「ポストペタスケール有限要素法に向けて」ccse.jaea.go.jp/ja/conf/workshop_24/okuda.pdf ·...
TRANSCRIPT

「ポストペタスケール有限要素法に向けて」
奥田 洋司東京大学大学院・新領域創成科学研究科
人間環境学専攻
第24回CCSEワークショップ 平成24年6月19日(火)先端的計算機の発展とモデリング&シミュレーション技術への期待と展望【第二部】 先端的計算機の発展とモデリング&シミュレーション技術への期待と展望
1998-2002 2002-2004 2005-2007

FrontISTR
メッシュサイズ=0.1mm

Outline
Background : Towards peta/exascale computing
Necessary advances in programming models and software
As an HPC tool for industry
Parallel FE Structural Analysis System: FrontISTR
Large-grain Parallelism
Assembly structures under hierarchical gridding
Small-grain Parallelism
Blocking with padding for multicore CPU and GPUs
Summary

Advanced characteristics Hierarchical mesh refinement
Assembly structure
Parallel computation with O(105) nodes
Practical nonlinear functions Hyper-elasticity/Thermal-elastic-plastic/Visco-
elastic/Creep, Combined hardening rule
Total/Updated Lagrangian
Finite slip contact, Friction
Portability From MPP to PC CAE cloud
FrontISTR: Nonlinear Structural Analysis SoftwareFrontISTR

Dynamics Rolling Contact Analysis between Rail and Wheel
Normal stress on contact surfaces
Joint research with Railway Technical Research Institute
High-speed stable run state has been realized.
FrontISTR

Thermal-Elastic-Plastic Analysis of Welding Residual Stress
Temperature
Joint research with IHI
von Mises stress
Heat source transfer along a welding line
Residual stress induced by plastic deformation
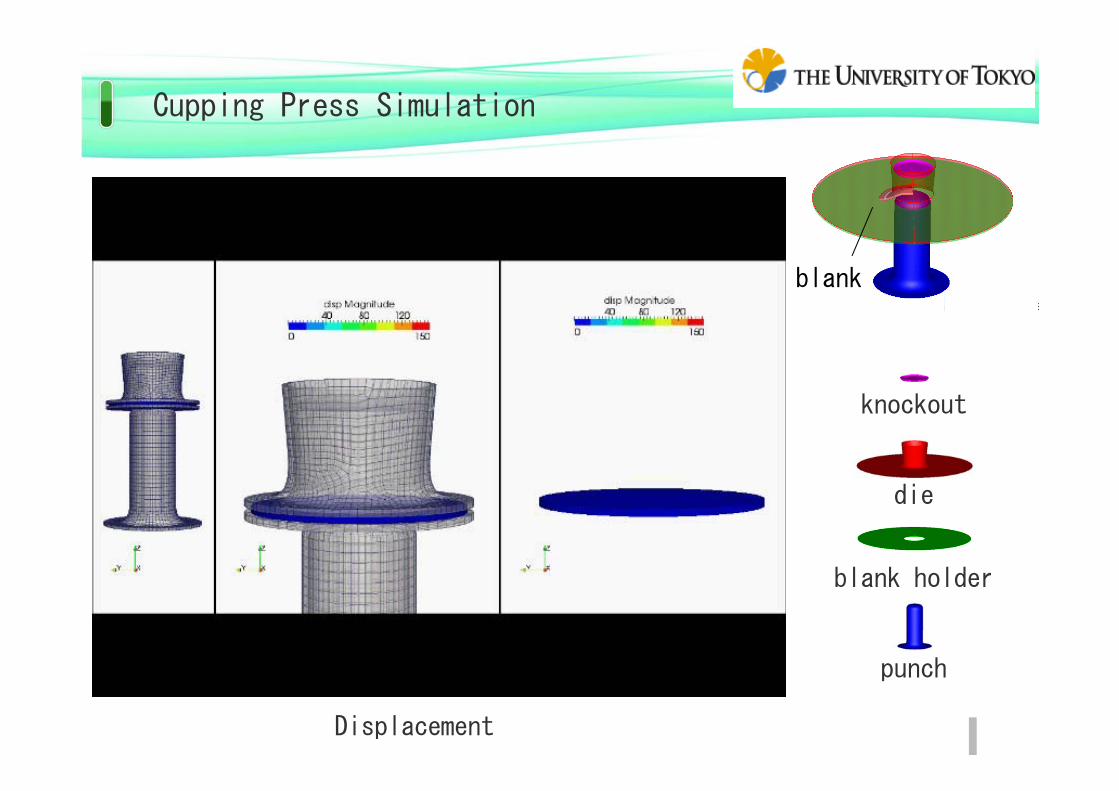
Cupping Press Simulation
Displacement
punch
blank holder
die
knockout
blank

