boosted trees for higgs discovery - home · indico · 2018-11-17 · boosted trees for higgs...
TRANSCRIPT

Boosted Trees for Higgs Discovery
TexPoint fonts used in EMF. Read the TexPoint manual before you delete this box.: AAA
Presenter: Tianqi Chen
Teamed with Tong He

Outline
• Introduction
• Gradient Boosting with Model Complexity Control
• Discussions and Final Remarks

Higgs Boson Classification Task
• Input: the properties of particles observed after collision
5 possible particles (tau, lep, 2 jets, mets)
Three types of physics property
Momentum
Energy
Mass
• Predict: Classify whether the event corresponds to higgs boson

General Supervised Learning Approach to the Problem
• Model: how to make prediction
Linear model:
• Parameters: the things we need to learn from data
Linear model:
• Objective Function:
Linear model: ,
Training Loss measures how
well model fit on training data
Regularization, measures
complexity of model
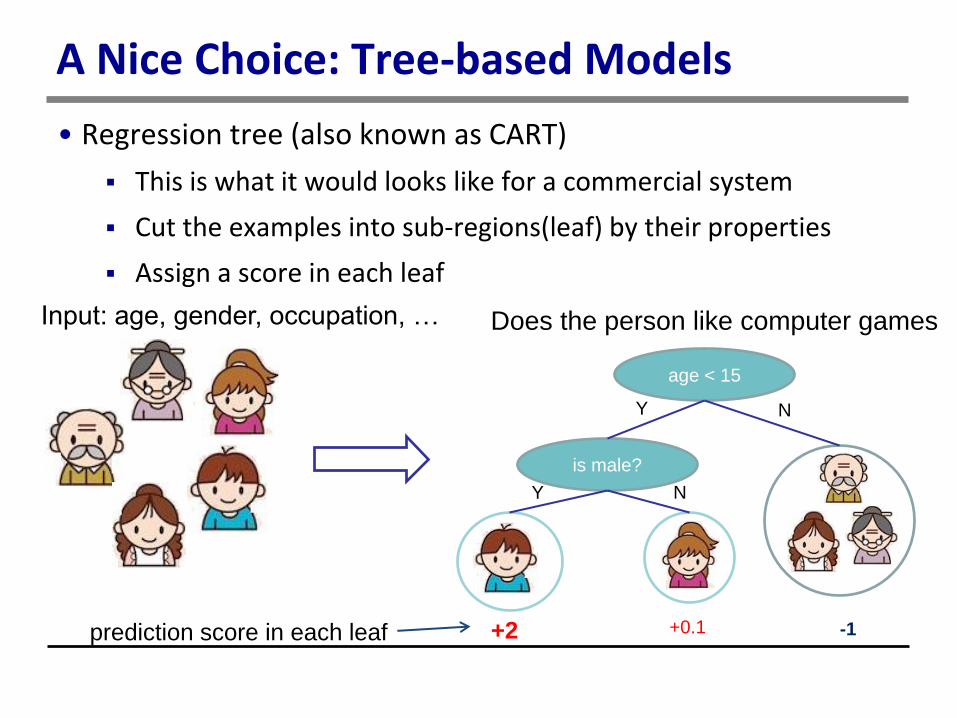
A Nice Choice: Tree-based Models
• Regression tree (also known as CART)
This is what it would looks like for a commercial system
Cut the examples into sub-regions(leaf) by their properties
Assign a score in each leaf
Input: age, gender, occupation, …
age < 15
is male?
+2 -1 +0.1
Y N
Y N
Does the person like computer games
prediction score in each leaf

Tree Ensemble: Go beyond Single Tree
age < 15
is male?
+2 -1 +0.1
Y N
Y N
Use Computer
Daily
Y N
+0.9 -0.9
tree1 tree2
f( ) = 2 + 0.9= 2.9 f( )= -1 + 0.9= -0.1

Find Interesting Physics Event with Trees
• Replace the little man with particles
Divide the events into regions of interest by physics properties
Assign confidence region
Input: mass, momentum, …
mass_lep < 50
Enegry_tau
< 12
+2 -1 +0.1
Y N
Y N
Made-up example:
How likely this is an interesting event
prediction score in each leaf

Learning Trees : Advantage and Challenges
• Advantages of tree-based methods
Highly accurate: almost half of data science challenges are won by tree based methods.
Easy to use: invariant to input scale, get good performance with little tuning.
Easy to interpret and control
• Challenges on learning tree(ensembles)
Control over-fitting
Improve training speed and scale up to larger dataset

XGBoost: Scaling up Boosted Trees
• Motivation: control over-fitting and scale up
• What is XGBoost
Open source software for boosted trees(i.e. BDT, GBDT, GBM)
Fast parallelized learning
Better model complexity control with careful regularization
Handles sparse matrices and missing value
In short, faster tool for learning better models

Examples of other features in XGBoost
• Interactive analysis of results
Usecase: Feature Importance Analysis with XGBoost in Tax audit
• External Memory Training to scale out-of-memory
• Native integration with R, python and Julia
• Distributed and portable

XGBoost and HiggsML Challenge
• XGBoost in HiggsML Challenge
Provide a good initial benchmark
Used by more than 200 participants
Including Physicists: Luboš Motl (ranked in top 10)
Insightful Blogpost: Winning solution of Kaggle Higgs competition: what a single model can do
Good final result with limited runtime.
• XGBoost in other challenges
Microsoft malware classification challenge
All the top-3 winners used xgboost
Winning solution tradeshift text classification
Among most popular tools in data science competitions

