budapesti mŰszaki fŐiskola -...
TRANSCRIPT

BUDAPESTI MŰSZAKI FŐISKOLA N E U M A N N J Á N O S I N F O R M A T I K A I F Ő I S K O L A I K A R
Készítette: Bors Bálint III. évfolyam Horváth Rudolf III. évfolyam Safranka Mátyás III. évfolyam
Konzulens:
Vámossy Zoltán

Cerberus Projekt
Szakdolgozat
2003
Készítette:
Bors Bálint
Horváth Rudolf
Safranka Mátyás
Konzulens:
Vámossy Zoltán
Honlap:
http://cerberus.harmless.hu/
E-mail:

TartalomjegyzékABSZTRAKT.........................................................................................................................................................................1
ABSTRACT ............................................................................................................................................................................2 BEVEZETÉS..........................................................................................................................................................................3
HAGYOMÁNYOS AZONOSÍTÁSI TECHNIKÁK (SAFRANKA) .................................................................................................3 BIOMETRIAI AZONOSÍTÁS (SAFRANKA)..............................................................................................................................3
A biometriai azonosítás története (Bors) .......................................................................................................................4 MIÉRT JOBB A BIOMETRIA MINT A HAGYOMÁNYOS MÓDSZEREK? (BORS) ......................................................................4 BIOMETRIAI TECHNIKÁK (BORS) ........................................................................................................................................5 A HANGAZONOSÍTÁS (SAFRANKA) .....................................................................................................................................6 AZ ARCAZONOSÍTÁS (SAFRANKA) ......................................................................................................................................6
IRODALMI ÖSSZEFOGLALÓ .........................................................................................................................................7 HANGFELISMERŐ RENDSZEREK (HORVÁTH, SAFRANKA) .................................................................................................7
IBM ViaVoice .................................................................................................................................................................7 Microsoft Speech SDK 5.1 .............................................................................................................................................8 Dragon Systems...............................................................................................................................................................8 Philips...............................................................................................................................................................................9 AT&T...............................................................................................................................................................................9
HANGBIZTONSÁGI RENDSZEREK (HORVÁTH) ..................................................................................................................10 Voice-Security ...............................................................................................................................................................10 Speechtechnologies .......................................................................................................................................................11
BEVEZETŐ (HORVÁTH)......................................................................................................................................................11 Jelfeldolgozás (Horváth) ...............................................................................................................................................12 Digitális hangfeldolgozás (Horváth) ............................................................................................................................12
A DIGITÁLIS JELFELDOLGOZÁS ALAPFOGALMAI (HORVÁTH) .........................................................................................14 Diszkrét idejű jelek és rendszerek ................................................................................................................................14
ABLAKOZÁS (HORVÁTH)...................................................................................................................................................15 I. Négyzetes ablak .........................................................................................................................................................15 II. Welch ablak ..............................................................................................................................................................15 III. Bartlett ablak ...........................................................................................................................................................16 IV. Hanning/Hamming ablak .......................................................................................................................................17 V. Kaiser-Bessel ablak ..................................................................................................................................................18
JELEK ÉS RENDSZEREK TRANSZFORMÁLT ALAKJA (HORVÁTH)......................................................................................19 A z-transzformált...........................................................................................................................................................19 Decimatorok és Interpolatorok: ....................................................................................................................................19 Digitális szűrők:.............................................................................................................................................................20
A HANG (HORVÁTH).........................................................................................................................................................20 Time-domain módszerek hangfeldolgozásra ...............................................................................................................21 Idő-függő hangfeldolgozás (time-dependent speech processing) ..............................................................................21 „Short-time” energia .....................................................................................................................................................21 „Short-time” null-átmenet.............................................................................................................................................22 „Short-time” autokorreláció..........................................................................................................................................22
LINEAR PREDICTION (LP) (HORVÁTH) .............................................................................................................................23 A linear predictive elemzés alapvető elve ...................................................................................................................24 Az autokorrelációs megoldás........................................................................................................................................26 A kovariencia eljárás.....................................................................................................................................................27 A hibajel függvény ........................................................................................................................................................30 A hang alapharmónikusának vizsgálata LP segítségével............................................................................................31
ARCFELISMERÉS (BORS) .................................................................................................................................................32 Geometriai tulajdonságokon alapuló............................................................................................................................33 Eigenface módszer ........................................................................................................................................................33 Sablon-illesztés..............................................................................................................................................................33 Neurális hálós módszer .................................................................................................................................................33 Rejtett Markov-modell ..................................................................................................................................................34 Hibrid módszerek ..........................................................................................................................................................34

LÉTEZŐ ARC-KERESŐ RENDSZEREK („FACE DETECTION”)(BORS) .................................................................................34 Rowley, Baluja, Kanade ...............................................................................................................................................34 Sung és Poggio ..............................................................................................................................................................34 Osuna, Freund és Girosi................................................................................................................................................35
ARC FELISMERŐ RENDSZEREK („FACE RECOGNITION”)(BORS) .....................................................................................35 FaceIt Face Recognition Technology...........................................................................................................................35 „BioID” technika...........................................................................................................................................................36 VisionSphere, UnMask .................................................................................................................................................36 IWS Inc., FaceID...........................................................................................................................................................37 Viisage Technology.......................................................................................................................................................37
A TAPASZTALATOK ÖSSZEGZÉSE (BORS) .........................................................................................................................38 MEGOLDÁS ........................................................................................................................................................................39
HANGAZONOSÍTÓ RÉSZ (HORVÁTH, SAFRANKA).........................................................................................................39 A FELADAT BEMUTATÁSA (SAFRANKA) ...........................................................................................................................39 AZ ELŐFELDOLGOZÓ (HORVÁTH) .................................................................................................................................40
A megvalósítás lépései:.................................................................................................................................................40 I. A hangfile beolvasása és feldolgozása .....................................................................................................................40 II. A Linear prediction megvalósítása ..........................................................................................................................44 III. Harmonikus vizsgálat .............................................................................................................................................47 Harmonikus vizsgálat LP analízis segítségével...........................................................................................................50 IV. Átlagos amplitúdó mérés........................................................................................................................................53 V. Formáns analízis.......................................................................................................................................................53 VI. Kapott eredmények eltárolása, vagy értékelése ....................................................................................................54 VII. Egyéb eljárások......................................................................................................................................................54
A FELDOLGOZÓ TESZTRENDSZER FELHASZNÁLÓI FELÜLET(HORVÁTH) ........................................................................56 TESZTELÉS (HORVÁTH) .....................................................................................................................................................62
Az egyes részek tesztelése: ...........................................................................................................................................62 ADATSPECIFIKÁCIÓ (HORVÁTH) .......................................................................................................................................68 ARCAZONOSÍTÓ RÉSZ (BORS) .........................................................................................................................................70
A hatásfok problémái ....................................................................................................................................................71 A RENDSZER VÁZLATA (BORS) .........................................................................................................................................71
Az egységek magyarázata:............................................................................................................................................71 ADATLEÍRÁS (BORS)..........................................................................................................................................................72 A BELSŐ MODULOK KAPCSOLATA (BORS)........................................................................................................................73 ELŐFELDOLGOZÁS (BORS) ................................................................................................................................................73
Szürke kép......................................................................................................................................................................74 Medián szűrő .................................................................................................................................................................74 Kontúr szűrő ..................................................................................................................................................................76 Binarizálás és invertálás................................................................................................................................................76 YCbCr (YUV) konvertálás ...........................................................................................................................................77 Erózió .............................................................................................................................................................................77
AZ ARC MEGTALÁLÁSA A KÉPEN (BORS) .........................................................................................................................78 Elvi működés .................................................................................................................................................................78 Bemenő paraméterek.....................................................................................................................................................79 Az ellipszis detektálás folyamata .................................................................................................................................80
A KÉP KIVÁGÁSA................................................................................................................................................................88 AZONOSÍTÁS GABOR SZŰRŐKKEL (BORS) .......................................................................................................................89
Gabor szűrők..................................................................................................................................................................89 A szűrők alkalmazása....................................................................................................................................................90 Csúcsok kiemelése ........................................................................................................................................................91 Hasonlóság vizsgálat .....................................................................................................................................................91 Lehetséges optimalizáció ..............................................................................................................................................92
AZ ARCDETEKTÁLÓ TESZTPROGRAM FELHASZNÁLÓI FELÜLETE (BORS) .......................................................................92 Parameters......................................................................................................................................................................93 Filters..............................................................................................................................................................................93 Auto detect.....................................................................................................................................................................94 Identify (képek) .............................................................................................................................................................94
TESZTELÉS (BORS).............................................................................................................................................................94 Fejlesztői környezet, adatok .........................................................................................................................................94 Sebesség.........................................................................................................................................................................95 Tesztelés modulonként..................................................................................................................................................97
AZ OSZTÁLYOZÓ RENDSZER (SAFRANKA) ..................................................................................................................102 A MEGVALÓSÍTOTT NEURÁLIS HÁLÓ JELLEMZŐI (SAFRANKA) .....................................................................................102
A backpropagation modell..........................................................................................................................................104 A MEGVALÓSÍTÁS MENETE(SAFRANKA) ........................................................................................................................107
Eljárások leírása...........................................................................................................................................................109 TESZTELÉS (SAFRANKA) .................................................................................................................................................111
Problémák ....................................................................................................................................................................111 A tesztelési körülmények............................................................................................................................................114
ADATLEÍRÁS.....................................................................................................................................................................115

ÉRTÉKELÉS .....................................................................................................................................................................117 HANGFELISMERÉS............................................................................................................................................................117 ARCFELISMERÉS (BORS)..................................................................................................................................................118
Teszteredmények értékelése .......................................................................................................................................118 Összehasonlítás más rendszerekkel............................................................................................................................119 Előnyök, hátrányok .....................................................................................................................................................119 Továbbfejlesztési lehetőségek ....................................................................................................................................119
OSZTÁLYOZÓ RENDSZER .................................................................................................................................................120 ÖSSZESÍTETT ÉRTÉKELÉS ................................................................................................................................................121
FÜGGELÉK .......................................................................................................................................................................124 FOURIER TRANSZFORMÁCIÓ (HORVÁTH) ......................................................................................................................124
A Fourier Transzformáció matematikai alapja ..........................................................................................................124 Exponenciális alak.......................................................................................................................................................125 Diszkrét Fourier transzformáció:................................................................................................................................126 Valós bemenő vektor...................................................................................................................................................127 A DFT kapcsolata a vizsgált függvény harmonikus összetevőivel..........................................................................127 Az eltolási és tükrözési tétel .......................................................................................................................................128 A gyors Fourier Transzformáció algoritmusa ...........................................................................................................128
„PITCH PERIOD” BECSLÉS (HORVÁTH) ...........................................................................................................................131 NEURÁLIS HÁLÓK A KÉPFELDOLGOZÁSBAN(BORS) ......................................................................................................134
Alapfogalmak, definíciók, működési elv ...................................................................................................................134 Felépítés .......................................................................................................................................................................135 A tanulás folyamata.....................................................................................................................................................137 Hopfield neurális háló .................................................................................................................................................137
SZEM ÉS SZÁJ DETEKTÁLÁS HISZTOGRAMMAL (BORS) .................................................................................................140 Azonosítás távolság alapján........................................................................................................................................141
SZEGMENTÁCIÓS TECHNIKÁK (BORS) ............................................................................................................................142 Lokális szemléletű megoldás......................................................................................................................................142 Globális szemlélet, Hough Transzformáció ..............................................................................................................144
NEURÁLIS HÁLÓZATOK (SAFRANKA).............................................................................................................................147 A neurális hálózat definíciója, működése ..................................................................................................................147 A neurális hálózat feldolgozó eleme ..........................................................................................................................147 Aktivitási állapotok és aktivitási függvény................................................................................................................148 Neurális hálózati topológiák .......................................................................................................................................150
A NEURÁLIS HÁLÓZAT TANULÁSA (SAFRANKA)............................................................................................................151 A tanulási módok.........................................................................................................................................................152 Hebb-szabály ...............................................................................................................................................................153 Delta-szabály ...............................................................................................................................................................153 Általánosított delta-szabály ........................................................................................................................................154
A NEURÁLIS HÁLÓZATOK ALAPVETŐ FELHASZNÁLÁSI TERÜLETEI (SAFRANKA) ........................................................154 A neurális hálózat, mint asszociatív memória ...........................................................................................................154 A neurális hálózat, mint osztályozó ...........................................................................................................................155 A neurális hálózat, mint optimalizáló rendszer .........................................................................................................155 Neurális hálózat idősorok kezelésére .........................................................................................................................156 A neurális hálózat, mint approximáló rendszer .........................................................................................................156
A HIDDEN MARKOV MODELL (SAFRANKA)...................................................................................................................156 Markov láncok.............................................................................................................................................................156 Markov forrás: beszéd példa.......................................................................................................................................157 Hidden Markov Modell (Rejtett Markov Modell) ....................................................................................................158 A HMM állapot kimenetű definíciója ........................................................................................................................159 HMM modellezésre alkalmas folyamatok.................................................................................................................160 Példa kétállapotú HMM-re .........................................................................................................................................160 Első eset .......................................................................................................................................................................161 Második eset ................................................................................................................................................................162 A HMM alkalmazása beszéd modellezésre ...............................................................................................................163 A Bayes-i HMM megvalósítás ..................................................................................................................................165 Megfigyelési sűrűségek...............................................................................................................................................167 HMM inicializálás (tanítás) ........................................................................................................................................167
A HMM MEGVALÓSÍTÁSA (SAFRANKA) ........................................................................................................................169 A Gauss modell számítása ..........................................................................................................................................169 A HMM modell implementálása ................................................................................................................................170 Az inicializálás HMM hierarchiája ............................................................................................................................171 A HMM és a Válószínűségi, Bayes-i és Neurális Hálós megoldások összehasonlítása.........................................173
TESZTELÉSI EREDMÉNYEK .....................................................................................................................................174
IRODALOMJEGYZÉK...................................................................................................................................................187

C E R B E R U S P R O J E K T
1
Absztrakt A célunk egy olyan rendszer megvalósítása, amely alternatívát kínál a hagyományos jelszó alapú azonosítás helyett. Az azonosításhoz két biometriai jellemzőt használunk fel, az egyén arcformáját illetve a hangjának jellemzőit. A megoldás előnye, hogy az azonosítás alapjául szolgáló információk a személy egyéni tulajdonságai.
A hangnak nem felismerése, szöveggé alakítása a cél, hanem a kapott hangmintából a beszélőre vonatkozó adatok kinyerése. Ezek alapján történhet annak megállapítására, hogy a beszélő az-e, akinek állítja magát. Az azonosítás első lépése a bejövő hangminta előfeldolgozása. Három eljárás kerül alkalmazásra: linear prediction módszert használunk spektrális analízishez, amely kiemeli a hang formáns struktúráját; az alapharmonikus-vizsgálat, amely egyénre jellemző hullámfüggvényt ad; míg az átlagos amplitúdó módszer felhasználásával a szavak szeparálása végezhető el. Ezután a kinyert jellemzők átadása következik az osztályozó rendszer számára.
A hang alapú azonosítást a hatékonyság növelése érdekében arcjellemzőket felhasználó technikával egészítettük ki. Már évtizedekkel ezelőtt írtak számítógépre arcfelismerő alkalmazásokat, azonban a gépi teljesítmény növekedésével vált igazán megbízhatóvá ez a megközelítés. Többféle megközelítési mód létezik a számítógép által nehezen értelmezhető képi információ feldolgozására, illetve az abból való információ kinyerésére. Az elkészült rendszeren belül a program először átalakítja a képet egy egyszerűbben értelmezhető formára, ezután a Randomized Hough transzformáció alkalmazásával megkeresi az arcot a képen, majd kiemeli jellemző pontjait (szemek, száj, stb.). Ezen a referencia pontok szolgálnak az azonosítás alapjául. Az osztályozó rendszer neurális hálózatos megvalósításban készült el. Ebben az esetben hasznos a neurális hálózatok asszociálási képessége vagyis, az hogy képes minták hasonlóságát, vagy éppen eltérését felismerni. Egy többrétegű (3 rétegű +1 bemeneti réteggel rendelkező), perceptron elvű, teljes összeköttetést alkalmazó, visszacsatolás nélküli hálózati topológiát választottunk. A bemeneti réteg és a két rejtett réteg elemszáma a bejövő információ méretétől függ. A tanítás egy felügyelt backpropagation algoritmussal történik, ahol a helyes kimenetet az output neuronok 1 értéke jelenti. A felismeréskor a minta végighalad a betanított hálón, majd a kimeneten a minden neurontól kívánt 1 értékű kimenettől való négyzetes eltérést vizsgáló függvény által visszaadott érték alapján történik az osztályozás.
Fejezet
1

C E R B E R U S P R O J E K T - B E V E Z E T É S
2
Abstract Our goal is to create a system which is an alternative for the traditional password based identification. We use two individual biometric features for identification and verification: the face and voice characteristics. The arguments for this solution are that these are unique features of each individual. These features are separated into three test parts, such as face recognition, a voice pre-processing and a neural network test program.
Our purpose is to get the significant information from the speaker’s voice. The speaker’s verification is based on these information. The first step is to pre-process the incoming voice signal. For the voice pre-processing, we use three methods: LP (linear prediction) analysis is used for spectral analysis (which can separate and emphasize the formants from the voice) and pitch period estimation, (average magnitude and energy is also used for reducing noise) which emphasis the significant information. These information are sent to the neural network.
To increase the efficiency of the voice recognition, we also use a face feature analysis. Face recognition applications have been written for computers decades ago, but these systems performance have become usable when the computer’s power has grown stronger. Many methods are known to process visual information with a computer. In our system the face recognition part is converts the picture to an easier to process format then a global detection method is used, the Randomized Hough transformation which can find the face on the picture, than a so called Gabor filter is used. The significant points on the face are found with these filters, and the identification is based on these points.
The classification test program is a backpropagation neural network implementation. We are using the neural networks ability to associate, and classify. The implemented network has 3+1 layers (3 layers + 1 input layer) and it is perceptron based with full connection feedback-free topology. The input layer’s and the hidden layer’s cell number is depends on the incoming information. The training is based on a supervised backpropagation algorithm. The decision is based on the values of the output cells. If they are near to “1” the samples are acceptable, if there is a little difference, a new sample is required, and if there is a bigger difference the sample is rejected

C E R B E R U S P R O J E K T - B E V E Z E T É S
3
Bevezetés Általános ismertető a projekthez kapcsolódó témakörökben.
Hagyományos azonosítási technikák (Safranka)Kerberosz, vagy eredeti írásmód szerint Cerberus, az ógörög mitológiai alak, az alvilág kapuját őrző háromfejű kutya. A névválasztással megpróbáltunk utalni a megvalósítandó rendszer feladatára. A projekt célja alapvetően egy olyan rendszer létrehozása, amely fizikai (biometriai) tulajdonságok alapján azonosítja a felhasználásra jogosult személyt.
Manapság a felhasználók azonosításának két elterjedt módja van. Egyik a „hagyományosnak“ nevezhető felhasználó név és jelszó bekérése. Minden belépésre jogosult személy kap egy egyéni azonosítót, és egy jelszót, amelyet időnként meg kell változtatnia. Ennek egy fejlettebb, „technikaibb“ megoldása az úgynevezett intelligens kártya (Smart Card). Itt egy a telefon kártyához hasonló kártyán van egy egyéni azonosító elhelyezve. A felhasználó a bejelentkezéskor ezt behelyezi a megfelelő kártyaolvasóba, beüti a saját (egészen pontosan a kártyához tartozó) PIN számot és ez alapján történik az azonosítás. A két módszer ugyan azokkal a gondokkal küszködik. A kártya másolása ugyan nehezebb, de az elvesztése ugyan úgy gondot okoz, és a pótlása nem olcsó. A felhasználó név (vagy kártya) és jelszó (vagy a PIN szám) megszerzésével illetéktelenek férhetnek hozzá a rendszeren tárolt kényes adatokhoz, esetlegesen károsíthatják is azokat. A jelszó adott idők közönkénti megváltoztatása és az új jelszó memorizálása, vagy a jelszó elfelejtése szintén elég sok kellemetlenséget okoz mind a felhasználónak, mind a rendszergazdának Viszont tagadhatatlan tény, hogy a jelszó megadás (vagy kártya behelyezés) egyáltalán nem hosszadalmas, időt rabló folyamat, vagyis ha valakinek szüksége van a munkájához valamilyen adatra a hálózatról, nem kell hosszú időt töltenie az azonosítási eljárással.
Tehát egy olyan azonosító eljárás volna ideális, amely a felhasználókat egyénileg azonosítja valami olyan módon, ahol az azonosítás alapjául szolgáló információt a felhasználó nem veszítheti el, kizárólag rá jellemző, nem másolható le és gyors (maximum néhány másodperc idejű) azonosítást tesz lehetővé. Legbiztosabb mód egy személy azonosítására valamilyen egyedi külső (fizikai) tulajdonság (vagy több tulajdonság) alapján történő azonosítás.
Biometriai azonosítás (Safranka) Ezen tulajdonságoknak a minden személy két egyéni jellemzőjét, mégpedig a hangot és az arcformát gondoljuk. Ha azt megnézzük, hogy mi magunk is, ha egy ismerőssel találkozunk, az alakja alapján sejtjük, hogy ki lehet, de az arcformája az a tulajdonság, amely alapján egyértelműen felismerjük az illetőt. Amennyiben telefonon beszélünk valakivel akkor, ha jól

C E R B E R U S P R O J E K T - B E V E Z E T É S
4
ismerjük a személyt, akkor a hangja alapján is felismerjük, anélkül hogy bemutatkozna. Az általunk tervezett rendszer e két azonosítási módot használná, melyek egymást kölcsönösen kiegészítenék.
Felhasználóbarát biztonsági azonosítást tesz lehetővé, elkerülhetővé válna az eddig szokásos azonosítások hátrányai és kellemetlenségei, mint például az azonosító megőrzése, esteleges elvesztésével járó kockázatok, a jelszó vagy intelligens kártyák illetéktelen kezekbe kerülése okozta veszélyek. Itt a felhasználónak az azonosítási eljárás során nincs szüksége másra, mint a saját nevére és a két vizsgált fizikai tulajdonságára (arcformájára és hangjára) melyek egyértelműen jellemeznek egy személyt. Ezen azonosítási eljárás által használt azonosítókat felhasználó nem veszítheti el (vagyis nem olyan könnyen, mint egy jelszót). Továbbá e jellemzők megszerzése, vagy „meghamisítása” nagyobb nehézségekbe ütközik, mint a jelszó vagy intelligens kártya alapú azonosítás esetében. Természetesen ez a módszer sem jelent teljes biztonságot, inkább pontosabb, nehezebben kijátszható és főképp a felhasználó számára kényelmesebb azonosítást.
A biometriai azonosítás története (Bors)
A számítógépek az utóbbi időben bekövetkezett fejlődésének köszönhetően egyre szélesebb körben használják. Az ember külső fizikai megjelenése alapján történő azonosítás azonban nem napjaink új gondolata. A kínaiak már 14. században azonosítottak ujjlenyomat alapján, melyre egyfajta aláírásként tekintettek. Később a rendőri munka fontos részévé vált: az 1890-es években a test mérésének módszerét alkalmazták azonosításra (Alphonse Bertillon után Bertillonage-nek nevezték el a módszert). Hátránya nyilvánvaló volt, előfordulhatott két hasonló ember méreteit tekintve, ezért ez a módszer hamar eltűnt. Helyette a ma is használatos ujjlenyomat azonosítást vezették be, a Scotland Yard-i Richard Edward Henry által fejlesztett módszer alapján. Gyakran vitatták (és vitatják ma is) az ujjlenyomatok tökéletes különbözőségét, főleg ha figyelembe vesszük hogy az egyes országokban különböző számú munitia pont szükséges az azonosításhoz. Azonban sok évtizeden át és jelenleg is ez az egyetlen és legmegbízhatóbb módszere a rendőrségnek. Az elektronika és a mikroprocesszorok teljesítményének kihasználásával számos elgondolás született a katonai és polgári szektorban való használatára. Napjainkban már számos módszer létezik. Biometriai azonosításra a következőket használják: DNS vizsgálat, ujjlenyomat, tenyér alakzat, írisz, retina, kézírás, hangazonosítás, arcfelismerés, és „szag” alapján történő azonosítás. A fejlődés még biztosan nem állt meg: egyre pontosabb és megbízhatóbb rendszerek elkészítésére van igény, melyek a fontos és hasznos feladatok mellett jobban hétköznapivá fognak válni, mintsem azt most gondolnánk.
Miért jobb a biometria mint a hagyományos módszerek? (Bors) A kutatási, fejlesztési költségek miatt a biometriai rendszerek számottevően drágábbak a hagyományos megoldásoknál. Mégis hosszútávon megéri a befektetés. Gondoljunk például egy nagy létszámú vállalat dolgozóinak azonosítására. Hagyományos rendszer esetén használhatnak azonosító kártyát, PIN kódot, jelszót stb. Ezeket könnyen elvesztheti a felhasználójuk, elfelejtheti, esetleg más tudomására juthat (például betörés esetén) az összes azonosítót talmazó

C E R B E R U S P R O J E K T - B E V E Z E T É S
5
adatbázis. Az újabb jelszók, kódok kiosztása rendkívül nagy adminisztratív költségek-kel járhat. Ilyen biometriai azonosító rendszer esetén nem történhet meg. Tehát ha a cégnek megéri az egyszeri nagy befektetés, később az alacsonyabb költségek miatt megtérülhet a beruházás.
A biometriai azonosító rendszerek egyre szélesebb skálájával találkozhatunk. Ez is azt mutatja, hogy egyre több cég kezd ezirányú fejlesztésekbe, egyre többen látják benne a megtérülés lehetőségét. A legújabb felmérések szerint a biometriai személyazonosítás napról-napra több tömegpiaci alkalmazásban kap szerepet. A Cahners In-Stat Group jóslata szerint a technológiai fejlődés, és a biztonsággal kapcsolatos aggodalmak előtérbe kerülése, valamint a csökkenő árak miatt az elkövetkező öt évben akár félmilliárd dolláros nagyságrendet is elérheti a biometriai eszközök és szolgáltatások értékesítése. Látható azonban hogy jelenleg az emberek még nem bíznak annyira a technológiában, hogy hétköznapjaink részévé válhasson. A német BioID, mely 1993 óta van a piacon többféle biometriai azonosító programjaival, jelenleg ezért került a csőd szélére.
Biometriai technikák (Bors) A biometriai technológia legelterjedtebb formája szem, arc, kéz és az ujj leképezése. Ezek közül a legklasszikusabb típus az ujjlenyomat azonosítás (lsd. rendőrség) A legújabb módszerek a retina és írisz vizsgálatok. Ezek a módszerek mind hatékonyak, ugyanakkor „kellemetlenséget” okoznak a felhasználónak. Az ujjlenyomat azonosításhoz egy szenzorra kell helyezni ujjunkat, beszédértéshez beszélnünk kell a számítógéphez. Ezek mind egy kicsit misztikusnak tűnhetnek egy átlagfelhasználó számára. Ezzel szemben az arc alapján történő azonosítás a legkényelmesebbnek tekinthető. Nem korlátozza helyzetét a személynek, akár távolból is képes azonosítani, az embernek semmilyen plusz tevékenységet nem szükséges végeznie hogy megtörténjen az azonosítás. Ha eltekintünk a részletektől, egy embert egy másik embertársa teljes biztonsággal tud azonosítani, amennyiben nemrégiben látta. Ha jobban belegondolunk, ez persze nem igaz, mert mi történik például egypetéjű ikrek esetén? Őket könnyen összekeveri az ember. A jelenlegi fejlettségi szint mellett elmondható, hogy a számítógépek is képesek már eltalálni hogy ki az aki éppen a látókörükbe került. Vagyis éppúgy mint az ember, felismerik. Viszont a nehezebb esetekben (lsd. egypetéjű ikrek) éppúgy tévedhetnek, mint az ember. Ez azonban egy biztonsági beléptető rendszer esetén nyilvánvalóan nem engedhető meg. A jelenlegi kutatások többek között ezirányban is folynak, kisebb-nagyobb sikerekkel. Egyik alternatíva lehet, arc-thermogram használata. Ilyenkor infra kamerával készítenek az arcról egy hőtérképet, mely a relatív hőmérsékletkülönbségeket mutatja függetlenül kortól, egészségi állapottól de még a test hőmérsékletétől is. Ezáltal már nagyban pontosodhat az azonosító eljárás, jelenleg a technológiai költségek nagysága ami visszatartja a fejlődését ennek a módszernek.
Alapvető különbség a különféle biometriai programok között a különböző hatásfok. Mitől is jó egy biometriai azonosító program? Nyilvánvalóan elsődleges szempont az azonosítás pontossága. A fejlesztések, újabb és újabb módszerek, technikák kidolgozása egyre pontosabb azonosítást tesz lehetővé. Jelenleg nehéz lenne 100% pontossággal működő biometriai azonosító programot mondani. Ha mégis, bizonyára erős korlátok közé szorítják az egész eljárást (például arcazonosítás esetén behatárolhatják az arc pozícióját, távolságát, fényerőt stb.) Természetesen nem feltétlenül szükséges és elengedhetetlen feltétele egy biometriai elven működő programnak a tökéletes találati aránnyal való működés. Vegyünk egy olyan programot (amely egyébként valóban létezik) ami egy stadionban figyeli a szurkolókat, és ha olyan személyt

C E R B E R U S P R O J E K T - B E V E Z E T É S
6
talál a nézőtéren, akit a rend szempontjából veszélyesnek tartanak a szervezők korábbi cselekedetei miatt, kiemelhetik a nézők közül, mielőtt valami baj történne. Vagy nézzünk például egy olyan intelligens alkalmazást, amely egy forgalmas utcán pásztázza az embereket akik éppen arra járnak, és közben figyeli, nincs-e közöttük keresett bűnöző. Nyilván a körülmények miatt is képtelen mindenkit tökéletesen azonosítani, de ha már 80% esetén sikerrel jár, egy forgalmas sétálóutca esetén naponta több ezer embert is megvizsgálhat. Vannak azonban olyan rendszerek, amelyek esetén a tévedés súlyos következményekkel is járhat. Ezek főleg a különböző jogosultságokat kiosztó programok. A probléma igazán itt kezdődik.
A hangazonosítás (Safranka) Napjainkban rendelkezésre állnak már hangfelismerésre alkalmas rendszerek, szoftverek, de széles körben még nem elterjedtek. Ennek oka a jelentős pontatlanság a felismerésben. Mivel ezek úgynevezett „Speech-To-Text” rendszerek, vagyis a folytonos beszédet kísérlik meg szöveggé alakítani. Ez a megoldás szükségessé tesz egy jelentős méretű adatbázist, mely a nyelv szavait, a szavak fonetikáját, a nyelv szabályait tartalmazza. Megkísérlik a szöveget felismerni, feldolgozni, a szavakat azonosítani, mindezt valós időben. Ma már egész jó hatékonyságú „Speech-To- Text” rendszerek vannak (pl.: a Microsoft, és az IBM fejlesztésében), bár még nem tökéletesek. Jelentős problémájuk, hogy egyrészt a felhasználónak „kalibrálnia” kell a saját hangjához, beszéd stílusához akcentusához, a hatékony felismerés érdekében. Így igazán jól csak olyan tudja használni, aki „betanította” a rendszert, így nem általánosan felhasználható. Ezek a rendszerek gyakran „tippelnek” vagyis nagyjából értik meg szöveget a gyorsabb feldolgozás érdekében, nem veti -a lehetőségek képest- teljes azonosítás alá, így gyorsítva a feldolgozást, amely kritikus a valós időbeni feldolgozás igénye miatt. Kiemelnénk hogy a mi célunk nem beszédet szöveggé alakító rendszer létrehozása, hanem a felhasználó hangmintájának azonosítása. Saját rendszert kívánunk létrehozni, nem tervezünk már meglévő elemeket felhasználni, de megvizsgáljuk a már megvalósított rendszereket. Így ezzel sok olyan nehézség nem érint minket, amely az említett „Speech-To-Text” rendszerek esetén felmerül. Ilyenek az egyén beszéd stílusa, akcentusa. Az azonosítás egy fix mintával való összehasonlítást jelent, a beszélő hangjára jellemző egyedi azonosítók keresése, és összevetése a mintával, mely nem igényel egy hatalmas adatbázist, és nyelvtani szintaktikai vizsgálatot. Persze ez esetben a hangminta minél tökéletesebb, és pontosabb vizsgálata, és ellenőrzésének módja jelent nehézséget. Így a minél pontosabb azonosítás feladat -mivel egy biztonsági rendszerről van- és nem szöveg felismerése, továbbá a zajok és zavaró körülmények lehető legteljesebb szűrése.
Az arcazonosítás (Safranka) Az azonosítási eljárás másik fázisa a felhasználó arcvonásainak vizsgálata. Ilyen jellegű alkalmazások még kevésbé elterjedtek, mint a hangfelismerő alkalmazások. Ehhez hasonló szoftverek a melyek képet alakítanak szöveggé. Ezek a szövegfelismerők, melyeket a szkennerek mellé adnak (a legismertebb ilyen jellegű szoftvereket fejlesztő cég a Recognita). Ezek is csupán az esetek többségében bizonyulnak hatékonynak, de nem tesznek lehetővé 100%-os felismerést. Ám mi itt sem ilyesmi jellegű feladatra vállalkozunk. A vizsgálat az azonosítandó személy arcvonásait vizsgálja, ezt hasonlítja ez előzőleg letárolt, időnként karbantartott mintával. Ez egy kamera által készített állókép alapján történik. A fejlesztési fázis alatt, először egy fájlban tárolt képállomány vizsgálata készül el, majd ez után, ha az eljárások elkészülnek, és le lettek tesztelve, utána kerül sor a kép rögzítés módjának elkészítése, a rendszer teljes integrálása előtt.

C E R B E R U S P R O J E K T
7
Irodalmi összefoglaló A hasonló rendszerek a felhasználható módszerek ismertetése és értékelése.
Hangfelismerő rendszerek (Horváth, Safranka)
IBM ViaVoice
Az IBM a ViaVoice szoftver csomagjával a felhasználó-számítógép kapcsolatot kívánja megújítani. Az operációs rendszer kezelése, és irodai funkciók, főként szövegbevitelt teszi egyszerűbbé. A program használatával tulajdonképpen szükségtelenné válik a billentyűzet használata, amennyiben a gépen általános felhasználói célokra kívánjuk használni. A program lényege egy szövegfelismerő rendszer, erre épül rá a keretalkalmazás rendszer, amely a feldolgozott szöveg alapján hajtja végre a feladatokat. Ezek a programok elindítása, bezárása, átméretezése, váltás a programok között, és egyéb program vezérlési parancsok fogadása. Átváltható diktáló módba. Ebben az esetben a program a beérkező szöveget egy szövegszerkesztő ablakba írja. Ez lehet a Jegyzettömb, a Word, vagy egyéb szövegszerkesztő, vagy a saját diktáló programja. Ilyenkor szöveg mellett szövegszerkesztési makrókat (pl.: új sor kéréséhez, azaz az Enter billentyű leütéséhez a New-Line parancsot kell kimondani. Ezt nem írja bele a szövegbe.) kezel a program. Az operációs rendszer vezérléséhez ki kell lépni a diktáló módból. Természetesen ez is megtehető szóbeli paranccsal. A program jelenleg a 9-es verziónál tart. A lényeges fejlődést a keretprogram által nyújtott lehetőségek növekedését jelenti.
Értékelés/megjegyzés:
A program nem hang alapú azonosítás, hanem megértéssel foglalkozik. Ily módon nem nagyon tudjuk vizsgálni, a mi rendszerünk számára hasznos részeket. Talán azt, hogy a program a felismerés nagyobb hatékonysága érdekében kér egy tanítást a felhasználóktól, és így létrehoz, egy a felhasználó hangjának és beszéd stílusának, kiejtésének alapján egy profilt.
Fejezet
2

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
8
Microsoft Speech SDK 5.1
Az SDK a Software Developement Kit vagyis szoftver fejlesztési csomag. Tehát ez nem egy alkalmazás, vagy program csomag, hanem egy Hangfelismerés, feldolgozáson, beszédszintézisen alapuló programok fejlesztését segítő csomag. Az a csomag tartalmaz egy ingyen terjeszthető Text-To-Speech rendszert (TTS) és egy Speech Recognintion (SR) rendszert. A SAPI (Speech Application Program Interface) a Microsoft .NET programja keretében készült. Ebben a rendszerben Visual Basic, Visual C++, ECMAScript, és egyéb Automation nyelveken keresztül lehet beszéd alapú alkalmazásokat fejleszteni. A program csomag telepíti a Hangfelismerő, és szintetizáló rendszert, továbbá néhány példa, vagy bemutató alkalmazást, a technológia reprezentálására (C, Visual Basic, és Script nyelven). Tartalmaz továbbá egyéni audio objektumok támogatását, példa forrásokkal, részletes dokumentációt (az SAPI grammatikáról), különböző nyelvi támogatásokat (Amarikai angol, japán, kínai, francia, német és spanyol nyelven).
A Microsoft ezen felül kínál egy Hidden Markov Modell könyvtár modul csomagot, C nyelven. Ez a csomag beszéd analízis, Hidden Markov Modell tanítás, tesztelés, és eredmény analízissel fogalakozik.
Értékelés/megjegyzés:
A projektünk tervezésének előrehaladásával, a megvalósítási fázisban érdemes megvizsgálni a Microsoft e szoftver csomagjait. Talán a hangfeldolgozás egyes fázisaiban adhat ötletet a SAPI, vagy főként a Hidden Markov Modell tanulmányozása. Bár ezen SDK nem hangazonosítás, hanem hang értelmezés, és feldolgozáson alapuló alkalmazások fejlesztésének segítésére készült. Mindenesetre érdemes részletesen megismerkedni az itt használt módszerekkel. A SAPI az IBM ViaVoice-hez hasonlóan egy adott szöveg felolvasatása segítségével vizsgálja az adott felhasználó hang, és beszéd jellemzőit.
Dragon Systems
Alapvetően diktáló program, az így bevitt hang nem csak diktálásra használható természetesen, hanem egy számítógép komplett vezérlésére is. Több féle szoftvert is kínál, különböző célokra, legfontosabb a "Dragon NaturallySpeaking®" (pillanatnyilag a 6-os verzió az aktuális). Alapvető céljuk ezekből, mint általában az összes hasonlónak egy olyan számítógép működtetése, ami nem igenyél begépelt inputot, csak szövegest, hang alapút.
Értékelés/megjegyzés:
Ez a termek csak annyiban közös a mi megvalósítandó rendszerünkkel, hogy mi is és ők is hangot használunk fel, de merőben különböző célokra. Ennek a termeknek alapvetően egy egyszerűbben kezelhető felhasználói felület a célja (mint a legtöbbnek)
Tehát összegezve ők egy speech-to-text rendszert fejlesztettek ki, amivel egyszerűbb PC irányítást akarják megoldani, a már meglevő programok irányítását. Irodai munkákban gépelést helyettesíteni stb.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
9
Philips
Ebben az esetben több termekről kell beszelnünk, mert a Philips összesen 3 kategóriába osztja a hangfelismeréssel kapcsolatos projektjeit:
a. Telefonos/telekommunikációs szolgálatok irányítása.
Értékelés/megjegyzés:
Nem kapcsolódik a mi projektünkhöz.. A már ma is létező telefon hanggal való irányítása, hanghívások stb.
b. Diktáló rendszerek
Értékelés/megjegyzés:
Lásd Dragonnál
c./ Hangvezérlés
Ez a legnagyobb a három közül, részletezve:
Ezen a kategórián belül is beszélhetünk alkategóriákról
- Hangvezérlő és irányító rendszerek autókba: itt gyakorlatilag a CD lejátszó és a navigációs rendszer a lényegi hangvezérelt eszköz, a telefon persze
- Hordozható eszközök hangvezérlése: itt a mobiltelefonok (lásd "a" pont) és a PALM-ok vezérlése, melyet ugye manapság fényceruzával használnak.
- Egyéb fogyasztói termékek: ebben a kategóriában elég széles a választék, a Philips is csak néhány termeket említ meg azért, mint pl.: TV, vagy audio eszközök hangvezérlése.
Értékelés/megjegyzés:
Azonosítással külön nem foglalkoznak. Nincsenek pontos adatok, hogy az utasítást bárkitől szöveg függetlenül elfogadja-e vagy nem, de valószinűleg ez megoldott probléma, hiszen ahhoz nem kell valakinek feltétlenül a tulajdonosnaknak lenni, aki be akarja kapcsolni a TV-t.
AT&T
Itt elsősorban a "WATSON"-nak elnevezett termék egyes fajtait taglalnám. Ez a rendszer elég összetett és az első, amit lehet mintának tekinteni. Három dolgora képes:
a. Speech recognition
Ahogy a többieknél is itt is lényegében hangvezérlésről van szó.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
10
b. Speaker verification
A WATSON egy szöveg-függő felhasználó azonosítást tesz lehetővé, mely álhat számokból, betűkből, vagy egy komplett "mondat jelszóból".
Blokkdiagramja:
1. ábra: A Watson működésének blokkdiagramja [AT&T]
A felhasználó kezdeményez egy azonosítási eljárást azzal hogy kimondd egy megfelelő számot, betűket, mondatot. Majd ezt a bejövő hangot a WATSON részekre bontja, egységek folyamatává képzi le. Majd a felhasználóra jellemző modell/minta és a szeparált részek betöltődnek az azonosítóba.
c. Text-to-speech synthesis
Nem kapcsolódik a mi munkánkhoz.
Hangbiztonsági rendszerek (Horváth)
Voice-Security
A Voice-security sokoldalú felhasználásra kínálja termekét, mely nem egy egyszerű számítógépes program, hanem önálló egységként üzemel. A hangokat külső RAM-ból vagy Smart kártyával lehet betölteni, akár közvetlenül az azonosítás előtt. Mindehhez a saját "Voice Protect® technology"-t használjak, állításuk szerint teljes biztonsággal.
Értékelés:
Tekinthető példaértékűnek, de érzésem szerint nem túl jó ha külső eszközökről viszünk be mintákat... Ez további biztonsági kérdéseket vethet fel.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
11
Megjegyzés:
A Weblapon található egy kis tesztelő, mely az Interneten elküldött hangot próbálja azonosítani, ezzel demonstrálva a termeket. A tesztelése sajnos nem sikerült a kivitelezés hiányosságai miatt.
Speechtechnologies
Ez a rendszer is alapvetően egy hangmintát használ, adott mintát illeszt, de nem önálló egységként működik, mint az előző termék, hanem egy külön software (csakúgy ahogy először mi is szándékozunk megoldani a problémát), a felhasználó adatinak, alkalmazásainak védelmére. Gyakorlatilag egy zár képezhető, mely hanggal oldható fel.
Abban az esetben, ha nem sikeres az azonosítás, feltesz egy előre definiált kérdést, melyre elvileg senki más nem tud válaszolni ("elfelejtettem a jelszót" típusú azonosítás), ezzel már vissza is vezették a problémát egy egyszerű jelszó azonosításra, aminek igy már nem sok köze van a hanghoz...
Bevezető (Horváth) Az „információ elmélet” szerint (Shannon), a beszédet két jellemzőjével lehet reprezentálni: az üzenet illetve információ tartalmával, valamit magával a jellel, ami az üzenetet hordozza.
Vizsgáljuk meg magát a beszédet egy picit közelebbről. A beszéd, hangoknak egy véges halmazából vett szimbólumaiból áll. Ezeket a szimbólumokat fonémáknak hívják.
Minden nyelvnek megvannak a saját fonémái, eltérő számban, tipikusan 30 és 50 között. Például az angol nyelvben 42 ilyen fonéma található.
A köznapi beszédben nyers becslések szerint átlagosan 10 fonémát használunk másodpercenként. Ha minden fonémát egy bináris számmal írunk le, akkor egy hat-bites kód több is mint elég arra, hogy az angol nyelv minden fonémáját számításba vegyük. Tekintve, hogy átlagosan 10 fonéma hangzik el másodpercenként, ez gyakorlatilag 60bit/másodpercet jelent. Ez persze csak egy átlagos érték, mely figyelmen kívül hagy mindenféle érzelmi tartalmat, vagy akár a beszélő beszédgyorsaságát.
A hangfeldolgozó rendszereknél a hangot többféleképpen továbbítják, tárolják, és dolgozzák fel, de általában van két közös pont minden rendszerben:
1. A hangjelben lévő üzenet megőrzése 2. A hangjel leírása olyan formában, hogy azt utána kényelmesen lehessen továbbítani, vagy
tárolni, és/vagy olyan formában hogy megfelelően „rugalmas” legyen, és olyan módosításokat lehessen végezni rajta, hogy az ne károsítsa jelentősen az üzenet tartalmat.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
12
Jelfeldolgozás (Horváth)
Esetünkben ugyebár az információ forrása a „beszélő”. A második négyzetnek általában maga a hullámjel felel meg.
2. ábra: Az információfeldolgozás és manipuláció folyamata [Rabiner 78]
A jel leírása egy valamivel összetettebb folyamat. Magában foglalja a megkapott jel ábrázolását egy választott modell alapján, és a tervezett alkalmazást is figyelembe vevő szempontok szerinti transzformációját, hogy ezáltal a felhasználásnak megfelelő, kényelmesen kezelhető formát kapjunk.
Az utolsó lépés az információ felhasználása, történhet egy ember, vagy közvetlenül egy gép által (automatikusan). Például egy beszélő azonosító rendszernél, mint amilyenről a mi esetünkben van szó, melynek feladata automatikusan felismerni egy adott beszélő hangmintáját a többi felhasználó hangmintája közül, használhat egy idő-függő spektrumábrázolást. Egy lehetséges transzformáció hogy az egész mondatra egy átlagos spektrumot készítünk, és ezt hasonlítjuk össze egy előre eltárolt mintákkal.
Digitális hangfeldolgozás (Horváth)
Alapvetően három területre kell koncentrálnunk: a jel leírására digitális formában, a megfelelő feldolgozó technika implementálására, és magára az alkalmazásra, mely nagyban támaszkodik a digitális feldolgozásra. [Rabiner 78]

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
13
A jel leírásához digitális formában fel kell használnunk az un. mintavételezési elméletet, miszerint egy sávlimitált jelet leírhatunk megfelelően sűrűn, időben periodikusan vett mintákkal.
3. ábra: A hangjel ábrázolásának lehetőségei [Rabiner 78]
A hanghullám ábrázolás alapja - mint azt a neve is mutatja – a hullám alakjának megőrzésén alapszik. Ellenben a paraméteres ábrázolási forma arra törekszik, hogy a hangot egy feldolgozó modell kimeneteként ábrázolja.
A két módszer másban is eltér, például a hullámforma ábrázolás magas adattárolási igényével szemben a paraméteres ábrázolás jóval kedvezőbb, de persze számos más szempontot is figyelembe kell venni: mint például a „rugalmasságot”, vagy a minőséget.
4. ábra: Digitális hangfeldolgozás fontosabb területei [Rabiner 78]
Digitális továbbítás és tárolás:
A hangfeldolgozás egyik legkorábbi és legfontosabb alkalmazása az un. vocoder vagy voice coder volt, melyet Homer Dudley fedezett fel 1930-ban. Ez képes volt redukálni a továbbításhoz szükséges sávszélességet, és ez a tulajdonság máig is nagyon hasznos, annak ellenére, hogy ma már számos megnövelt sávszélességű technika áll rendelkezésünkre. (gondoljunk csak a műholdakra, vagy a mikrohullámú technológiára)
Hang/beszéd szintézis:
Leginkább a gazdaságos hangtárolás a számítógépes beszéd-válasz rendszerekhez gerjesztette eme terület fejlődését. Ezek a rendszerek alapvetően automatikus információs rendszerek, melyekhez kérdéseket lehet feltenni egy konzolról, vagy billentyűzetről, és az hangban válaszol rá.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
14
Beszélő azonosítás és felismerés:
A beszélő azonosítás és felismerés magában foglalja egy adott személy hangjának authentikációját vagy identifikációját a lehetséges beszélők egy nagyobb halmazából.
Egy hangazonosító rendszernek el kell tudni döntenie, hogy az adott személy az-e akinek kiadja magát. Ezen ágazatnak az élet számos területén van jövője, a hétköznapi felhasználástól (hiteltranzakciós azonosítások) akár a katonai vagy egyéb biztonságtechnikai felhasználásig.
Beszédfelismerés:
A beszédfelismerés legáltalánosabb definíciójának lehet mondani, hogy a hangot (hanghullámot), pontosabban a hang által hordozott információ tartalmat írott szöveggé konvertálja. Ennek hatékonysága nagyban függ a beszélő érzelmi állapotától, beszédének jellegzetes vonásaitól, az adott helyzettől, és az üzenettartalomtól is. Legelterjedtebb területei az un. diktáló alkalmazások, és a számítógéppel való kommunikálást segítő alkalmazások.
Hátrányos helyzetűeket segítő rendszerek:
Ez a terület arra törekszik, hogy az információt könnyebben elérhetővé tegye, mint ahogy az eredetileg elérhető lenne.
Jelminőség javítása:
Számos helyzetben előfordul, hogy egy jel minősége leromlik valami miatt, ezzel a kommunikáció hatékonyságát csökkentve. Ebben a helyzetben alkalmazhatók technikák melyekkel elérhetjük a jel minőségének javulását. Például ebbe a kategóriába tartozik egy hangjelből a visszhang eltávolítása, vagy a hang helyreállítása, melyet egy hélium-oxigén kevert környezetből vettek melyet búvárok használnak.
A digitális jelfeldolgozás alapfogalmai (Horváth)
Diszkrét idejű jelek és rendszerek
Bármilyen helyzetben, legyen az kommunikáció vagy információ feldolgozás, természetes, hogy a jel, mint egy időben változó minta reprezentációjával kell kezdenünk. Az természetben előforduló hangok, mint az emberi hang is, leírható egy (egyváltozós) időben változó függvénnyel (t).
Azonban lehetőség van ugyanezen jel leírására egy számsorozattal is, melyet már fentebb említettünk, periodikusan vett mintákból áll. (A mintavételezési törvényt lásd Fourier transzformációnál) Sok beszédelemző módszer pedig pont arra lett kitalálva, hogy számos időben változó paramétert megbecsüljön a hanghullámból.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
15
)(*)()()()( nhnxknhkxnyk∑
∞
−∞=
=−=
A lineáris eltolás-mentes rendszerek egyik speciális formája rendkívül jól használható a hangfeldolgozásban. Ezeknél a rendszereknél a kimenet egyenesen a bemenetből, x(n), és a válasz alakból h(n) számítható, a konvolúciós szumma felhasználásával.
)(*)()()()( nhnxknhkxnyk∑
∞
−∞=
=−=
ahol „*” jelenti a diszkrét konvolúciót. Ezt máshogy is írhatjuk:
)(*)()()()( nxnhknxkhnyk∑
∞
−∞=
=−=
Ablakozás (Horváth) A digitális jelek feldolgozásában igen gyakori, hogy nem az egész jelsorozatot vizsgáljuk egyszerre, hanem szegmentáljuk, úgynevezett ablakozást alkalmazunk, a jelek mindig csak egy kis részletével foglalkozunk egyszerre. [Bourke 98]
Az ablakok típusa azonban többféle lehet.
I. Négyzetes ablak
A legtriviálisabb ablakfajta
w(i) = 1 0 ≤ i ≤ N-1
0 egyébként
II. Welch ablak
A Welch ablak N pontra a következőképpen definiálható:
2
2
21)(
−−=
N
Niiwelch