Necessary advances in programming models and software
Fast SpMV for unstructured grid
Consistency and stability NOT affected
Two (at most) nested programming model, i.e. message passing and loop decomposition
Good B/F ratio program consistent with H/W
Automatic generation of compiler directives, which can consider the “dependency”, after trial runs.
“middleware ( mid-level interface )”, bridging the application and the BLAS based numerical libraries.
Uncertainty or risk in the physical model
Hierarchical consistency between H/W configuration and the physical modeling, particularly in engineering fields.
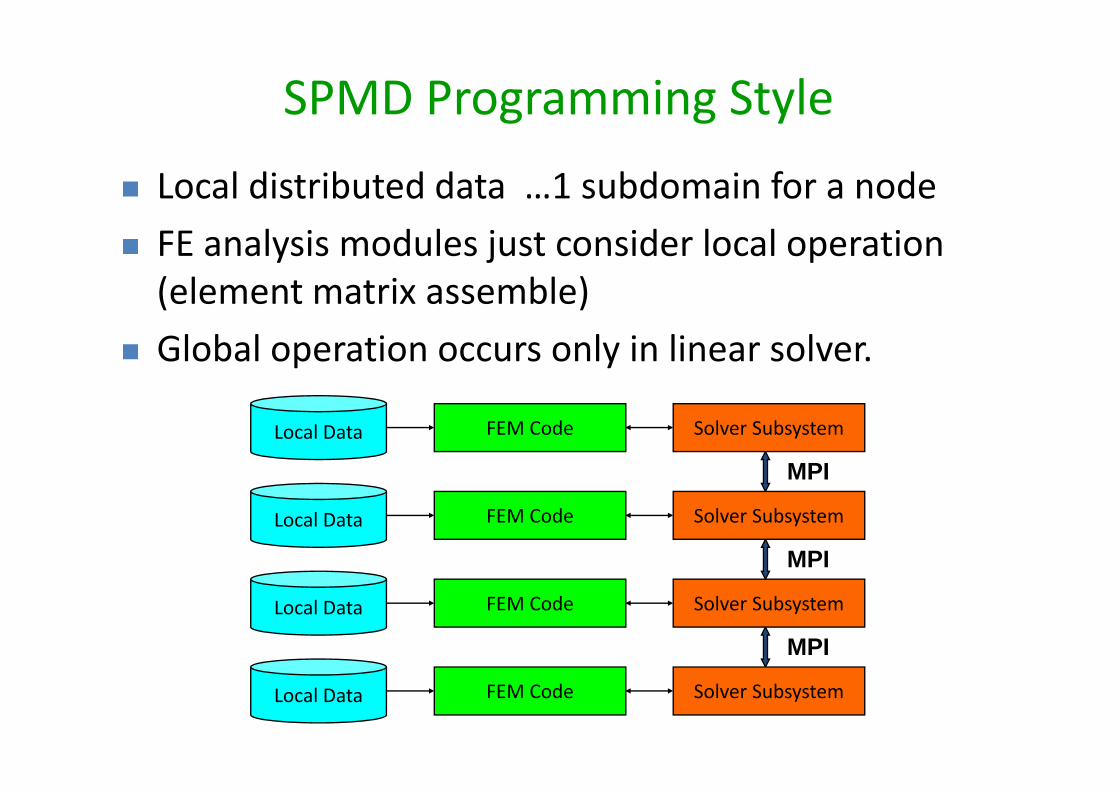
Local distributed data …1 subdomain for a node FE analysis modules just consider local operation (element matrix assemble)
Global operation occurs only in linear solver.
Local Data
Local Data
Local Data
Local Data
MPI
MPI
MPI
Solver Subsystem
Solver Subsystem
Solver Subsystem
Solver Subsystem
FEM Code
FEM Code
FEM Code
FEM Code
SPMD Programming Style

1 2 3 4 5
21 22 23 24 25
1617 18 19
20
1112 13 14
15
67 8 9
10
1 2 3
4 5
6 7
8 9 11
10
14 13
15
12
Node 0
7 8 9 10
4 5 6 12
3111
2
7 1 2 3
10 9 11 12
568
43
48
69
10 12
1 2
5
11
7
1 2 3 4 5
21 22 23 24 25
1617 18 19
20
1112 13 14
15
67 8 9
10
Node 0Node 1
Node 2Node 3
1 2 3 4 5
21 22 23 24 25
1617 18 19
20
1112 13 14
15
67 8 9
10
節点ベース領域分割

Assembly structures
Products in its practical form are the assembled structures composed of various parts and blocks.
Model data are also managed by parts.
Contact and/or MPC with iterative parallel solvers are crucial functions.

