bÁo cÁo thỰc hiỆn ĐỀ tÀi - jaist.ac.jpbao/vlsp-text/nov2007/sp74baocao11-2007.pdf · (xin...
TRANSCRIPT

BÁO CÁO THỰC HIỆN ĐỀ TÀI
1. Tên đề tài nhánh: SP7.4
2. Thời gian thực hiện: 5/2007-10/2007
3. Người phụ trách: Hồ Bảo Quốc
4. Kế hoạch của đề tài
Kế hoạch thực hiện theo như phụ lục 3-2007 của hợp đồng nhánh như sau

PHỤ LỤC 3 NỘI DUNG VÀ SẢN PHẨM CẦN ĐẠT CỦA NĂM 2007 Đơn vị:
triệu đồng
TT
Sản phẩm phải đạt
Yêu cầu chất lượng đối với sản
phẩm
Tiến độ
hoàn thành
1 2 3 4
SP7.4: Hai kho ngữ liệu cõu Anh- Việt cú & khụng cú chỳ giải
- Nghiên cứu nội dung các kho ngữ liệu song ngữ. 1 báo cáo T12/2007
- Nghiên cứu tham khảo cấu trúc các kho ngữ liệu song ngữ. 1 báo cáo T12/2007
- Thiết kế nội dung kho ngữ liệu câu Anh- Việt. 1 báo cáo T12/2007
- Thiết kế cấu trúc cho kho ngữ liệu câu Anh- Việt. 1 báo cáo T12/2007

- Thiết kế xây dựng khuôn dạng dữ liệu cho hai kho ngữ liệu câu Anh- Việt.
1 báo cáo T12/2007
- Nghiên cứu tiêu chí chọn mẫu ngữ liệu song ngữ Anh-Việt. 1 báo cáo T12/2007
- Công cụ hỗ trợ lọc các cặp câu dịch tốt từ các văn bản song ngữ. SP phần mềm. Đầu vào: Văn bản song ngữ. Đầu ra: Tập câu song ngữ chất lượng tốt. Giao diện hỗ trợ duyệt và lựa chọn các cặp câu song ngữ chất lượng dịch tốt.
Thiết kế và phân tích Modul chương trình
T12/2007
- Thu thập ngữ liệu song ngữ Anh-Việt từ các nguồn khác nhau theo tiêu chí đó định. SP: Kho ngữ liệu 20.000 cặp câu trong lĩnh vực CNTT.
Kho ngữ liệu 20.000 cặp câu, trong đó 1 phần chuyên về CNTT
T12/2007
5. Nội dung đã thực hiện
1. Nghiên cứu hiên trạng về nội dung, cấu trúc và phương pháp xây dựng kho ngữ liệu song ngữ Anh –Việt
(Xin xem báo cáo kỹ thuật đính kèm)
2. Thử nghiệm việc khai thác các site song ngữ
5.2.1 Xây dựng công cụ mining tự động các kho ngữ liệu song ngữ từ Internet
5.2.2 Gióng hàng các tài liệu song ngữ đến mức câu
3. Các công cụ và tài nguyên đã xây dựng được
5.3.1 Công cụ
- Công cụ phân đoạn từ ( Vietnamese Word Segmentation)

- Công cụ khai thác dữ liệu song ngữ từ Internet
- Công cụ gióng hàng tài liệu song ngữ đến mức câu
5.3.2 Tài nguyên
- Kho ngữ liệu song ngữ Anh – Việt thô (chưa được Manual Revise) gồm khoảng: 50.000 cặp câu
6. Người thực hiện đề tài
1. Hồ Bảo Quốc
2. Đặng Bác Văn
3. Phạm Đào Minh Vũ
4. Lương Vỹ Minh
5. Nguyễn Trường Sơn
7. Đánh giá kết quả
Các kết quả đạt được chỉ ở mức khởi đầu và mang tính thử nghiệm các khả năng. Trong thời gian tới cần phải được nghiên cứu sâu thêm về lý thuyết, ra các quyết định chọn lựa các tiêu chí cho kho ngữ liệu sẽ xây dựng, chọn và tập hợp các tài nguyên, thử nghiệm và hoàn thiện các chương trình để tạo công cụ cho việc đánh giá và thao tác (thêm, xóa sửa) kho ngữ liệu thủ công (do các người giỏi hai ngôn ngữ đảm trách)

Kho ngữ liệu song song (Parallel Corpus)
Mục lục 0. Dẫn nhập ......................................................................................................................................6
I. Các định nghĩa cơ sở ..............................................................................................................6
II. Một số kho ngữ liệu song ngữ : ...............................................................................................8
III. Các tiêu chí xây dựng kho ngữ liệu song ngữ .................................................................9
IV. Định dạng kho ngữ liệu song ngữ.....................................................................................10
V. Các phương pháp xây dựng kho ngữ liệu song ngữ .......................................................11
VI. Đánh giá kho ngữ liệu song ngữ song song...................................................................12
VII. Tài liệu tham khảo ...............................................................................................................13
Phụ Lục A : CES DTD ......................................................................................................................14

