cassandra – a decentralized structured storage system a. lakshaman 1, p.malik 1 1 facebook sigops...
TRANSCRIPT

Cassandra – A Decentralized Structured Storage System
A. Lakshaman1, P.Malik1
1Facebook
SIGOPS ‘10
2011. 03. 18.
Summarized and Presented by Sang-il Song, IDS Lab., Seoul National University
Copyright 2010 by CEBT
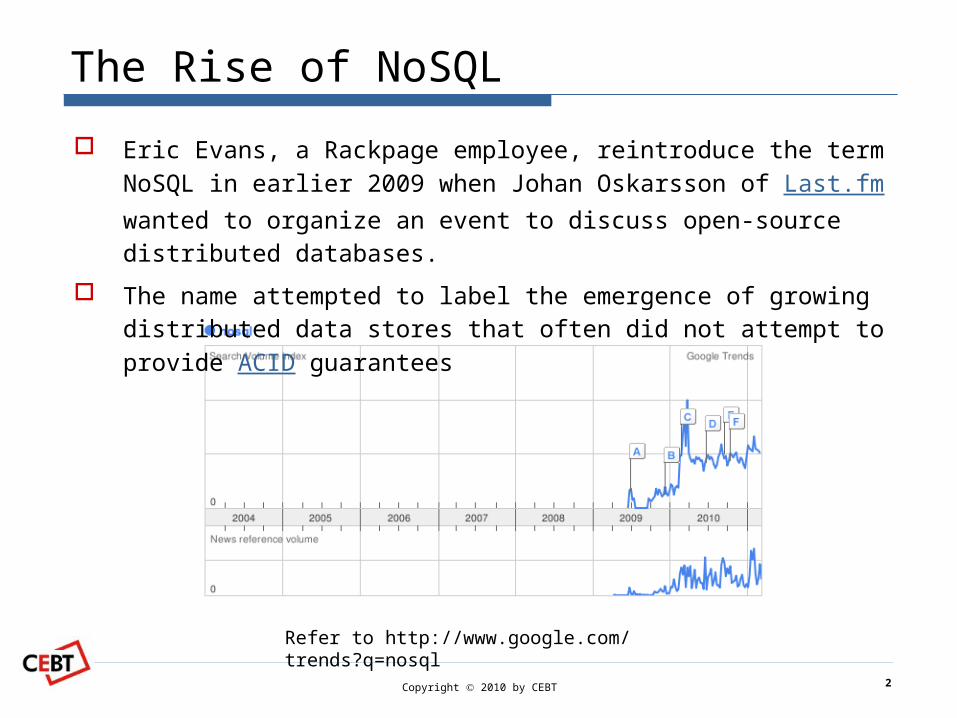
The Rise of NoSQL
2
Refer to http://www.google.com/trends?q=nosql
Eric Evans, a Rackpage employee, reintroduce the term NoSQL in earlier 2009 when Johan Oskarsson of Last.fm wanted to or-ganize an event to discuss open-source distributed databases.
The name attempted to label the emergence of growing dis-tributed data stores that often did not attempt to provide ACID guarantees

Copyright 2010 by CEBT
NoSQL Database
Based on Key-value
memchached, Dynamo, Volemort, Tokyo Cabinet
Based on Column
Google BigTable, Cloudata, Hbase, Hypertable, Cassandra
Based on Document
MongoDB, CouchDB
Based on Graph
Meo4j, FlockDB, InfiniteGraph
3

Copyright 2010 by CEBT
NoSQL BigData Database
Based on Key-Value
memchached, Dynamo, Volemort, Tokyo Cabinet
Based on Column
Google BigTable, Cloudata, Hbase, Hypertable, Cassandra
Based onDocument
MongoDB, CouchDB
Based on Graph
Meo4j, FlockDB, InfiniteGraph
4

Copyright 2010 by CEBT 5
Refer to http://blog.nahurst.com/visual-guide-to-nosql-systems

Copyright 2010 by CEBT
Contents
Introduction
Remind: Dynamo
Cassandra
Data Model
System Architecture
Partitioning
Replication
Membership
Bootstrapping
6
Operations
WRITE
READ
Consistency level
Performance Bench-mark
Case Study
Conclusion

Copyright 2010 by CEBT
Remind: Dynamo
Distributed Hash Table
BASE
Basically Available
Soft-state
Eventually Consistent
Client Tunable consistency/availability
7
NRW Configuration
W=N, R=1 Read optimized strong consis-tency
W=1, R=N Write optimized strong consis-tency
W+R ≦ N Weak eventual consistency
W+R > N Strong consistency

Copyright 2010 by CEBT
Cassandra
Dynamo-Bigtable lovechild
Column-based data model
Distributed Hash Table
Tunable tradeoff
– Consistency vs. Latency
Properties
No single point of Failure
Linearly scalable
Flexible partitioning, replica placement
High Availability (eventually consistency)
8