Data structure for assembly structures with parallel and hierarchical gridding
A) Partitioning ( MPI ranks )B) Hierarchical levelC) Assembly model
Refine
Assembly_2Level_1
Assembly_1Level_1
MPC
Partitioning
Assembly_2Level_2
Assembly_1Level_2
MPC
Partitioning
A)
A)
C)
C)
B)C)
C)

Parallel FEM structural analysis system: FrontISTR*
* Components are separately made and assembled.* 1 domain model is at most O(10^8 DOF) due to limitation of CAD and mesh builders.
Partitioned into O(10^3) subdomains, and each subdomain is recursively refined ( several times, CAD data fitted ) to enhance the accuracy and use O(10^5) cores.
*) A part of ‘the Next Generation Manufacturing Simulation System’ promoted in the project of ‘Research and Development of Innovative Simulation Software’
refined
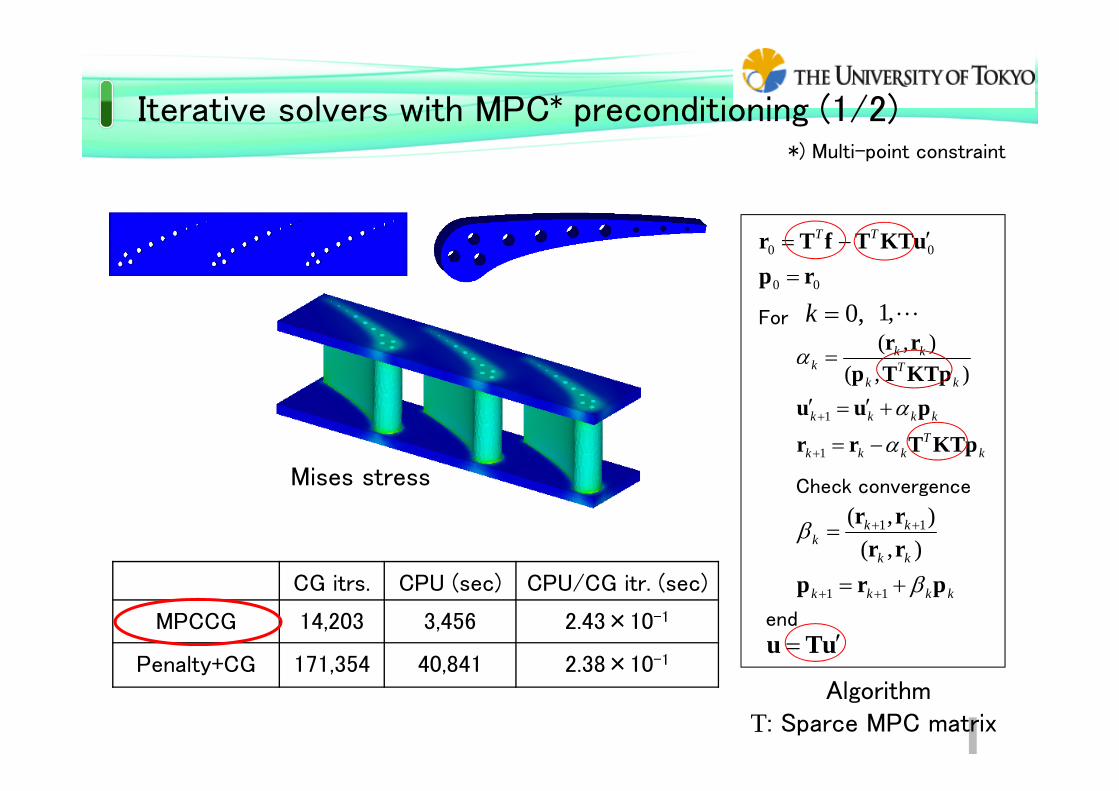
Iterative solvers with MPC* preconditioning (1/2)
CG itrs. CPU (sec) CPU/CG itr. (sec)
MPCCG 14,203 3,456 2.43×10-1
Penalty+CG 171,354 40,841 2.38×10-1
Mises stress
00
00
rpuKTTfTr
TT
,0k ,1
kT
kkk
kkkk
kT
k
kkk
KTpTrr
puuKTpTprr
1
1
),(),(
kkkk
kk
kkk
prprrrr
11
11
),(),(
uTu
For
Check convergence
end
Algorithm
*) Multi-point constraint
T: Sparce MPC matrix

