cassandra overview
TRANSCRIPT

Sergey TitovSoftware Architect@sergtitov

AgendaA
GE
ND
A
•Cassandra Architecture•CAP theorem and Consistency•Scalability•Astyanax client•Data Modeling•Queries•DataStax OpsCenter•Resources
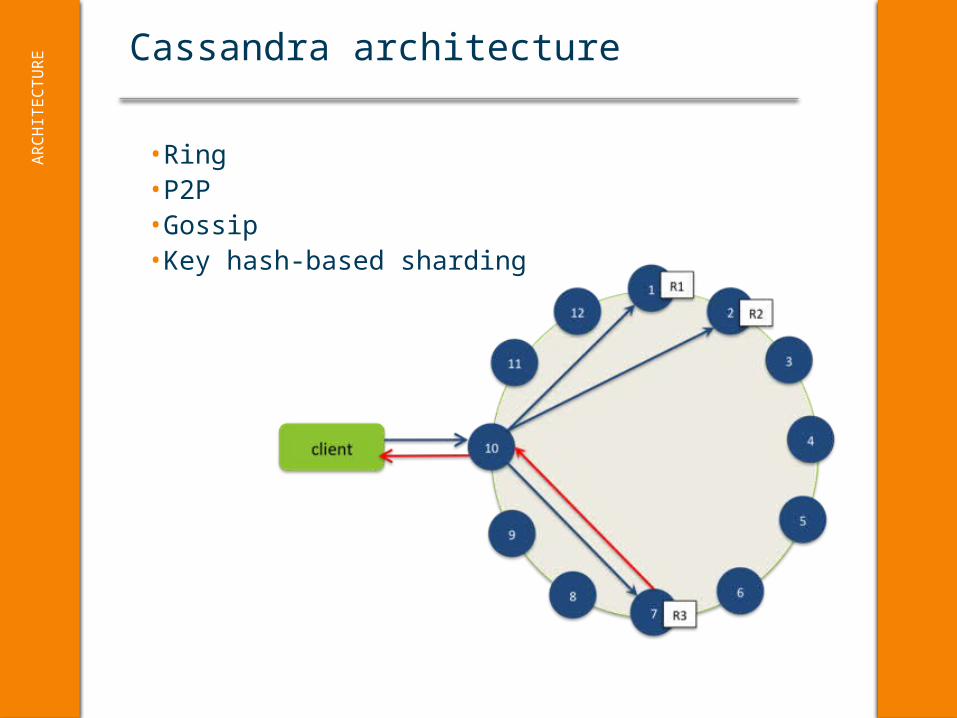
Cassandra architectureA
RC
HIT
EC
TU
RE
•Ring•P2P•Gossip•Key hash-based sharding
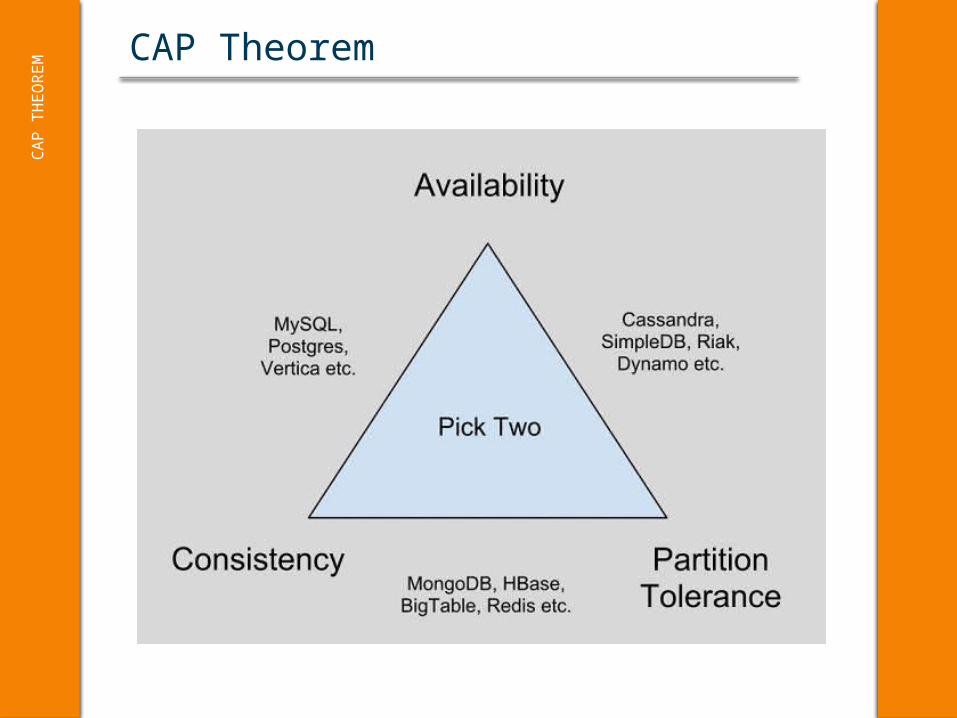
CAP TheoremC
AP
TH
EO
RE
M