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
16
5. ábra: Welch ablak nulla középponttal ábrázolva [Bourke 98]
Gyakran alkalmazzák logaritmikus spektrumábrázoláshoz.
6. ábra: Amplitúdó válasz [Bourke 98]
III. Bartlett ablak
Vagy más néven az egyszerű háromszög ablak N mintára a következőképpen definiált:
≤≤−+
≤≤−=
egyébkéntiNNi
NiNiiw
002//21
2/0/21)(

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
17
A függvény pedig:
7. ábra: Bartlett ablak [Bourke 98]
8. ábra: Bartlett ablak a frekvencia függvényében [Bourke 98]
tππ t)sin(sinc(t) =
A frekvenciaválasz pedig a sinc2:
IV. Hanning/Hamming ablak
„Emelet cosinus ablak” –ként is ismert
A Hanning ablak N pontra:
)2cos(*5.05.0)(N
iiw π+=

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
18
A Hamming ablak pedig:
)2cos(*46.054.0)(N
iiw π+=
Aholis -N/2 ≤ i < N/2
Ezen ablaktípusok tökéletes példái a w(i) = a + (1 - a) cos(2 π / N) alakú függvényeknek.
9. ábra: Összehasonlítás: Hamming, Hanning, és Kaiser-Bessel ablak [Bourke 98]
10. ábra: Amplitúdó válasz [Bourke 98]
V. Kaiser-Bessel ablak
A Kaiser, vagy Kaiser-Bessel ablak diszkrét formában:
−<=<=−−
−−=
egyébként
NnNN
nBInwk
0
2/)1(2/)1(1
21)(21
2
0

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
19
Ahol is N az ablak hossza, B pedig az időtartomány fele.
Jelek és rendszerek transzformált alakja (Horváth)
A z-transzformált
A z-transzformáltat [Rabiner 78] egy egyenletpárossal írhatjuk le:
∫ −=C
n dzzzXj
nx 1)(21)(π
∑∞
−∞=
−=k
nznxnX )()(
ahhoz hogy a z-transzformált értéke véges legyen szükségképpen konvergálnia kell valamilyen értékhez, ennek feltétele:
∞<∑∞
−∞=
−
n
nznx )(
Decimatorok és Interpolatorok:
Számos esetben szükségünk lehet rá, hogy egy jel mintavételezési frekvenciáját változtassuk. Például akkor ha egy hangmintát alacsony frekvenciával vettek fel, de a visszaállításához szükség van ennek növelésére. [Rabiner 78]
Decimatorok:
Tételezzük fel, hogy egy jel mintavételezési frekvenciát csökkentjük egy M faktorral.
Tehát szeretnénk egy új számsorozatot kapni a régi helyett, egy olyan xa(t) sorozatot melynek periódusa T’ = MT
)()'()( nTMxnTxny aa ==
Ebből könnyen megállapítható hogy:
)()( Mnxny =
-∞ < n < ∞
Interpolatorok:
Most tételezzük fel azt, hogy egy jel x(n) = xa(nT), mintavételezési frekvenciáját növelni akarjuk egy L faktorral. Tehát az új számsorunk periódusa így fog kinézni: T’ = T/L

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
20
)/()'()( LnTxnTxny aa ==
Így y(n) = x(n/L) n=0, ±L, ± 2L … de ezenkívül még ki kell egészítenünk az ismeretlen mintákat az n összes értékére vonatkozóan.
Digitális szűrők
A digitális szűrők diszkrét idejű eltolás-mentes rendszerek. Ezekből is alapvetően kétfélét különböztetünk meg . Vannak az un. „finite duration impulse response” (FIR), rendszerek, és vannak az un. „infinite duration impulse response” (IIR) rendszerek. [Rabiner 78]
Részletesebb leírásukra most nem térünk ki, csak egy kis összehasonlításra:
A FIR rendszerek előnyei:
Az egyik legfontosabb választás amit el kell végeznünk ha decimatorokat és interpolatorokat akarunk implementálni, az alacsony-áteresztő szűrők kiválasztása. Jelentős számítási idő takaríthatunk meg a különböző szűrőfajtákon a FIR használatával. Ez annak köszönhető, hogy a decimatoroknál csak egy az M számú kimenetből számítandó, amíg az interpolatoroknál minden L-ből L-1 bemeneti jel nulla értékű és így nem szól bele a számításokba. Ezek a jellemzőn nem teljesen használhatók ki IIR szűrők alkalmazásával.
Ősszegezve, a szükséges szűrések elvégezhetők FIR szűrőkkel, mivel a mintavételezési frekvenciában történő nagy változások könnyen csökkenthetők interpolatorok alkalmazásával, vagy decimatorok sokszori egymás utáni felhasználásával.
A hang (Horváth) Ahhoz hogy hatékonyan fel tudjunk dolgozni egy hangjelent, fontos valamennyire megismernünk magát a hangot is , nem csak azt hogy ezt hogyan tudjuk digitálisan feldolgozni.
A beszéd hangok sorozatából épül fel. A hangok, és a köztük lévő átmenetek az információ egy szimbolikus megjelenései. Ezeket a megjelenéseket a nyelv szabályai határozzák meg. A nyelv szabályaival foglalkozó tudományágat nyelvészetnek, a hangokat pedig fonémáknak nevezik.
Az emberi hangképzés folyamatának bemutatása túl messzire vinne bennünket az adott témától, így inkább csak arra térünk ki, milyen típusú hangok lesznek az emberi hangképzés eredményei, és ezeknek mi a legfontosabb jellemzője.
Alapvetően három nagy csoportot különböztetünk meg: a zöngés, zöngétlen, és zárhangokat.
A hangképzésben egy hangra jellemző rezonanciafrekvenciákat formánsoknak nevezik. Minden hangot alapvetően leírhatunk formánsaival.
A formánsokra vonatkozó pontos, számszerű adatokat lásd a [Rabiner 78]-ban.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
21
Time-domain módszerek hangfeldolgozásra
Egy hangjel feldolgozása során a célunk az, hogy kapjunk egy kényelmesebb vagy jobban használható formáját a hang által hordozott információnak. A time-domain feldolgozás jelentése hogy a jelet az idő függvényében vizsgáljuk, ellentétben például a Fourier vagy LP (Linear Prediction) technikáknak melyek elsősorban a frekvencia függvényében vizsgálódnak.
Idő-függő hangfeldolgozás (time-dependent speech processing)
Alapvető dolog, hogy a hang tulajdonságai az időben változnak. Például egy zöngés és egy zöngétlen hang között jelentős amplitúdóbeli különbségek vannak, valamit a frekvencia is változó. Viszont azt is megállapíthatjuk, hogy a hang tulajdonságai „viszonylag” lassan változnak az idő függvényében. Erre alapozva számos „short-time” feldolgozó módszer született. Ezek lényege, hogy a hangot kis, elkülönített részekre bontják, és egyenként dolgozzák fel. Ezek a kis részek, melyeket gyakran neveznek „analysis frame”-nek (azaz vizsgálati keretnek/rész-nek) fedhetik is egymást, valamit egy-egy kis rész feldolgozásából kaphatunk egy kifejezett értéket (számot), vagy értékek (számok) egy sorozatát is.
„Short-time” energia
Természetes dolog az –mint már említettük- ,hogy egy zöngés hang amplitúdója magasabb mint egy zöngétlen hangé. [Rabiner 78] A „short-time” energia egy kényelmes megoldást nyújt olyan ezek ábrázolására, mely képes megfelelően tükrözni ezeket az amplitúdó különbségeket. Ezt az energiát általánosan így szoktuk felírni:
[ ]∑∞
−∞=
−=m
n mnwmxE 2)()(
Mely írható ebben az alakban is:
∑∞
−∞=
−=m
n mnhmxE )(*)(2
aholis:
h(n) = w2(n)
Ez az eljárás azonban erősen „ablakfüggő”. Mivel ugyebár a jel egy szakaszát vizsgáljuk ki kell térnünk a lehetséges ablaktípusokra is, melyben az éppen vizsgált jelünk van.
Alapvetően két fontos és elterjedt típust említenék meg. Az egyik a hagyományosnak mondható négyzetes ablak:
h(n) = 1 0 ≤ n ≤ N-1
0 különben

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
22
a másik az un. Hamming ablak:
h(n) = 0.54-0.46cos(2πn/(N-1)) 0 ≤ n ≤ N-1
h(n) = 0 különben
„Short-time” null-átmenet
Ezen tulajdonság egy igen egyszerűen leírható, de bizonyos esetekben fontos tulajdonsága a hangnak (a jeleknek) [Rabiner 78]. Előnye, hogy akár a frekvenciából is kiszámítható (bizonyos esetekben), például egy egyszerű szinuszos jelnek, melynek frekvenciája F0, és mintavételezési frekvenciája Fs, Fs/F0 mintája van a szinusz egy körülfordulása alatt. Minden körülfordulásnak két null-átmente van, így a hosszú-idejű átlagos null-átlépések száma
Z = 2F0/Fs
Hogy ez miként alkalmazható a mi problémánkra ahhoz előbb meg kell említenünk, hogy felhasználva a hangenergiát, megállapíthatjuk, hogy a zöngés hangok energiája 3kHz alatt koncentrálódik, míg a zöngétlen hangoké magasabb frekvencián jellemező. Mivel a magasabb frekvencia magasabb null-átmenetet gerjeszt, az alacsonyabb pedig kisebbet, látható hogy a null-átmenet és az energia között erős kölcsönhatás van. Ebből általánosan azt a következtetést lehet levonni, hogy ha a null-átmenetek száma sok, akkor a hang zöngétlen, ha kicsi, akkor a hang zöngés. Persze az itt leírt elmélet koránt sem egzakt, mivel a kicsi/kis és a sok/nagy eléggé relatív fogalmak, de átlagosan kijelenthetjük, hogyha a null-átmenetek száma 49/10msec körül van akkor a hang zöngétlen, ha 14/10msec körüli akkor zöngés.
Ebből azonban az is kiderül, hogy ezt a döntést nem alapozhatjuk csupán erre az eljárásra, de mindenképpen érdemes ezt is figyelembe venni.
A fent említett két módszer (energia, és null-átmenet), továbbá bizonyos fokig alkalmas még arra is, hogy a jelünket megtisztítsuk a zajoktól.
„Short-time” autokorreláció
Egy diszkrét idejű determinisztikus jel autokorrelációs függvénye az alábbi egyenlettel írható le [Rabiner 78] :
∑∞
−∞=
+=Φm
kmxmxk )()()(
periodikus esetben:
∑−=
∞→+
+=Φ
N
NmNkmxmx
Nk )()(
121lim)(

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
23
Az autokorrelációs ábrázolásmód egy kényelmes megoldás a jel pontos tulajdonságainak leírására. Például ha egy jel periodikus P mintánként akkor könnyen belátható hogy :
)()( Pkk +Φ=Φ
egy periodikus jel autokorrelációs függvénye szintén periodikus. Más fontos tulajdonságai még:
1. φ(k) = φ(-k)
2. A maximális értékét k = 0 –nál veszi fel. |φ(k)| ≤ φ(0) az összes k-ra
3. φ(0) megegyezik az determinisztikus jelek energiájával.
∑∞
−∞=
−−+−=m
n mknwkmxmnwmxkR )()()()()(
Mivel ezzel a módszerrel egyszerűen meghatározható a periodicitás minden jelnél (beleértve a hangjeleket is), igen elterjedt, sok helyen használják. Együtthatói kulcsfontosságúak az LP analízishez. Ezeket az alábbi módon kaphatjuk meg:
11. ábra: A hang szakaszos feldolgozásának jelölései (a továbbiakban) [Rabiner 78] Megjegyeznénk még azt is, hogy ezzel a technikával megvalósítható a „pitch period” becslés is. Ennek kifejtésére most nem térünk ki.
Linear Prediction (LP) (Horváth) Az egyik leghatékonyabb beszédelemző technika a linear predictive analízis. Az idők folyamán ez a módszer vált dominánssá a hang alapvető paramétereinek becslésében és meghatározásában a hangfeldolgozás terén, akár „pitch”, „spectra” , formáns, stb. analízisről van szó. Mellesleg az sem elhanyagolható, hogy általa alacsony bitsűrűséggel vagyunk képesek tárolni és továbbítani a hangot. Térhódításának titka abban rejlik, hogy amellett hogy kiemelkedő pontossággal képes a hang paramétereit meghatározni, viszonylag gyors és számítási igénye is kisebb [Rabiner 78].
Az alapvető elmélet a linear prediction mögött az, hogy egy hangminta előállítható az előtte lévő minták lineáris kombinációjaként. Ha minimalizáljuk a négyzetes hibaösszegek nagyságát (egy véges intervallumban), az éppen vizsgált hangminta és a „lineárisan megjósolt” között, akkor a

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
24
becsléshez szükséges együtthatók meghatározhatók. (a becslési együtthatók a súlyozási együtthatók, melyeket a lineáris kombinációnál használunk)
A linear predictive elemzés alapvető elve
12. ábra: A Linear Predictive analízis fázisai [Rabiner 78]
Átviteli függvény:
∑=
−−== p
k
kkza
GzUzSzH
1
1)()()(
S(z) kimenet z-transzormáltja, U(z):gerjesztés.
A hangjelek s(n) , kapcsolatban állnak a kapcsoló utáni jellel az alábbi összefüggés szerint:
∑=
+−=p
kk nGuknsans
1
)()()(
Egy lineáris predictor, predikciós együtthatókkal, αk leírható egy olyan rendszerként melynek kimenete
∑=
−=p
kk knsns
1
)()(~ α

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
25
A predikciós hiba e(n), pedig leírható így:
kp
kkznsnsnsne −
=∑−=−=
1
)()(~)()( α
Emlékezzünk arra, hogy nekünk a négyzetes hibát kell egy adott intervallumon minimalizálni. Ezért írjuk fel a négyzetes hibát is:
∑ ∑∑∑=
−−=−==m
p
knkn
mnn
mnn kmsmsmsmsmeE 2
1
22 ))()(())(~)(()( α
(Megfigyelhető, hogy az összegzések határa nem mindenhol van egyértelműen megadva.)
A hibát minimalizáló αk-nak ki kell elégítenie az alábbi egyenletet:
0=∂∂
i
nEα
i=1,2,..., p
Így tehát a következő egyenletet kapjuk:
)()(ˆ)()(1
kmsimsmsims nm
n
p
mkn
mn −−=− ∑∑∑
=
α
1 ≤ i ≤ p
Ahol felülvonás αk felülvonás αk azon értékei, melyek minimalizálják En-t (mivel ez az érték egyéni, és csak ez az érték számít nekünk, a továbbiakban a felülvonást elhagyjuk, és egyszerűen αk-ról beszélünk)
Definiáljuk az alábbiakat:
)()(),( kmsimski nm
nn −−= ∑φ
Ennek felhasználásával az előbbi egyenlet felírható komplexebb alakban is:
)0,(),(1
iki n
p
knk φφα =∑
=
i=1,2,...,p
Ezzel a módszerrel kaptunk ugyanannyi egyenletet, mint ismeretlent (p), azokra az αk együtthatókra, melyek minimalizálják a négyzetes hibát az s(m) szakaszon.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
26
∑ ∑∑ −−==m m
nn
p
kknn kmsmsmsE )()()(
1
2 α
Ezek felhasználásával a négyzetes hiba az alábbi módon írható fel:
Vagyis:
∑=
−=p
knknn kE
1
),0()0,0( φαφ
Hogy megkapjuk az együtthatókat, előszöris ki kell számolnunk φk(i,k) értékeit ha 1 ≤
)0,(),(1
iki n
p
knk φφα =∑
=
i≤ p, és 0 ≤ k ≤ p,
ezután az egyenletet megoldva megkapjuk αk-t
Még mindig tisztázatlan azonban az összegzési határok kérdése. Ezek kiszámítása az alkalmazott módszertől függ, melyek tipikusan autokorreláció, vagy kovarancia.
Az autokorrelációs megoldás
Ezen eljárás során, a vizsgált intervallumon kívül (0 ≤ m ≤ N-1) a jelet nullának tekintjük.
Ez az alábbi módon írható le:
sn(m)=s(m+n)w(m)
ahol w(m) egy véges hosszúságú ablak (például Hamming ablak), amely szintén nulla a vizsgált tartományon kívül.
Mivel sn(m) a vizsgált tartományban viszont nem nulla, ezért az ennek megfelelő prdikciós hiba , en(m) sem lesz nulla, egy p-ed rangú predikcióra a 0 ≤ m ≤ N-1+p intervallumban.
Ennek tükrében a En-t a következőképpen lehet kifejezni
∑−+
=
=1
0
2 )(pN
mnn meE
Az összegzés határait tehát így kaphatjuk meg:
∑−+
=
−−=1
0
)()(),(pN
mnnn kmsimskiφ

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
27
∑−−−
=
−+=)(1
0
)()(),(kiN
mnnn kimsmskiφ
1 ≤ i ≤ p
0 ≤ k ≤ p
Látható, hogy ebben az esetben a φk(i,k) megegyezik az autokorrelációs függvénnyel.
φk(i,k) =Rn(i-k)
ahol:
∑−−
=
+=)1
0
)()()(kN
mnnn kmsmskR
(Rn(k) kiszámítását az autokorrelációnál tárgyaltuk)
A négyzetes hiba pedig ennek megfelelően:
∑=
==p
knknn kRRE
1
)()0( α
Mátrix formában ez az alábbi módon írható le:
)(...
)3()2()1(
...*
)0(...)3()2()1(...............
)3(...)0()1()2()2(...)1()0()1()1(...)2()1()0(
3
2
1
pR
RRR
RpRpRpR
pRRRRpRRRRpRRRR
n
n
n
n
pnnnn
nnnn
nnnn
nnnn
=
−−−
−−−
α
ααα
Világosan látszik, hogy ez a mátrix egy speciális mátrix (úgynevezett Toeplitz), mely lehetővé teszi hatékony megoldó algoritmusok alkalmazását.
A kovariencia eljárás
Egy másik lehetséges eljárás arra, hogy megállapítsuk az összegzés határait, ha a hibát nem egy végtelen, hanem egy véges tartományon próbáljuk minimalizálni, és φk(i,k)-t meghatározni.
Először határozzuk meg az alábbi kifejezést:
∑−
=
=1
0
2 )(N
mnn meE

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
28
ezután φk(i,k) a következőképpen alakul:
∑−
=
−−=1
0
)()(),(N
mnnn kmsimskiφ
1 ≤ i ≤ p
0 ≤ k ≤ p
Ha megváltoztatjuk az összegzési határokat, kifejezhetjük φk(i,k)-t az alábbi módon:
∑−−
−=
−+=1
)()(),(iN
imnnn kimsmskiφ
vagy
∑−−
−=
−+=1
)()(),(kN
kmnnn ikmsmskiφ
1 ≤ i ≤ p
0 ≤ k ≤ p
Annak ellenére, hogy az egyenletek nagyon hasonlóak, megfigyelhető, hogy az összegzési határok másak.
Ha összehasonlítjuk ezen egyenleteket az autokorrelációnál használt
∑−−−
=
−+=)(1
0
)()(),(kiN
mnnn kimsmskiφ
egyenlettel, akkor megállapíthatjuk hogy ez az eljárás más megoldási folyamatot, és számításokat igényel, és más egyenletekhez vezet, mely a következő:
)0,(),(1
iki n
p
Knk φφα =∑
=
Az egyenletek mátrix felírása:
)0,(...
)1,3()1,2()1,1(
...*
),(...)1,()1,()1,(...............
),3(...)3,3()2,3()1,3(),2(...)3,2()2,2()1,2(),1(...)3,1()2,1()1,1(
3
2
1
pppppp
ppp
n
n
n
n
pnnnn
nnnn
nnnn
nnnn
φ
φφφ
α
ααα
φφφφ
φφφφφφφφφφφφ
=

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
29
Ez a mátrix is szimmetrikus, de ellentétben az autokorrelációnál használt mátrixszal, nem Toeplitz típusú. Ugyanakkor látható, hogy az elemek kapcsolata a következő egyenlettel leírható:
)1()1()1()1(),()1,1( kNsiNsksiskiki nnnnnn −−−−−−−−−+=++ φφ
Ez a módszer a kovariancia eljárás néven terjedt el, pont azért, mert a mátrix rendelkezik egy kovariancia mátrix tulajdonságaival.
A továbbiakban részletesen az autokorrelációs megoldással foglakozunk, mivel ez a módszer jobban alkalmazható, és a Toeplitz mátrix könnyebben kezelhető.
Az autokorrelációs módszer gyors és egyszerű megoldására alkalmas az úgynevezett Durbin eljárás, mely rekurzívan határozza meg az LP együtthatókat, és a predikciós hibát.
Az eljárás a következő:
)0()0( RE =
)1(1
1
1 /))()(( −−
=
−∑ −−= ii
j
iji EjiRiRk α
ii
i k=)(α
1)1()( −−
− −= ijii
ij
ij k ααα
)1(2)( )1( −−= ii
i EkE
Az alábbi feltételek mellett:
1 ≤ i ≤ p ,és 1 ≤ j ≤ i-1
Ezt rekurzívan megoldva i = 1,2,...,p értékekre a végeredményt az alábbi kifejezés adja meg:
)( pjj αα =
ha 1 ≤ j ≤ p
Ebben a megoldásban észrevehető, hogy nemcsak a p-ed rangú prediktor együtthatókat kaptuk meg, hanem az összes p-nél kisebb rangú prediktor együtthatóit is [Rabiner 78], továbbá a perdikciós hibát, melyet a harmonikus vizsgálatnál fel is tudunk használni.
Léteznek még más technikák is, a már említett kovariancia, és a felhasznált autókorrelációs eljáráson kívül megtalálható még például az úgynevezett Lattice eljárás is.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
30
Ezeknek gyors összehasonlítását az alábbi táblázat szemlélteti
Kovariancia
eljárás
Autokorrelációs
Eljárás
Lattice
Eljárás
(Cholesky dekompozició) (Durbin eljárás) (Burg eljárás)
Tárhely
Adat N1 N2 3N3
Mátrix p2/2 –vel arányos p–vel arányos -
Ablak 0 N2 -
Számítás
(Szorzás)
Ablakozás 0 N2 -
Korreláció N1p –vel arányos N2p –vel arányos -
Mátrix megoldás p3–al arányos p2–el arányos 5N3p
Ahol N1 a kovariancia eljáráshoz használt pontok száma, és így tovább N2-re és N3-ra (Hangsúlyozzuk, hogy ezeknek az értékeknek nem feltétlenül kell megegyezniük)
Az így meghatározott perdikciós együtthatók segítségével az LP spektrum megállapítható, ha az együtthatókat sorba fejtjük (1, a1, a2, a3 ..., ap), majd az elérni kívánt frekvenciafelbontástól függően kiegészítjük a sort nullákkal, és végül a sort Fourier transzformáljuk.
A hibajel függvény
A perdikciós hibafüggvényt a következőképpen definiálhatjuk [Rabiner 78]
∑=
=−−=p
kk nGuknsnsne
1
)()()()( α
Tekintve, hogy az adott hangjelet egy olyan rendszer generálta, melyet viszonylag jól modellez egy időben változó p-ed rangú lineáris perdikció, az e(n) is egy viszonylag jó közelítése a gerjesztésnek. Ebből az okból kifolyólag, az lenne az elvárt, hogy a perdikciós hiba nagy legyen (zöngés hangokra), minden harmonikus összetevő kezdetén. Ezt figyelembe véve a hang harmonikus meghatározható lenne a hibajelből közvetlenül, olymódon hogy ahol a jel értéke elér egy bizonyos küszöbértéket ott harmonikus összetevőt jelzünk. Azonban elterjedtebb és

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
31
kibővítettebb formája ennek a módszernek, ha ezek a jelen végzünk egy autókorrelációs analízist, és megkeressük a legnagyobb csúcsot az adott tartományban.
Egy másik megközelítés a hibajel fontosságának megmutatására a harmonikusvizsgálathoz az, hogy a hibajel spektruma megközelítőleg sima, mivel a formánsokat már eltávolítottuk belőle.
A hang alapharmónikusának vizsgálata LP segítségével
A hibajel leírásánál már utaltunk arra, milyen fontos ennél a módszernél a perdikciós hiba. Az ott leírtak azonban nem adnak mindig egyértelmű, és helyes megoldást. Ennek finomítására vezette be Markel az úgynevezett SIFT (Simple inverse filtering tracking) algoritmust. (Egy hasonló eljárást fejlesztett ki Maksysm is) [Wolfgang 83]
Működését az alábbi ábra szemlélteti:
13. ábra: A SIFT algoritmus blokkvázlata [Rabiner 78]
A bemenő jel tehát alacsony áteresztő szűrésen esik át 900Hz küszöbfrekvenciával. Majd a mintavételi frekvenciát a decimator segítségével leredukáljuk 2kHz-re (egyszerűen 11 mintából 10-et eldobunk), az ily módon szűrt bemeneti jel, x(n) átesik egy autókorrelációs analízisen (a szűrő rangja, p = 4). Egy negyedrangú szűrő már elegendő hogy modellezzük a jel spektrumát a 0-1kHz frekvencia intervallumban, mivel ebben a tartományban általában csak 1-2 formáns található. Majd az x(n) jel inverz szűrésen esik át, mely az y(n), viszonylag sima spektrumú jelet eredményezi. Az eddigi lépésekből sok minden megspórolható, ha lineáris perdikciót alkalmazunk, mivel az y(n) kimenet egyszerűen egy 4-ed rangú lineáris perdikció perdikciós hibája.
A harmonikus összetevőt az y(n) autókorrelációs analízise után, a vizsgált tartományból kiválasztott legnagyobb csúcs adja meg.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
32
Ha szeretnénk további részletesebb információt kapni az összetevőről, akkor a csúcs környéki jelet kibővíthetjük interpolátor segítségével. Továbbá a zöngés-zöngétlen osztályozás is elvégezhető, annak alapján, hogy a jelcsúcs átlép-e egy megadott küszöbértéket.
Tehát a SIFT algoritmus felhasználja a lineár prediktív analízist hogy viszonylag egyenes spektrumú jelet kapjon. Ha a spektrum megfelelően lapos, a módszer jónak nevezhető a harmonikus vizsgálatra. Ugyanakkor megjegyeznénk, hogy magas alapharmónikusú beszélők (mint például kisgyerekek) számára ez a simítás gyakran sikertelen, mivel ebben az esetben több harmonikus összetevő is található a 0-900Hz frekvenciatartományban (ez különösen telefonos hangátvitelnél jelentkezik)
Arcfelismerés (Bors) Napjaink egyik legjelentősebb problémájára, a terrorista támadások kivédésére nagy hatással lehetnek a jól működő, megbízható arcazonosító rendszerek. A fejlesztések nagy erővel elindultak többnyire a különböző légitársaságok megbízásából. Az alapelgondolás, ha sikerülne kiszűrniük a potenciális veszélyt jelentő személyeket már a reptéren, nem történhetne tragédia. Már jelenleg is használnak ilyen rendszereket, például a sidney-i reptéren.
Többféle módszer létezik az arc azonosítására.
Németországban ATM automatákhoz készítettek olyan rendszert, amely biometriai azonosítást végez (BioTrust projekt). A nem kielégítő mértékű adatvédelem és a meglévő banki rendszerbe való nehéz illeszkedése miatt a projektet leállították.
Vannak akik úgy gondolják, a jövőbeli egyik felhasználása a biometriai rendszereknek az un. viselhető rendszerek [Pentland 97] (wearable systems). Lévén az arcazonosítás nagyon függ a külső körülményektől, egyesítenék a hangfelismerő programokkal. A mikrofonok és kamerák méretének csökkenésével egy alig észrevehető szerkezetet viselhetnének az emberek, ezzel megkönnyítve személyek azonosítását. Az Egyesült Államok hadserege tesztel is egy ilyen rendszert Boszniában, mely a határőrök munkáját hivatott elősegíteni.
Egyik jelenlegi alkalmazására példa a Tampa városában beüzemelt biometriai rendszerek, melyek célja, hogy az utcákra elhelyezett kamerák segítségével képesek legyenek megtalálni az elveszett gyerekeket, illetve a törvénysértőket.
Már évtizedekkel ezelőtt írtak számítógépre arcfelismerő alkalmazásokat, azonban a gépi teljesítmény növekedésével vált igazán megbízhatóvá a technika. Tökéletes módszert nehéz találni, a különféle megoldásoknak különböző a hatásfoka, mindegyik más előnnyel és hátránnyal rendelkezik. Körülbelül meg tudjuk határozni, hogy melyik módszertől milyen hatásfok az elvárható.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
33
A legtöbb esetben az alábbi megközelítések valamelyikét használják[Madai 02]:
Geometriai tulajdonságokon alapuló
Az ilyen elven működő azonosító programok alapja, hogy az arc bizonyos pontjait kiemelik. Ezek általában a szemek, száj, orr, fül. De van olyan rendszer is ami sokkal több jellemzővel dolgozik. Ezek a pontok egyértelműen azonosítják az arcot, vagyis a személyt.
Kanade rendszere (1973), a jellemző pontok közötti euklideszi távolságokat vizsgálja Összesen 16 ilyen jellemzővel dolgozik. 20 személyből képes volt 15-öt azonosítani. (Pontosság: 45-75%)
Brunelli és Poggio (1993), két technikát együtt használtak: geometriai tulajdonságokat emeltek ki és mintaillesztést alkalmaztak. (Pontosság: 90% körüli)
Cox, Ghosu, Yianilos rendszere (1995), több távolságon alapuló technika. Hátránya, hogy emberi közreműködés kellett a távolságok meghatározására. (Pontosság: 95% körüli).
Eigenface módszer
Az arcról készült képeket az eredeti képek lényeges részeire vetítik. Többnyire az arc középső részét vágják ki, és azt használják. Egyszerű és gyors módszer, azonban érzékeny a pixelek intenzitásának eltérésére az adatbázis képeihez képest, ezért célszerű normalizálni. Egyik ilyen eljárást használó rendszert Turk és Pentland készítették 1991-ben.
Sablon-illesztés
A technika lényege, hogy képrészleteket közvetlenül hasonlítanak össze, hátránya hogy a megvilágításnak, iránynak, és méretnek azonosnak kell lenni.
Az ötlet a módszer mögött, hogy egy mesterséges mintát próbálnak illeszteni az arc jellegzetes tulajdonságaihoz igazodóan. Nem nagyon hatékony módszer, mert az eltárolt és vizsgált mintának ugyanakkorának kell lennie, továbbá irány és megvilágítás érzékeny.
Yuville et al két mintát használt: egyet a szemekhez, egyet a szájhoz. Ez után a mintát úgy deformálta, hogy az minél jobban megközelítse a szemek és a száj pozícióját.
Neurális hálós módszer
A neurális hálók jól használhatók osztályozási feladatok megoldására. Ezt a tulajdonságát használják ki különböző arcok azonosításakor is. Napjainkban egyre népszerűbbé válik, hatékony azonosító eljárások írhatók segítségével.
Deers, Cottrell (1993), kis adatbázissal dolgoztak, meghatározták a legfőbb 50 tulajdonságot. Asszociatív Neurális hálókat használtak, a felismerés perceptonok segítségével történt.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
34
Rejtett Markov-modell
A ma ismert egyik leghatékonyabb módszer. Más fizikai tulajdonságot mérő biometriai rendszerek esetén is feltűnik. Nagy pontosság jellemzi.
Hibrid módszerek
A fenti módszerek ötvözete, a leghatékonyabb megoldás.
Steve Lawrence, C. Lee Giles Ah Chung Tsoi, és Andrew D. Back publikációjukban leírnak egy olyan rendszert ami hibrid módszereket használ. Programukban szerepel egy önszervező térkép (Self Organizing Map, SOM), összehasonlításul a Karhunen-Loeve transzformációt használják, és alkalmaznak egy konvolúciós neurális hálót is.
Létező arc-kereső rendszerek („Face Detection”)(Bors)
Rowley, Baluja, Kanade
Programuk[Rowley 98] működésének lényege, hogy megállapítja egy ablakon belül, található-e a képen arc vagy sem. Szürke képen neurális háló segítségével keres. A hagyományos arcfelismeréstől, ahol a különböző osztályok a különböző arcoknak felelnek meg, itt két osztályt vizsgálnak: van, vagy nincs arc a képen.
A teszt során 90.5 % -os találatot értek el.
Két fő részre bontható: neurális háló alapú szűrők, melyek a kép különböző részeinek vizsgálatával keresik az arcot, és egy összesítő, ami az eredményeket összefésüli és a lehetséges megoldást kalkulálja.
A program on-line tesztelhető Interneten keresztül is.
Értékelés: a kutatás célja más, mint a saját projekten belüli célkitűzés. Az arcfelismerő projekt feltételezi hogy a kamera előtt áll személy, és a felismert arc alapján fog osztályozni. Neurális hálókat feltételezhetően a saját projekten belül is fogok használni.
Sung és Poggio
Az ő rendszerük hasonló az előzőhöz. Ugyanúgy egy kisebb ablakkal „pásztáznak” a képen, és a kapott eredmények alapján állapítják meg, hogy van-e arc az ablakban. A tanítási folyamatban itt is pozitív és negatív példákat is mutatnak.(itt 4000 pozitív és 47500 negatív).

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
35
Osuna, Freund és Girosi
Ebben a fejlesztésben[Edgar 97] már nem neurális hálózatokat használnak, helyette az un. „support vector machine”-t fejlesztették ki a képek osztályozására. Valójában több fontos jellemzőt rögzítenek, ami alapján megkülönböztethető az arcot ábrázoló és nem ábrázoló kép.
Értékelés: kevésbé pontos rendszer a neurális hálós megoldásokhoz képest. Azonban a különbség nem nagy, ami bizonyítja, hogy nem csak neurális hálókkal lehet a problémát hatékonyan megoldani. Állandó (egyelőre megoldatlan) probléma a fenti rendszerekkel, hogy nem képesek a kb. 20 fokos elfordulás után megtalálni az arcokat. A fejlesztések leginkább ebben az irányban folynak.
Arc felismerő rendszerek („Face Recognition”)(Bors)
FaceIt Face Recognition Technology
A magyarországi Inventix Kft. [Inventix] foglalkozik az amerikai Visionics cég biometrikus technológiájára alapuló, számítógépes arcfelismerésre alkalmas rendszerek készítésével. A következő rendszereket kínálják kereskedelmi forgalomban:
FaceIt survelliance
Bármely meglévő zártláncú videó megfigyelő rendszer hatékonyságát jelentősen megnöveli a monoton emberi munka automatizálásával. A FaceIt Surveillance arcokat keres videó bemeneten és manuális, vagy automatikus keresést végez előre meghatározott – valamilyen oknál fogva kiszűrendő – személyeket tartalmazó arc adatbázisban. Folyamatosan monitorozza a videó bemenetet és automatikusan elkülöníti az arcképeket. A felhasználó által fenntartott arc adatbázisban lévő személyek felismerésekor riasztja az operátort.
FaceIt sentinel
A FaceIt Sentinel a fent ismertetett FaceIt Surveillance termék olcsóbb, könnyített változata. A FaceIt Sentinel-t úgy tervezték, hogy kielégítse az alkalmanként felmerülő – nem folyamatos, szúrópróbaszerű – távfelügyeleti igényeket (on-demand surveillance). Biztosítja a FaceIt Surveillance összes standard tulajdonságát, kivéve az automatikus arckeresést. Ehelyett az arcokat manuálisan kell megadni a video-képen történő klikkeléssel, vagy az “egész képernyő megragadása” parancs végrehajtásával. A keresés ezután a már korábban összeállított listán (pl. “keresett személyek listáján”) hajtódik végre.
FaceIt DB Enterprise
Közepes és nagyméretű képadatbázisok létrehozását, illetve ezekkel szembeni “one-to-many” és “many-to-many” kereséseket támogató alkalmazás. Automatikus arckeresés a képen. A

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
36
keresés 1 másodpercig, míg az “arclenyomat” elkészítése 2 másodpercig tart. Az adatbázis visszakeresés 15 millió kép/perc-es sebességgel történik.
„BioID” technika
Arc, hang, és ajakmozgás alapján azonosít. 1993 óta folyik a fejlesztés.
A program minimális rendszerkövetelménye Pentium 233Mhz-es processzor 64MB RAM-al. A tapasztaltak alapján ennél gyorsabb gépet igényel.
Működés: a program telepítésekor elmenti az adatbázisába a kamera által felvett információt a felhasználóról, majd kicseréli a Windows kezdő „log-in” üzenetét, így nem kóddal, hanem arc és hang segítségével lesz azonosítva a felhasználó. Több felhasználó is lehetséges. (10-2000)
A kapott képet korrigálja a világítási viszonyoknak megfelelően, és normalizálja a szürkeszintet. Az arcfelismerés statikus, míg az ajakmozgást dinamikus vizsgálat alá veti. A személy kisfokú „változásaival”, például szemüveg, meglehetősen toleránsan viselkedik.
Megbízhatóság: állítható biztonsági szinttel rendelkezik. A leírás szerint 1% esetén 1:1 millióhoz az esély a tévedésre, ha mindhárom vizsgálati szint aktív (arc, hang, ajakmozgás).
Jelenlegi ára rendkívül magas (667.000 Ft), ezért hétköznapi felhasználásra egyelőre nehezen lehet számítani. Azonban egy biometriai program esetén ez nem számít soknak. A cég otthoni felhasználásra is szánja programját.
Értékelés: Valóban hatékony programról van szó. A minimális rendszerkövetelmények túl alacsonyak, ezen a gépen meglehetősen instabilnak és lassúnak bizonyul. A programot fejlesztő cég egyébként azért vált nemrég fizetésképtelenné, mert az átlagfelhasználó nem használ jelszót a gépére való bejelentkezéskor, ami helyett ezt a programot lehetne használni. Másrészről magas ára miatt egyelőre kevés felhasználónak éri meg a befektetés.
VisionSphere, UnMask
Dr. Martin Levine fejlesztésén alapul az egyébként kereskedelmi forgalomban is kapható program. Először kereső algoritmusok segítségével megtalálja az arcot és a szemet. Normalizál, és levágja az arc körül a kép fölösleges részeit. Második lépésként kiemeli a meghatározó részeket, ez alapján hasonlít. Így minden archoz egyedülálló jellemzőket kap.
(Holistic Feature Code – csak itt használt technológia).
Értékelés: a program fejlesztésekor a szerzők hasonló módszert használtak, a saját projekt esetén alkalmazottakhoz. Tehát kiemeli az adott egyéni tulajdonságokat és ezek alapján történik az azonosítás.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
37
IWS Inc., FaceID
A program alapvető célja, hogy a rendőrök számára megkönnyítse az esetleges gyanúsítottak felismerését. A szemet felhasználva referenciapontként, egy komplex matematikai formula segítségével minden archoz hozzárendel egy rekordot. Többféle forrás alapján is képes azonosítani (fénykép, videofelvétel stb.). A kereső motor rátalál a keresett arcra, még akkor is, ha az eredeti képen mások a fényviszonyok, különbözik az illető haja, arckifejezése, vagy akár pozíciója (35 fokig) is. Eredményként egy listát ad, melynek elején találhatók a legnagyobb valószínűséggel, az eredetihez leginkább hasonló (vagy azonos) személyek.
Értékelés: a technikának egy speciális terülten való felhasználására példa az IWS programja. A saját projekt elkészült változata akár ilyen célra is használható lesz. Belsőbb, technikai megoldásra utaló leírást nem találtam a programmal kapcsolatban. (Kereskedelmi program).
Viisage Technology
Az arcfelismerés számos alkalmazása jelenik meg a cég különálló programjaiban
FaceFINDER
Segítségével képesek lehetünk személyek „kiszúrására” a tömegből. Biztonsági szempontból rendkívül fontos szerepe lehet. Képes akár nagy távolságból is megtalálni a keresett személyt. Hasznos lehet például stadionokban, reptereken stb.
FaceEXPLORER
Nagy méretű kép adatbázisok kutatására alkalmas. Képes akár 20 millió kép feldolgozására néhány másodperc alatt.
FacePASS (PC, Mobile, Internet)
A hagyományos „password” általi azonosítást cserélhetjük le kényelmesebb biometriai módszerre.
FacePASS (Physical Access/Keyless Entry)
Arcfelismerés segítségével azonosít bennünket, használható akár iroda vagy lakás bejáratnál, a hagyományos módszerek helyett.
FacePIN
Felhasználása például ATM automaták esetén, így az azonosítás egyszerűbb és gyorsabb.

C E R B E R U S P R O J E K T - I R O D A L M I Ö S S Z E F O G L A L Ó
38
FaceTOOLS
„Software Developement Kit” (SDK) fejlesztőknek Windows alá. Tartalmazza a teljes Viisage Face Recognition Engine-t.
A tapasztalatok összegzése (Bors) A megvizsgált arcfelismerő rendszerek mindegyike képes volt valamilyen szinten felismerni, illetve detektáló rendszereknél megtalálni az arcokat. A lényeges különbség közöttük a teljesítményben és a felhasználási területben van. Teljesítmény szempontjából fontos hogy az adott rendszer milyen sebességgel illetve mekkora tárterület igénylésével képes működni. (ha azonos hatásfokúnak tekintjük őket). Ez pedig nagyban függ az alkalmazott módszertől és a fejlesztésre szánt időtől.
Az elkészítendő projektben cél hogy minél pontosabban sikerüljön az adott arcot felismerni. A pontosságnak többnyire a rendelkezésre álló idő szab határt. Azonban az eredetileg tervezett beléptető-biztonsági rendszer több részből épül fel (hangfelismerés és ujjlenyomat is), és ezek összevetésével növelhetjük a találati arányt.

C E R B E R U S P R O J E K T
39
Megoldás Az általunk kiválasztott megoldási módszerek bemutatása, leírása.
Hangazonosító rész (Horváth, Safranka)
A feladat bemutatása (Safranka) Mivel az általános céljainkat az első fejezetben kifejtetem, ezért ezzel nem kívánok itt foglalkozni. A mostani részben azt kívánjuk bemutatni, hogy a project hangazonosítási részét hogyan tervezzük megoldani.
A hangfelismerő rész több alrészből tevődik össze. Ezek az előfeldolgozó rész(ek) és az osztályozó. Az előfeldolgozó feladata a rögzített hangminta transzformálása, amely az osztályozóba megy. E transzformációk által igyekszünk csökkenteni a zajokat, és a rögzítésből adódó nem kívánt hatásokat, amelyek megnehezítik, vagy túl bonyolulttá tennék az osztályozó feladatát. A zajok kiszűrésének szükségessége evidens. A további transzformációkra azért van szükség, mert a mintavételezési értéknek hogy egy hang minta teljes értékű információt hordozzon, ahhoz az előforduló legnagyobb frekvencia kétszeresének kell lennie. [Oppenheim 89] Mivel az emberi beszéd körülbelül 3000-8000 Hz tartományba esik így a mintavételezésnél használt hang minőségünk jóval nagyobb adat mennyiséget jelent, mint amennyi szükséges. E nagymennyiségű adat túlságosan megnehezítené az osztályozó feladatát, lelassítva így a feldolgozás sebességét. Ezért van szükség olyan transzformációkra, melyek kiszűrik az azonosításhoz szükséges leglényegesebb információkat.
Ezután a kiszűrt információkat az osztályozóba küldjük. A feladata, eldönteni az aktuális mintáról, hogy az lehet-e a bejelentkezni kívánó felhasználóé, vagy pedig illetéktelen belépési kísérletről van szó. Amennyiben az azonosítás nem végezhető el (mert pl.: túl zajos volt a minta), de nem egyértelműen elutasítandó, ez esetben kérjen ismételt mintát. Az osztályozó modellnek a neurális hálós modellt választottuk, részben mivel ehhez jelentős mennyiségű irodalmat találtunk, részben mert már igen sok tapasztalat van vele a világon. A beszédfelismerő (speech recognition) rendszerek előszeretettel használják a hangok osztályozásánál a neurális hálós modellt.
Fejezet
3

C E R B E R U S P R O J E K T - M E G O L D Á S
40
14. ábra: A hangfeldolgozás lépései [Rabiner 78]
Az előfeldolgozó (Horváth)
A megvalósítás lépései:
I. Hangfile (wav) beolvasása és feldolgozása
II. Linear Prediction
III. Harmonikus vizsgálat
IV. Átlagos amplitúdó mérés
V. Formáns analízis
VI. Eredmények eltárolása, vagy értékelése
VII. Egyéb megvalósult, de jelen állapot szerint még fel nem használt részek
I. A hangfile beolvasása és feldolgozása
Egy új felhasználó felvitelekor, vagy egy már létező felhasználó belépésekor a hangot először rögzítenünk kell valamilyen tárolóra. A hangfelvételi eljárást jelenleg a Windows végzi el, így megkímél bennünket a hangkártya programozás részleteitől.

C E R B E R U S P R O J E K T - M E G O L D Á S
41
(Tekintve, hogy bemutató jellegű a program). A minta egy nyers, kódolatlan „Wav” formátumú fájlba kerül. A kódolása 16 bites amplitúdó, mono hangmintával, 22kHz-es mintavételi frekvenciával történik. A WAV fájlokat a Microsoft definiálta, tulajdonképpen a RIFF - mint általános multimédiás formátum - speciális esete. A WAV fájlok annyira elterjedtek (és egyszerűek), hogy szerkezetük ismertetését az alábbiakban megkíséreljük:
Eltolás Mező Hossz Jelentés
00h "RIFF" 4 byte azonosítja a Riff formátumot
04h RdataLength 4 byte Riff adatok hossza
08h WAVEfmt 8 byte ez a Riff egy Wave
10h WheaderLength 4 byte Wav fejléc hossza
14h WFormat 2 byte hullámtárolási mód = 1 tömörítetlen
16h nCh 2 byte csatornák száma = 1 mono, =2 sztereó
18h fmv 4 byte mintavételi frekvencia Hz-ben
1Ch BytePerSec 4 byte átviteli sebesség Byte/s-ban = fmv*BytePerBlock
20h BytePerBlock 2 byte BytePerBlock csoportokban helyezkednek el a minták az adattömbön belül =nCh*(BitPerCh / 8)
22h BitPerCh 2 byte 8 ill. 10h (8 v. 16 bites minták)
24h "data" 4 byte azonosítja az adatblokk kezdetét
28h WdataLength 4 byte minták adattömbjének hossza
2Ch WDataArray wDataLength byte
minták adattömbje, wDataLength hosszú

C E R B E R U S P R O J E K T - M E G O L D Á S
42
Példaként egy wav fájl kezdete látható az alábbiakban. A fájl mérete: 882048 byte.
15. ábra: A Wav fájl szerkezete
000D7578h = 882040 byte a Riff adathossz 00000010h = 16 byte wav fejléc hossza
0001h = 1, azaz tömörítetlen wav file 0002h = 2, azaz sztereó (jelen példában)
00005622h = 22050 Hz a mintavételi frekvencia 00015888h = 88200 byte/s átviteli sebesség (=22050*2*2)
0004h = 4 byte/blokk 0010h = 16 bit/minta
000D7554h = 882004 byte hosszú adattömb következik
Sztereo esetben ezután következnek a bal illetve jobb csatornák 16 bites mintái:
L csatorna: F884h, F81Dh, F82Ah, F84Ch, F904h, F74Ch ¼
R csatorna: 0322h, 046Dh, 031Ah, 0580h, 0456h, 0039h ¼
Mono esetben természetesen csak egy csatorna van.
Az eddigiekben ismertetett hangfájlok egy az egyben tartalmazták a minták értékeit bináris formában (természetesen a megfelelő fejléccel). Ha utána számolunk, hogy egy 22050 Hz-el mintavételezett, 16 bites mono csatorna percenként 22050Hz*2Byte*60s = 2646000/(1024*1024)MByte = 2.52MByte adatot termel
1. Első lépésünk tehát a felvett hangminta beolvasása a memóriába, egy dinamikus tömbbe. Ez a tömb egy globális változó pillanatnyilag, a neve array, nagysága dinamikusan alkalmazkodik a fájl méretéhez
2. Következő lépés a fejléc feldolgozása a fentiek alapján. Erre támaszkodva megállapíthatjuk a fájl alapvető tulajdonságait.

C E R B E R U S P R O J E K T - M E G O L D Á S
43
Itt problémát jelenthetnek a változó hosszúságú mezők, hiszen a fejléc elemeiből némelyik mindössze 1 byte, de van olyan is amely 8 byte hosszú, ezért ezekre külön oda kell figyelni. Az adattömböt egy másik dinamikus tömbbe, az un. v_array-be tároljuk el. Hosszát az l_array változó tartalmazza
3. A fejléc feldolgozása után következhet az adattömb feldolgozása. A mi esetünkben egy minta 2 byteon tárolódik (tekintve 16 bites kódolást és a mono csatornát)
4. Az innen származó adatokat, melyek most már integer típusúak, és 0..65535 közötti értékeket vesznek fel.
Ha ezt így, ebben a formában használnánk fel, egyszerűen azt feltételezve, hogy az ofszet a 32768-es értéknél, vagyis a tartomány közepén van akkor valami ilyesmit látnánk:
Az értékek a tartományban az alábbi rajz szerint alakulnak:
16. ábra: A nullpont magyarázata, demonstrálása egyszerű szinusz jellel
Mivel nekünk értékekre a –32767..32767 tartományban van szükségünk a pozitív tartományba tartozó rész megfelelő helyen van, csak a „felső” (32767..65535) tartományban lévő darabot kell a negatív tartományba mozgatnunk, így helyesen az alábbi ábra rajzolható fel:
17. ábra: A helyesen felvett nullpont

C E R B E R U S P R O J E K T - M E G O L D Á S
44
Ezzel az adatokat előkészítettük a feldolgozásra. Az eredeti tömböt akár fel is szabadíthatjuk, a továbbiakban már csak az újat használjuk.
II. A Linear prediction megvalósítása
A linear prediction, a hang egy összetett analízise, több fázisból álló feldolgozása. Számunkra fontos eredménye az úgynevezett LP Spektrum, mely kiemeli a hang formáns összetevőit, valamint az LP hibafüggvénye, mely lényegében egy olyan jel, melyből a formánsokat már eltávolítottuk, és ugyancsak LP analízishez kötődik a hang alap harmonikus detektálása.
Mint minden mást is a hangfeldolgozásban, ezt az analízist is a hangon szakaszonként végezzük el, úgynevezett ablakozást alkalmazunk. Az ablak típusa tipikusan négyzetes, vagy Hamming.
Az LP spektrum képzésének lépései:
1. Autokorreláció
2. Durbin eljárás
3. Fourier Transzformáció
Az első lépés az LP spektrumhoz vezető úton az, hogy a jelen autokorrelációt hajtunk végre.
Ennek lépései:
Átadjuk a kívánt ablak kezdőindexét (index), és az ablak hosszát (windowlength) a feldolgozó eljárásnak
∑∞
−∞=
−−+−=m
n mknwkmxmnwmxkR )()()()()(
A jelre alkalmazzuk az autokorreláció definícióját, vagyis hogy megkapjuk a k-adik autokorrelációs „lag”-ot
Ez tehát lényegében annyit jelent, hogy a jelszakaszon a k-adik együttható meghatározásához megszorozzuk az aktuális jelet a tőle k-val feljebb lévővel, ha az még belefér a szegmensbe, és a jelen végighaladva ezeket összegezzük. A kapott eredményeket az eljárás betölti egy R tömbbe. Ha több ciklusban hajtódik végre a teljes vizsgálat (ez általában így van, mivel a jelet ablakozva, szakaszonként vizsgáljuk, és minden szakaszra végre kell hajtani ezt az eljárást), akkor a szakaszonként kapott R értékek átkerülnek egymás után egy R_all tömbbe. Az LP spektrumhoz 15 ilyen együtthatót használunk pillanatnyilag szegmensenként, ezeket visszaadjuk.
Az eljárást addig ismételjük, míg az összes jelrészletet feldolgozzuk

C E R B E R U S P R O J E K T - M E G O L D Á S
45
Ezen együtthatókat ábrázolhatjuk is függvényként. (Természetesen a szemléletesség kedvéért most több alapponttal dolgozunk)
17. ábra: Normalizált autokorelláció (R(n)/R(0))
(Az ábra már az úgynevezett „normalizált” autokorrelációt mutatja, vagyis az összes R érték és az R[0] hányadosát, a továbbiakban is mindig ebben az alakban kerül felhasználásra)
Miután ezeket az együtthatókat meghatároztuk, ki kell számolnunk az LP együtthatókat is.
Ehhez segítségül kell hívnunk az előbbiekben kiszámolt autokorrelációs együtthatókat, valamint az úgynevezett Durbin eljárást, mely optimális megoldást nyújt az autokorrelációs egyenletek megoldásához, kihasználva az egyenleteket leíró mátrix Toeplitz típusú.
A Durbin eljárást szintén vizsgált szegmensenként ismételjük, hiszen minden szegmensből kíváncsiak vagyunk az LP együtthatókra, és a későbbiekben felhasználásra kerülő LP hibaegyütthatókra, melyek a hibajel felírásához elengedhetetlenek (lásd alap harmonikus)
(Az algoritmus részleteit lásd az irodalomkutatás résznél)
A módszer eredménye tehát az a LP együtthatók sora az adott hangrészletre, az E hibaegyütthatók, melyeket az eljárás lefutása után az a_all, és E_all tömbbe helyezünk át.
Ezenkívül az eljárás eredménye még minden olyan LP együttható is, melynek rendje alacsonyabb az akkor vizsgáltnál.
Vagyis ha 15 autokorrelációs együttható felhasználásával 15 LP együtthatót kaptunk, akkor ezzel megkapjuk az összes 15nél kisebb rendű LP analízis együtthatóit is. Ennek kiemelt jelentősége lesz az alkalmazott hang alapharmonikus detektálásnál.
Az utolsó lépésben szükségünk van a Fourier transzformációra, hogy megkapjuk az LP spektrumot.
A Fourier transzformációt végző eljárás két bemenő paramétere a forrás vektor, és a vektor hossza, mely mindenképpen kettő hatvány kell hogy legyen. (Az olyan esetekben ha a a transzformálni kívánt adatok száma nem kettő hatványa, akkor két megoldást szoktak alkalmazni. Vagy kiegészítik a vektort nullákkal, amíg a hossza el nem éri a következő kettő hatványt, vagy csonkolják a hozzá legközelebbihez).