0. Dẫn nhập
Trong tính toán ngôn ngữ học (linguistic computing) một tài nguyên rất cần thiết đó là các kho ngữ liệu song ngữ song song (parallel corpus). Các kho ngữ liệu song ngữ song song này có thể được sữ dụng cho nhiều mục tiêu khác nhau như : nghiên cứu ngôn ngữ học so sánh, tìm kiếm thông tin xuyên ngữ, dịch máy .v.v. Kết quả của các bài toán trên phụ thuộc rất nhiều vào độ lớn và chất lượng của kho ngữ liệu song song được sử dụng. Trên thế giới đã có rất nhiều kho ngữ liệu song ngữ song song được xây dựng để phục vụ cho các mục tiêu như trên (xin xem chi tiết ở phần II). Hiện nay chưa có một kho ngữ liệu song song Anh - Việt được công bố chính thức và cho phép cộng đồng nghiên cứu liên quan đến có thể chia sẽ sử dụng cho các mục tiêu nghiên cứu. Do đó mục tiêu của đề tài nhánh này nhằm nghiên cứu các cách tiếp cận xây dựng kho ngữ liệu song ngữ song song, cấu trúc và định dạng lưu trữ của các kho ngữ liệu song ngữ song song và các tiêu chí và phương pháp đánh giá một kho ngữ liệu song ngữ song song Anh – Việt. Trong khuôn khổ cho phép của kinh phí đề tài, mục tiêu của đề tài nhánh là xây dựng được một kho ngữ liệu song ngữ Anh – Việt song song gióng hàng đến mức câu (Sentence Aligment) gồm 100.000 cặp câu song song Anh – Việt trong đó 80.000 cặp câu cho các lĩnh vực kinh tế - xã hội và 20.000 cặp câu cho lĩnh vực tin học. Trong các phần dưới đây chúng tôi xin được lần lượt trình bày : các định nghĩa cơ sở ở phần I, khảo sát một số kho ngữ liệu song ngữ song song trên thế giới ở phần II, phần III sẽ nêu các tiêu chí trong việc xây dựng một kho ngữ liệu song ngữ song song, Phần IV là các định dạng được sử dụng để tổ chức lưu trữ các kho ngữ liệu song ngữ song song và cuối cùng trong phần V là phương pháp đánh giá chất lượng của một kho ngữ liệu song song.
I. Các định nghĩa cơ sở Định nghĩa 1 : Kho ngữ liệu (corpus)
Theo EAGLES (Expert Advisory Group on Language Engineering Standards) kho ngữ liệu là một tập hợp các mảnh ngôn ngữ (pieces of language) được chọn lựa và sắp xếp theo một số tiêu chí ngôn ngữ học rõ ràng để được sử dụng như một mẫu của ngôn ngữ