Consistency in CassandraC
ON
SIS
TE
NC
Y
•ACID - Atomicity Consistency Isolation Durability•BASE - Basically Available Soft-state Eventual consistency•Isolation on the row level•Atomic batches starting Cassandra 1.2•Consistency level for READs and WRITEs set for every request•Tunable consistency•Log: CL_WRITE = ANY or ONE•Strong: CL_READ + CL_WRITE > REPLICATION_FACTOR•Recommended default: LOCAL_QUORUM

Consistency in Cassandra - continuedC
ON
SIS
TE
NC
Y
Level Description
ANY
A write must be written to at least one node. If all replica nodes for the given row key are down, the write can still succeed once a hinted handoff has been written. Note that if all replica nodes are down at write time, an ANY write will not be readable until the replica nodes for that row key have recovered.
ONE A write must be written to the commit log and memory table of at least one replica node.
QUORUM A write must be written to the commit log and memory table on a quorum of replica nodes.
LOCAL_QUORUMA write must be written to the commit log and memory table on a quorum of replica nodes in the same data center as the coordinator node. Avoids latency of inter-data center communication.
EACH_QUORUM A write must be written to the commit log and memory table on a quorum of replica nodes in all data centers.
ALL A write must be written to the commit log and memory table on all replica nodes in the cluster for that row key.
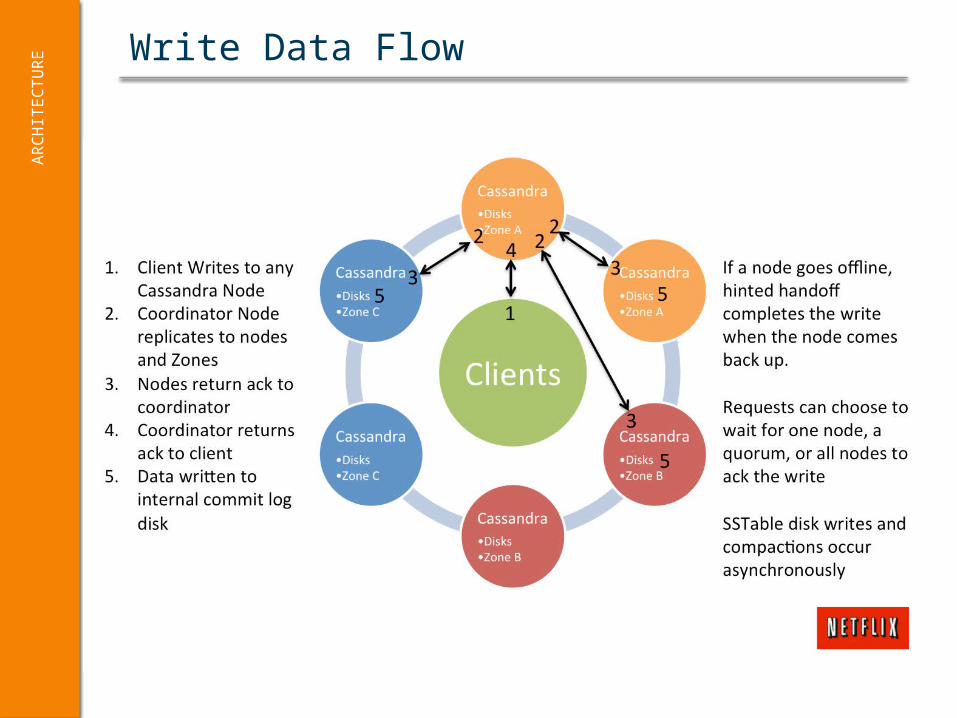
Write Data FlowA
RC
HIT
EC
TU
RE
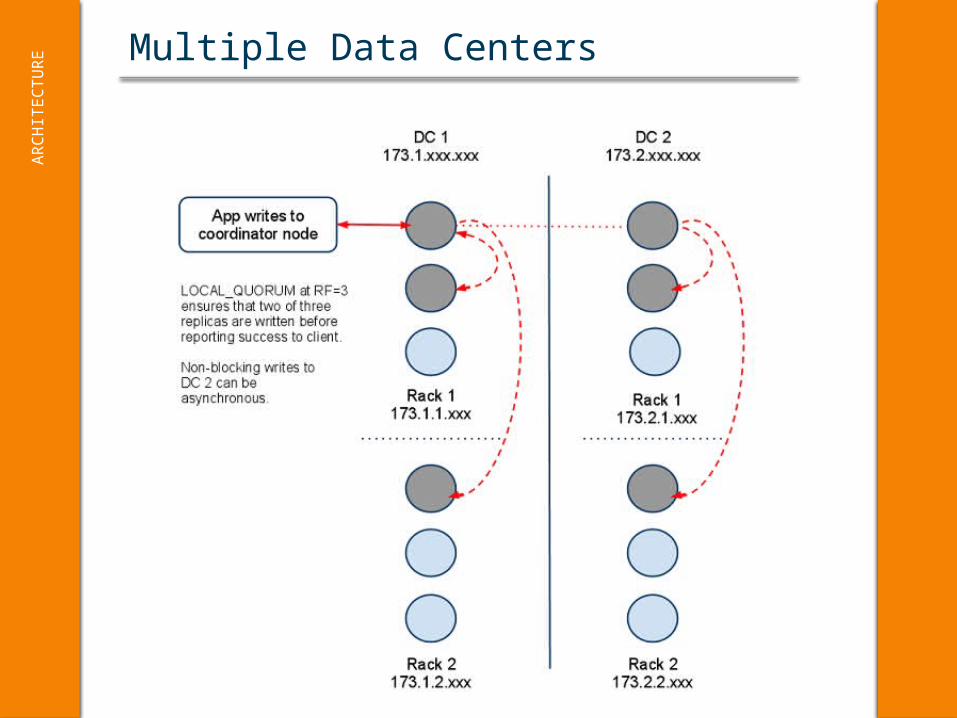
Multiple Data CentersA
RC
HIT
EC
TU
RE
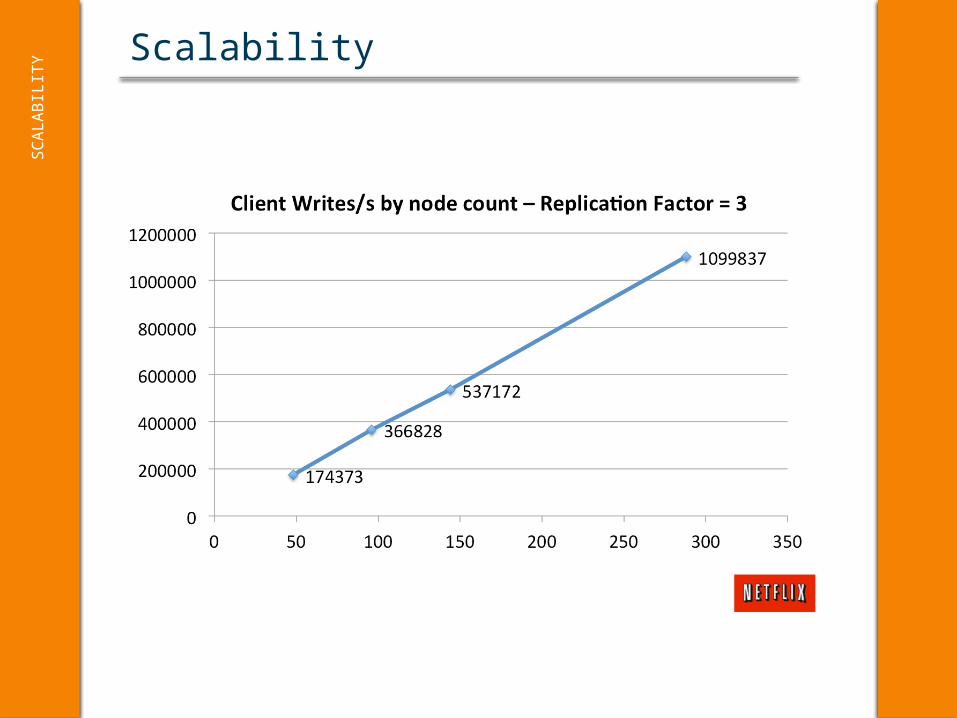
ScalabilityS
CA
LA
BIL
ITY