Iterative solvers with MPC preconditioning (2/2)
MPCCG : 8,631 CG itrs.Penalty : 42,898 CG itrs.
124,501nodes, 513,982elements ( 1st order Tet. Mesh )
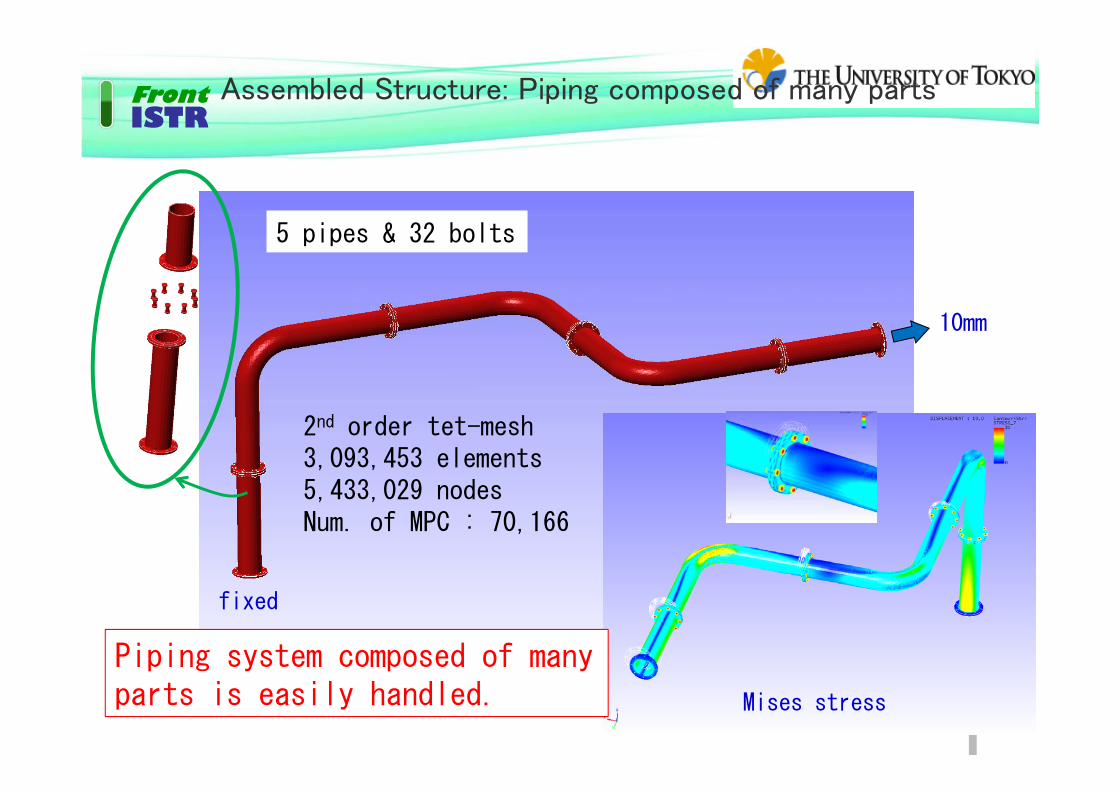
Assembled Structure: Piping composed of many parts
2nd order tet-mesh3,093,453 elements5,433,029 nodesNum. of MPC : 70,166
fixed
10mm
Mises stress
Piping system composed of many parts is easily handled.
5 pipes & 32 bolts
FrontISTR
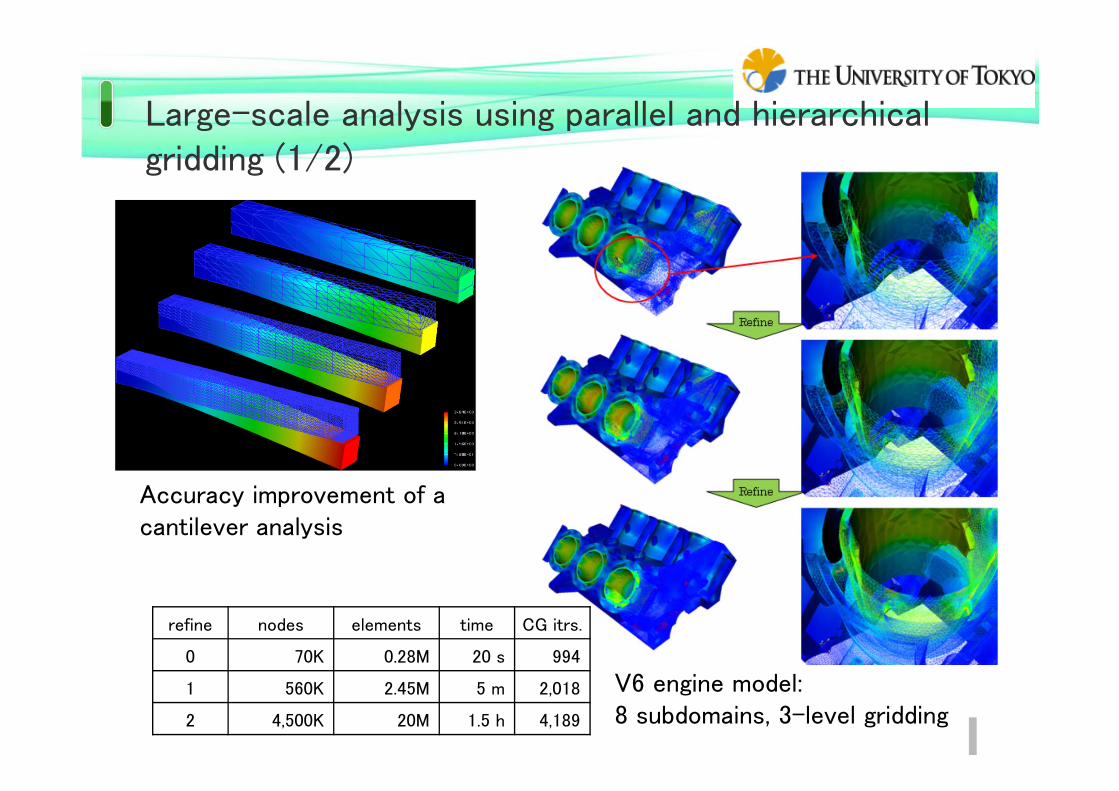
Large-scale analysis using parallel and hierarchical gridding (1/2)
Accuracy improvement of a cantilever analysis
V6 engine model:8 subdomains, 3-level gridding
refine nodes elements time CG itrs.
0 70K 0.28M 20 s 994
1 560K 2.45M 5 m 2,018
2 4,500K 20M 1.5 h 4,189