C E R B E R U S P R O J E K T - M E G O L D Á S
46
A kapott paramétereket tehát sorba fejtjük, oly módon, hogy az első elem a vektorban 1, majd ezt követik az LP együtthatók (a), és végül a nullákkal való kiegészítés. (Más padd-elő technikák is léteznek, melyek nagyon kis különbségeket okoznak. A sorbafejfétés például úgy is elvégezhető, hogy nem a vektor elejére, hanem aközepére rakjuk az értékeket, valamint egységes értékkel szorozhatjuk is azokat)
Annyi nullát kell a sorhoz fűznünk, amilyen frekvenciafelbontást el szeretnénk érni.
Esetünkben 512 elem hosszú vektor használatával 22050 / 512 = 43.066Hz frekvenciafelbontást érünk el.
Az eljárás a transzformált értékeket a forrásvektor helyére írja vissza, mégpedig úgy, hogy a vektor első fele a valós, a második a képzetes részeket tartalmazza (És mivel lényegében valós transzformációról van szó, nem számoljuk ki a DC, és Nyquist imaginárius részeket, mert ezek értéke mindig nulla)
Ahhoz, hogy megkapjuk a spektrum megfelelő képét, Frekvencia - Log Amplitúdó (db) dimenziókra kell alakítanunk a kapott eredményt. Ezt forja tárolni a logspectr tömb
Ez a következőképpen történik:
logspectr[i] = fourier[2*i];
logspectr[i] *= logspectr[i];
logspectr[i] += fourier[2*i+1]*fourier[2*i+1];
logspectr[i] = 10*logn(logspectr[i],10);
Ahol fourier a transzformált vektor, és a logn függvény (második paramétere szerint) tízes alapú logaritmust képez. (i a ciklusváltozó)
18. ábra: Tipikus LP spektrum
A formánsok kimagaslanak a jelből.

C E R B E R U S P R O J E K T - M E G O L D Á S
47
III. Harmonikus vizsgálat
A hang alap harmonikusát (pitch period) kétféleképpen is megvizsgáltuk, első megközelítésben az úgynevezett „parallel processing method” eljárás tűnt könnyen megvalósíthatónak, és mégis eredményesnek.
Megvalósítása:
Hangjel aluláteresztő szűrése (low-pass filtering)
Csúcsvizsgálatok hat szempont szerint
A kapott eredmények feldolgozása és előkészítése a végső pitch period megállapítására
1. Szűrés
Szűrésre két féle eljárás alkalmazható esetünkben. Léteznek az úgynevezett FIR (finite impulse response), és az IIR (infinite impulse response) szűrők.
A szűrők általános formája [Coleman]:
y[n] = b0x[n] + b1 x[ n-1] + b2 x[n -1] + ... + bk x[n - k] - a1 y[n-1] + .... + aj y[n-j]
Megvalósításukhoz szükséges meghatároznunk a szűrő együtthatóit (a, és b):

C E R B E R U S P R O J E K T - M E G O L D Á S
48
Az együtthatókat egy ötödrendű IIR low-pass szűrőhöz a következő táblázat mutatja.
Az első két oszlop tartalmazza a 8kHz-es, és a 16kHz-es mintavételi sűrűséggel vett minta megfelelő küszöbfrekvenciájához (cut-off frquency) tartozó szűrő együtthatókat, míg a harmadik oszlop az ezektől eltérő mintavételű együtthatókat segít kiszámolni. Ebben az esetben a küszöbfrekvenciát el kell osztani a mintavételi frekvenciával, és az oszlopban a legközelebb eső érték sorából kiolvasni az ötödrangú, alul áteresztó Butterworth IIR szűrő „a” és „b” együtthatóit.

C E R B E R U S P R O J E K T - M E G O L D Á S
49
Ez esetünkben 900 / 22050 = 0.0408
Tehát a szűrő együtthatók:
„a” együtthatók: 0,-4.5934, 8.4551, -7.7949, 3.5989, -0.6657
„b” együtthatók: 8.04e-7, 4.02e-6, 8.04e-6, 8.04e-6, 4.02e-6, 8.04e-7
Behelyettesítve a szűrő képletébe, a szűrés elvégezhető. Az eljárásnak átadjuk a szűrni kívánt adatokat egy tömbben (v_array), és a tömb hosszát (l_array), majd az visszatér a szűrt adatokkal (filtered).
(FIR szűrő esetén az „a” együtthatókat nullára kell állítani)
2. Csúcsvizsgálat
A csúcsvizsgálatot hat különböző szempont alapján végeztük, ezek elmélete megtalálhatók az irodalomkutatás résznél.
A feldolgozásra hat különböző függvény volt hivatott (examine_m1-6).
A jelen végighaladva lokális maximum esetén az m1 rögzítette a csúcs paramétereit, majd működésbe hozta az m2, és m3 eljárásokat is, melyek az előző maximum, vagy minimum ponthoz viszonyítva jegyezték fel a távolságokat, valamint visszaadták csúcs, vagy völgy értékét, ezzel felülírva ezek legutolsó értékeit (erre szolgáltak a last_peak és last_valley változók). Ugyanez játszódott le lokális minimum észlelésekor is m4-5-6-ra.
3. Végső pitch period becslés
Az eddigiekkel ellentétben itt már komolyabb nehézségek akadtak a megvalósítással, pontosabban annak elméletével. A megfelelő küszöbértékek helyes megválasztásához hiányzó információk nélkül sajnos a módszer használhatatlan az utolsó fázisban. Így ezt a módszert zsákutcának tekintettük, és áttértünk egy jobb módszerre a harmonikus vizsgálathoz, nevezetesen az LP analízisen alapuló harmonikus vizsgálatra.

C E R B E R U S P R O J E K T - M E G O L D Á S
50
Harmonikus vizsgálat LP analízis segítségével
A módszer elmélete a SIFT (simple inverse filtering tracking) algoritmus, illetve annak bizonyos részei, hiszen ez az algoritmus többre is képes a harmonikus összetevők detektálásánál. Mi most csak az idevágó részére térünk ki.
Megvalósítás:
• A jel alacsony-áteresztő szűrése
• Decimator alkalmazása
• Linear Prediction
• Hibajel generálás
• Autokorreláció és csúcskeresés
1. Jelszűrés
A jelszűrés ugyanazon az elven működik, mint a fenti esetben, ezen a ponton még nincs szükség semmi változtatásra benne, hiszen ez az algoritmus is a 0-900Hz tartományban dolgozik.
19. ábra: Eredeti hang

C E R B E R U S P R O J E K T - M E G O L D Á S
51
20. ábra: Szűrt jel
2. Decimálás
Ezen lépés során a szűrt jel mintavételi frekvenciáját 2kHz-re redukáljuk, mivel ez a minta is tökéletesen megfelel a céljainknak, és ezzel csökkenthető az adatmennyiség.
Az eljárás azzal az egyszerű megoldással csökkenti a mintasűrűséget, hogy esetünkben a 22kHz-en vett minta 11 eleméből 10-et eldob, s a maradékot egy vektorban visszaadja.
Bemenő paramétere tehát a forrásvektor (filtered), a hányados (ratio, jelen esetben 22/2 azaz 11). Az eredményt a dec_res nevű vektorban kapjuk vissza, valamint egy l_pp változót, mely az új vektor hosszát tartalmazza.
21. ábra: 2kHz-es jel
3. Linear Prediction
A kapott jelen linear predction-t hajtunk végre (p=4, azaz negyedrangú), de most nem az LP együtthatókra (a) vagyunk kíváncsiak, hanem a hibaegyütthatókra az egyes szegmensekben (E), melyek a teljes LP analízis lefutása után az E_all tömbben tárolódnak.

C E R B E R U S P R O J E K T - M E G O L D Á S
52
4. Hibajel
Ezekből kell előállítanunk a hibajelet, melyre a produce_errorsignal eljárás szolgál, mely bemenő paraméterként kapja tehát a dec_res tömböt, ennek hosszát, azaz az l_pp-t az ablak hosszát, és az LP rendjét (4).
Ezen paraméterekből állítja elő a hibajelet egy „e” tömbbe.
22. ábra: A hibajel spektruma
5. Autokorreláció és csúcskeresés
Az így kapott hibajelen autokorrelációt hajtunk végre, és a keletkező autokorrelációs függvény maximális pontját megjelöljük mint harmonikus összetevőt, paramétereit a pitchinfo tömbben tároljuk.
23. ábra: Pitch kontúr

C E R B E R U S P R O J E K T - M E G O L D Á S
53
IV. Átlagos amplitúdó mérés
Az átlagos amplitúdó mérésérre szolgál az a average_magnitude függvény, és a hozzá tartozó avg_magnitude tömb.
Az eljárás roppant egyszerű. A jelen végighaladva az értékeket abszolút értékben véve bizonyos szakaszonként (szegmensenként/ablakonként) átlagolunk, és ezt az eredményt eltároljuk a kimenő vektorban.
24. ábra: Eredeti hang
25. ábra: Átlagos amplitúdó (nagyított)
V. Formáns analízis
Ezen eljárás segítségével elméletileg még tovább csökkenthető az azonosítási hibaarány. Valamint alapvető továbbfejlesztési lehetőségként megjegyeznénk, hogy a formáns analízis részletesebb kidolgozása már lehetőséget nyújt nemcsak azonosítási, de beszédfelismerési funkciók beépítésére is, és ezzel esetleg egy sokkal komplexebb rendszer építésére. A megvalósítás továbbra is az LP analízisen alapul, hiszen ez a technika napjaink elsőszámú technikája a formánsok követésére. Célunk nem egy ilyen kategóriájú rendszer (beszédfelismerő) kifejlesztése volt, hanem egy hangazonosító rendszer megépítése. Mindenesetre érdekes távlatokat nyithat a megvalósítása.

C E R B E R U S P R O J E K T - M E G O L D Á S
54
VI. Kapott eredmények eltárolása, vagy értékelése
Az itt leírt módszerek természetesen csupán előfeldolgozást végeznek a hangon, a belépni kívánó személy azonosításának elsőgítéseként. A felhasználó hangjából most kiemeltünk lényeges, egyéni összetevőket, melyek természetesen soha nem fognak 100%osan egyezni egy tárolt mintával. Az azonosítási folyamat második fele ezért a neurális hálós vizsgálat, melynek ezeket az adatokat átadjuk. Jelenleg az adatok átadása tipikusan fájlként történik.
VII. Egyéb eljárások
Jelen rendszerben nem alkalmazzuk a nullátmenet vizsgálatot, és lényeges mérétkben az energiamérést, ám ezek a funkciók is nagymértékben segíthetik a munkánkat, főleg különböző ezen alapuló szűrések lehetővé tételével. (gondolva itt nemcsak zajszűrésre, de akár zöngés-zöngétlen hangok szeparációjára is, bár erre természetesen léteznek hatékonyabb módszerek is)
A nullátmenetek számlálása egy hangszegmensen két egymás melletti minta vizsgálatát igénylik, itt kell vizsgálnunk, hogy a jel előjelet váltott-e.
26. ábra: Eredeti hang
27. ábra: Nullátmenetek
Ezt a funkciót látja el az avegare_zero_crossing eljárás, mely bemenő paraméterként a vizsgálandó jelet, valamint az ablak hosszát kapja, és ebből képzi a szakaszonkénti eredményt, melyet a zero_crossing vektorban ad vissza.
A hangenergia hasonló eljáráson alapul, mint az átlagos amplitúdó függvény, csak itt a jelet nem egyszerűen abszolút értékben vesszük, hanem négyzetre emeljük, és úgy átlagoljuk.

C E R B E R U S P R O J E K T - M E G O L D Á S
55
Az ezt végző eljárás az average_energy , melynek bemenő paraméterei megegyeznek a null-átmenet, és az átlagos amplitúdó bemenő paramétereivel, eredményét pedig az energy vektorba rakja.
28. ábra: Eredeti hang
29. ábra: Energia
Rendszerünkben jelenleg lehetőség van a bejövő minták egyszerű zajszűrésére. Ez a szűrés a hangenergián alapul, és jelenleg hangerőfüggő. (alacsony hangerő esetén van rá esély, hogy többet is kivág a hangból, minthogy az feltétlenül szükséges, vagy indokolt lenne). A programnak ezen része teljesen moduláris, azaz a kapott mintából egy küszöbértéknek megfelelően kivágja a túl alacsony amplitudójú értékeket, majd a maradékot egy új fileba menti, mely szintén önálló hangfile (wav). Megírja ennek új fejlécét, és feltölti az adattömböt.
30. ábra: Eredeti hang

C E R B E R U S P R O J E K T - M E G O L D Á S
56
31. ábra: Vágott hang
A feldolgozó tesztrendszer felhasználói felület(Horváth)
32. ábra: Felület 1.

C E R B E R U S P R O J E K T - M E G O L D Á S
57
Funkciók:
• File megnyitása
• Információs ablak
• Hullámforma kirajzolás (Ablakszélesség beállítása, Ablaktípus kiválasztása, máretarány)
Használat:
A „browse” gombra kattintva megnyithatunk egy wav filet, majd a „process selected file” gombra kattintva beolvastatjuk a rendszerrel. Ekkor megjelenik a file információs ablakban a file fejlécében található információ. A „draw waveform” gombbal pedig a beállított paramétereknek megfellően kirajzoltathatjuk a hullámformát (Windowlength – vizsgálati ablakszélesség, windowtype – ablaktípus, Size ratio – vertikális méretarány, csúszka – horizontális méretarány)
33. ábra: Felület 2.
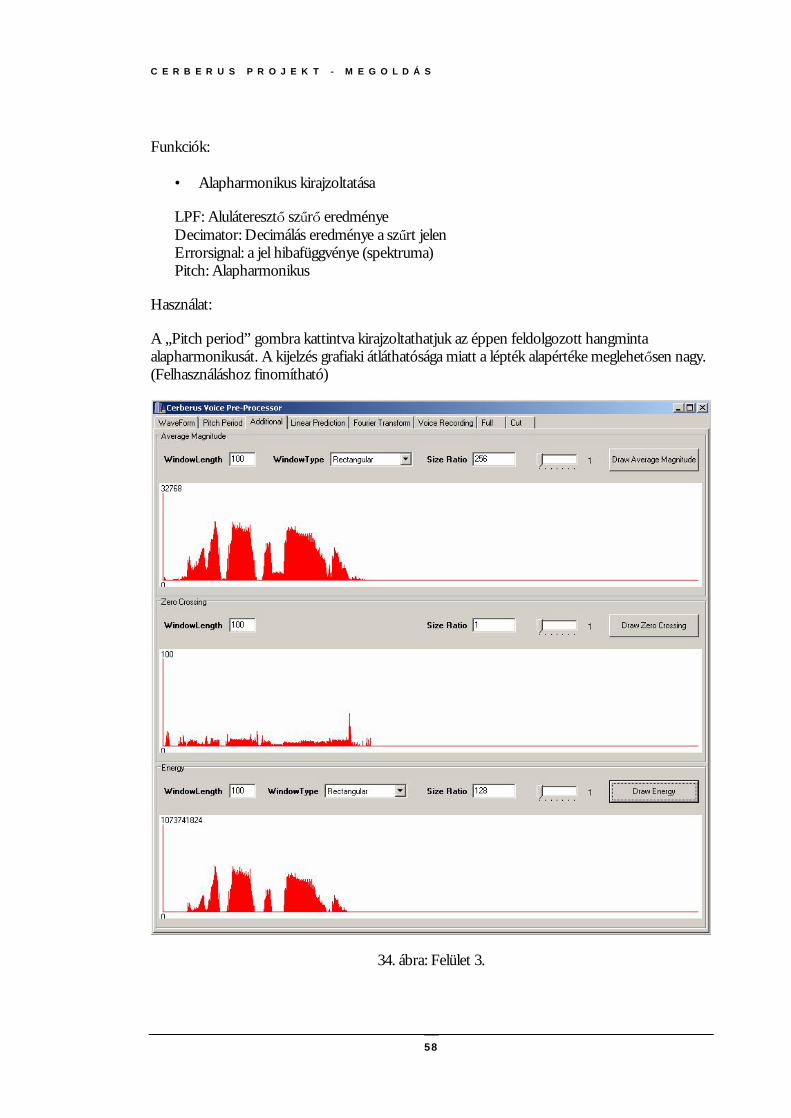
C E R B E R U S P R O J E K T - M E G O L D Á S
58
Funkciók:
• Alapharmonikus kirajzoltatása
LPF: Aluláteresztő szűrő eredménye Decimator: Decimálás eredménye a szűrt jelen Errorsignal: a jel hibafüggvénye (spektruma) Pitch: Alapharmonikus
Használat:
A „Pitch period” gombra kattintva kirajzoltathatjuk az éppen feldolgozott hangminta alapharmonikusát. A kijelzés grafiaki átláthatósága miatt a lépték alapértéke meglehetősen nagy. (Felhasználáshoz finomítható)
34. ábra: Felület 3.

C E R B E R U S P R O J E K T - M E G O L D Á S
59
Funkciók:
• Átlagos amplitudó
• Nullátmenetek
• Hangenergia
Haszálat:
A „draw average magnitude” gomb segítségével kirajzolható az éppen feldolgozott hangminta átlagos amplitudó diagrammja, a „draw zero crossing” gombbal a nullátmenet diagrammja, valamint a „draw energy” gomb segítségével a hangenergia. (a függőleges, és vizszintes méretarány szabályzás ugyanúgy működik, mint a hanghullám esetében)
35. ábra: Felület 4.

C E R B E R U S P R O J E K T - M E G O L D Á S
60
Funkciók:
• Linear Prediction spektrum (Coefficioents: Együtthatók száma)
• Autokorrelációs függvény
Használat:
Az hangminta Linear Prediciotn spektruma rajzolható ki a „draw spectrum” gombsegítségével. A függvény képe alatti gombokkal a kapott eredmény scrollozható.
36. ábra: Felület 5.

C E R B E R U S P R O J E K T - M E G O L D Á S
61
Funkciók:
• Hangmiták vétele
• Teljes analízis elvégzése, eredmény fileba írása
• Hangvágás
Használat:
Ezen a fülön 3 különböző funkció hozzáférhető.
A hangrögzítési funkciókat ellátó rész („record” csoport)feladata a hangminták vétele. Elengedhetetlen kelléke a könyvtárában található „blank\blank.wav” file Mivel a felhasznált MedaPlayer komponens hiányosságai miatt, ez a komponns nemtud új filet létrehozni, és abba rögzíteni, csak egy már létezőt képes folytatni (Borland bug). Ebből kifolyólag ezt a bizonyos balnk.wav, pár századmásodperces üres, filet nyitja meg, folytatás céljából.
A felvevő használata egyszerű. Írjuk be a létehozandó file nevét a „username” –hez. Majd a felvételhez nyomjuk meg a „Start Recording” feliratú gombot. Mikor végeztünk a „stop recording” gombbal megállítható a felvétel. Az ily módon felvett hang visszajáccható a „Play Current Sample” feliratú gomb kétszeri megnyomásával. Ha a mintátá jónak ítéljük a „save” gombra kattintva elmenthetjuk, ha rossznak, akkor a „repeat” gomb lenyomásával újrafelvehetjük azt. (a „repeat” gomb lenyomásakor automatikusan újra elindul a felvétel, melyet a „stop recording” gombbal állíthatunk meg). Az elmentett hangminták a „users” könyvtárban tárolódnak, a beírt név és egy indexszám filenévvel (például: username_1.wav). Három minta vétele után, vagy a „new user” gombra kattintva a felvelőpanel alapállapotba kerül.
A teljes analízis fileba rögzítésére szolgál az „Output file of complete analysis” feliratú csoport. Itt csupán meg kell adnunk a rögzítendő file nevét majd a „write file” feliratú gombra kattintva megvárni a, hogy a gomb alatti felirat „Comlete”-re váltson. Ekkor két filet kell kapnunk a megadott helyen. Egy beírtnév_lp.cer , és egy beírtnév_pp.cer nevű filet, melyből az első a linear prediction spektrum adatiat rögzíti, második pedig az alapharmonikus adatait.
A „cut” csoportnál van lehetőségünk az éppen betöltött hangminta megvágására. A vágás energia alapú, a „cut waveform” feliratú gomb melletti mezőben megadhatjuk a vágási határértéket. (Mivel az iylen jellegú vágás nagyon hangerőfüggő)
Mivel egy biztonsági beléptető rendszernek teljesen kész állapotban nincs szüsége egy ehhez hasonló felhasználói felületre, a grafikus megjeleítések feleslegessége miatt, ezért a tesztrendszer ezen (megjelenítő) része kevésbé kidolgozott, és csak tesztelési célokat szolgált.
Megjegyzés: bármilyen transzformáció elvégzése előtt egy hangfile (wav) megnyitása, és beolvastatása („process selected file”) feltétlenül szükséges!

C E R B E R U S P R O J E K T - M E G O L D Á S
62
Tesztelés (Horváth) A tesztelés részleteihez egyrészt Internetes forrásokból származó más, már létező szoftvereket (főleg shareware) használtunk, másrészt az iSPL (intel Signal processing library) újabb változatát (IPP2 – intel performance primitives 2.0). Sajnos minden részt külön így sem sikerült tesztelni, de alapjaikat igen.
Az egyes részek tesztelése:
1. A wav fájl beolvasása
Első, de egyben egyik kulcsfontosságú része a feldolgozásnak a hangfájl beolvasása.
Ennek ellenőrzésére részben a „goldwave” wav szerkesztő alkalmazást, másrészben az IPP-t használtuk. Az összevetést ez utóbbi szerint ismertetjük.
A felhasznált tesztjel: egyszerű sinushullám
37. ábra: Az IPP által rajzolt kép
Szöveges értéklista (részlet):
0, 371, 742, 1114, 1485, 1856, 2227, 2597, 2968, 3337, 3707, 4076, 4444, 4812, 5179, 5545, 5911, 6276, 6640, 7004, 7366, 7728, 8088....

C E R B E R U S P R O J E K T - M E G O L D Á S
63
38. ábra: A által rajzolt kép
Szöveges értéklista (részlet a cerberus logfájlból):
Real value: 0000 ,converted value at position 0: 0 Real value: 0173 ,converted value at position 1: 371 Real value: 02e6 ,converted value at position 2: 742 Real value: 045a ,converted value at position 3: 1114 Real value: 05cd ,converted value at position 4: 1485 Real value: 0740 ,converted value at position 5: 1856 Real value: 08b3 ,converted value at position 6: 2227 Real value: 0a25 ,converted value at position 7: 2597 Real value: 0b98 ,converted value at position 8: 2968 Real value: 0d09 ,converted value at position 9: 3337 Real value: 0e7b ,converted value at position 10: 3707 Real value: 0fec ,converted value at position 11: 4076 Real value: 115c ,converted value at position 12: 4444 Real value: 12cc ,converted value at position 13: 4812 Real value: 143b ,converted value at position 14: 5179 Real value: 15a9 ,converted value at position 15: 5545 Real value: 1717 ,converted value at position 16: 5911 Real value: 1884 ,converted value at position 17: 6276 Real value: 19f0 ,converted value at position 18: 6640 Real value: 1b5c ,converted value at position 19: 7004 Real value: 1cc6 ,converted value at position 20: 7366 Real value: 1e30 ,converted value at position 21: 7728 Real value: 1f98 ,converted value at position 22: 8088 .... Az egyezés tehát adatok, és vizuális kép alapján is megerősíthető. (Az értékeke természetesen a továbbiakban is megegyeznek)
A beolvasást megfelelőnek tekintjük, és továbblépünk a feldolgozás felé.

C E R B E R U S P R O J E K T - M E G O L D Á S
64
2. Autokorreláció
Talán a legfontosabb eljárás a feldolgozási fázisban, mivel az összes feldolgozó eljárás alapját képezi. Megtalálható mint a linear prediction első, és a harmonikus vizsgálat befejező lépése, tehát egyformán kulcsfontosságú.
39. ábra: Az IPP által rajzolt kép
Szöveges értéklista (részlet):
512, 512, 512, 512, 512, 512, 511, 511, 510, 510, 509, 508, 508, 507, 506, 505, 504, 503, 502, 501, 499, 498, 497, 495, 494, 492, 491, 489, 487, 485, 483....
40. ábra: A általunk rajzolt kép
Szöveges értéklista (részlet):
Value of autocorrealtion function at position 0: 512 Value of autocorrealtion function at position 1: 512 Value of autocorrealtion function at position 2: 512 Value of autocorrealtion function at position 3: 512 Value of autocorrealtion function at position 4: 512 Value of autocorrealtion function at position 5: 512 Value of autocorrealtion function at position 6: 511 Value of autocorrealtion function at position 7: 511 Value of autocorrealtion function at position 8: 510 Value of autocorrealtion function at position 9: 510 Value of autocorrealtion function at position 10: 509 Value of autocorrealtion function at position 11: 509

C E R B E R U S P R O J E K T - M E G O L D Á S
65
Value of autocorrealtion function at position 12: 508 Value of autocorrealtion function at position 13: 507 Value of autocorrealtion function at position 14: 506 Value of autocorrealtion function at position 15: 505 Value of autocorrealtion function at position 16: 504 Value of autocorrealtion function at position 17: 503 Value of autocorrealtion function at position 18: 502 Value of autocorrealtion function at position 19: 501 Value of autocorrealtion function at position 20: 499 Value of autocorrealtion function at position 21: 498 Value of autocorrealtion function at position 22: 497 Value of autocorrealtion function at position 23: 495 Value of autocorrealtion function at position 24: 494 Value of autocorrealtion function at position 25: 492 Value of autocorrealtion function at position 26: 491 ... A továbbiakban az értékek csak kis mértékű eltéréseket mutatnak, ez a kerekítésekből adódik, mivel mi normalizált autokorrelációt használunk, vagyis az értékeink –1 és 1 közötti lebegőpontos számok, az ábrázoláshoz, és az összehasonlításhoz viszont más értékhatárokra, és egész számokra volt szükség.
3. Fourier transzformáció
Az LP spektrumképzés egyik utolsó transzformációs lépése a Fourier transzformáció, melyet tipikusan FFT (Fast Fourier Transform) eljárással végeznek.
Tesztjelünk még mindig sinusjel, de ezúttal nem három, hanem ötperiódusnyi.
41. ábra: Az IPP által rajzolt kép
Szöveges értékek (részlet):
39, 0, 40, -2, 42, -4, 47, -7, 55, -11, 72, -17, 115, -33, 380, -128, -228, 88, -81, -35, -47, -23, -32, 17, -24, 14, -19, 12, -15....

C E R B E R U S P R O J E K T - M E G O L D Á S
66
42. ábra: Az általunk rajzolt kép
Szöveges értékek (részlet):
Value of Fourier Transform at position 0: 39 Value of Fourier Transform at position 1: 6 Value of Fourier Transform at position 2: 51 Value of Fourier Transform at position 3: 20 Value of Fourier Transform at position 4: 88 Value of Fourier Transform at position 5: 3 Value of Fourier Transform at position 6: 52 Value of Fourier Transform at position 7: 4 Value of Fourier Transform at position 8: 51 Value of Fourier Transform at position 9: 9 Value of Fourier Transform at position 10: 206 Value of Fourier Transform at position 11: 9 Value of Fourier Transform at position 12: 215 Value of Fourier Transform at position 13: 2 Value of Fourier Transform at position 14: 331 Value of Fourier Transform at position 15: -110 Value of Fourier Transform at position 16: -169 Value of Fourier Transform at position 17: 63 Value of Fourier Transform at position 18: -86 Value of Fourier Transform at position 19: -44 Value of Fourier Transform at position 20: -71 Value of Fourier Transform at position 21: -74 Value of Fourier Transform at position 22: 12 Value of Fourier Transform at position 23: -22 Value of Fourier Transform at position 24: 37 Az értékek némileg eltérést mutatnak, ezek a különböző részmódszerekből adódó eltérések. Hatásuk nem jelentős a felhasználás szempontjából.
4. Átlagos Amplitúdó
Az átlagos amplitúdó vizsgálat nem igényel komolyabb tesztelést. Egyrészről az algoritmus egyszerűsége, másrészről az egyszerű (más referenciaprogramot nem igénylő) tesztelhetőség miatt.

C E R B E R U S P R O J E K T - M E G O L D Á S
67
(Tesztjel továbbra is a 3 periódusnyi sinushullám)
43. ábra: Eredeti jel
44. ábra: Átlagos amplitúdó
Hasonlóan egyszerű módszerrel tesztelhető az energia, és a null-átmenetek száma is, ám mivel ezeket pillanatnyilag nem használjuk, tesztelésüket most nem mutatjuk be.
5. Egyéb
Durbin eljárás
A Durbin eljárás tesztelését külön nem tudtuk elvégezni, de elmélete, és rekurzív algoritmusa tökéletesen egyezik az intel leírásával, és az összes fellelhető irodalomban. Miután bemenete az autokorrelációból származik, (melyet sikeresen teszteltünk), és miután a kapott eredmények egy részét írásban „utánellenőriztük”, valamint az eljárás kódolása megfelel az elméletben leírtaknak, így elfogadjuk hogy a kimenete is megfelelő.
Szűrő
Sajnos az IPPben található szűrő rendje csak kettő, és az együtthatóit is persze meg kell adni. Nekünk azonban csak ötöd rangú szűrőegyütthatóink vannak.
Ezért a szűrés teszteléséhez igénybevettük a goldwave segítségét
Tesztminta: 3 periódus sinusjel, küszöbfrekvencia: 1kHz

C E R B E R U S P R O J E K T - M E G O L D Á S
68
45. ábra: A GoldWave által rajzolt kép
46. ábra: Az általunk rajzolt kép
Az értéklista mellékelésétől ebben az esetben eltekintünk, mert az egyezés láthatóvá tételéhez nagyon hosszú értéksorozatot kellene bemutatnunk.
Adatspecifikáció (Horváth) Fontosabb adatok és eljárások ismertetése
Az eljárás neve Bemenő paraméterek Feladata process_header Char[255] fn
int header[] Az fn nevű file tartalmának feldolgozása. A fejlés információk a header tömbbe kerülnek, az adattömb pedig a v_array globális tömbbe
pitch_period int windowlength A hang alap harmonikusát vizsgálja, bemenő paramétere az ablak hossza

C E R B E R U S P R O J E K T - M E G O L D Á S
69
average_magnitude int windowlength,
int windowtype Átlagos amplitúdót mér, ablakhossz, és ablaktípus alapján.
autocorrelation double R[], int number_off_coeff, int N, int index, int source_v[]
Autokorrelációt számit egy adott jelszakaszon. Eredményét az R tömbbe teszi. Az együtthatók számát a number_off_coeffel adjuk át, míg a szakasz hossza az N, pozíciója pedig az index. Az adatokat pedig a source_v-ből veszi.
linear_prediction int coeff_number, int windowlength, int source_array[], int s_length
coeff_number rendű Linear predictiont hajt végre a source_array tömbön, melynek hossza s_length. A vizsgálatot windowlength méretű ablakkal végzi.
durbin double R[], double a[], double E[], int p
A durbin eljárást végző függvény, melynek paraméterei az R, autokorrelációs együtthatókat tartalmazó tömb, az a tömb, melyben az LP együtthatókat fogjuk tárolni, az E , keletkező LP hibaegyüttható tároló tömb, valamint a p, az LP rendje
cutspace Char[255] fn, int data[], int RDL, int WF, int NCH, int BR, int BPC, int WDL, int cutoff
Létrehoz egy fn nevű, vágott filet. A hangfile adattömbje a data, míg az RDL (RawDataLength), WF (WaveFormat), NCH (NumberOfChannels), BR (BitRate), BPC (BytePerChannel), és a WDL (WaveDataLength) paraméterek a fejléc létrehozásához szükségesek. A cutoff pedig a vágási küszögérték
filter900 int source_v[], int length, int filtered[]
900hz-es aluláteresztő szűrő. Kiinduló adatai a source_v tömbben vannak, melynek hossza length. A szűrt eredményt a filtered tömbbe rakja
average_energy int windowlength, int windowtype
Energiát számol, ablakhossz, és ablaktípus alapján.
fourier_tr double source_vector[], int length
Fourier transzformációt végez a source_vector-on, melynek hossza length

C E R B E R U S P R O J E K T - M E G O L D Á S
70
Fontosabb változók Neve Típusa Feladata pitchinfo float[] A hang alap harmonikusának paramétereit tartal-mazza
a_all double[] az összes LP együtthatót tartalmazza
R_all double[] az összes autokorrelációs együtthatót tartalmazza
E_all double[] az összes LP hibaegyütthatót tartalmazza
lpspectrum double[] Az LP spektrumot tartalmazza
avg_magnitude long[] Az átlagos amplitúdót tartalmazza átlagolások előtt
v_array int[] A feldolgozott array adatait tartalmazza
(32767..-32767)
l_array long v_array hossza
Arcazonosító rész (Bors) A cél egy olyan rendszer elkészítése, amely szoftveres úton képes „látni”, érzékelni a bejövő jelet és azt osztályozni, majd ez alapján a megfelelő kimenetet biztosítani. A bejövő jel tulajdonképpen egy kamera által érzékelt kép, a kimenő jel pedig legyen a személy egyedi azonosítója (neve, kódja stb.) Hagyományos módszerekkel vagy neurális hálókkal próbálja (remélhetőleg minél nagyobb pontossággal) megbecsülni az adott input jel hovatartozását.
Röviden összefoglalva, a cél megállapítani egy emberi arc alapján, hogy ki az illető személy. Az eszköz, amelyen keresztül érkezik a bejövő információ, egy kamera. Az általa érzékelt képet láthatóvá kell tenni a felhasználó számára is, azért hogy a megfelelő helyzetbe tudjon helyezkedni. A program először alakítsa a képet a számítógép által értelmezhető formára, keresse meg az arcot a képen, majd emelje ki az arc megfelelő pontjait (száj, szemek). Ezek az információk alapján történjen az azonosítás.
Miután megtörtént az osztályozás, az output jelenjen meg a képernyőn, vagy továbbítsa valamilyen perifériának, eszköznek, amely ennek megfelelően végezze el feladatát. Az output kezelésére a projekt ezen része nem terjed ki. Az eredmény alapszinten a következő legyen: a képernyőn jelenítse meg a rendszer - korábbi tapasztalatokból merítve - az általa érzékelt jel alapján az illető nevét vagy azonosítóját.
Elvárt, hogy a teljes azonosítás folyamata rövid időn belül megtörténjen, továbbá az osztályozás pontossága a lehető legjobb legyen.

C E R B E R U S P R O J E K T - M E G O L D Á S
71
A hatásfok problémái
Nem teljesen megoldott még az a probléma, ha a felhasználó nagy szögben elfordul. Próbálkoznak különféle technikákkal, de az eredmény legfeljebb körülbelül 30 fokos elfordulás mellett való érzékelés. Most elsődleges célom, hogy a kamerának pont szemben álló embert képes legyen érzékelni a program, ettől feltehetőleg kb. 10 fokos eltéréssel fog működni. Továbbá hátrányos a döntött fejtartás, mivel a szem és száj pozíció meghatározása egyértelműen vízszintes fejtartást feltételez.
Zavaró tényező lehet, ha a háttér is hordoz információt, vagyis ha nem egyszínű. Jelen rendszer célja hogy bármilyen háttér előtt működjön, a béta változat kis mértékben változatos háttér előtt képes azonosításra. A szűrőknek köszönhetően egy bizonyos fokig nem zavarja a változatos háttér.
A bejövő kép minősége elképzelhető, hogy nem eléggé éles, nagyon zajos. Ezen különböző szűrőkkel fog a program segíteni.
Egypetéjű ikrek esetén, illetve ha az azonosítandó személy maszkot visel, könnyen megtéveszthető a számítógép. Ezekre az esetekre a termogramos vizsgálat jelenthetne kellő biztonságot.
A rendszer vázlata (Bors) A külvilág és az arcfelismerő program kapcsolata látható az alábbi képen.
47. ábra: A rendszer blokkvázlata
Az egységek magyarázata:
Felhasználó: különbséget kell tenni a felhasználók között
§ Azon személyek, amelyeket a rendszer azonosít, semmilyen módosítási, feltöltési vagy törlési joggal nem rendelkeznek

C E R B E R U S P R O J E K T - M E G O L D Á S
72
§ Azon személy(ek), aki karbantartja a rendszert, minden módosításhoz, változtatáshoz vagy éppen törléshez joga van.
§ Olyan személyek, akik szerepelnek az adatbázisban (vagyis a rendszer felismeri őket) tehát nem a rendszer karbantartói, mégis rendelkeznek a saját adataik esetleges módosításának jogával.
Jogosultság ellenőrzés: ez is a rendszer szoftver része (jelentősége miatt szerepel külön). A program itt tesz különbséget az egyes felhasználói szintek között, és ez alapján adja meg a felhasználónak a megfelelő jogokat.
Kamera: az input eszköz. Alapvetően bármilyen számítógépre csatlakoztatható kamera megfelel a célnak. A szükséges felbontás 320x240 pixel, 256 szín.
Rendszer szoftver: feladata a teljes azonosítási eljárás a beérkező kép alapján, majd miután megtörtént az osztályozás, továbbítása a képernyőre, vagy más eszközre. Feladata még a kép megjelenítése a felhasználói felületen. További részletezés a következő fejezetben.
Képernyő/külső eszköz: a képernyőn fontos megjeleníteni a képet, ezáltal segíteni a felhasználónak olyan helyzetbe helyezkedni, amiben a program képes az azonosításra. Az osztályozás (azonosítás) eredménye megjelenhet képernyőn vagy hatással lehet valamilyen „külső eszköz”-re is. Ilyen például egy zár, ami a megfelelő felhasználó érkezésekor nyílna. Megjegyzem ezen lehetséges külső eszköz(ök) vezérlésére nem tértem ki a tervezés folyamán.
Adatleírás (Bors) Az azonosításhoz felhasznált legfőbb adatok:
parMat 6xn elemű tömb real a kapott paraméterek
points nx2 elemű tömb integer információt
hordozó pixelek koordinátái
kep 320x240 pixel image a szűrt és binarizált kép (input)
kep2,kep3 320x240 pixel image segédképek
t1,t2,t3,t4,t5 320x240 elemű tömb RGB automatikus
azonosításhoz
p,q,r1,r2,theta változók real ellipszis detektálás
kimeneti paraméterei
ablak 3x3 elemű tömb integer a szűrőkhöz ablak

C E R B E R U S P R O J E K T - M E G O L D Á S
73
Személyi információk az adatbázisban:
felhnev 0..40 karakter string a felhasználó neve
azonosito 0..10 karakter string a gép által készített
azonosítója a felhasználónak
jogosultsag paraméter byte leírja adott személy
jogait a rendszerben
letrehozo dátum xxxx.xx.xx string az azonosító
létrehozásának dátuma
utolsobelep dátum string az utolsó használat időpontja
A belső modulok kapcsolata (Bors)
48. ábra: A belső modulok kapcsolata
Előfeldolgozás (Bors) Az első lépésként el kell végeznünk bizonyos szűréseket hogy a képet a számítógép által feldolgozható formára hozzuk. Gyakorlati tapasztalat alapján a következő szűrőket alkalmazza a program a megfelelő kép elérése érdekében:
1. szürke kép
2. medián szűrő (3x)
3. kontur szűrő

C E R B E R U S P R O J E K T - M E G O L D Á S
74
4. binarizálás/inverz
A szem és száj megtalálása szempontjából a következő algoritmusokat használjuk:
1. YCbCr konverter (szem, száj kereséshez)
2. erózió (szem, száj kereséshez)
További vizsgálatok céljából a programba beépítésre kerültek a következő algoritmusok:
1. Sobel éldetektáló
2. vonalvégkonyító (skeletonization)
Szürke kép
Színes képből (RGB) úgy nyerünk szürke képet, ha vesszük minden pont esetén a három komponens átlagát. Az osztás művelet kihagyására használhatunk előre feltöltött tömböt. Így gyorsabb eredményt érhetünk el. Jelen programban azonban a szürke képpé konvertálás időigénye elhanyagolható a többi programrészlethez képest.
3),(),(),(),(
3),(),(),(),(
3),(),(),(),(
yxByxGyxRyxB
yxByxGyxRyxG
yxByxGyxRyxR
++=
++=
++=
Medián szűrő
A feldolgozás kezdeti lépéseként a képen medián szűrőt alkalmazok. Erre azért van szükség, mert a bejövő kép meglehetősen zajos. Ennek mértéke elsősorban a rögzítő kamerától függ. A medián szűrő előnyös tulajdonsága, hogy a kisebb zavarokat megszünteti, míg a nagyobbakat nem változtatja meg. Így elkerülhetővé válik a kisebb zajok esetleges foltosodása.

C E R B E R U S P R O J E K T - M E G O L D Á S
75
49. ábra: Medián szűrő
Az intenzitás értékek:
ωrr →1 A használt képlet:
)2
1(),( +=
ωrjig
ahol g az eredeti kép
r(x) x intenzitás értéke
w a képpontok szám az ablakon belül
i,j adott x,y képpont koordináta
Algoritmus
1. Kijelöljük az ablakméretet (tipikusan 3x3).
2. Beolvassuk a képről az ablakba (mátrix) tartozó aktuális intenzitás értékeket.
3. Rendezzük intenzitás szerin növekvően a mátrix elemeit.
4. Az adott g(i,j) eredeti képen lévő pontnak a mátrix középső elemének megfelelő intenzitás-értéket adjuk.
5. Ismételjük a 2. ponttól amíg a teljes képet meg nem vizsgáltuk.

C E R B E R U S P R O J E K T - M E G O L D Á S
76
Itt jegyzem meg, hogy a medián szűrővel van egybeépítve egy „objektum elkülönítő” megoldás. Ez pedig azt jelenti, hogy az intenzitásokból levonunk valamennyit, ami ennek hatására ha kisebb lesz mint 0 szélsőértékbe csapódik. Általában az egy részhez tartozó pontok (pl arc) közel egyforma intenzitásúak. Így ezek a pontok egyszerre váltanak, míg a háttér nem változik. Az érték amit kivonunk, változtatható a kezelőfelületen.
Kontúr szűrő
A kontúr szűrő kiemeli az éleket. Erre azért van szükség, hogy a fej (arc) formája jól kirajzolódjon. Valójában ez adja az alapját a későbbi ellipszis detektálásnak.
A felhasznált képlet a következő:
ωrr →1
1),( rrjig −= ω Algoritmus
1. Kijelöljük az ablakméretet (tipikusan 3x3).
2. Beolvassuk a képről az ablakba (mátrix) tartozó aktuális intenzitás értékeket.
3. Rendezzük intenzitás szerint növekvően a mátrix elemeit (vagy gyorsabb, ha megkeressük a maximális és minimális értékeket, hiszen csak ezekre lesz szükség).
4. Az adott g(i,j) eredeti képen lévő pontnak a mátrix középső elemének megfelelő intenzitás-értéket adjuk (amit a fenti képletből számoltunk).
5. Ismételjük a 2. ponttól amíg a teljes képet meg nem vizsgáltuk.
Binarizálás és invertálás
Mivel az ellipszis detektálónak mindenképpen binarizált (tehát olyan kép amin egy helyen vagy van vagy nincs érték) van szüksége, ezért utolsó lépésként mindenképp binarizálnunk kell a képet. Az invertálás mindössze annyit tesz, hogy megcseréli, vagyis ahol volt pont ott nem lesz és forditva.
A binarizáláshoz egy küszöbértéket kell használnunk. Ez a küszöb alatt fekete pont fog megjelenni, fölötte fehér (ez invertálással cserélgethető). Alapvetően szürke képpel dolgozunk így nem számít melyik komponensét nézzük az RGB-nek.
Algoritmus
1. Kiindulunk a bal felső sarokban levő pontból.

C E R B E R U S P R O J E K T - M E G O L D Á S
77
2. Ha adott küszöb felett van az intenzitása, fehérre cseréljük (255), egyébként feketére(0).
3. Vesszük a következő pontot.
4. Folytatjuk a 2. ponttól, míg végighaladunk az egész képen.
YCbCr (YUV) konvertálás
Ha az RGB színeket átkonvertáljuk ilyen formára, valamivel jobban kiemelődnek az arc egyes komponensei, melyeket hisztogrammal könnyebben leszűrhetünk majd. A konvertálás három egyenletből áll:
128071.0368.0439.0128439.0291.0148.0
16098.0504.0257.0
+−−=++−=
+++=
bgrCrbgrCb
bgrY
Egyes vizsgálatok szerint kiderült, hogy a szem körül magas Cb és alacsony Cr értékek vannak, továbbá magas Cr értékek találhatók a száj körül. Egyre többen használják ezeket az információkat arcfelismerés céljából. Jelen program is kihasználja a YUV[Rein] lehetőségeit.
Erózió
Az erózió („hámozás”) a legkisebb intenzitás elemet veszi érvényesnek minden egyes ablakpozícióban. Mivel az arc esetén a bőr erőteljes intenzitású a száj és szemekkel szemben, ha többször végrehajtjuk az eróziót, tökéletesen kiemeli a szájat és a szemeket. Ezeket utána már könnyen kiszűrhetjük.
A képlet a következő:
ωrr →1
1),( rjig =
ahol r az intenzitás, g(i,j) képpont.
Algoritmus
1. Kijelöljük az ablakméretet (tipikusan 3x3).
2. Beolvassuk a képről az ablakba (mátrix) tartozó aktuális intenzitás értékeket.
3. Rendezzük intenzitás szerin növekvően a mátrix elemeit (vagy gyorsabb, ha megkeressük a legkisebb értékeket, hiszen csak erre lesz szükség).
4. Az adott g(i,j) eredeti képen lévő pontnak a mátrix középső elemének megfelelő intenzitás-értéket adjuk (amit a fenti képletből számoltunk).

C E R B E R U S P R O J E K T - M E G O L D Á S
78
5. Ismételjük a 2. ponttól amíg a teljes képet meg nem vizsgáltuk.
Az arc megtalálása a képen (Bors) Az elkészült arcdetektáló algoritmus alapja, hogy az arcot mint egy ellipszist tekinti. Az ellipszis nagysága, elhelyezkedése, dőlésszöge változó lehet. Gyakorlati tapasztalat, hogy ha egy képen található fejforma, azt a program ellipszisnek tekinti, és megtalálja. Az algoritmus alapja az un. Randomized Hough Transform (RHT). Az eddigi vizsgálódások alapján még nem használták arcfelismerésre a technikát (használva volt már például sejtek vizsgálatakor). Ennek fő oka, hogy meglehetősen új gondolat. Az RHT első leírása Xu et al-tól származik (1990), melyet később McLaughlin továbbfejlesztett (1997). Ő leegyszerűsítette lineáris problémává a folyamatot, így az RHT használható lett ellipszis detektálásra.
Az algoritmus végrehajtásához binarizált képre van szükség. A kép nagysága 320x240 pixel. Előre kellően leszűrt, RGB=255,255,255 (fehér) és RGB=0,0,0 (fekete) pontokkal számol. Az információt hordozó pont a fekete.
Elvi működés
A bemenő paraméterek és a kép alapján az algoritmus a következő értékeket adja eredményül:
p az ellipszis középpontjának x koordinátája
q az ellipszis középpontjának y koordinátája
r1 vízszintes tengely
r2 függőleges tengely
θ dőlésszög
Ezen értékek egyértelműen meghatároznak egy ellipszist. A p,q,r1,r2,θ paraméter halmaz. Több ellipszis esetén több paraméter halmazt határoz meg az algoritmus, melyek a paraméter mátrixban fognak elhelyezkedni.

C E R B E R U S P R O J E K T - M E G O L D Á S
79
50. ábra: Az ellipszis geometriai vizsgálata
1. Húzunk három érintőt az ellipszishez (p1,p2,p3 pontban metszik az ellipszisünket)
2. Megkeressük ezen érintők metszéspontjait (t1,t2)
3. Kiszámoljuk p1 és p2 továbbá p2 és p3 közötti távolság felét. (m1,m2)
4. Összekötjük a következő pontokat: t1m1 és t2m2
5. A t1m1 és t2m2 egyenesek metszéspontja a keresett p és q
6. A megfelelő egyenletek alkalmazásával kiszámoljuk r1 r2 és θ értékét is
Bemenő paraméterek
A következő paraméterek megfelelő beállítása éppolyan fontos az algoritmus szempontjából mint a megfelelő kép biztosítása. Ha rosszul állítjuk be, az algoritmus nem fog működni. Ezen paraméterek pontos beállítására csak egyszer van szükség, egy fájlban elraktározva induláskor betöltődnek (params.sav)
minPdist, maxPdist
Minimális és maximális távolság, az ellipszisek nagyságának meghatározása. Segítségükkel meghatározhatjuk, hogy a három kiválasztott pont milyen távolságra lehet egymástól (minimum és maximum). Tehát közvetve meghatározhatjuk körülbelül mekkora ellipsziseket keresünk.
countThreshold
A keresés során többször is megtalálhatjuk ugyanazt az ellipszist. Ilyenkor nem kerül még egyszer eltárolásra, helyette a korábban már megtalálttal összeveti, és növeli a count értékét egyel. Ha ugyanazon helyen több ellipszist is talált, nagy lesz ez az érték. Hogy a legvégén milyen határ fölötti paraméter halmazokat tekintünk ellipszisnek ezt határozza meg a számláló küszöb.