Astyanax clientA
ST
YA
NA
X
• Based on Hector• High level, simple object oriented interface to Cassandra.• Fail-over behavior on the client side.• Connection pool abstraction (round robin connection pool)• Monitoring to get event notification from the connection pool.• Complete encapsulation of the underlying Thrift API.• Automatic retry of downed hosts.• Automatic discovery of additional hosts in the cluster.• Suspension of hosts for a short period of time after timeouts.
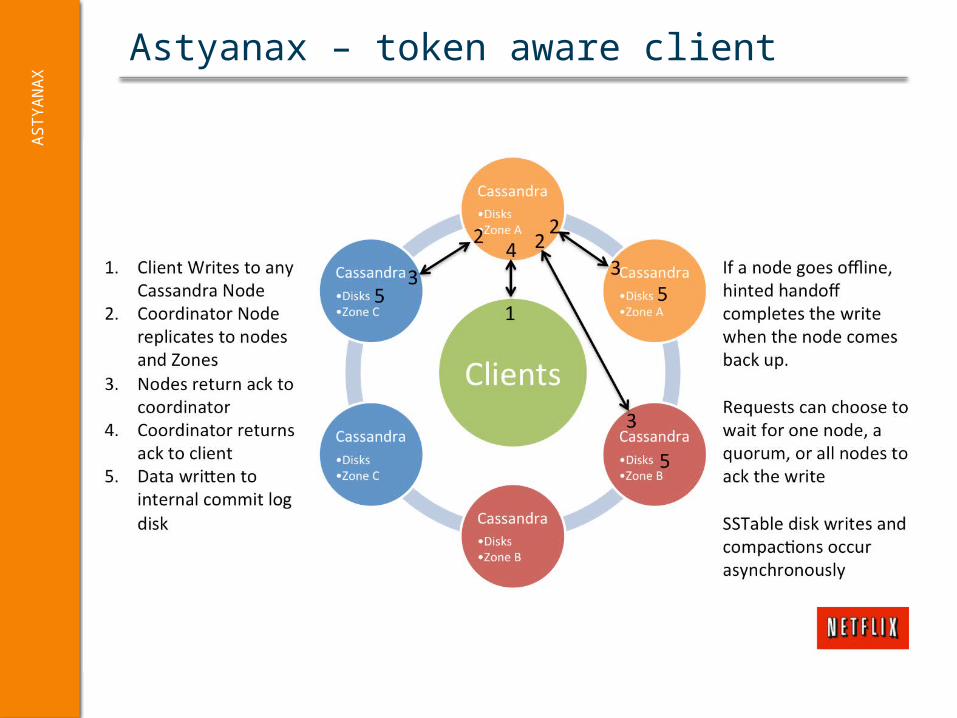
Astyanax – token aware clientA
ST
YA
NA
X