Large-scale analysis using parallel and hierarchical gridding (2/2)
Cap model :max 512 subdomains, Three-level gridding
Machine : HA8000 (Quad Opteron), Univ. of Tokyo
Parallel efficiency
Number of cores
measured
predicted line
refineNumber of elements
Number of nodes DOF
0 4,473,212 802,140 2,406,420
1 35,785,696 6,417,120 19,251,360
2 286,285,568 51,336,960 154,010,880
It is estimated that for problems of 0.27 billion DOF or over, at least 50% of the parallel efficiency would be obtained when 10^5 cores are used.
This model was solved by using 128, 256 and 512 cores
Estimated parallelization ratio : 0.99984

Parallel Performance of FrontISTR (FlatMPI, Strong Scalability)
2nd order tet-mesh
PRIMERGY BX900 at FOCUS
Refine Elements Nodes
0 684,807 1,008,911
1 5,478,456 7,707,758
2 43,827,648 60,089,084
Detailed stress analysis is realized by‘Refiner’.(180MDOF, 2,157sec using 1,157cores)
1.0E+02
1.0E+03
1.0E+04
1.0E+05
96 576 768 1152
計算時間(sec)
コア数
リファイン1段 リファイン2段20,714(s)
3,651(s)2,811(s)
2,157(s)
Initial mesh Refined twice
Mises stress
Number of cores
CPU time (sec)
Initial mesh
Refined twice
FrontISTR