Kho ngữ liệu số hóa (computer corpus) : là kho ngữ liệu được mã hóa theo một chuẩn nhất định và đồng nhất để có thể khai thác cho các ứng dụng khác nhau
Định nghĩa 2 : Một tập các văn bản (tài liệu) được viết bằng nhiều ngôn ngữ thì gọi là kho ngữ liệu đa ngữ (multilingual corpora). Định nghĩa 3 : Một tập các văn bản (tài liệu) trong các ngôn ngữ khác nhau mà có cùng chủ đề chính thì được gọi là kho ngữ liệu (có thể) so sánh (comparable corpus). Định nghĩa 4 : Kho ngữ liệu song song (Parallel Corpus) là một tập các văn bản (tài liệu) trong nhiều ngôn ngữ khác nhau, trong đó có một ngôn ngữ nguồn và một (hoặc nhiều) ngôn ngữ đích (được dịch từ ngôn ngữ nguồn). Định nghĩa 5 : Sự gióng hàng (Alignment) của các tài liệu song ngữ trong kho ngữ liệu song ngữ có thể ở các múc như sau
- Mức tài liệu (Document Alignment) : Các tài liệu trong kho ngữ liệu được gióng hàng đôi một, tài liệu này là bản dịch của tài liệu kia
- Mức đoạn (Paragraph Alignment) : Các đoạn trong 2 tài liệu của 2 ngôn ngữ sẽ được gióng hàng, đoạn này sẽ là bản dịch của đoạn kia
- Mức câu (Sentence Alignment) : Các tài liệu song ngữ được gióng hàng ở mức câu : câu này là bản dịch của câu kia
- Mức ngữ (Phrase Alignment) : Các ngữ trong cặp câu sẽ được gióng hàng từng đôi một : ngữ này lả bản dịch của ngữ kia
- Mức Từ (Word Alignment) : các từ trong câu sẽ được gióng hàng từng cặp : từ này là từ dịch của từ kia
Mục tiêu của đề tài là xây dựng một kho ngữ liệu song ngữ song song gióng hàng ở mức câu
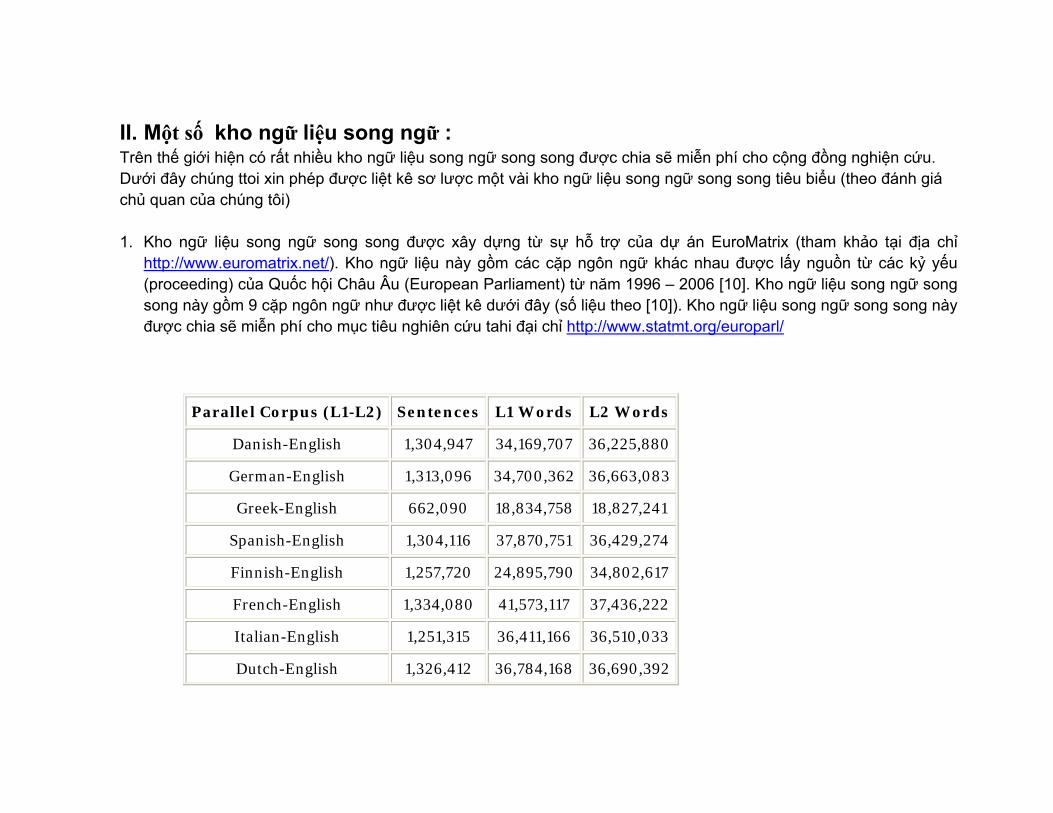
II. Một số kho ngữ liệu song ngữ : Trên thế giới hiện có rất nhiều kho ngữ liệu song ngữ song song được chia sẽ miễn phí cho cộng đồng nghiện cứu. Dưới đây chúng ttoi xin phép được liệt kê sơ lược một vài kho ngữ liệu song ngữ song song tiêu biểu (theo đánh giá chủ quan của chúng tôi) 1. Kho ngữ liệu song ngữ song song được xây dựng từ sự hỗ trợ của dự án EuroMatrix (tham khảo tại địa chỉ
http://www.euromatrix.net/). Kho ngữ liệu này gồm các cặp ngôn ngữ khác nhau được lấy nguồn từ các kỷ yếu (proceeding) của Quốc hội Châu Âu (European Parliament) từ năm 1996 – 2006 [10]. Kho ngữ liệu song ngữ song song này gồm 9 cặp ngôn ngữ như được liệt kê dưới đây (số liệu theo [10]). Kho ngữ liệu song ngữ song song này được chia sẽ miễn phí cho mục tiêu nghiên cứu tahi đại chỉ http://www.statmt.org/europarl/
Parallel Corpus (L1-L2) Sentences L1 Words L2 Words
Danish-English 1,304,947 34,169,707 36,225,880
German-English 1,313,096 34,700,362 36,663,083
Greek-English 662,090 18,834,758 18,827,241
Spanish-English 1,304,116 37,870,751 36,429,274
Finnish-English 1,257,720 24,895,790 34,802,617
French-English 1,334,080 41,573,117 37,436,222
Italian-English 1,251,315 36,411,166 36,510,033
Dutch-English 1,326,412 36,784,168 36,690,392