Data Modeling in CassandraD
ATA
MO
DE
LIN
G
• Column Families are NOT tables!• Map<RowKey, SortedMap<ColumnKey, ColumnValue>>
• Values could be and often are stored in column names• Number of columns could be different for different rows • There could be 2 billions columns in one row!• Use UUIDs• Separate read-heavy from write-heavy data
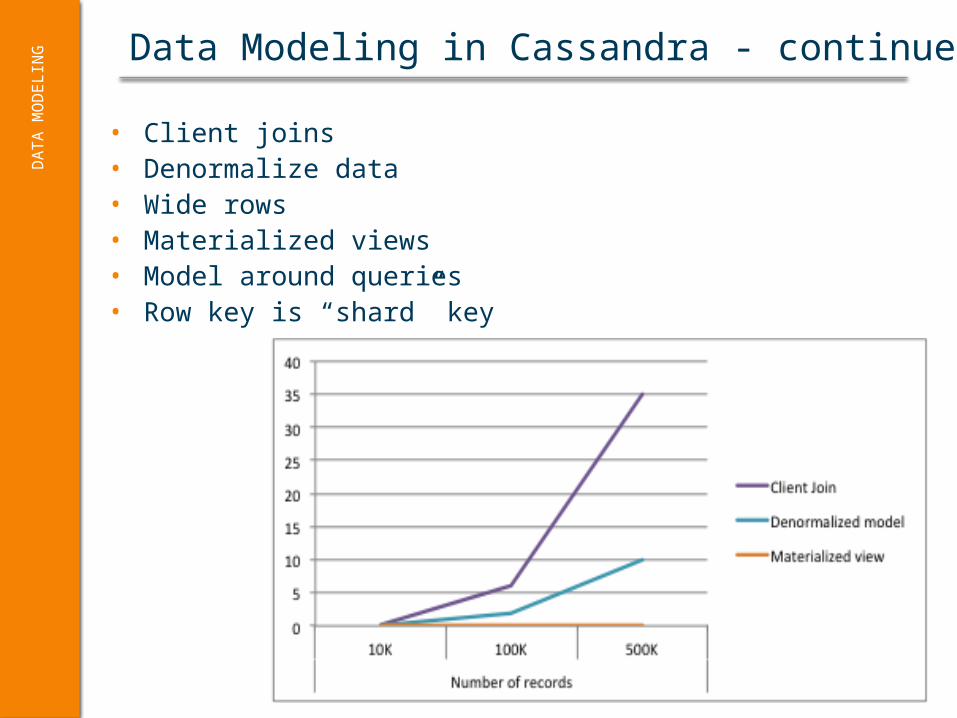
Data Modeling in Cassandra - continuedD
ATA
MO
DE
LIN
G
• Client joins• Denormalize data• Wide rows• Materialized views• Model around queries• Row key is “shard” key

Modeling nested entities and documentsD
ATA
MO
DE
LIN
G
Motivation• Parent-child decomposition lacks performance in Cassandra.• No JOIN operator in CQL!• The only solution is to store tree-like structure with nested “children”• Cassandra doesn’t have built-in support for a document object
Solution• Column Families are NOT tables• Domain object fields are traversed along with the nested entities• Collection and Map fields (of any level of deepness) are unwrapped into plain key-value pairs (mapped to Cassandra column name – value)

Modeling nested entities and documents. ExampleD
ATA
MO
DE
LIN
G
class Parent { @Id private UUID id; @Column private String stringField1;
@NestedCollection private Map<String, byte[]> imageMap;
@NestedCollectionprivate List<Child> children;}
class Child { @Column private Integer kidsNumber;}

Modeling nested entities and documents. ExampleD
ATA
MO
DE
LIN
G
Let’s use JSON notation:
If Parent is
{ “id” : “edc39a6c-355f-4ad0-a4de-b2103dbd610d”, “stringField1” : “value1”, “imageMap”: [ “name1” : “SW1hZ2VEYXRhMQ==“, “name2” : “SW1hZ2VEYXRhMg==“ ], “children” : [ { “kidsNumber” : 1 }, { “kidsNumber” : 2 } ]
}
the corresponding Cassandra columns will be:
• “id” -> “edc39a6c-355f-4ad0-a4de-b2103dbd610d”• “stringField1” -> “value1”• “imageMap:name1” -> “SW1…MQ==“• “imageMap:name2” -> “SW1…MQ==“• “children:0:kidsNumber” -> 1• “children:1:kidsNumber” -> 2

