYNA on Crash Simulation with the Multicore Architecture”. In 7th European LS-DYNA Conference, 2009.
4. Dr. C. Cleve Ashcraft, Roger G. Grimes, and Dr. Robert F. Lucas. “A Study of LS-DYNA Implicit Performance in MPP”. In Proceedings of 7th European LS-DYNA Conference, Austria, 2009.
5. Dr. C. Cleve Ashcraft, Roger G. Grimes, and Dr. Robert F. Lucas. “A Study of LS-DYNA Implicit Performance in MPP (Update)”, 2009.
6. Olivier Schreiber, Michael Raymond, Srinivas Kodiyalam, LS-DYNA® Performance Improvements with Multi-Rail MPI on SGI® Altix® ICE cluster, 10th International LS-DYNA® Users Conference, June 2008.
7. Olivier Schreiber, Scott Shaw, Brian Thatch, and Bill Tang. “LS-DYNA Implicit Hybrid Technology on Advanced SGI Architectures”. July 2010.
8. Olivier Schreiber, Tony DeVarco, Scott Shaw and Suri Bala, ‘Matching LS-DYNA Explicit, Implicit, Hybrid technologies with SGI architectures’ In 12th International LS-DYNA Conference, May 2012.
9. Leveraging LS-DYNA Explicit, Implicit, Hybrid technologies with SGI hardware, Cyclone Cloud Bursting and d3VIEW, Olivier Schreiber*, Tony DeVarco*, Scott Shaw* and Suri Bala† *SGI, †LSTC, 9th European Users Conference, 3-4th June 2013-Manchester, UK.
10. Daniel Thomas, Jean-Pierre Panziera, John Baron: MPInside: a performance analysis and diagnostic tool for MPI applications. WOSP/SIPEW 2010: 79-86, ACM, (2010) http://www.sgi.com/products/software/sps.html http://techpubs.sgi.com/library/manuals/5000/007-5780-002/pdf/007-5780-002.pdf.
11. Experimental Analysis of the Dual Recursive Bipartitioning Algorithm for Static Mapping. Research report RR-1138-96, LaBRI, September 1996. F. Pellegrini and J. Roman. http://www.labri.fr/perso/pelegrin/scotch.
TEL : 03-5488-1811(大代表) FAX:03-5420-7201TEL : 06-6479-3918( 代表 ) FAX : 06-6479-3919TEL : 0565-35-2561( 代表 ) FAX : 0565-35-2189TEL : 029-858-1551( 代表 ) FAX : 029-858-1071TEL : 022-221-2301( 代表 ) FAX : 022-221-2304TEL : 082-258-5037( 代表 ) FAX : 082-258-5038
本 社西 日 本 支 社中 部 支 社つ く ば 営 業 所東 北 営 業 所広 島 営 業 所
http://www.sgi.co.jp
〒150-6031 東京都渋谷区恵比寿4-20-3 恵比寿ガーデンプレイスタワー31階
このカタログは、環境に配慮した植林木を使用しております。日本SGIは様々なソリューションの提供を通じてお客様の製品の開発・設計の過程において発生する紙や燃料等の資源消費量やCO2排出量の低減を行い、省資源、省エネルギー化に貢献しています。
日 本 S G I は 地 球 環 境 に 優 し い 企 業 へ
©2015 SGI Japan, Ltd. All Rights Reserved. 仕様は予告なしに変更される場合があります。SGI、ICE、UV、Rackable、NUMAlink、Performance Suite、Accelerate、ProPack、OpenMP および SGI のロゴは Silicon Graphics International Corp. または、アメリカ合衆国および / またはその他の国の子会社の商標または登録商標です。LS-DYNA は Livermore Software Technology Corp. の登録商標です。インテル、Intel、Xeon は、アメリカ合衆国および / またはその他の国における Intel Corporation の登録商標です。その他の会社名、製品名は、各社の登録商標または商標です。(11/2015)