C E R B E R U S P R O J E K T - M E G O L D Á S
80
epoch
A ciklusok száma mielőtt ellenőrzi a talált paraméter halmazt. Minél nagyobb ez a szám, annál nagyobb a valószínűsége, hogy több mint egy ponthalmazt talál azonos ellipszis paraméterekhez.
tangentSearchWindowRadius
Az érintő keresésnél meg kell határozni, mekkora legyen az ablak az adott pont körül. Minél nagyobb, annál pontosabban lehet meghatározni az érintőt. Viszont annál nehezebb meghatározni kisebb ellipsziseket.
ellipsisRangeTolerance
Mikor ellenőrizzük, hogy a paraméterek által meghatározott ellipszis valóban megtalálható-e a képen, bizonyos toleranciával kell dolgoznunk. Tehát figyelembe kell venni azokat a pontokat is, melyek az él közelében fekszenek. Túl nagy tolerancia okozhat téves találatokat, viszont általában az életben nem teljesen szabályos ellipszisek vannak.
minCoverage
Meg kell határozni mekkora eltérést engedünk meg az ellipszis ellenőrzésekor a matematikailag biztosan lehetséges ellipszistől.
maxDiffError
Hogyan tudjuk meg, hogy két paraméter halmaz elég közel van-e egymáshoz? Az errori=abs(pi-p)+abs(qi-q)+abs(r1i-r1)+abs(r2 i -r2)+abs(θi -θ) az i-dik paraméter halmaz hibája az aktuálisan vizsgálthoz képest. θ kis érték, súlyozni kell. Ez a paraméter adja meg az error lehetséges maximális értékét.
Az ellipszis detektálás folyamata
Elvárt ugyan egy algoritmustól, hogy akárhányszor lefuttatva ugyanazt az eredményt adja, jelen esetben azonban olyan algoritmus került implementálásra, amely mindig mást fog eredményül adni. Ez az algoritmus jellegéből adódik (randomized)

C E R B E R U S P R O J E K T - M E G O L D Á S
81
51. ábra: Az ellipszis detektálás folyamata
Inicializálás
Kezdeti paraméterek megadása, tömbök nullázása. A points tömbben tároljuk el azokat a pontokat, ahol fekete képpont van az előfeldolgozott képen. Fontos művelet, mivel a továbbiakban ezzel dolgozik az algoritmus. Tfh. a (200,100) helyen fekete pont van, ekkor
points[n,1]=200 points[n,2]=100
A három pont meghatározása
Először kiválasztunk a points tömb három, véletlen szám generátor által megadott pontját. (p1, p2, p3) Ezeket a points tömbből vegyük, hogy csak olyan pontot válasszunk, ami információt hordoz (tehát jelen esetben fekete). Ellenőrizzük a kapott pontok közötti távolságokat:
212
212 )()( yyxxh −+−=
Végezzük el minden pontra, az eredményt vessük össze minPDist, és maxPDist-el. Ha nem teljesül a feltétel, keressünk új pontokat.
Ellipszis közepének meghatározása
Ez az egyik legösszetettebb része, rendkívül fontos a jó eredmény elérése, hiszen ezen alapszik az összes többi számítás. Ha pontatlanul találjuk meg az ellipszis közepét, a további műveletek sem lesznek pontosak. Ezért fontos hogy minden lépés tökéletesen működjön.

C E R B E R U S P R O J E K T - M E G O L D Á S
82
Első lépésként meg kell határozni az érintőket. Ehhez az un. „least squares” módszert használjuk.
2
20
20
radius ha ,)()(
<∀=
−+−=
ii
iii
rrinrangeyyxxr
Természetesen radius értékét előre megadjuk (tangentSearchWindowRadius). Így kapunk egy tömböt, amely valójában az ellipszis pont körül elhelyezkedő része kinagyítva. Ha a sugarat kettőnek választjuk, a következő eredményt kaphatjuk (checkp):
Az érintők meghatározásakor eredményképp kapunk egy irányvektort. Az irányvektor y koordinátája mindig 1. Csak az x érték változik. Ennek meghatározása az előbb nyert tömb segítségével:
22
2
2
)(*)(
)(
)(
ycheckpxcheckpppxcheckpxsxsycheckpysys
ii
i
i
+=
+=
+=
Amennyiben p értéke nem 0, a következő egyenlettel számoljuk az x értéket:
++⋅−±−=
ppxsysxsysysxs
xt
222 4221
Ha p értéke 0, akkor vagy függőleges, vagy vízszintes az értinő, mivel valamelyik négyzetes tag a szorzatban biztosan 0. Ez azonban ritka eset, de erre is fel kell készülni (ilyen esetben tehát
0 és 1 == tt yx , vagy 1 és 0 == tt yx ).
Ahhoz azonban, hogy meg tudjuk határozni, hogy az xt számításakor kapott két eset közül melyik a megfelelő, meg kell vizsgálni az egyes pontok távolságát az érintőponthoz képest, majd az lesz a megfelelő x és y érték a kettő közül, amelyikhez tartozó pontok összege kisebb (sum).
),(),( ttii yxyxcheckpcross ×=
22tt yxq +=

C E R B E R U S P R O J E K T - M E G O L D Á S
83
∑=q
crosssum i
A kapott x és y meghatározzák az érintő irányát. Ha például 45 fokos az érintőnk az x tengelyre nézve, ekkor mivel y mindig 1, x-nek is 1 értéket kell felvennie. Az x érték esetén egyébként ez a maximum, ezért később a metszetszámításnál célszerű arányosan mindkét értéket felszorozni.
Következő lépés a metszetek kiszámítása. Ehhez szükség van az egyenes egyenletére. Azt az x és y értéket keressük, amely mindkét egyenes egyenletét kielégíti. Így megkapjuk a két érintő koordinátáit.
αtgmbmxy
=+=
Mindezt megcsináljuk kétszer, a 2-2 érintővel. Az eredmény t1 és t2 pontok.
A felezőpontok keresése könnyű feladat. Adott p1(x,y) és p2(x,y) pontok. Ezen szakasz felezőpontját a következő egyenlet segítségével határozzuk meg:
2),(),(
),( 12 yxpyxpyxm −=
Innentől minden információnk megvan a középpont meghatározására. Kiszámoljuk a megfelelő egyenesek metszetét a fenti módszerrel:
metszete és 2211 mtmtc = Ezzel meghatároztuk az ellipszis középpontját, vagyis a kimenő paraméterek közül már kettő megvan (p,q).
Az ellipszis tengelyeinek és dőlésszögének számítása
Kezdő lépésként p és q paramétereket vesszük a középpontnak (0,0). Így az ellipszis három pontja a következőképpen alakul (o(x,y) a talált középpont):
),(),(),(
33
22
11
yxoptpyxoptpyxoptp
−=−=−=
Célunk, hogy megkapjuk r1,r2 (tengelyek) és θ (dőlésszög) paramétereket. Ehhez több lépésen keresztül juthatunk el. Az ellipszis egyenlet:
1)())((2)( 22 =−+−−+− qycqypxbpxa
A fenti egyenlet három ismeretlenes. a,b, és c értékét keressük, p-t és q-t ismerjük. x és y értékeket p1(x,y) p2(x,y) és p3(x,y) értékekből nyerjük. Így összesen három egyenletünk van p1,

C E R B E R U S P R O J E K T - M E G O L D Á S
84
p2 és p3 esetére. Egy ilyen egyenletrendszer megoldására használható az un. „Reduced Row Echelon” alakra hozás[RREF] (Gauss Jordan Elimination). A három egyenletet mint egy mátrixot kezeljük. A transzformáció lépéseinek részletezése nélkül a következő pontoknak kell hogy megfeleljen a kapott mátrix:
§ ha egy sorban nem csak 0 van, akkor az első szám ami nem 0 a sorban az 1 (vezető 1)
§ ha létezik olyan sor, amely csak nullákat tartalmaz, akkor ezek a sorok a mátrix alján helyezkednek el
§ ha egy sorban nem csak 0 van, akkor a vezető 1-es a felette levő sor 1-eséhez képest a a mátrixnak jobb oldalához közelebb van
§ minden oszlop, amiben vezető egyes van, ezen kívül csak 0-kat tartalmaz
A kapott mátrix a következő formájú:
cba
100010001
ahol a,b,c a kapott eredmények. Ezután leteszteljük hogy az adott a,b,c értékek alapján valóban ellipszisről van-e szó. Ehhez a következő egyenlőtlenségnek kell teljesülnie:
0)( 2 >−⋅ bca
Ha nem teljesül, vissza a középpontszámításig. Ha teljesül, akkor folytatjuk r1,r2, és θ számítását.
cabbacacaccab
r+−
++−+−−+−−⋅= 2
2222 )42(*)(2
211
cabbacacaccab
r+−
++−+++−⋅= 2
2222 )42(*)(2
212
Theta (θ) értékének kiszámítása nem ennyire egyértelmű. A komplex számok tartományát is igénybe kell vennünk.
11
22
22
21
rrrrbfac
−⋅
⋅=

C E R B E R U S P R O J E K T - M E G O L D Á S
85
facfac
facy2
2 4114122
41 −+−
⋅−+−=
2412221 facx −⋅+=
Gyakorlati megvalósítás szempontjából előfordulhat, hogy gyök alatt negatív szám szerepel. Ekkor azonban valós megoldás nem létezik. Mivel x és y nem komplex számok, az ilyenkor keletkező kivételt le kell kezelni.
22ln
yxiyxi
+
+⋅−=θ
A művelet komplex számok segítségével történik, azonban theta értékének képzetes része 0 lesz, így elegendő a továbbiakban valós számként tekinteni rá. Így sikerült elérnünk hogy mind az öt paraméterünk (p,q,r1,r2,θ) megvan. Ezzel a feladat matematikai része le is zárult.
Paraméter halmazok eltárolása
A parMat (6xn) mátrix fogja tartalmazni az 5 paramétert. Azért 6 soros, mert kell egy count érték, ami megmondja, hány ilyen vagy ehhez hasonló paraméterhalmazt találtunk. Lássunk egy példát a paraméter mátrixra:
13211323.0766.0235.0424.0643.04.224.662.331.315.122.431.145.134.322.10
116104455537431018811574
−−
Fentről lefelé a paraméterek sorrendben: p,q,r1,r2,θ és a vonal alatt count. Mikor érkezik egy új paraméter készlet, a program végigmegy ezeken a már eltárolt paraméterhalmazokon, és megvizsgálja melyikhez hasonlít leginkább.
∑=
=5
1iiparMatsumvec
Ez az érték fogja tartalmazni egy adott oszlop első 5 paraméterének összegét. A theta érték mivel mindig kis szám ötszörös súllyal szerepel az összegben. A kezdeti megadott paramétertől függ milyen eltéréssel veszi még az adott halmazba tartozónak (maxDiffError). Ha az újonnan érkezett paraméterhalmaz paramétereinek összege és az adott oszlop paramétereinek összege közötti különbség kisebb mint a megadott küszöb, növeli az aktuális oszlop 6. sorát (count),

C E R B E R U S P R O J E K T - M E G O L D Á S
86
továbbá átlagolja az új és a régi értéket (ahol count értéke eleve több mint 1, azokat a paramétereket nagyobb súllyal veszi). Ha végighaladva az összes oszlopon nem talál ilyet, akkor új oszlopként beírja a mátrixba az új paraméter halmazt.
Hogy melyik paraméter halmazt tekintjük mostantól ellipszisnek, függ az előre meghatározott küszöb (countThreshold) értékétől.
Ellenőrzés
Ebben a fázisban megvizsgáljuk, hogy a talált paraméter halmaz által meghatározott alakzat valóban ellipszis-e. Mostantól csak azokkal a paraméterekkel foglalkozzunk, amelyek count értéke egy meghatározott küszöb felett van.
2
2
2
2
2)))sin())(()cos())(((
1)))cos())(()sin())(((
rpxpoqypo
rpxpoqypoeli
θθ
θθ
⋅−+⋅−
+⋅−+⋅−
=
ahol po a points tömb megfelelő sora vagy oszlopa (x vagy y).
)2,1max(/ rregeTolerancellipseRantol =
2
2
11
tollToltolutol
−=
+=
22 iToleluTol i ≤≤
Ezzel kiszűrtük a megfelelő pontokat. Ezután vizsgáljuk a minCoverage paramétert:
epsion = minCoverage / 100
Majd azt tekintjük valóban ellipszisnek, amelyre a következő feltétel teljesül:
epsilonrr
j≥
+ )21(4
ahol j el vektorban szereplő értékek száma.

C E R B E R U S P R O J E K T - M E G O L D Á S
87
Visszahelyettesítés
Végül kapunk egy vagy több paraméterhalmazt, amelynek kirajzolása az értékek visszahelyettesítésével történik. Gyakorlatban végighaladunk a kép összes pixelén, és ahol teljesül az egyenlet (bizonyos toleranciával) oda helyezünk egy pontot. Az így kapott képünk egy (vagy több) ellipszist fog ábrázolni.
2
2
2
2
2)))sin())(()cos())(((
1)))cos())(()sin())(((
rpxkqyk
rpxkqykeli
θθ
θθ
⋅−+⋅−
+⋅−+⋅−
=
Ezúttal a megfelelő értékek behelyettesítésével (k a képernyő összes képpontja) el vektort ismét feltöltöttük. Vizsgáljuk ismét a következő egyenlőtlenséget:
2
2
11
tollToltolutol
−=
+=
22 iToleluTol i ≤≤
ilpts =][
pts tömbben eltároljuk a megfelelő pontok indexét. Ezáltal kirajzolásnál már tudni fogjuk hányadik pixelt jelöljük meg. Kirajzoljuk az ellipszist.
Ezzel befejeződött az algoritmus. Látható hogy meglehetősen számolásigényes feladatról van szó. Ugyanakkor magában foglal bizonyos önellenőrzési mechanizmusokat, melyek meggátolják abban hogy pontatlan eredményt kapjunk. Az így kapott ellipszist továbbadja a program későbbi feldolgozásra.
Fontos megjegyezni, hogy az algoritmus képes több ellipszis megtalálására is, azonban az arcfelismerő program esetén lekorlátoztam egyre, vagyis az első megtalált ellipszis után felhagy a további számításokkal (elegendő egy ellipszis és sebesség növekedés szempontjából volt fontos).

C E R B E R U S P R O J E K T - M E G O L D Á S
88
A kép kivágása Miután megtaláltuk az ellipszist, célunk, hogy a hátteret eltüntessük. Ugyanakkor figyelembe kell vennünk a következő lépést is, mikor a talált ellipszis formát további szűrőkön kell átvinnünk. A két gondolatot egyesítve a következő lépésekre lesz szükség:
1. A kamera által adott folyamatos képről készítünk két állóképet (kép1, kép2).
52. ábra: A bejövő információ (kép1 és kép2)
2. Megjelöljük a talált ellipszis körvonalát (kép2).
3. Jobbról illetve balról elindulva az első körvonalpontig átmásoljuk egy másik képre (vagy tömbbe) a megfelelő pontokat, így a fej helyén fehér marad (kép3).
53. ábra: A kivágott kép (kép3)
4. Az állóképen végrehajtjuk a szem és száj detektáláshoz szükséges szűréseket. Ezek: YCbCr konvertálás és erózió ötször. (kép1).
5. Tekintjük mindazon pontokat, ahol kép3 fehér maradt, és ezen pontok kivételével az összest levágjuk kép1-ről, ezzel megvan a leszűrt és kivágott ellipszisünk.

C E R B E R U S P R O J E K T - M E G O L D Á S
89
54. ábra: A kivágás eredménye
Az Y értéket ha az RGB zöld komponensébe írjuk kiíratáskor, akkor meglehetősen intenzív zöld értéket fedezhetünk fel az arc esetén. A háttér illetve a szemek és a száj helyén ez az érték alacsony.
A kivágással elértük, hogy a háttér bármennyire összetett és változatos, a szem és szájkeresőnek már csak az arcot kell vizsgálnia.
Azonosítás Gabor szűrőkkel (Bors)
Gabor szűrők
A különböző arcfelismerő rendszerek általában speciális pontokat (features) keresnek az arcon, ami az azonosítás alapjául szolgál. Bizonyos pontok kiemelése fontos lehet például nagy méretű arcadatbázisok létrehozásakor, mivel így elég kevesebb információt eltárolnunk, azokat az információkat, melyek meghatározzák az arcot.
A Gabor szűrők [Kepenekci 2001] (Gabor filters) az utóbbi időben egyre terjedő megoldás az arcazonosításban. Például különböző arcra illeszkedő gráfok létrehozása esetén sikerrel alkalmazhatók a Gabor szűrők által adott válaszok (responses). A 2D-s szűrők tulajdonképpen kiemelik a völgyeket és csúcsokat a képen. Arc esetén ezek a száj, szemek, orr és az arcon található egyéb jellemző, kiemelkedő helyek. Ezáltal létrehozhatunk egy arcokra jellemző tulajdonság halmazt (feature map) amely egyedi, személyenként változó.
Az eredeti Gabor szűrőket zajdetektálásra használták. A jelenlegi célnak megfelelő változatok 2 dimenziós térbeli hullámok.
( )2 2 2 2j j
j j2 2
k k xx exp( ) exp(ik x) exp( )
2 2 σ
Ψ = − − − σ σ
jx vj
jy v
k k cosk
k k sinµ
µ
θ = = θ

C E R B E R U S P R O J E K T - M E G O L D Á S
90
55. ábra: Gabor filter térben [Kepenekci 2001]
A szűrők alkalmazása
A szűrőket elkészítjük 8 szögben ( 0..7µ = ) és 5 különböző frekvenciával (v=0..4). Ezeket mindet külön-külön alkalmazzuk a képen.
56. ábra: Gabor szűrők felülnézetből
Az alkalmazott szűrő mérete 12x12 pixel. A képen végighaladva megkapjuk az un. szűrő válaszokat(Ri.) Alapvetően szűrke képpel dolgozunk. A képek szélénél előforduló pontatlanságokat le kell vágni.
, ,i iR (x) I(x) (x x )dx= ψ −∫
r r r r r
A fenti módszer segítségével összesen 5x8, tehát 40 féle módon leszűrt képünk lesz az arcról.
57. ábra: Leszűrt kép

C E R B E R U S P R O J E K T - M E G O L D Á S
91
Csúcsok kiemelése
Célunk, hogy az „erős” információkat kiemeljük a szűrt képekből. Ezek valójában pontok lesznek, melyek elhelyezkedése többnyire a szemek, száj és orr környékén lesz. A kiemelése ezen pontoknak egy kis ablak (W0 ) segítségével történik. Az ablak mérete legyen WxW.
0j 0 0 j(x,y) W
R (x , y ) max (R (x, y)) j 1..40∈
= =
1 2N N
j 0 0 jx 1 y 11 2
1R (x , y ) R (x, y)N N = =
> ∑∑
Így megkapjuk a szükséges pontokat. Gyakorlati tapasztalat alapján a 9x9-es ablakméret a megefelelő. A kiemeléseket mind a 40 leszürt képen végre kell hajtani. A kapott eredmények eltárolása 42 elemű vektorokban (tulajdonság vektor) történik.
{ }i,k k k i, j k kv x , y , R (x , y ) j 1..40= =
Tehát 2 információ a pozícióra vonatkozólag (x,y), és 40 az adott pontban kapott szűrő válaszokhoz.
Hasonlóság vizsgálat
Két tulajdonság vektor összehasonlítása megoldható egyetlen függvény (S) használatával.
i,k t , jl
i 2 2
i,k t ,kl l
v (l) v (l)S (k, j)
v (l) v (l)=
∑
∑ ∑
A kapott érték 0 és 1 közötti lesz. Ha 0, az azt jelenti hogy egyáltalán nem hasonlít a két pont, ha 1, akkor pontosan ugyanaz a két pont. Mivel arconként több ilyen tulajdonság vektorunk is van, többet is meg kell vizsgálnunk, továbbá kevés a valószinüsége, hogy két vett mintán ugyanott helyezkedik el egy bizonyos pont.
Meg kell adni azt a távolságot, amin belül még vizsgáljuk a két pont közötti hasonlóságot.
2r t r t(x x ) (y y ) th− + − <
ahol r a referencia, t a teszt rövidítése (a két arc). A megfelelő közelségben levő pontok hasonlóságát vizsgáljuk, és a legjobban hasonlókat kiemeljük.
k ,ji, j il N
Sim max(S (l, j))∈
=
Végső megoldásként a két kép hasonlóságának összátlagát vizsgáljuk.

C E R B E R U S P R O J E K T - M E G O L D Á S
92
( )i i, jOS mean Sim=
A két arc közötti hasonlóság értéke itt is 0 és 1 közé tehető. Általában valóban egyező arcok esetén ez az érték 0,95 felett van, különböző arcoknál 0,6-0,8 körül.
Lehetséges optimalizáció
A pontosság növelhető, ha egy gráfot próbálunk ráilleszteni az arcra úgy, hogy annak csúcsai a szemeken, orron, és a száj két szélén van. Ezáltal az esetlegesen rossz helyeken detektált pontok (pl. az arcvonal és a háttér találkozása) kiszűrhetők. Így pontosabb eredményeket érhetünk el. Az illeszkedés autómatikus, mivel a speciális pontok a gráf csúcsainál vannak, így lassú mozgással ráállíthatjuk. Ez azonban kissé időigényes, és csak mozgó kép esetén használható.
Az arcdetektáló tesztprogram felhasználói felülete (Bors)
58. ábra: Felhasználói felület

C E R B E R U S P R O J E K T - M E G O L D Á S
93
Parameters
Az ellipszis detektáláshoz szükséges paramétereket itt lehet beállítani. Ezek minCoverage…exitCond. Az epoch és exitThreshold skála az ellipszisdetektálás köztes folyamatainak aktuális állását mutatja. A found a talált ellipsziseket jelzi (10%=1).
§ Load/Save: elmenthetjük illetve visszatölthetjük a paraméterek beállított értékeit.
§ Show: állóképet biztosít.
§ StopCam/StartCam: értelemszerüen a kamera felvételének leállítása/indítása.
§ Start: az ellipszisdetektálás megindítása.
§ Dist: megjeleníthetjük az ellipszis detektálásnál használt maximális és minimális ponttávolságot (minPDist, maxPDist).
Filters
§ Eye Filters: a szem és száj detektáláshoz szükséges szűrők egymásutánja, amit a program végrehajt. Ezek a következők:
1. binarizálás
2. invertálás
3. Sobel
4. kontúr szűrő
5. medián szűrő
6. vonalvékonyító
7. erózió
8. YCbCr konvertálás
§ Face Filters: az ellipszis detektáláshoz szükséges szűrők egymás utáni végrehajtásának sorrendje. A számok jelentése lsd. Eye Filters.
§ Eyes&Mouth detect: miután megjelöljük, arcdetektálásról átvált szem és szájdetektáló üzemmódba
§ HisztogramX,Y: függőleges és vízszintes hisztogram rajzolás.
§ LoadEM: betölthető egy korábban elmentett, már csak az arcot ábrázoló kép.
§ ShowArray: az automatikus feldolgozásnál használatos tömbök közül a választottat kirajzolja.
§ Bin. threshold: a binarizáláshoz szükséges küszöb értéke.

C E R B E R U S P R O J E K T - M E G O L D Á S
94
§ Sub: itt állíthatjuk, hogy mennyit vonjon ki a pixelekből (bővebben lásd medián szűrő).
Auto detect
§ Active: ilyenkor van bekapcsolva, a jobb felső képen folyamatosan keresi a megadott paramétereket.
§ Ellipse: bejelölésével automatikusan keresi az arcot (ellipszist) a képen.
§ Eyes&Mouth: automatikusan keresi a szájat és a szemeket.
§ Lines: bejelöli az arc jobb és bal oldalát, a szem és száj detektáláshoz felhasznált alsó és felső vízszintes vonalakat.
Identify (képek)
Ez a fül alatt található a program kimenete, összesen négy ablakban:
§ Bal felső ablak: mindig a kamera által érzékelt bejövő jelet mutatja.
§ Jobb felső ablak: vagy a folyamatosan szűrt képet mutatja, vagy a megtalált szemet szájat arcvonalakat, ha automatikus keresésre állítjuk.
§ Bal alsó ablak: kép kivágott arccal.
§ Jobb alsó ablak: a felhasználóról készült állókép.
A jelenlegi változatban sok funkció a tesztelés elősegítésére került beépítésre. A végleges változatban a felhasználó ezekkel nem fog találkozni (illetve nem módosíthatja például a paraméterek beállításait).
Tesztelés (Bors)
Fejlesztői környezet, adatok
Programnyelv: Delphi 7.0
Hardver környezet: AMD Athlon XP1700 (~1480Mhz), Asus A7V266-EX alaplap, 256MB DDR RAM, Logitech CCD kamera
Operációs rendszer: Windows XP (Prof.)

C E R B E R U S P R O J E K T - M E G O L D Á S
95
A szükséges felbontás (minimálisan): 1024x768, SVGA
Felhasznált input képméret: 320x240 pixel
Arcdetektáló egység
Jelenlegi verziószám: 1.0béta
Nyelv: angol
A program moduljai: unit1 (főmodul, kezelői felület, lépésenkénti felismerés)
unit2 (automatikus felismerés, optimalizált)
szurok (az előfeldolgozó rutinok)
Az arcdetektáló egység összterjedelme: 4300 sor
Ezen kívül felhasznált külső modulok:
§ videocap (kameravezérlő egység)
§ zprofiler (sebesség mérő, optimalizáláshoz)
Arcfelismerő egység
Jelenlegi verziószám: 1.0b, teszt
Modulok: unit1 (főmodul, vezérlő elemek, tesztprogram)
unit2 (szűrők)
Felhasználók tárolása: külön fájlokban .fr2 formátumban (kb. 50K)
Az arcfelismerő egység összterjedelme: 2600 sor
Sebesség
Egyik legfontosabb tényezője a programnak a sebesség. Elengedhetetlen feltétele a rendszer működésének, hogy a teljes személyazonosító algoritmus véges (és minél rövidebb) időn belül lefusson. Ez főképpen jellemző az automatikus szem, száj detektáló programrészre, ahol valós időben fut az algoritmus és keresi az adott tulajdonságokat az arcon. Ezért itt optimalizálásokra volt szükség. Ennél a résznél például mivel nem kell megjeleníteni a közbenső állapotokat (arc kivágás stb) célszerü mindent a háttérben, tömbök segítségével megoldani. Célszerü továbbá a rendezéseket lecserélni például maximum, minimum keresésekre, ezzel sokat gyorsíthatunk az algoritmusokon (lsd kontur szűrő).

C E R B E R U S P R O J E K T - M E G O L D Á S
96
A sebesség mérésére Zprofiler nevü mérőprogram lett használva, amely képes megmondani, hogy a felismerés egy-egy fázisa mennyi időt vesz igénybe. A képen a következő értékek szerepelnek az egyes sorokban:
1. puffertömbök feltöltése, értékük a kameráról érkező kép
2. szürke képpé konvertálás
3. medián szűrő (ezt az értéket szorozzuk 3-mal)
4. kontur szűrő
5. binarizálás
6. ellipszis keresés
7. ellipszis rajz
8. kivágás
9. szem és száj kereséséhez szükséges szűrések elvégzése
10. szem és száj megtalálása
59. ábra: Az egyes feladatok futási ideje (Zprofiler)
Látható, hogy a teljes művelet legtöbb számítást (időt) igénylő művelete az ellipszis megkeresése (arcdetektálás). Ennek többnyire oka a sok osztás és gyökvonás, illetve a nagyarányú ismétlésszám. Széles skálán mozog az ellipszis megtalálásának ideje. Ez a detektáló algoritmus jellegéből adódik (randomized). Ezt követik a szűrések. Kiemelten a medián szűrő lassú, és ezt

C E R B E R U S P R O J E K T - M E G O L D Á S
97
fokozza hogy háromszor is végre kell hajtani. Ha jobban megvizsgáljuk, észrevehetjük, hogy a medián szűrő a rendezés miatt lesz lassu. Ugyanezt lehet tapasztalni a kontur szűrő esetén is.
A mérési eredmények alapján a következők állapíthatók meg:
§ A teljes algoritmus lefutásának ideje: 800 - 2100 ms (átlag 1450ms = 1.45s).
§ A leglassabb egység: ellipszis detektáló (átlag 700ms = 0.7s).
§ Legkevesebb időt igénylő részek: binarizálás, szürke kép, tömb feltöltések, szem és száj keresése (átlag ≤ 10ms).
Összességében a fenti hardverkörülmények között képes megfelelő sebességgel futni, ugyanakkor elvárhatóak bizonyos sebesség optimalizálások, a kényelmesebb felhasználás érdekében.
Gabor szűrő sebessége
A szűrők elkészítésének ideje (ha nem fájlból olvassuk be): átlag ≤ 40ms
A szűrők alkalmazása az arcon (40-szer): átlag 900ms
Speciális pontok detektálása: átlag ≤ 10ms
Azonosító függvények alkalmazása: átlag ≤ 20ms
Tesztelés modulonként
A tesztelést pontosabban el tudjuk végezni, ha a teljes keresési-azonosítási algoritmust modulokra osztjuk, és azokat külön-külön teszteljük. Ezek a modulok a következők:
1. medián szűrő
2. kontur szűrő
3. binarizálás
4. ellipszis detektálás
5. erózió, YCbCr konverzió
6. hisztogram, szem és szájdetektálás
Medián szűrő
A szűrő feladta a zajok eltüntetése a képről. A működés tesztelése kétféleképpen történhet:

C E R B E R U S P R O J E K T - M E G O L D Á S
98
1. Egy kellően zajos kép bevitele, ha a vizuálisan is látható zajok eltüntek, a szűrő működik.
2. Kisebb zajok pontosabb (és biztosabb) teszteléshez létrehozhatunk például egy 9x9 nagyságú képet, amiben mesterségesen elhelyezünk valamilyen zajt, végrehajtjuk az eljárást, majd akár a kép pontjainak kiiratásával is, vizsgálhatjuk az eredményt.
A tapasztaltak alapján megfelelően működik a beépített medián szűrő. Többszörös végrehajtás esetén kiszűri a nagyobb pontokat is. Lassítója a rendezés. Optimalizálás szükséges.
Kontúr szűrő
Vizsgálati módszer lehet a képen látható eredmény vizsgálata. Ez alapján valóban láthatóvá válnak az élek. Pontosabb vizsgálat elvégzése történt egy 3x3-as méretű ablak pixelintenzitásainak megfigyelésével, a következő elven:
3 2 2
1 3 2
1 2 1
A számok az adott pont intenzitását jelölik. Ekkor a két szélső értéknek a következőnek kell lennie:
13
1 ==
rrω
Így a kapott középpont a következő kell hogy legyen: 3-1 = 2
3 2 2
1 2 2
1 2 1
A fenti elven történő vizsgálat véghezvitele után a szűrő megfelelően működött.
Binarizálás
Ennek az egységnek a tesztelése rendkívül egyszerűen történhet (lévén maga az algoritmus is egyszerű). Megnézzük a küszöböt maximális és minimális érték esetén. Minimális esetben a képen csak az egyik színnek kell szerepelnie, maximális esetben pedig pont az ellenkezőnek. Továbbá vizsgálhatjuk pontonként is a helyes működést. A vizsgálat szerint a binarizálás megfelelően működött.

C E R B E R U S P R O J E K T - M E G O L D Á S
99
Ellipszis detektálás
Ennek az egységnek a működési eredménye nem lehet tökéletes szinte soha. Nem is ez a cél. A cél hogy megfelelő pontossággal megtalálja az arcot a képernyőn. A találat pontosságára kiható tényezők a következők voltak:
§ fényerő
§ bemenő paraméterek értéke
§ kamera által adott kép minősége
§ szűrők (előfeldolgozás) minősége
§ háttér változatossága
§ hardver sebessége (a minimális szint elérése után kényelmi szempont)
§ a kamera elé álló személy felismerhetősége
Látható, hogy nagyon sok mindentől függ a jó eredmény. Így a vizsgálatokat csak bizonyos feltételek megszabásával végezhetjük, résztalálat számok feljegyzését végezhetjük csak el. A lenti eredmények csak az ellipszisre megtalálására vonatkoznak!
1. Teszt: minden feltétel állandó volt, az azonosítandó személye is. Az elhelyezkedés a kamera előtt ami változott. Előzetesen pontosan be lett állítva a binarizálási küszöb.
Eredmény: - találati arány: 90 %
- ellipszis pontossága archoz képest: 60-70 %
Az ellipszis detektálást nagy mértékben befolyásolta a háttér változatossága. Ennek köszönhetően lett kicsi az ellipszis pontossága.
2. Teszt: minden feltétel állandó, kivétel, hogy a háttér nem változatos.
Eredmény: - találati arány: 98 %
- ellipszis pontossága archoz képest: 80-90 %
3. Teszt: kis mértékben változatos háttér előtt különböző arcok vizsgálata. A többi feltétel állandó.
Eredmény: - találati arány: 80-90 %

C E R B E R U S P R O J E K T - M E G O L D Á S
100
- ellipszis pontossága archoz képest: 60-70 %
4. Teszt: szinte teljesen egyenletes háttér előtt, különböző arcok vizsgálata. A többi feltétel állandó.
Eredmény: - találati arány: 90 %
- ellipszis pontossága archoz képest: 70-80 %
A fényerő változásának kompenzálására a binarizálás küszöbértékét és a kivonó-t (lsd medián szűrő) kellett használni. Egyértelműen jobb eredményt mutat, ha a háttér nem változatos. Pozitívumként azonban elmondható, hogy kisebb hatásfokkal, de képes megtalálni az arcot változatos háttér előtt is. Összességében elmondható, hogy az ellipszis detektálás megfelelően működik, bizonyos körülmények között téved.
Erózió, YCbCr
Az YCbCr konverzió eredményét csak úgy tekinthetjük meg, ha visszaírtuk a kapott három értéket RGB színekre. Az arc esetén magas Y értéket kell tapasztalnunk.
Az erózió vizsgálata hasonlóan történhet a kontúr szűrőhöz. Először azonban célszerű funkcionalitás szempontjából megvizsgálni működését. Az erózió olyan mintha az adott objektumot „hámoznánk”. Vagyis az erős intenzitás pontok eltűnnek, a kis intenzitás pontok előtérbe kerülnek. Ha ezt figyelembe vesszük, a kapott eredménynek úgy kell kinéznie, hogy az arc (magas intenzitás) eltűnik, és előtérbe kerül a szem és a száj környéke. Vizsgálhatjuk közelebbről is:
3 2 2
1 2 2
1 2 1
Az erózió szabályai szerint a legkisebb intenzitásúnak kell kerülnie középre, tehát:
3 2 2
1 1 2
1 2 1
A fenti módokon a vizsgálatot elvégeztem, és az algoritmus megfelelően működött.
Arcfelismerés hisztogrammal
Az ellipszisdetektálás mellett ez a másik olyan feladata a teljes azonosítási folyamatnak, ami nem lehet egyértelműen pontos. Azonban ha sikerül körülbelüli (tehát nem pixelre) pontos megoldást elérni, azt már találatnak számolhatjuk. Külön vizsgáltam az adott részszámítások pontosságát, majd végül az átlagos találati arányt. Ezek az eredmények is függetlenek az ellipszis

C E R B E R U S P R O J E K T - M E G O L D Á S
101
detektálásnál kapottaktól. Feltételezzük hogy mindig pontosan megtalálta az ellipszis az arcot. A kettő együttes találati aránya az összegzéseknél olvasható.
A következő részekre bontható a szem és száj megtalálásának mérése:
§ fej vonalának (jobb és bal oldal) megtalálása
§ szem pozíciójának megtalálása
§ száj pozíciójának megtalálása
Továbbá két esetet vizsgálunk: egy személy többszöri vizsgálata után elért eredmény, és több személy vizsgálata után elért találatok száma (és ha talált mennyire pontos).
1. Teszt: a fej vonalának meghatározása.
§ egy személy esetén (ismétlődő keresések)
találati arány: 95 %
pontosság: 80 %
§ több személy esetén:
találati arány: 95 %
pontosság: 80 %
2. Teszt: szem vízszintes pozíciójának megtalálása.
§ egy személy esetén (olyan esetén akinél nagy a találati arány)
pontosság: 70 %
§ több személy esetén:
találati arány: 50-60 %
pontosság: 70 %
3. Teszt: száj vízszintes pozíciójának megtalálása.
§ egy személy esetén (olyan esetén akinél nagy a találati arány)
pontosság: 80 %

C E R B E R U S P R O J E K T - M E G O L D Á S
102
§ több személy esetén:
találati arány: 30-40 %
pontosság: 80 %
Látható, hogy a rendszer leggyengébb pontja a száj detektálása. Ez jelenti a legnagyobb nehézséget a számítógép számára. Kiküszöbölésére két mód lehetséges: a hatásfok javítása módszerváltással vagy finomítással és a másik, ha kirajzoltatjuk valós időben a találatot, és a felhasználó állítja le a detektálást mikor a legpontosabban a szemén és a száján jelzi a találatot a program . Ez egyébként nyilván nem túl kényelmes megoldás, de általában használják arcfelismerő programok esetén (pl. BioID). Összegezve bizonyos esetekben a szem és a száj pozíciójának meghatározása még nem kielégítő.
Arcfelismerés Gabor szűrőkkel
Ha tökéletesen detektáltuk az arc helyzetét, a Gabor szűrő általi felismerési arány 3 személy esetén 95%-os, folyamatosan növelve a felhasználók számát ez az érték csökken. Arcadatbázison tesztelve több személy esetén az azonosítás 85% feletti. A gráf illesztése mozgó kép esetén sok esetben nehézkes, és lassú, ezért további optimalizálásra szorul.
Összességében a Gabor szűrős azonosítási mód nagyobb megbízhatóságú, azonban minimális idővel lassabban végrehajtható megoldás a hisztogrammoshoz képest.
Az osztályozó rendszer (Safranka) Az osztályozó végül is neurális hálós megvalósításban lett implementálva. Ez azért tűnik jobbnak, mint a HMM modelles megvalósítás, mert az inkább alkalmas folyamatok előre jelzésére, vagyis például a soron következő hangrészlet megjósolása. Ebből kifolyólag a rejtett Markov modell inkább megfelelő egy Speech-To-Text rendszerben, ahol az a cél, hogy a bejövő mintából, vagy annak (töredékéből) igyekezzünk megbecsülni a fonémát, és így betűvé alakítani, illetve következtetni arra, hogy milyen fonéma követheti. Míg a mi esetünkben inkább hasznos a neurális hálózatok asszociálási képessége vagyis, hogy a minták hasonlóságát, vagy éppen eltérését képes felismerni, nem azt vizsgálni, hogy egy ponttól hogyan kéne folytatódnia a mintának. A HMM osztályozórendszer tanulmányozására szóló könyv a [Becchetti 99] könyv is egy ilyen Speech-To-Text rendszer megvalósítására használja.
A megvalósított neurális háló jellemzői (Safranka) Egy többrétegű (egészen pontosan 3 rétegű +1 bemeneti réteggel rendelkező), perceptron elvű, teljes összeköttetést alkalmazó, visszacsatolás nélküli hálózati topológiát választottam. A bemeneti réteg és a két rejtett réteg elemszáma a bejövő információ méretétől függ. A kimenet eredetileg egy két neuront tartalmazó réteg lett volna, de a megvalósítás után a tesztelések eredménye alapján ezt a számot megnöveltem. A tanítás egy felügyelt backpropagation

C E R B E R U S P R O J E K T
103
algoritmussal történik, ahol a helyes kimenetet az output neuronok 1 értéke jelenti. A felismeréskor a minta végighalad a betanított hálón, majd a kimeneten a minden neurontól kívánt 1 értékű kimenettől való négyzetes eltérést (ugyan az, amely a tanításnál a súlytényező meghatározására szolgáló függvény) vizsgáló függvény által visszaadott 1-től való eltérés alapján történik.
Ez a két neuronnál nem volt megfelelően nagy különbségű az elfogadható és az elutasítható minták között. A két kimeneti neuronnál az elfogadható mintaértékek a [0, 0,25] intervallumokba estek előfordult, hogy az elutasítandó minták, pedig a [~0,2, 1] intervallumban voltak. Vagyis a két intervallumnak volt egy metszete, azaz nemhogy nem különült el a két érték, hanem még metszete is volt, vagyis nem lehetett egy egyértelmű elfogadható, nem elfogadható minták közti határvonal kijelölése. A tanulási algoritmus küszöbértékének( )η módosításával (amely nagyságrendekkel növelte a tanulási ciklusok számának, és így a tanulási idő igényét) nem sikerült az elfogadható, és nem elfogadható minták értékeinek jól elhatárolható eltérését elérni.
A sejtszámok növelésével (kettőről ötre, majd hétre) viszont sikerrel járt, még durvább (nagyobb) η értékkel is. Konkrétan ez azt jelenti, hogy míg most már az elfogadható minták a [0-0,3] körüli intervallumba kerültek, az elutasítandóak pedig a 0,95 feletti eltérést mutattak. Mint látható ebben az esetben az elfogadhatóság határa már könnyebben meghúzható.
A következő táblázat mutatja a teszt neurális hálózaton végzett mérések eredményét. A színezés egy kissé megtévesztő lehet, mert a zöld a 0,65–nél kisebb kimeneti eltérést, a sárga a 0,65 és 0,95 közötti eltérést, a piros a 0,95-nél nagyobb kimeneti eltérést jelenti, amelyet a 7 kimenet esetében találtam a megfelelő limitnek, így nem igaz, hogy az lenne az elfogadható érték az 5 illetve 2 kimenet esetén is. Viszont azért hagytam meg a színezést, mert jól látszik, hogy milyen tartományokba kerülnek az értékek, és pl. jól észrevehető mennyire nem lehet a két kimenet esetén elhatárolni az elfogadható és nem elfogadható értékeket. Mivel a kimeneti elemszámon kívül a hálók minden más paramétere azonos volt a tesztek alatt az is jól megfigyelhető, hogy mennyire növeli a kimeneti elemszámok növelése a tanulási ciklusok számát (ugyan azon ε eltérést figyelembe véve)
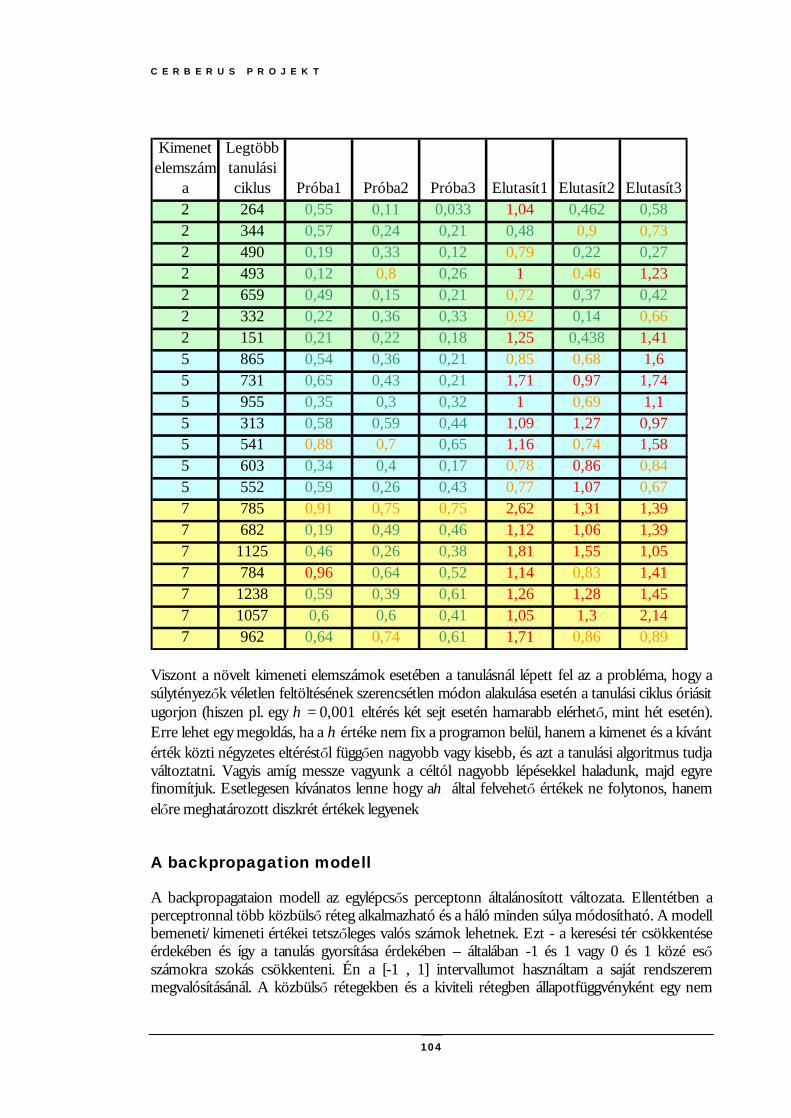
C E R B E R U S P R O J E K T
104
Kimenet elemszám
a
Legtöbb tanulási ciklus Próba1 Próba2 Próba3 Elutasít1 Elutasít2 Elutasít3
2 264 0,55 0,11 0,033 1,04 0,462 0,582 344 0,57 0,24 0,21 0,48 0,9 0,732 490 0,19 0,33 0,12 0,79 0,22 0,272 493 0,12 0,8 0,26 1 0,46 1,232 659 0,49 0,15 0,21 0,72 0,37 0,422 332 0,22 0,36 0,33 0,92 0,14 0,662 151 0,21 0,22 0,18 1,25 0,438 1,415 865 0,54 0,36 0,21 0,85 0,68 1,65 731 0,65 0,43 0,21 1,71 0,97 1,745 955 0,35 0,3 0,32 1 0,69 1,15 313 0,58 0,59 0,44 1,09 1,27 0,975 541 0,88 0,7 0,65 1,16 0,74 1,585 603 0,34 0,4 0,17 0,78 0,86 0,845 552 0,59 0,26 0,43 0,77 1,07 0,677 785 0,91 0,75 0,75 2,62 1,31 1,397 682 0,19 0,49 0,46 1,12 1,06 1,397 1125 0,46 0,26 0,38 1,81 1,55 1,057 784 0,96 0,64 0,52 1,14 0,83 1,417 1238 0,59 0,39 0,61 1,26 1,28 1,457 1057 0,6 0,6 0,41 1,05 1,3 2,147 962 0,64 0,74 0,61 1,71 0,86 0,89
Viszont a növelt kimeneti elemszámok esetében a tanulásnál lépett fel az a probléma, hogy a súlytényezők véletlen feltöltésének szerencsétlen módon alakulása esetén a tanulási ciklus óriásit ugorjon (hiszen pl. egy 001,0=η eltérés két sejt esetén hamarabb elérhető, mint hét esetén). Erre lehet egy megoldás, ha a η értéke nem fix a programon belül, hanem a kimenet és a kívánt érték közti négyzetes eltéréstől függően nagyobb vagy kisebb, és azt a tanulási algoritmus tudja változtatni. Vagyis amíg messze vagyunk a céltól nagyobb lépésekkel haladunk, majd egyre finomítjuk. Esetlegesen kívánatos lenne hogy aη által felvehető értékek ne folytonos, hanem előre meghatározott diszkrét értékek legyenek
A backpropagation modell
A backpropagataion modell az egylépcsős perceptonn általánosított változata. Ellentétben a perceptronnal több közbülső réteg alkalmazható és a háló minden súlya módosítható. A modell bemeneti/kimeneti értékei tetszőleges valós számok lehetnek. Ezt - a keresési tér csökkentése érdekében és így a tanulás gyorsítása érdekében – általában -1 és 1 vagy 0 és 1 közé eső számokra szokás csökkenteni. Én a [-1 , 1] intervallumot használtam a saját rendszerem megvalósításánál. A közbülső rétegekben és a kiviteli rétegben állapotfüggvényként egy nem

C E R B E R U S P R O J E K T
105
lineáris függvény alkalmazható. Az elkészült program a leggyakoribban használt szigmoid felhasználásával lett tesztelve, de az algoritmus tartalmazza a tangens hiperboikus átviteli függvényt is. [Borgulya 98]
Nem csak lineárisan szeparálható osztályozási feladatokat, hanem összetett osztályozási, asszociatív, függvényközelítési feladatokat is meg tud oldani. A közbülső rétegek nem lineáris állapotfüggvényei és változtatható súlyai révén e modell hasonlóságok felismerésére, interpolációra és olyan általános parametrikus modellek megoldására is felhasználhatóak, amelyben a súlyok a paraméterek. A legkülönbözőbb alkalmazási területeken számolnak be sikeres alkalmazásáról.
A többrétegű hálózatok felépítését az alábbi ábra igen jól szemlélteti. Az ábra egy három aktív réteget tartalmazó hálózatot mutat, amelyben az első és második aktív rétegben (a rejtett rétegekben) n darab a harmadik – jelen esetben kimeneti rétegben – két processzáló elem található. A hálózat tehát egy többrétegű előre csatolt hálózat. Mint korábban láttuk egy megfelelő méretű, többrétegű, folytonos nemlinearitásokat tartalmazó hálózat –a súlyvektorok kialakítása után – tetszőleges folytonos nemlineáris függvény approximációjára képes. A súlyvektorok meghatározása gradiens alapú ellenőrzött tanuló eljárással, tehát összetartozó tanító párok felhasználásával történik.
Az ábra az általam megvalósított neurális hálózat elméleti modellje:
60. ábra A Backpropagation modell vázlata [Horváth 98]
A tanuló eljárás bemutatása [Horváth 98] könyv alapján: vezessük be a következő jelöléseket: legyen l a réteg index, i a rétegen belüli processzáló elem (PE) indexe, j a PE bemeneteit megkülönböztető index, k pedig a diszkrét időindex. A ( )kw l
ij)( pegid az l-edik rétek, i-edik
processzáló elemének, j-edik komponensének súlyösszeköttetését jelenti a k-akid időpillanatban. Az egyszerűség kedvéért tekintsünk egy két aktív rétegű hálózatot, ahol a (2) jelű réteg a kimeneti réteg.