Range queries in CassandraQ
UE
RIE
S
Motivation• No CQL equivalent for SQL clause:WHERE “field_name” >= value1 and “field_name” <= value2• For indexed fields the only possible query is WHERE “field_name” [<,>,<=,>=,=] “value” but “field_name” can be specified in a cql query only once
Solution• Any name of Cassandra column is a byte buffer ~ byte [] columnName• Column names (in comparison with the values) may be filtered by the specified range, i.e. if two border values
• byte [] lowMargin,• byte [] highMargin
are defined it is possible to select columns with columNameWHERE columnName >= lowMargin AND columnName <= highMargin• As there are ~ 2 bln columns can be persisted for the same key it is possible to search quickly among lists of size < 2 * 10^9

Composite Column FamiliesQ
UE
RIE
S
Motivation• Raw untyped column names are not convenient in processing.• If there are 2 or more components of a column name serialized to a same byte buffer it is hard to build quick search on a single part.
For instance, let’s introduce column name consisting of two components:• person_name: String• time_stamp: Date
How to build a column range returning all the previously persistedcombinations of person_name = “Tom” and time_stamp >= “1999-01-01” andtime_stamp <= “2012-01-01”?
SolutionCassandra has built-in CompositeType comparator which can be defined for number of components and sorts columns first by component number 0, 1, …

Composite Column Families - mappingQ
UE
RIE
S
public class ReferenceCategoryValue { @Id private String category; //maps to row key
@Component(ordinal = 0) //the following three fields are serialized private UUID id; //into a column name
@Component(ordinal = 1) private String description;
@Component(ordinal = 2) private String code; @Value private String value // the value which is saved for the column}
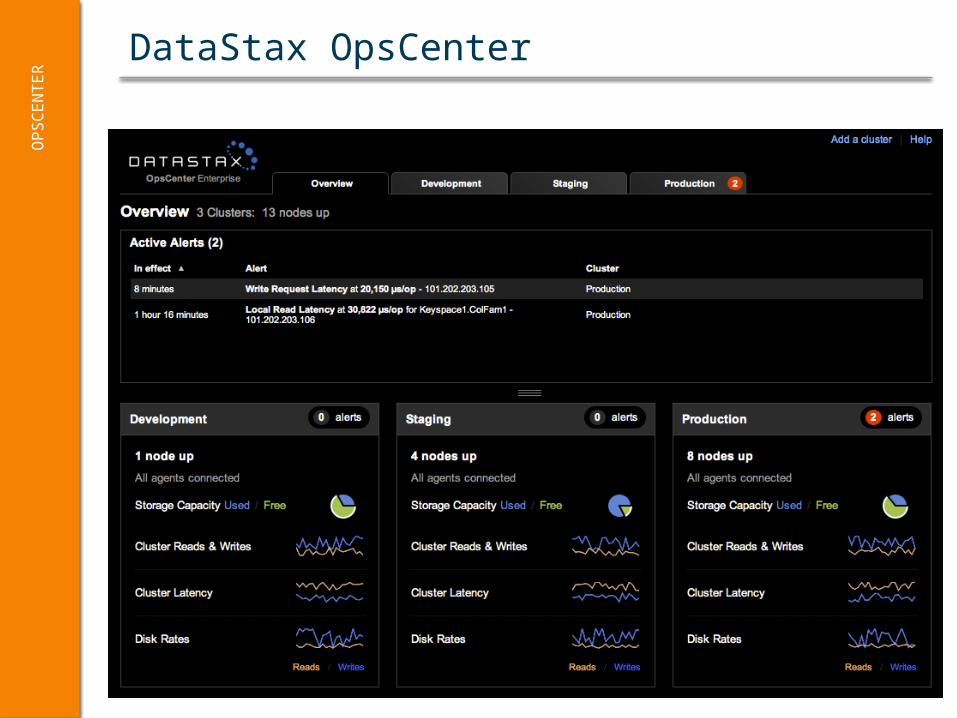
DataStax OpsCenterO
PS
CE
NT
ER

ResourcesR
ES
OU
RC
ES
•DataStax Documentation•Free Cassandra Academy•Tutorials•Apache Cassandra Home Page•Cassandra Summit Presentations•2014 Summit Videos•Netflix blog•Astyanax•Ebay Cassandra Data Modeling best practices part 1 and part 2