chapter 7 decision tree. data warehouse and data mining chapter 6 2 decision trees an algorithm for...
TRANSCRIPT

Chapter 7
Decision Tree

Chapter 62Data Warehouse and Data Mining
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
1. Let T be the set of training instances.
2. Choose an attribute that best differentiates the instances contained in T.
3. Create a tree node whose value is the chosen attribute. Create child links from this node where each link represents a unique value for the chosen attribute. Use the child link values to further subdivide the instances into subclasses.

Chapter 63Data Warehouse and Data Mining
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
4. For each subclass created in step 3:
a. If the instances in the subclass satisfy predefined criteria or if the set of remaining attribute choices for this path of the tree is null, specify the classification for new instances following this decision path.
b. If the subclass does not satisfy the predefined criteria and there is at least one attribute to further subdivide the path of the tree, let T be the current set of subclass instances and return to step 2.

Chapter 64Data Warehouse and Data Mining
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
Decision TreesDecision TreesAn Algorithm for Building Decision Trees

Chapter 65Data Warehouse and Data Mining
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
Decision TreesDecision TreesAn Algorithm for Building Decision Trees

Chapter 66Data Warehouse and Data Mining
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
Decision TreesDecision TreesAn Algorithm for Building Decision Trees

Chapter 67Data Warehouse and Data Mining
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
Decision TreesDecision TreesAn Algorithm for Building Decision Trees
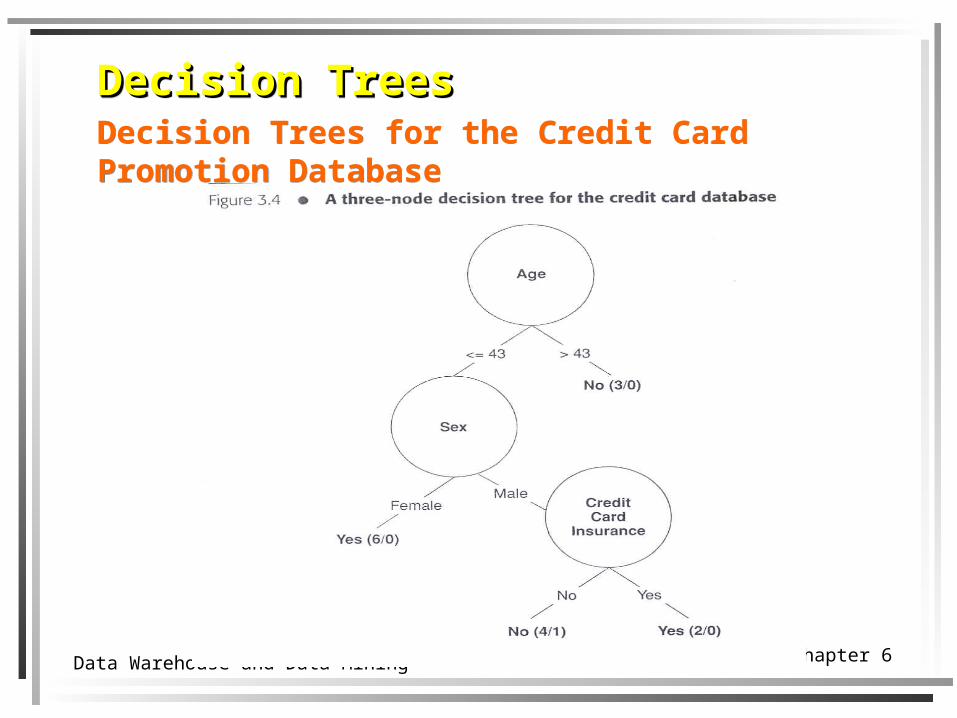
Chapter 68Data Warehouse and Data Mining
Decision TreesDecision TreesDecision Trees for the Credit Card Promotion Database
Decision TreesDecision TreesDecision Trees for the Credit Card Promotion Database