Portuguese-English 1,287,757 37,342,426 36,355,907
Swedish-English 1,164,536 28,882,142 32,053,628
2. Kho ngữ liệu song ngữ song song Anh-Pháp, Canadian Hansard Corpus, của hiệp hội dữ liệu ngôn ngữ học (Linguistic Data Consortium- LDC) kho ngữ liệu này gồm 2.8 triệu cặp câu (theo http://www.ldc.upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC95T20). Dữ liệu văn bản thuần chủ yếu được lấy từ trang web của Quốc hội Canada http://www.parl.gc.ca.
3. JENAAD Japanese – English Parallel Corpus do Masao Utiyama và Hitoshi Isahara xây dựng, bao gồm 45.000 cặp câu, trong đó có 15.000 câu được canh theo tỉ lệ 1:1 và 30.000 câu theo tỉ lệ 1:n. (2003).
4. Kho ngữ liệu song ngữ song song Hoa – Anh PKU 863 của đại học Bắc kinh gồm hơn 200.000 cặp câu thuộc nhiều lĩnh vực kinh tế xă hội khác nhau (tham khảo http://www.ling.lancs.ac.uk/corplang/863parallel/ )
III. Các tiêu chí xây dựng kho ngữ liệu song ngữ Kho ngữ liệu song ngữ song song có thể được xây dựng theo các tiêu chí sau : 1. Lĩnh vực của kho ngữ liệu : tin tức, pháp luật, máy tính … 2. Biểu diễn được mô hình thực của ngôn ngữ (các câu trong văn bản thực tế sử dụng của ngôn ngữ) 3. Thời gian của tài liệu (tài liệu cũ, mới, trong khoảng thời gian nào) 4. Mức độ gióng hàng (theo các mức được định nghĩa trong phần I) 5. Các mức độ chú giải ngôn ngữ học (linguistic annotation) : không chú giải, chú giải phân đoạn đoạn, ngữ,
câu, từ, chú giải từ loại của từ 6. Máy tính đọc được (Bộ mã Encodage)

Các tiêu chí xây dựng kho ngữ liệu nói chung và kho ngữ liệu song ngữ song song nói riêng có thể tham khảo tại http://www.ilc.cnr.it/EAGLES/browse.html
IV. Định dạng kho ngữ liệu song ngữ Có rất nhiều định dạng được dùng để mã hóa kho ngữ liệu song ngữ song song sử dụng SGML, TEI hoặc XML. Dưới đây chúng tôi liệt kê 2 định dạng thường được sử dụng 1. CES (Corpus Encoding Standard) : là một chuẩn dựa trên SGML, nhằm đưa ra các hướng dẫn (guidelines)
cho việc mă hóa các kho ngữ liệu. Một tài liệu dưới dạng CES gồm 3 phần : a. Phần dữ liệu nguyên thủy (primary data) :
i. Thông tin về văn bản : id, title, authors … : được gọi là phần đầu Header ii. Thông tin về cấu trúc và nội dung: các phần (section), đoạn (paragraph), câu (sentence)… :
được gọi phần Text
Phần này được mô tả chi tiết trong cesDOC DTD được đính kèm trong phần I của phụ lục A
b. Phần chú giải ngôn ngữ học (linguistic annotation) i. Ranh giới đoạn, câu, từ ii. Từ loại của từ (POS) iii. Gốc từ (lemma)
Phần này được mô tả chi tiết trong cesAna DTD được đính kèm trong phần II của phụ lục A
c. Thông tin về gióng hàng (alignment) Phần này được mô tả chi tiết trong cesAlign được đính kèm trong phần III của phụ lục A

Thông tin chi tiết có thể tham khảo thêm tại http://www.cs.vassar.edu/CES/ CES hiện nay cũng đã có phiên bản XML, tham khảo tại http://www.cs.vassar.edu/XCES/
2. Định dạng theo kho ngữ liệu song ngữ Anh – Nauy Kho ngữ liệu song ngữ song song này được lưu trữ theo chuẩn TEI (Text Encoding Initiative). Cấu trúc cũng tương tự như chuẩn CES (được mô tả ở phần I). Thông tin chi tiết có thể tham khảo tại http://www.hf.uio.no/ilos/forskning/forskningsprosjekter/enpc/ENPCmanual.html.
V. Các phương pháp xây dựng kho ngữ liệu song ngữ Do mục tiêu của đề tài nhánh là xây dựng kho ngữ liệu song ngữ song song Anh – Việt gióng hàng ở mức câu và không có chú giải, nên chúng tôi chỉ tập trung vào các phương pháp để xây dựng kho ngữ liệu song ngữ thỏa tiêu chí trên.
Xây dựng kho dữ liệu song ngữ song song gồm có 2 bước chính 1. Xây dựng nguồn tài liệu song song 2. Gióng hàng các tài liệu song song
1. Xây dựng nguồn tài liệu a. Chọn nguồn tài liệu
Chọn nguồn tài liệu phù hợp với lĩnh vực xác định trước hoặc bao phủ nhiều lĩnh vực khác nhau.
b. Thủ công : i. Nhập vào máy tính từ các tài liệu trên giấy ii. Mua các kho ngữ liệu song song điện tử như : sách song ngữ, báo chí song ngữ …
c. Bán tự động

i. Khai thác dữ liệu song ngữ từ Internet ii. Tiến hành gióng hàng ở mức tài liệu
2. Gióng hàng i. Phương pháp thống kê : sử dụng phương pháp thống kê để tính độ “tương đồng” của 2 câu trong hai
ngôn ngữ thông qua các đơn vị (token) trong câu. Các đơn vị ở đây có thể là các uni-gram, bi-gram hoặc là từ, cụm từ …Phương pháp này không cần phải có một từ điển song ngữ [5].
ii. Phương pháp sử dụng từ điển song ngữ
Trong phương pháp này sử dụng một từ điển song ngữ để xác định các điểm neo (anchor) là các từ được biết là từ dịch của nhau nhờ vào từ điển từ đó chỉ một độ đo tương tự giữa hai câu.[
iii. Các phương pháp máy học
Học từ một kho ngữ liệu song ngữ song song gióng hàng ở mức câu cho trước từ đó sử dụng các tương ứng về từ có được sau giai đoạn học để gióng hàng cho một kho ngữ liệu song ngữ mới.
VI. Đánh giá kho ngữ liệu song ngữ song song
a. Đánh giá thủ công : nhờ chuyên gia ngôn ngữ đánh giá trên các mẩu được chọn ngẫu nhiên từ kho ngữ liệu
b. Đánh giá tự động : sử dụng kho ngữ liệu song ngữ song song cho dịch tự động bằng phương pháp thông kê (SMT) và đánh giá độ đo bleu của chất lượng dịch.