Outline
Background : Towards peta/exascale computing
Necessary advances in programming models and software
As an HPC tool for industry
Parallel FE Structural Analysis System: FrontISTR
Large-grain Parallelism
Assembly structures under hierarchical gridding
Small-grain Parallelism
Blocking with padding for multicore CPU and GPUs
Summary
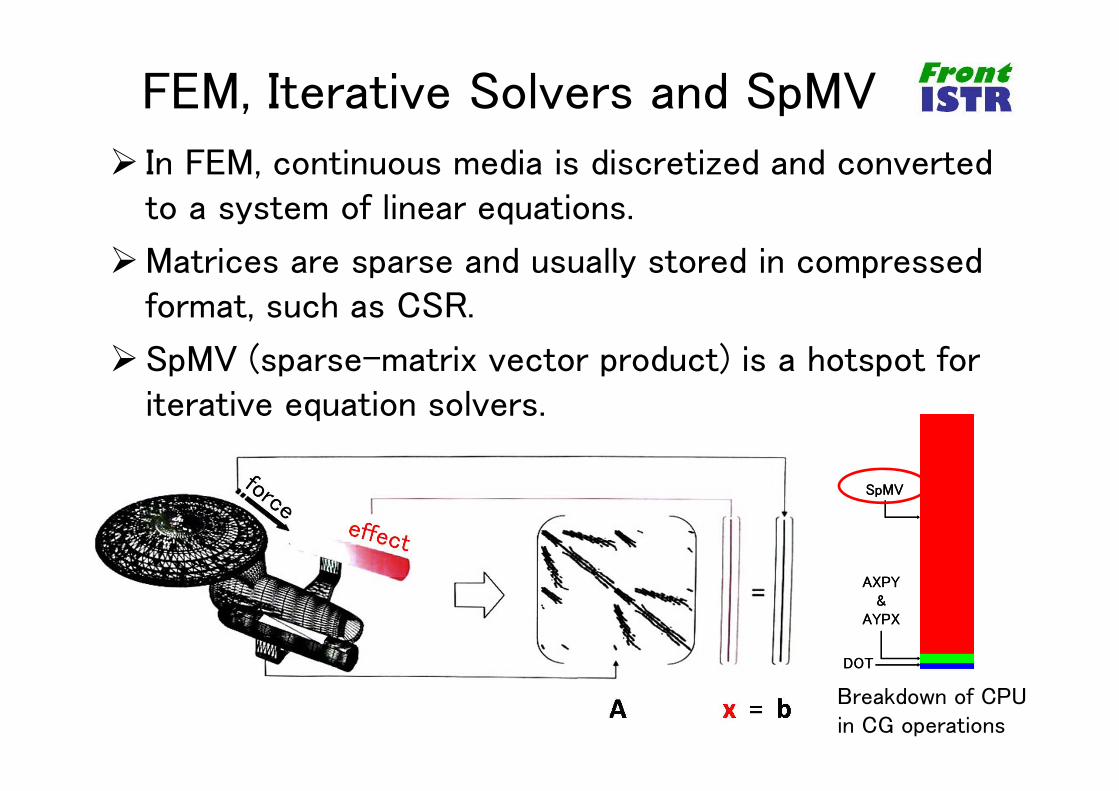
FEM, Iterative Solvers and SpMV In FEM, continuous media is discretized and converted
to a system of linear equations.
Matrices are sparse and usually stored in compressed format, such as CSR.
SpMV (sparse-matrix vector product) is a hotspot for iterative equation solvers.
SpMV
AXPY&
AYPX
DOT
SpMV
AXPY&
AYPX
DOT
Breakdown of CPU in CG operations

Blocking with padding for multicore CPU and GPUs
SpMV in iterative solvers is crucial for unstructured grid.
For improving B/F ratio
Blocking, Padding, ELL+CSR.
SpMV
AXPY&
AYPX
DOT
SpMV
AXPY&
AYPX
DOT
Breakdown of CPU in CG operations
Blocked CSR HYB format = ELL + CSR4