C E R B E R U S P R O J E K T
106
A kimeneti hiba:
( ) ( )222
211
22
21
2 dydy −+−=+= εεε
A súlymódosításhoz a megfelelő pillatatnyi gradienseket )(
2
lijw∂
∂ε kell kiszámítani.
A kimeneti szinten (l=2) a pillanatnyi gradiens megegyezik a kimeneti hibával.
( ) )2()2()2()2()(
2
2'2 jijiilij
xxssgmw
δεε
−=−=∂∂
A súlymódosítás tehát:
( ) ( ) ( ) ( ) ( ) ( ) ( )kxkwkxssgmkkwkw jiijjiiijij)2()2()2()2()2()2()2( 2'21 µδµε +=+=+
A rejtett réteg processzáló elemeinél a fenti összefüggések nem alkalmazhatók közvetlenül, mivel nem ismerjük az egyes elemek kimenetén fellépő hibát. A lánc szabály alkalmazásával azonban a deriváltakat itt is meg tudjuk határozni, hiszen a rejtett réteg processzáló elemeinek súlytényezői befolyásolják ezen processzáló elemek lineáris (s) és nem lineáris (y) kimeneteit, továbbá ezen kimeneteken keresztül a későbbi rétegek kimeneteit is. Tehát a parciális deriváltak lépésenként számolhatók.
( ))1(
)1(
)1(
22
2)1(
)1(
)1(1
1)1(
)1(
)1(
22
)1(
)1(
)1(
21
)1(
)1(
)1(
22
21
)1(
)1(
)1(
2
)1(
2
22ij
i
iij
i
iij
i
iij
i
iij
i
iij
i
iij ws
sws
sws
sws
sws
sws
sw ∂∂
∂∂
+∂∂
∂∂
=∂∂
∂∂
+∂∂
∂∂
=∂∂
∂+∂
=∂∂
∂∂
=∂∂ ε
εε
εεεεεεε
Ismét a lánc szabályt alkalmazva a hibakomponensek parciális deriváltjai meghatározhatók. Az 1ε -re bemutatva:
( ) ( ))1()2(1
)2(1)1(
)1(
)1(
)2(1
)2(1
1)1(
1 '' iii
i
ii
ssgmwssgmsy
ys
ss−=
∂∂
∂∂
∂∂
=∂∂ εε
majd az 2ε -re hasonlóan nyerhető deriváltat felhasználva a gradiens a következőkre adódik:
( ) ( ) ( ) ( )
( ) ( ) )1()1()1()()2(2
)2(2
)2(1
)2(1
)1(
)1()1()2(
2)2(
22)1(
)1()1()2(
1)2(
11)1(
2'22
''2''2
jiji
iiii
ij
iii
ij
iii
ij
xxssgmww
wsssgmwssgm
wsssgmwssgm
w
δδδ
εεε
−=+−=
=∂∂
−∂∂
−=∂∂
így a súlymódosítás:

C E R B E R U S P R O J E K T
107
( ) ( ) ( ) ( ) ( ) ( )( ) ( )( ) ( )( ) ( ) ( )kxkkw
kxkssgmkwkkwkkwkw
jiij
jiiiijij
)1()1()1(
)1()1()2(2
)2(2
)2(1
)2(1
)1()1(
2
'21
µδ
δδµ
+
=++=+
ahol
( ) ( ))1()2(2
)2(2
)2(1
)2(1
)1( ' iiii ssgmww δδδ +=
az úgynevezett „visszaterjesztett hiba”. A súlyozó együtthatók megegyeznek az adott hálózat részben az előrecsatolásnál szereplő súlytényezőkkel. A súlymódosítás ennek alapján tetszőleges rétegre is megadható:
( ) ( ) ( ) ( ) ( )( ) ( )
( ) ( ) ( )kxkkw
kxkssgmkwkkwkw
lj
li
lij
lj
li
N
r
lri
lr
lij
lij
l
)()()(
)()(
1
)1()1()()(
2
'211
µδ
δµ
+=
=
+=+ ∑
+
=
++
ahol a „vissza terjesztett” hiba:
( ) ( ) ( ) ( )( )kssgmkwkk li
N
r
lri
lr
li
l)(
1
)1()1()( '1
= ∑
+
=
++δδ
és az 1+lN az (l+1)-edik réteg bemeneteinek száma.
A megvalósítás menete(Safranka) Mivel a Rejtett Markov modelles megvalósítás során akadályokba ütköztem, úgy döntöttem, hogy megpróbálkozom a neurális hálós megoldással, mely végül is sikeresnek bizonyult. Mivel amikor projekt többi tagja elkezdte a hang előfeldolgozó és az arcfelismerő részek gyakorlati megvalósítását, nekem is akkor el kellet kezdenem a neurális hálós osztályozó megvalósítását, nem várhattam, meg míg ők elkészülnek és én az után kezdek bele. (mivel hogy az osztályozó az előfeldolgozók által szolgáltatott adatok alapján végzi a felismerést) Ezért, hogy én is haladjak, illetve gyakorlati tapasztalatot szerezzek a neurális hálók terén én is belekezdtem egy program írásába. Ez a program, egy osztályozó modell program, amely az általam generált adatok betanulására és felismerésére képes, azonos eljárásokat és technikákat alkalmazva, mint amit majd a projekt végleges osztályozójába szánok. A modellnek a Red Queen (Vörös Királynő) nevet adtam. Ez képes szöveges (.txt) adatokat beolvasni, majd azokhoz hasnolókat felismerni. Én a saját nevemet taníttattam be három mintával melyek közül, egyik minta a nevem helyesen leírva, a másik csak angol abc betűivel és a harmadik a kereszt nevem helyett a becenevem kisbetűvel. A felismerendő adatokban „zajokkal” szerepelt a nevem. Ez azt jelenti, hogy az egyikben a nevemben szereplő„a” betűk helyett „q” betűk vannak, a másikban betűk vannak felcserélve, a harmadik vége „elveszett” az utolsó két karakter helyett „e”-k vannak. Az elutasítandó adatok véletlenszerűen választott szövegek.

C E R B E R U S P R O J E K T
108
A Red Queen tesztrendszer a karaktereket bitenként kezeli. Vagyis a beolvasott karaktert ASCII kóddá alakítja és az így kapott „0” és „1”-esek kerülnek a hálózat bemenetére. Elvileg a backpropagation modell esetén a bemenet bármilyen valós szám lehet, viszont erősen ajánlott a [0,1ˇesetleg a [-1,1] intervallumra szűkíteni (pl egy legnagyobb értékkel való osztással) mert jelentősen lecsökkenti a keresési teret, vagyis gyorsabb algoritmust eredményez.
A fejlesztés első lépésében létrehoztam egy saját objektum osztályt „Cmatrix” névvel. Azzal próbálkoztam, hogy a másik két rész esetleg elkészül, és én a végleges megvalósítást írhatom. Vagyis részben időhalogatási célja volt annak, hogy első időben a mátrix kezelő osztályom létrehozásán és szépítgetésén dolgoztam. Hamar kiderült, hogy a többi rész nem fog egyhamar elkészülni, mindenkinek meg voltak a saját problémái. Így mivel az idő sürgetett és szükséges volt, hogy valamilyen tapasztalatot szerezzek neurális hálók terén neki kezdtem a Red Queen tesztrendszer fejlesztésének.
A létrehozott mátrixkezelő objektum osztály később igen hasznosnak bizonyult, és sokat könnyített a megvalósítás során azáltal, hogy a megvalósítás során rengeteg feladatot átvett. A mátrix osztály (az 1.5-ös verzió) a következő feladatokat képes elvégezni:
• Létrehoz a paraméterekben sor és oszlopszámmal megadott méretű mátrixot (dinamikus helyfoglalással), float típusú elemekkel
• Létrehoz a paraméterekben sor és oszlopszámmal megadott méretű mátrixot (dinamikus helyfoglalással), és a bemenő vektor paraméter adataival feltölti (a vektornak sor*oszlop db elemet kell tartalmaznia)
• Megadni a mátrix adatait
• Képes a mátrixok között a négy alapművelet elvégzésére (mátrix mátrixxal szorzására, igen de mátrix mátrixxal való osztársára értelemszerűen nem). Egyszerűen a megyszokott operátorok használatával.
• A mátrix minden eleméhez hozzáadni, kivonni, megszorozni és elosztani egy valós számmal.
• Transzponálni a mátrixot
• Kiírni a mátrix tartalmát konzolba (teszt funkciók)
• Kiírni a mátrix tartalmát egy .txt fájlba (naplózás, tesztelési célokra)
• Kimenteni és betölteni a mátrix tartalmát fájlba
• Bizonyos csomópontok értékét lekérdezni, és megváltoztatni
• Hibákat észlelni, és értesítést adni (pl érvénytelen elem koordináta)
Mint láthattuk a neurális hálózatok használata során rengeteg mátrixxal dolgozunk, így nagy egyszerűsítést jelent a mátrix műveletek támogatása az osztály segítségével. Különösen, mivel a

C E R B E R U S P R O J E K T
109
bemeneti, a rejtett és kimeneti rétegek vektorait is egy 1 sorból álló mátrix ként használja a program. Így a súlytényezők segítségével az egyes rétegek kiszámítása (az előző réteg és a súlymátrix összeszorzása) a kódban két változó összeszorzásaként jelenhet meg, ezáltal áttekinthetőbbé tehető a kód.
Eljárások leírása
A tesztprogram elindítása után a tanít gomb segítségével olvastathatatjuk be a tanítandó állományokat. A tanításhoz a szövegfájlok karakterei az ASCII kód alapján, így egy karakter 8 bemeneti feldolgozó elemet igényel. Ennél jobb megoldást jelent, ha a karakter (decimális értékben kifejezett) ASCII kódját 255-el (az egybájtos karakter által felvehető legnagyobb értékkel) elosztjuk, így a [0,1] intervallum béli számmá képezve a karaktert. Ezzel az egyszerű osztással máris nyolcad akkorára csökkentettük a szükséges réteg elemszámokat foglalást, arról nem is beszélve, hogy ez mekkora gyorsulást jelent az tanulási algoritmusban. Összehasonlításképpen: 15 karakter bitenkénti lebontásban egy 15*8=120 elemszámú bemeneti, első és második rejtett réteget igényelne, ezek között, pedig 2db (bemeneti és első rejtett, első rejtett és második rejtett közötti) 120*120=14400 elemszámú mátrixot és 1db (második rejtett és kimeneti réteg közötti) 7*120=840 elemszámú mátrixot igényelne. Mivel float adatokról van szó, amely 32 bites (4 bájtos) adatot jelent, így a teljes adatstruktúra (3*120+7+2*14400+840)*4=120028 bájt memóriát igényelve (nem beszélve a járulékos adatok igényéről, amelyek a struktúra elkészítéséhez szükségesek. Míg a második esetben ugyan azon 15 bájt adat feldolgozásához kell 15*3+7 elemszám lenne ami a rétegeknek kell, és 2*225+7*15 az átmeneti mártixokra, vagyis összesen (25*3+7+2*225+7*15)*4=2548 bájt elegendő. És nagyobb adatoknál (és biztosan ennél nagyságrendekkel nagyobb adatok használata lesz szükséges) ez az igény négyzetesen növekvő lesz, mivel a rétegek memóriafoglalásának négyzetét foglalják az átmeneti mártixok, és a méret növeléssel azok helyfoglalása egyre dominánsabb). Mint az előzőekben említettem a memóriafoglalás csökkentése nem elsősorban a kisebb fizikai memória igény elérése, szó nélkül áldoznék a memóriából, ha az algoritmust ezzel hatékonyabbá, vagy gyorsabbá tehetném. Viszont ebben az esetben a nagyobb memória igény azt is jelenti, hogy több elemet kell feldolgozni, ami mivel exponenciális függvény hívásokat tartalmazó szigmoid (vagy szintén exponenciális elemeket tartalmazó tangens hiperbolikus) átmeneti függvények, amelyek időigénye magas elemszám esetén drasztikus sebesség csökkenést eredményeznek.
A beolvasó eljárás létrehozza a bemeneti réteget, és feltölti a fájlból nyert adatokkal, majd meghívja a tanulást inicializáló eljárást. Ez az eljárás hozza létre a struktúra többi elemét (rejtett rétegek, kimeneti réteg, átmeneti mátrixok). A létrehozáskor az átmenetek súlytényező mátrixait [-1 ,1] intervallum béli véletlen számokkal tölti fel. A rejtett rétegek és a kimeneti réteg elemeinek tartalma ekkor a világon senkit nem érdekel. Mivel amikor szükség lesz a rétegekben levő elemek értékeinek kiszámítására akkor a bemeneten levő adatok és az átmeneti tényezőkből szépen végig lépegetve kiszámításra kerül, rétegről, rétegre. Ez az inicializálás csak egyszer fut le az első tanulás előtt, illetve a felhasználói felületen elhelyezet jelölő négyzet kipipálásával lehet kikényszeríteni az inicializálás lefuttatását (ami az eddig megtanultak törlését jelenti). Az inicializáló ezután átadja a vezérlést a tanító programrésznek.
A tanuló programrész elindulhat az inicializálást követően, illetve amennyiben már volt inicializálva közvetlenül a beolvasás után is következhet. Ez a rész a program lelek. Minden

C E R B E R U S P R O J E K T
110
ennek a sikerességétől függ. Amennyiben sikerül egy jó tanulással az általánosítási képességet jól beállítani, a lekérdezések jók és pontosak ellenkező esetben kérdéses. Vagyis ennek az programrésznek a sebességre optimalizálása másodlagos a pontosság és jósághoz képest, noha ez a leginkább időigényes része a programnak. Az időigényességét jól mutatja, hogy a lefutás egy három ciklusmélységű algoritmus, ahol a második mélységbe 6 darab kettő mélységű ciklus van. A legkülső, hátul tesztelő ciklus feladata, hogy megnézze, a háló által adott kimenet mennyire tér el az előre definiált ε értéktől. Ez jelenti a kilépést a ciklusból. Ezen cikluson belül egy két mélységű ciklus kiszámítja a kimeneti eltérésre vonatkozóan a visszaterjesztett hibát (backpropagation) a kimeneti réteg és a második rejtett réteg közti súlytényezők hatását. Majd elvégzi a szükséges súlytényező módosításokat. A következő lépésbe egy az előzőtől különböző képlet alapján (lásd backpropagaton modell, súlytényező módosítások része) az első és második rejtett réteg átmeneti súlytényező mátrixának a kimenetre gyakorolt hibáit, majd ezután a bemeneti és első rejtett réteg közötti átmenet által okozott hibát. Ezután a lekérdezéssel megegyező módon a bemeneti réteg elemeiből és az új, módosított súlytényezők alapján a rejtett és kimeneti rétegek elemeinek értékét. Az így kapott kimeneti értékek és a kívánt kimeneti értékek négyzetes hibáját meghatározza, majd az ε értékét erre módosítja. Ezután a legkülső hátul tesztelő ciklus feltétel része megvizsgálja, hogy az így kapott ε érték az előre definiált értéknél kisebb-e. Ha nem a ciklus újra elindul, ha igen kilép. A kilépés után a súlytényezőket elmenti. A tanulás végeztével vissza adja a vezérlést a főablaknak (Form-nak).
A lekérdező eljárás tulajdonképpen nem más mind egy kicsi a beolvasó eljárásból, egy kicsi a tanulás eljárásból. Mivel a lekérdezendő adatok ugyan olyan formában adandók, meg mint a tanítási minták, így a lekérdező eljárás ugyan úgy nyitja meg, olvassa be, és kódolja át a szöveges állományokat, mint a beolvasó eljárás. Természetesen ez nem hívja meg az inicializáló eljárást, helyette viszont betölti a súlytényező mátrixokat. Ezután a bemeneti réteg és a bemeneti és az első rejtett réteg közötti súlytényező mátrixból kiszámolja az első rejtett réteget, az első és második rejtett réteg közötti súlytényez mátrix és a kiszámított első rejtett rétegből meghatározza a második rejtett réteg elemeinek értékét. A második rejtett és a kimeneti réteg közötti súlytényező mátrixból meghatározza a kimenetet. Utána kiszámítja a négyzetes hibát a kimeneteken valóban kapott érték és a kívánt ideális érték között, pont ugyan azon a módon, mint ahogy a tanulási eljárás számolja a hibát a kilépési feltételhez. A kapott eltérést kategóriákba osztja amely kategóriák a tesztadatok alapján megállapított értékek. Ez a hét kimeneti réteg esetén azt jelenti, hogy a 0,65 és annál kisebb értékek elfogadhatóak, a 0,65 és 0,85 közötti értékek nem eldönthetőek és a 0,85-nél nagyobb eltérésű értékek elutasítandóak. A táblázatokban látható színezések e határok alapján történt.
A program tartalmaz egy külön transition (átmenet) eljárásokat, amelyek képesek a kiválasztott átmeneti függvényeket alkalmazni egyetlen feldolgozó elem, vagy egy egész mátrixra vonatkozóan, oly módon hogy meghívják az használni kívánt átmeneti függvényt tartalmazó eljárást. Ez természetesen lassítja az algoritmust, de áttekinthetővé teszi az algoritmust, ugyan úgy mint a #define C makrók használata, hiszen a programkód amikor az elemek közötti átmeneti értékszámítása során meg kell határozni az értéket így a kódban csak ennek az eljárásnak a meghívását helyeztem el. Ennek az oka, hogy mivel ez egy tesztprogram itt szükség van arra is, hogy könnyedén ki lehessen próbálni a különböző átmeneti függvényeket. Nem lenne kezelhető, és biztonságos, ha a kódban minden helyen át kéne írni az átmeneti függvény képleteket kézzel, hisz figyelmetlenség következtében ez káoszhoz vezetne, hisz az egyik rétegben már az új átmeneti függvény van, a figyelmetlenségből kihagyottban meg még a régi.

C E R B E R U S P R O J E K T
111
Természetesen a projekt végleges osztályozójában ezek a felesleges és időt pazarló függvényhívások ki lesznek hagyva.
Tesztelés (Safranka) A most következőkben a teszteléseim eredményét, illetve az azokból levont következetéseket és az így végrehajtott módosításokat írom le. A módosítások érintenek további irodalomkutatásokat, amelyeknek a lényegét is leírnám a most következőkben.
Átmeneti függvény választása
A tangens hiperbolikus és a szigmoid függvények azok a leggyakrabban alkalmazott átmeneti függvények, amelyek megfelelnek a backpropagation azon igényének, hogy az átmeneti függvény nemlineáris legyen. Mind a kettő egy viszonylag szűk intervallumban ad eredményt, ami azért hasznos mivel ez nagyban csökkenti a keresési tér méretét.
A szigmoid függvény szemmel látható előnye, hogy kisebb tartományban ad vissza értéket. További látható előnye, hogy nem ad vissza negatív értékeket. Hiszen a negatív értékekkel végzett súlytényező módosítás ellentétes hatást vált ki mint a pozitívval végzett.
Nem is igazán tudtam teszteléseket végezni a tangensi hiperbolikus megoldással, mivel az esetek többségében a számított hiba érték egyre távolodott a megoldástól. Ezt persze csak a forráskód folyamatos figyelemmel tartásával (watch) lehetett észlelni. A program kívülről csak az elfoglaltságot mutatta. Így hamarosan abbahagytam a vizsgálódást a tangens hiperbolikus megoldással. A szigmoid esetén a program mindenképpen a megoldás felé halad (legalábbis a szigmoidnál soha sem tapasztaltam, hogy a megoldástól távolodott volna). Azonban a szerencsétlen inicializálás esetén a kezdeti távolság olyan messze lehet, hogy a megtalálása az átlagosnál nagyságrendekkel (akár több ezerszeres) időigényű lenne. Ez szerencsére elvileg az első néhány ciklus után észre vehető, és ilyen esetben, egy új inicializálással kijavíthatóvá lehet tenni. Az itt a későbbiekben feltüntetett eredmények készítésekor is ez történt.
Problémák
A tanulás során a cél a globális minimum megtalálása egy felületen. A globális minimum keresése egy gradiens eljárás segítségével történik. Abból kifolyólag, hogy a tanulás során a súlymódosítás csak hibafüggvény egy adott pontjának szűk környezete alapján történik, a tanulási folyamat konvergenciájánál problémák léphetnek fel. Így ha egy lokális minimumot elér a tanulási folyamat, nem biztos, hogy el tudja hagyni e helyet, hogy tovább keresse a globális minimumot.

C E R B E R U S P R O J E K T
112
61. ábra Beragad a globális minimumba[Horváth 98]
Felléphet, hogy a hibafüggvény egy sík felületrészen mozogva a súlymódosítás közel nulla, és nagyon sok tanulási ciklus után fog csak ismét a minimum felé haladni az eljárás.
62. ábra Sík felületen halad [Horváth 98]
A súlymódosítás léptékétől ( µ ) függően oszcilláció is felléphet: ha egy lokális minimumhelyről nem tud eltávolodni, folyamatosan visszatér az előző pontokra.
63. ábra Oszcillál [Horváth 98]
Más esetben pont a fordítottja léphet fel, a megtalált globális minimum közeléből kilépve elhagyja a jó megoldást.

C E R B E R U S P R O J E K T
113
64. ábra Elhagyja a jó megoldást [Horváth 98]
E problémák elkerülésére, valamint a konvergencia gyorsítására többféle stratégiát javasolnak. Természetesen tökéletes megoldás nem létezik, de sok esetben konvergensé tehető a tanulási folyamat. Sok múlik a tanulási ráta ( µ ) megválasztásán. Ha nagy az értéke, nem biztos, hogy megtalálja a globális minimumot, vagy oszcilláció alakulhat ki. Ha a ráta értéke túl kicsi nagyon hosszú lehet a tanulási idő. A ráta megválasztása függ a problémától és a hálózat topológiájától és nagyságától is.
A többféle megoldási változat közül a leggyakrabban alkalmazott az úgynevezett momentum módszer, amely célja a konvergencia gyorsítása, valamint a lokális minimumban való „beragadás” elkerülése. A momentum módszer egy heurisztikus eljárás, melynél a súlymódosítást az előző súlymódosítás is befolyásolja. A p-ik mintánál:
( ) ( )kwokw ijppjiijp ∆+=+∆ αδη1
ahol [ ]1,0∈α a momentum együtthatója. Az új tag a súlymódosítás tehetetlenségét növeli, azonos irányban növeli a változás mértékét, az ellenkező irányban pedig visszafogja, csökkenti a változást.
A momentum módszer előnyét mutatja, hogy a módszer megvalósításának köszönhetően a tanulási ciklus szám a 23%-ára csökkent, vagyis 77%-al kevesebb időre van szükség. Természetesen e tesztelésnél a hálózat minden egyéb paramétere, így a pontosság is változatlan volt, csak a momentum módszer okozta a tanulási ciklusszám csökkenést. A hálózat felismerési pontosságára pedig nem volt hatással, amit az alábbi tesztelési táblázat is bizonyít:

C E R B E R U S P R O J E K T
114
Kimenet elemszám
a
Legtöbb tanulási ciklus Próba1 Próba2 Próba3 Elutasít1 Elutasít2 Elutasít3
2 131 0,21 0,26 0,1 0,79 0,49 0,932 125 0,48 0,33 0,23 1 0,18 0,992 117 0,24 0,59 0,41 1,11 0,92 1,052 64 0,75 0,48 0,49 1,95 0,49 0,42 81 0,42 0,2 0,23 0,58 1,29 0,72 116 0,6 0,45 0,45 0,67 0,29 0,682 38 0,1 0,12 0,22 0,95 1,24 0,465 61 0,69 0,64 0,43 1,12 0,98 0,975 208 0,48 0,54 0,38 0,78 0,65 1,475 174 0,81 0,84 0,39 0,96 0,98 0,555 202 0,24 0,41 0,32 0,77 0,34 0,875 70 0,74 0,76 0,33 1,71 0,84 1,135 232 0,36 0,54 0,49 0,94 0,63 1,085 177 0,84 0,31 0,61 1,54 0,79 1,427 199 0,76 0,73 0,64 1,6 1,1 1,87 265 0,64 0,6 0,48 1,38 1,13 0,997 169 0,5 0,64 0,54 1,41 0,74 1,657 114 0,87 0,74 0,43 0,97 0,95 1,77 214 0,84 0,81 0,38 1,22 1,68 1,287 208 0,64 0,61 0,59 1,38 1,09 1,887 293 0,42 0,59 0,37 1,29 0,78 0,75
A tesztelési körülmények
A tesztelést általam kitalált szöveges állományokon végeztem. Három egymáshoz hasonló, de nem teljesen azonos minta szolgált tanítási mintául, ezekhez hasonló, de szintén egyikkel sem azonos három mint a tesztminták, amelyeket elfogadhatónak minősíthet és három eltérő minta amelyek elutasítandók. Természetesen mivel hasonlóak a tanulásra szánt és az elfogadandónak szánt állományok szabadon cserélgethetőek anélkül, hogy a tesztelésre hatással lennének. Nem is szabad hogy hatásuk legyen.
A teszteléshez használt rendszer leírása:
• Hardware: Intel Celeron 800E, 512Mbyte memória
• Software: Windows XP, Borland C++ Builder 5
• A rendszer részei:

C E R B E R U S P R O J E K T
115
o matrix unit (és a header fileja) 1.5 verzió
o redqueenu unit (és a header fileja) 1.0b verzió
Adatleírás A rendszer által használt előre definiált értékek (#define makrók):
ACTIVATION_LIMIT 0
Az egyes feldolgozó elemek számára felállított küszöb érték. Ha ennél kisebb érték lenne az elem kimenetén akkor nincs kimenete (0). Mivel a szigmoid csak 0 vagy annál nagyobb értéket ad, így ezzel a nulla értékkel tulajdon képpen kikapcsoltuk ezt a funkciót, hisz minden kimemet átmegy rajta.
ALPHA 0,7
A momentum módszer súlytényezője. Meghatározza, hogy milyen súlyal vegye figyelembe az előző lépés hatását. A szakirodalmak 0,5 és 0,8 közötti értéket javasolnak
Epsilon 0,01
A négyzetes eltérés azon értéke amely esetén az eltérést már elfogadhatjuk. Ha a négyzetes eltérés a tanulás során ennél az értéknél kisebb lesz, befejeződik a tanulás
MU 0,007
A lépésköz mértéke. Az értéke megyadja, hogy az egyes tanulási ciklusokban milyen mértékben változzanak a súlytényezők, a relatív hibához képest
A programban nem szereplenek globális változók, de minden alprogramban azonos néven szerepelnek bizonyos változók:
InputLayer CMatrix A bemeneti réteg értékei
Hidden1 CMatrix Az első rejtett réteg (az átmeneti függvénny alkalmazása utáni) értékei.
Hidden2 CMatrix A második rejtett réteg (az átmeneti függvénny alkalmazása utáni) értékei.
OutputLayer CMatrix A kimeneti réteg (az átmeneti függvénny alkalmazása utáni) értékei.
AIH CMatrix A súlytényező mátrix a bemeneti réteg és az első rejtett réteg között
AHH CMatrix A súlytényező mátrix akét rejtett réteg között
AHO CMatrix A súlytényező mátrix a második rejtett réteg és a kimeneti réteg között

C E R B E R U S P R O J E K T
116
WoldIH float[] Az előző tanulási ciklusban az AIH értékein végzett súlytényező módosítás értékei. Szerepe a momentum módszer megvalósításánál van.
WoldHH Float[] Az előző tanulási ciklusban az AHH értékein végzett súlytényező módosítás értékei. Szerepe a momentum módszer megvalósításánál van.
WoldHO Float[] Az előző tanulási ciklusban az AHO értékein végzett súlytényező módosítás értékei. Szerepe a momentum módszer megvalósításánál van.

C E R B E R U S P R O J E K T
117
Értékelés Az egyes modulok (arcfelismerés, hangfelismerés és osztályozó) eredményeinek ismertetése után, a fejezet végén a teljes rendszer összefoglaló értékelésére kerül sor.
Hangfelismerés Az eredeti tervekhez képest, melyek négy bemeneti réteggel számoltak, mint lehetséges azonosítási rétegek a neurális háló bemenetén, végülis csak 3 készült el, és csak kettő került alkalmazásra. (Megjegyeznénk, hogy igen jó azonosítási arányhoz már maga az LP spektrum egyedül is elégséges, a további rétegek a finomítást szolgálnák). A megvalósított részek a Linear Predcion spektrum, az alapharmonikus detektálás, és az átlagos amplitudó. A kiaradt réteg pedig a formáns analízis, mely inkább már beszédfelismerést, és nem beszéd azonosítást szolgáló funkció.
Az idő kritikus tényező egy beléptető rendszernél, hiszen nem várhatjuk el a felhasználótól, hogy hosszú ideig kelljen várnia egy belépésvizsgálatra. Az idő dimenzióját valahol a pár másodpercnél kell meghúzni előfeldolgozási szempontból.. Jelenleg a három feldolgozórész futási ideje:
A bemeneti hangfile mérete: ~150k, hossza ~4-5 másodperc
Linear Predicition (tizedrangú)
• Autokorreláció: 7-8 másodperc
• Durbin: 0-1 másodperc (elhanyagolható)
• Fourier transzformáció: 1 másodperc (file mérete a lényegkiemelés után ~5-10k)
Az autokorreláció tehát a fedolgozás szűk keresztmetszete. Azonban ennek feloldására létezik egy egyszerű módszer, mégpedig az, hogy az autokorreláció áltaá használt lépésközt megválaszthatjuk úgy is, hogy kevesebb mintát vegyen alapul (vagyis nagyobb lépésközzel dolgozzon), ezáltal jelentős sebességnövekedés érhető el, viszonylag kis minőségromlással (Ezek a paraméterek jelenleg csak a kódban változtathatók)
Fejezet
4

C E R B E R U S P R O J E K T
118
Alapharmónikus
• Aluláteresztő szűrő: 0-1 másodperc (elhanyagolható)
• Decimator: 0-1 másodperc (elhanyagolható)
• Linear Prediciotn (negyedrangú): 2-3 másodperc
• Hibajel: 0-1 másodperc (elhanyagolható)
• Autokorreláció: 2-3 másodperc (file mérete a lényegkiemelés után ~0.5-1k)
Egyéb eljárások:
• Átlagos amplitúdó: 0-1 másodperc (elhanyagolható)
• Hangenergia: 0-1 másodperc (elhanyagolható)
• Nullátmenetek: 0-1 másodperc (elhanyagolható)
• Vágás: 1 másodperc
Tesztgép: AMD Athlon 1800+ XP, 512 MB DDR-Ram
Jelentős időveszteséget jelent még az egyes események, eljárások részletes és mindenre kiterjedő logolása, mely I/O műveletek sokaságát eredményezi (Egy futás alatt akár 100MB log is keletkezhet)
Arcfelismerés (Bors)
Teszteredmények értékelése
Egy arcazonosító rendszernél a pontosság az elsődleges és legfontosabb szempont. Minden arcfelismerő programot fejlesztő cég (személy) célja, hogy minél pontosabb eredményeket sikerüljön elérnie. Ez nagyban függ az alkalmazott módszerektől, illetve azok megfelelő alkalmazásától. Az elkészült rendszer arcdetektáló része már megfelelő találati szint elérésére képes. A további fejlesztések során a szem illetve száj detektálásra kell nagyobb hangsúlyt fektetni. Bizonyos esetekben láthatóan pontos találatokat ért el a program, azonban időnként nehézségekbe ütközött a szem, de főleg a száj keresésekor. Ha a program jellegét is figyelembe vesszük, nem várható el a szinte pontos működés. Alapvetően a program a célnak megfelelően működik, csak még érzékeny a zavaró tényezőkre.

C E R B E R U S P R O J E K T
119
Összehasonlítás más rendszerekkel
Általában az arcfelismerő programok egyszínű, nem változatos háttér előtt működnek. Jelen projekt célul tűzte ki, hogy változatos háttér előtt is megtalálja a személyt. Többnyire elkülönülnek az arc-detektáló és arc-azonosító programok. Ennek oka, hogy így az adott problémára koncentrálva minél pontosabb eredményt sikerüljön elérni. Ezen program magába foglalja mindkét területet. Ennek viszont hátránya hogy nem jut idő mélyebben csak az egyik területre koncentrálni. Ami új szemlélet, az az ellipszis detektálás használata fejek helyzetének megtalálására. Ezen belül is a RHT használata. Erre a célra egyébként használnak például „bőrkereső” algoritmusokat[Rein], ahol a megfelelő színkomponenseket emelik ki. De keresnek még neurális hálókkal (Rowley, Baluja, Kanade[Rowley 98]) is. A projektben felhasznált módszer azért hatékony, mert kellő szűrés mellett képes a hátteret figyelmen kívül hagyva megtalálni az arcot.
A felhasznált technikát tekintve, a program geometriai távolságok vizsgálatán alapul. Ezt a megközelítést alkalmazta Kanade (1973), Brunelli és Poggio (1993) vagy Cox,Ghosu Yianilos
(1995). Ezzel a technikával meglehetősen pontos találati arányt lehet elérni a tapasztalatok alapján.
Előnyök, hátrányok
A program legfontosabb előnyei közé tartozik, hogy képes változatos háttér előtt is – kellő előfeldolgozás esetén – megtalálni az adott személyt. Az arc megtalálása viszonylag gyorsan végbemegy (lsd. tesztelés). Képes kiszűrni a kép minőségéből származó pontatlanságokat, és az élek esetenkénti határozatlanságából származó hibákra érzéketlen. Előfordulhat, hogy a szűrés során az arc körvonalának csak bizonyos részét érzékeli a program (fényviszonyok, pozíció stb. miatt). Azonban ilyenkor is képes a hiányos részt kipótolva, meghatározni az ellipszist. Vagyis képes akár fél ellipszisből is teljeset meghatározni. Hátránya, hogy erősen változatos háttér előtt pontatlan lehet az ellipszis(arc) detektálás. A teljes felismerési folyamat sebességét növelni kell a kényelmes felhasználás érdekében. A szemek, de főként a száj keresésekor téves pontokat talál időnként. Nagyon hasonló emberek esetén tévedhet akkor is, ha egyébként a paraméterek detektálása megfelelő volt. Hátránya továbbá, hogy a távolságok adottak. Tehát megfelelő távolságra kell lenni az adott személynek, hogy az azonosítás sikeres legyen. Fej elfordulásra és döntésre érzékeny. Ha a száj nehezen látható (pl. szakáll miatt), nem fogja tudni megtalálni.
Továbbfejlesztési lehetőségek
Természetesen a megfelelő sebességoptimalizálások, és találati pontosságok finomítása (volt és) lesz az elsődleges feladat mindvégig. Ezek a szempontok a legfontosabbak egy biometriai rendszernél.
Jelenleg a fényerő okozta eltéréseket manuálisan kell kis mértékben ellen-szabályozni, ahhoz hogy minél pontosabb találatot kapjunk az ellipszis detektálásakor. Ennek automatizálása az intenzitásértékekből számított átlag alapján fog megtörténni. További fejlesztés tárgya lesz, hogy a kezdeti személy-kamera távolságnak ne kelljen állandónak lennie, és ezt a program

C E R B E R U S P R O J E K T - É R T É K E L É S
120
automatikusan tudja kezelni bizonyos szélsőértékek között. Célom, hogy a program tesztelését nagyméretű arckép adatbázisokon is véghez tudjam vinni, így más programokkal is pontosabban össze lehet majd hasonlítani a találati arányokat. Egyes arcok vizsgálatakor minél több referenciapontot sikerül detektálni, annál pontosabb lehet az azonosítás. Az ilyen irányú törekvések további lehetőségeket nyújtanak egy megbízható rendszer elkészítéséhez.
Osztályozó rendszer Az osztályozó rendszer tesztelése és finomítása a fejlesztés korai szakaszával párhuzamosan megkezdődött, abból az okból kifolyólag, hogy a rendszer paraméterek megválasztása és beállítása jelentette a fejlesztés jelentős részét a keretrendszer, az algoritmus implementálása után. A megfelelő paraméterek megválasztása, kezdetben a szakirodalmak által adott útmutatások alapján választott értékek voltak. A tesztrendszer, mint említettem szöveges értékek összehasonlításán alapult. Jelenlegi fázisban az osztályozó tesztrendszerről az előfeldolgozóktól származó adatokhoz igazítás fázisában áll a rendszer. Ezáltal a felismerés hatékonyságának növekedését várhatjuk, mivel a hálózat egy nem általános célú minta összehasonlítást végezne, hanem a speciális adatokra igazítva. Vagyis a hálózat figyelembe veszi a mintákból származó értékek jellegzetességeit, ezzel javítva a felismerést, nem pedig csak általános bitsorozatnak kezeli azokat.
A tesztrendszer elsődleges célja tapasztalat gyűjtés volt az osztályozó rendszerek implementálásához. Az első próbálkozásként elkészített Rejtett Markov Modelles (Hidden Markov Model – HMM) megvalósítása nem váltotta be a hozzá fűzött reményeket, továbbá az implementációja is a várakozásoknál nehézkesebben ment. Ezen problémák és nehézségek miatt, illetve korábbi rendszerek tapasztalatai alapján a neurális hálózatos megoldás mellett döntöttünk. Ezután visszalépve, egy új osztályozó rendszer elkészítése kezdődött meg, visszaterjesztett hiba (backpropagation) megvalósítással. Mivel ennek implementálása gördülékenyen és a várakozásoknak megfelelően haladt, továbbá a felismeréssel szemben támasztott kezdeti követelményeknek is megfelelt, így az ebből elkészült tesztrendszer szolgált a végleges rendszer osztályozó rendszerének alapjául. A tesztrendszerek elkészítése jelentős szempont volt a tovább fejleszthetőség és specializálhatóság, így az implementálásnál általánosan felhasználható és igények szerint tovább bővíthető modulok elkészítése volt a cél. Erre jó példa, a mátrix műveleteket elvégző modul, amelynek „őse” a legelső, HMM megvalósításnak is a beépülő modulja volt, mely további funkciókkal való bővítések után a jelenlegi neurális hálózat kiszolgáló modulja is.
Már a kezdeti teszt adatok esetén felmerült sebesség problémák is arra sarkalltak, hogy optimalizáljam, javítsam a tanulási algoritmust. Ennek során került a tanulást hatékonyabbá tevő momentum módszer bevezetésre. Az átírt algoritmus esetén szükségessé vált annak a bizonyítása, hogy az új algoritmussal nem romlott a hálózat felismerő képessége. Ez a teljes korábbi tesztminták ismételt elvégzését jelentette, majd az eredmények összevetését a korábbi eredményekkel. Az összehasonlítás fentebb található a tesztelési rész leírásánál. Az eredményekből egyértelműen bebizonyosodott, hogy a módszer hatására a felismerés pontossága nem változott, ellenben a tanulásra szükséges idő (ciklusszám) nagyjából a negyed részére csökkent.

C E R B E R U S P R O J E K T - É R T É K E L É S
121
A jelenlegi fázisban a már említett végleges rendszerhez igazítás történik. Ennek az alapja a neurális hálózat tesztrendszere. További, a tesztelések és közös konzultációk során felmerülő új ötletek beépítése, melyek növelik a felismerés pontosságát, vagy javítják a tanulási pontosságot hatékonyságot.
Összesített értékelés Kezdetben a rendszert a projekt tagoktól vett minták segítségével teszteltük, kiküszöbölve a kezdeti hibákat, tökéletesítve és tovább finomítva a felismerés pontosságát. Ezután kiterjesztettük a tesztalanyok körét, így kívánunk további tapasztalatokat szerezni. Célunk a program sebességének optimalizálása és az azonosítás pontosságának növelése, kihasználva a több felismerő egység együttes felhasználásából származó előnyöket.
A tesztelés jelenlegi fázisában az egyes modulok által adott eredmények alapján a globális döntést a következő döntési tábla alapján határozzuk meg:
Arcfelismerés Hangfelismerés Találat A eset Igen Nem Új minta B eset Igen Igen Elfogad C eset Nem Igen Új minta D eset Nem Nem Elutasít E eset Bizonytalan Igen Elfogad F eset Igen Bizonytalan Elfogad G eset Bizonytalan Nem Elutasít H eset Nem Bizonytalan Elutasít I eset Bizonytalan Bizonytalan Új minta
Az egyes modulok különálló tesztelését lásd feljebb. Jelenlegi fázisban a teljes rendszert összeillesztve folyik a fejlesztés. Így volt alkalmunk kipróbálni hogyan működnek az egyes részek együtt, illetve lehetőség volt kezdeti éles tesztelésre.

C E R B E R U S P R O J E K T - É R T É K E L É S
122
Elfogadandó(1), Elutasítandó(0)
Arcfelismerés (S érték)
Hangfelismerés (S érték)
Döntés
A 1 0.19 0.49 Elfogad A 1 0.35 0.5 Elfogad A 1 0.91 0.75 Új minta A 0 1.6 1.27 Elutasít A 0 1.12 1.39 Elutasít B 1 0.58 0.59 Elfogad B 1 0.96 0.7 Elutasít ! B 1 0.64 0.74 Elfogad B 0 1.71 0.91 Elutasít B 0 2.62 1.31 Elutasít C 1 0.22 0.36 Elfogad C 1 0.66 0.73 Új minta C 1 0.58 0.61 Elfogad C 0 1.14 0.83 Elutasít C 0 0.77 1.7 Elutasít D 1 0.29 0.52 Elfogad D 1 0.82 0.72 Új minta D 1 0.61 0.55 Elfogad D 0 0.96 1.11 Elutasít D 0 0.64 1.39 Új minta E 1 0.48 0.67 Elfogad E 1 0.52 0.8 Elfogad E 1 0.43 0.47 Elfogad E 0 1.1 0.98 Elutasít E 0 1.92 1.25 Elutasít F 1 0.14 0.51 Elfogad F 1 0.69 0.75 Új minta F 1 0.21 0.36 Elfogad F 0 0.63 0.54 Elfogad ! F 0 1.37 1.46 Elutasít
A táblázat értékeinél a neurális háló relatív távolság értéke szolgált a minta elfogadhatóságának alapjául. Ez a következőképpen alakul: [0...0.65] közti értékek elfogadhatók, ]0.65..0.95[ bizonytalan, és 0.95 fölött elutasítandó.
A vizsgálathoz 6 személytől vett mintát szemléltet az ábra. Három elfogadandót (1) és kettő elutasítandó (0) mintát próbáltunk minden egyes személyre. Ez alapján lehetőségünk nyílt az egyes modulok összevetésére, illetve az egész rendszer használhatóságára vonatkozó eredmények megismerésére. Látható, hogy előfordult még hibás azonosítás (elutasítandó minta elfogadása vagy elfogadandó minta elutasítása), illetve sokszor kellett hagyatkoznunk arra, hogy az egyik rész bizonytalan és csak a másik modul eredménye alapján történt a döntés. Egy igazán jó biztonsági rendszer esetén csak mind a két rész által elfogadott információ a megfelelő. A

C E R B E R U S P R O J E K T - É R T É K E L É S
123
teszteredményekből láthatóan, még további finomításra van szükség az egyes modulok esetén, hogy kiküszöböljük az ilyen jellegű hibákat.
Összesítve tapasztalatainkat meghállapítható, hogy a kezdeti nehézségeken sikerült átlépni, az integráció okozta problémák felszámolása megtörtént, jelenlegi továbbhaladás iránya a hatásfok minél további tökéletesítése.

C E R B E R U S P R O J E K T
124
Függelék A fejezet tárgyalja azokat a megoldási módokat, amelyek terén végeztünk kutatásokat, ám a megvalósítás során nem kerültek felhasználásra
Fourier Transzformáció (Horváth) Hangfeldolgozás Fourier Transzformációval:
A hangfeldolgozás terén számos megoldás, számos technika látott már napvilágot, ezek közül a már szinte etalonnak számító Fourier transzformációt mutatnánk most be, mint rendszerünk egy lehetséges megvalósítását. Persze a továbbiakban több módszert is vizsgálni fogunk, erre elsősorban azért van szükség, mert a különböző hangfeldolgozási technikák, más-más jellegű feldolgozást tesznek lehetővé, és más-más dolgokra célszerű használni őket.
A Fourier módszer ismertetése a [Székely 94] könyv alapján készült.
A Fourier Transzformáció matematikai alapja
Ismeretes hogy egy f(t) periodikus időfüggvény felbontható egy konstans tag, továbbá végtelen sok szinuszos, koszinuszos időfüggésű összetevő összegére. A periodikus jel T periódusidejének reciproka adja az alapharmonikus frekvenciáját, a további összetevők frekvenciája ezen alapfrekvencia egész többszöröse [Székely 94]. Matematikai formában tehát ez így írható le:
∑∞
=
+
+=
1nnn0
Ttn*2πcosb
Ttn*2πcosacf(t)
∫=T
0
0 f(t)dtT1c
Fejezet
5

C E R B E R U S P R O J E K T - F Ü G G E L É K
125
ahol c0 stacionárius, „egyenáramú” összetevőt így kapjuk:
dtTtn*2πf(t)cos
T2a
T
0
n ∫
=
a koszinuszos, szinuszos összetevők amplitúdóját pedig így számolhatjuk:
dtTtn*2πf(t)sin
T2b
T
0
n ∫
=
Ahhoz hogy ez a sorba fejtés lehetséges legyen a függvénynek teljesítenie, kell bizonyos nem túl szigorú matematikai feltételeket. Elegendő például ha az f(t) függvény a T tartományon korlátos, integrálható és legalább szakaszonként differenciálható. Gyakorlati gondokat ez a kérdés nemigen okoz, mert a hangfeldolgozásban előforduló függvények mindig megfelelnek a közölt elégséges feltételeknek.
Exponenciális alak
Felhasználva, hogy a trigonometrikus függvények a komplex exponenciális függvénnyel kifejezhetők [Székely 94]
( )jxjx ee2j1sin(x) −−=
( )jxjx ee21cos(x) −+=
az 1.1 egyenlet így is írható:
∑∞
=
+−++=
1n
Ttn*j2π-
nTtn*j2π
nTtn*j2π-
nTtn*j2π
n0 ejbejbeaea21cf(t)
Levezetés, és egyszerűsítés után pedig összefoglalva kijelenthetjük, hogy az L hosszúságú periodikus valós f(x) függvényre a Fourier sor együtthatóit így számoljuk:
dxf(x)eL1C
L
0
Lxn*j2π
n ∫−
=
az együtthatókból a függvényt így állíthatjuk vissza:
∑∞
−∞=
=n
Lxn*j2π
neCf(x)

C E R B E R U S P R O J E K T - F Ü G G E L É K
126
Könnyen beláthatjuk, hogy a fenti összefüggések akkor is alkalmazhatók, ha az f(x) függvény komplex értékű. Nyilvánvaló ugyanis, hogy mind az f(x)→Cn sorfejtés, mind a Cn → f(x) visszaállítás lineáris művelet, abban az értelemben, hogy az összeadással és a konstans szorzással felcserélhető.
Diszkrét Fourier transzformáció:
Ha digitális módszerekkel végezzük egy jel analízisét, általában arra kell számítatnunk, hogy a jel, a függvény nem folytonos formában áll rendelkezésünkre, hanem csak diszkrét mintáival. [Székely 94]
65. ábra: Diszkrét jelminta [Székely 94] A vizsgált függvény továbbra is L szerint periodikus, de értékét csak véges számú x helyen ismerjük, véges számú minta áll rendelkezésünkre. Legyen ezek jele fi. Az L hosszúságú periódusra essék N darab minta. Ekkor a minták távolsága:
NLΔx =
Nyilvánvaló, hogy a mintákat elegendően sűrűn kell venni a függvényből. Hogy az mit is jelent az „elegendően” azt a mintavételi tételből tudhatjuk meg, mely kimondja, hogy a mintavétel olyan sűrű legyen, hogy a jelben előforduló legmagasabb frekvenciájú összetevő egy periódusára legalább két minta essék.
Felhasználva az 1.13-mas képletet, megállapíthatjuk hogy az N elemből álló fi értéksorozat, diszkrét Fourier transzformáltját így számíthatjuk:
∑−
=
−=
1N
0i
inN2πj
in efN1D
∑−
=
=1N
0n
knN2πj
n k eDN1f

C E R B E R U S P R O J E K T - F Ü G G E L É K
127
0 ≤ n ≤ N-1
A visszatranszformálást az alábbi szummával végezzük:
0 ≤ k ≤ N-1
Mind a transzformált, mind a visszatranszformált értéksor N-nel periodikus
Dn+N = Dn, fk+N = fk
Valós bemenő vektor
Ha az fi értéksorozat valós értékekből áll, a Dn transzformált egyes elmei bizonyos szimmetria összefüggések állnak fenn [Székely 94]. Ezek az alábbiak:
• D0 valós
• D-n = Dn, ami így is írható: DN-n = Dn
• DN/2 valós
Az első és a második állítás közvetlenül következik 1.28-ból ,a második állítás értelmében DN/2 önmaga konjugáltja kell legyen – tehát csak valós lehet. Az N valós számból álló értéksorozat diszkrét Fourier transzformáltját tehát egyértelműen megadhatjuk a Dn transzformált értéksor felével. Pontosabban az alábbiakkal:
D0, D1, D2,… DN/2-1, DN/2
Mivel az első és az utolsó adat valós, a közbülsők komplexek, ez éppen N darab számértéket jelent.
A DFT kapcsolata a vizsgált függvény harmonikus összetevőivel
Tegyük fel hogy egy valós értékű f(x) jelből ∆x lépésközzel N darab mintát veszünk, s ezekből az fi mintákból előállítjuk a diszkrét Fourier transzformáltat, tehát a Dn értéksorozatot (D0 – DN/2). Kikötjük, hogy a függvény előzetes alul áteresztő szűrésen esett át, aminek eredményeként 2∆x-nél rövidebb periódushosszú összetevő biztosan nem fordul elő benne.
Ez esetben állítható, hogy az f(x) függvény vizsgált szakaszát egyértelműen visszaadja az alábbi kifejezés:
( ) ( )∑=
−
+=
N/2
1nnn0 x
L2πnsinDImx
L2πncosDRe2Df(x)

C E R B E R U S P R O J E K T - F Ü G G E L É K
128
A fent feltételek mellett a DFT elemei egy véges felharmonikus számig végzett Fourier sorfejtés együtthatóival azonosíthatók – oly módon, hogy
• D0 adja a stacionárius összetevőt
• Dn adja az n-edik felharmonikus amplitúdóját (méghozzá: a valós rész a koszinuszos, a képzetes rész a negativ előjellel a szinuszos összetevőt)
Az eltolási és tükrözési tétel
Az eltolási tétel szerint, ha az értéksort k elemmel „odébbtoljuk”, az értéksor DFT transzformáltjának Dn elemei az exp((j*2π/N)*kn) tényezővel szorzódnak. Mivel az fi értéksor N-nel periodikus, az „odébbtolással” a [0,N-1] tartományból kicsúszott értékek a túloldalon visszajönnek. Más szóval: ez az odébbtolás ciklikus [Székely 94]
66. ábra: Eltolási és tükrözési tétel [Székely 94]
A bizonyításra itt nem térünk ki.
A tükrözési tétel: Ennek a valós fi értéksornál látjuk leginkább hasznát. Ezen ugyanis a következőt állíthatjuk. A valós értéksor 0 indexű elmére vett tükörképének DFT-je az eredeti értéksor DFT-jének konjugáltja
A bizonyításra itt sem térünk ki.
A gyors Fourier Transzformáció algoritmusa
Már megállapítottuk, hogy az fi értéksorozat diszkrét Fourier transzformáltját az alábbi módon számoljuk ki: [Székely 94]
∑−
=
−=
1N
0i
irN1j2π
ir efN1D
0 ≤ r ≤ N-1

C E R B E R U S P R O J E K T - F Ü G G E L É K
129
Ahhoz, hogy Dr minden elemét kiszámoljuk, a szumma-jel alatti műveleteket N2-szer kell elvégeznünk. Ez N2 szorzást és N(N-1) összeadást jelent – a műveletek időigénye tehát kb:
TOP = N2(tmul + tadd)
Ahol tmul ill. tadd a szorzás és az összeadás időigénye. (Az exponenciális függvény kiértékelését külön nem számoltuk, mert e függvény összesen N-féle argumentummal fordul elő; táblázatosan előre elkészíthető.)
Az alappontok számának növelésével az időigény tehát négyzetesen növekszik. Ez egy határ felett már irreálisan nagy számítási időt jelent. Szerencsére a számítás műveletigénye látványosan csökkenthető, anélkül, hogy a (2.1) definíciós egyenlettől bármiben is eltérnénk.
Erre ma általánosan használják az ún. gyors Fourier transzformációs algoritmust (Fast Fourier Transform - FFT). Az eljárást J. W. Cooley és J. W. Tukey dolgozták ki, és először 1965-ben publikálták.
Az algoritmust N alappontra adjuk meg; N kettő hatványa. A Transzformálandó függvény fi elemei komplex értékűek lehetnek.
Az FFT algoritmus alapgondolata: az N alappontú transzformáltat N/2 alappontú rész-transzformáltakból kell előállítani, utóbbiakat N/4 alappontra támaszkodó rész-transzformáltakból, stb. Ezért célszerű az általános „rész-transzformált” definíciójában és jelölésében. Legyen ez a következő:
10 −≤≤pNr
0 ≤ q ≤ p-1
ahol
• r a résztranszformált elemeinek futó indexe, a felülre írt indexek jelentése pedig:
• q a rész-transzformált alappont sorozata az fq alapponton kezdődik,
• p a rész-transzformált alappont sorozata fi egymástól p-re lévő elemeiből áll (p mindig 2 hatványa)

C E R B E R U S P R O J E K T - F Ü G G E L É K
130
67. ábra: A transzformált elemei [Székely 94]
Mivel fi-nek N elem van, a rész-transzformált N/p alappontra támaszkodik. Ezért a transzformált ugyanennyi elemből áll
állítás:
10 −≤≤pNr
Ha p = N, N darab rész-transzformáltunk van, amelyek egyenként megegyeznek az fi transzformálandó minta-sorozat egymás utáni elemeivel.
Igazolás: a képlet alján Dr futó indexe csak r = 0 lehet. A kifejezésben ezért az exponenciális tényező értéke 1. Maga a szumma az egyetlen k = 0 értékre terjed ki.
Ezzel:
q
qN,
0 fD = 0 ≤ q ≤ N-1
állítás:
Ha p = 1, egy darab transzformáltunk van, ami azonos a kiszámítandó diszkrét Fourier transzformálttal.
Igazolás: Ha p = 1, szerint q csak 0 értékű lehet. Ezt felhasználva a képletben, az alábbi egyenletre jutunk.
∑−
=
−=
1N
0k
krN1j2π
k 1,0
0 efD
0 ≤ r ≤ N-1
Ami megegyezik a diszkrét Fourier transzformált (2.1) szerinti definícióval.