Chapter 69Data Warehouse and Data Mining
Decision TreesDecision TreesDecision Trees for the Credit Card Promotion Database
Decision TreesDecision TreesDecision Trees for the Credit Card Promotion Database

Chapter 610Data Warehouse and Data Mining
Decision TreesDecision TreesDecision Trees for the Credit Card Promotion Database
Decision TreesDecision TreesDecision Trees for the Credit Card Promotion Database

Chapter 611Data Warehouse and Data Mining
Decision TreesDecision TreesDecision Tree Rules
Decision TreesDecision TreesDecision Tree Rules
IF Age <= 43 & Sex = Male & Credit Card Insurance = No
THEN Life Insurance Promotion = No
IF Sex = Male & Credit Card Insurance = No
THEN Life Insurance Promotion = No

Chapter 612Data Warehouse and Data Mining
Decision TreesDecision TreesGeneral Considerations
Decision TreesDecision TreesGeneral Considerations
Here is a list of a few of the many advantages decision trees have to offer.
Decision trees are easy to understand and map nicely to a set of production rules.
Decision trees have been successfully applied to real problems.
Decision trees make no prior assumptions about the nature of the data.
Decision trees are able to build models with datasets containing numerical as well as categorical data.

Chapter 613Data Warehouse and Data Mining
Decision TreesDecision TreesGeneral ConsiderationsGeneral Considerations
Decision TreesDecision TreesGeneral ConsiderationsGeneral Considerations
As with all data mining algorithms, there are several issues surrounding decision tree usage. Specifically,
• Output attributes must be categorical, and multiple output attributes are not allowed.
• Decision tree algorithms are unstable in that slight variations in the training data can result in different attribute selections at each choice point with in the tree. The effect can be significant as attribute choices affect all descendent subtrees.
• Trees created from numeric datasets can be quite complex as attribute splits for numeric data are typically binary.

Chapter 614Data Warehouse and Data Mining
Classification by Decision Tree Induction• Decision tree
– A flow-chart-like tree structure– Internal node denotes a test on an attribute– Branch represents an outcome of the test– Leaf nodes represent class labels or class distribution
• Decision tree generation consists of two phases– Tree construction
• At start, all the training examples are at the root• Partition examples recursively based on selected
attributes– Tree pruning
• Identify and remove branches that reflect noise or outliers
• Use of decision tree: Classifying an unknown sample– Test the attribute values of the sample against the decision
tree