The “K-computer”
• 10 PFLOPS• # of CPUs > 80,000• # of cores > 640,000• Total memory > 1PB
• Parallelism• Inter-node (node⇔node) : MPI• Intra-node (core⇔core) : Thread• Flat MPI is NOT recommended
• Hybrid programming is crucial for “K”.
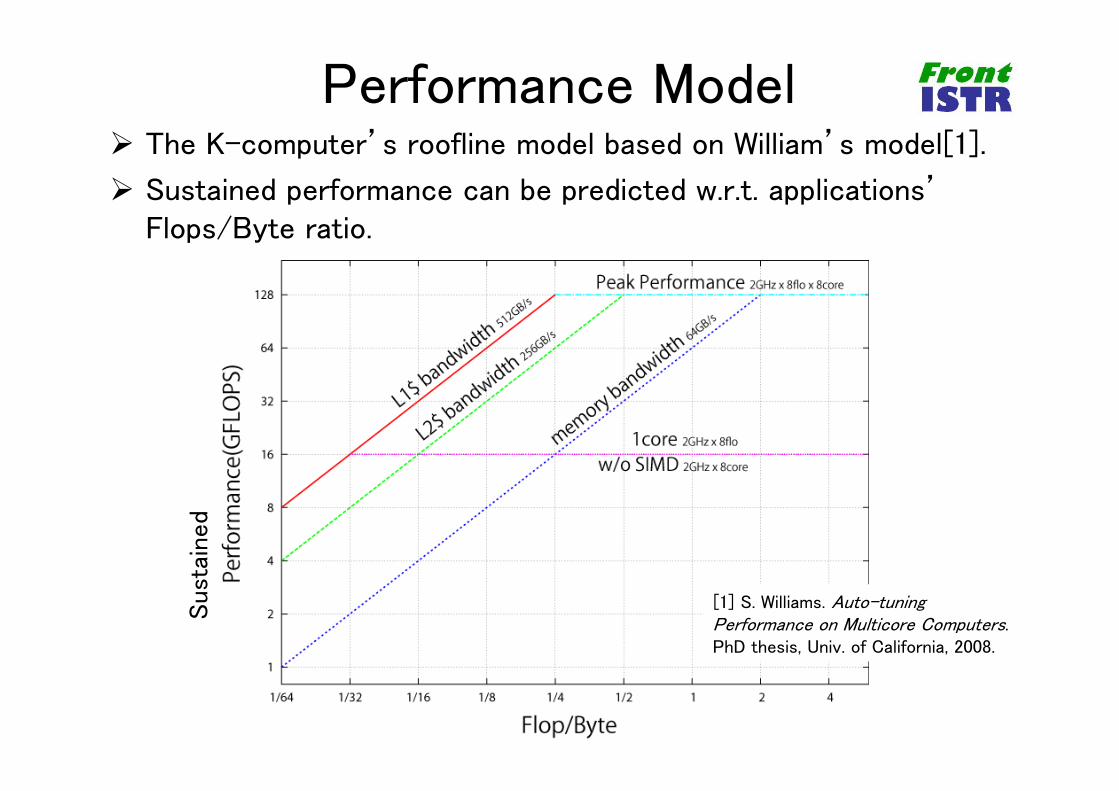
Performance Model The K-computer’s roofline model based on William’s model[1].
Sustained performance can be predicted w.r.t. applications’ Flops/Byte ratio.
[1] S. Williams. Auto-tuning Performance on Multicore Computers. PhD thesis, Univ. of California, 2008.
Sust
ained
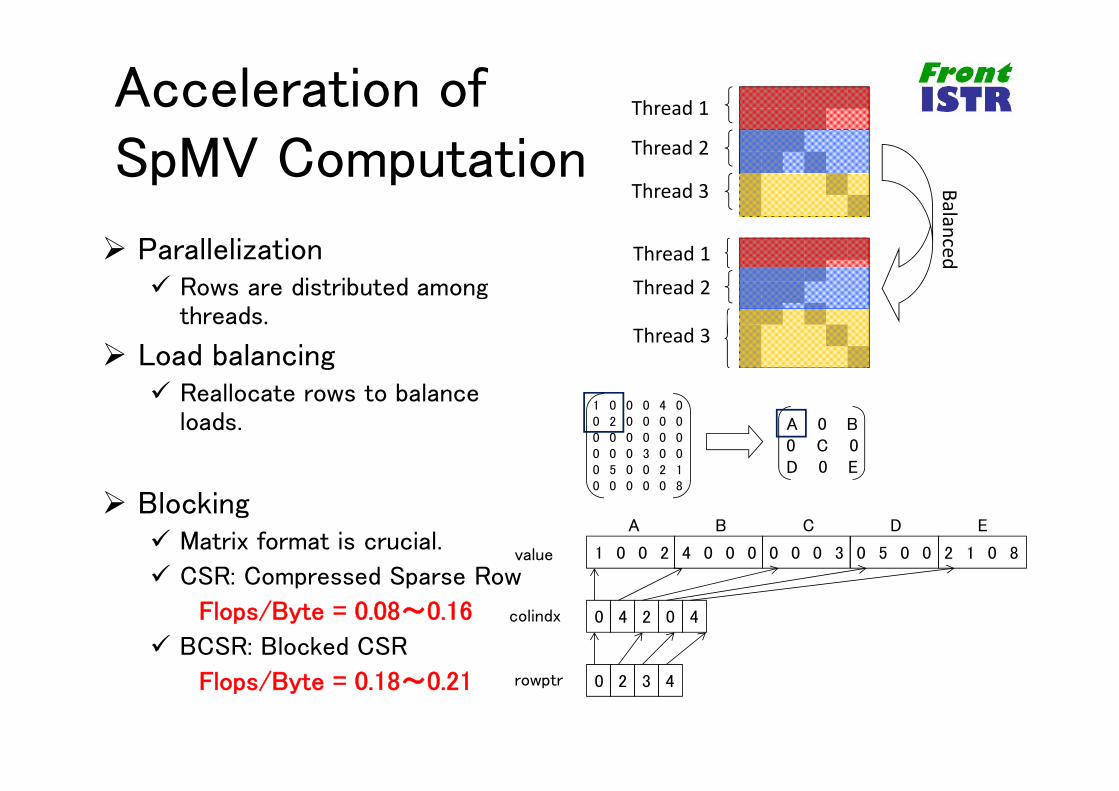
Acceleration of SpMV Computation
Parallelization Rows are distributed among
threads.
Load balancing Reallocate rows to balance
loads.
Blocking Matrix format is crucial.
CSR: Compressed Sparse Row
Flops/Byte = 0.08~0.16
BCSR: Blocked CSR
Flops/Byte = 0.18~0.21
Balanced
Thread 1
Thread 2
Thread 3
Thread 1Thread 2
Thread 3
1 0 0 0 4 00 2 0 0 0 00 0 0 0 0 00 0 0 3 0 00 5 0 0 2 10 0 0 0 0 8
A 0 B0 C 0D 0 E
1 0 0 2 4 0 0 0 0 0 0 3 0 5 0 0 2 1 0 8
0 4 2 0 4
0 2 3 4
value
colindx
rowptr
A B C D E