Copyright 2010 by CEBT
Data Model
Cluster
Key Space is corresponding to db or table space
Column Family is corresponding to table
Column is unit of data stored in Cassandra
9
Row Key Column Family: “User” Column Family: “Article”
“userid1”
name: Username, value: uname1name: Email, value: [email protected]
name: Tel, value: 123-4567
“userid2”
name: Username, value: uname2name: Email, value: [email protected]
name: Tel, value: 123-4568
name: ArticleId, value:userid2-1name: ArticleId, value:userid2-2name: ArticleId, value:userid2-3
“userid3”
name: Username, value: uname3name: Email, value: [email protected]
name: Tel, value: 123-4569
Copyright 2010 by CEBT
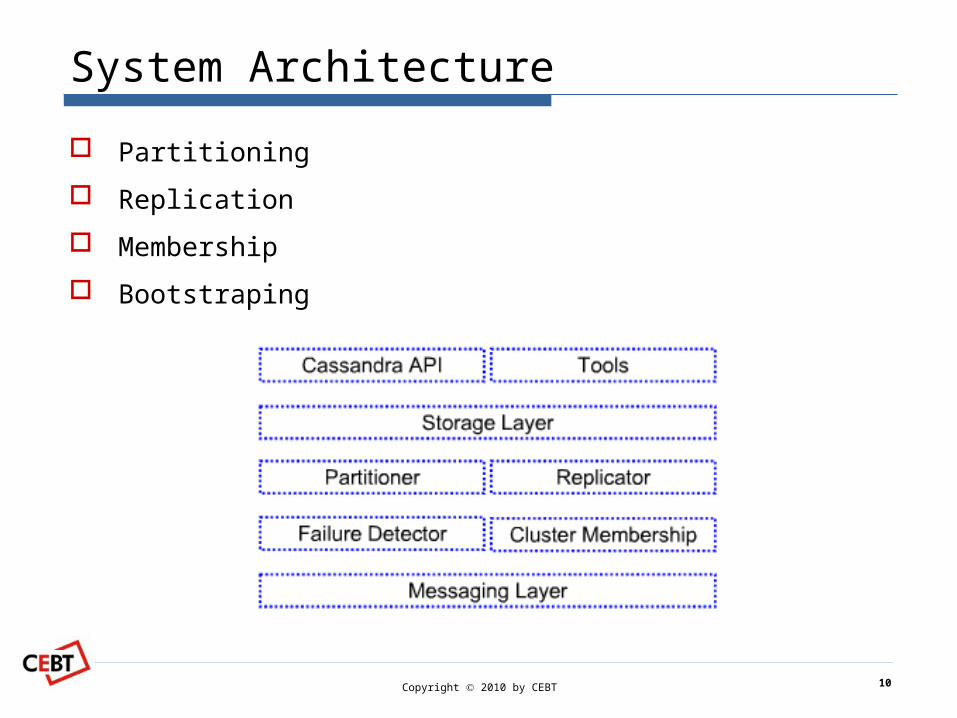
System Architecture
Partitioning
Replication
Membership
Bootstraping
10

Copyright 2010 by CEBT
Partitioning Algorithm
Distributed Hash Table
Data and Server are located in the same address space
Consistent Hashing
Key Space Partition: arrangement of the key
Overlay Networking: Routing Mechanism
11
N1
N3 N2
Hash(key1)value
N3
N2
hash(key1)
N1
high
low
N2 is deemed the coordinator of key 1

Copyright 2010 by CEBT
Partitioning Algorithm (cont’d)
Challenges
Non-uniform data and load distribution
Oblivious to the heterogenity in the performance of nodes
Solutions
Nodes get assigned to multiple positions in the circle (like Dynamo)
Analyze load information on the ring and have lightly loads move on the ring to alleviate heavily loaded nodes (like Cassandra)
12
N1
N3 N2
N2
N1
N3 N2
N2N1
N2
N3N2
N1
N3

Copyright 2010 by CEBT
Replication
RackUnware
RackAware
DataCenter-Shared
13
E
AB
C
D
FGH
I
J data1
Coordinator of data 1

Copyright 2010 by CEBT
Cluster Membership
Gossip Protocol is used for cluster membership
Super lightweight with mathematically provable proper-ties
State disseminated in O(logN) rounds
Every T Seconds each member increments its heartbeat counter and selects one other member send its list to
A member merges the list with its own list
14

Copyright 2010 by CEBT
Gossip Protocol
15
server 1
server1: t1
t1
server 1
server1: t1
server 2
server2: t2
t2
server 1
server1: t1server2: t2
server 2
server2: t2
t3
server 1
server1: t4server2: t2
server 2
server1: t4server2: t2
t4
server 1server1: t4server2: t2server3 :t5
server 2
server1: t4server2: t2
t5
server 3
server3: t5
server 1server1: t6server2: t2server3 :t5
server 2server1: t6server2: t6server3: t5
t6
server 3server1: t6server2: t6server3: t5