Chapter 615Data Warehouse and Data Mining
Training Datasetage income student credit_rating buys_computer
<=30 high no fair no<=30 high no excellent no30…40 high no fair yes>40 medium no fair yes>40 low yes fair yes>40 low yes excellent no31…40 low yes excellent yes<=30 medium no fair no<=30 low yes fair yes>40 medium yes fair yes<=30 medium yes excellent yes31…40 medium no excellent yes31…40 high yes fair yes>40 medium no excellent no
This follows an example from Quinlan’s ID3
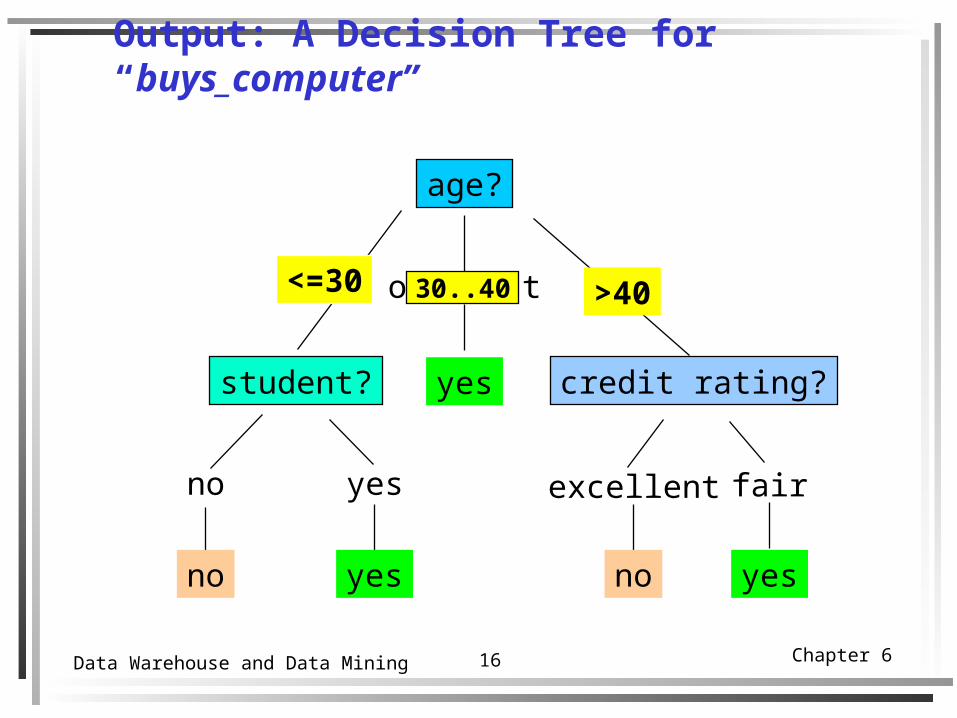
Chapter 616Data Warehouse and Data Mining
Output: A Decision Tree for “buys_computer”
age?
overcast
student? credit rating?
no yes fairexcellent
<=30 >40
no noyes yes
yes
30..40

Chapter 617Data Warehouse and Data Mining
Algorithm for Decision Tree Algorithm for Decision Tree InductionInduction
• Basic algorithm (a greedy algorithm)– Tree is constructed in a top-down recursive divide-and-
conquer manner– At start, all the training examples are at the root– Attributes are categorical (if continuous-valued, they are
discretized in advance)– Examples are partitioned recursively based on selected
attributes– Test attributes are selected on the basis of a heuristic or
statistical measure (e.g., information gain)
• Conditions for stopping partitioning– All samples for a given node belong to the same class– There are no remaining attributes for further partitioning –
majority voting is employed for classifying the leaf– There are no samples left

Chapter 618Data Warehouse and Data Mining
weather
sunnycloudyrainy
windyTemp > 75
BBQ Eat in
Eat in
BBQ Eat in
yesno

Chapter 619Data Warehouse and Data Mining
Attribute Selection Attribute Selection MeasureMeasure
• Information gain (ID3/C4.5)– All attributes are assumed to be categorical– Can be modified for continuous-valued attributes
• Gini index (IBM IntelligentMiner)– All attributes are assumed continuous-valued– Assume there exist several possible split values
for each attribute– May need other tools, such as clustering, to get
the possible split values– Can be modified for categorical attributes

Chapter 620Data Warehouse and Data Mining
Information Gain (ID3/C4.5)
• Select the attribute with the highest information gain
• Assume there are two classes, ....P and ....N
– Let the set of examples S contain
• ...p elements of class P
• ...n elements of class N
– The amount of information, needed to decide if an arbitrary example in S belongs to P or N is defined as
npn
npn
npp
npp
npI
22 loglog),(

Chapter 621Data Warehouse and Data Mining
Information Gain in Decision Tree Induction
• Assume that using attribute A
a set S will be partitioned into sets {S1, S2 , …,
Sv}
– If Si contains pi examples of P and ni examples of
N ,the entropy, or the expected information needed to classify objects in all subtrees Si is
• The encoding information that would be gained by branching on A
1),()(
iii
ii npInp
npAE
)(),()( AEnpIAGain