C E R B E R U S P R O J E K T - F Ü G G E L É K
131
állítás: A p = 2p eset rész-transzformáltjainak birtokában a p = P eset összes rész-transzformáltja kiszámítható az alábbi rekurzív formula segítségével:
Pq2P,
rPr
N1j2πq2P,
r
qP,
r DeDD+−
+=
Pq2P,r
PrN1j2πq2P,
r
qP,
2PN
r DeDD+−
+ −=
12PNr0 −≤≤
0 ≤ q ≤ P-1
Ezt nem bizonyítjuk
A fenti három állítás alapján most pontosan megadhatjuk az FFT algoritmust – a következő módon:
• Az 1. Állítás alapján a kiinduló fi adatsor egyben a p=N eset rész-transzformáltjainak sora
• A 3. Állítás többszöri (log2N-szeri) egymás utáni alkalmazásával megkapjuk a p=N/2, p=N/4, stb., végül a p=1-hez tartozó rész-transzformáltakat.
• A 2. Állítás szerint utóbbi azonos a keresett transzformálttal.
Értékelés:
Összegzésül elmondanám, hogy a Fourier transzformációval azért foglalkoztunk csupán ennyit, mert egy korábbi project tapasztaltait felhasználva ezt a módszert kis mértékben találtuk alkalmasnak a feladat megoldásához. Természetesen ezt a feladatot nem lehet úgy elvégezni, hogy semmit se tudjuk erről az alapkőnek számító módszerről, de a tapasztalatok azt mutatják, hogy a hangazonosítás terén ez a módszer kisebb hatékonysággal alkalmazható.
„Pitch period” becslés (Horváth) A „pitch period” becslés az egyik legfontosabb eljárása a hangfeldolgozásnak. Számos helyen használják, vocodereknél, beszélő azonosításnál, vagy akár rászorultakat segítő rendszereknél. [Rabiner 78]
Fontosságából adódóan sok megvalósítási formája ismert, de kijelenthetjük azt is, hogy teljes megbízhatóságot minden helyzetre egyik sem ad. Itt konkrétan azzal a megvalósítással szeretnénk foglalkozni, melyet először Gold fejlesztett ki, majd később Rabiner segítségével módosította. Ennek két oka van: egyrészt ez a módszer viszonylag jól alkalmazható sok területen, valamit tisztán time-domain módszereken alapszik, valamint könnyen

C E R B E R U S P R O J E K T - F Ü G G E L É K
132
implementálható úgy is hogy, gyorsan működjenek általános célú számítógépeken is, továbbá jól bemutatja a párhuzamos feldolgozás elvét is hangjelekre.
A módszert a következő példán kívánjuk bemutatni.
A hangjelünk 10kHz-es, valamint a hang előszűrésen ment át.
68. ábra: A paralell processing metóduson alapuló harmónikusbecslés blokkvázlata [Rabiner 78]
A következő ábra egy kis magyarázatra szorul:
x(n) : Szűrőböl kijövő jel
mx(n) : x. PPE-be menő adat
Továbbá:
m1(n): a csúcs amplitúdó értékével megegyező nagyságú jel, helyében is megegyezik az eredeti jel csúcs amplitúdójának helyével.
m2(n): a csúcs amplitúdó és az előző mélypont különbsége.
m3(n): a csúcs amplitúdó és az előző csúcs amplitúdó különbsége
m4(n): abszolút értékben vett mélypont.
m5(n): abszolút értékben vett mélypont, plusz az előző csúcspont nagyságának összege.

C E R B E R U S P R O J E K T - F Ü G G E L É K
133
m6 (n): mélypont, és az azt megelőző mélypont különbsége.
69. ábra: A preprocessing szálak értékei [Rabiner 78]
Ezután kerülhet sor a végső „pitch period” megállapítására.

C E R B E R U S P R O J E K T - F Ü G G E L É K
134
Ennek folyamatát az alábbi ábra szemlélteti:
70. ábra: A végső Pitch Period becslés [Rabiner 78]
Amikor egy elegendően nagy amplitúdójú jel érkezik a bemenetre, akkor a kimenetet beállítjuk erre az értékre és ott is tartjuk egy szünetidőszakig („blanking interval”), mely alatt egyetlen más jelet sem detektálunk, legyen az nagyobb vagy alacsonyabb amplitúdójú az adott jelnél. A szünetidőszak végén a kimenet exponenciálisan csökkenni kezd, amíg egy a pillanatnyi értékénél nagyobb jelet nem talál. Ekkor a folyamat megismétlődik.
Ezt a műveletet megismételjük mind a hat jelsorozatra periodikusan (például 100 mintánként)
Majd ezeket a jelsorozatokat összehasonlítjuk, és összekombináljuk, és a legtöbbször előforduló elem (bizonyos tűréssel) adja a „pitch period” értékét az adott részen.
Egy másik harmónikus detektálási módszer, mely szintén egyszerűnek mondható, az LP analízisre épülő vizsgálat, erre majd ott térünk ki.
Neurális hálók a képfeldolgozásban(Bors) A jelenleg elkészült program még nem alkalmaz neurális hálózatot. Elsődleges célom az arc detektálása és egyedi jellemzőinek kinyerése volt. Az osztályozás céljára jól használhatók a neurális hálók. A saját projektben egyfajta döntéshozó rendszerként fog funkcionálni. A célnak megvalósítása Hopfield neurális hálót választottam, mely elvi működésének tanulmányozására implementáltam egy kisebb mintákkal dolgozó programot. (Hopfield neurális háló fejezet).
Alapfogalmak, definíciók, működési elv
A neurális hálókra[5,8] ugyan csak nemrég figyeltek föl, valójában már a 60-as években tudtak róluk. Egy akkori leírás már foglalkozott a BSP technológiával. Az utóbbi évtizedben terjedt azonban el igazából. Ennek fő oka, hogy most lettek a számítógépek elég gyorsak, hogy szimulálják őket. És mivel a neurális hálók erősen matematikai jellegűek, nem valósíthatóak meg fizikailag, csak szoftveres vagy megfelelő szilikon alapú modell segítségével.
A digitális számítógépeknek azonban vannak határai. Lehet hogy egyre gyorsabbak, kisebbek és olcsóbbak, de csak digitális információt képesek feldolgozni, és determinisztikus bináris

C E R B E R U S P R O J E K T - F Ü G G E L É K
135
modelleket használnak a számításra. A neurális hálók azonban más számítási modellt használnak. Erősen párhuzamos, felosztott, valószínűségi modellekkel, melyek nem úgy oldanak meg egy problémát mint a számítógép, hanem egy olyan modell, amely cellák hálózatából áll és amely inkább biológiai módon állapítja meg a lehetséges megoldást kis darabonként, majd végül összegzi az eredményt.
Felépítés
A használt neuron modell az (50 évvel ezelőtt felfedezett) emberi neuronon alapul.
Három része van:
§ dentrit: gyűjti a bejövő jeleket
§ soma: a jelek fő feldolgozásáért és összegzéséért felelős
§ axon: felelős a jelek átviteléért más dentritekbe
Az átlagos emberi agy kb. 1011 neuront tartalmaz és 10.000 kapcsolatot a dentriteknek köszönhetően. A jelek továbbítása Na, K, Cl ionok közreműködésével történik. Ezen ionok felhalmozódása és potenciál különbségei okozzák. A jelek egyszerű elektromos impulzusok, amelyek az axonok és dentritek között közlekednek. Ez a kapcsolat a szinapszis.
Működési elv: a dentritek összegyűjtik a beérkező jeleket más neuronoktól, majd a soma elvégzi az összegzést, majd az eredménytől függően az axon tüzel és továbbítja a jelet.
Bemenetek: X1..Xn és B (memória)
Mindegyikhez külön súlyok: w1..wn, és b
Összegző csomópont: Y, és egy y kimenet
Alapműködés: az egyes Xi input-okat megszorozzuk a megfelelő súlyokkal és összegezzük. Az így kapott eredmény az Ya. A függvény fa(x) és a kimenet y.
∑=
⋅+⋅=n
iiia wXbBY
1
( )aa Yfy =
Az input értékek: +/- integer értékek vagy bináris, de lehet +1/-1 is (bipoláris rendszerek – matematikailag jobb mintha bináris értékeket használnánk.)
A súly értékek (wi) +/- végtelen között mozoghatnak.

C E R B E R U S P R O J E K T - F Ü G G E L É K
136
Aktívációs függvények típusai / fa(x) /:
Lépcsős Lineáris Logisztikus
Fs(x) =1, ha x ≥θ Fl(x) = x, minden x Fe(x) = 1/(1+e-σ x)
71. ábra: Aktivációs függvények
§ Lépcsős típusú: a neuron tüzel, mihelyst a bejövő jel elér egy kritikus értéket (küszöb)
§ Lineáris típusú: a kimenet itt jobban követi a bejövő jelek változásait.
§ Logisztikus típusú: itt az output nem-lineáris. Fejlettebb neurális hálók. Használhatók még akár hiperbolikus, logaritmikus hálók is a célnak megfelelően.
Egyrétegű neurális hálózat esetén a be és kimenet rétege ugyanaz.
Kétrétegű neurális hálózat esetén a belső réteg „rejtett”, és az output réteg felelős a válaszért. Nincs határ hogy hány réteget használunk, azonban a legjobb ha egy vagy két réteges neurális hálókat készítünk és összekapcsoljuk őket mint külön komponenseket.
Idő: az agy meglehetősen lassú a digitális komputerekkel összehasonlítva. Az agy ciklusideje milisecond nagyságú, míg a mai számítógépeké nanosec vagy annál is kisebb.
A neurális hálók valójában egyfajta memóriák. Kétféle típusa létezik: rövid (Short Term Memory) és hosszú távú (Long Term Memory). Ez két szempontot hoz elő:
§ alakíthatóság: mennyire képes az új információval „megbirkózni”
§ stabilitás: képes-e nagy mennyiségű információt tárolni anélkül hogy átlapolná őket
A fő felhasználási területe a neurális hálóknak olyan memóriák, amelyek képesek az azon input információk feldolgozására amelyek nem teljesek vagy zajosak. A tárolás módja lehet például egy n-dimenziós tér. Az arcfeldolgozás során pont ezt a tulajdonságát használom ki.
Minél függetlenebbek egymástól a bemenő vektorok annál jobb.

C E R B E R U S P R O J E K T - F Ü G G E L É K
137
A függetlenség fokának mérésére a Hamming távolságot használhatjuk.
A tanulás folyamata
A leképezést nagymértékben befolyásolják a háló paraméterei:
Az input és output neuronokon kívül hány rétegben (rejtett rétegek (hidden layers)) és mennyi neuronja van a hálónak (rejtett neuronok (hidden neurons)).
A neurális hálók tanulása során ezeket a paramétereket állítja be az alkalmazott tanulóalgoritmus úgy, hogy modellezze a kimeneti és bemeneti paraméterek közti összefüggéseket. A tanuló algoritmusokat[Viharos 02] három nagy csoportra szokás osztani:
§ Az egyes neuronoknak a paraméterei.
§ A neuronok között összeköttetések erőssége (wij).
A következő tanulási módszerek léteznek:
§ felügyelt tanulás (supervised learning),
A tanítás input-output párok (minta) alapján történik. Reprezentatív a mintahalmaz, ha minden lehetséges és fontos minta szerepel benne. A hálózat a minták alapján asszociál és a minták közötti teret is lefedi (előny).
§ felügyelet nélküli tanulás (unsupervised learning)
A hálózat a bemenetére csatolt mintákat csoportokba sorolja, és ezek alapján kerül valamilyen a mintát reprezentáló állapotba. Pl. hasonló elemek csoportosítása, clusterezésre is alkalmas.
§ megerősítéses tanulás (reinforcement learning).
Az első neurális hálót 1943-ban McCulloch és Pitts készítette. Célja az volt, hogy egyszerű logikai függvényeket (AND, OR, XOR) és azok kombinációit számolja neurális hálós módszerrel.
Azóta számos megvalósítása született. Ezek közül nézzünk meg közelebbről kétféle típust.
Hopfield neurális háló
John Hopfield fizikus találmánya ez a struktúráját tekintve egyszerűnek mondható neurális háló[André 02]. Egyetlen régete van, és annyi mesterséges neuront tartalmaz ahány bemenete van. Mindegyik neuron csatlakozik az összes többihez, és a bemenetei egyben a kimenetei is. A visszacsatolásnak (feedback) köszönhetően kaphatunk megfelelő, vagy a helyeshez legközelebb álló eredményt.

C E R B E R U S P R O J E K T - F Ü G G E L É K
138
A Hopfield háló egy iteratív asszociatív memória, tehát csak egy vagy több ciklus után kaphatunk helyes eredményt. A működési algoritmusa:
1. a súlyok meghatározása
2. input értékek bevitele
3. az eredmény ellenőrzése, ha ugyanaz mint ami az input érték, akkor kész, ha nem, akkor fogjuk az eredmény vektort, és „visszacsatoljuk” a hálózaton
A tanuló algoritmus a Hebb szabályon alapul (A bemeneti vektorokat használja a súlyok állítására). A súlyokat egy mátrixban tároljuk (W). Ezen mátrix számítása a következő:
∑=
×=k
ii
tikxk IIW
1)(
ahol I input vektorok bipoláris formában (-1, 1), k elemű
n input vektorok száma, hivatkozás rájuk Ij
yj output értékek, k db, minden I j –hez
W súlymátrix, kxk dimenziós
Az aktivációs függvény a következő:
fh(x) = 1, ha x ≥ 0 0, ha x < 0
Lépcsős típus, bináris kimenettel. Ebből következik, hogy a bemenetnek is binárisnak kell lenni. Tehát át kell alakítani a bináris értékeket bipolárissá.
Az elvi működés és megvalósítás egyszerűbben megérthető, ha egy példán keresztül végigmegyünk a lépéseken[André 02]. Implementáltam egy egyszerű értékekkel működő neurális hálót és a vártaknak megfelelően működött. A megvalósítás a következő:
1. Adott I1 = (0,0,1,0) I2 = (1,0,0,0) I3 = (0,1,0,1) bemeneti vektor.
2. Konvertáljuk bipolárisra I1 = (-1,-1,1,-1) I2 = (1,-1,-1,-1) I3 = (-1,1,-1,1)
3. Számoljuk ki W-t.
W1= [ I1*t x I1
* ] = (-1,-1,1,-1)t x (-1,-1,1,-1) =
1111111111111111
−−−−
−−

C E R B E R U S P R O J E K T - F Ü G G E L É K
139
W2 = [ I2*t x I2
* ] = (1,-1,-1,-1)t x (1,-1,-1,-1) =
1111111111111111
−−−
−−−
W3 = [ I3*t x I3
* ] = (-1,1,-1,1)t x (-1,1,-1,1) =
1111111111111111
−−−−
−−−−
4. Adjuk össze a súlyokat W1+2+3 =
3131131131311113
−−−−−
−−−−−
5. Nullázzuk ki a főátlót. (itt: minden 3-ast cseréljünk 0-ra)
Ezzel elkészült a súlymátrixunk.
Ellenőrizzük a háló működését, ha a bemenetre I1..3 vektort adjuk:
I1 x W = (-1,-1,0,-1) → fh((-1,-1,0,-1)) = (0,0,1,0)
I2 x W = (0,-1,-1,-1) → fh((0,-1,-1,-1)) = (1,0,0,0)
I3 x W = (-2,3,-2,3) → fh((-2,3,-2,3)) = (0,1,0,1)
Ha az eredményt átadjuk a függvénynek visszakapjuk I1..3-at, tehát a háló jól működik.
A zajszűrés és becslés szempontjából azonban annak van nagy jelentősége, hogy ha nem pontos értéket adunk meg, mit fog adni a kimenetén, mennyire képes a helyes eredményt kikövetkeztetni a korábbi tapasztalatokból.
I3 = (0,1,0,1)
I3’ = (0,1,1,1) - zajos input
I3’ x W = (-3, 2, -2, 2)
fh((-3,2,-2, 2)) = (0,1,0,1)

C E R B E R U S P R O J E K T - F Ü G G E L É K
140
Tehát egy ilyen hálózat képes arra, hogy nem pontos adatokból megbecsülje, hogy az adott információ „olyan mint” a korábban már tapasztalt értékek valamelyike. Ezt a tulajdonságát kihasználva, a súlymátrixot memóriaként használva a szegmentált kép meghatározó pontjait input adatként használva ad a neurális háló minél pontosabb eredményt.
Szem és száj detektálás hisztogrammal (Bors) A sokszoros eróziónak köszönhetően a szemek és a száj kiemelődik határozottan. A bőr esetén erős Y intenzitás (zöld) kihasználható: szűréssel elkészíthető egy arc maszk.
72. ábra: Kivágott kép (fent), detektálás (lent)
A piros X-el jelölt helyen megtaláltuk a szemet és a szájat. Az algoritmus:
1. Átlagszámítás: a kivágott képünket (fent) alapul véve, az Y értékek intenzitásaiból kihozunk egy átlagértéket. Erre azért van szükség, mert ha például sötétebb van, kevésbé magas Y intenzitása („kevésbé zöldes”) a kép. Ez az átlagérték lesz a küszöb.
2. Megvizsgáljuk az összes pontot, és ahol alacsonyabb mint a kiszámolt küszöb, kivágjuk a képből. Így eltűnik a háttér, a szemek a száj, és általában az orr is.
3. Hisztogrammokat készítünk: megnézzük vízszintes irányban hány pontunk van soronként, illetve függőleges irányban oszloponként.
4. A hisztogrammok vizsgálata: a fejvonal meghatározása. Az algoritmus a következő:
1. Elindulunk balról jobbra a függőleges hisztogram értékein ( nhh ...1 ).

C E R B E R U S P R O J E K T - F Ü G G E L É K
141
2. Ha 25≥ih , bal oldal = i, szélesség=0
3. Növeljük szélesség értékét 1-gyel, és lépünk a következő értékre.
4. Vissza a 3. pontra mindaddig, amíg 25≤ih nem lesz és a szélesség legalább 50 Legyen a jobb oldal értéke i.
5. A szem vízszintes helyzetének meghatározása. Algoritmus:
1. Elindulunk fentről lefelé haladva. A hisztogram értékei nhh ...1 , delta=30
2. Ha deltahh ii ≥− +5 , a szem felső vízszintes vonalának helye i.
3. Haladjunk lefelé tovább értékenként.
4. Ha deltahh ii ≥−+5 és már megvan a felső vízszintes, a szem alsó vízszintes vonalának helye legyen i.
5. Korrigáljuk az értéket, a lenti vízszinteshez adjunk 5-öt.
6. (szemfent+szemlent)/2 = szem vízszintes helyzete
6. A száj vízszintes helyzetének meghatározása. Algoritmus:
1. Elindulunk alulról, és egészen a szem alsó vízsintes vonaláig haladunk. A hisztogram értékei nhh ...1 , delta=15
2. Ha deltahh ii ≥− +3 , a száj alsó vízszintes vonalának helye i.
3. Haladjunk felfelé tovább értékenként.
4. Ha deltahh ii ≥−+3 és már megvan az alsó vízszintes, a száj felső vízszintes vonalának helye legyen i.
5. Korrigáljuk az értéket, a lenti vízszinteshez adjunk 3-mat.
6. (szájfent+szájlent)/2 = száj vízszintes helyzete
7. A fej középvonala = (a fej jobb oldala + fej bal oldala)/2 (=száj függőleges pozíciója)
8. Bal szem függőleges pozíciója: (fej bal oldala+fej középvonala)/2
9. Jobb szem függőleges pozíciója: (fej középvonala+fej jobb oldala)/2
Azonosítás távolság alapján
Az azonosítási eljárás során az arc bizonyos pontjai közötti távolságot vizsgáljuk. Ezen kiemelt referencia pontok közötti távolságok személyenként változóak. Minél több ilyen pontot sikerül detektálnunk az arcon, annál pontosabb eredményt kapunk azonosításkor.

C E R B E R U S P R O J E K T - F Ü G G E L É K
142
Mivel a pozíció amely rendelkezésünkre áll, a képen belüli abszolút elhelyzetkedés, ezen információk alapján nem lehetne összevetni különböző adatokat. Helyette relatív (egymáshoz képest való) távolságokat számolunk:
212
212 )()( yyxxh −+−=
Ezek után a kapott távolságokat hozzárendeljük személyekhez:
t1 t2 t3 … tn P1 14.5 24.4 29.2 … 11.4 P2 17.6 27.5 31.3 … 15.3 … … … … … … Pn 15.3 26.3 28.4 … 14.3
ahol t1... tn vizsgált tulajdonságok közötti távolságok P1... Pn személyi azonosítók A t1...tn értékek esetén előre meghatározott, hogy mely referencia pontok közötti távolságot jelölik. Így a szemek közötti távolság (t1), a száj-bal szem (t2), száj-jobb szem (t3) illetve további referencia pontok esetén azok meghatározása és eltárolása (tn). Ezen távolságokat a program - lehetőségeihez képest - a lehető legpontosabban igyekszik meghatározni, majd átadni az osztályozó egységnek.
Szegmentációs technikák (Bors) A szegmentálás[Segmentation 02] lényege, hogy kiemeljük a számunkra fontos információt az adott képből. Ez most maga az arc, figyelmen kívül hagyva a hátteret. Több módszer is létezik a szegmentálás végrehajtásához.
A lokális él összekötés esetén adott megfelelő pont grádiensének nagysága és/vagy az iránya. Ezen információk segítségével meghatározható, hogy az adott pixel valóban az élhez tartozik-e. A globális szemlélet szerint minden élpont, ami a képen van bekerül egy élhalmazba. Majd valamilyen hasonlósági korlát szerint köti össze őket (például ugyanazt az él-egyenletet elégítik ki). Az egyik legelterjedtebb és leghatékonyabb módszer a Hough transzformáció.
Lokális szemléletű megoldás
A következő módszer három lépésből áll.
Adott személyre vonatkozó leíró

C E R B E R U S P R O J E K T - F Ü G G E L É K
143
73. ábra: Három lépéses képszegmentálás [Segmentation 02]
Az első részben Sobel szűrő[Image 02] segítségével meghatározzuk az éleket (Edge Detection).
Az élek összekötése (Edge Linking)
Ahhoz, hogy tudjuk szegmentálni a képet, előbb el kell végeznünk az élek összekötését. Problémát jelent, ha a valódi élnek egy kis része hiányzik, vagy pont az ellenkezője, ha a zaj miatt úgy tűnik, mintha valódi él lenne az adott helyen.
Terület növelés (Region Growing)
Itt válasszuk le a környezettől az adott objektumot. Kiválasztunk egy pontot (seed pixel) ami körül élek vannak, majd összehasonlítjuk a környezetében lévő pontokkal hasonló tulajdonságok, szürkeségi szint, textura vagy szín alapján. Addig növeljük a területet, amíg el nem érünk egy olyan pontot, ami már nem hasonló a fenti szempontból az eredeti ponthoz.

C E R B E R U S P R O J E K T - F Ü G G E L É K
144
74. ábra: Terület növelés [Segmentation 02]
Globális szemlélet, Hough Transzformáció
Globális szemléletű megközelítés esetén nem az egyes pixelekből és azok környezetéből indulunk ki, hanem az egész képet tekintjük, és azon próbálunk bizonyos szabályokat felállítani.
A Hough transzformációt[Fisher] primitív alakzatok felismerésére használják. A technika 1962-ben P.V.C. Hough felfedezése volt, mely módszert először használtak mintafelismerésre a 80-as évek elején. A legegyszerűbb változata, mikor egy vonalat detektálunk. Azonban használható komplexebb alakzatok keresésére is. Létezik egy un. Általánosított Hough transzformáció (Generalized Hough Transform – GHT), mikor valamilyen komplex, nem szabályos alakzatot keresünk.
A Hough transzformáció nagy előnye, hogy zajos, pontatlan körvonalak esetén is képes az adott alakzatot felismerni. A következőkben látható lesz hogyan használható a Hough transzformáció vonaldetektálás esetén. Fektessünk adott pontokra vonalakat.
75. ábra: Hough Transzformáció vonaldetektálás esetén [Fisher]

C E R B E R U S P R O J E K T - F Ü G G E L É K
145
A következő egyenlet használható:
xcosθ+ysinθ = r
ahol r a normális hossza az origóból az adott vonalhoz (ponthoz)
θ r iránya, az x tengelyhez képest
76. ábra: Vonaldetektálás [Fisher]
Az egyenes meghatározásához r és θ értékeket keressük. Ehhez egy másik koordináta rendszerre lesz szükségünk. Adott (x,y) koordinátarendszerből elkészítünk egy (r,θ) teret. Ezután un. akkumulátor tömböket használunk. Vagyis egy adott tömb azon értékeit növeljük, amelyik éppen kielégítik a fenti egyenletet. A csúcsértékek jelzik a megfelelő r, θ értékeket
Tekintsük mindezt algoritmus szerűen:
1.Ciklus 0-tól 360-ig (θ).
2. r = x0cosθ+y0sinθ
3. P[r, θ] = P[r, θ]+1
4. Vissza az első pontra.
5. Megkeresni a maximális értéket (r0,θ0).
Felhasználható kör keresésére is, ebben az esetben az egyenlet a következő:
(x-a) 2+(y-b) 2 = r2

C E R B E R U S P R O J E K T - F Ü G G E L É K
146
ahol a,b a kör középpontjának koordinátái
r sugár
Itt arra kell ügyelnünk, hogy mivel három paramétert keresünk, három dimenziós akkumulátor tömbre lesz szükségünk.
Mindkét esetben feltételeztük, hogy valamilyen egyszerűsített, csak éleket tartalmazó képet vizsgáltunk. Továbbá 0 vagy 1 (azaz van pont nincs pont) típusú volt. Ennek elérésére többnyire éldetektáló algoritmusokat használnak[Yang] (Robert kereszt, Sobel, Canny éldetektáló).
A Hough transzformáció valójában arra jó, hogy a programnak egyértelművé váljon, hogy milyen objektum látható a képen. Ha nem tudjuk kellő matematikával leírni az adott alakzatot, a program számára a kép egy meghatározatlan ponthalmaz, ami számára az alakzatról semmilyen információt nem takar.
Nézzük meg, milyen eredményt hoz a Hough transzformáció a következő forma esetén[Fisher]:
Az első képen az eredeti objektumunk látható. A másodikon valamilyen éldetektáló segítségével leszűrjük (előfeldolgozás). A harmadik képen a Hough transzformáció eredménye látható: egyértelmű vonalakkal meghatároztuk az objektumot.
Vizsgáljuk meg, mi történik, ha mintánk nem egyértelműen körülhatárolt:
Nem történt jelentős változás. A Hough transzformáció egyik legnagyobb előnye, hogy érzéketlen a zajra, ezért is vált az egyik legnépszerűbb technikává.
A globális szemléletű megközelítés nagy előnye, hogy míg a lokális szemlélet esetén a kisebb zajok, élszakadások könnyen megtévesztik az algoritmust, globális vizsgálat esetén ez nem jelent problémát. A saját projekben az un. Randomized Hough Transzformációt[Schuler] alkalmaztam ellipszis meghatározására. A részletek az „Arc megtalálása” című fejezetben olvashatók.

C E R B E R U S P R O J E K T
147
Neurális Hálózatok (Safranka)
A neurális hálózat definíciója, működése
A neurális hálózatok definíciója a [Horváth 98 2. fejezet] könyv alapján:
Neurális hálózatnak nevezzük azt a hardver, vagy szoftver megvalósítású párhuzamos, elosztott működésre képes információ-feldolgozó eszközt, amely:
azonos, vagy hasonló típusú, lokális feldolgozást végző műveleti elemek, neuronok (processing element, neuron) rendezett topológiájú, nagymértékben összekapcsolt rendszerből áll,
rendelkezik tanulási algoritmussal (learning algorithm), mely általában minta alapján való tanulást jelent és az információ-feldolgozás módját határozza meg,
rendelkezik a megtanult információ felhasználását lehetővé tevő információk előhívási algoritmussal (recall algorithm)
A neurális hálózat feldolgozó eleme
Először röviden vizsgáljuk meg a biológiai párhuzamot: az emberi agy neuronjai olyan sejtek, amelyek idegi (feszültség) impulzusok fogadására és továbbítására képesek. Az idegsejt több fogadó nyúlvánnyal rendelkezik (amelyeket dendritek nevezünk), melyek a környezetében levő sejtek tengelynyúlványaihoz (axonjaihoz) csatlakozhatnak, amely a sejtek egy kiemelt nyúlványa az ingerület elvezetésére. A dendritek és a sejt test is lehet az ingerület felvevő. Az axonok és dendritek között nem közvetlen a kapcsolat. Van egy „rés” amelyet szinapszisnak nevezünk. Az ingerület átadása a szinapszisban történik speciális vegyületek segítségével. Az egyes sejtek rendelkeznek egy ingerület küszöbbel. Ez azt jelenti, hogy van egy határérték (nagyjából 70 mV) és ha a bejövő gerjesztések nem érik el ezt az értéket, akkor a sejt nem bocsát ki ingerületet. Ellenkező esetben az idegsejt kibocsát egy rövid jelet. Vagyis ezáltal „kiszűri” a zavaró jeleket, illetve a küszöb értéken alapszik az információ-feldolgozás folyamata azáltal, hogy bejövő jel az idegsejtek hálózatán tovább terjed, attól függően, hogy egyes sejteknél létre jön-e a gerjesztés, vagy sem. Ez persze egy elég vázlatos összefoglalása a természetes neurális hálózatoknak.
A mesterséges neurális hálók alapja a „mesterséges neuron”(szokás még feldolgozóegységnek, vagy processzor elemnek nevezni), mely működését aktiválási állapotával, a bemenő adatok (input) feldolgozás módjával és a kimenő adatok (output) előállítási módjával jellemezhetjük. [Borgulya 98 2. fejezet].
A feldolgozás egy adott t időpontjában minden PEj –hez egy aj(t) aktivitási állapot tartozik. Az input adatok feldolgozása után az új aktivitási állapotot az Fj aktivitási függvény értéke adja.
−Θ>−−
=különbenta
ttInputtaFhatInputtaFta
j
jjjjjjjj )1(
)())(),1(())(),1(()(

C E R B E R U S P R O J E K T
148
Ahol )1( −ta j adja az előző aktivitási állapotot, )(tInput j a bemenő adatokat feldolgozó függvény, )(tjΘ pedig a processzor küszöbfüggvényének értéke. Az aktivitási állapot csak akkor változik meg, ha küszöbfüggvény értékénél nagyobb az jF új értéke. A feldolgozó elem bemeneti jelre adott válaszát az jf kimeneti függvény határozza meg. Egy adott elem kimeneti értéke az új aktivitási értéktől függ:
))(()( tafty jjj =
Aktivitási állapotok és aktivitási függvény
A különböző neurális hálózati architektúrák más-más állapotokat engednek meg. Alapvetően vannak folytonos, illetve diszkrét állapotú rendszerek. Egyes architektúrák csak diszkrét egy, vagy több értékű állapotokat engednek meg és diszkrét beviteli/kiviteli értékekkel számolnak.
Egy adott processzor elem a vele kapcsolatban álló, előző réteg béli elemek kimeneti jeleit, vagy közvetlenül az input jeleket kaphatja bemeneti adatként. Az Input (vagy propagation) függvény a bemeneti adatokból:
∑=
=n
iijij twtxtInput
1)(*)()(
Ahol ix az i rétegbeli elemek jeleit, vagy a bemenetre adott jelet jelöli és )(twij az i és j réteg közti ( ji ≠ ) összeköttetés súlytényező mátrixát jelenti.
Legegyszerűbb diszkrét állapot függvény a bináris lépcsős kimeneti függvény, mely a küszöbértéknél nagyobb input jel esetén 1 értéket ad a kimenetén ellenkező esetben nullát.
A legegyszerűbb (és futási idő szerint leggyorsabb) folytonos átmeneti függvény a telítéses lineáris függvény. A telítéses azt jelenti, hogy a függvény értéke nem vehet fel -1 –nél kisebb és +1 –nél nagyobb értékeket. Ezen átmeneti függvény gyakorlati használhatósága igen csekély, mivel tulajdon képen nem csinál mást, mint egyszerűen ami a bemenetén van azt adja a kimenetén, ha benne van a [-1, 1] intervallumban, egyébként levágja -1, vagy 1-re.
A gyakorlatban a lineárisnál jobban használhatóak a valamilyen e-ados függvények, pl.: a tangens hiperbolikus függvény. Ez is a [-1, 1] intervallumban szolgáltat kimeneti értékeket.
A legkedveltebb átmeneti függvény a szigmoid (vagy egyes irodalmakban logisztikus) függvény. Ennek nagy előnye, hogy minden bemeneti értékre egy a [0,1g intervallum béli értéket, vagyis csak pozitív 1-nél kisebb számokat ad. (Megj.: a backpropagation tanítási algoritmus csak ezzel a függvénnyel működik)

C E R B E R U S P R O J E K T
149
Ezen függvények felhasználhatók mind átmeneti függvények és mind kimeneti függvények egyaránt. A kimeneti függvényeknél szokás még egy a győztest kiválasztó „winner takes it all” függvény amelynél a kimenet:
≠==
=különben
jiésnitatajhatyty ij
j 0...,2,1))(max()()(
)(
azaz több az i réteg béli elem állapotát vizsgálva határozzuk meg a j kimeneti értékét.
77. ábra: Folytonos, lineáris átmeneti függvények (lépcsős és lineáris) [Horváth 98]
Θ>
=különben
ttInputhaty jj
j 0)()(1
)(
−<−≤≤−
>+=
1111
11)(
sss
sty j
78. ábra: Folytonos, nem lineáris átmeneti függvények (tangens hiperbólikus és szigmoid) [Horváth 98]
011)( >
+−
= −
−
Keety Ks
Ks
j 01
1)( >+
= − Ke
ty Ksj

C E R B E R U S P R O J E K T
150
Neurális hálózati topológiák
A neurális hálózatok topológiáját a neuronok összekapcsolási rendszerét és egymáshoz való viszonyát értjük. A neuronokat az esetek többségében rétegekbe (layer, field, slab) szervezzük. A sejtek közötti kapcsolat lehet a rétegek közötti kapcsolatok, a rétegen beüli kapcsolatok és a sejtek önmagukkal is kapcsolatba hozhatók (vagyis a kimenetet visszacsatoljuk a sejt bemenetére). Mivel a gyakorlatban használt neurális hálók rétegekbe szervezettek, így a továbbiak csak ezzel a struktúrával foglalkozom.
Lehetséges egy rétegekbe szervezett neurális háló neuronjait három diszjunk halmazra bontani a funkciók szerint [Horváth 98]:
Bemeneti neuronok, melyek típusukban is különböznek a többitől, mivel nem végeznek jelfeldolgozást, átmeneti puffer tároló jellegük van. Bemenetük a hálózat bemenete, kimenetük más neuronok meghajtására szolgál. Emiatt nem is szoktuk a rétegszámba beleszámítani ezt a réteget.
Kimeneti neuronok, melyek feladata a környezetbe tövábbítani az információt, nem feltétlenül különbözve a többi neurontól
Rejtett neuronok (hidden), melyek mind bemenetükkel, mind kimenetükkel más neuronokhoz kapcsolódnak
Fontos megjegyezni, hogy az egyes rétegek elemszáma eltérhet
Megkülönböztethetünk neurális hálózati topológiákat a szerint, hogy az i rétegben levő neuronok mely i+1 réteg béli neuronokkal vannak kapcsolatban. Eszerint megkülönböztetünk teljes összeköttetést, ahol minden i. rétegbeli neuron, mindegyik i+1. réteg béli neuronnal kapcsolatban vannak. Elképzelhető véletlen szerű összeköttetés, ahol az egyes rétegek neuronjai közt véletlen számú kapcsolatot definiálunk, és létezhet egy-egy kapcsolat, ahol az i. réteg j. neuronja csak és kizárólag az i+1. rétek j. neuronjával van kapcsolatban. Az említett kapcsolatokat szemléletesen mutatja a 66. ábra:
79. ábra: Összeköttetési típusok (teljes, véletlen szerű, egy az egy) [Horváth 98]
Az információ-feldolgozás iránya szerint is csoportosíthatjuk a neurális hálózatokat. Eszerint megkülönböztetünk egy irányba haladó, visszacsatolás nélküli (Feedforward) hálózatokat, ahol az információ a bemeneti réteg felöl a kimeneti réteg felé halad és nincs visszacsatolás. Továbbá vannak a visszacsatolást alkalmazó hálózatok, amelyben a továbbitott információ közvetlenül, vagy közvetve visszacsatolódik a bemenetre. Visszacsatolás rétegek közt, vagy rétegen belül is

C E R B E R U S P R O J E K T
151
elképzelhető. Vannak olyan hálózati topológiák is amelyben az i. réteg nem csak az i+1. réteggel van kapcsolatban, hanem egy az i+1. után levővel is.
80. ábra: Visszacsatolás nélküli hálózati topológiák [Horváth 98]
Illetve vannak visszacsatolást alkalmazó neurális hálózatok is.
81. ábra: Visszacsatolásos hálózato topológiák [Horváth 98]
A neurális hálózatok esetén az információtárolást gyakorlatilag a rétegek közötti összeköttetések súlytényezői jelentik. A topológia hatással van a tanulási algoritmusra, annak hatékonyságára, és a lekérdezések jóságára, az algoritmusok futásidejére. Ezen okok nagyon fontos a megfelelő hálózati topológia kiválasztása.
A neurális hálózat tanulása (Safranka) A tanulás az a folyamat (algoritmus), amely során a training példák hatására önállóan változnak meg a NH egyes összetevői, leggyakoribban használtan a kapcsolatok erősségét kifejező súlytényezők. Ezáltal a neurális háló képes lesz a megtanult példákhoz hasonló feladatok önálló megoldására, illetve minta felismerés esetén az asszociációra. [Borgulya 98 2.4 fejezet]
A tanulás a következő elvek alapján történhet:

C E R B E R U S P R O J E K T
152
Új kapcsolatok kialakítása, régebbi kapcsolatok törlése útján.
A kapcsolatok erősségének (a súlytényezők) módosításával.
Az aktivizációs függvény küszöbértékének (Θ ) módosításával.
A feldolgozóelem jellemző függvényeinek módosításával
Új feldolgozó elem beiktatásával, vagy régi törlésével.
Esetleg a felsorolta kombinálásával
A több módszer együttes használata ellen igen jelentős ellenérv az, hogy nehéz az egyes módszerek által okozott változtatások a kimenetre gyakorolt jóságának mérése, és ez alapján a tanulási folyamat módosítása, hogy a kívánt eredményt elérjük.
A leggyakoribb (mivel a legegyszerűbb) módszer a súlytényezők módosítása, és mivel én is ezen módszert használom, így csak ennek az ismertetésére szorítkozom. Súlyszám-módosító tanulásnál a training minden lépésében az eredmények kiértékelésével, vagy a kimeneti réteg elemeinek állapot vizsgálatával dönthetjük el, milyen irányú és nagyságú legyen az a
ijw∆ súlymódosítás, amely az i és j réteg között szükséges. Általánosan megfogalmazva a
)()()( twtwtw ijijijrégiúj ∆+= képletet kell alkalmazni, ahol a )(twij∆ értékét általában egy
hibafüggvény segítségével határozzuk meg. Ilyen hibafüggvény lehet, az általam is alkalmazott módszer, vagyis a háló kimenetén kapott eredmény és az ismert helyes eredmény négyzetes különbsége. Legyen jd a kimeneti réteg j. eleménél kapott eredmény jo a j. elemnél kívánt helyes eredmény (aminek kimeneten kellene lennie), ezt a négyzetes külömbséget összegezve megkapjuk egy mintára a hibát:
( )∑=
−=m
jjj odH
1
222
Ahol m a kimeneti réteg elemeinek a száma. E hibafüggvény felírható a súlyok függvényében is:
( ) ( )nmwwwHWH ,...,, 1211=
Itt a H(W) hibafüggvény már a súlyok függvényében fejezi ki az eredmény hibáját. Ennek értékeit egy n+1 dimenziós hiperfelületet képeznek és e felület globális minimum pontja adja a legjobb megoldást. Ezen pont megkeresése lehetséges valamilyen szélsőérték-kereső módszerrel.
A tanulási módok
A tanulási módok több szempont szerint is csoportosíthatóak. [Borgulya 98 2.4 fejezet]:

C E R B E R U S P R O J E K T
153
Asszociatív tanulásnál a hálózatnak az a feladata, hogy adott input mintákhoz meghatározott output mintákat rendeljen. Beszélhetünk auto és heteroasszociatív tanulásról. Autoasszociatív tanulásnál minden input minta saját magával asszociál. A heteroasszociatív tanulásnál az input mintához egy tőle különböző output mintát rendel.
Felfedező tanulásnál a háló az input mintákat tulajdonságaik alapján kategóriákba, osztályokba sorolja. Az asszociatív tanulással ellentétben a hálónak az input mintákból automatikusan kell a szabályszerűségeket felismerni, az osztályok kialakításához nem szükséges helyes output mintákat megadni.
A rendelkezésre álló training minták alapján beszélhetünk felügyelt (supervised) és felügyelet nélküli tanulásról (unsupervised learning):
A felügyelt tanulásnál a training minden lépésben ellenőrizhető, hogy a kívánt eredményt adja-e a háló. Ehhez természetesen ismerni kell a megoldásokat.
Felügyelet nélküli tanulásnál ismeretlenek a megoldások. A hálózatnak önállóan kell a szabályszerűségeket felismernie.
A tanulási szabály két tetszőleges i. és j. réteg beli neuron közti kapcsolat erősségét kifejező ijw súly változtatásának módját leíró algoritmus. A teljesség igénye nélkül vizsgáljunk meg
néhány szabályt.
Hebb-szabály
Ezt az alapvető tanulási szabályt D. Hebb pszichológus fogalmazta meg 1949-ben. Az emberi agy neuronjai közötti ingerület-átvitellel kapcsolatban megfogalmazott szabály matematikai fogmája egy rétegű neurális hálóknál a következő:
jiij aow η=∆
ahol a ijw∆ a ijw súlytényező módosítása, η a tanulási ráta, amely a súlyváltoztatás „léptékét” meghatározó konstans, io ai i-d feldolgozó elem outputja és ja pedig a j-edik feldolgozóelem aktivitási állapota a t időpontban. A Hebb-szabály csak bináris aktivitási állapotokat alkalmaz és csak súlynövekedést tesz lehetővé. A gyakorlatban azonban -1, 1aktivitási állapotokat szokás alkalmazni, így a súlyok növelése és csökkenése egyaránt lehetségessé válik. A Hebb-szabály többféle interpretációja is létezik. [Borgulya 98, 2.4 fejezet]
Delta-szabály
A delta, vagy Widrow-szabály, amely szintén egyrétegű neurális hálózatoknál alkalmazható, a felügyelt tanulási módok közé tartozik. E szabálynál a súlymódosítást az aktuális aktivitási állapot és az ismert, helyes aktivitási állapot jt különbsége adja:

C E R B E R U S P R O J E K T
154
jijjiij oatow δηη =−=∆ )(
ahol a jδ a j-edik feldolgozóegységnél fellépő hibát jelöli. Ez a legegyszerűbb szabály, amely mintaasszociációkra alkalmazható. . [Borgulya 98, 2.4 fejezet]
Általánosított delta-szabály
Összetettebb asszociációs, osztályozási feladatoknál már többrétegű neurélis hálózatok képesek csak megoldani a feladatok. Ezeknél a delta-szabály nem megfelelő, olyan általánosítása szükséges, amely a súlymódosításokat több rétegen keresztül ki tudja számolni, át tudja vezetni.
Az általánosított delta-szabály, vagy más néven backpropagation szabály nem lineáris, monoton és differenciálható f állapotfüggvények (pl.: szigmoid) esetén alkalmazható. Formája az analóg delta-szabályhoz:
jio δη
ahol most a jδ egy összetettebb kifejezés:
−
= ∑k
kjkjj
jjjj
j rétegbenközbülsőwInputfrétegbenkivitelidInputf
)*()()(*)(
δδ
δ
A közbülső, rejtett réteg béli elemeknél az összegzést minden megelőző elemre, amellyel kapcsolatban van ki kell számolni. [Borgulya 98 .24 fejezet]
A neurális hálózatok alapvető felhasználási területei (Safranka) A neurális hálózatok alapvető ismertetése után röviden tekintsük át azokat a legfontosabb területeket, ahol a neurális hálók ígéretes alternatívát jelentenek más megoldásokhoz képest.
A felhasználási területek leírásai a [Borgulya 98] 2.6 fejezete és a [Horváth 98] 2.3 fejezete alapján készül.
A neurális hálózat, mint asszociatív memória
A neurális háló definíciójából is látható, hogy felfogható speciális adattárolóként, memóriaként melybe a tanulás (learning) útján információt írunk be, s ezt később visszaolvassuk (recall). Az általánosan használt véletlen elérésű (RAM) memóriáknál az adat kiválasztott címre történő beírása tekinthető tanulásnak, előhíváskor pedig a címinformációt használjuk bemeneti jelként,

C E R B E R U S P R O J E K T
155
melyre válaszként a tárolt adatot kapjuk meg. Ezzel szemben a neurális háló egy adattal címezhető memória, vagy mint asszociatív memória használható
Az adattal címezhető memória esetén nagyjából egy osztályozási feladatot igyekszünk megvalósítani. Vagyis a tanulás folyamán a tanítási halmaz elemeit kapcsoljuk a hálózat bemenetére és a hálózat autonóm, vagy felügyelt módon azonos címekhez igyekszik rendelni az összetartozó adatokat. Előhíváskor a bemenetre kapcsolt adat alapján a hálózat által visszaadott cím hordozza az információt.
Asszociatív memóriaként alkalmazva a neurális hálót összetartozó adat párokat használunk, és a hálózatot arra tanítjuk, hogy az adott bemenetre a megfelelő kimeneti adatot rendelje. Az előhívás során a bemeneti adatra adott válasz is egy bemenetihez kapcsolt, asszociált adat. Az asszociáció két változatát szokás megkülönböztetni, az autoasszociációt és a heteroasszociációt. A lényeges különbség a két asszociáció között az, hogy az autoasszociáció a bemeneti mintákat önmagukkal asszociálja, azzal a céllal, hogy az előhíváskor a tanult minták egy zajos változata kerül a bemenetre. Vagyis a tanulási jelvektor mintáit tárolja el a háló és egy zajos jelre adandó lekérdezés a lényeg. A heteroasszociatív hálóknál (vagy mintaaszociónál) a bemenetre adott mintákhoz tetszőleges kimeneti minták társíthatók. A háló tehát összetartozó párokat keres. Ilyen jellegű feladatokra a legalkalmasabb modellek egyike a backpropagation modell.
A neurális hálózat, mint osztályozó
Ez a feladat speciális esete a heteroasszociációnak. Most több különböző beviteli mintához kell ugyan azt a kiviteli mintát társítania a hálózatnak. A kimeneteknek diszjunk osztályokat kell képezniük, melyhez egyértelműen tudja a háló a beviteli mintákat rendelni. A tanulás előre adott osztályok (azaz kimenetek) alapján történik és a tanulás végére a háló képes lesz bizonyos mértékig a nem tanult bemeneti mintákat is helyesen osztályozni. Mivel a feladat a mintaasszociáció speciális esete így a legmegfelelőbb erre a célra továbbra is a backpropagation modell.
A neurális hálózat, mint optimalizáló rendszer
Az optimalizálás a mérnöki tevékenység egyik alapvető lépése.Optimalizálás során valamilyen költséget kívánunk minimalizálni, a rendszer struktúrájának, paramétereinek megválasztásával. Általában a költségfüggvénynek két fontos jellemzője van, egyrésze minden megoldáshoz egyértelműen hozzárendel egy skalár mennyiséget, másrészt ez a skalár mennyiség kifejezi valamilyen szempontból a megoldás jóságát. Neurális hálózatokat sikerrel alkalmaztak bizonyos optimalizálási feladatokra. A megoldás menete általában az, hogy egy, minimalizálni kívánt költség kifejező skalár függvényt keresünk és ezután egy olyan hálózatot hozunk létre, melynek paramétereihez egyértelműen hozzárendelhező a költségfüggvény. Az optimalizálási feladatokra alkalmas hálók többnyire visszacsatolt struktúrájúak, vagyis valamely kiinduló állapotból egy tranziens során jut el a megoldáshoz. Amennyiben a hálózatot úgy tudjuk kialakítani, hogy tetszőleges kiinduló állapotból indulva a lejátszódó tranziens során a költségfüggvény minden lépésben csökkenjen, akkor a végállapot valamilyen költségminimumot reprezentál. Természetesen ez nem feltétlenül biztosítja a globális költség minimumot, tehát az optimális megoldást, de ezt más módszerek sem feltétlenül biztosítják.