Outline
• Introduction
• Gradient Boosting with Model Complexity Control
• Discussions and Final Remarks

Control Overfitting: Carefully Choose Obj.
• Model: assuming we have K trees
• Objective
• Optimizing training loss encourages predictive models
Fitting well in training data at least get you close to training data which is hopefully close to the underlying distribution
• Optimizing regularization encourages simple models
Simpler models tends to have smaller variance in future predictions, making prediction stable
Training Loss measures how
well model fit on training data Regularization, measures
complexity of trees
Space of Regression trees

Why Regularization is Important
• Consider the example of learning tree on a single variable t
The tree can be represented as step function
The predictive and simple model both matters
Raw Data

Define Complexity of a Tree
• We define tree by a vector of scores in leafs, and a leaf index mapping function that maps an instance to a leaf
Leaf 1 Leaf 2 Leaf 3
q( ) = 1
q( ) = 3
w1=+2 w2=0.1 w3=-1
The structure of the tree
The leaf weight of the tree mass_lep < 50
Enegry_tau
< 12
Y N
Y N

Define Complexity of a Tree (cont’)
• Define complexity as (this is not the only possible definition)
Leaf 1 Leaf 2 Leaf 3
w1=+2 w2=0.1 w3=-1
Number of leaves L2 norm of leaf scores
mass_lep < 50
Enegry_tau
< 12
Y N
Y N

So How do we Learn?
• Objective:
• We can not use methods such as SGD, to find f (since they are trees, instead of just numerical vectors)
• Solution: Additive Training (Boosting)
Start from constant prediction, add a new function each time
Model at training round t
New function
Keep functions added in previous round

Additive Training
• How do we decide which f to add?
Optimize the objective!!
• The prediction at round t is
• Consider square loss
This is what we need to decide in round t
Goal: find to minimize this
This is usually called residual from previous round

Taylor Expansion Approximation of Loss
• Goal
Seems still complicated except for the case of square loss
• Take Taylor expansion of the objective
Recall
Define
• In terms of square loss

Our New Goal
• Objective, with constants removed
• Define the instance set in leaf j as
Regroup the objective by leaf
This is sum of T independent quadratic function

The Structure Score
• Two facts about single variable quadratic function
• Let us define
• Assume the structure of tree ( q(x) ) is fixed, the optimal weight in each leaf, and the resulting objective value are
This measures how good a tree structure is!

The Structure Score Calculation
Instance index
1
2
3
4
5
g1, h1
g2, h2
g3, h3
g4, h4
g5, h5
gradient statistics
The smaller the score is, the better the structure is
mass_lep < 50
Enegry_tau
< 12
Y N
Y N

Searching Algorithm for Single Tree
• Enumerate the possible tree structures q
• Calculate the structure score for the q, using the scoring eq.
• Find the best tree structure, and use the optimal leaf weight
• But… there can be infinite possible tree structures..

Greedy Learning of the Tree
• In practice, we grow the tree greedily
Start from tree with depth 0
For each leaf node of the tree, try to add a split. The change of objective after adding the split is
Remaining question: how do we find the best split?
the score of left child
the score of right child
the score of if we do not split
The complexity cost by
introducing additional leaf

Efficient Finding of the Best Split
• What is the gain of a split rule ? Say is age
• All we need is sum of g and h in each side, and calculate
• Left to right linear scan over sorted instance is enough to decide the best split along the feature
g1, h1 g4, h4 g2, h2 g5, h5 g3, h3
a

Pruning and Regularization
• Recall the gain of split, it can be negative!
When the training loss reduction is smaller than regularization
Trade-off between simplicity and predictivness
• Pre-stopping
Stop split if the best split have negative gain
But maybe a split can benefit future splits..
• Post-Prunning
Grow a tree to maximum depth, recursively prune all the leaf splits with negative gain

Outline
• Introduction
• Gradient Boosting with Model Complexity Control
• Discussions and Final Remarks

Modules in Boosted Tree Learning
• Feature engineering
Add new derived physics quantity
• Objective function
Optimization for weighted data
• Function class and Structure scoring
Design function class to solve the domain specific problem
• Separation of the modules allow independent improvement

Modules(cont’)
• Feature engineering
Sum of momentum, energy and mass of any subset in {tau, jet, 2 leps, met}
Improve AMS to 3.72
Physics motivated feature helps
• Objective function
Weighted logistic loss:
Directly optimize AMS?
Maybe not a good choice since AMS is not stable

Function Class and Structure Scoring
• Function class that handles missing value
Each branch have a missing value direction
Search over the extended space
Equivalent to “learn” imputation value
• Scoring function
Physics guided scoring function?
mass_lep < 50
Enegry_tau
< 12
Y N
N
Missing missing value direction
Y

Final Remark: Scale up XGBoost Further
• Part of DMLC: Distributed Machine Learning Common
Open-source common library for distributed ML
https://github.com/dmlc
Distributed version runs on Hadoop, MPI, SGE etc.
Direct read data from HDFS and AWS S3
Scales up to billions of examples with 20 machines
• Other DMLC projects
minerva: efficient GPU tensor engine on python
cxxnet: fast, concise and distributed deep learning

Recap: Take aways
• XGBoost provides a scalable and accuracy implementation of Boosted Trees
• Carefully regularize the model class for better generalization
• Modularized component could be potentially used to incorporate more of our prior knowledge into learning
• It is a combination of right tool, objective and domain knowledge to win a data science challenge

Thank You