Chapter 622Data Warehouse and Data Mining
Attribute Selection by Information Gain Computation
age pi ni I(pi, ni)<=30 2 3 0.97130…40 4 0 0>40 3 2 0.971
age income student credit_rating buys_computer<=30 high no fair no<=30 high no excellent no31…40 high no fair yes>40 medium no fair yes>40 low yes fair yes>40 low yes excellent no31…40 low yes excellent yes<=30 medium no fair no<=30 low yes fair yes>40 medium yes fair yes<=30 medium yes excellent yes31…40 medium no excellent yes31…40 high yes fair yes>40 medium no excellent no

Chapter 623Data Warehouse and Data Mining
Attribute Selection by Information Gain Computation
Class P: buys_computer = “yes”
Class N: buys_computer = “no”
I(p, n) = I(9, 5) = 0.940
Compute the entropy for age:
age pi ni I(pi, ni)<=30 2 3 0.97130…40 4 0 0>40 3 2 0.971
np
n
np
n
np
p
np
pnpI
22 loglog),(
)(),()( AEnpIAGain
1),()(
iii
ii npInp
npAE
9 5
-9/(9+5)log2 9/(9+5) – 5/(9+5)log25/(9+5)

Chapter 624Data Warehouse and Data Mining
Attribute Selection by Information Gain Computation
Similarly
age pi ni I(pi, ni)<=30 2 3 0.97130…40 4 0 0>40 3 2 0.971
692.0)2,3(14
5
)0,4(14
4)3,2(
14
5)(
I
IIageE
048.0)_(
151.0)(
029.0)(
ratingcreditGain
studentGain
incomeGain
)(),()( ageEnpIageGain
1),()(
iii
ii npInp
npAE
I(p, n) = I(9, 5) =0.940
Gain(age) = 0.940 –0.692 = 0.248

Chapter 625Data Warehouse and Data Mining
Extracting Classification Rules from Trees
• Represent the knowledge in the form of IF-THEN rules
• One rule is created for each path from the root to a leaf
• Each attribute-value pair along a path forms a conjunction
• The leaf node holds the class prediction• Rules are easier for humans to understand
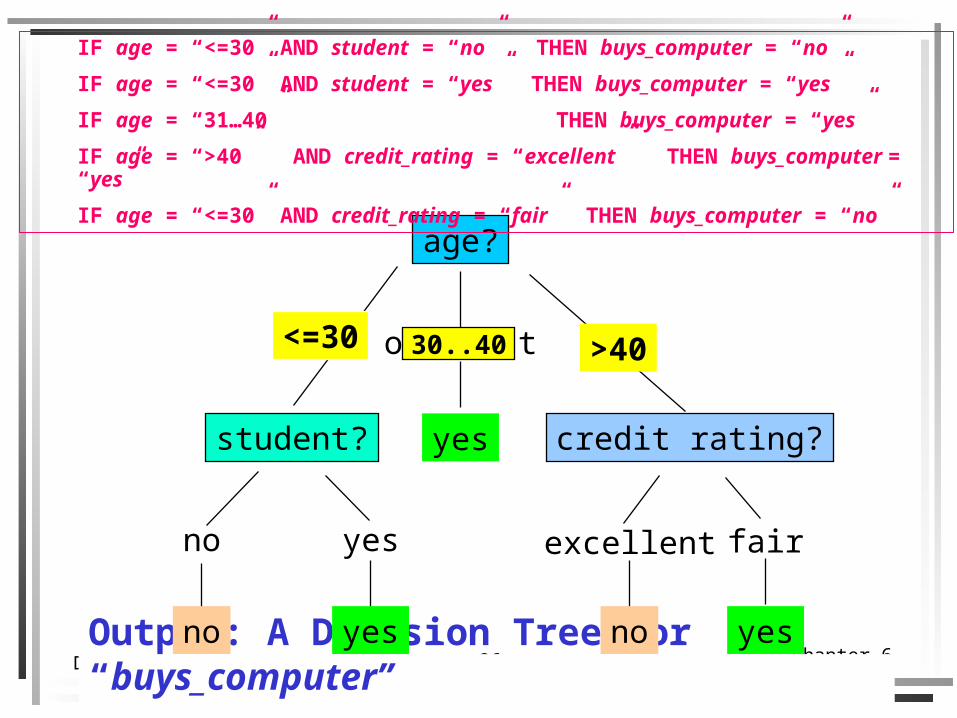
Chapter 626Data Warehouse and Data MiningOutput: A Decision Tree for “buys_computer”
age?
overcast
student? credit rating?
no yes fairexcellent
<=30 >40
no noyes yes
yes
30..40
IF age = “<=30” AND student = “no” THEN buys_computer = “no”
IF age = “<=30” AND student = “yes” THEN buys_computer = “yes”
IF age = “31…40” THEN buys_computer = “yes”
IF age = “>40” AND credit_rating = “excellent” THEN buys_computer = “yes”
IF age = “<=30” AND credit_rating = “fair” THEN buys_computer = “no”