VII. Tài liệu tham khảo [1] Johann Gamper, Encoding a Parallel Corpus for Automatic Terminology extraction, Proceedings of EACL
'99 [2] Nancy Ide, Greg Priest-Domain and Jean Veronic (1996), Corpus Encoding Standard,
http://www.cs.vassar.edu/CES/. [3] CHANG Baobao, Chinese-English Parallel Corpus Construction and its Application, PACLIC 18, December
8th-10th, 2004, Waseda University, Tokyo [4] M. Gavrilidou, P. Labropoulou, E. Desipri, V. Giouli, V. Antonopoulos, S. Piperidis, Building parallel corpora
for eContent professionals, MLR2004: PostCOLING Workshop on Multilingual Linguistic Resources, 28 August 2004, Geneva, Switzerland
[5] William A.Gale, Kenneth W.Church (1991), A program for aligning sentences in bilingual corpora. In Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics.
[6] P. Resnik, Noah A. Smithy (2003), The web as parallel corpus. [7] J.Y. Nie, J. Chen (2002), Exploiting the Web as Parallel Corpora for Cross Languague
Information Retrieval, WI02. [8] C.C. Yang, K.W. Li (2002), Mining English/Chinese Parallel Documents from the World Wide
Web. Proceedings of the International World Wide Web Conference, Honolulu, Hawaii, May 7-11, 2002 [9] J. Chen, R. Chau, C.H. Yeh (2004), Discovering Parallel Text from the World Wide Web. In Proc.
Australasian Workshop on Data Mining and Web Intelligence (DMWI2004), Dunedin, New Zealand. CRPIT, 32. Purvis, M., Ed. ACS. 157-161
[10] Phillip Koehn, Europarl: A Parallel Corpus for Statistical Machine Translation

Phụ Lục A : CES DTD I. CesDOC DTD
<!-- --> <!-- --> <!-- Corpus Encoding Standard --> <!-- --> <!-- CES --> <!-- --> <!-- Encoding conventions for level 1 --> <!-- --> <!-- --> <!-- --> <!-- $Date: 1996/12/06 17:03:10 $ $Revision: 4.3 $ --> <!-- --> <!-- ENTITY DECLARATIONS --> <!-- --> <!-- Global attributes --> <!ENTITY % a.global ' id ID #IMPLIED n CDATA #IMPLIED lang IDREF #IMPLIED' > <!ENTITY % a.text '%a.global rend CDATA #IMPLIED wsd CDATA #IMPLIED' > <!-- Elements that can appear between paragraphs --> <!ENTITY % m.inter ' bibl | quote | list | poem | note | caption | figure | table ' >

<!-- Sub-paragraph elements --> <!ENTITY % x.token '' > <!ENTITY % m.token '%x.token; abbr | date | num | measure | name | term | time |' > <!ENTITY % m.phrase '%m.token; corr | distinct | foreign | gap | hi | list | mentioned | ptr | q | ref | reg | s | title' > <!-- Content model declarations --> <!ENTITY % base.seq '(%x.token; #PCDATA | num | abbr)*' > <!ENTITY % phrase.seq '(%m.phrase; | #PCDATA)*' > <!ENTITY % par.seq '(p | sp | %m.inter;)*' > <!-- --> <!-- ELEMENT DECLARATIONS --> <!-- --> <!-- HIGH-LEVEL COMPONENTS --> <!ELEMENT cesCorpus - - (cesHeader,(cesDoc+ | cesCorpus+)) > <!ATTLIST cesCorpus %a.global; type CDATA #IMPLIED version CDATA #REQUIRED TEIform CDATA 'teiCorpus.2' > <!ELEMENT cesDoc - - (cesHeader, text) >

<!ATTLIST cesDoc %a.global; type CDATA text version CDATA #REQUIRED TEIform CDATA 'TEI.2' > <!ENTITY % ces.header PUBLIC "-//CES//ENTITIES Header//EN" > %ces.header; <!-- WRITTEN TEXTS --> <!ELEMENT text - - (body | group) > <!ATTLIST text %a.global; complete (y |n ) y decls IDREFS #IMPLIED > <!ELEMENT body - - (%par.seq;, div*) > <!ATTLIST body %a.text; decls IDREFS #IMPLIED > <!ELEMENT group - - (%par.seq;, body+) > <!ATTLIST group %a.text; decls IDREFS #IMPLIED > <!ELEMENT div - - ((opener | head | byline)*, (((p | sp | %m.inter;)+, div*) | div+), (closer | byline)* ) > <!ATTLIST div %a.text; complete (y | n) y type CDATA #REQUIRED decls IDREFS #IMPLIED > <!-- Opening elements -->