C E R B E R U S P R O J E K T
156
Neurális hálózat idősorok kezelésére
Az eddig vizsgált alapfeladatoknál, mint osztályozás, mintaasszociáció, stb. az idő nem játszott szerepet. A feladat megoldása egyik esetben sem függött az előző bemeneti, vagy kimeneti mintától, korábbi állapotoktól. A problémát statikusan az időtől függetlenül lehetett kezelni. Sok feladatnál azonban olyan rendszerrel találkozunk, melyek időben változnak és a következő állapot, vagy részfeladat függ az előzményektől. Időben változó értéksorok anaílzise, előrejelzése is ilyen feladat. Idősorok kezelését a modellek különböző módszerekkel valósíthatják meg. Megvalósítható tartalomcellák révén az előző állapotok, minták értékére emlékezhetnek, vagy egymás után következő minták részsorozatait egyszerre figyelik, folyamatosan új mintákat hozzávéve és a legutolsót elhagyva. Továbbá a magam részéről ilyen jellegű feladatok modellezésére és megoldására a vizsgálataim alapján legalkalmasabbnak a Hidden Markov modellt találtam. A neurális hálózatok egyébként a Hidden Markov Modell speciális eseteként kezelhetők.
A neurális hálózat, mint approximáló rendszer
A megfelelő (statikus) matematikai leképezés előállítása központi feladat a mérnöki alkalmazások számos területén, pl.:képfeldolgozásban, alakfelismerésben, osztályozási feladatokban, szabályozás technikában, jelfeldolgozásban. Ezért a neurális hálózatok igen fontos tulajdonsága, hogy a hálózat jelentős része képes minták előállítására. Számos matematikai felismerés született neurális hálók approximációs (leképezést közelítő) képességeivel kapcsolatban, ezek az eredmények a terület jelentőssége miatt nagy mértékben fokozták a neurális hálók iránti érdeklődést.
A Hidden Markov Modell (Safranka) A valószínűség számításon alapuló hangfeldolgozás
Az általunk végzett irodalomkutatásunk során főként általános, hang analízissel (digitális feldolgozással) és kifejezetten a szöveg felismeréssel (Speech Recognition) foglalkozó anyagokat találtunk. Nekünk pedig hangazonosítás a feladatunk, így e könyveknek a számunkra nem lényeges részeivel (pl.: szöveg adatbázisok, felismerés, stb.) nem, vagy csak felületesen foglalkoztunk. Ez a módszer a [Becchetti 99] könyv alapján készült, amely egészében a hang felismeréssel foglalkozik, méghozzá úgy hogy a Hidden Markov Modellt hasznosítja. A könyv részletes leírást ad a módszerről (4. fejezet, a 168. oldaltól), amelyet most ismertetnék.
Markov láncok
A HMM sztochasztikus folyamatok bemutatására szolgál, melyet a Markov láncok (Markov Chains) valószínűségi változói írnak le. Először vezessük be a Markov lánc definícióját. (Megjegyzés: A Markov láncokat egyes irodalmakban nevezik Észlelhető Markov Modellnek is)

C E R B E R U S P R O J E K T
157
Egy első rendű, N állapotú Markov lánc, egy ( )π,, AS hármas, ahol az S az N egészek halmaza, melyek az állapotokat jelölik, az A egy NN × -es mátrix, mely az állapotok közötti átmenetek valószínűségeit tartalmazza és a π egy N-dimenziójú sorvektor, amely azokat a valószínűségeket tartalmazza, mely megmutatják, hogy az adott állapot milyen valószínűséggel a kezdő állapot. A következő kikötéseket tesszük:
1. az A minden sorának összege 1
2. 1=∑i
iπ
Az S elemei az Ss i ∈ állapotok, az A-t az átmeneti valószínűségi mátrixnak, a π -t a kezdeti valószínűségek vektorának nevezik. A Markov lánc egy állapot modellje egy folyamatnak, amelyben az állapot átmenet csak a megelőző, diszkrét állapottól függ.
Markov forrás: beszéd példa
Nézzünk egy példát néhány akusztikus tulajdonságra, hangképzésben és néhány beszéd folyamatban egy Markov Láncal. Minket az érdekel, hogy felismerjünk különbséget a szünetet (csend), a hangok (beszédhangok) és a zavarok (zajok) között, és készítsünk egy algoritmust, mely hatékonyan felismeri ezeket. Egy ilyen beszéd folyamot modellezhetünk egy háromállapotú Markov Lánccal, ahol minden állapot egy ilyen beszédbeli tulajdonságnak feleltethető meg. Az ehhez tartozó Markov láncot szemlélteti a 69 ábra
82. ábra: Példa egy 3 állapotú Markov láncra [Becchetti 99]
Ennek a modellnek a segítségével meghatározhatjuk a beszédhang, a zaj vagy a szünet egy bekövetkezési sorozatának valószínűségét.
Tulajdonképpen az állapotok egy sorozatának TS valószínűsége egy Markov láncban egy A valószínűségi mátrixa:

C E R B E R U S P R O J E K T
158
( )tt ssTtSiT aSP
11 ,2 −== Π= π
Ahol a π jelöli a kezdeti (t=1-beni) valószínűséget. Az egyszerűség kedvéért mi bevezetünk egy ál kezdeti állapotot, amelyet „0”-val jelöltünk, továbbá definiáljuk az ia0 -t a
1Si=π valószínűségét. Összefoglalva ezek után a következőképp módosul az összefüggésünk:
( )tt ssTtT aSP
1,1 −=Π=
A Markov lánc túl egyszerű ahhoz, hogy szöveg felismerés, vagy egyéb más összetett probléma esetén alkalmazható legyen. Valójában a tulajdonságok, melyeket megbecsülhetünk egy beszédből nem tudják hatékonyan azonosítani a természetes megfigyelést, pl. melyik a megfelelő fonéma. Vagyis a Markov modellt ki kell terjeszteni, hogy tartalmazza azt esetet, amelyben a megfigyelés maga is egy valószínűségi állapot változó ként van leírva.
A kiterjesztett modell, a Hidden Markov Modell (rejtett Markov modell, HMM), mely egy kettős sztochasztikus folyamat, melyet egy az állapotok változását leíró sztochasztikus folyamat alkot. A megfigyeléshez tartozik továbbá, hogy minden állapotot egy-egy valószínűségi változó ír le. Az állapotok ismertek kellenek, hogy legyenek mikor a véletlen folyamat határozza meg az alakulásukat, amely nem ismert (rejtett) a beszéd esetén.
Hidden Markov Modell (Rejtett Markov Modell)
A HMM egy Markov lánc ahol a kimeneti jelek, vagy valószínűségi változók írják le a kimenetet, melyek hozzá vannak rendelve vagy az egyes állapotokhoz, vagy az egyes állapotok közti átmenethez. Az első definíció az állapot-kiment HMM (state-output HMM), míg a második a él-kimenetű HMM (edge-output) Mivel ebben a második esetben az állapot váltási mechanizmus könnyebben leírható, először ezt mutatjuk be:
Egy (edge-output) HMM egy négyváltozós { }( )π,,, kTYS=Θ függvényként írható le, ahol az S és az Y az állapotokat, és kimeneti szimbólumokat tartalmazó halmazok, illetőleg hozzájuk tartoznak az elemszámokat tartalmazó véges elemű SN = és YM = halmazok.
{ } { }1,,0 −== MkTT kk Κ Az NN × -es mátrixok halmaza és a π mely a kezdeti állapotok
valószínűségi (N hosszúságú) vektora. A{ }kT közös mátrixok kijt elemeinek ki kell elégítenie a
következőket:
i∀ esetén 1,10,
=−≤≤ ∑kj
kijtNi
i∀ és j∀ esetén 1,0 −≤≤ Nji és 10 −≤≤ Mk , 0≥kijt
Egy HMM Markov láncára úgy hivatkozunk mint ( )π,,, kTYS halmazra. Az S elemei az állapotok, melyek leírják a Markov láncot. Az Y elemei jelek. A { }kT közös mátrixok reprezentálják az közös eloszlások halmazát (set of joint distributions) a következő

C E R B E R U S P R O J E K T
159
állapotokban, ahol Sj ∈ és a kimeneti jelek következő sorrendben. Ha Sji ∈, és Yk ∈ ás a Markov lánc az i állapotban van, akkor annak a valószínűsége, hogy a kibocsátott jel k és a következő állapot a j lesz az ( )ikjPt k
ij ,= . A négy változó közül az utolsó a π mely a kezdeti valószínűségi eloszlás.
Továbbá definiáljunk két kisegítő mátrixot. Az A átmeneti mátrixa egy HMM-nek a következőképpen definiálható:
∑=k
kijij ta
A B kimeneti mátrix egy NN × -es mátrix amelyben a jkb elemek adják a valószínűségét, hogy a kimeneti jel Yk ∈ a Sj ∈ állapot esetén. Ez esetben a B a következőképp írható le:
∑=j
kijik tb ,
A kikötések biztosítják, hogy az A és B mátrixok sztochasztikus mátrixok, mivel a soraik összege egyenlő 1-el. Megemlítenénk továbbá, hogy egy HMM Markov lánca leírható a következő képen is:
{ }π,, AS
A HMM állapot kimenetű definíciója
Az irodalmakban található egy másik definíció is a HMM-re. Általában a modell kimeneteihez állapotokat rendelnek és nem állapot átmeneteket. Ezek az állapot kimenetű (satat-output) modellek. Egyszerűen bizonyítható, hogy ezek a modellek könnyedén visszavezethetők egy egyenértékű él-kimenetű (edge-output) modellre. Az állapot kimenetű HMM-ek általánosságban több állapotot követelnek meg, mint a él-kimenetűek, melyet az előzőekben ismertettünk. Valójában az A és B segéd mátrixok, melyek leírják az állapot kimenetű HMM-eket, nem megfelelők, hogy visszaadják a { }kT -t. Például. Egy állapot kimenetű HMM-el kezdve a mátrixok megfelelően kifejezhetők, a ∑=
k
kijij ta és a ∑=
j
kijik tb , egyenletek segítségével, a
következőképp jkijkij bat = . A jobbak oldalak kiszámítása lehetővé teszi, hogy megkapjuk az
átmenti és kimeneti mátrixokat, és utána meghatározzuk az jkijba értéket, a kapott eredmény nem azonos az eredeti mátrixokkal. Általánosságban, egy állapot kimenetű HMM felépíthető egy él kimeneti HMM-ből, de az állapot kimeneti HMM-hez több állapot szükséges, mert az él kimenetű HMM-eknek több szabadsági foka van állapotonként, mint az állapot kimenetűeknek.
A beszéd feldolgozásban leggyakrabban használt modelleknél a megfigyelések (observations) a valós számok halmazába tartoznak. Ez esetben a „kimeneti mátrix”, B helyettesíthető egy
( ){ }.ibB = sűrűségi valószínűség függvények (probability density functions, pdf) halmazával, melyek jelölik az állapot kimeneti HMM esetén állapotokat. A pdf-ek általában a normális pdf-ek

C E R B E R U S P R O J E K T
160
keverékei, ez esetben az eredmény HMM egyértelmű kapcsolatban van az úgy nevezett „Radiális Alap Függvények”-el (Radial Basis Functions)
HMM modellezésre alkalmas folyamatok
A HMM egy sztochasztikus folyamat modellje, amely arra szolgál, hogy csökkentsük a nem állandó folyamatokat részben állandó folyamatokká. Valójában a jelek, amelyekkel mi általában találkozunk a természetben tekinthetők úgy, mint véletlen folyamatok, melyek általában nem állandók. A fizikai rendszer, mely ezeket a jeleket kelti, gyakran az állapotuk folytonos változásával keltik a jeleket, vagy a hordozó közeg állapotai melyben a jelek változnak.
Véletlen, nem állandó folyamatok modellezhetők egy kétszeres sztochasztikus folyamatként, ahol a paraméterek, amelyek az észlelhető folyamatot meghatározzák, maguk statisztikailag leírhatók, különböző (rejtett) folyamatokként. Ezek a paraméterek, általában folytonos változók, melyeket folyamatosan megjelölünk, mivel a változásuk az időben folytonosan történik. A modell egyszerűsítve diszkrét időbeli változókkal leírhatók, ahol diszkrét értékek tartoznak az állapotokhoz.
A végső állapot modell feltevése lehetővé teszi a HMM számítását. A rejtett Markov folyamat úgy viselkedik, hogy összerendeli a megfigyelést egy érvényes állapottal. A gyakorlatban a megfigyelés sorozatot két alsorozatra osztjuk, melyek különböző, részben állandó folyamatok. A beszéd esetében ez a megfigyelés gyakran az egy fonémához tartozó három különböző folyamat, mely leírja az első, a középső és a végső megfigyelést.
A megfigyelési folyamat ellenőrzése (control) függ a Markov lánc megfigyelés elöl rejtett állapotaitól, átmeneteitől. Az ellenőrzés azon alapszik, hogy új valószínűségi függvényeket rendeljünk a kimeneti jelekhez, minden állapot átmenet esetén.
Érdemes megjegyezni, hogy egy nem állandó folyamat modellezése egy HMM-el egy állandó nézőpont a forrásából, ami létrehozza a jeleket, mivel a szavak statisztikája időben állandó.
Példa kétállapotú HMM-re
A HMM egy egyszerű modell mellyel magyarázhatók összetett természeti folyamatok. Most erre nézzünk két példát.
Két urnából veszünk ki fehér és fekete golyókat, ahol az urnák felelnek meg a Markov modell állapotainak. Az urnákban a golyók különböző eloszlásúak. A két különböző szín feleltethető meg a két különböző megfigyelt jelnek. Egy általánosabb helyzetben, a megfigyelt kimeneti karakterisztika folytonosan változhat. A golyók kivétele úgy történik, hogy véletlenszerűen kiválasztjuk azt az urnát, amelyből kiveszünk. A kiválasztott urnából kivett golyó színe a megfigyelés jelét reprezentálja. A kivett golyót ezután visszatesszük abba az urnába, amelyből kivettük, így az nem befolyásolja a következő kivételek valószínűségeit.
Ebben a nem állandó kivétel folyamatban a folyamat egy fehér vagy fekete golyókból álló sorozat. Ez esetben a sorozat interpretálható egy HMM megfigyelés kimeneteleként. A

C E R B E R U S P R O J E K T
161
paraméterek értékei a HMM modellezésben a kivevési folyamat, amit a két urna kombinációja, és a kiválasztás mechanizmusa határoz meg.
Első eset
Kezdetben az urnák közül azonos valószínűséggel választhatunk. Az első urna (0-s) csak fekete golyókat tartalmaz (1-es jel). A második urna (1-es) mind a két színből azonos mennyiséget tartalmaz. Minden kivételt a 0-s urnából követhet egy kivétel a 0-s és az 1-es urnából, azonos valószínűséggel. A fehér golyó (0-s jel) kivétele meghatározza, hogy a kivétel az 1-es urnából történt. A ezt a folyamatot úgy is nevezik, hogy egyszerű nem determinisztikus forrás, és ezt két állapot modellezi. Az ebből következő HMM a következőképpen definiálható:
{ }1,0=S , { }1,0=Y ,
=
21,
21
π ,
= 0
21
000T ,
=
21021
21
1T .
83. ábra: Az első példa állapotai [Becchetti 99]
A kimeneti szavak megfigyelése ebben a HMM-ben lehetővé teszi a specifikus sorozatok valószínűségének meghatározását, amit itt úgy definiálunk, mint szavakat. Legyen n
nw 01= egy szó, amely úgy épül fel, hogy egy 0-t követ n darab 1-es. Jelöljük nA -el az állapotok szekvenciáját, amely ahhoz szükséges, hogy nw szavakat készítsünk. A nw -hez tartozó átmeneti mátrix a következő:
( )
== −−−− 11
10
2200
nnnw
nTTT n
A nwT első sora mutatja annak valószínűségét, hogy az n+1 időben a 0 vagy 1 állapotban van, úgy hogy 0 állapotból jött a 0 időben és kibocsátott nw -t. Ennek a valószínűsége 0, mivel 0 kibocsátás a kezdetben egy kell, hogy legyen az 1-es állapotban. A második sora a nwT annak a valószínűsége, hogy a 0 vagy 1 állapotban van, úgy hogy az 1 állapotból jött a 0 időben. Az ármeneti mátrixok néhány módosításával, és bevezetve a kezdeti valószínűséget, leellenőrizhető, hogy az nA állapotok sorozata végtelen, és ezek különböznek valószínűségi párokban, melyek

C E R B E R U S P R O J E K T
162
lehetnek 0, vagy 1 állapotban, amit a ( ) ( )
++ 1
,1
1n
nn
összefüggésből származik. A kezdeti
folyamat állapot ( )0,10 =A , mivel ( ) 10 ==állapotP és ( ) 01 ==állapotP . A végső folyamat állapot pedig ( )1,0=∞A , mivel ( ) 00 ==állapotP és ( ) 11 ==állapotP . A ( )nwjelP 0=
valószínűség egyenlő azzal, hogy
+⋅
15,0
nn . A 78. ábra mutatja a folyamat állapotokat és az
egyes jelek valószínűségét.
84. ábra: Folyamat állapotok és az egyes jelek valószínűsége [Becchetti 99]
Második eset
Most nézzünk egy másfajta urna feltöltést, és egy másfajta kiválasztó mechanizmust. Ez esetben a két urna mindegyike tartalmaz mindkét fajta golyót. A különböző golyókból 100-100 darabunk van, de nem egyenletesen, hanem 45/55, 55/45 arányban elosztva a két urnában. A kiválasztó mechanizmus pedig a következő: Akkor váltunk urnát, ha olyan golyót veszünk ki, amely az adott urnában kisebb darabszámban van (feketét a 0-s urnából, vagy fehéret az 1-es urnából). Ennek megfelelő él kimenetelű átmeneti HMM-et a 72 ábra mutatja:
85. ábra: Az második példa állapotai [Becchetti 99]
Ez az egyszerű modell alkalmazható sok gyakorlati esetben. Az első esetnél említett ábrája alapján készült. Az egyszerűség kedvéért töröltünk egy állapotot, és visszavezettük egy hang-nem hang kétállapotú problémára. A megfigyeléshez választhatunk, úgy hogy, „alacsony energia = 0” vagy „magas energia = 1” az aktuális hangjelre alapozva. Jegyezzük, meg, hogy az alacsony energia nem következésképpen jelenti, hogy a minta a nem hang; és ugyan ez igaz a magas energiára is. Ez a modell egy használható modell lehet fizikai folyamatoknál, és meghatározhat

C E R B E R U S P R O J E K T
163
egy valószínűséget, amely egy megfigyelésből származik. AZ automatikus beszéd felismerés hasonló alapokra épül, amelyek sok állapotot és megfigyelést tartalmaznak, melyeket a beszéd jelből szerzünk.
A HMM alkalmazása beszéd modellezésre
A hang feldolgozásnál az első lépés, hogy a mintából kiszűrjük a lényeges tulajdonságokat, vagyis csökkentsük a redundanciát. A beszédre jellemző vektorokat nevezzük megfigyeléseknek. A most következő részekben az ( )TT yyY ,,1 Κ= a T megfigyelés sorozataként definiáljuk.
A beszélt nyelv elképzelhető úgy, mint ezeknek az egységeknek a sorozata, amin nyelvi egységeknek nevezünk, melyek egymást követik a képzési szabályoknak megfelelően. Jelöljük S-el a nyelvi egységek egy sorozatát, a probléma megtalálni a megfelelő S sorozatot az Y megfigyelésből.
86. ábra: Hangfelismerő rendszerek blokk vázlata [Becchetti 99]
A 73 ábra mutatja a hangfelismerő rendszerek általános sémáját. Még ha a beszédnek nagy fokú változatossága is van, az összes megengedett Y és S halmazok szekvenciája még mindig sokkal kevesebb, mint az összes lehetséges kombinációja mind az akusztikus, mind a nyelvtani kényszernek. Például az \ae\ fonéma tartalmazza egy korlátozott számát az akusztikus mintáknak; továbbá nem minden fonéma sorozat megengedett. A felismerés folyamata tovább osztható két különböző állapotra:
HMM beszéd modell építése, a megfigyelés sorozat Y és az állapotok sorozatára S alapozott Θ (tanítás)
Beszéd felismerése a tárolt HMM modell Θ és az aktuális megfigyelés Y alapján
Minél több HMM reprezentálja az Y és S szekvenciákat az eredmény annál tökéletesebb lesz. Ha lehetséges volna minden lehetséges Y megfigyelés és S sorozat közti megfeleltetés, akkor a hangfelismerés problémája meg lenne oldva. Valóságban nagyon nagy modelleket használnánk akkor a számítási idő, és a memória igény kezelhetetlenül nagyra növekedne.

C E R B E R U S P R O J E K T
164
Nézzük meg miért „rejtett” a beszéd HMM modellje, és hogyan példázható egyszerűen a nyelv. A beszélő agyában a nyelvi egységeket képzelhetjük úgy, mint megfelelő szekvenciába összefűzött összetett modell, melyet az évek során tanult meg. Feltehetjü, hogy ez a modell egy Markov lánc, aminek az állapotai megfeleltethetők a nyelvi egységéknek. Az emberek számára a jelfeldolgozó a fül, amely végrehajtja a különböző szűréseket, az érzékletek arányában.
A beszéd felismerő rendszerekben ez egy „jellemzők kivonása” előfeldolgozó blokkot jelent. A forrás feldolgozás az agyban folytatódik, nem közvetlenül megfigyelve, vagy más szóval „rejtve”.
Vegyünk egy akusztikus Y sorozatot és egy Θ beszéd folyamat modellt. Egy hangfelismerő rendszernek meg kell találnia a legjobb S* szekvenciát, amelynél az utólagos valószínűség ( )Θ,YSP :
( )Θ= ,* YSPArgMaxS s
A maximalizálás egyenértékű, ha megtaláljuk azt az S*-ot mely:
( ) ( )ΘΘ= SPSYPArgMaxS s ,* (Bayes tétel)
Mivel egy általános ts függ a megelőző és az utána következő nyelvi egységtől és megfigyelésektől, maximalizálás problémája nem megengedhető.
Valójában a beszéd leírható, mint egy folyamat, mely minden idő pillanatban a megengedett állapotok halmazának egyik állapotában van, és amely állapot változáson megy át egyenlően osztott diszkrét időkben.
Továbbá a modell állandó és a nyelvi egység előfordulásának valószínűsége, a következő t+1-s idő pillanatban csak attól függ, hogy a t idő pillanatban, melyik állapotban van. Ezért a
( )ΘSP kifejezés közvetlenül leírható a HMM átmenet valószínűségeket felhasználva:
( ) ( ) ( )tt ssTtsittTt assPsPSP
11 ,21,21 ,−==−= Π=ΘΠ=Θ=Θ π
Egy másik feltevéssel, melynél minden megfigyelés ty statisztikailag független minden más megfigyeléstől és az eloszlása csak attól függ, hogy melyik állapot generálja ty -t. Ezért a ( )Θ,SYP leírható a HMM pdf-jét (probability density functions, sűrűségi valószínűség függvény) felhasználva a következőképpen:
( ) ( ) ( )tsTtttTt ybsyPSYPt,1,1 ,, == Π=ΘΠ=Θ
Mivel egy adott S és Y esetén a két kifejezés ( )Θ,SYP és ( )ΘSP egyszerűen számítható a felismerés problémája megközelíthető lett. A probléma még a legjobb S* sorozat megtalálása amit meg kell oldanunk.

C E R B E R U S P R O J E K T
165
Nem ér semmit, ha megkövetelt modell csak egy durva reprezentációja a beszéd folyamatnak. Továbbá a felismert sorozat csak akkor lesz optimális, ha figyelembe veszi az adott modellt. Habár a feltevések megengednek nagyon sok egyszerűsítést, a beszédfelismerés még továbbra is jelentős méretű számítási modell megvalósítását igénylik.
A Bayes-i HMM megvalósítás
A HMM elmélet megvalósítható egy új szerkezetben, a Bayes-i szemléletben. A lényege, hogy a Markov lánc felfogható egy korábbi részvételként, és a megfigyelési valószínűség egy utólagos tapasztalati bizonyítékként.
Az utólagos valószínűség ( )Θ,YSP egy adott S állapot sorozatra megfigyelhető egy adott HMM modell esetén egy adott Y megfigyelési sorozat szorozva az előző állapotok sorozatára a megfigyelési sorozat valószínűsége, mint a ( ) ( )ΘΘ= SPSYPArgMaxS s ,* képletben.
Egy adott sorozat megbecsülhető, mint ami származikΘ a HMM modell forrásból, aminek a legnagyobb utólagos valószínűsége előállítja.
Az optimális modell keresés az utólagos valószínűségi modell egy adottΘ modell, adott Y megfigyelési sorozat esetén, úgy determinálható, mint a megfigyelési sorozatok megelőző valószínűségeinek összege, az összes lehetséges állapot sorozatra, súlyozva az állapotok utólagos valószínűségei és az utólagos valószínűsége a Θ modellnek. A *Θ modell eredményezi a maximális értékét a valószínűségnek egy HMM felismerőben:
( ) ( ) ( )
ΘΘΘ=Θ ∑∈Θ δs
SYPSPPArgMax ,*
Továbbá a HMM tekinthető úgy mint egy végső állapotú Bayes-i modell egy markovi előzménnyel, ami statisztikailag leírja az állapot átmeneteket, és egy halmaza a pdf-eknek ami leírja a kimeneti folyamatot minden állapotban.
A valószínűségi következtetés a HMM-ekben: előre és hátra haladó folyamatok
A egy megfigyelés sorozat pdf-je egy HMM-modelben Θ , feltételes egy állapot sorozatban adott a ( ) ( ) ( )tsTtttTt ybsyPSYP
t,1,1 ,, == Π=ΘΠ=Θ képletből. Egy megfigyelési sorozat közös pdf-je és az állapotok sorozata ezért:
( ) ( ) ( )tsssTtssTT ybaybYSPttt 111 ,21,
−=Π=Θ π
A egy TY sorozat feltétlen pdf-je kifejezhető figyelembe véve, hogy az állapotok sorozata rejtett, és ezért szükséges összeadni az összes lehetséges δ∈TS sorozat hozzájárulását:
( ) ( ) ( )tsssTtS ssT ybaybYPtttT 111 ,21 −=∈
Π=Θ ∑ δπ

C E R B E R U S P R O J E K T
166
A kiszámítása az összes lehetséges állapot sorozatok mennyisége miatt lehetetlen Egy hatékony eljárás segíthet megismerni a részleges állapotok sorozatának valószínűségeit és megfigyeléseket, pl. a sorozatok megcsonkítása egy bizonyos t időre. Legyen ( ) ( )Θ= tti sYPj ,α a részleges megfigyelések közös valószínűsége (a t ideig) és a js j = kezdeti állapot a t időben, ez a valószínűség, amit előre haladó valószínűség, a következőképpen számítható:
( )( )
( ) ( )
= ∑=
−
N
itjijt
iii
t ybaia
ybj
11
πα
NjTtNi
≤≤≤≤≤≤
121
Amelyhez hasonlóan definiálhatjuk a β visszafelé haladó valószínűséget:
( )( )
( ) ( )
=
= ∑=
++
N
jtjijt
T
t ybaj
ii
111
1
β
ββ
1,,111
Κ−=≤≤≤≤
TtNjNi
Ez esetben a ( )TtTt ssS ,,1,1 Κ++ = különböző állapot sorozatok összege, a t+1 időtől a végső T időig, és az esemény, hogy ist = állapotban van a t időben.
A végső ismétlődésben megkülönböztetjük a valószínűség eredményes becslése által kívánt eredményt, a TY megfigyelési sorrend valószínűségétől az előre haladó számításból, figyelembe véve, hogy a definíció szerint ( ) ( )TTT YisPi ,==α :
( ) ( ) ( )∑∑ ==Θii TT iiYP 1βα
Hasznos ezt a számítást ábrázolni, melyet a 81 ábra mutat, amely leírja az összes utat, ami egy három kibocsátó állapotú HMM gráf bejárását jelenti, mely előállítja a 51 yy Κ öt darab megfigyelést:
1y 2y 3y 4y 5y ( )46α
( )23α
( )00α
87. ábra: Három kibocsájtó állapotú HMM gráf bejárási összes útja [Becchetti 99]

C E R B E R U S P R O J E K T
167
Az állapot-idő rács ismétléses és szabályos struktúrája a balról jobbra haladó HMM, ahol minden oszlop az első állapottal indul (az ál kezdeti állapottal (dummy initial state)) és az utolsó állapottal végződik (az ál utolsó állapottal (dummy final state)). Egy N állapotú HMM TN különböző állapot szekvenciát hozhat létre az állapot-idő rácson. Grafikus értelemben ez egyenértékű az ( )it 1−α értékek számításával összerendelve a rács t. sorát használva a megelőző oszlop értékét, számításba véve a megengedett átmenetek valószínűségeit és a megfigyelési valószínűségeket. A visszafelé haladó használható a tanítási problémák hatékony megoldásában, mint a következőkben látni fogjuk.
Megfigyelési sűrűségek
Miután kiértékeltük az y vektorok tulajdonságait, kiszámítottuk ( )yb j valószínűségeket, adott y esetén minden j állapotban. Az egyszerűbb választás egy a jellemző vektor értéken végrehajtott vektor mennyiségi (vector quantization (VQ)) művelet. Ez esetben, y –nak Kk Κ,1= diszkrét értékei vannak, N az adott állapotok száma, ( )kb j a NK × valószínűsége annak, hogy a j állapot a k.-ik jellemző értéket bocsátja ki.
Egy alternatív választás abból áll, hogy y-t egy véletlen D-dimenziójú folytonos változónak tekintjük, amely egy megfelelő pdf-hez tartozik. Egy kézenfekvő választás ez esetben egy több változós közös sűrűség létrehozása az egy dimenziós Gauss-i pdf-ből, amit az jµ átlag vektor és az jU kovariancia mátrix ír le:
( )( )
( ) ( )
−−−= jj
Tj
jDj yUy
Uyb µµ
π 21exp
det2
1 Nj ,,1 Κ=
HMM inicializálás (tanítás)
A sztochasztikus megközelítés a beszéd fonémák és nyelvi elemek statisztikai változatain alapszik, a tanítási minták nagy beszéd adatbázisok esetén különböző (szöveg) összefüggésben rögzítettek és több beszélő esetén.
A tanítás (training) célja, a valószínűségi függvény (likelihood function) maximalizálása adottΘ modellnél ( )ΘTYP megfigyelési sorozat esetén. Ezen eljárás első lépéseként a modell paramétereit véletlen értékekkel inicializáljuk vagy értékekkel melyeket valamilyen módon szereztünk. A második lépés a modell paraméterek újra becslése végrehajtva a formulákat, melyek figyelembe veszik a kezdeti értékeket és a tanítási megfigyelések sorozatát. Az újra becslés folyamatát megszakítjuk, mikor a ( )ΘTYP nem mutat javulást.
A Baum maximum valószínűségi becslés (maximum likelihood estimation, MLE) azon a tényen alapszik, hogy egy állapot sorozat, amely előállít egy bizonyos megfigyelési sorozatot, nem ismert. Ezért, a valószínűség maximalizált figyelembe véve minden lehetséges állapot utat, ami kibocsáthatja a tanítási minta megfigyelési sorozatát. A Baum algoritmus ismételgeti az A, B és

C E R B E R U S P R O J E K T
168
π tömbök javított becsléseinek eredményét, maximalizálva a megfigyelési sorozat valószínűségét. A bizonyítás, hogy az algoritmus konvergál a kívánt értékek felé megtalálható a [Baum 67]
A Baum tanítási eljárás egy MLE eljárás, amely a lokális minimumhoz konvergál, így érzéken a modell inicializálására. Ezért a modell kezdeti értékeinek megadása kritikus lépés a becslési folyamat során, különösen a folytonos sűrűségű modelleknél, mint ahogy a tapasztalati bizonyítékok mutatják.
Az A átmenet mátrix inicializálása kevésbé kritikus, mivel az átmeneti valószínűségek korlátozott hatásúak a felismerés során. Lényegében az átmenetek valószínűségei az azonos állapotra vagy folytonos állapotokra vonatkozóan inicializálhatók azonos értékekre, míg az átmeneti valószínűségeket nem folytonos állapotokban általában 0-ra szokás venni.
A kezdeti értékadás megtehető vagy iteratív eljárásokkal, hogy tökéletesítse a modellt, vagy szegmentációs eljárásokat használva és adat összegyűjtéssel, hogy jobb kezdeti becsléseket adjunk.
Az iterációs modell kiemelés azon a megfontoláson alapszik, hogy a modell pontossága továbbfejleszthető tekintve egy egyszerűsített modellt sokkal kevesebb paraméterrel a tanítás első ismétlésében, és utána fokozatosan növelve a modell komplexitását. Például egy sok állapotból összetett modell becsülhető azon a becslésen alapulva, amely több egyszerű, egy állapotú vagy egy minden állapothoz egy egyszerű kovariencia mátrixot használó modellt használ.
A szegmentálás és összegyűjtéses módszerek általában arra használatosak, hogy a tanításhoz használt beszédmód minták halmazát felosszuk fonémákra és fonéma állapotokra, továbbá inicializáljuk az összes állapothoz tartozó pdf-eket a megfelelő adatokkal. Kezdeti fonéma szegmentálás megtehető egy szakember által, aki értékeli a jelfeldolgozások eredményeit, mint a spektogram. Finomított fonéma állapot szegmentálás elkezdhető egységes szegment hossz nélkül. Felügyelet nélküli automatikus szegmentálás durván érhető el egységes hosszúságú szegmenseket használva. Jobb szegmentálás érhető el spektrális stabilitást használva, vagy olyan módszerekkel, melyek minimalizálják a szegmensek közötti eltéréseket.
A Viterbi tanító algoritmus szintén használható lehet modell inicializálásra, megtalálva a modell paramétereket, amik maximalizálják a közös megfigyelések valószínűségét és állapot sorozatokét. Ez esetben a Viterbi tanítás összeolvasztja a szegmentálást és a paraméter becslést. Ezért lehetséges elkezdeni a tanítást nem precíz szegmentációkkal és modellekkel és hozzájutni a jóval pontosabb modellekhez egy néhány ismétlés után. [Rabiner 1993]
A Baum algoritmust határosnak (bounded) nevezik, azaz amikor a tanítási anyag szegmentációja elérhető, vagy egy beágyazott (embedded) eljárás használata, amikor a tanítási anyag nem szegmentált, mint ahogy gyakran történik. Bevált gyakorlat végrehajtani egy kezdeti tanítást egy határos Baum újra becsléssel néhány, elérhető, fonetikailag szegmentált tanítási mintán és egy beágyazott újrabecslés végrehajtása, az általában jobban konzisztens, nem szegmentált adaton. Valóban nagyon nehéz nagy fonetikailag szegmentált adatbázisok létrehozása, mivel a szegmentáció költsége igen nagy. Továbbá a kézi szegmentálásnak megvan az a hátránya, hogy jelentős mértékben szubjektív megtalálni a határt a fonémák között. Semmit nem ér egy olyan

C E R B E R U S P R O J E K T
169
szegmentáció, amely csak arra szükséges, hogy modelleket inicializáljunk, amelyek függenek a használt algoritmusoktól, de nem szükségesek a Baum algoritmussal való tanításhoz. Ezzel szemben az észlelési sorozatok fonetikus címkézése mindig szükséges, egyébként a megfelelő HMM fonéma sorozat modellek, amelyek megfelelőek minden szónak, nem biztosíthatók tanítási algoritmusokkal.
A HMM megvalósítása (Safranka) Ebben a részben a HMM modell megvalósítását mutatom be. Ezt a részt főképp a [Becchetti 99] könyv alapján készítem.
Az osztályozó három különböző részre bontható.
88. ábra: Az osztályozó blokkvázlata [Becchetti 99]
A Gauss modell számítása
Kezdetben egy Gauss-i pdf (probability density functions) van minden fonémához. A jelölje a bemenő adatot y, λ azt, hogy az y milyen fonémához tartozik, és továbbá szelekciós eljárás meghatároz egy s-t, amelyhez az (y, λ ) szükségesek. Ezután a következő lépésben további Gauss-i pdf-eket adunk mindegyik részhez. Így a régi M Gaussi HMM modell kovarienciája segítségével meghatározhatjuk az összes pdf torzítását.
A torzítás segítségével megkapjuk az új Gauss-i pdf-kekt ás meghatározhatjuk az új 11 +Mµµ Κ jelentés és '
11' , +MUU Κ kovariencia halmazokat.

C E R B E R U S P R O J E K T
170
A HMM modell implementálása
A HMM-et használja mind a három modul: az inicializáló, a tanító és a felismerő, ezért ezek a modulok egy egyedül álló HMM osztály hierarchiát használnak, amely a 76 ábrán az „Általános HMM” oszlopban található
89. ábra: A HMM modell implementálásának moduljai [Becchetti 99]
Ez a hierarchia csupán azokat az adatokat és függvényeket foglalja magában, amelyek közösek az összes modulban. A specifikus modulok egyéb osztály hierarchiát az „Általános HMM”-ből származtatják. Az általános HMM hierarchia ismertetését kezdjük az alacsonyabb szinttel a Gauss-i pdf- implementációjával, ezen osztály header-jét a következőképpen néz ki:
Class Gaussian { Boolean full_cov //teljes, vagy átlós kovariencia mátrix t_real weight; //a Gauss-i súlytényezők naplói a kevertben VetDouble mean; //az átlag vektor MatrixOfDouble inv_cov; //a teljes inverz kovearencia mátrix DiagMatrixOfDouble diaf_inv_cov; //átlós inverz kovariencia mátrix t_real gConst; //a Gauss-i modellek konstans része t_real Evaluate_Exp_Gauss(const VetDouble& obs_vet)const; void Read(ifstream& s, const t_index stat_dim); //I/O funkciók void Write(ofstream& s); };

C E R B E R U S P R O J E K T
171
A HMM osztály header-je a következőképpen alakul:
Az osztályba bekerültek olyan metódusok is amelyek feladata a kimeneti, bemeneti kapcsolatok biztosítása a megfelelő fájlokon keresztül. A választás a full_cov mezőben jelentkezik. A
weight tartalmazza a kc értékeket a ( ) ( ) ( ) ( )( )ik
ik
M
k
ik UyNcisyP ,,
1µ∑
=
== képletben amelyben
a ( )ikµ , ( )i
kU , ( )ikc a kovariencia mátrixok vektorai és a súlytényezői a ( )⋅⋅⋅ ,,N Gauss-i pdf-nek és
az ( ) 11
=∑ =
M
ki
kc jelenti a konzisztenciát. Megjegyzés: a pdf (probability density function) nem
más, mint a ( )isyP = . A gconst konstans a konstans faktor a pdf-ben, amely nem függ az y megfigyelésektől. A gconst konstans előszámítása csökkenti a szükséges számítások mennyiségét.
A NodeSpecShape osztály reprezentálja a Gauss-i keveréket. Az osztály neve emlékeztet minket arra a tényre, hogy az állapotokat más néven „csomópontoknak” nevezzük, és a keverékek statisztikailag leírják az y megfigyeléseket, ami a bejövő beszéd adat „spektruma”. Végezetül a HMM osztály tartalmazza az adatokat, amelyek egy fonémát reprezentálnak.
Az inicializálás HMM hierarchiája
Az InitCluster header-je:
Template <class E> Class Hmm:public ImpObjectList<E> { void Read_Transition_Matrix (ifstream & input_f); Public: Boolean full_covariance //a teljes/átlós kovariencia t_index phoneme; //az aktuális fonémák száma t_index num_states; //a HMM-beli állapotok száma t_index num gauss; //A Gauss-i modellek száma, minden állapotra t_index stat_dim; //a tulajdonság vektor dimenziója MatrixOfDouble trans_mat //átmeneti mátrix //függvények az osztályok inicialziálására void Configure (t_index phon, t_index st_d, t_index stat, t_index gauss); //I/O funkciók void Read (ifstream& input_f, Boolean is_full); void Write (const String & f_out_name); //függvények a Gauss-i modellek constansainak kiszámítására Boolean Compute_G_Const(); };
class InitCluster : Public Gaussian { public t_index population; //a keretek száma egy egységben VetDouble centroid; //átlag vektor t_real distortion; void Compute_Cluster_Distortion(); void Do_Averages(); //az átlag vektor és a covariencia mátrix számítása };

C E R B E R U S P R O J E K T
172
Az InitCluster a Gaussian osztályból került származtásra. A kiterjesztések azokat azokkal a hozzá adatokkal és függvényeket jelenti, amelyek szükségesek a felosztó algoritmus számára. Végezetül a HMM szint megkövetel további funkciókat. Az erre vonatkozó osztály az InitCodebook amely tartalmazza a függvényeket az maszatolás (splotting) eljáráshoz, amely ahhoz szükséges, hogy megbecsüljük a HMM paramétereket, melyek lehetővé teszik a pdf-ek keverékenkénti számának meghatározását. Először, ha csak néhány adat tartozik a pdf-hez a kovariencia mátrix gyengén feltételezett és az inverze valószínűleg érvénytelen. Általánosságban , amikor néhány adat érhető csak el, a paraméterek gyengén becsülhetők és a felismerés hatékonysága is csökken és nem kezd növekedni, akkor sem ha több pdf-et adunk a keverékhez. Csak akkor van értelme növelni a pdf-ek számát, ha minden lépésben lehetőségünk van ellenőrizni a modell becslési hatékonyságát, bizonyítva hogy a felismerés hatékonyságának csökkenése abbamaradt. Az algoritmust a következő táblázat ismerteti:
Split_Higher_Distortion_Cluster_of_Each_Section()
Index_Of_Clusters_To_Spilt(clusters_to_split) Visszatér azokkal a clusters_to_split –ekkel, amyelye nagyobb torzításúak, mint amit felosztani kell
Add_One_Cluster_To_Section() Memória foglalás a további Cluster-ek számára minden szakaszban
Calculate_New_Centroids(clusters_to_split) Az új központokat (centroids) Reset_Clusters_Statistic() Újra kezdi az átlag és kovariencia változókat
Assign_Actual_Frame_ToIts_Cluster() Minden bemenő adat kiolvasásra kerül és hozzá rendelődik a legközelebbi központhoz
Up_Normalized_Sum_SqrSum_AndPop() Minden bemenő adat felhalmozódik a megfelelő átlagban és kovarienciában
Do_Averages()
Miután az összes elérhető keret összegződött, az átlag és kovariencia gyűjtő elosztásra kerül a megengedett átlag és kovariencia adatok számával

C E R B E R U S P R O J E K T
173
Az InitCodebook hearer-je:
Az adatok leírásai:
A HMM és a Válószínűségi, Bayes-i és Neurális Hálós megoldások összehasonlítása
A HMM tekinthető egy sokkal általánosabb modell osztálynak: a valószínűségi hálózatok vagy a grafikus valószínűségi modellek [Buntine 96] amik magukban foglalják a Bayes-i modellt, és a
class InitCodebook : public HMM<InitNodeSpecShape> { public //osztály tagok inicializálása void Initialize(t_index num sections, const t_index num_mix, t_index statistics_dim, Boolean full_covar); //az aktuális megfigyelésből számított mátrix void Up_Normalized_Sum_SqrSum_And_Pop(const VetDouble& act_frame, VetDouble & sum, MatrixOfDouble & square_sum, ,DiagMatrixOfDouble &diag_square_sum, t_index & cardinality); void Accumulate(const ImpObjectList<VetDouble>& phon_instance, const t_index stat_dim); //memória foglalás void Add_one_cluster_to_Section(const t_index section, const t_index stat_dim); //a torzulások kiszámítása void Compute_Whole_Codeboob_Clusters_Distortions(); //a súlytényezők kiszámítása void Compute_Cluster_Weights(); void Calculate_New_Centroids(const t_index section, const t_index father_cluster, const t_index son_cluster); void Reset_Clusters_Statistics(t_index section); //A HMM modell tárolása egy fájlban void Store_Codebook(const String& output_fname, Const t_index act_phon, Boolean load_mixture);
};
DiagMatrix diag; MatrixOfDouble mat; T_real num; Diag[0][0]=num; diag[1][1]=mat[3][5]; num=diag[9][8]; diag[8][9]=num; mat<<=diag;
T_index; ImpDiagMatrix<t_index> diag;… Num=diag[8][9]

C E R B E R U S P R O J E K T
174
neurális hálózat fajták, amelyek úgy fejlődtek ki, mint valószínűségi modellek. Ezek a megoldások arra használatosak, hogy összetett modelleket készítsünk egyszerű komponensekből. Ezek a hálózatokban közös, hogy korábbi információt használnak a tanulási folyamat során. Viszont ez a korábbi adat általában olyan adatból származik, amely később alkalmazásra került különböző környezetekben, követve egy látszólag Bayes-i (quasi-Bayesian) megközelítést. [Buntine 96].
Javasolt az előre felé táplált neurális hálózatok (feed-forward neural networks) transzformációi Bayes-i hálózatokká. Hasonló egyenlőség létre jött a Bayes-i hálózatok és a HMM-ek közt. Viszont, a HMM egy dinamikus folyamat modellje, míg a Bayes-i hálózat egy statikus reprezentációja néhány változó között a közös, vagy feltételes valószínűségeknek, és így ezek a hálózatok ismételt egységek halmazai, amelyek időben kiterjesztettek.
Érdekes, hogy viszont sok algoritmus lett kifejlesztve a Bayes-i, hálózatokhoz alkalmazhatók sokkal általánosabb modellekre, mint azok amelyes a HMM számára készültek. Ezzel az elvvel készíthetők olyan eszközök, amelyek sokkal erőteljesebb HMM modellek osztályait képesek elkészíteni. Például be lett bizonyítva, hogy a PIN-ek (Probabilistic Inference Networks) következtetés algoritmusok és a Dawid algoritmusok az Előre-Hátra haladó valószínűség (Forward-Backward probability) következtetés és a Viterbi algoritmus általánosítása. Ráadásul a HMM MLE Baum tanítási algoritmusa alapjában egy becslés maximalizáló (Estimate-Maximize) eljárás a paraméter modellek megtudásáért , amikor rejtett vagy hiányzik adat, továbbá arra használt, hogy megtudjuk a Bayes-i hálózatok paramétereit.
A HMM kiterjesztése megtehető, bevezetve az elosztott állapot reprezentációs modelleket (distributed state representation modell), vagy más néven Faktoriális HMM-eket. Ez ötleten alapszik, hogy az időbeni fejlődést kódolja egy egy állapotú változóba, szigorú korlátok közé szorítva a reprezentálási kapacitását, mivel túl sok eltérő állapotra lenne szükség egy HMM-ben néhány bit információ tárolásához.
Egy másik kiterjesztése a modellnek azon alapszik, hogy a t…t-p időbeni kibocsátás által alkotott p+1 vektort úgy tekinti, mint a többdimenziós megfigyelés a t időben. Ez a megközelítés lehetővé teszi, hogy figyelembe vegyük a folyamatot hosszabb időben, ezért ez valahogy lecseréli az igényt egy magasabb mint egy rendű Markov láncra a HMM-ben. Viszont a nagyobb számítási igény miatt nehézkes bizonyos esetekben. A hasonló struktúrákban a következtetéshez hozzávetőleges algoritmusok már léteznek.