Performance Test (1/3)Load Balancing
• x10,000 SpMV of unbalanced matrices from the library[2]
• Left: w/o. load balancing
• Right: without load balancing
[2] T. A. Davis. University of Florida sparse matrix collection, 1997.
on Nehalem (Core i7 975)

Performance Test (2/3)Parallelization and Matrix Format
• Performance of SpMV on Nehalem (Core i7 975)
• CSR / BCSR format
matrix #
perf
orm
ance [
MFLO
PS]

Performance Test (3/3)Overall CG Solver
• CG solver’s performance over CSR single thread on Nehalem (Core i7 975)
matrix #
perf
orm
ance o
ver
CSR
sin
gle t
hre
ad
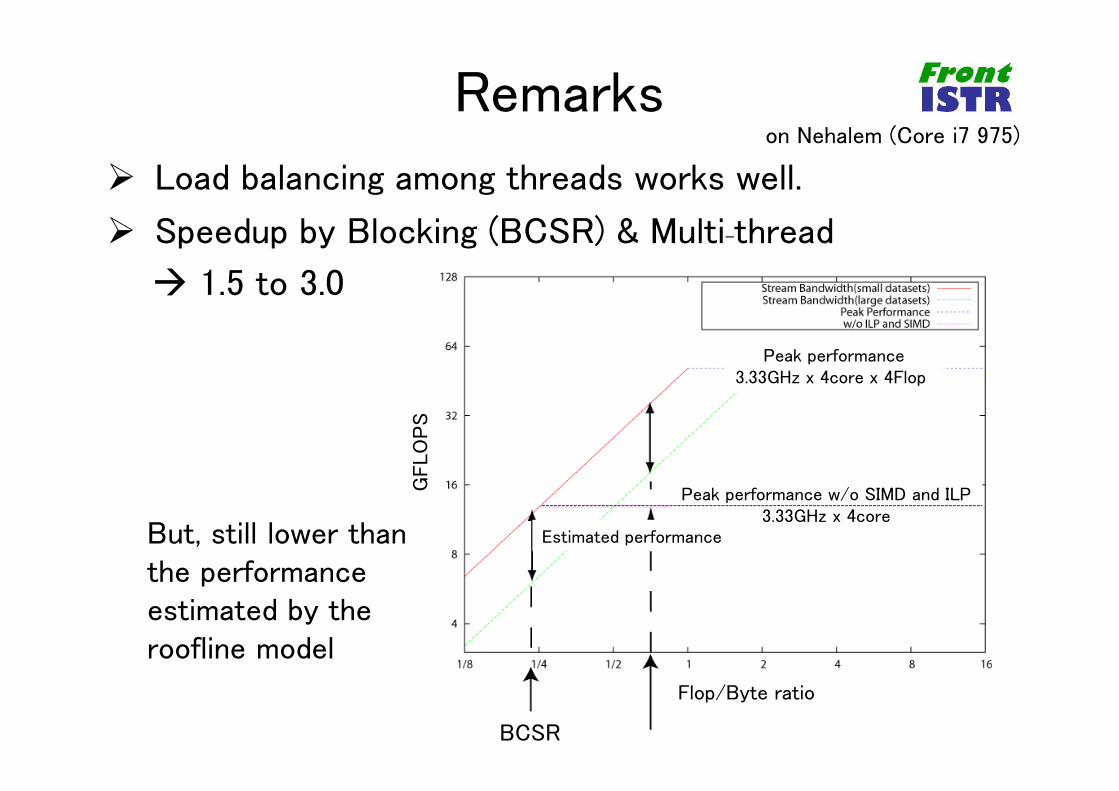
Remarks
Load balancing among threads works well.
Speedup by Blocking (BCSR) & Multi-thread
1.5 to 3.0
Blocked CSR
Peak performance3.33GHz x 4core x 4Flop
Flop/Byte ratio
GFLO
PS
Peak performance w/o SIMD and ILP3.33GHz x 4core
Estimated performance
BCSR
But, still lower than the performance estimated by the roofline model
on Nehalem (Core i7 975)

Summary
A parallel structural analysis system for tackling the assemble structure as a whole is being developed.
Hierarchical gridding strategy is used for enhancing the accuracy ( helping powerless mesh builders and accelerating the convergence ).
For intra-node, multithreading with considering the blocking/padding has been explored on multicore CPU and GPU (currently small number of nodes ).
Future work
Intra-node ILU (or LU)preconditioning
Hiding data translation time
Performance model