<!ELEMENT opener - - (dateline | keywords | %phrase.seq;)* > <!ATTLIST opener %a.text; > <!ELEMENT head - - %phrase.seq; > <!ATTLIST head %a.text; type CDATA #IMPLIED > <!-- Keyword lists, bylines, datelines --> <!ELEMENT keywords - - (term+ | list) > <!ATTLIST keywords %a.text; scheme IDREF #IMPLIED > <!ELEMENT byline - - (%phrase.seq; | docAuthor)* > <!ATTLIST byline %a.text; > <!ELEMENT docAuthor - - (%base.seq;) > <!ATTLIST docAuthor %a.text; > <!ELEMENT dateline - - (date | time | name | address | %base.seq;)* > <!ATTLIST dateline %a.text; > <!ELEMENT address - - (%base.seq;) > <!ATTLIST address %a.text; > <!-- Closing element --> <!ELEMENT closer - - (dateline | keywords | %phrase.seq;)* > <!ATTLIST closer %a.text; > <!-- PARAGRAPH-LEVEL ELEMENTS THE CLASS M.INTER --> <!-- Written paragraphs -->

<!ELEMENT p - - (%phrase.seq;) > <!ATTLIST p %a.text; > <!-- Quotations --> <!ELEMENT quote - - ((p | poem)+ | (%phrase.seq;)) > <!ATTLIST quote %a.text; next IDREF #IMPLIED prev IDREF #IMPLIED type CDATA #IMPLIED broken (yes | no) no > <!-- Lists --> <!ELEMENT list - - (head?, (item+ | (label, item)+)) > <!ATTLIST list %a.text; > <!ELEMENT item - - (p+ | (%phrase.seq;)) > <!ATTLIST item %a.text; > <!ELEMENT label - - %phrase.seq; > <!ATTLIST label %a.text; > <!-- Annotations --> <!ELEMENT note - - (p+ | (%phrase.seq;)) > <!ATTLIST note %a.text; place (side | foot | end | unspec) unspec > <!ELEMENT bibl - - (%phrase.seq; | author)* > <!ATTLIST bibl %a.text;

%a.declarable; > <!ELEMENT author - - (%base.seq;) > <!ATTLIST author %a.text; > <!-- Poems --> <!ELEMENT poem - - (head?, (lg | l )+ ) > <!ATTLIST poem %a.text; > <!ELEMENT lg - - (l | lg)+ > <!ATTLIST lg %a.text; type CDATA #IMPLIED part (y | n | u) u > <!ELEMENT l - - %phrase.seq; > <!ATTLIST l %a.text; part (y | n | u) u > <!-- Figures --> <!ELEMENT figure - - (head?, p*, figDesc?, text?) > <!ATTLIST figure %a.text; entity ENTITY #IMPLIED > <!ELEMENT figDesc - - %phrase.seq; > <!ATTLIST figDesc %a.text; > <!-- Tables --> <!ELEMENT table - - (head?, row+) > <!ATTLIST table %a.text; rows NUMBER #IMPLIED cols NUMBER #IMPLIED >

<!ELEMENT row - - (cell | table)+ > <!ATTLIST row %a.text; role CDATA data > <!ELEMENT cell - - (%phrase.seq) > <!ATTLIST cell %a.text; role CDATA data rows NUMBER 1 cols NUMBER 1 > <!-- Captions --> <!ELEMENT caption - - %phrase.seq; > <!ATTLIST caption %a.text; type ( byline | display | attached | unspec ) unspec > <!-- Transcriptions of dialogues, speeches, debates, --> <!-- interviews, etc., and drama --> <!ELEMENT sp - - (speaker*,p+) +(stage) > <!ATTLIST sp %a.text; who NAME #IMPLIED > <!ELEMENT speaker - - (%base.seq;) > <!ATTLIST speaker %a.text; > <!ELEMENT stage - - (%base.seq;) > <!ATTLIST stage %a.text; type CDATA #IMPLIED > <!-- SENTENCES, QUOTED DIALOGUE WITHIN PARAGRAPHS -->

<!ELEMENT s - - (%phrase.seq;) > <!ATTLIST s %a.text; next IDREF #IMPLIED prev IDREF #IMPLIED type CDATA #IMPLIED broken (yes | no) no > <!ELEMENT q - - (%phrase.seq;) > <!ATTLIST q %a.text; next IDREF #IMPLIED prev IDREF #IMPLIED type CDATA #IMPLIED direct (y | n | unspecified) unspecified who CDATA #IMPLIED broken (yes | no) no > <!-- PHRASE-LEVEL ELEMENTS THE CLASS M.PHRASE --> <!-- Editorial Changes --> <!ELEMENT gap - o EMPTY > <!ATTLIST gap %a.text; desc CDATA #IMPLIED reason CDATA #IMPLIED resp CDATA #IMPLIED cert CDATA #IMPLIED > <!ELEMENT reg - - (%phrase.seq;) > <!ATTLIST reg %a.text; orig CDATA #IMPLIED resp CDATA #IMPLIED cert CDATA #IMPLIED >