C E R B E R U S P R O J E K T
175
Tesztelési eredmények A hangfelismerő rendszer esetén három állapotot különböztetünk meg. Ezek: mikor egy hangmintát elfogad, elutasít, illetve bizonytalan esetben új mintát kér. Ezt a döntést az aktuális minta betanított neurális hálón való végig haladása után a háló kimenetén megjelenő eltérési érték alapján hozza. Amenyiben a kimeneten az „1”-től való eltérés kissebb, mint 2,5 a minta elfogadható, a 2,5 és 6 közé eső érték esetén új mintát kér és a 6-nál nagyobb eltérés esetén elutasít.
.wav fájl neve Betanított minták Kimeneti érték Döntés balint_1 balint_1;balint_2;balint_3 1,856 Elfogadható balint_2 balint_1;balint_2;balint_3 1,82 Elfogadható balint_3 balint_1;balint_2;balint_3 1,343 Elfogadható balint_bodo balint_1;balint_2;balint_3 15,689 Nem elfogadható balint_csaba balint_1;balint_2;balint_3 8,135 Nem elfogadható balint_feb balint_1;balint_2;balint_3 11,285 Nem elfogadható balint_matyee balint_1;balint_2;balint_3 5,84 Nem eldönthető balint_nylac balint_1;balint_2;balint_3 11,843 Nem elfogadható balint_rudi balint_1;balint_2;balint_3 3,635 Nem eldönthető balint_2_1 balint_1;balint_2;balint_3 2,449 Elfogadható balint_2_2 balint_1;balint_2;balint_3 2,369 Elfogadható bodopeti_1 balint_1;balint_2;balint_3 9,65 Nem elfogadható bodopeti_2 balint_1;balint_2;balint_3 12,984 Nem elfogadható bodopeti_3 balint_1;balint_2;balint_3 14,795 Nem elfogadható bodo_balint balint_1;balint_2;balint_3 11,345 Nem elfogadható bodo_csaba balint_1;balint_2;balint_3 7,265 Nem elfogadható bodo_feb balint_1;balint_2;balint_3 13,19 Nem elfogadható bodo_matyee balint_1;balint_2;balint_3 4,37 Nem eldönthető bodo_nylac balint_1;balint_2;balint_3 11,69 Nem elfogadható bodo_rudi balint_1;balint_2;balint_3 5,795 Nem eldönthető bodo_2_1 balint_1;balint_2;balint_3 14,42 Nem elfogadható bodo_2_2 balint_1;balint_2;balint_3 10,535 Nem elfogadható csaba_1 balint_1;balint_2;balint_3 3,41 Nem eldönthető csaba_2 balint_1;balint_2;balint_3 4,52 Nem eldönthető csaba_3 balint_1;balint_2;balint_3 15,065 Nem elfogadható csaba_balint balint_1;balint_2;balint_3 2,63 Nem eldönthető csaba_bodo balint_1;balint_2;balint_3 16,775 Nem elfogadható csaba_feb balint_1;balint_2;balint_3 11,885 Nem elfogadható csaba_matyee balint_1;balint_2;balint_3 4,685 Nem eldönthető csaba_nylac balint_1;balint_2;balint_3 3,935 Nem eldönthető csaba_rudi balint_1;balint_2;balint_3 16,595 Nem elfogadható csaba_2_1 balint_1;balint_2;balint_3 7,85 Nem elfogadható csaba_2_2 balint_1;balint_2;balint_3 16,73 Nem elfogadható feb_1 balint_1;balint_2;balint_3 11,06 Nem elfogadható feb_2 balint_1;balint_2;balint_3 9,41 Nem elfogadható

C E R B E R U S P R O J E K T
176
.wav fájl neve Betanított minták Kimeneti érték Döntés feb_3 balint_1;balint_2;balint_3 7,46 Nem elfogadható feb_balint balint_1;balint_2;balint_3 4,91 Nem eldönthető feb_bodo balint_1;balint_2;balint_3 14,42 Nem elfogadható feb_csaba balint_1;balint_2;balint_3 7,765 Nem elfogadható feb_matyee balint_1;balint_2;balint_3 9,155 Nem elfogadható feb_nylac balint_1;balint_2;balint_3 10,1 Nem elfogadható feb_rudi balint_1;balint_2;balint_3 8,48 Nem elfogadható feb_2_1 balint_1;balint_2;balint_3 10,985 Nem elfogadható feb_2_2 balint_1;balint_2;balint_3 13,835 Nem elfogadható matyee_1 balint_1;balint_2;balint_3 16,07 Nem elfogadható matyee_2 balint_1;balint_2;balint_3 11,72 Nem elfogadható matyee_3 balint_1;balint_2;balint_3 15,785 Nem elfogadható matyee_balint balint_1;balint_2;balint_3 4,355 Nem eldönthető matyee_bodo balint_1;balint_2;balint_3 11,18 Nem elfogadható matyee_csaba balint_1;balint_2;balint_3 4,79 Nem eldönthető matyee_feb balint_1;balint_2;balint_3 6,38 Nem elfogadható matyee_nylac balint_1;balint_2;balint_3 13,04 Nem elfogadható matyee_rudi balint_1;balint_2;balint_3 15,965 Nem elfogadható matyee_2_1 balint_1;balint_2;balint_3 8,525 Nem elfogadható matyee_2_2 balint_1;balint_2;balint_3 9,125 Nem elfogadható nylac_1 balint_1;balint_2;balint_3 15,995 Nem elfogadható nylac_2 balint_1;balint_2;balint_3 9,065 Nem elfogadható nylac_3 balint_1;balint_2;balint_3 14,555 Nem elfogadható nylac_balint balint_1;balint_2;balint_3 6,05 Nem elfogadható nylac_bodo balint_1;balint_2;balint_3 5,65 Nem eldönthető nylac_csaba balint_1;balint_2;balint_3 6,995 Nem elfogadható nylac_feb balint_1;balint_2;balint_3 12,185 Nem elfogadható nylac_matyee balint_1;balint_2;balint_3 11,315 Nem elfogadható nylac_rudi balint_1;balint_2;balint_3 6,395 Nem elfogadható nylac_2_1 balint_1;balint_2;balint_3 13,415 Nem elfogadható nylac_2_2 balint_1;balint_2;balint_3 9,86 Nem elfogadható rudi_1 balint_1;balint_2;balint_3 6,275 Nem elfogadható rudi_2 balint_1;balint_2;balint_3 10,625 Nem elfogadható rudi_3 balint_1;balint_2;balint_3 5,435 Nem eldönthető rudi_balint balint_1;balint_2;balint_3 6,035 Nem elfogadható rudi_bodo balint_1;balint_2;balint_3 11,285 Nem elfogadható rudi_csaba balint_1;balint_2;balint_3 5,585 Nem eldönthető rudi_feb balint_1;balint_2;balint_3 9,5 Nem elfogadható rudi_matyee balint_1;balint_2;balint_3 12,02 Nem elfogadható rudi_nylac balint_1;balint_2;balint_3 7,7 Nem elfogadható rudi_2_1 balint_1;balint_2;balint_3 13,16 Nem elfogadható rudi_2_2 balint_1;balint_2;balint_3 12,38 Nem elfogadható balint_1 bodopeti_1;bodopeti_2;bodopeti_3 15,95 Nem elfogadható balint_2 bodopeti_1;bodopeti_2;bodopeti_3 8,165 Nem elfogadható balint_3 bodopeti_1;bodopeti_2;bodopeti_3 9,08 Nem elfogadható balint_bodo bodopeti_1;bodopeti_2;bodopeti_3 15,155 Nem elfogadható balint_csaba bodopeti_1;bodopeti_2;bodopeti_3 4,61 Nem eldönthető

C E R B E R U S P R O J E K T
177
.wav fájl neve Betanított minták Kimeneti érték Döntés balint_feb bodopeti_1;bodopeti_2;bodopeti_3 10,34 Nem elfogadható balint_matyee bodopeti_1;bodopeti_2;bodopeti_3 14,15 Nem elfogadható balint_nylac bodopeti_1;bodopeti_2;bodopeti_3 11,48 Nem elfogadható balint_rudi bodopeti_1;bodopeti_2;bodopeti_3 10,22 Nem elfogadható balint_2_1 bodopeti_1;bodopeti_2;bodopeti_3 11,27 Nem elfogadható balint_2_2 bodopeti_1;bodopeti_2;bodopeti_3 3,315 Nem eldönthető bodopeti_1 bodopeti_1;bodopeti_2;bodopeti_3 1,583 Elfogadható bodopeti_2 bodopeti_1;bodopeti_2;bodopeti_3 1,103 Elfogadható bodopeti_3 bodopeti_1;bodopeti_2;bodopeti_3 1,535 Elfogadható bodo_balint bodopeti_1;bodopeti_2;bodopeti_3 12,56 Nem elfogadható bodo_csaba bodopeti_1;bodopeti_2;bodopeti_3 5,075 Nem eldönthető bodo_feb bodopeti_1;bodopeti_2;bodopeti_3 12,965 Nem elfogadható bodo_matyee bodopeti_1;bodopeti_2;bodopeti_3 14,225 Nem elfogadható bodo_nylac bodopeti_1;bodopeti_2;bodopeti_3 13,175 Nem elfogadható bodo_rudi bodopeti_1;bodopeti_2;bodopeti_3 4,295 Nem eldönthető bodo_2_1 bodopeti_1;bodopeti_2;bodopeti_3 2,432 Elfogadható bodo_2_2 bodopeti_1;bodopeti_2;bodopeti_3 2,057 Elfogadható csaba_1 bodopeti_1;bodopeti_2;bodopeti_3 10,73 Nem elfogadható csaba_2 bodopeti_1;bodopeti_2;bodopeti_3 8,06 Nem elfogadható csaba_3 bodopeti_1;bodopeti_2;bodopeti_3 6,71 Nem elfogadható csaba_balint bodopeti_1;bodopeti_2;bodopeti_3 5,36 Nem eldönthető csaba_bodo bodopeti_1;bodopeti_2;bodopeti_3 16,145 Nem elfogadható csaba_feb bodopeti_1;bodopeti_2;bodopeti_3 12,395 Nem elfogadható csaba_matyee bodopeti_1;bodopeti_2;bodopeti_3 16,16 Nem elfogadható csaba_nylac bodopeti_1;bodopeti_2;bodopeti_3 12,995 Nem elfogadható csaba_rudi bodopeti_1;bodopeti_2;bodopeti_3 14,915 Nem elfogadható csaba_2_1 bodopeti_1;bodopeti_2;bodopeti_3 14,285 Nem elfogadható csaba_2_2 bodopeti_1;bodopeti_2;bodopeti_3 15,55 Nem elfogadható feb_1 bodopeti_1;bodopeti_2;bodopeti_3 5,87 Nem eldönthető feb_2 bodopeti_1;bodopeti_2;bodopeti_3 16,31 Nem elfogadható feb_3 bodopeti_1;bodopeti_2;bodopeti_3 16,256 Nem elfogadható feb_balint bodopeti_1;bodopeti_2;bodopeti_3 15,258 Nem elfogadható feb_bodo bodopeti_1;bodopeti_2;bodopeti_3 7,584 Nem elfogadható feb_csaba bodopeti_1;bodopeti_2;bodopeti_3 10,824 Nem elfogadható feb_matyee bodopeti_1;bodopeti_2;bodopeti_3 9,873 Nem elfogadható feb_nylac bodopeti_1;bodopeti_2;bodopeti_3 5,614 Nem eldönthető feb_rudi bodopeti_1;bodopeti_2;bodopeti_3 11,748 Nem elfogadható feb_2_1 bodopeti_1;bodopeti_2;bodopeti_3 11,012 Nem elfogadható feb_2_2 bodopeti_1;bodopeti_2;bodopeti_3 14,365 Nem elfogadható matyee_1 bodopeti_1;bodopeti_2;bodopeti_3 16,24 Nem elfogadható matyee_2 bodopeti_1;bodopeti_2;bodopeti_3 15,948 Nem elfogadható matyee_3 bodopeti_1;bodopeti_2;bodopeti_3 5,996 Nem eldönthető matyee_balint bodopeti_1;bodopeti_2;bodopeti_3 15,336 Nem elfogadható matyee_bodo bodopeti_1;bodopeti_2;bodopeti_3 8,845 Nem elfogadható matyee_csaba bodopeti_1;bodopeti_2;bodopeti_3 9,025 Nem elfogadható matyee_feb bodopeti_1;bodopeti_2;bodopeti_3 15,341 Nem elfogadható matyee_nylac bodopeti_1;bodopeti_2;bodopeti_3 8,574 Nem elfogadható

C E R B E R U S P R O J E K T
178
.wav fájl neve Betanított minták Kimeneti érték Döntés matyee_rudi bodopeti_1;bodopeti_2;bodopeti_3 7,896 Nem elfogadható matyee_2_1 bodopeti_1;bodopeti_2;bodopeti_3 11,976 Nem elfogadható matyee_2_2 bodopeti_1;bodopeti_2;bodopeti_3 6,442 Nem elfogadható nylac_1 bodopeti_1;bodopeti_2;bodopeti_3 14,152 Nem elfogadható nylac_2 bodopeti_1;bodopeti_2;bodopeti_3 11,638 Nem elfogadható nylac_3 bodopeti_1;bodopeti_2;bodopeti_3 13,478 Nem elfogadható nylac_balint bodopeti_1;bodopeti_2;bodopeti_3 16,548 Nem elfogadható nylac_bodo bodopeti_1;bodopeti_2;bodopeti_3 11,778 Nem elfogadható nylac_csaba bodopeti_1;bodopeti_2;bodopeti_3 10,25 Nem elfogadható nylac_feb bodopeti_1;bodopeti_2;bodopeti_3 4,254 Nem eldönthető nylac_matyee bodopeti_1;bodopeti_2;bodopeti_3 8,526 Nem elfogadható nylac_rudi bodopeti_1;bodopeti_2;bodopeti_3 6,698 Nem elfogadható nylac_2_1 bodopeti_1;bodopeti_2;bodopeti_3 5,124 Nem eldönthető nylac_2_2 bodopeti_1;bodopeti_2;bodopeti_3 14,153 Nem elfogadható rudi_1 bodopeti_1;bodopeti_2;bodopeti_3 12,77 Nem elfogadható rudi_2 bodopeti_1;bodopeti_2;bodopeti_3 9,842 Nem elfogadható rudi_3 bodopeti_1;bodopeti_2;bodopeti_3 14,885 Nem elfogadható rudi_balint bodopeti_1;bodopeti_2;bodopeti_3 13,524 Nem elfogadható rudi_bodo bodopeti_1;bodopeti_2;bodopeti_3 12,32 Nem elfogadható rudi_csaba bodopeti_1;bodopeti_2;bodopeti_3 10,028 Nem elfogadható rudi_feb bodopeti_1;bodopeti_2;bodopeti_3 10,798 Nem elfogadható rudi_matyee bodopeti_1;bodopeti_2;bodopeti_3 14,578 Nem elfogadható rudi_nylac bodopeti_1;bodopeti_2;bodopeti_3 3,726 Nem eldönthető rudi_2_1 bodopeti_1;bodopeti_2;bodopeti_3 15,82 Nem elfogadható rudi_2_2 bodopeti_1;bodopeti_2;bodopeti_3 9,72 Nem elfogadható balint_1 csaba_1;csaba_2;csaba_3 7,578 Nem elfogadható balint_2 csaba_1;csaba_2;csaba_3 10,532 Nem elfogadható balint_3 csaba_1;csaba_2;csaba_3 8,446 Nem elfogadható balint_bodo csaba_1;csaba_2;csaba_3 7,074 Nem elfogadható balint_csaba csaba_1;csaba_2;csaba_3 12,884 Nem elfogadható balint_feb csaba_1;csaba_2;csaba_3 6,64 Nem elfogadható balint_matyee csaba_1;csaba_2;csaba_3 16,734 Nem elfogadható balint_nylac csaba_1;csaba_2;csaba_3 10,966 Nem elfogadható balint_rudi csaba_1;csaba_2;csaba_3 6,178 Nem elfogadható balint_2_1 csaba_1;csaba_2;csaba_3 6,304 Nem elfogadható balint_2_2 csaba_1;csaba_2;csaba_3 9,202 Nem elfogadható bodopeti_1 csaba_1;csaba_2;csaba_3 13,738 Nem elfogadható bodopeti_2 csaba_1;csaba_2;csaba_3 11,988 Nem elfogadható bodopeti_3 csaba_1;csaba_2;csaba_3 14,018 Nem elfogadható bodo_balint csaba_1;csaba_2;csaba_3 12,436 Nem elfogadható bodo_csaba csaba_1;csaba_2;csaba_3 4,624 Nem eldönthető bodo_feb csaba_1;csaba_2;csaba_3 10,56 Nem elfogadható bodo_matyee csaba_1;csaba_2;csaba_3 11,4 Nem elfogadható bodo_nylac csaba_1;csaba_2;csaba_3 14,254 Nem elfogadható bodo_rudi csaba_1;csaba_2;csaba_3 11,48 Nem elfogadható bodo_2_1 csaba_1;csaba_2;csaba_3 13,962 Nem elfogadható bodo_2_2 csaba_1;csaba_2;csaba_3 11,484 Nem elfogadható

C E R B E R U S P R O J E K T
179
.wav fájl neve Betanított minták Kimeneti érték Döntés csaba_1 csaba_1;csaba_2;csaba_3 1,556 Elfogadható csaba_2 csaba_1;csaba_2;csaba_3 2,078 Elfogadható csaba_3 csaba_1;csaba_2;csaba_3 1,418 Elfogadható csaba_balint csaba_1;csaba_2;csaba_3 9,034 Nem elfogadható csaba_bodo csaba_1;csaba_2;csaba_3 15,978 Nem elfogadható csaba_feb csaba_1;csaba_2;csaba_3 7,564 Nem elfogadható csaba_matyee csaba_1;csaba_2;csaba_3 10,238 Nem elfogadható csaba_nylac csaba_1;csaba_2;csaba_3 15,568 Nem elfogadható csaba_rudi csaba_1;csaba_2;csaba_3 12,734 Nem elfogadható csaba_2_1 csaba_1;csaba_2;csaba_3 2,77 Nem eldönthető csaba_2_2 csaba_1;csaba_2;csaba_3 2,279 Elfogadható feb_1 csaba_1;csaba_2;csaba_3 12,724 Nem elfogadható feb_2 csaba_1;csaba_2;csaba_3 12,688 Nem elfogadható feb_3 csaba_1;csaba_2;csaba_3 12,076 Nem elfogadható feb_balint csaba_1;csaba_2;csaba_3 9,976 Nem elfogadható feb_bodo csaba_1;csaba_2;csaba_3 9,469 Nem elfogadható feb_csaba csaba_1;csaba_2;csaba_3 10,576 Nem elfogadható feb_matyee csaba_1;csaba_2;csaba_3 11,344 Nem elfogadható feb_nylac csaba_1;csaba_2;csaba_3 5,128 Nem eldönthető feb_rudi csaba_1;csaba_2;csaba_3 13,672 Nem elfogadható feb_2_1 csaba_1;csaba_2;csaba_3 10,612 Nem elfogadható feb_2_2 csaba_1;csaba_2;csaba_3 12,076 Nem elfogadható matyee_1 csaba_1;csaba_2;csaba_3 9,988 Nem elfogadható matyee_2 csaba_1;csaba_2;csaba_3 9,772 Nem elfogadható matyee_3 csaba_1;csaba_2;csaba_3 10,816 Nem elfogadható matyee_balint csaba_1;csaba_2;csaba_3 13,276 Nem elfogadható matyee_bodo csaba_1;csaba_2;csaba_3 13,504 Nem elfogadható matyee_csaba csaba_1;csaba_2;csaba_3 6,736 Nem elfogadható matyee_feb csaba_1;csaba_2;csaba_3 13,108 Nem elfogadható matyee_nylac csaba_1;csaba_2;csaba_3 9,748 Nem elfogadható matyee_rudi csaba_1;csaba_2;csaba_3 10,192 Nem elfogadható matyee_2_1 csaba_1;csaba_2;csaba_3 14,524 Nem elfogadható matyee_2_2 csaba_1;csaba_2;csaba_3 6,268 Nem elfogadható nylac_1 csaba_1;csaba_2;csaba_3 8,272 Nem elfogadható nylac_2 csaba_1;csaba_2;csaba_3 6,484 Nem elfogadható nylac_3 csaba_1;csaba_2;csaba_3 13,285 Nem elfogadható nylac_balint csaba_1;csaba_2;csaba_3 13,665 Nem elfogadható nylac_bodo csaba_1;csaba_2;csaba_3 10,18 Nem elfogadható nylac_csaba csaba_1;csaba_2;csaba_3 14,038 Nem elfogadható nylac_feb csaba_1;csaba_2;csaba_3 13,228 Nem elfogadható nylac_matyee csaba_1;csaba_2;csaba_3 12,45 Nem elfogadható nylac_rudi csaba_1;csaba_2;csaba_3 5,404 Nem eldönthető nylac_2_1 csaba_1;csaba_2;csaba_3 12,388 Nem elfogadható nylac_2_2 csaba_1;csaba_2;csaba_3 11,325 Nem elfogadható rudi_1 csaba_1;csaba_2;csaba_3 4,624 Nem eldönthető rudi_2 csaba_1;csaba_2;csaba_3 6,544 Nem elfogadható rudi_3 csaba_1;csaba_2;csaba_3 14,644 Nem elfogadható

C E R B E R U S P R O J E K T
180
.wav fájl neve Betanított minták Kimeneti érték Döntés rudi_balint csaba_1;csaba_2;csaba_3 8,932 Nem elfogadható rudi_bodo csaba_1;csaba_2;csaba_3 9,676 Nem elfogadható rudi_csaba csaba_1;csaba_2;csaba_3 14,62 Nem elfogadható rudi_feb csaba_1;csaba_2;csaba_3 8,308 Nem elfogadható rudi_matyee csaba_1;csaba_2;csaba_3 7,324 Nem elfogadható rudi_nylac csaba_1;csaba_2;csaba_3 8,668 Nem elfogadható rudi_2_1 csaba_1;csaba_2;csaba_3 15,465 Nem elfogadható rudi_2_2 csaba_1;csaba_2;csaba_3 15,748 Nem elfogadható balint_1 feb_1;feb_2;feb_3 10,288 Nem elfogadható balint_2 feb_1;feb_2;feb_3 4,864 Nem eldönthető balint_3 feb_1;feb_2;feb_3 12,064 Nem elfogadható balint_bodo feb_1;feb_2;feb_3 9,568 Nem elfogadható balint_csaba feb_1;feb_2;feb_3 12,196 Nem elfogadható balint_feb feb_1;feb_2;feb_3 5,656 Nem eldönthető balint_matyee feb_1;feb_2;feb_3 8,8892 Nem elfogadható balint_nylac feb_1;feb_2;feb_3 6,732 Nem elfogadható balint_rudi feb_1;feb_2;feb_3 4,944 Nem eldönthető balint_2_1 feb_1;feb_2;feb_3 11,952 Nem elfogadható balint_2_2 feb_1;feb_2;feb_3 7,136 Nem elfogadható bodopeti_1 feb_1;feb_2;feb_3 4,495 Nem eldönthető bodopeti_2 feb_1;feb_2;feb_3 11,385 Nem elfogadható bodopeti_3 feb_1;feb_2;feb_3 140,24 Nem elfogadható bodo_balint feb_1;feb_2;feb_3 9,643 Nem elfogadható bodo_csaba feb_1;feb_2;feb_3 13,075 Nem elfogadható bodo_feb feb_1;feb_2;feb_3 6,211 Nem elfogadható bodo_matyee feb_1;feb_2;feb_3 12,074 Nem elfogadható bodo_nylac feb_1;feb_2;feb_3 10,787 Nem elfogadható bodo_rudi feb_1;feb_2;feb_3 13,231 Nem elfogadható bodo_2_1 feb_1;feb_2;feb_3 4,521 Nem eldönthető bodo_2_2 feb_1;feb_2;feb_3 12,243 Nem elfogadható csaba_1 feb_1;feb_2;feb_3 7,68 Nem elfogadható csaba_2 feb_1;feb_2;feb_3 6,913 Nem elfogadható csaba_3 feb_1;feb_2;feb_3 7,368 Nem elfogadható csaba_balint feb_1;feb_2;feb_3 12,685 Nem elfogadható csaba_bodo feb_1;feb_2;feb_3 4,911 Nem eldönthető csaba_feb feb_1;feb_2;feb_3 8,109 Nem elfogadható csaba_matyee feb_1;feb_2;feb_3 13,611 Nem elfogadható csaba_nylac feb_1;feb_2;feb_3 7,188 Nem elfogadható csaba_rudi feb_1;feb_2;feb_3 12,555 Nem elfogadható csaba_2_1 feb_1;feb_2;feb_3 3,221 Nem eldönthető csaba_2_2 feb_1;feb_2;feb_3 8,252 Nem elfogadható feb_1 feb_1;feb_2;feb_3 1,857 Elfogadható feb_2 feb_1;feb_2;feb_3 1,985 Elfogadható feb_3 feb_1;feb_2;feb_3 2,156 Elfogadható feb_balint feb_1;feb_2;feb_3 7,485 Nem elfogadható feb_bodo feb_1;feb_2;feb_3 5,483 Nem eldönthető feb_csaba feb_1;feb_2;feb_3 8,226 Nem elfogadható

C E R B E R U S P R O J E K T
181
.wav fájl neve Betanított minták Kimeneti érték Döntés feb_matyee feb_1;feb_2;feb_3 6,224 Nem elfogadható feb_nylac feb_1;feb_2;feb_3 12,36 Nem elfogadható feb_rudi feb_1;feb_2;feb_3 10,384 Nem elfogadható feb_2_1 feb_1;feb_2;feb_3 2,458 Elfogadható feb_2_2 feb_1;feb_2;feb_3 2,785 Nem eldönthető matyee_1 feb_1;feb_2;feb_3 3,975 Nem eldönthető matyee_2 feb_1;feb_2;feb_3 12,529 Nem elfogadható matyee_3 feb_1;feb_2;feb_3 5,093 Nem eldönthető matyee_balint feb_1;feb_2;feb_3 12,386 Nem elfogadható matyee_bodo feb_1;feb_2;feb_3 11,034 Nem elfogadható matyee_csaba feb_1;feb_2;feb_3 5,847 Nem eldönthető matyee_feb feb_1;feb_2;feb_3 8,577 Nem elfogadható matyee_nylac feb_1;feb_2;feb_3 11,944 Nem elfogadható matyee_rudi feb_1;feb_2;feb_3 13,855 Nem elfogadható matyee_2_1 feb_1;feb_2;feb_3 7,641 Nem elfogadható matyee_2_2 feb_1;feb_2;feb_3 6,718 Nem elfogadható nylac_1 feb_1;feb_2;feb_3 10,696 Nem elfogadható nylac_2 feb_1;feb_2;feb_3 11,125 Nem elfogadható nylac_3 feb_1;feb_2;feb_3 8,044 Nem elfogadható nylac_balint feb_1;feb_2;feb_3 4,612 Nem eldönthető nylac_bodo feb_1;feb_2;feb_3 11,489 Nem elfogadható nylac_csaba feb_1;feb_2;feb_3 3,351 Nem eldönthető nylac_feb feb_1;feb_2;feb_3 11,203 Nem elfogadható nylac_matyee feb_1;feb_2;feb_3 9,825 Nem elfogadható nylac_rudi feb_1;feb_2;feb_3 4,053 Nem eldönthető nylac_2_1 feb_1;feb_2;feb_3 6,926 Nem elfogadható nylac_2_2 feb_1;feb_2;feb_3 12,568 Nem elfogadható rudi_1 feb_1;feb_2;feb_3 12,62 Nem elfogadható rudi_2 feb_1;feb_2;feb_3 10,93 Nem elfogadható rudi_3 feb_1;feb_2;feb_3 9,389 Nem elfogadható rudi_balint feb_1;feb_2;feb_3 5,262 Nem eldönthető rudi_bodo feb_1;feb_2;feb_3 11,463 Nem elfogadható rudi_csaba feb_1;feb_2;feb_3 9,916 Nem elfogadható rudi_feb feb_1;feb_2;feb_3 5,621 Nem eldönthető rudi_matyee feb_1;feb_2;feb_3 7,42 Nem elfogadható rudi_nylac feb_1;feb_2;feb_3 6,845 Nem elfogadható rudi_2_1 feb_1;feb_2;feb_3 10,007 Nem elfogadható rudi_2_2 feb_1;feb_2;feb_3 8,241 Nem elfogadható balint_1 matyee_1;matyee_2;matyee_3 5,613 Nem eldönthető balint_2 matyee_1;matyee_2;matyee_3 11,385 Nem elfogadható balint_3 matyee_1;matyee_2;matyee_3 13,866 Nem elfogadható balint_bodo matyee_1;matyee_2;matyee_3 6,25 Nem elfogadható balint_csaba matyee_1;matyee_2;matyee_3 13,036 Nem elfogadható balint_feb matyee_1;matyee_2;matyee_3 11,06 Nem elfogadható balint_matyee matyee_1;matyee_2;matyee_3 6,523 Nem elfogadható balint_nylac matyee_1;matyee_2;matyee_3 6,146 Nem elfogadható balint_rudi matyee_1;matyee_2;matyee_3 10,234 Nem elfogadható

C E R B E R U S P R O J E K T
182
.wav fájl neve Betanított minták Kimeneti érték Döntés balint_2_1 matyee_1;matyee_2;matyee_3 4,924 Nem eldönthető balint_2_2 matyee_1;matyee_2;matyee_3 8,395 Nem elfogadható bodopeti_1 matyee_1;matyee_2;matyee_3 10,254 Nem elfogadható bodopeti_2 matyee_1;matyee_2;matyee_3 11,567 Nem elfogadható bodopeti_3 matyee_1;matyee_2;matyee_3 5,067 Nem eldönthető bodo_balint matyee_1;matyee_2;matyee_3 11,658 Nem elfogadható bodo_csaba matyee_1;matyee_2;matyee_3 7,342 Nem elfogadható bodo_feb matyee_1;matyee_2;matyee_3 3,572 Nem eldönthető bodo_matyee matyee_1;matyee_2;matyee_3 8,629 Nem elfogadható bodo_nylac matyee_1;matyee_2;matyee_3 5,353 Nem eldönthető bodo_rudi matyee_1;matyee_2;matyee_3 9,279 Nem elfogadható bodo_2_1 matyee_1;matyee_2;matyee_3 4,482 Nem eldönthető bodo_2_2 matyee_1;matyee_2;matyee_3 11,372 Nem elfogadható csaba_1 matyee_1;matyee_2;matyee_3 13,673 Nem elfogadható csaba_2 matyee_1;matyee_2;matyee_3 8,811 Nem elfogadható csaba_3 matyee_1;matyee_2;matyee_3 6,848 Nem elfogadható csaba_balint matyee_1;matyee_2;matyee_3 13,53 Nem elfogadható csaba_bodo matyee_1;matyee_2;matyee_3 11,255 Nem elfogadható csaba_feb matyee_1;matyee_2;matyee_3 11,099 Nem elfogadható csaba_matyee matyee_1;matyee_2;matyee_3 7,316 Nem elfogadható csaba_nylac matyee_1;matyee_2;matyee_3 11,424 Nem elfogadható csaba_rudi matyee_1;matyee_2;matyee_3 15,012 Nem elfogadható csaba_2_1 matyee_1;matyee_2;matyee_3 6,51 Nem elfogadható csaba_2_2 matyee_1;matyee_2;matyee_3 5,99 Nem eldönthető feb_1 matyee_1;matyee_2;matyee_3 7,035 Nem elfogadható feb_2 matyee_1;matyee_2;matyee_3 4,976 Nem eldönthető feb_3 matyee_1;matyee_2;matyee_3 9,617 Nem elfogadható feb_balint matyee_1;matyee_2;matyee_3 12,477 Nem elfogadható feb_bodo matyee_1;matyee_2;matyee_3 11,814 Nem elfogadható feb_csaba matyee_1;matyee_2;matyee_3 10,956 Nem elfogadható feb_matyee matyee_1;matyee_2;matyee_3 4,261 Nem eldönthető feb_nylac matyee_1;matyee_2;matyee_3 6,224 Nem elfogadható feb_rudi matyee_1;matyee_2;matyee_3 12,282 Nem elfogadható feb_2_1 matyee_1;matyee_2;matyee_3 8,59 Nem elfogadható feb_2_2 matyee_1;matyee_2;matyee_3 9,851 Nem elfogadható matyee_1 matyee_1;matyee_2;matyee_3 2,399 Elfogadható matyee_2 matyee_1;matyee_2;matyee_3 2,513 Nem eldönthető matyee_3 matyee_1;matyee_2;matyee_3 1,718 Elfogadható matyee_balint matyee_1;matyee_2;matyee_3 4,677 Nem eldönthető matyee_bodo matyee_1;matyee_2;matyee_3 8,005 Nem elfogadható matyee_csaba matyee_1;matyee_2;matyee_3 10,267 Nem elfogadható matyee_feb matyee_1;matyee_2;matyee_3 5,574 Nem eldönthető matyee_nylac matyee_1;matyee_2;matyee_3 10,293 Nem elfogadható matyee_rudi matyee_1;matyee_2;matyee_3 4,193 Nem eldönthető matyee_2_1 matyee_1;matyee_2;matyee_3 2,478 Elfogadható matyee_2_2 matyee_1;matyee_2;matyee_3 2,174 Elfogadható nylac_1 matyee_1;matyee_2;matyee_3 4,56 Nem eldönthető

C E R B E R U S P R O J E K T
183
.wav fájl neve Betanított minták Kimeneti érték Döntés nylac_2 matyee_1;matyee_2;matyee_3 12,971 Nem elfogadható nylac_3 matyee_1;matyee_2;matyee_3 11,385 Nem elfogadható nylac_balint matyee_1;matyee_2;matyee_3 13,946 Nem elfogadható nylac_bodo matyee_1;matyee_2;matyee_3 7,846 Nem elfogadható nylac_csaba matyee_1;matyee_2;matyee_3 10,592 Nem elfogadható nylac_feb matyee_1;matyee_2;matyee_3 8,746 Nem elfogadható nylac_matyee matyee_1;matyee_2;matyee_3 5,444 Nem eldönthető nylac_rudi matyee_1;matyee_2;matyee_3 7,238 Nem elfogadható nylac_2_1 matyee_1;matyee_2;matyee_3 9,487 Nem elfogadható nylac_2_2 matyee_1;matyee_2;matyee_3 9,357 Nem elfogadható rudi_1 matyee_1;matyee_2;matyee_3 6,445 Nem elfogadható rudi_2 matyee_1;matyee_2;matyee_3 4,482 Nem eldönthető rudi_3 matyee_1;matyee_2;matyee_3 11,125 Nem elfogadható rudi_balint matyee_1;matyee_2;matyee_3 8,083 Nem elfogadható rudi_bodo matyee_1;matyee_2;matyee_3 7,563 Nem elfogadható rudi_csaba matyee_1;matyee_2;matyee_3 7,004 Nem elfogadható rudi_feb matyee_1;matyee_2;matyee_3 4,196 Nem eldönthető rudi_matyee matyee_1;matyee_2;matyee_3 4,534 Nem eldönthető rudi_nylac matyee_1;matyee_2;matyee_3 10,15 Nem elfogadható rudi_2_1 matyee_1;matyee_2;matyee_3 7,59 Nem elfogadható rudi_2_2 matyee_1;matyee_2;matyee_3 8,66 Nem elfogadható balint_1 nylac_1;nylac_2;nylac_3 8,26 Nem elfogadható balint_2 nylac_1;nylac_2;nylac_3 4,06 Nem eldönthető balint_3 nylac_1;nylac_2;nylac_3 7,52 Nem elfogadható balint_bodo nylac_1;nylac_2;nylac_3 6,717 Nem elfogadható balint_csaba nylac_1;nylac_2;nylac_3 7,454 Nem elfogadható balint_feb nylac_1;nylac_2;nylac_3 8,571 Nem elfogadható balint_matyee nylac_1;nylac_2;nylac_3 5,205 Nem eldönthető balint_nylac nylac_1;nylac_2;nylac_3 8,745 Nem elfogadható balint_rudi nylac_1;nylac_2;nylac_3 9,129 Nem elfogadható balint_2_1 nylac_1;nylac_2;nylac_3 10,092 Nem elfogadható balint_2_2 nylac_1;nylac_2;nylac_3 10,758 Nem elfogadható bodopeti_1 nylac_1;nylac_2;nylac_3 5,691 Nem eldönthető bodopeti_2 nylac_1;nylac_2;nylac_3 10,911 Nem elfogadható bodopeti_3 nylac_1;nylac_2;nylac_3 7,032 Nem elfogadható bodo_balint nylac_1;nylac_2;nylac_3 5,79 Nem eldönthető bodo_csaba nylac_1;nylac_2;nylac_3 9,489 Nem elfogadható bodo_feb nylac_1;nylac_2;nylac_3 8,409 Nem elfogadható bodo_matyee nylac_1;nylac_2;nylac_3 10,479 Nem elfogadható bodo_nylac nylac_1;nylac_2;nylac_3 4,053 Nem eldönthető bodo_rudi nylac_1;nylac_2;nylac_3 9,417 Nem elfogadható bodo_2_1 nylac_1;nylac_2;nylac_3 6,672 Nem elfogadható bodo_2_2 nylac_1;nylac_2;nylac_3 6,6 Nem elfogadható csaba_1 nylac_1;nylac_2;nylac_3 4,944 Nem eldönthető csaba_2 nylac_1;nylac_2;nylac_3 11,901 Nem elfogadható csaba_3 nylac_1;nylac_2;nylac_3 9,732 Nem elfogadható csaba_balint nylac_1;nylac_2;nylac_3 5,007 Nem eldönthető

C E R B E R U S P R O J E K T
184
.wav fájl neve Betanított minták Kimeneti érték Döntés csaba_bodo nylac_1;nylac_2;nylac_3 7,167 Nem elfogadható csaba_feb nylac_1;nylac_2;nylac_3 9,03 Nem elfogadható csaba_matyee nylac_1;nylac_2;nylac_3 6,699 Nem elfogadható csaba_nylac nylac_1;nylac_2;nylac_3 7,239 Nem elfogadható csaba_rudi nylac_1;nylac_2;nylac_3 10,533 Nem elfogadható csaba_2_1 nylac_1;nylac_2;nylac_3 9,237 Nem elfogadható csaba_2_2 nylac_1;nylac_2;nylac_3 11,451 Nem elfogadható feb_1 nylac_1;nylac_2;nylac_3 8,571 Nem elfogadható feb_2 nylac_1;nylac_2;nylac_3 8,445 Nem elfogadható feb_3 nylac_1;nylac_2;nylac_3 11,361 Nem elfogadható feb_balint nylac_1;nylac_2;nylac_3 6,384 Nem elfogadható feb_bodo nylac_1;nylac_2;nylac_3 8,958 Nem elfogadható feb_csaba nylac_1;nylac_2;nylac_3 9,462 Nem elfogadható feb_matyee nylac_1;nylac_2;nylac_3 7,788 Nem elfogadható feb_nylac nylac_1;nylac_2;nylac_3 5,523 Nem eldönthető feb_rudi nylac_1;nylac_2;nylac_3 9,048 Nem elfogadható feb_2_1 nylac_1;nylac_2;nylac_3 6,582 Nem elfogadható feb_2_2 nylac_1;nylac_2;nylac_3 9,624 Nem elfogadható matyee_1 nylac_1;nylac_2;nylac_3 11,532 Nem elfogadható matyee_2 nylac_1;nylac_2;nylac_3 10,371 Nem elfogadható matyee_3 nylac_1;nylac_2;nylac_3 10,722 Nem elfogadható matyee_balint nylac_1;nylac_2;nylac_3 9,756 Nem elfogadható matyee_bodo nylac_1;nylac_2;nylac_3 9,66 Nem elfogadható matyee_csaba nylac_1;nylac_2;nylac_3 11,811 Nem elfogadható matyee_feb nylac_1;nylac_2;nylac_3 7,662 Nem elfogadható matyee_nylac nylac_1;nylac_2;nylac_3 11,352 Nem elfogadható matyee_rudi nylac_1;nylac_2;nylac_3 8,607 Nem elfogadható matyee_2_1 nylac_1;nylac_2;nylac_3 5,997 Nem eldönthető matyee_2_2 nylac_1;nylac_2;nylac_3 8,959 Nem elfogadható nylac_1 nylac_1;nylac_2;nylac_3 1,418 Elfogadható nylac_2 nylac_1;nylac_2;nylac_3 1,763 Elfogadható nylac_3 nylac_1;nylac_2;nylac_3 1,673 Elfogadható nylac_balint nylac_1;nylac_2;nylac_3 9,867 Nem elfogadható nylac_bodo nylac_1;nylac_2;nylac_3 7,986 Nem elfogadható nylac_csaba nylac_1;nylac_2;nylac_3 9,687 Nem elfogadható nylac_feb nylac_1;nylac_2;nylac_3 6,312 Nem elfogadható nylac_matyee nylac_1;nylac_2;nylac_3 7,275 Nem elfogadható nylac_rudi nylac_1;nylac_2;nylac_3 11,325 Nem elfogadható nylac_2_1 nylac_1;nylac_2;nylac_3 2,229 Elfogadható nylac_2_2 nylac_1;nylac_2;nylac_3 1,956 Elfogadható rudi_1 nylac_1;nylac_2;nylac_3 4,269 Nem eldönthető rudi_2 nylac_1;nylac_2;nylac_3 5,196 Nem eldönthető rudi_3 nylac_1;nylac_2;nylac_3 8,508 Nem elfogadható rudi_balint nylac_1;nylac_2;nylac_3 11,082 Nem elfogadható rudi_bodo nylac_1;nylac_2;nylac_3 7,455 Nem elfogadható rudi_csaba nylac_1;nylac_2;nylac_3 6,548 Nem elfogadható rudi_feb nylac_1;nylac_2;nylac_3 6,069 Nem elfogadható

C E R B E R U S P R O J E K T
185
.wav fájl neve Betanított minták Kimeneti érték Döntés rudi_matyee nylac_1;nylac_2;nylac_3 10,776 Nem elfogadható rudi_nylac nylac_1;nylac_2;nylac_3 11,019 Nem elfogadható rudi_2_1 nylac_1;nylac_2;nylac_3 7,544 Nem elfogadható rudi_2_2 nylac_1;nylac_2;nylac_3 8,742 Nem elfogadható balint_1 rudi_1;rudi_2;rudi_3 9,156 Nem elfogadható balint_2 rudi_1;rudi_2;rudi_3 9,759 Nem elfogadható balint_3 rudi_1;rudi_2;rudi_3 5,464 Nem eldönthető balint_bodo rudi_1;rudi_2;rudi_3 9,867 Nem elfogadható balint_csaba rudi_1;rudi_2;rudi_3 8,022 Nem elfogadható balint_feb rudi_1;rudi_2;rudi_3 10,569 Nem elfogadható balint_matyee rudi_1;rudi_2;rudi_3 6,771 Nem elfogadható balint_nylac rudi_1;rudi_2;rudi_3 8,85 Nem elfogadható balint_rudi rudi_1;rudi_2;rudi_3 11,586 Nem elfogadható balint_2_1 rudi_1;rudi_2;rudi_3 11,622 Nem elfogadható balint_2_2 rudi_1;rudi_2;rudi_3 5,898 Nem eldönthető bodopeti_1 rudi_1;rudi_2;rudi_3 6,812 Nem elfogadható bodopeti_2 rudi_1;rudi_2;rudi_3 9,795 Nem elfogadható bodopeti_3 rudi_1;rudi_2;rudi_3 6,303 Nem elfogadható bodo_balint rudi_1;rudi_2;rudi_3 7,131 Nem elfogadható bodo_csaba rudi_1;rudi_2;rudi_3 8,121 Nem elfogadható bodo_feb rudi_1;rudi_2;rudi_3 6,546 Nem elfogadható bodo_matyee rudi_1;rudi_2;rudi_3 10,929 Nem elfogadható bodo_nylac rudi_1;rudi_2;rudi_3 8,556 Nem elfogadható bodo_rudi rudi_1;rudi_2;rudi_3 7,941 Nem elfogadható bodo_2_1 rudi_1;rudi_2;rudi_3 8,652 Nem elfogadható bodo_2_2 rudi_1;rudi_2;rudi_3 7,194 Nem elfogadható csaba_1 rudi_1;rudi_2;rudi_3 9,462 Nem elfogadható csaba_2 rudi_1;rudi_2;rudi_3 7,707 Nem elfogadható csaba_3 rudi_1;rudi_2;rudi_3 11,838 Nem elfogadható csaba_balint rudi_1;rudi_2;rudi_3 8,346 Nem elfogadható csaba_bodo rudi_1;rudi_2;rudi_3 9,408 Nem elfogadható csaba_feb rudi_1;rudi_2;rudi_3 6,847 Nem elfogadható csaba_matyee rudi_1;rudi_2;rudi_3 10,326 Nem elfogadható csaba_nylac rudi_1;rudi_2;rudi_3 9,678 Nem elfogadható csaba_rudi rudi_1;rudi_2;rudi_3 6,222 Nem elfogadható csaba_2_1 rudi_1;rudi_2;rudi_3 5,16 Nem eldönthető csaba_2_2 rudi_1;rudi_2;rudi_3 7,716 Nem elfogadható feb_1 rudi_1;rudi_2;rudi_3 5,034 Nem eldönthető feb_2 rudi_1;rudi_2;rudi_3 10,974 Nem elfogadható feb_3 rudi_1;rudi_2;rudi_3 6,591 Nem elfogadható feb_balint rudi_1;rudi_2;rudi_3 6,744 Nem elfogadható feb_bodo rudi_1;rudi_2;rudi_3 8,02 Nem elfogadható feb_csaba rudi_1;rudi_2;rudi_3 5,772 Nem eldönthető feb_matyee rudi_1;rudi_2;rudi_3 6,573 Nem elfogadható feb_nylac rudi_1;rudi_2;rudi_3 4,242 Nem eldönthető feb_rudi rudi_1;rudi_2;rudi_3 9,192 Nem elfogadható feb_2_1 rudi_1;rudi_2;rudi_3 10,479 Nem elfogadható

C E R B E R U S P R O J E K T
186
.wav fájl neve Betanított minták Kimeneti érték Döntés feb_2_2 rudi_1;rudi_2;rudi_3 11,208 Nem elfogadható matyee_1 rudi_1;rudi_2;rudi_3 11,874 Nem elfogadható matyee_2 rudi_1;rudi_2;rudi_3 9,192 Nem elfogadható matyee_3 rudi_1;rudi_2;rudi_3 10,434 Nem elfogadható matyee_balint rudi_1;rudi_2;rudi_3 5,475 Nem eldönthető matyee_bodo rudi_1;rudi_2;rudi_3 7,338 Nem elfogadható matyee_csaba rudi_1;rudi_2;rudi_3 11,991 Nem elfogadható matyee_feb rudi_1;rudi_2;rudi_3 9,291 Nem elfogadható matyee_nylac rudi_1;rudi_2;rudi_3 6,501 Nem elfogadható matyee_rudi rudi_1;rudi_2;rudi_3 11,541 Nem elfogadható matyee_2_1 rudi_1;rudi_2;rudi_3 10,845 Nem elfogadható matyee_2_2 rudi_1;rudi_2;rudi_3 6,634 Nem elfogadható nylac_1 rudi_1;rudi_2;rudi_3 4,809 Nem eldönthető nylac_2 rudi_1;rudi_2;rudi_3 8,634 Nem elfogadható nylac_3 rudi_1;rudi_2;rudi_3 6,663 Nem elfogadható nylac_balint rudi_1;rudi_2;rudi_3 6,287 Nem elfogadható nylac_bodo rudi_1;rudi_2;rudi_3 8,922 Nem elfogadható nylac_csaba rudi_1;rudi_2;rudi_3 9,408 Nem elfogadható nylac_feb rudi_1;rudi_2;rudi_3 6,537 Nem elfogadható nylac_matyee rudi_1;rudi_2;rudi_3 10,407 Nem elfogadható nylac_rudi rudi_1;rudi_2;rudi_3 11,559 Nem elfogadható nylac_2_1 rudi_1;rudi_2;rudi_3 11,019 Nem elfogadható nylac_2_2 rudi_1;rudi_2;rudi_3 7,563 Nem elfogadható rudi_1 rudi_1;rudi_2;rudi_3 1,382 Elfogadható rudi_2 rudi_1;rudi_2;rudi_3 1,289 Elfogadható rudi_3 rudi_1;rudi_2;rudi_3 1,676 Elfogadható rudi_balint rudi_1;rudi_2;rudi_3 8,765 Nem elfogadható rudi_bodo rudi_1;rudi_2;rudi_3 7,225 Nem elfogadható rudi_csaba rudi_1;rudi_2;rudi_3 11,252 Nem elfogadható rudi_feb rudi_1;rudi_2;rudi_3 6,807 Nem elfogadható rudi_matyee rudi_1;rudi_2;rudi_3 5,971 Nem eldönthető rudi_nylac rudi_1;rudi_2;rudi_3 8,193 Nem elfogadható rudi_2_1 rudi_1;rudi_2;rudi_3 2,255 Elfogadható rudi_2_2 rudi_1;rudi_2;rudi_3 1,028 Elfogadható
Elfogadandó: Elutasítandó: Nem eldönthető: Összesen: 35 Összesen: 504 Darab: 80 Elfogadva: 32 Elutasítva: 427 Arány: 14,84% Arány: 91,43% Arány: 84,72%

C E R B E R U S P R O J E K T
187
Irodalomjegyzék
[André 02]
André LaMonte: Neural Netware (utolsó lát. 2002. 04. 29) http://www.gamedev.net/reference/articles/article771.asp
[Baum 67]
An inequality with applications to statiatical estimation for probabilistic functions of Markov processes and to a model for ecology; Baum L. E., Eagon J. A., Bull. Amer. Math Soc. 73, 1967
[Becchetti 99]
Speech Recognition (Theory and C++ Implementation); Claudio Becchetti and Lucio Prina Ricotti, John Wiley & Sons Ltd., Reptinted August 1999
[Borgulya 98]
Borgulya István: Neurális hálók és fuzzy-rendszerek, Dialóg Campus Kiadó, Budapest, 1998
[Bordás 01]
Bordás Henrik: Belépés vezérlés ujjnyomat azonosító rendszerrel (Access control by Fingerprint Identification System) TDK dolgozat (2001)
[Buntine 96]
A guide to literature on learning probabilistic networks from data ; Buntine W., IEEE Trans. On Knowledge and Data Engineering 1996

C E R B E R U S P R O J E K T - I R O D A L O M J E G Y Z É K
188
[Charl 02]
Charl Linssen: Backpropagation network (utolsó lát. 2002. 04. 20.) http://www.futureai.com/tutorials/backprop.html
[Dawid 92]
Applications of general propagation algorithm for probapilistic expert systems, Dawid A. P., Statistic and Computing 2 pp 25-36, 1992
[Devin 02]
Devin McAuley: The backpropagation network: Learning by Example (utolsó lát. 2002. 04. 20.) http://psy.uq.oz.au/~brainwav/Manual/BackProp.html
[Dunay 98]
Dunay R, dr. Horváth G.: Neurális hálózatok és műszaki alkalmazásaik. Műegyetemi kiadó, Budapest, 1998.
[Edgar 97]
Edgar Osuna, Robert Freund, and Federico Girosi. Training support vector machines: an application to face detection. In Computer Vision and Pattern Recognition, pages 130– 136, 1997.
[Fisher]
R. Fisher, S. Perkins, A.Walker, E.Wolfart http://www.dai.ed.ac.uk/HIPR2/hough.htm
[Horváth 98]
Horváth Gábor: Neurális hálózatok és műszaki alkalmazásai, Műegyetemi Kiadó, Budapest, 1998
[Image 02]
Image Processing: Sobel Edge Detection (utolsó lát. 2002. 04. 29.) http://dcsun1.comp.brad.ac.uk/~ksjchan/Sobel.html

C E R B E R U S P R O J E K T - I R O D A L O M J E G Y Z É K
189
[Inventix]
Inventix: FaceIt Face Recognition Technology http://gaia.inventix.hu
[Madai 02]
Madai Péter, Szigetvári Áron, (utolsó lát.2002.04.01)
http://www2.mit.bme.hu/services/vimm3241/tanul/beadott/regi/SzigetvariMadai/main.htm
[Nagy 02]
Nagy Tamás: Neurális hálózatok (utolsó lát. 2002. 04. 20) http://human.kando.hu/~av/html/MI-Neuralis_Halok.htm
[Nathan 95]
Nathan Intrator, Daniel Reisfeld, Yehezkel Yeshurun: Face Recognition using a Hybrid Supervised/Unsupervised Neural Network. Department of Computer Science, Tel-Aviv University, 1995
[Oppenheim 89]
Digital Signal Processing; Oppenheim A. V. Schafer R. W., Pentice Hall 1989
[Pentland 97]
Alex Pentand, Tanzeem Choudhury: Personalizing Smart Environment, Face Recognition for Human Interaction, Massechusetts Institute of Technology, 1997
[Peter 83]
Peter J. Burt, Edward H. Adelson: Laplacian Pyramid as a Compact Image Code
IEEE Transactions on communications, Vol. COM-31, No. 4, April 1983

C E R B E R U S P R O J E K T - I R O D A L O M J E G Y Z É K
190
[Rabiner 78]
Digital Processing of Speech Signals; Rabiner L. R, Schafer R.W., Prentice Hall 1978
[Rabiner 93]
Fundamentals of Speech Recognition; Rabiner L.R., Juang B.H, Prentice Hall 1993
[Rein]
Rein-Lien Hsu, Mohamed Abdel-Mottaleb, Anil K. Jain: Face Detection in Color Images http://www.cse.msu.edu/~hsureinl/facloc/index_facloc.html (utolsó lát. 2002. október)
[RREF]
Gauss-Jordan Elimination (RREF) http://www.aspire.cs.uah.edu/textbook/gauss.html (utolsó lát. 2002. 09.22)
[Rowley 98]
Rowley, Baluja, and Kanade: Neural Network-Based Face Detection (PAMI, January 1998) Neural Network-Based Face Detection
[Schuler]
Andrew Schuler: Randomized Hough Transform http://www.andy-schuler.com (utolsó lát. 2002. október)
[Segmentation 02]
Segmentation Technique (utolsó lát. 2002. 04. 29.) http://microsys6.engr.utk.edu/~yhe/HomeLinks/segmentation/background.html
[Susanne 00]
Susanne Krabbe: Studienarbeit zur Still Image Segmentation. (2000)

C E R B E R U S P R O J E K T - I R O D A L O M J E G Y Z É K
191
[Székely 94]
Képkorrekció, hanganalízis, térszámítás PC-n; Gyors Fourier transzformációs módszerek, Budapest, ComputerBooks, 1994
[Tick 01]
Dr. Tick József, Bevezetés a szoftvertechnológiába, Előadás jegyzet Budapesti Műszaki Főiskola, 2001
[Viharos 02]
Viharos Zsolt János: Intelligens módszerek gyártási folyamatok modellezésében és optimalizálásában (utolsó lát. 2002. 04. 29.) http://www.sztaki.hu/~viharos/homepage/PhD/Viharos_Zsolt_Janos_PhD.html
[Wolfgang 83]
Wolfgang, Hess: Pitch Determination of speech signals, Springer, 1983
[Yang]
GZ Yang, DF Gillies: Image Processing and Edge Detection. Department of Computing, Imperial Colleg
[Bourke 98]
Paul Bourke: Ablaktípusok (Window) (utolsó lát. 2003. 01. 10.) http://astronomy.swin.edu.au/~pbourke/analysis/windows/
[Coleman]
John Coleman: Filtering (utolsó látogatás 2003. 01. 10.) http://www.phon.ox.ac.uk/~jcoleman/SLP/Lecture_2/filtering.htm
[Kepenekci]
Burcu Kepenekci: Face Recognition Using Gabor Wavelet Transform, 2001

C E R B E R U S P R O J E K T - I R O D A L O M J E G Y Z É K
192
[AT&T]
AT&T (utolsó látogatás 2002. 08. 10.) http://www.att.com

193