Copyright 2010 by CEBT
Accrual Failure Detector
Valuable for system management, replication, load bal-ancing
Designed to adapt to changing network conditions
The value output, PHI, represents a suspicion level
Applications set an appropriate threshold, trigger suspi-cions and perform appropriate actions
In Cassandra the average time taken to detect a failure is 10-15 seconds with the PHI threshold set at 5
16
where

Copyright 2010 by CEBT
Bootstraping
New node gets assigned a token such that it can allevi-ate a heavily loaded node
17
N1
N2
N1
N3 N2

Copyright 2010 by CEBT
WRITE
Interface
Simple: put(key,col,value)
Complex: put(key,[col:val,…,col:val])
Batch
WRITE Opertation
Commit log for durability
– Configurable fsync
– Sequential writes only
MemTable
– Nodisk access (no reads and seek)
Sstables are final
– Read-only
– indexes
Always Writable
18

Copyright 2010 by CEBT
READ
Interface
get(key,column)
get_slice(key,SlicePredicate)
Get_range_sllices(keyRange,SlicePredicate)
READ
Practically lock-free
Sstable proliferation
Row cache
Key cache
19

Copyright 2010 by CEBT
Consistency Level
Level Description
ZERO Hail Mary
ANY 1 replica
ONE 1 replica
QUORUM (N/2)+1
ALL All replica
20
Level Description
ZERO N/A
ANY N/A
ONE 1 replica
QUORUM (N/2)+1
ALL All replica
Write Operation Read Operation
Tuning the consistency level for each WRITE/READ opera-tion
Copyright 2010 by CEBT
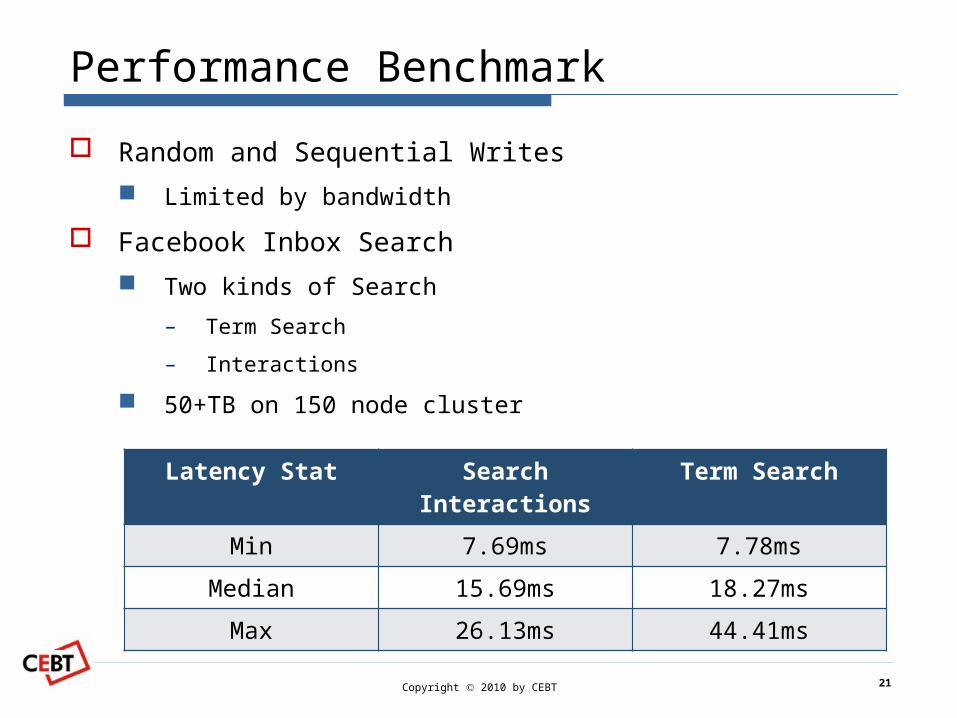
Performance Benchmark
Random and Sequential Writes
Limited by bandwidth
Facebook Inbox Search
Two kinds of Search
– Term Search
– Interactions
50+TB on 150 node cluster
21
Latency Stat Search Interac-tions
Term Search
Min 7.69ms 7.78ms
Median 15.69ms 18.27ms
Max 26.13ms 44.41ms

Copyright 2010 by CEBT
vs MySQL with 50GB Data
MySQL
~300ms write
~350ms read
Cassandra
~0.12ms write
~15ms read
22

Copyright 2010 by CEBT
Case Study
Cassandra as primary data store
Datacenter and rack-aware replica-tion
~1,000,000 ops/s
high sharding and low replication
Inbox Search
100TB
5,000,000,000 writes per day
23

Copyright 2010 by CEBT
Conclusions
Cassandra
Scalability
High Performance
Wide Applicability
Future works
Compression
Atomicity
Secondary Index
24