<!ELEMENT corr - - (%phrase.seq;) > <!ATTLIST corr %a.text; sic CDATA #IMPLIED resp CDATA #IMPLIED cert CDATA #IMPLIED > <!-- Highlighted text --> <!ELEMENT hi - - (%phrase.seq) -(hi) > <!ATTLIST hi %a.text; > <!-- Other Phrase-level Elements --> <!ELEMENT date - - (%base.seq;) > <!ATTLIST date %a.text; ISO8601 CDATA #IMPLIED > <!ELEMENT foreign - - (%phrase.seq;) -(foreign) > <!ATTLIST foreign %a.text; > <!ELEMENT distinct - - (%phrase.seq;) -(distinct) > <!ATTLIST distinct %a.text; type CDATA #IMPLIED > <!ELEMENT mentioned - - (%phrase.seq;) -(mentioned) > <!ATTLIST mentioned %a.text; > <!ELEMENT measure - - (%base.seq;) > <!ATTLIST measure %a.text; type (weight, length, count, area, volume, temperature, currency) #IMPLIED value CDATA #IMPLIED >

<!ELEMENT name - - (%base.seq;) > <!ATTLIST name %a.text; type CDATA #IMPLIED > <!ELEMENT term - - (%base.seq;) > <!ATTLIST term %a.text; type CDATA #IMPLIED > <!ELEMENT time - - (%base.seq;) > <!ATTLIST time %a.text; ISO8601 CDATA #IMPLIED type (am | pm | 24hour | descriptive) #IMPLIED > <!ELEMENT title - - (%phrase.seq;) -(title) > <!ATTLIST title %a.text; type CDATA #IMPLIED > <!ELEMENT abbr - - (#PCDATA) > <!ATTLIST abbr %a.text; expan CDATA #IMPLIED resp IDREF #IMPLIED cert CDATA #IMPLIED type CDATA #IMPLIED > <!ELEMENT num - - (#PCDATA) > <!ATTLIST num %a.text; type CDATA #IMPLIED value CDATA #IMPLIED > <!-- SEGMENTATION, LINKING, ALIGNMENT --> <!-- Simple cross references -->

<!ELEMENT ptr - o EMPTY > <!ATTLIST ptr %a.text; corresp IDREFS #IMPLIED next IDREF #IMPLIED prev IDREF #IMPLIED type CDATA #IMPLIED resp CDATA #IMPLIED crdate CDATA #IMPLIED targType NAMES #IMPLIED targOrder (y | n | u) u evaluate (all | one | none) #IMPLIED target IDREFS #REQUIRED > <!ELEMENT ref - - (%phrase.seq;) > <!ATTLIST ref %a.text; corresp IDREFS #IMPLIED next IDREF #IMPLIED prev IDREF #IMPLIED type CDATA #IMPLIED resp CDATA #IMPLIED crdate CDATA #IMPLIED targType NAMES #IMPLIED targOrder (Y | N | U) U evaluate (all | one | none) #IMPLIED target IDREFS #IMPLIED > <!-- PUBLIC ENTITY SETS --> <!ENTITY % ISOlat1 PUBLIC "ISO 8879-1986//ENTITIES Added Latin 1//EN" > %ISOlat1; <!ENTITY % ISOlat2 PUBLIC

"ISO 8879-1986//ENTITIES Added Latin 2//EN" > %ISOlat2; <!ENTITY % ISOnum PUBLIC "ISO 8879-1986//ENTITIES Numeric and Special Graphic//EN" > %ISOnum; <!ENTITY % ISOpub PUBLIC "ISO 8879-1986//ENTITIES Publishing//EN" > %ISOpub;
II. CesAnna DTD
<!-- --> <!-- --> <!-- Corpus Encoding Standard --> <!-- --> <!-- CES --> <!-- --> <!-- Encoding conventions for annnotated data --> <!-- --> <!-- --> <!-- --> <!-- $Date: 1997/04/28 20:05:54 $ $Revision: 4.6 $ --> <!-- --> <!-- Global attributes --> <!ENTITY % a.global ' id ID #IMPLIED n CDATA #IMPLIED lang IDREF #IMPLIED' >

<!ENTITY % a.ana '%a.global; type CDATA #IMPLIED wsd CDATA #IMPLIED' > <!ENTITY % lex.seq '(base | ctag | msd )' > <!ELEMENT cesAna - - (cesHeader?, chunkList) > <!ATTLIST cesAna %a.ana; doc CDATA #IMPLIED version CDATA #REQUIRED > <!ENTITY % ces.header PUBLIC "-//CES//ENTITIES Header//EN" > %ces.header; <!ELEMENT chunkList - - (chunk)+ > <!ATTLIST chunkList %a.ana; > <!ELEMENT chunk - - (tok | s | par | data )+ > <!ATTLIST chunk %a.ana; doc CDATA #IMPLIED from CDATA #IMPLIED to CDATA #IMPLIED > <!ELEMENT par - - (tok | s | data )+ > <!ATTLIST par %a.ana; from CDATA #IMPLIED to CDATA #IMPLIED > <!ELEMENT s - - (tok | s | data | #PCDATA)+ > <!ATTLIST s %a.ana; from CDATA #IMPLIED to CDATA #IMPLIED next IDREF #IMPLIED prev IDREF #IMPLIED broken (yes | no) no >