Chapter 627Data Warehouse and Data Mining
Avoid Overfitting in Classification
• The generated tree may overfit the training data
– Too many branches...., some may reflect anomalies due to noise or outliers
– Result is in poor accuracy for unseen samples
• Two approaches to avoid overfitting – Prepruning: Halt tree construction early—do not split a
node if this would result in the goodness measure falling below a threshold
• Difficult to choose an appropriate threshold– Postpruning: Remove branches from a “fully grown”
tree—get a sequence of progressively pruned trees• Use a set of data different from the training data to
decide which is the “best pruned tree”

Chapter 628Data Warehouse and Data Mining
Approaches to Determine the Final Tree Size
• Separate training (2/3) and testing (1/3) sets
• Use cross validation, e.g., 10-fold cross validation
• Use all the data for training– but apply a statistical test (e.g., chi-square) to estimate
whether expanding or pruning a node may improve the entire distribution
• Use minimum description length (MDL) principle: – halting growth of the tree when the encoding is
minimized

Chapter 629Data Warehouse and Data Mining
Enhancements to basic decision tree induction
• Allow for continuous-valued attributes– Dynamically define new discrete-valued attributes that
partition the continuous attribute value into a discrete set of intervals
• Handle missing attribute values– Assign the most common value of the attribute– Assign probability to each of the possible values
• Attribute construction– Create new attributes based on existing ones that are
sparsely represented– This reduces fragmentation, repetition, and replication

Chapter 630Data Warehouse and Data Mining
Classification in Large Databases
• Classification—a classical problem extensively studied by statisticians and machine learning researchers
• Scalability: Classifying data sets with millions of examples and hundreds of attributes with reasonable speed
• Why decision tree induction in data mining?– relatively faster learning speed (than other classification
methods)– convertible to simple and easy to understand classification
rules– can use SQL queries for accessing databases– comparable classification accuracy with other methods

Chapter 631Data Warehouse and Data Mining
Chapter SummaryChapter SummaryChapter SummaryChapter Summary
•Decision trees are probably the most popular structure for supervised data mining.
•A common algorithm for building a decision tree selects a subset of instances from the training data to construct an initial tree.
•The remaining training instances are then used to test the accuracy of the tree.
•If any instance is incorrectly classified the instance is added to the current set of training data and the process is repeated.

Chapter 632Data Warehouse and Data Mining
Chapter SummaryChapter SummaryChapter SummaryChapter Summary
•A main goal is to minimize the number of tree levels and tree nodes, thereby maximizing data generalization.
•Decision trees have been successfully applied to real problems, are easy to understand, and map nicely to a set of production rules.

Chapter 633Data Warehouse and Data Mining
Reference
Data Mining: Concepts and Techniques (Chapter 7 Slide for textbook), Jiawei Han and Micheline Kamber, Intelligent Database Systems Research Lab, School of Computing Science, Simon Fraser University, Canada