<!ELEMENT tok - - (orth, ((disamb*, lex*) | (%lex.seq)*), aNote*) > <!ATTLIST tok %a.ana; class CDATA #IMPLIED from CDATA #IMPLIED to CDATA #IMPLIED > <!ELEMENT orth - - (#PCDATA) > <!ATTLIST orth %a.ana; > <!ELEMENT disamb - - (%lex.seq | aNote )+ > <!ATTLIST disamb %a.ana; > <!ELEMENT lex - - (%lex.seq | aNote )+ > <!ATTLIST lex %a.ana; > <!ELEMENT base - - (#PCDATA) > <!ATTLIST base %a.ana; > <!ELEMENT msd - - (#PCDATA) > <!ATTLIST msd %a.ana; certainty CDATA #IMPLIED > <!ELEMENT ctag - - (#PCDATA) > <!ATTLIST ctag %a.ana; certainty CDATA #IMPLIED > <!ELEMENT data - - (#PCDATA) > <!ATTLIST data %a.ana; > <!ELEMENT aNote - - (#PCDATA) > <!ATTLIST aNote %a.ana; resp CDATA #IMPLIED > <!-- PUBLIC ENTITY SETS -->

<!ENTITY % ISOlat1 PUBLIC "ISO 8879-1986//ENTITIES Added Latin 1//EN" > %ISOlat1; <!ENTITY % ISOlat2 PUBLIC "ISO 8879-1986//ENTITIES Added Latin 2//EN" > %ISOlat2; <!ENTITY % ISOnum PUBLIC "ISO 8879-1986//ENTITIES Numeric and Special Graphic//EN" > %ISOnum; <!ENTITY % ISOpub PUBLIC "ISO 8879-1986//ENTITIES Publishing//EN" > %ISOpub;
III. CesAlign DTD
<!-- --> <!-- --> <!-- Corpus Encoding Standard --> <!-- --> <!-- CES --> <!-- --> <!-- Encoding conventions for aligned data --> <!-- --> <!-- --> <!-- $Date: 1996/10/14 20:48:37 $ $Revision: 4.1 $ --> <!-- --> <!-- Global attributes --> <!ENTITY % a.global ' id ID #IMPLIED

n CDATA #IMPLIED lang IDREF #IMPLIED' > <!ENTITY % a.align '%a.global wsd CDATA #IMPLIED' > <!ELEMENT cesAlign - - (cesHeader?, linkList) > <!ATTLIST cesAlign %a.align; type (par | sent | tok) #IMPLIED fromDoc CDATA #IMPLIED toDoc CDATA #IMPLIED version CDATA #REQUIRED > <!ENTITY % ces.header PUBLIC "-//CES//ENTITIES Header//EN" > %ces.header; <!ELEMENT linkList - - (linkGrp+) > <!ATTLIST linkList %a.align; > <!ELEMENT linkGrp - - (link | xptr | ptr)+ > <!ATTLIST linkGrp %a.align; type CDATA #IMPLIED fromDoc CDATA #IMPLIED toDoc CDATA #IMPLIED fromLoc CDATA #IMPLIED toLoc CDATA #IMPLIED targType NAMES #IMPLIED domains CDATA #IMPLIED > <!ELEMENT link - o EMPTY > <!ATTLIST link %a.align; targType NAMES #IMPLIED targOrder (y | n | u) u evaluate (all | one | none) #IMPLIED fromDoc CDATA #IMPLIED

toDoc CDATA #IMPLIED fromLoc CDATA #IMPLIED toLoc CDATA #IMPLIED targets IDREFS #IMPLIED xtargets CDATA #IMPLIED certainty CDATA #IMPLIED > <!ELEMENT xptr - o EMPTY > <!ATTLIST xptr id ID #IMPLIED n CDATA #IMPLIED lang CDATA #IMPLIED wsd CDATA #IMPLIED targType NAMES #IMPLIED doc CDATA #CURRENT from CDATA #IMPLIED to CDATA #IMPLIED > <!ELEMENT ptr - o EMPTY > <!ATTLIST ptr %a.align; type CDATA #IMPLIED targType NAMES #IMPLIED targOrder (y | n | u) u evaluate (all | one | none) #IMPLIED targets IDREFS #REQUIRED > <!-- PUBLIC ENTITY SETS --> <!ENTITY % ISOlat1 PUBLIC "ISO 8879-1986//ENTITIES Added Latin 1//EN" > %ISOlat1; <!ENTITY % ISOlat2 PUBLIC "ISO 8879-1986//ENTITIES Added Latin 2//EN" >

%ISOlat2; <!ENTITY % ISOnum PUBLIC "ISO 8879-1986//ENTITIES Numeric and Special Graphic//EN" > %ISOnum; <!ENTITY % ISOpub PUBLIC "ISO 8879-1986//ENTITIES Publishing//EN" > %ISOpub;